
View-Invariant Spatiotemporal Attentive Motion Planning and Control Network for Autonomous Vehicles

 , ,
, ,  ,
, 
Abstract
:1. Introduction
- We propose an end-to-end motion planning and control network for ADVs based on imitation learning. The proposed ViSTAMPCNet takes front and top-view image sequences and first learns view-invariant spatiotemporal representations, which are more robust to domain shift and more interpretable than directly mapping raw camera images or using detailed environment map post-processing. Then, use the learned shared invariant representations to predict feasible future motion plans and control commands simultaneously.
- We conducted ablation studies to verify the benefit of shared view-invariant spatiotemporal representations for joint motion planning and high-level control.
- In order to demonstrate its superiority, we also compared ViSTAMPCNet to other baselines and existing state-of-the-art methods on a large-scale driving dataset with dynamic obstacles and weather/lighting conditions (e.g., clear, rainy, and foggy).
2. Related Work
2.1. End-to-End Learning Methods
2.2. Multi-Task Learning Methods
2.3. Attention-Based Methods
2.4. Invariant Representation Learning
3. Proposed Approach
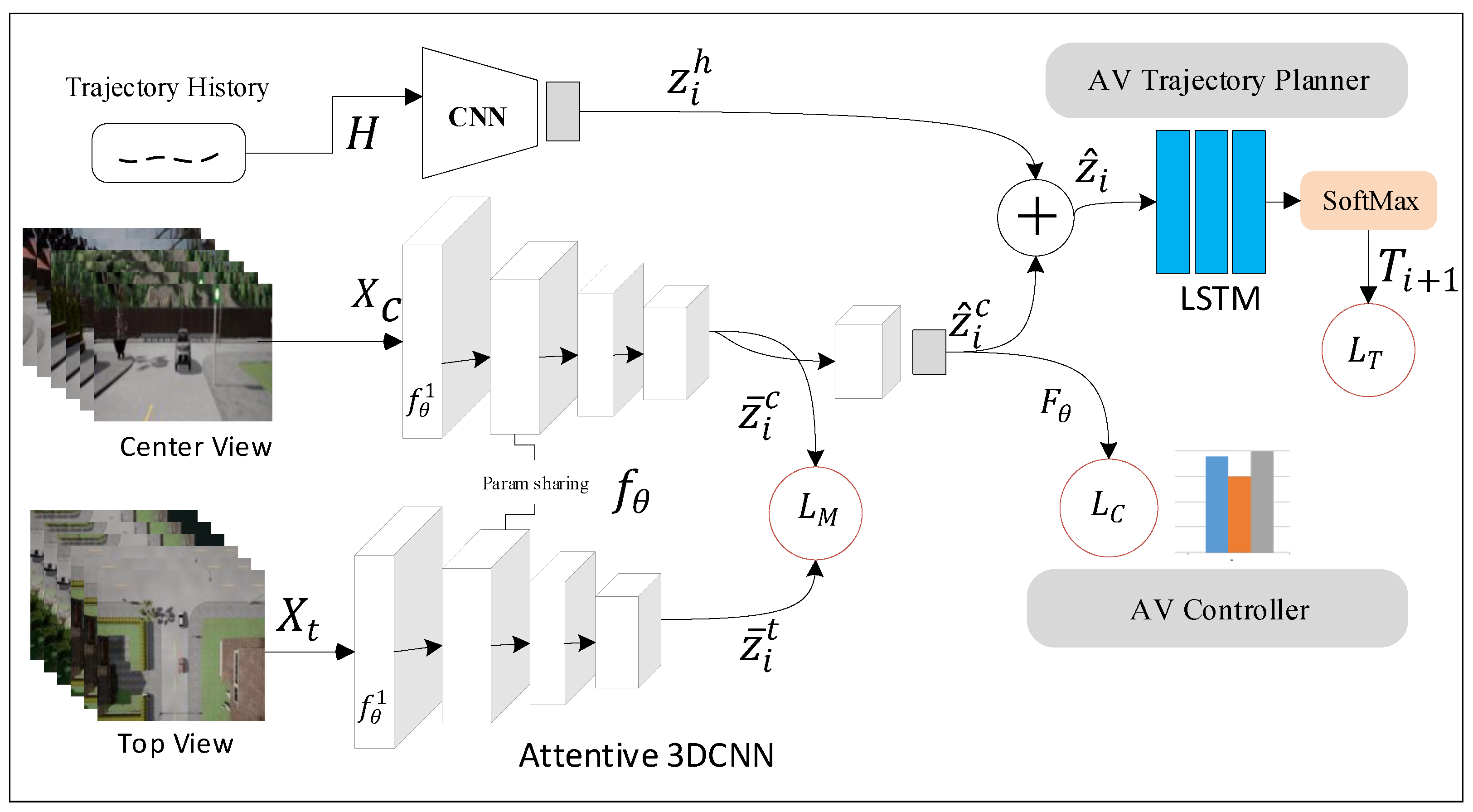
3.1. Overview
3.2. Problem Formulation
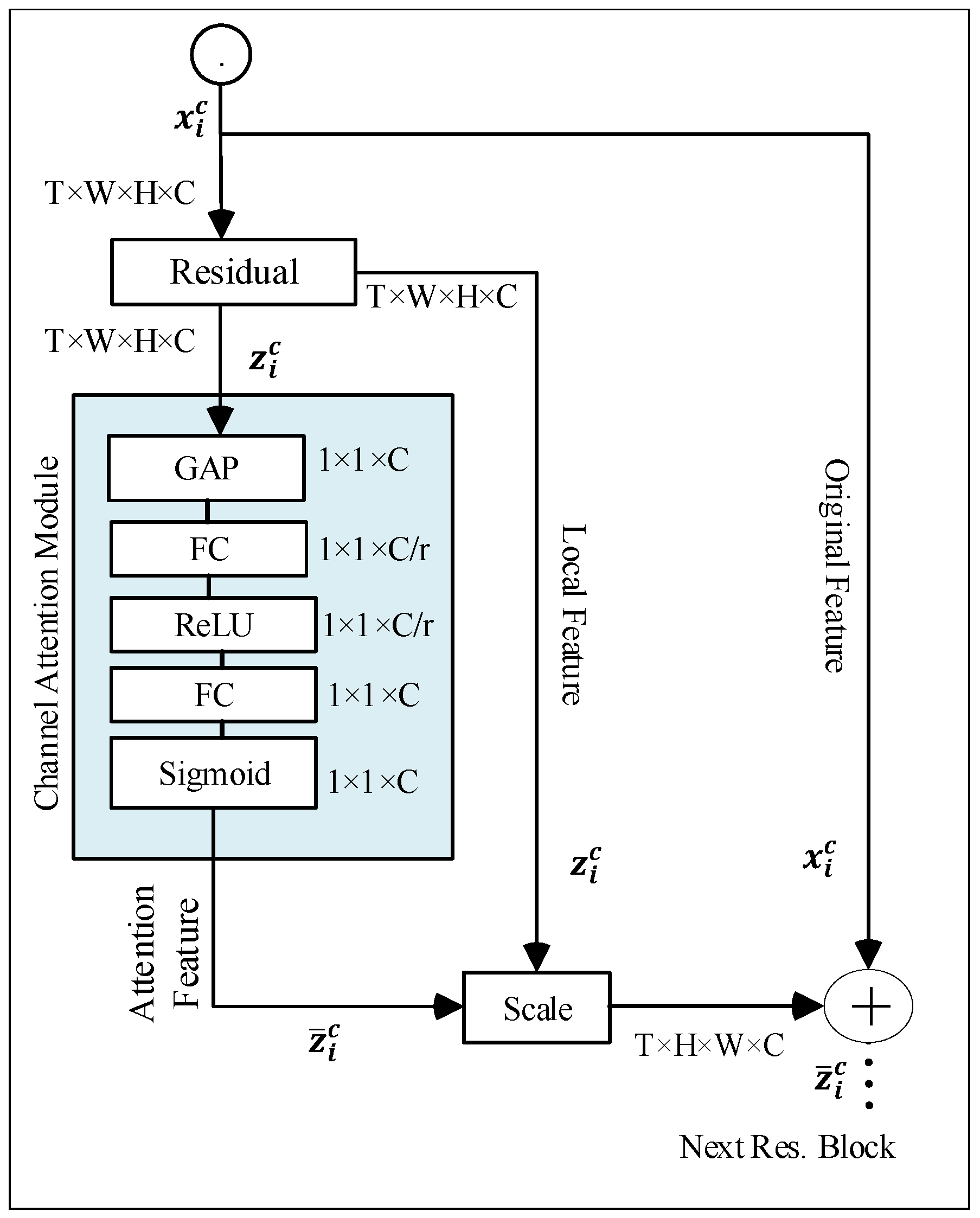
3.3. View-Invariant Representation Learning Module
3.4. Trajectory Planning and Control Module
4. Experiments
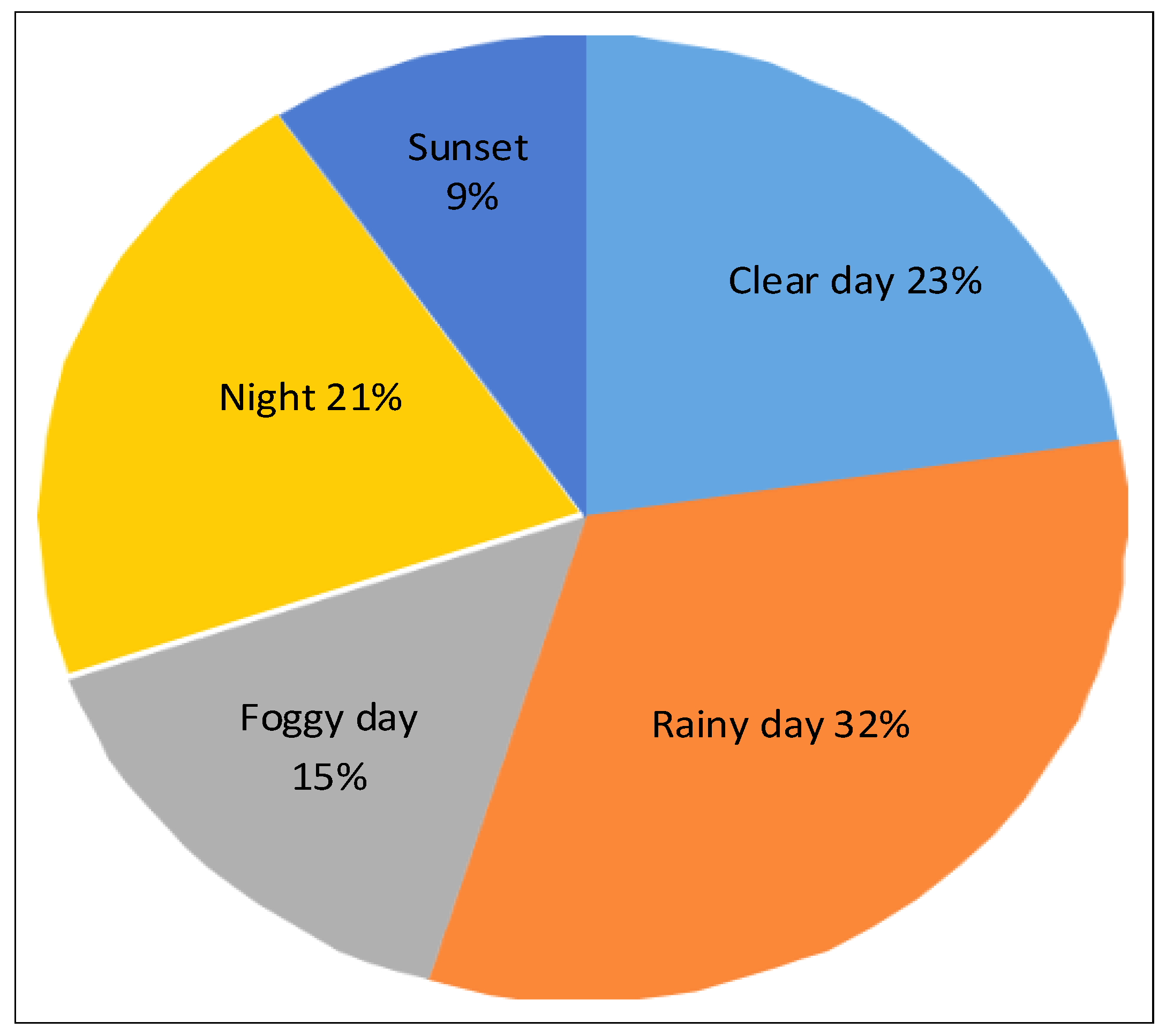
4.1. Dataset and Evaluation Metrics
4.2. Implementation Settings
4.3. Experiment Results and Discussion
4.3.1. Ablation Study
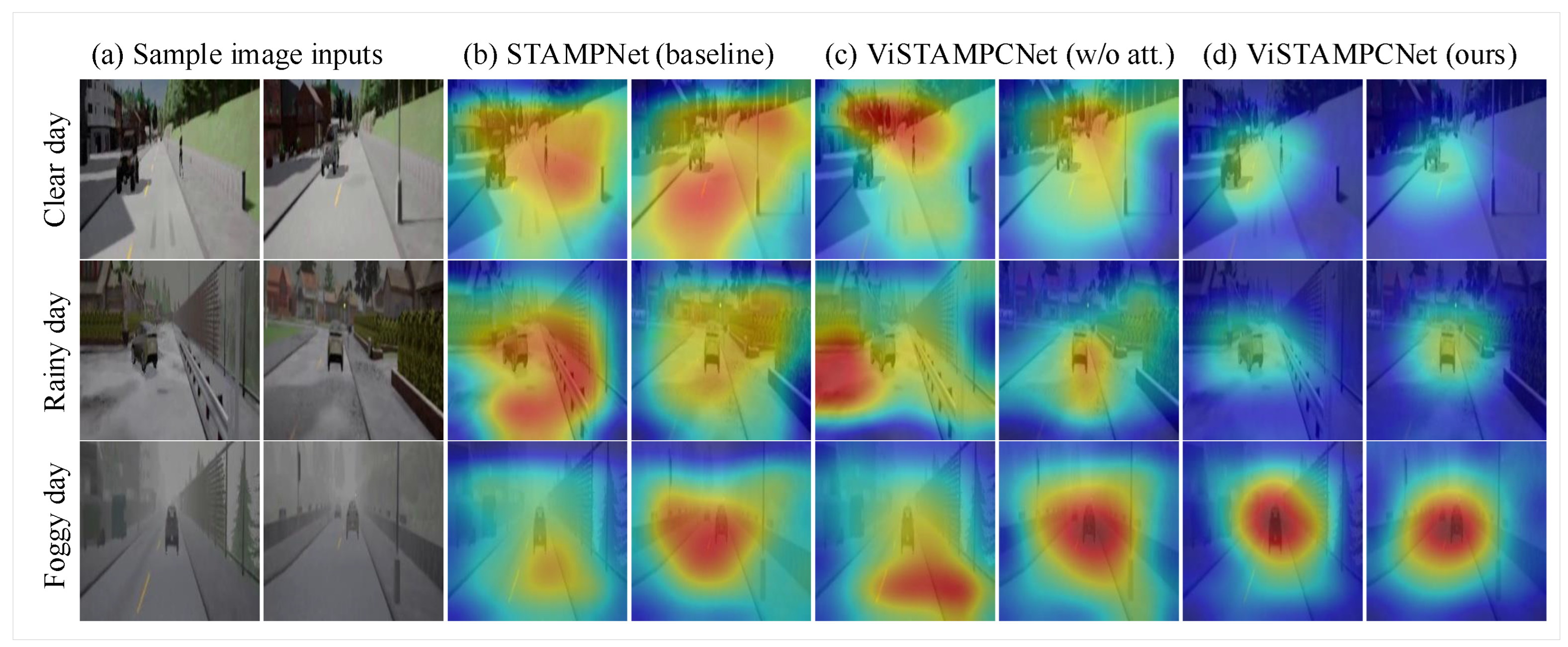
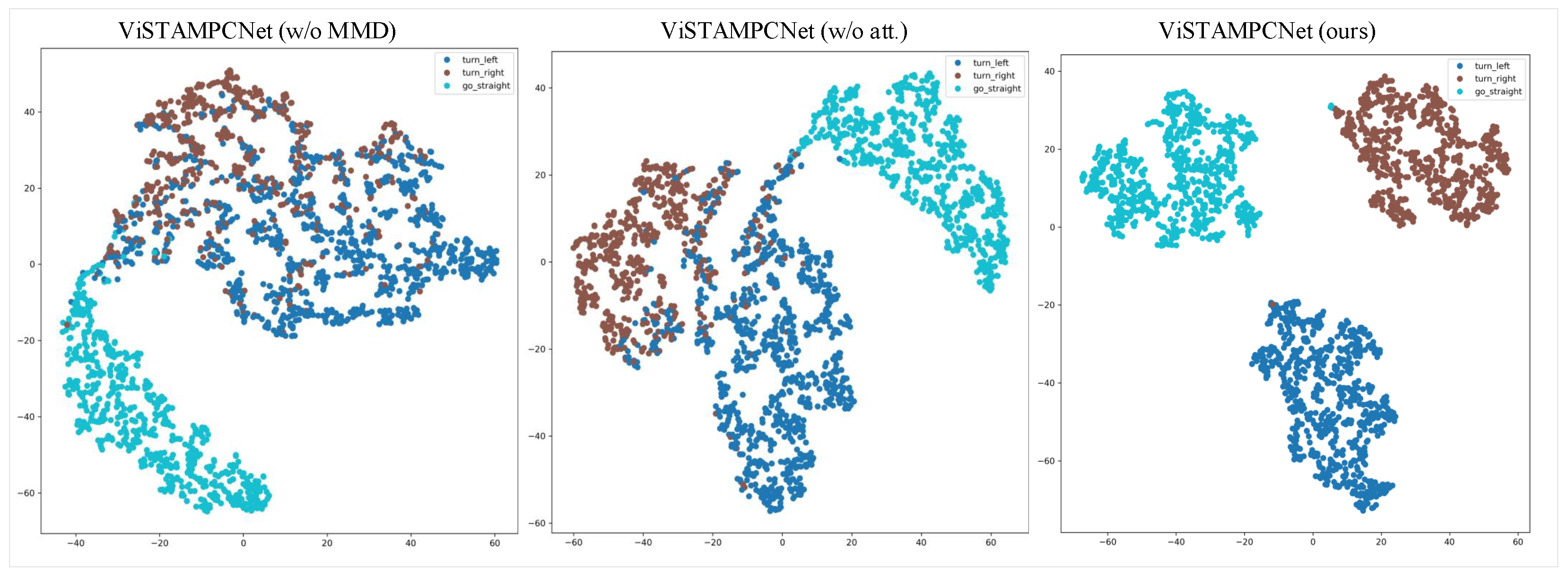
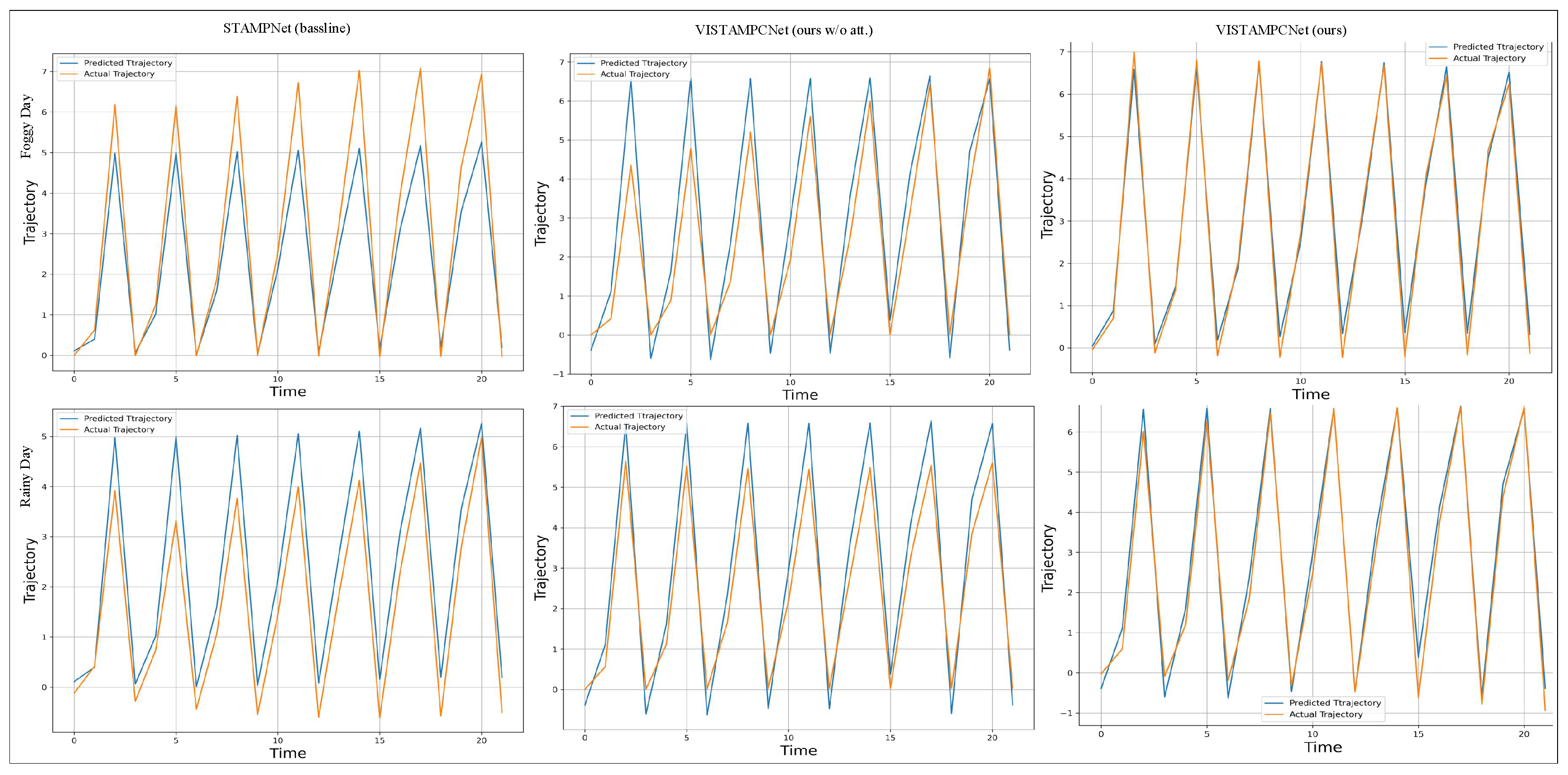
4.3.2. Qualitative Analysis
4.3.3. Comparison with State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Paden, B.; Čáp, M.; Yong, S.Z.; Yershov, D.; Frazzoli, E. A survey of motion planning and control techniques for self-driving urban vehicles. IEEE Trans. Intell. Veh. (T-IV) 2016, 1, 33–55. [Google Scholar] [CrossRef] [Green Version]
