


Adaptive Neural-PID Visual Servoing Tracking Control via Extreme Learning Machine
by
 , , ,
, , ,
Junqi Luo
1,2,
Liucun Zhu
1,3,*,
Ning Wu
2,*,
Mingyou Chen
3,
Daopeng Liu
4,
Zhenyu Zhang
3 and
Jiyuan Liu
3 1
College of Mechanical Engineering, Guangxi University, Nanning 530004, China
2
Key Laboratory of Beibu Gulf Offshore Engineering Equipment and Technology, Beibu Gulf University, Qinzhou 535000, China
3
Advanced Science and Technology Research Institute, Beibu Gulf University, Qinzhou 535000, China
4
School of Mechanical Engineering, Jiangsu University, Zhenjiang 212000, China
*
Authors to whom correspondence should be addressed.
Machines 2022, 10(9), 782; https://doi.org/10.3390/machines10090782
Submission received: 31 July 2022
/
Revised: 31 August 2022
/
Accepted: 5 September 2022
/
Published: 7 September 2022
(This article belongs to the Topic Intelligent Systems and Robotics)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:The vision-guided robot is intensively embedded in modern industry, but it is still a challenge to track moving objects in real time accurately. In this paper, a hybrid adaptive control scheme combined with an Extreme Learning Machine (ELM) and proportional–integral–derivative (PID) is proposed for dynamic visual tracking of the manipulator. The scheme extracts line features on the image plane based on a laser-camera system and determines an optimal control input to guide the robot, so that the image features are aligned with their desired positions. The observation and state–space equations are first determined by analyzing the motion features of the camera and the object. The system is then represented as an autoregressive moving average with extra input (ARMAX) and a valid estimation model. The adaptive predictor estimates online the relevant 3D parameters between the camera and the object, which are subsequently used to calculate the system sensitivity of the neural network. The ELM–PID controller is designed for adaptive adjustment of control parameters, and the scheme was validated on a physical robot platform. The experimental results showed that the proposed method’s vision-tracking control displayed superior performance to pure P and PID controllers.
1. Introduction
Robotic vision has important commercial and domestic applications such as in assembly and welding, fruit picking, and household services. Most robots, however, follow a set program to complete repetitive tasks. When discrepancies occur in the target or the robot, it tends to be unable to make timely environmental adjustments, which is largely due to the inherent lack of an adequate perception capability [1]. Visual servoing enables dexterous control of robots through continuous visual perception and has drawn consistent attention.
Since 1996, Hutchinson’s three classic surveys [2,3,4] have provided a systematic understanding of visual servoing. According to the representation of control signals, it can be categorized as position-based (PBVS), image-based (IBVS) or hybrid (HVS). In particular, IBVS has attracted widespread interest for its simple structure and insensitivity to calibration accuracy. Common methods of IBVS control are adaptive [5], sliding mode [6], fuzzy [7] and learning-based [8]. Saleem et al. [9] proposed an adaptive fuzzy-tuned proportional derivative (AFT-PD) control scheme to improve the visual tracking control of a mobile wheeled robot. YANG et al. [10] used radial basis function (RBF) neural networks to estimate the dynamic parameters of the robot and compensate for the robot’s torque to improve the tracking performance of the controller.
Most IBVS studies have been carried out under the assumption that the target is stationary, so visual tracking in dynamic scenes has rarely been considered. Certain researchers have estimated the Jacobi matrix of IBVS by developing an adaptive algorithm. Chang [11] and Gongye [12] proposed Kalman filtering to provide the unknown depth information of the image Jacobi matrix in real time and verified its practicality on a manipulator. Music [13] established particle filtering and the Broyden algorithm to estimate the Jacobian matrix. Simulation experiments were performed to compare the trajectory tracking performance in static and dynamic scenes. The results showed that the Broyden computation time was much less than that of particle filtering, but its performance was vulnerable to noise interference.
In recent work, learning-based IBVS control has been used to optimize the parameters or to construct nonlinear estimators [14,15]. RBF neural networks combined with PI controllers were used to improve the accuracy of trajectory tracking of a dual robotic arm [16]. From a different perspective, the RBF is used as the inverse kinematics solver of the robotic arm, which was obtained by training the samples of the forward kinematics. The results showed that the method effectively improves the positioning accuracy of visual servoing [17]. To address the low stability of the visual servoing, Shi [18] proposed using Q-learning to adjust the control parameters of visual servoing adaptively, and to optimize the parameters of Q-learning further using a fuzzy-based method to improve the convergence and the stability of the control system. Overall, the above works have proved the effectiveness of the method only in static scenarios. Indeed, the dynamic convergence and responsiveness have not been adequately analyzed.
The image feature extraction is also an essential aspect that affects the reliability behavior of the control system. In visual servoing, the system needs to extract valid features in the image sequence and drive the robot motion while minimizing errors between the current and the reference image. Therefore, the representation of the image Jacobi matrix, i.e., the velocity variation relationship between the target in image space and in Cartesian space, is an essential part of vision tracking. The point features [19], optical flow [20] and image moments [21] have been extensively studied in visual tracking. However, the reliability problem of feature matching in complex scenes has not been well addressed. To ameliorate that, direct visual servoing (DVS) has been proposed in recent years [22,23,24].
Instead of the common local image feature extraction techniques, DVS uses the whole image to construct a mapping relationship with the robot’s joint pose, which is obtained by acquiring a large amount of data, (usually several thousand samples) and feeding it into a neural network. Although DVS enhances the robustness of feature extraction and significantly reduces the time spent on image processing, the acquisition of its samples and the training process are time-consuming. Additionally, the network needs to be retrained when the environment changes, which greatly diminishes its practical feasibility.
As mentioned, in previous research findings, the primary limitation of the robot’s visual servoing dynamic tracking performance is the estimation speed and accuracy of the image Jacobi matrix, and the design of the controller [25]. Therefore, our work in this paper is focused on the above-mentioned bottlenecks. In the hardware system, a laser-camera vision system implements the acquisition of image information. The system consists of a camera rigidly mounted on the robot end-effector, and a laser stripe generator. The camera is used to acquire image information and the laser stripe generator is used to project visible light onto the table. The inertial principal axis of the target is recognized and used as desired image features, while the visible straight line on the plane is used as the current image feature. Hence, in this paper the visual tracking problem was transformed into an error minimization problem of line feature, the inimitable strengths of which have been proven in welding robots and bricklaying robots [26,27].
This research is concerned with implementing line feature visual servoing. This work was conducted within the framework of a robotic bricklaying project. The main partner was a construction company in Guangxi Province, and the primary concerns were to automate the robot’s masonry work, particularly precise brick placement, since relatively large operating errors may adversely affect the strength of the building. Cutting-edge masonry robots still require strict calibration of the hand-eye and working environment, which may lead to deteriorating operational effectiveness if unexpected deviations of the robot’s position occur. Thus, it is necessary to use the sensing technology with closed-loop control, such as visual servoing. Since manual masonry typically uses laser lines for alignment and the bricks are composed of three intersecting orthogonal planes from which points features may not be reliably extracted, we focused our research on enabling visual servoing based on line features.
