1. Introduction
Under normal operating conditions, the life test for high-reliability products is frequently time-consuming and expensive because it would take a considerable amount of time before acquiring a sufficient number of failures for the necessary analysis. To rapidly and cheaply gather data regarding such products under experimental time constraints, accelerated life tests (ALTs) are typically conducted. As part of the ALTs, stress variables are typically set, including the temperature, humidity, voltage, pressure, etc. To determine the life characteristics of the products, the data gathered throughout the accelerated testing can be analyzed and extrapolated to the normal operating conditions. Nelson [
1], Meeker and Escobar [
2], Tang [
3] and Balakrishnan [
4] have all offered substantial reviews on past findings on the topic of ALTs. One of the most often utilized tests in reliability engineering is the constant-stress ALT (CSALT). As a result of the CSALT, the researchers can divide the products into several groups and test each group at a specific level of stress. A constant level of stress is applied during the entire test duration, for example, to semiconductors and microelectronics, see Luo et al. [
5]. There are usually two or more levels at which products are tested separately. For time saving, tests are even run simultaneously when possible. Numerous studies have been conducted on the statistical inferences for the CSALT under various lifetime distributions using both classical and Bayesian approaches. For instance, when the product lifetime follows the Weibull distribution, Wang [
6] discussed the inference of the CSALT. Lin et al. [
7] investigated the inferences of the CSALT for log-location-scale lifetime distributions. Sief et al. [
8] studied the inference of the CSALT from the generalized half-normal distribution. Nassar et al. [
9] investigated the estimation issues of the Lindley distribution with the CSALT. See also Hakamipour [
10], Kumar et al. [
11] and Wu et al. [
12] for more detail.
Although the main objective of the ALTs is to shorten the period of the experiment, the researchers spend a lot of time waiting for all test units to fail. In such situations, it is crucial to deal with censored data. In general, censoring means that actual failure times are known for just a part of the units under investigation. The Type-I, Type-II, and progressive Type-II censoring (PT-IIC) schemes are the most frequently utilized censoring schemes in ALTs. The PT-IIC is more powerful than traditional Type-I and Type-I censoring which enables researchers to withdraw live units at various testing stages. Consider an experiment in which
n identical units are put on a life test with a predetermined censoring plan
, where
m is the desired number of observed failures. For
, at the time of the
th failure,
units from the remaining units are picked at random and removed from the test. Immediately, upon the occurrence of the last failure, all the remaining units
are removed and the test is ended, i.e.,
In engineering experiments, some items must be removed for a more in-depth inspection or saved for use as test samples in future investigations. In this case, the PT-IIC plan naturally arises from such experiments. The test procedure of the CSALT in the presence of PT-IIC data will be discussed in detail in the next section. The PT-IIC scheme has received a lot of attention in the literature, for example, see Balakrishnan et al. [
13], Balakrishnan and Lin [
14], Chen and Gui [
15], Wu and Gui [
16], Dey et al. [
17] and Alotaibi et al. [
18]. A good introduction to the idea of progressive censoring as well as a leading review article is provided by Balakrishnan [
19].
In view of the importance of the CSALT in rapidly ending the life test and the flexibility of the PT-IIC scheme over the conventional censoring schemes, our main aim in this paper is to investigate the estimation issues of the XLindley (XL) distribution when the data are gathered based on the PT-IIC plan with the CSALT. As far as we are aware, no work has yet addressed the CSALT model when PT-IIC data from the XL distribution are utilized. Although numerous studies investigated the estimation problems in the presence of CSALTs, few works studied the estimations of the reliability function (RF) and hazard rate function (HRF) under normal use conditions. In other words, the majority of the available studies considered only the estimation problems of the unknown parameters and say nothing regarding the estimation of the reliability indices under operating settings. Therefore, we think it is of interest to reliability engineers and other practitioners to identify the reliability measures under normal operating conditions in the case of the XL distribution. For more detail about the reliability estimation, see Wang et al. [
20], Wang et al. [
21] and Zhuang et al. [
22]. In this study, the model parameters are estimated using both classical and Bayesian approaches and then after some reliability measures are evaluated under normal use conditions. Using the maximum likelihood method, as a classical approach, the maximum likelihood estimates (MLEs) of the different quantities are acquired and the associated approximate confidence intervals (ACIs) are also obtained. On the other hand, the Bayes estimates are investigated based on the squared error (SE) loss function. Due to the complex form of the joint posterior distribution, the Markov chain Monte Carlo (MCMC) procedure is implemented to obtain the required Bayes estimates as well as the Bayes credible intervals (BCIs). It is important to mention here that the derived estimators from the two estimation procedures cannot be theoretically compared because of their complicated structures. To get over this problem, we consider carrying out simulation research to compare the effectiveness of different estimators (point or interval) based on some statistical standards. Additionally, two examples are provided to illustrate how different approaches can be used. The simulation findings show that the MCMC procedure provides more accurate estimates of the model parameters as well as the RF and HRF under normal operating settings than those acquired based on the classical maximum likelihood method. Moreover, the real data analysis demonstrates that the XL distribution can be considered as a suitable model to fit constant-stress accelerated data sets, namely the oil of insulating fluid and transformer life-testing (TLT) data.
The article’s structure is as follows: A description of the model, the test method, and the assumptions are given in
Section 2. The MLEs as well as the ACIs confidence intervals are covered in
Section 3. The Bayes estimation and BCIs of the unknown parameters are provided in
Section 4.
Section 5 presents the findings of the simulation research that was carried out to assess the effectiveness of the various estimators. Finally, two data sets are examined in
Section 6, and some concluding remarks are offered in
Section 7.
