
A Data-Driven Machine Learning Algorithm for Predicting the Outcomes of NBA Games

Abstract
:1. Introduction
1.1. Outline of the Paper
1.2. Review of the Related Works
2. Player’s and Team’s Efficiencies and the Game Outcomes
2.1. NBA Player Efficiency Index
2.2. Notation of the Games, Teams, and Players
2.3. Team Efficiency Indices—Absolute and Relative
2.4. Relative Score and the Game Real and Estimated Win Functions
2.5. Predicted Team Efficiency Index, Absolute and Relative
2.6. Predicted Game Outcome
3. Data Collection and Preparation
3.1. Data Collection
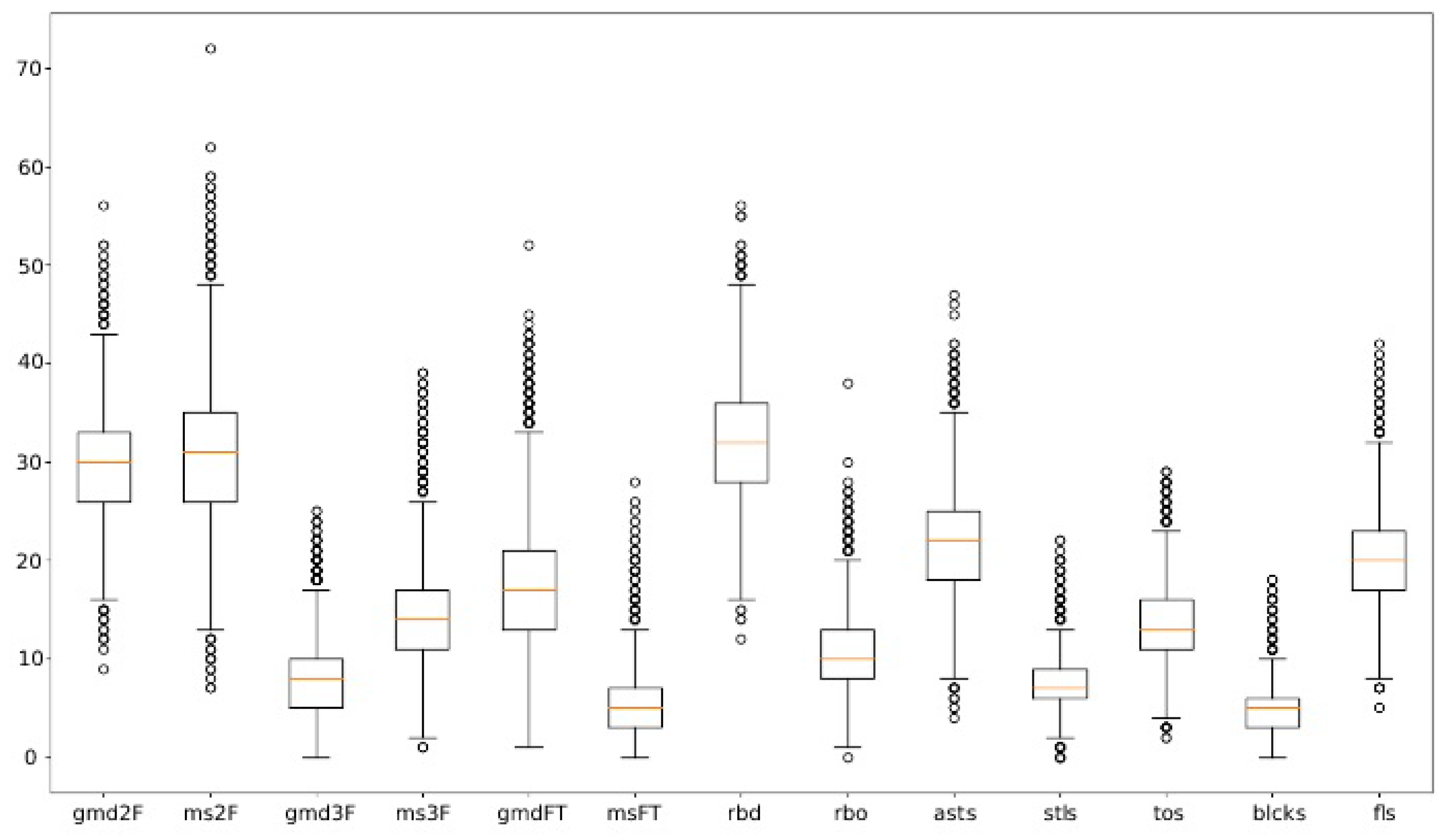
3.2. Data Preparation and Feature Extraction
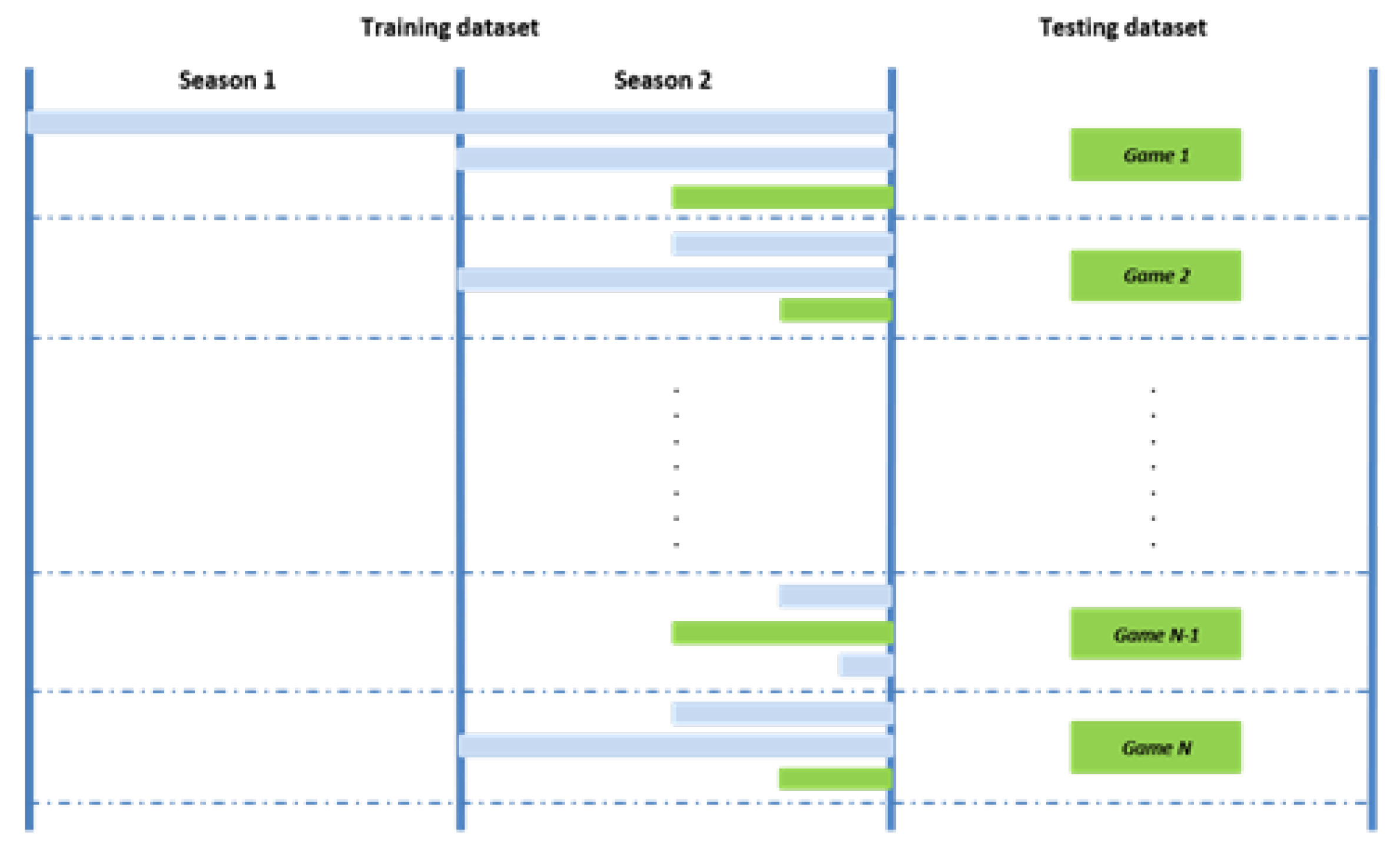
3.3. Optimal Time Window
4. Prediction Model
4.1. Predictions by the Standard Supervised Learning Algorithms
4.2. The Proposed Prediction Model
5. Results
5.1. Estimating the Relevance of the NBA Team Efficiency Index
5.2. Results of the Game Outcome Predictions
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Prasetio, D.; Harlili, D. Predicting football match results with logistic regression. In Proceedings of the 2016 International Conference On Advanced Informatics: Concepts, Theory And Application (ICAICTA), Penang, Malaysia, 16–19 August 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Delen, D.; Cogdell, D.; Kasap, N. A comparative analysis of data mining methods in predicting NCAA bowl outcomes. Int. J. Forecast. 2012, 28, 543. [Google Scholar]
- Valero, C.S. Predicting Win-Loss outcomes in MLB regular season games – A comparative study using data mining methods. Int. J. Comput. Sci. Sport 2016, 15, 91–112. [Google Scholar] [CrossRef]
- Elfrink, T. Predicting the Outcomes of MLB Games with a Machine Learning Approach; Vrije Universiteit Amsterdam: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Horvat, T.; Job, J. The use of machine learning in sport outcome prediction: A review. WIREs Data Min. Knowl. Discov. 2020, 10, e1380. Available online: https://onlinelibrary.wiley.com/doi/pdf/10.1002/widm.1380 (accessed on 19 January 2023). [CrossRef]
