
Balanced K-Star: An Explainable Machine Learning Method for Internet-of-Things-Enabled Predictive Maintenance in Manufacturing


Abstract
:1. Introduction
- (i)
- This paper proposes an improved method called “Balanced K-Star”. This is an effective attempt to enable the K-Star algorithm to deal with imbalanced data;
- (ii)
- Our work is also original in that it contributes to representing an explainable artificial intelligence model based on the K-Star algorithm with efficient prediction on predictive maintenance datasets in industrial IoT environments;
- (iii)
- The results of the experiments showed that the proposed Balanced K-Star method outperformed the standard K-Star method on the same dataset;
- (iv)
2. Related Works
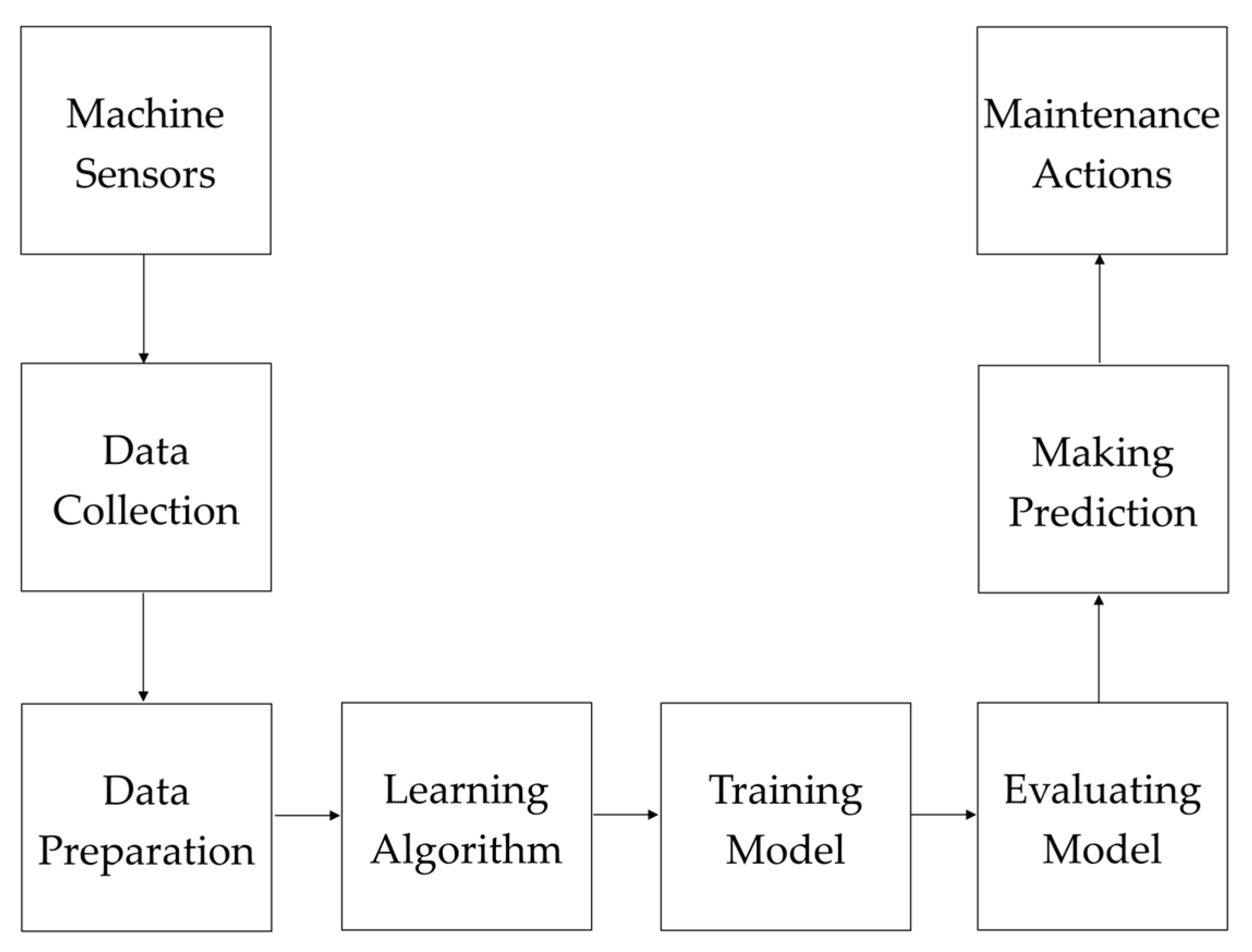
3. Material and Methods
3.1. The Proposed Model
3.2. The Proposed Method: Balanced K-Star
- Imbalanced data make the detection of patterns from a minority class more difficult and lead to unsatisfactory classification performance. The proposed method provides a way to alleviate class imbalance; therefore, the algorithm can successfully learn from samples belonging to all classes during the training process. It builds a robust model by eliminating the dominance of majority classes during training.
- The other advantage of the proposed method is that it can be used for both balanced and imbalanced data. However, many standard classification algorithms are only suitable for balanced data due to their limitations. Our method overcomes this limitation, thereby expanding the application field of standard classification algorithms.
- One of the key advantages of Balanced K-Star is its implementation simplicity. After determining and selecting strong objects by using the Bayes theorem in a straightforward manner, the classification task can be easily performed.
- Another advantage is that the proposed method was designed to process any type of dataset that is suitable for classification. The method can easily be applied to a dataset without background information about the data. Thus, it does not require any specific knowledge of the given data.
