
Optimization of Convolutional Neural Networks Architectures Using PSO for Sign Language Recognition


Abstract
:1. Introduction
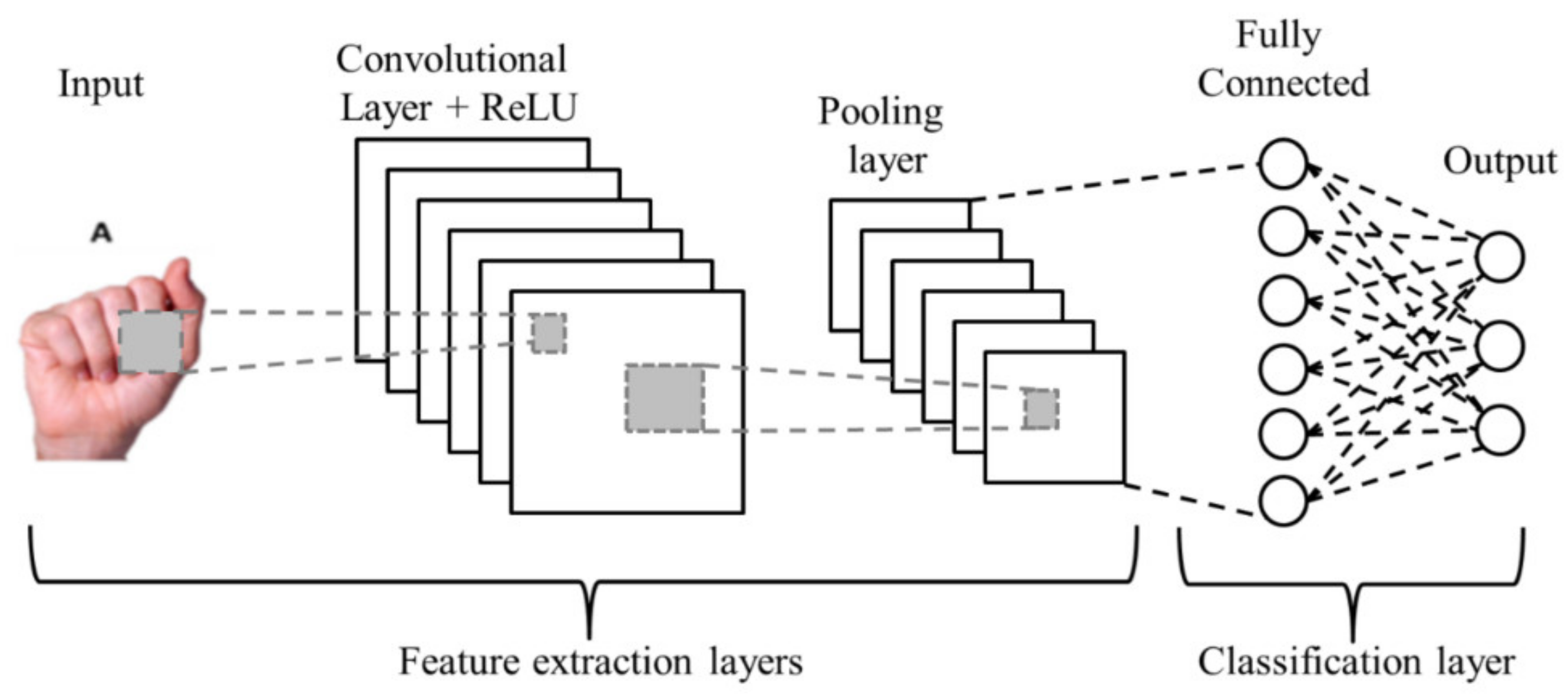
2. Convolutional Neural Networks
2.1. Input Layer
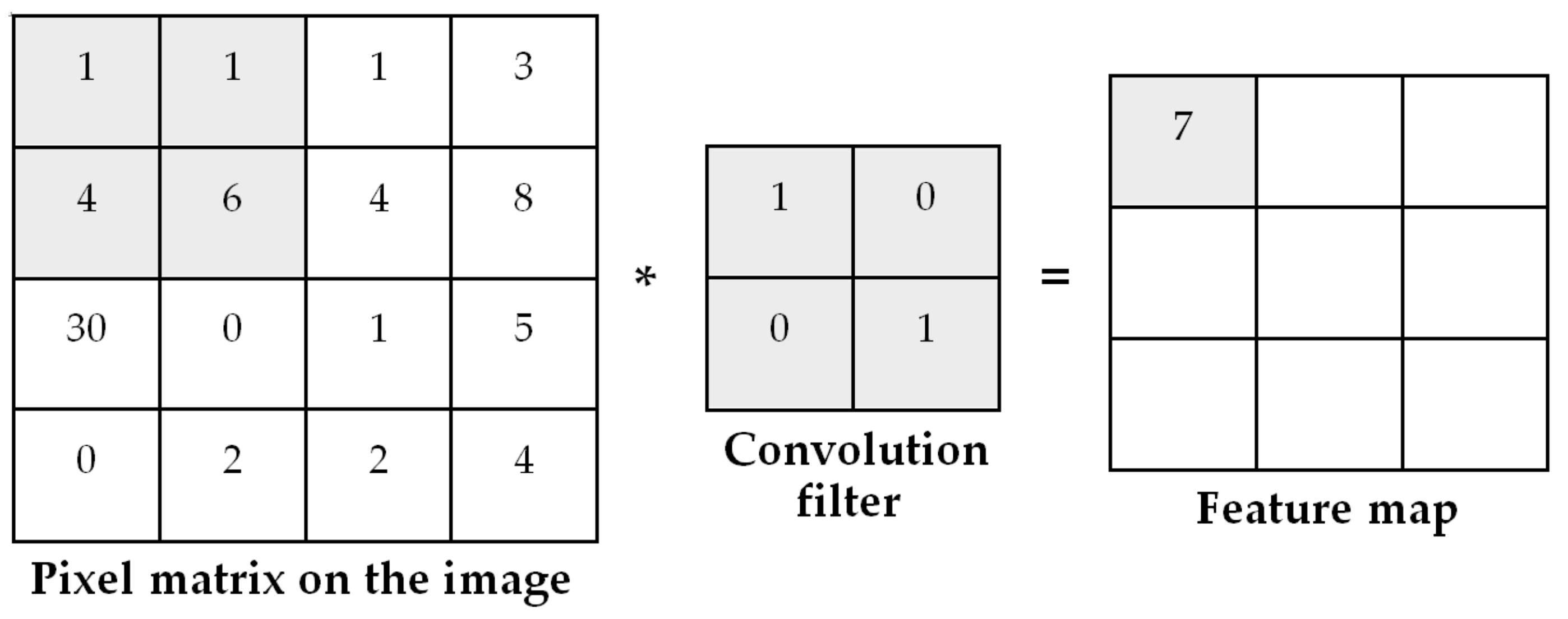
2.2. Convolution Layer
2.3. Non-Linearity Layer
2.4. Pooling Layer
2.5. Classifier Layer
3. Particle Swarm Optimization
| Algorithm 1. The PSO algorithm |
| Initialize the parameter of the problem (a random population). |
| while (completion criteria are not met) |
| begin |
| For each particle i do |
| begin |
| Update the position using (1). |
| Update the velocity using (2). |
| Evaluate the fitness value of the particle |
| If is necessary using (3)(4) |
| Update pbesti(t) and gbesti(t). |
| end |
| end |
4. Convolutional Neural Network Architecture Optimized by PSO
- The number of convolutional layers;
- The filter size or filter dimension used in each convolutional;
- The number of filters to extract the future maps (the convolution filter number);
- The batch size number: this value represents the number of images that are entered into CNN in each training block.
