
Cloud Computing-Based Framework for Breast Cancer Diagnosis Using Extreme Learning Machine


 , ,
, , 
Abstract
:1. Introduction
- A design of a cloud-based diagnosis system to monitor remote user health data for breast cancer diagnosis is proposed. Through an analysis of consumer health data stored on cloud servers, the method is flexible enough to diagnose and classify a variety of diseases.
- ELM is used to classify patient data for breast cancer detection.
- The ELM model is compared with other traditional classification algorithms. Large datasets are supported using the cloud to reduce execution time; these classification models are compared using the cloud as well as a standalone platform.
- To further improve the model’s classification performance, feature selection is used to remove irrelevant features, and the hidden layer nodes of ELM are tuned.
- The best performance results of ELM for both standalone and cloud environments are compared.
2. Related Work
- Most of the studies did not consider feature selection and ELM as their primary algorithm for the diagnosis of breast cancer.
- The most important issue is that many of the previous studies restricted their models to standalone systems, and thus, they are not available anytime and anywhere.
- Many of these studies are unique to a particular field of study, but the approach should apply to all fields.
- ELM is considered as the primary classification algorithm.
- To further improve the model’s classification performance, feature selection is used and the hidden layer nodes of ELM are tuned.
- The ELM model is deployed in the cloud environment.
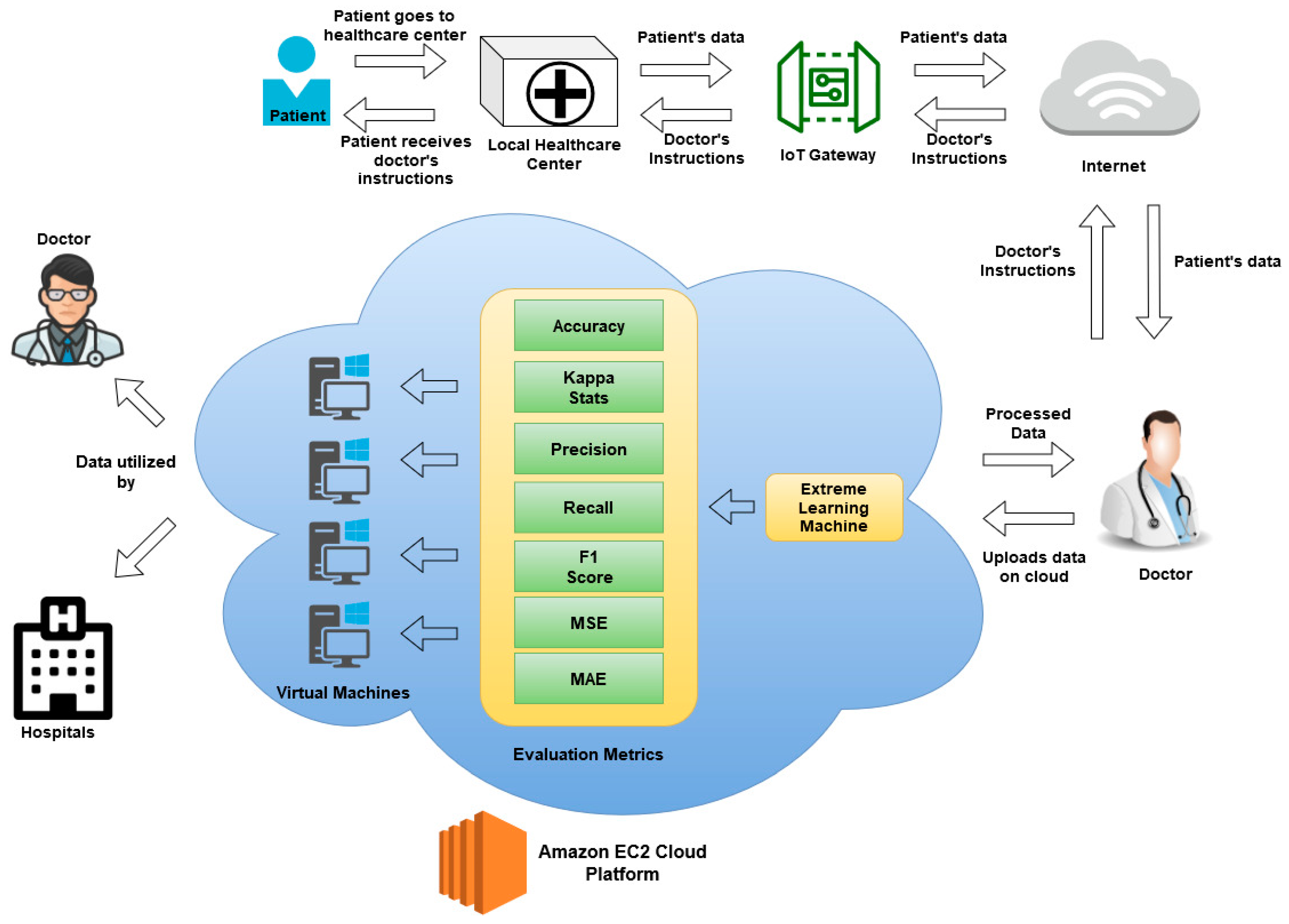
3. Cloud-Based Breast Cancer Diagnosis Model
3.1. Gain Ratio
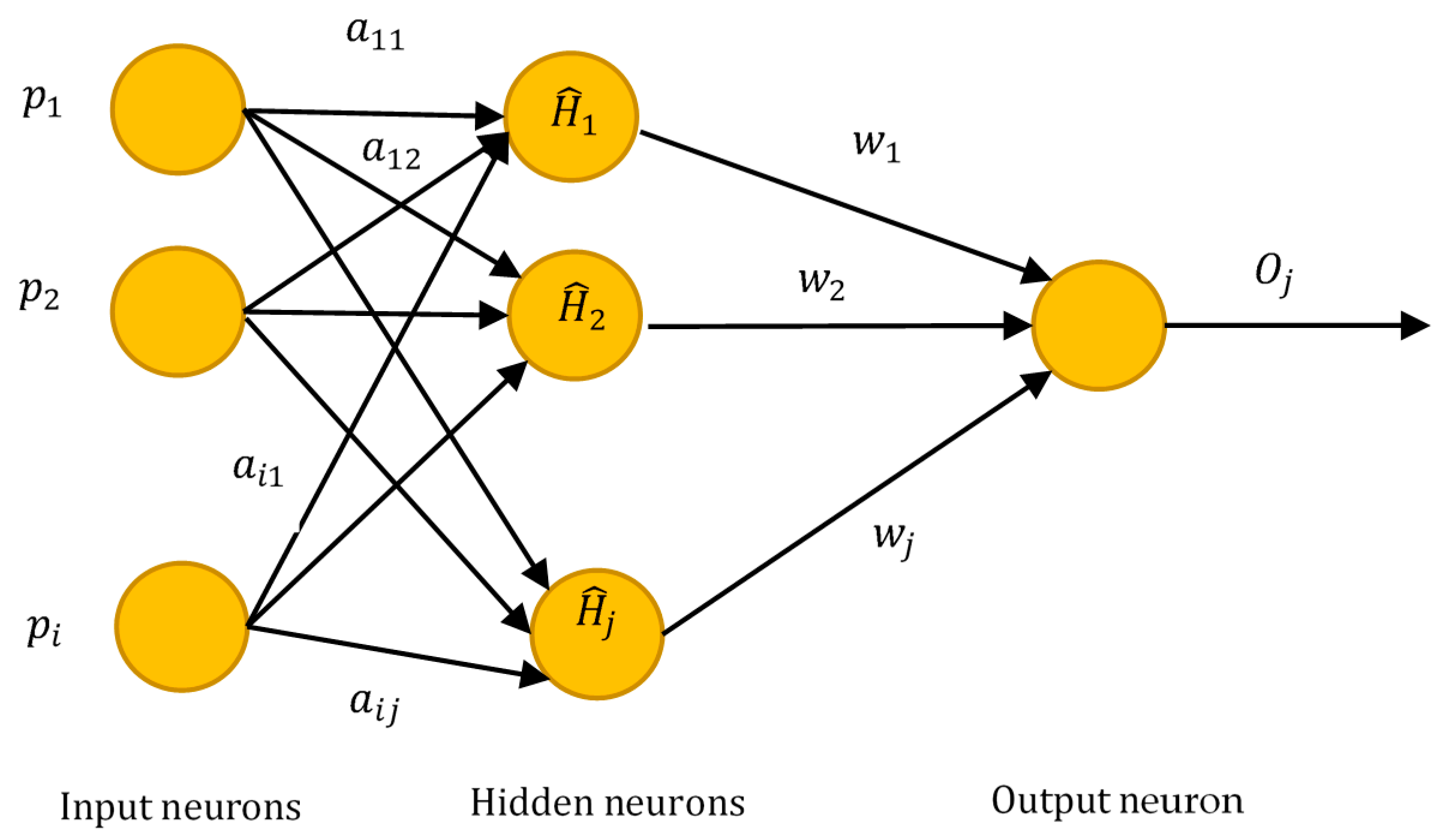
3.2. Extreme Learning Machine (ELM)
- The weights wi of input and bias bi are allocated randomly.
