1. Introduction
The gastrointestinal (GI) tract is the tubular duct that connects the mouth to the anus. It is a long, continuous tube that runs from the mouth to the anus, and is responsible for the process of digestion. It is divided into two main regions: the upper GI tract (including the mouth, pharynx, esophagus, stomach) and the lower GI tract (including the small intestine, large intestine, rectum, and anus). The GI tract is lined with a mucous membrane and muscular layers that work together to move food through the tract and break it down for absorption and elimination [
1].
The GI tract is also vulnerable to various medical disorders that may necessitate examination by medical specialists. Gastrointestinal illnesses, tissue inflammations, and irregular growth are examples of these. Acid reflux, for example, can induce changes in the lining of the esophagus, an unusual response can create inflammations, and proliferate cells can cluster together to form a polyp on the colon lining. These anomalies, like ulcers or sores, can be dangerous themselves. Another potential is that some anomalies can emerge, such as polyps that might become cancerous. Adenomatous polyps are polyps that have the potential to become malignant over time. Colorectal cancer (CRC) frequently begins as a precancerous polyp that can be benign or malignant. If left untreated, it is predicted that 30% of adenomas may progress to malignancy. Polyp cancer incidence varies based on the kind of polyp and population, although it is usually regarded as a common disease. According to the American Cancer Society, approximately one in every 20 persons may acquire colorectal cancer from an adenoma over their lifetime. Polyp screening, particularly for adenomatous polyps, is an essential method of preventing colorectal cancer.
Colonoscopy, which allows the doctor to see inside the rectum and colon, is currently the most effective screening method for detecting precancerous polyps and early stage colorectal cancer. Colorectal cancer (CRC) is the world’s third-most prevalent disease in males and the second-most common cancer in women. In 2018, there were approximately 1.8 million new cases and 0.9 million deaths from CRC, according to the World Health Organization (WHO). It is also a frequent disease in the United States, with an expected 148,810 new cases and 53,200 deaths in 2021. It is more frequent in older persons, with around 90% of occurrences occurring in those over the age of 50. However, due to increased screening, early identification, and improved treatment, the incidence of colorectal cancer is decreasing in many industrialized nations. Hence, visual evaluation of organs in the GI system is required by medical practitioners [
1]. The most common types of stomach issues are gastrointestinal (GI) anomalies such as bleeding, pylorus, erosion, ulcers, and polyps, which require considerable medical treatment because stomach abnormalities induce a variety of diseases. In 2018, stomach cancer was one of the top five most common cancers globally, according to the World Health Organization (WHO) report.
Endoscopy traditionally gives an interior view of the GI tract. Furthermore, because the small intestine is so extensive and convoluted, this old approach cannot view it. Furthermore, patients find this endoscopic approach unpleasant and uncomfortable. Wireless capsule endoscopy is a medical procedure that allows users to see inside the gastrointestinal tract. It involves ingesting a small, pill-sized capsule that contains a camera and wireless transmitting device. The capsule takes about 60,000 images and transmits them to a receiver worn by the patient as it travels through the digestive system. The images are then used by a doctor to diagnose and monitor conditions such as Crohn’s disease, ulcerative colitis, and other digestive tract disorders. The procedure is noninvasive, safe, and does not require sedation, making it a popular alternative to traditional endoscopic procedures [
2].
The primary diseases diagnosed by the WCE include ulcers, bleeding, pylorus, erosion, and polyps in the digestive tract. The WCE images are utilized to identify anatomical landmarks, pathological abnormalities, and polyp removal, all of which are important GI illnesses. Providing a range of images makes it easier to identify tumors and gastrointestinal hemorrhages, especially in the small intestine, which is now more properly studied [
3]. It took a long time to analyze every image taken from each patient [
4]. Furthermore, there is occasionally a high resemblance rate in distinct contextual images; this is why most expert doctors confront obstacles that require a significant amount of time to examine all of the data. This commonly leads to misdiagnosis due to clinician ineptitude or carelessness [
5]. All of these challenges motivate researchers to develop a computer-aided bleeding-detection approach in order to reduce the pressure on gastroenterologists. With its ever-expanding uses, certain approaches for detecting bleeding images in WCE video have been developed [
6,
7].
Medical image segmentation is the process of distinguishing pixels from medical images that contain lesions. It gives details regarding the sizes and forms of areas of interest (ROIs) [
8,
9,
10]. Previously, automatic segmentation approaches were based on both, traditional image processing and handcrafted features [
11]. Deep learning techniques have recently made substantial advances in medical imaging [
12]. These techniques based on their structure may be classified into two categories. Some models are based on the encoder–decoder structure like U-Net, FCN, and SegNet. Although others can maintain appropriate spatial information by employing fewer downsample operations and dilated convolution (Deep Lab-V3) [
13].
In this study, we propose the AttResU-Net architecture for gastrointestinal image segmentation. We tested our model by using three publicly available datasets. Our experimental results show that the enhanced model is efficient and outperforms the popular U-Net and V-Net designs. In summary, the following are the paper’s contributions.
- (1)
We present the AttResU-Net architecture, a semantic segmentation neural network that uses residual blocks and attention blocks. When compared to other cutting-edge approaches, AttResU-Net markedly enhanced segmentation findings for colorectal bleeding and polyps. Even with fewer images, the suggested architecture works effectively.
- (2)
We test the improved architecture on a diverse collection of datasets, including MICCAI 2017, Kvasir-SEG, and CVC-ClinicDB, and compare our suggested techniques to current state-of-the-art algorithms. Furthermore, we compared our findings to those of other recent studies.
- (3)
Our approach detects tiny, flat, or sessile polyps that are typically overlooked during colonoscopy, which is a significant advantage over previous studies.
The remainder of this paper is organized as follows.
Section 2 examines a few interesting works.
Section 3 is devoted to the description of architecture. Baseline experiments are detailed in
Section 4. Finally,
Section 5 brings the paper to a close and offers future directions.
2. Literature Review
During the last few decades, many efforts have been undertaken by researchers to develop computer-aided frameworks to segment and detect gastrointestinal lesions [
12,
14,
15,
16]. Polyp segmentation has specifically been given consideration. The efficiency of the AI algorithms has approached the degree of expertise of experienced endoscopists.
Prior works were particularly centered around handcrafted descriptor-based feature learning. Handcrafted features that are focused on shape, texture, edges, and color are extracted and fed to classifiers that isolate lesions from the background. Hwang and Celebi [
17] suggested an unsupervised approach for detecting polyps in VCE. Watershed segmentation was proposed, along with an initial marker selection technique based on Gabor texture features and K-means clustering. Curvature-based geometric information was used to extract polyp pixels from the obtained segments. Fu et al. [
18] take into consideration arbitrary form automatically picked by superpixel segmentation. In this technique, the red ratio in RGB space is used to define the attributes of each superpixel, which are then aggregated to train a binary classifier. Ganz et al. [
19] and Mamonov et al. [
20] utilize shape and contour information for polyps segmentation. Color and texture information was employed as features by Gross et al. [
21] and Bernal et al. [
22] to determine the location of polyps.
