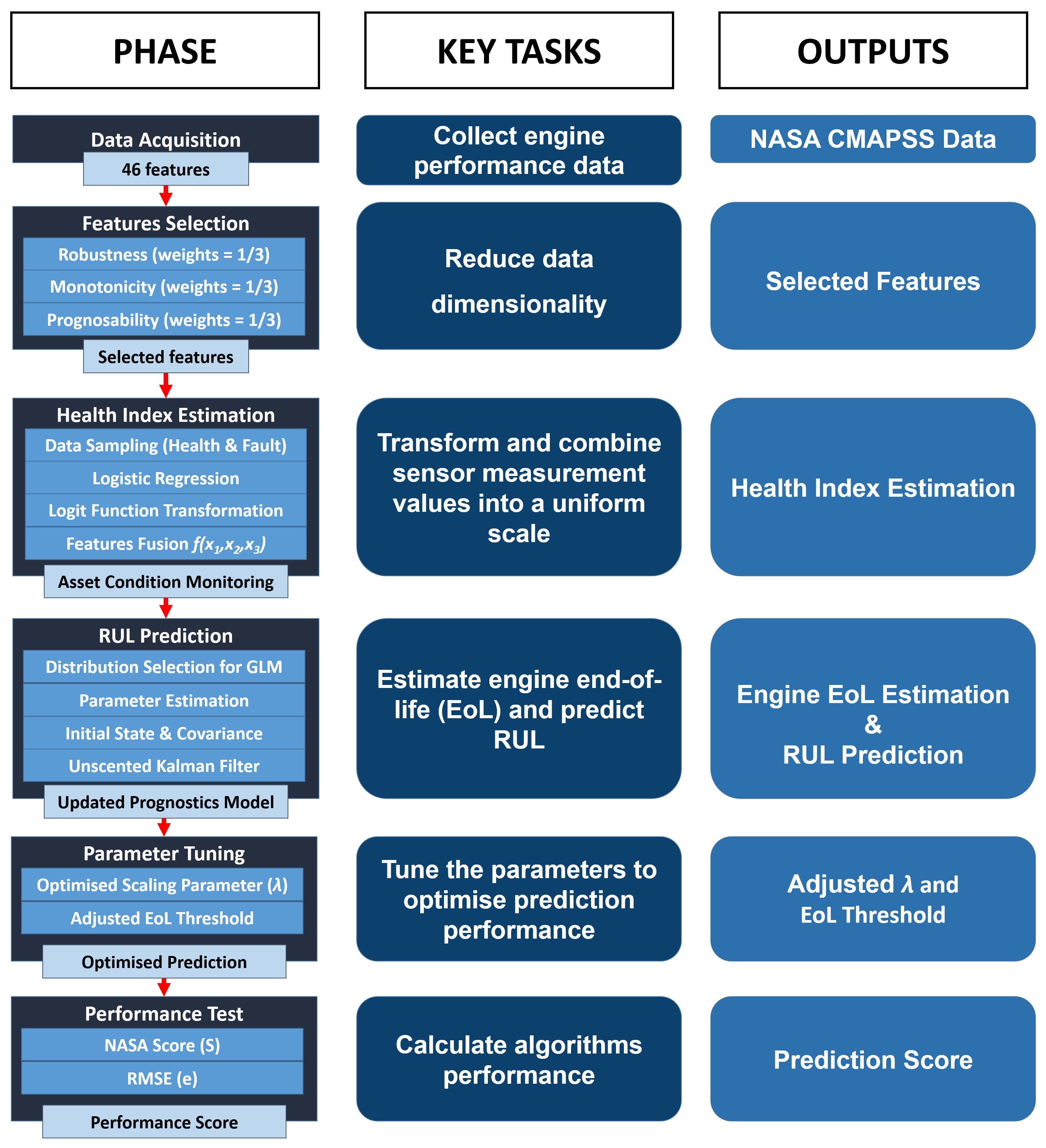
3.1. Results
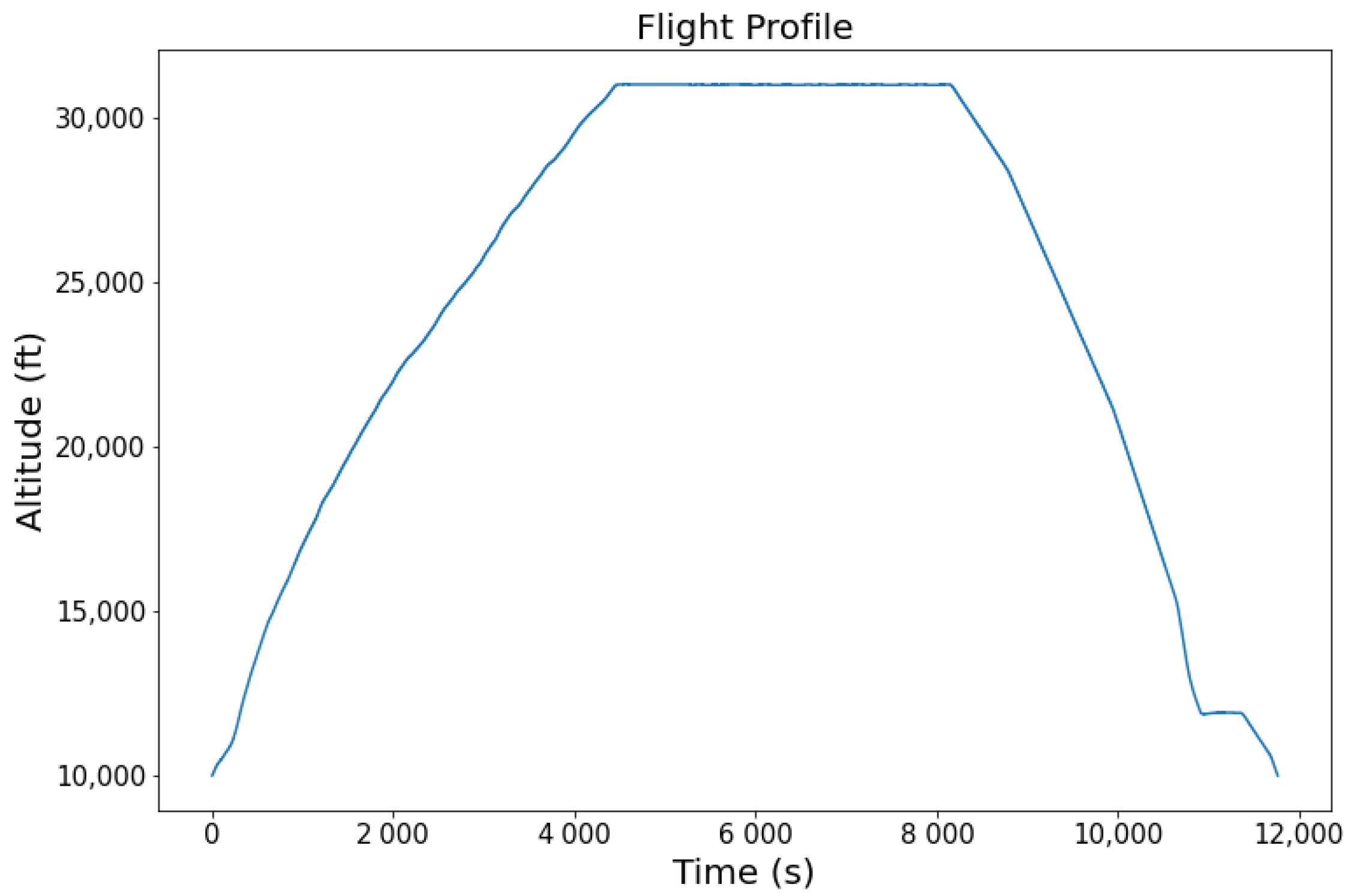
From the Data Acquisition, it is found that the chosen dataset comprises 46 parameters, including scenario descriptor, measurement, real EoL, and model health parameters. Some of the parameters recorded in this dataset are altitude and fuel flow. It is shown in
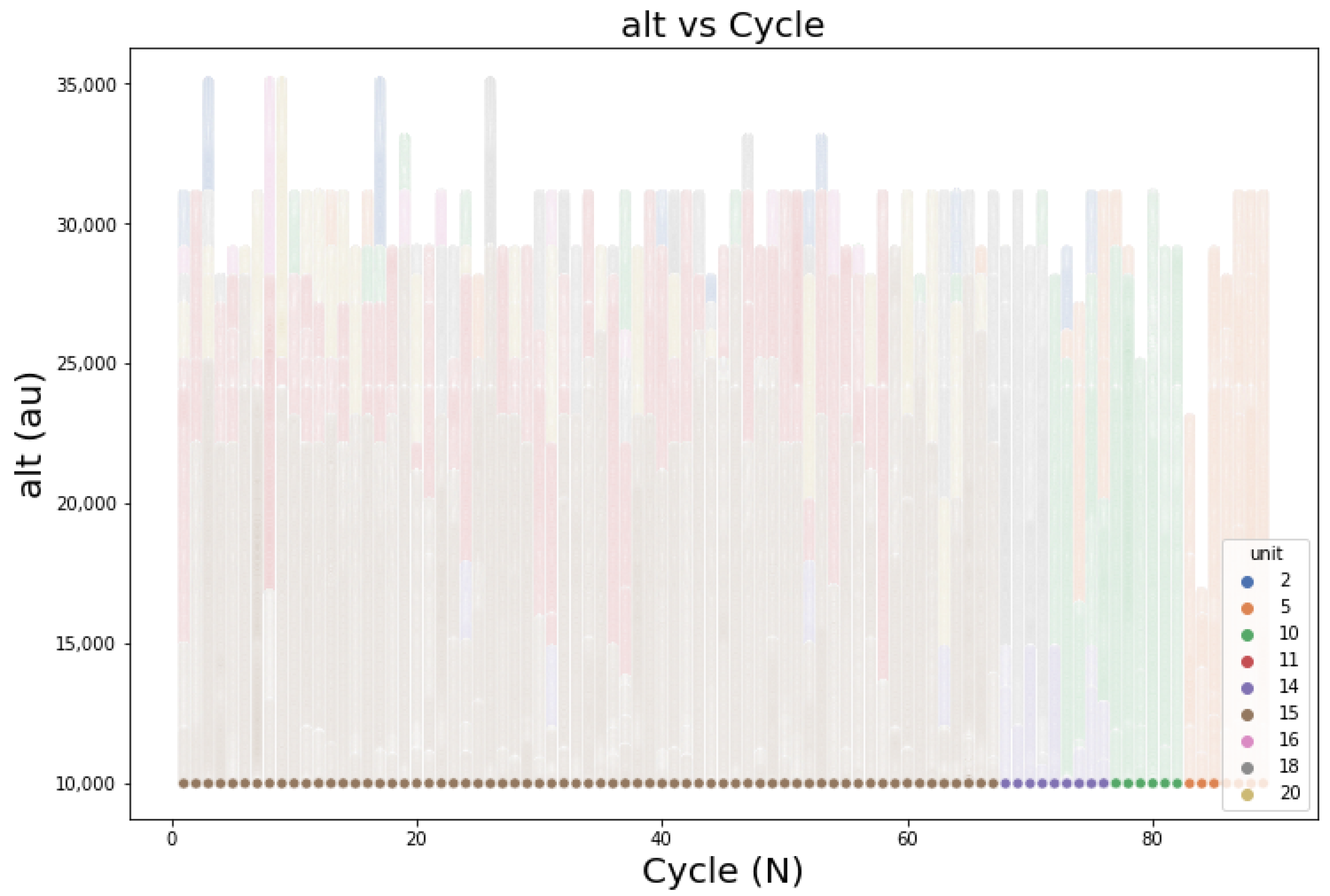
Figure 5 how the aircraft altitude changes over time. The increasing altitude from 10,000 to 30,000 ft occurs in the early flight phase. The steady altitude is maintained for more than 1 h. The height steadily decreased and held for a while before returning to 10,000 ft.
