3.1. Industry-Specific Default Heterogeneity Indicators
It is an effective method to construct different categories of samples’ indicators as independent variables impacting credit risk. For example, Batrancea [
21] constructed 10 ratios concerning financial performance to study their influence on bank assets and the liabilities of the most important 45 banks in Europe and Israel, the United States of America, and Canada, which provides a good basis for the research in this paper. In this paper, we extend the forward intensity model by constructing industry-specific heterogeneity indicators for all industries to compute PDs for multiple periods.
Duffie et al. [
9] described defaults and other types of delisting excluding bankruptcy (other exit) as two independent doubly stochastic Poisson processes. For the
i-th firm, default and other exit intensities can be denoted by
and
, respectively. The two intensities represent two average arrival rates during the interval
with observation time point
. Here,
is set as one month, which means the basic time interval. Therefore, in a basic time interval,
and the default intensity is deterministic, so we can get the following probabilities:
Here,
,
, and
are the probabilities of default, other exit and survival, respectively, during the interval
and observed at the time point
. Obviously,
For more details, readers are referred to Duan et al [
1].
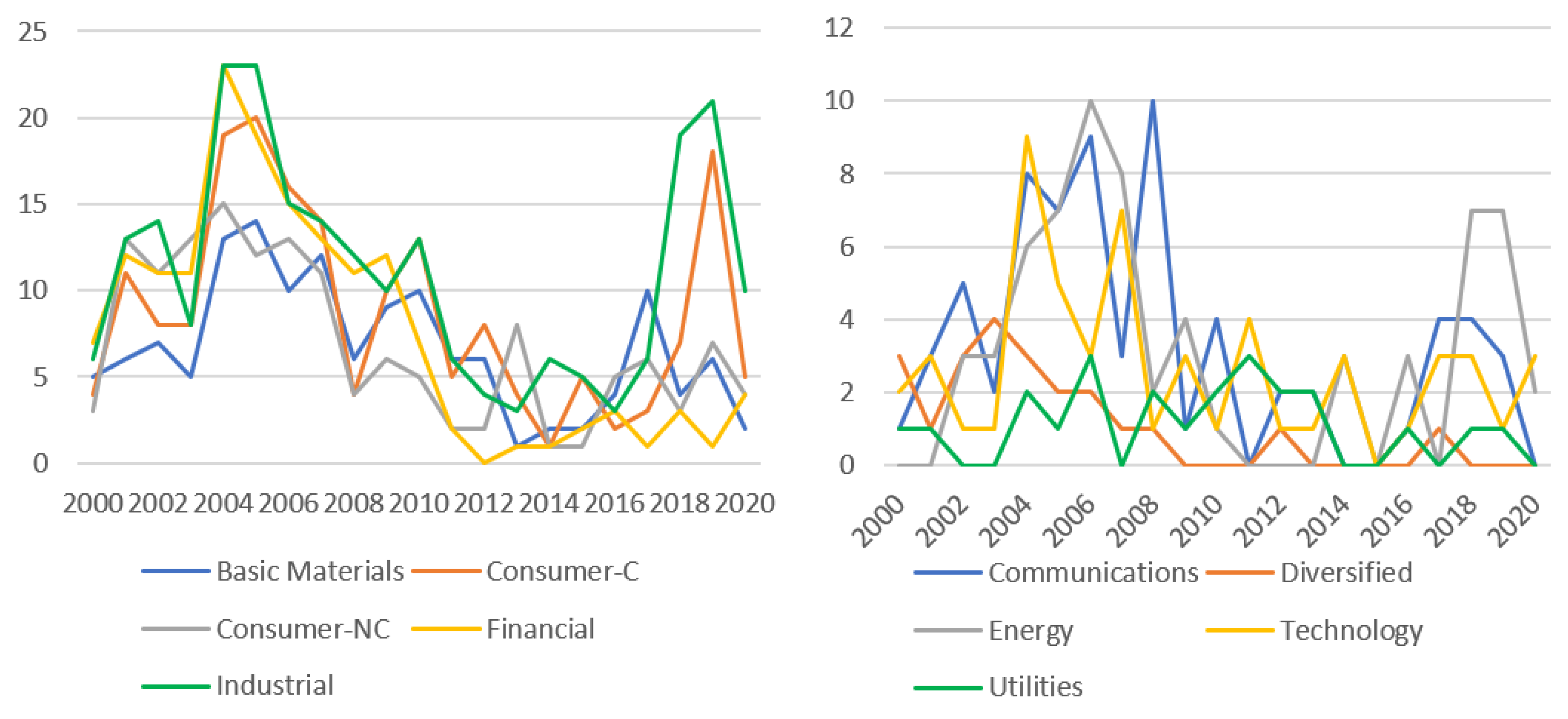
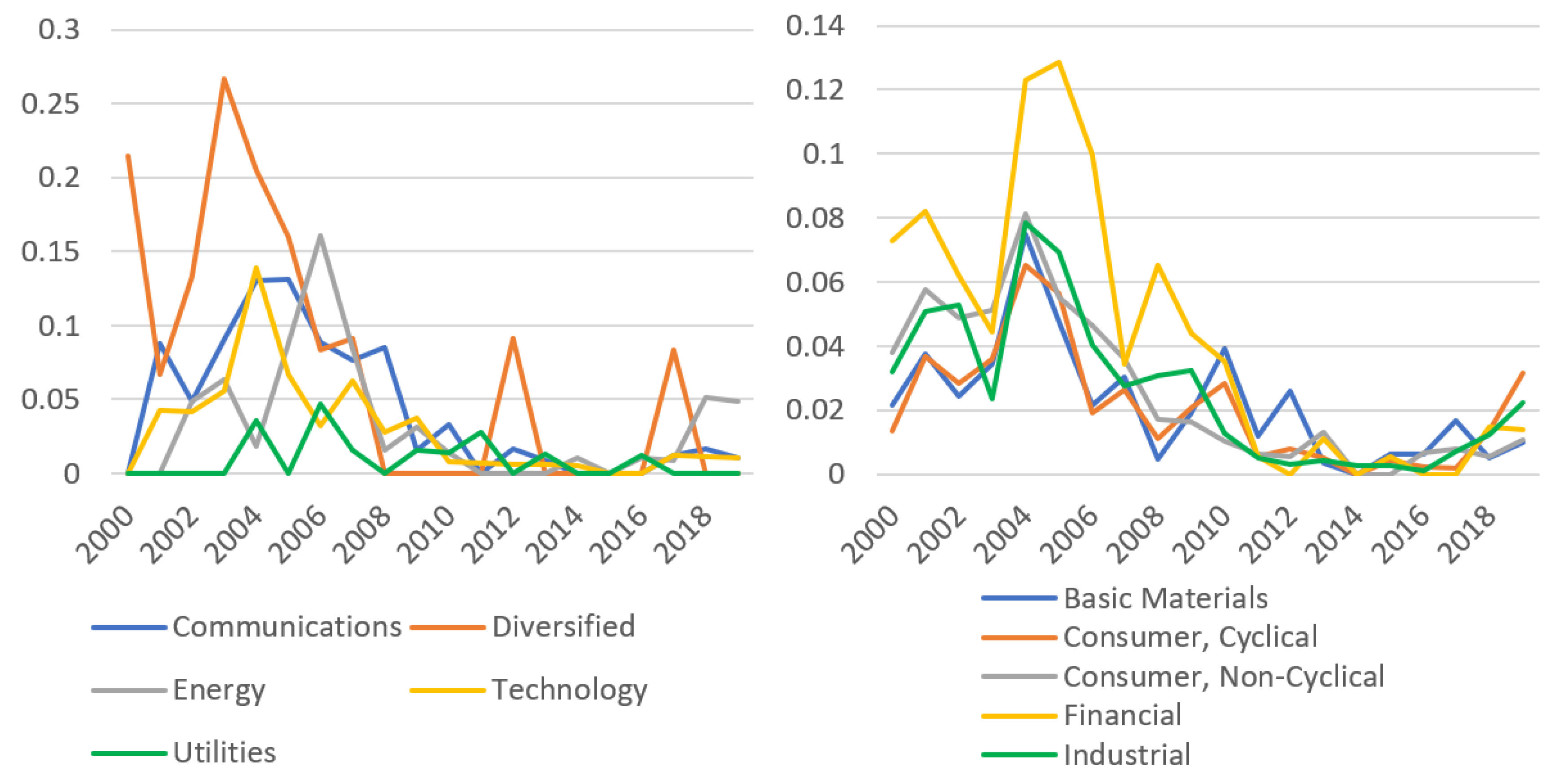
A lot of evidence shows that industry-specific default heterogeneity exists in different industries. In our preliminary analysis, Chinese-listed firms also show that there are different co-movements in different industries over time. Besides, a firm’s default tendency changes with co-movements of defaults in the industry and in the whole economy.
Section 5 shows the details of the preliminary analysis. To study unobserved co-movements of defaults in industries, we take an industry as a whole by averaging the default intensities of all the firms in the industry:
where
is the total number of surviving firms in the sample at the time point
in the
j-th industry.
