1. Introduction
Non-communicable chronic diseases are the leading cause of death in the world [
1]. Non-communicable chronic diseases are a group of illnesses that do not transmit infections from one person to another because they do not involve viruses or bacteria. Such diseases occur slowly, and patients do not show any signs of illness. Non-communicable chronic diseases are closely related to lifestyles and healthy behavior, such as the type of food we eat, motor behavior (daily exercises), or bad habits such as smoking. Diabetes is one of the most common non-communicable chronic diseases in the world. According to the World Health Organization (WHO), most people with diabetes have type 2 diabetes (
https://www.who.int/news-room/fact-sheets/detail/diabetes, accessed on 14 February 2023). This type of diabetes is primarily caused by excessive body weight and physical inactivity. Recent statistics from the International Diabetes Federation (IDF) showed that type 2 diabetes accounts for 90% of all diabetes cases (
https://www.idf.org/aboutdiabetes/type-2-diabetes.html, accessed on 14 February 2023). The IDF reported that the current number of cases of diabetes will rise to approximately 700 million by 2045. This is concerning, especially considering the scary side effects of type 2 diabetes, such as malfunctioning and permanent damage to body organs. In the long run, type 2 diabetes may result in several critical conditions such as retinopathy (not life-threatening but sight-threatening), diabetic kidney disease, coma, destruction of pancreatic beta cells, joint failure, and many other conditions. Injection of adequate insulin is the best remedy option for treating type 2 diabetes. Although there is no long-term cure, type 2 diabetes can be controlled if detected at an early stage [
2]. One way to predict type 2 diabetes is through the predictive modeling and analysis of medical datasets.
Researchers have used data mining and machine learning techniques to analyze medical datasets to determine the best ways to increase the accuracy and efficiency of type 2 diabetes prediction [
3]. Data-mining methods are used to preprocess datasets to discover hidden patterns and select the most relevant dataset of features [
4]. This will enable faster training of machine-learning algorithms for detecting type 2 diabetes [
5]. However, analyzing medical datasets is not a trivial task, as medical datasets are often massive in dimension and have complex features, leading to data noise and dependency among features. Therefore, it is vital to remove irrelevant and redundant features before analyzing datasets to increase prediction accuracy and improve result comprehensibility. Feature selection is a complex process that requires artificial intelligence methods to solve it [
6]. The success of the feature selection process depends on reducing the number of attributes and increasing accuracy rates. Several studies have been conducted on the detection of type 2 diabetes using ordinary feature selection algorithms (a recent review can be found in [
7]).
However, limited research has focused on the use of bio-inspired metaheuristic feature selection algorithms to detect type 2 diabetes [
8]. The efficiency of metaheuristic algorithms can be attributed to their ability to imitate the best natural features [
9]. Among several bio-inspired metaheuristic feature selection algorithms, the genetic algorithm (GA) has proven to be one of the most effective evolutionary techniques for solving a wide range of global optimization problems [
10]. To the best of our knowledge, the GA is the only metaheuristic algorithm used to diagnose type 2 diabetes. The work in [
2] combined GA with a multiple objective evolutionary fuzzy classifier (MOEFC) to predict type 2 diabetes in the Pima Indian Diabetes dataset. While the GA has successfully handled feature selection in detecting type 2 diabetes with an accuracy rate of (83.0435%), however, our work aims to enhance the accuracy rates by utilizing a bio-inspired feature selection algorithm called the cuttlefish algorithm (CFA). The essential subset of features selected by the CFA was evaluated using six classifiers: K-nearest neighbor (KNN), support vector machine (SVM), naïve Bayes (NB), random forest (RF), decision tree (DT), and logistic regression (LR).
The implementation of the algorithms was applied to two datasets: the Pima Indian Diabetes (PID) dataset, which was extracted from the UCI repository, and the hospital Frankfurt Diabetes (HFD) dataset. PID and HFD datasets are two of the most widely used medical datasets for predicting type 2 diabetes [
7]. The PID dataset contained information about 768 instances (i.e., patients), whereas the HFD dataset contains 2000 instances. Both datasets shared the same features (eight features), including insulin level, body mass index (BMI), and blood pressure; generally, these datasets are asymmetry, but some of the features in these datasets are close to symmetry. The evaluation results showed that the accuracy rates for the CFA were better than those of the GA, particularly when data instances were increased (using the HFD dataset, which has more instances than the PID dataset).
