
An Improved DCC Model Based on Large-Dimensional Covariance Matrices Estimation and Its Applications

Abstract
:1. Introduction
- We propose a new large covariance matrix estimator to realize the sparsity and positive-definiteness by constructing a nonconvex optimization model with smoothly clipped absolute deviation (SCAD) and hard threshold penalty functions based on the rotation-invariant estimator.
- To improve the performance of the DCC model, we use the new covariance matrix estimator to replace the unconditional covariance matrix in the DCC model.
- We show that the improved DCC model has a smaller loss and lower out-of-sample risk in portfolio optimization model.
2. Preliminary Work
2.1. Covariance Matrix Estimation Based on Convex Combination
2.2. Classical DCC Model
3. An Improved DCC Model Based on Nonconvex Combination
- Step 1: Solve the model (1) to obtain the covariance matrix estimation .
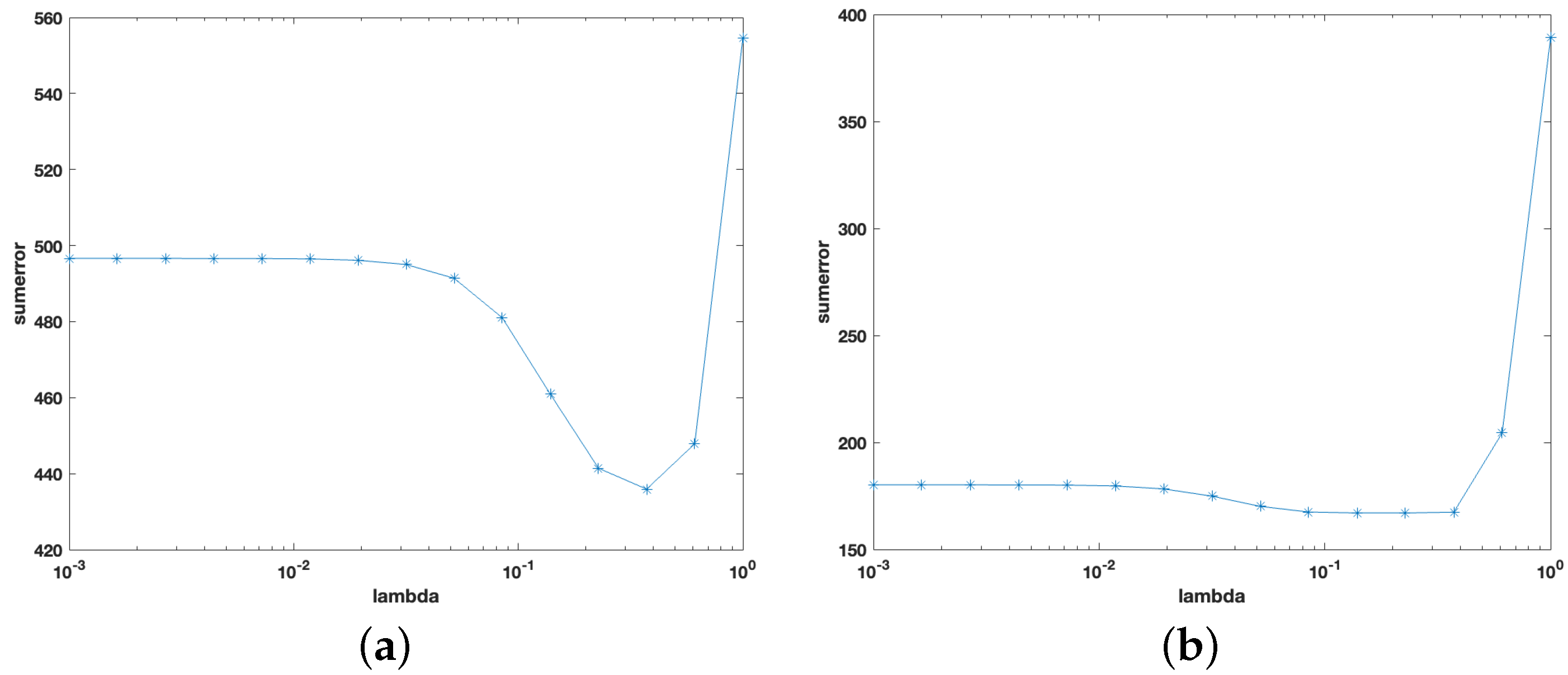
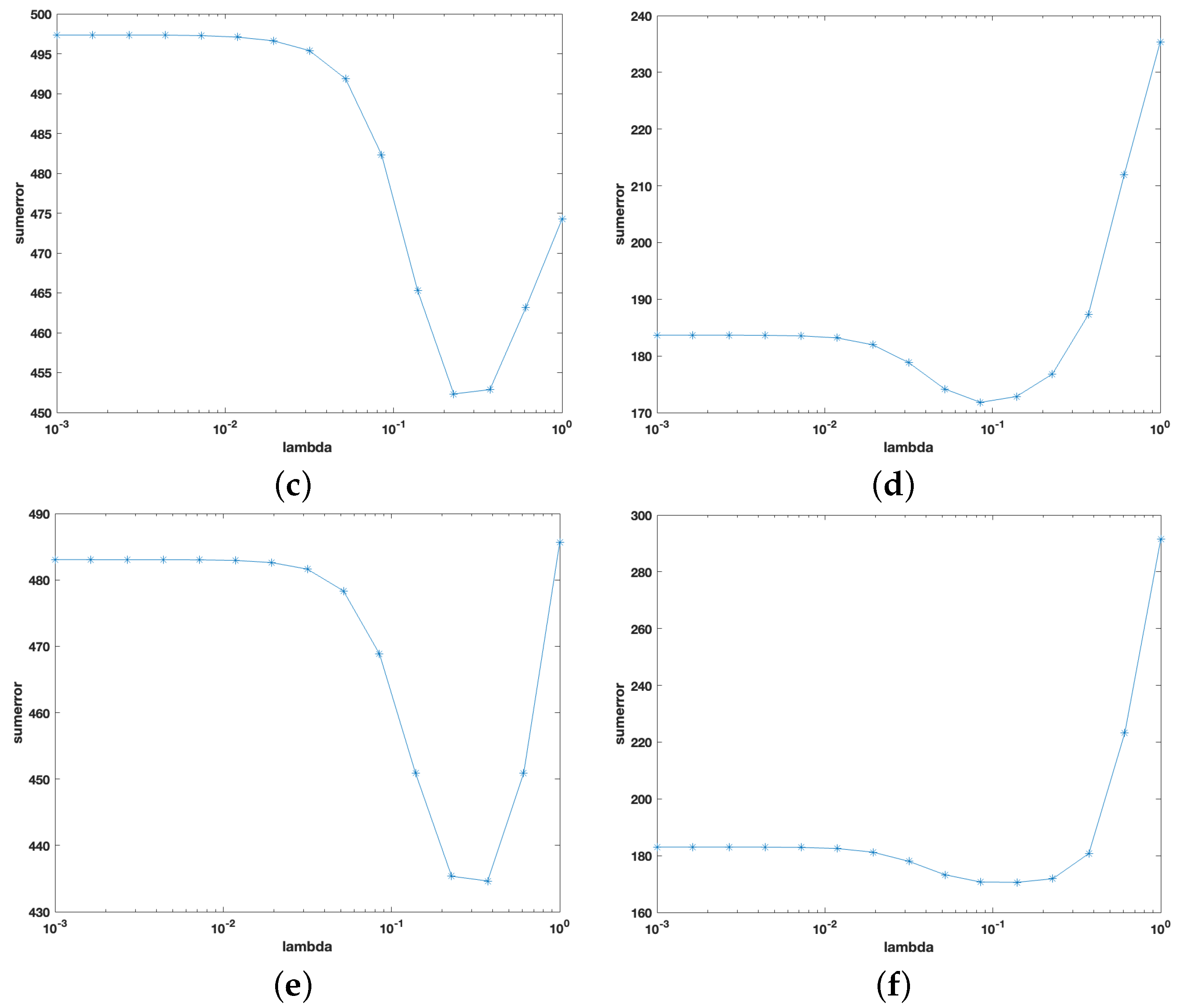
- Step 2: Input into the nonconvex optimization model (7) and use ADM to solve it to obtain the covariance matrix estimation .
