1. Introduction
Statistical methodology plays an important role in quantitative methods, given the hypothesis testing and inferential procedures. Nonetheless, the comparison across features is given based on a generated function estimated from the data information. Most often, mild suppositions are assumed, which compromises the generalization of the results.
Under the perspective of statistical generalization (inferential method), some challenges are found for bounded distribution estimation. For instance, the confidence interval, which is often adopted from the maximum likelihood estimation approach and asymptotic supposition, is also assumed. Specially, interval estimation can be seen as the parameter space domain.
One exemplification is the case in which bounded information data are observed and, nonetheless, normality is commonly assumed to be true. This is the case of proportion/rate data, which are double bounded in the lower limit equal to zero and upper limit equal to one. Relative humidity is an example of this scenario in which every decision-making should be
[
1,
2], or rates commonly used in the fields of finance, economics and demography, to number a few.
In the case of rates and proportions processes, as well as other processes whose variables of interest assume values in the range
, there is a well-represented class of models, the unit distributions family, which deals with this type of double-bounded data. Among the many existing unit distributions, it is noteworthy mentioning the power distribution, beta distribution [
3], Kumaraswamy distribution [
4], unit-logistic distribution [
5], simplex distribution [
6], unit-Weibull distribution [
7,
8], unit-Lindley distribution [
9], unit-half-normal distribution [
10], unit log-log distribution [
11], modified Kumaraswamy and reflected modified Kumaraswamy distributions [
12], unit-Teissier distribution [
13], unit extended Weibull families of distributions [
14], lognormal distribution [
15], unit folded normal distribution [
16], Marshall-Olkin reduced Kies distribution [
17], and unit-Chen distribution [
18].
Despite the applicability of the unit distributions in double-bounded variables, another important fact is that the interval estimation for the parameter may also be limited in a domain (like positive real number). In the face of it, we also presented an inferential alternative through the delta method.
This study starts with a presentation of an important theorem that changes from a modification of the standard normal distribution into a class of density functions that can be seen as a unit. Then, as an exemplification, a second moment case was chosen to illustrate the usefulness of this class of probabilistic models. This class of distributions shows to be competitive for high-frequency data with range greater than 0.4, important to real-world applications, whereas a classical unit distribution fails [
19]. Additionally, two different data sets were selected to illustrate the adjustment of the proposed model. The first one is related to the Chilean inflation (ultimate post-military era), and the second one comes from the driest area of the planet (excluding the north and south poles).
This paper is structured in four parts.
Section 2 presents the proposed one-parameter unit distribution. In
Section 3, the inferences for the distribution parameter adopting the uniformly minimum-variance unbiased estimator (UMVUE) and maximum likelihood estimator (MLE) as point estimators, as well as interval estimations, are discussed. A simulation study is also presented in this section. In
Section 4, two real data sets are used to illustrate the proposed methodology, one from the Chilean inflation in the post-military period, and other one from the relative humidity water monitoring in the Atacama Desert. Finally,
Section 5 lists the conclusions of this study. Nevertheless, before moving on into the described structure, a wide class of models that can be generated in many different random variable supports is presented. Therefore, a theorem is elicited and, as a special case, the whole paper will consider an order two for exemplification of this powerful class of distributions.
Motivation
The normal (or Gaussian) distribution is very important to the history of statistics, and numerous modifications to this distribution have been proposed in the literature [
20,
21]. An interesting fact related to the normal distribution is that its even moments can be used to generate new distributions, which is the case presented below, through a definition and a result embodied in a theorem that accounts for the characterization of these new distributions.