The main contributions of this research are as follows:
Apply the CFA and GA bio-inspired metaheuristic algorithms to the PID and HFD datasets for feature selection. Features in both datasets were reduced by applying a cost function for the logistic regression for the CFA.
Combine the CFA and GA bio-inspired metaheuristic algorithms with several classification algorithms to predict type 2 diabetes.
Analyze the performance of the CFA and GA over two datasets: PID and HFD.
The remainder of this paper is organized as follows.
Section 2 discusses related work.
Section 3 presents preliminaries. The proposed approach is presented in
Section 4.
Section 5 describes the results, and
Section 6 concludes the paper.
2. Related Works
In this section, relevant related work to feature selection and classification algorithms that were applied to detecting diabetes and other medical applications contexts such as Parkinson’s and cancer are highlighted.
Several feature selection algorithms have been applied to detect type 2 diabetes. The study in [
2] proposed a feature selection approach that applied the GA to the PID dataset. The four best features in the PID dataset were identified. Several classification approaches have been used, including naïve Bayes (NB), decision tree (DT), and MOEFC. The results showed that the MOEFC provided the highest accuracy rate of (83.04%). A feature selection approach using ranker and wrapper algorithms was applied in [
11] to two datasets: the PID dataset and the Diabetes 130-US hospital dataset. The authors used a support vector machine (SVM) classification algorithm and applied a 10-fold cross-validation. The results showed that the ranker algorithm had the highest accuracy of (72.49%), whereas the wrapper algorithm had lower accuracy of (71.11%). Machine learning classification algorithms were applied in [
12] to predict type 2 diabetes. The algorithms included logistic, K-nearest neighbor (KNN), SVM, NB, DT, and random forest (RF). The results indicated that RF provided the highest accuracy of (77.4%). The work in [
13] used F-score feature selection to identify valuable features. A fuzzy SVM was used to train the dataset and generate fuzzy rules, and accuracy rates reached (89.02%). The study in [
14] used RF, DT, and NB classification algorithms to identify significant features for predicting diabetes. The results showed that NB had the highest accuracy of (82.30%). The authors of [
15] compared three machine learning algorithms, namely LR, NB, and DT, and applied them to a diabetic dataset to predict diabetes. The results show that the three algorithms yielded the same accuracy of (76.60%). The work in [
16] used fusion classifiers based on belief functions together with traditional machine learning classifiers to detect diabetes, where accuracy results reached (98.00%) when the long short-term memory and gated recurrent unit methods were combined.
Feature selection algorithms have also been applied in other medical domain applications, such as diagnosing Parkinson’s and cancer. For example, the CFA was used to diagnose Parkinson’s at an early stage [
17]. This approach had an accuracy rate of (94.00%) with KNN. The work in [
18] proposed an enhanced moth-flame optimization (MFO) feature selection algorithm. The approach was applied to 23 medical datasets of different contexts taken from the UCI and Kaggle repositories, and the results showed that the proposed approach outperformed other methods across (83%) of the datasets. An approach for encoding gene data based on unsupervised deep learning clustering with GA was proposed in [
19]. Three classifiers were used: support vector machine (SVM), KNN, and RF. This approach was applied to six cancer datasets. Accuracy results ranged between 66.00% for the RF and 99.00% for the SVM. A hybrid deep learning model based on a Laplacian core-convolutional neural network was proposed in [
20] for the gene selection and classification of cancer data. Ten datasets were used to test the performance. The results show that the proposed model outperforms other algorithms.
Another application of feature selection algorithms is the work in [
21], where the authors used a GA based on hierarchical feature selection to optimize handwritten word images. The proposed method was applied to 12 K words, and the results showed that word recognition was enhanced by 1.28% compared with the recognition obtained with the unreduced feature set.
Bio-inspired metaheuristic algorithms have become powerful optimization tools for complex problems [
22]. Among the several purposes of bio-inspired algorithms, we focused on the feature-selection problem. Previous studies have shown that metaheuristic bio-inspired algorithms are more efficient than ordinary feature selection algorithms [
23]. However, research on the utilization of bio-inspired algorithms to detect type 2 diabetes is limited. To the best of our knowledge, the GA is the only natural bio-inspired metaheuristic algorithm that has been utilized for diagnosing type 2 diabetes [
7]. In this work, we utilized another bio-inspired metaheuristic algorithm called CFA as a search strategy to ascertain the optimal subset of features for diagnosing type 2 diabetes. The obtained features from CFA were classified using several classification algorithms. The proposed approach was applied to two datasets of different sizes: the PID and HFD datasets.
