1. Introduction
The solutions of large-scale finite-sum optimization problems have become essential in several machine learning tasks including binary or multinomial classification, regression, clustering, and anomaly detection [
1,
2]. Indeed, the training of models employed in such tasks is often performed by solving the optimization
where
N is the size of the available data set and the functions
are continuously differentiable for all
. As a result, the efficient solution of a machine learning problem calls for efficient numerical algorithms for (
1).
When the data set is extremely large, the evaluation of the objective function
and its derivatives may be computationally demanding, making deterministic optimization methods inadequate for solving (
1). A common strategy consists of approximating both the function and derivatives by employing a small number of loss functions
sampled randomly, making stochastic optimization methods the preferred choice [
3,
4,
5]. A major issue is the sensitivity of most stochastic algorithms to their parameters, such as the learning rate or sample sizes used for building the function and gradient approximations, which usually need to be tuned through multiple trials and errors before the algorithm exhibits acceptable performance. A possible remedy to burdensome tuning is to employ adaptive optimization methods, which compute the parameters according to appropriate globalization strategies [
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20]. Most of these methods have probabilistic accuracy requirements for the function and gradient estimates in order to ensure either the iteration complexity of the expectation [
7,
8,
9,
10,
11,
13,
15,
19,
21,
22] or the convergence in probability of the iterates [
6,
12,
16,
17,
18,
20]. In turn, these requirements are reflected in the choice of sample size, which needs to progressively grow as the iterations proceed, resulting in an increasing computational cost per iteration.
In [
11], the authors proposed the so-called stochastic inexact restoration trust-region (SIRTR) method for solving (
1). SIRTR employs subsampled function and gradient estimates and combines the classical trust-region scheme with the inexact restoration method for constrained optimization problems [
23,
24,
25]. This combined strategy involves the reformulation of (
1) as an optimization problem with two unknown variables
, where
x is the object to be recovered and
M is the sample size of the function estimate, upon which the constraint
is imposed. Based on this reformulation of (
1), the method acts on the two variables in a modular way: first, it selects the sample size with a deterministic rule aimed at improving
feasibility with respect to the constraint
; then, it accepts or rejects the inexact trust-region step by improving
optimality with respect to a suitable merit function. SIRTR has shown good numerical performance on a series of classification and regression test problems, as its inexact restoration strategy drastically reduces the computational burden due to the selection of the algorithmic parameters. From a theoretical viewpoint, the authors in [
11] provided an upper bound on the expected number of iterations to reach a near-stationary point under some appropriate probability accuracy requirements on the random estimators; remarkably, such requirements are less stringent than others employed in the literature. However, the convergence in probability of SIRTR remains unproved, thus leaving open the question of whether the gradient of the objective function in (
1) converges to zero with a probability of one. A positive answer to this question would be an important theoretical confirmation of the numerical stability of the method.
In this paper, we improve on the existing theoretical analysis of SIRTR, showing that its iterates drive the gradient to zero with a probability of one. The results will be obtained by combining the theoretical properties of SIRTR with some tools from martingale theory, as typically done for the convergence analysis of adaptive stochastic methods [
6,
16,
18]. Furthermore, we show the numerical results obtained by applying SIRTR on nonconvex binary classification, discussing the impact of the probabilistic accuracy requirements on the performance of the method.
The paper is structured as follows. In
Section 2, we briefly outline the method and its main steps. In
Section 3, we perform the convergence analysis of the method, showing that its iterates converge with a probability of one. In
Section 4, we provide a numerical illustration of a binary classification test problem. Finally, we report the conclusions and future work in
Section 5.
Notations: Throughout the paper, is the set of real numbers, whereas the symbol denotes the standard Euclidean norm on . We denote with a probability space, where is the sample space, is the algebra of events, and is the probability function. Given an event , the symbol stands for the probability of the event A, and denotes the indicator function of an event A, i.e., the function such that if , or otherwise. Given a random variable , we denote with the expected value of X. Let be n random variables, and the notation stands for the algebra generated by .
2. The SIRTR Method
Here, we present the stochastic inexact restoration trust-region (SIRTR) method, which was formerly proposed in [
11]. SIRTR is a trust-region method with subsampled function and gradient estimates, which combines first-order trust-region methodology with the inexact restoration method for constrained optimization [
25]. In order to provide a detailed description of SIRTR, we reformulate (
1) as the constrained problem
where
is a sample set of the size of the cardinality
such that
. To measure the infeasibility distance of
M from the constraint
, we introduce a function
h that measures the distance of
from
N. Function
h is supposed to satisfy the following properties.
Assumption 1.
The function is monotonically decreasing and satisfies , .