In any case, these handcrafted-based methods can perform well, only for some ordinary polyps with fixed features. To further develop the semantic polyp segmentation, CNN-based architectures were adopted for the extraction of more discriminative characteristics. To improve the segmentation results for the colorectal polyps, Jha et al. [
23] present the ResUNet++ architecture, a semantic segmentation neural network that employs residual and squeeze blocks, attention blocks, and atrous spatial pyramidal pooling (ASPP). Their architecture works effectively with a limited amount of images. The polyps in the CVC-ColonDB dataset were segmented by using a fully convolutional neural network (FCN-8S) by the authors of [
24]. A method for image patch selection was applied in the training phase. Otsu thresholding is also used on the probability map as a postprocessing technique. They achieved a Dice score of 81%. Qadir et al. [
25] used Mask R-CNN as a feature extractor to segment polyp areas in colonoscopy images by using different CNN architectures (ResNet50, ResNet101, and InceptionResNetV2). This method obtained a Dice score of 70.42% and a Jaccard index of 61.24% on CVC-ColonDB dataset. In their study [
26], Poorneshwaran et al., utilized generative adversarial network (GAN) for the task of polyp image segmentation. The network achieved a Dice index of 88.48% on the CVC-ClinicDB dataset. Working also on colonoscopy images, Nguyen and Lee [
27] employed a deep encoder–decoder technique. This work’s structure is made up of atrous convolution and depthwise separable convolution. On the CVC-ColonDB dataset, the suggested model received 88.9% of the Dice score and 89.35% of the Jaccard index.
On the other hand, several studies employed deep learning networks to segment digestive anomalies by using images collected from WCE the novel technology. Hajabdollahi et al. [
28] suggest a simple and efficient approach for segmenting WCE bleeding images. MLP structure is used to classify appropriate colon channels. The authors proposed a quantized neural network with no multiplication which can be used as an automated diagnostic technique within the capsule. Ghosh et al. [
29] used SegNet layers with three classes to train CNN. The training network is used to segment the endoscopic images, and the observed bleeding areas are indicated. Among several color planes, the hue saturation and value (HSV) color space provides the best performance. The framework achieved 94.42% global accuracy when tested on a publicly available dataset. The paper [
30] presents a method for precise and efficient semantic calibration and refinement in convolutional neural networks (ConvNets) for real-time polyp segmentation from colonoscopy videos. The goal is to improve the accuracy of polyp segmentation, which is an important task in the diagnosis and monitoring of colon cancer. The method involves using ConvNets to analyze colonoscopy videos and identify polyps, and then refining the results by using a semantic calibration and refinement process. The authors in [
31] present a new deep learning architecture for the simultaneous joint classification and segmentation of endoscopic images. The network consists of two parallel branches, a classification branch and a segmentation branch, which interact with each other through a synergistic interaction mechanism. The results show that the proposed architecture outperforms state-of-the-art methods on the benchmark datasets for endoscopic image classification and segmentation. The RA-UNet that was proposed by Jin et al. [
32], focuses on preserving the high-level features of the image and enhances the resolution of the feature maps by using residual attention mechanisms in the encoding path. The AttU-Net part of the architecture focuses on refining the segmentation results by using an attention mechanism in the decoding path. The proposed RA-UNet architecture was tested on a public dataset of CT scans and showed improved accuracy and robustness compared to other state-of-the-art models for liver and tumor segmentation.
3. Materials and Methods
We present an overview of our suggested Attention Residual U-Net (AttResU-Net) approach in this section. We begin by providing a quick overview of the data preprocessing techniques used in this work. Then we describe the three model components: the residual encoding module, the attention gate (AG) module, and the residual decoding module. Finally, we describe how all of the elements are combined for further improvement. To improve the depth of the network while expediting network training and enhancing network performance, the usual convolution block in the encoder–decoder structure is replaced with a preactivated residual block. The AG module is included to record and screen for high-level features with additional spatial contextual information.
3.1. Data Preprocessing
The original datasets contain images of various resolutions. Some colonoscopic images have a dimension of 574 × 500, necessitating a much higher computing cost. As a result, the images must be resized before being fed to the segmentation models. We chose the appropriate size of 128 × 128 based on several experiments. Recent research has proved the benefits of data augmentation strategies in increasing the quality and size of training data to handle all data variations. Thus, various data augmentation techniques including vertical and horizontal flipping, rotating, and zooming are used in our case to extend the dataset and help in the successful accomplishment of the segmentation task. For most cases, pixel values of image data are integers with values ranging from 0 to 255. However, because the mechanism of neural networks uses minimal weight values, inputs with large values can slow the learning process. To that purpose, data normalization is considered to be a good solution, such that the value of each pixel should be between 0 and 1. That can be obtained by dividing all pixel values by 255, the largest pixel value. Normalizing the image can also make it more robust to changes in lighting conditions and other factors that might affect the overall brightness and contrast of the image.
3.2. AttResU-Net Architecture
We use a U-Net like structure for our network design, inspired by Ronneberger [
33], with an encoder with numerous downsampling layers that extract features of various sizes and a decoder with several upsampling layers that scale the feature maps to the appropriate output resolution. To generate the skip connections, the intermediate outputs of the downsampling layers are merged with the intermediate outputs of their respective upsampling layers of the same size. Unlike Ronneberger work [
33], we employ residual blocks rather than typical convolutional layers, as explained in
Section 3.2.2. As described in
Section 3.2.3, we also used attention modules to train the network to focus on relevant features for segmenting bleeding lesions and polyps.
3.2.1. U-Net Architecture
U-Net is one of the most popular architectures used in image-segmentation tasks. This method was originally proposed by Ronneberger et al. [
33] for biomedical image segmentation. Fundamentally, the U-Net is based on the fully convolutional network [
34]. The UNet model is made up of two paths: contractive (encoder) and expansive (decoder). Deep features are learned along the first path based on the learned features. The encoder consists of a combination of convolution layers with filters of size 3 × 3 followed by ReLU and MaxPooling layers. The decoder, on the other hand, constructs an output segmentation map through a series of operations. This path comprises upconvolution, followed by convolution, ReLU, and MaxPooling layers. Through a skip connection, each encoder stage provides special features to the associated decoder stage. The key purpose of skip connection is to ensure that the model builds an increasingly exact output.