For the design of the controller, a hybrid ELM–PID control scheme was proposed for real-time visual tracking by a six-degree-of-freedom robot. We gave the observation and the state-space equations by analyzing the motion rules of the camera and the object. The system was then represented as a time-varying multi-input/multi-output autoregressive moving average model. Subsequently, an ELM model was proposed to predict the relevant Jacobian information, which uses the measured data of the previous moment as an input to predict the result of the next moment. These prediction parameters were then used as the online input of the gradient descent algorithm. To perform faster adaptive tuning of the controller parameters, a three-layer structured BP neural network was used. The aim of this study was to perform an algorithm-level validation of robotic autonomous masonry and to further assess the positioning accuracy and control speed in static and dynamic environments.
This paper is organized as follows: Section 2 presents visual tracking modeling. In Section 3, we introduce the adaptive estimation of visual tracking. Section 4 analyzes the ELM–PID controller implementation. Section 5 shows the experimental design, and Section 6 analyzes the experimental results. Finally, conclusions are drawn in Section 7.
2. Visual Tracking Modeling
2.1. Camera Model and Feature Motion
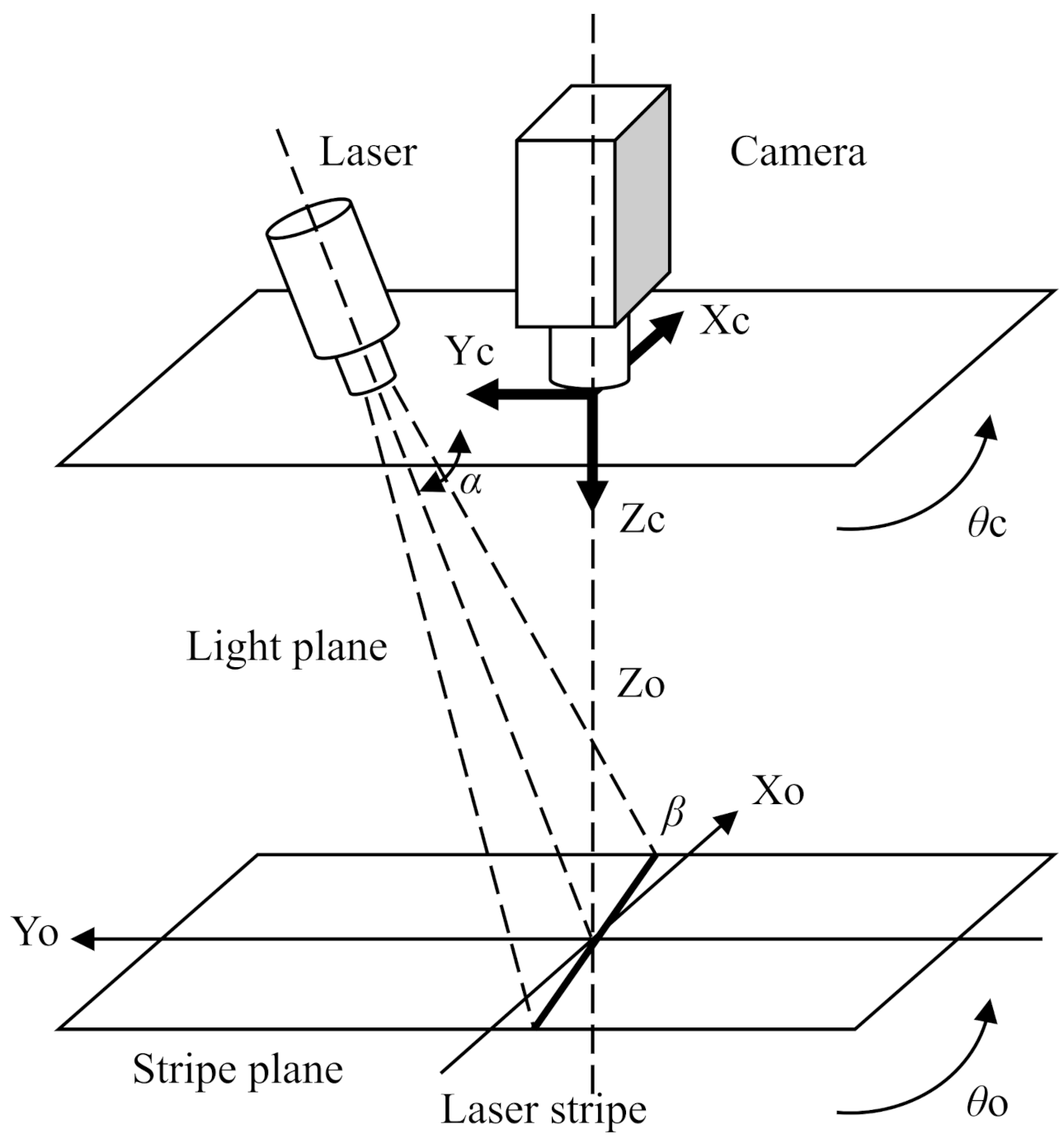
Visual tracking is implemented by a laser-camera system consisting of a camera mounted on the end-effector to acquire image information and guide the robot’s movement, as shown in Figure 1. The vision-tracking task in this paper was to align the laser streak line with the principal axis of inertia of the target image. A laser streak is visible light projected onto a plane by a laser sensor. The principal axis of inertia can be obtained by simple image processing. We define the camera’s focal point as the origin of the image plane. Assuming a perspective projection and the focal length to be unity, a point in the camera frame projects onto a in the image coordinates such that
Taking the temporal derivative of the projection in Equation (1), we obtain
Consider a camera moving with a body velocity in the world frame and observing a world point with camera-relative coordinates . Assume that the camera moves with a transnational velocity and a rotational velocity . The velocity of the point relative to the camera frame is
which we can write in scalar form as
Equation (5) defines the image Jacobi of the point features, which describe the velocity transformation between the spatial motion of the camera and the image feature points. Consider the visible light line as the laser beam’s projection on the image plane. The equation of the line on the image is expressed as follows
where is the signed vertical distance of the line to the origin, and is the angle of the line with respect to the x-axis. The coordinates of the points on the line are denoted as x and y. The velocity relationship of line feature can be given as
where , and . The parameters of , , and are the normal vectors of the polyhedral plane.
To convert from two-dimensional image coordinates to three-dimensional spatial coordinates, the system shown in Figure 1 must be calibrated accurately. In the process, the values of the disparity angle , the tilt angle , and the offset will be determined.