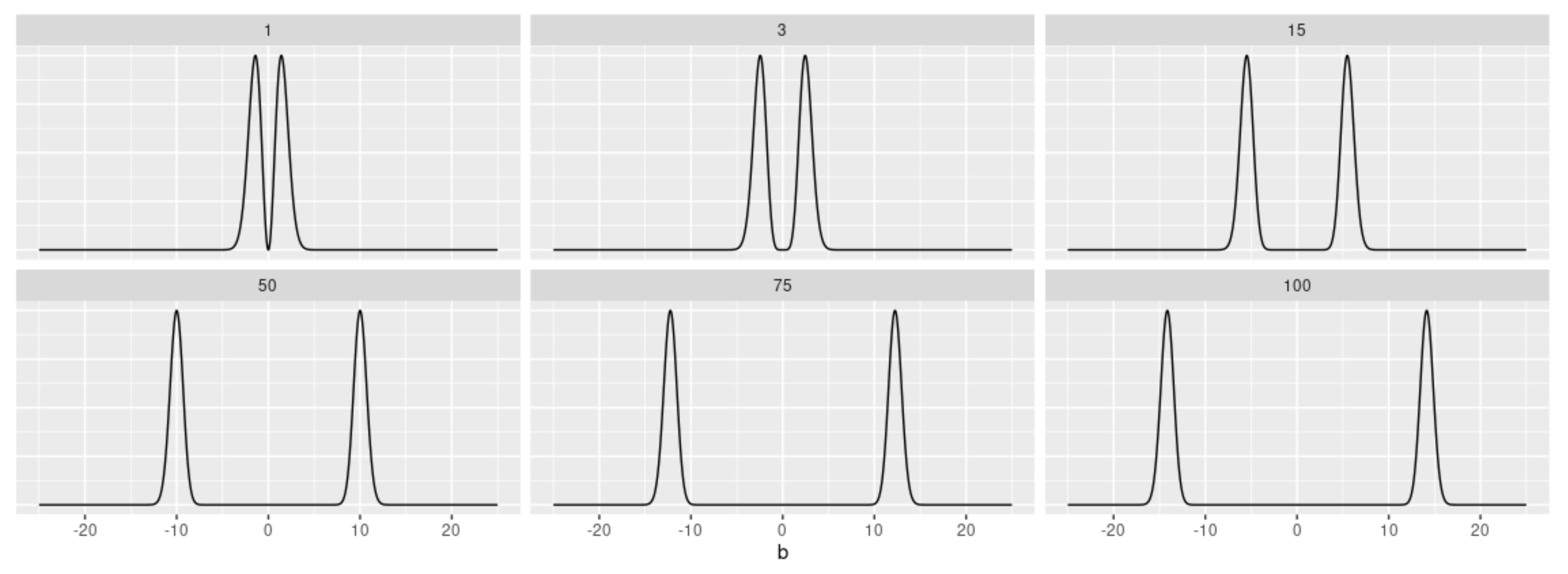
Definition 1. A random variable B is said to be distributed according to a Bimodal Normal (BN) distribution of order k, that is, (discussed in [22]), if its probability density function (PDF) is given byin which is the PDF of the standard normal distribution, and . This class of distributions is always bimodal, which means that the observed modes move away from each other when the order
k increases (as depicted by
Figure 1).
It is noteworthy mentioning that transformations derived from the distribution may lead to other domains of interest, e.g., the unit domain. For example, let , then a scale parameter , the transformation , and then the transformation . Thus, the stochastic characterization of a distribution can be obtained according to the following theorem.
Theorem 1. Let and be independent random variables, in which is such that and . Then, So, this theorem is mainly motivated by the result that shows that if
, then
. The entire demonstration is presented in
Appendix A.
2. The Model
In this section, a new unit distribution, named Alpha-Unit, which presents a single parameter, , is discussed. Its stochastic representations (probability density and cumulative distribution functions), moments (including mean and variance), moment-generating function, and how to generate pseudo-random numbers from it will be presented. Moreover, a proposal of statistical control chart for unit data based on the Alpha-Unit distribution will also be shown.
