
Diagnosis of Diabetes Mellitus Using Gradient Boosting Machine (LightGBM)


Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Overview of Proposed Approach
- Problem statement: Identify and solve scientific challenges to diagnose diabetes by machine learning in order to prevent or reduce its impact on physical and social well-being.
- Relevant data collection: diabetes-related data were collected from Zewditu Memorial Hospital.
- Diabetes dataset: the collected diabetes data were converted to machine learning model recognizable (tabular) format.
- Data preprocessing: patterns underlying the data were visualized by box-plot and correlation heat-map. Irrelevant data elements and column values were removed and replaced, respectively. The correlation coefficient of each input variable (attributes) to the dependent variable (diabetes or not) was calculated to identify the important features. Each input variable has values in a different range; fast blood sugar (FBS) has minimum 60 and maximum 200 values; whereas, gender has binary values (minimum 0 and maximum 1) but machine learning algorithms recognize patterns numerically, meaning they give higher priority to attributes with large numerical values. By this scenario, FBS has higher priority over gender, which is logically not always true. To avoid such confusion, the attribute values were normalized in a common range using the Min-Max normalization technique [43]. Finally, the preprocessed dataset was split into training and test data samples.
- Light Gradient Boosting Machine (LightGBM): the state-of-the-art LightGBM algorithm has been proposed to predict diabetes mellitus. Here, the LightGBM was optimized by calculating the optimal values of the hyperparameters using 10-fold cross-validation. Finally, we developed other classifier models viz. KNN, SVM, NB, Bagging (constructed on decision tree), RF, and XGBoost and compared the results with the optimal LightGBM model.
LightGBM
3.2. Data Collection and Feature Selection
3.3. Data Preprocessing
3.4. Evaluation
4. Experimental Results and Discussion
4.1. Experimental Results
- Number of trees: The number of boosted trees or estimators will influence the LightGBM performance. To decide on the optimal number in case of the ZMHDD dataset, models with varying numbers of trees were constructed and evaluated.
- Maximum tree depth: To avoid the occurrence of overfitting, we have to limit the maximum depth of trees for tree-based models. This is especially important for small- or mid-sized datasets.
- The number of tree leaves: is the main parameter to control the complexity of the tree model. Theoretically, we can set to obtain the same number of leaves as a depth-wise tree. However, this is not always true in practice. Because a leaf-wise tree is typically much deeper than a depthwise tree for a fixed number of leaves. Unconstrained depth can induce overfitting [46]. Thus, when trying to optimize the num_leaves, we should let it be smaller than .
- LightGBM model optimization: Several LightGBM models at variation of the , , and parameters were constructed using 10-fold cross-validation grid search to define the optimal parametrization in the sense of a validation metric. Following the grid search, our model achieved the best accuracy of 98.15% at the configuration , , and . The 3D visualization of the 10-fold cross-validation grid search result is shown in Figure 4. The size of the bullets in Figure 4 indicates the validation score, the bubble colors indicate the training time.