- Step 4: Use the covariance matrix to estimate to replace the unconditional covariance matrix in Equation (6), and get the matrix by maximizing the composite likelihood function.
- Step 5: Standardize and calculate the dynamic conditional correlation matrix in Equation (2).
4. Numerical Experiments and Application
4.1. The Simulation Datasets
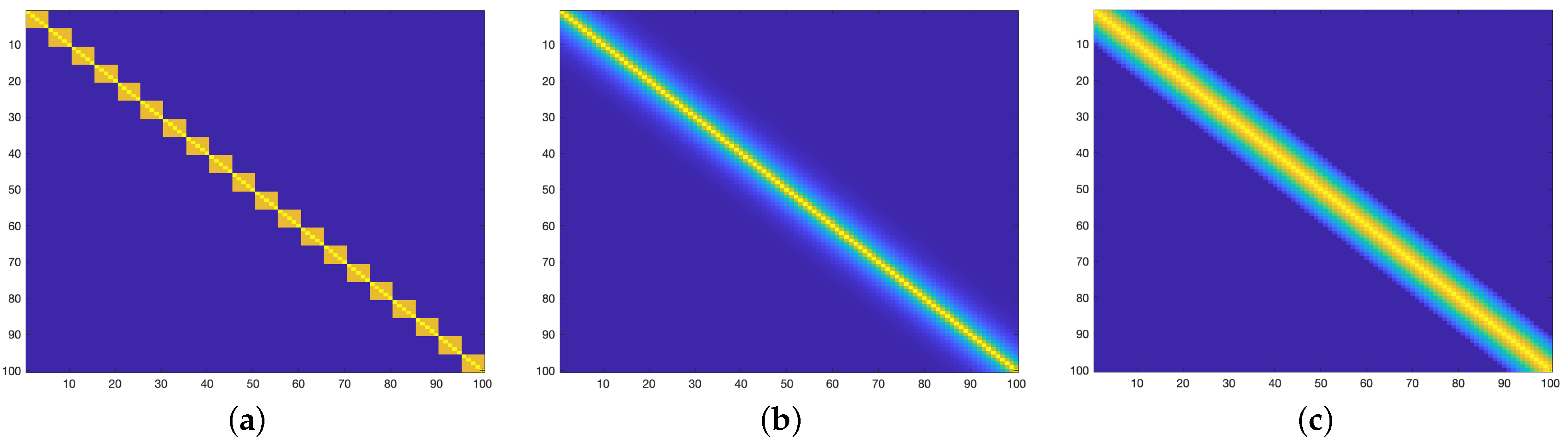
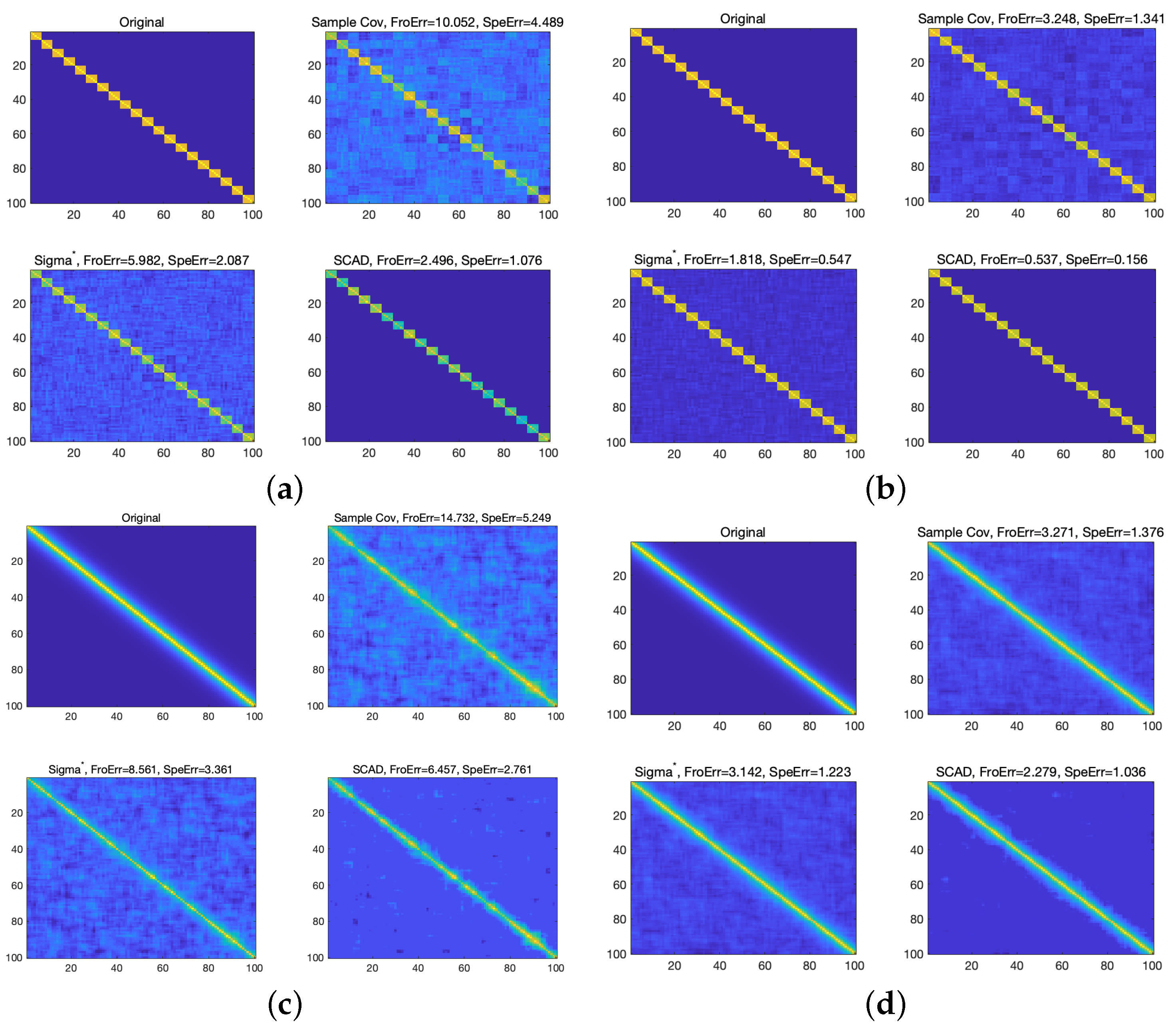
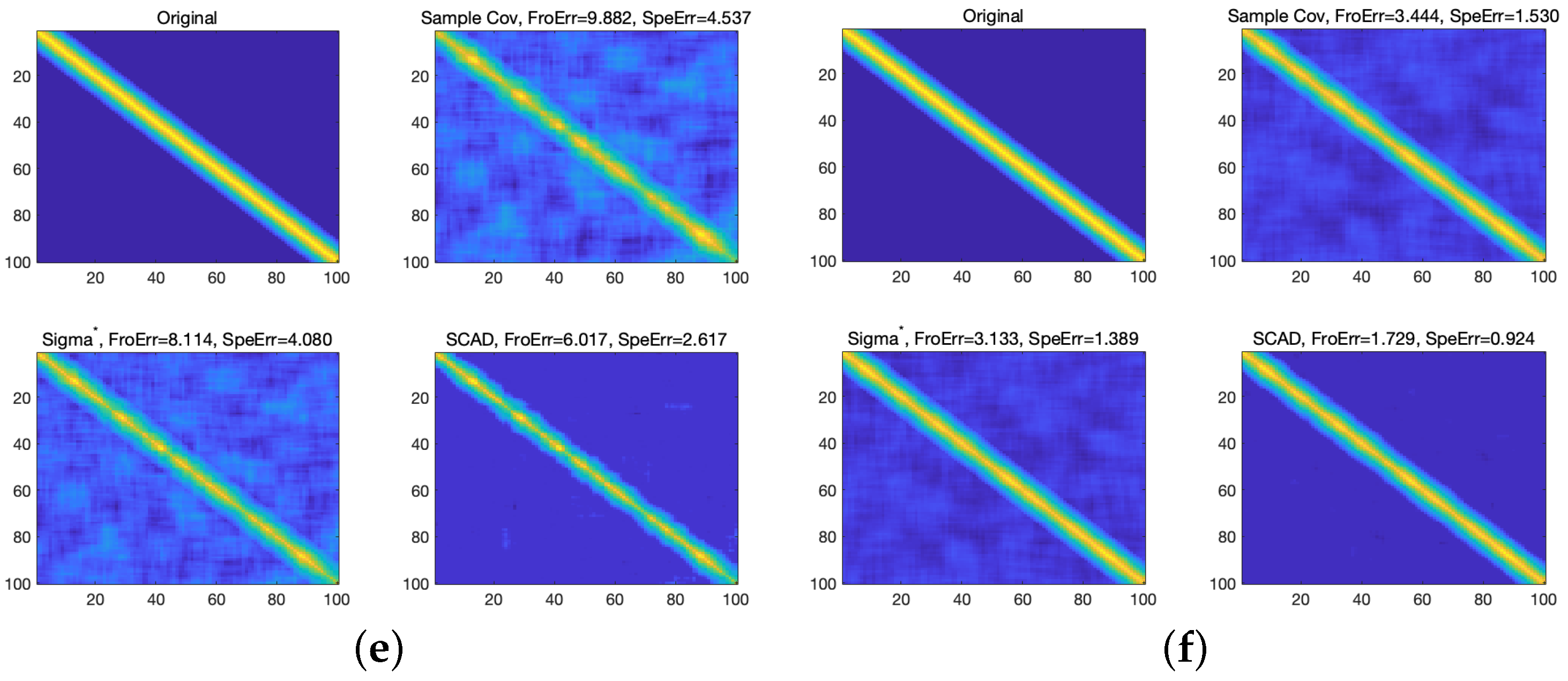
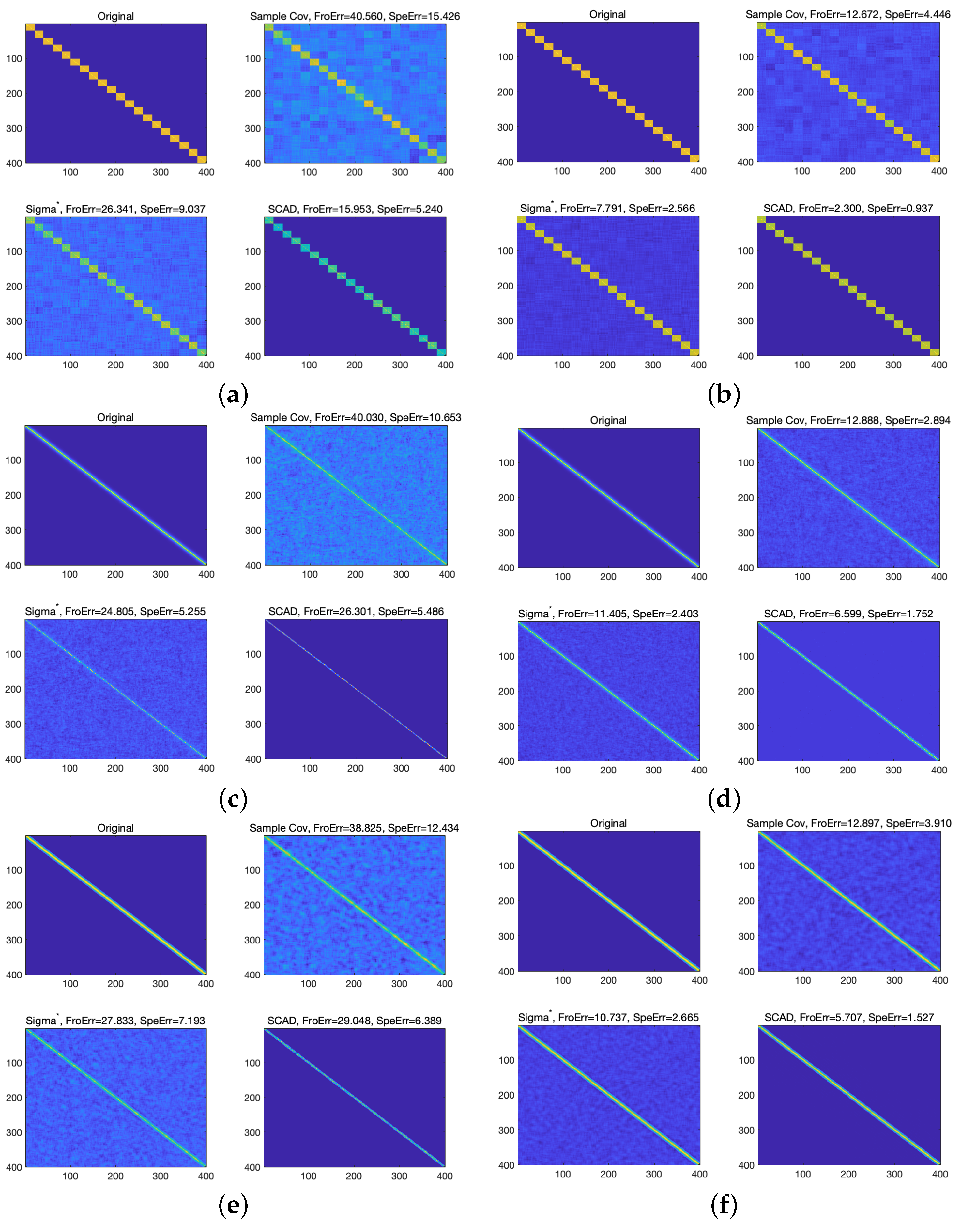
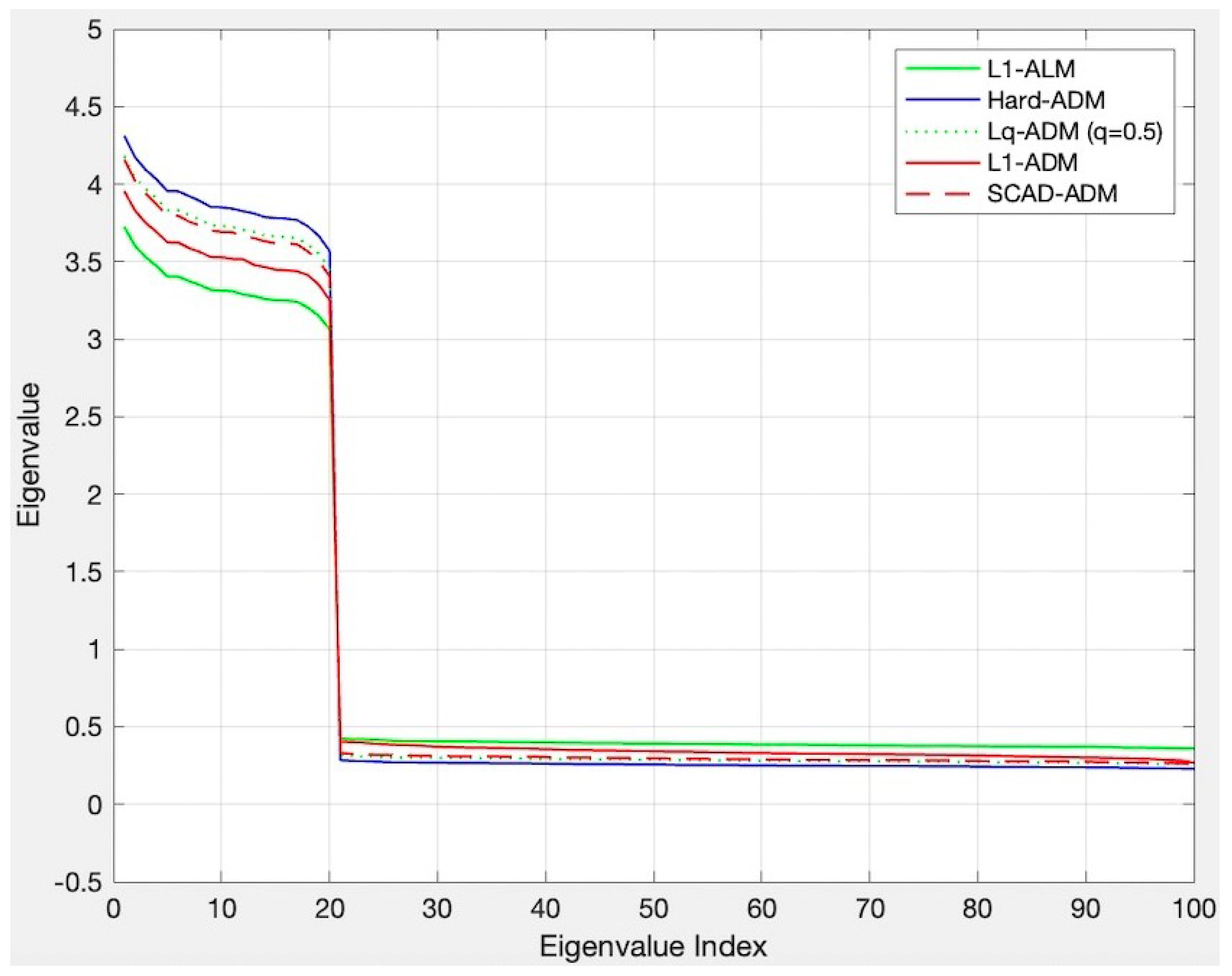
4.1.1. The Simulation of Typical Sparse Covariance Matrix
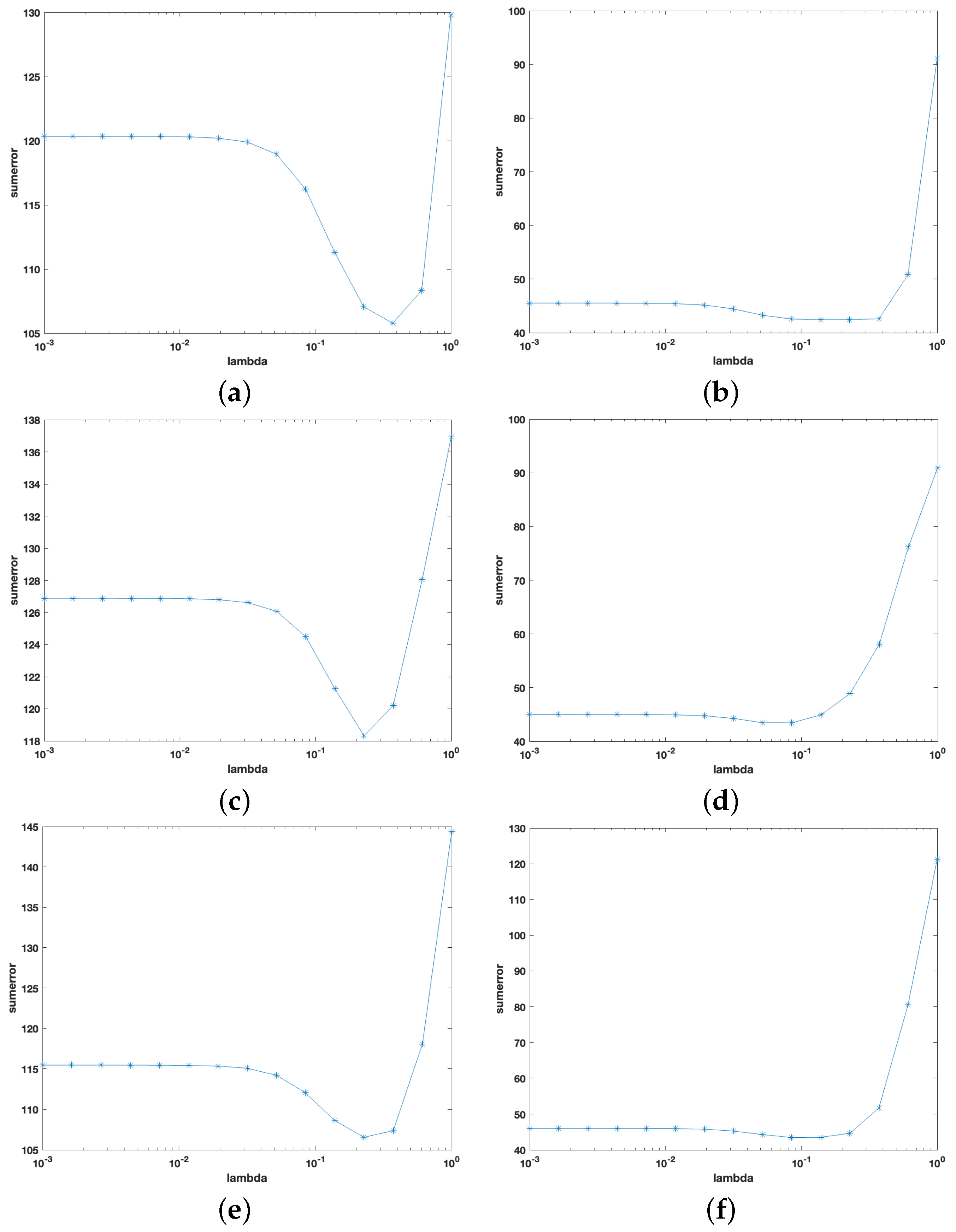
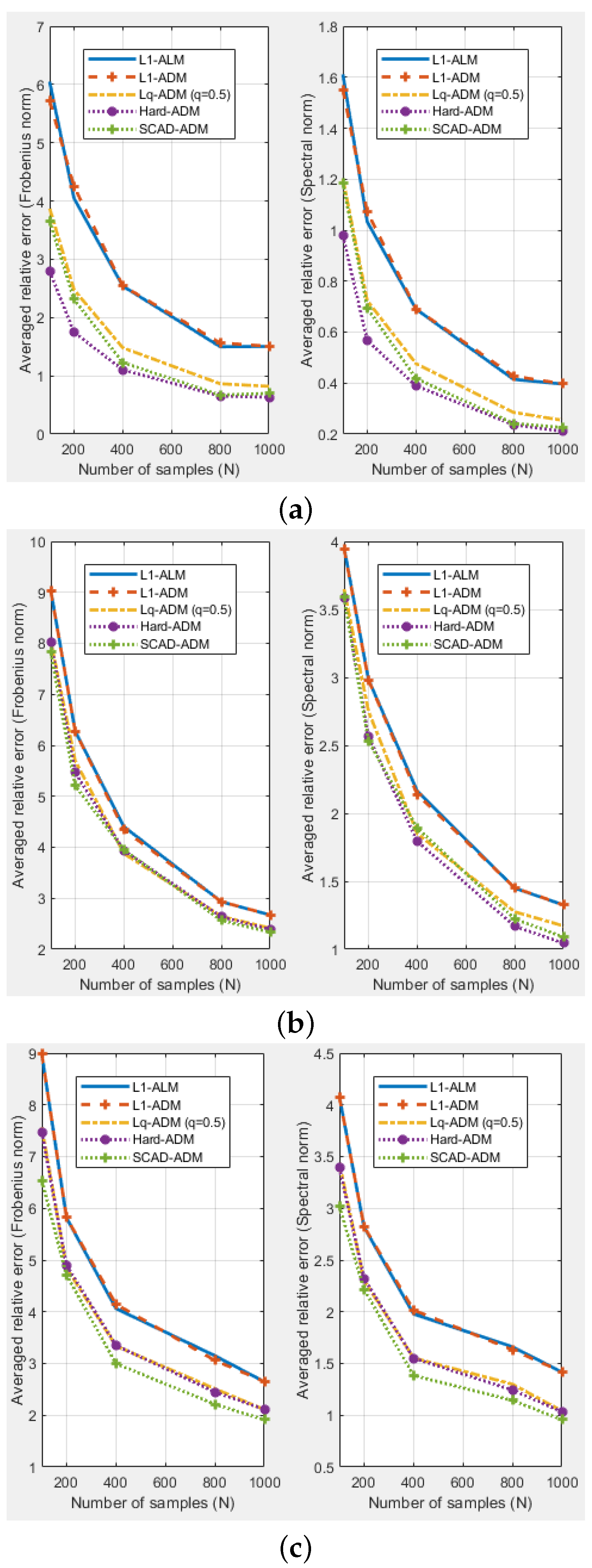
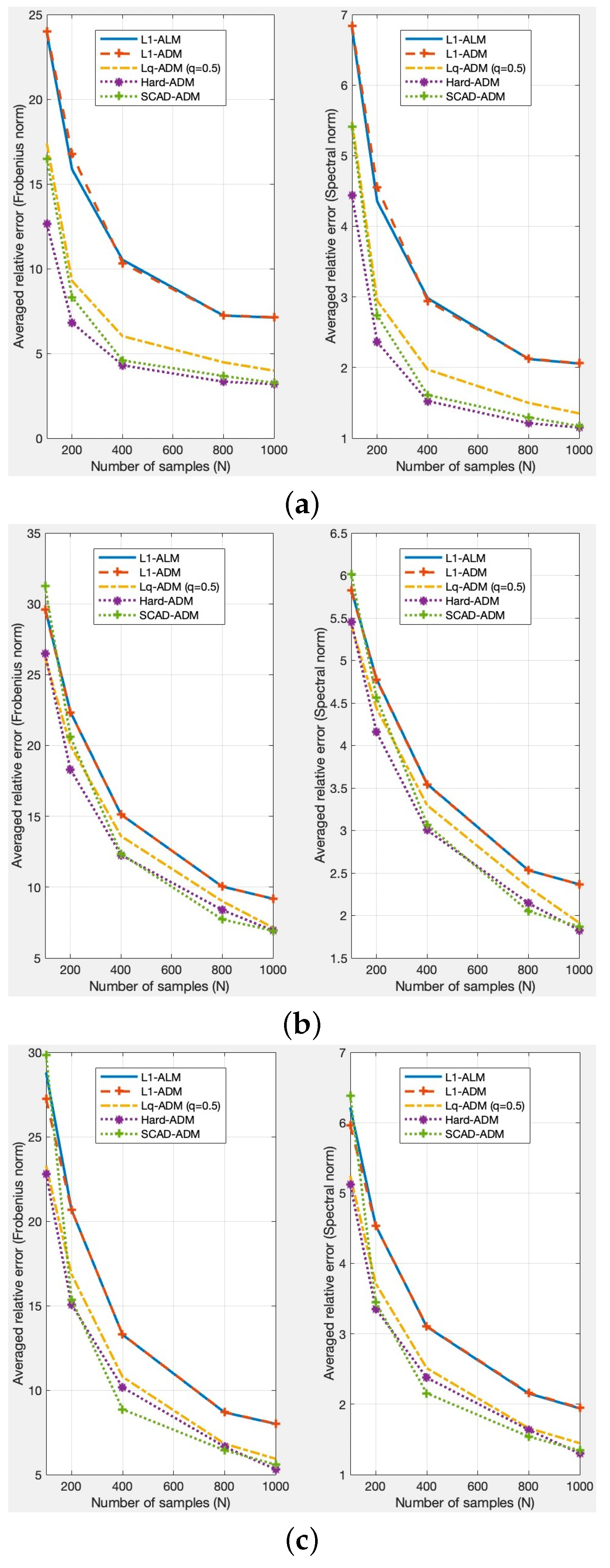
4.1.2. The Monte Carlo Simulation
- DCC-S: The in the DCC model is replaced by the sample covariance matrix .
- DCC-L2: The in the DCC model is replaced by the estimator obtained from the method of Engle and Ledoit [7].
- DCC-NL: The in the DCC model is replaced by the estimator obtained from the method of [18].
- DCC-NCP1: The in the DCC model is replaced by the estimator obtained from the model (7) based on the hard-threshold penalty function.
