
Multi-Label Classification of E-Commerce Customer Reviews via Machine Learning

Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
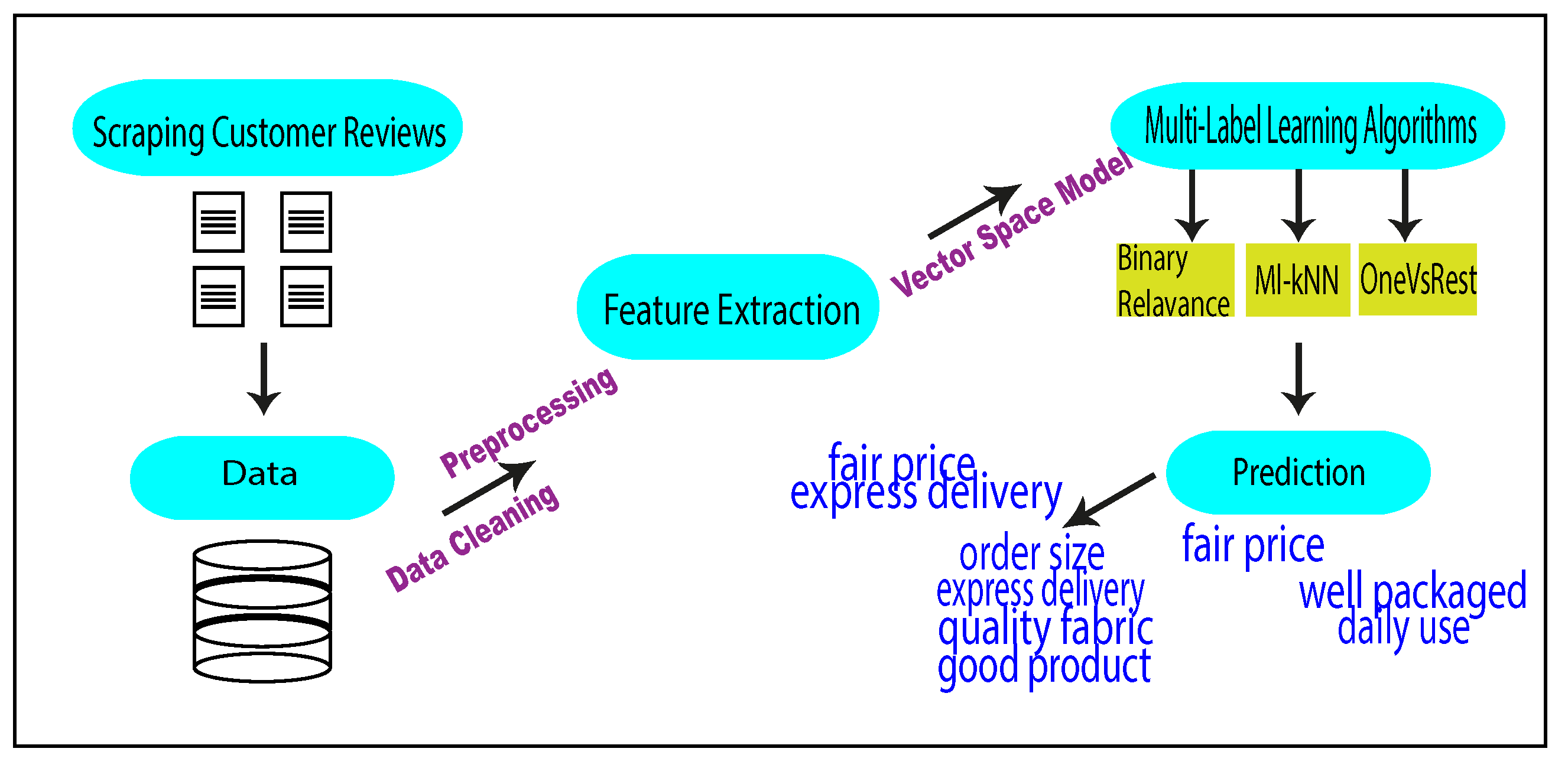
3.1. Data
3.2. Feature Extraction and Data Representation
3.2.1. Term Frequency-Inverse Document Frequency
3.2.2. Word2Vec
3.2.3. Global Vectors for Word Representation
3.2.4. Bidirectional Encoder Representations from Transformers
3.3. Multi-Label Classifiers
3.4. Evaluation Metrics
4. Experimental Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| NLP | Natural Language Processing |
| BR | Binary Relevance |
| SVM | Support Vector Machine |
| RF | Random Forest |
| LR | Linear Regression |
| SVC | Support Vector Classifier |
| SGD | Stochastic Gradient Descent |
| HL | Hamming Loss |
| Ml-kNN | Multi-Label k Nearest Neighbours |
References
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Rusli, A.; Young, J.C.; Iswari, N.M.S. Identifying fake news in Indonesian via supervised binary text classification. In Proceedings of the 2020 IEEE International Conference on Industry 4.0, Artificial Intelligence, and Communications Technology (IAICT), Bali, Indonesia, 7–8 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 86–90. [Google Scholar]
- Al-Rawashdeh, G.; Mamat, R.; Abd Rahim, N.H.B. Hybrid water cycle optimization algorithm with simulated annealing for spam e-mail detection. IEEE Access 2019, 7, 143721–143734. [Google Scholar] [CrossRef]
- Shehnepoor, S.; Salehi, M.; Farahbakhsh, R.; Crespi, N. NetSpam: A network-based spam detection framework for reviews in online social media. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1585–1595. [Google Scholar] [CrossRef]