4.2. Comparison
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Afework, Y.K.; Debelee, T.G. Detection of bacterial wilt on enset crop using deep learning approach. In International Journal of Engineering Research in Africa; Trans Tech Publ.: Bäch, Switzerland, 2020; Volume 51, pp. 131–146. [Google Scholar]
- Debelee, T.G.; Schwenker, F.; Ibenthal, A.; Yohannes, D. Survey of deep learning in breast cancer image analysis. Evolv. Syst. 2020, 11, 143–163. [Google Scholar] [CrossRef]
- Debelee, T.G.; Kebede, S.R.; Schwenker, F.; Shewarega, Z.M. Deep learning in selected cancers’ image analysis—A survey. J. Imaging 2020, 6, 121. [Google Scholar] [CrossRef]
- Debelee, T.G.; Amirian, M.; Ibenthal, A.; Palm, G.; Schwenker, F. Classification of mammograms using convolutional neural network based feature extraction. In Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Springer: Berlin/Heidelberg, Germany, 2018; Volume 244, pp. 89–98. [Google Scholar]
- Debelee, T.G.; Schwenker, F.; Rahimeto, S.; Yohannes, D. Evaluation of modified adaptive k-means segmentation algorithm. Comput. Visual Media 2019, 5, 347–361. [Google Scholar] [CrossRef] [Green Version]
- Debelee, T.G.; Gebreselasie, A.; Schwenker, F.; Amirian, M.; Yohannes, D. Classification of mammograms using texture and cnn based extracted features. J. Biomimetics Biomater. Biomed. Eng. 2019, 42, 79–97. [Google Scholar] [CrossRef]
- Rahimeto, S.; Debelee, T.G.; Yohannes, D.; Schwenker, F. Automatic pectoral muscle removal in mammograms. Evol. Syst. 2019, 42, 1–8. [Google Scholar] [CrossRef]
- Kebede, S.R.; Debelee, T.G.; Schwenker, F.; Yohannes, D. Classifier based breast cancer segmentation. J. Biomimetics Biomater. Biomed. Eng. 2020, 47, 41–61. [Google Scholar] [CrossRef]
- Biratu, E.S.; Schwenker, F.; Debelee, T.G.; Kebede, S.R.; Negera, W.G.; Molla, H.T. Enhanced region growing for brain tumor mr image segmentation. J. Imaging 2021, 7, 22. [Google Scholar] [CrossRef] [PubMed]
- Biratu, E.S.; Schwenker, F.; Ayano, Y.M.; Debelee, T.G. A Survey of Brain Tumor Segmentation and Classification Algorithms. J. Imaging 2021, 7, 179. [Google Scholar] [CrossRef]
- Veazie, S.; Winchell, K.; Gilbert, J.; Paynter, R.; Ivlev, I.; Eden, K.B.; Nussbaum, K.; Weiskopf, N.; Guise, J.-M.; Helfand, M. Rapid evidence review of mobile applications for self-management of diabetes. J. Gen. Internal Med. 2018, 33, 1167–1176. [Google Scholar] [CrossRef] [Green Version]
- Kanellakis, S.; Mavrogianni, C.; Karatzi, K.; Lindstrom, J.; Cardon, G.; Iotova, V.; Wikström, K.; Shadid, S.; Moreno, L.A.; Tsochev, K.; et al. Development and validation of two self-reported tools for insulin resistance and hypertension risk assessment in a european cohort: The feel4diabetes-study. Nutrients 2020, 12, 960. [Google Scholar] [CrossRef] [Green Version]
- Fatima, M.; Pasha, M. Survey of machine learning algorithms for disease diagnostic. J. Intell. Learn. Syst. Appl. 2017, 9, 1. [Google Scholar] [CrossRef] [Green Version]
- Sarwar, A.; Ali, M.; Manhas, J.; Sharma, V. Diagnosis of diabetes type-ii using hybrid machine learning based ensemble model. Int. J. Inform. Technol. 2020, 12, 419–428. [Google Scholar] [CrossRef]
- Choudhury, A.; Gupta, D. A survey on medical diagnosis of diabetes using machine learning techniques. In Recent Developments in Machine Learning and Data Analytics; Springer: Berlin/Heidelberg, Germany, 2019; pp. 67–78. [Google Scholar]