2.2. Observation Equation
Considering that quite a large part of the research has explored the use of lines in visual servoing by pegging out constant depth information (e.g., automated welding, lane keeping for autonomous driving), we simplified the problem to a set of assumptions. Suppose the object is moving in plane and the camera and laser stripe sensor are moving in plane . Here, the two planes are parallel to each other, and the distance between them () is constant. The z-axis of the camera is perpendicular to these two planes. Consider a coordinate point p, the intersection of a straight line and its perpendicular line through the origin. In the image space, the laser-stripe lines will be aligned with the minimum inertia principal axis of the object. The observation equations can be given as
where is the tangent angle of the line; ; and is an observation noise vector. The measurement vector is acquired in a manner slightly different from the method used to track individual feature points.
2.3. State–Space Equation
Define each time , where denotes the sampling period, so that the observation Equation (11) becomes
The output vector can be obtained directly as the output of the vision. The state variables can be obtained if the white noise terms are ignored due to uncertainties.
To construct the state equation to describe the system dynamics, the velocities of the camera were defined as and , and the velocities of the object feature were denoted as and . Combining Equations (4)–(7) and (13), we have
where , and are the components of the tracking motion of the camera. , and are the components of the tracking motion of the object. If the optical flow of the point at moment k is , its optical flow can be expressed as
where
3. Adaptive Estimation of Visual Tracking
3.1. Adaptive Estimation Model
Dynamic parameters (i.e., relative poses between the camera and the object) are necessary for visual servoing. When they are known, the Kalman filter method can be used to control the system. However, in a practical scene, the dynamics of the camera and the object may be unknown. Adaptive control techniques can be used as an alternative method. Equation (27) can be expressed as the last n states and control inputs such that
Suppose is a characteristic polynomial such that
and by applying the Cayley–Hamilton theorem, we can obtain
According to the ARMAX model, the previous system can be written as
where
where is the dimension of the vector; and are the n-dimensional output and input, respectively; is the n-dimensional noise term that is a combination of the state noise and the observation noise ; and is the unit delay operator. Since the image processing requires a finite time, d is defined as a delay factor with a value of 1. is a scalar polynomial in . and are the scalar polynomial matrices of and , respectively. Moreover, is a sequence of independent equidistributed Gaussian variables with 0 mean and variance.
3.2. Estimation Schemes
The unknown parameters of the system can be estimated by the least squares method. The predictor gives the optimal prediction based on the historical measurements. Equation (33) can be expressed in the form of an optimal predictor (d = 1) such that
where
where the and are obtained by using the division algorithm, and , respectively. The term denotes the optimal output prediction, and the term denotes the output of the adaptive predictor.
If is denoted as the ith row of both and , we have
If the polynomials have some of their zeros on the unit circle, a predictor with sub-optimal performance can be designed. is given by
where
Due to the time-varying nature of the estimated parameters, the well-known least square error method is used to estimate the unknown values of the parameters and can be estimated on-line by
where the superscript i refers to the object model; the caret indicates the estimated value; is a forgetting factor used to discount an exponential decay of the past data. is a covariance matrix.
4. ELM–PID Control Algorithm for Visual Servo
4.1. Extreme Learning Machine
ELM is a single hidden layer feedforward neural network proposed by Huang [28]. It differs significantly from the traditional feedforward neural network by using a gradient descent algorithm in the training phase. The weights and biases between the input and hidden layers of the network are set randomly and not adjusted after setting. Instead of iterative adjustment, the weights between the hidden and output layers are determined by solving the generalized inverse matrix. Compared with traditional back-propagation learning algorithms, ELM has better training speed and generalization performance [29,30]. For N arbitrary samples , where ; and . The output of the network with L hidden layer nodes can be expressed as
where is the sigmoid activation function; ; and b is the weight and the bias between the input and hidden layers, and is the weight between the hidden and output layers.
The goal of learning in this network is to minimize output error, which can be expressed as
and can also be written in matrix form such as
where is the output matrix of the hidden layer; is the weight of the output layer; and is the desired output matrix of the network. They are expressed as
The solution can be obtained as
where is the Moore–Penrose matrix of .
4.2. ELM–PID Visual Tracking Controller
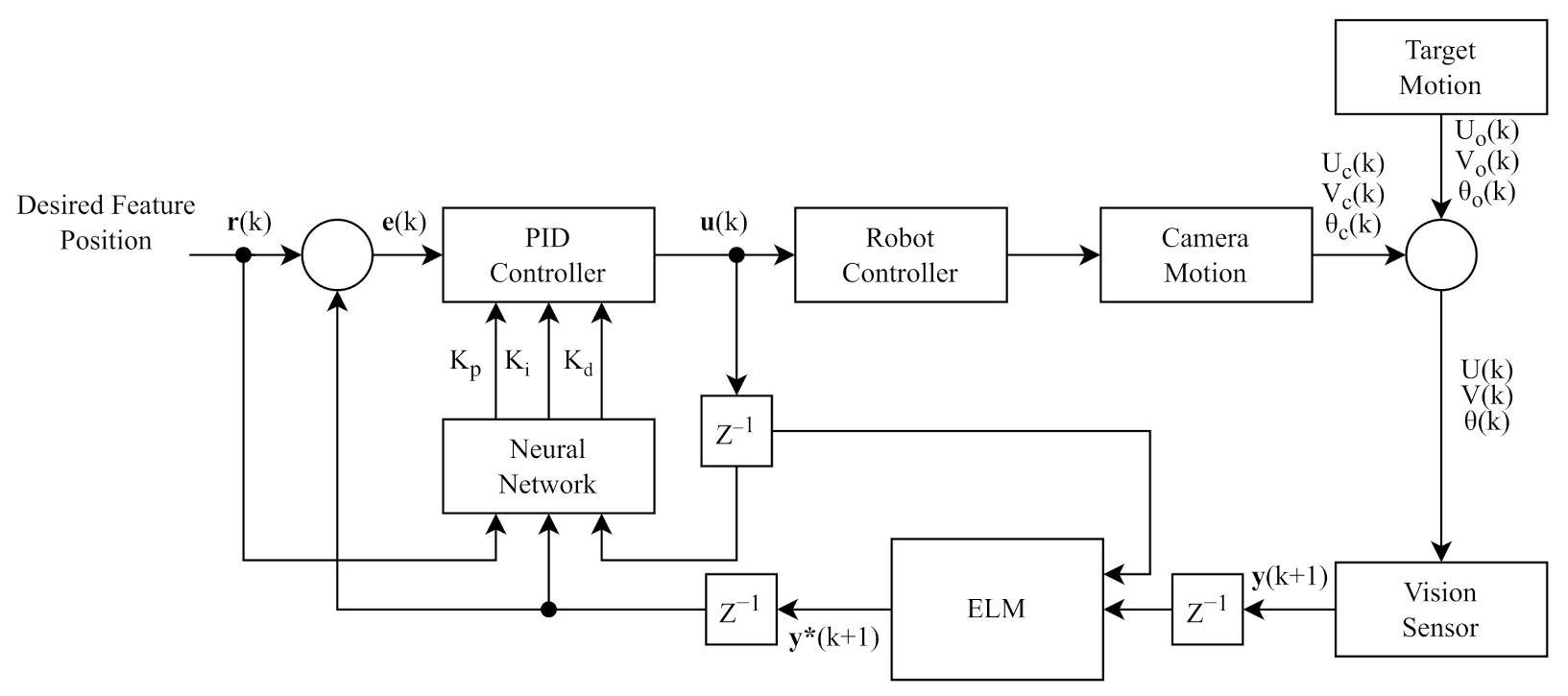
In the ELM–PID scheme, the ELM network is used to predict the system output value, which is the image Jacobian information. The structure of the ELM network is defined as six input nodes, eighteen hidden nodes and three output nodes. The input vector is , and the output vector is . The block diagram of the ELM–PID controller is shown in Figure 2. In this scheme, and are the desired feature position and system error signal, respectively; is the PID output signal; and and are the output of the current and predicted feature position respectively. The tracking process of the visual servo includes the training and self-adjusting phases.