- Alterkavı, S.; Erbay, H. Novel authorship verification model for social media accounts compromised by a human. Multimed. Tools Appl. 2021, 80, 13575–13591. [Google Scholar] [CrossRef]
- Alterkavı, S.; Erbay, H. Design and Analysis of a Novel Authorship Verification Framework for Hijacked Social Media Accounts Compromised by a Human. Secur. Commun. Netw. 2021, 2021, 8869681. [Google Scholar] [CrossRef]
- Liu, S.; Cheng, X.; Li, F.; Li, F. TASC: Topic-adaptive sentiment classification on dynamic tweets. IEEE Trans. Knowl. Data Eng. 2014, 27, 1696–1709. [Google Scholar] [CrossRef]
- Esposito, F.; Corazza, A.; Cutugno, F. Topic Modelling with Word Embeddings. In Proceedings of the Third Italian Conference on Computational Linguistics (CLiC-it 2016) & Fifth Evaluation Campaign of Natural Language Processing and Speech Tools for Italian. Final Workshop (EVALITA 2016), Napoli, Italy, 5–7 December 2016. [Google Scholar]
- Leeuwenberg, A.; Vela, M.; Dehdari, J.; van Genabith, J. A minimally supervised approach for synonym extraction with word embeddings. Prague Bull. Math. Linguist. 2016, 105, 111. [Google Scholar] [CrossRef]
- WPForms. 68 Useful eCommerce Statistics You Must Know in 2022. Available online: https://wpforms.com/ecommerce-statistics/ (accessed on 4 August 2022).
- Nasdaq. UK Online Shopping and E-Commerce Statistics for 2017. Available online: https://www.nasdaq.com/articles/uk-online-shopping-and-e-commerce-statistics-2017-2017-03-14 (accessed on 4 August 2022).