- Pendleton, S.D.; Andersen, H.; Du, X.; Shen, X.; Meghjani, M.; Eng, Y.H.; Rus, D.; Ang, M.H., Jr. Perception, planning, control, and coordination for autonomous vehicles. Machines 2017, 5, 6. [Google Scholar] [CrossRef]
- Chen, H.Y.; Zhang, Y. An overview of research on military unmanned ground vehicles. Acta Armamentarii 2014, 35, 1696–1706. [Google Scholar]
- Schwarting, W.; Alonso-Mora, J.; Rus, D. Planning and decision-making for autonomous vehicles. Annu. Rev. Control Robot Auton. Syst. 2018, 1, 187–210. [Google Scholar] [CrossRef]
- Ly, A.O.; Akhloufi, M. Learning to drive by imitation: An overview of deep behavior cloning methods. IEEE Trans. Intell. Veh. (T-IV) 2020, 6, 195–209. [Google Scholar] [CrossRef]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2722–2730. [Google Scholar]
- Thrun, S.; Montemerlo, M.; Dahlkamp, H.; Stavens, D.; Aron, A.; Diebel, J.; Fong, P.; Gale, J.; Halpenny, M.; Hoffmann, G.; et al. Stanley: The robot that won the DARPA Grand Challenge. J. Field Robot 2006, 23, 661–692. [Google Scholar] [CrossRef]
- Fan, H.; Zhu, F.; Liu, C.; Zhang, L.; Zhuang, L.; Li, D.; Zhu, W.; Hu, J.; Li, H.; Kong, Q. Baidu apollo em motion planner. arXiv 2018, arXiv:1807.08048. [Google Scholar]
- McAllister, R.; Gal, Y.; Kendall, A.; Van Der Wilk, M.; Shah, A.; Cipolla, R.; Weller, A. Concrete problems for autonomous vehicle safety: Advantages of Bayesian deep learning. In Proceedings of the International Joint Conferences on Artificial Intelligence (IJCAI), Melbourne, Australia, 19 August 2017; pp. 4745–4753. [Google Scholar]
- Pomerleau, D.A. Alvinn: An Autonomous Land Vehicle in a Neural Network. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Denver, CO, USA, 27–30 November 1989. [Google Scholar]