In the training phase the initial parameters of , and are set at 10, 1 and 0.01, respectively. The robot controller is essentially an image Jacobi matrix, which describes the mapping relationship between the motion velocity of the features in image space and the robot joint angle. It guides the manipulator movement according to the input signal and outputs the corresponding feature position. The sampling frequency is set to 50 ms. The collected input value and output value are used as the ELM’s training set. which will be normalized for the training.
In the self-adjusting phase the incremental PID algorithm is employed, and the digital PID controller can be expressed in discrete time as
The control law is given as
where is output of the PID controller; k is the iteration step, and
The cost function of the controller is defined as
During the operation, back-propagation was used to adjust the weights of the network and minimize the cost function E. The self-tuning steps are given as
where is the learning rate, and is the Jacobian parameter of the visual servoing system.
Assuming that the sampling period were small enough, the two adjacent sampling points could be considered as linearly varying. Thus, we can obtain an approximation of the inverse Jacobi matrix such that
where l is the number of nodes in the hidden layer; is the output weight; b is the bias of the hidden layer; and is the corresponding weight in vector with input . The calculation , and for incremental PID is given as
where is the momentum coefficient.
5. Experiments
As previously mentioned, this research pursued the accurate and rapid localization, and anti-disturbance capability of a line feature visual servoing. In this section, we focus on the experimental validation of the control scheme of the line feature visual servo, especially in its behavior of positioning accuracy and dynamic performance. The proposed method was validated and evaluated by testing on a six-degree-of-freedom manipulator arm. The controller code was implemented in a Robot Operating System (ROS) and the connection between the ROS and the robot was based on TCP/IP. During the tests, the tracking accuracy, the convergence speed of the feature error, the velocity component and the trajectory of the end-effector among the comparative methods will be verified.
In the experiment, a black line 230 mm long and 1 mm wide was printed on paper to simulate the line features of the target. The goal of visual tracking is to control the movement of the robotic arm so that the visible red line emitted by the thlaser generator on the robot arm is aligned with the black line on the working plane. Figure 3 shows the Universal Robots UR3 robot used in this experiment. An Intel RealSense D415 RGB-D camera was used to provide RGB and depth information about the scene. Both sensors were mounted on the end-effector of the UR3 robot.
Due to the simplified representation of the target, the image lines can be identified in a straightforward way by applying the Hough transform. The block diagram of the control loop of the system is shown in Figure 2. During aligning, the target and end-effector planes are kept parallel at a distance of = 680 mm. The z-axis of the camera coordinate system was perpendicular to the above two planes. The control system input was the desired position, which was the translation of the x-axis and y-axis of the camera coordinate system and the rotation of the z-axis. The unknown 3D parameters between the camera and the object were estimated by using the adaptive optimal predictor in Equations (31)–(33). The sampling period of the experiments was set to 50 ms.
