

Efficient Sender-Based Message Logging Tolerating Simultaneous Failures with Always No Rollback Property

Division of AI Computer Science and Engineering, Kyonggi University, Suwon 16227, Republic of Korea
Symmetry 2023, 15(4), 816; https://doi.org/10.3390/sym15040816
Submission received: 6 February 2023
/
Revised: 13 March 2023
/
Accepted: 27 March 2023
/
Published: 28 March 2023
(This article belongs to the Special Issue Symmetry in Distributed Algorithms and Parallel Algorithms and Their Applications)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Most of the existing sender-based message logging protocols cannot commonly handle simultaneous failures because, if both the sender and the receiver(s) of each message fail together, the receiver(s) cannot obtain the recovery information of the message. This unfortunate situation may happen due to their asymmetric logging behavior. This paper presents a novel sender-based message logging protocol for broadcast network based distributed systems to overcome the critical constraint of the previous ones with the following three features. First, when more than one process crashes at the same time, the protocol enables the system to ensure the always no rollback property by symmetrically replicating the recovery information at each process or group member connected on a network. Second, it can make the first feature persist even if the general form of communication for the system is a combination of point-to-point and group ones. Third, the communication overhead resulting from the replication can be highly lessened by making full use of the capability of the standard broadcast network in both communication modes. Experimental outcomes verify that, no matter which communication patterns are applied, it can reduce about 4.23∼9.96% of the total application execution time against the latest enabling the traditional ones to cope with simultaneous failures.
1. Introduction
A tightly coupled distributed system is well used in practice to provide a small or medium scale high-performance computing environment for missions’critical long-executing applications [1,2]. It is generally formed as a set of processes running on multiple hosts inter-connected on a broadcast network, called a cluster computing system. However, if at least one process or host crashes in the system, it may forget all the contents in its volatile storage, leading to making the system state inconsistent [3]. To counteract the negative effects of the misfortune, low overhead fault-tolerance techniques are essentially required for the system [4]. For this purpose, the rollback recovery technique is one of the appropriate tools and classified into two kinds, the checkpoint-based and message logging-based [5]. First, the checkpoint-based technique fulfills the fault-tolerance by letting each process periodically record its local state, called a checkpoint, on stable storage [6]. According to ensuring the system consistency, there are two types of checkpointing, as follows. Uncoordinated checkpointing does not require this sort of synchronization on checkpointing and, when process failures occur, finds a consistent global system state during recovery [7]. Due to this feature, a joint effort of every process made may become totally useless. Coordinated checkpointing forces all or related processes to have their local states consistent with each other’s state on checkpointing, incurring higher failure-free overhead [8]. However, this technique has the insufficiency that, even if failed processes roll back to their latest consistent global checkpoint, they may not replay the messages in the same receipt order such as in their pre-failure states. This feature forces live processes to stop their execution and invalidate a part of the execution performed after their latest checkpoints.
Secondly, to overcome this kind of limitation, the message logging-based technique has been developed toward two directions, optimistic and pessimistic message logging [9]. The optimistic message logging technique [10,11] has the same disadvantage as the checkpointing-only recovery because it makes each process save the recovery information of each message only on the volatile storage of the receiver [12]. Pessimistic message logging protocols [13,14,15,16,17,18,19] let each message logged in secure places be unaffected by failures of message receivers, having no surviving process come back to its previous state. Despite their higher than normal operation cost, they become a popular fault-tolerance technique for the system.
Among them, sender-based message logging (hereafter noted as SBML) [13,14,15,16,17,18] is well known as one of the most lightweight choices because it uses only volatile logging at message senders compared with receiver-based ones [19] requiring stable storage accesses mandatorily. However, the traditional SBML protocols [13,14,15,16,17,18] cannot commonly handle simultaneous failures because, if the senders of each message fail together, its receiver(s) cannot obtain the recovery information of the message, called the determinant. This unfortunate situation may cause the system inconsistency. In this paper, a novel SBML protocol is presented to solve this important problem with the following features. First, the proposed protocol makes no rollback of the live processes permitted during recovery even in the case of concurrent process failures, called the always no rollback property [5], by the symmetric distribution of redundant determinants of each message. Second, it can still preserve the first feature even in the network environment, enabling a composite of point-to-point and group communication. Third, it can make full use of the performance efficiency the standard broadcast network generally embeds for decreasing the communication overhead occurring in the replication of the recovery information.
2. Preliminaries
2.1. Distributed System Model
We assume an asynchronous distributed system with no global memory, consisting of a set of processors, processes and communication channels. Processes can communicate with each other by exchanging messages at finite but arbitrary transmission delays through unreliable channels, meaning messages may be dropped or duplicated on these channels. However, it is assumed that the channels are immune to partitioning. In addition, we assume that processes may fail based on the crash-failure model, in which they lose contents in their volatile memories and stop their executions [5]. This system is augmented with an unreliable failure detector [20] in order to solve the impossibility problem on distributed consensus. A process p starting at its initial state, s, generates a sequence of events, [e, e, …, e]. These events are classified into internal, sending, and delivery. Process p may produce an internal event to execute a particular computation without any communication. A sending event of a message m, denoted by sending(m), is generated by sending message m to another process, and a delivery event of m, delivery(m), by actually delivering the message after its receipt to its corresponding application. After applying the sequence of events [e, e, …, e] to s in order, p has a unique local state s(k > 0). Events of processes occurring in a failure-free execution are ordered using Lamport’s, and happened before the relationship [5].
2.2. Related Works
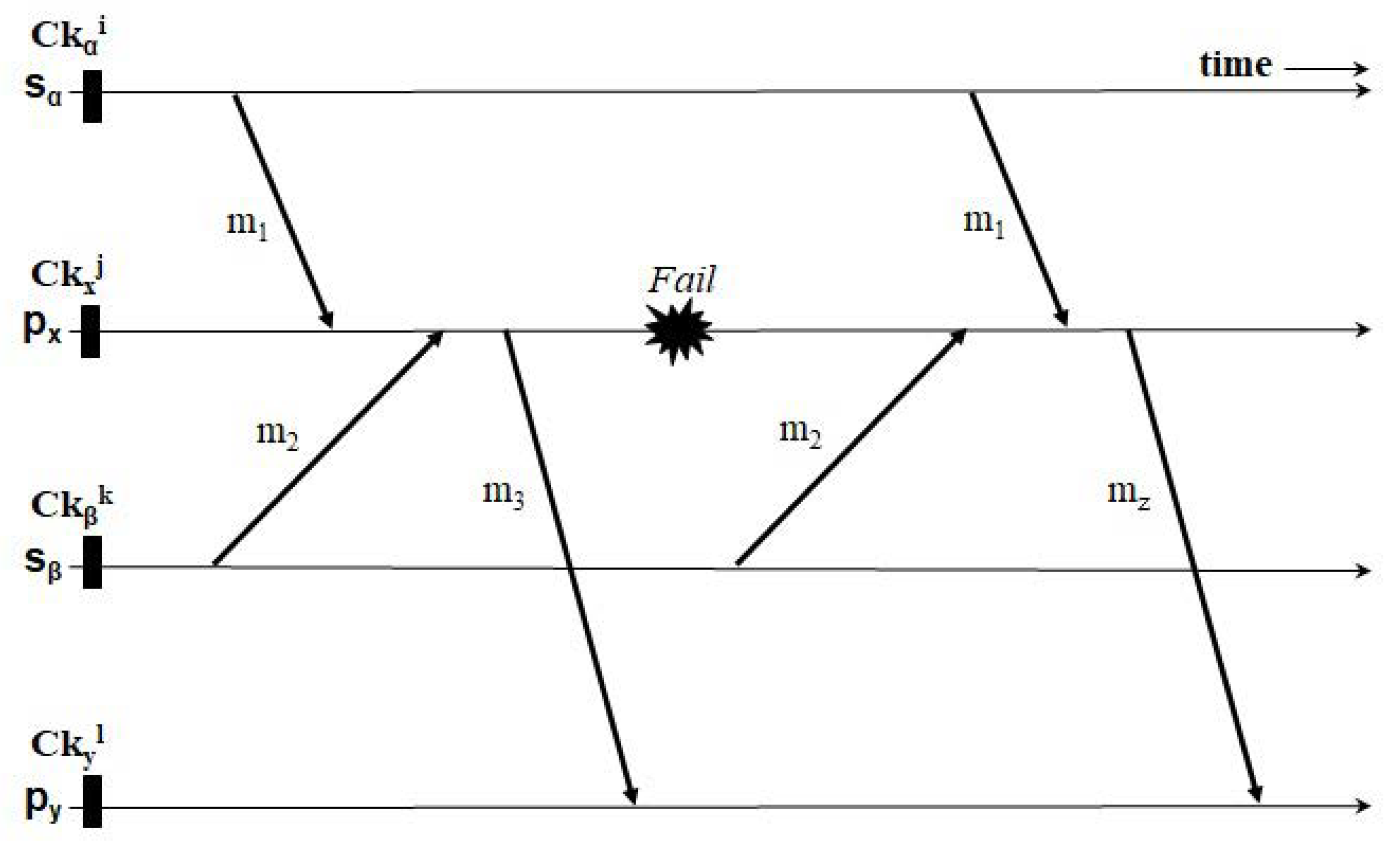
The coordinated or uncoordinated checkpoint-based recovery with optimistic message logging may force live processes to nullify a part of their execution due to process failures [12]. The primary reason is that, if they crash, processes lose the log information of received messages in their volatile memories. In this case, if the surviving processes have received any messages from those failed, depending on the lost ones, their states may be inconsistent with the states of the recovered even after completing its recovery procedure. Let us take a look at the shortcomings with an illustration. In Figure 1, process receives two messages and from two processes, and , in order, individually. Hereafter, it transmits a message to another process . If crashes later and tries to recover, like in this figure, it should come back to its latest checkpoint and replay the receipt of the two messages. However, as cannot obtain their receive sequence numbers(hereafter noted as s) from anywhere, may arrive at earlier than during recovery, unlike in the pre-failure state. If so, it creates a message to different from that generated before the failure. To make the system have a consistent state, this situation causes a live process to return to its most recent checkpoint before delivering and then receiving . The rollback recovery of may also force other live processes, although not demonstrated in this figure, to revert to their past states in the series. To minimize this kind of invalidation effect of normal operation execution, pessimistic message logging is an essential building block that enables each failed process to carry out its own recovery procedure consistently without any rollback of live ones, which is called the always no rollback property [5].