- Muller, U.; Ben, J.; Cosatto, E.; Flepp, B.; Cun, Y. Off-road obstacle avoidance through end-to-end learning. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 12 May–12 August 2005. [Google Scholar]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to end learning for self-driving cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Jhung, J.; Bae, I.; Moon, J.; Kim, T.; Kim, J.; Kim, S. End-to-end steering controller with CNN-based closed-loop feedback for autonomous vehicles. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 617–622. [Google Scholar]
- Kocić, J.; Jovičić, N.; Drndarević, V. An end-to-end deep neural network for autonomous driving designed for embedded automotive platforms. Sensors 2019, 19, 2064. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chi, L.; Mu, Y. Deep steering: Learning end-to-end driving model from spatial and temporal visual cues. In Proceedings of the 24th International Conference on Pattern Recognition, Beijing, China, 20 August 2018. [Google Scholar]
- Xu, H.; Gao, Y.; Yu, F.; Darrell, T. End-to-end learning of driving models from large-scale video datasets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21 July 2017; pp. 2174–2182. [Google Scholar]
- Song, S.; Hu, X.; Yu, J.; Bai, L.; Chen, L. Learning a deep motion planning model for autonomous driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1137–1142. [Google Scholar]
- Fern, O.T.; Denman, S.; Sridharan, S.; Fookes, C. Going deeper: Autonomous steering with neural memory networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Deo, N.; Trivedi, M.M. Convolutional social pooling for vehicle trajectory prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1468–1476. [Google Scholar]
- Bergqvist, M.; Rödholm, O. Deep Path Planning Using Images and Object Data. Master’s Thesis, Chalmers University of Technology, Gothenburg, Sweden, 2018. [Google Scholar]
- Cai, P.; Sun, Y.; Chen, Y.; Liu, M. Vision-based trajectory planning via imitation learning for autonomous vehicles. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019. [Google Scholar]
