1. Introduction
There are many situations in life-testing and reliability experiments in which units are lost or removed from the test before failure. The data observed from such experiments are called censored data. To save time and costs, censored data are used. Type-I and Type-II censoring schemes are the two most frequently used censoring schemes. In Type-I censoring, failures are observed until the pre-determined time
(time censoring), while in Type-II censoring (failure censoring), when the time of
r failures is reached, the experiment is terminated, where
r is specified before experimenting with
n items on the test:
. Various modified censoring schemes such as progressive censoring and multiply censoring are also available and are used to analyze the lifetime data. In different situations, it is more common to provide the optimal test period and the corresponding number of failures needed for statistical inference. A mixture of Type-I and Type-II censoring schemes is known as a hybrid censoring scheme (HCS). This type of scheme has received considerable attention among practitioners. Several HCSs have been introduced in the literature. For example, Childs et al. [
1] introduced the generalized Type-I and Type-II HCSs, Kundu and Joarder [
2] introduced the progressively Type-II HCSs, and Balakrishnan et al. [
3] and Lone and Panahi [
4] introduced unified HCSs.
In real-life experiments, a product can fail for a variety of reasons, and these reasons are referred to as competing risks since we can only observe the product failing for one reason but not the others. In reliability and survival analysis, this kind of observations are modeled by a competing risks model. When using the competing risks models, our goal is to assess the risk of a particular cause in relation to other potential causes for failure. This model has been used earlier by different authors; for example, Cox [
5] discussed the competing risks model using the exponential populations.
Several properties of a competing risks model have been presented by Crowder [
6], Balakrishnan and Han [
7], Modhesh and Abd-Elmougod [
8], Bakoban and Abd-Elmougod [
9], Debnath and Mohiuddine [
10] and Alghamdi [
11]. Recently, the characteristics of the competing risks model under the accelerated life test model were discussed by many authors; for example, Ganguly and Kundu [
12] and Hanaa and Neveen [
13]. A joint censoring scheme (JCS) may occur while conducting comparative life tests on products from different lines of production under the same conditions. This type of censoring scheme has been discussed by different authors. For example, Rao et al. [
14] developed the rank order theory under JCS, while Johnson and Mehrotra, [
15] presented the most locally powerful rank tests under JCS. Mehrotra and Bhattacharyya [
16] used JCS to explore the problem of measuring the equality of two exponential distributions. The confidence intervals using JCS regarding the exponential distribution were developed by Mehrotra and Bhattacharyya [
17]. Balakrishnan and Rasouli [
18] and Rasouli and Balakrishnan [
19] developed the exact likelihood inferences for the exponential distributions under JSCs and progressive JSCs. The estimation and prediction of two exponential distributions are discussed in the work of Shafay et al. [
20]. Recently, this problem has been handled by Algarni et al. [
21], Mondal-Kundu [
22], Mondal-Kundu [
23], Almarashi et al. [
24], Tahani el al. [
25] and Abdulaziz et al. [
26]. To describe human mortality and provide actuarial tables, the Gompertz distribution was developed. This distribution is widely used as a life time distribution in demography, actuarial, biology, and medical research and plays a vital role in modelling survival times. Many product ’s life times are modelled in reliability and survival studies by an increasing hazard rate or a Gompertz distribution. Assuming skewness and kurtosis of this distribution are fixed constants and independent of the distribution parameters, the Gompertz distribution has been used to obtain age-specific fertility rates. Comparative life tests are adopted for products deriving from different lines of production under the same conditions in the presence of the competing risks model. The problem of inference of unknown quantities in the population is formulated using the population characteristics and censoring methodologies. Here, we discuss these problems when the failure time of population units has a Gompertz lifetime distribution with a CDF given by
The Gompertz distribution has density function that is in zero mode when
and hence monotonically decreases at
However, if
then take the mode
; hence, it increases in
and decreases in
For more details, see Soliman et al. [
27,
28]. The statistical inference of Gompertz distribution for independent competing risks model was developed by Lodhi et al. [
29] and for dependent competing risks model was developed by Wang et al. [
30]. Gompertz distribution reduces to exponential distribution when
. As far as we know, no works were observed under joint Type-II GHCS in the case of Gompertz distribution. In this paper, we adopted the joint Type-II GHCS in comparative Gompertz populations in the presence of a competing risks model. We used different methods of estimation: the ML, bootstrap and Bayes methods. The model parameters and reliability of the system were estimated using point and interval estimates. Different tolls such as MSE and coverage percentage were used to assess and compare the results through Monte Carlo simulation studys. Finally, we analysed a real data set to demonstrate our goals.
The rest of the article is organized as follows: A description of a generalized hybrid censoring scheme is presented in
Section 2. The model and its assumptions are formulated in
Section 3. In
Section 4, using joint Type-II GHC competing risks data, we discuss the maximum likelihood estimation MLE of the parameters, as well as the reliability and failure rate functions. Based on the asymptotic normality of the MLEs, the approximate confidence intervals were obtained in the same section. Two bootstrap confidence intervals (based on bootstrap-p and bootstrap-t methods) are discussed in
Section 5. The Bayes estimations under squared error loss function and gamma priors are obtained in
Section 6. An assessment and comparison of the results, using a Monte Carlo simulation study, are reported in
Section 7.
Section 8 deals with a real-life data set for illustration purposes. Finally, conclusions and concluding remarks are discussed in
Section 9.