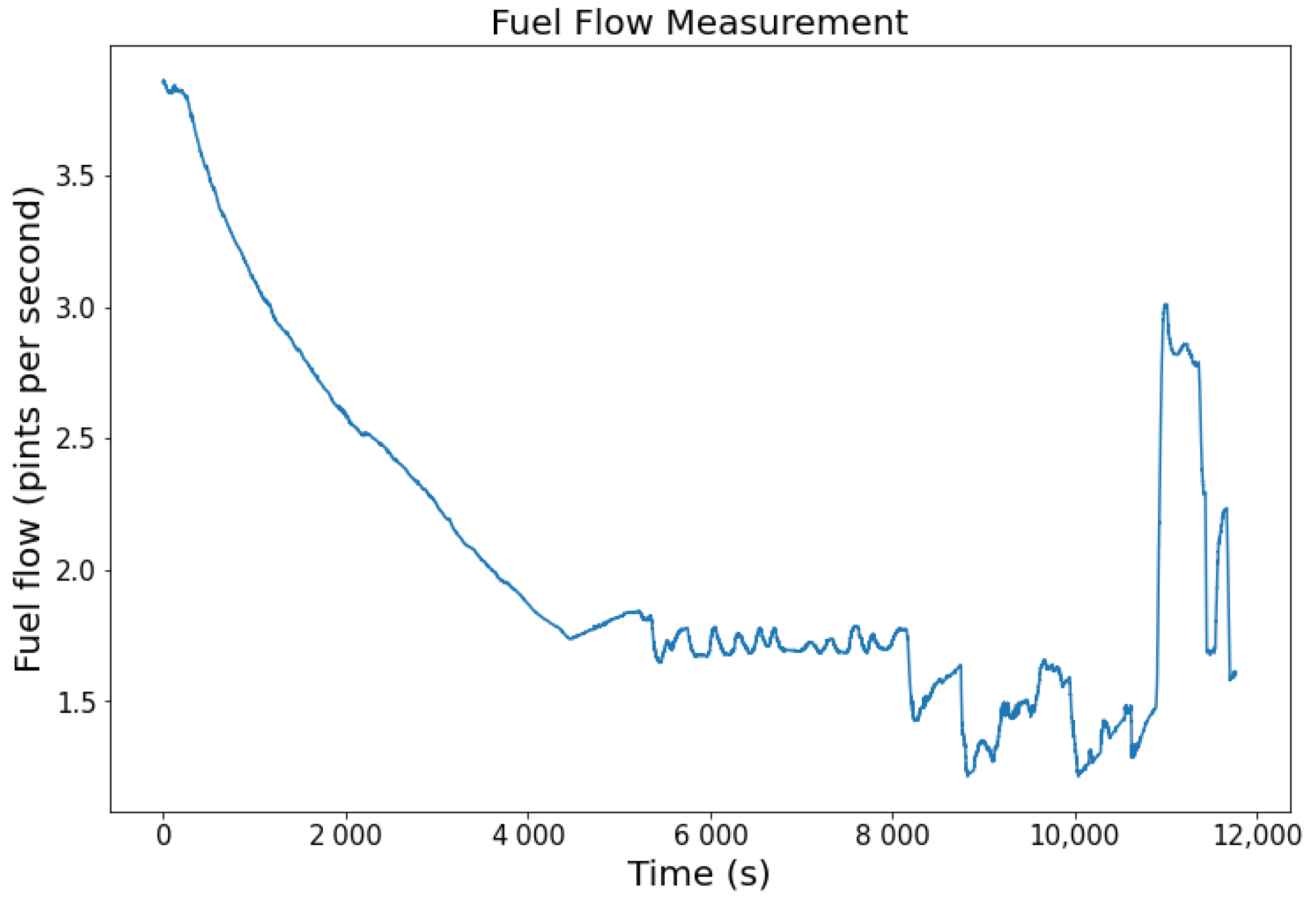
The second example is the fuel flow record as seen in
Figure 6. In the early phase, the fuel flow starts at 3.5 pps before rapid degradation is detected. Small fluctuations in the middle sector happen for more than 4000 s. As it approaches the end of the flight, the fuel flow exhibits high volatility, where its highest peak is 3 pps before instantaneously dropping at the end.
Following the flight altitude (see
Figure 5), the fuel flow parameter of the same aircraft (
Figure 6) is a match for the same flight. The high fuel flow at the beginning shows that the aircraft requires high power during the take-off and climb phase. The fuel flow becomes steady during the cruise. In the descend and landing phases, the fuel flow fluctuated depending on the pilot’s demand to maintain or decrease the altitude. This synchronicity between these two parameters shows that the CMAPSS data approximate the real flight condition. Furthermore, sub-system degradation can be monitored in each cycle until it fails. For instance, degradation in
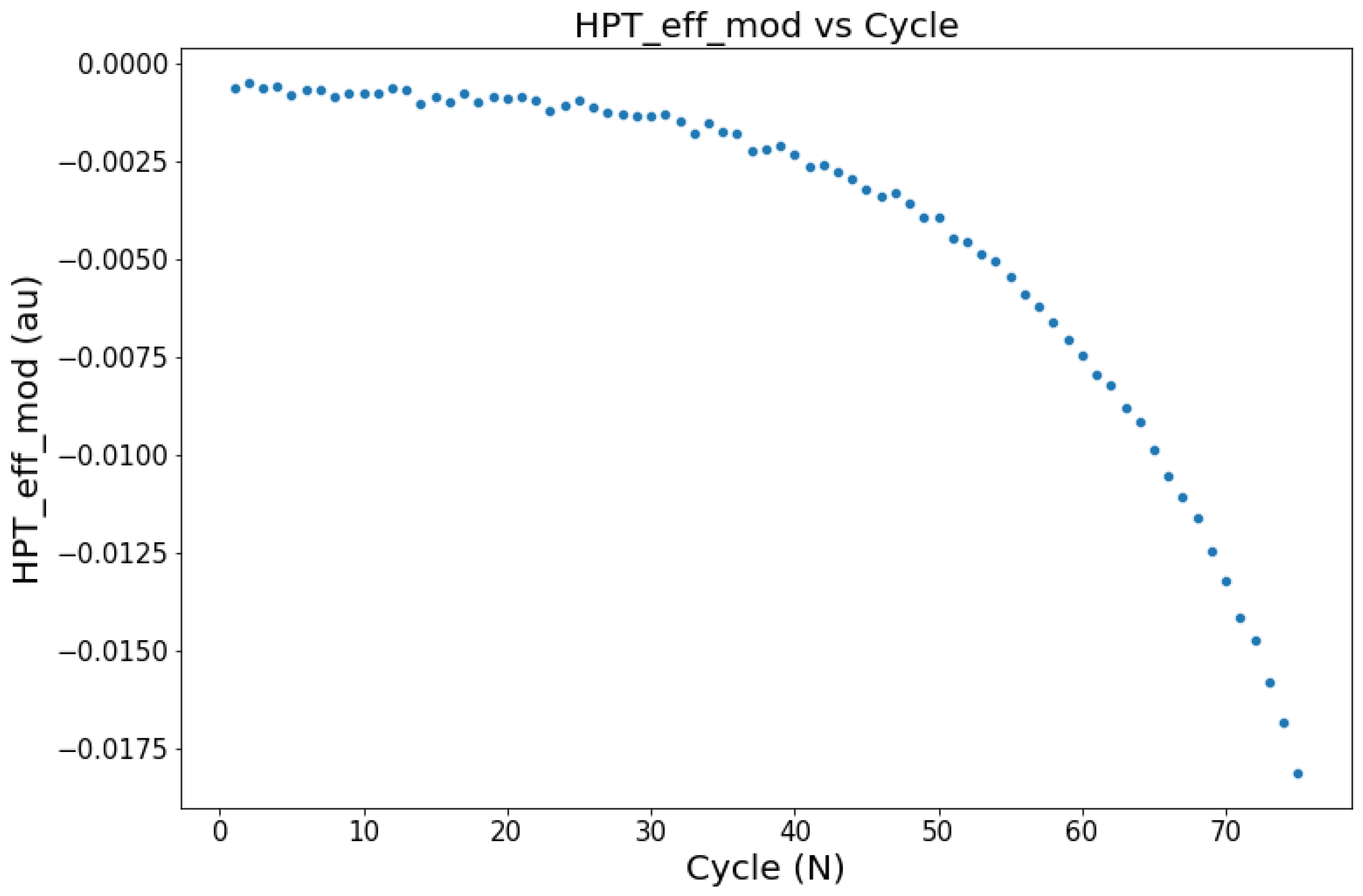
in
Figure 7 may occur on a real system due to operating conditions. These factors are ideal to build a model that approximates the real flight condition.
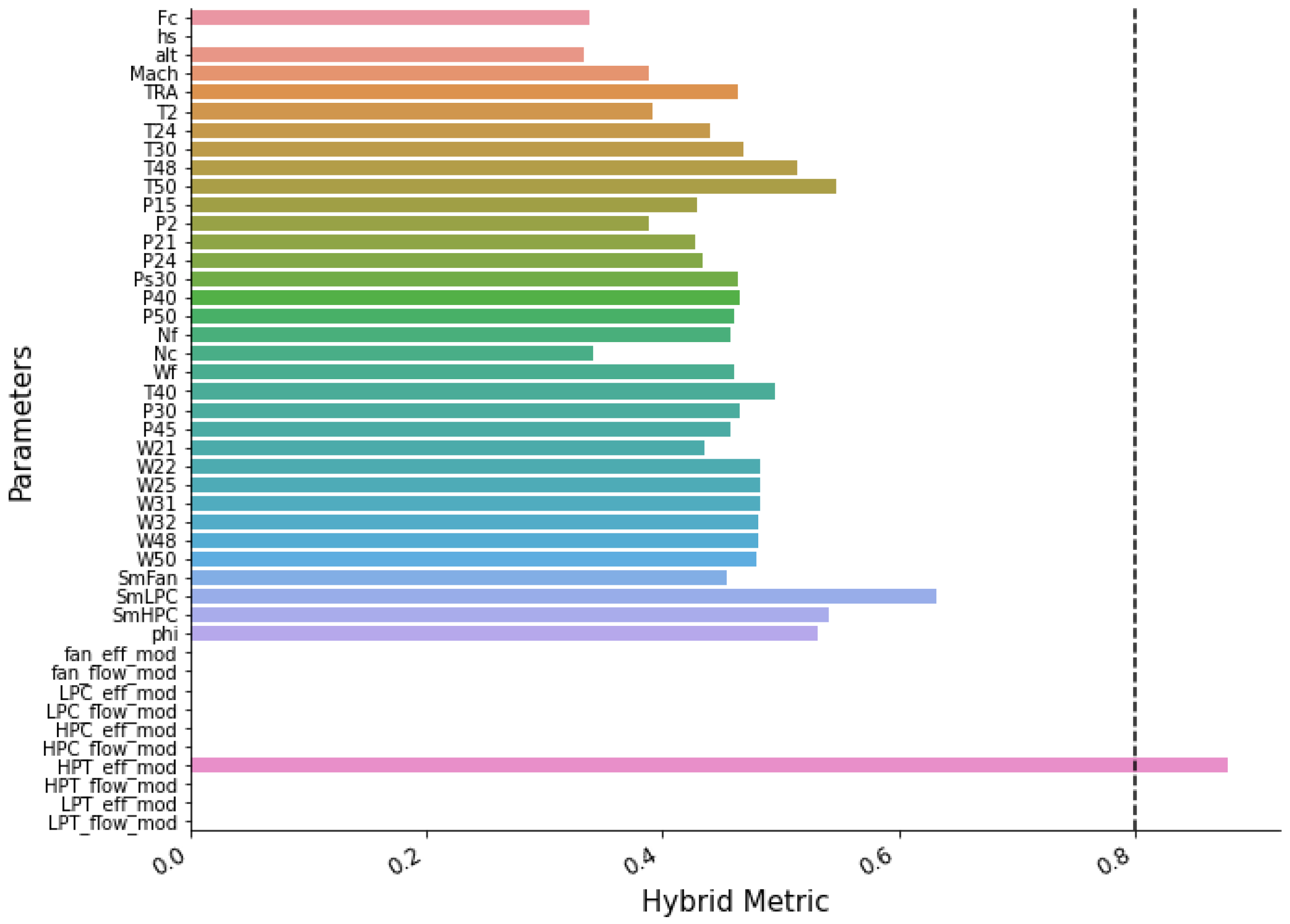
All features from DS02 and DS03 are passed through the hybrid metrics in the Feature Selection phase. A threshold is assigned, and only feature(s) that have a metric score above the threshold will be the selected feature. The 0.8 metric value is set as the threshold since it is a high enough value to filter a good feature but not too high where none will pass.
Figure 8 presents the result of the hybrid filtering of DS02. It shows that
has the highest metric score (0.87) and is the only feature that passes the threshold. It is noted that several features show metric scores of 0, such as the fan efficiency modifier (
) and low-pressure turbine (LPT) efficiency modifier (
). Altitude is the feature with a non-zero and the lowest metric score with 0.33.