- Cai, P.; Sun, Y.; Wang, H.; Liu, M. VTGNet: A Vision-based Trajectory Generation Network for Autonomous Vehicles in Urban Environments. IEEE Trans. Intell. Veh. (T-IV) 2021, 6, 419–429. [Google Scholar] [CrossRef]
- Ross, S.; Gordon, G.; Bagnell, D. A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics(AISTATS), Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 627–635. [Google Scholar]
- Ayalew, M.; Zhou, S.; Assefa, M.; Yilma, G. spatiotemporal Attentive Motion Planning Network for Autonomous Vehicles. In Proceedings of the 18th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 17 December 2021; pp. 601–605. [Google Scholar]
- Hecker, S.; Dai, D.; Van Gool, L. End-to-end learning of driving models with surround-view cameras and route planners. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 435–453. [Google Scholar]
- Xiao, Y.; Codevilla, F.; Gurram, A.; Urfalioglu, O.; López, A.M. Multimodal end-to-end autonomous driving. IEEE Trans. Intell. Transp. Syst. 2020, 23, 537–547. [Google Scholar] [CrossRef]
- Huang, Z.; Lv, C.; Xing, Y.; Wu, J. Multi-modal sensor fusion-based deep neural network for end-to-end autonomous driving with scene understanding. IEEE Sens. J. 2020, 21, 11781–11790. [Google Scholar] [CrossRef]
- Hawke, J.; Shen, R.; Gurau, C.; Sharma, S.; Reda, D.; Nikolov, N.; Kndall, A. Urban driving with conditional imitation learning. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 251–257. [Google Scholar]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. Deep reinforcement learning framework for autonomous driving. Electron. Imaging 2017, 2017, 70–76. [Google Scholar] [CrossRef]
- Bansal, M.; Krizhevsky, A.; Ogale, A. Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst. arXiv 2018, arXiv:1812.03079. [Google Scholar]
- De Haan, P.; Jayaraman, D.; Levine, S. Causal confusion in imitation learning. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, DC, USA, 10–12 December 2019. [Google Scholar]