- DCC-NCP2: The in the DCC model is replaced by the estimator obtained from the model (7) based on the SCAD penalty function.
4.2. The Application
4.2.1. Global Minimum Variance Portfolio
4.2.2. Analysis of Empirical Research
5. Discussion
6. Conlusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Engel, J.; Buydens, L.; Blanchet, L. An overview of large-dimensional covariance and precision matrix estimators with applications in chemometrics. J. Chemom. 2017, 31, e2880. [Google Scholar] [CrossRef]
- Fan, J.; Liao, Y.; Liu, H. An overview of the estimation of large covariance and precision matrices. Econom. J. 2016, 19, C1–C32. [Google Scholar] [CrossRef]
- Tong, T.; Wang, C.; Wang, Y. Estimation of variances and covariances for high-dimensional data: A selective review. Wiley Interdiscip. Rev. Comput. Stat. 2014, 6, 255–264. [Google Scholar] [CrossRef]
- Stein, C. Lectures on the theory of estimation of many parameters. J. Sov. Math. 1986, 34, 1373–1403. [Google Scholar] [CrossRef]
- Engle, R.F.; Ledoit, O.; Wolf, M. Large dynamic covariance matrices. J. Bus. Econom. Stat. 2019, 37, 363–375. [Google Scholar] [CrossRef]