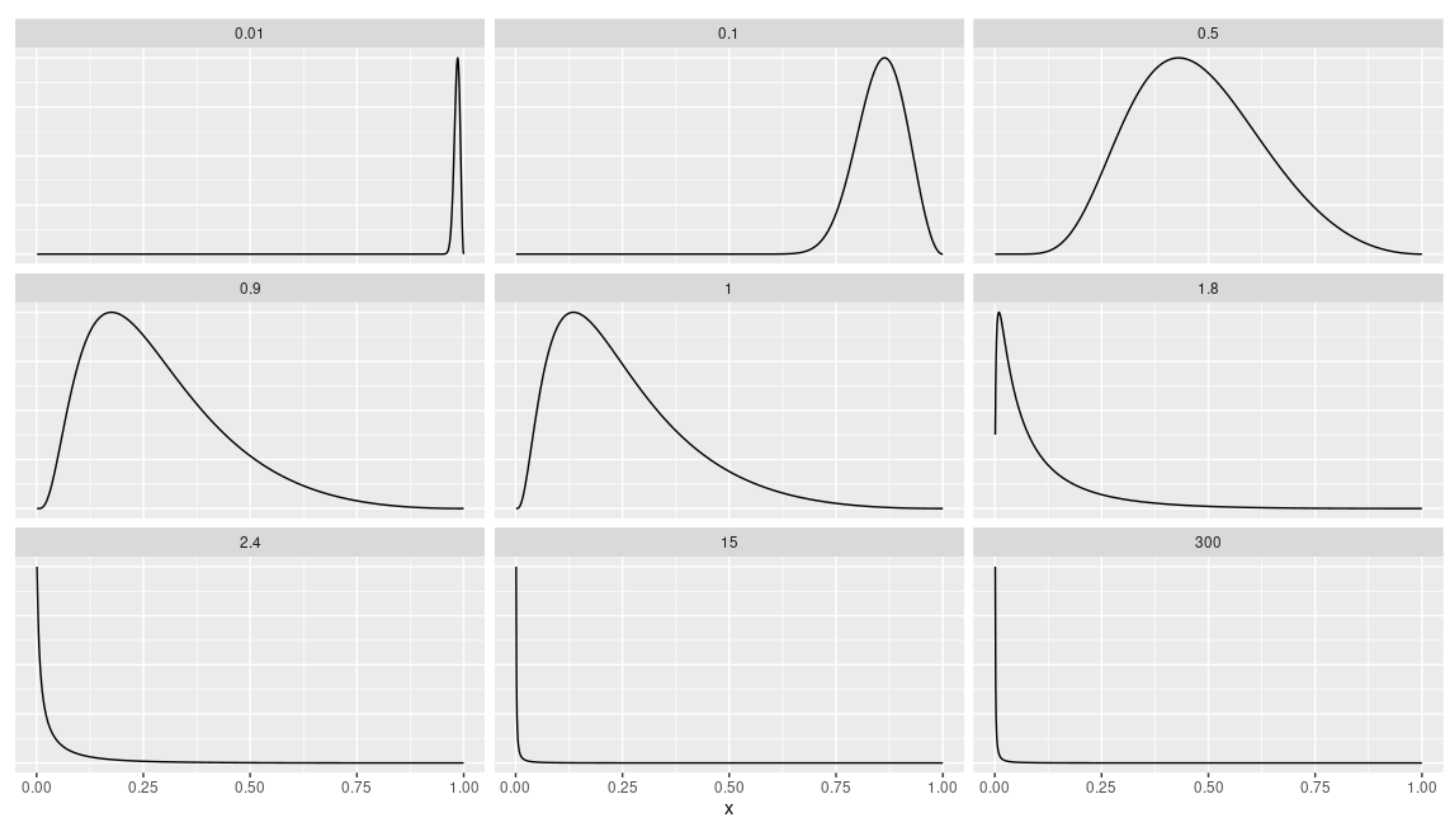
The Alpha-Unit density is originated from the general theorem (Theorem 1), by considering . Moreover, it represents the second moment of the standard normal distribution and, later, transformed its domain. However, as k increases, the concentration of the distribution intensifies and other densities could be obtained.
Properties and Characterization
Definition 2. (Alpha-Unit distribution). A random variable X follows an Alpha-Unit (AU) distribution with parameter , that is, , if its PDF is given by Remark 1. If , then its PDF is unimodal.
Proof. The maxima of the AU distribution are studied, to which the criterion of the first derivative is first considered:
By solving algebraically for
x, we obtain:
By working algebraically, it can be seen that this is only true for (ii), and is a global maximum, given that the solution is in between 0 and 1. Therefore, the AU distribution is unimodal. □
Proposition 1. If,
then itsr-
th order moment is given byin whichis the cumulative distribution function (CDF) of the standard normal distribution.
Proof. From the definition of the
r-th order moment, we have:
By changing the variables:
then substituting into Equation (
3) and developing algebraically, we obtain:
Then, by making another change of variables:
,
; and replacing these expressions in the previous equation, we have:
By solving the integrals, we get to:
Then, by solving algebraically, we go down to the expression of Proposition 1. □
Out of Proposition 1, we obtain the mean and variance of the
model as it follows:
Remark 2. As an illustration, Figure 2 displays the generated asymmetry and kurtosis based on the chosen α parameter of the AU distribution. Proposition 2. If,
then its CDF is given by Proof. By definition, the CDF is:
By making the change of variables:
then substituting into Equation (
4) and reducing expressions algebraically, we get to:
By calculating the integral, we find:
Then, by multiplying and commuting, we get to the expression of Proposition 2. □
Additionally, if
X denotes the monitored variable, then the PDF of
X is given by (
2). Also, consider that the probability of false alarm (known as type I error) is
. Thus, we get to:
in which
is the in-control process parameter (that is, the parameter that controls the quality characteristic based on the in-control state), and LCL and UCL are the lower and upper control chart limits, respectively. Given the CDF
, then the quantile function of
X is defined by
,
, which can be obtained by setting to zero and solving (numerically) for
x the following equation:
Following [
23], the control limits and centerline (CL) of the proposed control chart for unit data based on the AU distribution or, simply, AU control chart, are given by
in which
is the quantile function of the
distribution.