- Loeffelholz, B.; Bednar, E.; Bauer, K.W. Predicting NBA games using neural networks. J. Quant. Anal. Sport. 2009, 5. [Google Scholar] [CrossRef]
- Miljković, D.; Gajić, L.; Kovačević, A.; Konjović, Z. The use of data mining for basketball matches outcomes prediction. In Proceedings of the IEEE 8th International Symposium on Intelligent Systems and Informatics, Subotica, Serbia, 10–11 September 2010; pp. 309–312. [Google Scholar] [CrossRef]
- Zdravevski, E.; Kulakov, A. System for Prediction of the Winner in a Sports Game. In Proceedings of the International Conference on ICT Innovations; Springer: Berlin/Heidelberg, Germany, 2009; pp. 55–63. [Google Scholar]
- Weka 3: Machine Learning Software in Java. Available online: https://www.cs.waikato.ac.nz/ml/weka/ (accessed on 3 March 2022).
- Kravanja, A. Napovedanje Zmagovalcev Košarkaških Tekem. Doctoral dissertation, Univerza v Ljubljani, Ljubljanatel, Slovenia, 2013. [Google Scholar]
- Torres, R.A. Prediction of NBA Games Based on Machine Learning Methods; University of Wisconsin: Madison, WI, USA, 2013. [Google Scholar]
- Lin, J.; Short, L.; Sundaresan, V. Predicting national basketball association winners. CS 229 FINAL PROJECT 2014, 1–5. [Google Scholar]
- Tran, T. Predicting NBA Games with Matrix Factorization. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2016. [Google Scholar]
- Cheng, G.; Zhang, Z.; Kyebambe, M.N.; Kimbugwe, N. Predicting the outcome of NBA playoffs based on the maximum entropy principle. Entropy 2016, 18, 450. [Google Scholar] [CrossRef]
- Avalon, G.; Balci, B.; Guzman, J. Various Machine Learning Approaches to Predicting NBA Score Margins, 2016. Final Project. 2016. [Google Scholar]
- Pai, P.F.; ChangLiao, L.H.; Lin, K.P. Analyzing basketball games by a support vector machines with decision tree model. Neural Comput. Appl. 2017, 28, 4159–4167. [Google Scholar] [CrossRef]
- Lam, M.W. One-match-ahead forecasting in two-team sports with stacked Bayesian regressions. J. Artif. Intell. Soft Comput. Res. 2018, 8, 159–171. [Google Scholar] [CrossRef]