3.3. Formal Description
| Algorithm 1. Balanced K-Star |
| Inputs: |
| D: the dataset D = {(x1, y1), (x2, y2), …, (xn, yn)} |
| Threshold: the probability value determined to be selected as a strong object |
| T: test set that will be predicted |
| Output: |
| C: the predicted class labels |
| Begin: |
| H = Bayes(D) |
| O = Ø |
| for i = 1 to n do |
| if yi majority class |
| pi = ClassificationProbability(H, xi) |
| if pi > threshold |
| O.Add(xi, yi) |
| end if |
| else |
| O.Add(xi, yi) |
| end if |
| end for |
| C = Ø |
| Model = KStar(O) |
| foreach x in T |
| c = Model(x) |
| C = C ∪ c |
| end foreach |
| End Algorithm |
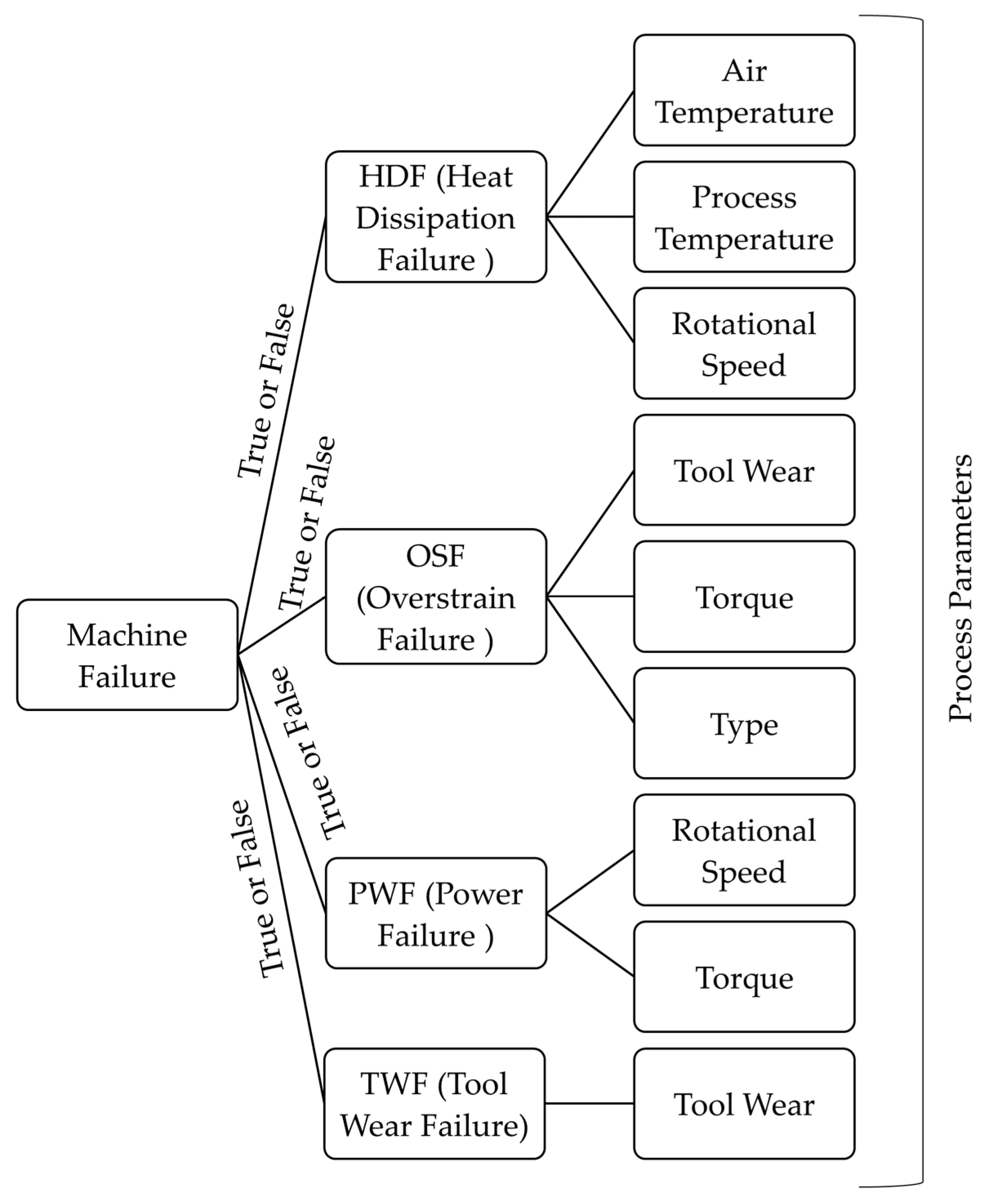
3.4. Dataset Description
4. Experimental Studies
4.1. Results
4.2. Comparison with the State-of-the-Art Methods
5. Conclusions and Future Works
- The Balanced K-Star method achieved a higher classification accuracy than the standard K-Star method on the same dataset;
- Our method (98.75%) outperformed the traditional machine learning methods, ensemble learning methods, and state-of-the-art methods (91.74%) on average;
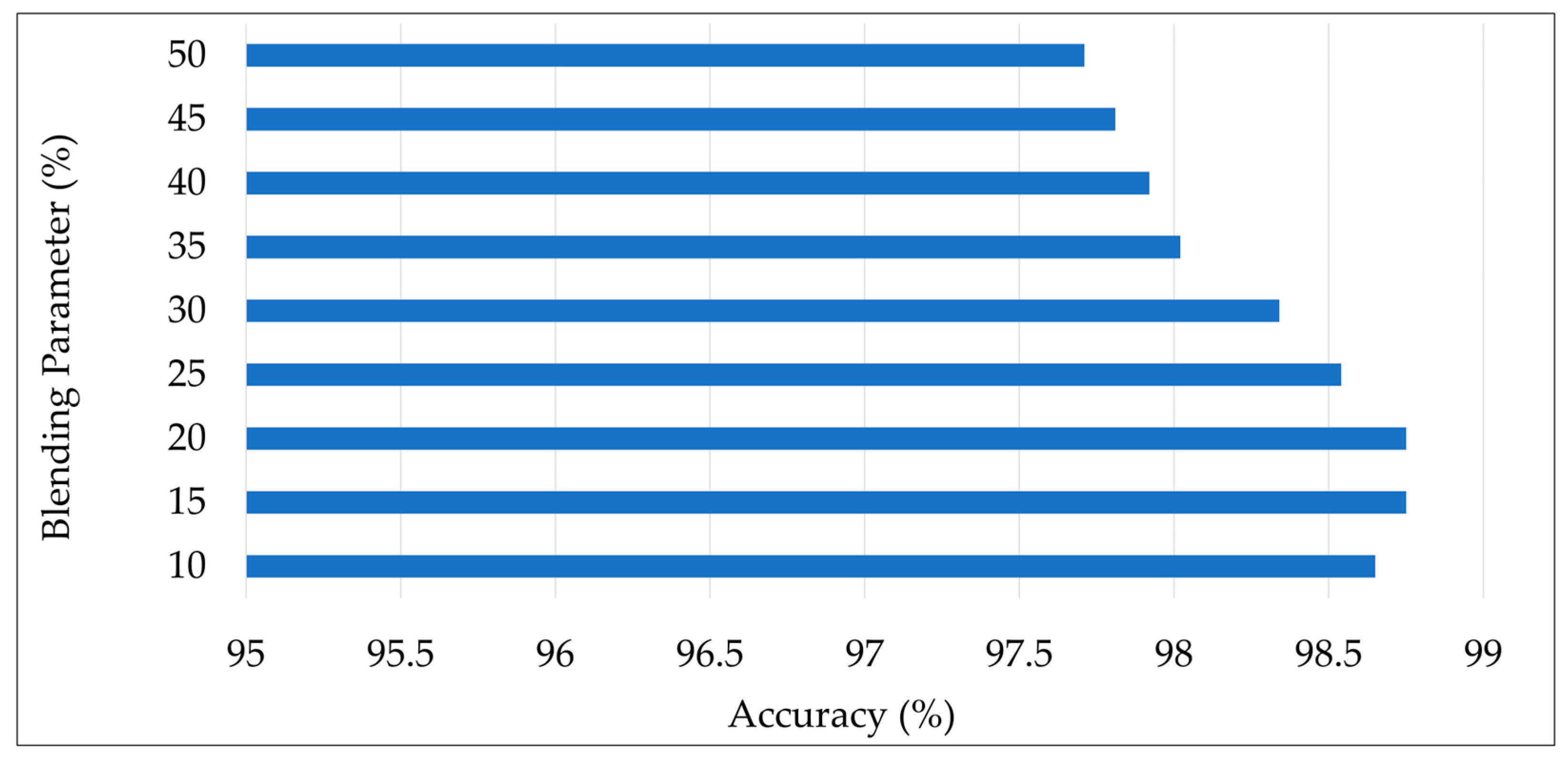
- The performance of the method was evaluated with different parameter settings, achieving the highest accuracy with 15% and 20% values of the blend parameters;
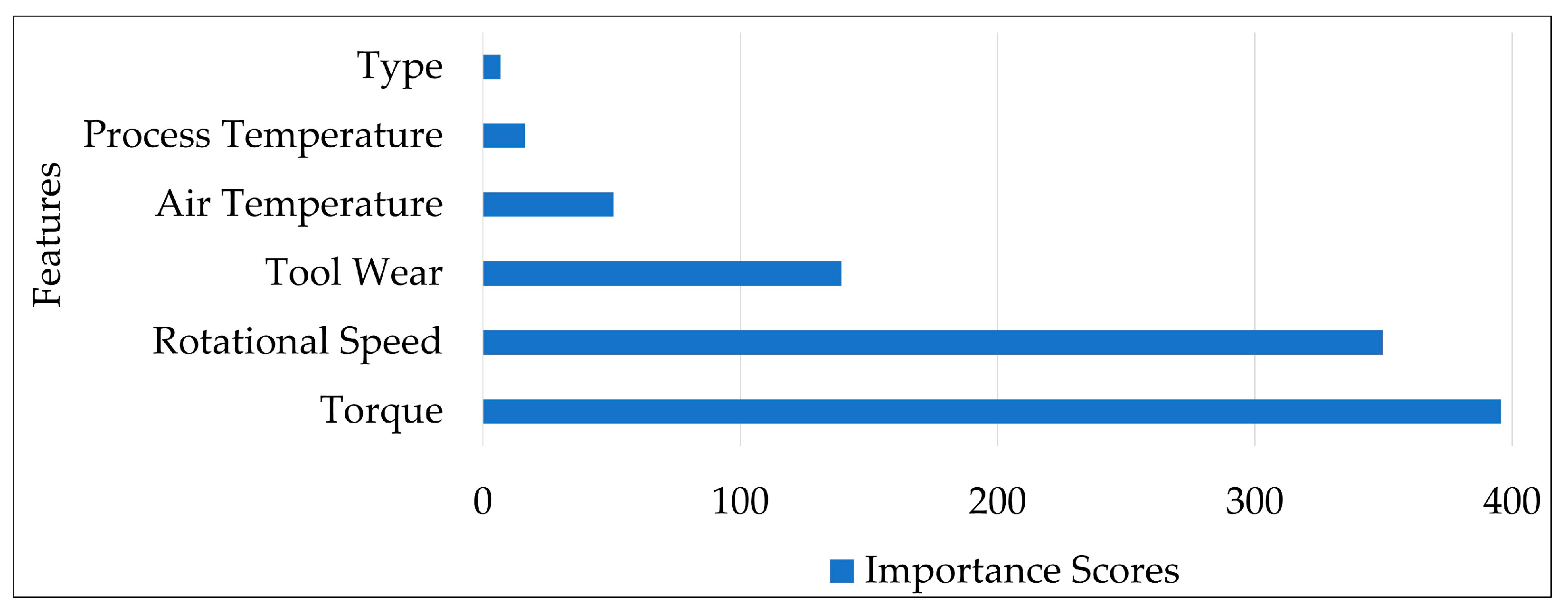
- When the importance of the features was investigated by the chi-square technique, it was revealed that the torque feature had the highest score.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AE | Autoencoder |
| ANN | Artificial neural network |
| BKS | Balanced K-Star |
| BLR | Binary logistic regression |
| CatBoost | Categorical boosting |
| CML | Conventional machine learning |
| ctGAN | Conditional tabular generative adversarial network |
| DFPAIS | Data-filling approach based on probability analysis in incomplete soft sets |
| DT | Decision tree |
| ECM | Engineering change management |
| EFNC-Exp | Evolving fuzzy neural classifier with expert rules |
| ELM | Extreme learning machine |
| EOC | Environmental and operational conditions |
| GANs | Generative adversarial networks |
| GB | Gradient boosting |
| HDF | Heat dissipation failure |
| HUS-ML | Hybrid unsupervised and supervised machine learning |
| IIoT | Industrial Internet of Things |
| IoT | Internet of Things |
| KNN | K-nearest neighbors |
| LIME | Local interpretable model-agnostic explanations |
| LR | Logistic regression |
| LWL | Locally weighted learning |
| ML | Machine learning |
| MLP | Multilayer perceptron |
| NN | Neural network |
| OC-SVM | One-class support vector machine |
| OSF | Overstrain failure |
| PCA | Principal component analysis |
| PdM | Predictive maintenance |
| PWF | Power failure |
| RF | Random forest |
| RNF | Random failure |
| RUL | Remaining useful life |
| RUSBoost | Random undersampling boosting |
| SHAP | Shapley additive explanation |
| SDFIS | Simplified approach for data filling in incomplete soft sets |
| SmoteNC | Synthetic minority oversampling technique for nominal and continuous |
| SODA | Self-organized direction-aware data partitioning |
| SVM | Support vector machine |
| TTML | Tensor train-based machine learning |
| TWF | Tool wear failure |
| UPM | Ultraprecision machining |
| XAI | Explainable artificial intelligence |
| XGBoost | Extreme gradient boosting |
References
- Resende, C.; Folgado, D.; Oliveira, J.; Franco, B.; Moreira, W.; Oliveira-Jr, A.; Cavaleiro, A.; Carvalho, R. TIP4.0: Industrial Internet of Things Platform for Predictive Maintenance. Sensors 2021, 21, 4676. [Google Scholar] [CrossRef] [PubMed]
- Palomar-Cosín, E.; García-Valls, M. Flexible IoT Agriculture Systems for Irrigation Control Based on Software Services. Sensors 2022, 22, 9999. [Google Scholar] [CrossRef] [PubMed]
- Wassan, S.; Suhail, B.; Mubeen, R.; Raj, B.; Agarwal, U.; Khatri, E.; Gopinathan, S.; Dhiman, G. Gradient Boosting for Health IoT Federated Learning. Sustainability 2022, 14, 16842. [Google Scholar] [CrossRef]
