
Efficiency of Orthogonal Matching Pursuit for Group Sparse Recovery


Abstract
:1. Introduction
| Algorithm 1 Orthogonal Matching Pursuit (OMP) |
| Input: measurement matrix measurement vector Initialization: Iteration: repeat until a stopping criterion is met at Output: the -sparse vector |
| Algorithm 2 Group Orthogonal Matching Pursuit ( |
| Input: encoding matrix the vector group structure a set , maximum allowed sparsity M. Initialization:, , .
|
2. Proof of Theorem 2
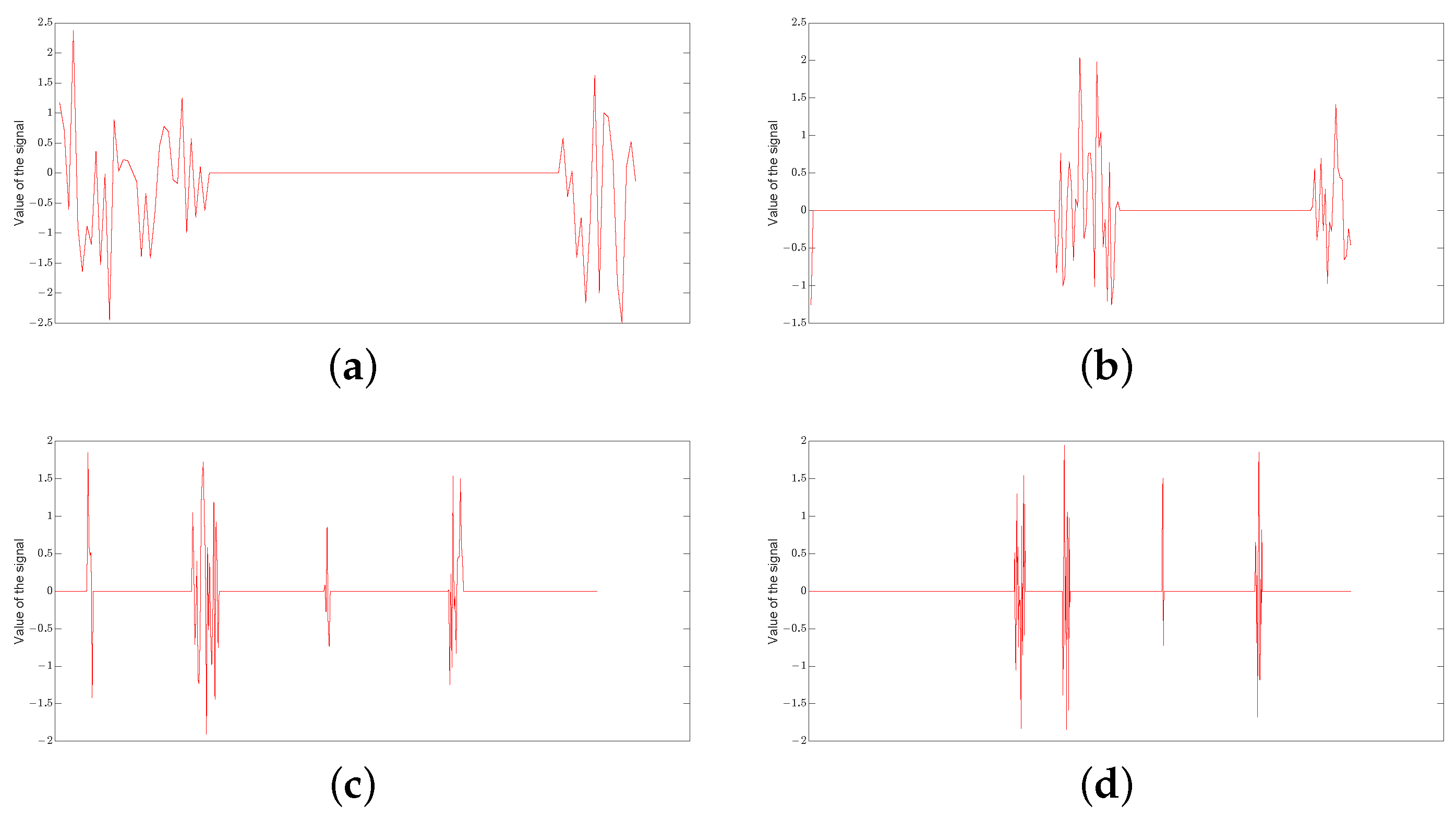
3. Simulation Results
3.1. Implementation
- i.