- The output matrix M of the hidden layer is computed.
- Compute the output weight w as
3.3. Evaluation Criteria
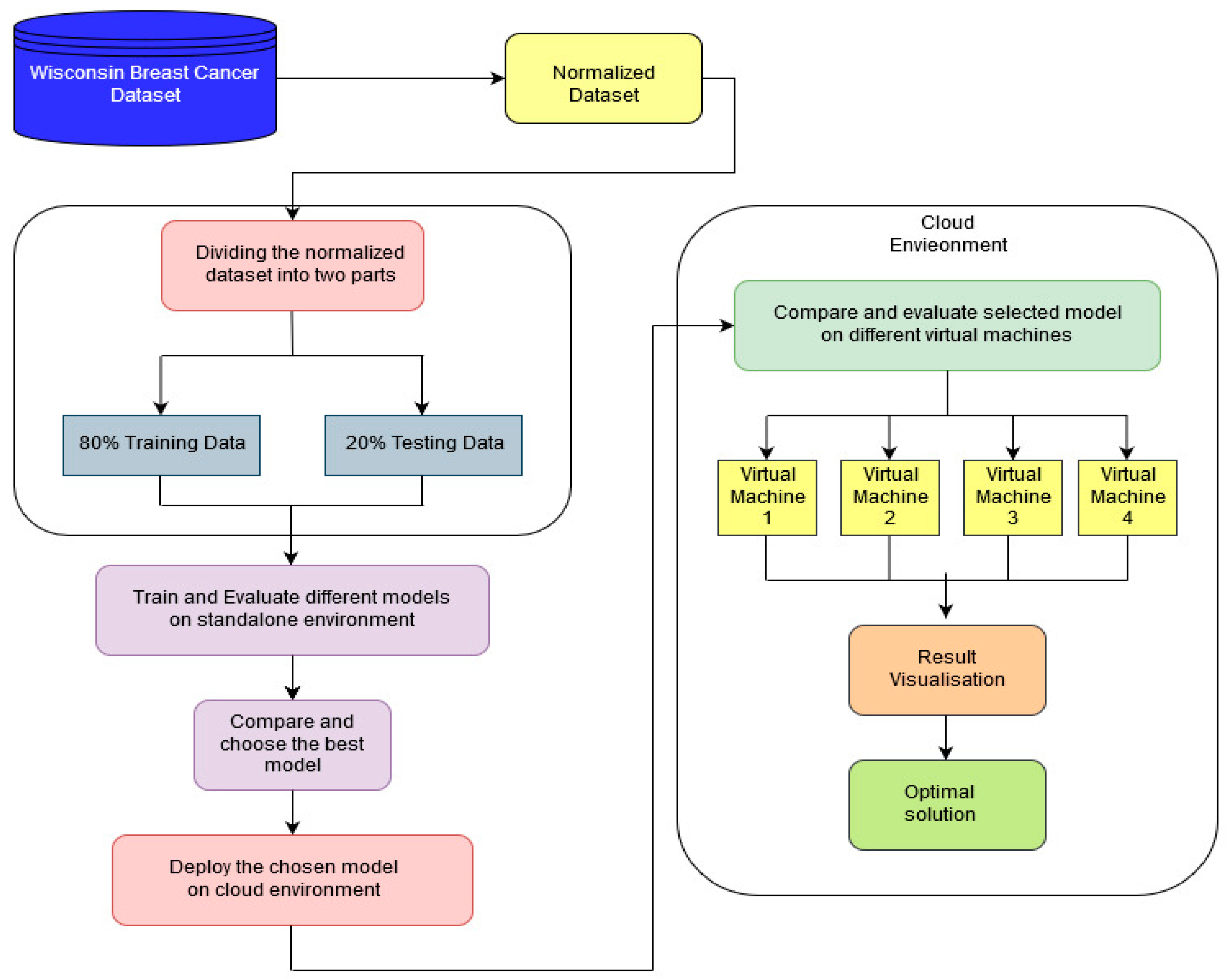
4. Research Materials and Methods
4.1. Cloud Environment
4.2. Standalone Environment
4.3. Collection of Data
5. Results
5.1. Performance Analysis on Standalone Environment
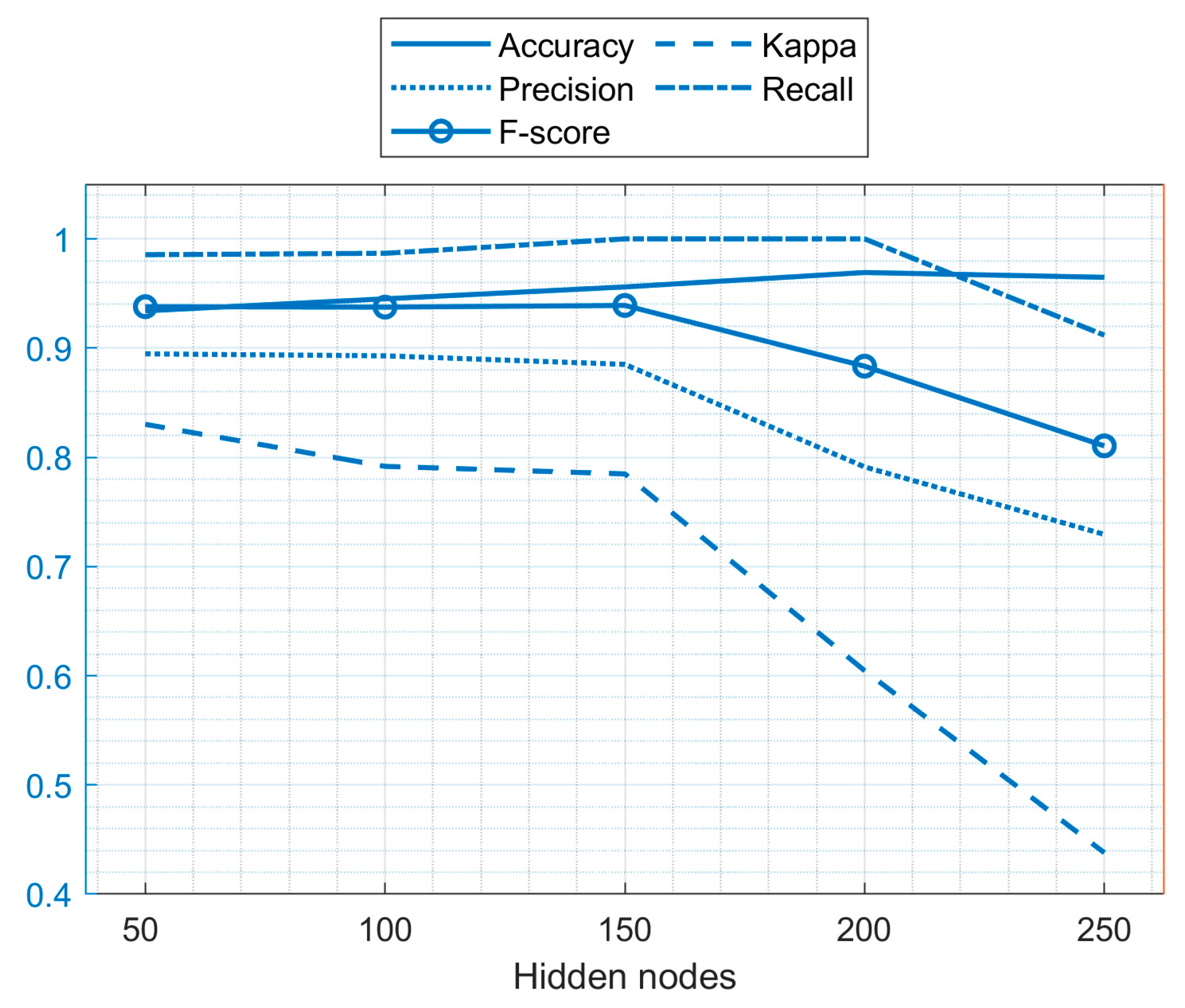
5.1.1. Performance Analysis of ELM with Different Hidden Nodes
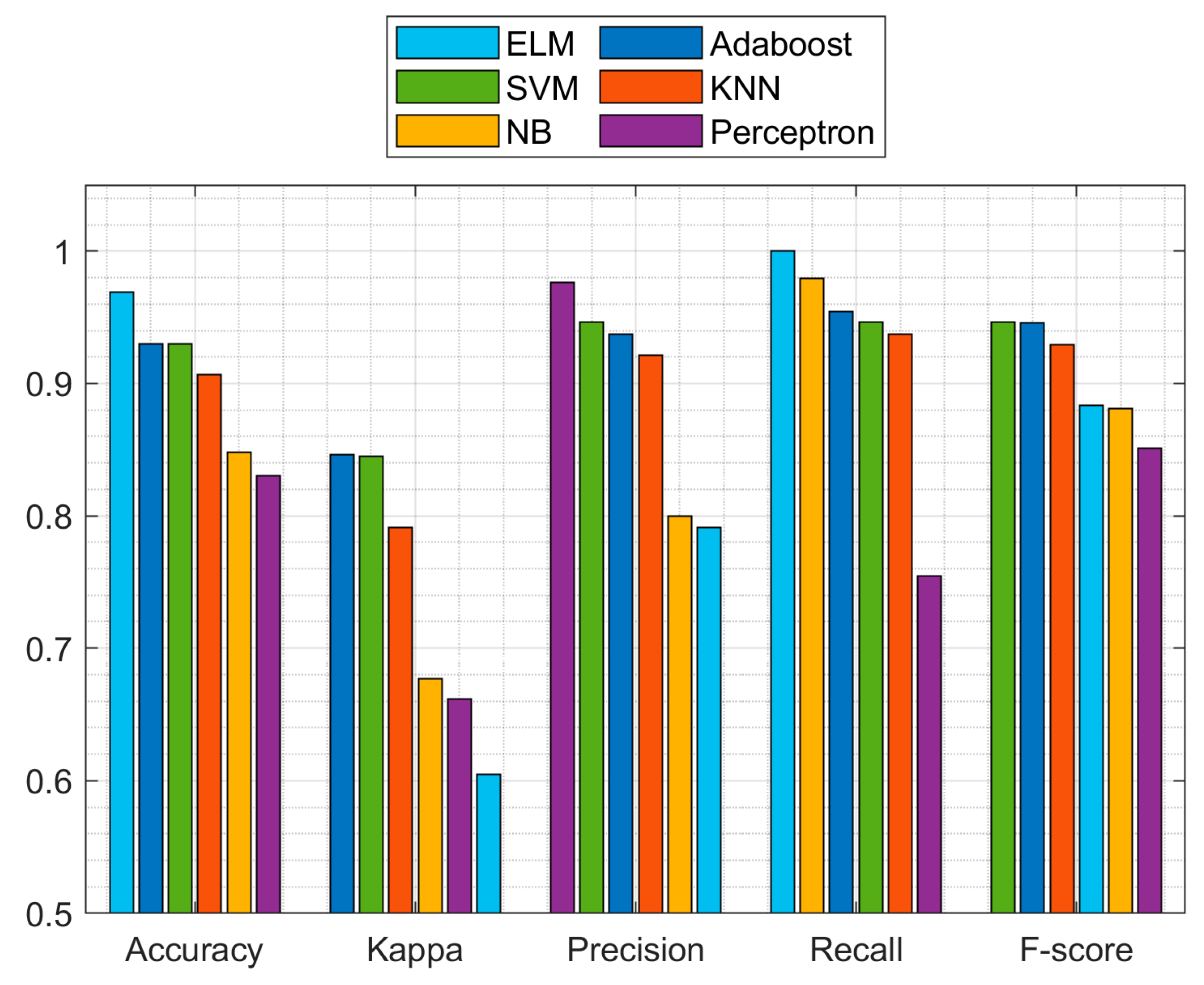
5.1.2. Performance Comparison of ELM with Various Classification Models
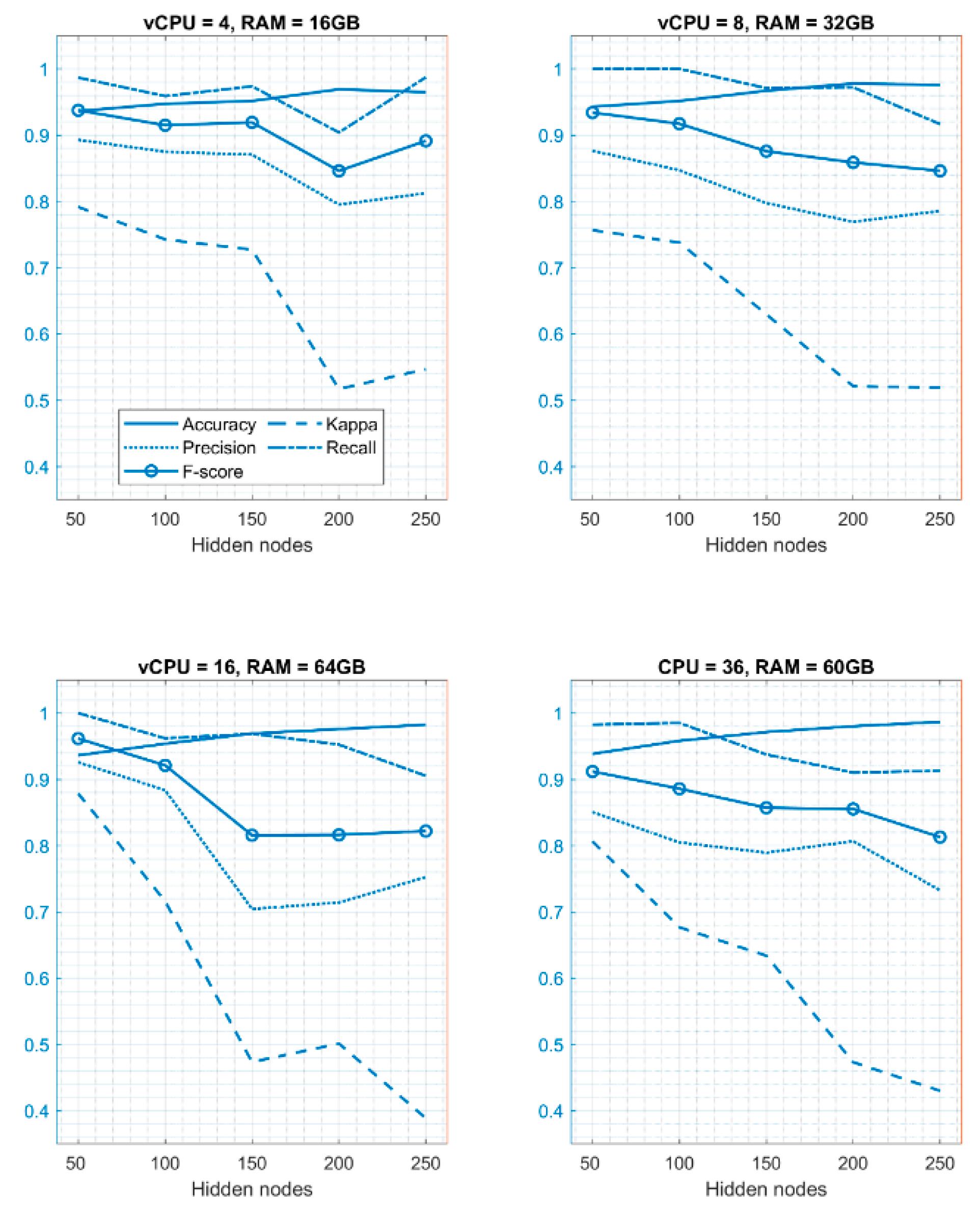
5.2. Performance Analysis on Cloud Environment (Amazon EC2)
Analysis of ELM Performance Using Different Hidden Layer Nodes
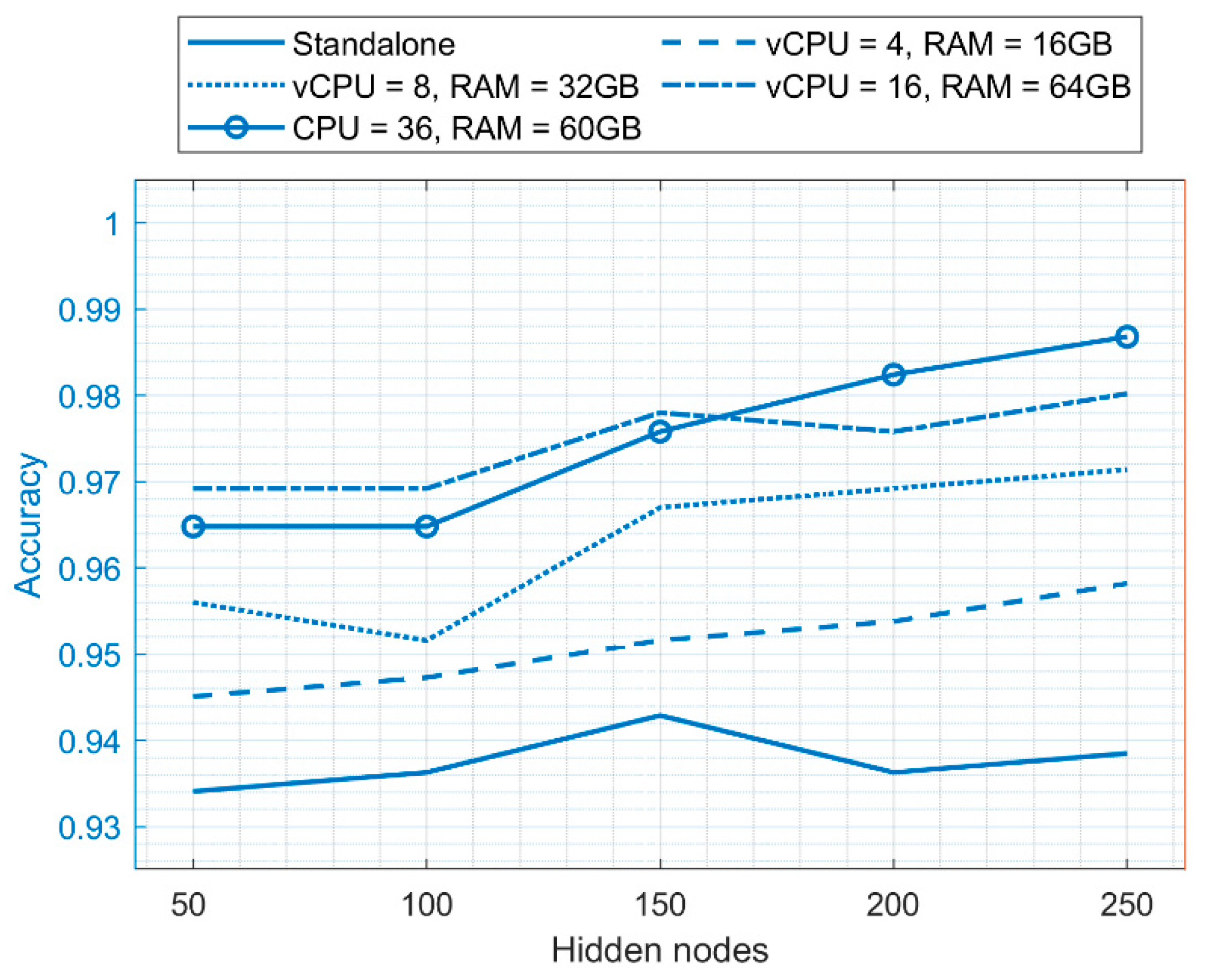
5.3. Performance Comparison of ELM on the Cloud Environment and Standalone Environment
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Momenimovahed, Z.; Salehiniya, H. Epidemiological characteristics of and risk factors for breast cancer in the world. Breast Cancer 2019, 11, 151–164. [Google Scholar] [CrossRef] [Green Version]
- Mohammed, M.A.; Al-Khateeb, B.; Rashid, A.N.; Ibrahim, D.A.; Abd Ghani, M.K.; Mostafa, S.A. Neural network and multi-fractal dimension features for breast cancer classification from ultrasound images. Comput. Electr. Eng. 2018, 70, 871–882. [Google Scholar] [CrossRef]
- Azamjah, N.; Soltan-Zadeh, Y.; Zayeri, F. Global Trend of Breast Cancer Mortality Rate: A 25-Year Study. Asian Pac. J. Cancer Prev. 2019, 20, 2015–2020. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. WHO Report on Cancer: Setting Priorities, Investing Wisely and Providing Care for All; WHO: Geneva, Switzerland, 2020. [Google Scholar]
- Obaid, O.I.; Mohammed, M.A.; Ghani, M.K.A.; Mostafa, A.; Taha, F. Evaluating the performance of machine learning techniques in the classification of Wisconsin Breast Cancer. Int. J. Eng. Technol. 2018, 7, 160–166. [Google Scholar]
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of things: A survey on enabling technologies, protocols, and applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Mohammed, M.A.; Abdulkareem, K.H.; Mostafa, S.A.; Ghani, M.K.A.; Maashi, M.S.; Garcia-Zapirain, B.; Oleagordia, I.; Alhakami, H.; AL-Dhief, F.T. Voice Pathology Detection and Classification Using Convolutional Neural Network Model. Appl. Sci. 2020, 10, 3723. [Google Scholar] [CrossRef]
- Botta, A.; De Donato, W.; Persico, V.; Pescapé, A. Integration of cloud computing and internet of things: A survey. Future Gener. Comput. Syst. 2016, 56, 684–700. [Google Scholar] [CrossRef]
- Maskeliunas, R.; Damaševicius, R.; Segal, S. A review of internet of things technologies for ambient assisted living environments. Future Internet 2019, 11, 259. [Google Scholar] [CrossRef] [Green Version]
- Połap, D.; Woźniak, M. Introduction to the model of the active assistance system for elder and disabled people. In Communications in Computer and Information Science, Proceedings of the International Conference on Information and Software Technologies, ICIST 2016, Druskininkai, Lithuania, 13–15 October 2016; Springer: Cham, Germany, 2016; Volume 639, pp. 392–403. [Google Scholar] [CrossRef]
