

Fault Diagnosis of Rotating Machinery Based on Two-Stage Compressed Sensing

Abstract
:1. Introduction
- (1)
- The proposed two-stage compression scheme provides an extremely high data compression efficiency for on-site fault diagnosis, while the original vibration data can be reconstructed for professional vibration analysis.
- (2)
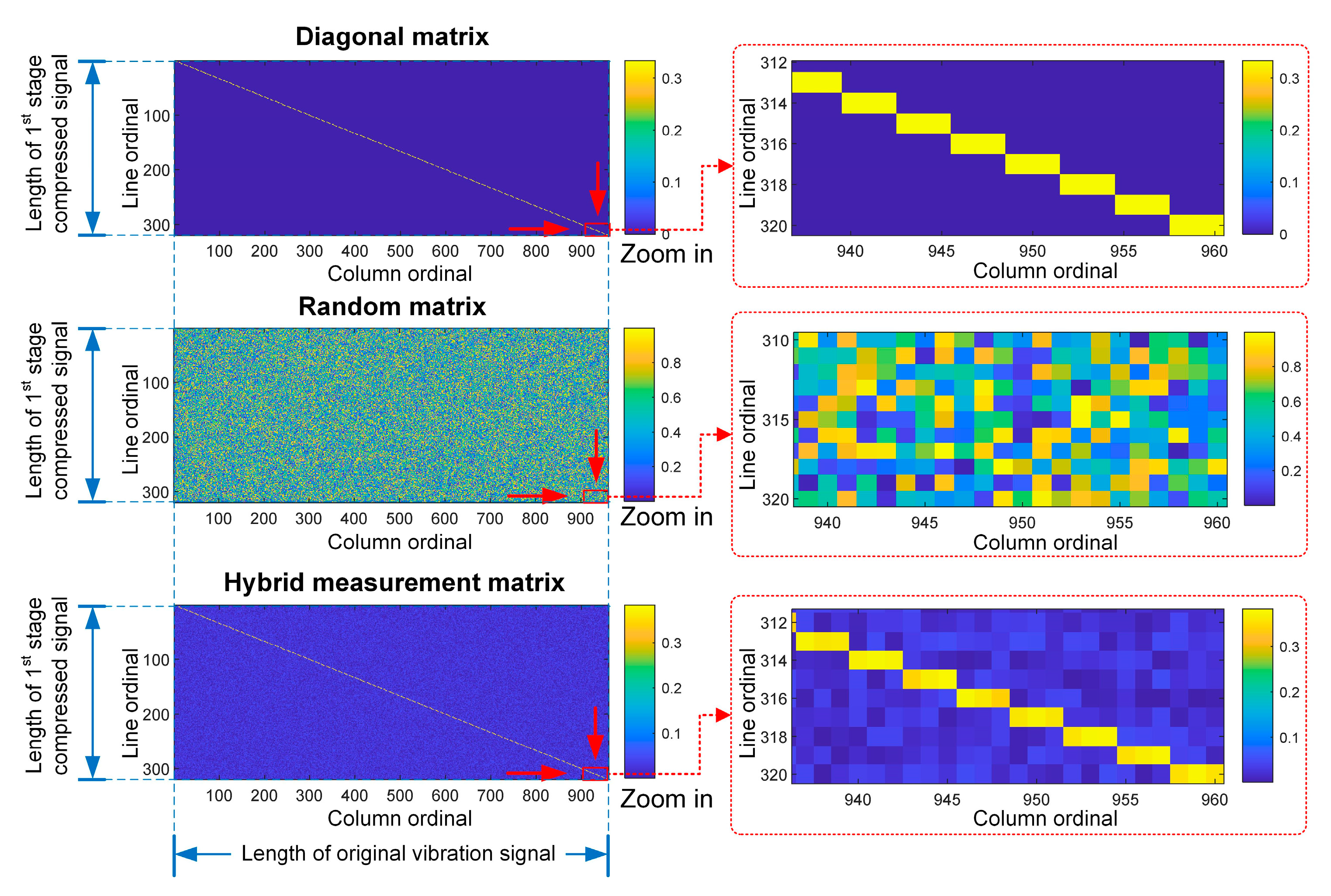
- Novel measurement matrices are designed for fault diagnosis based on compressed sensing, which emphasize retention of frequency characteristics, high-frequency noise reduction, and multisource data fusion.
- (3)
- For sparse representation-based classification, a batch match pursuit algorithm is proposed, which improves the efficiency of sparse vector calculation in sparse representation.
2. Methodology
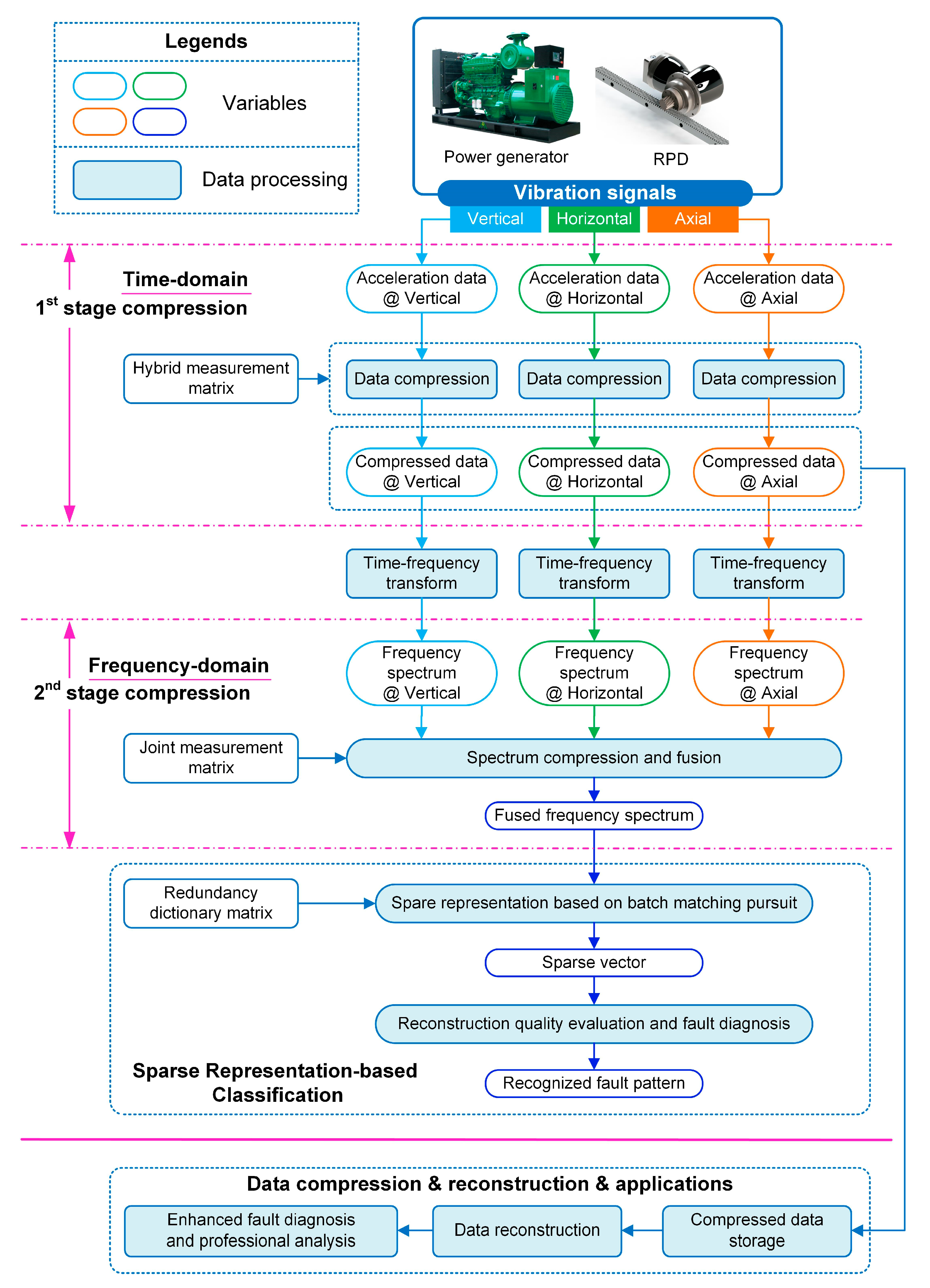
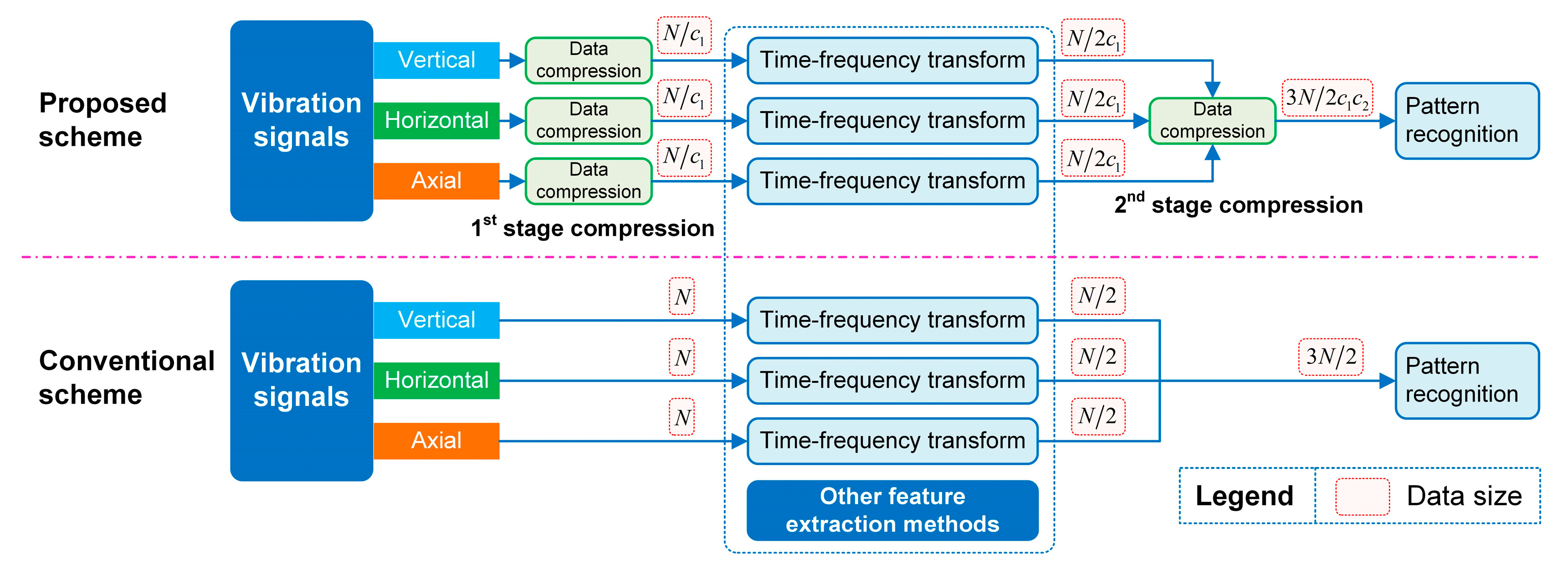
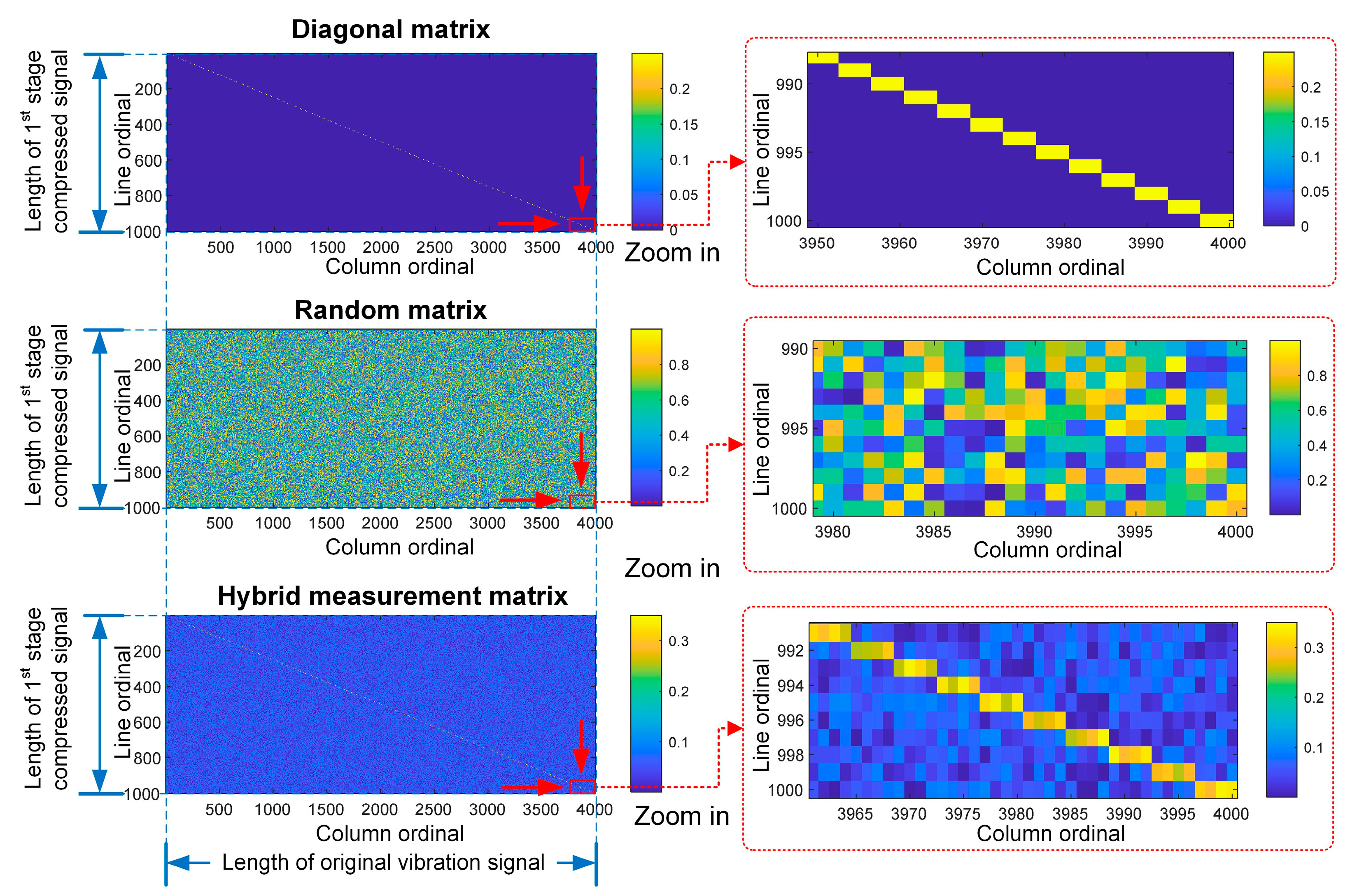
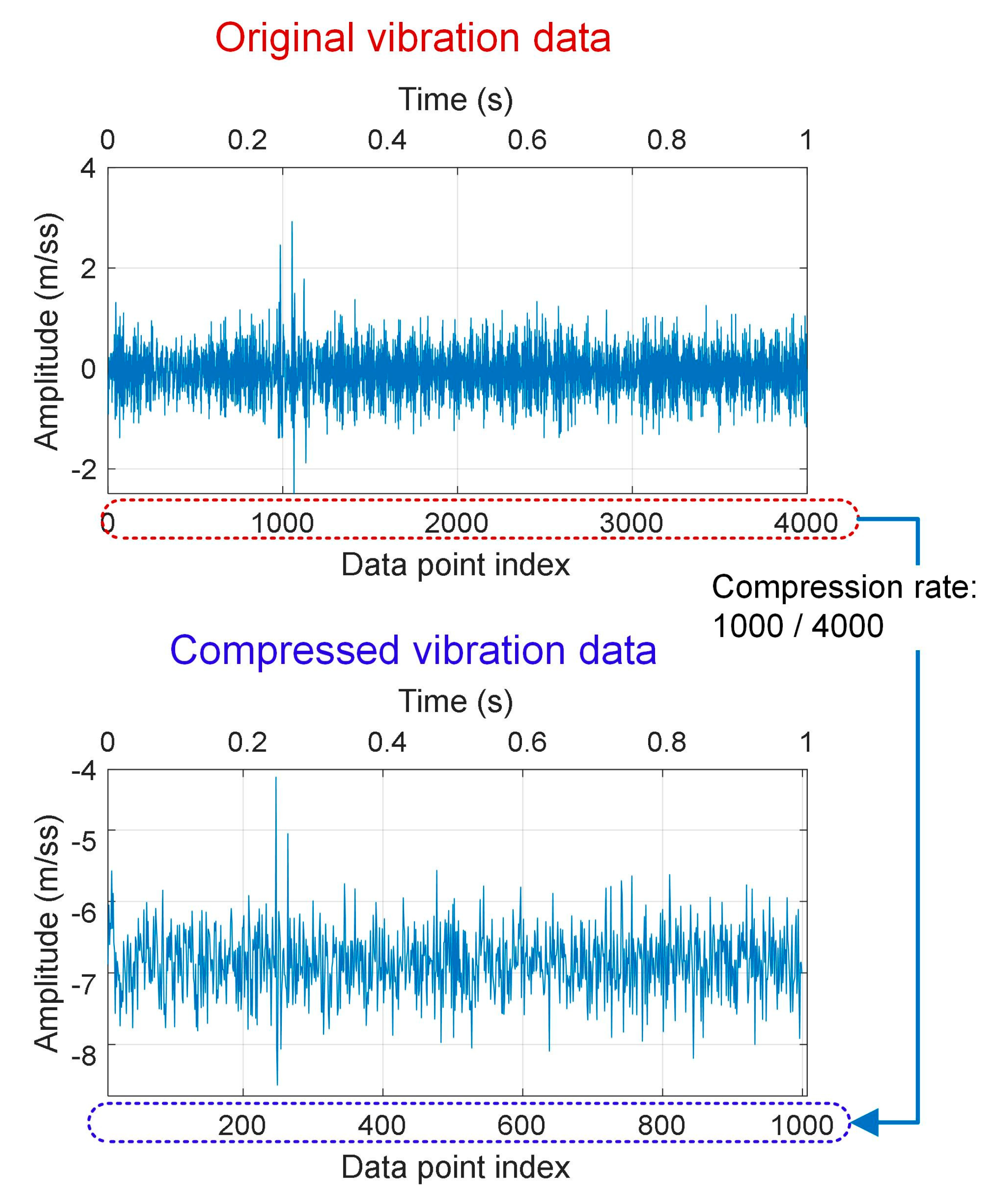
2.1. Vibration Data Compression Based on Compressed Sensing
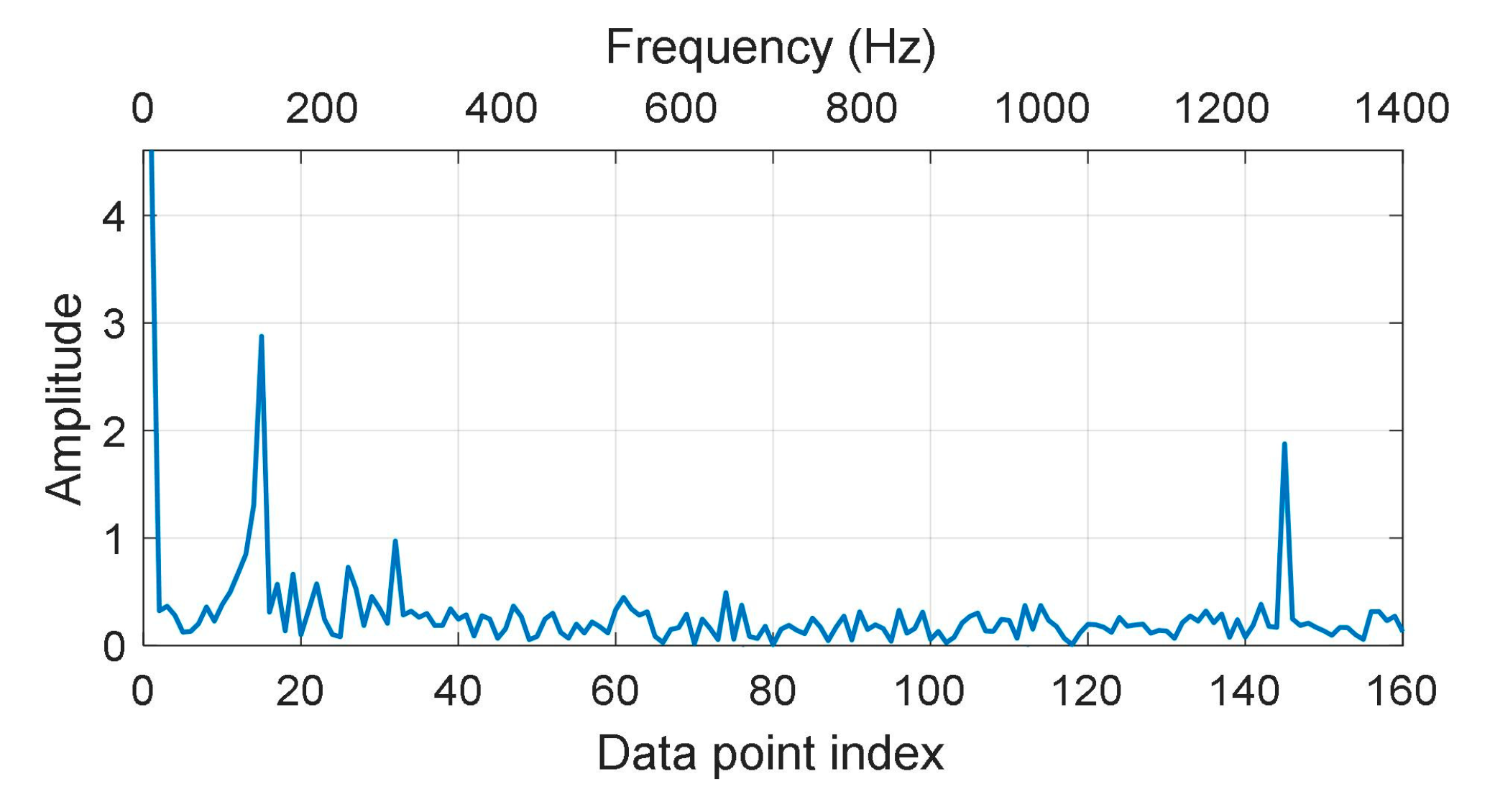
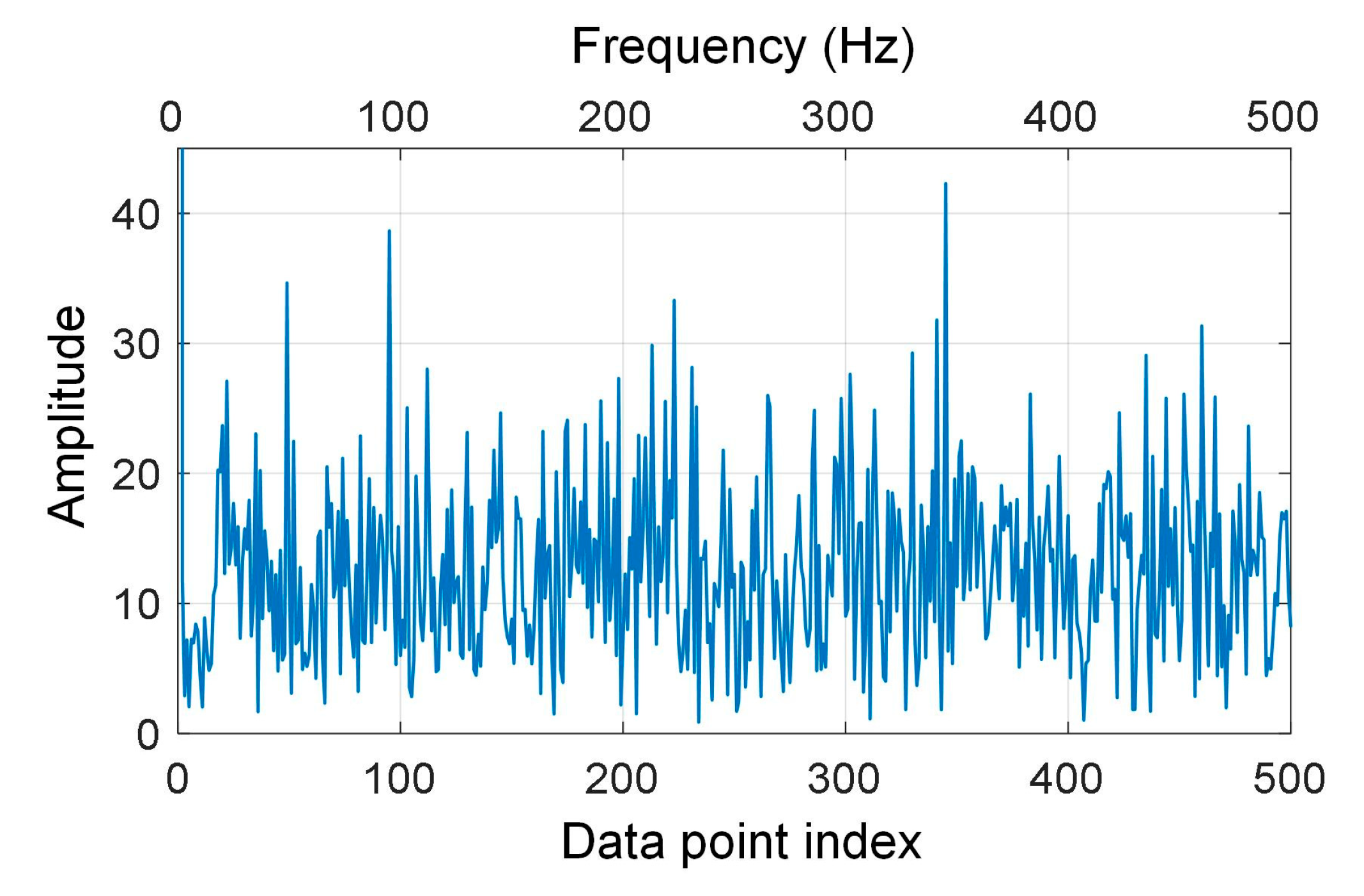
2.2. Time-Domain Compression and Time-Frequency Transform
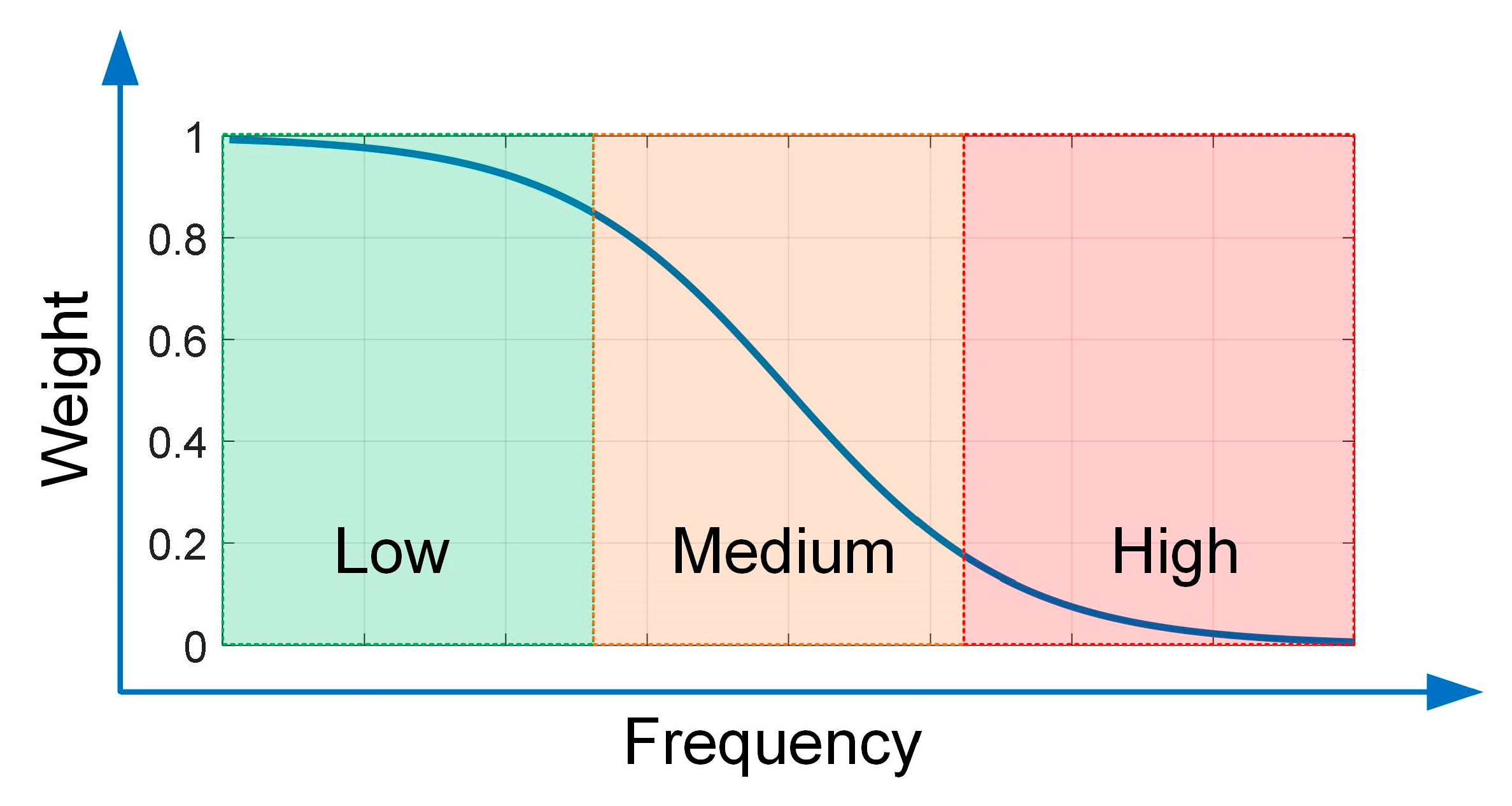
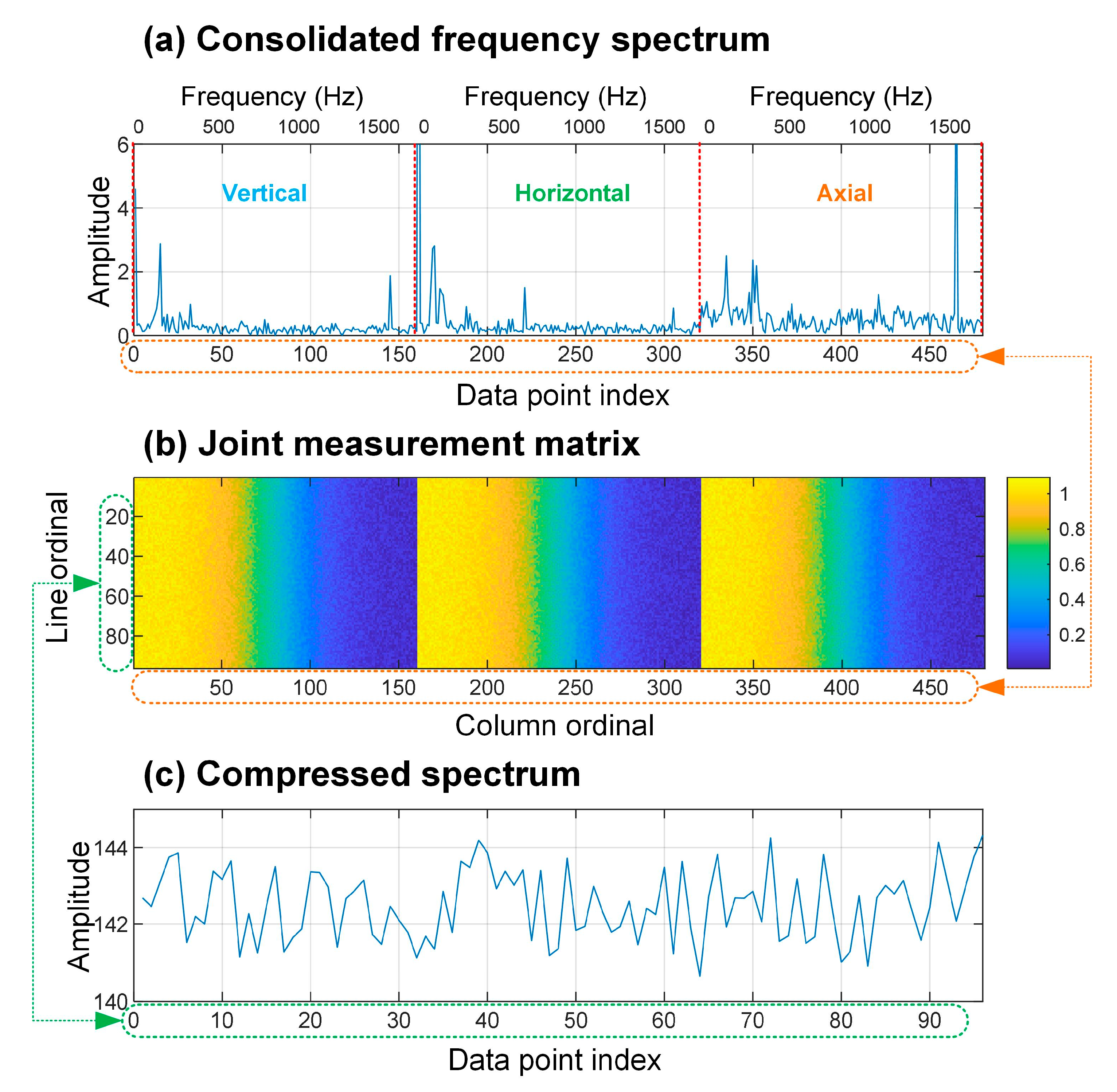
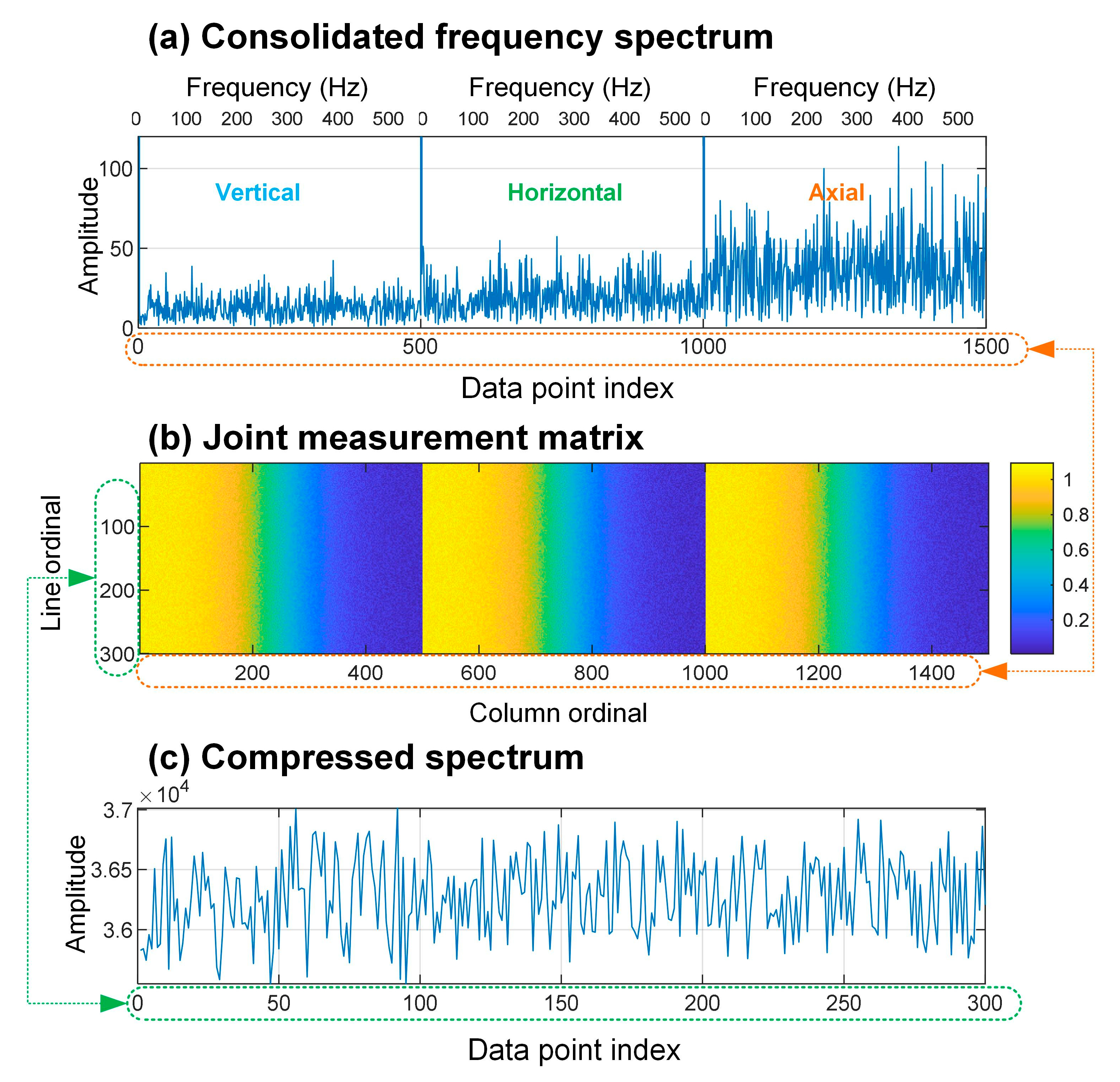
2.3. Frequency-Domain Compression and Fusion
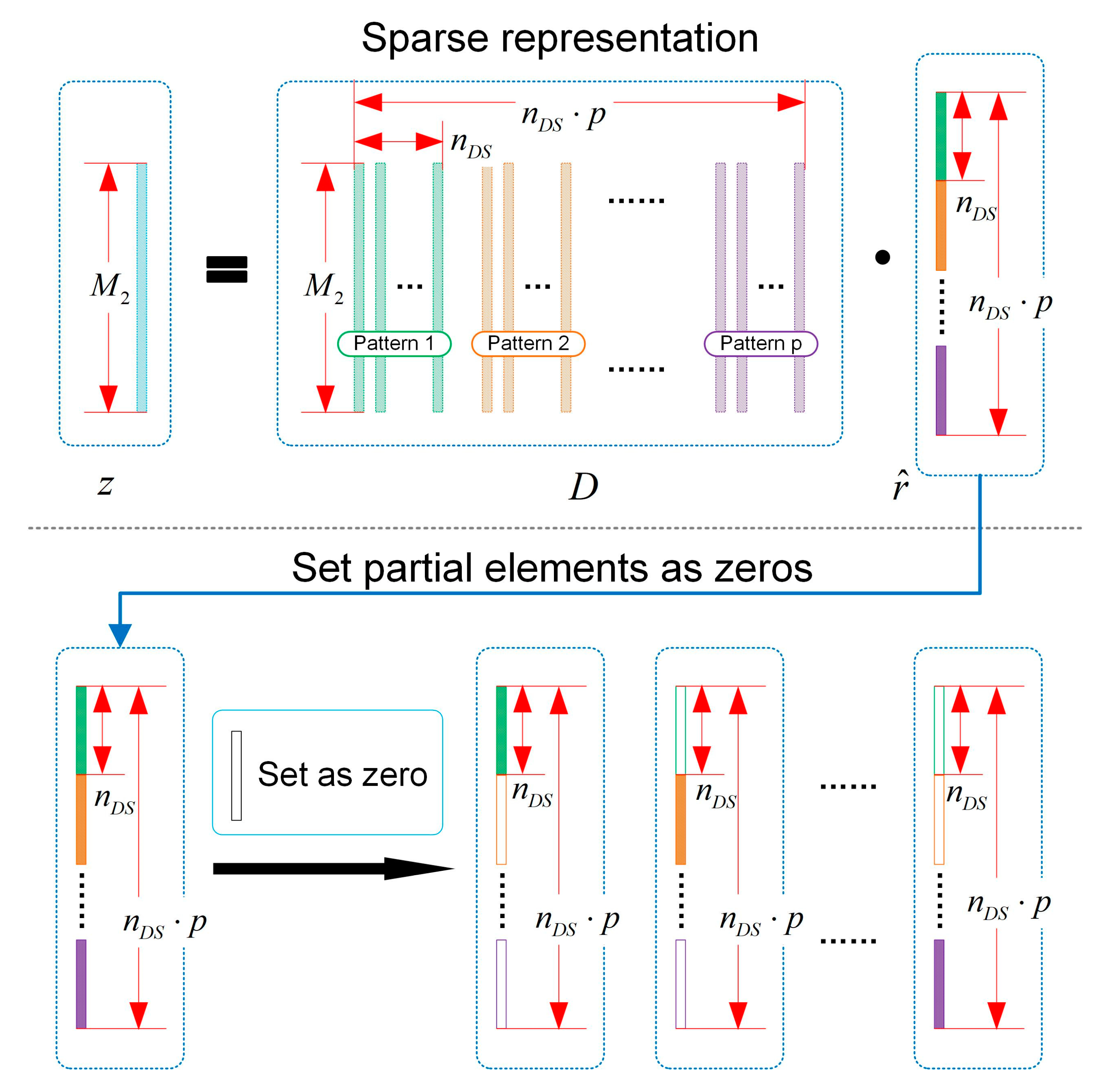
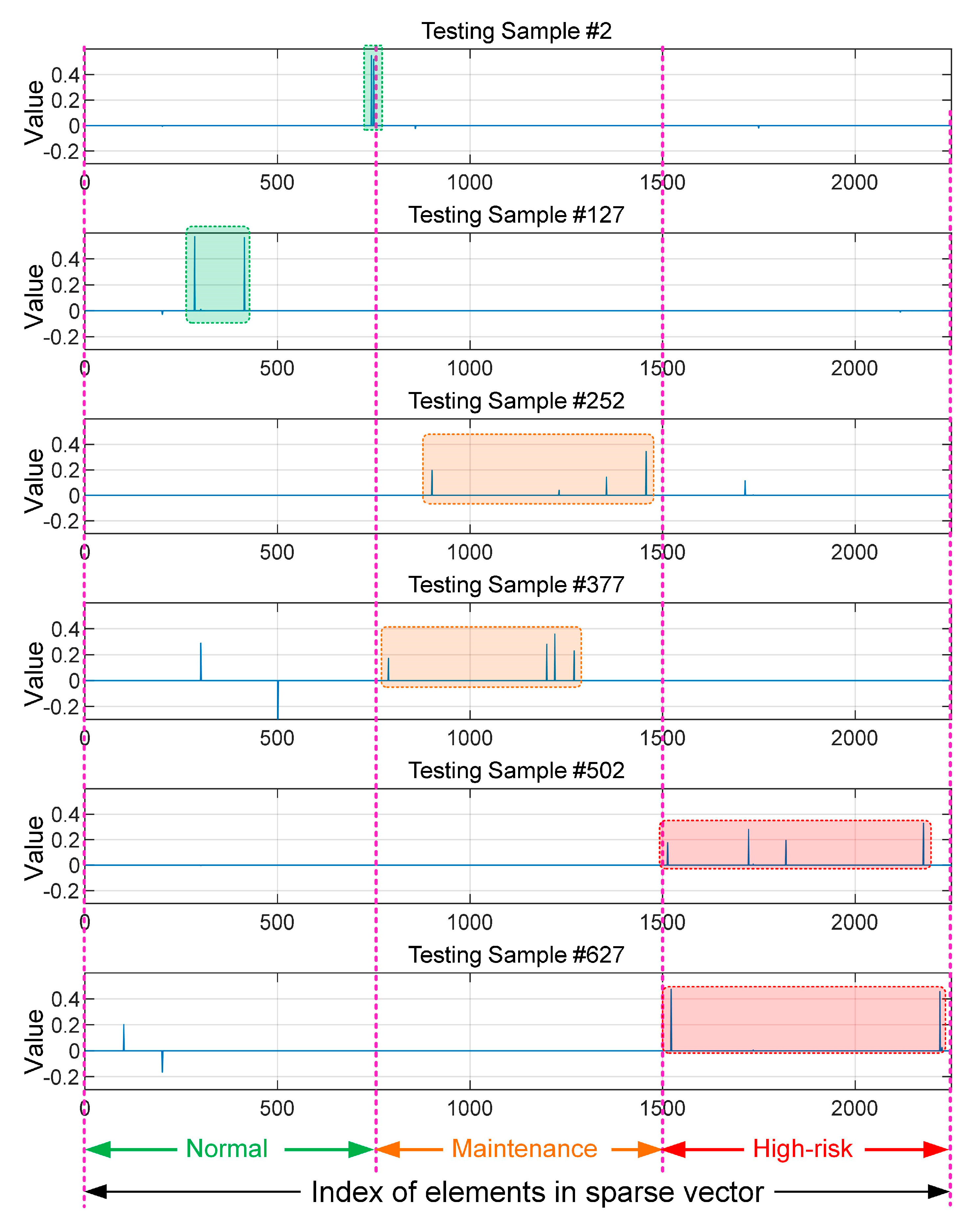
2.4. Sparse-Representation-Based Classification and Fault Diagnosis