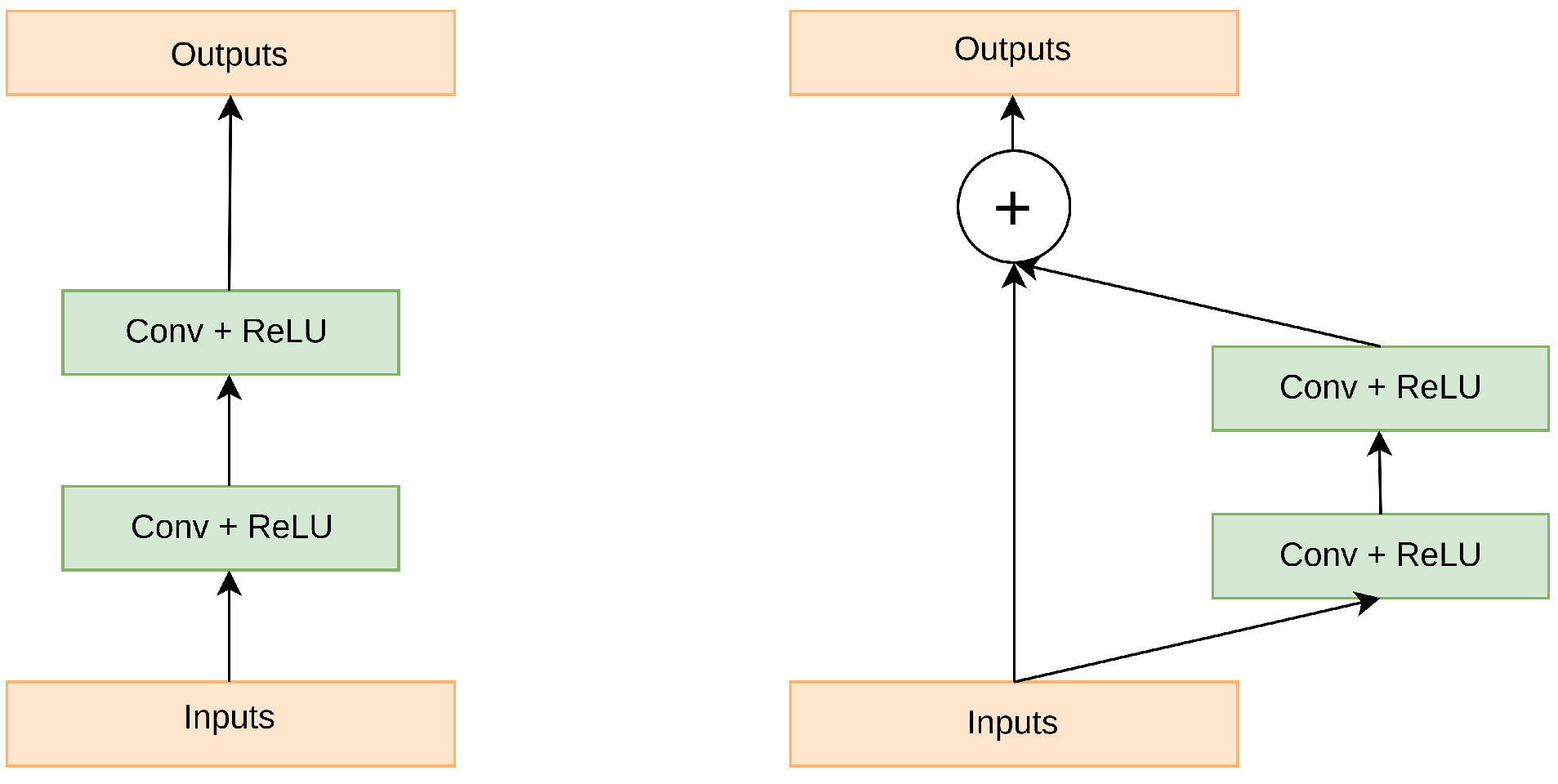
3.2.2. Residual Units
Expanding network depth while training a deep neural network might potentially increase overall performance. However, simply stacking the CNN layer may impede the training process and result in exploding/vanishing gradients during backpropagation. Residual connections allow the gradient to bypass one or more layers in the neural network by adding the input of a layer to the output of a later layer. This allows the gradient to flow more directly to earlier layers, reducing the chance of the gradient becoming too small (vanishing) during backpropagation. Additionally, this structure allows the network to learn an identity mapping, allowing the network to learn an identity mapping when the layers are close to the identity function, making it easier to optimize [
35]. A residual block is a building block used in deep residual neural networks and it mathematically defined as follows: Given an input tensor x, a residual block applies one or more layers of nonlinear transformations (such as convolutional layers, batch normalization, and ReLU activation) to produce an output tensor y. The final output of the residual block is then computed as the elementwise sum of the input tensor x and the output tensor y, added via an elementwise addition operation. This is represented mathematically in Equation (
1) below,
where F(x) is the nonlinear transformation applied to x. This structure allows the network to learn the residual mapping between the input x and the output y, allowing for the network to be much deeper and still be able to train effectively. This is because the residual block allows for the network to learn the difference between the input and output, rather than having to learn the entire function from scratch. This structure is also known as residual connection, which allows the gradients to flow more easily through the deep network, making it easier to train.
Figure 1 depicts the residual coding structure.
3.2.3. Attention Units
Deep learning’s attention mechanism may be linked back to the study of human vision. Humans communicate signals through neurons and brain processing after obtaining external visual information, which causes human attention to focus on the regions of interest and reduces the attention weight value of irrelevant regions. When the attention mechanism [
36] is used in the deep learning process, the processing of human visual information is emulated by introducing the attention module. The attention to irrelevant areas will be limited by raising the information weight of the region of interest in the feature extraction process of the input image. Naive skip connections simply concatenate the encoder and decoder features, wasting computing resources and producing duplicate information. Because the encoder feature contains extensive location information, it is preferable to concentrate on relevant regions that are useful for determining the position of the item and determining the target structure of the object.