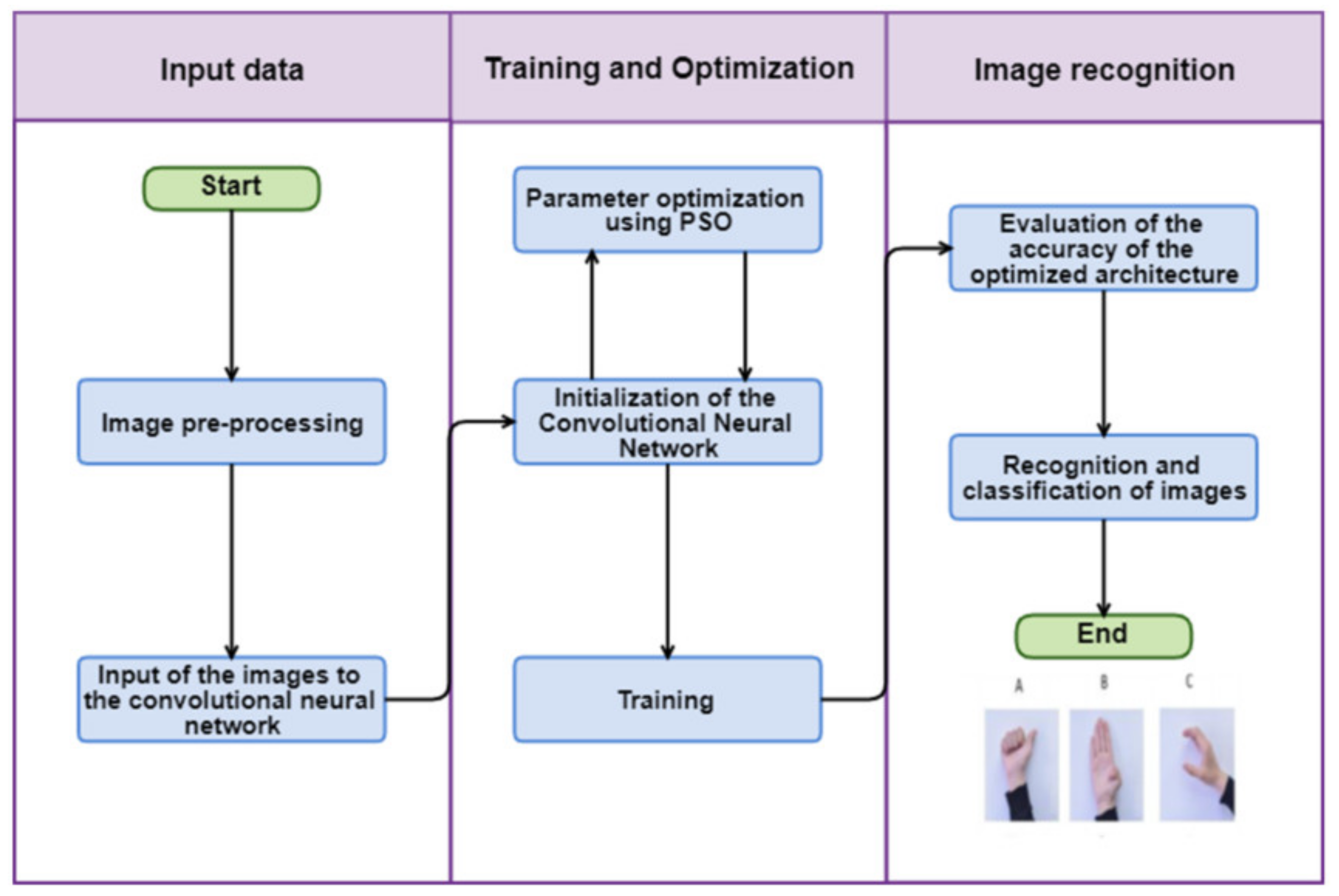
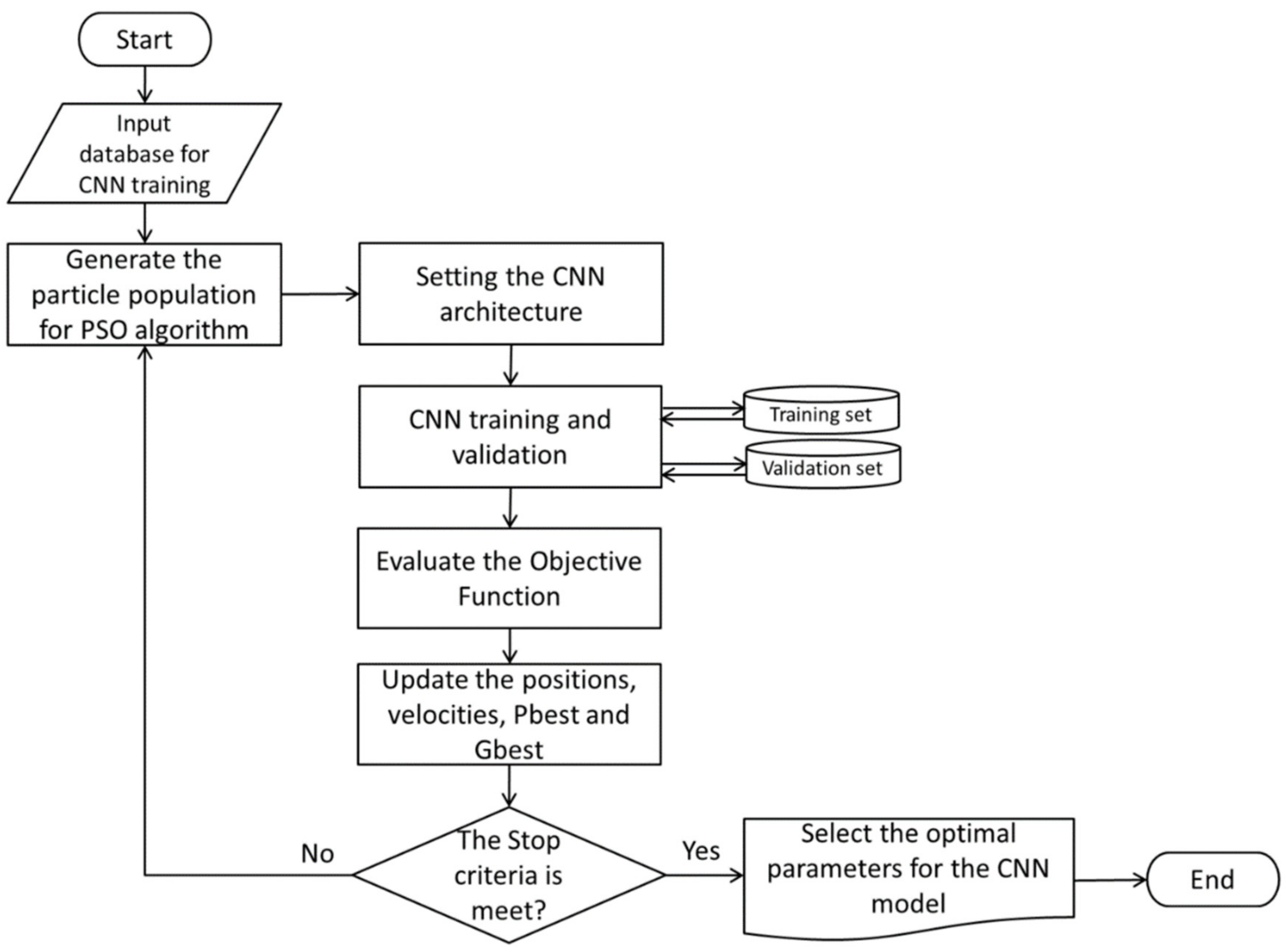
- Input database to train the CNN. This step consists of selecting the database to be processed and classified for the CNN (ASL alphabet, ASL MINIST and MSL alphabet). Is important to mention that all the elements of each database need to keep a similar structure or characteristics. In other words, images with the same scale and color gamma (grayscale, RGB, CMYK); additionally, with the same dimensions of pixels and a similar format of file (JPGE, PNG, TIFF, BMP, etc.).
- Generate the particle population for the PSO algorithm. The PSO parameters are set to include the number of iterations, the number of particles, inertial weight, cognitive constant (W1), and social constant (W2); the parameters used in the experimentation are presented in Table 8. This step involves the design of the particles; the structures of these are presented in Tables 1 and 3 according to the two optimization architecture proposals in this paper.
- Initialize the CNN architecture, with the parameter obtained by the PSO (convolution layers number, the filter size, number of convolution filters, and the batch size) the CNN is initialized and in conjunction with the additional parameter specified in Table 8, the CNN is ready to train the input database.
- CNN training and validation. The CNN reads and processes the input databases taking the images for training, validation, and testing; this step produces a recognition rate and the AIC value. These values return to the PSO as part of the objective function.
- Evaluate the objective function. The PSO algorithm evaluates the objective function to determine the best value. As in this research, we are considering two approaches, in the first, the objective function is only the recognition rate (Equation (5)) and in the second, the objective function consists of the recognition rate and the AIC value (Equation (6)).
- Update PSO parameters. At each iteration, each particle updates its velocity and position depending on its own best-known position (Pbest) in the search-space and the best-known position in the whole swarm (Gbest).
- The process is repeated, evaluating all the particles until the stop criteria are found (in this case, it is the number of iterations).
- Finally, the optimal solution is selected. In this process, the particle represented by Gbest is the optimal one for the CNN model.
4.1. PSO-CNN Optimization Process (PSO-CNN-I)
4.2. PSO-CNN Optimization Process (PSO-CNN-II)
5. Experiments and Results
5.1. Sign Language Databases Used in the Study Cases
5.1.1. American Sign Language (ASL Alphabet)
5.1.2. American Sign Language (ASL MNIST)
5.1.3. Mexican Sign Language (MSL Alphabet)
5.2. Parameters Used in the Experimentation
5.3. Optimization Results Obtained by the PSO-CNN-I Approach
5.4. Optimization Results Obtained by the PSO-CNN-II Approach
5.5. Statistical Test between PSO-CNN-I and PSO-CNN-II Optimization Process
- A confidence level of 95% (α = 0.05).
- The null hypothesis is given that (): the PSO-CNN-I architecture () is equal to PSO-CNN-II architecture (), expressed as .
- The alternative hypothesis is (): affirm that PSO-CNN-I architecture () is greater than that PSO-CNN-II architecture (), expressed as .
- The objective is to reject the hypothesis null () and support the alternative hypothesis ().
5.6. State-of-the-Art Analysis Comparison
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hemanth, J.D.; Deperlioglu, O.; Kose, U. An enhanced diabetic retinopathy detection and classification approach using deep convolutional neural network. Neural Comput. Appl. 2020, 32, 707–721. [Google Scholar] [CrossRef]