- Kaur, J.; Santhoshkumar, N.; Nomani, M.Z.M.; Sharma, D.K.; Maroor, J.P.; Dhiman, V. Impact of Internets of Things (IOT) in Retail Sector. Mater. Today Proc. 2021, 51, 26–30. [Google Scholar] [CrossRef]
- Madhiarasan, M. Design and development of IoT based solar powered versatile moving robot for military application. Int. J. Syst. Assur. Eng. Manag. 2021, 12, 437–450. [Google Scholar] [CrossRef]
- Mahmoud, H.H.; Alghawli, A.S.; Al-shammari, M.K.M.; Amran, G.A.; Mutmbak, K.H.; Al-harbi, K.H.; Al-qaness, M.A.A. IoT-Based Motorbike Ambulance: Secure and Efficient Transportation. Electron. 2022, 11, 2878. [Google Scholar] [CrossRef]
- Dang, L.M.; Piran, M.J.; Han, D.; Min, K.; Moon, H. A Survey on Internet of Things and Cloud Computing for Healthcare. Electronics 2019, 8, 768. [Google Scholar] [CrossRef] [Green Version]
- Motlagh, N.H.; Mohammadrezaei, M.; Hunt, J.; Zakeri, B. Internet of Things (IoT) and the Energy Sector. Energies 2020, 13, 494. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Ni, Z.; Karlsson, M.; Gong, S. Methodology for Digital Transformation with Internet of Things and Cloud Computing: A Practical Guideline for Innovation in Small- and Medium-Sized Enterprises. Sensors 2021, 21, 5355. [Google Scholar] [CrossRef]
- Zikria, Y.B.; Ali, R.; Afzal, M.K.; Kim, S.W. Next-Generation Internet of Things (IoT): Opportunities, Challenges, and Solutions. Sensors 2021, 21, 1174. [Google Scholar] [CrossRef]
- Fraga-Lamas, P.; Fernández-Caramés, T.M.; Castedo, L. Towards the Internet of Smart Trains: A Review on Industrial IoT-Connected Railways. Sensors 2017, 17, 1457. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Raposo, D.; Rodrigues, A.; Sinche, S.; Sá Silva, J.; Boavida, F. Industrial IoT Monitoring: Technologies and Architecture Proposal. Sensors 2018, 18, 3568. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Varga, P.; Peto, J.; Franko, A.; Balla, D.; Haja, D.; Janky, F.; Soos, G.; Ficzere, D.; Maliosz, M.; Toka, L. 5G support for Industrial IoT Applications— Challenges, Solutions, and Research gaps. Sensors 2020, 20, 828. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pech, M.; Vrchota, J.; Bednář, J. Predictive Maintenance and Intelligent Sensors in Smart Factory: Review. Sensors 2021, 21, 1470. [Google Scholar] [CrossRef]
- Sheuly, S.S.; Ahmed, M.U.; Begum, S. Machine-Learning-Based Digital Twin in Manufacturing: A Bibliometric Analysis and Evolutionary Overview. Appl. Sci. 2022, 12, 6512. [Google Scholar] [CrossRef]
- Calabrese, M.; Cimmino, M.; Fiume, F.; Manfrin, M.; Romeo, L.; Ceccacci, S.; Paolanti, M.; Toscano, G.; Ciandrini, G.; Carrotta, A.; et al. SOPHIA: An Event-Based IoT and Machine Learning Architecture for Predictive Maintenance in Industry 4.0. Information 2020, 11, 202. [Google Scholar] [CrossRef] [Green Version]
- Yakhni, M.F.; Hosni, H.; Cauet, S.; Sakout, A.; Etien, E.; Rambault, L.; Assoum, H.; El-Gohary, M. Design of a Digital Twin for an Industrial Vacuum Process: A Predictive Maintenance Approach. Machines 2022, 10, 686. [Google Scholar] [CrossRef]
- Hung, Y.-H. Improved Ensemble-Learning Algorithm for Predictive Maintenance in the Manufacturing Process. Appl. Sci. 2021, 11, 6832. [Google Scholar] [CrossRef]
- Niyonambaza, I.; Zennaro, M.; Uwitonze, A. Predictive Maintenance (PdM) Structure Using Internet of Things (IoT) for Mechanical Equipment Used into Hospitals in Rwanda. Future Internet 2020, 12, 224. [Google Scholar] [CrossRef]
- Kerboua, A.; Metatla, A.; Kelailia, R.; Batouche, M. Fault Diagnosis in Induction Motor using Pattern Recognition and Neural Networks. In Proceedings of the International Conference on Signal, Image, Vision and their Applications, Guelma, Algeria, 26–27 November 2018; pp. 1–7. [Google Scholar]
- Dolatabadi, S.H.; Budinska, I. Systematic Literature Review Predictive Maintenance Solutions for SMEs from the Last Decade. Machines 2021, 9, 191. [Google Scholar] [CrossRef]