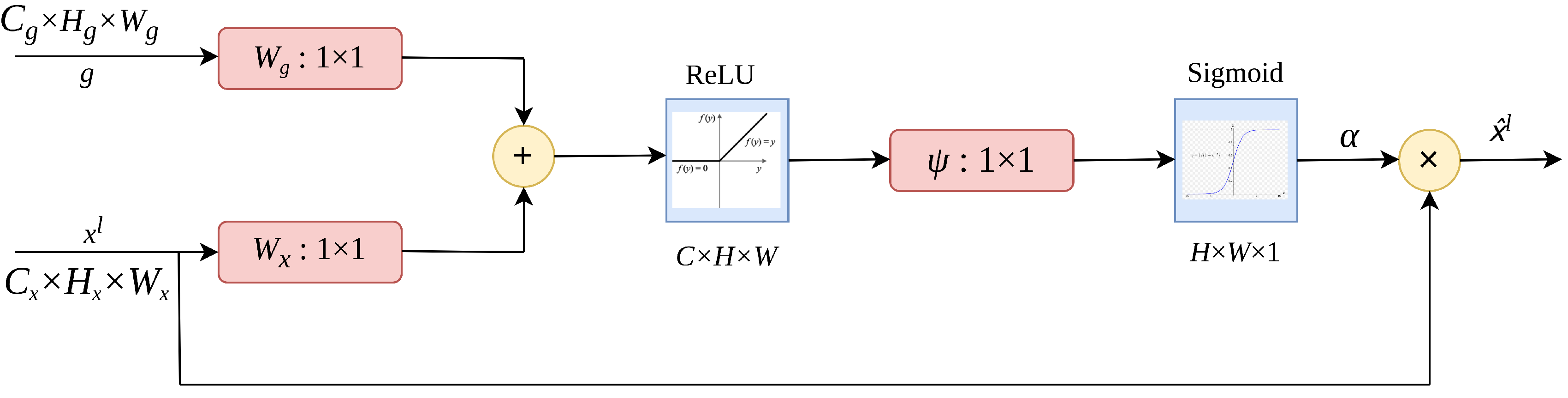
The attention gates as proposed by Oktay et al. [
37] uses additive soft attention. An attention gate unit combines the input feature vector with the attention vector to produce a new, weighted feature vector. As depicted in
Figure 2, the vectors
and
g are fed into the attention gate. The vector,
g, is retrieved from the network’s next lowest layer. Because data originates from deeper in the network, the vector has lower dimensions and greater feature representation. Vector
in the preceding case would be
(filters × height × width), and vector
g would be
. Vector
undergoes a strided convolution, whereas vector
g undergoes a 1 × 1 convolution. The two vectors are summed elementwise. As a result of this process, aligned weights get larger while unaligned weights become smaller. The resulting vector is subjected to a
activation layer and a 1 × 1 convolution, which reduces the dimensions to
. This vector is sent via a sigmoid layer, which scales it between [0, 1], yielding the attention coefficients (weights), with coefficients closer to 1 indicating more significant information. Using trilinear interpolation, the attention coefficients are upsampled to the original dimensions of the
vector. The attention coefficients
are multiplied by the original
vector element by element (elementwise multiplication), scaling the vector
according to significance. This is then passed along normally in the skip connection.
3.2.4. Our Network Structure
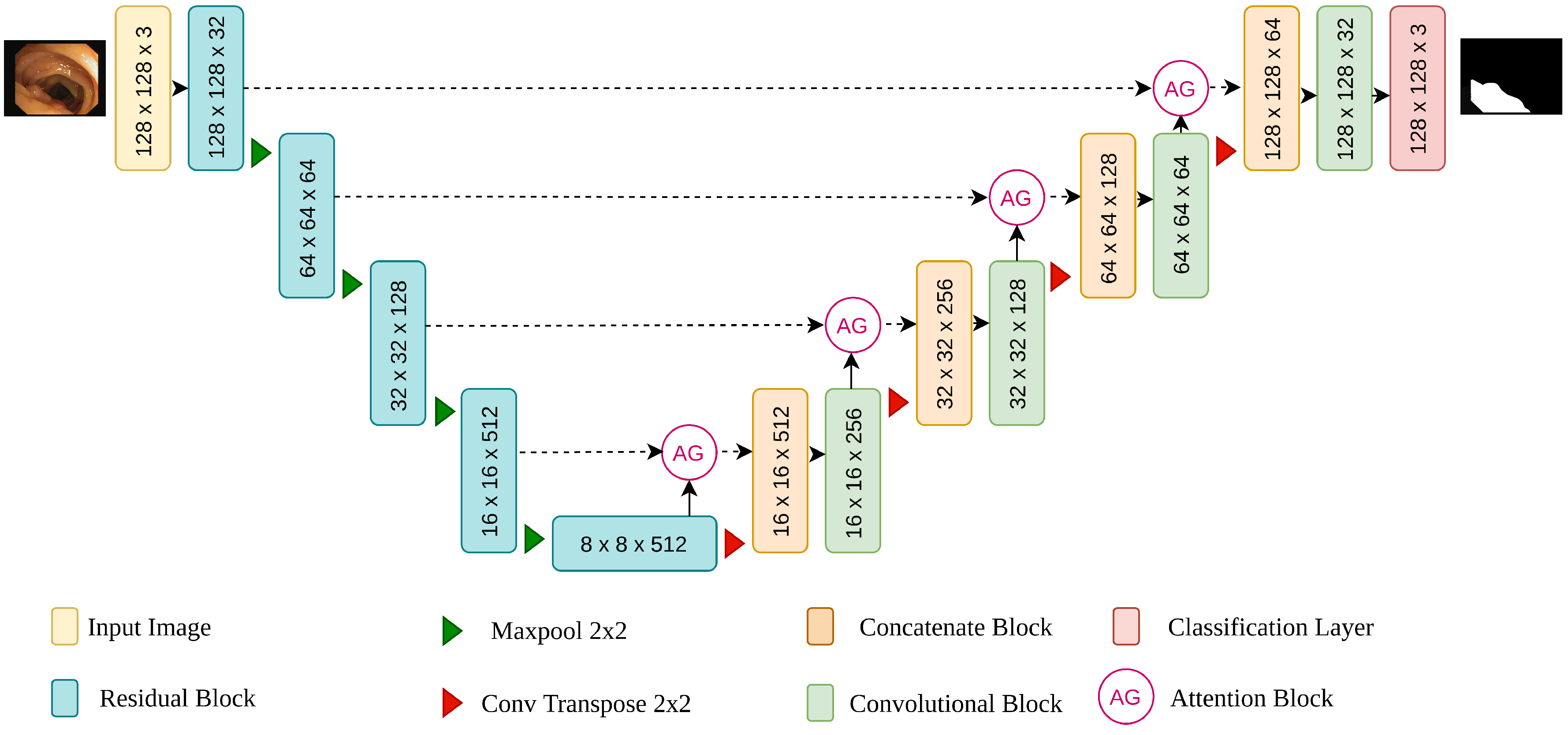
In this study, we present a convolution neural network called attention residual UNet (AttResU-Net) for bleeding and polyps segmentation. The network adopts UNet as the network’s backbone, allowing a smooth translation from the image to the segmentation mask by combining the encoder and decoder structure with shallow semantic information. The network’s design may be separated into three components, as illustrated in
Figure 3: encoder, skip connection with attention mechanism, and decoder. Different from the work of Liu et al. [
38], the convolution block is replaced with an upgraded convolution residual module in the encoder and the decoder paths to prevent the gradient vanishing and explosion problem in the deep neural network and make the forward and backward propagation of information smoother. In addition to the suggested residual structure that is shown in
Figure 4, this module contains a max pooling layer following it. The convolution kernel of the convolution operation is 3 × 3, and it is followed by a batch normalization layer and a ReLU. The max pooling layer reduces the size of the input image to half its original size. The number of input feature channels will be doubled after each encoder building block, and the image size will be half. The residual structure is not employed in the decoder path. The maximum pooling layer is replaced with an upsampling layer. Finally, we utilize the concatenation method to return the feature map to its original size. The upsampling rate is set to 2 in each decoder building block to guarantee that the output is the same size as the encoder output. To make better use of the information in the multiresolution feature map, the attention gate is embedded in the skip connection part to strengthen the useful features in the channel dimension and suppress the inaccurate background features, hence improving the computational efficiency of the network model. The output of this part is then concatenated with the output of the previous layer of the decoder and fed into the current layer’s decoder.