In the first experiment, The ELM–PID controller was implemented to verify the positioning capability of the static target. Line segments printed on paper represented the line features of the target, and the projection of the laser beam on a plane was used as the current line feature, as shown in Figure 4. The robot was initialized with a specific pose, and its end-effector was 40 cm above the table. The target was placed in a random pose but always within the camera’s field of view.
In the second experiment, the performance of the ELM–PID controller in dynamic visual tracking is evaluated by using the black-lined paper to simulate the line feature of target. This piece of paper was attached to a hand grip, and random translational motions of the target were carried out by pulling the hand grip manually, as shown in Figure 5. The target was always within the camera’s field of view during the motion. The visual servoing control performance of the proposed method will be analyzed for pixel error of the image features, the convergence speed of feature error and the trajectories of motion.
6. Results
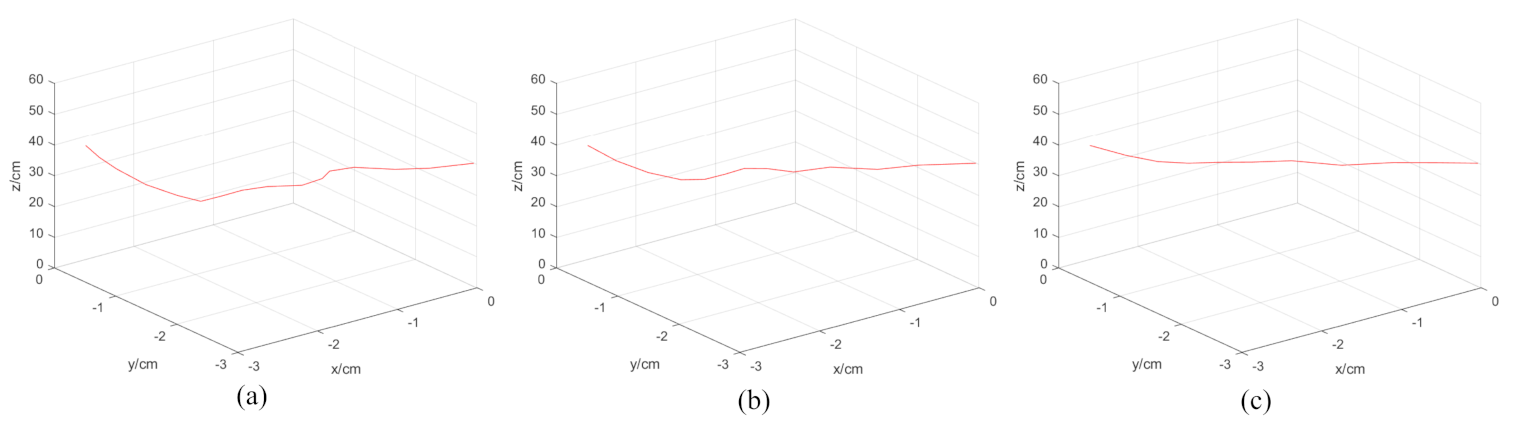
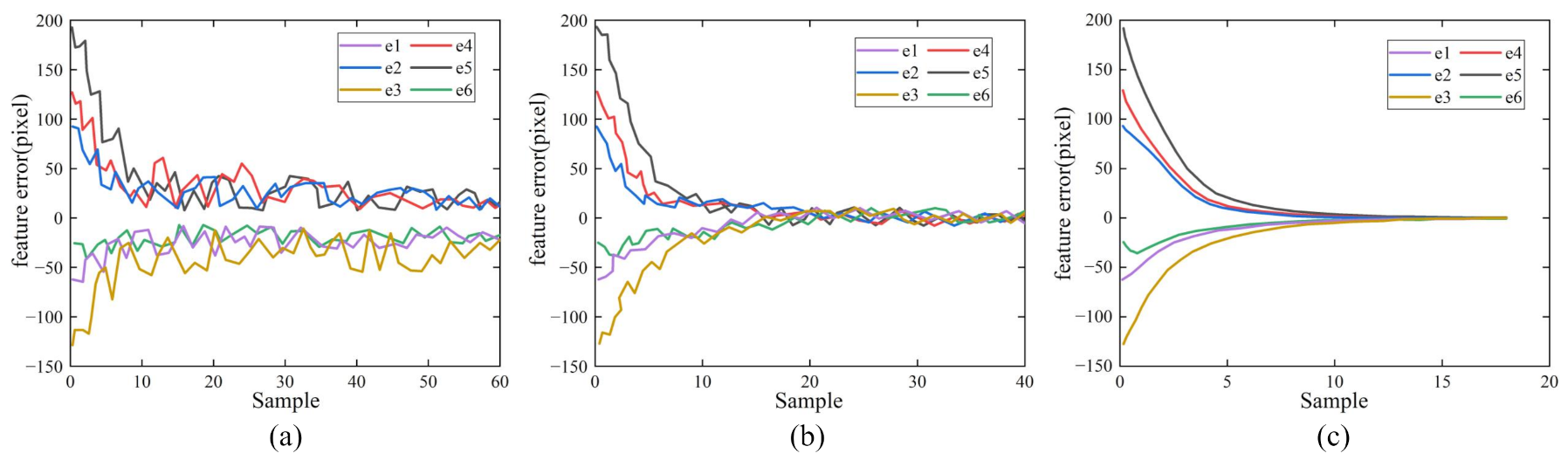
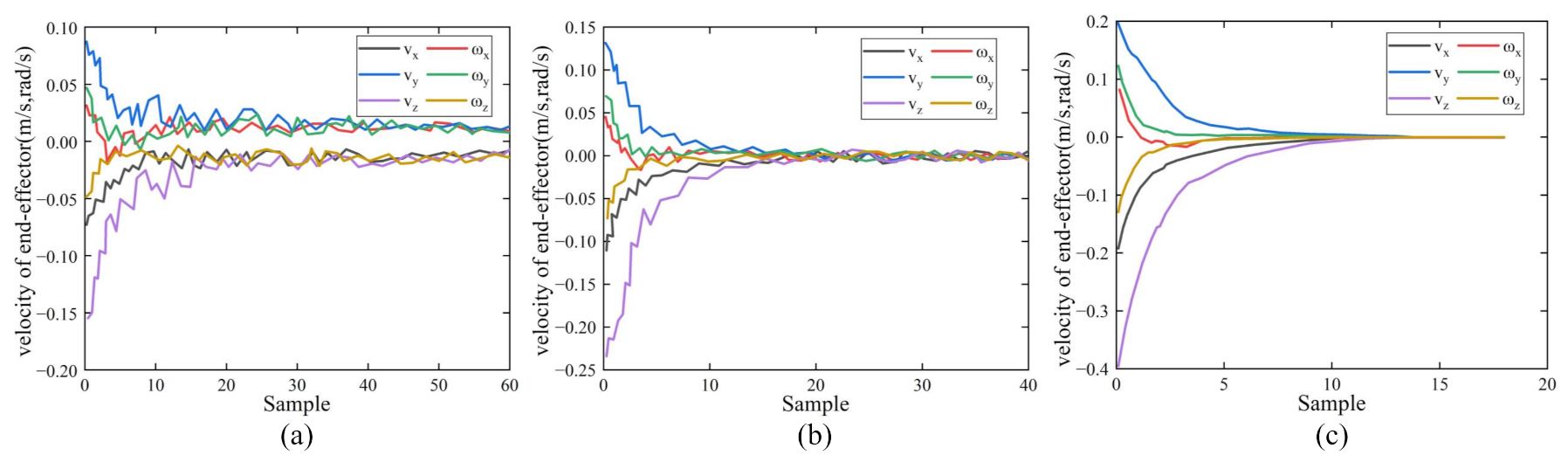
The static test of the first experiment showed that all three methods guided the robot to the target and achieve the positioning of line features. Figure 6 shows the feature error convergence curves for the current and desired features in the image plane. As shown in Figure 6a, the error convergence curve of the P controller had significant fluctuations, and convergence was completed at the 49th sample. It can be seen in Figure 6b that, the convergence curve of the PID controller was smoother than that of the P controller, which converged at the 29th sample. The ELM–PID controller had the best performance regarding the convergence curve and convergence rate, which had a smooth curve and reached the vision-servoing task at only the 14th sample. Figure 7 shows the velocity comparison of the robot’s end-effector with the three controllers. It can be seen in Figure 7a,b that, the P controller and the PID controller exhibited noticeable peaks in the motion velocity trajectory, which implied that there may be some defects in the smoothness of the robot motion. Its initial translational velocities in the x-, y- and z-axes were −0.19, 0.19, and 0.40 m/s, respectively, and the corresponding rotation velocities were 0.08, 0.12, and −0.13 rad/s, which were around 155 and 70% larger than P and PID controllers in overall initial velocity. Accordingly, we found that the motion trajectory of the robot arm showed some jitter from Figure 8a,b. In Figure 8c, it can be seen that the ELM–PID algorithm had a larger initial motion velocity, faster convergence, and smoother motion velocity profile of the end-effector. The Cartesian space motion trajectory of the ELM–PID algorithm was also much closer to a straight line, as shown in Figure 8c.