- Li, P.; Li, J.; Wang, G. Application of Convolutional Neural Network in Natural Language Processing. IEEE Access 2018, 64–70. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Liang, S.D. Optimization for Deep Convolutional Neural Networks: How Slim Can It Go? IEEE Trans. Emerg. Top. Comput. Intell. 2020, 4, 171–179. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G. Evolving Deep Convolutional Neural Networks for Image Classification. IEEE Trans. Evol. Comput. 2020, 24, 394–407. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Yen, G.G.; Yi, Z. Evolving Unsupervised Deep Neural Networks for Learning Meaningful Representations. IEEE Trans. Evol. Comput. 2019, 23, 89–103. [Google Scholar] [CrossRef]
- Ma, B.; Li, X.; Xia, Y.; Zhang, Y. Autonomous deep learning: A genetic DCNN designer for image classification. Neurocomputing 2020, 379, 152–161. [Google Scholar] [CrossRef] [Green Version]
- Baldominos, A.; Saez, Y.; Isasi, P. Evolutionary convolutional neural networks: An application to handwriting recognition. Neurocomputing 2018, 283, 38–52. [Google Scholar] [CrossRef]
- Poma, Y.; Melin, P.; Gonzalez, C.I.; Martinez, G.E. Optimization of Convolutional Neural Networks Using the Fuzzy Gravitational Search Algorithm. J. Autom. Mob. Robot. Intell. Syst. 2020, 14, 109–120. [Google Scholar] [CrossRef]
- Poma, Y.; Melin, P.; Gonzalez, C.I.; Martinez, G.E. Filter Size Optimization on a Convolutional Neural Network Using FGSA. In Intuitionistic and Type-2 Fuzzy Logic Enhancements in Neural and Optimization Algorithms; Springer: Cham, Switzerland, 2020; Volume 862, pp. 391–403. [Google Scholar]
- Poma, Y.; Melin, P.; Gonzalez, C.I.; Martinez, G.E. Optimal Recognition Model Based on Convolutional Neural Networks and Fuzzy Gravitational Search Algorithm Method. In Hybrid Intelligent Systems in Control, Pattern Recognition and Medicine; Springer: Cham, Switzerland, 2020; Volume 827, pp. 71–81. [Google Scholar]
- Lee, W.-Y.; Park, S.-M.; Sim, K.-B. Optimal hyperparameter tuning of convolutional neural networks based on the parameter-setting-free harmony search algorithm. Optik 2018, 172, 359–367. [Google Scholar] [CrossRef]
- Wang, B.; Sun, Y.; Xue, B.; Zhang, M. A hybrid differential evolution approach to designing deep convolutional neural networks for image classification. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Wellington, New Zealand, 11–14 December 2018; Springer: Cham, Switzerland, 2018; pp. 237–250. [Google Scholar]
- Gülcü, A.; KUş, Z. Hyper-Parameter Selection in Convolutional Neural Networks Using Microcanonical Optimization Algorithm. IEEE Access 2020, 8, 52528–52540. [Google Scholar] [CrossRef]
- Zhang, N.; Cai, Y.; Wang, Y.; Tian, Y.; Wang, X.; Badami, B. Skin cancer diagnosis based on optimized convolutional neural network. Artif. Intell. Med. 2020, 102, 101756. [Google Scholar] [CrossRef]
- Tuba, E.; Bacanin, N.; Jovanovic, R.; Tuba, M. Convolutional Neural Network Architecture Design by the Tree Growth Algorithm Framework. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 17–19 July 2019; pp. 1–8. [Google Scholar]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G. A particle swarm optimization based flexible convolutional autoencoder for image classification. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2295–2309. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Singh, P.; Chaudhury, S.; Panigrahi, B.K. Hybrid MPSO-CNN: Multi-level Particle Swarm optimized hyperparameters of Convolutional Neural Network. Swarm Evol. Comput. 2021, 63, 100863. [Google Scholar] [CrossRef]