- Calabrese, F.; Regattieri, A.; Botti, L.; Mora, C.; Galizia, F.G. Unsupervised Fault Detection and Prediction of Remaining Useful Life for Online Prognostic Health Management of Mechanical Systems. Appl. Sci. 2020, 10, 4120. [Google Scholar] [CrossRef]
- Ullah, I.; Yang, F.; Khan, R.; Liu, L.; Yang, H.; Gao, B.; Sun, K. Predictive Maintenance of Power Substation Equipment by Infrared Thermography Using a Machine-Learning Approach. Energies 2017, 10, 1987. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Zhang, C.; Zhu, J.; Xu, F. Fault Diagnosis of Motor Vibration Signals by Fusion of Spatiotemporal Features. Machines 2022, 10, 246. [Google Scholar] [CrossRef]
- Abidi, M.H.; Mohammed, M.K.; Alkhalefah, H. Predictive Maintenance Planning for Industry 4.0 Using Machine Learning for Sustainable Manufacturing. Sustainability 2022, 14, 3387. [Google Scholar] [CrossRef]
- Çınar, Z.M.; Abdussalam Nuhu, A.; Zeeshan, Q.; Korhan, O.; Asmael, M.; Safaei, B. Machine Learning in Predictive Maintenance towards Sustainable Smart Manufacturing in Industry 4.0. Sustainability 2020, 12, 8211. [Google Scholar] [CrossRef]
- Von Hahn, T.; Mechefske, C.K. Machine Learning in CNC Machining: Best Practices. Machines 2022, 10, 1233. [Google Scholar] [CrossRef]
- Kang, Z.; Catal, C.; Tekinerdogan, B. Machine Learning Applications in Production Lines: A Systematic Literature Review. Comput. Ind. Eng. 2020, 149, 106773. [Google Scholar] [CrossRef]
- Cleary, J.G.; Trigg, L.E. K*: An instance-based learner using an entropic distance measure. In Proceedings of the 12th International Conference on Machine Learning, Tahoe City, CA, USA, 9–12 July 1995; pp. 108–114. [Google Scholar]
- Ropelewska, E.; Cai, X.; Zhang, Z.; Sabanci, K.; Aslan, M.F. Benchmarking machine learning approaches to evaluate the cultivar differentiation of plum (Prunus domestica L.) kernels. Agriculture 2022, 12, 285. [Google Scholar] [CrossRef]
- Perez-Escamirosa, E.; Alarcon-Paredes, A.; Alonso-Silveri, G.A.; Oropesa, I.; Camacho-Nieto, O.; Lorias-Espinoza, D.; Minor-Martinez, A. Objective classification of psychomotor laparoscopic skills of surgeons based on three different approaches. Int. J. Comput. Assisted Radiol. Surg. 2020, 15, 27–40. [Google Scholar] [CrossRef]
- Chen, C.-W.; Chang, K.-P.; Ho, C.-W.; Chang, H.-P.; Chu, Y.-W. KStable: A computational method for predicting protein thermal stability changes by k-star with regular-mRMR feature selection. Entropy 2018, 20, 988. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, S.R.; Waheed, S. Analysis of classification algorithms for liver disease diagnosis. J. Sci. Tech. Environ. Inf. 2017, 5, 361–370. [Google Scholar] [CrossRef]
- Kumar, S.; Hiwarkar, T. Comparative analysis to predicting student’s performance using k-star algorithm. Int. J. Res. Anal. Rev. 2019, 6, 204–210. [Google Scholar]
- Rai, A. Explainable AI: From Black Box to Glass Box. J. Acad. Mark. Sci. 2019, 48, 137–141. [Google Scholar] [CrossRef] [Green Version]
- Gunning, D.; Stefik, M.; Choi, J.; Miller, T.; Stumpf, S.; Yang, G.-Z. XAI—Explainable Artificial Intelligence. Sci. Rob. 2019, 4, 7120. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kong, Z.; Lu, Q.; Wang, L.; Guo, G. A Simplified Approach for Data Filling in Incomplete Soft Sets. Expert Syst. Appl. 2023, 213, 119248. [Google Scholar] [CrossRef]
- Souza, P.V.C.; Lughofer, E. EFNC-Exp: An evolving fuzzy neural classifier integrating expert rules and uncertainty. Fuzzy Sets Syst. 2022, in press. [Google Scholar]
- Chen, C.-H.; Tsung, C.-K.; Yu, S.-S. Designing a Hybrid Equipment-Failure Diagnosis Mechanism under Mixed-Type Data with Limited Failure Samples. Appl. Sci. 2022, 12, 9286. [Google Scholar] [CrossRef]
- Vandereycken, B.; Voorhaar, R. TTML: Tensor trains for general supervised machine learning. arXiv 2016, arXiv:2203.04352. [Google Scholar]
- Falla, B.F.; Ortega, D.A. Evaluación De Algoritmos De Inteligencia Artificial Aplicados Al Mantenimiento Predictivo. Ph.D. Thesis, Corporación Universitaria Autónoma de Nariño (AUNAR), Villavicencio, Colombia, 3 June 2022. [Google Scholar]