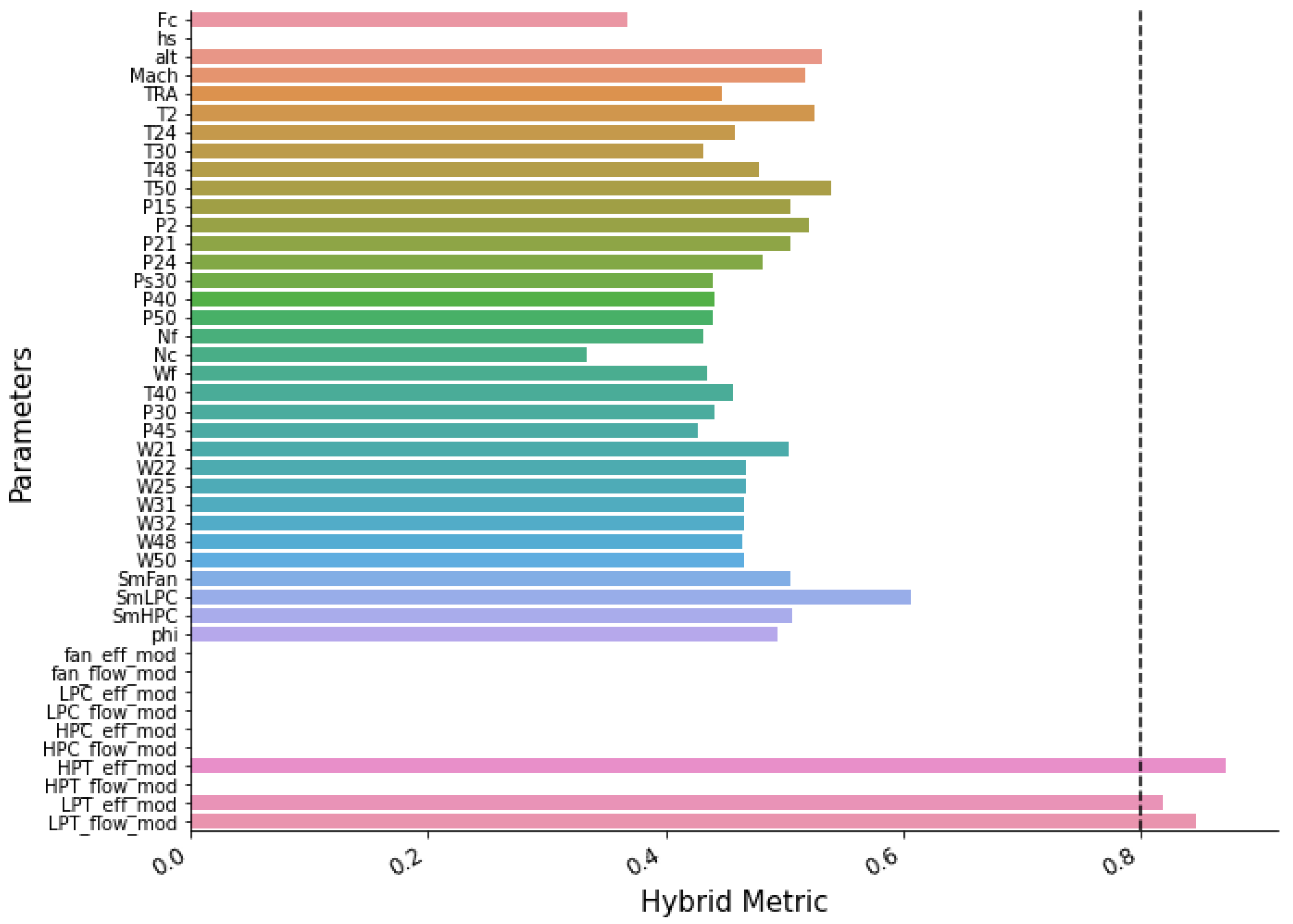
The filtering of DS03 exhibits a different result, as shown in
Figure 9. These three features pass the filtering process, namely
,
, and LPT flow modifier (
). These features yield high metric scores with
as the highest (0.87) followed by
(0.84) and
(0.81). Like in the DS02, several parameters show a 0 metric score. The lowest score and non-zero feature is physical core speed (
Nc), with a 0.33 metric score.
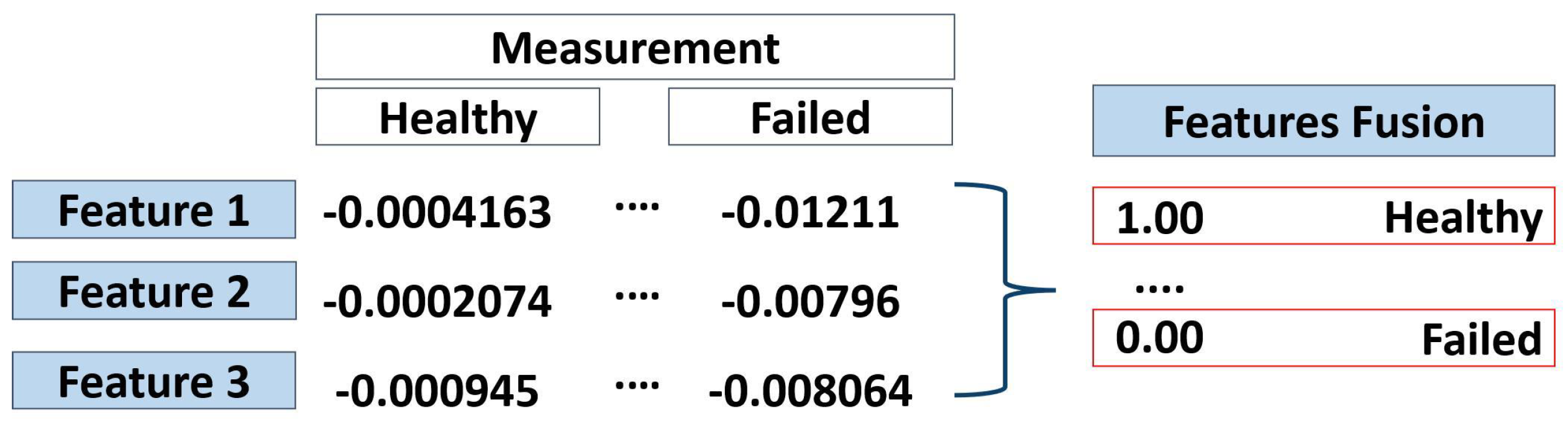
In the Health Index Estimation phase, the data sampling from the selected features is performed to check the measurement values when the engine is in a healthy (
) and failed (
) state. The tables in
Appendix A show the example of sampling data from DS02 (
Table A1 and
Table A2) and DS03 (
Table A3 and
Table A4). Five measurements of
and
of the selected features are taken across the engine fleet. As seen in the tables, the value and range of the features are different even if they represent the same state (healthy or failed state).
This sample data is then used for logistic regression to obtain function parameters. The computed parameters of each engine are employed to identify the health index (HI) from measurement data.
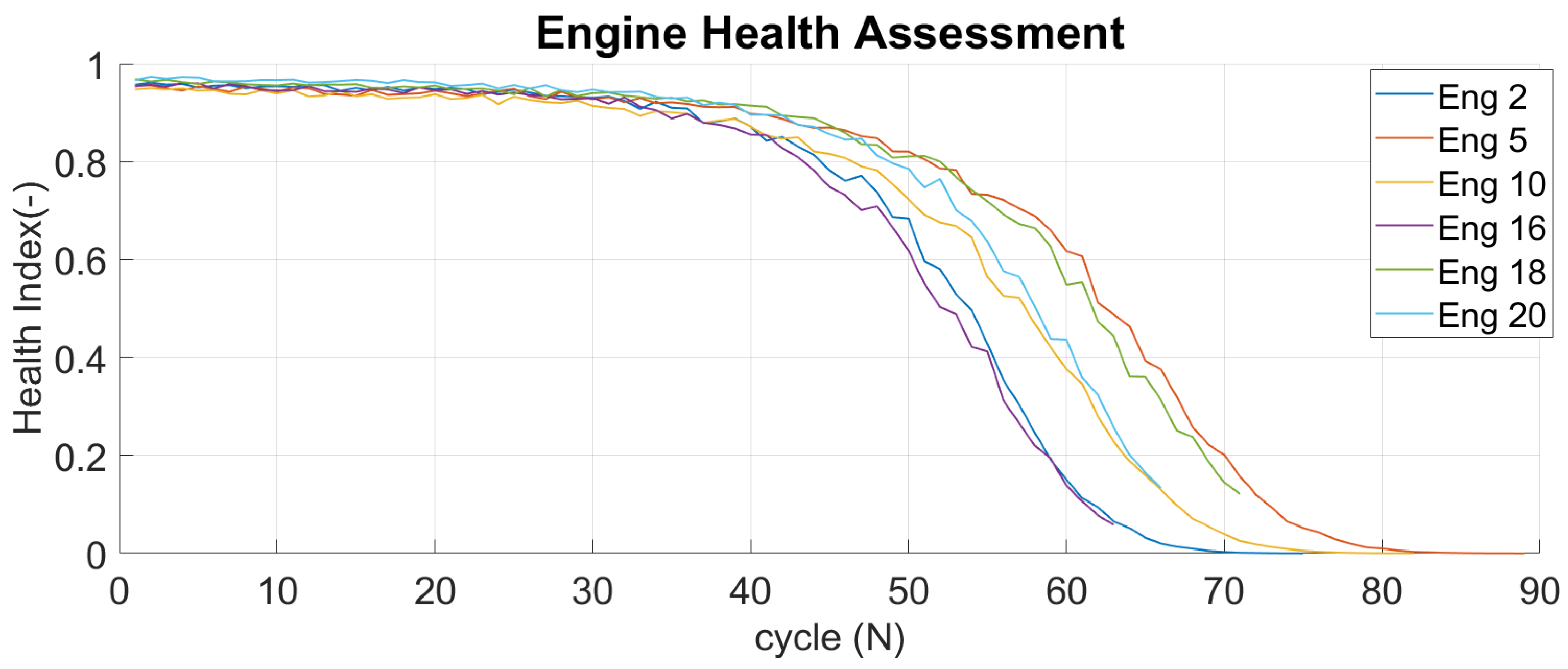
Figure 10 compares HI from across the fleet of DS02. Similarly,
Figure 11 provides the same comparison for DS03 and it also shows the strict HI range from 1 (healthy) and 0 (failed). Although both datasets show the same pattern across the fleet, each unit has a unique and distinctive degradation rate. Since each engine has different parameter values, the HI becomes a measure of the engine’s health for engine condition monitoring process.
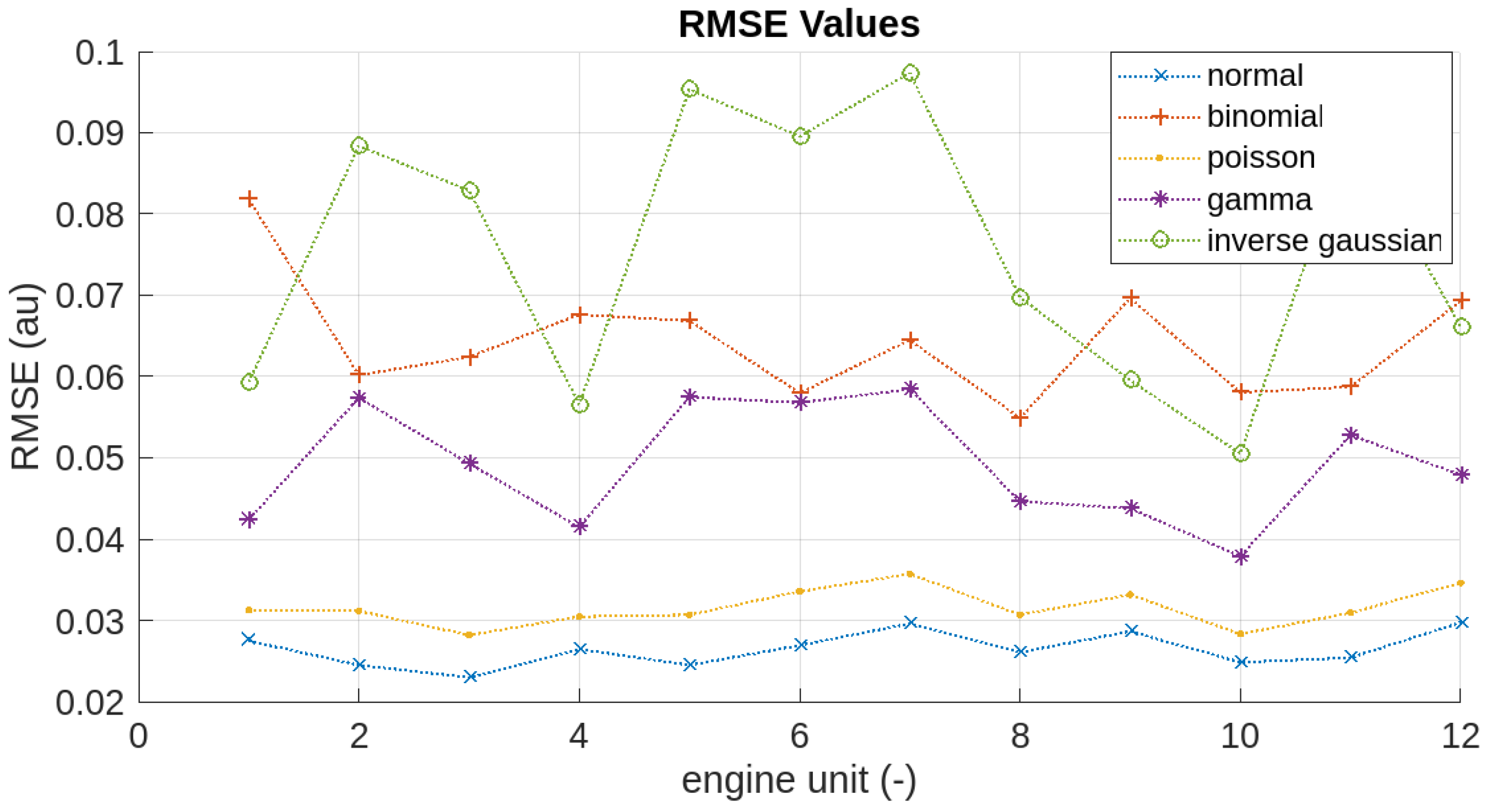
The distribution selection of the response variable (engine HI) is evaluated by calculating the RMSE value in the RUL Prediction phase.