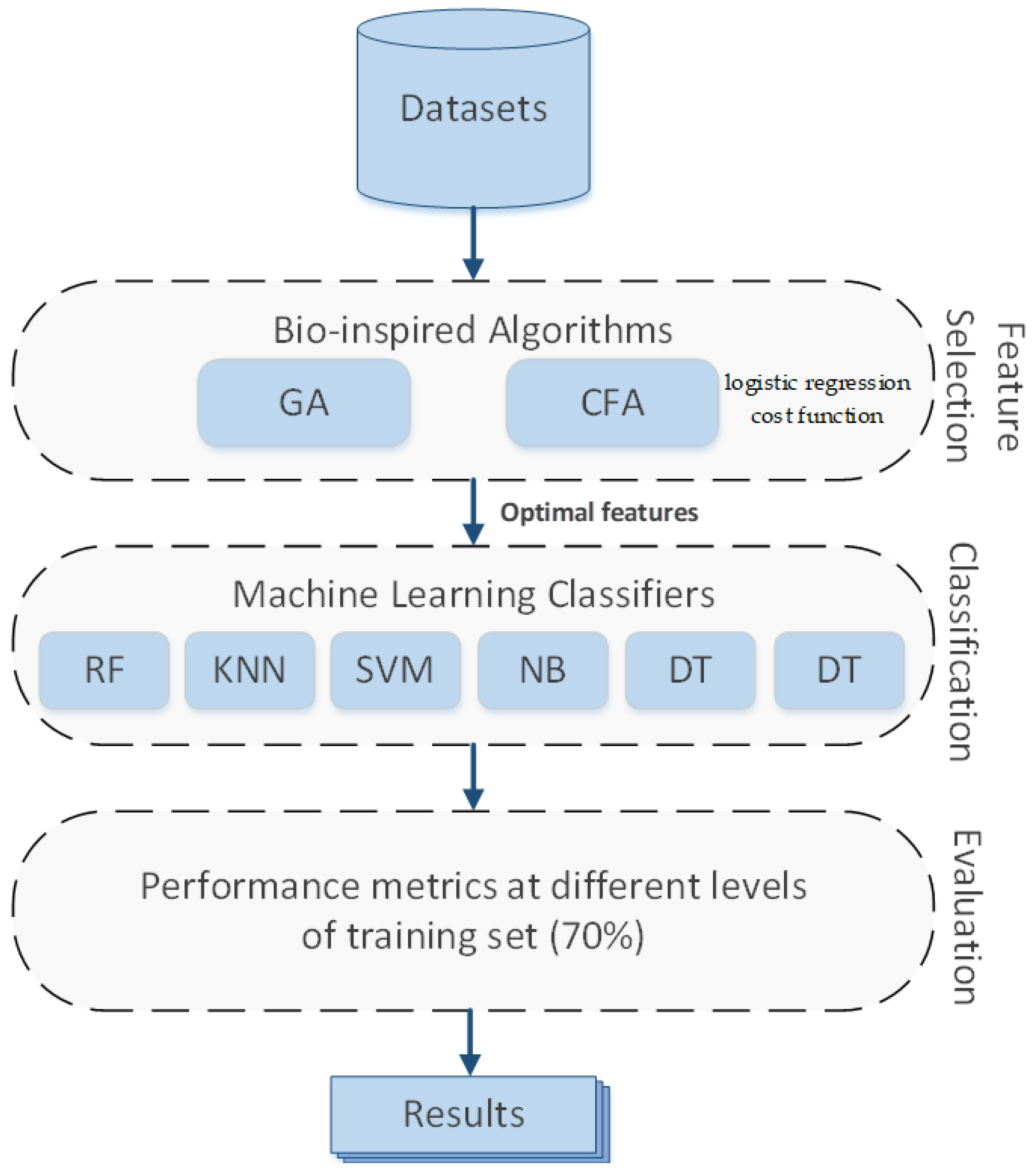
5. Results and Discussion
The CFA was evaluated against the GA using two datasets, PID and HFD. To the best of our knowledge, the GA is the only metaheuristic algorithm used to detect type 2 diabetes. Both the CFA and GA algorithms were evaluated using six classifiers: K-NN, RF, DT, LR, SVM, and NB. The algorithms were trained using the same methodology to ensure the fairness of the results. The classifiers were available in the scikit-learn library in Python (Python provides built-in libraries that are used to implement feature selection algorithms). The implementation of the CFA uses several input parameters (line 1 in Algorithm I).