- Ledoit, O.; Wolf, M. Nonlinear shrinkage of the covariance matrix for portfolio selection: Markowitz meets goldilocks. Rev. Financ. Stud. 2018, 30, 4349–4388. [Google Scholar] [CrossRef]
- Ledoit, O.; Wolf, M. Honey, I shrunk the sample covariance matrix. J. Portfolio. Mange. 2004, 30, 110–119. [Google Scholar] [CrossRef]
- Bickel, P.J.; Elizaveta, L. Covariance regularization by thresholding. Ann. Stat. 2008, 36, 2577–2604. [Google Scholar] [CrossRef]
- Rothman, A.J.; Bickel, P.J.; Levina, E.; Zhu, J. Sparse permutation invariant covariance estimation. Electron. J. Stat. 2008, 2, 494–515. [Google Scholar]
- Balmand, S.; Dalalyan, A.S. On estimation of the diagonal elements of a sparse precision matrix. Electron. J. Stat. 2016, 10, 1551–1579. [Google Scholar]
- Ravikumar, P.; Wainwright, M.J.; Raskutti, G.; Yu, B. High-dimensional covariance estimation by minimizing L1-penalized log-determinant divergence. Electron. J. Stat. 2011, 5, 935–980. [Google Scholar] [CrossRef]
- Zhou, S.; Xiu, N.H.; Luo, Z.; Kong, L.C. Sparse and low-rank covariance matrix estimation. J. Oper. Res. Soc. China 2015, 3, 231–250. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Fan, J.; Peng, J. Nonconcave penalized likelihood with a diverging number of parameters. Ann. Stat. 2004, 32, 928–961. [Google Scholar] [CrossRef]