SBML is one of the pessimistic logging techniques holding this property on a sequential failure tolerance only: each message is logged in the volatile storage of its sender [13,14,15,16,17,18]. This asymmetric behavior allows each crashed process to attain the determinant and the contents of every message it received before the failure from the sender. After the process replayed the message at the same receipt position, its state always becomes consistent with the current one of an arbitrary live process. For example, in Figure 1, after performing SBML during normal operation, and currently possess the recovery information of and in their respective memories. When it crashes, can collect the determinants and message contents of the two messages from them and replay the delivery of the messages in the same order it was in before the failure, regenerating the identical message sent to . Then, the final recovered state of becomes consistent with the current one of .
However, the previous SBML protocols [13,14,15,16,17,18] commonly possess the critical constraint due to its asymmetric logging behavior: It can only tolerate consecutive failures, not simultaneous failures. In other words, each crashed process cannot replay messages received in the same order like before the failure if their senders fail together, because they lose the determinants of the messages in their volatile memories. This consequence may give rise to another type of system inconsistency. In particular, when a sender transmits a message m to a group of processes on the network, the protocols have no functionality to handle the issue of the existence of multiple s of m assigned by the group of processes. Moreover, it possess no capability of decreasing the communication cost incurred by the replication by utilizing the embedded efficiency of the broadcasting network.
3. The New SBML Protocol
3.1. Basic Concepts and Algorithms
A new SBML protocol is designed with the following advantageous features for a distributed system composed of a set of processes on a broadcast network.
- None of the live processes in the system are rolled back during recovery, even in the case of concurrent process failures.
- The protocol supports a fault-tolerance for distributed applications exchanging messages in a mix of point-to-point and group communication modes.
- With little communication cost, it can maintain the recovery information of each application message on redundant volatile storages in a symmetric manner.
To fulfill all the three requirements in the proposed protocol, each process should keep the following variables for saving a replicated recovery information of messages.
- : the sequence number of the most recent one among all the messages has transmitted since its initial execution state.
- : the sequence number of the most recent one among all the messages has delivered to applications since its initial execution state.
- : a set keeping the recovery information of each message transmitted. Its element e is composed of the identifier of the receiver (), send sequence number (), list of the receive sequence numbers (), and data () of the message. Here, the first field can be the identifer of a process or a process group. Moreover, the third field is a set whose component is a form of (, ) of the message received and assigned to . It may contain multiple s of each sent message if the message is transferred to a group of processes.
- : a set keeping the determinant of each message received. Its element e is composed of the identifier of the sender (), , , and of the message. Here, the second field and the fourth field have the same respective meanings as in .
- : a table for sensing duplication of application messages already delivered that their senders have regenerated in their recovery procedures. Its field contains the of the most recent one that has received from another process .
The protocol consists of five primary procedures for to make the determinant of each received message m, maintained not only at its sender’s and receiver’s volatile storages, and , but also at those of others on the network, (j≠i and j≠m’s sender). The first procedure, Send_M(), allows a sender to transmit each message and keep the recovery information for the message in its volatile log. The second, Receive_M(), has each process receiving the message send its to the group of the process as well as its sender, keep the determinant of the message in its volatile log and indicate the execution of all the send operations invoked after the message should be delayed. The third, Receive_Det(), enables the sender or the group member to insert the into the element for recovering the message and then notifies the receiver of the completion of the volatile logging task. The fourth, Receive_Ack(), checks whether the receiver obtains the notification from both the sender and every other group member. If so, it actually performs all the send operations delayed between the message and its immediate next message. The last, Take_Checkpoint(), forces each process to save its checkpointed state with its local variables on the stable storage and then performs all the send operations delayed before the checkpoint. With this symmetric feature, it can hold the always no orphan property, which the receiver-based pessimistic message logging using stable storage must mandatorily have for tolerating simultaneous crashes.
Let us examine how its logging procedure works according to communication types in detail. First, when a process receives an application message in the point-to-point communication mode, it allows the other processes to maintain the duplicate determinants of the message including the of the message on their volatile memories. Second, every process receiving a message destined to its group g should hold determinants recording all the distinct s assigned by the other group members as well as itself in its own storage in a cooperative manner. Moreover, the new protocol is developed to make better use of the performance efficiency that the standard broadcast network generally embeds in a wise manner, minimizing the communication overhead coming from the replication of the recovery information for overcoming multiple failures occurring at the same time. Figure 2 formally describes all the procedures in the proposed protocol that each process performs depending on the type of event action.
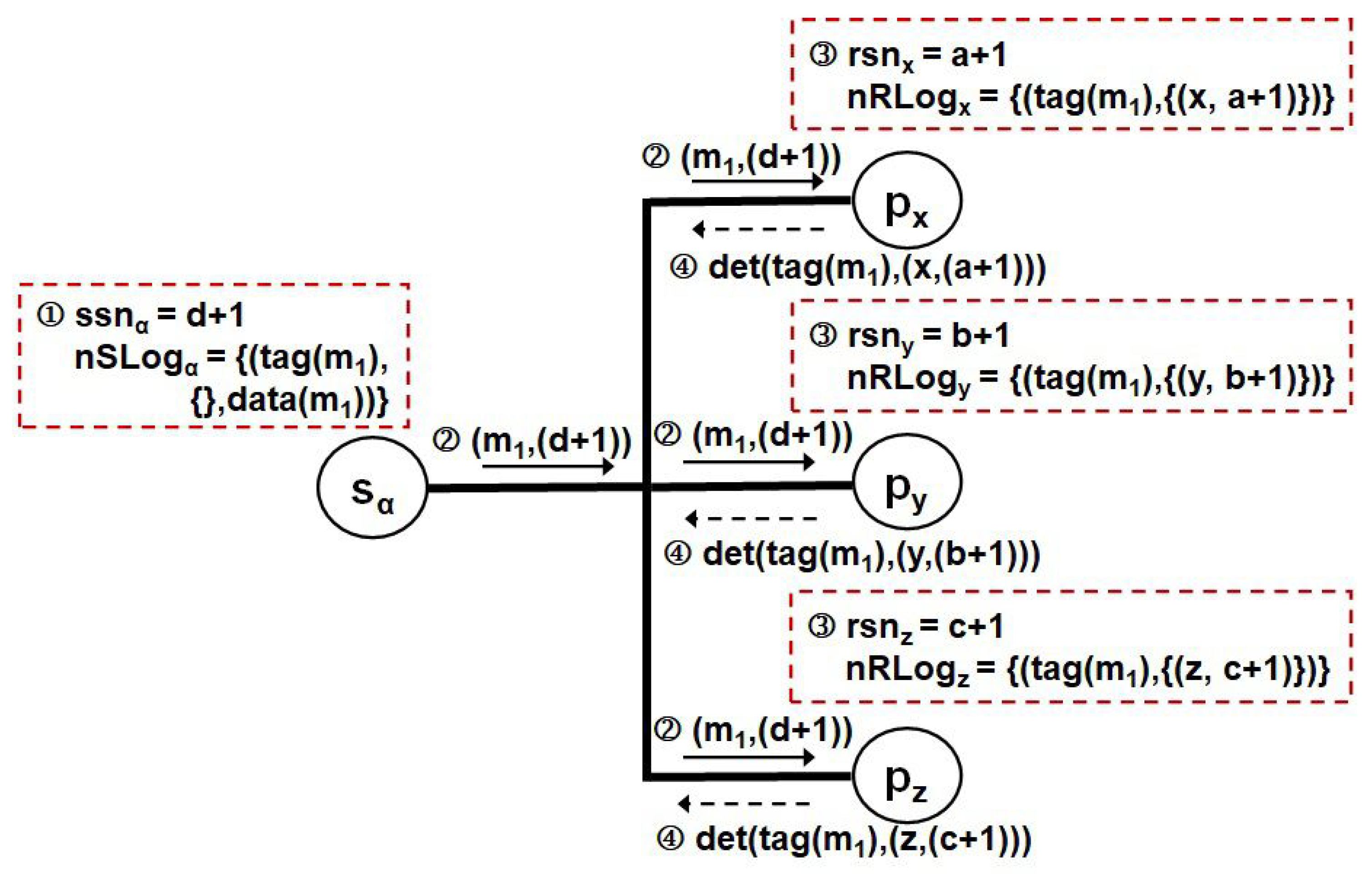
We show pictorial examples to help understand how the protocol can hold all the beneficial features stated above. In Figure 3, Figure 4, Figure 5 and Figure 6, it is assumed four processes , , , can communicate with each other through a broadcast network. In these examples, first sends an application message to a process group g composed of , and in Figure 3 and Figure 4, and then a point-to-point one to in Figure 5 and Figure 6. Suppose the initial values of , , and in Figure 3 are d, a, b and c. In this figure, increments by one and transmits with to the broadcast network (by invoking procedure Send_M() in Figure 2). After that, it creates an element for recording the recovery information of and saves both the () and data of on . Here, () consists of , , and of . At this time, as the s of are not decided by its receivers, the list type field recording some pairs of the identifier of the respective receiver and the of assigned by the receiver is initialized to an empty set. As is destined to group g, each member can sense its presence as group message and obtain it from the network. Hereafter, it increments its own by one and sends a control message containing a pair of its identifier and the into the network while creating and saving the determinant of , including the pair on its volatile memory (by invoking procedure Receive_M() in Figure 2). The control message is transferred not only to the sender of , but also to every other member.