Figure 12 is the result of the RMSE plotting across the engine fleet of DS02. RMSE values are collectively highest for engine 10 and lowest for engine 20. Inverse Gaussian and Gamma distributions have relatively high fluctuation, while Binomial, Poisson, and Normal distributions are steadier in all engines. Compared to others, Normal distribution consistently results in the fleet’s lowest RMSE value.
RMSE plotting of DS03 is shown in
Figure 13. Higher volatility is seen in DS03 compared to DS02. Inverse Gaussian, Binomial, and Gamma distributions have distinct peaks and bottom differences across the fleet. Even though fluctuate, Poisson and Normal distributions show less peak-bottom difference variance. Similar to DS02, the Normal distribution shows the lowest RMSE for this dataset. Hence, both datasets use the Normal distribution for GLM fitting process.
The GLM fitting with logistic regression transforms these sampling data and results in each engine’s logit function (
and
) parameters.
Table A5 (see
Appendix B) provides these parameters of DS02 for each engine. The same process goes for DS03, resulting in different values of logit function parameters that are shown in
Table A6 in
Appendix B.
The computed parameters of each engine are then used to identify the estimated health index (HI).
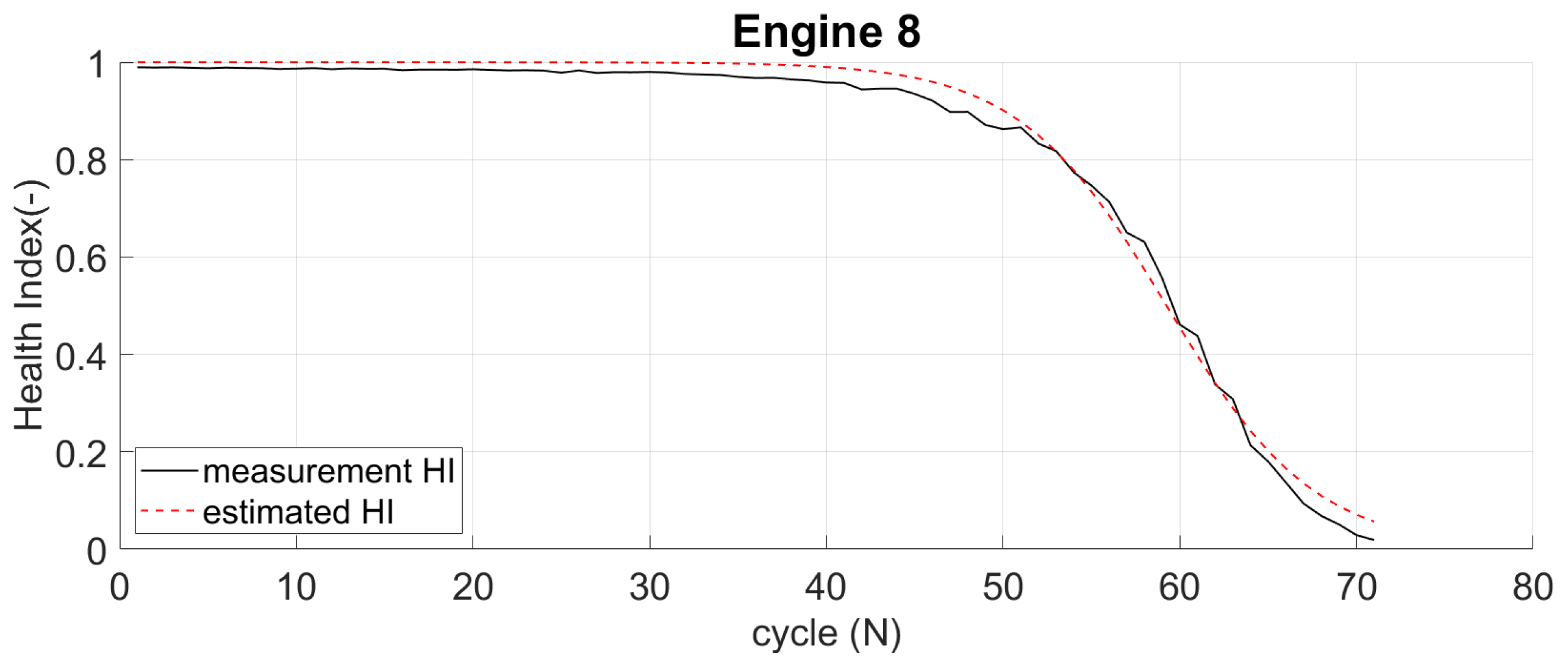
Figure 14 compares HI from measurement and estimated HI from the logistic regression of engine 16 (DS02). Similarly,
Figure 15 provides the same comparison for engine 8 (DS03). The HI from measurement begins near 1 (but not at 1), while the estimated HI always starts at 1 (100% healthy). Even though there is a slight difference, both show the engine in a healthy state at the beginning. Both end almost at the same values when the aircraft is in a failed state.
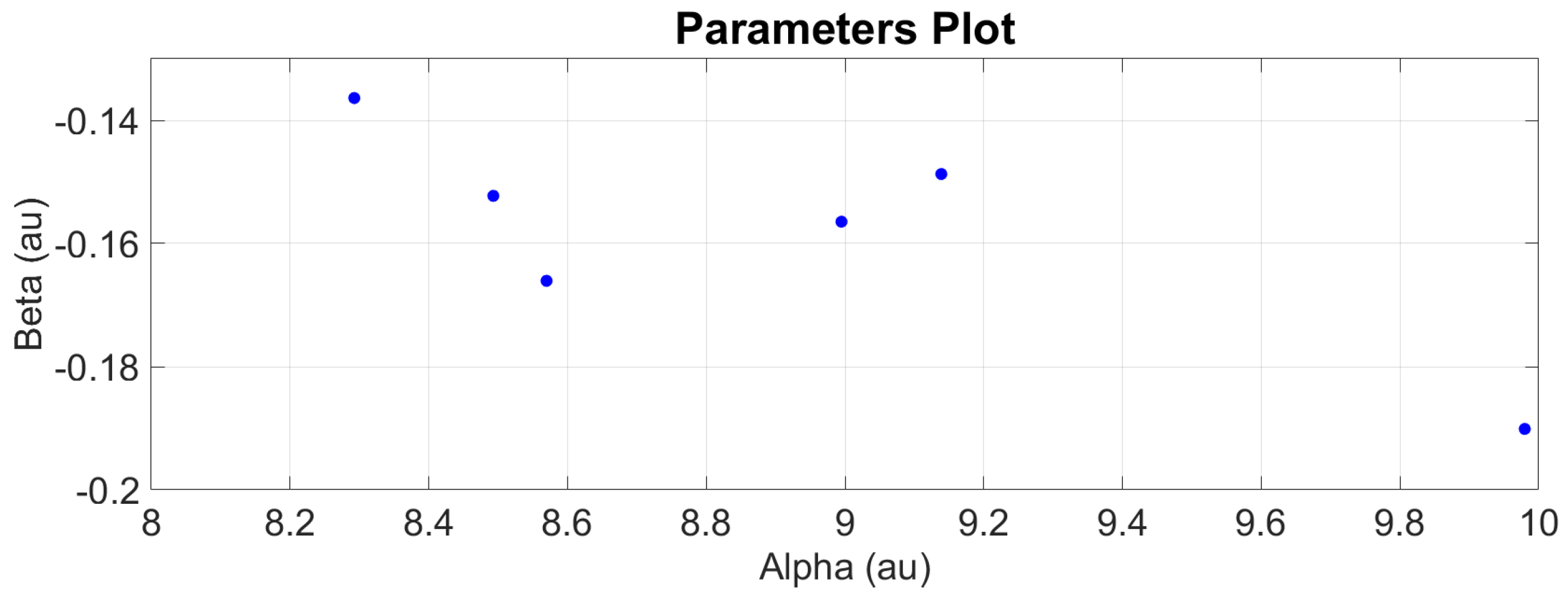
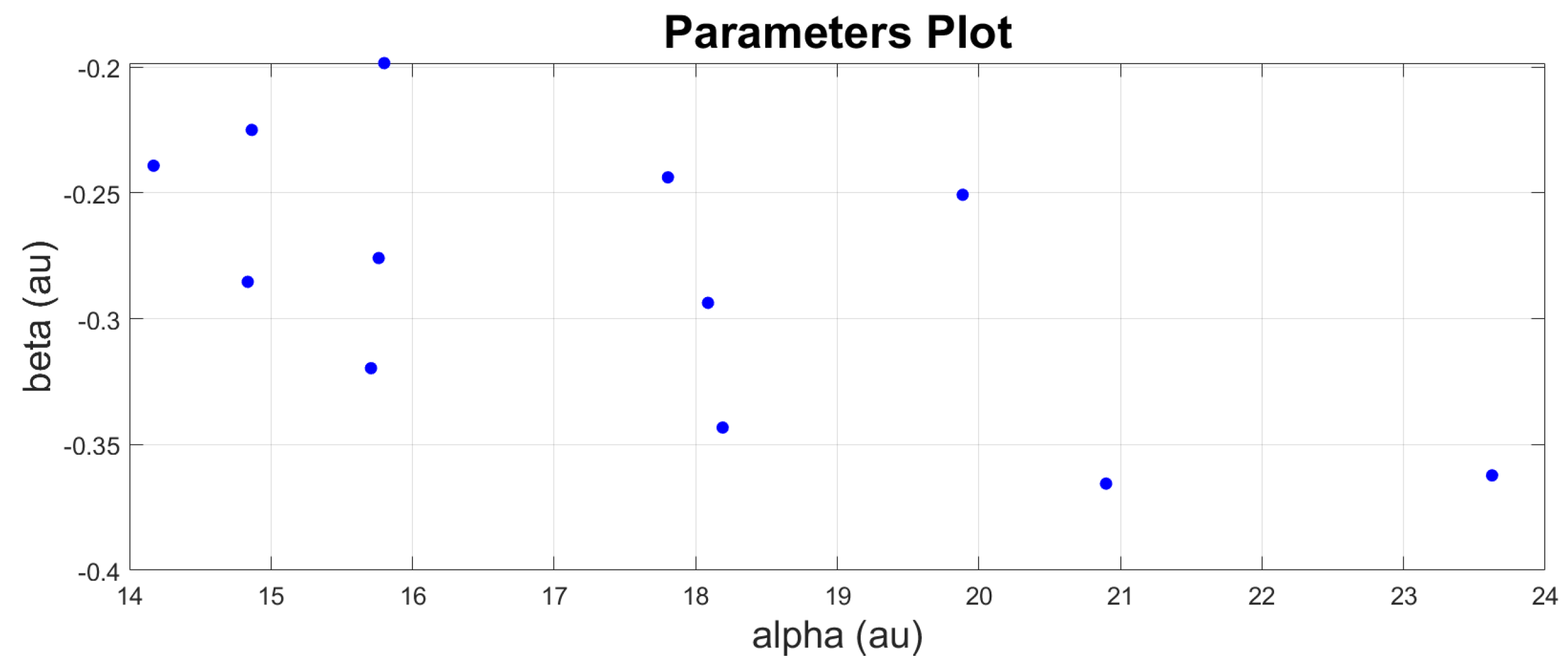
The parameters of each engine are then plotted against each other to identify their scatter points.