- Iantovics, L.B.; Enachescu, C. Method for Data Quality Assessment of Synthetic Industrial Data. Sensors 2022, 22, 1608. [Google Scholar] [CrossRef]
- Sharma, N.; Sidana, T.; Singhal, S.; Jindal, S. Predictive Maintenance: Comparative Study of Machine Learning Algorithms for Fault Diagnosis. Social Sci. Res. Network (SSRN) 2022. [Google Scholar] [CrossRef]
- Harichandran, A.; Raphael, B.; Mukherjee, A. Equipment Activity Recognition and Early Fault Detection in Automated Construction through a Hybrid Machine Learning Framework. Computer-Aided Civ. Infrastruct. Eng. 2022, 38, 253–268. [Google Scholar] [CrossRef]
- Kamel, H. Artificial Intelligence for Predictive Maintenance. J. Physics: Conf. Ser. 2022, 2299, 012001. [Google Scholar] [CrossRef]
- Jo, H.; Jun, C.-H. A Personalized Classification Model Using Similarity Learning via Supervised Autoencoder. Appl. Soft Comput. 2022, 131, 109773. [Google Scholar] [CrossRef]
- Vuttipittayamongkol, P.; Arreeras, T. Data-driven Industrial Machine Failure Detection in Imbalanced Environments. In Proceedings of the IEEE International Conference on Industrial Engineering and Engineering Management, Kuala Lumpur, Malaysia, 7–10 December 2022; pp. 1224–1227. [Google Scholar]
- Mota, B.; Faria, P.; Ramos, C. Predictive Maintenance for Maintenance-Effective Manufacturing Using Machine Learning Approaches. In Proceedings of the 17th International Conference on Soft Computing Models in Industrial and Environmental Applications, Salamanca, Spain, 5–7 September 2022; Lecture Notes in Networks and Systems. Volume 531, pp. 13–22. [Google Scholar]
- Diao, L.; Deng, M.; Gao, J. Clustering by Constructing Hyper-Planes. IEEE Access 2021, 9, 70167–70181. [Google Scholar] [CrossRef]
- Torcianti, A.; Matzka, S. Explainable Artificial Intelligence for Predictive Maintenance Applications using a Local Surrogate Model. In Proceedings of the 4th International Conference on Artificial Intelligence for Industries, Laguna Hills, CA, USA, 20–22 September 2021; pp. 86–88. [Google Scholar]
- Pastorino, J.; Biswas, A.K. Data-Blind ML: Building privacy-aware machine learning models without direct data access. In Proceedings of the IEEE Fourth International Conference on Artificial Intelligence and Knowledge Engineering, Laguna Hills, CA, USA, 1–3 December 2021; pp. 95–98. [Google Scholar]
- Matzka, S. Explainable artificial intelligence for predictive maintenance applications. In Proceedings of the Third International Conference on Artificial Intelligence for Industries, Irvine, CA, USA, 21–23 September 2020; pp. 69–74. [Google Scholar]
- Schiller, E.; Aidoo, A.; Fuhrer, J.; Stahl, J.; Ziörjen, M.; Stiller, B. Landscape of IoT Security. Compt. Sci. Rev. 2022, 44, 100467. [Google Scholar] [CrossRef]
- Poongodi, T.; Krishnamurthi, R.; Indrakumari, R.; Suresh, P.; Balusamy, B. Wearable Devices and IoT. In A Handbook of Internet of Things in Biomedical and Cyber Physical System; Springer: Berlin/Heidelberg, Germany, 2019; Volume 165, pp. 245–273. [Google Scholar]
- Urbina, M.; Acosta, T.; Lázaro, J.; Astarloa, A.; Bidarte, U. Smart Sensor: SoC Architecture for the Industrial Internet of Things. IEEE Internet Things J. 2019, 6, 6567–6577. [Google Scholar] [CrossRef]
- Dragulinescu, A.-M.; Halunga, S.; Zamfirescu, C. Unmanned Vehicles’ Placement Optimisation for Internet of Things and Internet of Unmanned Vehicles. Sensors 2021, 21, 6984. [Google Scholar] [CrossRef]
- Junior, F.R.; Bianchi, R.; Prati, R.; Kolehmainen, K.; Soininen, J.; Kamienski, C. Data reduction based on machine learning algorithms for fog computing in IoT smart agriculture. Biosyst. Eng. 2022, 223, 142–158. [Google Scholar] [CrossRef]
- Siaterlis, G.; Franke, M.; Klein, K.; Hribernik, K.; Papapanagiotakis, G.; Palaiologos, S.; Antypas, G.; Nikolakis, N.; Alexopoulos, K. An IIoT approach for edge intelligence in production environments using machine learning and knowledge graphs. Procedia CIRP 2022, 106, 282–287. [Google Scholar] [CrossRef]
