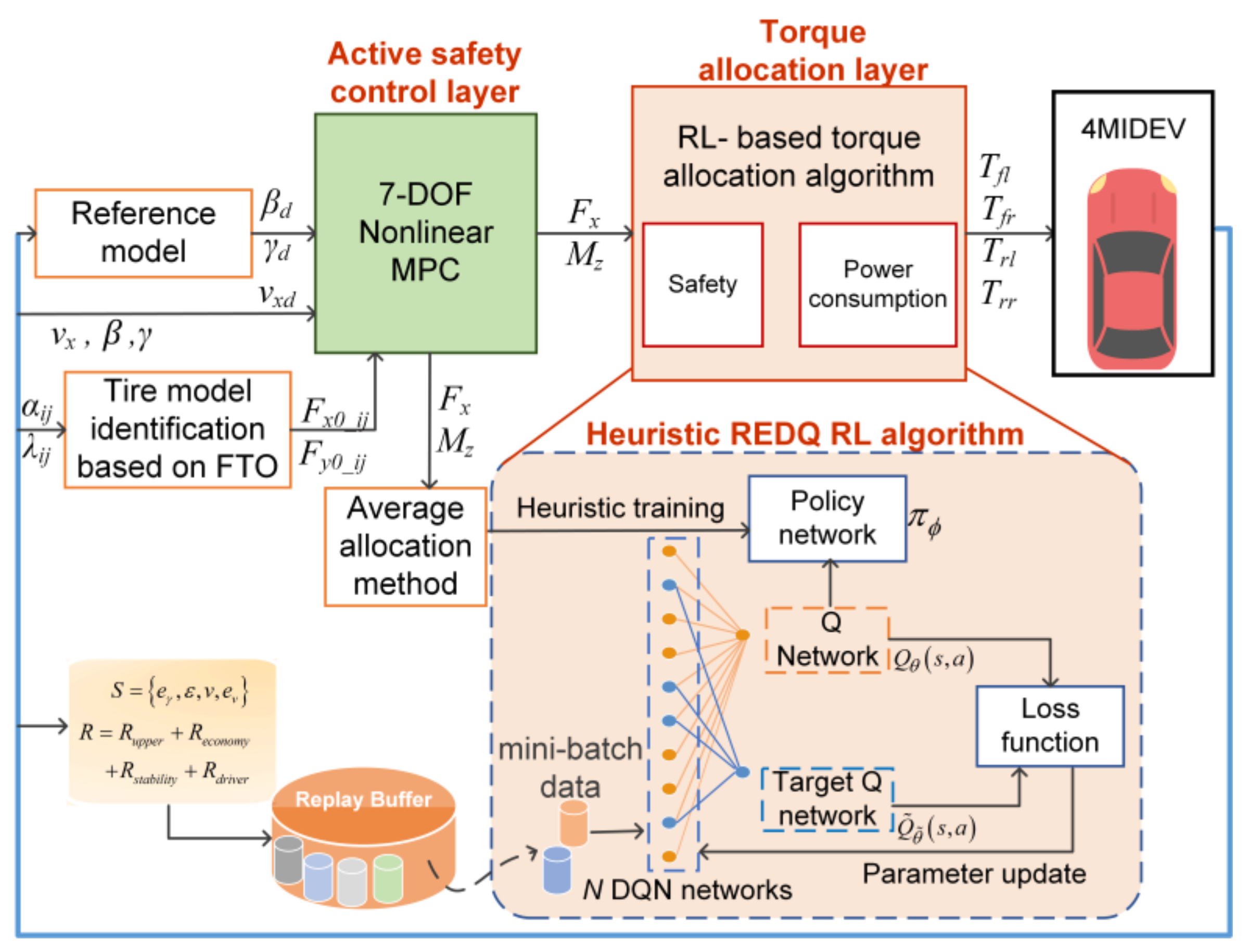
To ensure the stability of the vehicle, the four-wheel torque needs to satisfy Equations (29) and (30). The aim of the torque allocation layer is to distribute the four-wheel torque to achieve and . For 4MIDEV, it is a typical over-actuated system with more actuators than degrees of freedom of the system. Therefore, torque allocation is a problem worth researching; it is important to reduce the power consumption of the motor while ensuring safety.