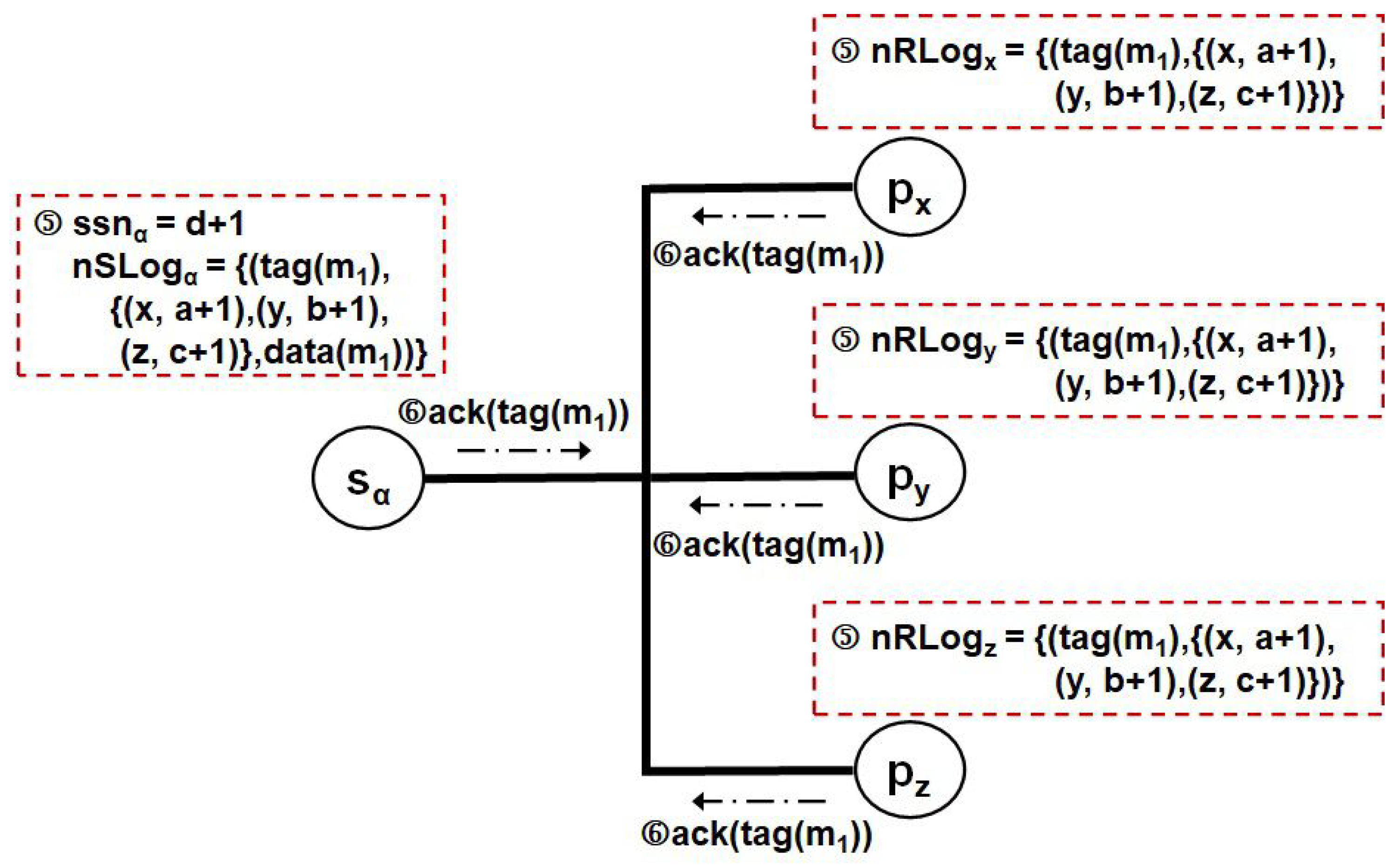
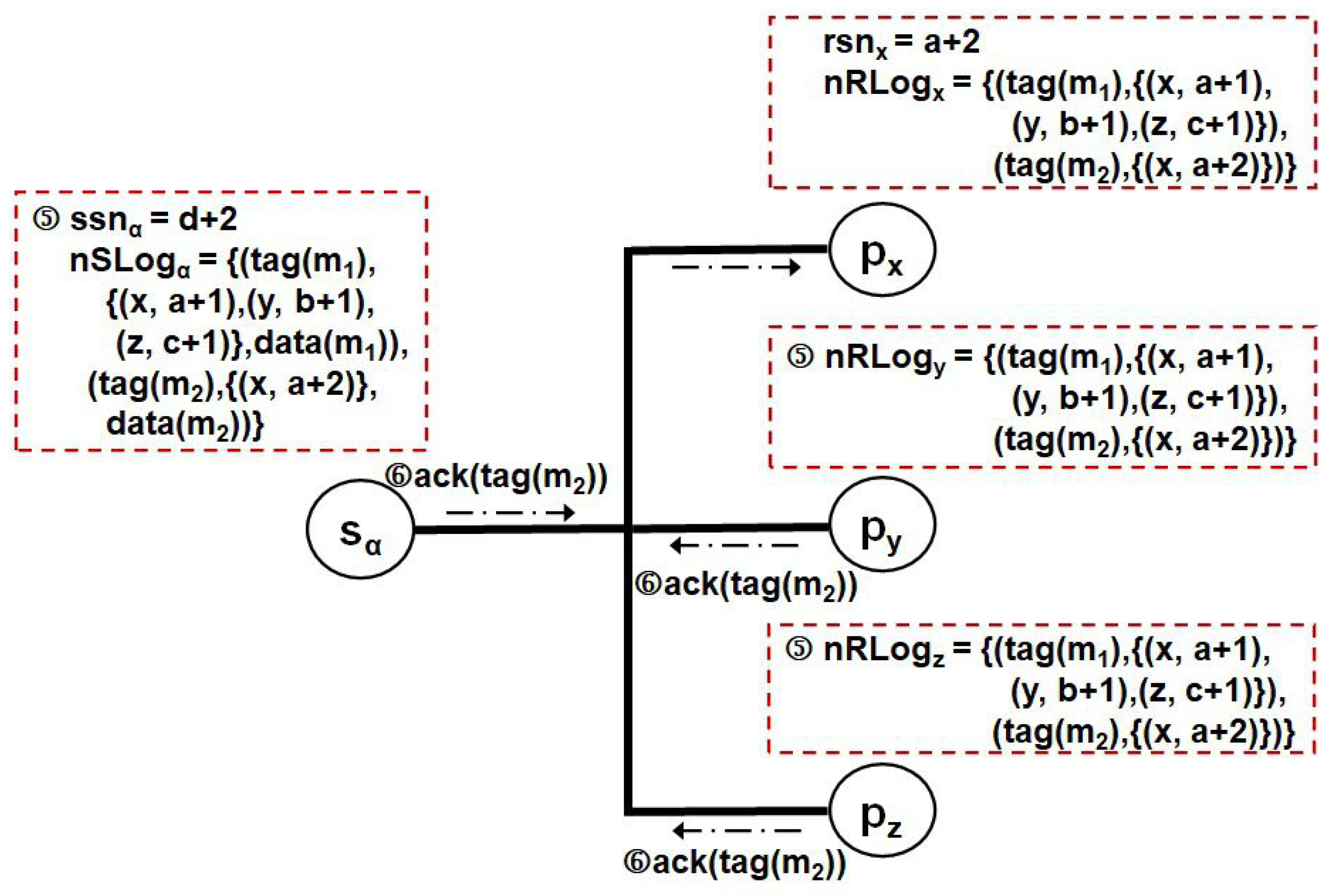
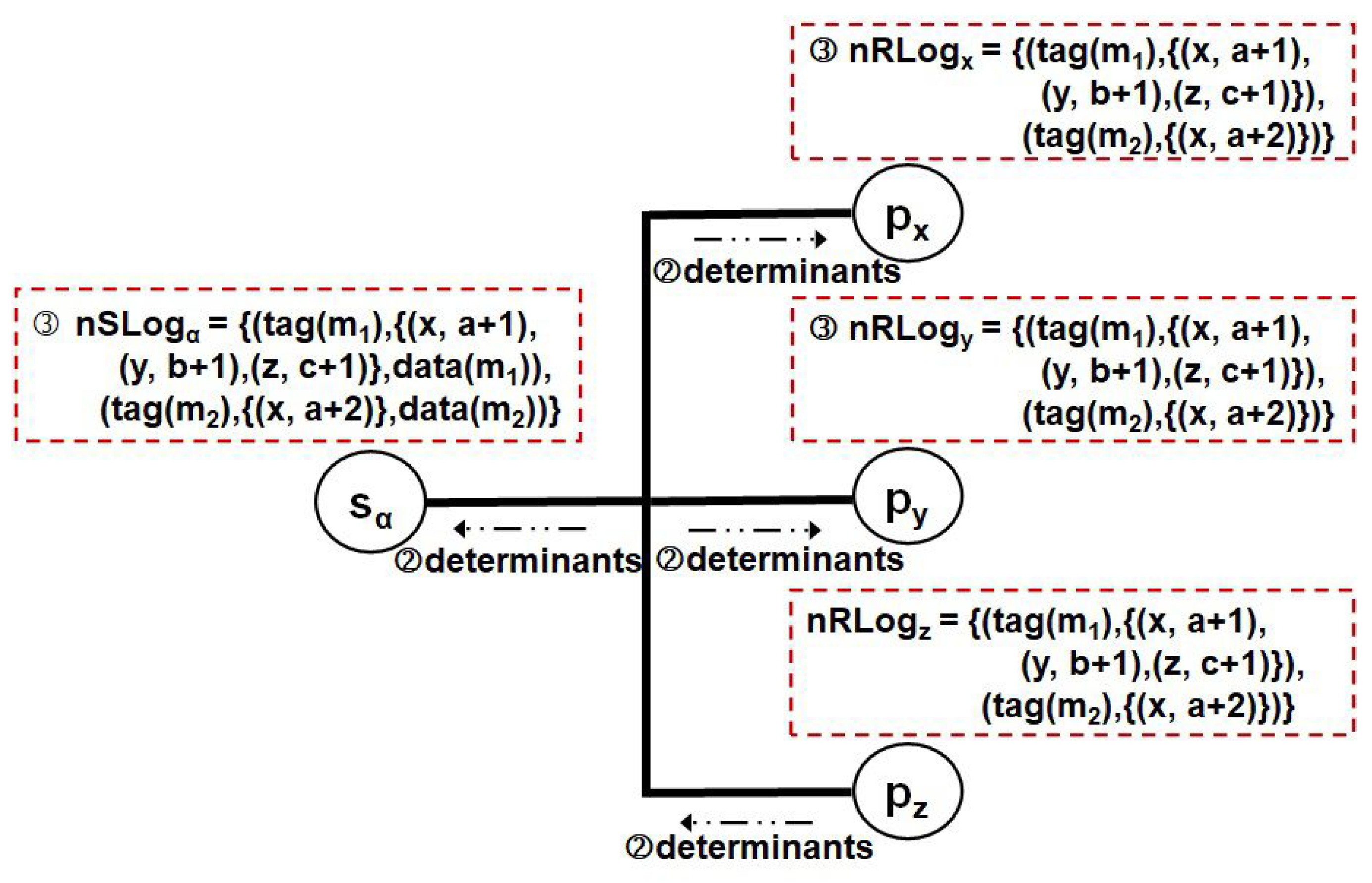
Then, in Figure 4, the sender extracts the pair from the control message and inserts it into the list field of the corresponding element in (by invoking procedure Receive_Det() in Figure 2). In this case, as the s of , , and may be different from each other, the three pairs should be kept on the list field. Similarly, when perceiving the group control messages from the others, each member maintains on its volatile log all other pairs including the s of assigned by the others (by invoking procedure Receive_Det() in Figure 2). Afterward, it transmits another control message (()) to group g. After receiving the second control message from both the sender and the other members, each member can recognize the procedure for replicating the of , which, assigned by itself, has been terminated (by invoking procedure Receive_Ack() in Figure 2).
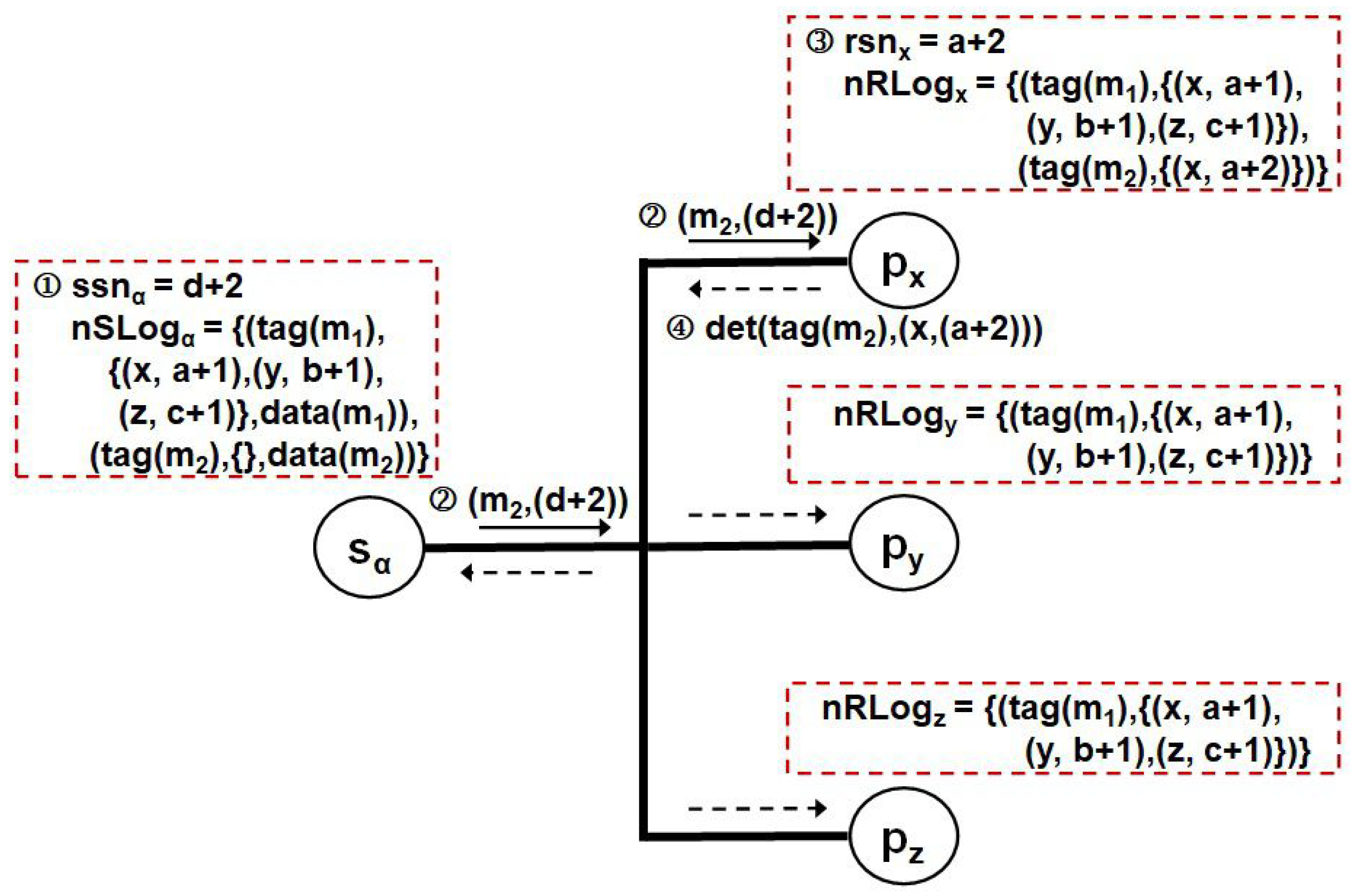
Figure 5 and Figure 6 show an example of sending a unicast message to . After increasing its , lets with the transmitted out to , and then puts ’s initial recovery information in its volatile storage in Figure 5 (by invoking procedure Send_M() in Figure 2). In this case, as the only target of is , broadcasts a control message with its incremented to the network (by invoking procedure Receive_M() in Figure 2). It also makes and keeps ’s determinant in . Detecting the control message from the network, , and pull out a pair of ’s identifier and the of from the message, and then update their respective volatile logs with the pair like in Figure 6 (by invoking procedure Receive_Det() in Figure 2). Next, they acknowledge their own volatile logging completion by conveying (()) to (by invoking procedure Receive_Ack() in Figure 2). Therefore, the protocol can reduce the number of the first control message down to one required to manage the recovery information redundancy for each application by making full use of the broadcasting capability in both communication modes.