2. Generalized Hybrid Censoring Scheme
For HCS, suppose that (
m) are the ideal test time and the corresponding number of failures. Hence, in Type-I HCS the test is terminated at min(
), where
is the failure time of
m-th failure. The test is terminated at max(
) in Type-II HCS. For an extensive review of HCSs, see Childs et al. [
1], Gupta and Kundu [
31], Zhang et al. [
32], Kundu and Pradhan [
33] and Algarn et al. [
34]. The problems of the low expected number of failures and long test time are still present in Type-I and Type-II HCSs. To solve these problems, Chanrasekar et al. [
35] established the generalized hybrid censoring scheme (GHCS), which can be described as follows:
Type-I GHCS: Consider a life testing experiment with
n units, two fixed positive integers
and the ideal test time
that was previously proposed, such that
. When the test is running, the failure time
is recorded until the failure
is observed. Hence, if
, then the test is terminated at
where
min(
,
). If
the test is terminated at
. Therefore, the data under Type-I GHCS are
where the number of failed units
k and the corresponding test termination time
are defined by
if
,
, if
,
, if
. For more details, see Chakrabarty et al. [
36].
Type-II GHCS: Assume that
n units are involved in the experiment. The two times
and the integer number
m have been proposed previously. When the test is running the failure time
is recorded until the time
is observed. If
, then the test is terminated at
. However, if
, the test is terminated at
and if
, the test is terminated at
. Therefore, the data under Type-II GHCS:
where
k is the number of failed units. The integer number
k and the corresponding test terminated time
are defined by
if
and
. In this paper, we adopted Type-II GHCS, which guarantees to terminate the experiment at a pre-fixed time
, with
and
as the shortest and longest test times, respectively. The time
is the absolute longest time for which the experiment is allowed to continue, which is suitable for many applications. Hence, experiments using Type-II GHCS are guaranteed to be completed by time
, which is the suitable time for which the researcher is willing to continue the experiment. The possibility of removing units from the test, other than the last point, is not available in two GHCS schemes (Type-I and Type-II). However, the possibility of removing survival units from the test is available in generalized progressive censoring schemes (GPCSs); see Balakrishnan [
37], Balakrishnan and Cramer [
38] and Elsherpieny et al. [
39].
3. Modeling
Suppose that, from a population consisting of two lines and , the joint random sample of size is randomly selected as ( from and from ). We considered only two potential causes of failure, and we adopted Type-II GHCS with two times and the integer number During the experiment, the failure time , unit type {1, 0} (where 1 means the unit from the line and 0 the unit from the line ) and the cause of failure {1, 2} (failure under causes one or two) were recorded. When the first failure was observed, we recorded ( ); when the second failure was observed, () was recorded. Under Type-II GHCS, the number of failure units and the corresponding test termination time were denoted by (k, ), respectively. The experiment was continued until the time . If, then the test was terminated at . However, if , the test was terminated at and if , the test was terminated at . Therefore, the observed joint Type-II GHC competing risks data were defined by: , where if and The proposed model under joint Type-II GHC competing risks data included the following assumptions
The number of failures taken from line is given by and those from line are given by .
The number of failures taken from line under cause j is given by and those from line are given by .
The latent failure time is defined by (), and s is used to define the unit type, .
The
i-th failure time
of the line
and cause
has the Gompertz lifetime distribution with CDF given by
The latent failure time
(
) has a Gompertz lifetime distribution with a CDF given by
The integer number of failure is obtained from the line under j; 2 have the binomial distribution .
The likelihood function of the joint Type-II GHC competing risks data
see Abdulaziz et al. [
26] is given by
where
and
are the density and reliability functions of type
s and cause
j, where
s,
j = 1, 2 and
are defined by
5. Bootstrap Confidence Intervals
The bootstrap method is a resampling technique for statistical inference that can be used to construct confidence intervals (CIs) for the model parameters. In the literature, the bootstrap technique is frequently used to gauge an estimator’s bias and variance. This technique is widely used in calibrate hypothesis tests. There are two types of bootstrap techniques, parametric and nonparametric techniques; see Davison and Hinkley [
44] and Efron and Tibshirani [
45]. In the parametric bootstrap technique, the percentile bootstrap-
p and bootstrap-
t techniques are applied; see Efron [
46] and Hall [
47]. In this section, we adopted the percentile bootstrap-
p and bootstrap-
t techniques to formulate the confidence intervals of the model parameters, which can be implemented with the following algorithm (Algorithm 1).
| Algorithm 1 Percentile bootstrap-p and bootstrap-t confidence interval. |
- Step 1:
For given the original joint competing risks Type-II GHC data , compute the ML estimates of the model parameters . - Step 2:
Generate two samples of size from Gompertz( ) and sample of size from Gompertz( ). - Step 3:
For a given and generate the joint Type-II GHC competing risks data defined by - Step 4:
Using the bootstrap sample , compute the integers and determine the termination time - Step 5:
The numbers of failure (obtained from the line under the obtained where 2) are generated from the binomial distribution with parameters and - Step 6:
The bootstrap estimates are computed using (10) and (15). - Step 7:
Repeat Steps (2–6) times. - Step 8:
The resulting bootstrap estimates are arranged in ascending order, ,
|
Percentile bootstrap confidence interval (PBCI)Let
be the empirical cumulative distribution function of
then, the point bootstrap estimate of
is given by
The corresponding
PBCIs are given by
where
.
Bootstrap-t confidence interval (BTCI)
From the ascending order sample
,
6, we built the order statistics values
where
Hence,
BTCIs are given by
where
is given by
and
is the cumulative distribution function of
.