- Given a sparse level K;
- ii.
- Produce a group structure randomly, satisfying for each index i;
- iii.
- Randomly select a set , such that ;
- iv.
- Let the set be the support, and produce a signal by random numbers from normal distribution .
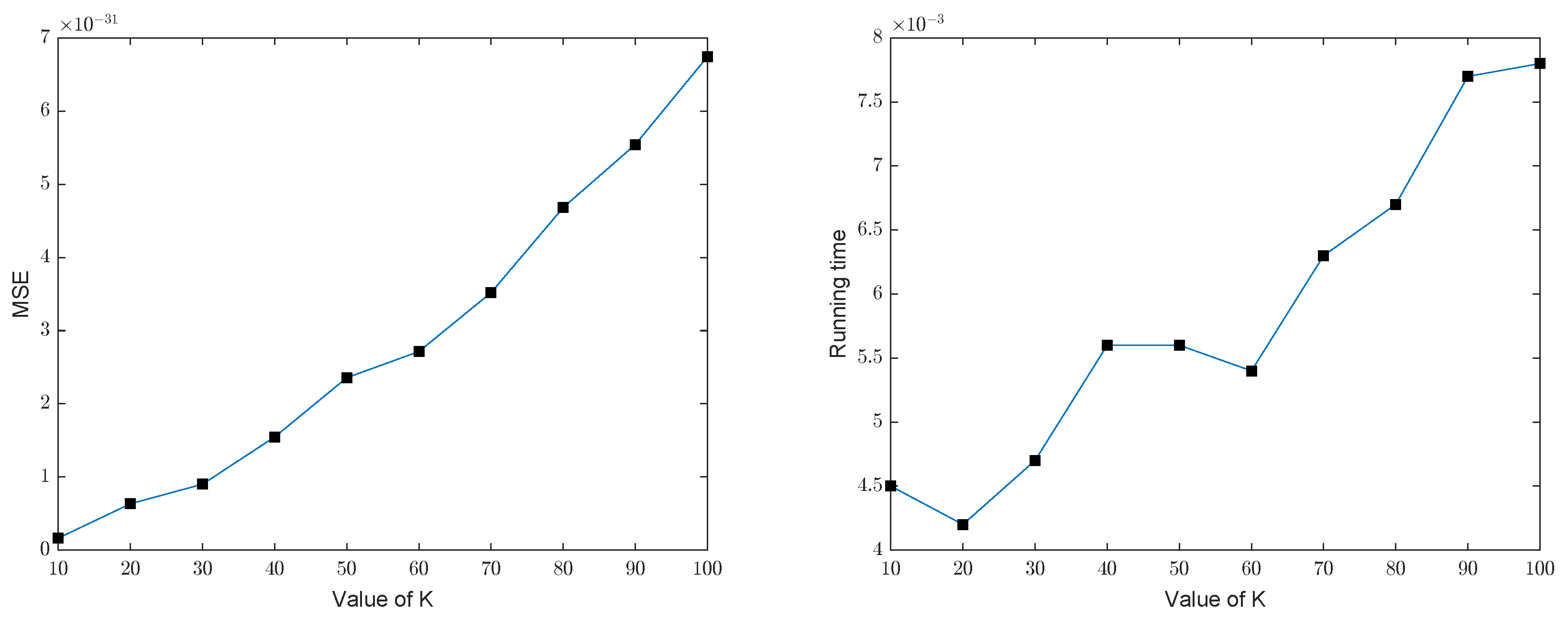
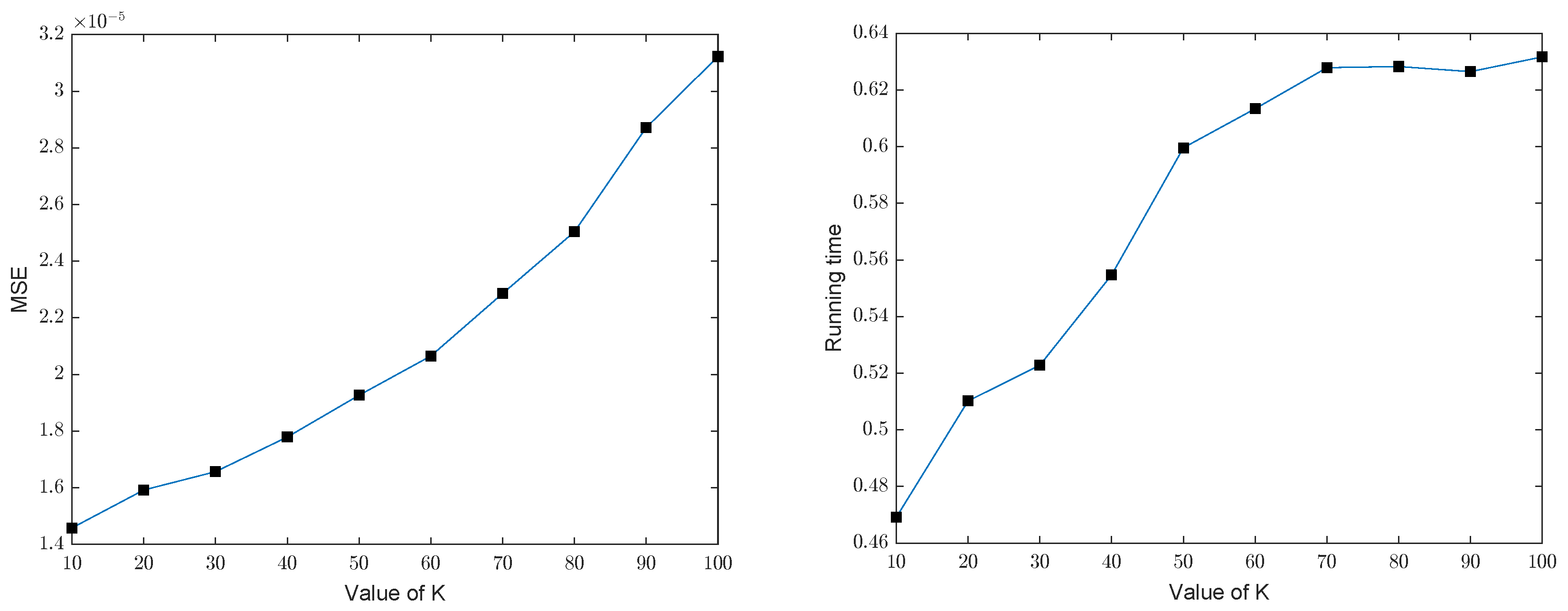
3.2. Effectiveness of the GOMP
3.3. Comparison with Basis Pursuit
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B
References
- Foucart, S.; Rauhut, H. A Mathematical Introduction to Compressive Sensing; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Cai, T.; Zhang, A. Sparse representation of a polytope and recovery of sparse signals and low-rank matrices. IEEE Trans. Inf. Theory 2014, 60, 122–132. [Google Scholar] [CrossRef]
- Günther, M.; Böhringer, S.; Wieczorek, D.; Würtz, R.P. Reconstruction of images from Gabor graphs with applications in facial image processing. Int. J. Wavelets Multiresolut. Inf. Process. 2015, 13, 1550019. [Google Scholar] [CrossRef]
- Ye, P.X.; Wei, X.J. Efficiency of weak greedy algorithms for m-term approximations. Sci. China. Math. 2016, 59, 697–714. [Google Scholar] [CrossRef]
- Yang, B.; Yang, C.; Huang, G. Efficient image fusion with approximate sparse representation. Int. J. Wavelets Multiresolut. Inf. Process. 2016, 14, 1650024. [Google Scholar] [CrossRef]
- Candès, E.; Kalton, N.J. The restricted isometry property and its implications for compressed sensing. C. R. Acad. Sci. Sér. I 2008, 346, 589–592. [Google Scholar] [CrossRef]
- Candès, E.J.; Tao, T. Decoding by linear programming. IEEE Trans. Inf. Theory 2005, 51, 4203–4215. [Google Scholar] [CrossRef]
- Yuan, M.; Lin, Y. Model selection and estimation in regression with grouped variables. J. R. Stat. Ser. B 2006, 68, 49–67. [Google Scholar] [CrossRef]
- Ou, W.; Hämäläinen, M.S.; Golland, P. A distributed spatio-temporal EEG/MEG inverse solver. NeuroImage 2009, 44, 932–946. [Google Scholar] [CrossRef]
