1. Introduction
Chronic kidney disease is a disorder that occurs when a patient’s kidney function deteriorates. As a result, their overall quality of life suffers. Chronic kidney disease affects one out of every 10 people worldwide (CKD). CKD is on the rise, and by 2040, it is expected to be the fifth leading cause of death worldwide [
1]. It is one of the leading causes of high medical costs. In high-income nations, the cost of transplantation and dialysis accounts for 2% to 3% of the annual medical budget [
2]. Most people with renal failure in low- and middle-income countries have insufficient access to life-saving dialysis and kidney transplants [
3]. The number of kidney failure cases is expected to rise unexpectedly in developing countries such as China and India [
4]. Chronic kidney failure makes to difficulties in removing extra fluids from the body blood. Advanced chronic kidney disease can cause dangerous levels of fluid, electrolytes, and wastes to build up in the body. It may lead to complications such as high blood pressure, anemia, weak bones, and nerve damage. The strongest indicator of renal function is the Glomerular Filtration Rate (GFR) [
5]. Doctors also determine kidney disease through glomerular filtration rate (GFR). The criteria for defining CKD are a kidney damage for ≥3 months with or without decreased GFR or glomerular filtration rate (GFR) less than 60 mL/min/1.73 m
2 for ≥3 months with or without kidney damage. GFR [
6] is the most accurate predictor of kidney function for detecting different phases of CKD, with each phase indicating a more severe reduction in glomerular filtration rate.
The GFR [
6] is also used to detect renal failure; if GFR < 15 mL/min, then it means kidney has failed or near to failure. This is the last (fifth) stage of chronic kidney disease. The diagnosis of CKD is a difficult task in medicine because it is based on a variety of symptoms. Clinical judgments are primarily dependent on physicians’ expertise and experience during the examination of the patient’s symptoms [
7]. As the health care system evolves and new medicines become accessible, physicians are finding it increasingly challenging to stay up with current clinical practice changes [
8].
The machine learning technique provides valid decision-making approaches for computer-assisted automatic disease identification [
9]. Machine learning is being used to intelligently interpret available data and transform it into useful knowledge to increase the diagnostic process efficiency [
1]. Machine learning is already being used to assess the state of the human body, analyze disease-related aspects, and diagnose a variety of disorders [
10]. Heart disease has been diagnosed using models based on machine learning techniques [
11]. Diabetes, heart disease, and retinopathy [
12], acute renal injury [
13], and cancer [
14] were all diagnosed using models created by machine learning algorithms. Many researchers have used supervised algorithms, such as Random Forest [
15], Fuzzy C Means [
16], Naive Bayes [
17], Support Vector Machine [
18,
19,
20,
21], Gradient Boosting [
19,
20,
21,
22], Logistic Regression [
20] classifiers in detecting chronic kidney disease. Machine learning can also help to enhance the quality of medical data, reduce the frequency of hospital admissions, and save money on medical expenses. As a result, these models are more commonly utilized in diagnostic analytic research than other older approaches [
23]. The only way to reduce chronic disease (CD) mortality is to diagnose it early and treat it effectively [
24]. The feature extraction and classification processes in traditional machine learning involve two separate methods. As a result, typical machine learning approaches take a long time to compute. Because of this, the traditional technique is no longer viable for real-time diagnostic applications.
The ability of Artificial Neural Networks (ANN) to learn about fault tolerance, generalization, and the environment is becoming more widespread in the area of medical diagnostics.
In many cases, the Neural Networks (NN) method outperforms standard machine learning techniques. The resource learning architecture can be enhanced to boost its performance even more. The neural networks [
25,
26,
27,
28,
29] models have been used for the detection of kidney disease. The majority of currently available CKD models have a low classification accuracy. As a result, this research introduces a novel model for Chronic Kidney Disease.
The main contributions of this paper are:
Deep neural networks have been proposed to detect and diagnose CKD.
Apply feature selection to improve efficiency and efficacy of deep neural network.
The computational accuracy of the proposed model is compared with existing classification methods from the literature.
Furthermore, the performance is evaluated through the various performance measures.
The following is a breakdown of the paper structure: The related works on machine learning approaches in the fields of CKD are presented in
Section 2.
Section 3 presents the proposed deep neural model for early detection of CKD. The results are discussed in
Section 4, along with a full explanation.
Section 5 wraps up the findings and looks ahead to the future.
2. Related Works
Machine learning models have been shown to be effective in predicting and diagnosing serious diseases. Early detection of chronic diseases, particularly the search for new treatments for chronic kidney disease, has gotten a lot of attention from doctors and researchers in recent years. Several recent research has demonstrated that machine learning and deep learning models may be used to successfully diagnose chronic kidney disease (CKD).
Table 1 presents a detailed comparison of machine learning methods for the diagnosis of Chronic Diseases from the existing literature.
Z. Chen, X.et al. proved the reliability of multivariate models in clinical practice risk assessment for patients with CKD [
30]. The Chronic Renal Failure (CFR) data bank at UC Irvine was used in this investigation. In their comparison investigation, they used the
KNN, SVM, and Soft independent modeling of class analogy. In comparison to the other two models, the SVM model processed noise within the data set better. In this comparison, the SVM accuracy was 99%. The author of [
31] developed a decision-making tool for doctors to forecast the occurrence of CRF in patients. The authors employed
KNN, Naive Bayes, LDA, random subspace, and tree-based classification techniques on the CRF data set from the UCI repository. The random subspace with the
KNN classifier has a 94% accuracy rate, according to the researchers. The authors of another study [
32] created decision support similar to [
31]. The authors classified CRF using Artificial Neural Networks (ANN), Naive Bayes, and decision tree algorithms in this paper. The performance of various machine learning algorithms was examined on Jordan’s Prince Hamza Hospital data set. The decision tree is predicted the most accurate when compared to two other approaches. Song et al. [
22] created a gradient boosting-based prediction model to detect CKD using diabetes patient’s EHR and billing data. The authors of [
33] published a study on UCI CKD data sets that used SVM, decision trees, Nave Bayes, and
KNN to detect CKD. The authors developed a ranking algorithm to choose features. With a score of 99.75, the decision tree outperformed three alternative machine learning methods. The authors of [
34] presented a hierarchical multiclass classification technique for detecting chronic renal disease in an unbalanced data set.
As a baseline, the authors used naive Bayes, logistic regression, decision trees, and random forests classifiers. Within each patient, the proposed classification approach discovered severe cases. A chronic renal disease diagnosis system was proposed in [
35] to diagnose CKD at an early stage. For preparing the data, the authors used the
K-means technique. On processed data, the
KNN, SVM, and Naive Bayes classification algorithms were used. Classification algorithms produced the greatest accuracy of 97.8%. Almasoud and Ward [
36] reported a study on CKD that used logistic regression, SVM, random forest, and gradient boosting techniques. Four categorization techniques were applied to selected features. Gradient boosting has the highest accuracy of 99%. E M Senan et al. [
37] recommended a study on early-stage CKD diagnosis. The RFE method was used to select characteristics from the CKD data set. The outcomes of the SVM,
KNN, random forest and decision tree algorithms were compared.