2. Model Description, Test Procedure, and Assumptions
A special combination of the exponential and Lindley distributions, known as the XL distribution, was introduced by Chouia and Zeghdoudi [
23] as a new variant of the Lindley distribution. They demonstrated that compared to other one-parameter models like the Xgamma, exponential, and Lindley distributions, the XL has greater flexibility. They demonstrated the flexibility and suitability of the XL distribution as a model for representing time-to-event data in the real world. In addition to having an increasing hazard function, which is typical in many fields, it also has a single parameter which considerably reduces the mathematical challenges in reliability estimation. Using an adaptive Type-II progressive hybrid censoring plan, Alotaibi et al. [
24] addressed the estimation problems, including both classical and Bayesian methods, of the XL distribution. They also demonstrated that data sets from chemical engineering may be modeled using the XL distribution rather than some other classical distributions, including gamma and Weibull distributions. Assume that
Y is an experimental unit’s lifetime random variable that follows the XL distribution with scale parameter
. As a result, the probability density function (PDF), distribution function (DF), RF and HRF corresponding to
Y are expressed, respectively, by
and
where
.
2.1. Test Procedure
Under CSALT, assume that we have
r accelerated stress levels
, where the stress level under usual conditions is
. Let
be
r subgroups created from a total of
N identical test items, where
. Assume that
is the level of stress applied to the
test units. The number of observed failure
is fixed before starting the experiment with a prefixed progressive censoring plan
, with the awareness that
. At stress level
, when the first failure, say
, occurred, from the remaining surviving items,
items are randomly removed. Similarly, at
,
items are randomly removed from the remaining items, and so on. At the time of the
failure, say