6. Bayesian Approach
In this section, to obtain the joint Type-II GHC competing risks data
we consider the problem of the Bayesian estimation of model parameters. We assume that the prior distributions for the unknown parameters are independent gamma priors. Therefore, the prior information formulated for the parameter vector
as
Hence, the joint prior density function of the model parameters is given by
The joint posterior density function of the model parameters is given by
Inserting (6) and (37) in (38) and ignoring the additive constant, the joint posterior density can be expressed as
Under the squared error loss (SEL) function, the Bayes estimate of the parameter is the posterior mean. Then, the Bayes estimate of the parameters or any function of the parameters, such as reliability or failure rate functions, say
(
), is given by
Equation (
40) shows that the Bayes estimate of
needs to compute a high-dimensional integral. Appropriate numerical methods could be used to approximate Bayesian estimation.
One of the most common methods applied in this paper is the Markov Chain Monte Carlo method (MCMC method). Compared with traditional methods, the MCMC method is more flexible and provides an alternative approach to parameter estimation. The key to the MCMC technique is obtaining posterior distribution in the empirical form and generating MCMC samples from the posterior distribution, and then computing Bayes estimators and constructing the associated credible intervals. Therefore, we describe this technique as follows.
From Equation (
39), the posterior full conditional density functions of the parameters and data can be obtained as
and
where
and, for example, (
mean (
The full conditional posterior distributions show that the posterior distribution is reduced to four gamma distributions, for which any conventional methods of generating random numbers can be used. And two general unknown functions make it impossible to generate random samples directly from the conditional posterior distributions. Therefore, to generate random samples from the two unknown distributions, the Metropolis–Hastings (M–H) algorithm with normal proposal distribution can be used; see [
48]. The following steps describe the algorithm used to generate from the posterior distribution (Algorithm 2).
| Algorithm 2 Gibbs with M-H sampler algorithms. |
- Step 1:
Begin with the indicated number and the initial parameter values . - Step 2:
The values and are generated from gamma distributions given by (40) and (41), respectively, 1, 2. - Step 3:
The values generated under M–H algorithms with a normal proposal distribution with a mean and variance , obtained from an approximate information matrix, 1, 2, as follows
- (I)
For the index , begin with starting points where . - (II)
Generate a candidate sample points , from N(), as proposal distributions. - (III)
Compute the probability (the acceptance probability) from (43) and (44)
- (IV)
Generate from uniform (0, 1). - (V)
If we accept the candidate sample points as . Otherwise, the values are rejected and is set.
- Step 4:
Put - Step 5:
Repeat steps (2–4) N times. - Step 6:
Put the generated parameter vector in ascending order; for example, ,
|
6.1. MCMC Bayesian Point Estimations
The initial simulated variants of the algorithm are often discarded at the start of the analysis (burn-in time) to eliminate the bias caused by the initially selected value. Suppose that the number of iterations needed to reach the stationary distribution is
(burn-in). In all computations, we take the number
iteration. Hence, the Bayes point estimator when using the MCMC method is given by
The corresponding variance in the Bayes estimate is given by
6.2. MCMC Bayesian Interval Estimations
To establish the two-sided credible intervals of
; sort
in ascending order. Hence,
credible intervals of
can be constructed as:
7. Simulation Studies
In this section, the estimation results obtained and developed in this paper are assessed and compared using the Monte Carlo simulation study. In our study, we assessed the effect of changing sample size
and affected sample size
two times (
,
and parameters vector
. Therefore, we adopted two sets of parameter values
and
,
. For the censoring schemes, different combinations were adopted and are shown in
Table 1,
Table 2,
Table 3 and
Table 4. The prior information was selected using the relation (prior mean
where
and
are hyper-parameters of gamma prior. The point estimate were tested by computing the mean squared error (MSE). The interval estimates were evaluated using average length (AL) criterion, as well as the coverage probabilities (CPs). Using the Bayesian approach, we adopted.
Non-informative prior (
) and informative prior (
), where P
(
0.0001, 0.0001
and
(0.5, 5), (0.5, 4), (1, 6), (1, 4), (1, 3), (2, 4)}
for and
(1, 3),
(2, 5), (2, 4), (1, 3), (2, 2), (3, 2)}
for are selected. For the MCMC method, we reported 11,000 iterations and the first 1000 iterations were discarded. The simulation results were formulated according to the following algorithm (Algorithm 3).
| Algorithm 3 Monte Carlo simulation study. |
- Step 1:
From Gompertz distribution with two parameters and generate samples of size and , respectively. - Step 2:
From the joint sample of size and for given censoring parameters m, If, ; then, and the test is terminated at . However, if and the test is terminated at and if and the test is terminated at - Step 3:
From step 2, the number of failures , test termination time and failure times are generated. Hence, the observed joint Type-II GHC competing risks data are obtained. - Step 4:
The two values and (number of units from the first and second line in joint Type-II GHC competing risks data) are observed. - Step 5:
The integer numbers are generated from binomial distributions. - Step 6:
We obtain various estimates by considering 1000 replications of samples. Steps (1–4) are repeated 1000 times. - Step 7:
For each sample, the MLE, bootstrap and Bayes estimate are computed. - Step 8:
|
Discussion: Recently, the problem of obtaining adequate information about the competing lifetime distributions and their parameters it has been of interest to many authors. Therefore, the reliability experimenter may resort to censoring techniques. In this paper, we proposed joint Type-II GHCS. The behavior of different estimation methods under different censoring schemes can be obtained from a simulation study. The numerical results presented in
Table 1,
Table 2,
Table 3 and
Table 4 show that the proposed model and the methods of estimation work well. The quality of the proposed model did not change for different model parameters. We summarize some points that describe the capabilities and the behavior of estimators as follows.