Table 5 lists the input parameters used in the implementation. Values of the parameters were identified through experimentation.
Table 6 presents the average accuracy of 30 runs for the CFA on the PID and HFD datasets using the logistic classifier. Both datasets (PID and HFD) were divided into 70% for training and 30% for testing. The algorithms were examined using different numbers of iterations (10 to 70) and different populations (10 to 100). The experimental results showed that the CFA and GA provided better accuracy results with 50 iterations and 100 populations because the operations in the GA depend on the possibility of selecting the best features, whereas the operations in the CFA depend on using its equation. Accordingly, all reported results were based on 50 iterations and 100 populations.
Table 7 and
Table 8 present the evaluation results for CFA and GA on the PID and HFD datasets, respectively, in terms of accuracy, kappa, and MAE. As for accuracy results, it is clear from the results that CFA had better results than GA on the HFD dataset, and the highest accuracy values were achieved with the RF classifier (maximum accuracy = 0.97). However, this was not the case with the PID dataset. The accuracy results for the CFA and GA on the PID varied for the different classifiers. The results showed that CFA provided better accuracy results with the LR, SVM, and NB classifiers. This shows that the CFA works well with larger datasets, particularly with the RF and DT classifiers. This is because DT is a series of sequential decisions made to reach a specific result regarding the importance of features, and the sequence of attributes to be checked is decided based on criteria such as the Gini Impurity Index or information gain. RF leverages the power of multiple decision trees to make decisions (i.e., a forest of trees).