- Antoniadis, A.; Fan, J. Regularization of wavelet approximations. J. Amer. Stat. Assoc. 2001, 96, 939–967. [Google Scholar] [CrossRef]
- He, Z.; Yu, W. Stable feature selection for biomarker discovery. Comput. Biol. Chem. 2010, 34, 215–225. [Google Scholar] [CrossRef]
- Mishali, M.; Eldar, Y.C. Blind multiband signal reconstruction: Compressed sensing for analog signals. IEEE Trans. Signal Process. 2009, 57, 993–1009. [Google Scholar] [CrossRef]
- Ahsen, M.E.; Vidyasagar, M. Error bounds for compressed sensing algorithms with group sparsity: A unified approach. Appl. Comput. Harmon. Anal. 2017, 42, 212–232. [Google Scholar] [CrossRef]
- Ranjan, S.; Vidyasagar, M. Tight performance bounds for compressed sensing with conventional and group sparsity. IEEE Trans. Signal Process 2019, 67, 2854–2867. [Google Scholar] [CrossRef]
- Tropp, J.A. Greedy is good: Algorithmic results for sparse approximation. IEEE Trans. Inform. Theory 2004, 50, 2231–2242. [Google Scholar] [CrossRef]
- Lin, J.H.; Li, S. Nonuniform support recovery from noisy measurements by orthogonal matching pursuit. J. Approx. Theory 2013, 165, 20–40. [Google Scholar] [CrossRef]
- Mo, Q.; Shen, Y. A remark on the restricted isometry property in orthogonal matching pursuit. IEEE Trans. Inf. Theory 2012, 58, 3654–3656. [Google Scholar] [CrossRef]
- Dan, W. Analysis of orthogonal multi-matching pursuit under restricted isometry property. Sci. China Math. 2014, 57, 2179–2188. [Google Scholar] [CrossRef]
- Xu, Z.Q. The performance of orthogonal multi-matching pursuit under RIP. J. Comp. Math. 2015, 33, 495–516. [Google Scholar] [CrossRef]
- Shao, C.F.; Ye, P.X. Almost optimality of orthogonal super greedy algorithms for incoherent dictionaries. Int. J. Wavelets Multiresolut. Inf. Process. 2017, 15, 1750029. [Google Scholar] [CrossRef]
- Wei, X.J.; Ye, P.X. Efficiency of orthogonal super greedy algorithm under the restricted isometry property. J. Inequal. Appl. 2019, 124, 1–21. [Google Scholar] [CrossRef]
