This section introduces the inception and fundamental structure of the Informer algorithm model. Initially, the problem of long series time forecasting is defined, followed by a novel analysis and exploration of the Informer algorithm model. A review of the framework treatment is also provided.
2.1. Basic Forecasting Problem Definition
LSTF utilizes the long-term dependencies between spatial and temporal domains, contextual information, and inherent patterns in data to improve predictive performance. Recent research has shown that the Informer algorithm model and its variants have the potential to further enhance this performance. In this section, we begin by introducing the input and output representations, as well as the structural representation, in the LSTF problem.
In the scrolling prediction setting with a fixed-size window, the input is represented by , while the output is the predicted corresponding sequence at time t. The LSTF problem is capable of handling longer output lengths than previous works, and its feature dimensionality is not limited to the univariate case ( ≥ 1).
The encoder–decoder operation is mainly carried out through a step-by-step process. Many popular models are designed to encode the input as a hidden state and decode the output representation from . The inference involves a stepwise process called “dynamic decoding”, in which the decoder computes a new hidden state from the previous state and other necessary outputs at step k, and then predicts the sequence at step (k + 1).
2.2. Informer Architecture
This section presents an overview of the refined Informer algorithm model architecture designed by Zhou et al. [
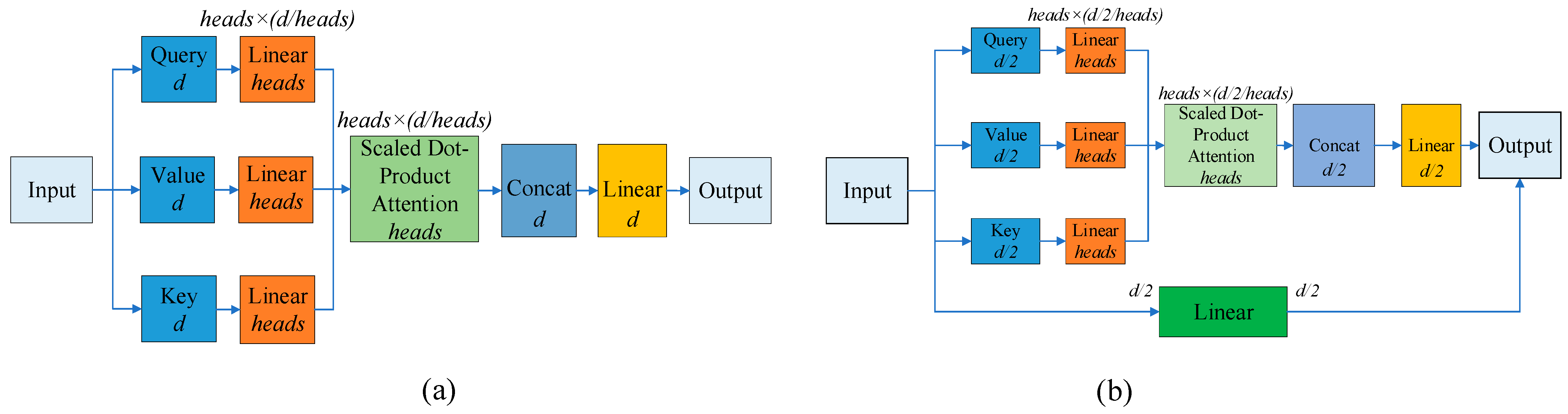
