
Research on Topic Evolution Path Recognition Based on LDA2vec Symmetry Model


Abstract
:1. Introduction
2. Related Work
2.1. Topic Recognition
2.2. Topic Evolution Analysis
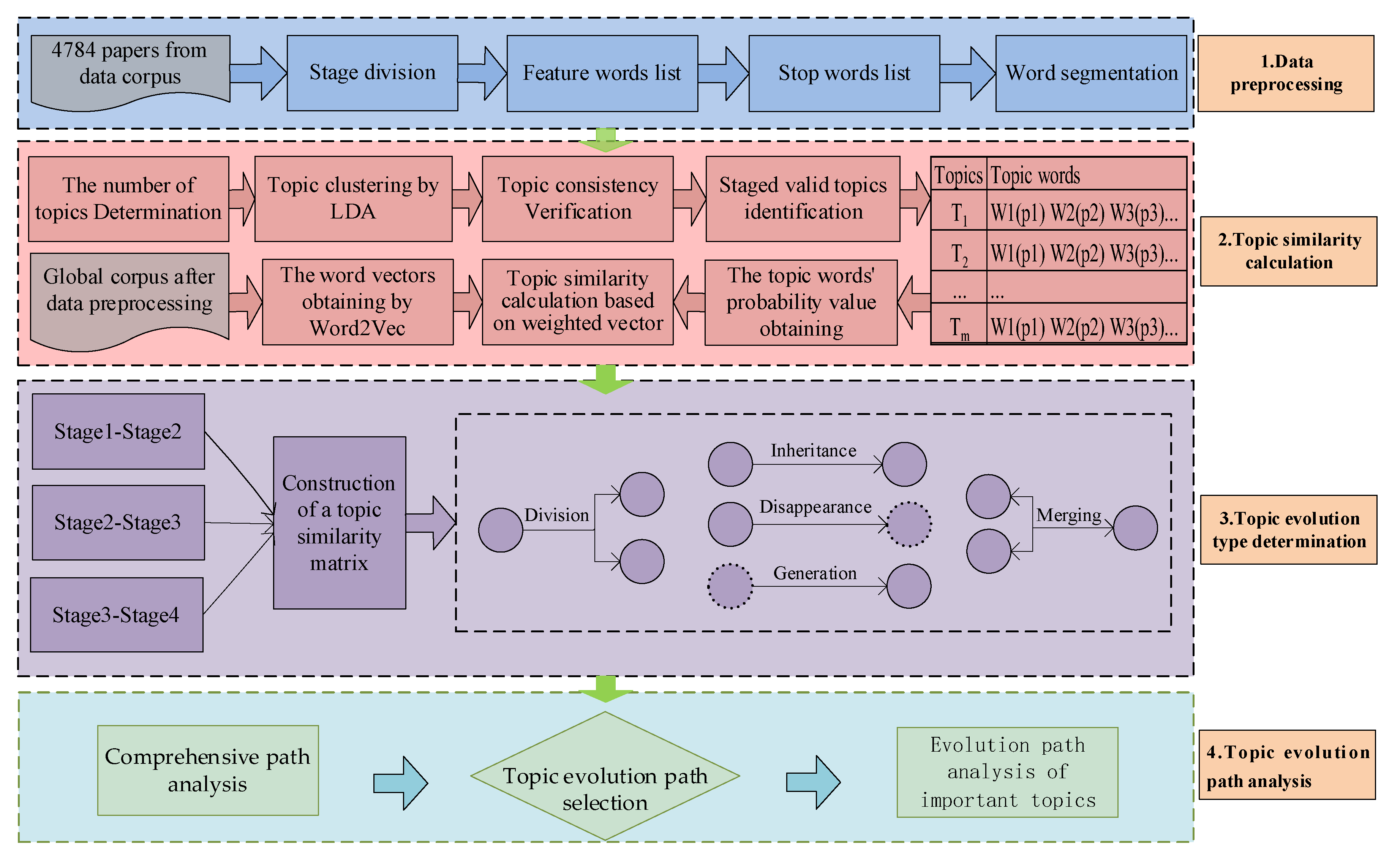
3. Methodology
3.1. Data Preprocessing
- (1)
- Domain feature word list construction: Given the real dilemma that the target domain is highly knowledgeable, specialized in vocabulary, and unsupervised, we extract the keywords of literature as the initial feature word list. Then, we use the TF-IDF algorithm to extract keywords in the target domain from the literature and add them to the initial feature word list. Finally, we perform de-duplication and filtering work to obtain the final feature word list.
- (2)
- Domain stop word list construction: To improve the accuracy of domain-oriented topic recognition and prevent the interference of high-frequency invalid words (such as “analysis”) appearing in each domain, this paper proposes to construct a target domain-oriented stop word list based on the universal stop word list. In the specific case application, we check the clustering results after the first LDA topic clustering, extract the meaningless words of the domain into the universal stop word list, and iterate the above process no more than five times to form the final stop word list.