- Engle, R. Dynamic conditional correlation: A simple class of multivariate generalized autoregressive conditional heteroskedasticity models. J. Bus. Econom. Stat. 2002, 20, 339–350. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. EERI Res. Paper. 1986, 31, 307–327. [Google Scholar] [CrossRef]
- Bollerslev, T. Modeling the coherence in short-run nominal exchange rates: A multivariate generalized ARCH model. Rev. Econ. Stat. 1990, 72, 498–505. [Google Scholar] [CrossRef]
- Ledoit, O.; Wolf, M. Nonlinear shrinkage estimation of large-dimensional covariance matrices. Ann. Stat. 2012, 40, 1024–1060. [Google Scholar] [CrossRef]
- De Nard, G.; Engle, R.F.; Ledoit, O.; Wolf, M. Large dynamic covariance matrices: Enhancements based on intraday data. J. Bank. Financ. 2022, 138, 1–16. [Google Scholar] [CrossRef]
- Jarjour, R.; Chan, K.S. Dynamic conditional angular correlation. J. Econom. 2020, 216, 137–150. [Google Scholar] [CrossRef]
- Tse, Y.K.; Tsui, A.K.C. A multivariate generalized autoregressive conditional heteroscedasticity model with time-varying correlations. J. Bus. Econom. Stat. 2002, 20, 51–362. [Google Scholar] [CrossRef]