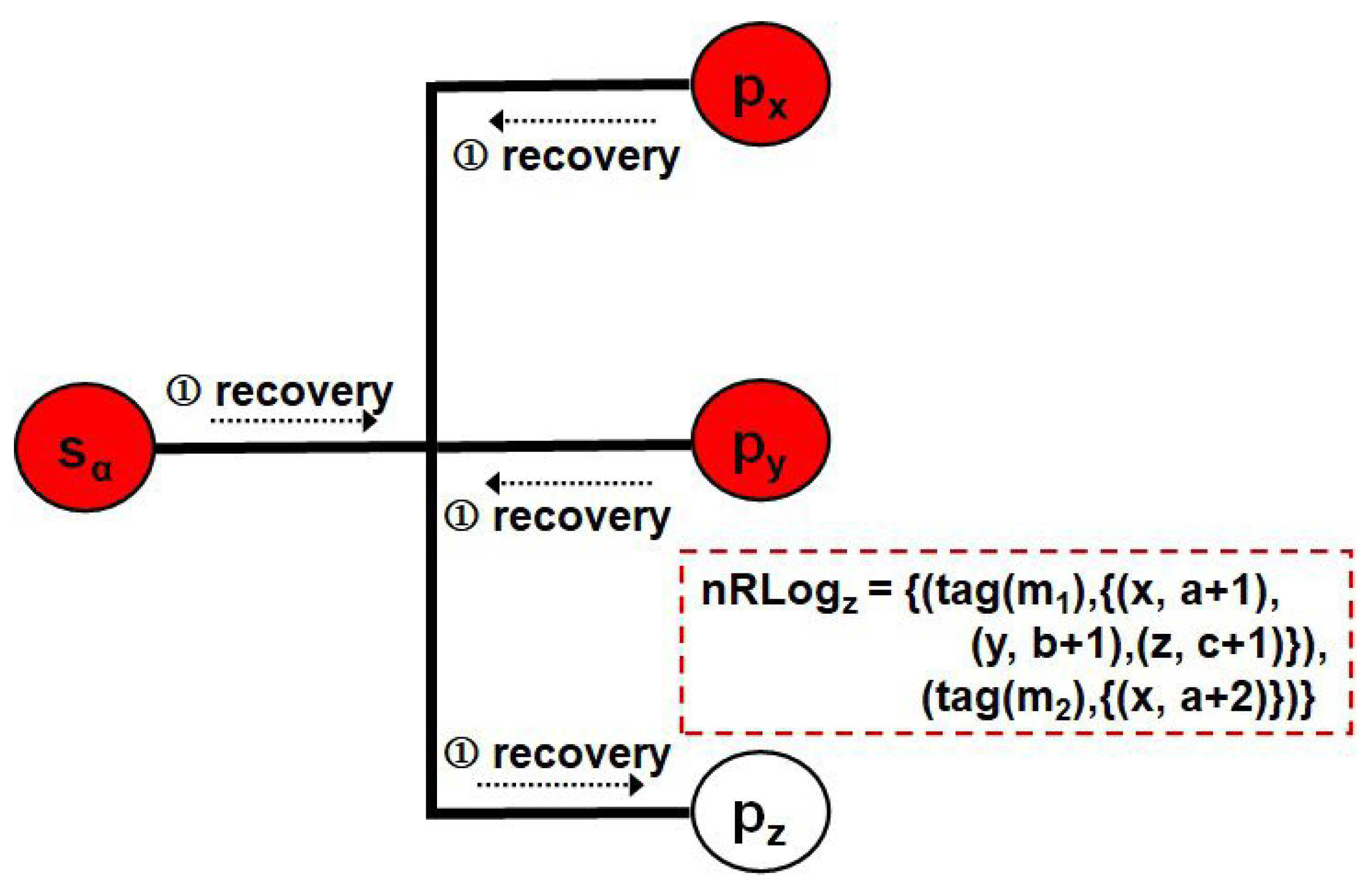
Let us verify whether the protocol with the symmetric behavior stated earlier can satisfy the first two requirements using a recovery scenario. Figure 7 illustrates the situation that all processes on the network except crash from the state of Figure 6. Each failed process rolls back to its latest checkpoint and disseminates a recovery message into the broadcast network. At that time, a live process possesses in the determinant(s) of every point-to-point or group message transmitted on the network during normal operation. Perceiving the recovery request from any crashed process, it provides them for the failed one using just one message transfer, such as in Figure 8. Hereafter, every recovering process can be restored into a pre-failure state consistent with the current state of .
3.2. Correctness
In this section, we prove that the proposed protocol guarantees a consistent recovery and satisfies the always no rollback property even in the case of simultaneous failures by Theorems 1 and 2, respectively. In particular, Theorem 2 means even though more than one process fails at the same time, they have only to roll back to their latest checkpointed states, while all other live processes can continue their own executions without requiring their rollbacks. The proof of the second theorem verifies that the number of live processes rolled back by process failures of our protocol is 0 at all times.
Theorem 1.
Even if the concurrent failures of processes on a broadcast network occur, our proposed protocol always enables the system to be recovered consistently.
Proof.
Let us denote the set of all processes on a broadcast network by N (3 ≤ |N|), the set of all concurrent crashed processes ∈N, by , and the set of all live processes ∈N, by . We prove the correctness of this theorem by induction on the number of all the concurrent crashed processes, || (2 ≤ || ≤ |N|).
[Base case]:
It is supposed || = 2, i.e., the two processes and , crash simultaneously. In this case, there exists at least one live process as || = |N| − ||. Before the failures, the protocol makes every process ∈ obtain from both and and maintain in or the determinants of all the point-to-point or group messages they received since their respective latest checkpoints by executing procedure Receive_Det() in Figure 2. Therefore, after each failed process ∈ has obtained them from and replayed their corresponding messages in the same order before the crashes, it can be restored to be a state consistent with ’s current state.
[Induction hypothesis]:
Suppose that the theorem is true in the case that || = k(2 ≤ k ≤ |N| − 1).
[Inductive step]:
By induction hypothesis, the recovered state of each process ∈ is consistent with the current states of all the processes ∈ despite the occurrence of k concurrent failures. With this assumption, let us verify whether the theorem is true in the case || = k + 1. Suppose a process ∈ joins at the same time interval. There are two cases we should consider.
Case 1: (k + 1) < |N|.
In this case, the subsequent steps are similar to the base case mentioned earlier.
Case 2: (k + 1) = |N|.
In this case, there exists no live process in the system, i.e., || = 0. It means the recovered state of the system always becomes consistent even though every failed process replays all the messages it delivered before the crashes in any receipt order.
By the induction, the protocol makes the system have a consistent state despite any number of simultaneous process crashes on a broadcast network. □
Theorem 2.
Our proposed protocol ensures the always no rollback property even if multiple processes crash at the same time.
Proof.