The values of MSEs decrease when sample size + or effected sample size m increases.
The model quality improves at increasing and .
The results under classical ML and non-informative Bayes estimation are both closed.
Informative prior Bayes estimates present the best estimation.
Estimation results under two Gompertz distribution parameters are more acceptable.
Interval estimations are more acceptable using bootstrap-t and informative Bayes estimation.
8. Real Data Analysis
Real datasets obtained from laboratory experiments were used to discuss the results of this paper. This data presented by Hoel [
49] describe the survival time of male mice under a conventional laboratory environment. The test time considered an age of 5–6 weeks and male mice were exposed to radiation dose of 300 roentgens. These data were analyzed by Pareek et al. [
50], Sarhan et al. [
51] and Cramer and Schmiedt [
52]. Data obtained under progressive first failure of compertz population were analyzed by Soliman et al. [
27,
28]. In this section, we considered two groups of radiated male mice, as shown in
Table 5. For causes of failure, we considered Thymine Lymphoma as the first cause and the other causes were considered the second cause of failure. The data were divided by 1000 for simplicity of computation. To generate the joint Type-II GHC competing risks sample, the following algorithms were used (Algorithm 4).
Table 5.
Two groups of failure for the laboratory radiation male mice and .
Table 5.
Two groups of failure for the laboratory radiation male mice and .
| Thymic Lymphoma |
| 159 | 189 | 191 | 198 | 200 | 207 | 220 | 235 | 245 | 250 | 256 | 261 | 265 | 266 |
| | 280 | 343 | 356 | 383 | 403 | 414 | 428 | 432 | | | | | | |
| Other causes |
| 40 | 42 |
51 | 62 | 163 | 179 | 206 | 222 | 228 | 252 | 249 | 282 | 324 | 333 |
| | 341 | 366 | 385 | 407 | 420 | 431 | 441 | 461 | 462 | 482 | 517 | 517 | 524 | 564 |
| | 567 | 586 | 619 | 620 | 621 | 622 | 647 | 651 | 686 | 761 | 763 | | | |
| Thymic Lymphoma |
| 158 | 192 | 193 | 194 | 195 | 202 | 212 | 215 | 229 | 230 | 237 | 240 | 244 | 247 |
| | 259 | 300 | 301 | 321 | 337 | 415 | 434 | 444 | 485 | 496 | 529 | 537 | 624 | 707 |
| | 800 | | | | | | | | | | | | | |
| Other causes |
| 136 | 246 | 255 | 376 | 421 | 565 | 616 | 617 | 652 | 655 | 658 | 660 | 662 | 675 |
| | 681 | 734 | 736 | 737 | 757 | 769 | 777 | 800 | 807 | 825 | 855 | 857 | 864 | 868 |
| | 870 | 870 | 873 | 882 | 895 | 910 | 934 | 942 | 1015 | 1019 | | | | |
| Algorithm 4 Generate joint Type-II GHC competing risks data. |
- Step 1:
Suppose that the censoring scheme has m = 70, , and ( . - Step 2:
For the joint sample of size given in Table 5 and Table 6 and the corresponding censoring scheme, we observed that, - Step 3:
Hence, the value of and the test was terminated at . - Step 4:
For the joint Type-II GHC data of zise 58 given in Table 7, we obtained from the first line and = 23 from the second line, and ( ) = (18, 17, 19, 4).
|
Table 6.
Jointly type-II GHCS competing risks sample from Hoal data with .
Table 6.
Jointly type-II GHCS competing risks sample from Hoal data with .
|
0.04 | 0.042 | 0.051 |
0.062 | 0.136 | 0.158 |
0.159 | 0.163 | 0.179 |
0.189 | 0.191 | 0.192 | 0.193 | 0.194 |
| 1 | 1 | 1 | 1 | 0 | 0 |
1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| 2 | 2 | 2 | 2 | 2 | 1 |
1 | 2 | 2 | 1 | 1 | 1 | 1 |
1 |
| 0.195 | 0.198 | 0.2 | 0.202 | 0.206 | 0.207 | 0.212 | 0.215 | 0.22 | 0.222 | 0.228 | 0.229 | 0.23 | 0.235 |
| 0 | 1 | 1 | 0 | 1 | 1 |
0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 1 | 2 | 1 |
1 | 1 | 1 | 2 | 2 | 1 | 1 |
1 |
| 0.237 | 0.24 | 0.244 | 0.245 | 0.246 | 0.247 | 0.249 | 0.25 | 0.252 | 0.255 | 0.256 | 0.259 | 0.261 | 0.265 |
| 0 | 0 | 0 | 1 | 0 | 0 |
1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 2 | 1 |
2 | 1 | 2 | 2 | 1 | 1 | 1 |
1 |
| 0.266 | 0.28 | 0.282 | 0.3 | 0.301 | 0.321 | 0.324 | 0.333 | 0.337 |
0.341 | 0.343 | 0.356 |
0.366 | 0.376 |
| 1 | 1 | 1 | 0 | 0 | 0 |
1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 |
| 1 | 1 | 2 | 1 | 1 | 1 |
2 | 2 | 1 | 2 | 1 | 1 | 2 |
2 |
| 0.383 | 0.385 | | | | | | | | | | | | |
| 1 | 1 | | | | | | | | | | | | |
| 1 | 2 | | | | | | | | | | | | |
Table 7.
Point estimates with 95% CIs of the parameters.
Table 7.