Proposition 3. If,
then its moment-generating function (MGF) is given by Proof. By definition, the MGF is:
By making the following change of variables:
then substituting and simplifying into Equation (
5), we get to:
Working algebraically, we obtain:
By making the following change of variables:
,
; then substituting it into the previous equation, we get to:
Then, by solving the integral and adjusting algebraically, we get to the expression of Proposition 3. □
The pseudo-code presented in Algorithm 1 describes the important steps for the generation of random (in fact, pseudo-random) numbers from the
distribution. Further proofs are attached under
Appendix B.
| Algorithm 1 Random number generation from the model. |
Step 1.Generate a random number . Step 2. Generate a random number . If , set ; otherwise, . Step 3. Based on the numbers obtained, generate , in which is a (positive) scale parameter and follows a Bimodal Half-Normal (BHN) distribution. Step 4. Conclude with the number generated by Step 3 as a negative power of base e, that is, . Step 5. Repeat Steps 1–4 n times to obtain a random sample of size n from the model.
|
3. Inference
In this section, the parameter estimation adopting the UMVUE and MLE approaches are discussed. At first, it will be demonstrated that the UMVUE can be obtained straightforwardly, since the proposed AU distribution is part of the exponential family. Later, the MLE will also be discussed, which will help to estimate not only the point estimation of the parameter, but also the interval estimation. We enrolled the reasoning considering the asymptotic convergence in distribution of the parameter estimator, as well as adapted a transformation that ensures that the interval of the parameter will always be on its domain (the delta method). The delta transformation procedure will enable the correct inferences and the standard error calculation associated with the parameter estimate. Later on, a simulation study to illustrate these theoretical results is presented.
3.1. UMVUE through the Exponential Family
Many of the distributions used in statistics belong to the exponential family, thereby implying in a considerable advantage over other models that do not belong to this family. Such an advantage is significantly declared when it comes to calculating the statistic of a random sample . Next, it is shown that the proposed distribution belongs to this family.
A random variable
X is said to belong to the
one-parameter exponential family if its associated PDF
can be written in the form of:
Let
, then the PDF of
X can be written in exponential form as it follows:
Then,
X belongs to the one-parameter exponential family if we define:
Let
be an observation (or realization) of the random sample
, with
, for
. Then, the joint PDF presented in exponential form is
from which it can be concluded that the statistic
is sufficient and complete, once the AU distribution is part of the exponential family.
Proposition 4. Letbe a random sample, with,
for,
and.
Then,
Proof. If
, then
. Thus,
n independent and identically distributed samples of
G will have the sum of
n, which will result in a chi-squared distribution with degrees of freedom equal to
, that is,
, since
so,
□
Proposition 5. Letbe a random sample, with,
for,
and.
Then,
is an unbiased estimator of.
Proof. First, remember that if
distribution, then
. Since the
parameter is observed to be squared, it will be necessary to apply it to find an unbiased estimator. So, considering the random variable
(with
as defined in Proposition 4), it follows that:
so,
□
Remark 3. Considering the two previous propositions and resorting to the Lehmann-Scheffé theorem, one can conclude that is UMVUE for α.
3.2. Estimation using the Maximum Likelihood Method
Let
be a realization of the random sample
taken from the
distribution. Then, the log-likelihood function is given by
The MLE of
, i.e.,
, is found by solving the following equation:
resulting
On the other hand, the second derivative of evaluated at is negative, therefore concluding that is MLE for .
It is known that, under certain regularity conditions,
in which
.
A two-sided
confidence interval for
can be calculated by
in which
is the
q-th percentile of the standard normal distribution. The variance of
can be approximated by the inverse of the observed Fisher information, as
Since
is a positive value and we cannot guarantee that the lower limit of the interval (
6) is positive, we resort to the delta method to remedy such situation. For this, we define the function
as
, and knowing that
we can, then, obtain an approximate two-sided
confidence interval for
through
3.3. Simulation Study
In order to illustrate the presented inferences for the estimation of the AU distribution, the MLE versus the UMVUE are compared (via simulation study) in this subsection. Moreover, we considered the scenarios in which the parameter
, considering sample sizes
, through the Monte Carlo method with
repetitions. This entire procedure took into account the random number generator for the
distribution shown in Algorithm 1. All analyses carried out in this study adopted the open-source R software [
24].