| Algorithm 1 |
| Algorithm input: Redundant dictionary: Compressed frequency spectrum: Number of (fault) patterns: Iteration times: Number of support vectors contained in each iteration: |
| Algorithm output: Estimated sparse vector: |
| Variables in the algorithm: Counter of iteration: Cosine distance between any two vectors: Indices of nonzero elements in : Nonzero elements in sparse vector: Selected support vector set for : Vector of residue: |
| Algorithm procedures: |
| Parameters initialization Counter of iteration: Sparse vector: Initial indices of nonzero elements in : Initial vector of residue: |
| b. Spare vector calculation Calculate the cosine distances between the vector of residue and each atom in the redundant dictionary: Selecting maximum values from , the position indices of these maximum values are: |
| c. Iteration The procedures in sparse vector calculation are repeatedly executed for times, and nonzero elements in the sparse vector are obtained. Finally, these nonzero elements are filled into the sparse vector in accordance with the vector of indices : |
3. Efficiency Analysis
3.1. Data Size Analysis
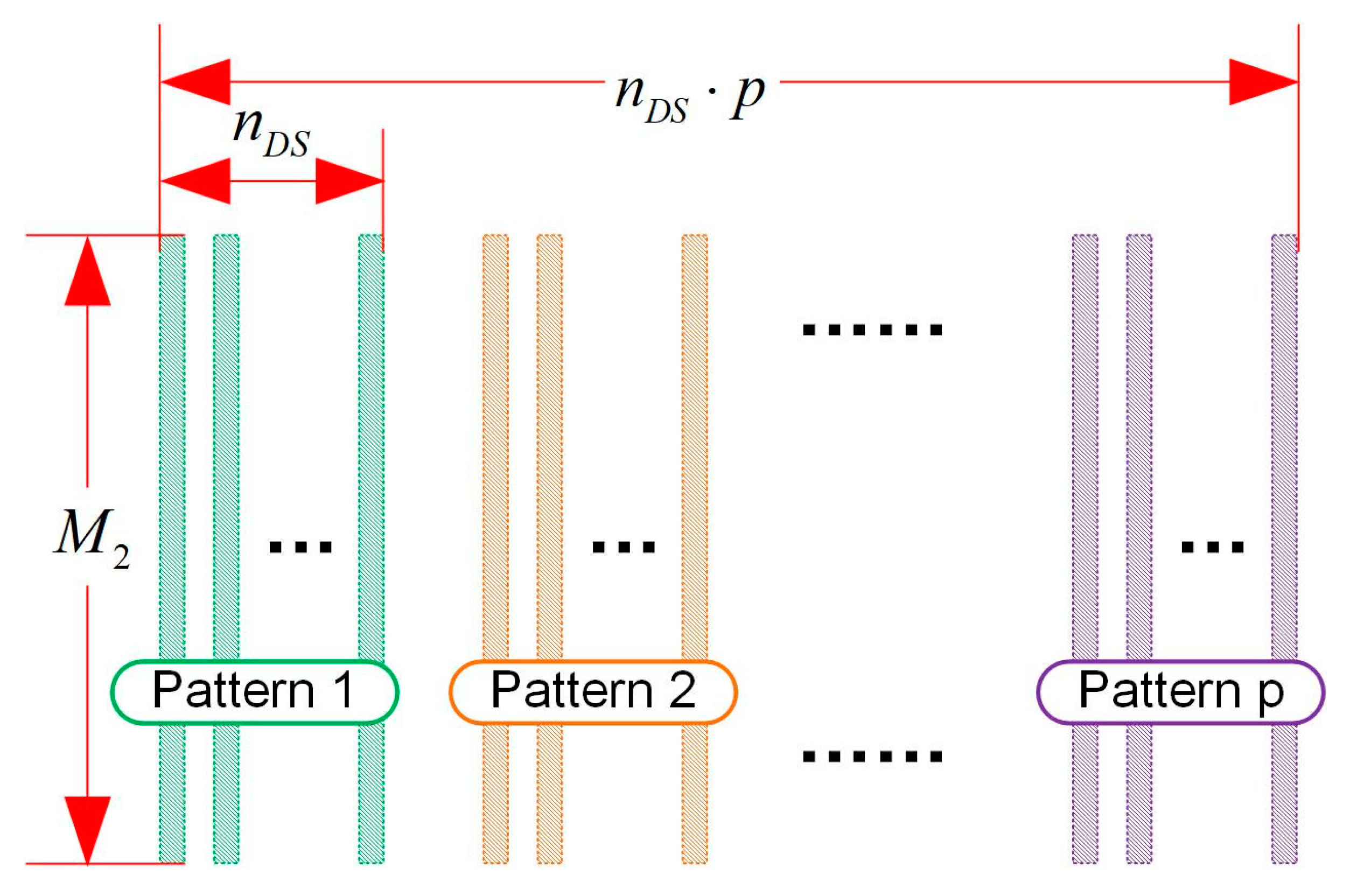
3.2. Sparse Representation Efficiency Analysis
4. Case Study
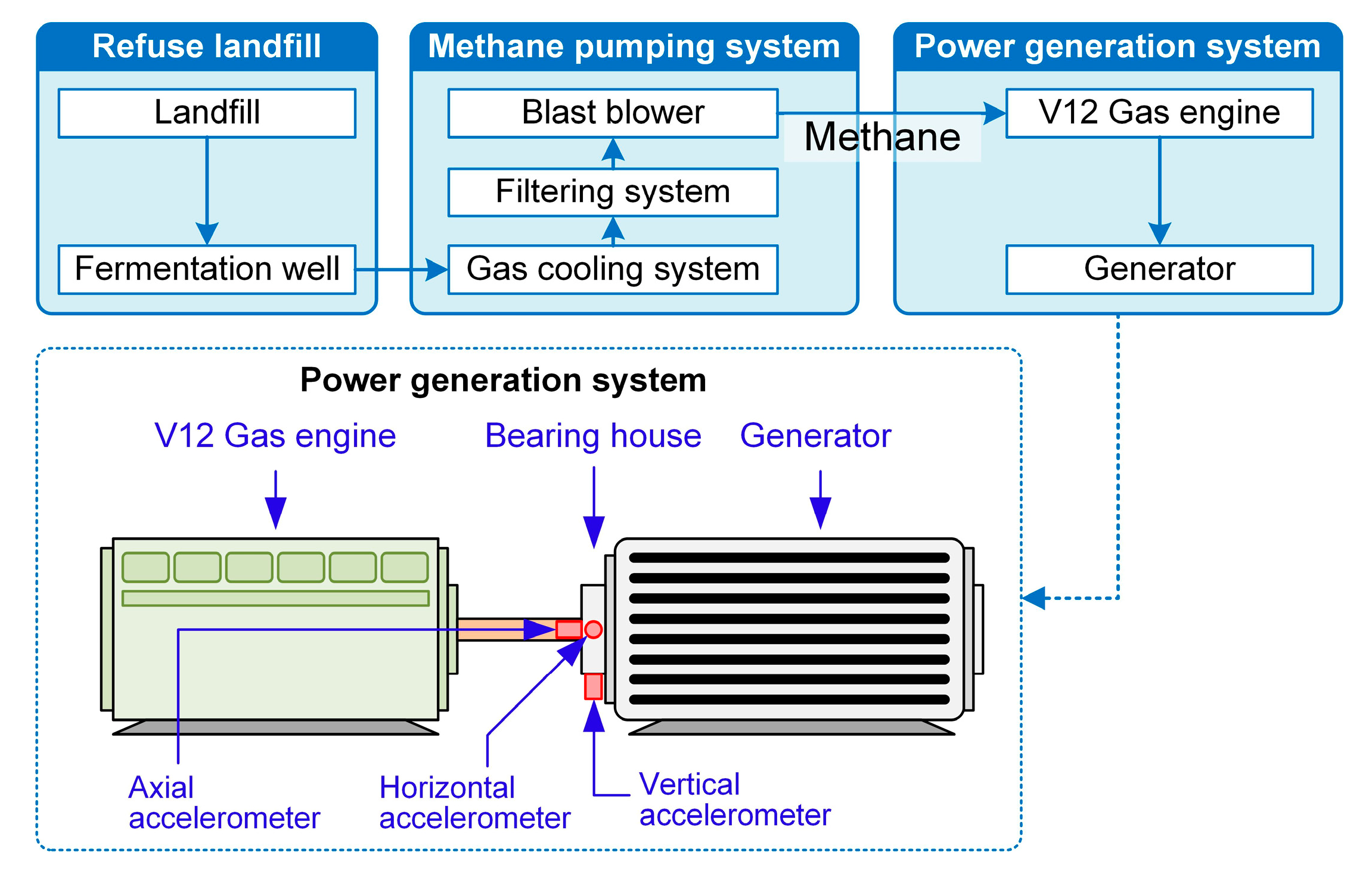
4.1. Maintenance Level Recognition of Landfill Gas Power Generator
4.1.1. Engineering Background
4.1.2. Data Set Description
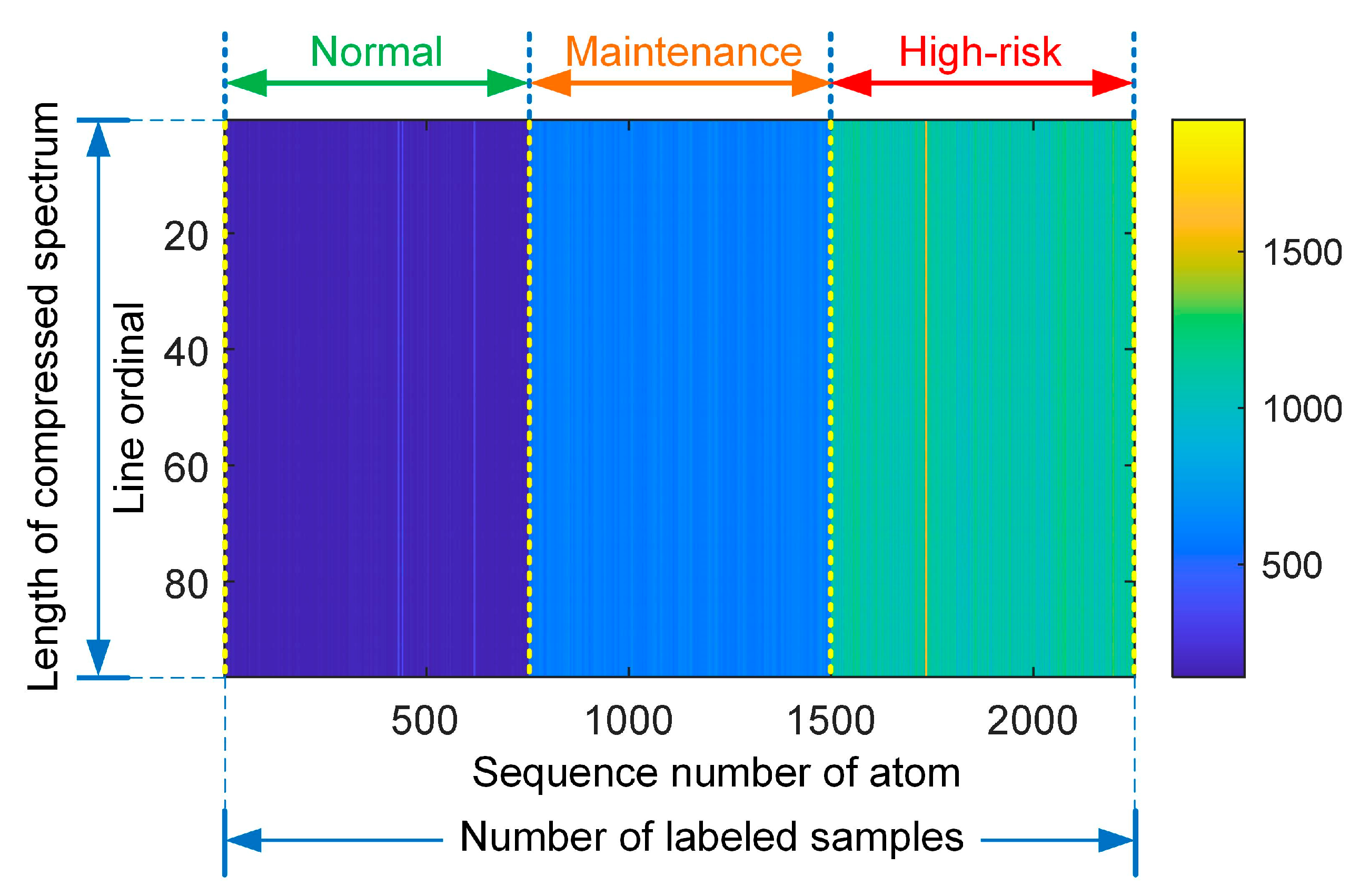