Figure 16 and
Figure 17 show how the parameters are distributed. It follows no pattern and is randomly distributed. The mean values of
and
are computed to represent the fleet parameters. The covariance is also computed to show how much alpha and beta vary together. The mean values and covariance matrix are then set as the initial state (
,
) for the unscented Kalman filter (UKF) process.
After estimating the engine system state, the UKF produces new (updated) parameters (
and
). The extrapolation of the logit function is computed based on these new parameters.
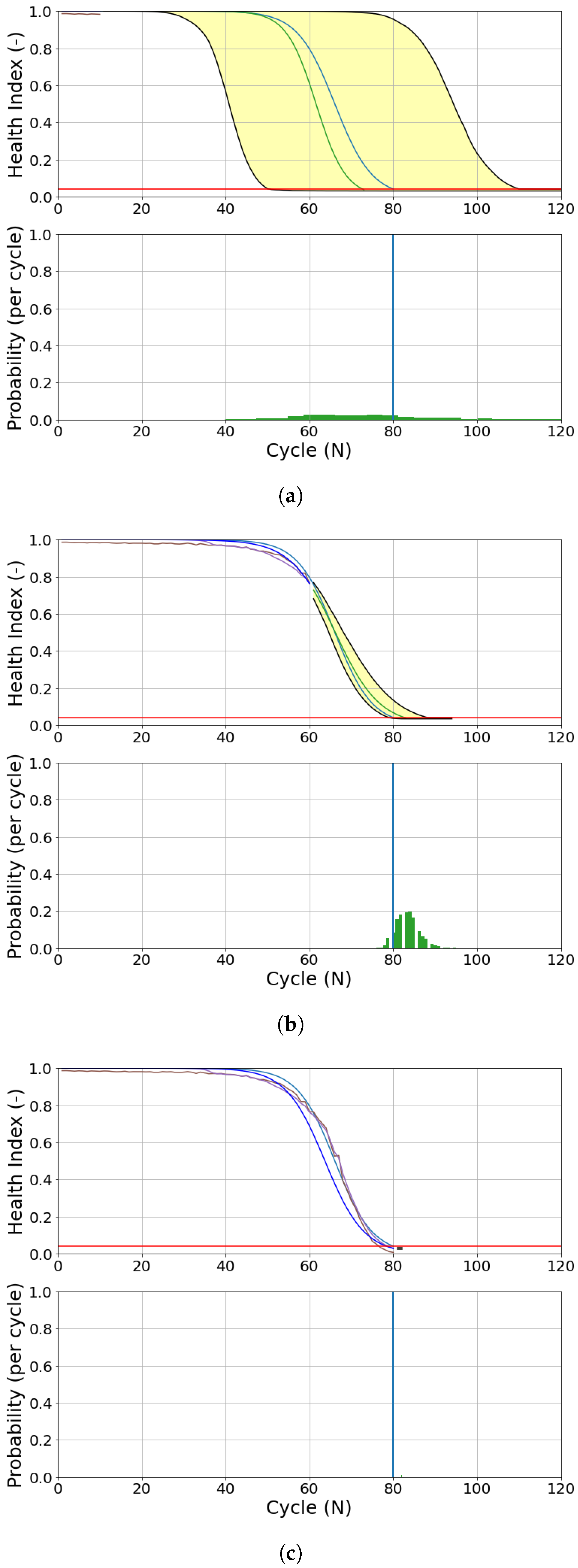
Figure 18 shows the engine end-of-life (EoL) and RUL distribution based on 1000 trajectory samples.
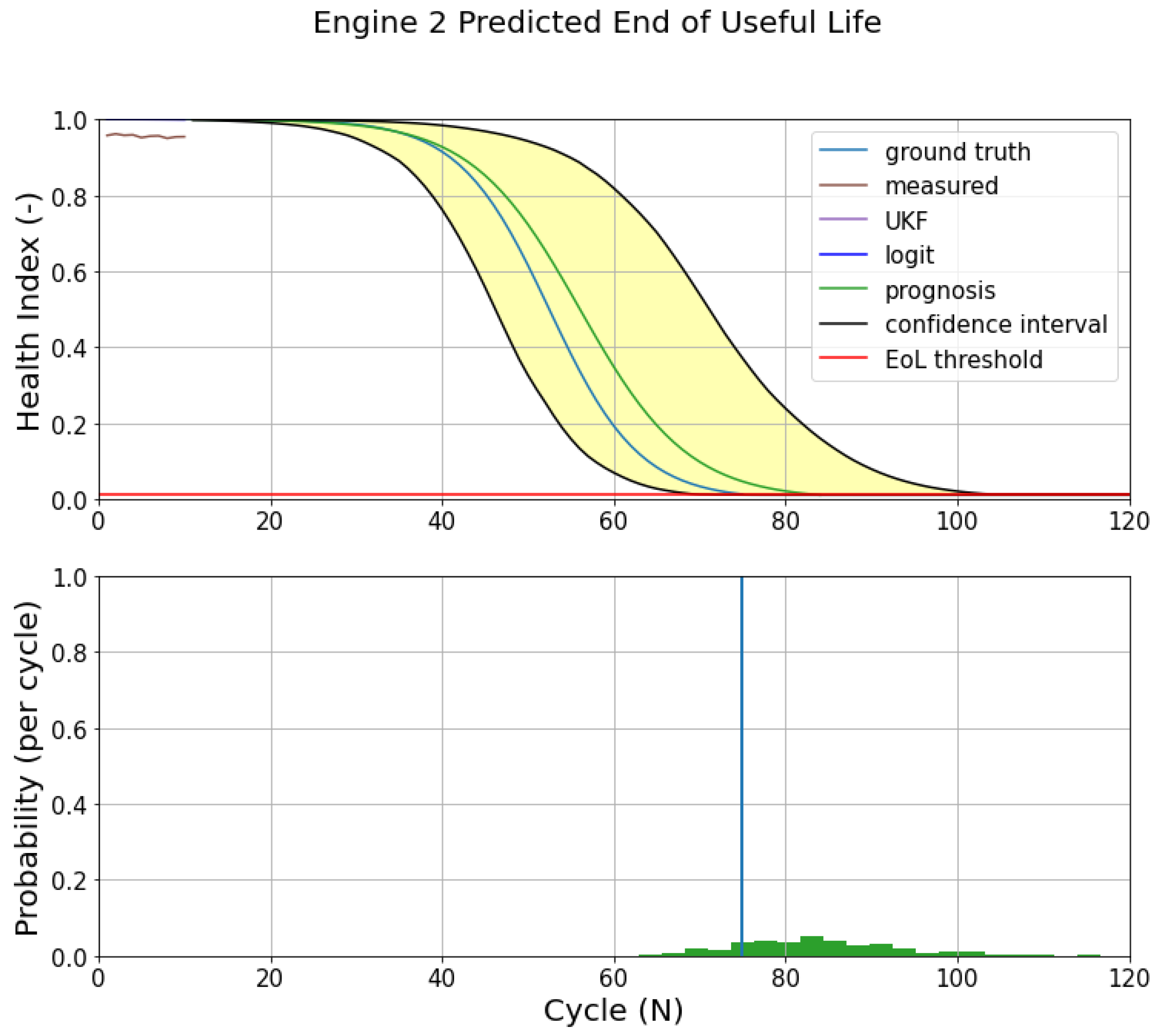
As a result of the recursive update in UKF, the parameters are updated in each cycle, producing a new (updated) prognostics model. This updated model extrapolates 1000 possible trajectories and estimates engine end-of-life (EoL) and RUL probability distribution. As seen in
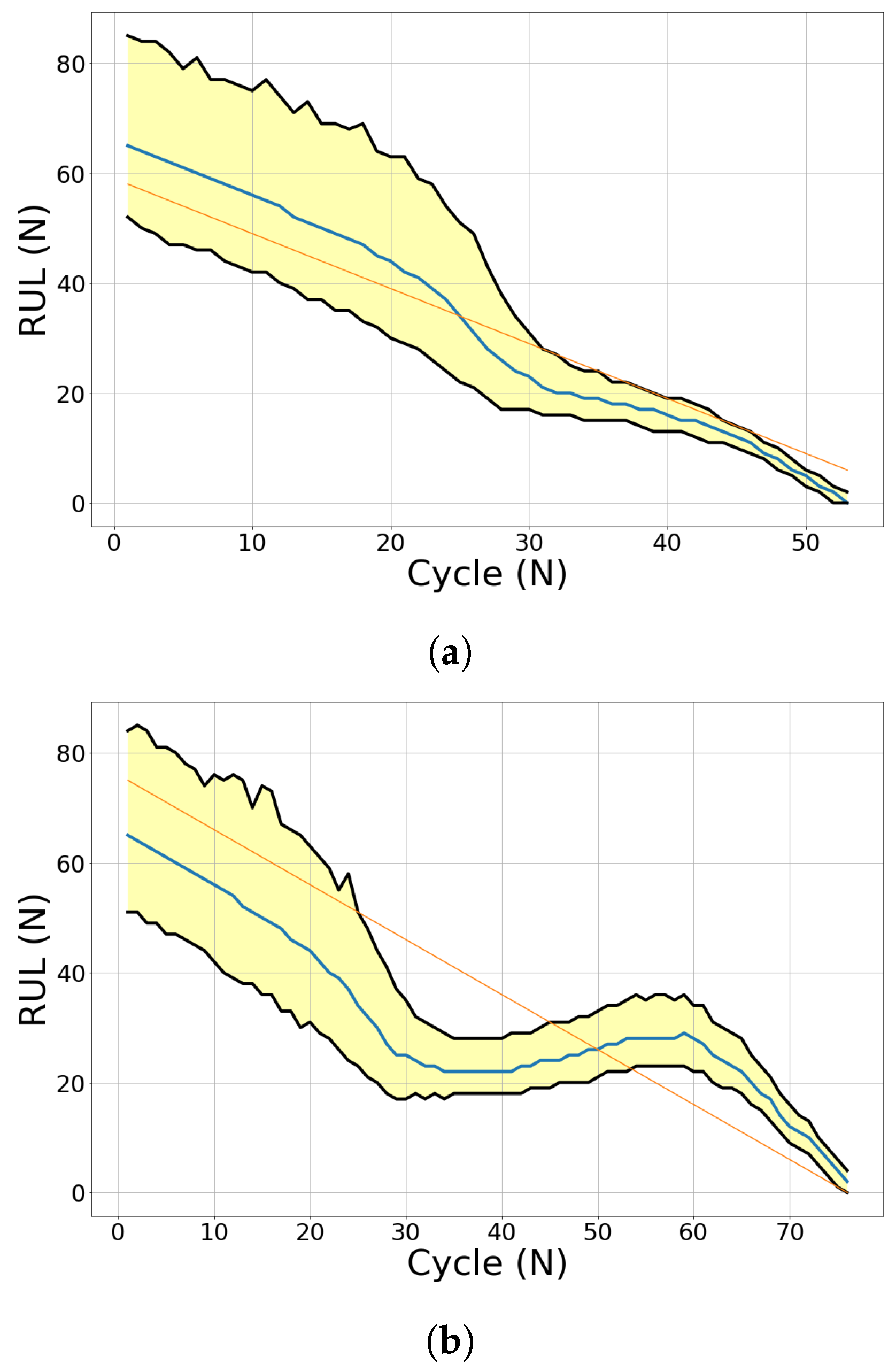
Figure 19 for Engine 2 (DS02), the prediction starts when there is information from measurement data (sensors). In the first 10 cycles, the EoL estimation has a poor performance, shown by a large 90%-confidence interval area (yellow-shaded area). The RUL prediction maps the probability distribution of these possible EOLs and still has a low probability value in the early flights (measurement).