- Rhinehart, N.; Kitani, K.M.; Vernaza, P. R2p2: A reparameterized pushforward policy for diverse, precise generative path forecasting. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 772–788. [Google Scholar]
- Sauer, A.; Savinov, N.; Geiger, A. Conditional affordance learning for driving in urban environments. In Proceedings of the 2nd Conference on Robot Learning (CoRL), Zurich, Switzerland, 29–31 October 2018; pp. 237–252. [Google Scholar]
- Müller, M.; Dosovitskiy, A.; Ghanem, B.; Koltun, V. Driving policy transfer via modularity and abstraction. arXiv 2018, arXiv:1804.09364. [Google Scholar]
- Ruder, S. An overview of multi-task learning in deep neural networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Luo, W.; Yang, B.; Urtasun, R. Fast and furious: Real-time end-to-end 3d detection, tracking, and motion forecasting with a single convolutional net. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zeng, W.; Luo, W.; Suo, S.; Sadat, A.; Yang, B.; Casas, S.; Urtasun, R. End-to-end interpretable neural motion planner. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA 15 June 2019; pp. 8660–8669. [Google Scholar]
- Sadat, A.; Casas, S.; Ren, M.; Wu, X.; Dhawan, P.; Urtasun, R. Perceive, predict, and plan: Safe motion planning through interpretable semantic representations. In Proceedings of the European Conference on Computer Vision(ECCV), Glasgow, UK, 23–28 August 2020; pp. 414–430. [Google Scholar]
- Yang, Z.; Zhang, Y.; Yu, J.; Cai, J.; Luo, J. End-to-end multi-modal multi-task vehicle control for self-driving cars with visual perceptions. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2289–2294. [Google Scholar]
- Codevilla, F.; Müller, M.; López, A.; Koltun, V.; Dosovitskiy, A. End-to-end driving via conditional imitation learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 4693–4700. [Google Scholar]