- Zhang, S.; Zhang, D.; Zhong, H.; Wang, G. A multiclassification model of sentiment for E-commerce reviews. IEEE Access 2020, 8, 189513–189526. [Google Scholar] [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef]
- Muslim, M.A. Support vector machine (svm) optimization using grid search and unigram to improve e-commerce review accuracy. J. Soft Comput. Explor. 2020, 1, 8–15. [Google Scholar]
- Xu, F.; Pan, Z.; Xia, R. E-commerce product review sentiment classification based on a naïve Bayes continuous learning framework. Inf. Process. Manag. 2020, 57, 102221. [Google Scholar] [CrossRef]
- Vanaja, S.; Belwal, M. Aspect-level sentiment analysis on e-commerce data. In Proceedings of the 2018 International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 11 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1275–1279. [Google Scholar]
- Jabbar, J.; Urooj, I.; JunSheng, W.; Azeem, N. Real-time sentiment analysis on E-commerce application. In Proceedings of the 2019 IEEE 16th International Conference on Networking, Sensing and Control (ICNSC), Banff, AB, Canada, 9–11 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 391–396. [Google Scholar]
- Parveen, N.; Santhi, M.; Burra, L.R.; Pellakuri, V.; Pellakuri, H. Women’s e-commerce clothing sentiment analysis by probabilistic model LDA using R-SPARK. Mater. Today Proc. 2021, in press. [CrossRef]
- Tripathi, P.; Singh, S.; Chhajer, P.; Trivedi, M.C.; Singh, V.K. Analysis and prediction of extent of helpfulness of reviews on E-commerce websites. Mater. Today Proc. 2020, 33, 4520–4525. [Google Scholar] [CrossRef]
- Kumar, K.S.; Desai, J.; Majumdar, J. Opinion mining and sentiment analysis on online customer review. In Proceedings of the 2016 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Chennai, India, 15–17 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–4. [Google Scholar]
- Miyoshi, T.; Nakagami, Y. Sentiment classification of customer reviews on electric products. In Proceedings of the 2007 IEEE International Conference on Systems, Man and Cybernetics, Banff, AB, Canada, 5–8 October 2017; IEEE: Piscataway, NJ, USA, 2007; pp. 2028–2033. [Google Scholar]
- Guan, Z.; Chen, L.; Zhao, W.; Zheng, Y.; Tan, S.; Cai, D. Weakly-Supervised Deep Learning for Customer Review Sentiment Classification. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16), New York, NY, USA, 9–15 July 2016; pp. 3719–3725. [Google Scholar]
- Shoja, B.M.; Tabrizi, N. Customer reviews analysis with deep neural networks for e-commerce recommender systems. IEEE Access 2019, 7, 119121–119130. [Google Scholar] [CrossRef]