A Bayesian approach was often employed when modeling the firms’ credit risk. Ni et al. [
22] found that Bayesian estimation can be employed on the firm’s default forward intensity to introduce default heterogeneity into the forward intensity model. In this paper, we take the industry’s average default intensity, estimated by the forward intensity approach, as the average prior default intensity of the industry. According to the additivity of Poisson processes, the number of firm defaults in the
j-th industry follows the Poisson distribution. If we take all firms in the
j-th industry as a whole, the number of defaults for every firm in the
j-th industry follows the Poisson distribution with the industry's average prior default intensity
. According to the properties of the Poisson process, in a basic time interval, the conjugate prior distribution of
is a Gamma distribution expressed as
, and
Then, the density function of
is
Let
denote whether the
i-th firm has a default during the interval
. When the observation time is after
, the probability function of
is expressed as
Because default is a low-probability event, we assume a firm defaults at most once a month. Let
denote the number of defaults during the interval
for all firms in the
j-th industry which are surviving in the sample at time point
. We then get the posterior distribution of
for the
j-th industry when the observation time is after
:
Let
be the parameter of the posterior intensity of
, then
According to the properties of the Gamma distribution, during the period
, the mean values of the prior and posterior default intensities can be expressed correspondingly as
Combining the above formulas to eliminate
, we have a relationship between
and
:
According to the properties of conjugate distributions,
higher
, the more confidence we have in
. Specially, as
approaches positive infinity,
, which means default intensity computed by the forward intensity approach completely dominates posterior default intensities. On the contrary, if
,
means that the posterior default intensity depends on the data we observe, which is the average number of defaults of all firms in the
j-th industry during the
n-th month. If we combine the above formulas:
The above equation shows the relationship between the average posterior intensity and the average prior intensity for all the
j-th industry’s firms. Here,
is the expectation of the number of defaults in the
j-th industry in month
n, which is estimated using the forward intensity approach, while
is actual number of defaults in the
n-th month in the same sample from this industry. If
, it means that the original model overestimates the default intensity of the whole industry in the
n-th month, then
. On the contrary, if
,it means that the original model underestimates the default intensity of the whole industry in the
n-th month, then
. Let the ratio of the posterior default intensity to the prior default intensity be the industry-specific default heterogeneity indicator, which reflects the extent to which the total number of defaults in the industry exceeds or falls below the aggregated prior PDs.
Note that the industry-specific default heterogeneity indicator is time-varying, and depends on the difference between the total number of firm defaults in the
n-th month and the expectation of the number of defaults estimated by the original model in the same industry in the same month. It can capture the co-movements of defaults in the industry. Because the original model does not consider industry-specific default heterogeneity, it can only capture less information on the time dynamics in the industry or the whole economy by including observable common factors in the input variables. Our industry-specific default heterogeneity indicator is calculated by comparing the posterior and prior default intensity in the industry, which can capture an unobserved part of the co-movements of defaults in industries. For example, when the average posterior default intensity is much greater than the average prior default intensity of an industry, we can know a co-rise of defaults in the industry has not been captured by the original model. If we ignore this information, we will underestimate the firms’ PDs when the default cluster occurs in this industry. Besides, we can also measure the average tendency to default in different industries over different time periods due to its time-varying nature. On the other hand, for industries with low credit risk, due to fewer default events within the industry, the number of realized defaults for different default prediction horizons will be far less than the aggregated PDs for all firms within the industry. According to Formula
, the industry-specific default heterogeneity indicator
will be less than 1. If a firm’s credit risk is very dependent on the industry-specific default heterogeneity indicator for its industry, when we estimate firms’ PDs in this industry, the new default forward intensity will be obviously lower than the original default forward intensity, which means the new PDs are lower. Therefore, when we estimate PDs, we will introduce default heterogeneity in the industries into the forward intensity function. Duan and Miao [
23] found that short-term PDs can capture more co-movements in credit risk. Therefore, we calculated the shortest horizon’s industry-specific default heterogeneity indicators to capture most co-movements by set
. Then,
denotes the
i-th firm’s default intensity during the
m-th month observed on the first day of the
m-th month. We assume that for firms in the same industry the posterior 1-month PDs share the same confidence in the 1-month prior PD. Then, we replace
and
by
and
respectively.
To predict forward PDs in the future, we assume that an industry maintains a similar industry default heterogeneity during close periods. We calculate the most recent available industry-specific default heterogeneity indicators to represent co-movements of defaults in industries in the current month. We define the industry-specific posterior default intensity of the
m-th month in terms of the prior default intensity multiplied by the most recent available industry-specific default heterogeneity indicator:
Here, we use 1-month-horizon prior default intensity and an industry-specific default heterogeneity indicator to make
as close as possible to the current situation. When we observe at the first day of the
m-th month,
is unknown. Then, the industry-specific posterior default intensity is as follows:
The 1-month industry-specific posterior default intensity of every firm is calculated taking industry-specific default heterogeneity into account. In addition, if the PDs of an industry are aggregated, the systematic credit risk of the industry can also be estimated, which can be applied for stress testing of the industry’s credit risk. This way of calculating portfolio credit risk by aggregating every firm’s PD is a bottom-up method. However, this industry-specific posterior default intensity cannot be regarded as our final calibrated default intensity. This is because a firm’s default can not only be influenced by the industry the firm is in, but may also be influenced by other industries. Therefore, if we calibrate a firm’s PD, we need to take all industries’ default situations into account. But we need industry-specific posterior default intensity to estimate , which will be introduced in the next section. With , we can calculate for all past months, which reflects the average level of default heterogeneity of the -th industry in the m-th month.