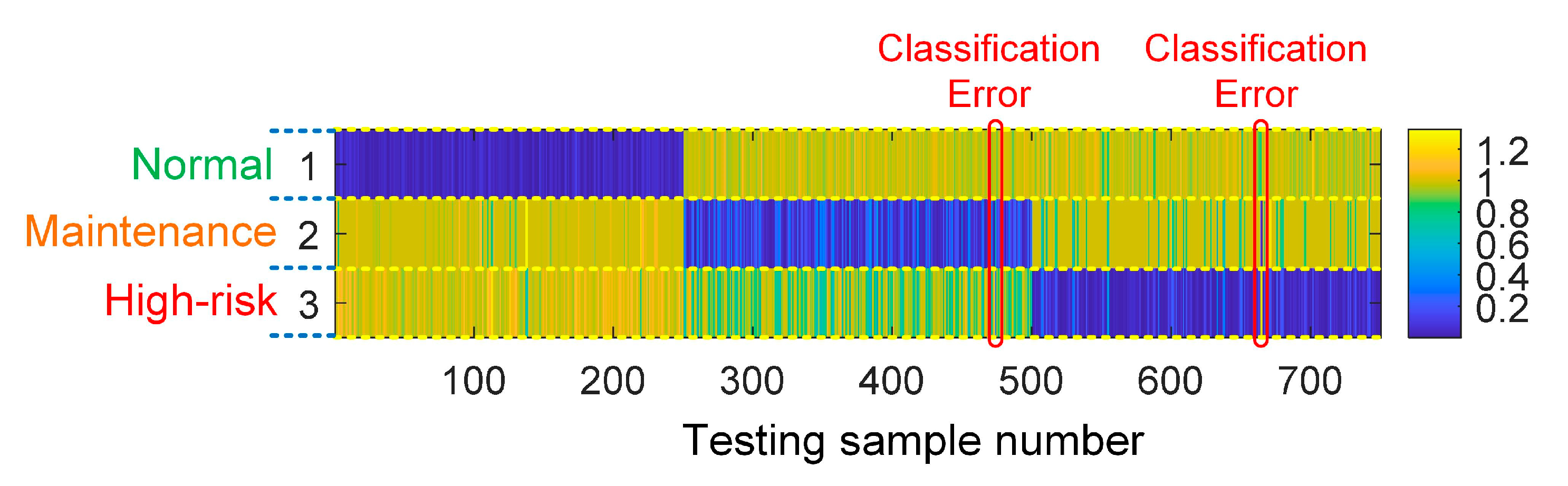
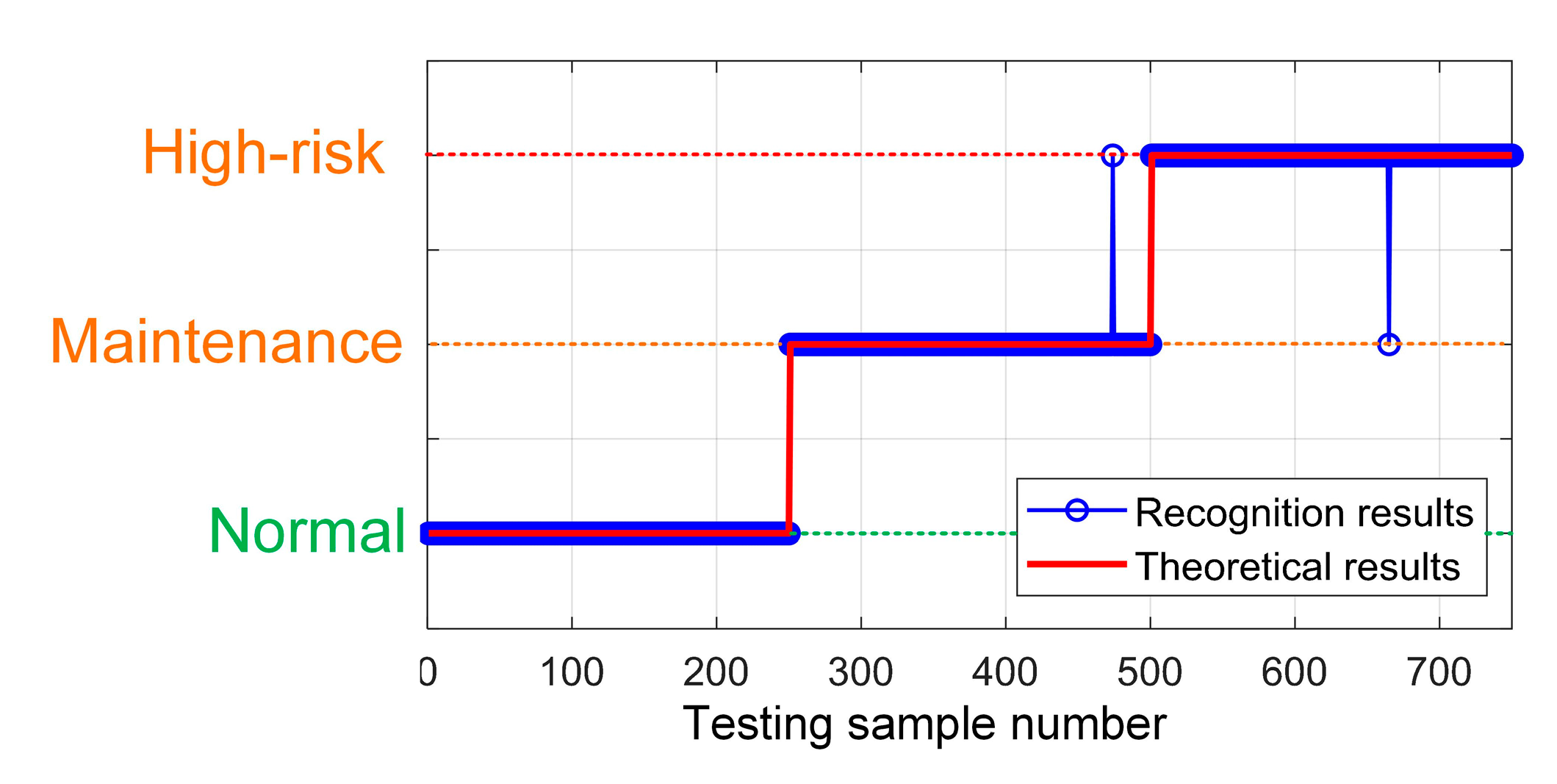
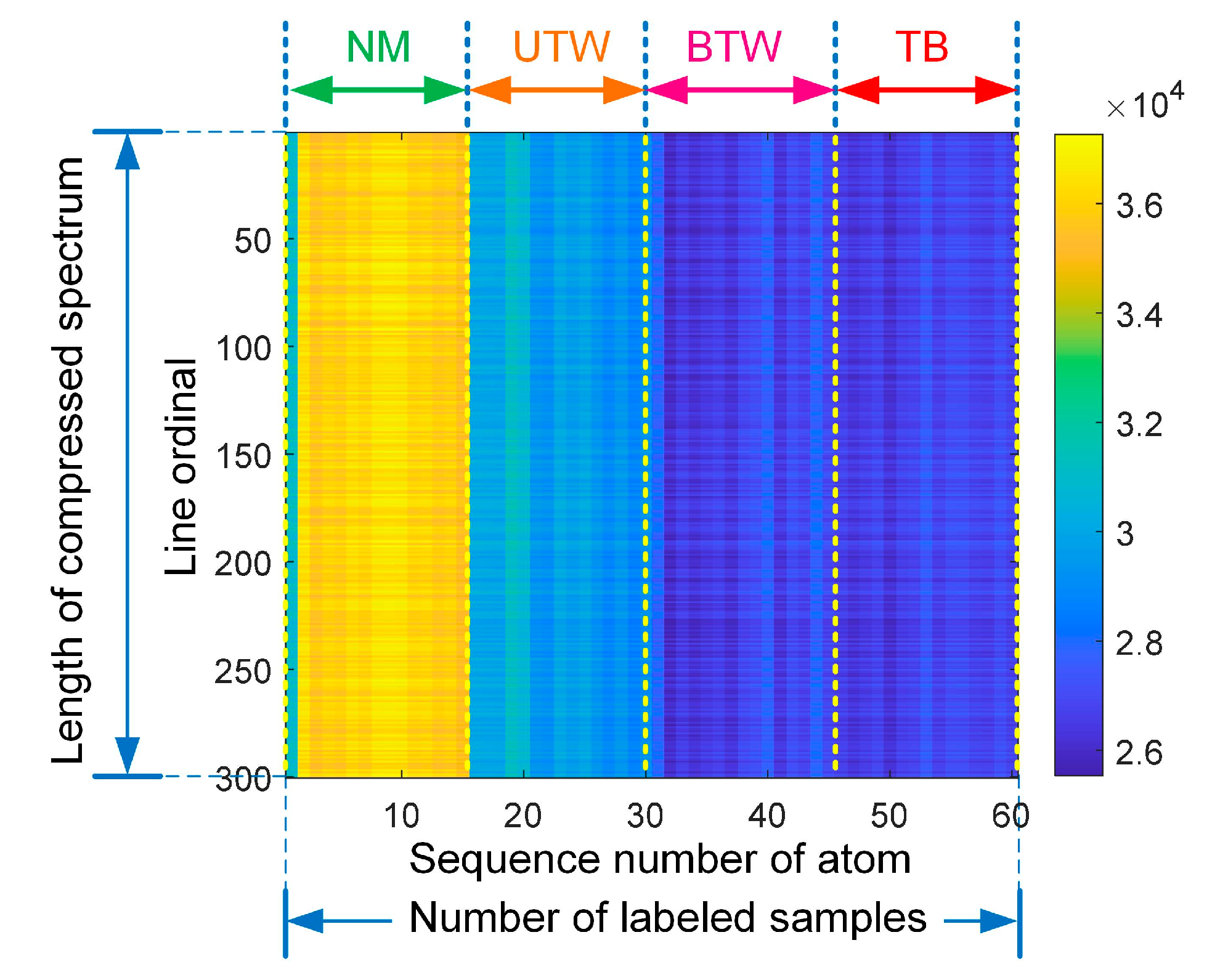
4.1.3. Data Processing and Pattern Recognition
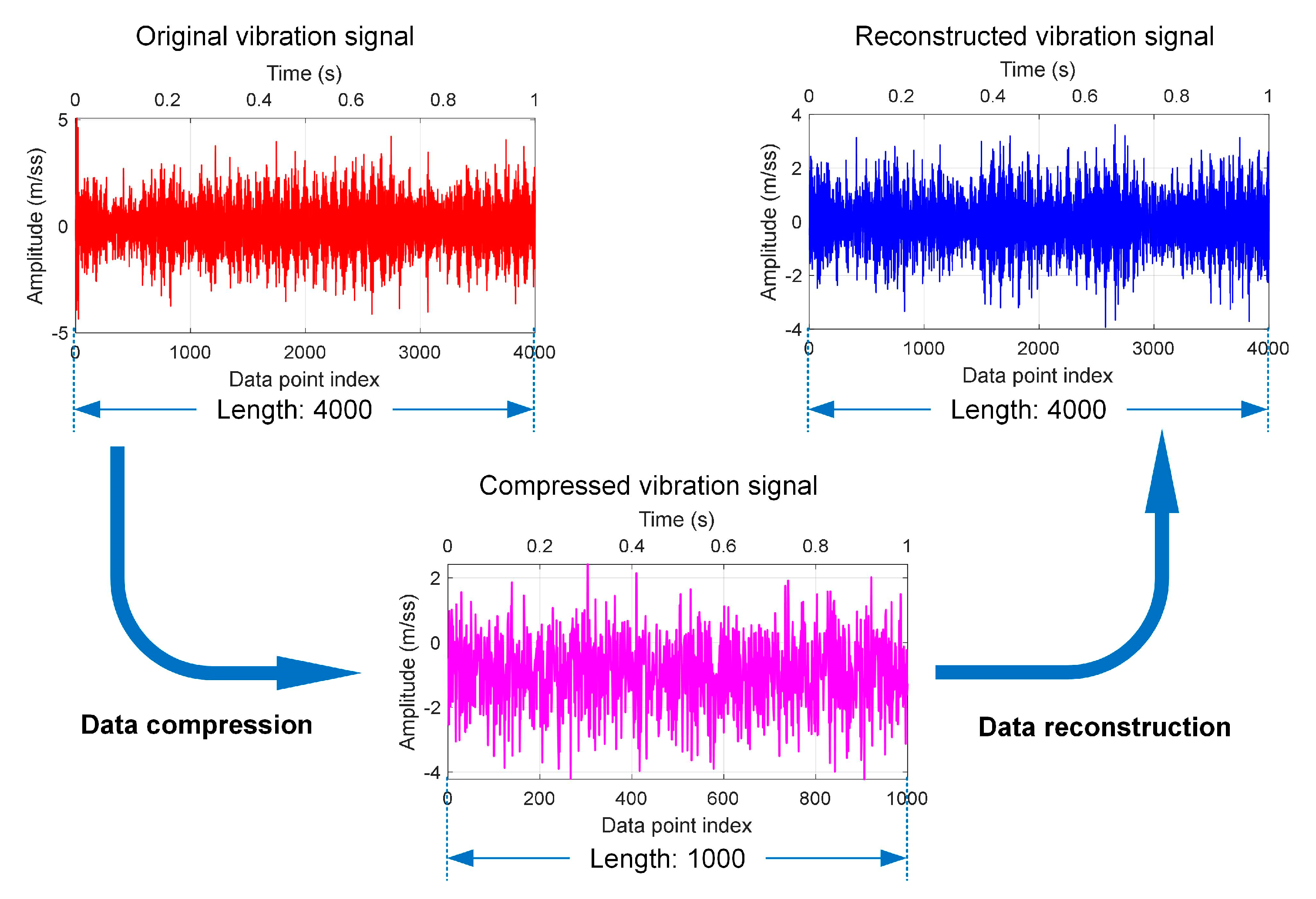
4.1.4. Data Reconstruction and Analysis
4.2. Fault Diagnosis of Driving Gear in Battery Swapping System
4.2.1. Engineering Background
4.2.2. Description of Data Sets
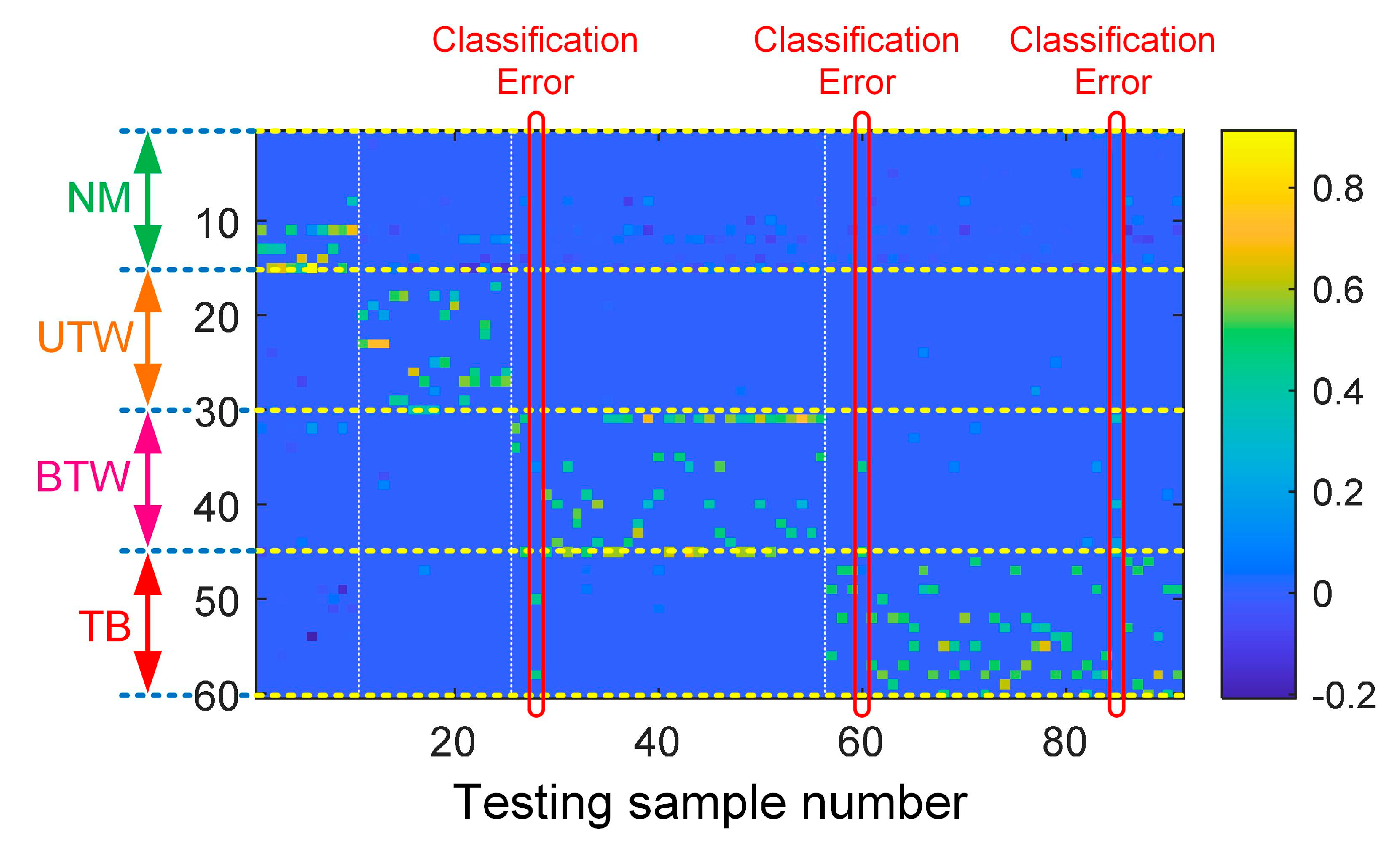
4.2.3. Data Processing and Fault Diagnosis
4.2.4. Data Reconstruction and Analysis
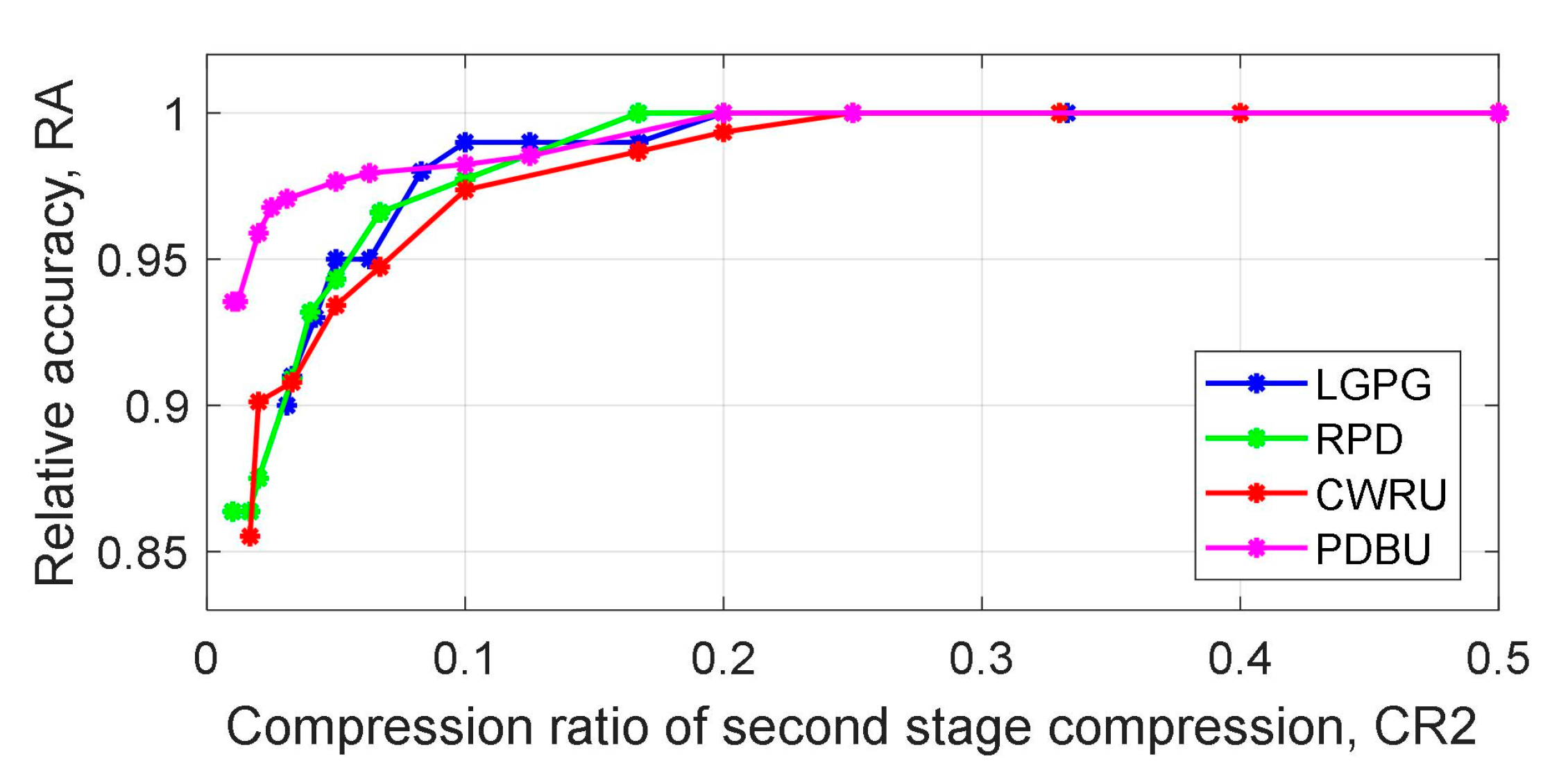
5. Comparative Case Study
5.1. Comparisons with State-Of-The-Art Fault Diagnosis Methods
5.2. Computational Efficiency Comparison between BMP and OMP
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Miao, Y.; Zhang, B.; Li, C.; Lin, J.; Zhang, D. Feature Mode Decomposition: New Decomposition Theory for Rotating Machinery Fault Diagnosis. Ieee Trans. Ind. Electron. 2023, 70, 1949–1960. [Google Scholar] [CrossRef]
- Zhao, H.; Niu, G. Enhanced order spectrum analysis based on iterative adaptive crucial mode decomposition for planetary gearbox fault diagnosis under large speed variations. Mech. Syst. Signal Process. 2023, 185, 109822. [Google Scholar] [CrossRef]
- Miao, Y.; Wang, J.; Zhang, B.; Li, H. Practical framework of Gini index in the application of machinery fault feature extraction. Mech. Syst. Signal Process. 2022, 165, 108333. [Google Scholar] [CrossRef]