- Arena, S.; Florian, E.; Zennaro, I.; Orrù, P.F.; Sgarbossa, F. A Novel Decision Support System for Managing Predictive Maintenance Strategies Based on Machine Learning Approaches. Saf. Sci. 2022, 146, 105529. [Google Scholar] [CrossRef]
- Hoffmann Souza, M.L.; da Costa, C.A.; de Oliveira Ramos, G.; da Rosa Righi, R. A Survey on Decision-Making Based on System Reliability in the Context of Industry 4.0. J. Manuf. Syst. 2020, 56, 133–156. [Google Scholar] [CrossRef]
- Manjunath, K.; Tewary, S.; Khatri, N.; Cheng, K. Monitoring and Predicting the Surface Generation and Surface Roughness in Ultraprecision Machining: A Critical Review. Machines 2021, 9, 369. [Google Scholar] [CrossRef]
- Herrero, R.D.; Zorrilla, M. An I4.0 Data Intensive Platform Suitable for the Deployment of Machine Learning Models: A Pre-dictive Maintenance Service Case Study. Procedia Comput. Sci. 2022, 200, 1014–1023. [Google Scholar] [CrossRef]
- Traini, E.; Bruno, G.; D’Antonio, G.; Lombardi, F. Machine Learning Framework for Predictive Maintenance in Milling. IFAC PapersOnLine 2019, 52, 177–182. [Google Scholar] [CrossRef]
- Sahal, R.; Alsamhi, S.H.; Brown, K.N.; O’Shea, D.; McCarthy, C.; Guizani, M. Blockchain-Empowered Digital Twins Collaboration: Smart Transportation Use Case. Machines 2021, 9, 193. [Google Scholar] [CrossRef]
- Cinar, E.; Kalay, S.; Saricicek, I. A Predictive Maintenance System Design and Implementation for Intelligent Manufacturing. Machines 2022, 10, 1006. [Google Scholar] [CrossRef]
- Pan, Y.; Stark, R. An Interpretable Machine Learning Approach for Engineering Change Management Decision Support in Automotive Industry. Comput. Ind. 2022, 138, 103633. [Google Scholar] [CrossRef]
- Wuest, T.; Irgens, C.; Thoben, K.-D. An Approach to Monitoring Quality in Manufacturing Using Supervised Machine Learning on Product State Data. J. Intell. Manuf. 2013, 25, 1167–1180. [Google Scholar] [CrossRef]
- Kirchner, E.; Bienefeld, C.; Schirra, T.; Moltschanov, A. Predicting the Electrical Impedance of Rolling Bearings Using Machine Learning Methods. Machines 2022, 10, 156. [Google Scholar] [CrossRef]
- Angelov, P.P.; Soares, E.A.; Jiang, R.; Arnold, N.I.; Atkinson, P.M. Explainable Artificial Intelligence: An Analytical Review. WIREs Data Min. Knowl. Discov. 2021, 11, e1424. [Google Scholar] [CrossRef]
- Roscher, R.; Bohn, B.; Duarte, M.F.; Garcke, J. Explainable Machine Learning for Scientific Insights and Discoveries. IEEE Access 2020, 8, 42200–42216. [Google Scholar] [CrossRef]
- Bussmann, N.; Giudici, P.; Marinelli, D.; Papenbrock, J. Explainable Machine Learning in Credit Risk Management. Comput. Econ. 2020, 57, 203–216. [Google Scholar] [CrossRef]
- Serradilla, O.; Zugasti, E.; de Okariz, J.R.; Rodriguez, J.; Zurutuza, U. Adaptable and Explainable Predictive Maintenance: Semi-Supervised Deep Learning for Anomaly Detection and Diagnosis in Press Machine Data. Appl. Sci. 2021, 11, 7376. [Google Scholar] [CrossRef]
- Hajgató, G.; Wéber, R.; Szilágyi, B.; Tóthpál, B.; Gyires-Tóth, B.; Hős, C. PredMaX: Predictive Maintenance with Explainable Deep Convolutional Autoencoders. Adv. Eng. Inf. 2022, 54, 101778. [Google Scholar] [CrossRef]
- Sampath, V.; Maurtua, I.; Martín, J.J.A.; Iriondo, A.; Lluvia, I.; Aizpurua, G. Intraclass Image Augmentation for Defect Detection Using Generative Adversarial Neural Networks. Sensors 2023, 23, 1861. [Google Scholar] [CrossRef]
- Vakharia, V.; Vora, J.; Khanna, S.; Chaudhari, R.; Shah, M.; Pimenov, D.Y.; Giasin, K.; Prajapati, P.; Wojciechowski, S. Experimental Investigations and Prediction of WEDMed Surface of Nitinol SMA Using SinGAN and DenseNet Deep Learning Model. J. Mater. Res. Technol. 2022, 18, 325–337. [Google Scholar] [CrossRef]
- Yuksel, A.S.; Atmaca, S. Driver’s black box: A system for driver risk assessment using machine learning and fuzzy logic. J. Intell. Transp. Syst. 2021, 25, 482–500. [Google Scholar] [CrossRef]