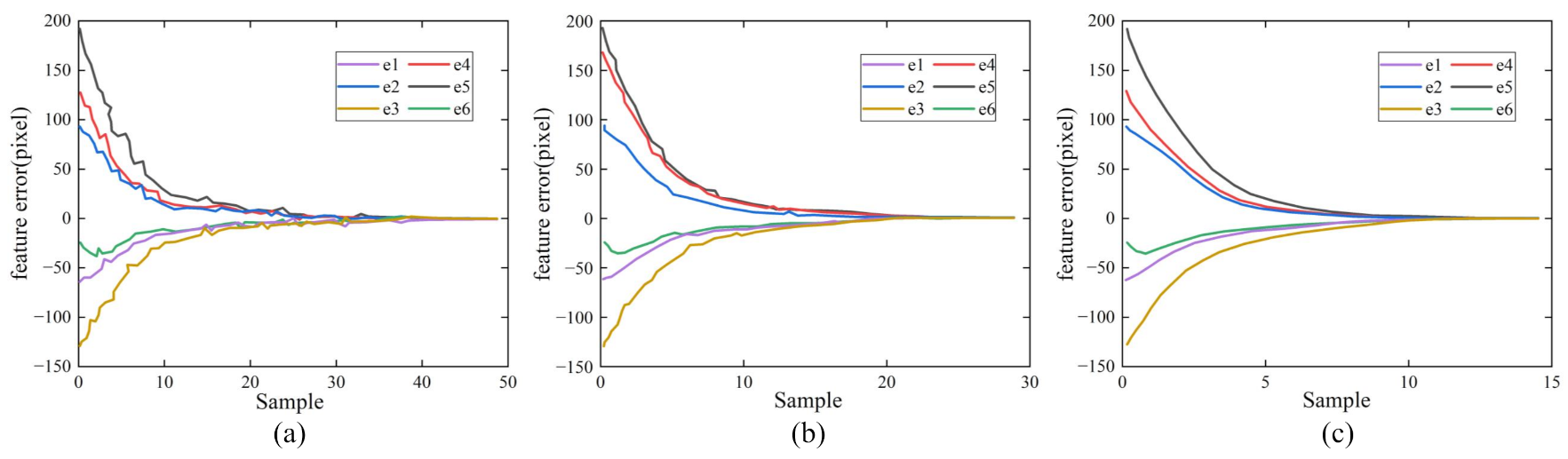
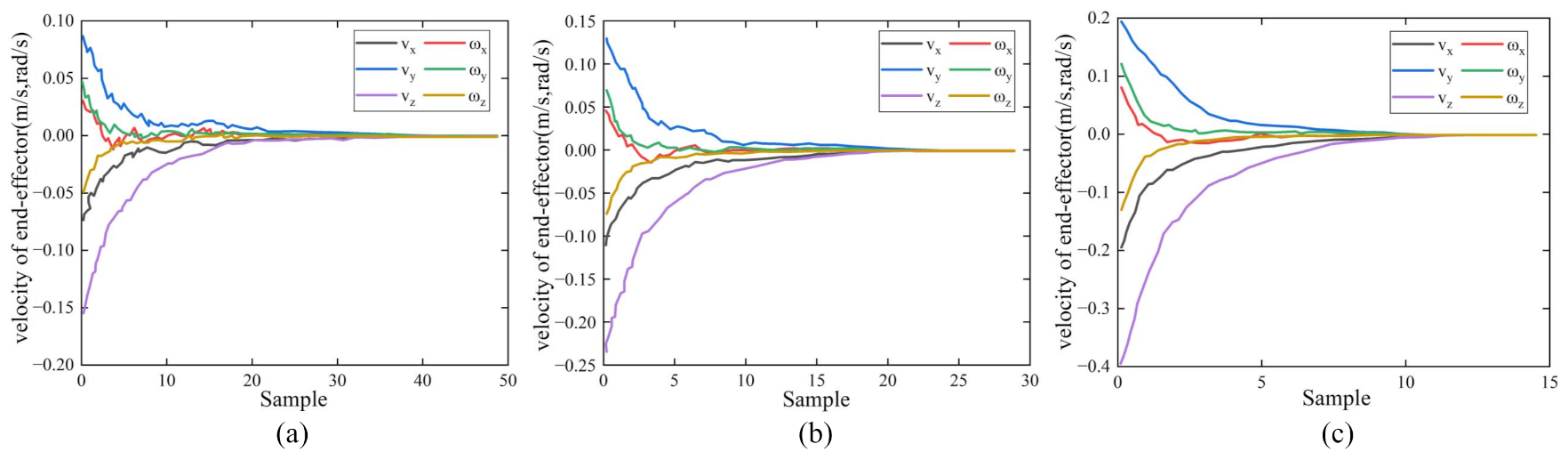
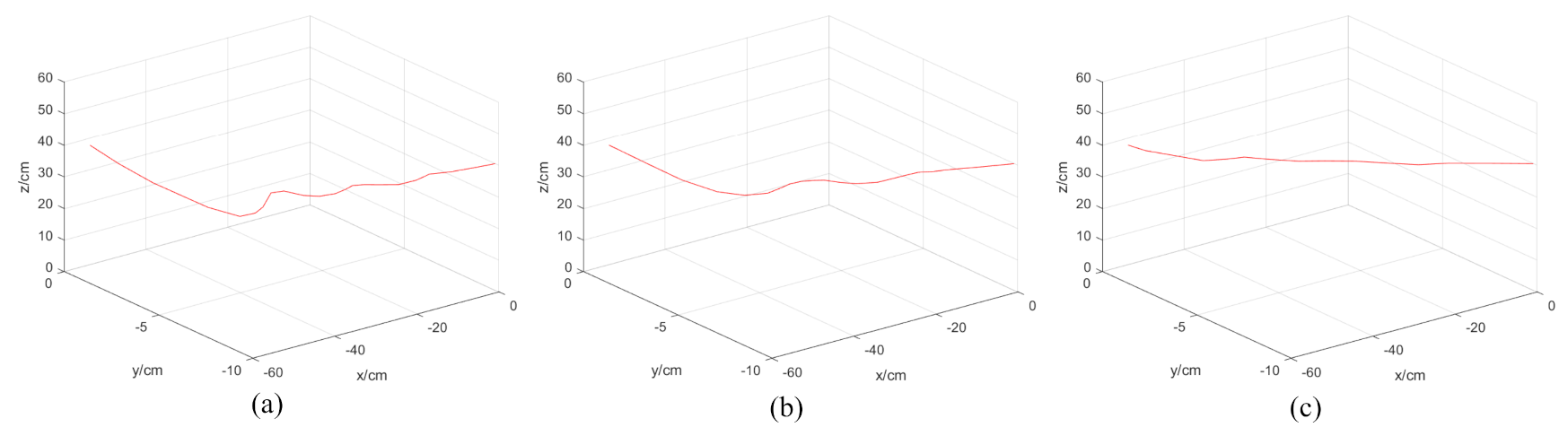
The dynamic tests of the second experiment showed that the ELM–PID controller had superior visual tracking performance for moving objects. Figure 9 illustrates the convergence curves of the feature error in the image plane between the current and reference features. Since the target was in constant motion, the feature error convergence curve was degraded compared to the first experiment. As shown in Figure 9a, the feature error curve of the P controller had noticeable jitter and failed to converge. Figure 9b shows that the convergence curve of the PID controller was more stable than that of the P controller, but the convergence took longer to complete. The ELM–PID controller had an ideal curve and converged faster, reaching the vision servo task at the 18th sample step. Figure 10 shows the velocity comparison of the end-effector corresponding to the above three vision controllers. It can be seen in Figure 10a,b that, prominent jagged peaks appeared in the motion velocity trajectories of the P and PID controller, which suggested that the robot motion process had poor smoothness. The ELM–PID algorithm improved the stability of the velocity components of the end-effector, as shown in Figure 10c. The ELM–PID still has a larger initial velocity and steeper velocity convergence curves in the dynamic test. Its initial translational velocities in the x-, y- and z-axis were −0.19, 0.19 and 0.40 m/s, respectively, and the corresponding rotational velocities were 0.08, 0.12 and −0.13 rad/s, which outperformed the P and PID controllers by around 156 and 71% in overall initial velocity. Figure 11 shows that the Cartesian space motion trajectory of the ELM–PID algorithm was closer to a straight line, and the path length was distinctly shorter than the previous two.