As a more conservative measure than accuracy, kappa results were measured and observed for the CFA and GA. The results showed that the CFA, in general, provided better performance than the GA, especially with the HFD dataset, because the HFD dataset has a large number of instances, and the classifier is trained using many instances. All classifiers provided better results, except the RF, which provided only (0.01) less than the GA. The performance of the classification algorithms using kappa varied in the PID, with all values being less than 0.50. This shows that the kappa coefficient aligns well with the accuracy results, particularly for larger datasets. Furthermore, classification algorithms should possess reduced MAE rates to prove that they have a better performance. The MAE results showed that the proposed CFA outperformed the GA in all cases on the PID and HFD datasets because the CFA selected better features than the GA. This suggests the application of the MAE as a performance metric for evaluating classification algorithms on datasets of various sizes.
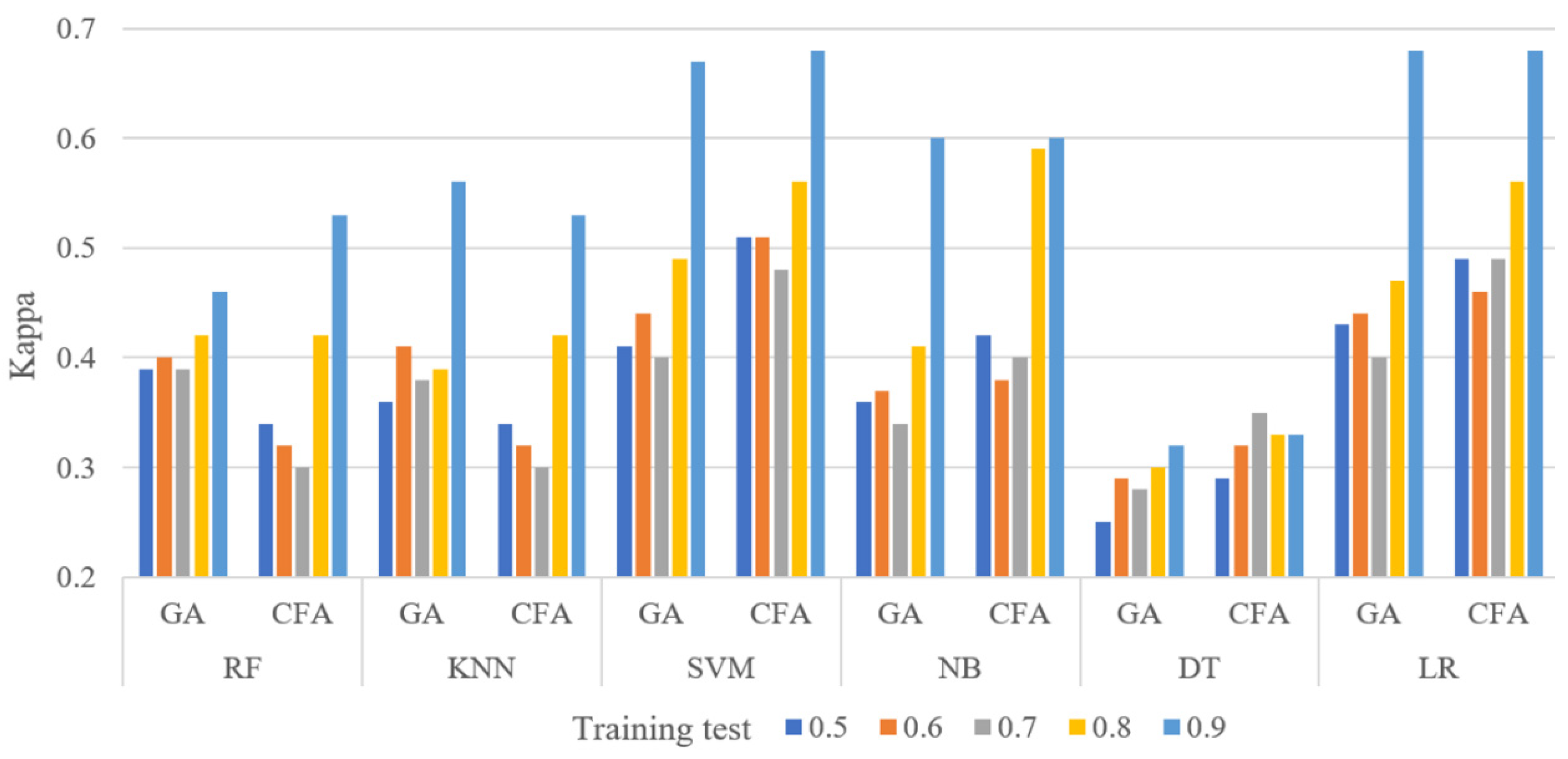
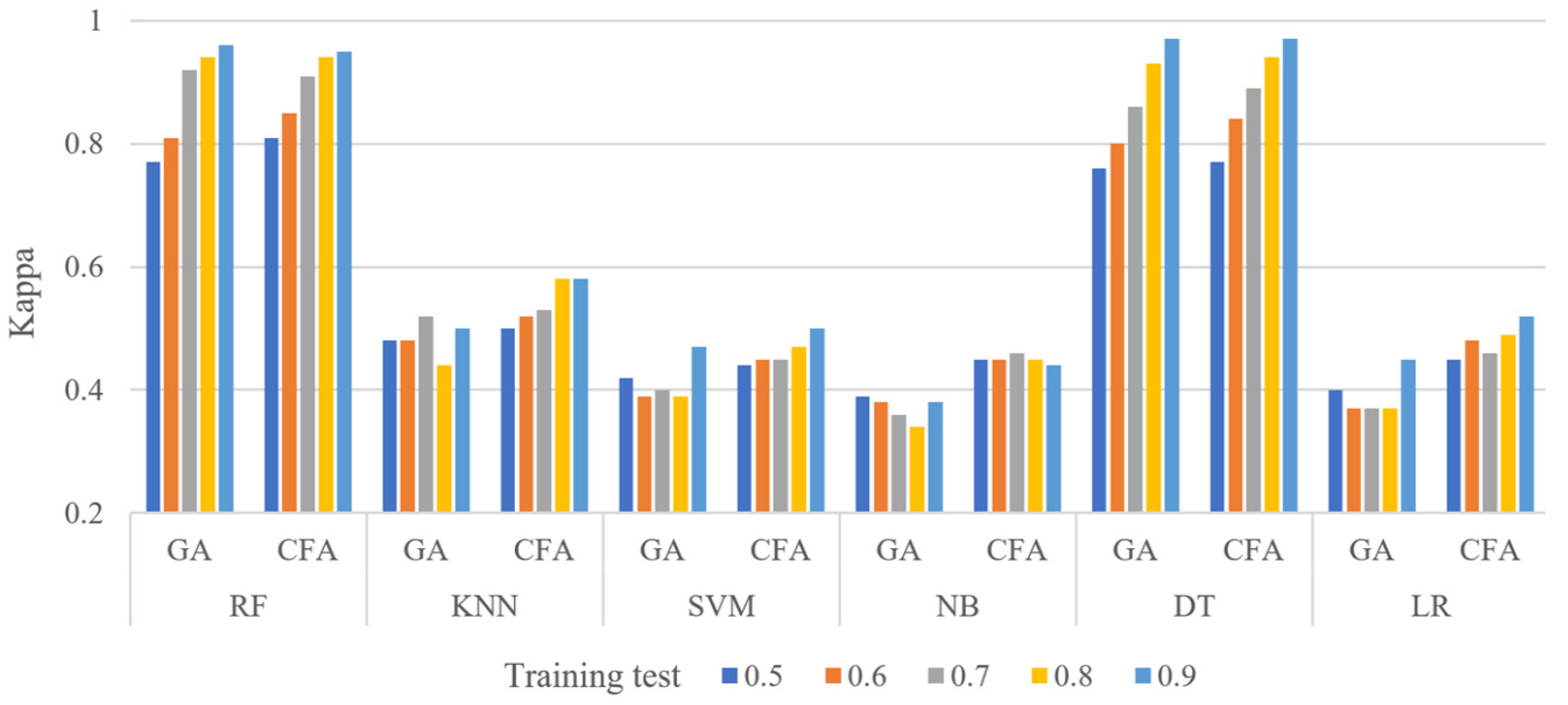
Figure 4 shows the kappa results of the six classifiers for the PID dataset at different training set levels (0.5 to 0.9). The features selected by the CFA in
Figure 4 provided better results than the GA when the LR, SVM, and NB classifiers were used because these classifiers are based on linear probability theory and statistics.
Figure 5 shows the kappa results of the six classifiers for the HFD dataset at different training set levels (0.5 to 0.9). As shown in