- Ray Dorsey, E.; Topol, E.J. State of telehealth. N. Engl. J. Med. 2016, 375, 154–161. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wilson, L.S.; Maeder, A.J. Recent directions in telemedicine: Review of trends in research and practice. Healthc. Inform. Res. 2015, 21, 213–222. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ayeni, B.; Sowunmi, O.Y.; Misra, S.; Maskeliūnas, R.; Damaševičius, R.; Ahuja, R. A web based system for the discovery of blood banks and donors in emergencies. In Advances in Intelligent Systems and Computing, Proceedings of the International Conference on Intelligent Systems Design and Applications, ISDA 2019, Pretoria, South Africa, 3–5 December 2019; Springer: Cham, Germany, 2019; Volume 1181, pp. 592–600. [Google Scholar] [CrossRef]
- Brezulianu, A.; Geman, O.; Zbancioc, M.D.; Hagan, M.; Aghion, C.; Hemanth, D.J.; Son, L.H. IoT Based Heart Activity Monitoring Using Inductive Sensors. Sensors 2019, 19, 3284. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hemanth, D.J.; Anitha, J.; Naaji, A.; Geman, O.; Popescu, D.E.; Hoang Son, L. A Modified Deep Convolutional Neural Network for Abnormal Brain Image Classification. IEEE Access 2019, 7, 4275–4283. [Google Scholar] [CrossRef]
- Almeida, J.S.; Rebouças Filho, P.P.; Carneiro, T.; Wei, W.; Damaševičius, R.; Maskeliūnas, R.; de Albuquerque, V.H.C. Detecting parkinson’s disease with sustained phonation and speech signals using machine learning techniques. Pattern Recognit. Lett. 2019, 125, 55–62. [Google Scholar] [CrossRef] [Green Version]
- Sahlol, A.T.; Elaziz, M.A.; Jamal, A.T.; Damaševičius, R.; Hassan, O.F. A novel method for detection of tuberculosis in chest radiographs using artificial ecosystem-based optimisation of deep neural network features. Symmetry 2020, 12, 1146. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE Int. Jt. Conf. Neural Networks, Seoul, Korea, 17–19 May 2004; Volume 2, pp. 985–990. [Google Scholar]
- Ting, W.-C.; Chang, H.-R.; Chang, C.-C.; Lu, C.-J. Developing a Novel Machine Learning-Based Classification Scheme for Predicting SPCs in Colorectal Cancer Survivors. Appl. Sci. 2020, 10, 1355. [Google Scholar] [CrossRef] [Green Version]
- Xia, J.; Chen, H.; Li, Q.; Zhou, M.; Chen, L.; Cai, Z.; Fang, Y.; Zhou, H. Ultrasound-based differentiation of malignant and benign thyroid Nodules: An extreme learning machine approach. Comput. Methods Programs Biomed. 2017, 147, 37–49. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, A.; Ai, Q.; Sun, H. An adaptive kernel-based weighted extreme learning machine approach for effective detection of parkinson’s disease. Biomed. Signal Process. Control 2017, 38, 400–410. [Google Scholar] [CrossRef]
- Khan, M.A.; Ashraf, I.; Alhaisoni, M.; Damaševičius, R.; Scherer, R.; Rehman, A.; Bukhari, S.A.C. Multimodal brain tumor classification using deep learning and robust feature selection: A machine learning application for radiologists. Diagnostics 2020, 10, 565. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.A.; Kadry, S.; Parwekar, P.; Damaševičius, R.; Mehmood, A.; Khan, J.A.; Naqvi, S.R. Human Gait Analysis for Osteoarthritis Prediction: A framework of Deep Learning and Kernel Extreme Learning Machine. Complex Intell. Syst. 2021. [Google Scholar] [CrossRef]