- Gu, T.; Xu, G.; Luo, J. Sentiment analysis via deep multichannel neural networks with variational information bottleneck. IEEE Access 2020, 8, 121014–121021. [Google Scholar] [CrossRef]
- Bİlen, B.; Horasan, F. LSTM network based sentiment analysis for customer reviews. Politek. Derg. 2021. [Google Scholar] [CrossRef]
- Vural, A.G.; Cambazoglu, B.B.; Senkul, P.; Tokgoz, Z.O. A framework for sentiment analysis in turkish: Application to polarity detection of movie reviews in turkish. In Computer and Information Sciences III; Springer: Berlin/Heidelberg, Germany, 2013; pp. 437–445. [Google Scholar]
- Acikalin, U.U.; Bardak, B.; Kutlu, M. Turkish sentiment analysis using bert. In Proceedings of the 2020 28th Signal Processing and Communications Applications Conference (SIU), Gaziantep, Turkey, 5–7 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar]
- Santur, Y. Sentiment analysis based on gated recurrent unit. In Proceedings of the 2019 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 21–22 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Ozyurt, B.; Akcayol, M.A. A new topic modeling based approach for aspect extraction in aspect based sentiment analysis: SS-LDA. Expert Syst. Appl. 2021, 168, 114231. [Google Scholar] [CrossRef]
- Kadhim, A.I. Term weighting for feature extraction on Twitter: A comparison between BM25 and TF-IDF. In Proceedings of the 2019 International Conference on Advanced Science and Engineering (ICOASE), Zakho, Iraq, 2–4 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 124–128. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Schweter, S. Berturk-Bert Models for Turkish. Zenodo 2020, 2020, 3770924. [Google Scholar] [CrossRef]
- Zhang, M.L.; Zhou, Z.H. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2013, 26, 1819–1837. [Google Scholar] [CrossRef]
- Zhang, M.L.; Li, Y.K.; Liu, X.Y.; Geng, X. Binary relevance for multi-label learning: An overview. Front. Comput. Sci. 2018, 12, 191–202. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Katakis, I. Multi-label classification: An overview. Int. J. Data Warehous. Min. (IJDWM) 2007, 3, 1–13. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification Type | Task | Labels |
|---|---|---|
| Binary | Spam Filter | Ham, Spam |
| Multi-class | Sentiment Analysis | Positive, Neutral, Negative |
| Multi-label | Toxic Comment Detection | Threat, Toxic, Obscene, Insult |
| Binary Classification | Multi-Class Classification | Multi-Label Classification |
|---|---|---|
|
|
|
| Data Set | Number of Review | Number of Labels |