11] The Informer algorithm model is an improvement on the transformer, and its structure is similar to the transformer in that it is a multi-layer structure made by stacking informer blocks. Informer modules are characterized by a ProbSparse multi-head self-focus mechanism, an encoder–decoder structure.
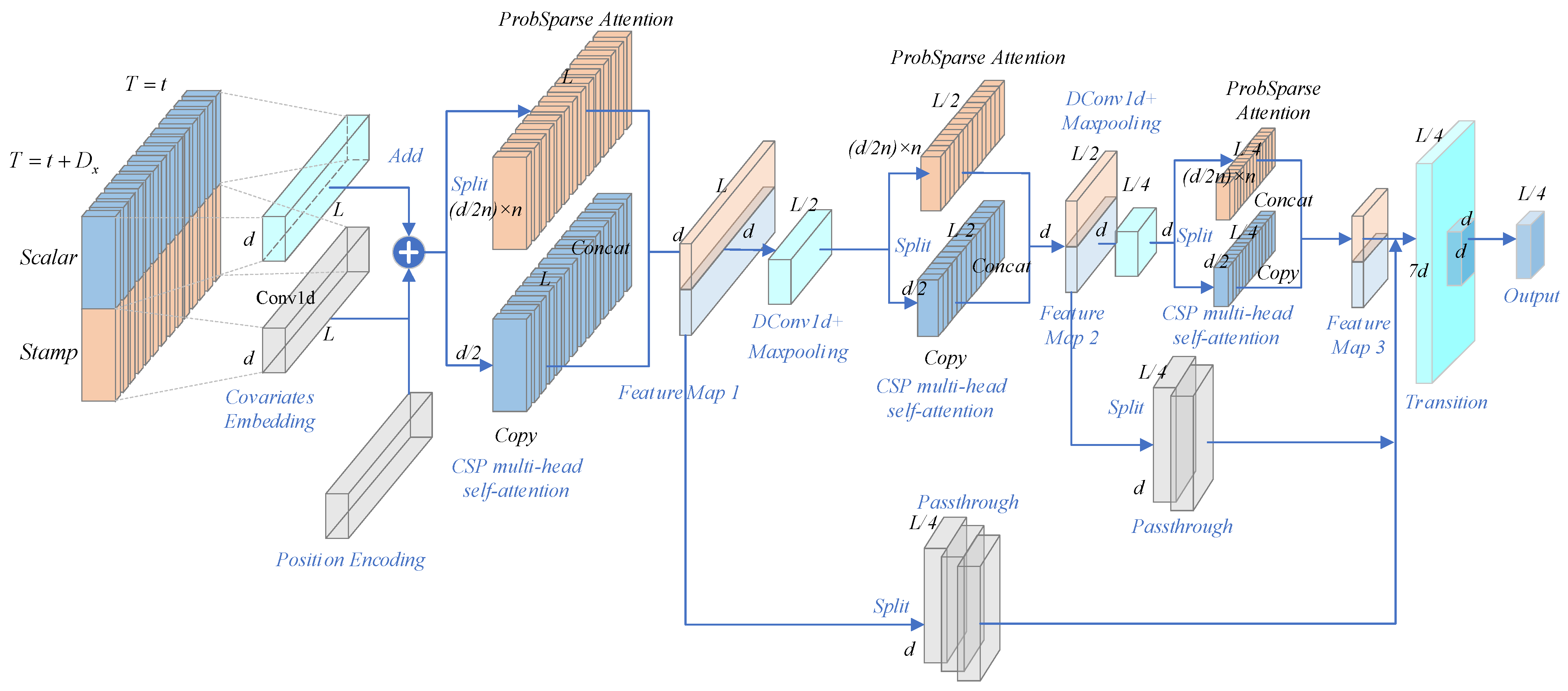
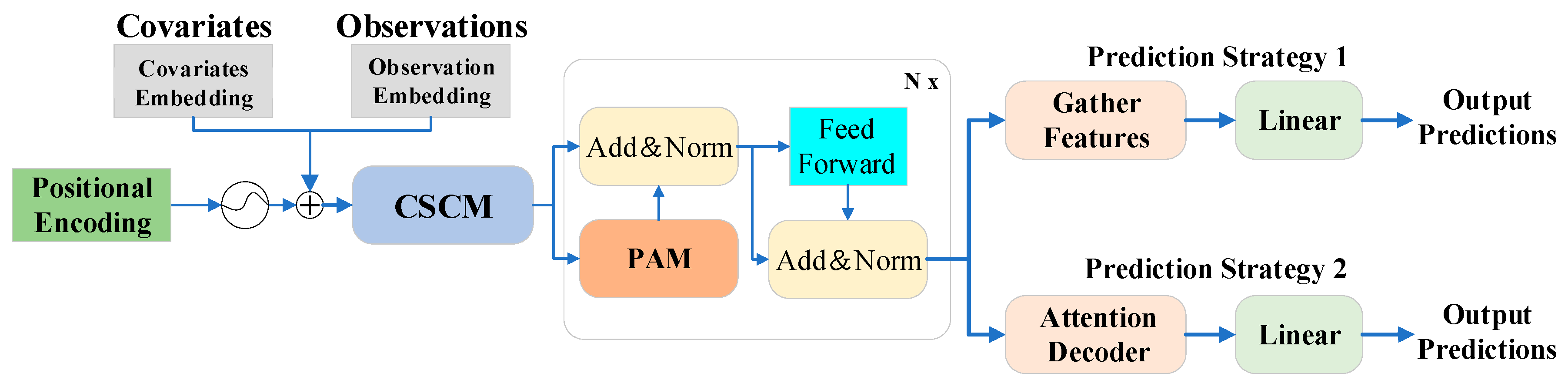
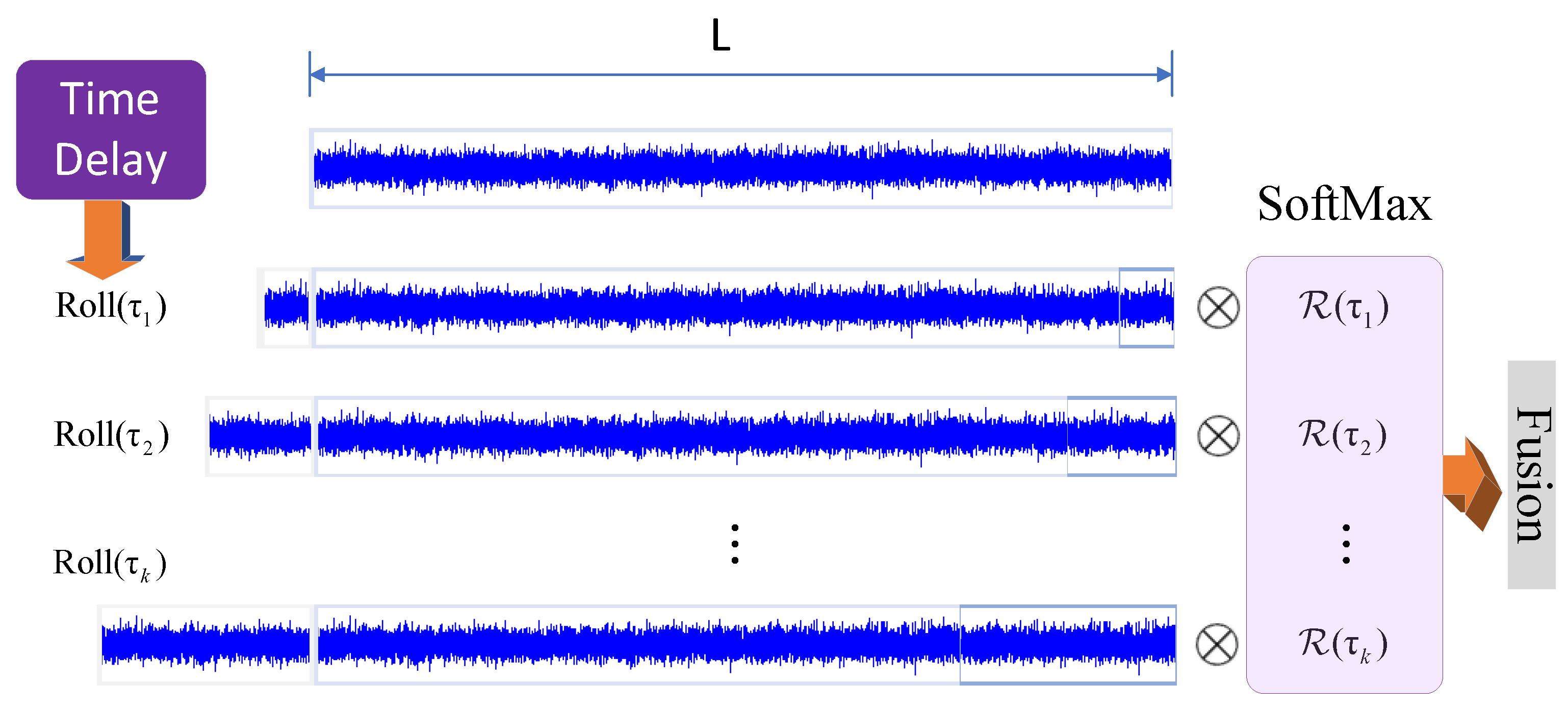
The following figure shows the basic architecture of the Informer algorithm model. The schematic diagram in the left part of the figure shows the encoder receiving a large number of long sequence inputs with the proposed ProbSparse self-attention instead of the canonical self-attention. The green trapezoid is a self-attention distillation operation that extracts the dominant attention and greatly reduces the network size. The layer-stacked copies increase the robustness. The decoder in the right part of the figure receives the long sequence input, fills the target element with zero, measures the weighted attentional composition of the feature map, and immediately predicts the output element in a generative manner.
The model successfully improves the predictive power of the LSTF problem and validates the potential value of the transformer family of models in capturing individual long-range dependencies between the output and the input of long time series. The ProbSparse self-attention mechanism is successfully proposed to effectively replace the canonical self-attention. The time complexity and memory footprint of dependency alignment is achieved. The research article presents the self-attention extraction operation to control the attention fraction in the stacked layers and significantly reduce the total space complexity to , which helps the model to receive long-range inputs. Meanwhile, researchers proposed a generative decoder to obtain long sequence outputs with only one forward step while avoiding the cumulative error expansion in the inference stage.
In the original transformer model, the canonical self-attention is defined based on tuple inputs, which are queries, keys, and values, and it performs the scaled dot product for
, where
,
,
and d represent the input dimensions. To further discuss the self-attention mechanism, let
represent the i-th row in
Q,
K, and
V, respectively. Following the formulas in references [
18,
19], the attention of the i-th query is defined as a kernel smoother in the form of probability:
where
and
choose the asymmetric index kernel
. The output obtained by self-attention is mainly derived by combining the values after calculating the probability
. Additionally, it requires quadratic dot product computation and memory. Additionally, its need for quadratic dot product computation and
memory is the main drawback of self-attention in the transformer.
The self-attention mechanism is an improved attention model, which is simply summarized as a self-learning representation process. Moreover, the computational overhead of self-attention is quadratically correlated with sequence length, which leads to low computational efficiency, slow computational speed and high training costs of the Transformer model, and the excessive computational overhead also makes the application of the model difficult; the processing capability of long sequence data is thus limited in the Transformer model.