From Assumption 1, the existence of some positive constants
and
follows such that
An example of a function
satisfying Assumption 1 is
.
SIRTR is a stochastic variant of the classical first-order trust-region method, which accepts the trial point according to the decrease of a convex combination of the function estimate with function h. We report SIRTR in Algorithm 1.
At the beginning of each iteration , we have at our disposal the iterate , the trust-region radius , the sample size , the penalty parameter , and the flag iflag, where iflag = succ if the previous iteration was successful, in the sense that is specified below, and iflag = unsucc otherwise. Then, in Steps 1–5, perform the following tasks.
In Step 1, if iflag = succ, we reduce the current value of the infeasibility measure and find some satisfying with . On the other hand, if iflag=unsucc, remains the same from one iteration to the other, i.e., we set . Note that if .
Step 2 determines a trial sample size that satisfies with and is used to form the random model. In principle, we could fix , but selecting a smaller sample size, if possible, yields a computational saving in the successive step. The relation between and depends on ; small values of give ; otherwise, is allowed to be smaller than .
Step 3 forms the random model
and the trial step
. The linear model is given by
, where
and
with
with cardinality
.
Minimizing
over the ball of center 0 and radius
gives the trial step
| Algorithm 1 Stochastic Inexact Restoration Trust-Region (SIRTR) |
| Given , , , , , , , , . |
- 0.
Set , iflag=succ. - 1.
Reference sample size If iflag=succ find such that and
Else set . - 2.
Trial sample size If set Else - 3.
Trust-region model Choose such that . Choose and such that . Compute as in ( 5), and set . Compute as in ( 4), and set . - 4.
Penalty parameter If Else - 5.
Acceptance test If and (success) set , , iflag=succ and go to Step 1. Else (unsuccess) set , , iflag=unsucc and go to Step 1.
|
In Step 4, we compute the penalty parameter
that governs the predicted reduction
in the function and infeasibility measure, which we define as
If
satisfies
then, we set
; otherwise, we compute
as the biggest value for which Inequality (
12) is satisfied and takes the explicit form given in (
8).
In Step 5, we establish if we accept (success) or reject (unsuccess) the trial point
. The actual reduction
at point
is defined as
and we declare a successful iteration whenever the following conditions are both met:
Condition (
14) reduces to the standard acceptance criterion of deterministic trust-region methods when
. If both conditions are satisfied, we accept the step
and set
, increase the trust-region radius based on the update rule (
9), and set
,
iflag=succ; otherwise, we retain the previous iterate, i.e.,
, reduce the trust-region radius according to (
10), and set
,
iflag = unsucc.
3. Convergence Analysis
In this section, we are interested in the convergence properties of Algorithm 1. To this aim, we note that the function estimates
in (
4) and gradient estimates
in (
5) are all random quantities. Consequently, Algorithm 1 generates a random process, that is, the iterates
, the trust region radii
, the gradient estimates
, and the values
of the Lyapunov function
in (
21) at iteration
k are to be considered as random variables, with their realizations denoted as
,
,
, and
.
Our aim is to show the convergence in probability of the iterates generated by Algorithm 1, in the sense that
i.e., the event
holds almost surely. We note that the authors in [
11] derived a bound on the expected number of iterations in Algorithm 1 required to reach the desired accuracy in the gradient norm, but did not show the convergence results of Type (
16).
3.1. Preliminary Results
We recall some technical preliminary results that were obtained for Algorithm 1 in [
11]. First, we impose some basic assumptions on the functions in Problem (
1).
Assumption 2.
- (i)
Each function is continuously differentiable for .
- (ii)
The functions , , are bounded from below on , i.e., there exists such that - (iii)
The functions , , are bounded from above on a subset , i.e., there exists such that Furthermore, the iterates defined by Algorithm 1 are contained in Ω.
Combining Step 4 of Algorithm 1 with Bound (
3) and Assumption 2(iii), it is possible to prove that for any realizations of the algorithm, the sequence
is bounded away from zero.
Lemma 1 ([
11], Lemma 2)
. Let Assumptions 1 and 2 hold and consider a particular realization of Algorithm 1. Let be defined as follows:Then, is a positive, non-increasing sequence such thatFurthermore, Condition (12) holds with . Since the acceptance test in Algorithm 1 employs function and gradient estimates, we cannot expect that the objective function
is decreased from one iteration to the other; however, the authors in [
11] showed that an appropriate Lyapunov function
is reduced at each iteration. This Lyapunov function is defined as
where
and
are any constants that satisfy
where such a constant exists thanks to Bound (
3) and Assumption 2(ii). For all
, we denote the values of
along the iterates of Algorithm 1 as follows:
Thanks to (
20) and the positive sign of
h (see Assumption 1), we can easily deduce that the sequence
is non-negative, indeed
Furthermore, the difference between two successive values
and
can be easily rewritten as
If
k is a successful iteration, then
. By recalling (
20) and the fact that the sequence
is monotone non-increasing (see Lemma 1), then, Equality (
23) yields
Otherwise, Algorithm 1 sets
and
. By inserting these updates in (
23), together with (
20) and the fact that
is non-increasing, we obtain
Using (
24) and (
25) in combination with Step 5 of Algorithm 1, we can prove the following results.