3.2. Calculation of Similarity Based on LDA2vec Symmetry Model
- (1)
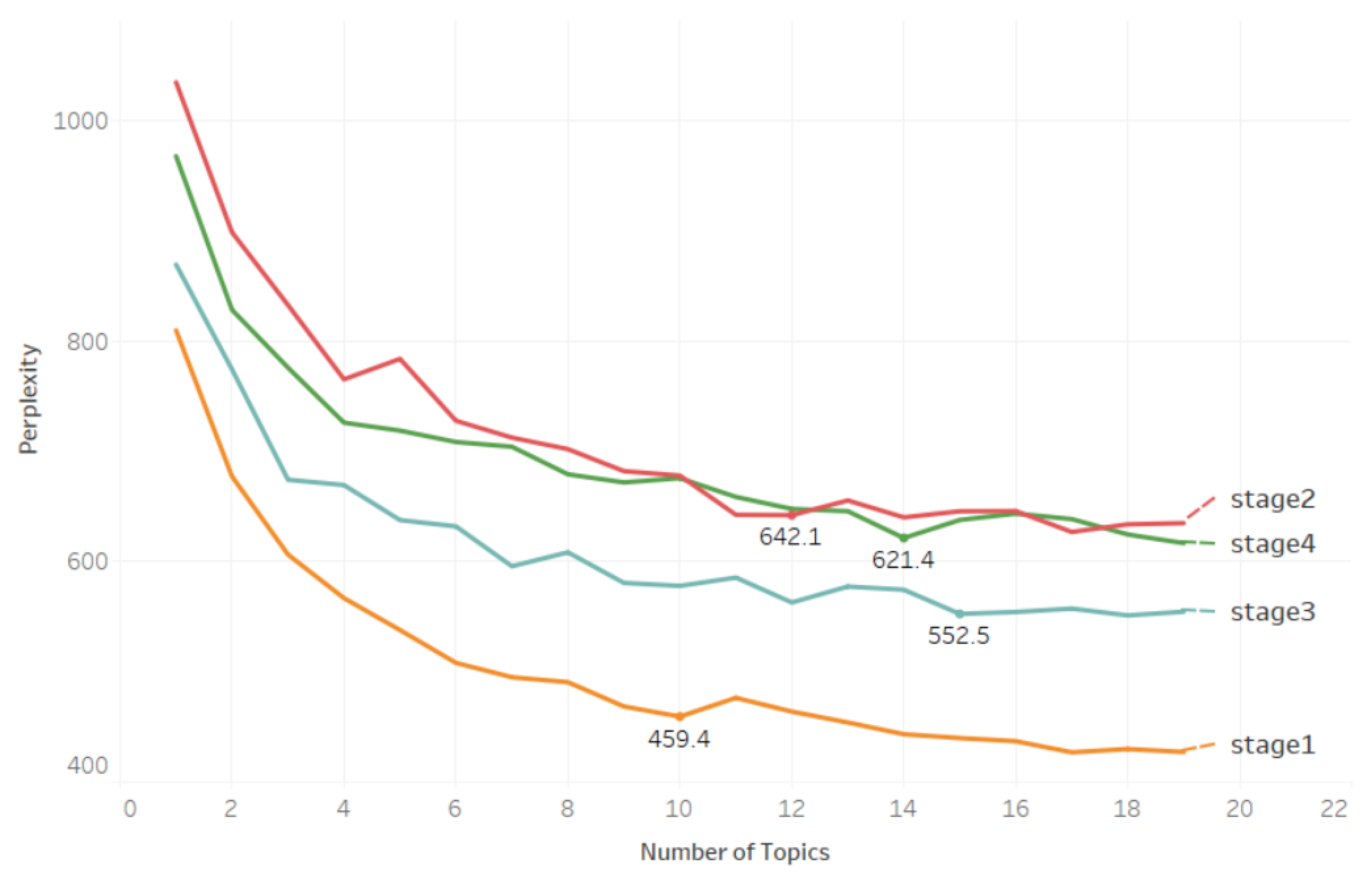
- K value determination: The perplexity, which indicates the uncertainty about the topic to which the literature belongs, is used to determine the number of global topics and staged topics. The lower the perplexity, the better the clustering effect is, and the number of topics is optimal [28]. The calculation of perplexity is shown in Equation (1).
