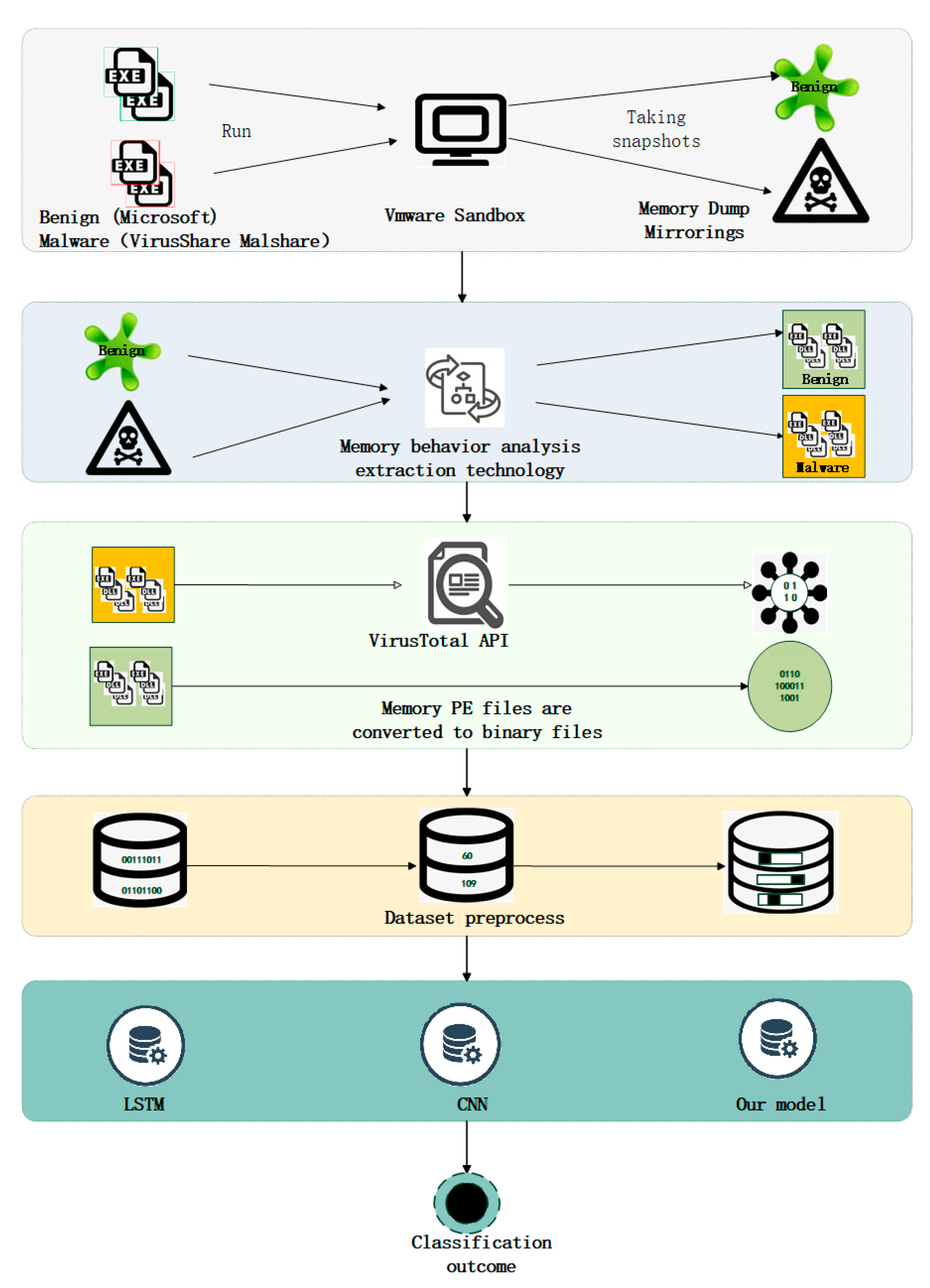
4.1. Gathering Memory Data
With regards to research on dynamic data, Wei [
27] used KDD99 for experiments, multiple studies [
28,
29] used the kernel structure as the dataset for dynamic detection, and another study [
5] used the binary file extracted from a single process to convert it into an image for the analysis. The process-related DLL files were not exploited yet. To maximize the malicious files in the memory, we extract all process and DLL files from the memory dump and created a dataset.