- Wang, B.; Sun, Y.; Xue, B.; Zhang, M. Evolving deep convolutional neural networks by variable-length particle swarm optimization for image classification. In Proceedings of the 2018 IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; Volume 1–8. [Google Scholar]
- Gonzalez, B.; Melin, P.; Valdez, F. Particle Swarm Algorithm for the Optimization of Modular Neural Networks in Pattern Recognition. Hybrid Intell. Syst. Control Pattern Recognit. Med. 2019, 827, 59–69. [Google Scholar]
- Varela-Santos, S.; Melin, P. Classification of X-Ray Images for Pneumonia Detection Using Texture Features and Neural Networks. In Intuitionistic and Type-2 Fuzzy Logic Enhancements in Neural and Optimization Algorithms: Theory and Applications; Springer: Cham, Switzerland, 2020; Volume 862, pp. 237–253. [Google Scholar]
- Miramontes, I.; Melin, P.; Prado-Arechiga, G. Particle Swarm Optimization of Modular Neural Networks for Obtaining the Trend of Blood Pressure. In Intuitionistic and Type-2 Fuzzy Logic Enhancements in Neural and Optimization Algorithms: Theory and Applications; Springer: Cham, Switzerland, 2020; Volume 862, pp. 225–236. [Google Scholar]
- Peter, S.E.; Reglend, I.J. Sequential wavelet-ANN with embedded ANN-PSO hybrid electricity price forecasting model for Indian energy exchange. Neural Comput. Appl. 2017, 28, 2277–2292. [Google Scholar] [CrossRef]
- Sánchez, D.; Melin, P.; Castillo, O. Comparison of particle swarm optimization variants with fuzzy dynamic parameter adaptation for modular granular neural networks for human recognition. J. Intell. Fuzzy Syst. 2020, 38, 3229–3252. [Google Scholar] [CrossRef]
- Fernandes, F.E.; Yen, G.G. Particle swarm optimization of deep neural networks architectures for image classification. Swarm Evol. Comput. 2019, 49, 62–74. [Google Scholar] [CrossRef]
- Santucci, V.; Milani, A.; Caraffini, F. An Optimisation-Driven Prediction Method for Automated Diagnosis and Prognosis. Mathematics 2019, 7, 1051. [Google Scholar] [CrossRef] [Green Version]
- Zhou, G.; Moayedi, H.; Bahiraei, M.; Lyu, Z. Employing artificial bee colony and particle swarm techniques for optimizing a neural network in prediction of heating and cooling loads of residential buildings. J. Clean. Prod. 2020, 254, 120082. [Google Scholar] [CrossRef]
- Karaboga, D.; Gorkemli, B.; Ozturk, C.; Karaboga, N. A comprehensive survey: Artificial bee colony (ABC) algorithm and applications. Artif. Intell. Rev. 2014, 42, 21–57. [Google Scholar] [CrossRef]
- Xianwei, J.; Lu, M.; Wang, S.-H. An eight-layer convolutional neural network with stochastic pooling, batch normalization and dropout for fingerspelling recognition of Chinese sign language. Spinger Multimed. Tools Appl. 2019, 79, 15697–15715. [Google Scholar]
- Hayami, S.; Benaddy, M.; El Meslouhi, O.; Kardouchi, M. Arab Sign language Recognition with Convolutional Neural Networks. In Proceedings of the 2019 International Conference of Computer Science and Renewable Energies (ICCSRE), Agadir, Morocco, 22–24 July 2019. [Google Scholar]
- Huang, J.; Zhou, W.; Li, H.; Li, W. Attention-Based 3D-CNNs for Large-Vocabulary Sign Language Recognition. IEEE Trans. Circ. Syst. Video Technol. 2019, 29, 2822–2832. [Google Scholar] [CrossRef]
- Kaggle. American Sign Language Dataset. 2018. Available online: https://www.kaggle.com/grassknoted/asl-alphabet (accessed on 10 February 2020).
- Kaggle. Sign Language MNIST. 2017. Available online: https://www.kaggle.com/datamunge/sign-language-mnist (accessed on 8 February 2020).