- (2)
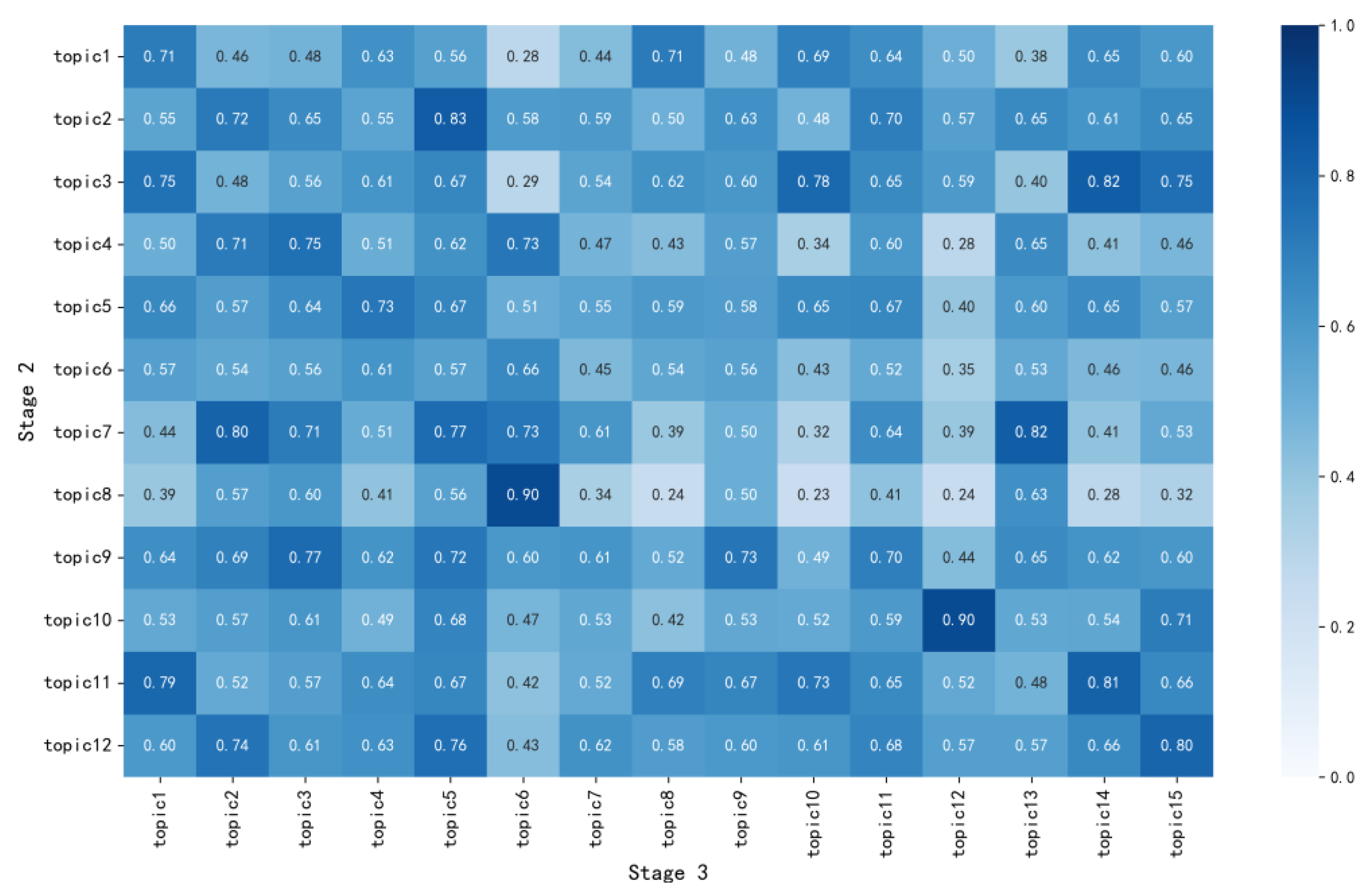
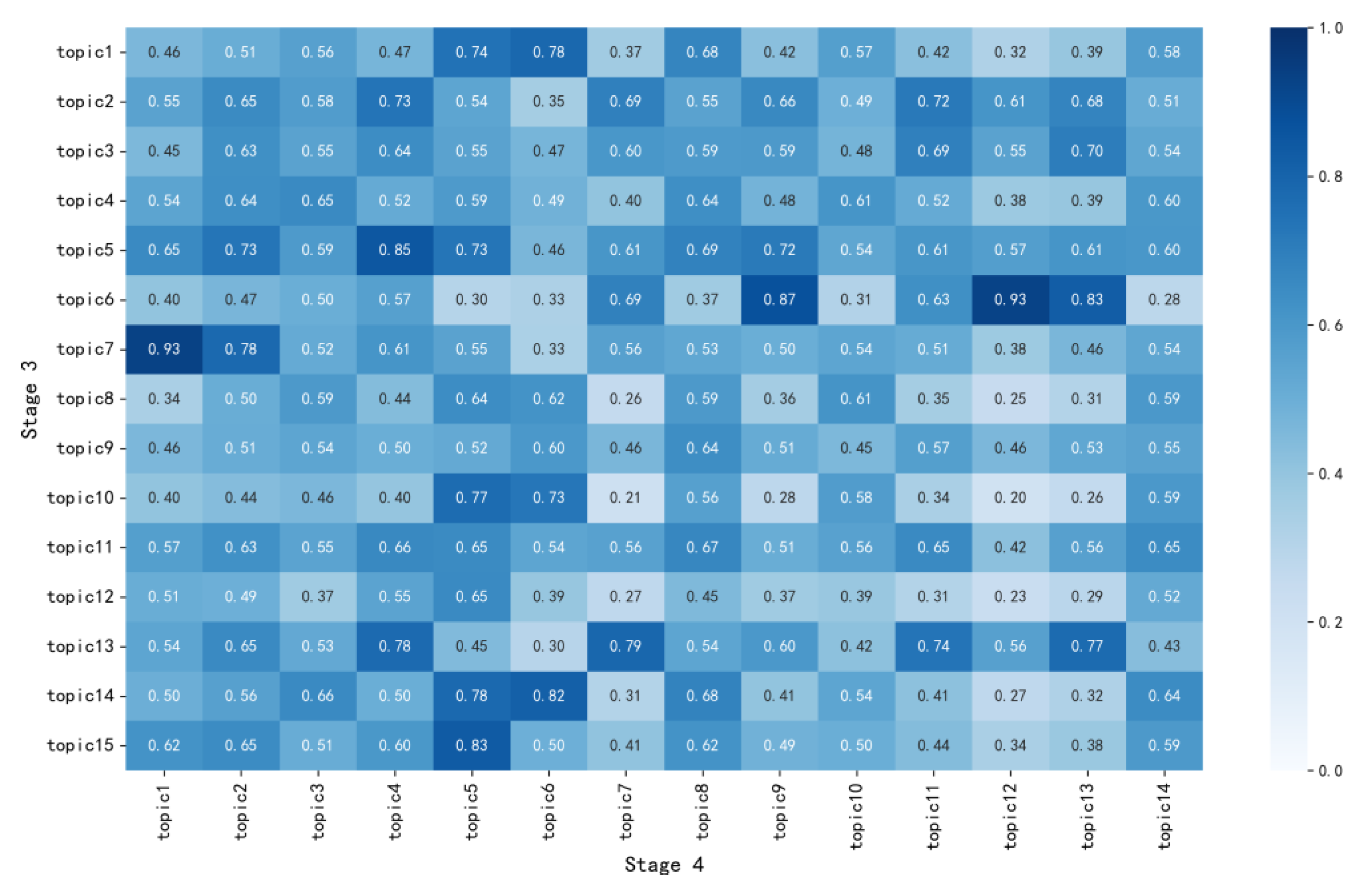
- Topic consistency verification: We respectively calculate the cosine similarity between the four-stage topics and the global topics, and compare the average of the similarity values named C with the threshold value of 0.5 to derive the result. If C ≥ 0.5, it proves that there is consistency among topics. If C < 0.5, it proves that there is no consistency among topics, which means these topics, named invalid topics, are not highly related to global topics and should be filtered out.
- (3)
- Similarity calculation based on the weighted vector: Word2vec provides two classical language models, which are the skip-gram model and the CBOW model, for training. Skip-gram predicts the nearby words by the central word, while CBOW predicts the current value by the context. The purpose of this paper is to perform the topic evolution path analysis based on similarity calculation for the topics (central words), similar to the principle of the skip-gram model. As a result, the skip-gram model was chosen. First of all, we use the preprocessed global dataset as word vectors to train data and use the functions in the gensim package of the Python language to train word vectors, constructing word vector models. Then, we use the trained Word2vec model to vectorize the topic words obtained by LDA model clustering and generate the word vectors corresponding to each of the topic words. Since the probability of a topic word represents the importance of a topic, to better measure the importance of topic–topic words, we multiply the probability of a topic word extracted by LDA as a weight by the corresponding word vector of Word2vec and perform a weighted sum to obtain a vectorized representation of the topic. Then, we use cosine similarity to calculate the similarity values between topics at adjacent stages and construct a stage inter-topic similarity matrix to determine the evolution type among topics. However, there are many hidden variables in LDA, and the multi-dimensional Gibbs sampling algorithm is used in the calculation process. To find the n-dimensional stable probability distribution during sampling, a new sample is obtained by rotating sampling on n-coordinate axes. The idea is to fix the random variable in n − 1 dimensions first, sample in the remaining dimension, and then rotate the sampling dimensions until the sampling converges to a certain high-dimensional space. The rotation sampling method adopted in the algorithm is to consider the status of each random variable to be equivalent, and the abstract shape of the sampled data in the high-dimensional space is symmetrical under the given conditions. For example, in a sphere with the center of the sphere at the origin of coordinates in a three-dimensional space, the coordinate variable of each dimension and its value are equivalent, and the structure of the space is symmetrical. The specific calculation is shown in Equations (2)–(4).