, all the remaining items are withdrawn. The PT-IIC data that were observed under the stress level
were collected in this manner
2.2. Basic Assumptions
In the context of CSALT, the following assumptions are applied across the whole paper:
Under the designed stress
and the accelerated stress levels
, the lifetime of test items follows the XL distribution with DF given by
It is assumed that the life-stress model for the scale parameter
of the XL distribution is log-linear, i.e.,
where
and
are unknown parameters depending on the product’s characteristics and need to be estimated.
Based on the above assumptions, without the normalized constant, we can write the joint likelihood function of the unknown parameters
and
, given the observed data, as follows
where
.
3. Maximum Likelihood Estimation
In this section, the MLEs of the unknown parameters
and
as well as the RF under designed stress are investigated. Moreover, the ACIs of these different parameters are discussed, employing the asymptotic properties of the MLEs. Using the aforementioned assumptions and by substituting the PDF and DF in the joint likelihood function presented in (
5) by the PDF and DF of the XL distribution given by (
1) and (
2), respectively, we obtain
where
and
. The log-likelihood function of (
6) is obtained as follows:
The MLEs of the model parameters, indicated by
and
, can be determined by solving the following non-linear likelihood equations which are obtained by setting the derivatives of the log-likelihood function in (
7) with respect to
and
to zero
and
Because the solutions to the previous equations cannot be found in a closed form, the Newton–Raphson method is frequently employed in these circumstances to produce the appropriate MLEs
and
. Based on the estimated values
and
, we can obtain the MLEs of RF and HRF under normal operating conditions
at mission time
t, respectively, using the invariance property of the MLEs, as demonstrated below:
and
where
After having the point estimates for the various parameters, it is now interesting to construct the confidence intervals for the unknown parameters