Point estimates with 95% CIs of the parameters.
| Pa. | (.) | (.) | (.) | ACI | Boot-p | Boot-t | CI |
|---|
| 0.3365 | 0.5412 | 0.4675 | (0.0501, 0.6228) | (0.0472, 1.3214) | (0.1784, 0.9115) |
(0.1903,
0.9029) |
| 0.3178 |
0.4578 | 0.4442 |
(0.0450, 0.5905) | (0.1472, 0.8897) | (0.1954, 0.8874) |
(0.1782,
0.8789) |
| 0.3156 |
0.4652 | 0.4636 |
(0.0006, 0.6306) | (0.0015, 0.9541) | (0.1924, 0.8556) |
(0.1778,
0.8789) |
| 0.0664 |
0.1243 | 0.1184 |
(-0.0216, 0.1545) | (0.0824, 0.4123) | (0.0336, 0.2911) |
(0.0298,
0.2824) |
| 5.1907 |
5.3254 | 4.1962 |
(2.1508, 8.2306) | (2.3652, 8.4562) | (1.4215, 7.1921) |
(1.3725,
7.0651) |
| 4.5269 |
4.7771 | 3.3093 |
(0.8129, 8.2408) | (0.9112, 8.7214) | (0.741, 6.4007) |
(0.6402, 6.4894) |
Using the joint Type-II GHCS presented by
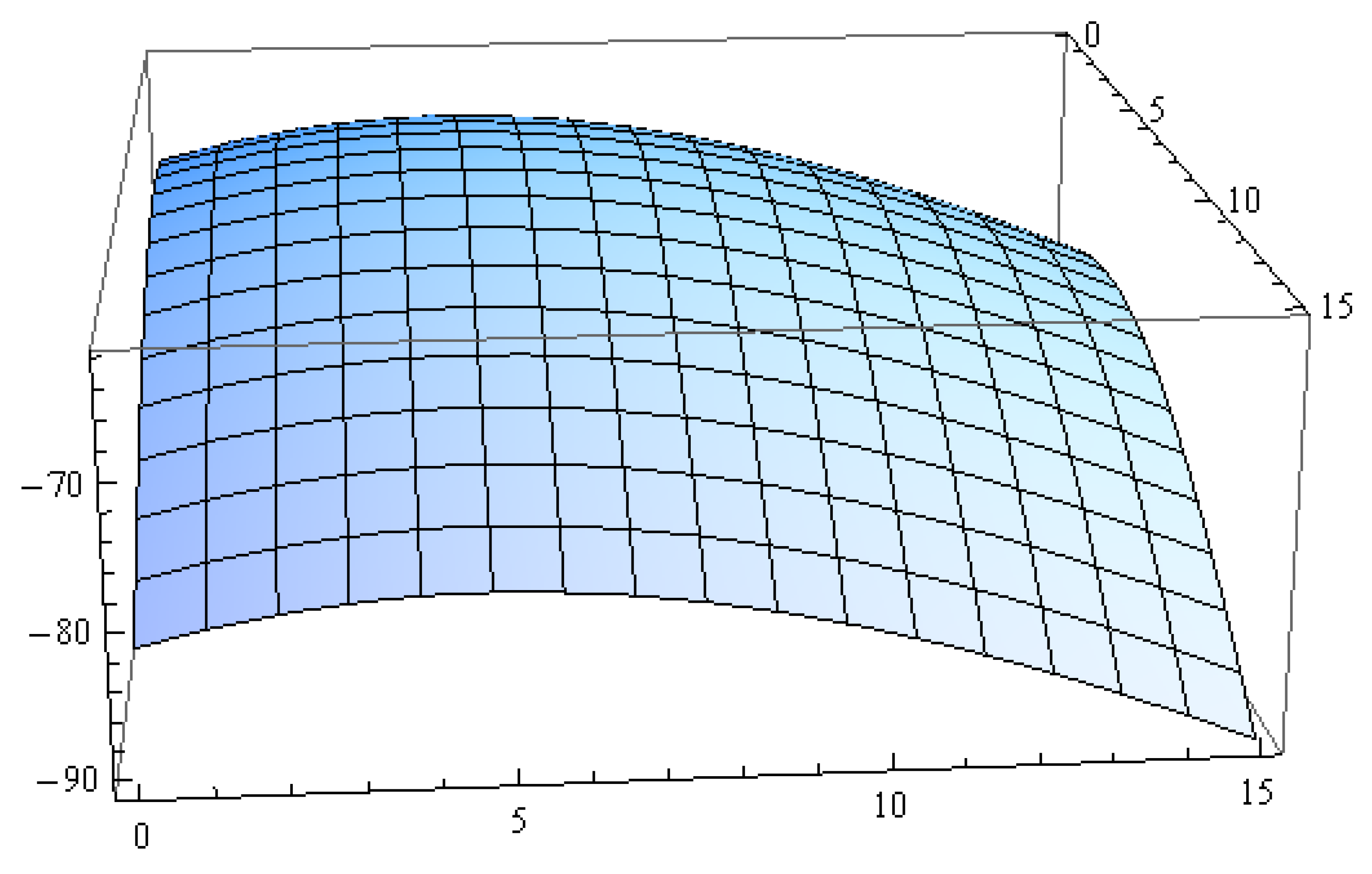
Table 6, we plotted the profile log-likelihood function (16) as in
Figure 1. The maximum values need to begin with initial values of the parameters