3.3. SegNet Architecture
The SegNet concept was suggested for the first time by Badrinarayanan et al. [
39] in 2017. SegNet is a deep neural network designed to simulate scene parts, similar to a road picture segmentation tool. It uses around ten times fewer learning parameters than the UNet model. The encoder–decoder architecture, as in VGG16, comprises 13 convolutional layers with filters of size 3 × 3, batch normalization, ReLU, and five layers of 2 × 2 max-pooling. A decoder is a reflected version of the encoder, it generates the segmentation mask by using pooling indices from the max-pooling layers of the associated encoder. Toward the end, there is a softmax activation that produces a classified binary image that divides pixels into two categories (abnormality/background).
3.4. V-Net Architecture
In medical image segmentation, V-Net [
40] is a well-known 3D fully convolutional neural network. It is symmetrically constructed and consists of an encoder and a decoder. The encoder extracts relevant features from the input image, and the decoder reconstructs those features to produce the final segmentation results. The network’s left side is a compression path, whereas the network’s right side decompresses the signal until it reaches its original size. The network’s left side is subdivided into stages that perform at various resolutions. Each one of those stages has one to three convolutional layers. At every stage, a residual function is learned. To train a residual function, the input of each stage is used in the convolutional layers, processed via the nonlinearities, and added to the output of the last convolutional layer of that stage. Convolutions are done in each step by using volumetric kernels with a size 5 × 5 × 5. Convolution with 2 × 2 × 2 kernels performed with stride 2 reduces resolution throughout the compression path.
4. Results
Our approach aims for GI tract abnormalities (bleeding and polyps) semantic segmentation, in order to generate pixelwise segmentation masks for each endoscopic and colonoscopic image. In this section, we will initially describe the three used datasets. Then, we will introduce the evaluation metrics and the experimental setup. Finally, both quantitative and qualitative findings will be discussed.
4.1. Datasets
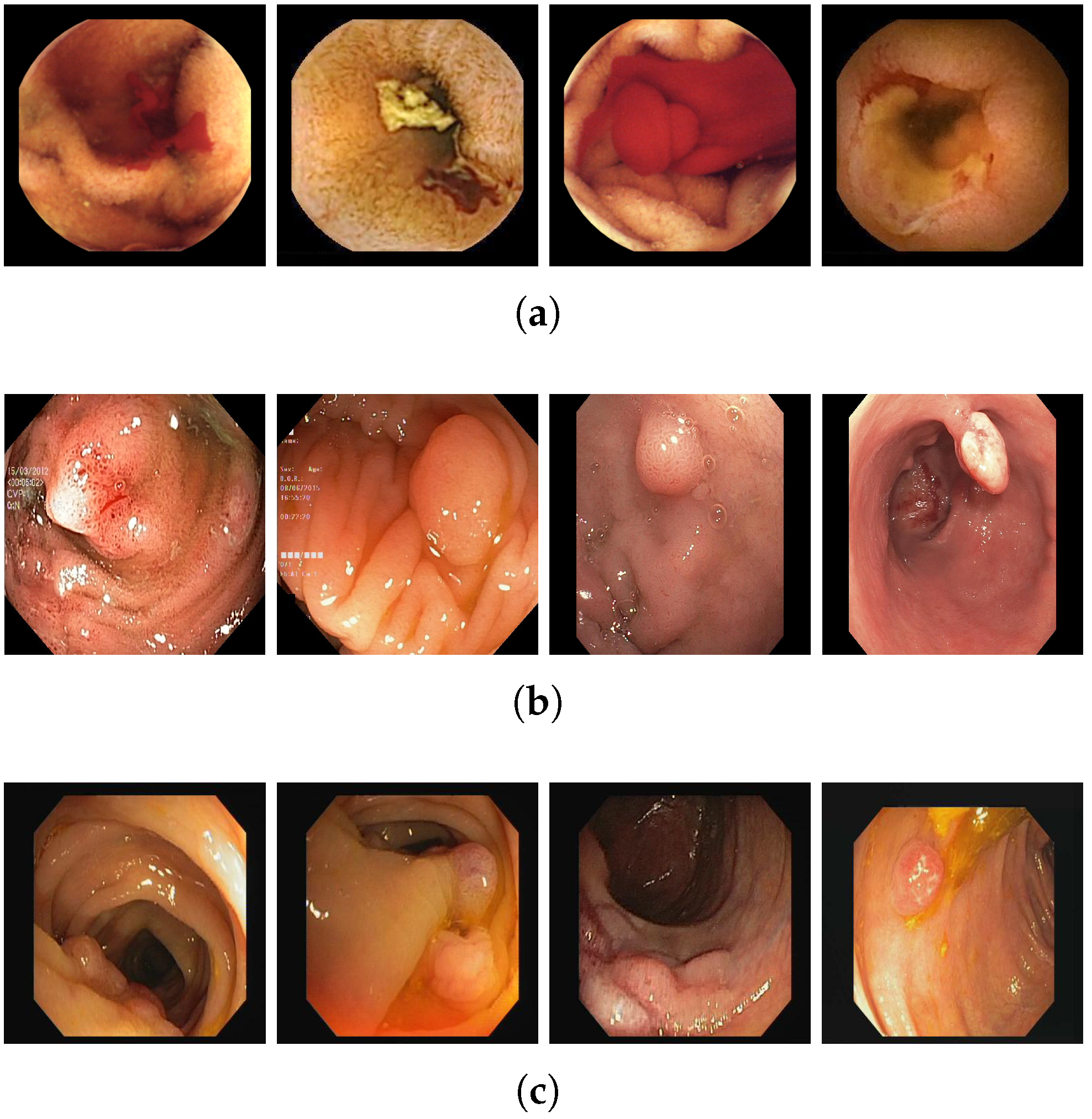
The suggested approach was validated by using three publicly available datasets. The first dataset has labeled red lesions in WCE images, whereas the second is the Kvasir-SEG dataset, and the CVC-ClinicDB dataset, which comprises colonoscopic images. These three datasets are briefly discussed below.