and
, or any function of them, such as the RF and HRF. Here, we utilize the asymptotic normality of the MLEs to obtain the ACIs of the different parameters. According to Miller [
25], the asymptotic distribution of the MLEs can be expressed as
, where
is the approximated variance–covariance matrix as presented below:
where
and
Therefore, for
, the
ACIs for
and
are provided by
where
and
are the main diagonal elements of (
10) and
is the upper
percentile point of the standard normal distribution.
As a matter of fact, in order to establish the confidence bounds of the RF and HRF under normal operating conditions, we should first determine the variances of their estimators. Here, we approximate the necessary estimated variances of
and
using the delta method. To apply this approach, we need the first derivatives of RF and HRF with respect to the parameters
and
as follows:
and
Let
and
, evaluated at the MLEs of
and
. Then, the approximate estimated variances of
and
are obtained as follows:
Consequently, the ACIs of
and
can be constructed, respectively, as
4. Bayesian Estimation
When the sample size is large or the data are well collected, MLEs usually produce results that are reasonably accurate. However, when there is a lot of information missing from the data or the sample size is limited, the Bayesian paradigm produces a more precise inference. We discuss the Bayesian inference for the model parameters as well as the RF and HRF in this section. As we are aware, in a Bayesian investigation, the model parameters are generally treated as random variables that follow a set of predetermined prior distributions. On the basis of the prior knowledge and the observed data, it is then possible to acquire the posterior distributions of the model parameters and obtain the Bayes estimators as well. Keep in mind that the mean time to failure of the testing units is often lower in ALTs because of the stress conditions. In our case and for the XL distribution, one can see from Chouia and Zeghdoudi [