In essence, the P controller had substantial limitations and poor following performance in the dynamic vision tracking tasks. Although the pure PID controller accomplished dynamic vision servoing, the tracking efficiency was unsatisfactory, which may be because of the PID parameters were not in the first-rank interval. The ELM–PID exhibited the optimal error accuracy and convergence speed, steadier speed performance and faster speed convergence in both the static and dynamic vision tracking tests. The end-effector’s trajectory profile further indicated that it had fewer redundant kinematic trajectories.
7. Conclusions
This paper proposed a hybrid ELM–PID control approach for real-time robotic visual tracking of a moving target. The system consists of a visual feedback controller with self-adjusting capabilities. The image processing and camera control are performed in parallel online. The approach uses an adaptive predictor to estimate the 3D-related parameters between the camera and the object in motion. The processing of the camera image necessitates the vision sampling periods to be 50 ms and the motion of the object is assumed to be smooth. Since the dynamics of the object are unknown, the velocity and position of the object determined from the successive images are predicted using an ARMAX model. The desired trajectory points are generated online based on the relative position and velocity of the camera and the object. The online planner determines the desired trajectory points (sub-goal) one sampling period ahead. The ELM–PID controller is then constructed for visual tracking of static and moving targets. Comparing the visual servo methods based on the P and PID controller, the ELM–PID controller demonstrated the optimal visual tracking capability in both the static and dynamic tracking tests. By this method, online estimation of image Jacobi matrices was performed with an extreme learning machine, which overcame the long training time of traditional neural networks and solved the singularity of the Jacobi matrices. The gradient descent algorithm was also used to adjust the PID controller parameters adaptively, improving the controller’s dynamic performance. The principal contributions of this work are as follows:
- We developed a mathematical expression for the visual tracking of a line feature. This model was based on measurements of the vector of discrete displacements obtained by a laser-camera system;
- We presented the self-tuning control scheme of a hybrid ELM–PID. The scheme was efficient for a nonlinear system and objects in motion by composing an ELM–PID control and adaptive prediction;
- The constructed laser camera system was able to achieve low-cost, real-time vision tracking. The comprehensive experiments validated the suitability of the method for vision tracking with combined vision and control.
In future work, an attempt would be made to transplant the algorithm to industrial robots and to further tune and optimize the algorithm in industrial scenes.
Author Contributions
Conceptualization, J.L. (Junqi Luo) and L.Z.; methodology, J.L. (Junqi Luo); validation, M.C., D.L., Z.Z. and J.L. (Jiyuan Liu); writing—original draft preparation, review and editing, J.L. (Junqi Luo) and N.W.; visualization, supervision, project administration, funding acquisition, L.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research is partially supported by Special Fund for Bagui Scholars of the Guangxi Zhuang Autonomous Region (2019A08) and partially supported by the 100-Scholar Plan of the Guangxi Zhuang Autonomous Region.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Castelli, F.; Michieletto, S.; Ghidoni, S.; Pagello, E. A machine learning-based visual servoing approach for fast robot control in industrial setting. Int. J. Adv. Robot. Syst. 2017, 14, 1729881417738884. [Google Scholar] [CrossRef]
- Hutchinson, S.; Hager, G.; Corke, P. Visual servoing with hand-eye manipulator-optimal control approach. IEEE Trans. Robot. Autom. 1996, 12, 651–670. [Google Scholar] [CrossRef]
- Chaumette, F.; Hutchinson, S. Visual servo control. I. Basic approaches. IEEE Robot. Autom. Mag. 2006, 13, 82–90. [Google Scholar] [CrossRef]
- Chaumette, F.; Hutchinson, S. Visual servo control. II. Advanced approaches [Tutorial]. IEEE Robot. Autom. Mag. 2007, 14, 109–118. [Google Scholar] [CrossRef]
- Wang, H.; Cheah, C.C.; Ren, W.; Xie, Y. Passive separation approach to adaptive visual tracking for robotic systems. IEEE Trans. Control Syst. Technol. 2018, 26, 2232–2241. [Google Scholar] [CrossRef]
- Liu, H.; Zhu, W.; Dong, H.; Ke, Y. Hybrid visual servoing for rivet-in-hole insertion based on super-twisting sliding mode control. Int. J. Control Autom. Syst. 2020, 18, 2145–2156. [Google Scholar] [CrossRef]
- Indrazno, S.; Laxmidhar, B.; McGinnity, T.; Sonya, C. Image-based visual servoing of a 7-DOF robot manipulator using an adaptive distributed fuzzy PD controller. IEEE Trans. Mechatron. 2014, 19, 512–523. [Google Scholar]
- Jardine, P.T.; Kogan, M.; Givigi, S.N.; Yousefi, S. Adaptive predictive control of a differential drive robot tuned with reinforcement learning. Int. J. Adapt. Control Signal Process. 2019, 33, 410–423. [Google Scholar] [CrossRef]
- Bhatti, O.S. Adaptive fuzzy-pd tracking controller for optimal visual-servoing of wheeled mobile robots. J. Control Eng. Appl. Inform. 2017, 19, 58–68. [Google Scholar]
- Yang, C.; Chen, J.; Ju, Z.; Annamalai, A.S. Visual servoing of humanoid dual-arm robot with neural learning enhanced skill transferring control. Int. J. Humanoid Robot. 2018, 15, 1750023. [Google Scholar] [CrossRef]
- Chang, T.Y.; Chang, W.C.; Cheng, M.Y.; Yang, S.S. Dynamic visual servoing with Kalman filter-based depth and velocity estimator. Int. J. Adv. Robot. Syst. 2021, 18, 17298814211016674. [Google Scholar] [CrossRef]
- Gongye, Q.; Cheng, P.; Dong, J. Image-based visual servoing with depth estimation. Trans. Inst. Meas. Control 2022, 44, 1811–1823. [Google Scholar] [CrossRef]
- Musić, J.; Bonković, M.; Cecić, M. Comparison of uncalibrated model-free visual servoing methods for small-amplitude movements: A simulation study. Int. J. Adv. Robot. Syst. 2014, 11, 108. [Google Scholar] [CrossRef]
- Durdevic, P.; Ortiz-Arroyo, D. A deep neural network sensor for visual servoing in 3d spaces. Sensors 2020, 20, 1437. [Google Scholar] [CrossRef]
- Shi, H.; Wu, H.; Xu, C.; Zhu, J.; Hwang, M.; Hwang, K.S. Adaptive image-based visual servoing using reinforcement learning with fuzzy state coding. IEEE Trans. Fuzzy Syst. 2020, 28, 3244–3255. [Google Scholar] [CrossRef]