and
, showing that the iteration can be run with initial values that are almost in the neighborhood of the maximum values in
Figure 1; therefore, the initial values were taken to be (
,
) = (5, 6). For Bayes estimation, we adopted non-informative prior with
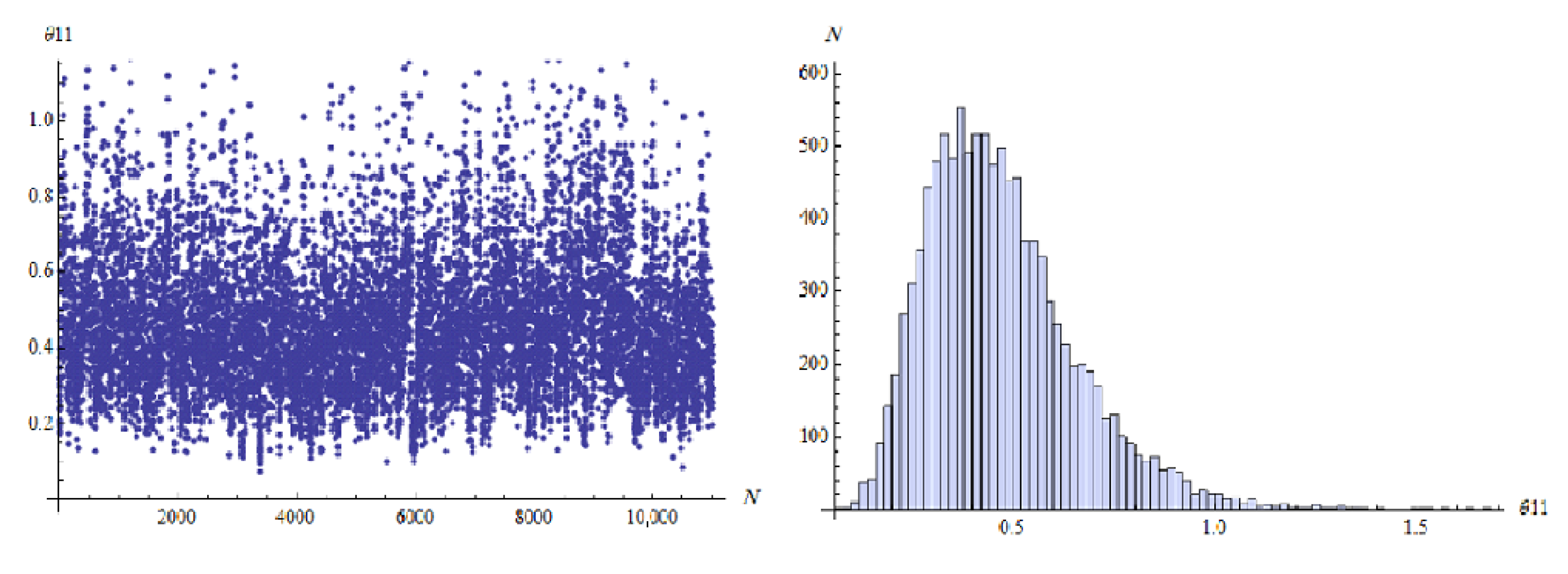
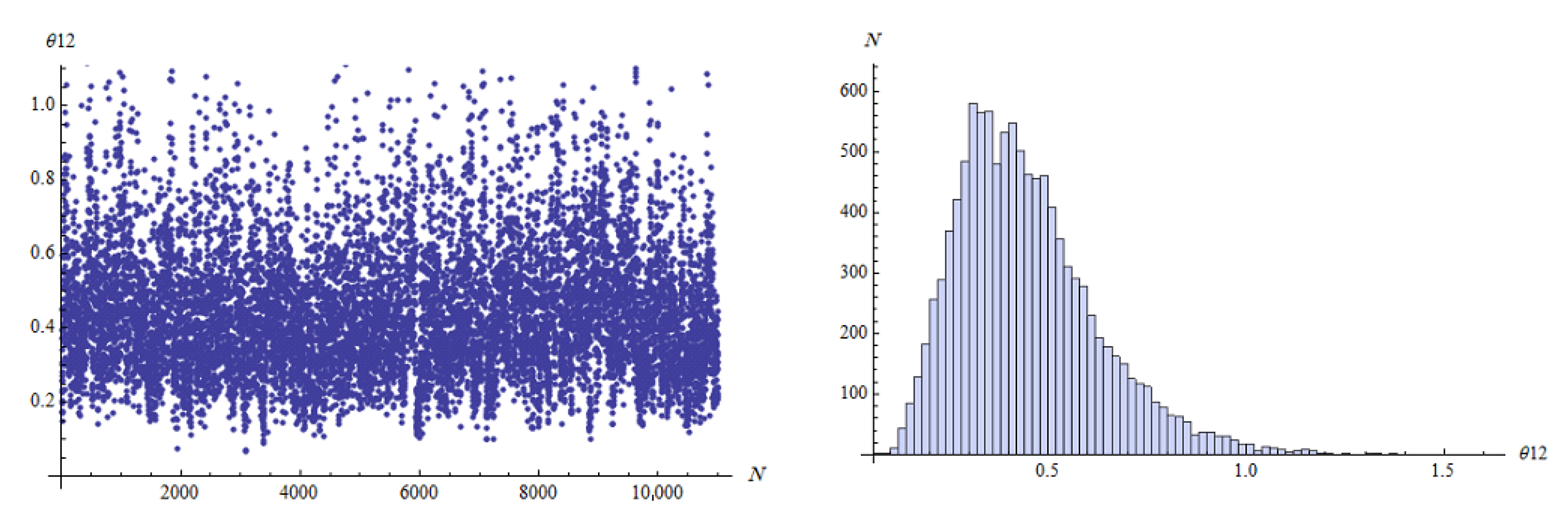
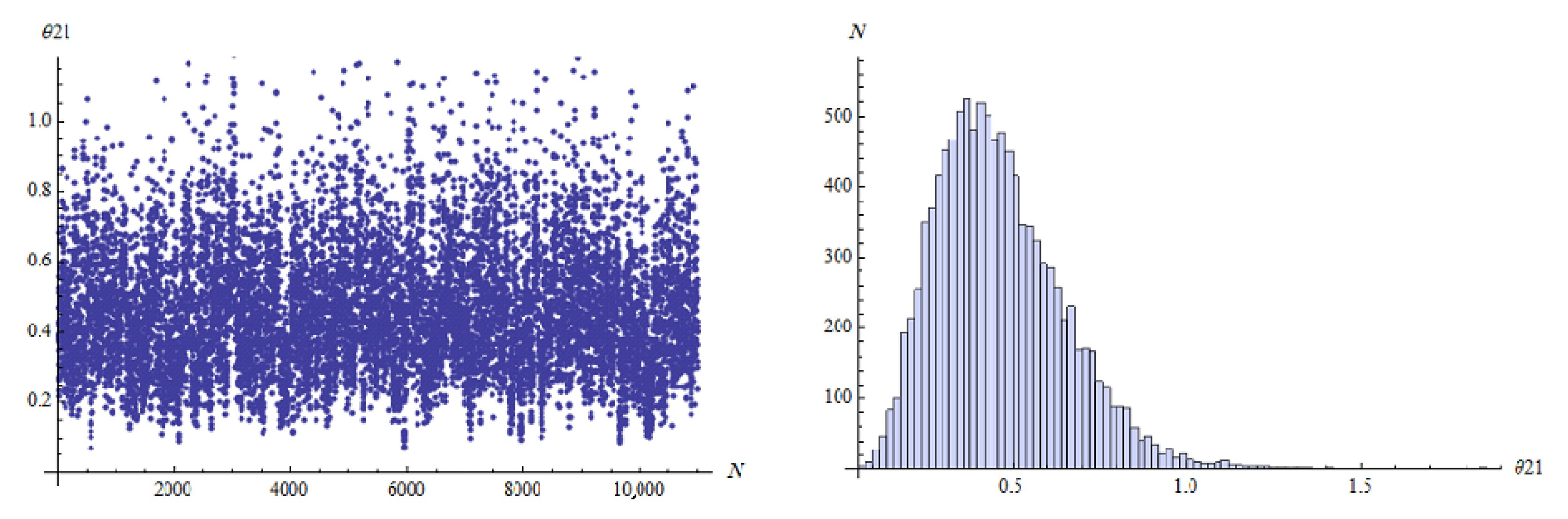
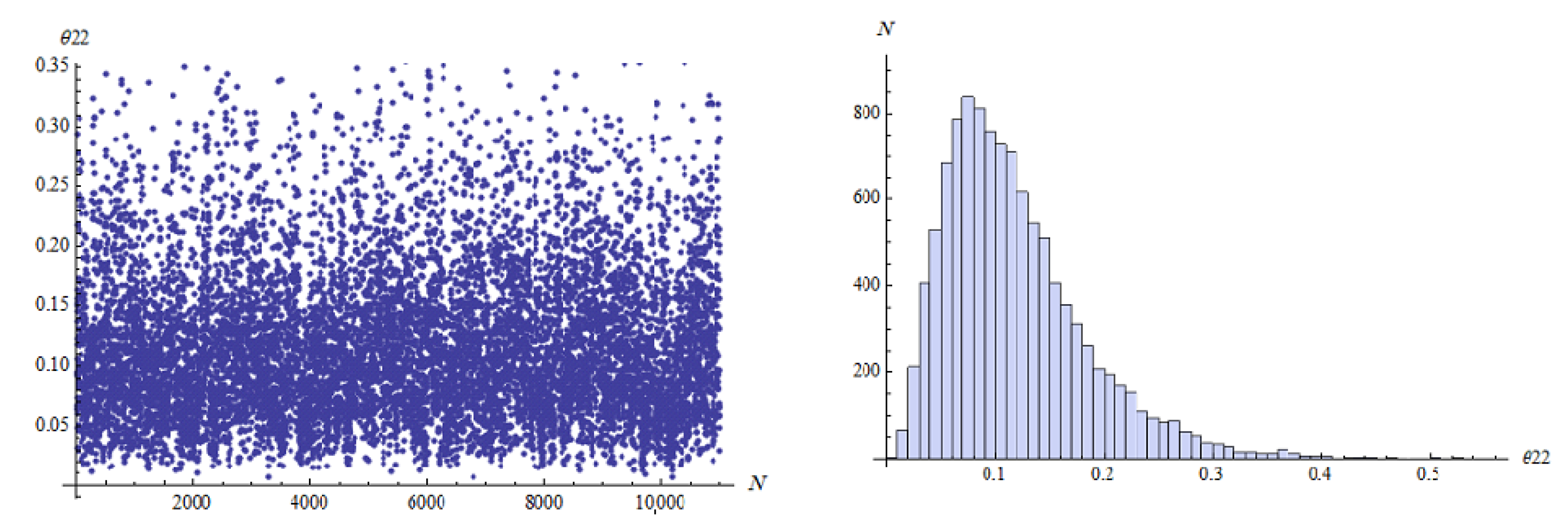
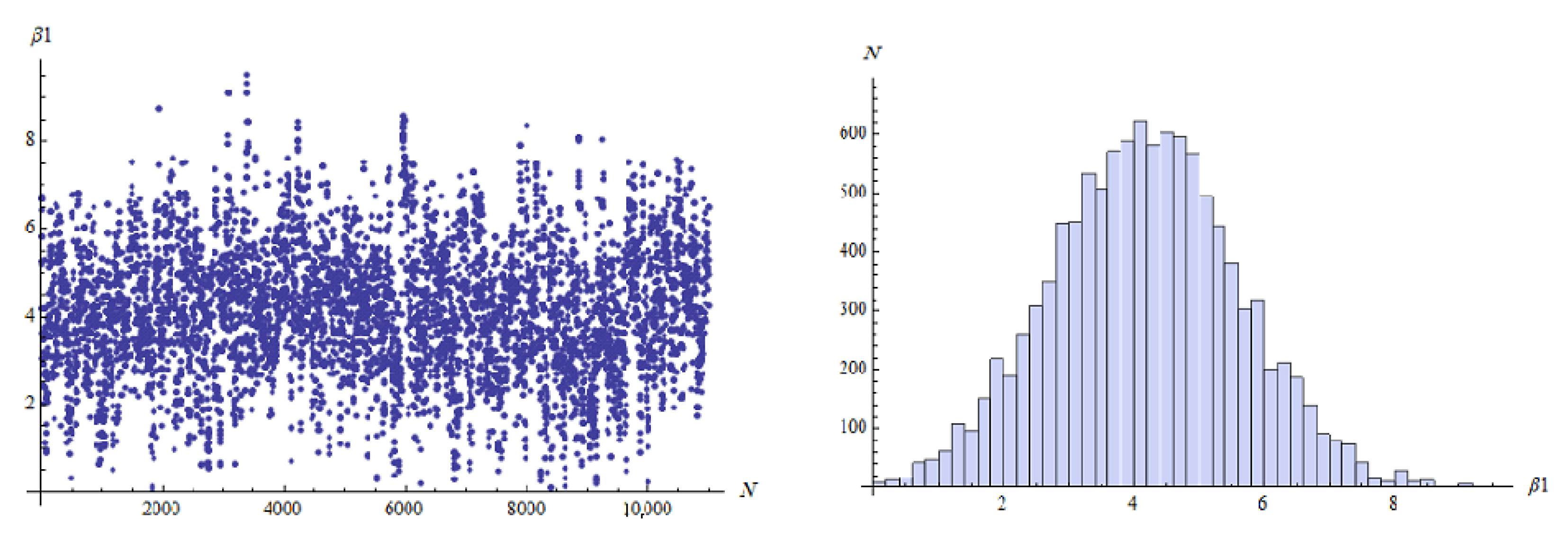