First of all, the common softwares (office, video, audio, and games et.) in the Windows system are downloaded. Then the softwares are executed and the memory process files are dumped. Mostly, memory dump files are dumped every 10 min and the operation is repeated ten times. PE files are dumped multiple times because the software does not load all files into memory at runtime. To collect malicious samples, static malicious PE files are downloaded from the VirusShare and Malshare malicious code, libraries which are widely used by researchers [
30,
31], and then malicious samples are executed in virtual machines. The extraction method of dynamic malicious samples is the same as that of benign samples. Malicious samples are dumped at a certain interval.
Finally, a total of 4896 data samples are obtained. To identify whether the extracted samples are benign or malicious samples, the benign and malicious samples are authenticated through the API interface of VirusTotal.
4.3. Our Model
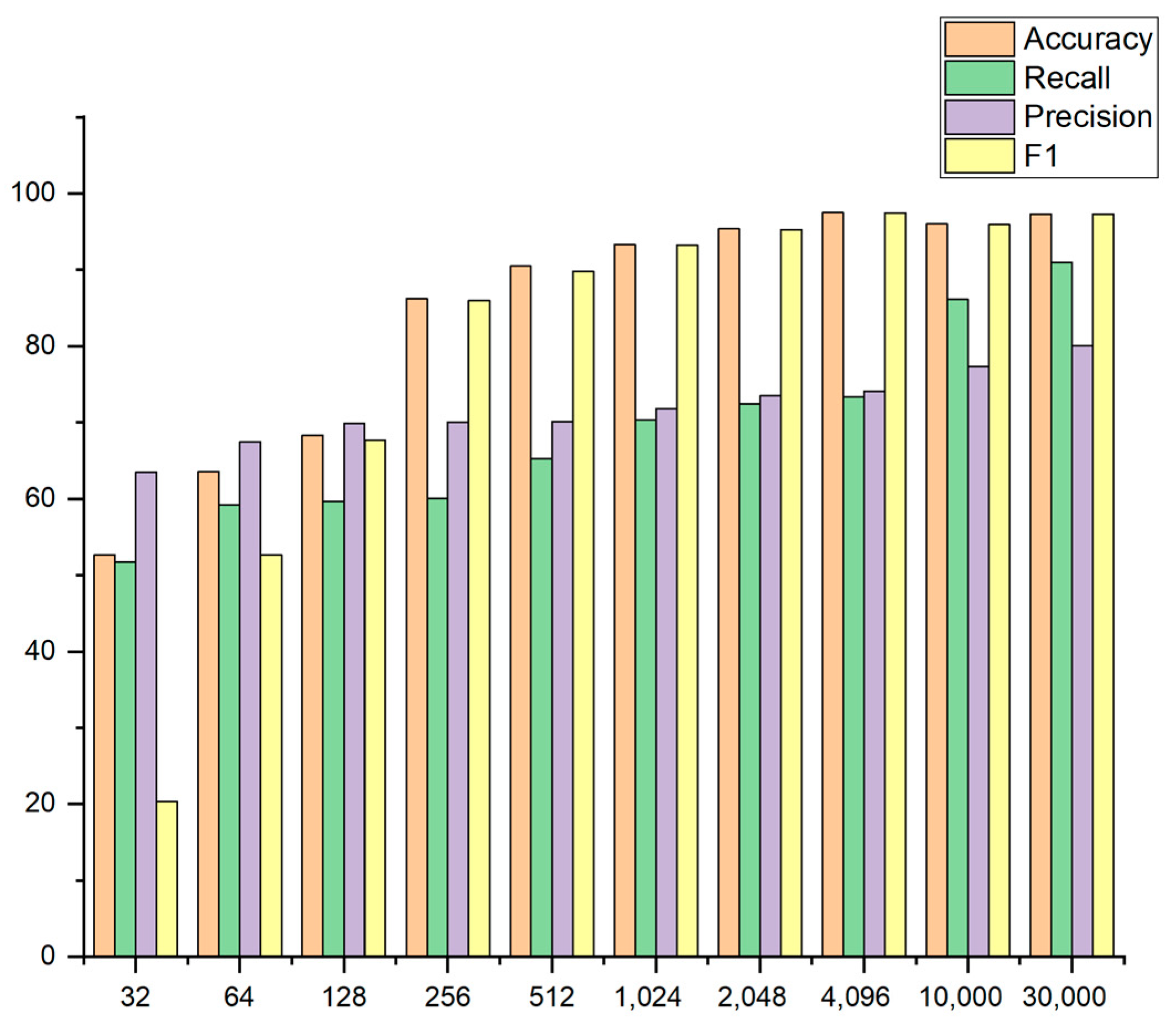
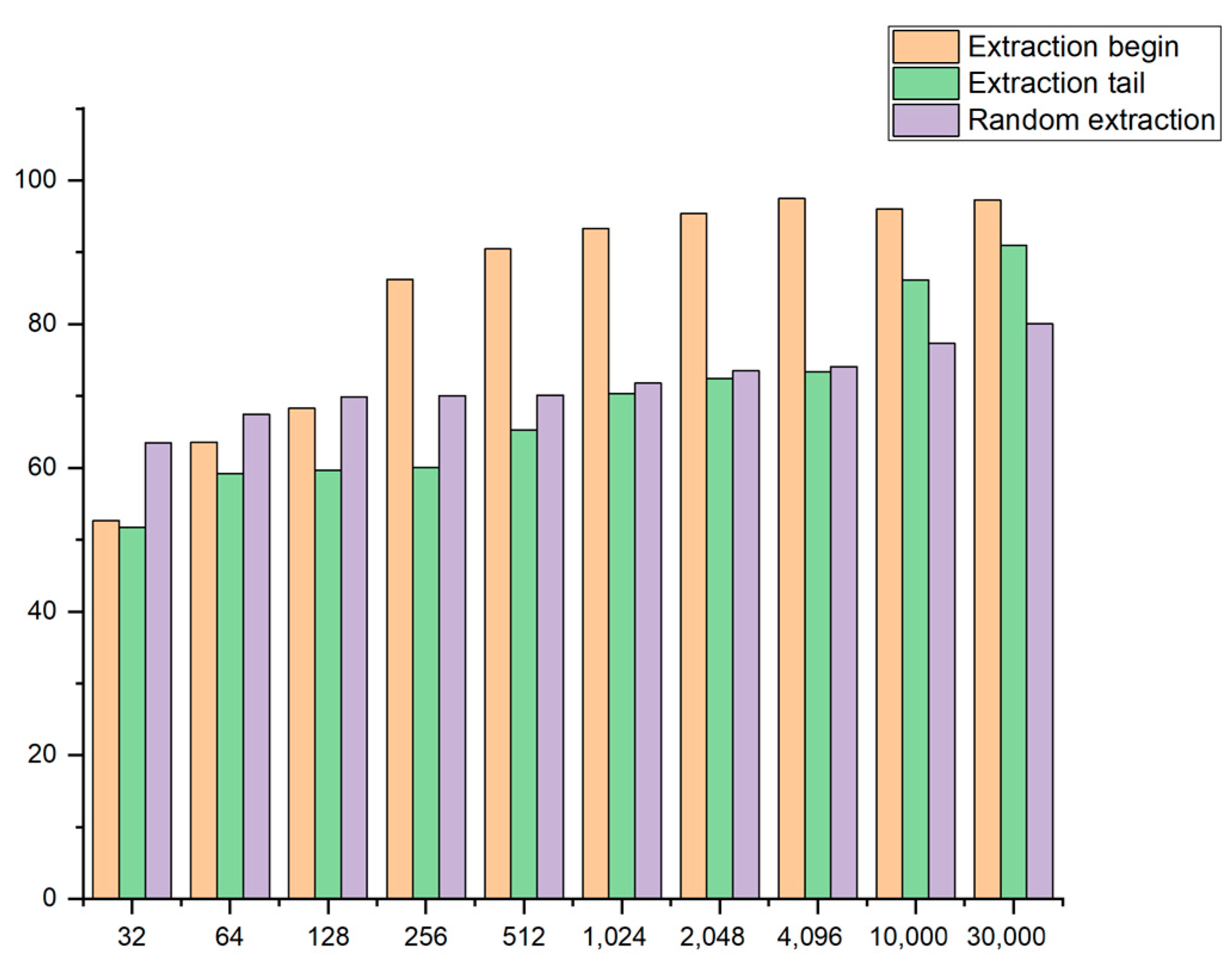
To address the problems that the dynamic PE files are incomplete and professional detection of malware is difficult, a deep model framework is proposed to learn the characteristics of the dynamic PE files to achieve the purpose of classification. The tiny fragment of the memory PE files (256 bytes) exhibits good detection results.