- Yuan, X.; Yu, W.; Yin, Z.X.; Wang, G.Q. Improved large dynamic covariance matrix estimation with graphical lasso and its application in portfolio selection. IEEE Access 2020, 8, 189179–189188. [Google Scholar] [CrossRef]
- Wen, F.; Yang, Y.; Liu, L.P.; Qiu, R.C. Positive definite estimation of large covariance matrix using generalized non-convex penalties. IEEE Access 2016, 4, 4168–4182. [Google Scholar] [CrossRef]
- Zhang, Y.; Tao, J.Y.; Yin, Z.X.; Wang, G.Q. Improved large covariance matrix estimation based on efficient convex combination and its application in portfolio optimization. Mathematics 2022, 10, 4282. [Google Scholar] [CrossRef]
- Ledoit, O.; Wolf, M. Quadratic shrinkage for large covariance matrices. Bernoulli 2022, 28, 1519–1547. [Google Scholar] [CrossRef]
- Antoniadis, A. Wavelets in Statistics: A Review (with discussion). J. Ital. Stat. Soc. 1997, 6, 97–130. [Google Scholar] [CrossRef]
- Pakel, C.; Shephard, N.; Sheppard, K.; Engle, R.F. Fitting vast dimensional time-Varying covariance models. J. Bus. Econ. Stat. 2021, 39, 652–668. [Google Scholar] [CrossRef]