- Khan, M.A.; Kadry, S.; Zhang, Y.-D.; Akram, T.; Sharif, M.; Rehman, A.; Saba, T. Prediction of COVID-19-Pneumonia based on Selected Deep Features and One Class Kernel Extreme Learning Machine. Comput. Electr. Eng. 2021, 90, 106960. [Google Scholar] [CrossRef] [PubMed]
- Elhoseny, M.; Mohammed, M.A.; Mostafa, S.A.; Abdulkareem, K.H.; Maashi, M.S.; Garcia-Zapirain, B.; Mutlag, A.A.; Maashi, M.S. A new multi-agent feature wrapper machine learning approach for heart disease diagnosis. Comput. Mater. Contin. 2021, 67, 51–71. [Google Scholar] [CrossRef]
- Gupta, N.; Ahuja, N.; Malhotra, S.; Bala, A.; Kaur, G. Intelligent heart disease prediction in cloud environment through ensembling. Expert Syst. 2017, 34, 1–14. [Google Scholar] [CrossRef]
- Saba, T.; Khan, S.U.; Islam, N.; Abbas, N.; Rehman, A.; Javaid, N.; Anjum, A. Cloud-based decision support system for the detection and classification of malignant cells in breast cancer using breast cytology images. Microsc. Res. Tech. 2019, 82, 775–785. [Google Scholar] [CrossRef] [PubMed]
- Gonçalves, C.B.; Leles, A.C.Q.; Oliveira, L.E.; Guimaraes, G.; Cunha, J.R.; Fernandes, H. Machine Learning and Infrared Thermography for Breast Cancer Detection. Proceedings 2019, 27, 45. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez-Ruiz, A.; Lång, K.; Gubern-Merida, A.; Broeders, M.; Gennaro, G.; Clauser, P.; Helbich, T.H.; Chevalier, M.; Tan, T.; Mertelmeier, T.; et al. Stand-Alone Artificial Intelligence for Breast Cancer Detection in Mammography: Comparison with 101 Radiologists. JNCI J. Natl. Cancer Inst. 2019, 111, 916–922. [Google Scholar] [CrossRef]
- Ragab, D.A.; Sharkas, M.; Marshall, S.; Ren, J. Breast cancer detection using deep convolutional neural networks and support vector machines. PeerJ 2019, 2019, 1–23. [Google Scholar] [CrossRef] [PubMed]
- Kashif, M.; Malik, K.R.; Jabbar, S.; Chaudhry, J. Application of machine learning and image processing for detection of breast cancer. In Innovation in Health Informatics; Elsevier: Amsterdam, The Netherlands, 2020; pp. 145–162. [Google Scholar] [CrossRef]
- Hamed, G.; Marey, M.A.E.R.; Amin, S.E.S.; Tolba, M.F. Deep Learning in Breast Cancer Detection and Classification. In Advances in Intelligent Systems and Computing, Proceedings of the International Conference on Artificial Intelligence and Computer Vision, AICV 2020, Cairo, Egypt, 8–10 April 2020; Hassanien, A.E., Azar, A., Gaber, T., Oliva, D., Tolba, F., Eds.; Springer: Cham, Germany, 2020; Volume 1153. [Google Scholar] [CrossRef]
- Ak, M.F. A Comparative Analysis of Breast Cancer Detection and Diagnosis Using Data Visualization and Machine Learning Applications. Healthcare 2020, 8, 111. [Google Scholar] [CrossRef] [PubMed]
- Jeyanathan, J.S.; Shenbagavalli, A.; Venkatraman, B.; Menaka, M.; Anitha, J.; de Albuquerque, V.H.C. Analysis of Transform-Based Features on Lateral View Breast Thermograms. Circuits Syst. Signal Process. 2019, 38, 5734–5754. [Google Scholar] [CrossRef]
- Abdar, M.; Zomorodi-Moghadam, M.; Zhou, X.; Gururajan, R.; Tao, X.; Barua, P.D.; Gururajan, R. A new nested ensemble technique for automated diagnosis of breast cancer. Pattern Recognit. Lett. 2020, 132, 123–131. [Google Scholar] [CrossRef]