In the torque allocation layer, we considered a combination of safety and power consumption. In particular, the power consumption and safety weights are dynamically adjusted according to the current vehicle state based on RL. To this end, the task of this paper is the torque allocation of the 4MIDEV, which guarantees the safety and power consumption of the EV.
3.2.2. RL-Based Torque Allocation Algorithm
This section describes the details of the RL-based torque allocation algorithm. The state plays a crucial role in the RL algorithm, and in this study, we define the state space using four states: the yaw rate of deviation
, the stability indicator
, velocity
, and velocity deviation
. Additionally, the action is defined as four-wheel torque.
where the
is obtained from the phase plane. In vehicle dynamics, the driving stability and instability regions can be depicted using a phase portrait [
27]. The
is defined as follows.
where
B1 and
B2 are the parameters associated with the adhesion coefficient. Their corresponding values are specified in reference [
28]. This paper aims to improve the economy of EVs while ensuring safety, so the reward function
is expressed as the following four parts:
Firstly, Equations (29) and (30) ensure that the four-wheel torque satisfies the additional yaw moment
and longitudinal force
from the active safety control layer. Therefore, to ensure vehicle stability, the torque allocation layer needs to satisfy the following equation:
where
,
,
.
Therefore, we constructed
to consider vehicle stability in the torque allocation layer from the perspective of the active safety layer:
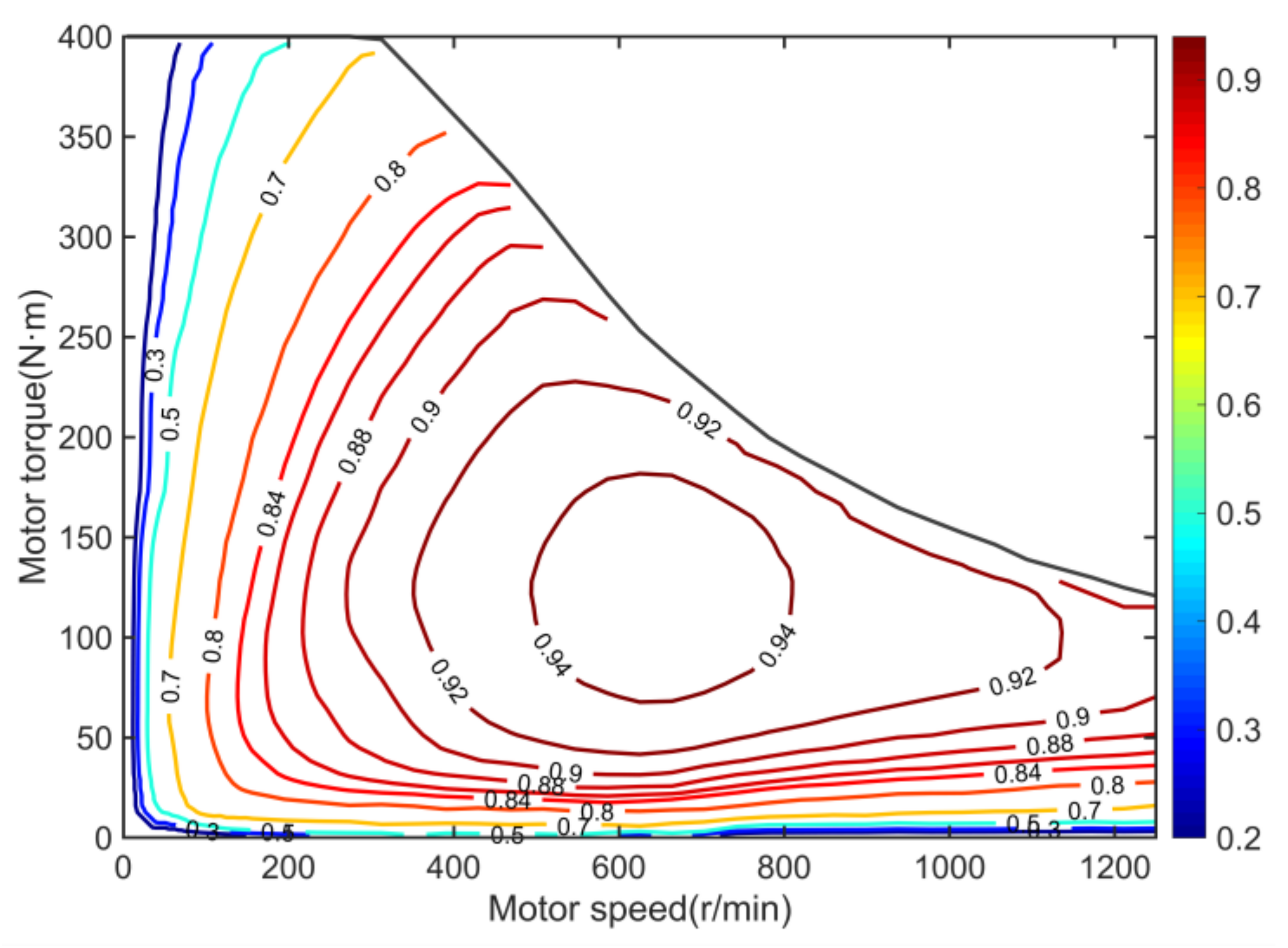
Second, the drive system power consumption is minimized by using the reward function Equation (36).