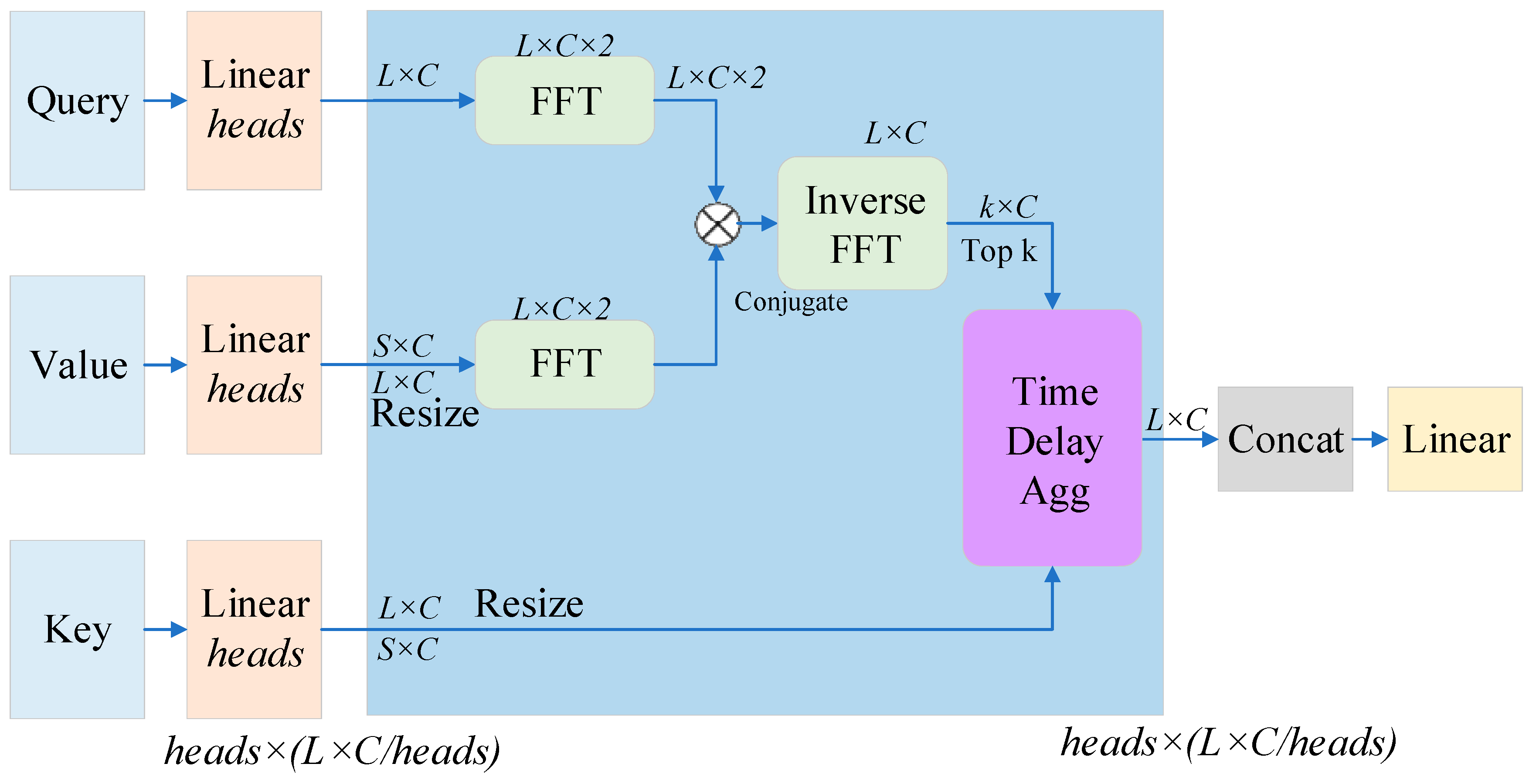
Therefore, studying variants of the self-attention mechanism to achieve an efficient Transformer has become an important research direction. The Informer algorithm model has been preceded by equally many proposals to reduce memory usage and computation and increase efficiency.
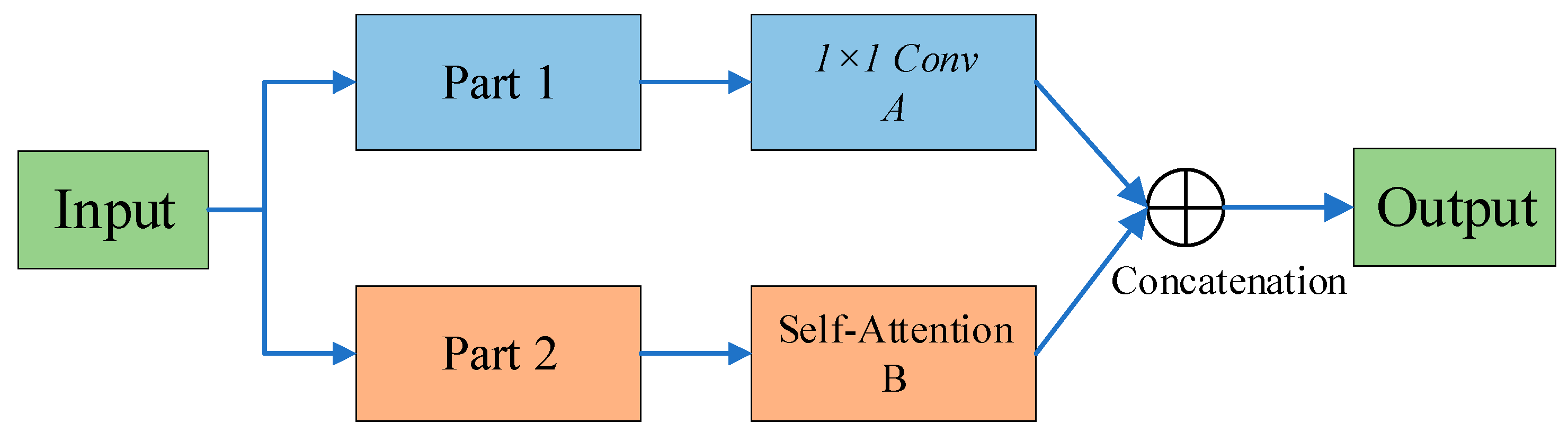
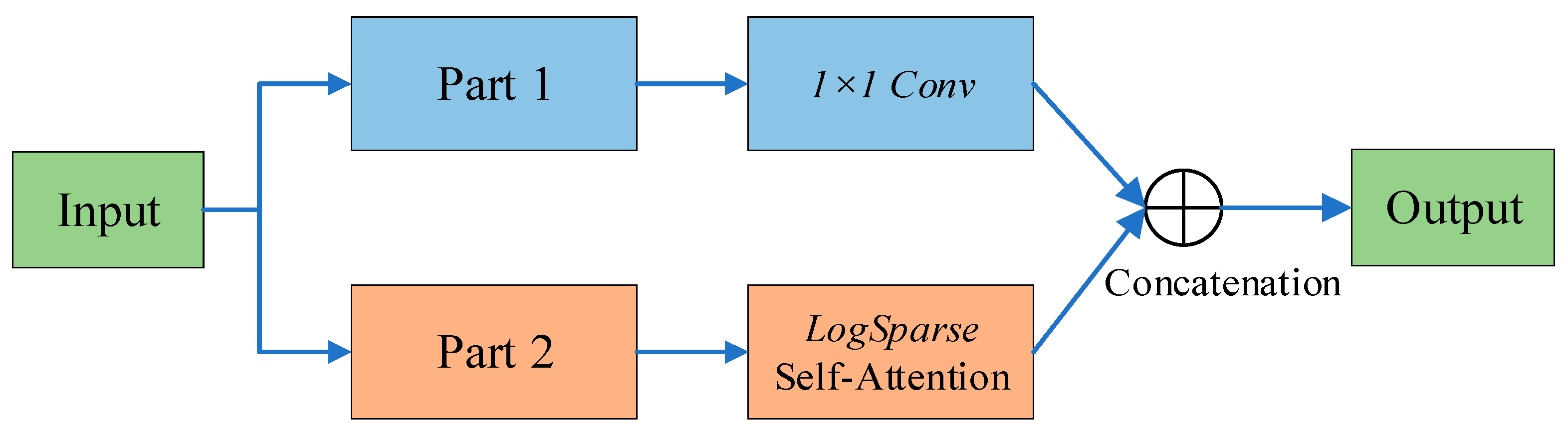
Sparse Transformer [
20] combines row output and column input, where sparsity comes from separated spatial correlations. LogSparse Transformer [
21] notes the circular pattern of self-attention and makes each cell focus on its previous cell in exponential steps. Longformer [
22] extends the first two works to more complex sparse configurations.
However, they use the same strategy to deal with each multi-headed self-attention, a mode of thinking that makes it difficult to develop novel and efficient models. In order to reduce memory usage and improve computational efficiency, researchers first qualitatively evaluated the learned attention patterns of typical self-attention in the Informer algorithm model, i.e., a few dot product pairs contribute major attention, while others produce very little attention.
The following discussion focuses on the differences between the differentiated dot products. From the above equation, the attention of the i-th query to all keys is defined as the probability
, and the output is its combination with the value V. The dominant dot product pair encourages the attention probability distribution of the corresponding query to be far from a uniform distribution. If
is close to a uniform distribution, which is
, then the result of the self-attention calculation becomes a numerically small sum of V values, which is redundant for the input. Therefore, the “similarity” between distributions p and q can be used to distinguish “important” queries. The “similarity” can be measured by the Kullback–Leibler scatter:
removing the constants, the sparsity measure for the i-th query is defined as the following equation:
where the first term is the Log-Sum-Exp of all keys
and the second term is their arithmetic mean. If the i-th query obtains a larger
, it has a more diverse attention probability p and is likely to contain dominant dot product pairs in the head fields of the long-tailed self-attention distribution. Additionally, ProbSparse self-attention is achieved by allowing each key to focus on only u primary queries:
where
is a sparse matrix of the same size as q, which contains only the Top-u queries under the sparse metric
. Under the control of a constant sampling factor c,
is set in such a way that ProbSparse self-attention only needs to compute
dot products for each query-key lookup, and memory usage per layer is kept at
.
In the multi-head perspective, this attention generates different sparse query-key pairs for each head, thus avoiding severe information loss. Additionally, to address the quadratic complexity problem and the fact that LSE operations have potential numerical stability, researchers proposed an empirical approximation for efficiently obtaining query sparsity measures.
Lemma 1. For each in the set K as well as , the bound is the following equation:
This equation also holds when
, starting with Lemma 1, and the maximum mean measure is proposed as the following equation [
11]:
randomly selected
dot product pairs are used to compute
, meaning that the other pairs are filled with zeros, from which the sparse Top-u is selected as
. The maximum operator in
is less sensitive to zero values and is numerically stable. In practice, the input lengths of queries and keys are usually equivalent in the self-attention computation, which means that
. This makes the total time complexity and space complexity of ProbSparse self-attention
.