Theorem 1 ([
11], Theorem 1)
. Let Assumptions 1–2 hold and consider a particular realization of Algorithm 1. In (19), choose , where is defined byThen, there exists a constant such thathence, the sequence in Algorithm 1 satisfies We now introduce a Lipschitz continuity assumption on the gradients of the functions
appearing in (
1).
Assumption 3.
Each gradient is Lipschitz continuous for . We use the notation .
The gradient estimates are bounded under Assumptions 2 and 3, as stated in the following lemma.
Lemma 2 ([
11], Lemma 5)
. Let Assumptions 2 and 3 hold. Then, there exists such that for any realization of Algorithm 1where , and is given in (17). Let us introduce the following events
where
is a positive parameter. By using a similar terminology to the one employed in [
22], the iteration
k is said to be
true if the events
and
are both true.
The next lemma shows that k is successful whenever the iteration k is true and the trust-region radius is sufficiently small. This result is crucial for the analysis in the next section.
Lemma 3 ([
11], Lemma 6)
. Let Assumptions 1–3 hold and set . Suppose that, for a particular realization of Algorithm 1, the iteration k is true and the following condition holdsThen, iteration k is successful. 3.2. Novel Convergence Results
Here, we derive two novel convergence results in probability holding for Algorithm 1. The results are provided under the assumption that the random variables and are sufficiently accurate estimators of the true gradient at , in the probabilistic sense specified below.
Assumption 4.
Let . Then, the events are true with sufficiently high probability conditioned to , and the estimators and are conditionally independent random variables given , i.e., First, we provide a liminf-type convergence result for SIRTR, which shows that the gradient of the objective function converges in probability to zero relative to a subsequence of the iterates.
Theorem 2.
Suppose that Assumptions 1–4 hold. Then, there holds Proof. The proof parallels that in ([
16], Theorem 4.16). By contrast, assume that there exists
such that the event
holds with positive probability. Then, let
be a realization of
such that
for all
, and
is the corresponding realization of
. From Theorem 1, we know that
; therefore, there exists
such that
Consider the random variable
with realizations given by
Note that satisfies the following properties.
- (i)
If
, then
; this is a consequence of (
34).
- (ii)
If
k is a true iteration and
, then
; indeed, since
is true and
, it follows that
Then,
yields
which, combined with (
34), implies that
satisfies Inequality (
31). Thus, Lemma 3 implies that the iteration
k is successful. Since
and the
k-th iteration is successful, by (
9) it follows that
. Hence,
.
- (iii)
If k is not a true iteration and , then ; this is because since we cannot apply Lemma 3 (k is not true), all we can say about the trust-region radius is that .
Then, defining the
-algebra
, which is included in
, it follows from properties (ii)–(iii) and Assumption 4 that
where the second inequality follows from
. Hence, we have that
is a submartingale. We also define the random variable
is also a submartingale as
where, again, the last inequality is due to the fact that
. Since
cannot have a finite limit, from ([
16], Theorem 4.4) it follows that the event
holds almost surely. Since we have
by definition of
and
, it follows that
has to be positive infinitely often with a probability of one. However, this contradicts property (i) listed above, which allows us to conclude that (
33) cannot occur. □
In the following, we show that SIRTR generates iterates such that the corresponding gradients evaluated at the SIRTR iterates converge (in probability) to zero. The next lemma is similar to ([
6], Lemma 4.2); however, some crucial modifications are needed here; indeed, unlike in [
6], we take into account the fact that SIRTR enforces the decrease in the Lyapunov function
defined in (
19) rather than the objective function.
Lemma 4.