- Hafner, C.M.; Reznikova, O. On the estimation of dynamic conditional correlation models. Comput. Stat. Data Anal. 2012, 56, 3533–3545. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N | DCC-S | DCC-L2 | DCC-NL | DCC-NCP1 | DCC-NCP2 |
|---|---|---|---|---|---|
| 100 | 4.6874 | 0.6223 | 0.4996 | 0.2279 | 2.4265 |
| 400 | 3.2222 | 2.4103 | 3.1089 | 2.6286 | 0.2583 |
| 800 | 5.6512 | 4.2802 | 4.9354 | 3.7852 | 1.4324 |
| Model | MR * | SD * | SR | |||
|---|---|---|---|---|---|---|
| 100 d | 200 d | 100 d | 200 d | 100 d | 200 d | |
| DCC-S | 37.80 | 37.80 | 20.783 | 16.561 | 1.735 | 2.177 |
| DCC-L2 | 37.80 | 37.80 | 20.700 | 16.417 | 1.742 | 2.196 |
| DCC-NL | 37.80 | 37.80 | 20.701 | 16.470 | 1.741 | 2.189 |
| DDC-NCP1 | 37.80 | 37.80 | 20.658 | 16.652 | 1.745 | 2.165 |
| DCC-NCP2 | 37.80 | 37.80 | 20.488 | 16.543 | 1.760 | 2.179 |
| Model | MR * | SD * | SR | |||
|---|---|---|---|---|---|---|
| 100 d | 200 d | 100 d | 200 d | 100 d | 200 d | |
| DCC-S | 37.800 | 37.800 | 15.447 | 15.393 | 2.334 | 2.2.342 |
| DCC-L2 | 37.800 | 37.800 | 15.305 | 15.174 | 2.355 | 2.376 |
| DCC-NL | 37.800 | 37.800 | 15.319 | 15.377 | 2.353 | 2.346 |
| DDC-NCP1 | 37.800 | 37.800 | 15.271 | 15.418 | 2.367 | 2.338 |