|---|---|---|
| Electronics | 14,557 | 6 |
| Women’s Wear | 24,274 | 5 |
| Home and Life | 12,563 | 10 |
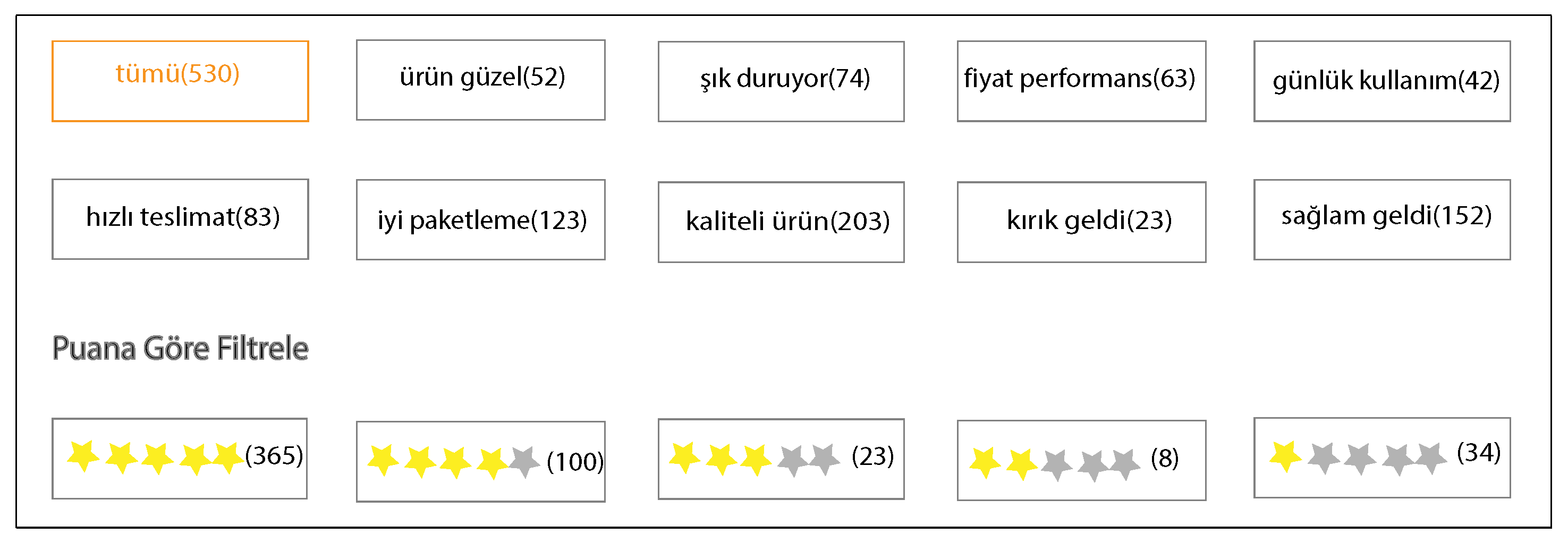
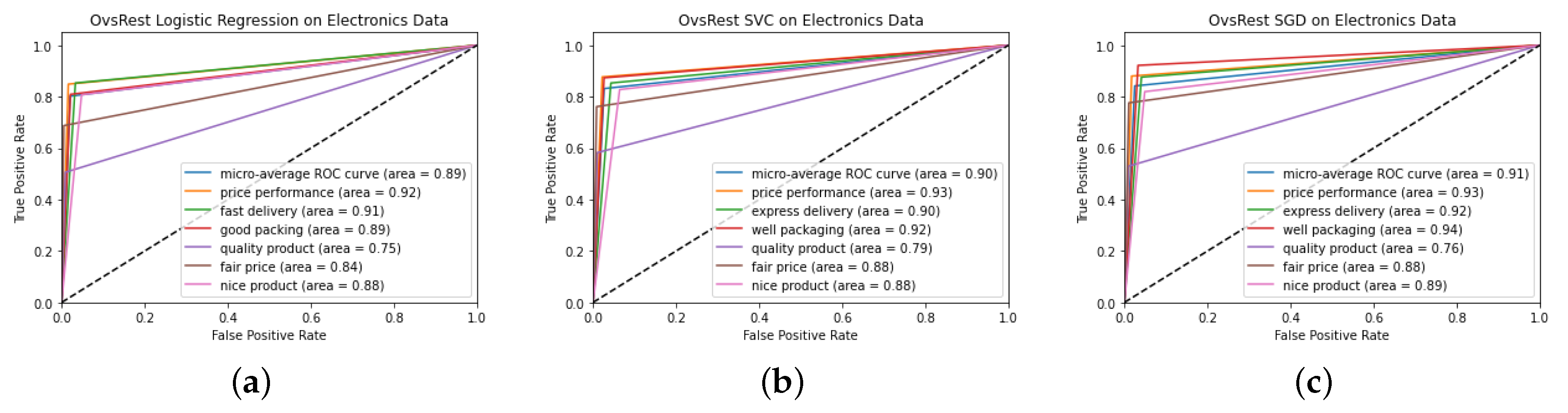
| Label Name | English Translation | Description |
|---|---|---|
| ürün güzel | nice product | Reviews with this label indicate that the product is liked by the user and found to be nice. |
| fiyat/performans | price/performance | Reviews with this label state the product as a price performance product. |
| hızlı teslimat | express delivery | Reviews with this label indicate that the product was delivered quickly. |
| iyi paketleme | well packaging | Reviews with this label indicate that the cargo packaging of the product is good. |
| kaliteli ürün | quality product | Reviews with this label indicate the quality of the product. |
| uygun fiyat | fair price | Reviews with this label indicate that the price of the product is appropriate. |
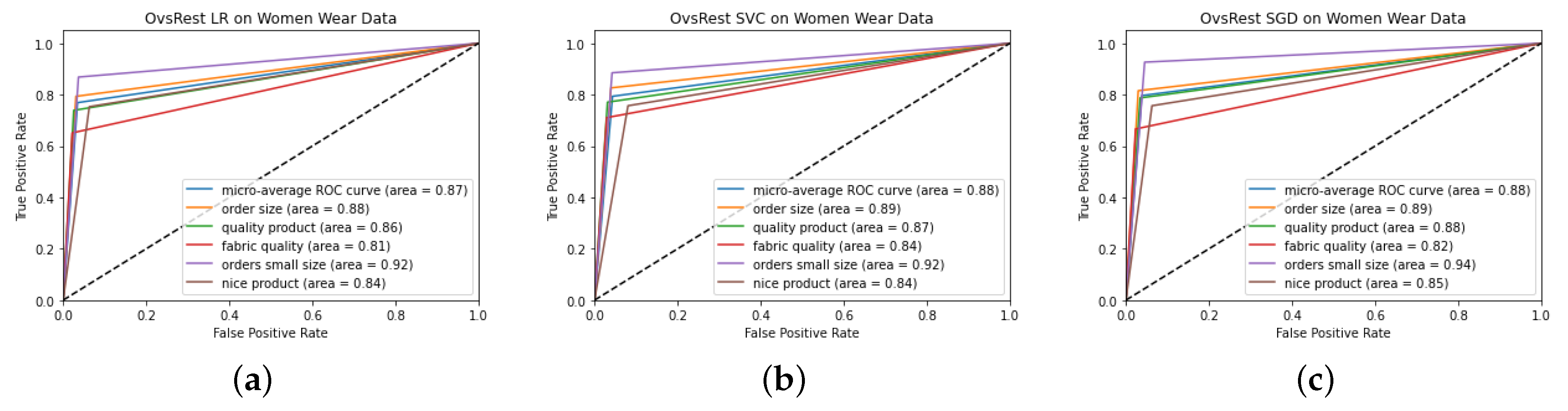
| Label Name | English Translation | Description |
|---|---|---|
| ürün güzel | nice product | Reviews with this label indicate that the product is liked by the user and found to be nice. |
| bedeninizi alın | order size | Reviews with this label advise other users to order the size they usually wear. |
| küçük alınabilir | order small size | Reviews with this label advise other users to order a size smaller than the size they usually wear. |
| kaliteli ürün | quality product | Reviews with this label indicate the quality of the product. |
| kumaş kalitesi | fabric quality | Reviews with this label provide information about the fabric quality of the product. |
| Label Name | English Translation | Description |
|---|---|---|
| ürün güzel | nice product | Reviews with this label indicate that the product is liked by the user and found to be nice. |
| şık duruyor | looks stylish | Reviews with this label indicate that the product looks stylish. |
| fiyat/performans | price/performance | Reviews with this label state the product as a price performance product. |
| günlük kullanım | daily use | Reviews with this label indicate whether the product is suitable for daily use. |
| hızlı teslimat | express delivery | Reviews with this label indicate that the product was delivered quickly. |
| iyi paketleme | well packaging | Reviews with this label indicate that the cargo packaging of the product is good. |
| kaliteli ürün | quality product | Reviews with this label indicate the quality of the product. |
| kırık geldi | broken | Reviews with this label indicate that the product arrived broken. |