Suppose that Assumptions 1–4 hold. Let and be the random sequences generated by Algorithm 1. For a fixed , define the following subset of natural numbersThen,holds almost surely. Proof. Let us consider the generic realizations
,
,
,
, and
of Algorithm 1. Furthermore, we let
be the subsequence of
, where the iteration is true, whereas
denotes the complementary subsequence so that
. First, we show that
. If
is finite, then there is nothing to prove. Otherwise, since
, there exists
such that
for all
, where
b is given in (
34). Let us consider any
. Since
is true,
, and
, we can reason as in (
36) and (
37) to conclude that
. Combining this lower bound with
, we have that Inequality (
31) is satisfied with
. Hence, iteration
is successful by Lemma 3 and we have
where the first inequality is the acceptance test (
14), the second follows from Step 4 of the SIRTR algorithm, the third follows from (
6), and the last follows from (
3) and Lemma 2. Now, starting from Inequality (
24) (which holds only for successful iterations), we can derive the following chain of inequalities
where the second inequality follows from (
39), (
9), and (
15). Now, recalling the definition of
given in (
26), we choose
v in (
19) as
and, consequently,
c in (
40) is positive while keeping Theorem 1 still applicable. Then, plugging
into (
40) yields
Summing the previous inequality over
,
, and noting that
for any
k (due to (
27)), we obtain
where the last inequality follows from (
22). Then, we have shown that
Furthermore, let us introduce the Bernoulli variable
, which takes a value of 1 when the iteration
k is true and a value of
otherwise. Note that due to Assumption 4,
Moreover, the sequence
is a sequence of non-negative uniformly bounded random variables. Then, we can proceed as in the proof in ([
6], Lemma 4.2), and using ([
6], Lemma 4.1) we obtain
This implies that almost surely
hence, the thesis follows. □
As a byproduct of the previous lemma, we obtain the expected convergence result in probability in the exact same way as in [
6].
Theorem 3.
Suppose that Assumptions 1–4 hold. Let be the sequence of random iterates generated by Algorithm 1. Then, there holds Proof. The proof follows exactly as in ([
6], Theorem 4.3). □
4. Numerical Illustration
In this section, we evaluate the numerical performance of Algorithm 1 equipped with the probabilistic accuracy requirements imposed in Assumption 4. Algorithm 1 was implemented using MATLAB R2019a, and the numerical experiments were performed on an 8 GB RAM laptop with an Intel Core i7-4510U CPU 2.00-2.60 GHz processor. The related software can be downloaded from
sites.google.com/view/optml-italy-serbia/home/software (accessed on 1 September 2022).
We perform our numerical experiments on a binary classification problem. Denoting with
a training set, where
is the
i-th feature vector, and
is the associated label, we address the following nonconvex optimization problem:
Note that (
42) can be framed in Problem (
1) by setting
,
, namely the composition of the least-square loss with the sigmoid function. Furthermore, it is easy to see that the objective function
satisfies Assumption 2 since each
is continuously differentiable and
is bounded from below and above.
In
Table 1, we report the four data sets used for our experiments. For each data set, we specify the number of feature vectors
N, the number of components
n of each feature vector, and the size
of the testing set
.
We implement two different versions of Algorithm 1, which differ from one another in the way the two sample sizes
and
for the estimators in (
4) and (
5) are selected.
: this is Algorithm 1 implemented as in [
11]. In particular, the infeasibility measure
h and the initial penalty parameter
are chosen as follows:
In Step 1, the reference sample size
is computed as follows:
where
. It is easy to see that Rule (
43) complies with Condition (
6) by setting
. In Step 2, the trial sample size
is chosen in compliance with Condition (
7) as
In Step 3, the sample size
is fixed as
where
. Furthermore, the set
for computing
and
is sampled uniformly at random using the MATLAB command randsample, whereas
is a sample average approximation as in (
5) using
. The other parameters are set as
,
,
,
,
,
,
. Note that Choices (
44)–(
45) for the sample sizes
are not sufficient to guarantee that Assumption 4 holds so that Theorems 2–3 do not apply to this version of Algorithm 1.
: this implementation of Algorithm 1 differs from the previous one only in the choice of the sample sizes
. In this case, we force these two parameters to comply with Assumption 4. According to ([
29], Theorem 7.2, Table 7.1), a subsampled estimator
with sample size
satisfies the probabilistic requirement
where
if the sample size
S complies with the following lower bound
where
. Based on the previous remark, we choose the samples sizes of
as follows
Setting
, choosing
as in (
48) and (
49), and sampling
and
uniformly and independently at random in
, we guarantee that Assumption 4 holds with
, thus ensuring the convergence in probability of
according to Theorems 2–3. For our tests, we set
and
.
For each data set, we perform 10 runs of both and and assess their performances by measuring the following metrics:
training loss, given as
with
defined in (
42);
testing loss, defined as
where
denotes the testing set and
its dimension;
classification error, defined as
where
denotes the true label of the
th feature vector of the testing set and
is the corresponding predicted label at iteration
k.