- Zhang, T. Sparse recovery with orthogonal matching pursuit under RIP. IEEE Trans. Inf. Theory 2011, 57, 6215–6221. [Google Scholar] [CrossRef]
- Xu, Z.Q. A remark about orthogonal matching pursuit algorithm. Adv. Adapt. Data Anal. 2012, 04, 1250026. [Google Scholar] [CrossRef]
- Cohen, A.; Dahmen, W.; DeVore, R. Orthogonal matching pursuit under the restricted isometry property. Constr. Approx. 2017, 45, 113–127. [Google Scholar] [CrossRef]
- Eldar, Y.C.; Mishali, M. Robust recovery of signals from a structured union of subspaces. IEEE Trans. Inf. Theory 2009, 55, 5302–5316. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef]
- Van Den Berg, E.; Friedlander, M.P. Theoretical and empirical results for recovery from multiple measurements. IEEE Trans. Inf. Theory 2010, 56, 2516–2527. [Google Scholar] [CrossRef]
- Eldar, Y.C.; Kuppinger, P.; Bölcskei, H. Block-sparse signals: Uncertainty relations and efficient recovery. IEEE Trans. Signal Process. 2010, 58, 3042–3054. [Google Scholar] [CrossRef]
- Lai, M.J.; Liu, Y. The null space property for sparse recovery from multiple measurement vectors. Appl. Comput. Harmon. Anal. 2011, 30, 402–406. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, J.; Wang, W. A perturbation analysis of block-sparse compressed sensing via mixed l2/l1 minimization. Int. J. Wavelets, Multiresolut. Inf. Process. 2016, 14, 1650026. [Google Scholar] [CrossRef]
- Chen, W.G.; Ge, H.M. A sharp recovery condition for block sparse signals by block orthogonal multi-matching pursuit. Sci. China Math. 2017, 60, 1325–1340. [Google Scholar] [CrossRef]
- Wen, J.M.; Zhou, Z.C.; Liu, Z.L.; Lai, M.J.; Tang, X.H. Sharp sufficient conditions for stable recovery of block sparse signals by block orthogonal matching pursuit. Appl. Comput. Harmon. Anal. 2019, 47, 948–974. [Google Scholar] [CrossRef]
- Candès, E.; Romberg, J. l1-Magic: Recovery of Sparse Signals via Convex Programming. Available online: https://candes.su.domains/software/l1magic/#code (accessed on 15 February 2023).