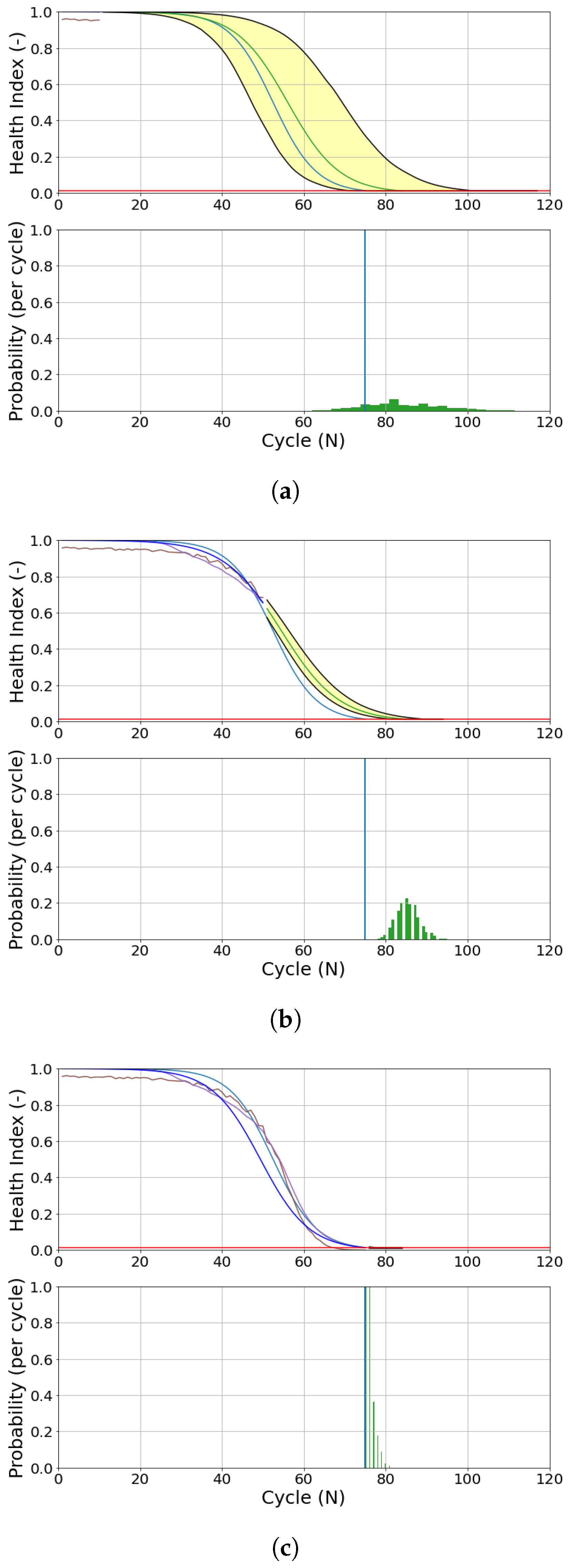
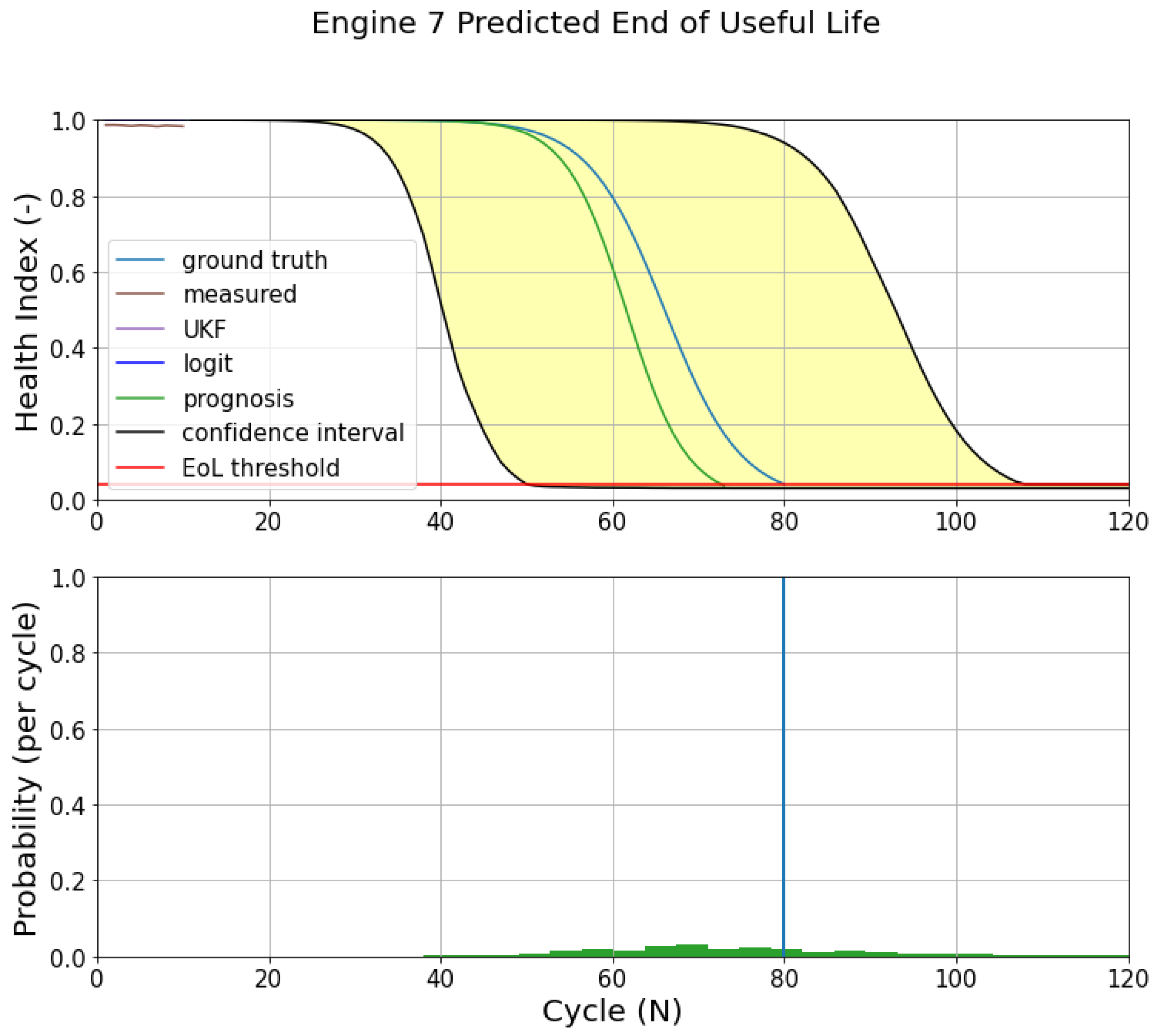
Like DS02, similar phenomena are also observed in DS03.
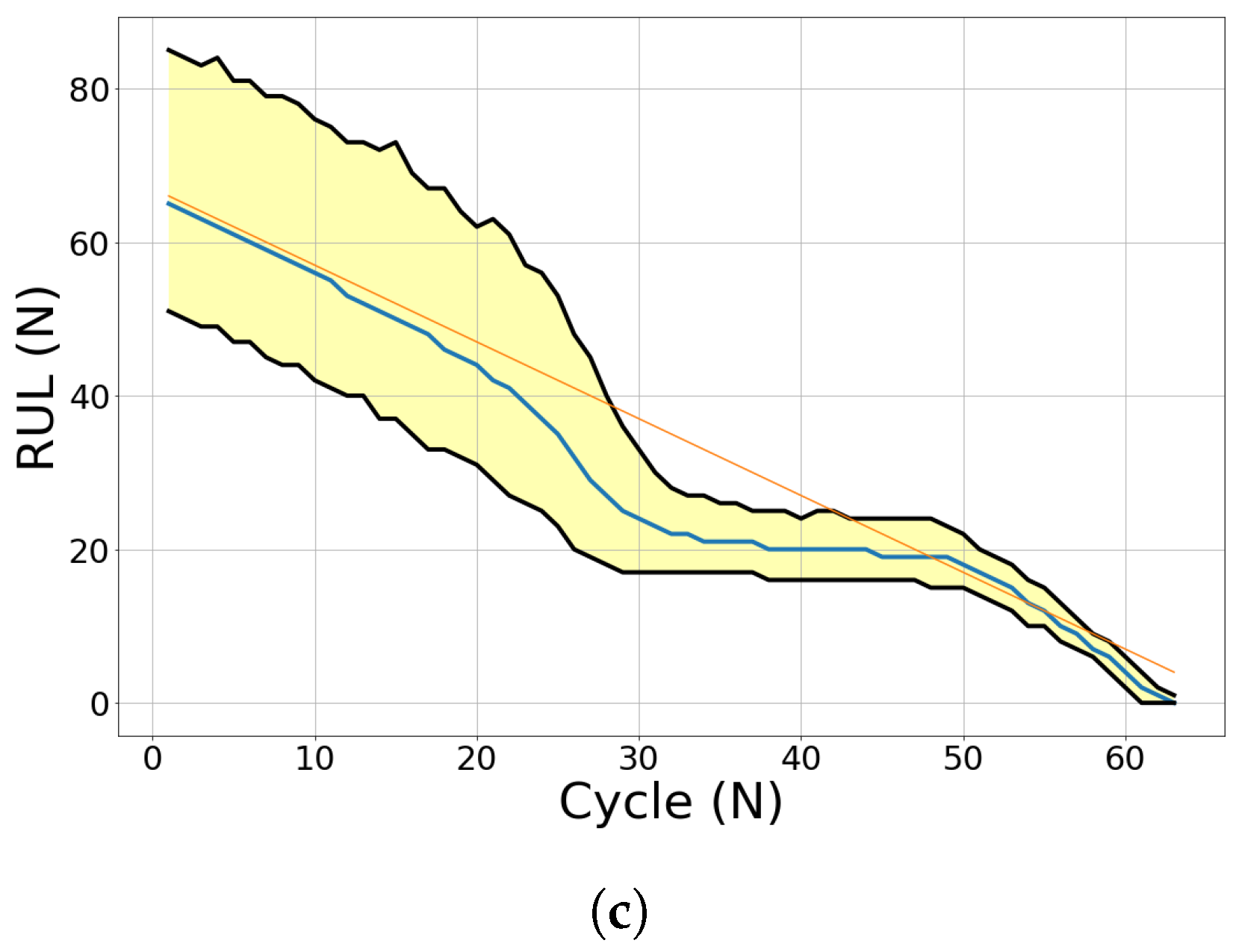
Figure 20 shows the prognostics model of engine 7 (DS03). The initial measurements (10 cycles) present a sub-optimal prediction. On the following flights (60 and 80 cycles), the updated prognostics model has a better prediction, as shown in
Figure 21c. Both EoL and RUL predictions converge around the ground truth EoL (80 cycles).