3.3. Topic Evolution Type Determination
3.4. Topic Evolution Path Analysis
4. Empirical Research
4.1. Data Sources
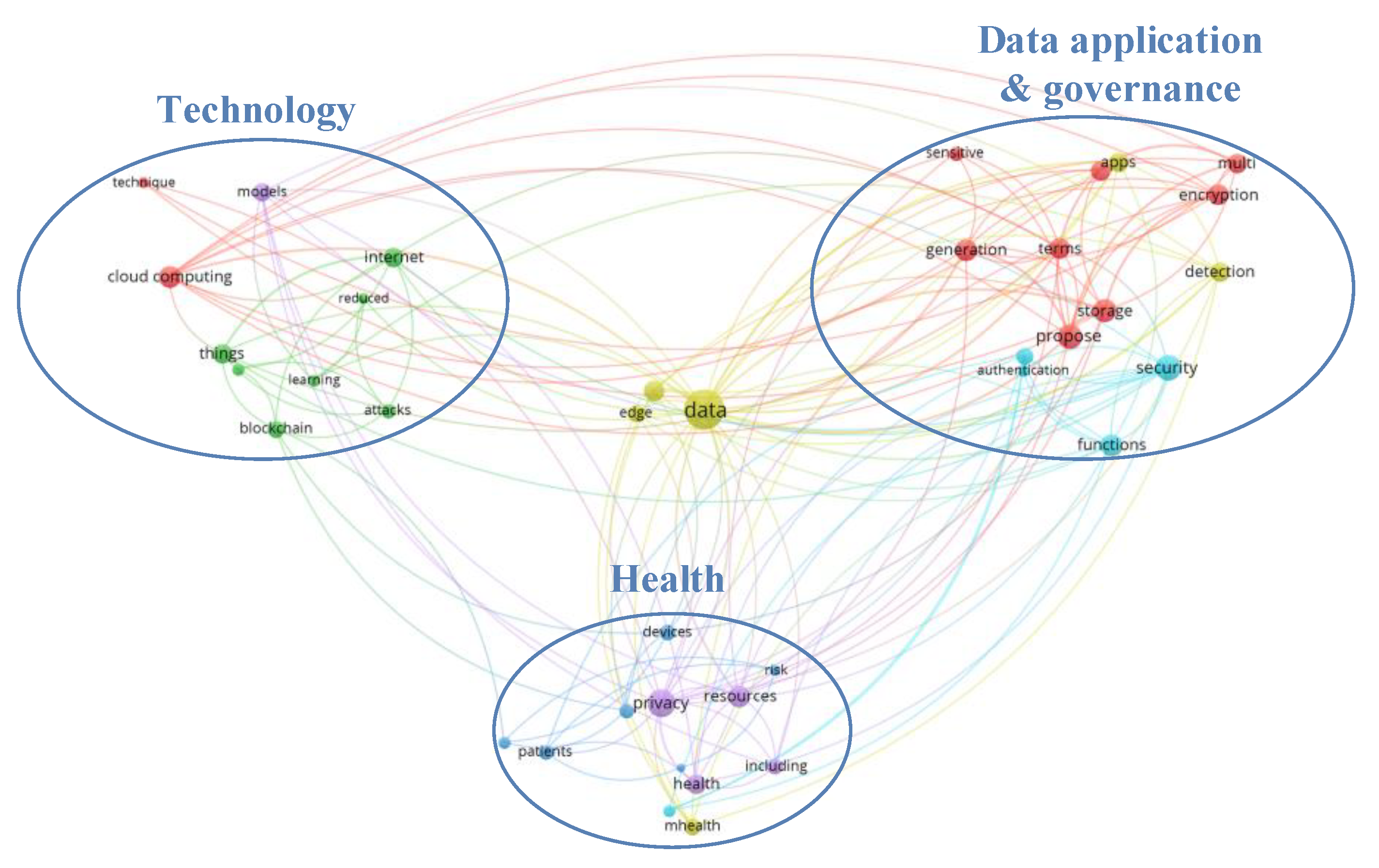
4.2. Topic Identification
4.2.1. Determination of the Number of Topics Based on the Perplexity
4.2.2. Topic Extraction
4.3. Topic Evolution Type Analysis
- (1)
- Topics of division and merging types
- (2)
- Topics of disappearance and generation types
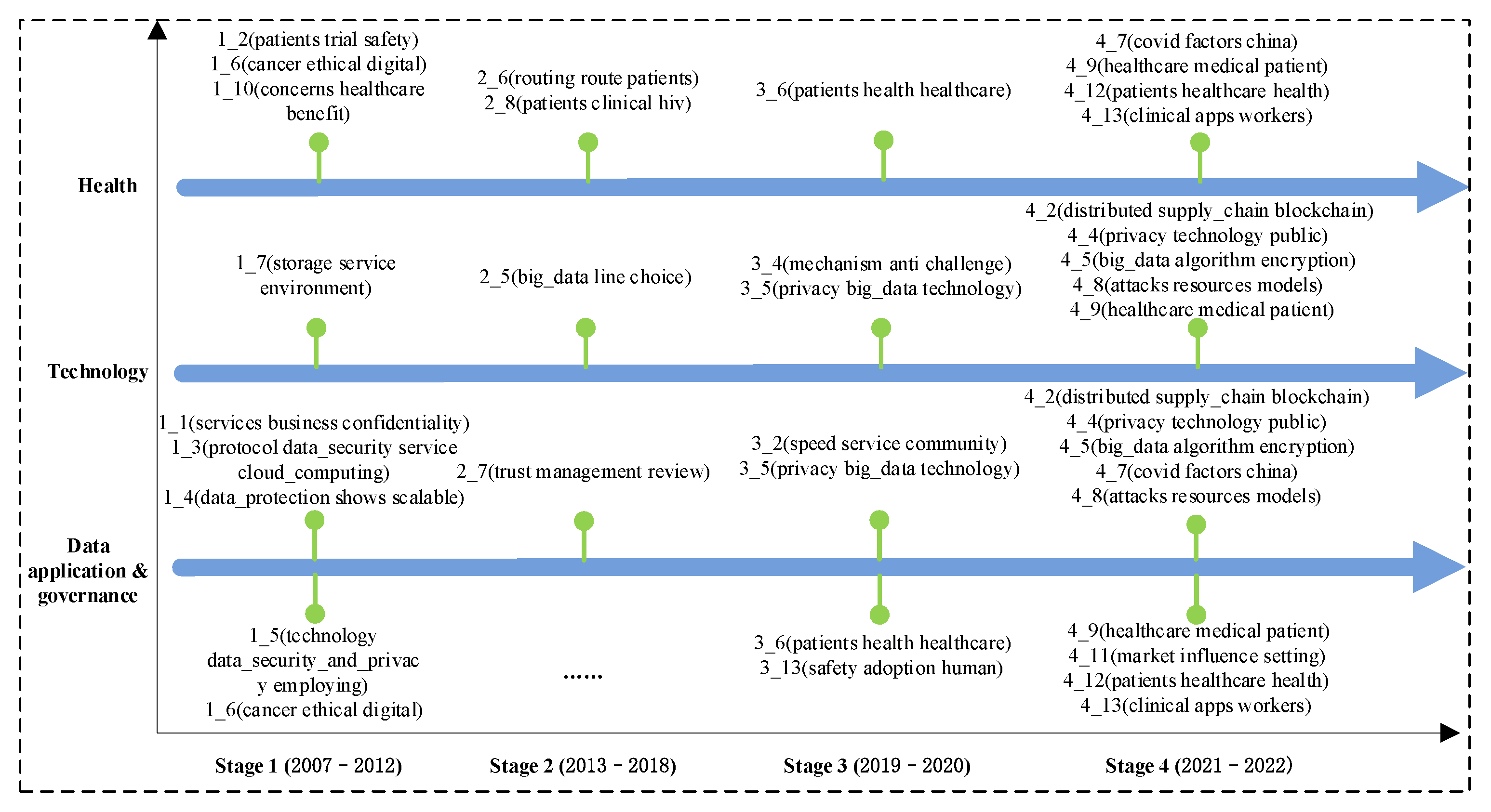
4.4. Comprehensive Path Analysis
4.4.1. Topic Evolution Path Selection
4.4.2. Evolution Path Analysis of Important Topics
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liang, S.; Liu, X. Research progress on topic evolution of scientific and technical literature based on text mining. Libr. Inf. Serv. 2022, 66, 138–149. [Google Scholar]
- Martin, G.; Tiago, P.P.; Eduardo, G.A. A network approach to topic models. Sci. Adv. 2018, 4, eaaq1360. [Google Scholar]
- Prasanna, K.; Seetha, M. A doubleton pattern mining approach for discovering colossal patterns from biological dataset. Int. J. Comput. Appl. 2015, 119, 41–47. [Google Scholar] [CrossRef]
- Kottapalle, P.; Maddala, S.; Gunjan, V.K. D-mine: Accurate discovery of large pattern sequences from biological datasets. In Proceedings of the International Conference on Soft Computing Systems: ICSCS 2015; Springer: New Delhi, India, 2016; Volume 1, pp. 647–661. [Google Scholar]
- Zhu, Q.; Leng, F. Analysis of topic evolution based on co-citation of documents on the main citation path. J. China Soc. Sci. Tech. Inf. 2014, 33, 498–507. [Google Scholar]
- Cobo, M.J.; López-Herrera, A.G.; Herrera-Viedma, E.; Herrera, F. An approach for detecting, quantifying, and visualizing the evolution of a research field: A practical application to the Fuzzy Sets Theory field. Informetrics 2011, 5, 146–166. [Google Scholar] [CrossRef]
- Santos, B.S.; Silva, I.; Costa, D.G. Symmetry in Scientific Collaboration Networks: A Study Using Temporal Graph Data Science and Scientometrics. Symmetry 2023, 15, 601. [Google Scholar] [CrossRef]
- Yan, N.; Feng, T.; Hu, Y.; Qi, X. Understanding Aging Policies in China: A Bibliometric Analysis of Policy Documents, 1978–2019. Int. J. Environ. Res. Public Health 2020, 17, 5956. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.J. Latent Dirichlet allocation. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Blei, D.M. Probabilistic topic models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef] [Green Version]
- Lechao, X.; Jeffrey, P. Synergy and Symmetry in Deep Learning: Interactions between the Data, Model, and Inference Algorithm. In Proceedings of the 39th International Conference on Machine Learning: ICML 2022, Baltimore, MD, USA, 17–23 July 2022; pp. 24347–24369. [Google Scholar]
- Ning, B.; Zong, X.; He, K.; Lian, L. PREIUD: An Industrial Control Protocols Reverse Engineering Tool Based on Unsupervised Learning and Deep Neural Network Methods. Symmetry 2023, 15, 706. [Google Scholar] [CrossRef]