- Rastgoo, R.; Kiani, K.; Escalera, S. Sign Language Recognition: A Deep Survey. Expert Syst. Appl. 2021, 164, 113794. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive fields of single neurons in the cat’s striate cortex. J. Physiol. 1959, 148, 574–591. [Google Scholar] [CrossRef]
- Kim, P. Matlab Deep Learning; Apress: Seoul, Korea, 2017. [Google Scholar]
- Cheng, J.; Wang, P.-s.; Li, G.; Hu, Q.-h.; Lu, H.-q. Recent advances in efficient computation of deep convolutional neural networks. Front. Inf. Technol. Electron. Eng. 2018, 19, 64–77. [Google Scholar] [CrossRef] [Green Version]
- Zou, Z.; Shuai, B.; Wang, G. Learning Contextual Dependence with Convolutional Hierarchical Recurrent Neural Networks. IEEE Trans. Image Process. 2016, 25, 2983–2996. [Google Scholar]
- Fukushima, K. A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Elsevier Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, C.C. Neural Networks and Deep Learning; Springer Nature: Cham, Switzerland, 2018. [Google Scholar]
- Jang, J.; Sun, C.; Mizutani, E. Neuro-Fuzzy and Soft Computing: A Computational Approach to Learning and Machine Intelligence; Prentice-Hall: Upper Saddle River, NJ, USA, 1997. [Google Scholar]
- Kennedy, J.; Eberhart, R.C. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks IV, Washington, DC, USA, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Sandeep, R.; Sanjay, J.; Rajesh, K. A review on particle swarm optimization algorithms and their applications to data clustering. J. Artif. Intell. 2011, 35, 211–222. [Google Scholar]
- Hasan, J.; Ramakrishnan, S. A survey: Hybrid evolutionary algorithms for cluster analysis. Artif. Intell. Rev. 2011, 36, 179–204. [Google Scholar] [CrossRef]
- Fielding, B.; Zhang, L. Evolving Image Classification Architectures with Enhanced Particle Swarm Optimisation. IEEE Access 2018, 6, 68560–68575. [Google Scholar] [CrossRef]
- Sedighizadeh, D.; Masehian, E. A particle swarm optimization method, taxonomy and applications. Proc. Int. J. Comput. Theory Eng. 2009, 5, 486–502. [Google Scholar] [CrossRef] [Green Version]
- Gaxiola, F.; Melin, P.; Valdez, F.; Castro, J.R.; Manzo-Martínez, A. PSO with Dynamic Adaptation of Parameters for Optimization in Neural Networks with Interval Type-2 Fuzzy Numbers Weights. Axioms 2019, 8, 14. [Google Scholar] [CrossRef] [Green Version]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, L. The Application of Convolution Neural Networks in Sign Language Recognition. In Proceedings of the 2018 Ninth International Conference on Intelligent Control and Information Processing (ICICIP), Wanzhou, China, 9–11 November 2018; pp. 269–272. [Google Scholar]
- Rathi, D. Optimization of Transfer Learning for Sign Language Recognition Targeting. Int. J. Recent Innov. Trends Comput. Commun. 2018, 6, 198–203. [Google Scholar]
- Bin, L.Y.; Huann, G.Y.; Yun, L.K. Study of Convolutional Neural Network in Recognizing Static American Sign Language. In Proceedings of the 2019 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 17–19 September 2019; pp. 41–45. [Google Scholar]
- Rodriguez, R.; Gonzalez, C.I.; Martinez, G.E.; Melin, P. An improved Convolutional Neural Network based on a parameter modification of the convolution layer. In Fuzzy Logic Hybrid Extensions of Neural and Optimization Algorithms: Theory and Applications; Springer: Cham, Switzerland, 2021; pp. 125–147. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Particle Coordinate | Hyper-Parameter | Search Space |
|---|---|---|
| Number of convolutional layers | [1, 3] | |
| Filter number | [32, 128] | |
| Filter size | [1, 4] | |
| Batch size in the training | [32, 256] |
| Search Space | |
|---|---|
| 1 | [3, 3] |
| 2 | [5, 5] |
| 3 | [7, 7] |
| 4 | [9, 9] |
| Particle Coordinate | Hyper-Parameter | Search Space |
|---|---|---|
| Convolutional layer number | [1, 3] | |
| Filter number (layer 1) | [32, 128] | |
| Filter size (layer 1) | [1, 4] | |
| Filter number (layer 2) | [32, 128] | |
| Filter size (layer 2) | [1, 4] | |
| Filter number (layer 3) | [32, 128] | |
| Filter size (layer 3) | [1, 4] | |
| Batch size in the training | [32, 256] |
| Architecture Number | Recognition Rate (%) | AIC Value |
|---|---|---|
| 1 | 98.50 | 466.78 |
| 2 | 98.50 | 350.85 |
| Name | ASL Alphabet Detail |
|---|---|
| Total images | 87,000 |
| Images for training | 82,650 |
| Images for test | 4350 |
| Images size | 32 × 32 |
| Database format | JPGE |
| Name | ASL MNIST Detail |
|---|---|
| Total images | 34,627 |
| Images for training | 24,239 |
| Images for test | 10,388 |