For the performance comparison of the proposed estimators (MLE and UMVUE), since the true parameter value is known, the bias and mean squared error (MSE) metrics were adopted, and they are defined, respectively, as it follows:
in which
is the estimate for
in the
i-th iteration (point estimation). Additionally, based on the asymptotic results presented in this study, we also calculated the 95% confidence interval (CI) length by adopting the delta method from Equation (
7) (interval estimation). That is, it analyzed the average of all the upper limits of the 95% confidence interval, as well as the average of all the lower limits, and then calculated their difference.
Table 1 presents the obtained average estimates (AvE) of the
parameter, for each sample size
n, as well as the corresponding bias, MSE and 95% CI length (this last one only for MLE) results.
The asymptotic convergence of the MLE towards the robustness is noticed as the sample size increases. In addition, both MLE and UMVUE’s bias and MSE are small and tend to decrease as n gets larger. On the other hand, the CI length also decreases as the sample size increases.
Finally, regarding the robustness of the estimators, the difference between the MLE and UMVUE estimates was taken, considering each different sample size n. Then, the interquartile range (IQR) was calculated per sample size group. That is, , in which and . For instance, the IQR for was , whereas for and , it went down to and , respectively. This points out, in short, that as the sample size gets larger, the error range gets smaller, regardless of the value of the parameter.
4. Real-World Exemplifications
In this section, two applications adopting the AU distribution with real-world issues are exemplified. The first case is related to the dynamics of the Chilean inflation in the post-military dictatorship period. The second case pertains to the relative humidity of the air in the northern Chilean city of Copiapó (Atacama region).
The Chilean inflation data are recorded annually, whose values considered the range from 1992 to 2021. These are based on the period after the military dictatorship of 1973–1990. It was analyzed the dynamics of the inflation data (in %), which were standardized by min-max transformation, resulting in a unit response variable (value between zero and one). The years 1990 and 1991 were excluded, since they are considered to be a period of transition. Then, the total amount of observations was of 30 years (from 1992 to 2021).
On the other hand, the relative air humidity data cover the period from February 2015 to October 2022, with a one-hour recording format (104,415 observations). Then, this data set was transformed into daily maximum observation (6226 observations).