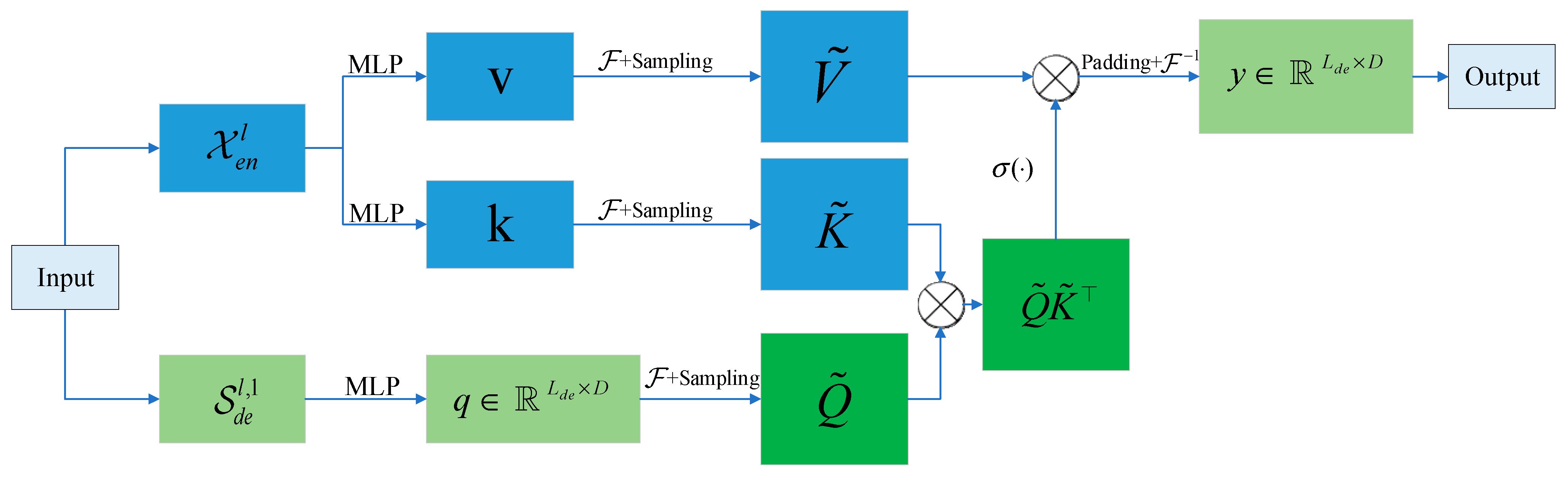
2.3. Encoder
In
Figure 1, it can be seen that Encoder receives a large number of long sequence inputs, while the model uses ProbSparse self-attention instead of self-attention in Transformer. The green trapezoid is the extraction operation of self-attention, which mainly extracts the dominant attention and drastically reduces the amount of computation and memory occupied. Additionally, the layer-stacked copies increase the robustness.
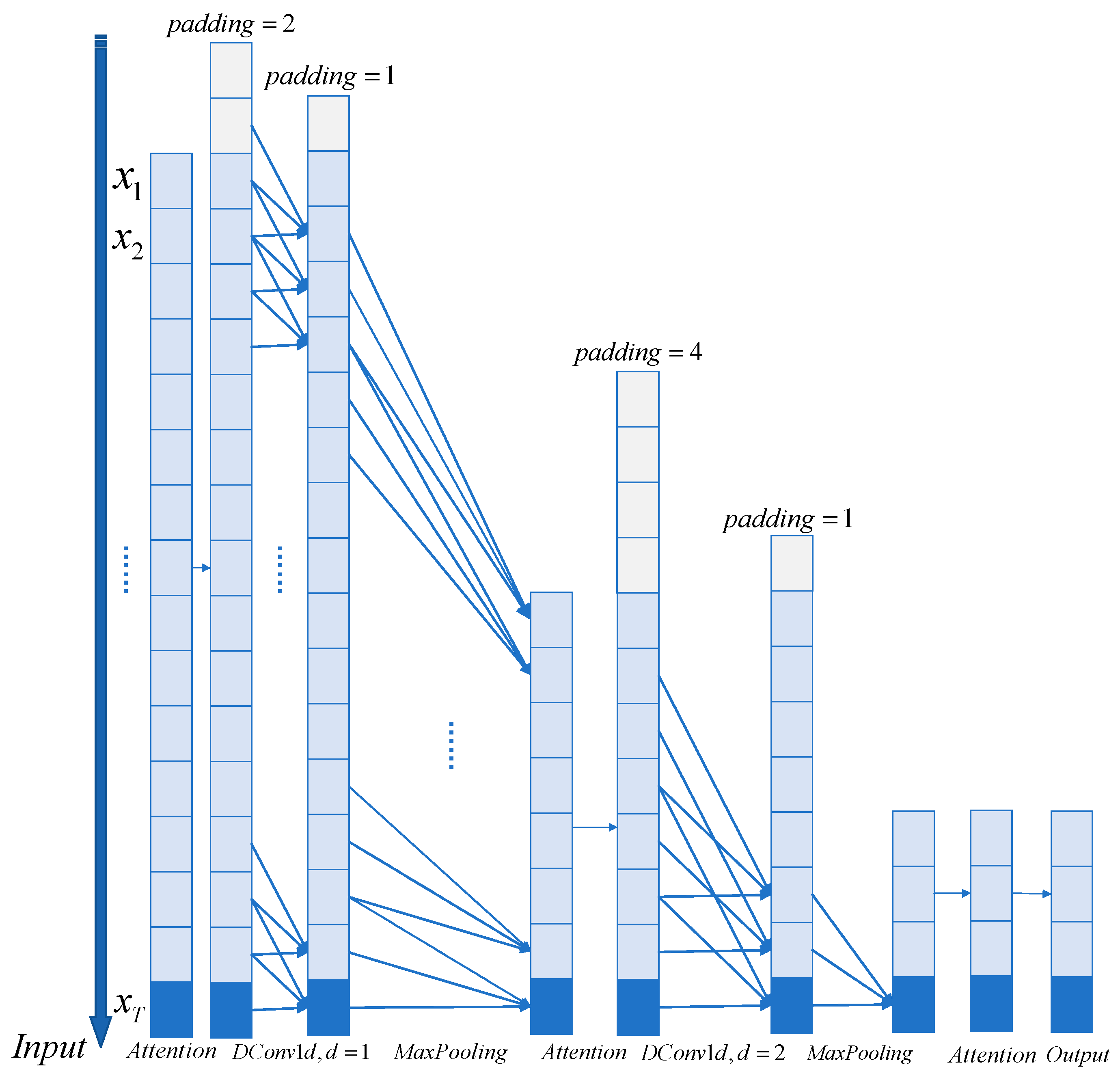
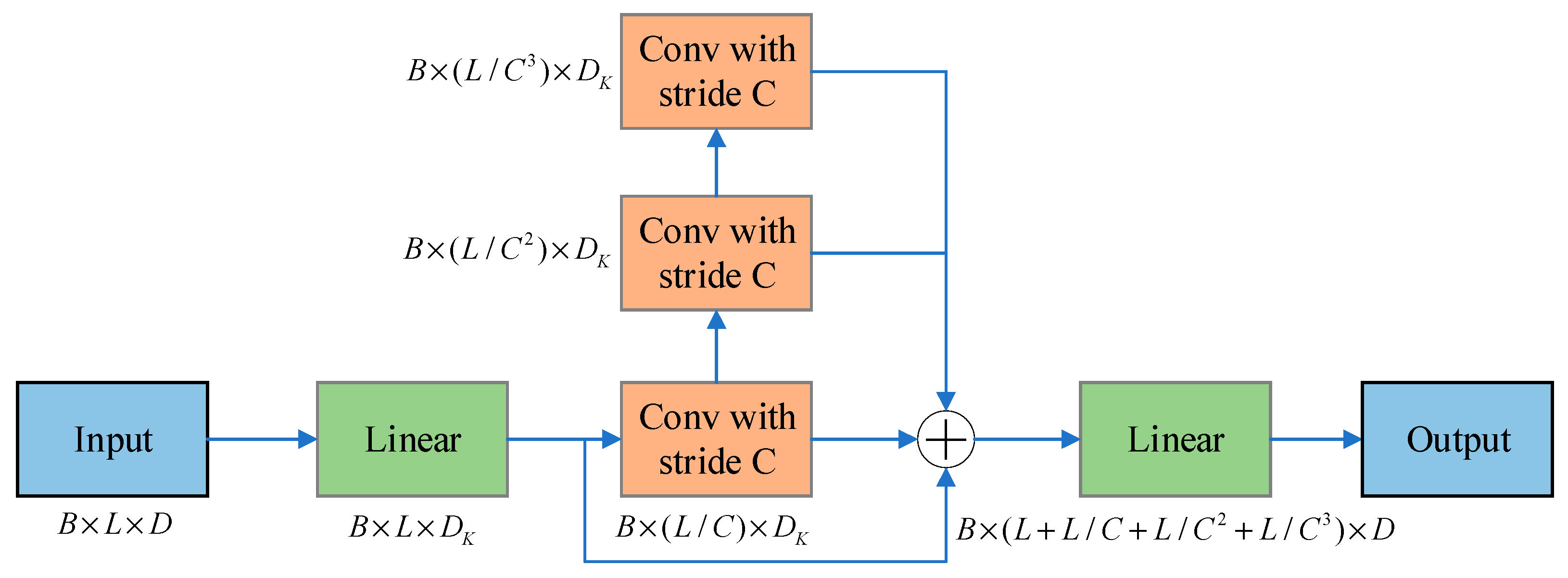
The encoder is designed to extract robust remote dependencies for long sequence inputs. After the input representation, the t-th sequential input has been shaped into a matrix , and the following diagram shows the structure of a single stack of the encoder:
In the above figure, the horizontal stack represents one of the copies of a single encoder. The one presented in
Figure 2 is the main stack that receives the entire input sequence. The second stack then acquires half of the slices of the input, and the subsequent stacks are repeated. The red layer is a dot product matrix, and the red layer is reduced in cascade by performing self-attention extraction on each layer. The output of the encoder is then performed by connecting the feature maps of all stacks.