- Dhahri, H.; Al Maghayreh, E.; Mahmood, A.; Elkilani, W.; Faisal Nagi, M. Automated breast cancer diagnosis based on machine learning algorithms. J. Healthc. Eng. 2019, 2019, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.; Islam, N.; Jan, Z.; Din, I.U.; Rodrigues, J.J.P.C. A novel deep learning based framework for the detection and classification of breast cancer using transfer learning. Pattern Recognit. Lett. 2019, 125, 1–6. [Google Scholar] [CrossRef]
- McKinney, S.M.; Sieniek, M.; Godbole, V.; Godwin, J.; Antropova, N.; Ashrafian, H.; Shetty, S. International evaluation of an AI system for breast cancer screening. Nature 2020, 577, 89–94. [Google Scholar] [CrossRef]
- Memon, M.H.; Li, J.P.; Haq, A.U.; Memon, M.H.; Zhou, W.; Lacuesta, R. Breast cancer detection in the IOT health environment using modified recursive feature selection. Wirel. Commun. Mob. Comput. 2019, 2019, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Ronoud, S.; Asadi, S. An evolutionary deep belief network extreme learning-based for breast cancer diagnosis. Soft Comput. 2019, 23, 13139–13159. [Google Scholar] [CrossRef]
- Ting, F.F.; Tan, Y.J.; Sim, K.S. Convolutional neural network improvement for breast cancer classification. Expert Syst. Appl. 2019, 120, 103–115. [Google Scholar] [CrossRef]
- Vijayarajeswari, R.; Parthasarathy, P.; Vivekanandan, S.; Basha, A.A. Classification of mammogram for early detection of breast cancer using SVM classifier and hough transform. Meas. J. Int. Meas. Confed. 2019, 146, 800–805. [Google Scholar] [CrossRef]
- Wu, N.; Phang, J.; Park, J.; Shen, Y.; Huang, Z.; Zorin, M.; Geras, K.J. Deep neural networks improve radiologists’ performance in breast cancer screening. IEEE Trans. Med. Imaging 2020, 39, 1184–1194. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Assiri, A.S.; Nazir, S.; Velastin, S.A. Breast Tumor Classification Using an Ensemble Machine Learning Method. J. Imaging 2020, 6, 39. [Google Scholar] [CrossRef]
- Li, L.N.; Ouyang, J.H.; Chen, H.L.; Liu, D.Y. A computer aided diagnosis system for thyroid disease using extreme learning machine. J. Med. Syst. 2012, 36, 3327–3337. [Google Scholar] [CrossRef] [PubMed]
- Sartakhti, J.S.; Zangooei, M.H.; Mozafari, K. Hepatitis disease diagnosis using a novel hybrid method based on support vector machine and simulated annealing (SVM-SA). Comput. Methods Programs Biomed. 2012, 108, 570–579. [Google Scholar] [CrossRef] [PubMed]
- Kumari, V.A.; Chitra, R. Classification of Diabetes Disease Using Support Vector Machine. Int. J. Eng. Res. Appl. 2013, 3, 1797–1801. [Google Scholar]
- Kaya, Y.; Uyar, M. A hybrid decision support system based on rough set and extreme learning machine for diagnosis of hepatitis disease. Appl. Soft Comput. J. 2013, 13, 3429–3438. [Google Scholar] [CrossRef]
- Wang, Z.; Yu, G.; Kang, Y.; Zhao, Y.; Qu, Q. Breast tumor detection in digital mammography based on extreme learning machine. Neurocomputing 2014, 128, 175–184. [Google Scholar] [CrossRef]
- Zheng, B.; Yoon, S.W.; Lam, S.S. Breast cancer diagnosis based on feature extraction using a hybrid of K-means and support vector machine algorithms. Expert Syst. Appl. 2014, 41 Pt 1, 1476–1482. [Google Scholar] [CrossRef]