23] that the mean is a decreasing function of the parameter
. Under the log-linear model, this can be achieved for positive
with any value for the parameter
. This idea can be incorporated into the priors. We assume that the parameters are independent, where the parameter
follows the normal distribution, which allows the parameter
to be negative or positive. On the other hand, the parameter
is assumed to follow the gamma distribution which is more flexible than other prior distributions and adapts the support of the parameter
, i.e.,
and
. Then, the joint prior distribution can be expressed as
where
and
are the hyperparameters. Equations (
6) and (
11), when combined, can provide the following as the joint posterior density function of
and
:
where
A is the normalized constant given by
We can draw Bayes estimators with respect to parameters of interest and/or functions of parameters, say
, using the SE loss function as follows:
Due to the ratio of two intractable integrals in (
13), it appears that the Bayes estimator cannot be derived analytically. Due to this difficulty, the MCMC method is used, which does not require the computation of a normalizing constant. First, we must derive the conditional distributions of the parameters
and
to apply the MCMC technique. In light of (
12), the following are the conditional posterior distributions of
and
, respectively,
and
It is noted that no analytical reduction to any well-known distributions can be achieved for the conditional distributions of
and
provided by (
14) and (
15), respectively. The main goal of MCMC algorithms is to generate samples from a given probability distribution. The “Monte Carlo” part of the method’s name is due to the sampling purpose, whereas the “Markov Chain” part comes from the kind of Markov chains. As a result, the Metropolis–Hastings (M-H) procedure is used to generate samples from these distributions in order to obtain the Bayes estimates and the BCIs. To implement the M-H procedure, we consider the normal distribution as the proposal distribution for both parameters. Thus, follow the steps listed below for the sample generation process:
To guarantee convergence and avoid the appeal of starting values, the first
D generated samples are eliminated. In this case, we have
, where
, where
. Based on large
M, one can compute the Bayes estimates of
based on the SE loss function as
where
and
. To obtain the BCI of
, sort
as
,
. Then, the
BCI of the
takes the form
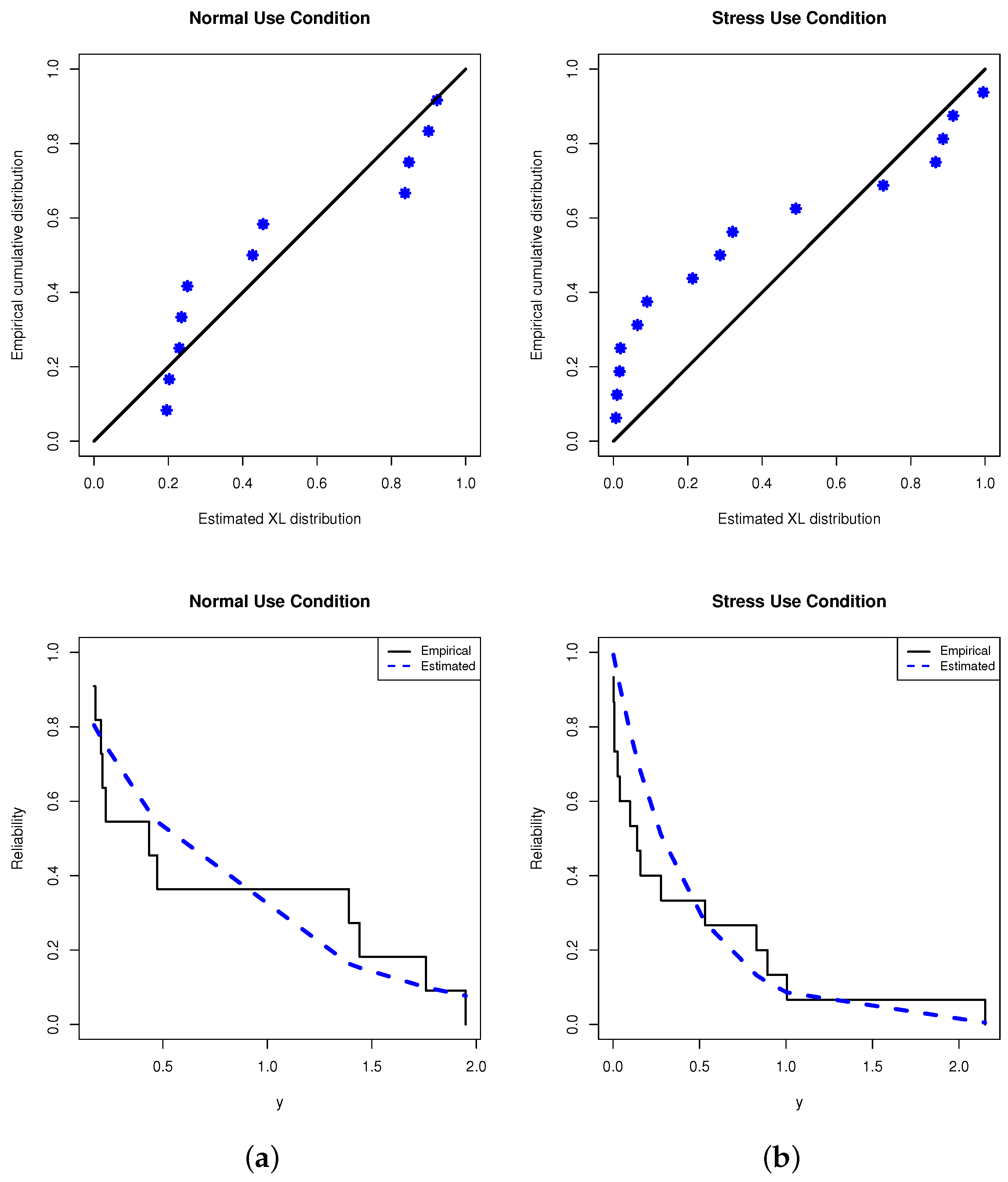
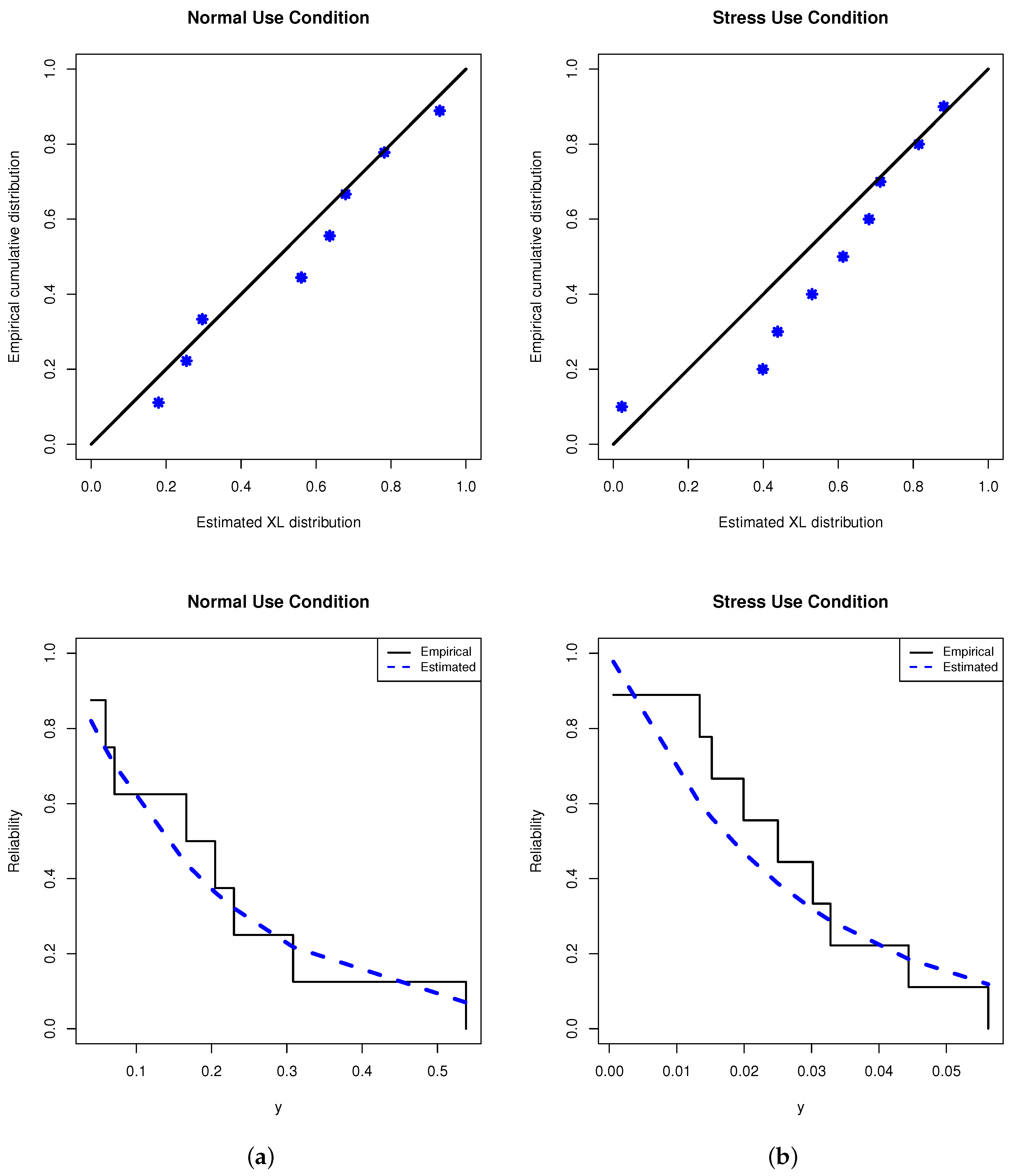
5. Monte Carlo Simulations
To compare the behavior of the proposed point and interval estimators of the XL model parameter
and its reliability characteristics RF
and HRF
, extensive simulation studies are conducted based on several combinations of
(stress levels),
(group size),
(effective sample size) and
(censoring pattern). We replicated the PT-IIC mechanism 1000 times when the true value of (
) is taken as (0.2, 0.5). At the same time, for the usual condition
, the acquired estimates of
and
at time
are evaluated when their actual values are taken as 0.9011 and 1.0438, respectively. Take 2 choices of stress levels
, namely (1, 2) and (3, 5),
, without loss of generality, and the failure percentages (FPs) are taken as
to a specific amount
m of each
n. Moreover, for each setting, different progressive censoring mechanisms are considered as follows:
Once 1000 constant stress PT-IIC samples are collected, the maximum likelihood and Bayes estimates of
,
,
(based on normal condition
),
and
along with their asymptotic and credible interval estimates are calculated. To perform the desired numerical evaluations, using
R 4.2.2 software, we suggest to install both the ‘
maxLik’ (proposed by Henningsen and Toomet [
26]) and ’
coda’ (proposed by Plummer et al. [
27]) packages in order to carry out the maximum likelihood and Bayesian analysis.
Following the mean and variance criteria of the proposed density priors, we have chosen different sets of the prior parameters
of
and