Figure 5, the CFA provided better results than the GA on the HFD, particularly with RF and DT, because these classifiers depend on ensemble learning algorithms. This suggests the need to use the RF and DT classifiers with larger datasets. This shows that the performance of the classifiers varied across datasets of different sizes. RF and DT outperformed the other classifiers when applied to a larger dataset (HFD), whereas LR, SVM, and NB provided better results for the CFA when applied to the PID dataset.
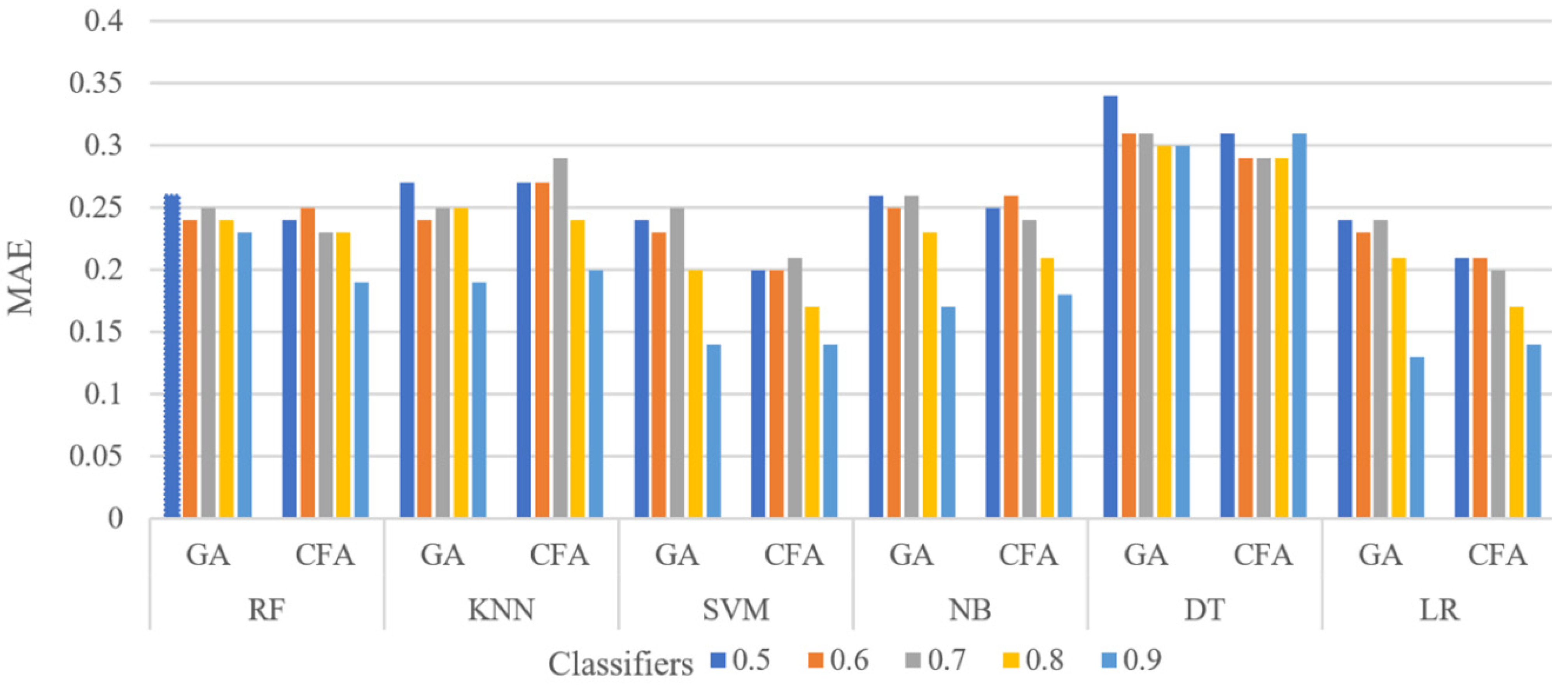
Figure 6 shows the MAE values of the six classifiers for the PID dataset at different training set levels (0.5 to 0.9) with 50 iterations and 100 iterations as the population size. The results show that each time the number of training samples in the PID dataset is increased, the features selected by the CFA provide better results than the GA using all classifiers except KNN.
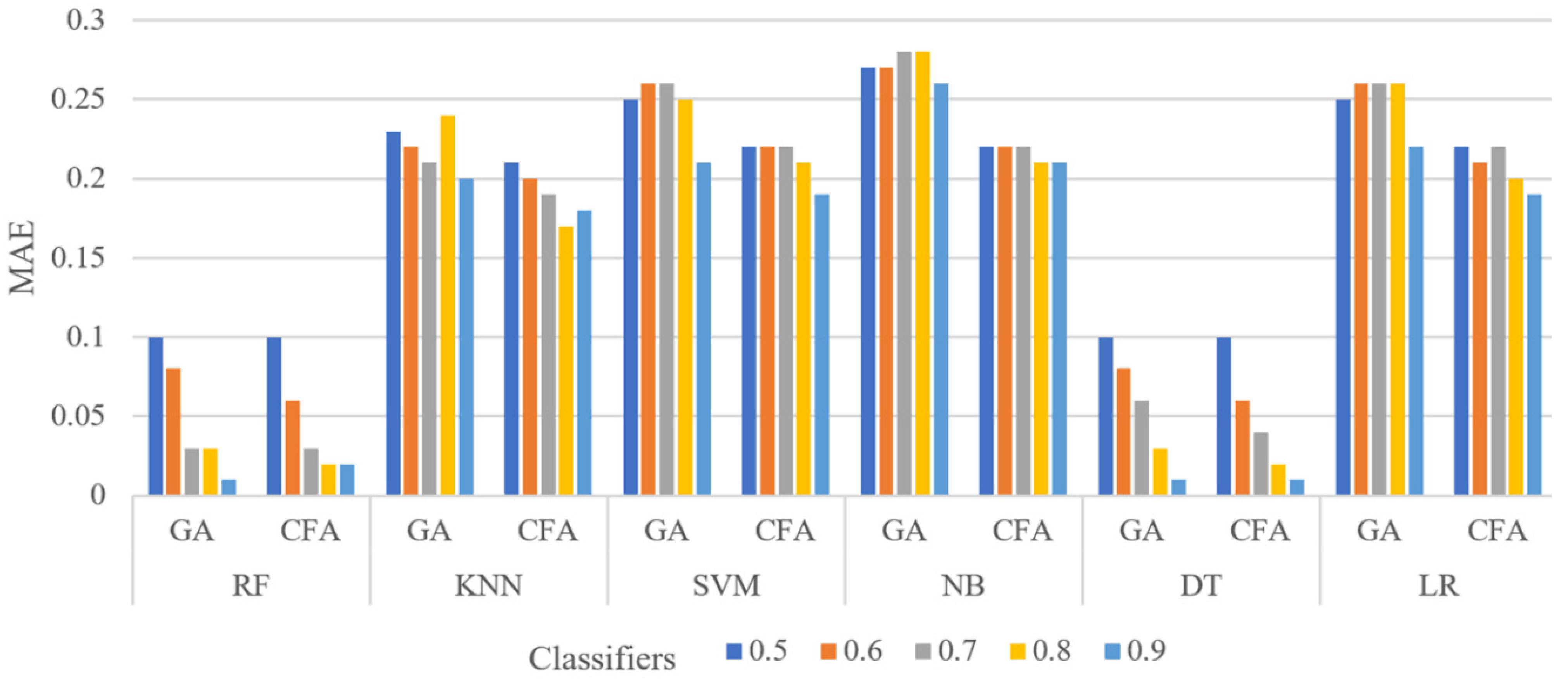
Figure 7 shows the MAE values of the six classifiers for the HFD dataset at different training set levels (0.5 to 0.9) with 50 iterations and 100 as the population size. The CFA provided better results than the GA, particularly with RF and DT. The main reason for this is that DT operates as a series of sequential decisions made to reach a particular output of the importance of features and attribute sequences based on criteria such as the Gini impurity index. The RF leverages the power of multiple DTs to make a decision.
Examination of the execution time of the CFA and GA showed that the CFA outperformed the GA in terms of execution time (CFA: 55 sec for the PID dataset and 68 sec for the HFD dataset; GA: 64 sec for PID and 75 sec for HFD). The algorithmic design of the GA was different from that of the CFA, and the solutions