- Prashanth, R.; Dutta Roy, S.; Mandal, P.K.; Ghosh, S. High-Accuracy Detection of Early Parkinson’s Disease through Multimodal Features and Machine Learning. Int. J. Med. Inform. 2016, 90, 13–21. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.-L.; Wang, G.; Ma, C.; Cai, Z.-N.; Liu, W.-B.; Wang, S.-J. An efficient hybrid kernel extreme learning machine approach for early diagnosis of Parkinson׳s disease. Neurocomputing 2016, 184, 131–144. [Google Scholar] [CrossRef] [Green Version]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Zheng, H.; Feng, Y.; Li, W. Prostate cancer diagnosis using deep learning with 3D multiparametric MRI. In Medical imaging 2017: Computer-Aided Diagnosis; International Society for Optics and Photonics: Bellingham, WA USA, 2017; Volume 10134, p. 1013428. [Google Scholar]
- Chen, M.; Hao, Y.; Hwang, K.; Wang, L.; Wang, L. Disease Prediction by Machine Learning Over Big Data From Healthcare Communities. IEEE Access 2017, 5, 8869–8879. [Google Scholar] [CrossRef]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference (SAI), London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar]
- Spencer, R.; Thabtah, F.; Abdelhamid, N.; Thompson, M. Exploring feature selection and classification methods for predicting heart disease. Digit. Health 2020, 6, 205520762091477. [Google Scholar] [CrossRef] [Green Version]
- Gabryel, M.; Damaševičius, R. The image classification with different types of image features. In Lecture Notes in Computer Science, Proceedings of the Artificial Intelligence and Soft Computing. ICAISC 2017, Zakopane, Poland, 11–15 June 2017; Springer: Cham, Germany, 2017; Volume 10245, pp. 497–506. [Google Scholar] [CrossRef]
- Jia, P.; Dai, J.; Pan, Y.; Zhu, M. Novel algorithm for attribute reduction based on mutual-information gain ratio. J. Zhejiang Univ. 2005, 40, 1041–1044. [Google Scholar]
- Ding, S.; Zhao, H.; Zhang, Y.; Xu, X.; Nie, R. Extreme learning machine: Algorithm, theory and applications. Artif. Intell. Rev. 2015, 44, 103–115. [Google Scholar] [CrossRef]
- Jiang, L.; Cai, Z.; Wang, D.; Jiang, S. Survey of Improving K-Nearest-Neighbor for Classification. In Proceedings of the Fourth International Conference on Fuzzy Systems and Knowledge Discovery (FSKD 2007), Haikou, China, 24–27 August 2007; pp. 679–683. [Google Scholar]
- Al-Aidaroos, K.M.; Bakar, A.A.; Othman, Z. Medical data classification with naive bayes approach. Inf. Technol. J. 2012, 11, 1166–1174. [Google Scholar] [CrossRef] [Green Version]
- Gallant, S.I. Perceptron-based learning algorithms. IEEE Trans. Neural Netw. 1990, 1, 179–191. [Google Scholar] [CrossRef]
- Hastie, T.; Rosset, S.; Zhu, J.; Zou, H. Multi-class AdaBoost. Stat. Interface 2009, 2, 349–360. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.; Lin, C. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Frank, E.; Hall, M.A.; Witten, I.H. The WEKA Workbench. Online Appendix for “Data Mining: Practical Machine Learning Tools and Techniques”, 4th ed.; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- PyCharm: The Python IDE for Professional Developers by JetBrains. Available online: https://www.jetbrains.com/pycharm/ (accessed on 18 October 2020).