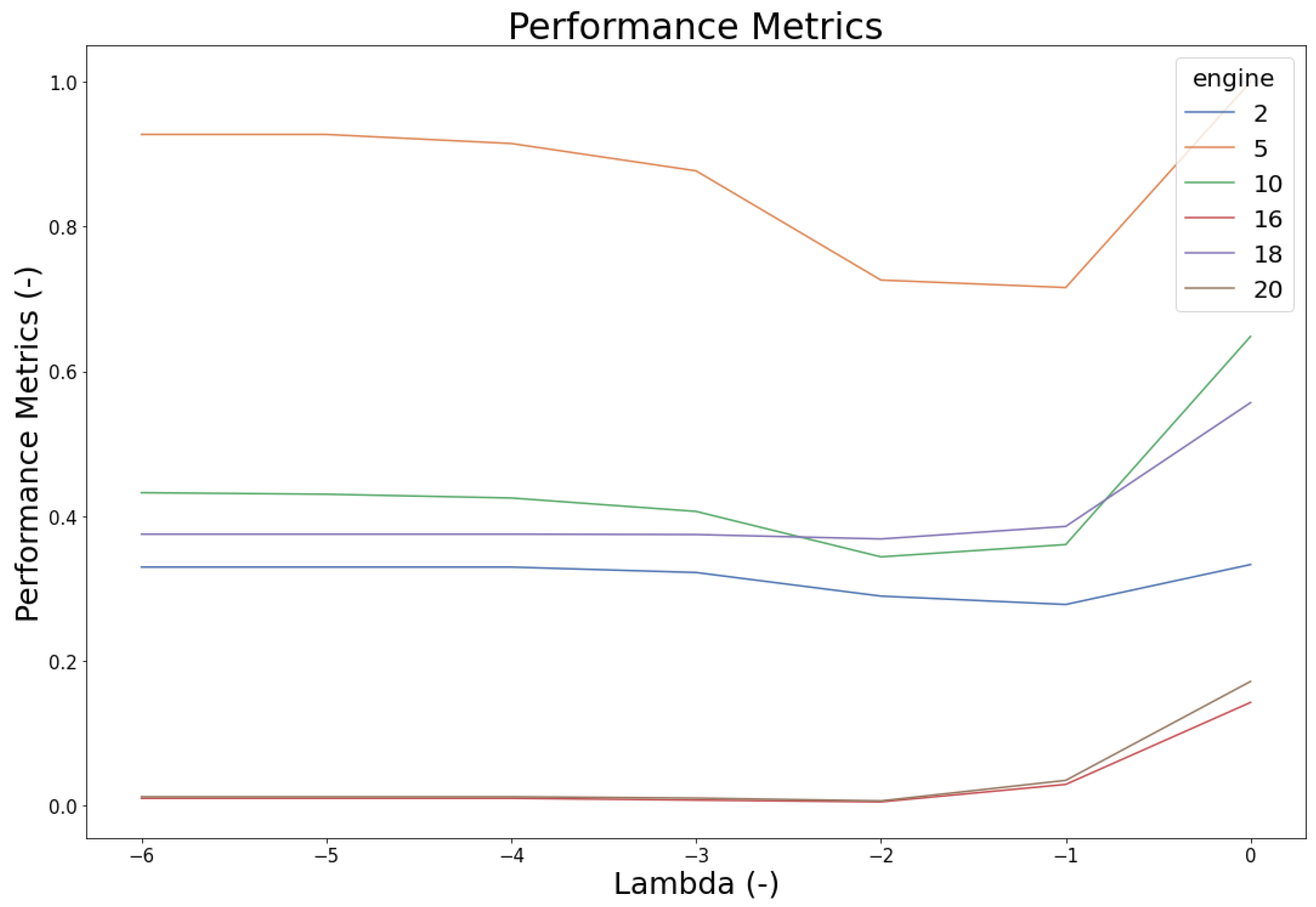
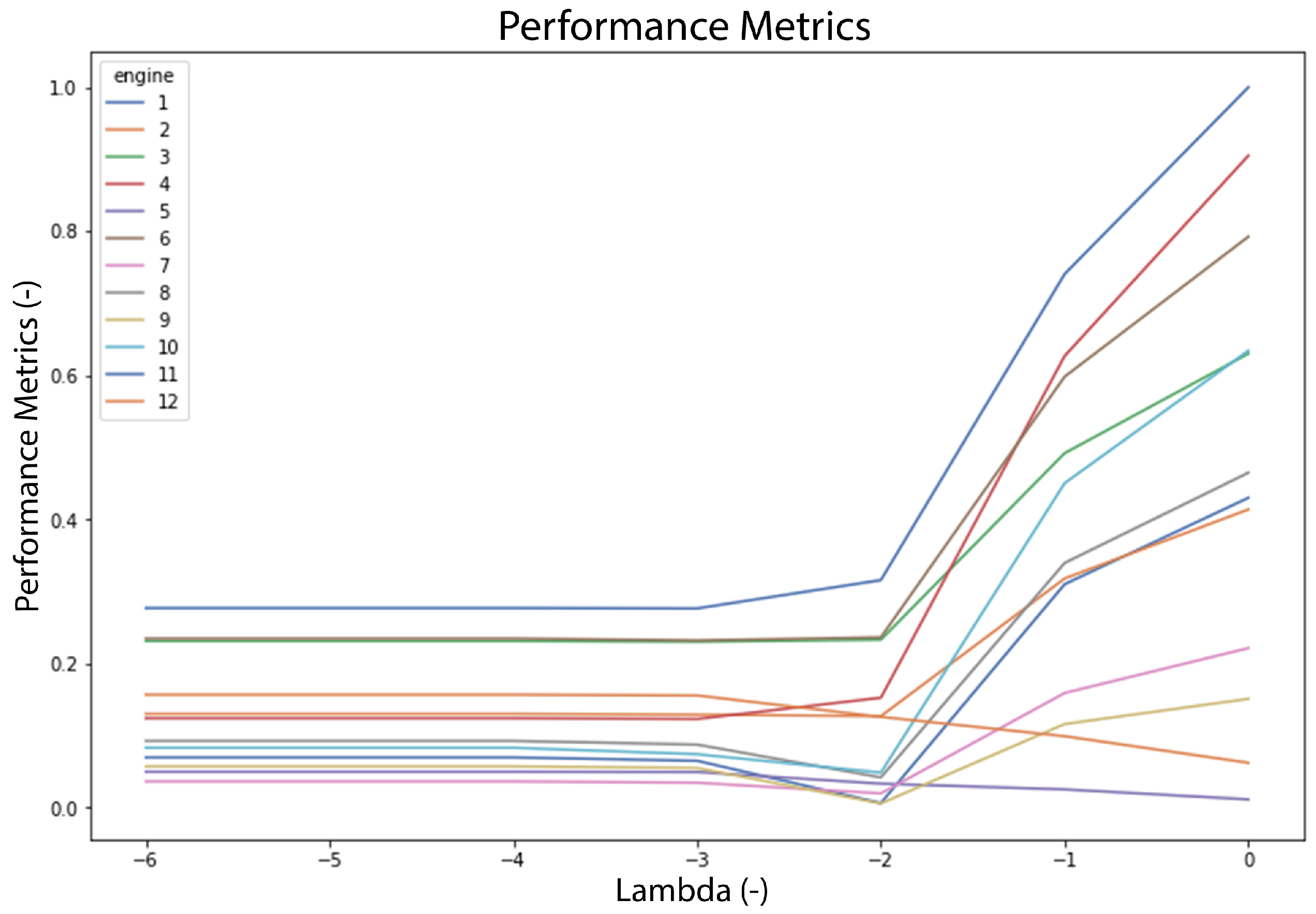
The Parameter Tuning phase attempts to find the optimised parameter in order to obtain the best prediction result. Once the base model has been set up, the scaling parameter (
) and EoL threshold are tuned and the prediction results are presented in performance metric (
p).
Figure 22 and
Figure 23 show that
value
yields the collective optimal result for both datasets. As for the EoL threshold, several approaches are explored by using mean, max, and SPC (with 1
, 2
, and 3
) value of the EoL from the training engines.
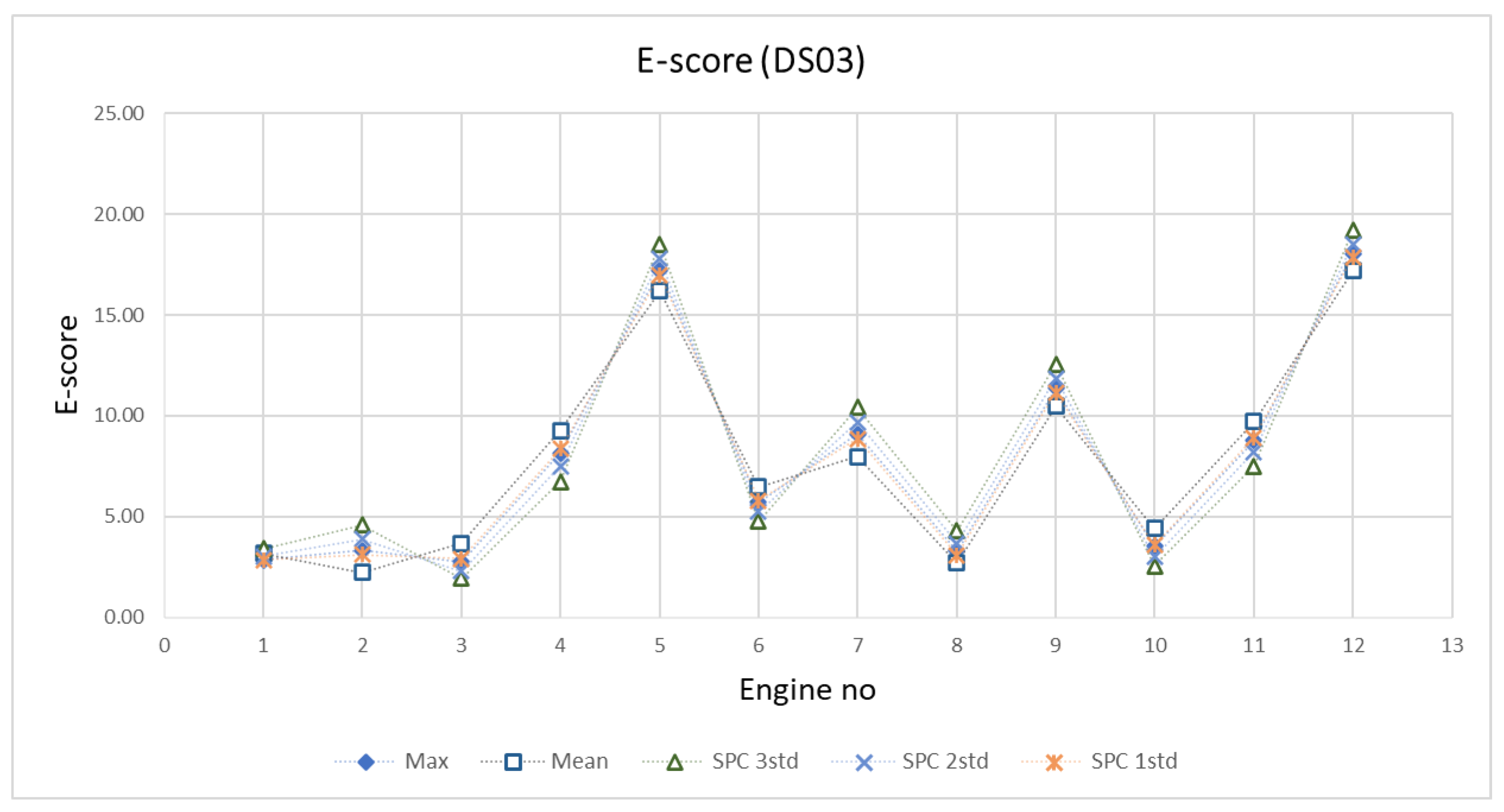
Figure 24 and
Figure 25 are the example of the EoL tuning process of DS03 by comparing
s and
e score of each method. From these figures, mean and SPC 1
show a good prediction performance. Even though the mean value provides good results, but the SPC 1
shows optimum performance fleet-wise. Hence, the SPC 1
value of EoL from the training engines will be the threshold.
The result of the optimised model from the training dataset is put into assessment in the Performance Test phase. The test engine dataset becomes the input of the trained algorithms. The evaluation metrics are computed against the prediction result of this test dataset.
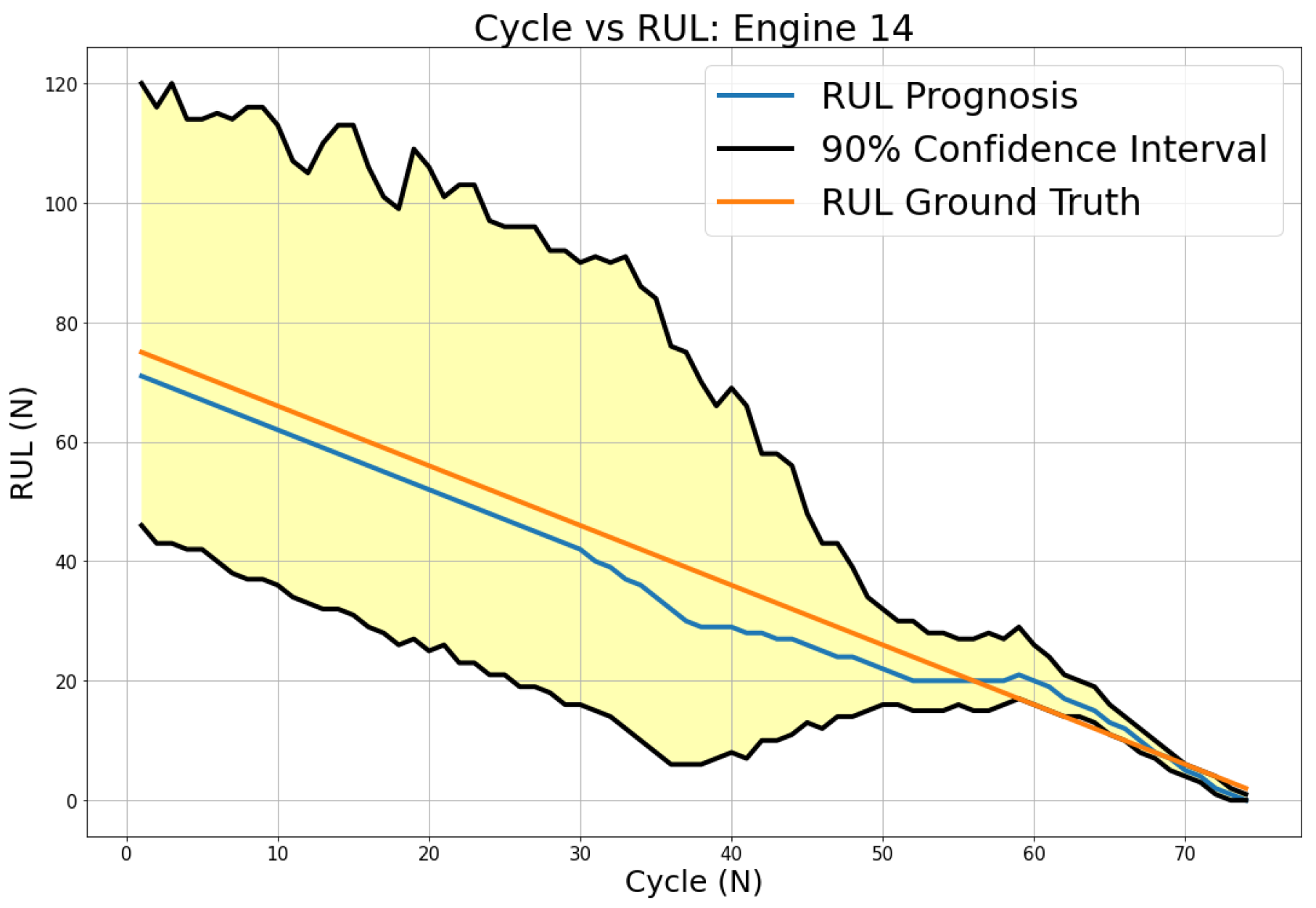
Figure 26 shows the sample of the algorithm RUL prediction performance on test engine 14 (DS03). The predicted RUL is plotted and compared to the ground-truth RUL.