| sağlam geldi | solid | Reviews with this label indicate that the product arrived solid. |
| uygun/fiyat | fair price | Reviews with this label indicate that the price of the product is appropriate. |
| Orjinal Data | Translation to English | ||
|---|---|---|---|
| Customer Reviews | Labels | Customer Reviews | Labels |
| Ürünü bizde yorumlar üzerine aldık gerçekten sorunsuz bir alışverişti paketlemesi kargo hızı gayet memnun kaldık ürünle yeni tanıştık umarım kullanım açısındanda memnun kalırız tşkler | güzel ürün, hızlı teslimat, iyi paketleme | We bought the product based on the comments, it was a really problem-free shopping, packaging, shipping speed, we were very satisfied, we just got the product, I hope we will be satisfied in terms of usage, thanks | nice product, express delivery, well packaging |
| Ürün gerçekten çok güzel. Fiyatı da uygun. Gerçekten almak isteyen arkadaşlar için şunu söylemek istiyorum: Tek kelime ile mükemmel. | güzel ürün, uygun fiyat | The product is really beautiful. The price is also appropriate. For those who really want to buy it, I want to say this: In one word, it’s perfect. | nice product, fair price |
| Ürün hemen elime ulaştı, paketlenmesi de güzeldi en ufak bir çizik bile yok bardakların kalitesi de güzel ince değil kaliteli duruyor. | iyi paketleme, kaliteli ürün, hızlı teslimat | The product arrived immediately, it was well packaged, there is not even the slightest scratch, the quality of the glasses is nice, not thin, but high quality. | well packaging, quality product, express delivery |
| Ben 40 beden giyiyorum, kızım 38 giyiyor. Hem m hem L beden aldım ama L bana büyük oldu, tam sarmadı ve toparlamadı. M tam oldu. Bir beden küçük alınmalı kesinlikle. Oldukça kaliteli güzel bir tayt. | güzel ürün, küçük alınabilir, kaliteli ürün | I wear size 40, my daughter wears 38. I bought both M and L sizes, but L was too big for me, it didn’t fit well. Medium is a great fir. Definitely go one size smaller. Pretty good quality tights. | nice product, order small size, quality product |
| Parameter | Value |
|---|---|
| attention probs dropout prob | 0.1 |
| hidden act | gelu |
| hidden dropout prob | 0.1 |
| hidden size | 768 |
| initializer range | 0.02 |
| intermediate size | 3072 |
| layer norm eps | |
| max position embeddings | 512 |
| model type | bert |
| num attention heads | 12 |
| num hidden layers | 12 |
| pad token id | 0 |
| type vocab size | 2 |
| vocab size | 128,000 |
| (a) Initial dataset | ||||
| Features | Class 1 | Class 2 | Class 3 | Class 4 |
| F1 | 0 | 1 | 0 | 1 |