- Codevilla, F.; Santana, E.; López, A.M.; Gaidon, A. Exploring the limitations of behavior cloning for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9329–9338. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Gedamu, K.; Yilma, G.; Assefa, M.; Ayalew, M. Spatio-temporal dual-attention network for view-invariant human action recognition. In Proceedings of the Fourteenth International Conference on Digital Image Processing (ICDIP 2022), Wuhan, China, 12 October 2022; Volume 12342, pp. 213–222. [Google Scholar]
- Kim, J.; Canny, J. Interpretable learning for self-driving cars by visualizing causal attention. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 25 December 2017; pp. 2942–2950. [Google Scholar]
- Mehta, A.; Subramanian, A.; Subramanian, A. Learning end-to-end autonomous driving using guided auxiliary supervision. In Proceedings of the 11th Indian Conference on Computer Vision, Graphics and Image Processing, Hyderabad, India, 18–22 December 2018; pp. 1–8. [Google Scholar]
- Fukui, H.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Attention branch network: Learning of attention mechanism for visual explanation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition(CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhao, X.; Qi, M.; Liu, Z.; Fan, S.; Li, C.; Dong, M. End-to-end autonomous driving decision model joined by attention mechanism and spatiotemporal features. IET Intell. Transp. Syst. 2021, 15, 1119–1130. [Google Scholar] [CrossRef]
- Mori, K.; Fukui, H.; Murase, T.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Visual explanation by attention branch network for end-to-end learning-based self-driving. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1577–1582. [Google Scholar]
- Liu, S.; Johns, E.; Davison, A.J. End-to-end multi-task learning with attention. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 5–20 June 2019; pp. 1871–1880. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 19–21 June 2018. [Google Scholar]
- Lopez-Paz, D.; Bottou, L.; Schölkopf, B.; Vapnik, V. Unifying distillation and privileged information. arXiv 2015, arXiv:1511.03643. [Google Scholar]