| DCC-NCP2 | 37.800 | 37.800 | 15.559 | 15.079 | 2.317 | 2.391 |
| Model | MR * | SD * | SR | |||
|---|---|---|---|---|---|---|
| 100 d | 200 d | 100 d | 200 d | 100 d | 200 d | |
| DCC-S | 37.800 | 37.800 | 13.132 | 13.452 | 2.745 | 2.680 |
| DCC-L2 | 37.800 | 37.800 | 13.029 | 13.543 | 2.767 | 2.662 |
| DCC-NL | 37.800 | 37.800 | 12.906 | 13.384 | 2.793 | 2.693 |
| DDC-NCP1 | 37.800 | 37.800 | 12.883 | 13.219 | 2.798 | 2.727 |
| DCC-NCP2 | 37.800 | 37.800 | 12.951 | 13.189 | 2.783 | 2.733 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Tao, J.; Lv, Y.; Wang, G. An Improved DCC Model Based on Large-Dimensional Covariance Matrices Estimation and Its Applications. Symmetry 2023, 15, 953. https://doi.org/10.3390/sym15040953
Zhang Y, Tao J, Lv Y, Wang G. An Improved DCC Model Based on Large-Dimensional Covariance Matrices Estimation and Its Applications. Symmetry. 2023; 15(4):953. https://doi.org/10.3390/sym15040953
Chicago/Turabian StyleZhang, Yan, Jiyuan Tao, Yongyao Lv, and Guoqiang Wang. 2023. "An Improved DCC Model Based on Large-Dimensional Covariance Matrices Estimation and Its Applications" Symmetry 15, no. 4: 953. https://doi.org/10.3390/sym15040953