- Ravikumar, K.N.; Madhusudana, C.K.; Kumar, H.; Gangadharan, K.V. Classification of gear faults in internal combustion (IC) engine gearbox using discrete wavelet transform features and K star algorithm. Int. J. Eng. Sci. Technol. 2022, 30, 101048. [Google Scholar] [CrossRef]
- Raja, M.N.A.; Shukla, S.K.; Khan, M.U.A. An intelligent approach for predicting the strength of geosynthetic-reinforced subgrade soil. Int. J. Pavement Eng. 2022, 23, 3505–3521. [Google Scholar] [CrossRef]
- Birant, K.U. Semi-Supervised k-Star (SSS): A Machine Learning Method with a Novel Holo-Training Approach. Entropy 2023, 25, 149. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques, 4th ed.; Morgan Kaufmann: Cambridge, MA, USA, 2016; pp. 1–664. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Properties | Attribute Properties | Related Tasks | Instances | Features | Missing Values | Field | Date | Web Hits |
|---|---|---|---|---|---|---|---|---|
| Time Series, Multivariate | Real, Boolean | Regression Classification | 10,000 | 14 | N/A | Manufacturing | 2020 | 94,531 |
| Variable Name | Variable Description |
|---|---|
| UID | Unique identifier |
| Product ID | Quality of product variants as serial numbers |
| Type | L (low), M (medium), or H (high), representing the quality of the product |
| Air Temperature | Temperature of air in kelvin |
| Process Temperature | Temperature of process in kelvin |
| Rotational Speed | Rotational speed in revolutions per minute (rpm) |
| Torque | Torque in newton meters (the force that causes rotation) |
| Tool Wear | Tool wear in minutes |
| Machine Failure | Indicates whether a failure has occured or not |
| TWF | Tool wear failure |
| PWF | Power failure |
| HDF | Heat dissipation failure |
| RNF | Random failures |
| OSF | Overstrain failure |
| Variable Name | Min | Max | Mean | Standard Deviation |
|---|---|---|---|---|
| Air Temperature | 295.3 | 304.5 | 300.0 | 2.000 |
| Process Temperature | 305.7 | 313.8 | 310.0 | 1.484 |
| Rotational Speed | 1168 | 2886 | 1538.8 | 179.284 |
| Torque | 3.8 | 76.6 | 39.9 | 9.969 |
| Tool Wear | 0 | 253 | 107.9 | 63.654 |
| Fold Number | Accuracy (%) | |
|---|---|---|
| K-Star | Balanced K-Star | |
| 1 | 97.20 | 96.91 |
| 2 | 97.10 | 98.96 |
| 3 | 97.10 | 97.92 |
| 4 | 97.50 | 97.92 |
| 5 | 96.80 | 100.00 |
| 6 | 96.90 | 98.96 |
| 7 | 97.10 | 98.96 |
| 8 | 97.30 | 98.96 |
| 9 | 97.40 | 98.96 |
| 10 | 97.10 | 100.00 |
| Average | 97.15 | 98.75 |
| UDI | Product ID | Type | Air Temp. | Process Temp. | Rot. Speed | Torque | Tool Wear | Failure Type | Explanation | Prediction Probability |
|---|---|---|---|---|---|---|---|---|---|---|
| 2672 | M17531 | M | 299.7 | 309.3 | 1399 | 41.9 | 221 | TWF | High tool wear Low rotation speed | 0.9643 |
| 3866 | H33279 | H | 302.6 | 311.5 | 1629 | 34.4 | 228 | TWF | High tool wear High air temperature | 0.9305 |
| 4079 | H33492 | H | 302.1 | 310.7 | 1294 | 62.4 | 101 | HDF | High torque Low rotation speed | 1.0000 |
| 4174 | M19033 | M | 302.2 | 310.6 | 1346 | 49.2 | 134 | HDF | High air temperature Low rotation speed | 1.0000 |
| 464 | L47643 | L | 297.4 | 308.7 | 2874 | 4.2 | 118 | PWF | High rotation speed Low torque | 0.9999 |
| 3001 | H32414 | H | 300.5 | 309.8 | 1324 | 72.8 | 159 | PWF | High torque Low rotation speed | 0.9999 |
| 8583 | M23442 | M | 297.5 | 308.1 | 1334 | 72 | 151 | PWF | High torque Low process temperature | 0.9947 |
| 5400 | H34813 | H | 302.8 | 312.4 | 1411 | 53.8 | 246 | OSF | High tool wear High air temperature | 1.0000 |
| 8571 | H37984 | H | 297.9 | 308.7 | 1545 | 35.9 | 120 | No Failure | Normal values | 0.9999 |
| 303 | H29716 | H | 297.8 | 308.4 | 1512 | 35.1 | 138 | No Failure | Normal values | 0.9999 |
| Reference | Year | Method | Accuracy (%) | Precision | Recall | F-Measure |
|---|---|---|---|---|---|---|
| Kong et al. [37] | 2023 | Data filling approach based on probability analysis in incomplete soft sets (DFPAIS) | 83.74 | - | - | - |