- Wolberg, W.H.; Street, W.N.; Mangasarian, O.L. Breast Cancer Wisconsin (Diagnostic) Data Set. UCI Machine Learning Repository. 1992. Available online: https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/ (accessed on 3 February 2020).
- Gnana Sheela, K.; Deepa, S.N. Review on Methods to Fix Number of Hidden Neurons in Neural Networks. Math. Probl. Eng. 2013, 2013, 425740. [Google Scholar] [CrossRef] [Green Version]
- Kumar, P.M.; Lokesh, S.; Varatharajan, R.; Chandra Babu, G.; Parthasarathy, P. Cloud and IoT based disease prediction and diagnosis system for healthcare using Fuzzy neural classifier. Futur. Gener. Comput. Syst. 2018, 86, 527–534. [Google Scholar] [CrossRef]
- Kim-Soon, N.; Abdulmaged, A.I.; Mostafa, S.A.; Mohammed, M.A.; Musbah, F.A.; Ali, R.R.; Geman, O. A framework for analyzing the relationships between cancer patient satisfaction, nurse care, patient attitude, and nurse attitude in healthcare systems. J. Ambient Intell. Hum. Comput. 2021, 1–18. [Google Scholar] [CrossRef]
- Abdulkareem, K.H.; Mohammed, M.A.; Salim, A.; Arif, M.; Geman, O.; Gupta, D.; Khanna, A. Realizing an Effective COVID-19 Diagnosis System Based on Machine Learning and IOT in Smart Hospital Environment. IEEE Internet Things J. 2021. [Google Scholar] [CrossRef]
- Awan, M.J.; Rahim, M.S.M.; Salim, N.; Mohammed, M.A.; Garcia-Zapirain, B.; Abdulkareem, K.H. Efficient Detection of Knee Anterior Cruciate Ligament from Magnetic Resonance Imaging Using Deep Learning Approach. Diagnostics 2021, 11, 105. [Google Scholar] [CrossRef]
- Baltres, A.; Al Masry, Z.; Zemouri, R.; Valmary-Degano, S.; Arnould, L.; Zerhouni, N.; Devalland, C. Prediction of Oncotype DX recurrence score using deep multi-layer perceptrons in estrogen receptor-positive, HER2-negative breast cancer. Breast Cancer 2020, 27, 1007–1016. [Google Scholar] [CrossRef] [PubMed]
- Zemouri, R.; Zerhouni, N.; Racoceanu, D. Deep Learning in the Biomedical Applications: Recent and Future Status. Appl. Sci. 2019, 9, 1526. [Google Scholar] [CrossRef] [Green Version]
- Zemouri, R.; Devalland, C.; Valmary-Degano, S.; Zerhouni, N. Neural network: A future in pathology? Ann. Pathol. 2019, 39, 119–129. [Google Scholar] [CrossRef] [PubMed]
- Zemouri, R.; Omri, N.; Devalland, C.; Arnould, L.; Morello, B.; Zerhouni, N.; Fnaiech, F. Breast cancer diagnosis based on joint variable selection and constructive deep neural network. In Proceedings of the 2018 IEEE 4th Middle East Conference on Biomedical Engineering (MECBME), Tunis, Tunisia, 28–30 March 2018; pp. 159–164. [Google Scholar]
- Zemouri, R.; Omri, N.; Morello, B.; Devalland, C.; Arnould, L.; Zerhouni, N.; Fnaiech, F. Constructive deep neural network for breast cancer diagnosis. IFAC-Paper 2018, 51, 98–103. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Disease | Year | Dataset | Classifier | Accuracy (Highest) |
|---|---|---|---|---|---|
| Li et al. [45] | Thyroid | 2012 | Thyroid database from UCI repository | PCA-ELM | PCA-ELM = 98.1% |
| Sartakhti et al. [46] | Hepatitis disease | 2012 | hepatitis B dataset UCI Repository | SVM-SA | SVM-SA = 96.2% |
| Kumari et al. [47] | Diabetes | 2013 | Pima Indian diabetes dataset, | SVM | SVM = 78% |
| Kaya et al. [48] | Hepatitis disease | 2013 | hepatitis B dataset from UCI Repository | Rough Set ELM | Test/Train split 80/20 = 100% |
| Wang et al. [49] | Breast Cancer | 2014 | 482 mammographs | ELM, SVM | ELM = 83% |
| Zheng et al. [50] | Breast Cancer | 2014 | Breast Cancer Wisconsin Dataset (BCWD) | K-SVM | K-SVM = 97.38% |
| Prashanth et al. [51] | Parkinson’s Disease | 2016 | PPMI database | Naïve Bayes, LR, Boosted Tree Random Forest, SVM | Random Forest = 96.18% |
| Chen et al. [52] | Parkinson’s disease | 2016 | PD dataset from UCI repository | ELM K-ELM | Accuracy = 96.47% |
| Esteva et al. [53] | Skin Cancer | 2017 | 129,450 clinical images, | Deep CNN | CNN = 72.1% |
| Liu et al. [54] | Prostate Cancer | 2017 | 341 cases | XMasNet (Based on CNN) | XMasNet = 84% |
| Chen et al. [55] | Disease Prediction | 2017 | 31,919 hospitalized | CNN-MDRP | CNN-MDRP = 94.8% |
| Case | Definition |
|---|---|
| True Positive (TP) | A model forecasts the positive class correctly. |
| True Negative (TN) | A model forecasts the negative class correctly. |
| False Positive (FP) | A model forecasts the positive class correctly. |
| False Negative (FN) | A model forecasts the negative class incorrectly. |
| Formula | Expected Value |
|---|---|
| High | |
| High | |
| High | |
| Value = 1 implies perfect agreement, and Value < 1 implies a less perfect agreement | |
| Best Value is 1, and Worst Value is 0 |
| S. No. | Attribute Name | Description |
|---|---|---|
| 1. | Id | Id Number |
| 2. | Diagnosis | The diagnosis of breast tissues (M = malignant, B = Benign) |
| 3. | Radius_Mean | Mean of distances from the center to points on the perimeter |
| 4. | Texture_Mean | Standard deviation of grayscale values |
| 5. | Perimeter_Mean | Mean size of the core tumor |