Krishnamurthy S. et al. [
38] developed various artificial intelligence models to predict Chronic Kidney Disease. The LightGBM model selected the most important features for CKD prediction: age, gout, diabetes mellitus, use of sulfonamides, and angiotensins. The convolutional neural networks achieved the best performance and the highest AUROC metric, 0.954, compared to other models. Mohamed Elhoseny et al. [
19] presented an intelligent prediction system for Chronic Kidney Disease. The density-based Feature Selection method eliminates the irrelevant features and then passes selected features to the Ant Colony-based Optimization classifier to predict CKD. Singh and Jain [
39] presented novel hybrid approach for diagnose CKD and achieved 92.5 % of prediction accuracy. An artificial neural network for CKD diagnosis was proposed by Neves et al. [
25]. The diagnostic sensitivity values ranged from 93.1% to 94.9%, and the diagnostic specificity values ranged from 91.9% to 94.2% in this work.
Vasquez-Morales et al. [
27] used large CKD data to generate a neural network classifier, and the model was 95% accurate. Makino et al. [
28] used textual data to extract patients diagnoses and treatment information in order to forecast the course of diabetic kidney disease. Ren et al. [
29] developed a predictive model for the identification of CKD from an Electronic Health Records (EHR) data set. This proposed model is based on a neural network framework that encodes and decodes the textual and numerical information from EHR. Ma F. et al. [
40] develop a deep neural network model to detect chronic renal disease. The presented model obtained the highest accuracy compared to ANN and SVM. Almansour et al. [
41] devised a way for preventing CKD using machine learning. The SVM and ANN were among the machine learning classification algorithms used by the researchers. The results of the experiments revealed that ANN had a greater accuracy of 99.75% than SVM.
J. Qin et al. [
42] presented a machine learning method for the early detection of CKD. They used logistic regression, random forest, SVM, naive Bayes classifier,
KNN, and feed-forward neural network to develop their models. The most accurate classification model was random forest, which had a 99.75% accuracy rate. Z. Segal et al. [
43] presented a machine learning technique based on an ensemble tree (XGBoost) for the early diagnosis of renal illness. The presented model was compared against Random Forest, CatBoost, Regression with Regularization. The proposed model showed better performance in all matrices, including c-statistics 0.93, sensitivity 0.715, and specificity 0.958. Khamparia et al. [
44] developed a deep learning model for early detection of CKD, in which features were selected from multimedia data using a stacked autoencoder model. The authors used A SoftMax classifier to predict the final class. It was observed that the proposed model achieved the highest performance in comparison to conventional classification techniques on the UCI CKD data set.
Polat, H. et al. [
45] presented a study on the role of effective feature selection methods in the accurate prediction of CKD. In this paper, wrapper and filter feature selection approaches were used to select the dimension of the Chronic Kidney Disease data set. The selected features are then passed to Support Vector Machine to classify Chronic Kidney Disease for diagnosis purposes. The experimental results presented that Support Vector Machine generates better results on selected features by the Best First search method with filtered subset evaluator. SVM achieved an accuracy rate (98.5%) in comparison to features selected by other wrapper and filter methods. Ebiaredoh-Mienye Sarah A. et al. [
46] presented a robust model for the prediction of CKD that integrates an enhanced sparse autoencoder (SAE) and Softmax regression. In this proposed model, autoencoders achieved sparsity by penalizing the weights. The Softmax regression was optimized for the classification task; therefore, the proposed model achieved excellent performance. The proposed model obtained an accuracy of 98% on the chronic kidney disease (CKD) data set. The proposed model achieved comparable performance with other existing methods. Zhiyong Pang et al. [
47] proposed a fully automated computer-aided diagnosis system to classify malignant and benign masses using breast magnetic resonance imaging. The texture features were selected by integration of support vector machine with ReliefF feature selection method. This system achieved an accuracy of 92.3%. Chen et al. [
21] presented a model in which Hepatitis was diagnosed with a hybrid method that integrates a Fisher discriminatory analysis algorithm and an SVM classifier. As a result of comparing the proposed method with the existing methods, the hybrid method outperforms the other methods, and the highest classification accuracy of 96.77% is achieved. The authors presented a breast cancer diagnosis model in this study [
48]. The selected features by sequential forward selection and the backward selection methods are passed to Artificial Neural Networks to classify breast cancer. SBSP + NN achieved the highest accuracy of 98.75%.
Table 1.
Comparative Accuracy analysis of the diagnosis of Chronic Diseases from literature.
Table 1.
Comparative Accuracy analysis of the diagnosis of Chronic Diseases from literature.