| F2 | 0 | 0 | 1 | 1 |
| F3 | 1 | 0 | 1 | 1 |
| F4 | 1 | 1 | 0 | 0 |
| (b) Class 1 Subdataset | ||||
| Features | Class 1 | |||
| F1 | 0 | |||
| F2 | 0 | |||
| F3 | 1 | |||
| F4 | 1 | |||
| (c) Class 2 Subdataset | ||||
| Features | Class 2 | |||
| F1 | 1 | |||
| F2 | 0 | |||
| F3 | 0 | |||
| F4 | 1 | |||
| (d) Class 3 Subdataset | ||||
| Features | Class 3 | |||
| F1 | 0 | |||
| F2 | 1 | |||
| F3 | 1 | |||
| F4 | 0 | |||
| (e) Class 4 Subdataset | ||||
| Features | Class 4 | |||
| F1 | 1 | |||
| F2 | 1 | |||
| F3 | 1 | |||
| F4 | 0 | |||
| Classifier | Hamming Loss | Micro F1 | Macro F1 | Micro P | Macro P | Micro R | Macro R |
|---|---|---|---|---|---|---|---|
| BR-RF | 0.0497 | 0.8747 | 0.8532 | 0.914 | 0.9102 | 0.8396 | 0.8093 |
| BR-SVC | 0.05 | 0.8744 | 0.8463 | 0.9094 | 0.9066 | 0.8419 | 0.8022 |
| BR-NB | 0.5539 | 0.3746 | 0.3631 | 0.2444 | 0.2534 | 0.8026 | 0.8021 |
| MLkNN | 0.0841 | 0.7853 | 0.7596 | 0.8316 | 0.8196 | 0.7439 | 0.7124 |
| OvsR-XGB | 0.044 | 0.8925 | 0.8779 | 0.9014 | 0.896 | 0.8837 | 0.8628 |
| OvsR-LR | 0.057 | 0.8533 | 0.8144 | 0.9118 | 0.8963 | 0.8018 | 0.7518 |
| OvsR-SGD | 0.0529 | 0.8684 | 0.8372 | 0.8941 | 0.8772 | 0.8441 | 0.8056 |
| OvsR-SVC | 0.056 | 0.8598 | 0.8328 | 0.8903 | 0.8779 | 0.8314 | 0.7956 |
| Embedding | Classifier | Hamming Loss | Micro F1 | Macro F1 | Micro P | Macro P | Micro R | Macro R |
|---|---|---|---|---|---|---|---|---|
| Word2Vec | BR-RF | 0.1144 | 0.6505 | 0.5749 | 0.8651 | 0.8675 | 0.5212 | 0.4546 |
| Word2Vec | XGB | 0.1042 | 0.7119 | 0.6694 | 0.8176 | 0.8171 | 0.6304 | 0.5787 |
| GloVe | BR-RF | 0.1086 | 0.6734 | 0.6173 | 0.8725 | 0.8911 | 0.5483 | 0.4876 |
| GloVe | XGB | 0.0921 | 0.75 | 0.7199 | 0.8412 | 0.8514 | 0.6767 | 0.6329 |
| BERT | BR-RF | 0.1125 | 0.6555 | 0.5585 | 0.8837 | 0.9111 | 0.5209 | 0.4355 |
| BERT | XGB | 0.0821 | 0.7812 | 0.748 | 0.8637 | 0.883 | 0.7131 | 0.6657 |
| Classifier | Hamming Loss | Micro F1 | Macro F1 | Micro P | Macro P | Micro R | Macro R |
|---|---|---|---|---|---|---|---|
| BR-RF | 0.0711 | 0.8359 | 0.8281 | 0.9042 | 0.905 | 0.7772 | 0.7691 |
| BR-SVC | 0.0694 | 0.846 | 0.8413 | 0.8769 | 0.8747 | 0.8171 | 0.8133 |
| BR-NB | 0.4126 | 0.441 | 0.444 | 0.3223 | 0.3353 | 0.6981 | 0.7077 |
| MLkNN | 0.1454 | 0.6604 | 0.6536 | 0.7249 | 0.7279 | 0.6065 | 0.5961 |
| OvsR-XGB | 0.0615 | 0.8679 | 0.8657 | 0.8691 | 0.8666 | 0.8668 | 0.8651 |
| OvsR-LR | 0.0804 | 0.8168 | 0.8101 | 0.8712 | 0.8963 | 0.7687 | 0.7608 |
| OvsR-SGD | 0.0757 | 0.8327 | 0.8272 | 0.8588 | 0.856 | 0.8081 | 0.8031 |
| OvsR-SVC | 0.0813 | 0.8198 | 0.8164 | 0.848 | 0.8464 | 0.7935 | 0.7898 |