| Images size | 28 × 28 |
| Database format | CSV |
| Name | MSL Alphabet Detail |
|---|---|
| Total images | 3780 |
| Images for training | 2646 |
| Images for test | 1134 |
| Images size | 32 × 32 |
| Database format | JPG |
| Parameters of CNN | |
|---|---|
| Learning function | Adam |
| Activation function (classifying layer) | Softmax |
| Non-linearity activation function | ReLU |
| Epochs | 5 |
| Parameters of PSO | |
| Particles | 10 |
| Iterations | 10 |
| Inertial weight (W) | 0.85 |
| Social constant (W2) | 2 |
| Cognitive constant (W1) | 2 |
| No. | No. Layers | No. Filters | Filter Size | Batch Size | Recognition Rate (%) |
|---|---|---|---|---|---|
| 1 | 3 | 99 | [7 × 7] | 107 | 98.85 |
| 2 | 3 | 104 | [9 × 9] | 256 | 99.66 |
| 3 | 3 | 128 | [9 × 9] | 256 | 99.70 |
| 4 | 3 | 128 | [7 × 7] | 256 | 99.79 |
| 5 | 3 | 128 | [9 × 9] | 256 | 99.72 |
| 6 | 3 | 128 | [7 × 7] | 256 | 99.62 |
| 7 | 2 | 32 | [7 × 7] | 256 | 98.18 |
| 8 | 3 | 109 | [7 × 7] | 256 | 99.73 |
| 9 | 3 | 128 | [7 × 7] | 197 | 99.75 |
| 10 | 3 | 128 | [7 × 7] | 256 | 99.81 |
| 11 | 3 | 66 | [7 × 7] | 181 | 99.31 |
| 12 | 3 | 118 | [7 × 7] | 256 | 99.87 |
| 13 | 3 | 128 | [9 × 9] | 256 | 99.67 |
| 14 | 3 | 128 | [7 × 7] | 256 | 99.85 |
| 15 | 3 | 128 | [9 × 9] | 256 | 99.61 |
| 16 | 3 | 128 | [9 × 9] | 256 | 99.63 |
| 17 | 3 | 90 | [9 × 9] | 256 | 99.66 |
| 18 | 3 | 128 | [7 × 7] | 256 | 99.82 |
| 19 | 3 | 128 | [7 × 7] | 256 | 99.79 |
| 20 | 3 | 128 | [7 × 7] | 256 | 99.76 |
| 21 | 3 | 128 | [9 × 9] | 256 | 99.68 |
| 22 | 3 | 128 | [9 × 9] | 256 | 99.67 |
| 23 | 3 | 128 | [7 × 7] | 256 | 99.75 |
| 24 | 3 | 123 | [7 × 7] | 32 | 98.38 |
| 25 | 3 | 128 | [9 × 9] | 256 | 99.64 |
| 26 | 3 | 128 | [7 × 7] | 256 | 99.82 |
| 27 | 3 | 128 | [9 × 9] | 215 | 99.56 |
| 28 | 3 | 128 | [7 × 7] | 256 | 99.87 |
| 29 | 3 | 100 | [9 × 9] | 256 | 99.64 |
| 30 | 3 | 128 | [7 × 7] | 256 | 99.84 |
| Mean | 99.58 |
| No. | No. Layers | No. Filters | Filter Size | Batch Size | Recognition Rate (%) |
|---|---|---|---|---|---|
| 1 | 3 | 128 | [9 × 9] | 137 | 99.27 |
| 2 | 2 | 128 | [9 × 9] | 218 | 99.54 |
| 3 | 2 | 128 | [7 × 7] | 205 | 99.52 |
| 4 | 3 | 128 | [7 × 7] | 136 | 99.33 |
| 5 | 2 | 128 | [9 × 9] | 232 | 99.59 |
| 6 | 3 | 96 | [9 × 9] | 107 | 98.82 |
| 7 | 2 | 118 | [7 × 7] | 189 | 99.36 |
| 8 | 2 | 128 | [9 × 9] | 256 | 99.59 |
| 9 | 2 | 112 | [9 × 9] | 256 | 99.49 |
| 10 | 2 | 128 | [9 × 9] | 256 | 99.60 |
| 11 | 2 | 128 | [7 × 7] | 256 | 99.59 |
| 12 | 2 | 128 | [7 × 7] | 256 | 99.61 |
| 13 | 2 | 128 | [9 × 9] | 220 | 99.67 |
| 14 | 2 | 128 | [9 × 9] | 256 | 99.57 |
| 15 | 2 | 128 | [9 × 9] | 256 | 99.51 |
| 16 | 2 | 128 | [7 × 7] | 237 | 99.55 |
| 17 | 2 | 128 | [7 × 7] | 256 | 99.61 |
| 18 | 2 | 128 | [9 × 9] | 256 | 99.58 |
| 19 | 2 | 128 | [9 × 9] | 256 | 99.53 |
| 20 | 2 | 128 | [9 × 9] | 256 | 99.65 |
| 21 | 2 | 128 | [7 × 7] | 148 | 99.42 |
| 22 | 2 | 128 | [9 × 9] | 256 | 99.51 |
| 23 | 2 | 128 | [9 × 9] | 215 | 99.53 |
| 24 | 2 | 128 | [9 × 9] | 255 | 99.56 |
| 25 | 2 | 128 | [9 × 9] | 256 | 99.65 |
| 26 | 2 | 128 | [7 × 7] | 256 | 99.57 |
| 27 | 2 | 128 | [9 × 9] | 256 | 99.53 |
| 28 | 2 | 117 | [7 × 7] | 129 | 99.98 |
| 29 | 3 | 128 | [5 × 5] | 242 | 99.87 |
| 30 | 2 | 128 | [7 × 7] | 256 | 99.55 |
| Mean | 99.53 |
| No. | No. Layers | No. Filters | Filter Size | Batch Size | Recognition Rate (%) |
|---|---|---|---|---|---|
| 1 | 2 | 101 | [7 × 7] | 93 | 98.95 |
| 2 | 1 | 128 | [3 × 3] | 56 | 98.95 |
| 3 | 1 | 110 | [3 × 3] | 52 | 98.82 |
| 4 | 1 | 128 | [3 × 3] | 121 | 99.20 |
| 5 | 1 | 128 | [3 × 3] | 128 | 99.32 |
| 6 | 1 | 128 | [3 × 3] | 128 | 99.07 |
| 7 | 1 | 128 | [3 × 3] | 110 | 99.24 |
| 8 | 1 | 101 | [5 × 5] | 114 | 98.82 |
| 9 | 1 | 128 | [3 × 3] | 128 | 99.24 |
| 10 | 1 | 74 | [3 × 3] | 88 | 98.95 |
| 11 | 1 | 128 | [3 × 3] | 128 | 99.32 |
| 12 | 1 | 128 | [3 × 3] | 32 | 98.48 |
| 13 | 1 | 128 | [3 × 3] | 93 | 99.28 |
| 14 | 1 | 128 | [3 × 3] | 97 | 99.11 |
| 15 | 1 | 128 | [3 × 3] | 32 | 98.74 |
| 16 | 1 | 128 | [3 × 3] | 72 | 99.32 |
| 17 | 1 | 128 | [3 × 3] | 93 | 99.37 |
| 18 | 1 | 63 | [3 × 3] | 47 | 98.44 |
| 19 | 1 | 128 | [3 × 3] | 128 | 99.20 |
| 20 | 1 | 126 | [3 × 3] | 128 | 99.28 |
| 21 | 1 | 128 | [3 × 3] | 128 | 99.32 |
| 22 | 1 | 128 | [3 × 3] | 83 | 99.20 |
| 23 | 1 | 128 | [3 × 3] | 63 | 99.20 |
| 24 | 1 | 122 | [3 × 3] | 128 | 99.37 |
| 25 | 1 | 128 | [3 × 3] | 128 | 99.32 |
| 26 | 1 | 114 | [3 × 3] | 84 | 99.32 |
| 27 | 1 | 128 | [3 × 3] | 32 | 98.74 |
| 28 | 1 | 128 | [3 × 3] | 89 | 99.28 |
| 29 | 1 | 43 | [3 × 3] | 53 | 97.81 |
| 30 | 1 | 128 | [3 × 3] | 72 | 98.99 |
| Mean | 99.10 |