- Ganguly, S.; Frank, N. The problem with win probability. In Proceedings of the 2018 MIT Sloan Sports Analytics Conference, Boston, MA, USA, 23–24 February 2018. [Google Scholar]
- Ivanković, Z.; Racković, M.; Markoski, B.; Radosav, D.; Ivković, M. Analysis of basketball games using neural networks. In Proceedings of the 2010 11th International Symposium on Computational Intelligence and Informatics (CINTI), IEEE, Budapest, Hungary, 18–20 November 2010; pp. 251–256. [Google Scholar]
- Trawiński, K. A fuzzy classification system for prediction of the results of the basketball games. In Proceedings of the International Conference on Fuzzy Systems, IEEE, Yantai, China, 10–12 August 2010; pp. 1–7. [Google Scholar]
- Zimmermann, A.; Moorthy, S.; Shi, Z. Predicting college basketball match outcomes using machine learning techniques: Some results and lessons learned. arXiv 2013, arXiv:1310.3607. [Google Scholar]
- Horvat, T.; Job, J.; Medved, V. Prediction of Euroleague games based on supervised classification algorithm k-nearest neighbours. In Proceedings of the 6th International Congress on Support Sciences Research and Technology Support, Setubal, Portugal, 20–21 September 2018; Volume 20, p. 21. [Google Scholar]
- Manley, M. Martin Manley’s Basketball Heaven; Doubleday Books: New York, NY, USA, 1989. [Google Scholar]
- Grossberg, S. Nonlinear neural networks: Principles, mechanisms, and architectures. Neural Netw. 1988, 1, 17–61. [Google Scholar] [CrossRef]
- Yu, L.; Liu, H. Efficient Feature Selection via Analysis of Relevance and Redundancy. J. Mach. Learn. Res. 2004, 5, 1205–1224. [Google Scholar]
- Han, J.; Kamber, M. Data Mining: Concepts and Techniques, 2nd ed.; The Morgan Kaufmann Series in Data Management Systems; Elsevier: Amsterdam, The Netherlands; Morgan Kaufmann: Burlington, MA, USA; Boston: San Francisco, CA, USA: San Francisco, CA, USA, 2006. [Google Scholar]
- Basketball Stats and History Statistics, Scores, and History for the NBA, ABA, WNBA, and Top European Competition. Available online: https://www.basketball-reference.com (accessed on 3 March 2022).