| Chronic Diseases Diagnosis | Model | Accuracy Achieved (%) | Reference |
|---|
| Kidney Renal Failure | Artificial Neural Networks | 91.9%–94.2% | [25] |
| Diabetic Kidney Disease | Convolutional Model | 71% | [28] |
| Chronic Kidney Disease | Neural Network Classifier | 95% | [27] |
| Breast Cancer | SBSP + NN | 98.57% | [48] |
| Hepatitis Disease | FDA and SVM | 96.77% | [21] |
| Breast Cancer | SVM + ReliefF | 92.3% | [47] |
| Chronic Kidney Disease | KNN, SVM | 99% | [30] |
| Chronic Renal Failure | Fisher Discriminatory Analysis and SVM | 96.7% | [21] |
| Chronic Renal Failure | KNN, Naive Bayes, LDA, Random Subspace and Tree-Based Decision | 94% | [31] |
| Chronic Kidney Disease | SVM, KNN, and Naïve Bayes Decision tree, | 99.7% | [33] |
| Chronic Kidney Disease | Logistic Regression, Decision Tree, Naïve Bayes, and Random Forests | 93% | [34] |
| Chronic Kidney Disease | KNN, SVM, and Naïve Bayes | 97.8% | [35] |
| Chronic Kidney Disease | SVM, KNN, and decision tree | 99.1% | [37] |
| Chronic Kidney Disease | Convolutional Neural Networks | 95.7% | [38] |