- Gunerkar, R.S.; Jalan, A.K.; Belgamwar, S.U. Fault diagnosis of rolling element bearing based on artificial neural network. J. Mech. Sci. Technol. 2019, 33, 505–511. [Google Scholar] [CrossRef]
- Miao, Y.; Zhao, M.; Hua, J. Research on sparsity indexes for fault diagnosis of rotating machinery. Measurement 2020, 158, 107733. [Google Scholar] [CrossRef]
- Pan, Z.; Meng, Z.; Zhang, Y.; Zhang, G.; Pang, X. High-precision bearing signal recovery based on signal fusion and variable stepsize forward-backward pursuit. Mech. Syst. Signal Process. 2021, 157, 107647. [Google Scholar] [CrossRef]
- Song, Q.; Zhao, S.; Wang, M. On the Accuracy of Fault Diagnosis for Rolling Element Bearings Using Improved DFA and Multi-Sensor Data Fusion Method. Sensors 2020, 20, 6465. [Google Scholar] [CrossRef] [PubMed]
- Bai, H.; Yan, H.; Zhan, X.; Wen, L.; Jia, X. Fault Diagnosis Method of Planetary Gearbox Based on Compressed Sensing and Transfer Learning. Electronics 2022, 11, 1708. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, G. Weak fault signature identification of rolling bearings based on improved adaptive compressed sensing method. Meas. Sci. Technol. 2021, 32, 105104. [Google Scholar] [CrossRef]
- Yuan, H.; Lu, C. Rolling bearing fault diagnosis under fluctuant conditions based on compressed sensing. Struct. Control Health Monit. 2017, 24, e1918. [Google Scholar] [CrossRef]