- Choi, H.S.; Lee, W.S.; Sohn, S.Y. Analyzing research trends in personal information privacy using topic modeling. Comput. Secur. 2017, 67, 244–253. [Google Scholar] [CrossRef]
- Zhang, T.; Ma, H. Clustering Policy Texts Based on LDA Topic Model. Data Anal. Knowl. Discov. 2018, 2, 59–65. [Google Scholar]
- Xue, J.; Chen, J.; Hu, R.; Chen, C.; Zheng, C.; Su, Y.; Zhu, T. Twitter Discussions and Emotions About the COVID-19 Pandemic: Machine Learning Approach. J. Med. Int. Res. 2020, 22, e20550. [Google Scholar] [CrossRef]
- Zhou, H.; Yu, H.; Hu, R. Topic evolution based on the probabilistic topic model: A review. Front. Comput. Sci. 2017, 11, 786–802. [Google Scholar] [CrossRef]
- Han, X. Evolution of research topics in LIS between 1996 and 2019: An analysis based on latent Dirichlet allocation topic model. Scientometrics 2020, 125, 2561–2595. [Google Scholar] [CrossRef]
- Han, W.; Han, X.; Zhou, S.; Zhu, Q. The Development History and Research Tendency of Medical Informatics: Topic Evolution Analysis. JMIR Med. Inform. 2022, 10, e31918. [Google Scholar] [CrossRef] [PubMed]
- Xu, S.; Shi, Q.; Qiao, X.; Zhu, L.; Zhang, H.; Jung, H.; Lee, S.; Choi, S.P. A Dynamic Users’ Interest Discovery Model with Distributed Inference Algorithm. Int. J. Distrib. Sens. Netw. 2014, 10, 239–245. [Google Scholar] [CrossRef]
- Zhu, H.; Qian, L.; Qin, W.; Wei, J.; Shen, C. Evolution analysis of online topics based on ‘word-topic’ coupling network. Scientometrics 2022, 127, 3767–3792. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: NAACL 2019, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Huang, L.; Chen, X.; Zhang, Y.; Wang, C.; Cao, X.; Liu, J. Identification of topic evolution: Network analytics with piecewise linear representation and word embedding. Scientometrics 2022, 127, 5353–5383. [Google Scholar] [CrossRef]
- Xie, Q.; Zhang, X.; Ding, Y.; Song, M. Monolingual and multilingual topic analysis using LDA and BERT embeddings. Informetrics 2020, 14, 101055. [Google Scholar] [CrossRef]
- Xiaowen, X.; Ying, G.; Xinna, S.; Jin, W. Research on the technical similarity visualization based on word2vec and LDA topic model. J. China Soc. Sci. Tech. Inf. 2021, 40, 974–983. [Google Scholar]
- Baosong, Y.; Longyue, W.; Derek, W.; Lidia, C.; Zhaopeng, T. Assessing the Ability of Self-Attention Networks to Learn Word Order. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: ACL 2019, Florence, Italy, 28 July–2 August 2019; pp. 2633–2643. [Google Scholar]
- Li, B.; Zhou, H.; He, J.; Wang, M.; Yang, Y.; Li, L. On the Sentence Embeddings from Pre-trained Language Models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: EMNLP 2020, Online, 16–20 November 2020; pp. 9119–9130. [Google Scholar]
- Griffiths, T.L.; Steyvers, M. Finding scientific topics. Proc. Natl. Acad. Sci. USA 2004, 101, 5228–5235. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- İlhan, N.; Öğüdücü, Ş.G. Predicting community evolution based on time series modeling. In Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining: ASONAM 2015, Paris, France, 25–28 August 2015; pp. 1509–1516. [Google Scholar]