| Chronic Kidney Disease | SVM, Random Forest, and Gradient Boosting | 99% | [36] |
| Chronic Kidney Disease | Logistic regression, KNN, SVM, Random Forest, Naive Bayes and ANN | 99.7% | [42] |
| Chronic Kidney Disease | XGBoost | 95.8% | [43] |
| Chronic Kidney Disease | SVM | 98.5% | [45] |
| Chronic Kidney Disease | Softmax Regression | 98% | [46] |
5. Conclusions and Future Work
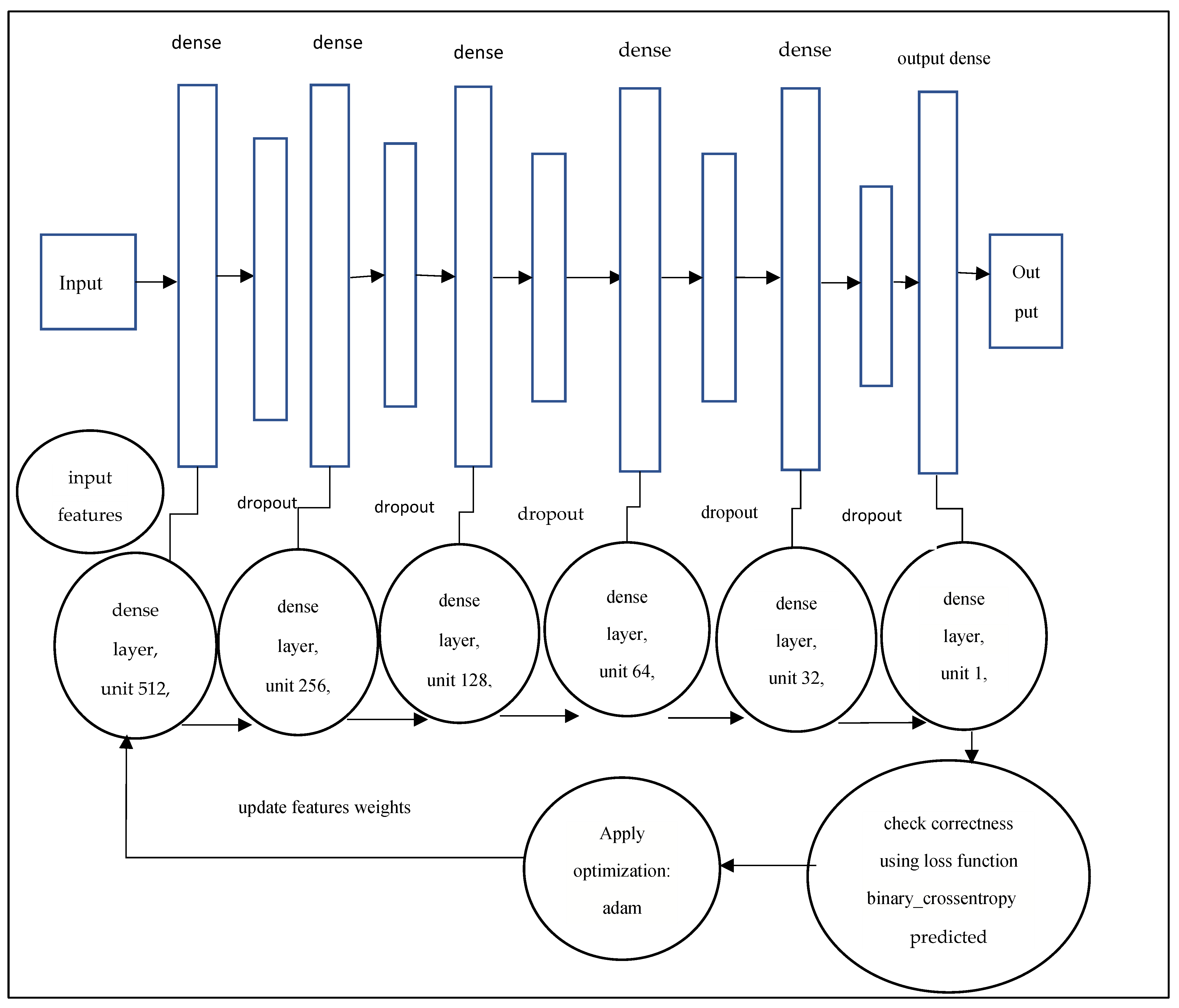
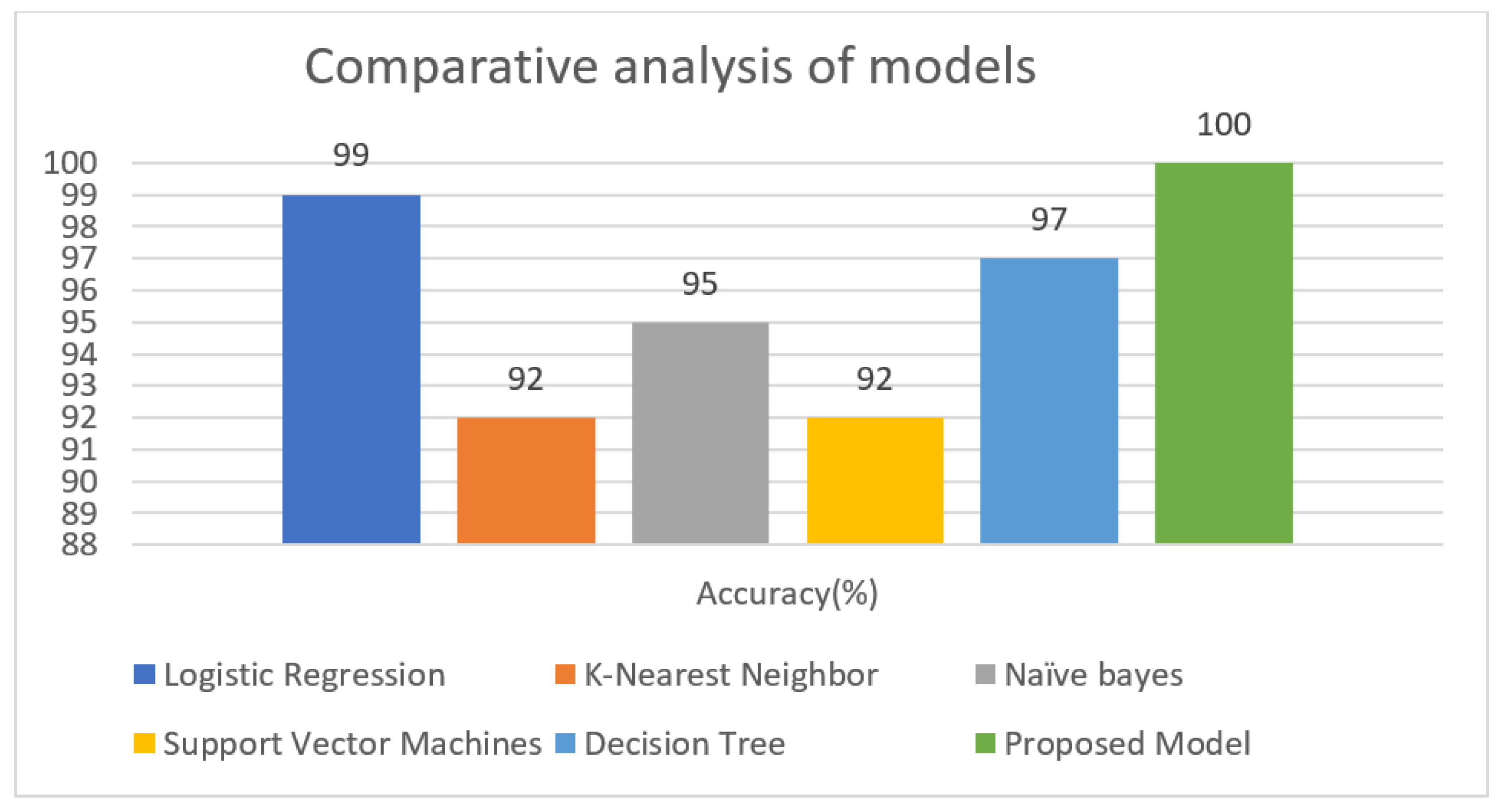
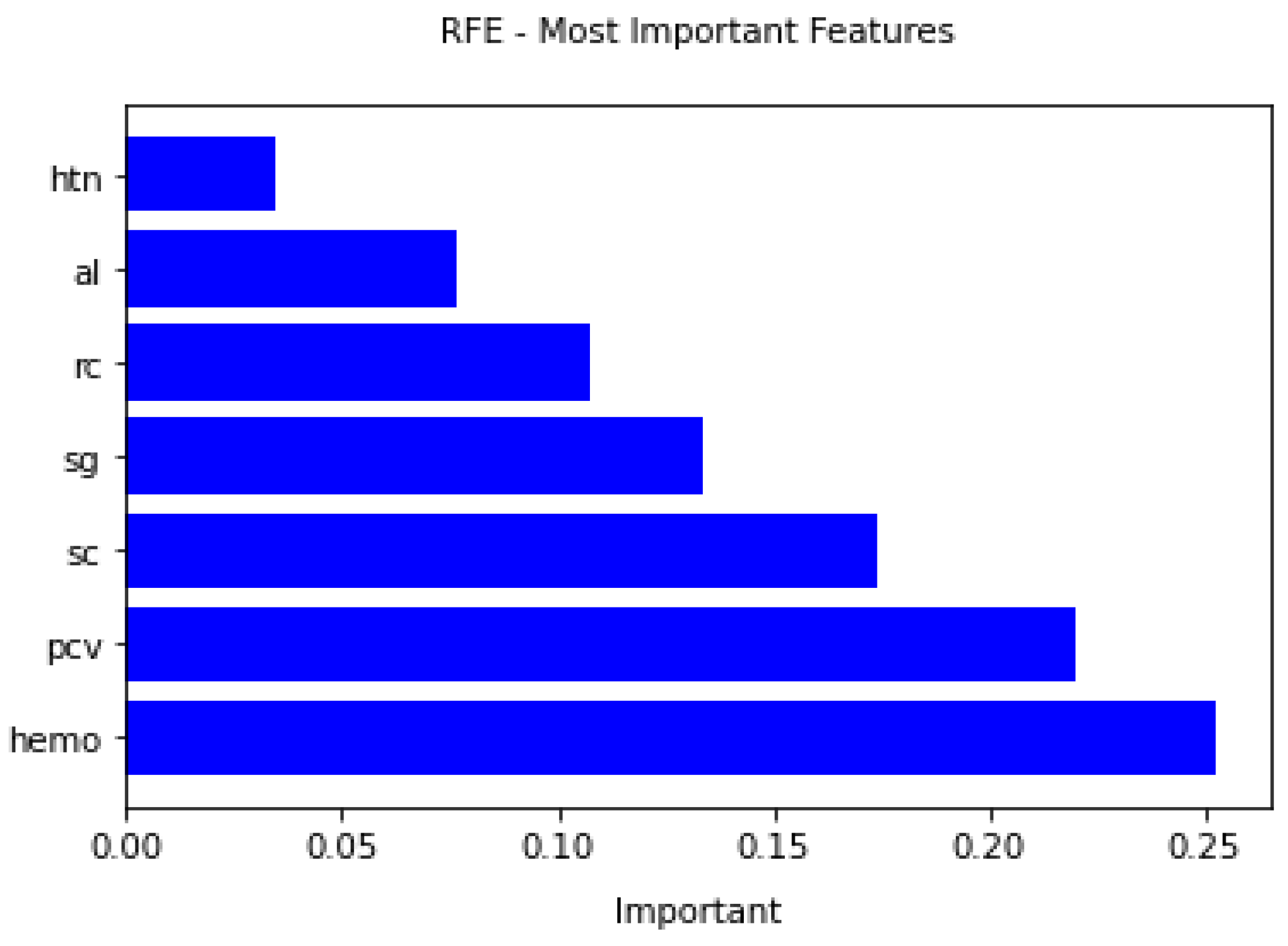
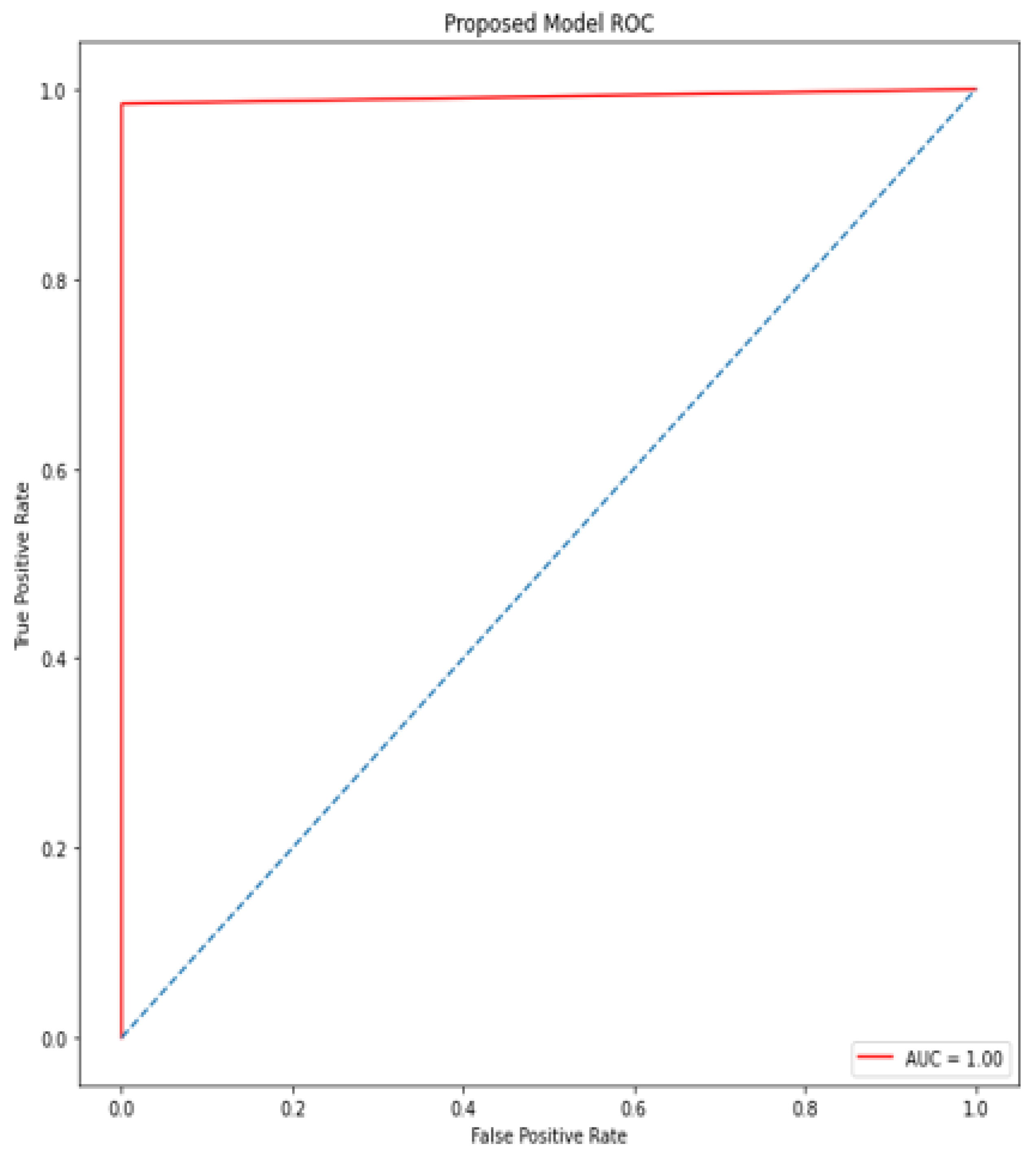
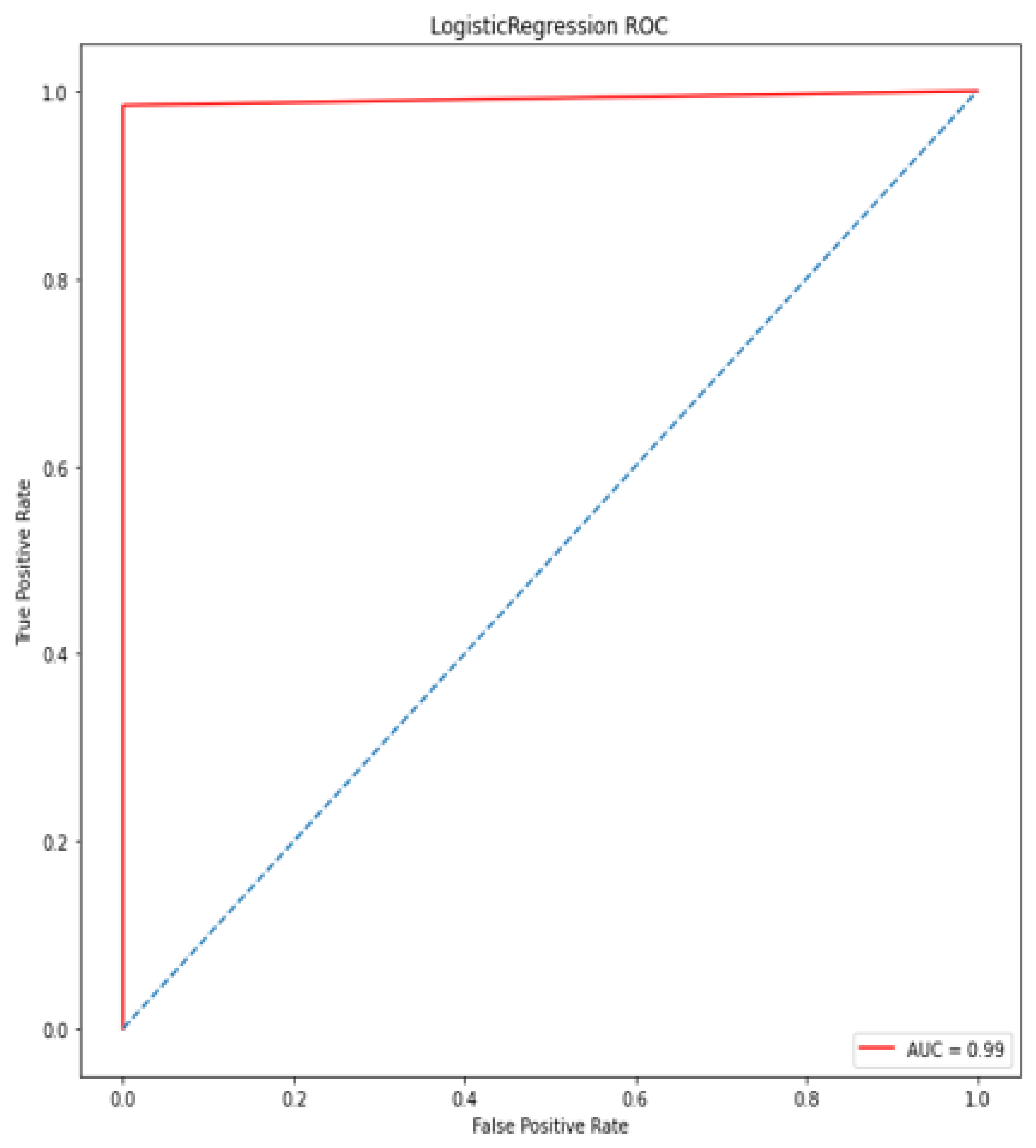