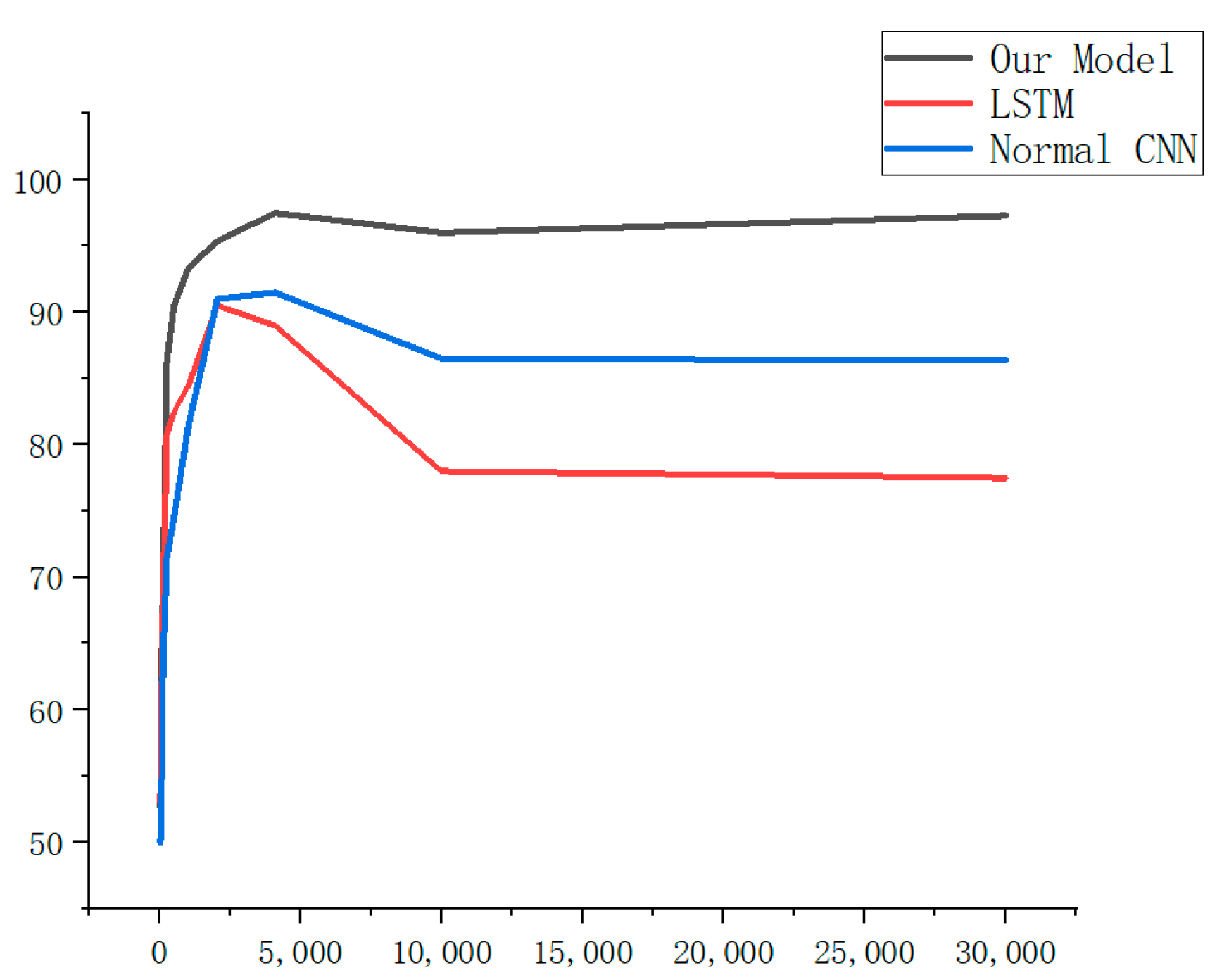
In the selection process of the deep learning model, long short-term memory [
33] (LSTM) is firstly used for the experiments. LSTM is relatively mature in the field of natural language processing [
34,
35,