- Li, H.; Hu, J.; Tong, Z. Subject Topic Mining and Evolution Analysis with Multi-Source Data. Data Anal. Knowl. Discov. 2022, 6, 44–55. [Google Scholar]
- Tan, C.; Xiong, M. Contrastive analysis at home and abroad on the evolution of hot topics in the field of data mining based on the LDA Model. Inf. Sci. 2021, 39, 174–185. [Google Scholar]
- Yigzaw, K.Y.; Olabarriaga, S.D. (Eds.) Health data security and privacy: Challenges and solutions for the future. In Roadmap to Successful Digital Health Ecosystems: A Global Perspective; Academic Press: Cambridge, MA, USA, 2022; pp. 335–362. [Google Scholar]
- Djenna, A.; Bouridane, A.; Rubab, S.; Marou, I.M. Artificial Intelligence-Based Malware Detection, Analysis, and Mitigation. Symmetry 2023, 15, 677. [Google Scholar] [CrossRef]
- Iqbal, F.; Boutaba, R. Data Security in Cloud Computing: Challenges and Solutions. IEEE Commun. Mag. 2021, 59, 88–94. [Google Scholar]
- Pathak, R.; Soni, B.; Muppalaneni, N.B. Role of Blockchain in Health Care: A Comprehensive Study. In Proceedings of the 3rd International Conference on Recent Trends in Machine Learning, IoT, Smart Cities and Applications: ICMISC 2022; Springer Nature: Singapore, 2023; pp. 137–154. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topic Types | Description of Determination Criteria |
|---|---|
| Division | When , a topic at the previous stage can be divided into two or more topics at the current stage. |
| Merging | When , two or more topics at the previous can be merged into one topic at the current stage. |
| Inheritance | When , it means that a topic at the previous stage is relevant to a topic at the current period. |
| Disappearance | When , the topic at the previous stage does not exist at the current stage. |
| Generation | When , the topic at the current stage does not exist at the previous stage. |
| Stages | Time Division | Description of the Characteristics at Each Stage | Number of Literature |
|---|---|---|---|
| Budding Stage | 2007–2012 | Related literature began to be published, but the number of literature per year was sporadic without a specific pattern. | 405 |
| Growing Stage | 2013–2018 | The number of literature increased slowly year by year. | 1225 |
| Development Stage | 2019–2020 | The number of literature increased rapidly year by year. | 1295 |
| Accelerated Development Stage | 2021–2022 | The number of literature increased year by year, and the growth rate maintained at a high level. | 1859 |
| Stages | Topics |
|---|---|
| Stage 1 | 1_1 (services business confidentiality); 1_2 (patients trial safety); 1_3 (protocol data_security service cloud_computing); 1_4 (data_protection shows scalable); 1_5 (technology data_security_and_privacy employing); 1_6(cancer ethical digital); 1_7 (storage service environment); 1_8 (image algorithm mechanism); 1_9 (privacy purpose clinical_trials); 1_10 (concerns healthcare benefit) |