| Embedding | Classifier | Hamming Loss | Micro F1 | Macro F1 | Micro P | Macro P | Micro R | Macro R |
|---|---|---|---|---|---|---|---|---|
| Word2Vec | BR-RF | 0.1565 | 0.5593 | 0.5102 | 0.8101 | 0.7955 | 0.427 | 0.4032 |
| Word2Vec | XGB | 0.1406 | 0.6552 | 0.6203 | 0.7623 | 0.7442 | 0.5744 | 0.5496 |
| GloVe | BR-RF | 0.1516 | 0.5734 | 0.5472 | 0.8301 | 0.8272 | 0.438 | 0.421 |
| GloVe | XGB | 0.1265 | 0.6991 | 0.6799 | 0.7827 | 0.7757 | 0.6316 | 0.614 |
| BERT | BR-RF | 0.1443 | 0.5965 | 0.5737 | 0.8503 | 0.8465 | 0.4594 | 0.4438 |
| BERT | XGB | 0.1057 | 0.7522 | 0.7418 | 0.8257 | 0.8251 | 0.6907 | 0.6786 |
| Classifier | Hamming Loss | Micro F1 | Macro F1 | Micro P | Macro P | Micro R | Macro R |
|---|---|---|---|---|---|---|---|
| BR-RF | 0.032 | 0.8631 | 0.8515 | 0.9059 | 0.9128 | 0.8242 | 0.8033 |
| BR-SVC | 0.029 | 0.8777 | 0.8656 | 0.9063 | 0.9049 | 0.8509 | 0.8324 |
| BR-NB | 0.6259 | 0.2463 | 0.217 | 0.1444 | 0.1354 | 0.8369 | 0.798 |
| MLkNN | 0.0575 | 0.7445 | 0.7599 | 0.8146 | 0.8233 | 0.6854 | 0.7088 |
| OvsR-XGB | 0.0278 | 0.8862 | 0.8814 | 0.8858 | 0.8815 | 0.8867 | 0.8831 |
| OvsR-LR | 0.0376 | 0.8337 | 0.8 | 0.907 | 0.9084 | 0.7714 | 0.7195 |
| OvsR-SGD | 0.031 | 0.8702 | 0.8592 | 0.8911 | 0.8866 | 0.8502 | 0.8365 |
| OvsR-SVC | 0.0336 | 0.8577 | 0.847 | 0.8895 | 0.885 | 0.8281 | 0.8141 |
| Embedding | Classifier | Hamming Loss | Micro F1 | Macro F1 | Micro P | Macro P | Micro R | Macro R |
|---|---|---|---|---|---|---|---|---|
| Word2Vec | BR-RF | 0.0822 | 0.5453 | 0.5054 | 0.8498 | 0.879 | 0.4015 | 0.3644 |
| Word2Vec | XGB | 0.0717 | 0.6544 | 0.6482 | 0.8017 | 0.8482 | 0.5528 | 0.5347 |
| GloVe | BR-RF | 0.0757 | 0.5898 | 0.5249 | 0.8809 | 0.8835 | 0.4433 | 0.3804 |
| GloVe | XGB | 0.0606 | 0.7148 | 0.6999 | 0.8466 | 0.8507 | 0.6186 | 0.698 |
| BERT | BR-RF | 0.0788 | 0.5551 | 0.4201 | 0.9157 | 0.9525 | 0.394 | 0.2882 |
| BERT | XGB | 0.0589 | 0.7242 | 0.679 | 0.8505 | 0.8502 | 0.6306 | 0.5738 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deniz, E.; Erbay, H.; Coşar, M. Multi-Label Classification of E-Commerce Customer Reviews via Machine Learning. Axioms 2022, 11, 436. https://doi.org/10.3390/axioms11090436
Deniz E, Erbay H, Coşar M. Multi-Label Classification of E-Commerce Customer Reviews via Machine Learning. Axioms. 2022; 11(9):436. https://doi.org/10.3390/axioms11090436
Chicago/Turabian StyleDeniz, Emre, Hasan Erbay, and Mustafa Coşar. 2022. "Multi-Label Classification of E-Commerce Customer Reviews via Machine Learning" Axioms 11, no. 9: 436. https://doi.org/10.3390/axioms11090436