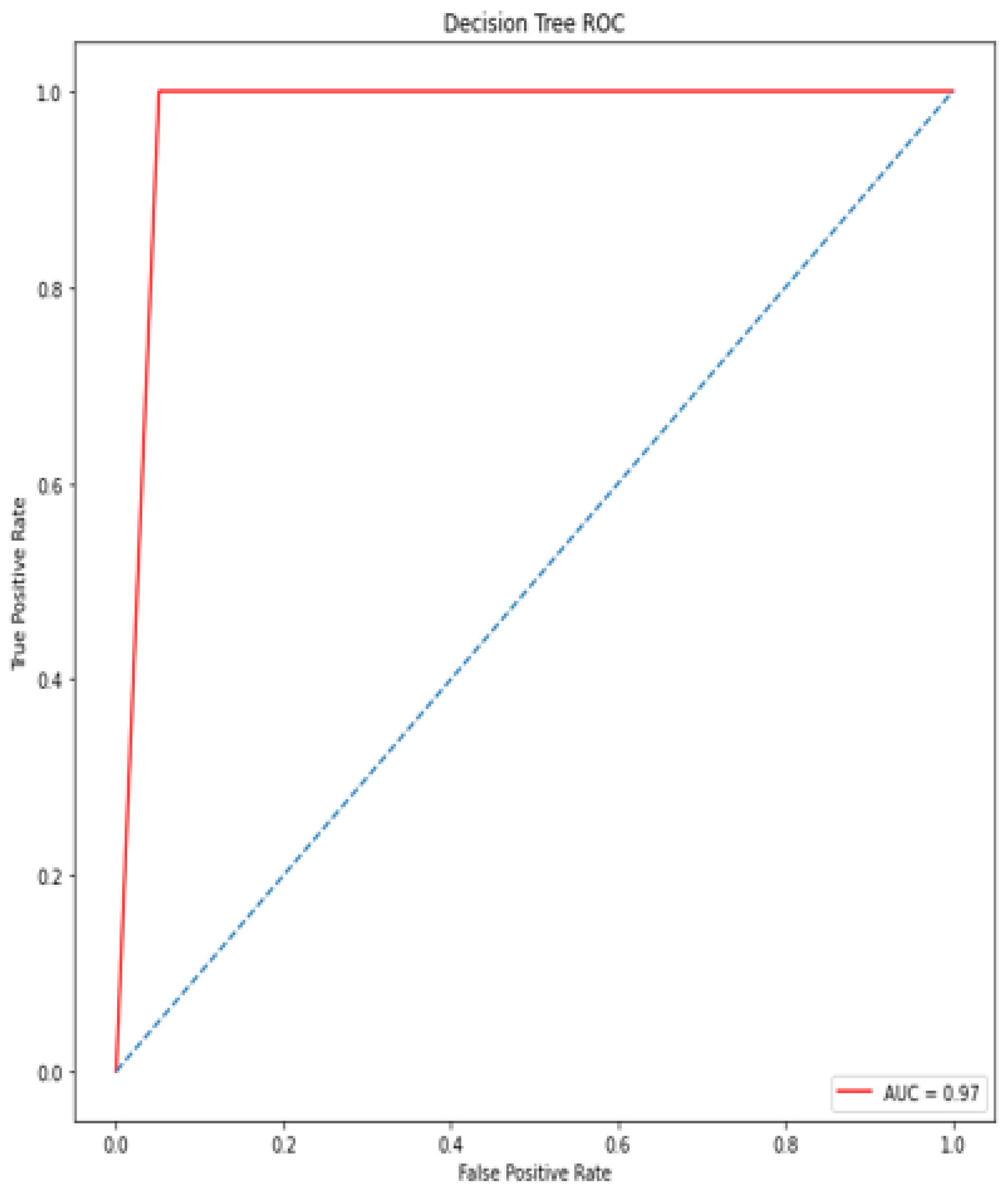
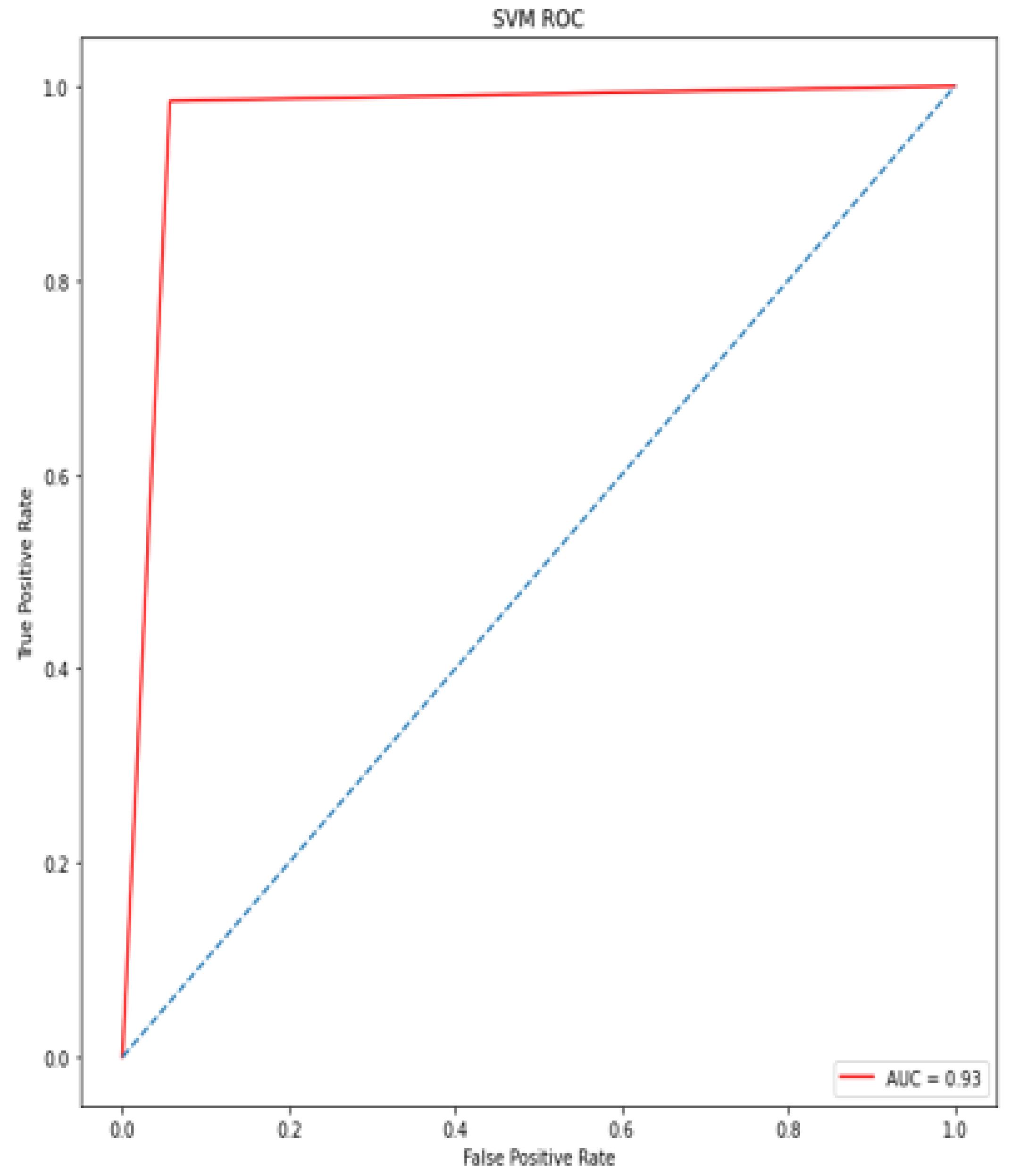
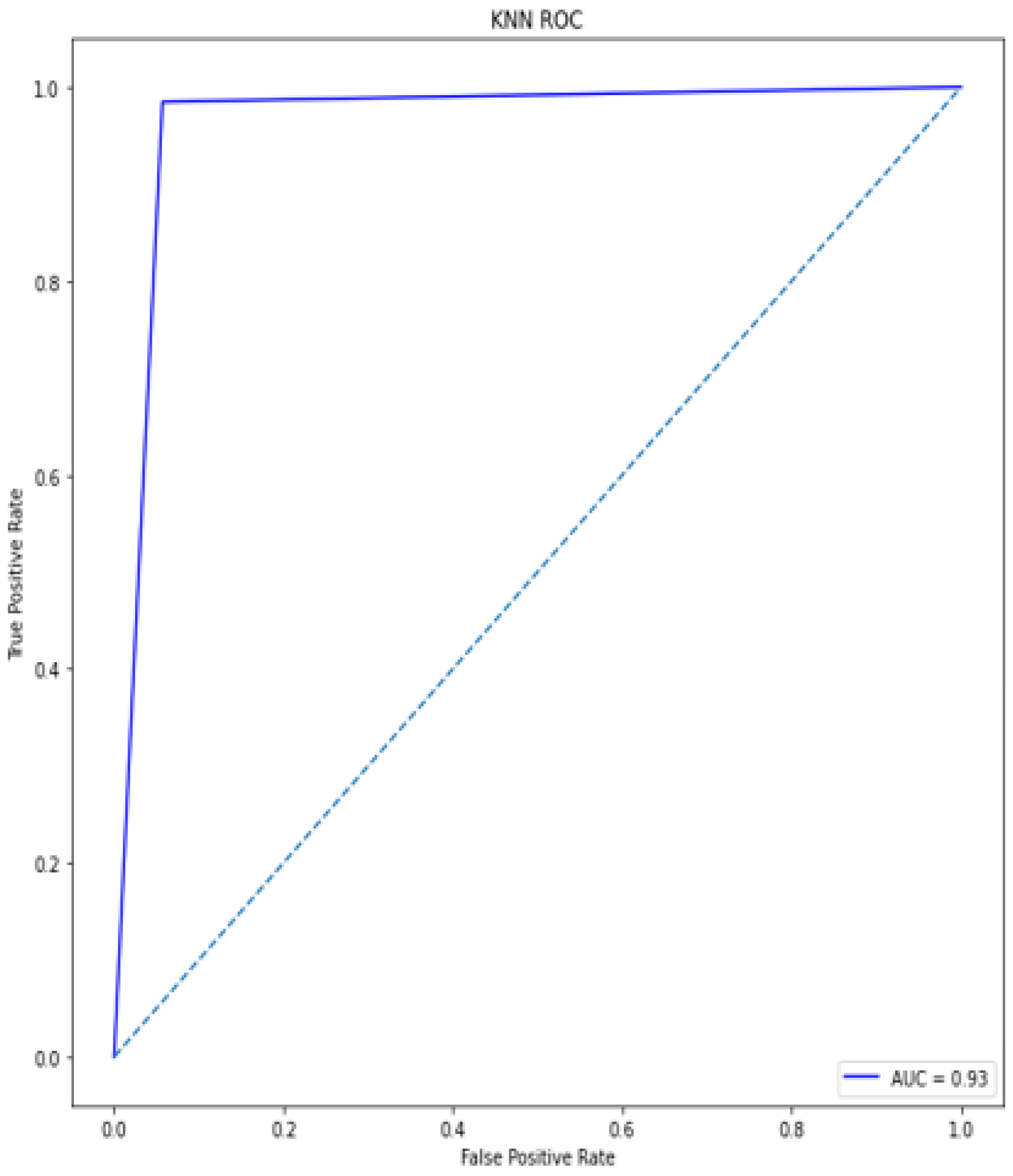
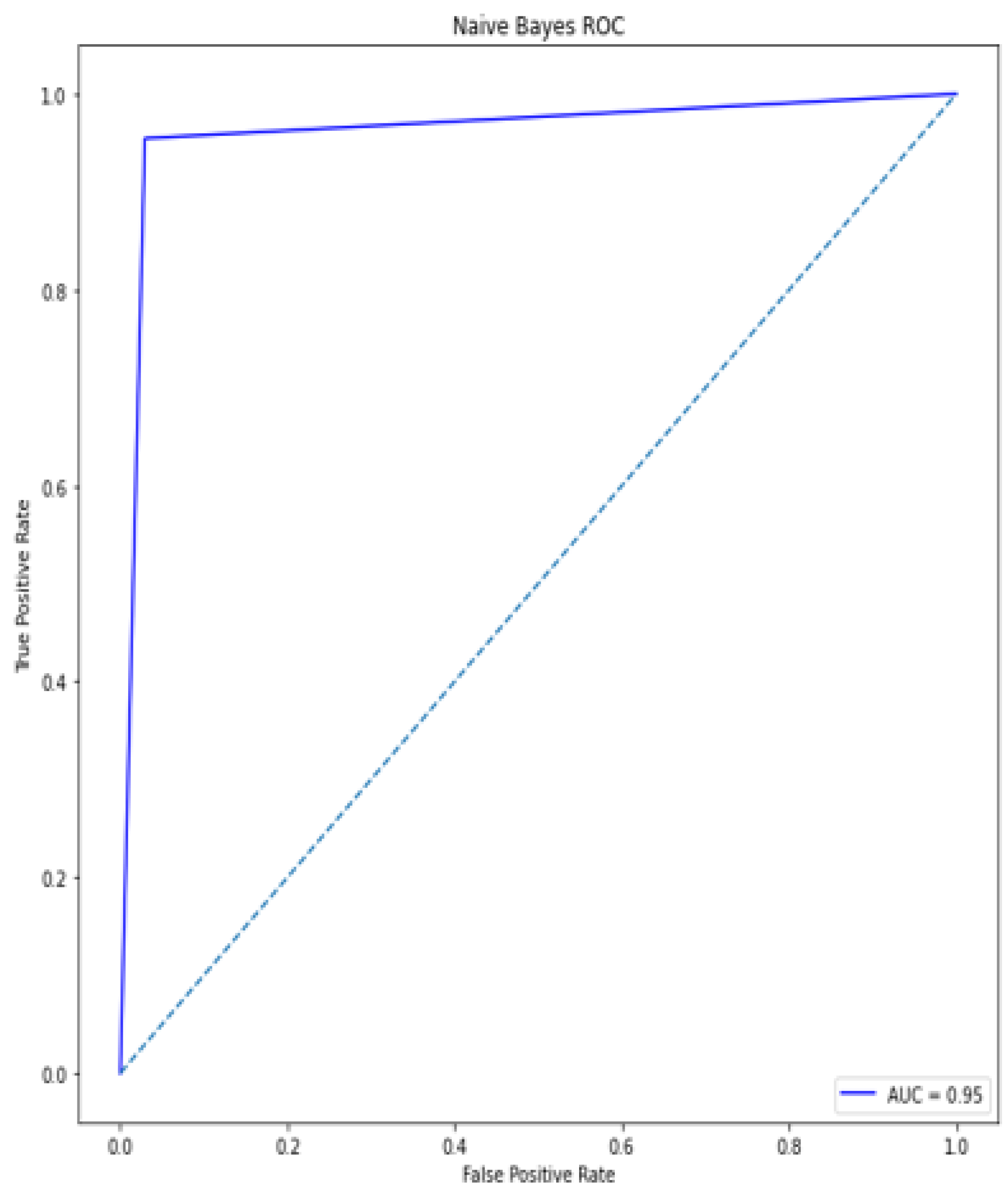
A deep learning model for the early diagnosis of chronic disease is presented in this work. In this research, the authors looked at the Recursive Feature Elimination approach to identify which features are the most important for prediction. The most essential CKD features are packed red blood cell count, albumin, cell volume, serum creatinine, specific gravity, hemoglobin, and hypertension. Classification algorithms are fed with a set of features. Different metrics, including classification accuracy, recall, precision, and f-measure, are used to estimate the comparative analysis. The proposed deep neural model outperformed the other five classifiers (Support Vector Machine (SVM), K-Nearest Neighbor (KNN), Logistic regression, Random Forest, and Naive Bayes classifier) by achieving 100% accuracy. The accuracy of KNN, SVM, Naïve Bayes, Decision tree, Random Forest, logistic regression is 92%, 92%, 95%, 97%, and 99%, respectively.