were ranked based on their fitness values. A GA usually clusters around good solutions within a population. This is based on the observation that the selection of parents in the GA is based on probabilities that favor fitness individuals. The solutions are more likely to be similar to the parents’ because the crossover operation produces offspring with the parents’ parts. The diversification aspect of GA is accomplished through a mutation operation that injects some differences in the solutions from time to time. The solution time of the GA also increases nonlinearly as the population size increases, whereas the CFA aims to find the optimal solution based on color-changing behavior. The patterns and colors observed in cuttlefish were produced by light reflected from the three layers. The simulation of light reflection and visibility of the matching patterns used was formulated.
6. Conclusions and Future Directions
Medical data analysis is a critical research field in which decisions can be made. However, medical datasets are often massive in dimension with complex redundant features, which increases the possibility of noise and dependency among features. Therefore, identifying a proper feature selection approach is important in the data preprocessing stages to reduce the redundancy and irrelevance among features, which positively affects the speed of performance and prediction accuracy. In this research, a bio-inspired algorithm called cuttlefish was adapted for feature selection, which was inspired by the color-changing behavior of cuttlefish to find the optimal solution. Earlier research has proven the effectiveness of the cuttlefish algorithm compared to other bio-inspired algorithms, such as the genetic algorithm, for solving various optimization problems. We applied the cuttlefish and genetic algorithms to two datasets: the Pima Indian diabetes dataset and the hospital Frankfort dataset, and the results were observed. The results show that the cuttlefish algorithm works well in predicting type 2 diabetes and has better performance and execution time than the genetic algorithm. The classification results showed that the RF and DT classifiers outperformed other classifiers when a larger dataset was used. The results also suggested using LR, SVM, and NB classifiers with small-scale datasets.
For future research directions, we propose using richer databases for predicting type 2 diabetes using modern features such as the features proposed in [
32]. Future applications of the CFA algorithm in the medical domain include the prediction of chronic kidney disease in diabetics, the prediction of chronic obstructive pulmonary disease in smokers, the prediction of strokes in patients with hypertension, the prediction of diabetes treatment choices, the prediction of cancer diseases, and classification of diabetic retinopathy caused by high blood sugar levels damaging the back of the eye (retina). Furthermore, the CFA algorithm can be applied to diabetes images [
33]. In addition, various heuristic and metaheuristic algorithms can be applied to predict diabetes, such as the A* heuristic search algorithm [
34], iterative deepening A* (IDA*) algorithm [
35], 2-opt local search algorithm [
36], nearest neighbor search algorithm [
37], harmony search algorithm [
38], chemical reaction optimization [
39], grey wolf optimizer [
40], and the most valuable player algorithm [
41] for different large high-dimensional datasets.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}