Let us prove this theorem by contradiction. It is assumed the protocol may not ensure the always no rollback property in case of simultaneous failures. This assumption means that there is at least one failed process p making live processes roll back for the system consistency. Suppose m is an arbitrary message p has received and completely logged since its latest checkpoint according to the protocol. Two cases should be considered.
Case 1: m is a group message.
Case 1.1: process q is the sender of m and does not crash.
As q maintains in m’s s all group members, including the p assigned for m before p’s failure; p can directly obtain them from q during recovery. Thanks to this procedure, p can always replay m in its pre-failure receipt order and then regenerate every point-to-point or group message which p sent to live process(es) between m and its immediate next message received before the failure. Therefore, p’s state becomes consistent with those of the live process(es).
Case 1.2: process q is the sender of m and crashes.
Two sub-cases should be considered.
Case 1.2.1: every process in the group fails.
There exists no live process affected by the recovered state of p regardless of m’s replaying order. Therefore, the system has no inconsistency problem.
Case 1.2.2: at least one live process r in the group exists.
The completion of logging m in the protocol has all live group members including r obtain the s they assigned for m together. Thanks to its behavior, r can provide p with the s in . Therefore, p can always replay m in its pre-failure receipt order and then regenerate every point-to-point or group message which p sent to live process(es) between m and its immediate next message received before the failure. Therefore, p’s state becomes consistent with r’s state.
Case 2: m is a point-to-point message.
All the subsequent steps are similar to case 1.
Therefore, the protocol makes no live process roll back even if multiple processes fail concurrently. This contradicts the hypothesis. □
4. Performance Evaluation
4.1. Simulation Environments
In this section, an extensive simulation has been conducted to measure the performance of the proposed protocol against the latest counterpart, called -R, with PARSEC simulation language [21]. As mentioned in Section 2.2, all the existing SBML protocols [13,14,15,16,17,18] have no functionality to overcome concurrent failures due to their asymmetric logging behavior. For this reason, they cannot be compared with in terms of failure-free overhead incurred by the creation, delivery and management of the redundant recovery information for this purpose. To verify how much performance benefit can provide, we developed an enhanced replication-enabling SBML protocol -R based on the common structure of all the previous SBML ones to cope with simultaneous failures for comparative study. In -R, whenever each process obtains a point-to-point or group communication type of application message m from another, the receiver transmits to every other process on a network an individual control message containing the determinant of m. Moreover, even if the process receiving the control message is not m’s sender, -R forces the process to keep the determinant of m in its volatile memory and convey an acknowledgement of the completion of logging m to the receiver of m.
A simulated distributed system is composed of n hosts exchanging point-to-point or group messages transferred on a broadcast network with 100 Mbps transmission capacity and 1 ms propagation delay. All processes in the system start and finish their corresponding executions together. Each process running on one host can send an application message whose size is scaled from 1 KB to 1 MB to an individual process or a group of processes, following an exponential distribution with a mean value of 3 sec. If one process performs one message send operation to a group, the network is capable of conveying the message to every group member using an IP multicast functionality [22]. The capacity of the volatile storage for the logging per process is 256 MB. The interval between consecutive checkpoints taken at a process conforms to an exponential distribution with a mean value of 5 min.