- Stojanov, P.; Gong, M.; Carbonell, J.; Zhang, K. Data-driven approach to multiple-source domain adaptation. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics (AISTATS), Naha, Japan, 16–18 April 2019; pp. 3487–3496. [Google Scholar]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A. A kernel two-sample test. J. Mach. Learn. Res (JMLR) 2012, 13, 723–773. [Google Scholar]
- Yilma, G.; Gedamu, K.; Assefa, M.; Oluwasanmi, A.; Qin, Z. Generation and Transformation Invariant Learning for Tomato Disease Classification. In Proceedings of the 2021 IEEE 2nd International Conference on Pattern Recognition and Machine Learning (PRML), Chengdu, China, 16 July 2021; pp. 121–128. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. (JMLR) 2008, 9, 2579–2605. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modules | Blocks | Conv Layers | Number of Blocks |
|---|---|---|---|
| (i) Spatiotemporal Feature Extractor (3DResNet) × 2 | Input | Conv3d (7,7), 110, stride = 2 | |
| MaxPool3d, 3 × 3, stride = 2 | |||
| BasicBlock | Conv3d, (3,3), 144, stride = 1 | 2 | |
| Conv3d, (1,1), 64, stride = 1 | |||
| Conv3d, (3,3), 144, stride = 1 | |||
| Conv3d, (1,1), 64, stride = 1 | |||
| AttentionBlock | FC(64,32), FC(32,64), Sigmoid | 2 | |
| BasicBlock | Conv3d, (3,3), 230, stride = 1 | 2 | |
| Conv3d, (1,1), 128, stride = 1 | |||
| Conv3d, (3,3), 288, stride = 1 | |||
| Conv3d, (1,1), 128, stride = 1 | |||
| AttentionBlock | FC(128,64), FC(64,128), Sigmoid | 2 | |
| BasicBlock | Conv3d, (3,3), 460, stride = 1 | 2 | |
| Conv3d, (1,1), 256, stride = 1 | |||
| Conv3d, (3,3), 576, stride = 1 | |||
| Conv3d, (1,1), 256, stride = 1 | |||
| AttentionBlock | FC(256,128), FC(128,256), Sigmoid | 2 | |
| BasicBlock | Conv3d, (3,3), 921, stride = 1 | 2 | |
| Conv3d, (1,1), 512, stride = 1 | |||
| Conv3d, (3,3), 1152, stride = 1 | |||
| Conv3d, (1,1), 512, stride = 1 | |||
| AttentionBlock | FC(512,256), FC(512,256), Sigmoid | 2 | |
| (ii) Trajectory | LSTM | LSTM(704, 512) | 3 |
| FC(512,66), FC(512,1) | 1 | ||
| Trajectory History | Conv1d,(1,1), 256, stride = 1 | 1 | |