where
is the penalty factors of economy, and
is the speed of motor
. Additionally, the motor efficiency
is shown in
Figure 4.
Lastly, the stability indicators and driver load are considered in the reward function:
where
and
are the penalty factors for safety and driver load, respectively.
The safety of torque allocation consideration consists of two parts:
and
. As safety is the primary concern in vehicle operation, we chose penalty factors to ensure that the reward function satisfies the following relationship:
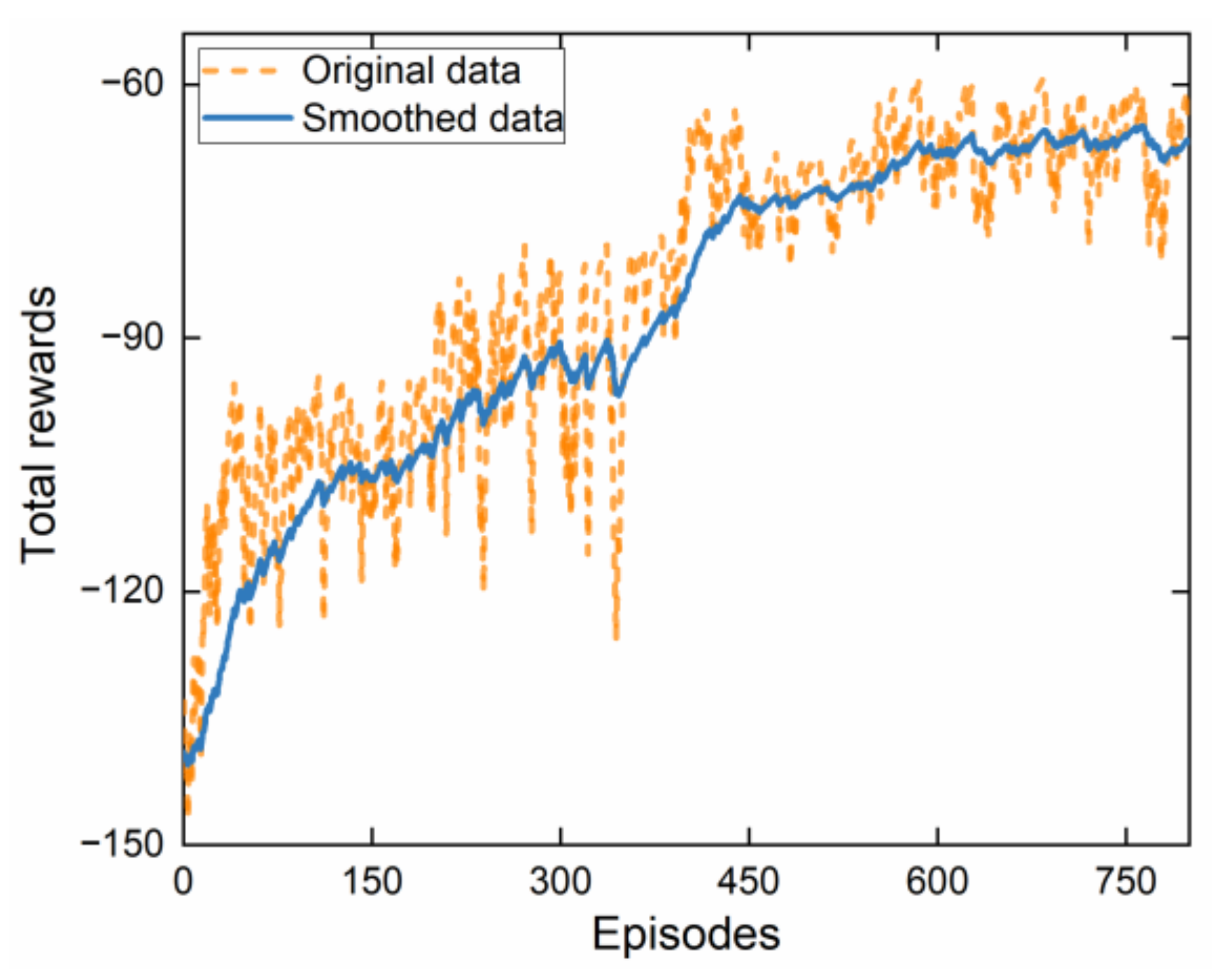
The goal of the RL is to learn a policy that maximizes the expected cumulative reward over time. To encourage exploration and prevent premature convergence, the entropy term is included in the policy
:
where
is a temperature parameter that determines the level of exploration, and the additional entropy term
encourages exploration and prevents premature convergence to suboptimal policies.
Heuristic REDQ is an improved algorithm of REDQ. REDQ is a deep RL algorithm that combines ideas from both ensemble methods and double Q-learning to improve stability and sample efficiency [
29]. In the REDQ algorithm, the Q function is expressed using the Bellman equation:
where
is the expected long-term reward of taking action
based on policy
in state
,
is the immediate reward based on state
,
is the discount factor,
is the next state after taking action
in state
, and
is the next action.
To improve stability and reduce overestimation, the REDQ algorithm maintains an ensemble of
N Q-networks, where each network is represented by a set of weights
, and the target value of
Q-function is calculated by randomly selecting
M Q-networks from
N Q-networks:
where the set
is
M random elements.
The updated rule of evaluating
Q-networks’ weights is by minimizing the loss:
The target Q-networks are updated using a Polyak averaging:
where
is a hyperparameter that determines the smoothing factor.
In addition, the parameter
of the policy
is trained by minimizing the loss:
As the action here is the four-wheeled torque, its action space is four-dimensional, which adds difficulty to the training convergence of the agent. Therefore, a heuristic decay method is introduced here, with the final action being randomly chosen from the set of action strategies
with distribution
. The probability of selecting action
is:
where
,
is the cumulative number of runs, and
is a constant that denotes the decay speed. The
is obtained from
Section 4.1, and the
is expressed as:
where
is an independent noise,
is the mean of the stochastic policy that maps the state
to an action, and
is a random noise sampled from a probability distribution that encourages exploration.
is the Hadamard product, and
is the maximum motor torque, which is determined by the external characteristics of the motor.
To reduce overestimation and improve stability, REDQ uses an ensemble of
Q-networks to estimate the
Q-values and takes the minimum of the target
Q-values from all the networks. To further improve sample efficiency, REDQ uses an update-to-data ratio denoted by
G, which enables control over the number of times the data is reused. Algorithm 2 shows the detailed steps of the heuristic REDQ.
| Algorithm 2. Heuristic REDQ algorithm |
| 1. Initialize an ensemble of Q-networks with parameters , Set target parameters |
| 2. Initialize the target Q-networks with parameters |
| 3. Initialize the replay buffer |
| 4. For each step t do: |
| 5. Randomly sample an action from the set of action strategies with distribution |
| 6. Execute the action and observe the next state , reward |
| 7. Store the experience tuple in the replay buffer |
| 8. for G updates do |
| 9. Sample a mini-batch experiences from replay buffer |
| 10. Randomly select m numbers from the set as a set |
| 11. Based on (42) compute the Q-value estimates |
| 12. for
do |
| 13. Based on (43), update the parameters using gradient descent method |
| 14. Based on (44), Update each target Q-network |
| 15. end for |
| 16. end for |
| 17. end for |
| 18. Return the learned Q-network ensemble. |


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}