We note that (
42) can be seen as the optimization problem arising from training a neural network with no hidden layers and the sigmoid function as the activation function for the output layer. Then, as in [
30,
31], we measure the computational cost of evaluating the objective function and its gradient in terms of forward and backward propagations. Namely, we count the number of full function and gradient evaluations, by considering the computation of a single function
equivalent to
forward propagations, and the evaluation of a single gradient
equivalent to
propagations. Regarding
, we note that the computational cost per iteration is determined by
propagations since
. On the contrary, the computational cost of
is determined by
propagations, as
and
are sampled independently from one another. For both algorithms, the computational cost per iteration increases as the iterations proceed; indeed, since
tends to zero as
k tends to infinity (Theorem 1), Rules (
44)–(
48) will eventually select the trial sample size
equal to the reference sample size
, which is increasing geometrically. We expect that the computational cost increases faster in
, as this algorithm also requires the gradient sample size
to increase due to Conditions (
47)–(
49). Finally, we note that the computational cost per iteration of both algorithms is higher than that of the standard stochastic gradient algorithm, which is usually
, with
being a prefixed gradient sample size. However, the increasing sample sizes result in more accurate function and gradient approximations so the higher computational cost likely implies a larger reduction in the training loss
per iteration, as seen in previous comparisons of SIRTR with a non-adaptive stochastic approach in [
11].
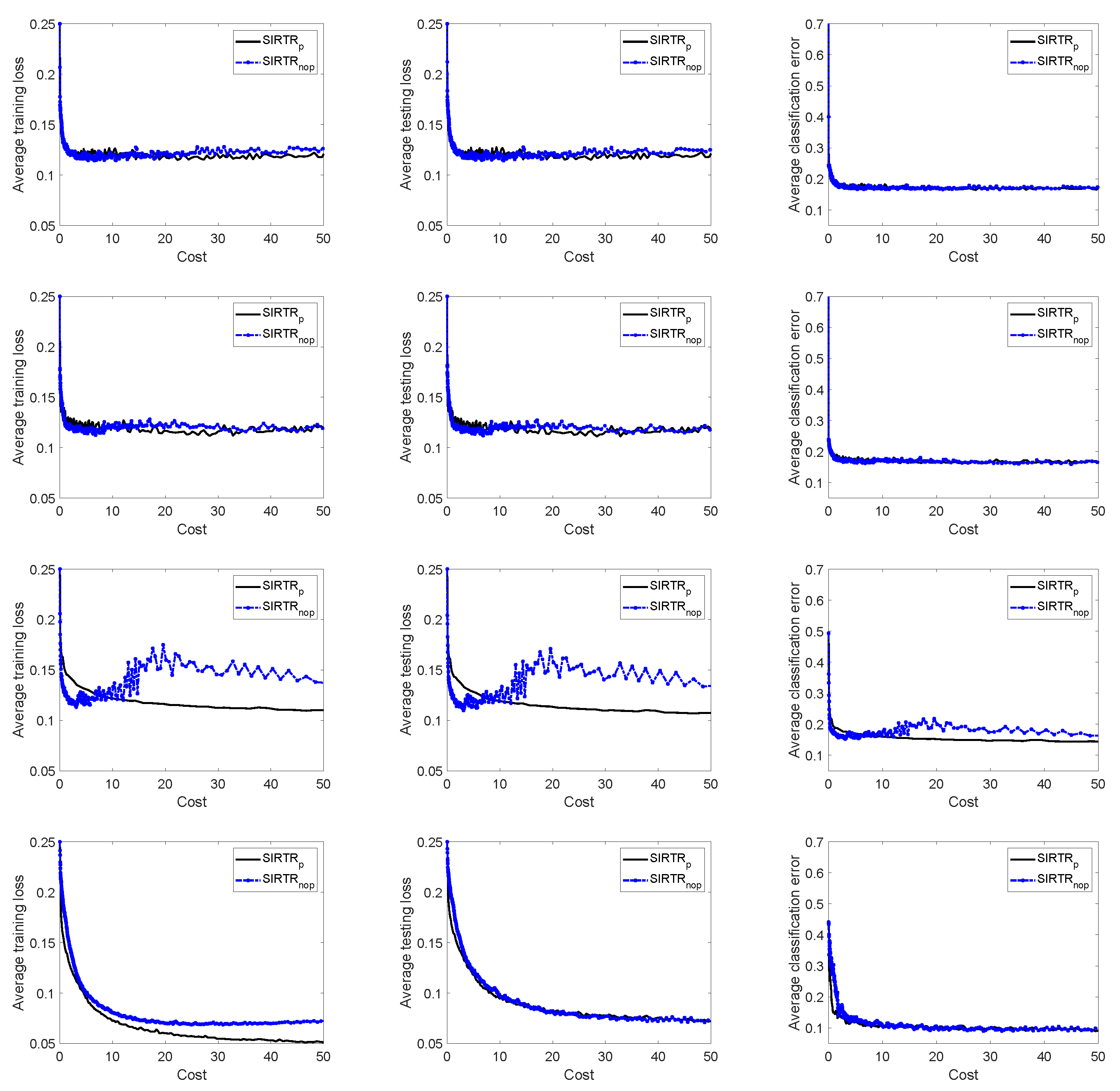
In
Figure 1, we show the decrease in the training loss, testing loss, and classification error (all averaged over the 10 runs) versus the average computational cost for the first 20 propagations. For most data sets, we observe that
performs comparably or even better than
. However, for one of the four data sets (mnist) in
, the accuracy deteriorates after the first propagations, whereas
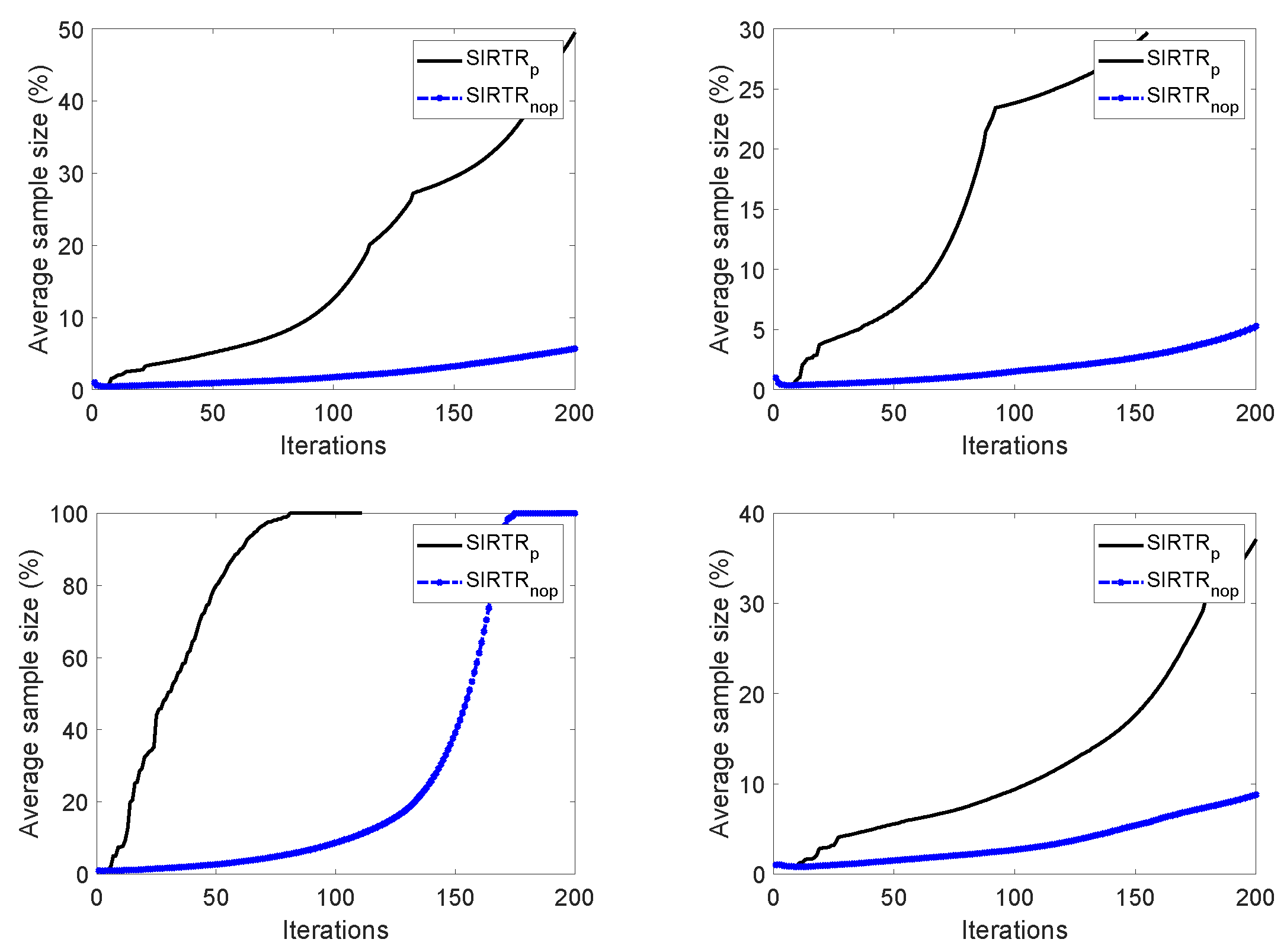
provides a more accurate classification and a quite steady decrease in the average training loss, testing loss, and classification error. This different performance of the two algorithms can be explained by looking at
Figure 2, which shows the increase in the percentage ratio
of the sample size
over the data set size
N (averaged over the 10 runs) for both algorithms. As we can see, the sample size in
rapidly increases to
of the data set size in the first 50 iterations, whereas the same percentage is achieved by
after 150–200 iterations. Overall, we can conclude that the probabilistic requirements of Assumption 4 ensure the theoretical support for convergence in probability but might be excessively demanding. In fact, the numerical examples show that a slower increase in the sample size than that imposed by the probabilistic requirements of Assumption 4 provides a good trade-off between the computational cost and the accuracy in the classification.