- Wang, C.; Liu, C.; Liao, M.; Yang, Q. An enhanced diagnosis method for weak fault features of bearing acoustic emission signal based on compressed sensing. Math. Biosci. Eng. 2021, 18, 1670–1688. [Google Scholar] [CrossRef]
- Shi, P.; Guo, X.; Han, D.; Fu, R. A sparse auto-encoder method based on compressed sensing and wavelet packet energy entropy for rolling bearing intelligent fault diagnosis. J. Mech. Sci. Technol. 2020, 34, 1445–1458. [Google Scholar] [CrossRef]
- Pei, X.; Zheng, X.; Wu, J. Intelligent bearing fault diagnosis based on Teager energy operator demodulation and multiscale compressed sensing deep autoencoder. Measurement 2021, 179, 109452. [Google Scholar] [CrossRef]
- Hu, Z.-X.; Wang, Y.; Ge, M.-F.; Liu, J. Data-Driven Fault Diagnosis Method Based on Compressed Sensing and Improved Multiscale Network. IEEE Trans. Ind. Electron. 2020, 67, 3216–3225. [Google Scholar] [CrossRef]
- Donoho, D.L. Compressed sensing. Ieee Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candes, E.J.; Eldar, Y.C.; Needell, D.; Randall, P. Compressed sensing with coherent and redundant dictionaries. Appl. Comput. Harmon. Anal. 2011, 31, 59–73. [Google Scholar] [CrossRef]
- Candes, E.J.; Wakin, M.B. An introduction to compressive sampling. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Gunerkar, R.S.; Jalan, A.K. Classification of Ball Bearing Faults Using Vibro-Acoustic Sensor Data Fusion. Exp. Tech. 2019, 43, 635–643. [Google Scholar] [CrossRef]