4.1.1. Red Lesion Dataset
The publicly available WCE dataset for small bowel lesions has been obtained from [
41]. It contains 1131 bleeding lesions and 2164 normal images. All frames were manually annotated by expert physicians. The images have 320 × 320 or 512 × 512 resolutions. The dataset was created with images from various cameras, such as MiroCam, PillCam SB1, SB2, and SB3, and with various red lesions, such as angioectasias, angiodysplasias, hemorrhage, and others.
4.1.2. Kvasir-SEG
The Kvasir-SEG was first introduced by Jha et al., in [
42]. It consists of 1000 polyp images acquired by high-resolution electromagnetic imaging systems. It also contains the 1000 corresponding ground truth masks that were annotated by expert endoscopists from Oslo University Hospital (Norway). The dataset includes images with resolutions ranging from 332 × 487 to 1920 × 1072 pixels. The images contain polyps of different sizes (large, medium, and small). All images are encoded using JPEG compression.
4.1.3. CVC-ClinicDB Dataset
The third dataset was first presented in 2012 by Bernal et al., in [
22]. It is an open-access dataset of 612 colonoscopy images of size 574 × 500 pixels. Each pixel in the images is annotated as polyp or background. The frames are obtained from 31 polyp video sequences collected from 23 patients.
Table 1 depicts some of the three datasets details, and
Figure 5 shows some of the bleeding and polyp images from different datasets.
4.2. Implementation Details
During the segmentation process, all the experiments were implemented in Python 3.6 by using the Keras framework with Tensorflow as a backend. They were conducted on an NVIDIA GeForce GTX 1050 (4 GB GPU memory) Core i7. We worked with a Ubuntu 16.04 LTS operating system with Cuda 8.0.61 version installed. For this study, we randomly selected 60% of each dataset for the training, 20% for the validation, and the resting 20% for the test set. We have manually conducted different experiments with multiple sets of hyperparameters on the same dataset and with the same model in order to get the optimal set of hyperparameters. Those sets were chosen based on the empirical evaluation. In the training phase of all the cases, our models performed well with the batch size of 40, Adam as an optimizer, and 50 for the epochs. and were set to 0.9 and 0.99, respectively. In addition, to prevent overfitting, we employed an early stopping mechanism. Early stopping is a type of regularization used when training a model by using an iterative approach like gradient descent. Because all neural networks train utilizing gradient descent, early stopping is a strategy that can be applied to any task. With each iteration, this strategy improves the model fit to the training data. This increases the model performance on data from the test set to a point. However, enhancing the model’s fit to the training data after that point leads to higher generalization error. Early stopping criteria specify how many iterations may be performed before the model begins to overfit.
4.3. Evaluation Metrics
There are several metrics for assessing and comparing the models’ performance. For medical image-segmentation applications, the most often utilized metrics are the Dice coefficient, Jaccard index, also known as intersection over union (IoU), and accuracy. These metrics are calculated as follows.
Dice Coefficient: The Dice coefficient is a relative metric for comparing the pixelwise results between given ground truth and predicted segmentation. Its value range is from 0 to 1, with 0 indicating no spatial overlap between two sets of binary segmentation results and 1 representing total overlap. The Dice coefficient is equal to twice the number of elements shared by both sets A and B, divided by the total number of elements in each set.
Jaccard Index: Another typical measure for evaluating a segmentation approach is the Jaccard index. It computes the similarity between predicted (A) and ground truth (B), as illustrated in the equation below:
Accuracy: A high accuracy indicates that the pixels were correctly classified,
where (TP), (TN), (FP), and (FN) represent true positive, true negative, false positive, and false negative, respectively.
4.4. Experimental Results