Figure 27 and
Figure 28 present visual information of how the prediction progresses over time for DS02 and DS03, respectively. The prediction performance on both datasets results in a high uncertainty (yellow-shaded area) at the early flight, but it decreases as the engine approaches the EoL. The RUL from the prognostics model fluctuates around ground-truth RUL, and it is noted that most of the predictions end under the ground truth. In comparison to DS02, the predicted RUL of DS03 is steadier relative to the ground truth, but it has a higher uncertainty level before rapidly decreasing toward the EoL.
The quantification of the performance on the test dataset is presented as
e and
s scores. As mentioned in
Section 2.6, these evaluation metrics are standard and comparable since they are widely used in this research area.
Table 2 provides the s and e scores of DS02 test engines (11,14, and 15) and DS03 Engines (13,14,15). Engine 11 (DS02) and engine 15 (DS03) retain the lowest with 91.29 and 87.26 for the
s score and 5.1 and 3.04 for the
e score for both engines, respectively. Slightly higher values are shown in engine 15 of DS02 with 97.7 (
s score) and 5.84 (
e score), while engine 14 of DS03 acquires 109.72
s score and 5.1
e score. Lastly, engine 14 has the highest score among DS02 with a
s score of 196.91 and
e score of 11.9. Similarly, engine 13 presents a 126.74
s score and 6.8
e score; both are the highest in DS03.
3.2. Discussions
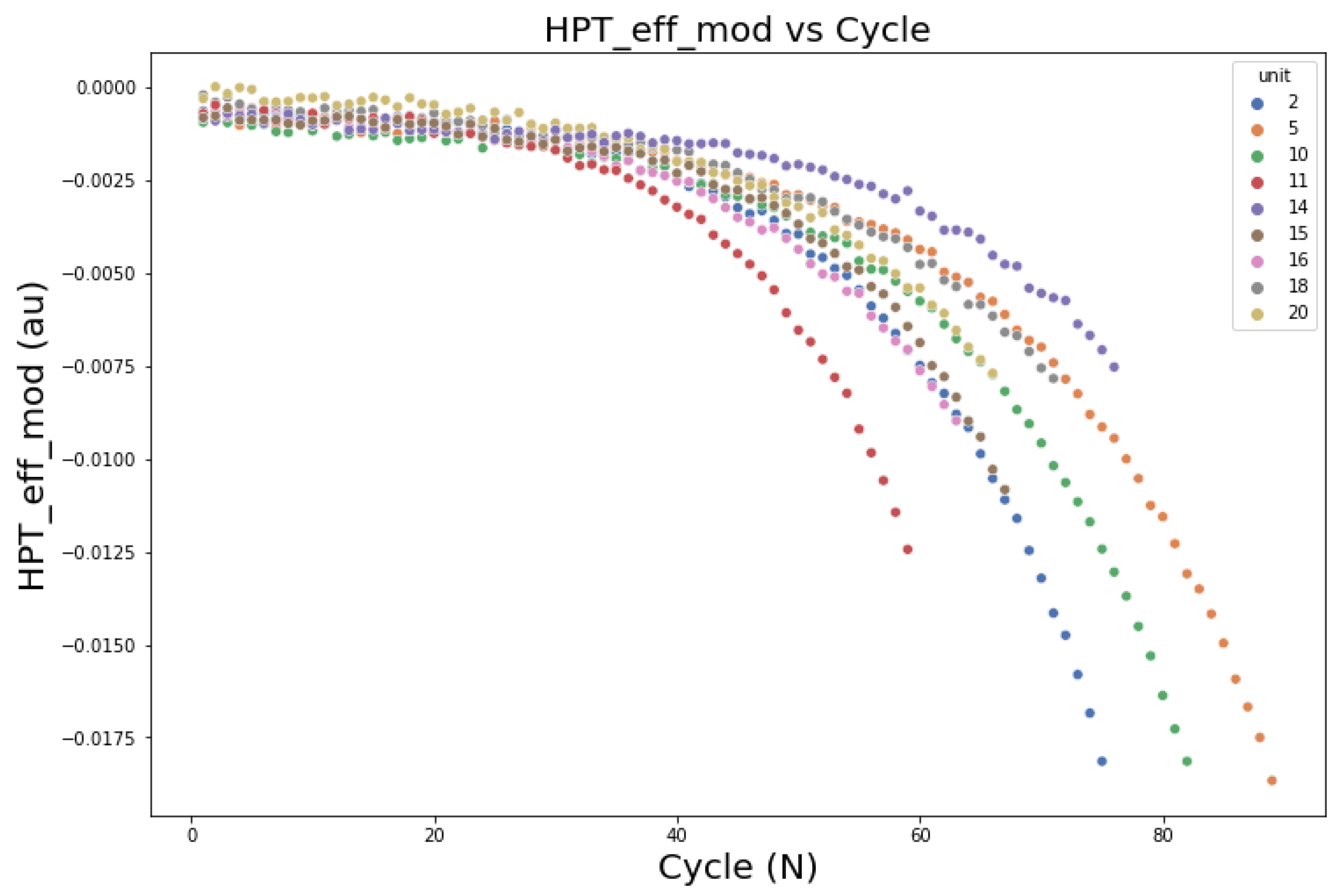
In the Features Selection phase, the hybrid filter effectively chooses the critical features for both DS02 and DS03.
Figure 29 is an example of a selected feature from DS02 and, like all selected features, it fulfills all criteria: robust, monotony, and prognosable. On the other hand, features with the worst metric value show a random pattern and are difficult to interpret (see
Figure 30). However, the filtered features from the sensors are still arbitrary, and it has little to no direct interpretable information (see
Figure 3). Hence, feature fusion and health index estimation are necessary to address this issue.
The results of Health Index Estimation are shown by health index (HI) value, ranging from 0 to 1 (0–100%). The logistic regression computes the function parameters that influence the HI value of each engine. The effects of these parameters are visually shown in both
Figure 10 and
Figure 11. The parameters (
and
) determine the engine’s health intercept and degradation rate, respectively. The lower the
, the faster the engine degrades. Since each engine has a different parameter value and shows a unique pattern, the HI is suitable for measuring the engine’s health for the individual condition monitoring process. Hence, the condition-based maintenance (CBM) strategy can be developed around this information.
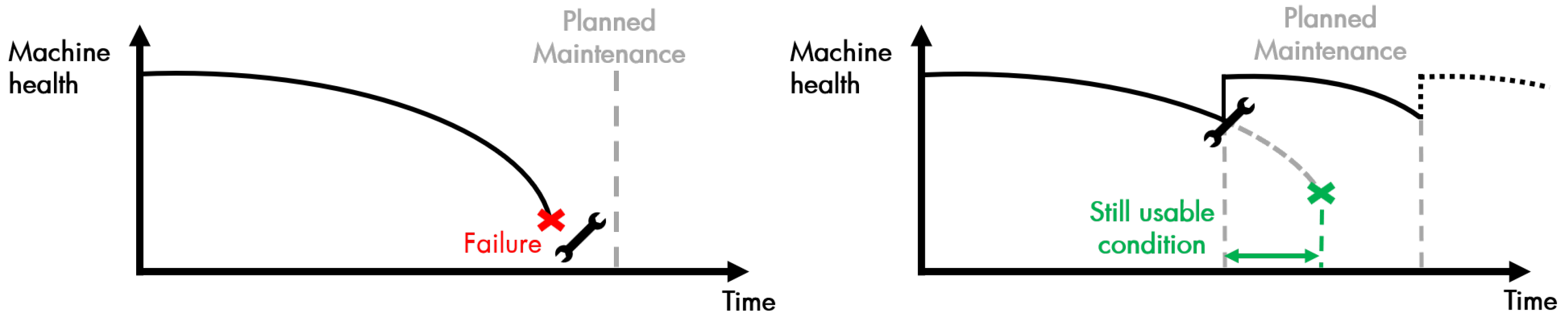
The advantages of the proposed technique in condition monitoring applications are:
It requires less training data.
This approach only needs five samples of engine healthy state and five samples from failed state . It is convenient if the available data is limited while maintaining a good approximation of asset conditions.
Intuitive HI.
The engine health condition is represented by a finite range of 0 to 1. This range can mean the level of engine healthiness where 0% is a complete failure and 100% means the engine is in a brand-new condition. The value between 0 and 100% offers more intuitive and meaningful information to the operator compared to the current approach that relies on prescribed intervals without knowing the reliability level of the engine (see
Section 1.1). With these finite values, a threshold(s) can be determined based on their experience or other consideration. For instance, the operator can start planning for a shop visit when the engine reliability level is at 25% or below.
It provides discrete HI information across the engine fleet.
As discussed in
Section 1.1, the downside of the current practice is only focusing on fleet-wise and lacks individual engine assessment. This paper offers a distinctive HI from measurement data of every single engine in DS02 and DS03. Individual health assessment means the maintenance schedule is tailored to each engine’s current condition rather than a fixed schedule.
It shows the engine degradation process.
In order to build a prognostics system, asset degradation must be clearly identified. This CBM process is part of prognostics phase where engine degradation detection and pattern recognition processes occur. Information from the CBM process will then be used in the next process of prognostics development.
However, despite the advantages, this paper does not cover all properties of PHM, such as:
A Filtering-based model is chosen for prognostics in RUL Prediction phase due to its suitability in estimating a joint state of the asset [
18]. The UKF updates the function parameters
and
based on a recursive process. These parameters are then used to extrapolate the prognostics model (green line) and predict engine EoL against the threshold (red line) (see
Figure 18).
Uncertainty Quantification (UQ) is shown by a yellow-shaded area representing a 90% confidence interval. Another UQ is shown by the probability distribution of RUL in the lower part of the same figure. As expected, the uncertainty decreases over time, as shown by the reduced yellow-shaded area and the increasing probability distribution around ground truth (blue line).
This approach provides several benefits, especially in prognostics applications, such as:
As seen in
Figure 27 and
Figure 28, the RUL predictions are mostly lower than the ground truth. Hence, it does not accurately predict the real RUL. However, it is intentional, by adjusting
and threshold, and convenient since it is preferable to predict early rather than later, considering the safety-critical nature of the aircraft engine. Significant uncertainty in the test engine of DS03 is another drawback of this algorithm, especially in the early to middle sector. Even though it significantly decrease in the last sector, it is still challenging to determine the appropriate maintenance intervention. Future research may benefit from exploring a way to reduce this uncertainty, especially in the early flights, which can improve prediction performance.
The results from the Performance Test phase were then compared to previous works. Among three previous works that used the latest CMAPSS data, only [
24] uses the same test engine and same evaluation metrics as this research.
Table 3 shows the evaluation metrics of the previous finding [
24] compared to this research.
The s score comparison shows that the proposed method performs better only for Engine 11 with a 91.29 score. While the proposed method accurately predicts RUL with relatively minimum error, it got penalised for overestimating the predicted RUL. The proposed method outperforms the previous work for e score for Engine 11 and 15 with 4.9 and 5.2, respectively. It is important to highlight that the proposed method offers a high level of transparency and uncertainty quantification while keep maintaining a good prediction. Further investigation on the tuning parameters needs to be explored to improve the evaluation metric score.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






