- Ravaut, M.; Sadeghi, H.; Leung, K.K.; Volkovs, M.; Rosella, L.C. Diabetes mellitus forecasting using population health data in ontario, canada. arXiv 2019, arXiv:1904.04137. [Google Scholar]
- Dagliati, A.; Marini, S.; Sacchi, L.; Cogni, G.; Teliti, M.; Tibollo, V.; De Cata, P.; Chiovato, L.; Bellazzi, R. Machine learning methods to predict diabetes complications. J. Diabetes Sci. Technol. 2018, 12, 295–302. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.; Wang, Z. A risk prediction model for type 2 diabetes based on weighted feature selection of random forest and xgboost ensemble classifier. In Proceedings of the 2019 Eleventh International Conference on Advanced Computational Intelligence (ICACI), Guilin, China, 7–9 June 2019; pp. 278–283. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inform. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Basha, S.M.; Rajput, D.S.; Vandhan, V. Impact of gradient ascent and boosting algorithm in classification. Int. J. Intell. Eng. Syst. 2018, 11, 41–49. [Google Scholar] [CrossRef]
- Benbelkacem, S.; Atmani, B. Random forests for diabetes diagnosis. In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, 3–4 April 2019; pp. 1–4. [Google Scholar]
- Xiong, X.-L.; Zhang, R.-X.; Bi, Y.; Zhou, W.-H.; Yu, Y.; Zhu, D.-L. Machine learning models in type 2 diabetes risk prediction: Results from a cross-sectional retrospective study in chinese adults. Curr. Med. Sci. 2019, 39, 582–588. [Google Scholar] [CrossRef] [PubMed]
- Husain, A.; Khan, M.H. Early diabetes prediction using voting based ensemble learning. In International Conference on Advances in Computing and Data Sciences; Springer: Berlin/Heidelberg, Germany, 2018; pp. 95–103. [Google Scholar]
- Mir, A.; Dhage, S.N. Diabetes disease prediction using machine learning on big data of healthcare. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018; pp. 1–6. [Google Scholar]
- Razavian, N.; Blecker, S.; Schmidt, A.M.; Smith-McLallen, A.; Nigam, S.; Sontag, D. Population-level prediction of type 2 diabetes from claims data and analysis of risk factors. Big Data 2015, 3, 277–287. [Google Scholar] [CrossRef] [Green Version]
- Krishnan, R.; NargesRazavian, Y.; Nigam, S.; Cross, I.B.; Blecker, S.; Schmidt, A.M.; Sontag, D. Early Detection of Diabetes from Health Claims. Available online: http://people.csail.mit.edu/dsontag/papers/KrishnanEtAl_nips13health.pdf (accessed on 14 July 2021).
- Abbas, H.T.; Alic, L.; Erraguntla, M.; Xi, J.X.; Abdul-Ghani, M.; Abbasi, Q.H.; Qaraqe, M.K. Predicting long-term type 2 diabetes with support vector machine using oral glucose tolerance test. PLoS ONE 2019, 14, e0219636. [Google Scholar] [CrossRef] [Green Version]
- Deberneh, H.M.; Kim, I. Prediction of Type 2 Diabetes Based on Machine Learning Algorithm. Int. J. Environ. Res. Public Health 2021, 18, 3317. [Google Scholar] [CrossRef]
- Chaki, J.; Ganesh, S.T.; Cidham, S.; Theertan, S.A. Machine learning and artificial intelligence based diabetes mellitus detection and self-management: A systematic review. J. King Saud Univ.-Comput. Inform. Sci. 2020, 11, 573–577. [Google Scholar] [CrossRef]
- Alassaf, R.A.; Alsulaim, K.A.; Alroomi, N.Y.; Alsharif, N.S.; Aljubeir, M.F.; Olatunji, S.O.; Alahmadi, A.Y.; Imran, M.; Alzahrani, R.A.; Alturayeif, N.S. Preemptive diagnosis of diabetes mellitus using machine learning. In Proceedings of the 2018 21st Saudi Computer Society National Computer Conference (NCC), Riyadh, Saudi Arabia, 25–26 April 2018; pp. 1–5. [Google Scholar]