4.1. Chilean Inflation (Post-Military Era)
Figure 3 presents the dynamics of the Chilean inflation in the post-military dictatorship period, demonstrating stability between the years of 1999 and 2008. The right panel displays the time series of inflation, in which time is measured in years, from year 1 (1992) to year 30 (2021). The left panel depicts the accumulation of the values throughout the time series, in which a predominant trend is shown around 0.1 of the inflation rate.
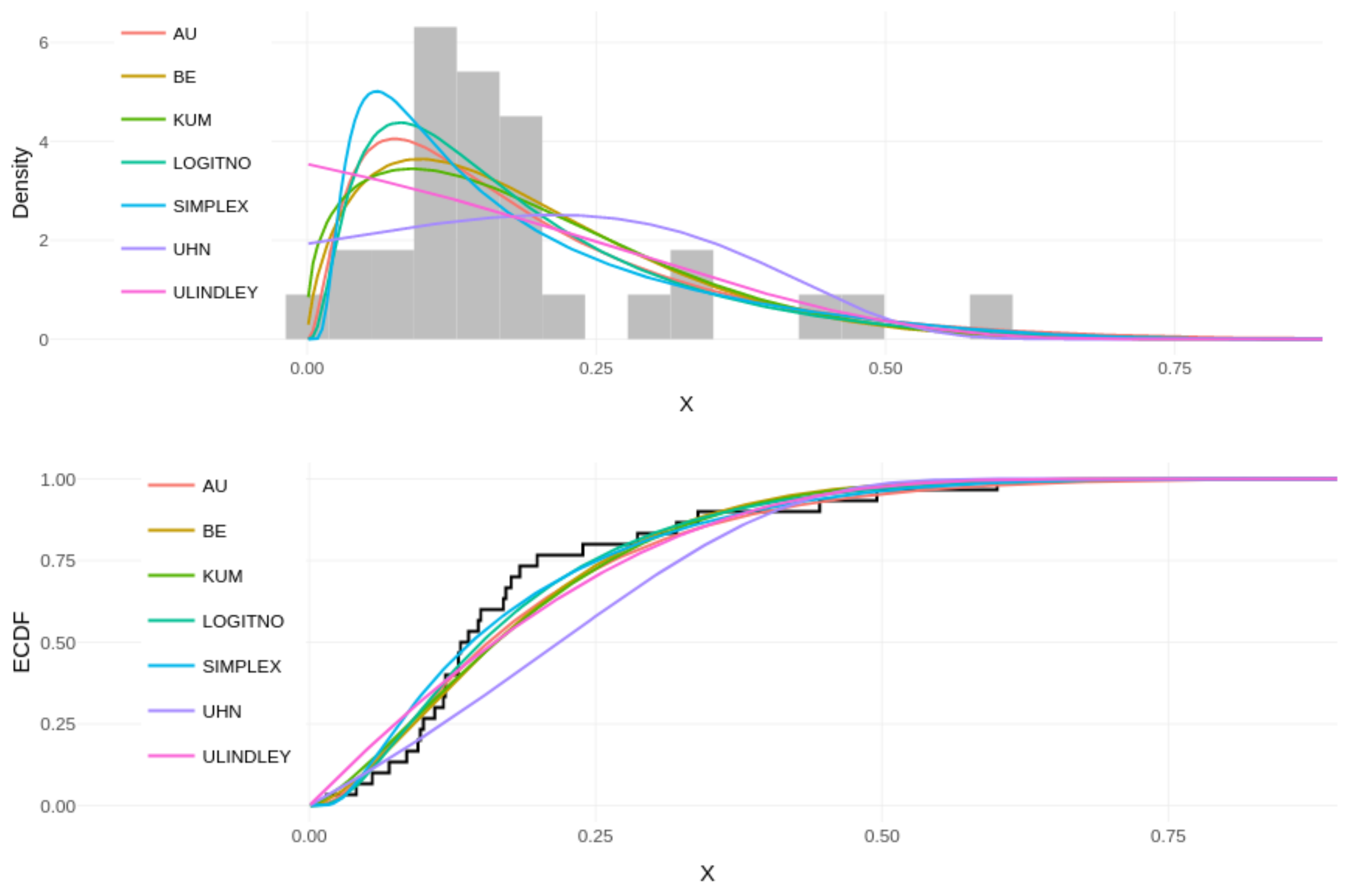
Once the empirical dynamics of these data was analyzed, the most common unit distributions, presented in the statistical literature, were fitted. The upper panel of
Figure 4 illustrates the histogram for the inflation data, in which it is compared with different fitted densities based on the MLE: AU, beta (BE), Kumaraswamy (KUM), logit-normal (LOGITNO), simplex (SIMPLEX), unit-half-normal (UHN), and unit-Lindley (ULINDLEY). The lower panel of the same figure presents the fitted CDFs superimposed to the empirical CDF (ECDF).
In order to quantify the performance of the fitted models, the Akaike Information Criterion (AIC) [
25] and the Bayesian (or Schwarz) Information Criterion (BIC) [
26] were analyzed. The obtained results (see
Table 2) indicated the AU model as the best-fitted model to this data set. In addition, it is possible to make an inference about the average of the phenomenon, that is, the expectation of the AU(
) model, resulting in
. In other words, the average Chilean inflation, in post-military era, is of 19.49%.
In the following subsection, it is illustrated the performance of the AU model when adopting a high-frequency data set originated from the relative humidity from a city located in the Atacama Desert.
4.2. Water Monitoring in Air Humidity
The hydrological regime of the main rivers of Atacama is characterized by ice sources: water flows from the peaks following the melting of snowfall, glaciers, and permafrost located in the upper parts of the Andes range. In the context of climate change, it is, therefore, essential to understand the hydrological cycle of these regions, in order to set up a sustainable management policy to them. Understanding the hydrological cycle requires the implementation of tools for forecasting river flows, relative humidity, groundwater reservoirs, or any other water-related quantity monitoring, which inevitably demands an in-depth knowledge with respect to the physical phenomena that rule the entire hydrological cycle and, more precisely, the complex interaction between atmosphere, climate, landforms, ice, snow and river flows.