- Horvat, T.; Havas, L.; Medved, V. Web Application for Support in Basketball Game Analysis. In Proceedings of the icSPORTS, Lisbon, Portugal, 15–17 November 2015; pp. 225–231. [Google Scholar]
- Horvat, T.; Havas, L.; Srpak, D.; Medved, V. Data-driven Basketball Web Application for Support in Making Decisions. In Proceedings of the icSPORTS, Vienna, Austria, 20–21 September 2019; pp. 239–244. [Google Scholar]
- Horvat, T.; Job, J. Importance of the training dataset length in basketball game outcome prediction by using naïve classification machine learning methods. Elektrotehniški Vestn. 2019, 86, 197–202. [Google Scholar]
- Horvat, T.; Havaš, L.; Srpak, D. The impact of selecting a validation method in machine learning on predicting basketball game outcomes. Symmetry 2020, 12, 431. [Google Scholar] [CrossRef]
- Zhang, G.P. Neural networks for classification: A survey. IEEE Trans. Syst. Man Cybern. Part C 2000, 30, 451–462. [Google Scholar] [CrossRef]
- Dean Oliver. Available online: https://en.wikipedia.org/wiki/Dean_Oliver_(statistician) (accessed on 3 March 2022).
- Horvat, T. An Adaptive Method for Predicting Sport Outcomes Based on the Efficiency Index and Optimal Time Window. Ph.D. Thesis, Faculty of Electrical Engineering, Computer Science and Information Technology, University of Osijek, Osijek, Croatia, 2020. [Google Scholar]



{kind=link}
{kind=link}
| Element (Type) | Abbreviation | Description |
|---|---|---|
| Basic (+) | gmd2F(3F)(FT) | Goals made 2-field (3-field) (free throws) |
| asts | Assists | |
| blcks | Blocks | |
| rbd, rbo | Rebounds defensive, offensive | |
| stls | Steals | |
| Basic (0) | gat2F(3F)(FT) | Goals attempted 2-fld. (3-fld.) (free throws) |
| Basic (−) | fls | Personal fouls |
| tos | Turnovers |
| Element (Type) | Abbreviation | Description |
|---|---|---|
| Derived (+) | pts | Total points scored |
| gmdFld | Goals made from (both 2- and 3-) field. | |
| rbs | Rebounds total | |
| Derived (0) | gatFld | Goals attempted from (2- and 3-) field. |
| Derived (−) | ms2(3)F | Goals missed from 2(3)-field |
| msFld(FT) | Goals missed from 2- and 3-field (free throws) |
| Game el. / Feature Abbrev. | Description | Calculation Formula |
|---|---|---|
| gScsFld, gScsFT | Field goal, and free throw success ratio | |
| gEffFld | Effective field goals (usually in %) | |
| ScsTruSht | True shooting success ratio (usually in %). | |
| gatFT/gatFld | Free throw attempt to field goal attempt ratio (free throw rate). | |
| rbd/rbs, rbo/rbs | Defensive and offensive rebound ratio | |
| asts/Pts | Ratio of the numbers of assists and total points | |
| blcks/OppGatFld | Ratio showing the number of blocks per one opponent-team field goal attempt | |
| poss | Number of ball possessions. | |
| Offens% | Offensive rating (percentage) | |
| tos/poss% | Turnover to possessions percentage | |
| GmScr | Hollinger’s Game Score |
| Game el. / Feature Abbrev. | Description | Label and Formula |
|---|---|---|
| WLR10LstGms | Win-loss record, i.e., the ratio (percentage) of the games won in the last 10 games. | |
| WLR10LG, HTHG | Win-loss record for a home team (HT) in (the last 10) home games (HG). | |
| WLR10LG, GTGG | Win-loss record for a guest team (GT) in (the last 10) guest games (GG). | |