| No. | No. Layers | Layer 1 | Layer 2 | Layer 3 | Batch Size | AIC Value | (%) Recogn. Rate | |||
|---|---|---|---|---|---|---|---|---|---|---|
| No. Filters | Filter Size | No. Filters | Filter Size | No. Filters | Filter Size | |||||
| 1 | 3 | 128 | [3 × 3] | 128 | [7 × 7] | 128 | [5 × 5] | 256 | 764.78 | 98.99 |
| 2 | 3 | 128 | [5 × 5] | 121 | [5 × 5] | 128 | [5 × 5] | 213 | 750.78 | 98.73 |
| 3 | 3 | 84 | [3 × 3] | 128 | [7 × 7] | 128 | [5 × 5] | 84 | 676.78 | 99.23 |
| 4 | 2 | 45 | [5 × 5] | 128 | [7 × 7] | 0 | 0 | 0 | 340.78 | 98.15 |
| 5 | 3 | 32 | [3 × 3] | 128 | [7 × 7] | 128 | [3 × 3] | 256 | 572.78 | 98.86 |
| 6 | 3 | 128 | [3 × 3] | 128 | [7 × 7] | 128 | [5 × 5] | 256 | 764.78 | 98.96 |
| 7 | 3 | 84 | [5 × 5] | 128 | [5 × 5] | 128 | [3 × 3] | 256 | 676.78 | 98.85 |
| 8 | 3 | 128 | [3 × 3] | 128 | [7 × 7] | 128 | [5 × 5] | 256 | 764.78 | 99.02 |
| 9 | 3 | 32 | [5 × 5] | 128 | [5 × 5] | 128 | [3 × 3] | 256 | 572.78 | 98.9 |
| 10 | 3 | 124 | [3 × 3] | 128 | [7 × 7] | 128 | [3 × 3] | 256 | 756.78 | 98.64 |
| 11 | 3 | 32 | [3 × 3] | 128 | [7 × 7] | 128 | [7 × 7] | 256 | 572.78 | 98.93 |
| 12 | 3 | 32 | [3 × 3] | 128 | [7 × 7] | 128 | [3 × 3] | 256 | 572.78 | 98.53 |
| 13 | 3 | 128 | [3 × 3] | 128 | [7 × 7] | 128 | [5 × 5] | 256 | 764.78 | 99.01 |
| 14 | 3 | 73 | [7 × 7] | 128 | [7 × 7] | 108 | [3 × 3] | 256 | 614.78 | 97.91 |
| 15 | 3 | 128 | [3 × 3] | 128 | [7 × 7] | 128 | [5 × 5] | 256 | 764.78 | 99.06 |
| 16 | 2 | 128 | [3 × 3] | 128 | [7 × 7] | 0 | 0 | 0 | 506.78 | 98.23 |
| 17 | 2 | 88 | [7 × 7] | 128 | [7 × 7] | 0 | 0 | 0 | 426.78 | 97.4 |
| 18 | 3 | 32 | [5 × 5] | 128 | [7 × 7] | 128 | [5 × 5] | 256 | 572.78 | 99.06 |
| 19 | 2 | 128 | [5 × 5] | 119 | [7 × 7] | 0 | 0 | 0 | 488.78 | 98.1 |
| 20 | 3 | 116 | [3 × 3] | 128 | [5 × 5] | 128 | [7 × 7] | 252 | 740.78 | 98.96 |
| 21 | 3 | 49 | [5 × 5] | 128 | [7 × 7] | 128 | [7 × 7] | 256 | 606.78 | 98.93 |
| 22 | 2 | 128 | [3 × 3] | 128 | [7 × 7] | 0 | 0 | 0 | 506.78 | 98.19 |
| 23 | 3 | 32 | [5 × 5] | 128 | [7 × 7] | 128 | [5 × 5] | 256 | 572.78 | 98.96 |
| 24 | 2 | 32 | [5 × 5] | 128 | [7 × 7] | 0 | 0 | 0 | 314.78 | 98.04 |
| 25 | 2 | 128 | [5 × 5] | 81 | [5 × 5] | 0 | 0 | 0 | 412.78 | 98.92 |
| 26 | 3 | 32 | [5 × 5] | 128 | [7 × 7] | 128 | [3 × 3] | 256 | 572.78 | 98.58 |
| 27 | 3 | 32 | [3 × 3] | 128 | [7 × 7] | 128 | [5 × 5] | 256 | 572.78 | 98.88 |
| 28 | 3 | 128 | [3 × 3] | 128 | [7 × 7] | 128 | [5 × 5] | 256 | 764.78 | 99.02 |
| 29 | 3 | 128 | [3 × 3] | 128 | [7 × 7] | 128 | [3 × 3] | 256 | 764.78 | 99.08 |
| 30 | 3 | 128 | [3 × 3] | 128 | [7 × 7] | 128 | [3 × 3] | 256 | 764.78 | 98.71 |
| Mean | 98.69 | |||||||||
| No. | No. Layers | Layer 1 | Layer 2 | Layer 3 | Batch Size | AIC Value | (%) Recogn. Rate | |||
|---|---|---|---|---|---|---|---|---|---|---|
| No. Filters | Filter Size | No. Filters | Filter Size | No. Filters | Filter Size | |||||
| 1 | 2 | 128 | [5 × 5] | 128 | [9 × 9] | 0 | 0 | 128 | 506.79 | 99.80 |
| 2 | 2 | 74 | [9 × 9] | 114 | [9 × 9] | 0 | 0 | 174 | 370.79 | 99.42 |
| 3 | 3 | 32 | [5 × 5] | 128 | [9 × 9] | 128 | [5 × 5] | 122 | 572.79 | 99.53 |
| 4 | 2 | 125 | [5 × 5] | 125 | [9 × 9] | 0 | 0 | 147 | 503.79 | 99.58 |
| 5 | 2 | 90 | [5 × 5] | 128 | [9 × 9] | 0 | 0 | 256 | 500.79 | 99.68 |
| 6 | 3 | 32 | [3 × 3] | 128 | [9 × 9] | 128 | [9 × 9] | 148 | 572.79 | 99.51 |
| 7 | 2 | 121 | [7 × 7] | 95 | [9 × 9] | 0 | 0 | 100 | 426.79 | 99.26 |
| 8 | 3 | 32 | [7 × 7] | 128 | [9 × 9] | 125 | [9 × 9] | 256 | 569.79 | 99.6 |
| 9 | 2 | 32 | [9 × 9] | 126 | [9 × 9] | 0 | 0 | 106 | 310.79 | 99.4 |
| 10 | 3 | 115 | [7 × 7] | 102 | [9 × 9] | 128 | [7 × 7] | 215 | 686.79 | 99.42 |
| 11 | 2 | 32 | [9 × 9] | 128 | [9 × 9] | 0 | 0 | 256 | 314.79 | 99.44 |
| 12 | 2 | 77 | [7 × 7] | 100 | [9 × 9] | 0 | 0 | 183 | 348.79 | 99.59 |
| 13 | 2 | 87 | [7 × 7] | 128 | [9 × 9] | 0 | 0 | 256 | 424.79 | 99.7 |
| 14 | 2 | 32 | [9 × 9] | 128 | [9 × 9] | 0 | 0 | 256 | 314.79 | 99.53 |
| 15 | 3 | 32 | [5 × 5] | 103 | [9 × 9] | 125 | [9 × 9] | 256 | 516.79 | 99.53 |
| 16 | 2 | 70 | [9 × 9] | 126 | [9 × 9] | 0 | 0 | 256 | 386.79 | 99.63 |
| 17 | 2 | 64 | [7 × 7] | 128 | [9 × 9] | 0 | 0 | 256 | 378.79 | 99.7 |
| 18 | 3 | 32 | [7 × 7] | 77 | [9 × 9] | 128 | [9 × 9] | 256 | 470.79 | 99.36 |
| 19 | 2 | 128 | [7 × 7] | 128 | [9 × 9] | 0 | 0 | 256 | 506.79 | 99.74 |
| 20 | 3 | 32 | [3 × 3] | 128 | [9 × 9] | 128 | [5 × 5] | 32 | 572.79 | 98.95 |
| 21 | 3 | 32 | [7 × 7] | 128 | [9 × 9] | 123 | [7 × 7] | 162 | 577.79 | 99.33 |
| 22 | 2 | 51 | [9 × 9] | 128 | [9 × 9] | 0 | 0 | 194 | 352.79 | 99.47 |
| 23 | 2 | 50 | [7 × 7] | 128 | [9 × 9] | 0 | 0 | 256 | 350.79 | 99.63 |