Additionally, a unique phenomenon called
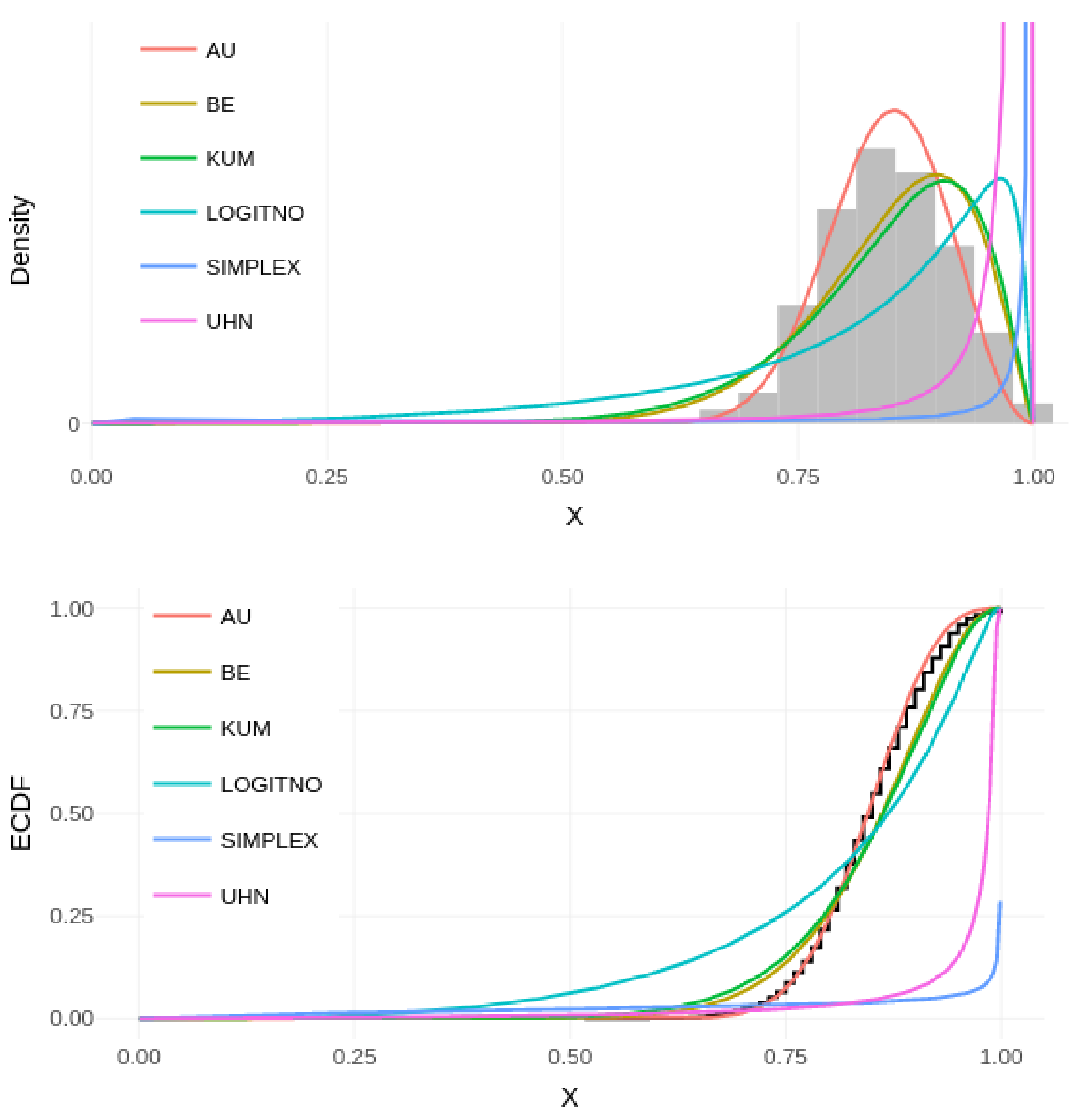
Camanchaca happens, which consists in a fog passing by the Copiapó city, recurrent only between midnight to around 10 a.m. Here, we demonstrate the variation of the relative humidity of Copiapó city, proposing a methodology that can be efficient, adjustable to these data. Using the daily maximum relative humidity, six different unit distributions were compared: AU, BE, KUM, LOGITNO, SIMPLEX, and UHN, as shown in
Figure 5.
After comparing the commonly used unit models, we demonstrate the advantage of fitting the AU model over others (visually).
Table 3 confirms the best fit of the AU model, based on information criteria (AIC and BIC), as well as depicts the estimation of the parameter(s) of each model.