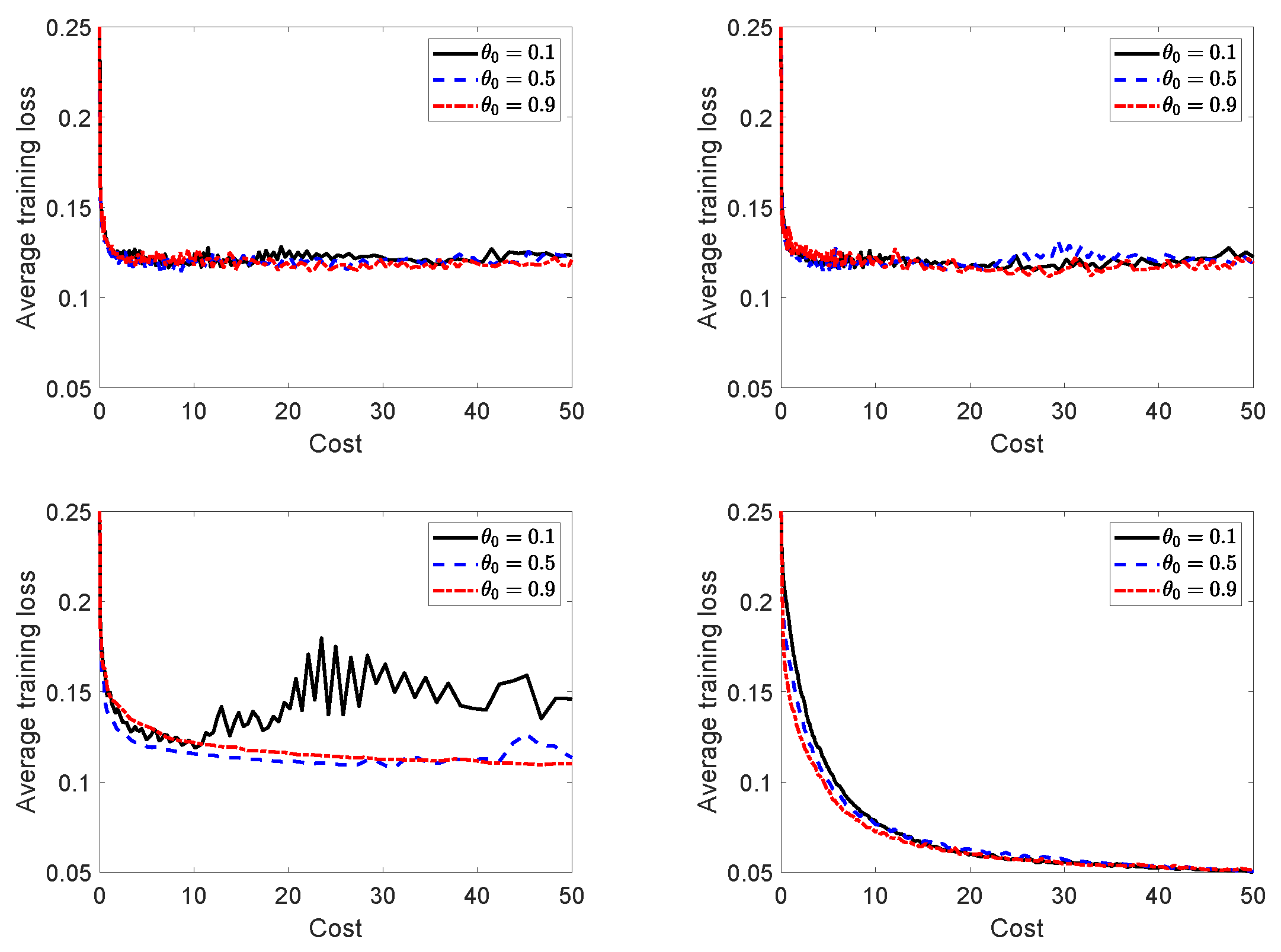
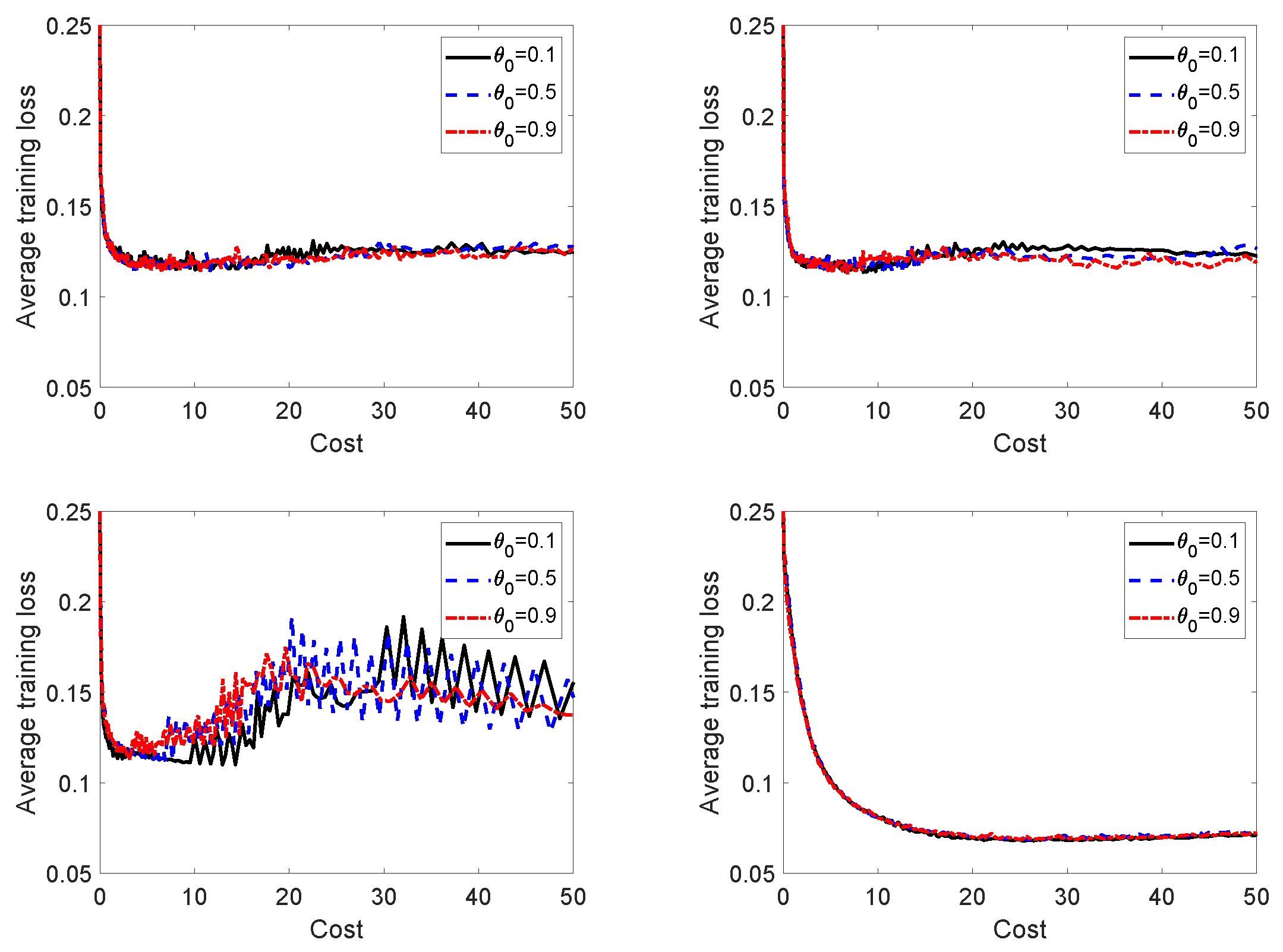
In
Figure 3, we test the sensitivity of
with respect to the initial penalty parameter
by reporting the average training loss versus the average computational cost obtained with three different values of
. We observe that the performance of the algorithm is not considerably affected by the choice of this parameter, although large oscillations in the average training loss occur for smaller values of
in mnist when
. As a general comment, small initial values of
may not be convenient, as the sequence
is non-increasing and small values of
promote a decrease in the infeasibility measure
h rather than a decrease in the training loss (see the definition of the actual reduction in (
13)). Similar considerations can be made for
in
Figure 4.








{kind=link}
{kind=link}
{kind=link}
{kind=link}