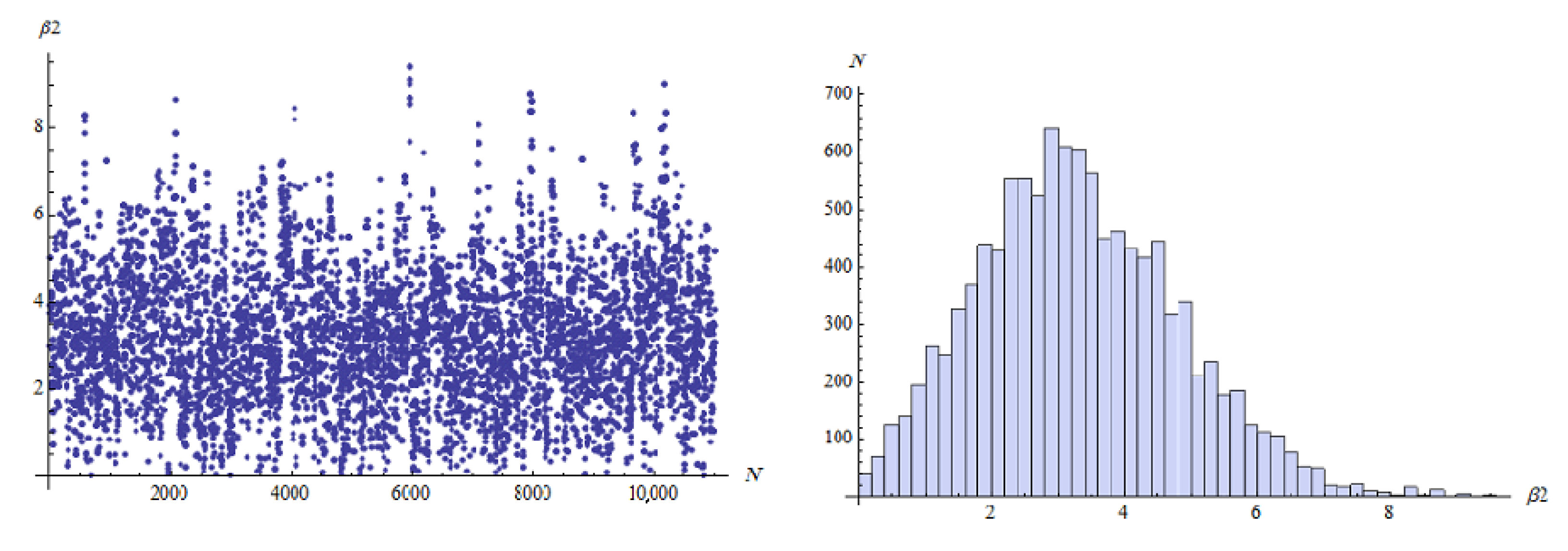
…, 6. For the MCMC approach in Bayes method, we ran the chain 11,000 with the first 1000 values as burn-in. The MCMC approach that describes the empirical posterior distribution is shown in
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7. Hence, the results of the ML point and interval estimates and different Bayes estimates were computed and the results are presented in
Table 7 and
Table 8.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