After obtaining the parameter estimate for
, the AU model (best-fitted model) was used to construct a Statistical Process Control (SPC) chart [
27], by calculating a tolerance upper-lower bound. Moreover, the Highest Density Interval (HDI) was adopted, considering a confidence degree of 99%, to monitor the daily maximum relative humidity records (as displayed by
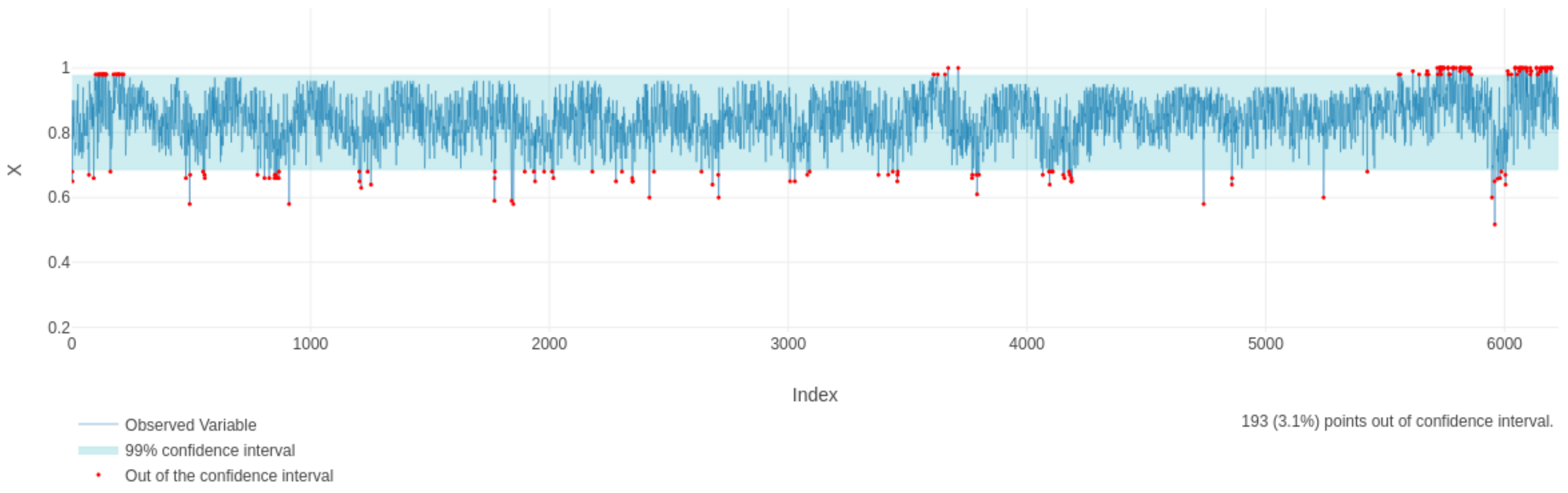
Figure 6).
The expected daily maximum water relative humidity is of 84.23% (based on the fitted AU model). The obtained control limits, considering a confidence (or tolerance) level of 99%, were: and . Thus, the control chart based on the AU model (AU control chart) is another exciting and valuable alternative to some well-known SPC tools, which enlightens the forecasting and opens new doors to discuss extreme events in the Atacama water particles monitored by probabilistic reasoning.
5. Conclusions
This study showed the competitiveness of the developed Theorem 1 (Equation (
1)), which enables for a great class of distributions that belong all to the exponential family. As an exemplification, we adopted the special case for
, which is equivalent to the moment of order two of the standard normal distribution, and after some transformations, we developed the Alpha-Unit (AU) distribution. Also, we dedicated to the unit range, given the importance of this stochasticity representation.
Unit distributions are useful for values that oscillate between zero and one, such as fractions, proportions and rates, among others, or for a set of values in which there is a minimum or maximum limitation, resorting to standardization through the min-max transformation. Most distributions of this type come from transforming a random variable with certain distribution so that it takes values between zero and one, as in the case of unit-Lindley distribution [
9], which comes from the Lindley distribution [
28,
29].
There are numerous studies based on (e.g., unit) distributions, by extending a model and applying it to several areas [
11,
14,
16]. In this study, we introduced and showed the competitiveness of the AU distribution, especially for data with a range greater than 0.4, or which present high asymmetry and low decay. Further studies shall investigate this hypothesis in a wider amount of data sets (through different sorts of wide data range). Additionally, an implementation of this model adopting hierarchical estimation and spatio-temporal dependence would be useful for forecast/predictable problems.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}