- Qu, J.; Zhang, F.; Fu, Y.; Li, G.; Guo, S. Adaptive neural network visual servoing of dual-arm robot for cyclic motion. Ind. Robot. Int. J. 2017, 44, 210–221. [Google Scholar] [CrossRef]
- Ak, A.; Topuz, V.; Ersan, E. Visual servoing application for inverse kinematics of robotic arm using artificial neural networks. Stud. Inform. Control 2018, 27, 183–190. [Google Scholar] [CrossRef]
- Shi, H.; Li, X.; Hwang, K.S.; Pan, W.; Xu, G. Decoupled visual servoing with fuzzy Q-Learning. IEEE Trans. Ind. Inform. 2016, 14, 241–252. [Google Scholar] [CrossRef]
- Muthusamy, R.; Ayyad, A.; Halwani, M.; Swart, D.; Gan, D.; Seneviratne, L.; Zweiri, Y. Neuromorphic eye-in-hand visual servoing. IEEE Access 2021, 9, 55853–55870. [Google Scholar] [CrossRef]
- Argus, M.; Hermann, L.; Long, J.; Brox, T. Flowcontrol: Optical flow based visual servoing. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 7534–7541. [Google Scholar]
- Shao, Q.; Hu, J.; Fang, Y.; Liu, W.; Qi, J.; Zhu, G.N. Image moments based visual servoing of robot using an adaptive controller. In Proceedings of the 2016 Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), Tokyo, Japan, 20–22 July 2016; pp. 57–61. [Google Scholar]
- Saxena, A.; Pandya, H.; Kumar, G.; Gaud, A.; Krishna, K.M. Exploring convolutional networks for end-to-end visual servoing. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3817–3823. [Google Scholar]
- Bateux, Q.; Marchand, E.; Leitner, J.; Chaumette, F.; Corke, P. Training deep neural networks for visual servoing. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3307–3314. [Google Scholar]
- Sadeghi, F.; Toshev, A.; Jang, E.; Levine, S. Sim2real viewpoint invariant visual servoing by recurrent control. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4691–4699. [Google Scholar]
- Wu, J.; Jin, Z.; Liu, A.; Yu, L.; Yang, F. A survey Of learning-Based control of robotic visual servoing systems. J. Frankl. Inst. 2022, 359, 556–577. [Google Scholar] [CrossRef]
- Andreff, N.; Espiau, B.; Horaud, R. Visual servoing from lines. Int. J. Robot. Res. 2002, 21, 679–699. [Google Scholar] [CrossRef]
- Wang, H.; Liu, Y.H.; Zhou, D. Adaptive visual servoing using point and line features with an uncalibrated eye-in-hand camera. IEEE Trans. Robot. 2008, 24, 843–857. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Liao, S.; Feng, C. Meta-ELM: ELM with ELM hidden nodes. Neurocomputing 2014, 128, 81–87. [Google Scholar] [CrossRef]
- Zou, W.; Yao, F.; Zhang, B.; Guan, Z. Improved Meta-ELM with error feedback incremental ELM as hidden nodes. Neural Comput. Appl. 2018, 30, 3363–3370. [Google Scholar] [CrossRef]
Figure 1.
Configuration of the laser-camera system with a camera and a laser stripe generator.

Figure 2.
Block diagram of adaptive visual tracking system with ELM–PID controller.

Figure 3.
The experimental platform of visual servoing tracking.

Figure 4.
Experiment 1: Static positioning with line features. (a) The robot’s pose before attempting to reach the goal. (b) The robot in the goal state.
Figure 4.
Experiment 1: Static positioning with line features. (a) The robot’s pose before attempting to reach the goal. (b) The robot in the goal state.

Figure 5.
Experiment 2: dynamic target tracking trials. (a) The laser line and the black line are not yet aligned, and the robot is tracking. (b) The laser line and the black line are aligned, and the robot is in the goal state.
Figure 5.
Experiment 2: dynamic target tracking trials. (a) The laser line and the black line are not yet aligned, and the robot is tracking. (b) The laser line and the black line are aligned, and the robot is in the goal state.

Figure 6.
Comparison of image feature errors of the three controllers on the static positioning test. (a) P controller. (b) PID controller. (c) ELM–PID controller.
Figure 6.
Comparison of image feature errors of the three controllers on the static positioning test. (a) P controller. (b) PID controller. (c) ELM–PID controller.

Figure 7.
Comparison of robot’s end-effector velocities of the three controllers on the static positioning test. (a) P controller. (b) PID controller. (c) ELM–PID controller.
Figure 7.
Comparison of robot’s end-effector velocities of the three controllers on the static positioning test. (a) P controller. (b) PID controller. (c) ELM–PID controller.

Figure 8.
Comparison of the robot’s end-effector trajectory of the three controllers on the static positioning test. (a) P controller. (b) PID controller. (c) ELM–PID controller.
Figure 8.
Comparison of the robot’s end-effector trajectory of the three controllers on the static positioning test. (a) P controller. (b) PID controller. (c) ELM–PID controller.

Figure 9.
Comparison of image feature errors of the three controllers on the dynamic visual tracking test. (a) P controller. (b) PID controller. (c) ELM–PID controller.
Figure 9.
Comparison of image feature errors of the three controllers on the dynamic visual tracking test. (a) P controller. (b) PID controller. (c) ELM–PID controller.

Figure 10.
Comparison of robot’s end-effector velocities of the three controllers on the dynamic visual tracking test. (a) P controller. (b) PID controller. (c) ELM–PID controller.
Figure 10.
Comparison of robot’s end-effector velocities of the three controllers on the dynamic visual tracking test. (a) P controller. (b) PID controller. (c) ELM–PID controller.

Figure 11.
Comparison of robot’s end-effector trajectory of the three controllers on the dynamic visual tracking test. (a) P controller. (b) PID controller. (c) ELM–PID controller.
Figure 11.
Comparison of robot’s end-effector trajectory of the three controllers on the dynamic visual tracking test. (a) P controller. (b) PID controller. (c) ELM–PID controller.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Luo, J.; Zhu, L.; Wu, N.; Chen, M.; Liu, D.; Zhang, Z.; Liu, J. Adaptive Neural-PID Visual Servoing Tracking Control via Extreme Learning Machine. Machines 2022, 10, 782. https://doi.org/10.3390/machines10090782
AMA Style
Luo J, Zhu L, Wu N, Chen M, Liu D, Zhang Z, Liu J. Adaptive Neural-PID Visual Servoing Tracking Control via Extreme Learning Machine. Machines. 2022; 10(9):782. https://doi.org/10.3390/machines10090782
Chicago/Turabian StyleLuo, Junqi, Liucun Zhu, Ning Wu, Mingyou Chen, Daopeng Liu, Zhenyu Zhang, and Jiyuan Liu. 2022. "Adaptive Neural-PID Visual Servoing Tracking Control via Extreme Learning Machine" Machines 10, no. 9: 782. https://doi.org/10.3390/machines10090782
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.