As a natural consequence of the ProbSparse self-attention mechanism, the feature maps of the encoder have redundant combinations of values V. The distillation operation is used to assign weights to the values with dominant features and to produce a new self-attention feature map at the next level. This operation substantially prunes the temporal dimension of the input, and the n-head weight matrix of the attention block is seen in
Figure 2. Inspired by the expansion convolution [
23], the “distillation” process advances from the j-th layer to the (
j + 1) layer, as follows:
where
represents the attention block. It contains the multi-headed ProbSparse self-attention and the basic operations, where
performs a one-dimensional convolutional filter in the time dimension using the
activation function [
24].
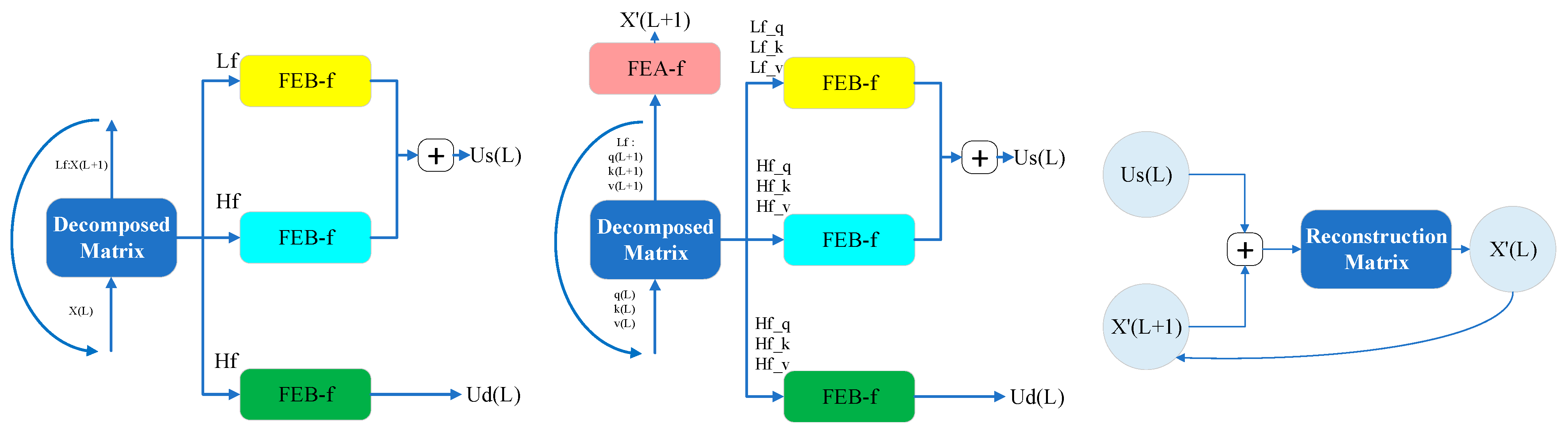
The Researchers add a maximum pooling layer spanning 2 and down-sample into half of its slices after stacking one layer, which reduces the overall memory usage to , where is a small number. To enhance the robustness of the extraction operation, copies of the main stack is also constructed using halved inputs, and the number of self-focused extraction layers is gradually reduced by performing one layer at a time, aligning their output dimensions and joining the outputs of all stacks to obtain the final hidden representation of the encoder.
2.4. Decoder
A standard decoder structure is used in the Informer algorithm model, which consists of two identical multi-headed attention layers. However, the generative inference is used to mitigate the speed plunge in long series time forecasting. The decoder takes the long sequence input, fills the target elements with zeros, measures the weighted attention composition of the feature map, and immediately predicts the output elements in a generative manner.
In
Figure 1, the decoder receives the long sequence input, fills the target elements with zero, measures the weighted attention composition of the feature map, and instantly predicts the output elements in a generative style. Regarding the implementation principle of the decoder, the following vectors are first provided to the decoder:
where
is the start marker and
is a placeholder for the target sequence (setting the scalar to 0). By setting the masked dot product to negative infinity, a multi-headed masked attention mechanism is applied in the ProbSparse self-attention calculation. It prevents each position from paying attention to the upcoming position, thus avoiding the autoregression. The fully connected layer obtains the final output, whose size
depends on whether univariate or multivariate prediction is performed.
Regarding the problem of long output length, the original transformer has no way to solve this problem; it is dynamically output with the same cascade output as the RNN-like model, which cannot handle long sequences. A start token in the dynamic decoding process of NLP is a great trick [
25], especially for the pre-training model stage, and the concept is extended in the Informer algorithm model for the long series time forecasting problem by proposing a generative decoder for the long sequence output problem, that is, generating all the predicted data at once. The Q, K, and V values in the first masked attention layer are obtained by multiplying the embedding values from the decoder input by the weight matrix, while the Q values in the second attention layer are obtained by multiplying the output of the previous attention layer by the weight matrix, and the K and V values are obtained by multiplying the output of the encoder by the weight matrix.




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}