| Simplified approach for data filling in incomplete soft sets (SDFIS) | 82.03 | - | - | - | ||
| Souza and Lughofer [38] | 2023 | Evolving fuzzy neural classifier with expert rules (EFNC-Exp) | 97.30 | - | - | - |
| Self-organized direction-aware data partitioning (SODA) | 96.80 | - | - | - | ||
| Chen et al. [39] | 2022 | Categorical Boosting (CatBoost) | 64.23 | - | 0.2868 | - |
| Synthetic Minority Over-Sampling Technique for Nominal and Continuous (SmoteNC) + CatBoost | 88.09 | - | 0.7881 | - | ||
| Conditional Tabular Generative Adversarial Network (ctGAN) + CatBoost | 87.08 | - | 0.8305 | - | ||
| SmoteNC + ctGAN + CatBoost | 88.83 | - | 0.9068 | - | ||
| Vandereycken and Voorhaar [40] | 2022 | Extreme Gradient Boosting (XGBoost) | 95.74 | - | - | - |
| Random Forest (RF) | 95.10 | - | - | - | ||
| Tensor Trains-based Machine Learning (TTML) + XGBoost | 77.00 | - | - | - | ||
| Tensor Trains-based Machine Learning (TTML) + RF | 78.00 | - | - | - | ||
| TTML + Multi-Layer Perceptron (MLP) 1 | 76.20 | - | - | - | ||
| TTML + Multi-Layer Perceptron (MLP) 2 | 65.00 | - | - | - | ||
| Falla and Ortega [41] | 2022 | Random Forest | 96.81 | 0.9740 | 0.7639 | 0.8563 |
| Neural Networks | 91.50 | 0.9166 | 0.8611 | 0.8880 | ||
| Iantovics and Enachescu [42] | 2022 | Binary Logistic Regression (BLR) | 97.10 | 0.9950 | 0.2830 | 0.4407 |
| Sharma et al. [43] | 2022 | Random Forest (RF) | 98.40 | - | - | - |
| Decision Tree (DT) | 98.30 | - | - | - | ||
| Support Vector Machine (SVM) | 97.40 | - | - | - | ||
| Logistic Regression (LR) | 96.80 | - | - | - | ||
| K-Nearest Neighbors (KNN) | 97.80 | - | - | - | ||
| Harichandran et al. [44] | 2022 | Hybrid Unsupervised and Supervised Machine Learning (HUS-ML) | 98.46 | 0.8300 | 0.7500 | 0.7880 |
| Conventional Machine Learning (CML) | 97.99 | 0.6500 | 0.5800 | 0.6130 | ||
| Kamel [45] | 2022 | Artificial Neural Networks (ANN) | 98.50 | 0.9953 | 0.6866 | 0.8126 |
| Jo and Jun [46] | 2022 | Logistic Regression (LR) | 97.07 | - | - | 0.3001 |
| K-Nearest Neighbors (KNN) | 96.60 | - | - | 0.0000 | ||
| KNN + LR | 97.65 | - | - | 0.5324 | ||
| Input + LR | 97.25 | - | - | 0.4023 | ||
| Autoencoder (AE) + LR | 97.27 | - | - | 0.3633 | ||
| Supervised Autoencoder | 97.93 | - | - | 0.6171 | ||
| Vuttipittayamongkol and Arreeras [47] | 2022 | Support Vector Machine (SVM) | - | 0.7229 | 0.5941 | 0.6522 |
| Decision Tree (DT) | - | 0.8391 | 0.7228 | 0.7766 | ||
| K-Nearest Neighbor (KNN) | - | 0.8108 | 0.2970 | 0.4348 | ||
| Random Forest (RF) | - | 0.8267 | 0.6139 | 0.7045 | ||
| Neural Network (NN) | - | 0.7333 | 0.2178 | 0.3359 | ||
| Mota et al. [48] | 2022 | Gradient Boosting (GB), Support Vector Machine (SVM), and proposed methodology | 94.55 | - | 0.9200 | - |
| Diao et al. [49] | 2021 | Constructing Hyper-Planes | - | - | - | 0.6200 |
| Torcianti and Matzka [50] | 2021 | Random Undersampling Boosting (RUSBoost) Trees | 92.74 | 0.3071 | 0.9085 | 0.4590 |
| Pastorino and Biswas [51] | 2021 | Data-Blind Machine Learning | 97.30 | - | - | - |
| Matzka [52] | 2020 | Bagged Decision Trees | 98.34 | 0.8673 | 0.9874 | 0.9234 |
| Average | 91.74 | 0.8052 | 0.6666 | 0.5760 | ||
| Proposed Method | Balanced K-Star | 98.75 | 0.9877 | 0.9875 | 0.9875 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghasemkhani, B.; Aktas, O.; Birant, D. Balanced K-Star: An Explainable Machine Learning Method for Internet-of-Things-Enabled Predictive Maintenance in Manufacturing. Machines 2023, 11, 322. https://doi.org/10.3390/machines11030322
Ghasemkhani B, Aktas O, Birant D. Balanced K-Star: An Explainable Machine Learning Method for Internet-of-Things-Enabled Predictive Maintenance in Manufacturing. Machines. 2023; 11(3):322. https://doi.org/10.3390/machines11030322
Chicago/Turabian StyleGhasemkhani, Bita, Ozlem Aktas, and Derya Birant. 2023. "Balanced K-Star: An Explainable Machine Learning Method for Internet-of-Things-Enabled Predictive Maintenance in Manufacturing" Machines 11, no. 3: 322. https://doi.org/10.3390/machines11030322