- Faruque, M.F.; Sarker, I.H. Performance analysis of machine learning techniques to predict diabetes mellitus. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’sBazar, Bangladesh, 7–9 February 2019; pp. 1–4. [Google Scholar]
- Guo, Y.; Bai, G.; Hu, Y. Using bayes network for prediction of type-2 diabetes. In Proceedings of the 2012 International Conference for Internet Technology and Secured Transactions, London, UK, 10–12 December 2012; pp. 471–472. [Google Scholar]
- Sun, X.; Liu, M.; Sima, Z. A novel cryptocurrency price trend forecasting model based on lightgbm. Finan. Res. Lett. 2020, 32, 101084. [Google Scholar] [CrossRef]
- Jin, D.; Lu, Y.; Qin, J.; Cheng, Z.; Mao, Z. Swiftids: Real-time intrusion detection system based on lightgbm and parallel intrusion detection mechanism. Comput. Sec. 2020, 97, 101984. [Google Scholar] [CrossRef]
- Liang, W.; Luo, S.; Zhao, G.; Wu, H. Predicting hard rock pillar stability using gbdt, xgboost, and lightgbm algorithms. Mathematics 2020, 8, 765. [Google Scholar] [CrossRef]
- Alsharkawi, A.; Al-Fetyani, M.; Dawas, M.; Saadeh, H.; Alyaman, M. Poverty classification using machine learning: The case of jordan. Sustainability 2021, 13, 1412. [Google Scholar] [CrossRef]
- Wang, M.; Yue, L.; Yang, X.; Wang, X.; Han, Y.; Yu, B. Fertility-lightgbm: A fertility-related protein prediction model by multi-information fusion and light gradient boosting machine. Biomed. Signal Process. Control 2021, 68, 102630. [Google Scholar] [CrossRef]
- Li, L.; Lin, Y.; Yu, D.; Liu, Z.; Gao, Y.; Qiao, J. A multi-organ fusion and lightgbm based radiomics algorithm for high-risk esophageal varices prediction in cirrhotic patients. IEEE Access 2021, 9, 15041–15052. [Google Scholar] [CrossRef]
- Yin, L.; Ma, P.; Deng, Z. Jlgbmloc—A novel high-precision indoor localization method based on lightgbm. Sensors 2021, 21, 2722. [Google Scholar] [CrossRef]
- Chun, P.-J.; Izumi, S.; Yamane, T. Automatic detection method of cracks from concrete surface imagery using two-step light gradient boosting machine. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 61–72. [Google Scholar] [CrossRef]
- Song, Y.; Jiao, X.; Yang, S.; Zhang, S.; Qiao, Y.; Liu, Z.; Zhang, L. Combining multiple factors of lightgbm and xgboost algorithms to predict the morbidity of double-high disease. In International Conference of Pioneering Computer Scientists, Engineers and Educators; Springer: Berlin/Heidelberg, Germany, 2019; pp. 635–644. [Google Scholar]
- World Health Organization. Classification of Diabetes Mellitus; WHO: Geneva, Switzerland, 2019. [Google Scholar]
- Al Shalabi, L.; Shaaban, Z. Normalization as a preprocessing engine for data mining and the approach of preference matrix. In Proceedings of the 2006 International Conference on Dependability of Computer Systems, Szklarska Poreba, Poland, 25–27 May 2006; pp. 207–214. [Google Scholar]
- Tyree, S.; Weinberger, K.; Agrawal, Q.K.; Paykin, J. Parallel boosted regression trees for web search ranking. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 387–396. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T. Welcome to Lightgbm’s Documentation. Available online: https://lightgbm.readthedocs.io/en/latest/ (accessed on 12 June 2021).