| WLR10LG, HTMG | Win-loss record for a home team (HT) in (the last 10) mutual games (MG) with an opponent. | |
| WLR, TstPer | Win-loss record in the testing period | |
| WnStrk | Winning streak = the number of games won in a row. | |
| GmsIn10LstDys | Number of games in the last 10 days. | |
| RstDys | Number of the rest days (the whole days without playing any game) before some observed game. |
| ML Classifier | Accuracy |
|---|---|
| Logistic Regression | 56.1% |
| Naive Bayes | 55.8% |
| Decision trees | 53.5% |
| Multilayer perceptron | 56.1% |
| K-nearest neighbours | 57.9% |
| Random forest | 56.3% |
| LogitBoost | 54.5% |
| Average | 55.8% |
| Feature Set (Type) | Feature Abbrev. | Change of |
|---|---|---|
| Basic (+) | asts, blcks | |
| Derived (+) | pts, rbs | –||– |
| Advanced (+) | gScsFld, gScsFT, gEffFld | |
| ScsTruSht, gatFT/gatFld | –||– | |
| rbd/rbs, rbo/rbs | –||– | |
| asts/Pts, blcks/OppGatFld | –||– | |
| poss | –||– | |
| Offens%, tos/poss% | –||– | |
| GmScr | –||– | |
| League standing (+) | WLR10LstGms | |
| WLR10LG, HTMG | –||– | |
| WLR10LG, HTHG | –||– | |
| RstDys | –||– | |
| WLR, TstPer | –||– | |
| WnStrk | ||
| League standing (−) | GmsIn10LstDys |
| Season (s) | Games Won / Games Lost | Percentage of Games Won |
|---|---|---|
| 2013/2014 | 764/555 | 57.9% |
| 2014/2015 | 755/556 | 57.6% |
| 2015/2016 | 782/534 | 59.4% |
| 2016/2017 | 763/546 | 58.3% |
| 2017/2018 | 770/542 | 58.7% |
| All five seasons | 3834/2733 | 58.4% |
| Dataset | Accuracy of -Based Estimated win Funct. | ||
|---|---|---|---|
| Training () | Testing () | (i) Whole Basic ftr. Set | (ii) Selctd. Featrs. Only |
| 2013–2015 | 2016–2017 | 92.0% | 79.5% |
| 2014–2015 | 2016–2017 | 79.0% | |
| 2015 | 2016–2017 | 78.0% | |
| 2013–2016 | 2017 | 91.8% | 78.0% |
| 2014–2016 | 2017 | 80.6% | |
| 2015–2016 | 2017 | 79.1% | |
| 2016 | 2017 | 78.4% | |
| Initial Dataset Seasons | Prediction Accuracy (Overall: ) | ||||||
|---|---|---|---|---|---|---|---|
| Training | Testing | (A) With Training Dataset () | (B) With Dataset from OTW () | ||||
| () | () | ||||||
| 2013–2015 | 2016–2017 | 63.7% | 65.1% | 64.7% | 63.8% | 67.3% | 67.6% |
| 2014–2015 | 2016–2017 | 63.6% | 66.1% | 65.7% | 63.6% | 67.4% | 68.0% |
| 2015 | 2016–2017 | 63.8% | 65.4% | 67.2% | 64.1% | 66.3% | 70.0% |
| 2013–2016 | 2017 | 62.8% | 62.8% | 62.8% | 63.5% | 65.2% | 65.2% |
| 2014–2016 | 2017 | 63.1% | 63.8% | 63.8% | 63.7% | 68.7% | 68.4% |
| 2015–2016 | 2017 | 63.0% | 63.9% | 64.5% | 64.4% | 70.2% | 70.9% |
| 2016 | 2017 | 63.9% | 66.3% | 68.3% | 65.9% | 72.4% | 77.9% |
| By columns: | |||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Horvat, T.; Job, J.; Logozar, R.; Livada, Č. A Data-Driven Machine Learning Algorithm for Predicting the Outcomes of NBA Games. Symmetry 2023, 15, 798. https://doi.org/10.3390/sym15040798
Horvat T, Job J, Logozar R, Livada Č. A Data-Driven Machine Learning Algorithm for Predicting the Outcomes of NBA Games. Symmetry. 2023; 15(4):798. https://doi.org/10.3390/sym15040798
Chicago/Turabian StyleHorvat, Tomislav, Josip Job, Robert Logozar, and Časlav Livada. 2023. "A Data-Driven Machine Learning Algorithm for Predicting the Outcomes of NBA Games" Symmetry 15, no. 4: 798. https://doi.org/10.3390/sym15040798