To verify our claim mentioned earlier, the two protocols make a comparison of efficiency with a key performance element () in terms of failure-free overhead resulting from their logging procedures for getting over concurrent failures. means the total time(marked in minutes) required to complete the execution of a distributed application. Moreover, to perform a rich analysis of logging overhead evaluation, four types of distributed applications, serial, circular, hierarchical and irregular, have been executed depending on the communication pattern [23]. This measurement method is a great help to identify a more accurate performance change arising from the susceptibility of communication patterns. We took an average of the experimental results of multiple runs.
4.2. Comparison Results
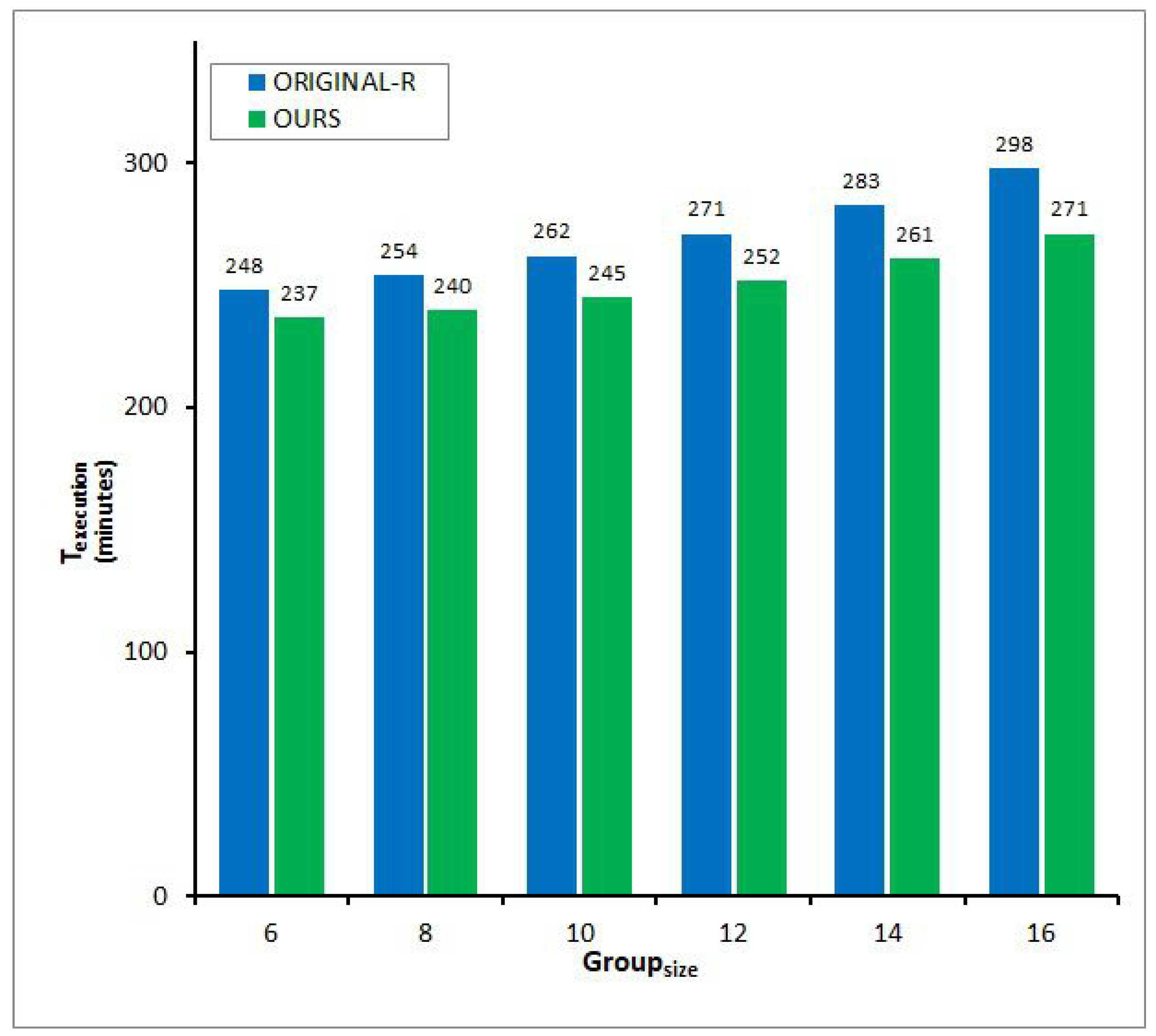
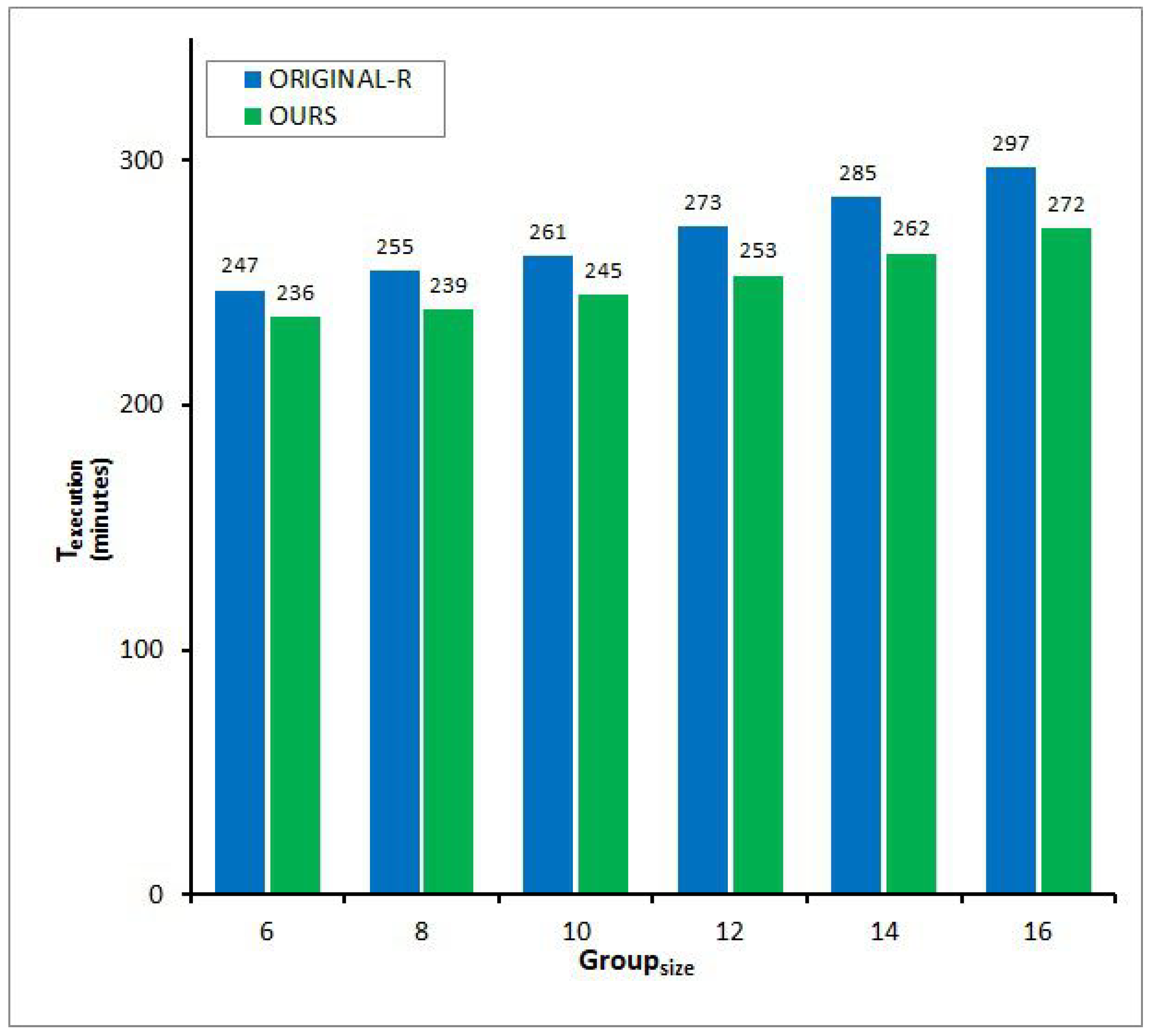
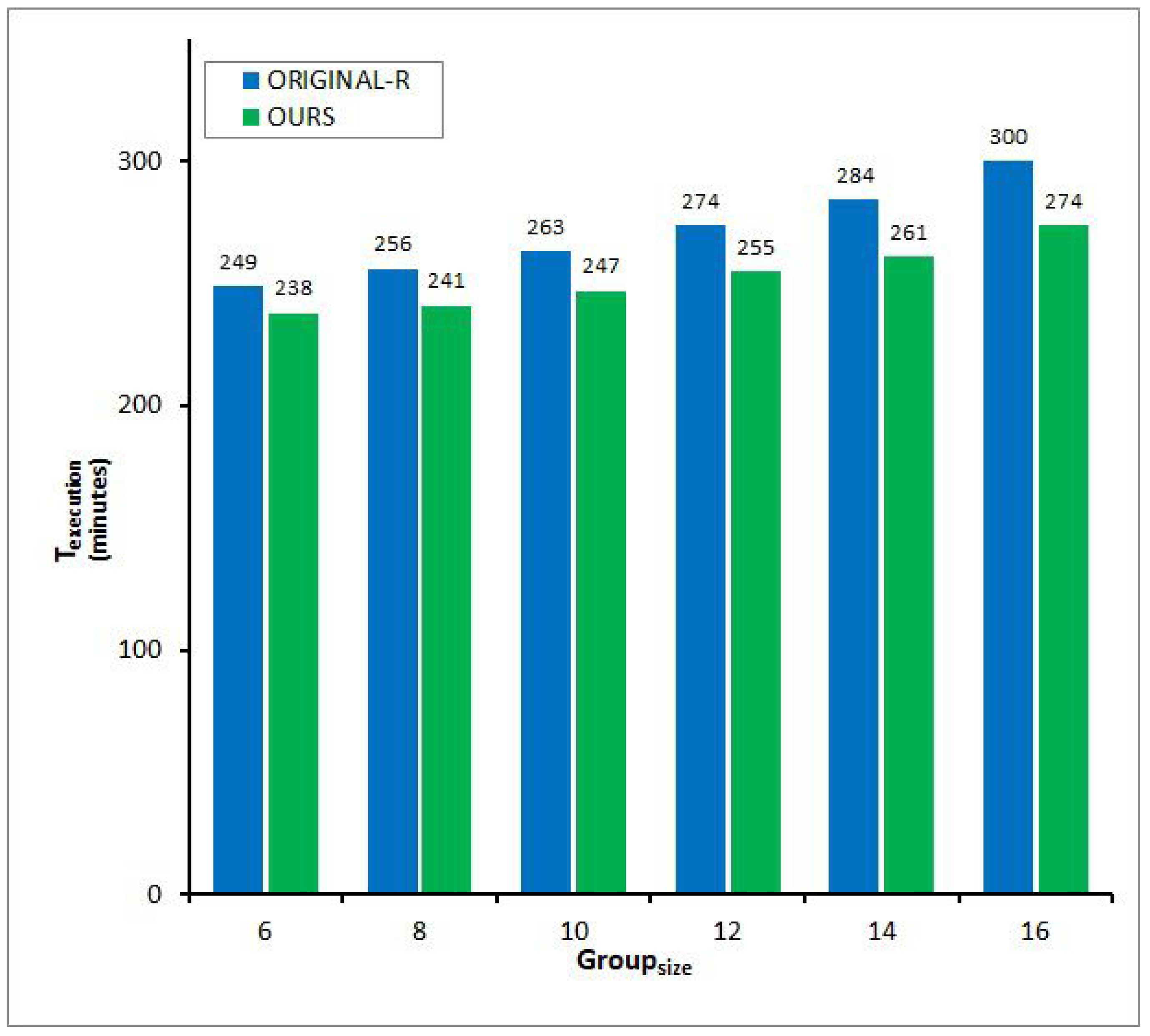
Figure 9, Figure 10, Figure 11 and Figure 12 illustrate of the two protocols by changing the size of the process group on a broadcast network, , ranging from 6 to 16 according to inter-process communication patterns. When increases, the values of for both proportionally become higher regardless of four communication patterns in Figure 9, Figure 10, Figure 11 and Figure 12. The results are determined because two protocols both generate quite a few additional control messages for carrying the determinant of each application message to every group member in order to prepare for simultaneous failures. However, these figures show that of -R is bigger than that of and the difference between the two arises quickly in proportion to the growth of , signifying that outperforms the counterpart, especially in large-scale broadcast networked systems. The phenomenon equally occurs in any communication pattern, such as in Figure 9, Figure 10, Figure 11 and Figure 12. The reduction rate of of over -R is scaled to 4.64∼9.96% in a serial pattern in Figure 9, 4.24∼9.52% in a circular pattern in Figure 10, 4.66∼9.19% in a hierarchical pattern in Figure 11, and 4.62∼9.49% in an irregular pattern in Figure 12. The primary cause is that, unlike -R, can transmit each control message to every other process or member with only one broadcast transfer of it for conveying the determinants or acknowledgements of the completion of volatile logging. This effectiveness may be enlarged in a group communication mode because the number of message receivers greatly increases.
With these results, we can recognize that when a distributed application is executed combining point-to-point and group messages, can achieve the goal of surviving k concurrent failures with much less communication overhead coming from the symmetric distribution of redundant determinants to each process or member compared with -R, by making better use of the cost-effective characteristic of broadcast networks irrespective of their delivery pattern.
5. Conclusions
Unlike the previous SBML protocols, the presented in this paper possesses the three desirable features, as follows. First, when more than one process crashes at the same time, allows a distributed system to make no rollback of the live processes permitted during recovery, even in the case of simultaneous failures by symmetrically replicating recovery information at each process or group member connected on a network. Second, can make the first feature persist even if the general form of communication for the system is a combination of point-to-point and group ones. Third, the communication overhead resulting from the replication can be highly lessened by making full use of the capability of the standard broadcast network in both communication modes. Through Theorem 2 in Section 3.2, we verified that prevents any surviving process from rolling back even in the case of concurrent failures, i.e., ensuring the always no rollback property. Moreover, from the experimental outcomes, we recognized that, no matter which communication patterns are applied, can reduce about 4.23∼9.96% of the total application execution time against the latest, enabling the traditional ones to cope with simultaneous failures. In particular, this enhancement may be magnified in the group communication mode that may significantly grow the number of receivers of messages generated.