- Jiao, Y.; Du, P. Performance measures in evaluating machine learning based bioinformatics predictors for classifications. Quant. Biol. 2016, 4, 320–330. [Google Scholar] [CrossRef] [Green Version]
- Clement, C.L.; Kauwe, S.K.; Sparks, T.D. Benchmark aflow data sets for machine learning. Integrat. Mater. Manufact. Innov. 2020, 9, 153–156. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Diabetes Indicators (Attribute) | Description | Unit | Correlation to Class Variable | |
|---|---|---|---|---|
| Age | patient age | years | −0.03 |  |
| Gender | patient gender | male/female | 0.014 |  |
| Insulin | hormone made by the pancreas organ that allows human body to use sugar (glucose) from food carbohydrates for energy conversion or storage | pmol/L | 0.009 |  |
| Systolic_BP | systolic value of blood pressure: indicates highest pressure exerted as blood pushes through heart | mmHg | 0.16 |  |
| Diastolic_BP | diastolic value of blood pressure: indicates the pressure maintained by the arteries when the vessels are relaxed between heartbeats | mmHg | −0.045 |  |
| BMI | body mass index: a person’s weight in kilograms divided by the square of height in meters | kg/ | 0.29 |  |
| Total_Cholesterol | Total blood cholesterol: accumulated figure of all different blood fats (includes high-density lipoprotein (HDL), low-density lipoprotein (LDL) and 20% of the total triglycerides) | mg/dL | 0.34 |  |
| Low_Density_Lipoprotein | low-density lipoprotein (LDL) cholesterol: often known as ‘bad cholesterol’, because it can build up in blood vessels | mg/dL | 0.11 |  |
| Pulse_Rate | a measurement of the heart rate, or the number of times the heart beats per minute; it also can indicate the heart rhythm and strength of the pulse. | bpm | 0.19 |  |