- Lessmeier, C.; Kimotho, J.K.; Zimmer, D.; Sextro, W. Condition Monitoring of Bearing Damage in Electromechanical Drive Systems by Using Motor Current Signals of Electric Motors: A Benchmark Data Set for Data-Driven Classification. Eur. Conf. Progn. Health Manag. Soc. 2016, 3. [Google Scholar] [CrossRef]
- Li, J.; Wang, H.; Song, L.; Cui, L. A novel feature extraction method for roller bearing using sparse decomposition based on self-Adaptive complete dictionary. Measurement 2019, 148, 106934. [Google Scholar] [CrossRef]
- Cheng, H.; Liu, Z.; Yang, L.; Chen, X. Sparse representation and learning in visual recognition: Theory and applications. Signal Process. 2013, 93, 1408–1425. [Google Scholar] [CrossRef]
- Alahari, R.; Kodati, S.P.; Kalitkar, K.R. Floating Point Implementation of the Improved QRD and OMP for Compressive Sensing Signal Reconstruction. Sens. Imaging 2022, 23, 20. [Google Scholar] [CrossRef]






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Maintenance Pattern | Normal | Maintenance | High-Risk | Total |
|---|---|---|---|---|
| Number of data files | 10 | 10 | 10 | 30 |
| Number of data samples | 1000 | 1000 | 1000 | 3000 |
| Number of labeled samples | 750 | 750 | 750 | 2250 |
| Number of testing samples | 250 | 250 | 250 | 750 |
| Maintenance Pattern | Normal | Maintenance | High-Risk |
|---|---|---|---|
| Atoms in dictionary matrix | #1–#750 | #751–#1500 | #1501–#2250 |
| Testing samples | #1–#250 | #251–#500 | #501–#750 |
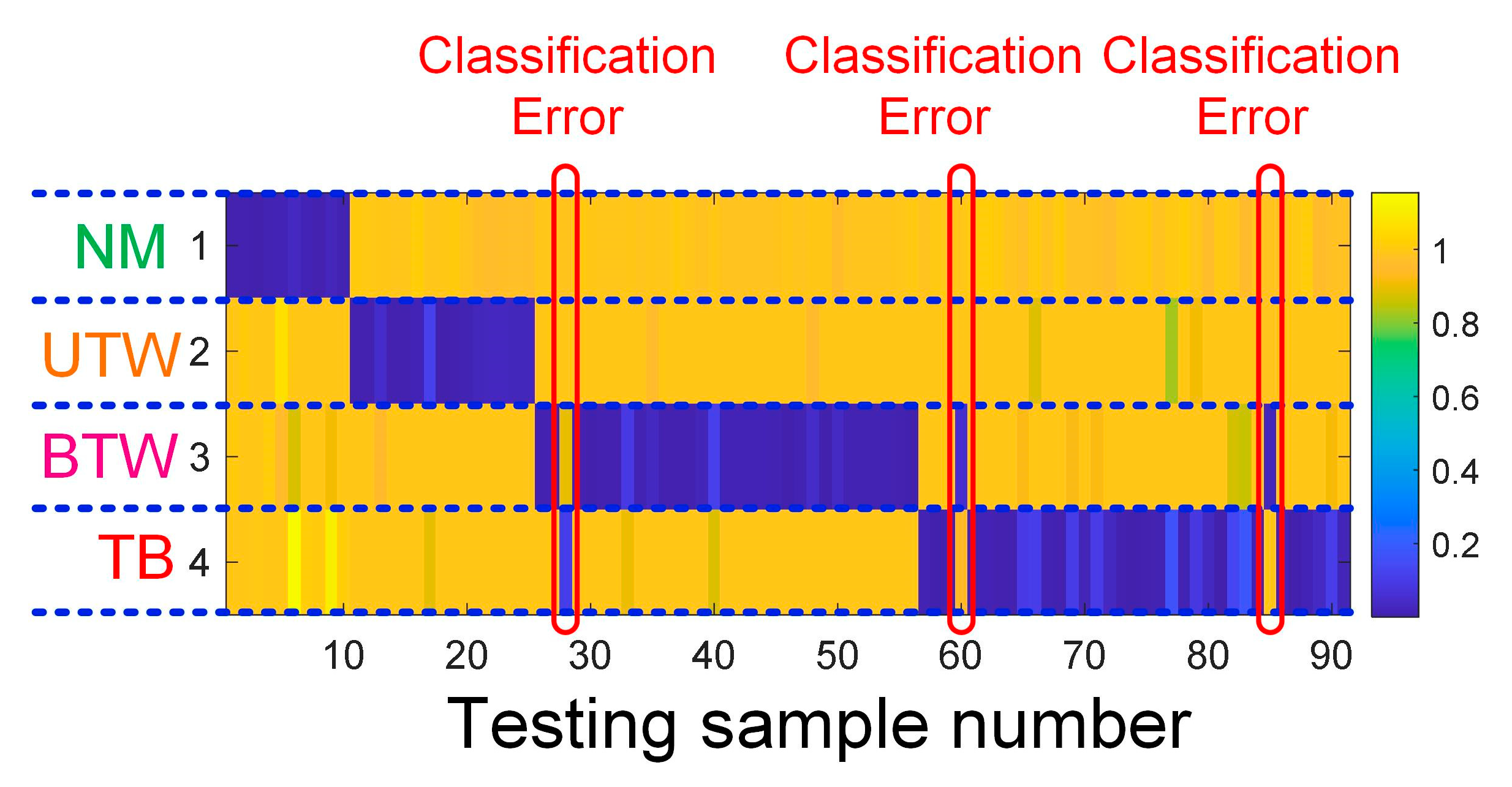