For future works, we attempt to access the practicality of our protocol by applying it into Open MPI library based high performance systems employing a large number of computing nodes with no message logging capabilities [24]. In particular, the protocol will be implemented with a representative failure detection mechanism combining a periodic liveness check with sporadic check.
Funding
This research was funded by Kyonggi University, grant number 2020-032.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author, J.A., upon reasonable request.
Conflicts of Interest
The author declares no conflict of interest.
References
- Wang, X.; Li, H.; Sun, Q.; Guo, C.; Zhao, H.; Wu, X.; Wang, A. The g-Good-Neighbor Conditional Diagnosability of Exchanged Crossed Cube under the MM* Model. Symmetry 2022, 14, 2376. [Google Scholar] [CrossRef]
- Wang, S.; Yao, Y.; Zhu, F.; Tang, W.; Xiao, Y. A Probabilistic Prediction Approach for Memory Resource of Complex System Simulation in Cloud Computing Environment. Symmetry 2020, 12, 1826. [Google Scholar] [CrossRef]
- Mansouri, H.; Pathan, A. Checkpointing distributed computing systems: An optimisation approach. Int. J. High Perform. Comput. Appl. 2019, 15, 202–209. [Google Scholar] [CrossRef]
- Chlebus, B.S.; Kowalski, D.R.; Olkowski, J. Brief announcement: Deterministic consensus and checkpointing with crashes: Time and communication efficiency. In Proceedings of the 2022 ACM Symposium on Principles of Distributed Computing, Salerno, Italy, 25–29 July 2022; pp. 106–108. [Google Scholar]
- Elnozahy, E.; Alvisi, L.; Wang, Y.; Johnson, D. A survey of rollback-recovery protocols in message-passing systems. ACM Comput. Surv. 2002, 34, 375–408. [Google Scholar] [CrossRef] [Green Version]
- Lion, R.; Thibault, S. From tasks graphs to asynchronous distributed checkpointing with local restart. In Proceedings of the IEEE/ACM 10th Workshop on Fault Tolerance for HPC at eXtreme Scale, Atlanta, GA, USA, 11 November 2020; pp. 31–40. [Google Scholar]
- Jayasekara, S.; Karunasekera, S.; Harwood, A. Optimizing checkpoint-based fault-tolerance in distributed stream processing systems: Theory to practice. Softw. Pract. Exp. 2022, 52, 296–315. [Google Scholar] [CrossRef]
- Abdelhafidi, Z.; Djoudi, M.; Lagraa, N.; Yagoubi, M.B. FNB: Fast non-blocking coordinated checkpointing protocol for distributed systems. Theory Comput. Syst. 2015, 57, 397–425. [Google Scholar] [CrossRef]
- Meyer, H.; Rexachs, D.; Luque, E. Hybrid message pessimistic logging. improving current pessimistic message logging protocols. J. Parallel Distrib. Comput. 2017, 104, 206–222. [Google Scholar] [CrossRef] [Green Version]
- Ropars, T.; Morin, C. Active optimistic and distributed message logging for message-passing applications. Concurr. Comput. Pract. Exp. 2011, 23, 2167–2178. [Google Scholar] [CrossRef]
- Ropars, T.; Morin, C. Improving message logging protocols scalability through distributed event logging. In Proceedings of the 16th International Euro-Par Conference, Ischia, Italy, 31 August–3 September 2010; pp. 511–522. [Google Scholar]
- Bouteiller, A.; Ropars, T.; Bosilca, G.; Morin, C.; Dongarra, J. Reasons for a pessimistic or optimistic message logging protocol in MPI uncoordinated failure, recovery. In Proceedings of the 2009 IEEE International Conference on Cluster Computing and Workshops, New Orleans, LA, USA, 31 August–4 September 2009; pp. 1–9. [Google Scholar]
- Ahn, J. Enhanced sender-based message logging for reducing forced checkpointing overhead in distributed systems. IEICE Trans. Inf. Syst. 2021, E104-D, 1500–1505. [Google Scholar] [CrossRef]
- Ahn, J. Scalable sender-based message logging protocol with little communication overhead for distributed systems. Parallel Process. Lett. 2019, 29, 1–10. [Google Scholar] [CrossRef]
- Johnson, D.; Zwaenpoel, W. Sender-based message logging. In Proceedings of the 7th International Symposium on Fault-Tolerant Computing, Pittsburgh, PA, USA, 6–8 July 1987; pp. 14–19. [Google Scholar]
- Gupta, B.; Nikolaev, R.; Chirra, R. A recovery scheme for cluster federations using sender-based message logging. J. Comput. Inf. Technol. 2011, 19, 127–139. [Google Scholar] [CrossRef] [Green Version]
- Jaggi, P.; Singh, A. Log based recovery with low overhead for large mobile computing systems. J. Inf. Sci. Eng. 2013, 29, 969–984. [Google Scholar]
- Luo, Y.; Manivannan, D. HOPE: A hybrid optimistic checkpointing and selective pessimistic mEssage logging protocol for large scale distributed systems. Future Gener. Comput. Syst. 2012, 28, 1217–1235. [Google Scholar] [CrossRef]
- Kumari, P.; Kaur, P. Checkpointing algorithms for fault-tolerant execution of large-scale distributed applications in cloud. Wirel. Pers. Commun. 2021, 117, 1853–1877. [Google Scholar] [CrossRef]
- Chandra, T.D.; Toueg, S. Unreliable failure detectors for reliable distributed systems. J. ACM 1996, 43, 225–267. [Google Scholar] [CrossRef]
- Bagrodia, R.; Meyer, R.; Takai, M.; Chen, Y.; Zeng, X.; Martin, J.; Song, H.Y. Parsec: A parallel simulation environments for complex systems. Comput. J. 1998, 31, 77–85. [Google Scholar] [CrossRef] [Green Version]
- Xiaohua, L.; Kai, C. The research and application of IP multicast in enterprise network. In Proceedings of the International Conference on Internet Computing and Information Services, Hong Kong, China, 17–18 September 2011; pp. 191–194. [Google Scholar]
- Andrews, G.R. Paradigms for process interaction in distributed programs. ACM Comput. Surv. 1991, 23, 49–90. [Google Scholar] [CrossRef]
- Losada, N.; Bosilca, G.; Bouteiller, A.; González, P.; Martín, M. Local rollback for resilient mpi applications with application-level checkpointing and message logging. Future Gener. Comput. Syst. 2019, 91, 450–464. [Google Scholar] [CrossRef]
Figure 1.
Example of replaying messages when fails.

Figure 2.
Procedures of each process for the proposed protocol.

Figure 3.
Example of transmitting a group message to , and in the proposed SBML.

Figure 4.
Example of replicating the three distinct determinants of on all the volatile storages of , , , and together in the proposed SBML.
Figure 4.
Example of replicating the three distinct determinants of on all the volatile storages of , , , and together in the proposed SBML.

Figure 5.
Example of transmitting a point-to-point message to in the proposed SBML.

Figure 6.
Example of replicating the determinant of on all the volatile storages of , , and in the proposed SBML.
Figure 6.
Example of replicating the determinant of on all the volatile storages of , , and in the proposed SBML.

Figure 7.
Example of the three failed processes requesting their recovery information by broadcasting to the network in the proposed SBML.
Figure 7.
Example of the three failed processes requesting their recovery information by broadcasting to the network in the proposed SBML.

Figure 8.
Example of enabling to provide the failed processes with all the determinants for restoring their respective pre-failure states in the proposed SBML.
Figure 8.
Example of enabling to provide the failed processes with all the determinants for restoring their respective pre-failure states in the proposed SBML.

Figure 9.
in case of serial pattern.

Figure 10.
in case of circular pattern.

Figure 11.
in case of hierarchical pattern.

Figure 12.
in case of irregular pattern.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ahn, J. Efficient Sender-Based Message Logging Tolerating Simultaneous Failures with Always No Rollback Property. Symmetry 2023, 15, 816. https://doi.org/10.3390/sym15040816
AMA Style
Ahn J. Efficient Sender-Based Message Logging Tolerating Simultaneous Failures with Always No Rollback Property. Symmetry. 2023; 15(4):816. https://doi.org/10.3390/sym15040816
Chicago/Turabian StyleAhn, Jinho. 2023. "Efficient Sender-Based Message Logging Tolerating Simultaneous Failures with Always No Rollback Property" Symmetry 15, no. 4: 816. https://doi.org/10.3390/sym15040816
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.