| FBS | fasting blood sugar: blood sugar when a patient has not eaten or consumed any calories in the past 8 h (usually, this is done overnight) | mg/dL | 0.37 |  |
| Class | observed diabetes status (0: nondiabetic, 1: diabetic) | – | 1.00 |  |
| Dataset | #Instances | #Indicators | #Classes |
|---|---|---|---|
| ZMHDD | 2109 | 10 | 2 |
| Metric | Value | |
|---|---|---|
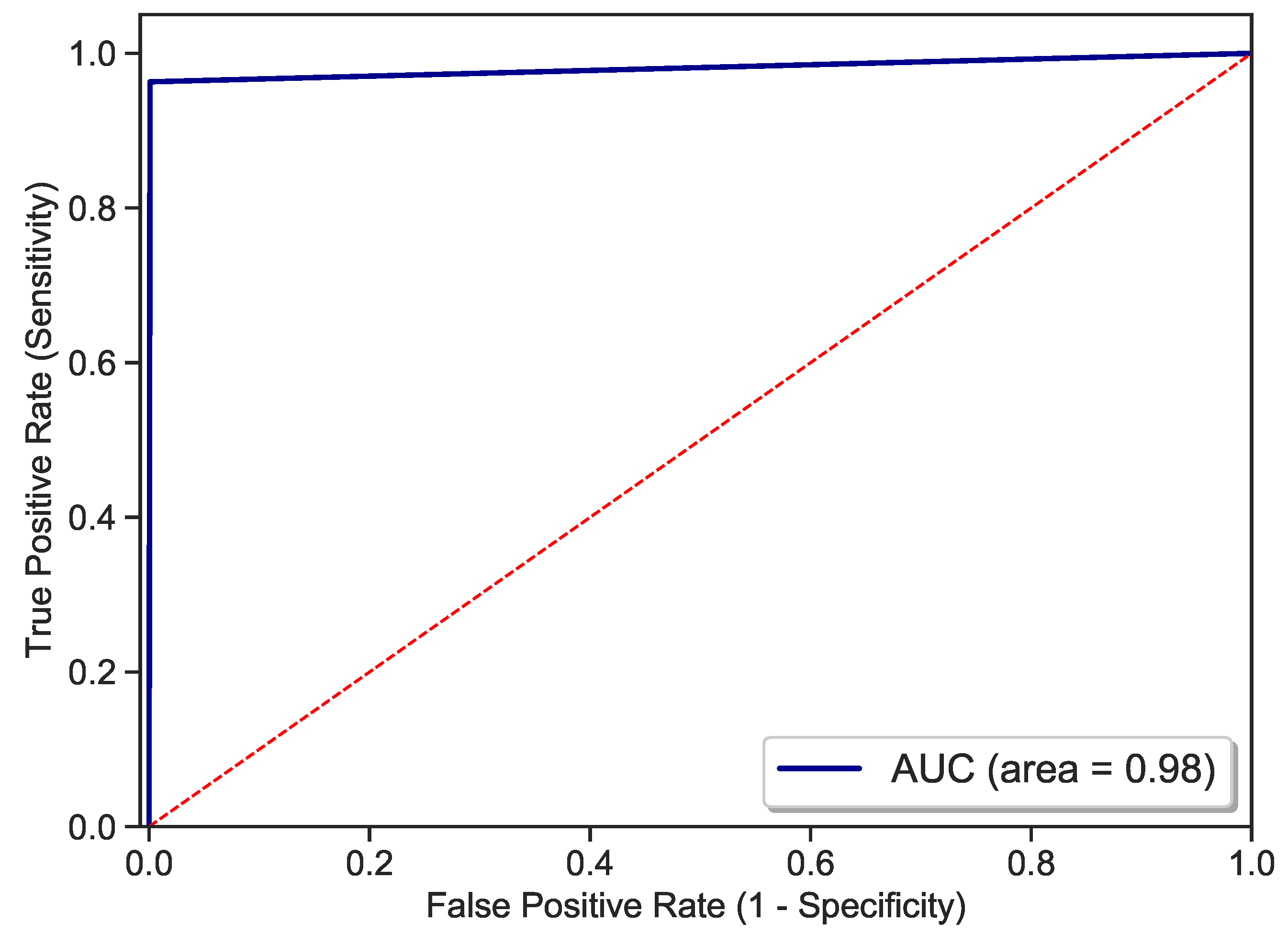
| Accuracy |  | 0.98 |
| Sensitivity |  | 0.99 |
| Specificity |  | 0.96 |
| Model | Accuracy | |
|---|---|---|
| KNN |  | 0.784 |
| SVM |  | 0.908 |
| NB |  | 0.927 |
| BG |  | 0.953 |
| RF |  | 0.969 |
| XGBoost |  | 0.965 |
| LightGBM |  | 0.981 |
| Algorithms | Accuracy | AUC | Sensitivity | Specificity | Computation Tims/s | |
|---|---|---|---|---|---|---|
| Training | Testing | |||||
| KNN | 78.4% | 77.8% | 62.1% | 93.6% | 0.012 | 0.32 |
| SVM | 90.8% | 90.4% | 82.3% | 98.6% | 0.081 | 0.007 |
| NB | 92.7% | 92.4% | 85.2% | 99.5% | 0.05 | 0.006 |
| BG | 95.3% | 95.2% | 94.1% | 96.3% | 1.3 | 0.02 |
| RF | 96.9% | 96.8% | 93.6% | 100% | 2.5 | 0.011 |
| XGBoost | 96.4% | 96.3% | 92.6% | 100% | 2 | 0.004 |
| LightGBM | 98.1% | 98.1% | 99.9% | 96.3% | 0.624 | 0.0015 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rufo, D.D.; Debelee, T.G.; Ibenthal, A.; Negera, W.G. Diagnosis of Diabetes Mellitus Using Gradient Boosting Machine (LightGBM). Diagnostics 2021, 11, 1714. https://doi.org/10.3390/diagnostics11091714
Rufo DD, Debelee TG, Ibenthal A, Negera WG. Diagnosis of Diabetes Mellitus Using Gradient Boosting Machine (LightGBM). Diagnostics. 2021; 11(9):1714. https://doi.org/10.3390/diagnostics11091714
Chicago/Turabian StyleRufo, Derara Duba, Taye Girma Debelee, Achim Ibenthal, and Worku Gachena Negera. 2021. "Diagnosis of Diabetes Mellitus Using Gradient Boosting Machine (LightGBM)" Diagnostics 11, no. 9: 1714. https://doi.org/10.3390/diagnostics11091714