| (Fault) Pattern | Normal | Unilateral Tooth Wear | Bilateral Tooth Wear | Tooth Break | Total |
|---|---|---|---|---|---|
| Abbreviation | NM | UTW | BTW | TB | - |
| Number of data samples | 25 | 30 | 46 | 50 | 151 |
| Number of labeled samples | 15 | 15 | 15 | 15 | 60 |
| Number of testing samples | 10 | 15 | 31 | 35 | 91 |
| (Fault) Pattern | NM | UTW | BTW | TB |
|---|---|---|---|---|
| Atoms in dictionary matrix | #1–#15 | #16–#30 | #31–#45 | #46–#60 |
| Testing samples | #1–#10 | #11–#25 | #26–#56 | #57–#91 |
| Processor | 12th Gen Intel(R) Core (TM) i7-12700H 2.70 GHz |
|---|---|
| Memory | Crucial DDR4 3200 MHz 8 GB × 2 |
| GPU | Intel Iris(R) Xe Graphics 128 MB |
| Hard drive | Intel SSD 512GB PCI-E 3 × 4 |
| # | Method | Accuracy | Time Consumption |
|---|---|---|---|
| 1 | TD + RBF | 99.20% | : 0.886 s : 6.595 s |
| 2 | FD + RBF | 98.80% | : 3.207 s : 7.225 s |
| 3 | TFD + RBF | 99.87% | : 91.761 s : 8.817 s |
| 4 | 1D-CNN | 99.87% | 369.708 s |
| 5 | 2D-CNN | 99.87% | 985.730 s |
| 6 | The proposed method | 99.73% | : 0.129 s : 2.285 s |
| # | Method | Accuracy | Time Consumption |
|---|---|---|---|
| 1 | TD + RBF | 92.31% | : 0.113 s : 0.902 s |
| 2 | FD + RBF | 90.11% | : 0.834 s : 1.420 s |
| 3 | TFD + RBF | 96.70% | : 5.855 s : 0.555 s |
| 4 | 1D-CNN | 92.31% | 98.759 s |
| 5 | 2D-CNN | 96.70% | 289.621 s |
| 6 | The proposed method | 96.70% | : 0.041 s : 0.014 s |
| OMP | BMP | |
|---|---|---|
| Number of required atoms | 6 | 6 |