, called Prior[1]:(0.2, 5, 0.5, 1) and Prior[2]:(0.2, 1, 2.5, 5). These values are determined in such a way that the expected prior refers to the sample mean for the coefficient of interest. Alternatively, the hyperparameter values can also easily be specified using the past-sample technique. Following the M-H sampler described in
Section 4, to obtain the Bayes point (or credible) estimates of
,
,
,
or
, we simulated
and
samples.
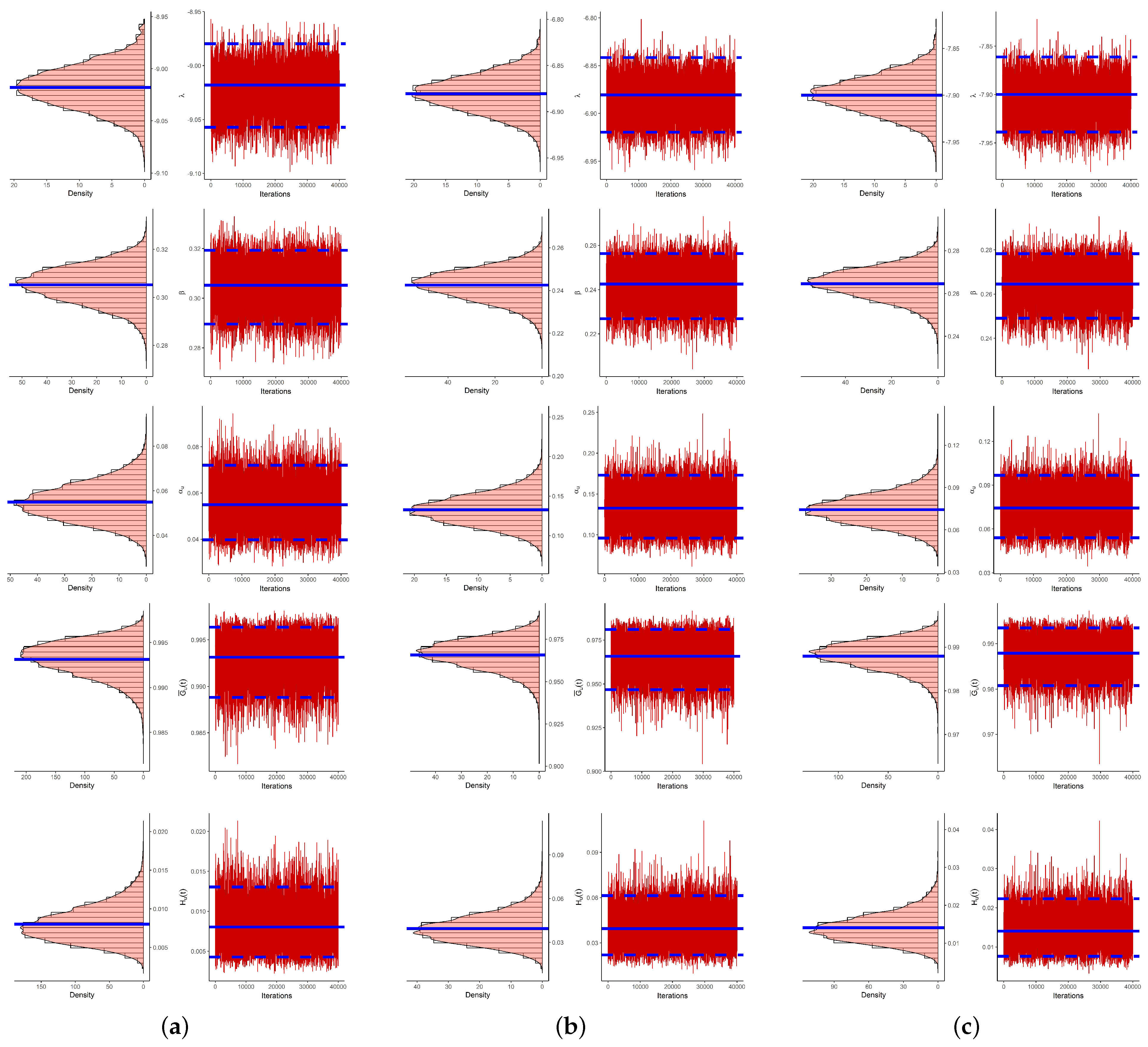
To evaluate the convergence of the simulated MCMC draws of
,
,
,
or
, when
,
and Scheme-1 (as an example), both the autocorrelation and trace convergence diagnostic plots are shown in
Figure 1. It shows that the samples drawn from the Markov chain of all the unknown parameters are mixed adequately, and thus the calculated estimates are satisfactory.
Now, the comparison between the acquired point estimates of
is made based on their root mean squared errors (RMSEs) and mean absolute biases (RABs), respectively, as
and
respectively, where
is the calculated estimate at
ith sample of
.
Additionally, taking
, the comparison between the acquired interval estimates of
is made based on their average confidence lengths (ACLs) and coverage percentages (CPs) as
and
respectively, where
is the indicator function,
is the two-sided interval estimate. In a similar fashion, both point and interval estimates of
,
,
and
can easily be developed.
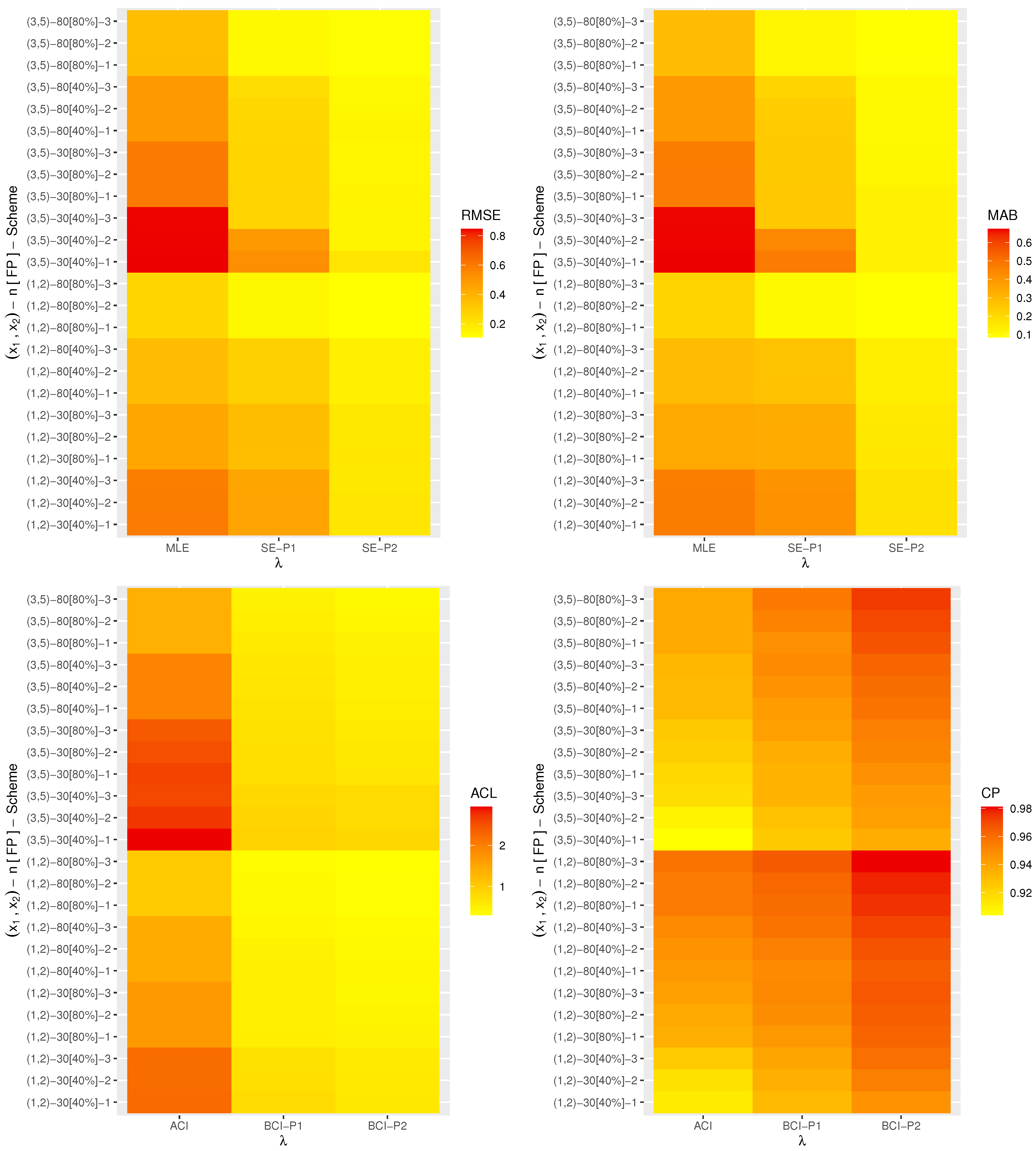
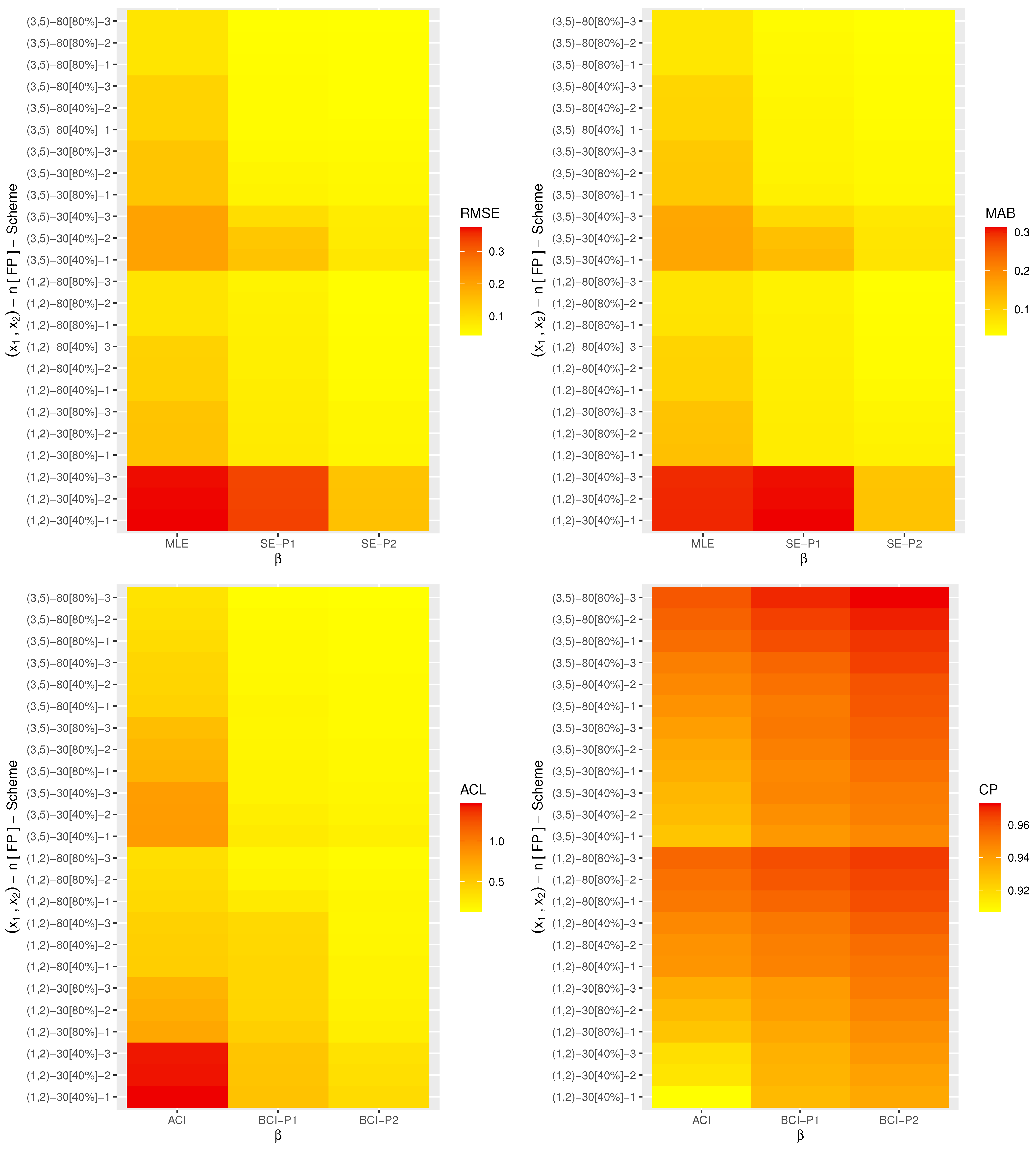
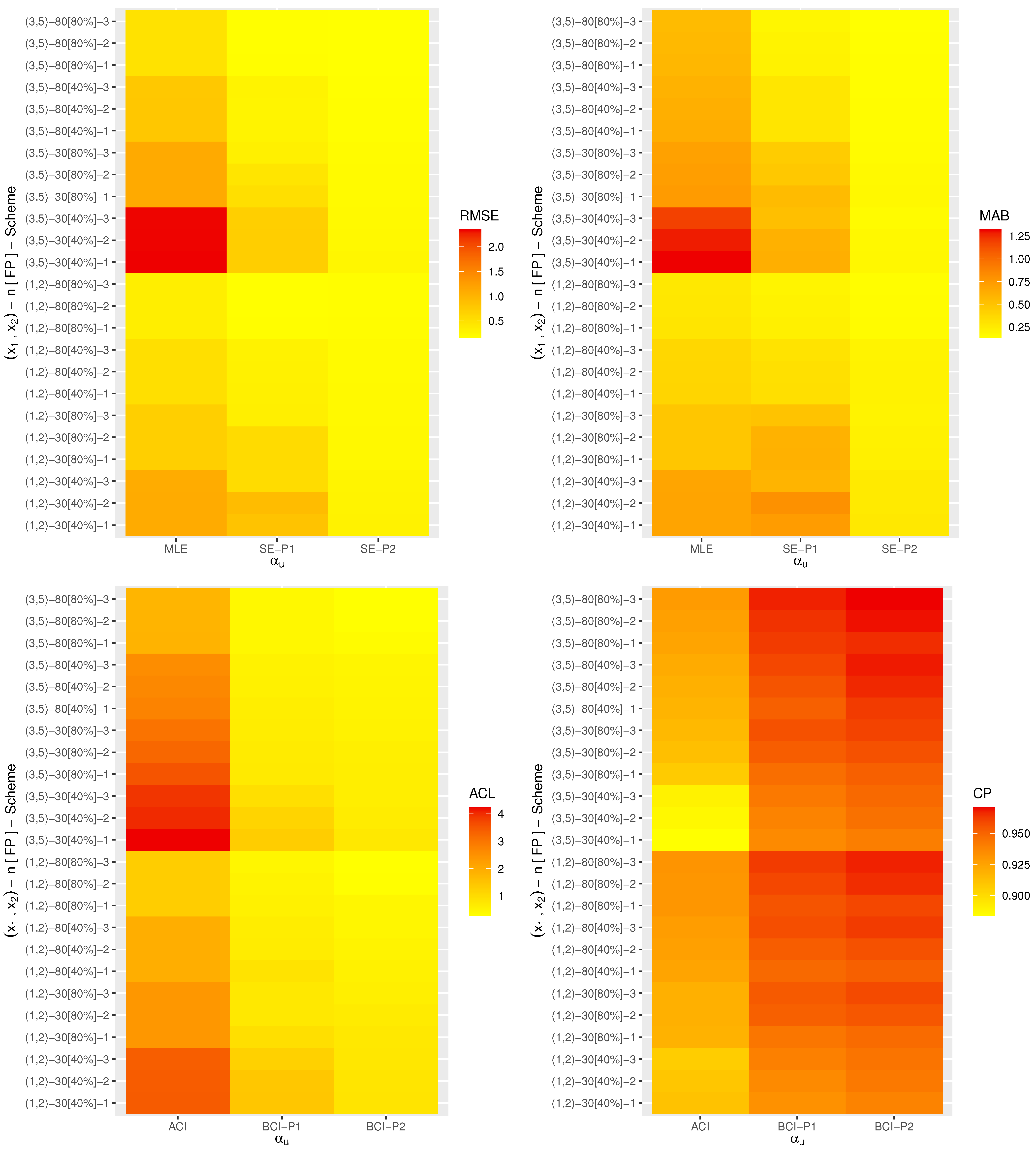
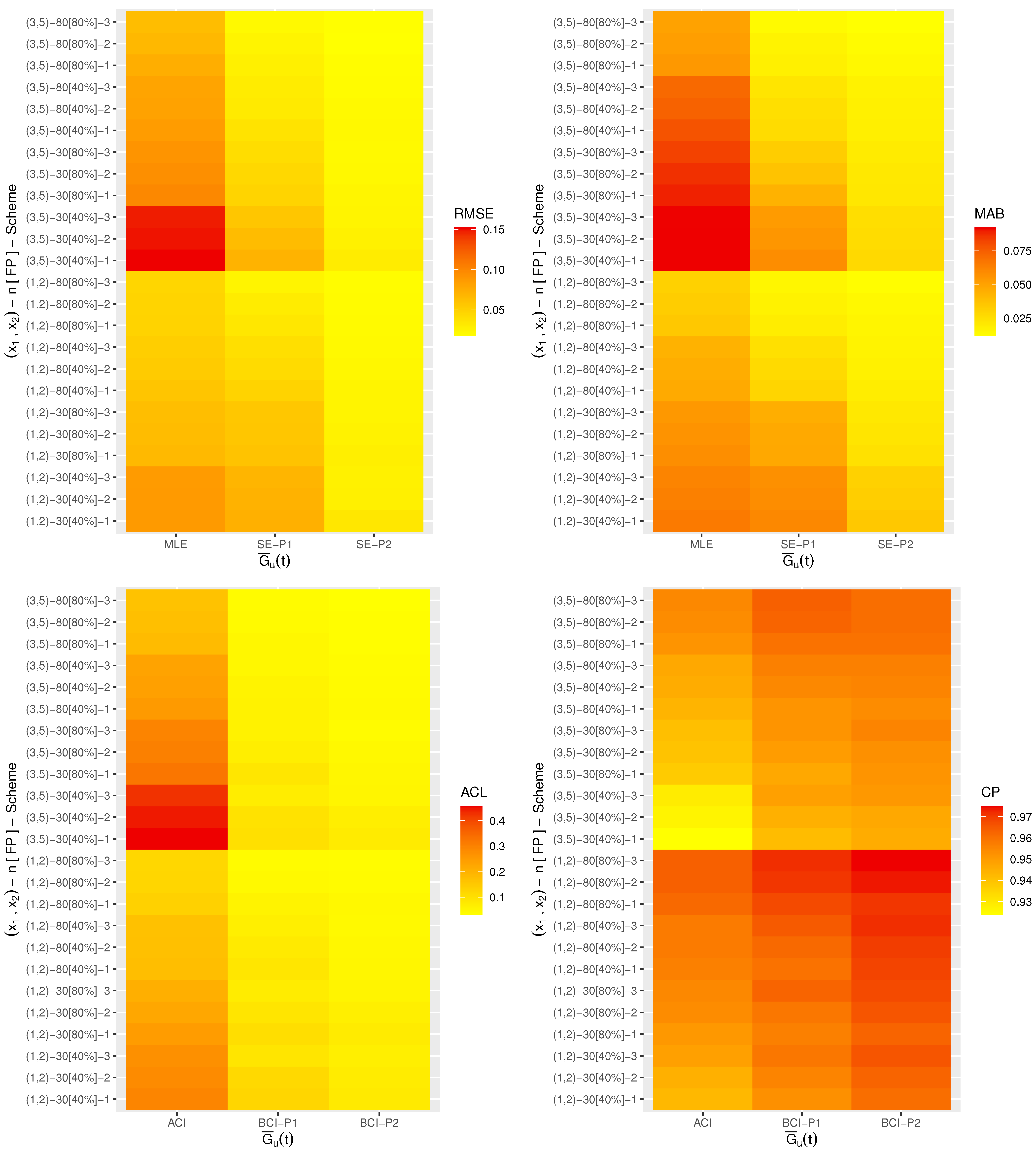
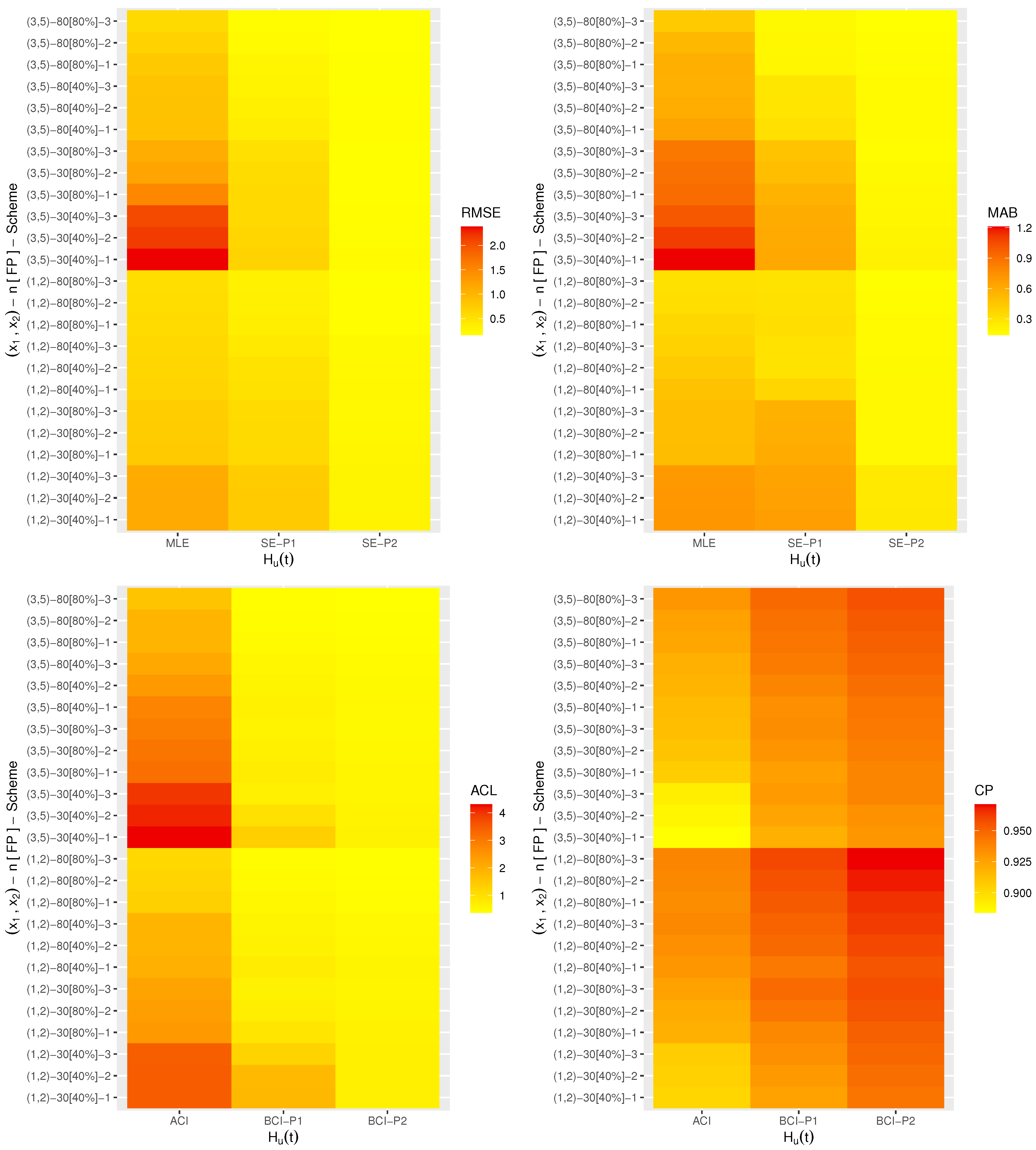
Nowadays, heat-map data visualization has become a popular tool for digital data representation as the value of each data point is indicated using specific colors. Therefore, all the simulated results (including the RMSE, MAB, ACL and CP) of
,
,
,
and
are displayed by a heat-map tool in
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6, respectively. Specifically, for Prior-1 (say P1) as an example, the Bayes estimates are mentioned as “BE-P1”, whereas the BCI estimates are mentioned as “BCI-P1”. All the numerical tables are also available as