| 24 | 2 | 128 | [7 × 7] | 128 | [9 × 9] | 0 | 0 | 162 | 506.79 | 99.67 |
| 25 | 2 | 100 | [5 × 5] | 76 | [5 × 5] | 0 | 0 | 76 | 346.79 | 98.23 |
| 26 | 2 | 52 | [9 × 9] | 128 | [7 × 7] | 0 | 0 | 256 | 354.79 | 99.54 |
| 27 | 2 | 128 | [5 × 5] | 128 | [9 × 9] | 0 | 0 | 142 | 506.79 | 99.53 |
| 28 | 3 | 83 | [3 × 3] | 125 | [9 × 9] | 0 | 0 | 136 | 410.79 | 99.38 |
| 29 | 3 | 128 | [5 × 5] | 128 | [9 × 9] | 128 | [9 × 9] | 256 | 764.79 | 99.57 |
| 30 | 2 | 74 | [7 × 7] | 120 | [9 × 9] | 0 | 0 | 256 | 382.79 | 99.72 |
| Mean | 99.48 | |||||||||
| No. | No. Layers | Layer 1 | Layer 2 | Layer 3 | BATCH SIZE | AIC Value | (%) Recogn. Rate | |||
|---|---|---|---|---|---|---|---|---|---|---|
| No. Filters | Filter Size | No. Filters | Filter Size | No. Filters | Filter Size | |||||
| 1 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 32 | 248.79 | 98.74 |
| 2 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 163 | 248.79 | 99.28 |
| 3 | 1 | 116 | [3 × 3] | 0 | 0 | 0 | 0 | 105 | 224.79 | 98.99 |
| 4 | 1 | 81 | [3 × 3] | 0 | 0 | 0 | 0 | 32 | 154.79 | 98.44 |
| 5 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 149 | 248.79 | 98.90 |
| 6 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 221 | 248.79 | 98.57 |
| 7 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 57 | 248.79 | 99.24 |
| 8 | 1 | 67 | [3 × 3] | 0 | 0 | 0 | 0 | 246 | 126.73 | 97.77 |
| 9 | 1 | 118 | [3 × 3] | 0 | 0 | 0 | 0 | 113 | 228.79 | 99.16 |
| 10 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 154 | 248.79 | 99.45 |
| 11 | 1 | 103 | [3 × 3] | 0 | 0 | 0 | 0 | 92 | 198.79 | 99.03 |
| 12 | 1 | 65 | [3 × 3] | 0 | 0 | 0 | 0 | 32 | 122.79 | 98.32 |
| 13 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 94 | 248.79 | 99.07 |
| 14 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 90 | 248.79 | 99.11 |
| 15 | 1 | 112 | [3 × 3] | 0 | 0 | 0 | 0 | 97 | 216.79 | 99.24 |
| 16 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 32 | 248.79 | 98.74 |
| 17 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 46 | 248.79 | 98.65 |
| 18 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 199 | 248.79 | 98.32 |
| 19 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 244 | 248.79 | 99.03 |
| 20 | 1 | 120 | [3 × 3] | 0 | 0 | 0 | 0 | 32 | 232.79 | 99.07 |
| 21 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 105 | 248.79 | 99.16 |
| 22 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 77 | 248.79 | 99.03 |
| 23 | 1 | 108 | [3 × 3] | 0 | 0 | 0 | 0 | 84 | 208.79 | 99.07 |
| 24 | 1 | 54 | [3 × 3] | 0 | 0 | 0 | 0 | 32 | 100.79 | 98.44 |
| 25 | 1 | 102 | [3 × 3] | 0 | 0 | 0 | 0 | 102 | 196.79 | 99.03 |
| 26 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 114 | 248.79 | 99.20 |
| 27 | 1 | 119 | [3 × 3] | 0 | 0 | 0 | 0 | 256 | 230.79 | 98.61 |
| 28 | 1 | 98 | [3 × 3] | 0 | 0 | 0 | 0 | 122 | 188.79 | 99.20 |
| 29 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 83 | 248.79 | 99.07 |
| 30 | 1 | 128 | [3 × 3] | 0 | 0 | 0 | 0 | 135 | 248.79 | 99.37 |
| Mean | 98.91 | |||||||||
| Database | PSO-CNN-I | PSO-CNN-II | ||||
|---|---|---|---|---|---|---|
| Best | Mean | AIC | Best | Mean | AIC | |
| ASL alphabet | 99.87% | 99.58% | 764.79 | 99.23% | 98.69% | 676.78 |
| ASL MNIST | 99.98% | 99.53% | 462.79 | 99.80% | 99.48% | 506.79 |
| MSL alphabet | 99.37% | 99.05% | 236.80 | 99.45% | 98.91% | 248.79 |
| Description | Hypothesis | |
|---|---|---|
| Null hypothesis | PSO-CNN-I architecture () = PSO-CNN-II architecture () | |
| Alternative hypothesis | PSO-CNN-I architecture () > PSO-CNN-II architecture (), |
| Comparison | R+ | R− | p-Value |
|---|---|---|---|
| ASL alphabet | 455 | 10 | <0.001 |
| Comparison | R+ | R− | p-Value |
|---|---|---|---|
| ASL MNIST | 245.5 | 189.5 | 0.545 |
| Comparison | R+ | R− | p-Value |
|---|---|---|---|
| MSL alphabet | 291 | 115 | 0.045 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fregoso, J.; Gonzalez, C.I.; Martinez, G.E. Optimization of Convolutional Neural Networks Architectures Using PSO for Sign Language Recognition. Axioms 2021, 10, 139. https://doi.org/10.3390/axioms10030139
Fregoso J, Gonzalez CI, Martinez GE. Optimization of Convolutional Neural Networks Architectures Using PSO for Sign Language Recognition. Axioms. 2021; 10(3):139. https://doi.org/10.3390/axioms10030139
Chicago/Turabian StyleFregoso, Jonathan, Claudia I. Gonzalez, and Gabriela E. Martinez. 2021. "Optimization of Convolutional Neural Networks Architectures Using PSO for Sign Language Recognition" Axioms 10, no. 3: 139. https://doi.org/10.3390/axioms10030139