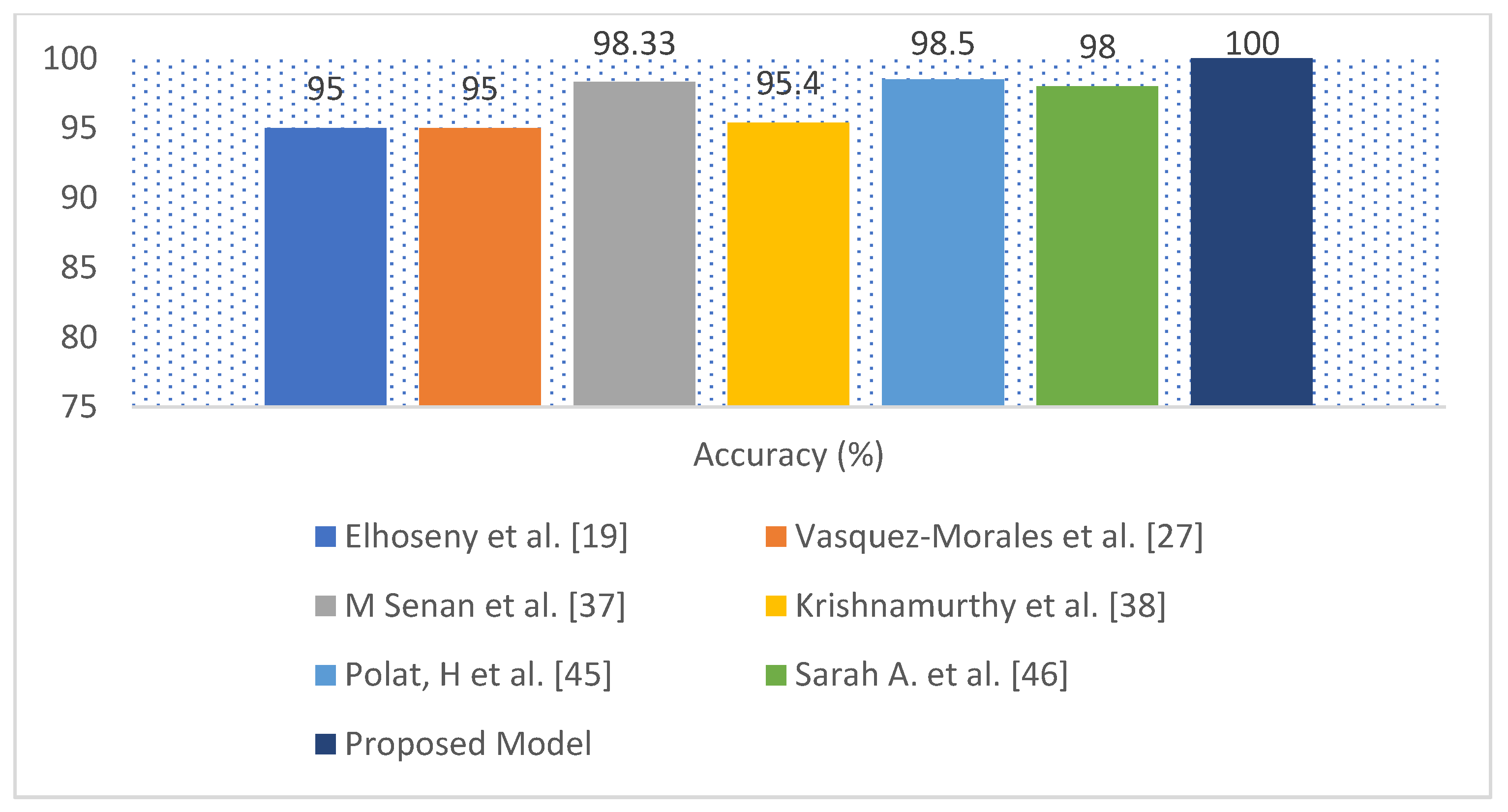
The performance of the proposed model compared with several recent scholarly studies, such as Ant Colony-based Optimization Classifier by Elhoseny et al. [
19], Neural network by Vasquez-Morales et al. [
27],
KNN by M Senan et al. [
37], Convolutional Neural Networks by Krishnamurthy et al. [
38], SVM by Polat, H. et al. [
45], and SAE and Softmax Regression proposed by Sarah A. et al. [
46]. The exiting works obtained the accuracy from 85% to 98.5%, while the proposed model has obtained an accuracy of 100%. The proposed approach could be a useful tool for nephrologists in detecting CKD.
The limitation of the proposed model was that it had been tested on small data sets. To improve the model performance, significant volumes of increasingly sophisticated and representative CKD data will be collected in the future to detect disease severity. The clinical data to be collected from pathologist’s experts. The performance of the proposed model will be evaluated on a large clinical data set based on acid-base parameters, hyperparathyroidism, inorganic phosphorus concentration, and night urination in the future. Additionally, new features will be applied to get a broader perspective on the informative parameters related to CKD disease to test the prediction accuracy.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