3.2. PDs for All Horizons
If the default heterogeneity of other industries is not taken into account, the impact of co-movement of the whole economy’s defaults will not be adequately considered. Thus, we constructed a new variable,
, denoting the weighted average industry-specific default heterogeneity of other firms:
Here,
and
both contribute to our calibrated default intensity. On the other hand, when we compute the longer prediction horizons’ PDs, it is not enough to just consider the current value of industry-specific default heterogeneity. Duan et al [
1] found trends in some input variables are helpful to predict PDs. We also take the trends in our industry-specific default heterogeneity indicators into account. Trends are calculated using the difference between current value and the average value over the past period of time. To be consistent, we take the average value of the past 12 months following Duan et al [
1]. Because the default intensity function is a proportional-hazards form of the original forward intensity approach, our forward default intensity function is as follows:
Here,
is a column vector and
is a row vector:
where
is the industry-specific default heterogeneity indicator of the
j-th industry. Here,
and
are the trends of
and
, respectively. The next section will describe how we estimate
for all the prediction horizons. As long as we estimate
, we can calibrate the default intensity estimated by the forward intensity approach to compute
, which considers co-movements in the industry’s credit risk. With
, we can compute cumulative POEs, PDs for different prediction horizons. Firstly, we compute conditional PDs and POEs by
and
, where
is calculated by the original models. Then, we can compute forward PDs, which are conditional PDs timed by probabilities that the firm survives between the predicting month and the observed month. Finally, we can compute cumulative PDs by cumulating forward PDs. For more details of computing PDs, readers may also refer to Duan et al. [
1].
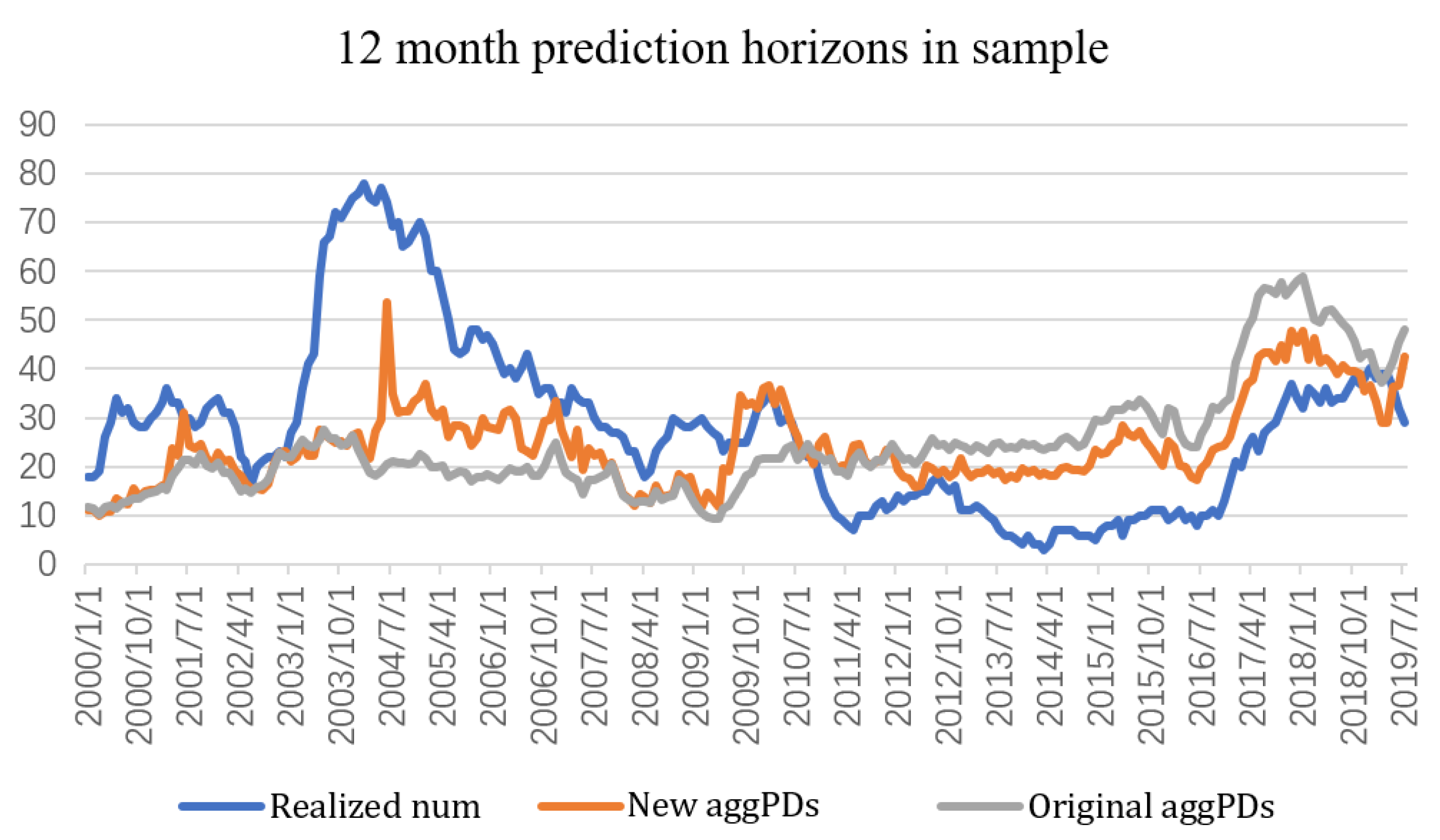