| Number of iterations | 6 | 3 |
| Number of testing samples | 750 | 750 |
| Time consumption/Test 1 | 3.992 s | 2.316 s |
| Time consumption/Test 2 | 3.921 s | 2.321 s |
| Time consumption/Test 3 | 3.928 s | 2.277 s |
| Time consumption/Test 4 | 3.962 s | 2.320 s |
| Time consumption/Test 5 | 3.910 s | 2.274 s |
| Time consumption/Average | 3.943 s | 2.302 s |
| OMP | BMP | |
|---|---|---|
| Number of required atoms | 4 | 4 |
| Number of iterations | 4 | 2 |
| Number of testing samples | 91 | 91 |
| Time consumption/Test 1 | 0.026 s | 0.017 s |
| Time consumption/Test 2 | 0.027 s | 0.015 s |
| Time consumption/Test 3 | 0.027 s | 0.016 s |
| Time consumption/Test 4 | 0.028 s | 0.015 s |
| Time consumption/Test 5 | 0.027 s | 0.015 s |
| Time consumption/Average | 0.027 s | 0.16 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
You, X.; Li, J.; Deng, Z.; Zhang, K.; Yuan, H. Fault Diagnosis of Rotating Machinery Based on Two-Stage Compressed Sensing. Machines 2023, 11, 242. https://doi.org/10.3390/machines11020242
You X, Li J, Deng Z, Zhang K, Yuan H. Fault Diagnosis of Rotating Machinery Based on Two-Stage Compressed Sensing. Machines. 2023; 11(2):242. https://doi.org/10.3390/machines11020242
Chicago/Turabian StyleYou, Xianglong, Jiacheng Li, Zhongwei Deng, Kai Zhang, and Hang Yuan. 2023. "Fault Diagnosis of Rotating Machinery Based on Two-Stage Compressed Sensing" Machines 11, no. 2: 242. https://doi.org/10.3390/machines11020242