To further verify the effectiveness of our method, we trained UNet, SegNet, V-Net, AttU-Net, and AttResU-Net on the MICCAI 2017, Kvasir-SEG, and CVC-ClinicDB datasets and tested them on the test sets. The accuracy, Dice coefficient, and intersection over union (IoU) of each model were calculated. The test results of each model on the three different datasets are presented in this subsection. In our experiments, we choose 80% of the images for training and the rest images are used for testing. We compare AttResU-Net with its baseline of U-Net, as well as two recently proposed networks including SegNet and V-Net.
4.4.1. Results on MICCAI 2017
Table 2 gives the performances of our proposed AttResU-Net and compared different SOTA algorithms on the test set of MICCAI 2017. It can be seen that the proposed AttResU-Net achieves the best performance in three metrics. As given in
Table 2, AttResU-Net achieves an accuracy of 99.16%, a dice coefficient of 94.91%, and a Jaccard index of 90.32% on the MICCAI 2017 datasets, outperforming the original U-Net by 6.42%, 8.37%, and 12.35% gains, respectively. We can clearly notice that AttResU-Net defeats the U-Net network, which has the best outcome compared with the two other segmentation models V-Net and SegNet. It also outperforms AttU-Net presented by Oktay et al. [
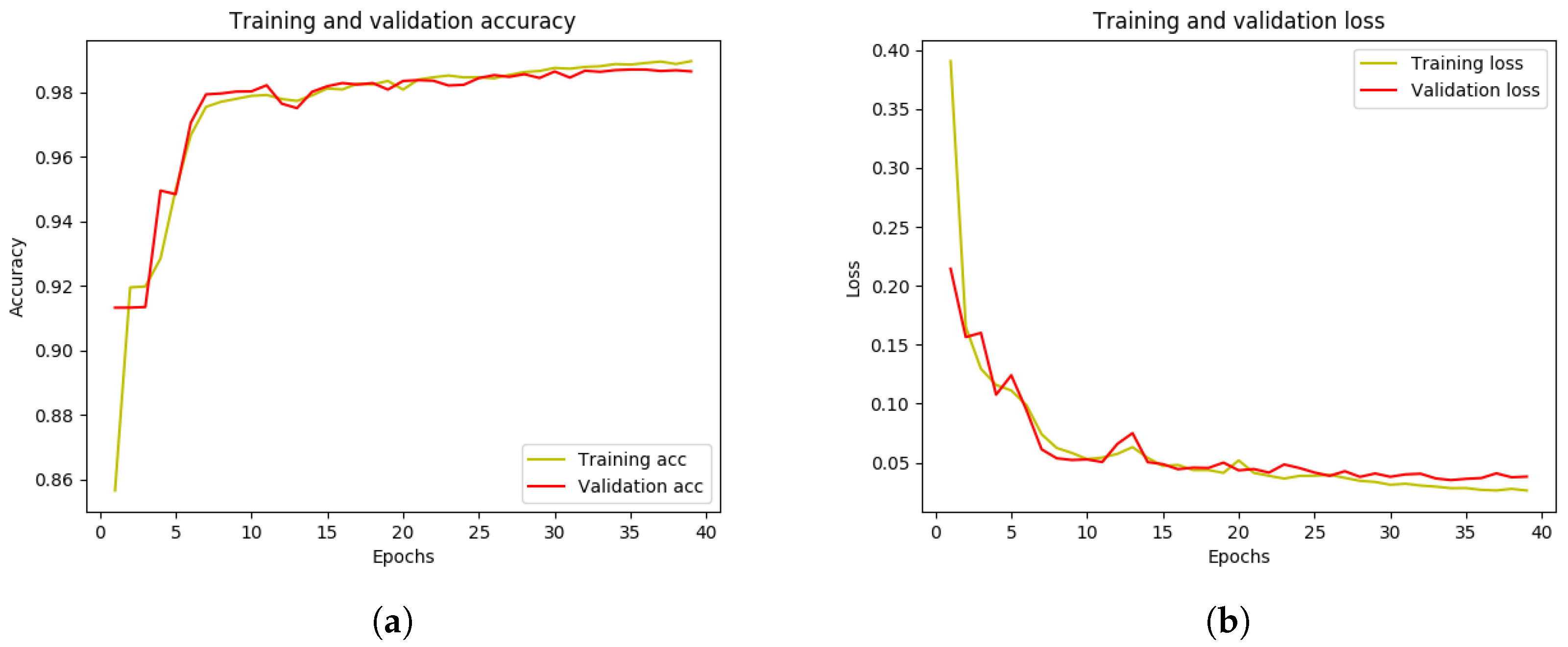
37] as an attention gate (AG) module based on the structure of the U-Net. To create the attention weight maps, the AG module uses the feature maps from the encoder as the input signal and the related upsampling results as the gating signal. They then multiplied the weighted feature maps by the original feature maps and replaced the U-Net skip connections with the weighted feature maps. The target regions were more responsive to the weighted feature maps. This can be explained by the importance of the two powerful modules that we add to the traditional U-Net, including the residual block and attention mechanism. On the other hand, the running time of our proposed framework takes more than five times compared to U-Net. We can say that this is very normal given the complexity of our network. However, as it is well known in the medical field, the precision of the results is favored over the running time. To further show the training process of our model, we present learning and loss curves in
Figure 6. The first figure shows the accuracy curve of the segmentation model. The x-axis represents the number of training epochs and the y-axis represents the accuracy of the model. As the model trains, the accuracy increases from an initial value of approximately 91% to a final value of approximately 99%. This increase in accuracy indicates that the model is improving and learning to make more accurate predictions. It can also be seen that the accuracy levels off after approximately 40 epochs, which suggests that the model has reached a convergence point and is no longer improving. As such, we can consider 40 epochs to be the optimal number of training epochs for this model. The final accuracy of 99% is relatively high, indicating that the model is making accurate predictions most of the time. The second figure shows a loss curve of our segmentation model. The loss curve is a graph that represents the change in the loss function over time as the model trains. As the model trains, the loss decreases from an initial value of around 0.22 to a final value of around 0.04. This decrease in loss indicates that the model is improving and learning to make more accurate predictions. The final loss of 0.04 is relatively low, indicating that the model is making accurate predictions.
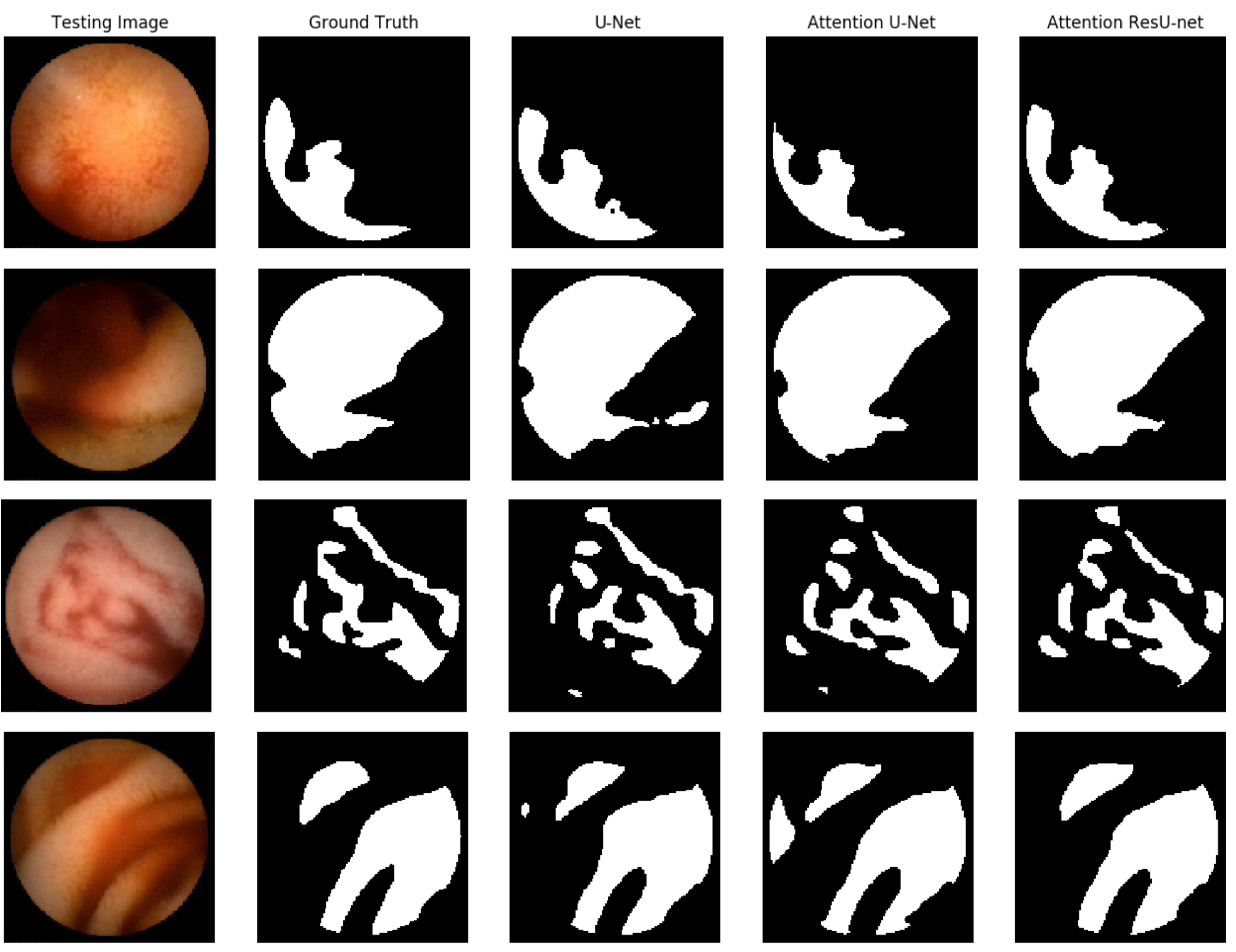
In
Figure 7, we demonstrate some qualitative endoscopic lesion segmentation findings from the MICCAI 2017 test set acquired by using several approaches. The four original images show varied lesions in regard to appearance and size, and there are no apparent structural borders between normal and lesion areas. Furthermore, certain areas with poor quality make data analysis difficult. All of these present challenges in distinguishing aberrant from normal areas. However, we can observe that the segmentation of our suggested AttResU-Net is close to the ground truth. On the contrary, other methods can capture big abnormal regions successfully but may miss certain tiny abnormal regions.