- Do, T.T.; Gan, L.; Nguyen, N.; Tran, T.D. Sparsity adaptive matching pursuit algorithm for practical compressed sensing. In Proceedings of the 2008 42nd Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 26–29 October 2008; pp. 581–587. [Google Scholar]
- Bi, X.; Leng, L.; Kim, C.; Liu, X.; Du, Y.; Liu, F. Constrained Backtracking Matching Pursuit Algorithm for Image Reconstruction in Compressed Sensing. Appl. Sci. 2021, 11, 1435. [Google Scholar] [CrossRef]
- Wang, R.; Qin, Y.; Wang, Z.; Zheng, H. Group-Based Sparse Representation for Compressed Sensing Image Reconstruction with Joint Regularization. Electronics 2022, 11, 182. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group Sparsity Level | GOMP | BP | ||
|---|---|---|---|---|
| MSE | Running Time | MSE | Running Time | |
| K = 10 | 0.0045s | 8.1887 | 0.3724 s | |
| K = 20 | 0.0042 s | 0.5158 s | ||
| K = 30 | 0.0047 s | 0.5358 s | ||
| K = 40 | 0.0056 s | 0.5544 s | ||
| K = 50 | 0.0056 s | 0.4513 s | ||
| K = 60 | 0.0054 s | 0.5099 s | ||
| K = 70 | 0.0063 s | 0.5634 s | ||
| K = 80 | 0.0067 s | 0.5831 s | ||
| K = 90 | 0.0077 s | 0.5946 s | ||
| K = 100 | 0.0078 s | 0.6087 s | ||
| Group Sparsity Level | GOMP | BP | ||
|---|---|---|---|---|
| MSE | Running Time | MSE | Running Time | |
| K = 10 | 0.0043 s | 1.4580 | 0.4691 s | |
| K = 20 | 0.0043 s | 0.5102 s | ||
| K = 30 | 0.0050 s | 0.5228 s | ||
| K = 40 | 0.0058 s | 0.5547 s | ||
| K = 50 | 0.0058 s | 0.5996 s | ||
| K = 60 | 0.0057 s | 0.6134 s | ||
| K = 70 | 0.0067 s | 0.6279 s | ||
| K = 80 | 0.0069 s | 0.6283 s | ||
| K = 90 | 0.0076 s | 0.6265 s | ||
| K = 100 | 0.0081 s | 0.6317 s | ||
| Dimension | GOMP | BP | ||
|---|---|---|---|---|
| MSE | Running Time | MSE | Running Time | |
| N = 1024 | 0.0057 s | 0.4513 s | ||
| N = 2048 | 0.0114 s | 1.6611 s | ||
| N = 3072 | 0.0195 s | 5.8170 s | ||
| N = 4096 | 0.0413 s | 11.3636 s | ||
| Dimension | GOMP | BP | ||
|---|---|---|---|---|
| MSE | Running Time | MSE | Running Time | |
| N = 1024 | 0.0066 s | 0.4521 s | ||
| N = 2048 | 0.0115 s | 2.6113 s | ||
| N = 3072 | 0.0200 s | 6.3476 s | ||
| N = 4096 | 0.0406 s | 12.1959 s | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, C.; Wei, X.; Ye, P.; Xing, S. Efficiency of Orthogonal Matching Pursuit for Group Sparse Recovery. Axioms 2023, 12, 389. https://doi.org/10.3390/axioms12040389
Shao C, Wei X, Ye P, Xing S. Efficiency of Orthogonal Matching Pursuit for Group Sparse Recovery. Axioms. 2023; 12(4):389. https://doi.org/10.3390/axioms12040389
Chicago/Turabian StyleShao, Chunfang, Xiujie Wei, Peixin Ye, and Shuo Xing. 2023. "Efficiency of Orthogonal Matching Pursuit for Group Sparse Recovery" Axioms 12, no. 4: 389. https://doi.org/10.3390/axioms12040389