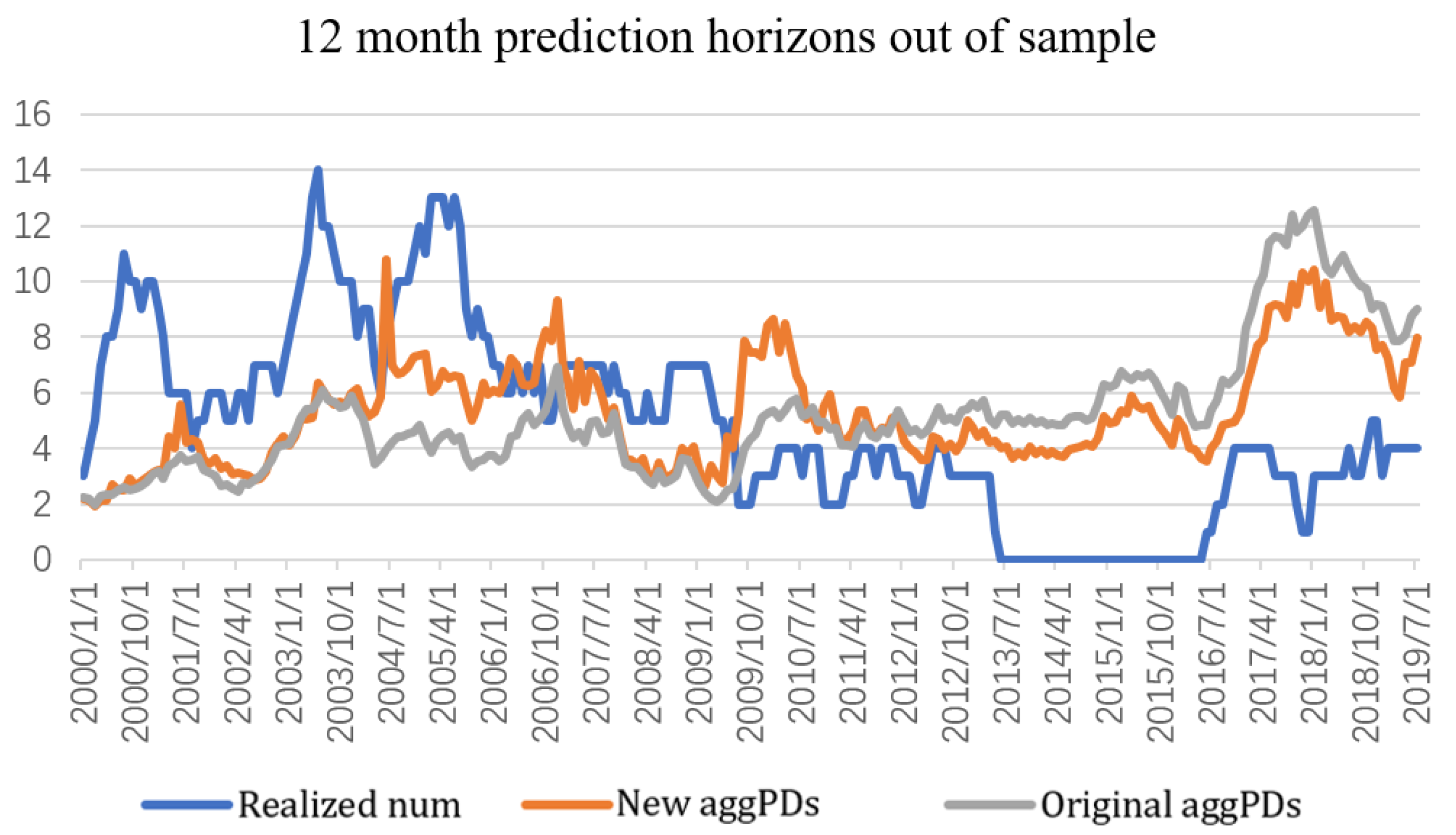
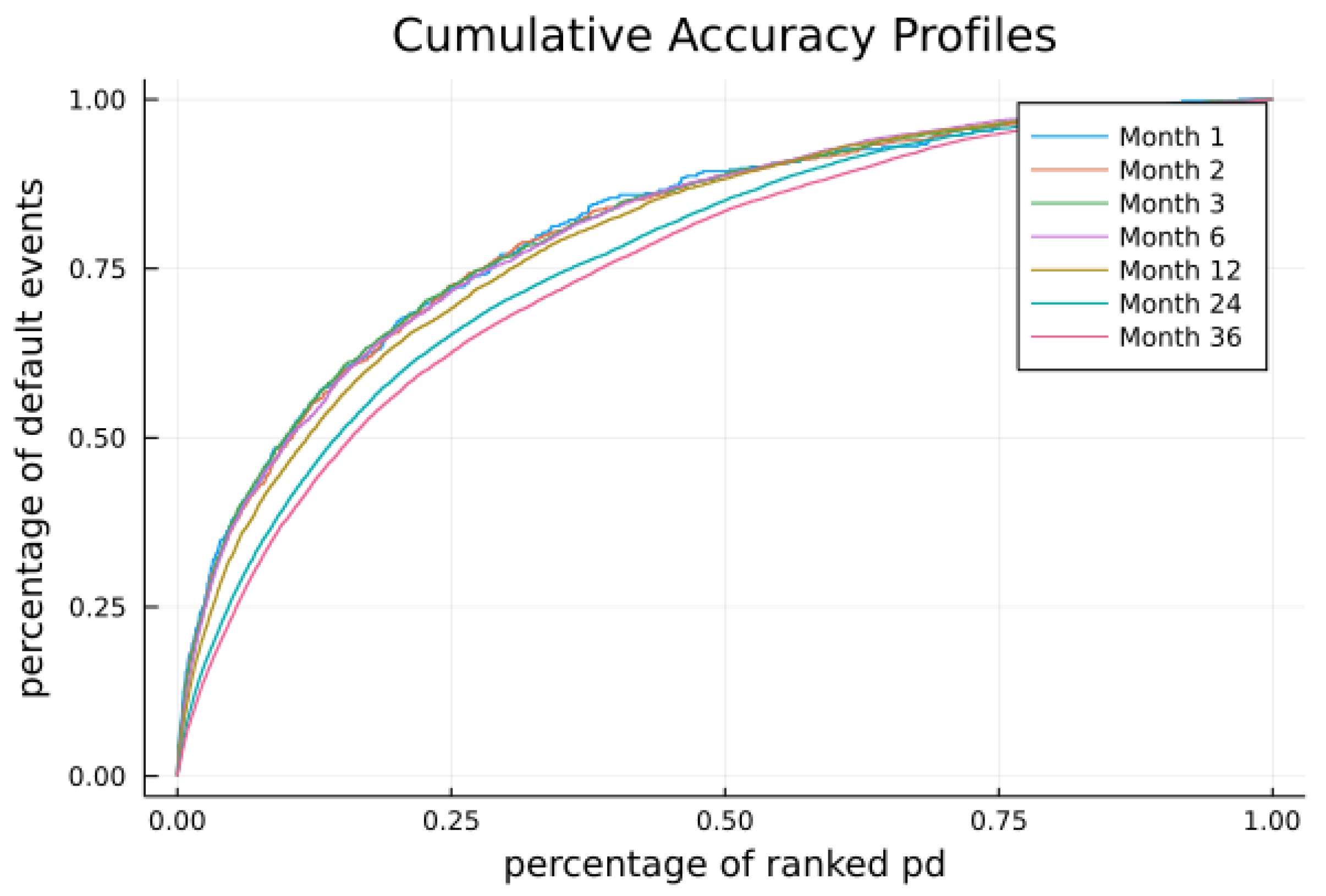
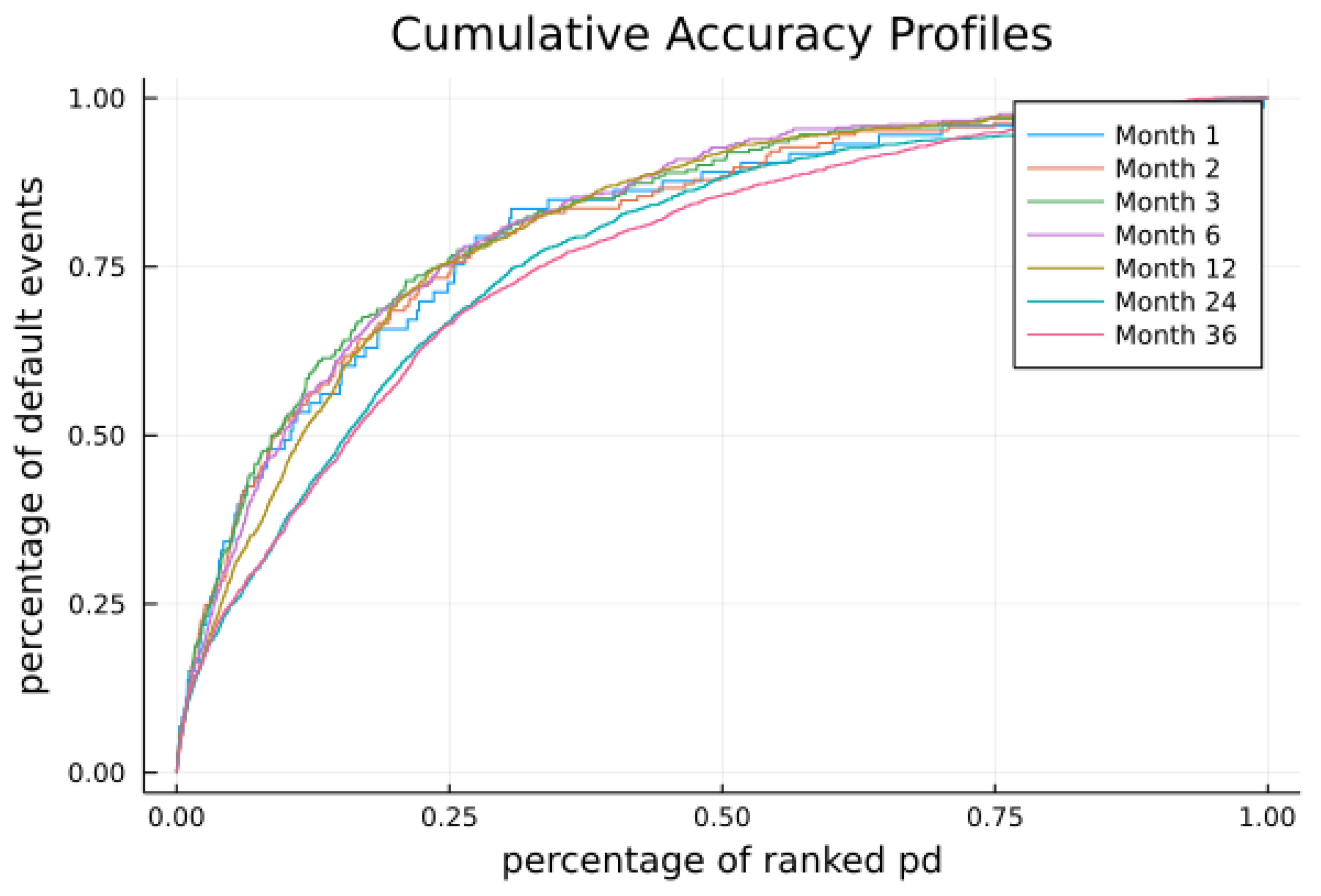
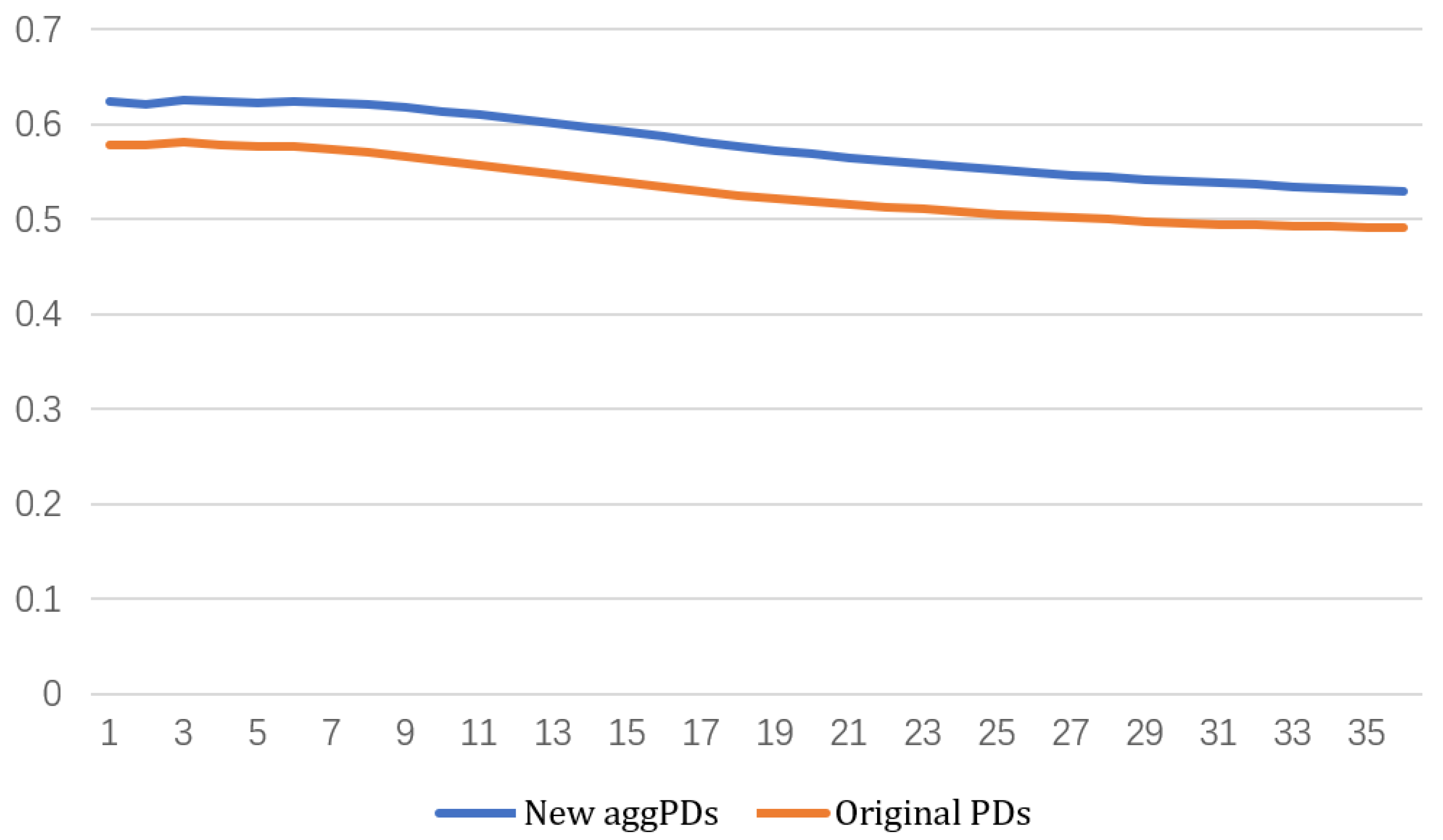
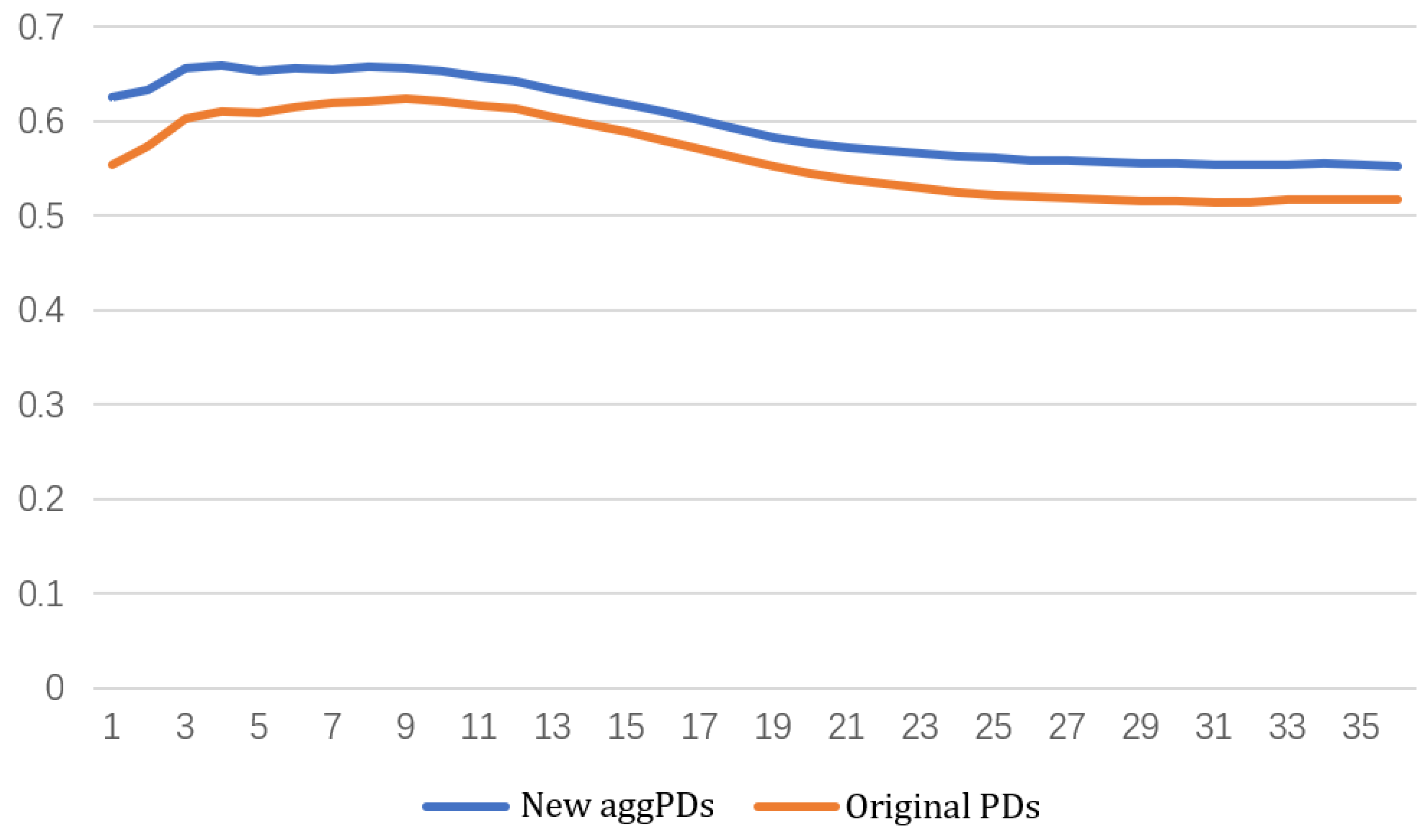
In this paper, we compute cumulative PDs for horizons from 1 month to 36 months and evaluate the prediction performance of our PDs computed with industry-specific default heterogeneity and PDs estimated by the original model in
Section 6.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}