| Stage 2 | 2_1 (protocol radio channels); 2_2 (privacy data_sharing make); 2_3 (storage algorithm trusted); 2_4 (intervention migration interest); 2_5 (big_data line choice); 2_6 (routing route patients); 2_7 (trust management review); 2_8 (patients clinical hiv); 2_9 (detection shared algorithms); 2_10 (multi apps effective); 2_11 (image carried sensor); 2_12 (service mechanism cloud_computing) |
| Stage 3 | 3_1 (technique evidence secret); 3_2 (speed service community); 3_3 (design tools apps); 3_4 (mechanism anti challenge); 3_5 (privacy big_data technology); 3_6 (patients health healthcare); 3_7 (blockchain supply_chain blockchain_technology); 3_8 (smart_devices merging packets); 3_9 (database hierarchical threat); 3_10 (encryption cryptography algorithm); 3_11 (selected usage university); 3_12 (attribute access_control abe); 3_13 (safety adoption human); 3_14 (image encrypted sensitive); 3_15 (cloud_computing file cloud_storage) |
| Stage 4 | 4_1 (blockchain blockchain_technology sharing); 4_2 (distributed supply_chain blockchain); 4_3 (video suggestions home); 4_4 (privacy technology public); 4_5 (big_data algorithm encryption); 4_6 (image encryption images); 4_7 (covid factors china); 4_8 (attacks resources models); 4_9 (healthcare medical patient); 4_10 (energy bit built); 4_11 (market influence setting); 4_12 (patients healthcare health); 4_13 (clinical apps workers); 4_14 (points trading joint) |
| Global | T_1 (technologies factors china); T_2(attacks supply_chain dynamic); T_3 (local including privacy); T_4 (patients care treatment); T_5 (covid participants education); T_6 (learning transaction share); T_7 (algorithm encryption compared); T_8 (edge attack detection); T_9 (healthcare digital_economy throughput); T_10 (optimization power lightweight); T_11 (machine_learning energy training); T_12 (authentication flow authenticated); T_13 (sharing distributed reduce mechanism); T_14 (big_data management cloud_computing); T_15 (ciphertext attribute cloud_storage); T_16 (patient medical health); T_17 (face delay obtained); T_18 (cyber growth reporting); T_19 (apps acceptance multimodal); T_20 (blockchain technology blockchain_technology); T_21 (image secured images) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Cui, W.; Liu, X.; Jiang, L.; Li, J. Research on Topic Evolution Path Recognition Based on LDA2vec Symmetry Model. Symmetry 2023, 15, 820. https://doi.org/10.3390/sym15040820
Zhang T, Cui W, Liu X, Jiang L, Li J. Research on Topic Evolution Path Recognition Based on LDA2vec Symmetry Model. Symmetry. 2023; 15(4):820. https://doi.org/10.3390/sym15040820
Chicago/Turabian StyleZhang, Tao, Wenbo Cui, Xiaoli Liu, Lei Jiang, and Jinling Li. 2023. "Research on Topic Evolution Path Recognition Based on LDA2vec Symmetry Model" Symmetry 15, no. 4: 820. https://doi.org/10.3390/sym15040820