4.4.2. Results Kvasir-SEG
Table 3 displays the results of AttResU-Net, AttU-Net, UNet, SegNet, and V-Net. The suggested model achieved the maximum Dice coefficient, mIoU, and accuracy for the Kvasir-SEG dataset, as shown in
Table 3. AttU-Net attained a high level of accuracy. The Dice coefficient and mIoU scores, on the other hand, are not competitive, which are essential metrics for semantic segmentation tasks. In terms of mIoU, the suggested design outperformed the baseline architectures by a large margin.
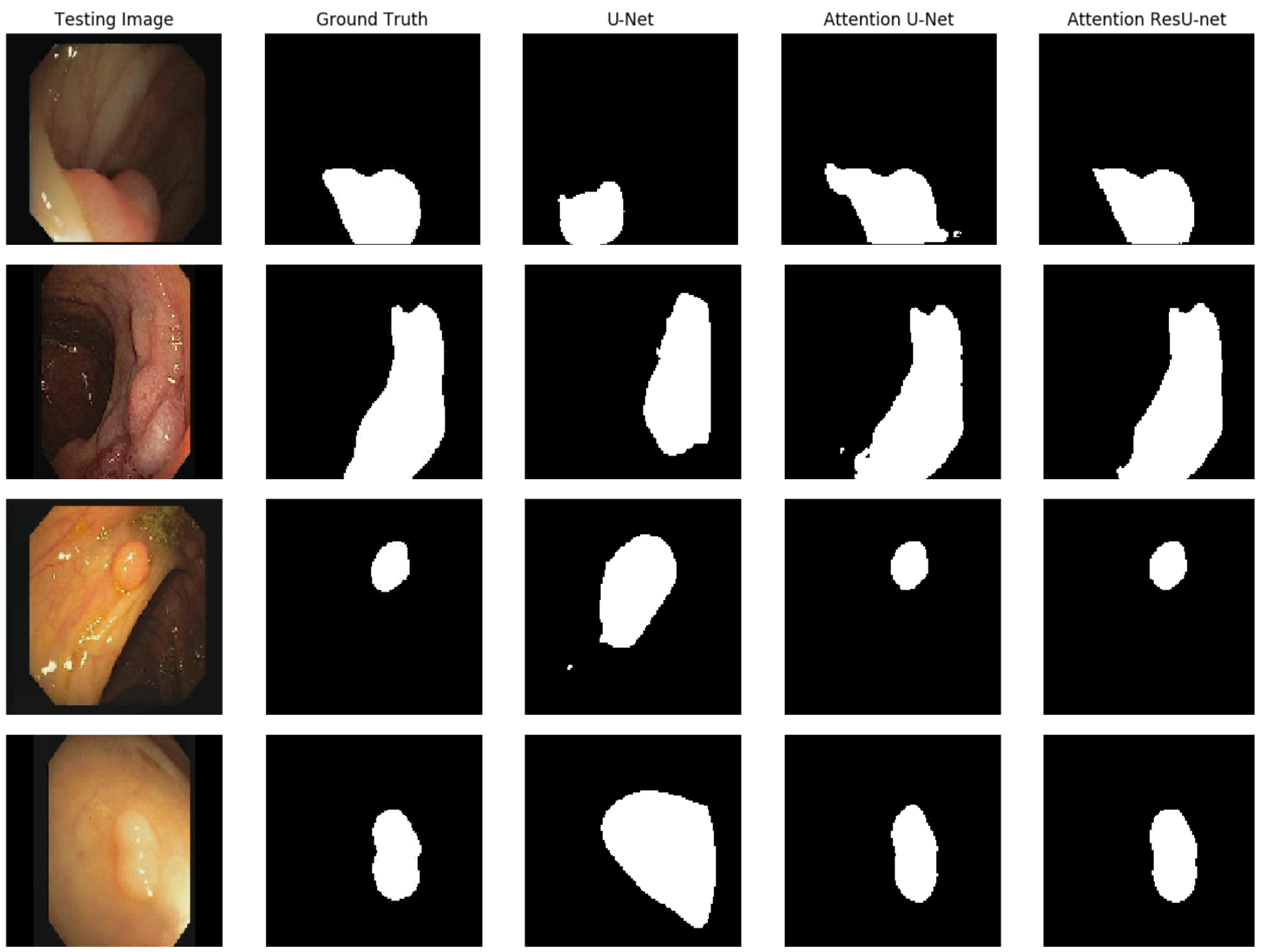
The qualitative outcome for the polyp detection and localization task is shown in
Figure 8. It is clear that all of the algorithms can detect polyps and provide high-quality masks. The best segmentation results are achieved for AttU-Net and AttResU-Net, especially for minor details, as seen in the first example. On basically all samples, our suggested network yields comparatively better predictions.
4.4.3. Results CVC-ClinicDB
To make segmentation more challenging, we tested our model by using the CVC-ClinicDB dataset, which only comprises 612 clinical digital images. We ran additional tests to conduct an in-depth performance investigation of autonomous polyp segmentation. As a result, we tried model generalization to test the suggested architecture’s generalizability on a new dataset. Generalizability would be a significant step toward developing a clinically appropriate model.
Table 4 displays the outcomes for all models on the CVC-ClinicDB dataset. The suggested model was shown to have the highest Dice coefficient, mIoU, and accuracy. The qualitative findings for all models are shown in
Figure 9. The suggested model may attain comparable patterns to those of the ground truth, with some exceptions for the predictions. The advantage of AttResU-Net over the baseline is demonstrated by
Table 4 and
Figure 9.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}