Supplementary Materials.
From
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6, in terms of the lowest level of the RMSE, MAB and ACL values as well as the highest level of the CP values, we list the following conclusions:
As a general comment, it is clear that the derived point (or interval) estimates of , , , or have a good performance.
As n (or m or both) increases, all the calculated estimates provide better results and hold the consistency property. An equivalent observation is also reached when decreases.
As increase, the following can be seen:
The RMSEs and MRABs of all the estimates of increase while of they decrease.
The RMSEs and MRABs of , and derived from the likelihood method increase while those derived from the Bayes method decrease.
The ACLs of increase while of they decrease. The CPs of decrease while of they increase.
The ACLs of , and obtained from the ACI method increase while those obtained from the BCI decrease. Regarding their CPs, the opposite result is noted.
It is known that more accurate estimates will be obtained when the priors are used more accurately. Thus, for all settings, the MCMC estimates of , , , and provide more accurate results compared to those obtained from the likelihood method.
Because the calculated variance of Prior[1] is higher than that associated with Prior[2], as anticipated, all the MCMC (or BCI) estimates using Prior[2] have more accurate results than the others, and both are better than those obtained from the MLE (or ACI) estimates.
Comparing the proposed censoring schemes 1, 2 and 3, for both the point and interval estimates, it is observed that the proposed estimation procedures of , , , or perform better based on Scheme-3 (right censoring) than the others.
To sum up, the simulation facts showed that the Bayes estimation method according to the M-H sampler for evaluating the XL parameters of life has a good performance and is recommended across different scenarios.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}