| FC(256,256), FC(256,256) | |||
| (iii) Control | Output | FC(8192,128), FC(128,Command = 3), Softmax | 1 |
| Attentive 3DCNN | Block Layers | L2 Loss | Accuracy (%) |
|---|---|---|---|
| Attentive 3DResNet18 | −1 | 5.580 | 79.890 |
| Attentive 3DResNet18 | −2 | 1.230 | 93.348 |
| Attentive 3DResNet18 | −3 | 3.220 | 92.970 |
| Weather | ViSTAMPCNet w/o Att. | ViSTAMPCNet w/o MMD | ViSTAMPCNet | |||
|---|---|---|---|---|---|---|
| L2 Loss | Acc. | L2 Loss | Acc. | L2 Loss | Acc. | |
| Foggy day | 3.123 | 85.205 | 4.820 | 78.950 | 2.944 | 88.242 |
| Rainy day | 2.741 | 87.164 | 3.404 | 85.001 | 2.401 | 91.857 |
| Clear Day | 2.491 | 87.424 | 1.601 | 93.207 | 1.23 | 93.348 |
| Approaches | Task | Architecture | L2 Loss | Accuracy (%) | |
|---|---|---|---|---|---|
| Bergqvist [20] | ✔ | – | CNNState-FCN | 1.444 | – |
| VTGNet [22] | ✔ | – | 2D-CNN-LSTM | 1.036 | – |
| STAMPNet [24] | ✔ | – | Att. 3D-CNN-LSTM | 1.015 | – |
| Xu et al [16] | ✔ | ✔ | FCN-LSTM | 2.907 | 72.400 |
| STAMPNet + [24] | ✔ | ✔ | Att.3D-CNN-LSTM | 1.601 | 93.207 |
| ViSTAMPCNet (without Att.) | ✔ | ✔ | Siamese 3D-CNN-LSTM | 2.491 | 87.424 |
| ViSTAMPCNet (Ours) | ✔ | ✔ | Siamese Att.3D-CNN-LSTM | 1.230 | 93.348 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ayalew, M.; Zhou, S.; Memon, I.; Heyat, M.B.B.; Akhtar, F.; Zhang, X. View-Invariant Spatiotemporal Attentive Motion Planning and Control Network for Autonomous Vehicles. Machines 2022, 10, 1193. https://doi.org/10.3390/machines10121193
Ayalew M, Zhou S, Memon I, Heyat MBB, Akhtar F, Zhang X. View-Invariant Spatiotemporal Attentive Motion Planning and Control Network for Autonomous Vehicles. Machines. 2022; 10(12):1193. https://doi.org/10.3390/machines10121193
Chicago/Turabian StyleAyalew, Melese, Shijie Zhou, Imran Memon, Md Belal Bin Heyat, Faijan Akhtar, and Xiaojuan Zhang. 2022. "View-Invariant Spatiotemporal Attentive Motion Planning and Control Network for Autonomous Vehicles" Machines 10, no. 12: 1193. https://doi.org/10.3390/machines10121193