| 6. | Area_Mean | Mean area of the core tumor |
| 7. | Smoothness_Mean | Mean of local variation in radius lengths |
| 8. | Compactness_Mean | Mean of perimeter2/area − 1 |
| 9. | Concavity_Mean | Mean of severity of concave portion of the contour |
| 10. | Concave points_mean | Mean for number of concave portions of the contour |
| 11. | Symmetry_mean | |
| 12. | Fractal_dimension_mean | Mean for coastline approximation − 1 |
| 13. | Radius_se | Standard error for the mean of distances from the center to the points on the perimeter |
| 14. | Texture_se | Standard error for standard deviation for grayscale values |
| 15. | Perimeter_se | |
| 16. | Area_se | |
| 17. | Smoothness_se | Standard error for local variation in radius lengths |
| 18. | Compactness_se | Standard error for perimeter2/area − 1 |
| 19. | Concavity_se | Standard error for severity of concave portions of the contour |
| 20. | Concave points_se | Standard error for the number of concave portions of the contour |
| 21. | Symmetry_se | |
| 22. | Fractal_dimension_se | Standard error for coastline approximation − 1 |
| 23. | Radius_worst | “worst” or largest mean value for the mean of distances from the center to points on perimeter |
| 24. | Texture_worst | “worst” or largest mean value for standard deviation of grayscale values |
| 25. | Perimeter_worst | |
| 26. | Area_worst | |
| 27. | Smoothness_worst | “worst” or largest mean value for local variation in radius length |
| 28. | Compactness_worst | “worst” or largest mean value for perimeter2/area − 1 |
| 29. | Concavity_worst | “worst” or largest mean value for severity of concave portions of the contour |
| 30. | Concave points_worst | “worst” or largest mean value for number of concave portions of the contour |
| 31. | Symmetry_worst | |
| 32. | Fractal_dimension_worst | “worst” or largest mean value for coastline approximation − 1 |
| Nodes in the Hidden Layer | 50 | 100 | 150 | 200 | 250 |
|---|---|---|---|---|---|
| Accuracy | 0.9341 | 0.9451 | 0.9560 | 0.9692 | 0.9648 |
| Kappa | 0.8302 | 0.7917 | 0.7848 | 0.6046 | 0.4379 |
| Precision | 0.8947 | 0.8929 | 0.8851 | 0.7912 | 0.7294 |
| Recall | 0.9855 | 0.9868 | 1.0 | 1.0 | 0.9118 |
| F-score | 0.9379 | 0.9375 | 0.9390 | 0.8834 | 0.8105 |
| AdaBoost | KNN | NB | Perceptron | SVM | ELM | |
|---|---|---|---|---|---|---|
| Accuracy | 0.9298 | 0.9064 | 0.8480 | 0.8304 | 0.9298 | 0.9692 |
| Kappa | 0.8460 | 0.7913 | 0.6768 | 0.6614 | 0.8447 | 0.6046 |
| Precision | 0.9375 | 0.9211 | 0.8000 | 0.9765 | 0.9464 | 0.7912 |
| Recall | 0.9545 | 0.9375 | 0.9796 | 0.7545 | 0.9464 | 1.000 |
| F-score | 0.9459 | 0.9292 | 0.8807 | 0.8513 | 0.9464 | 0.8834 |
| vCPU = 4 RAM = 16 GB | ELM (50) | ELM (100) | ELM (150) | ELM (200) | ELM (250) |
|---|---|---|---|---|---|
| Accuracy | 0.9363 | 0.9473 | 0.9516 | 0.9692 | 0.9648 |
| Kappa | 0.7917 | 0.7428 | 0.7273 | 0.5171 | 0.5471 |
| Precision | 0.8929 | 0.8750 | 0.8706 | 0.7952 | 0.8125 |
| Recall | 0.9868 | 0.9589 | 0.9737 | 0.9041 | 0.9873 |
| F-score | 0.9375 | 0.9150 | 0.9193 | 0.8462 | 0.8914 |
| vCPU = 8 RAM = 32 GB | |||||
| Accuracy | 0.9429 | 0.9516 | 0.9670 | 0.9780 | 0.9758 |
| Kappa | 0.7567 | 0.7381 | 0.6297 | 0.5214 | 0.5190 |
| Precision | 0.8764 | 0.8471 | 0.7976 | 0.7692 | 0.7857 |
| Recall | 1.0000 | 1.0000 | 0.9710 | 0.9722 | 0.9167 |
| F-score | 0.9341 | 0.9172 | 0.8758 | 0.8589 | 0.8462 |
| vCPU = 16 RAM = 64 GB | |||||
| Accuracy | 0.9363 | 0.9538 | 0.9692 | 0.9758 | 0.9824 |
| Kappa | 0.8786 | 0.7162 | 0.4736 | 0.5015 | 0.3889 |
| Precision | 0.9259 | 0.8837 | 0.7045 | 0.7143 | 0.7528 |
| Recall | 1.0000 | 0.9620 | 0.9688 | 0.9524 | 0.9054 |
| F-score | 0.9615 | 0.9212 | 0.8158 | 0.8163 | 0.8221 |
| vCPU = 36 RAM = 60 GB | |||||
| Accuracy | 0.9385 | 0.9582 | 0.9714 | 0.9802 | 0.9868 |
| Kappa | 0.8064 | 0.6769 | 0.6341 | 0.4734 | 0.4302 |
| Precision | 0.8507 | 0.8049 | 0.7895 | 0.8068 | 0.7326 |
| Recall | 0.9828 | 0.9851 | 0.9375 | 0.9103 | 0.9130 |
| F-score | 0.9120 | 0.8859 | 0.8572 | 0.8554 | 0.8129 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lahoura, V.; Singh, H.; Aggarwal, A.; Sharma, B.; Mohammed, M.A.; Damaševičius, R.; Kadry, S.; Cengiz, K. Cloud Computing-Based Framework for Breast Cancer Diagnosis Using Extreme Learning Machine. Diagnostics 2021, 11, 241. https://doi.org/10.3390/diagnostics11020241
Lahoura V, Singh H, Aggarwal A, Sharma B, Mohammed MA, Damaševičius R, Kadry S, Cengiz K. Cloud Computing-Based Framework for Breast Cancer Diagnosis Using Extreme Learning Machine. Diagnostics. 2021; 11(2):241. https://doi.org/10.3390/diagnostics11020241
Chicago/Turabian StyleLahoura, Vivek, Harpreet Singh, Ashutosh Aggarwal, Bhisham Sharma, Mazin Abed Mohammed, Robertas Damaševičius, Seifedine Kadry, and Korhan Cengiz. 2021. "Cloud Computing-Based Framework for Breast Cancer Diagnosis Using Extreme Learning Machine" Diagnostics 11, no. 2: 241. https://doi.org/10.3390/diagnostics11020241