36]. However, the experimental results show that the time cost of model training is higher than that for CNN. Owing to the complex and diverse forms of malicious code, the features extracted by the CNN have translation invariance characteristics [
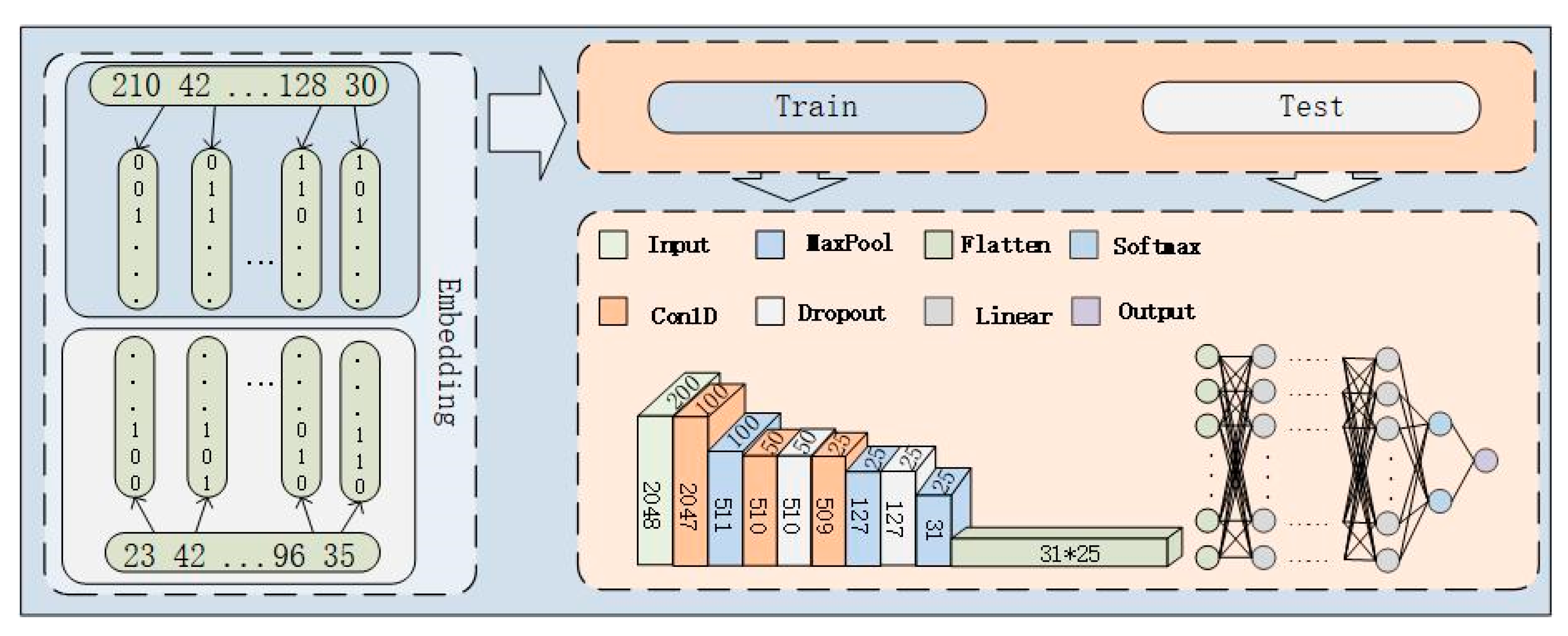
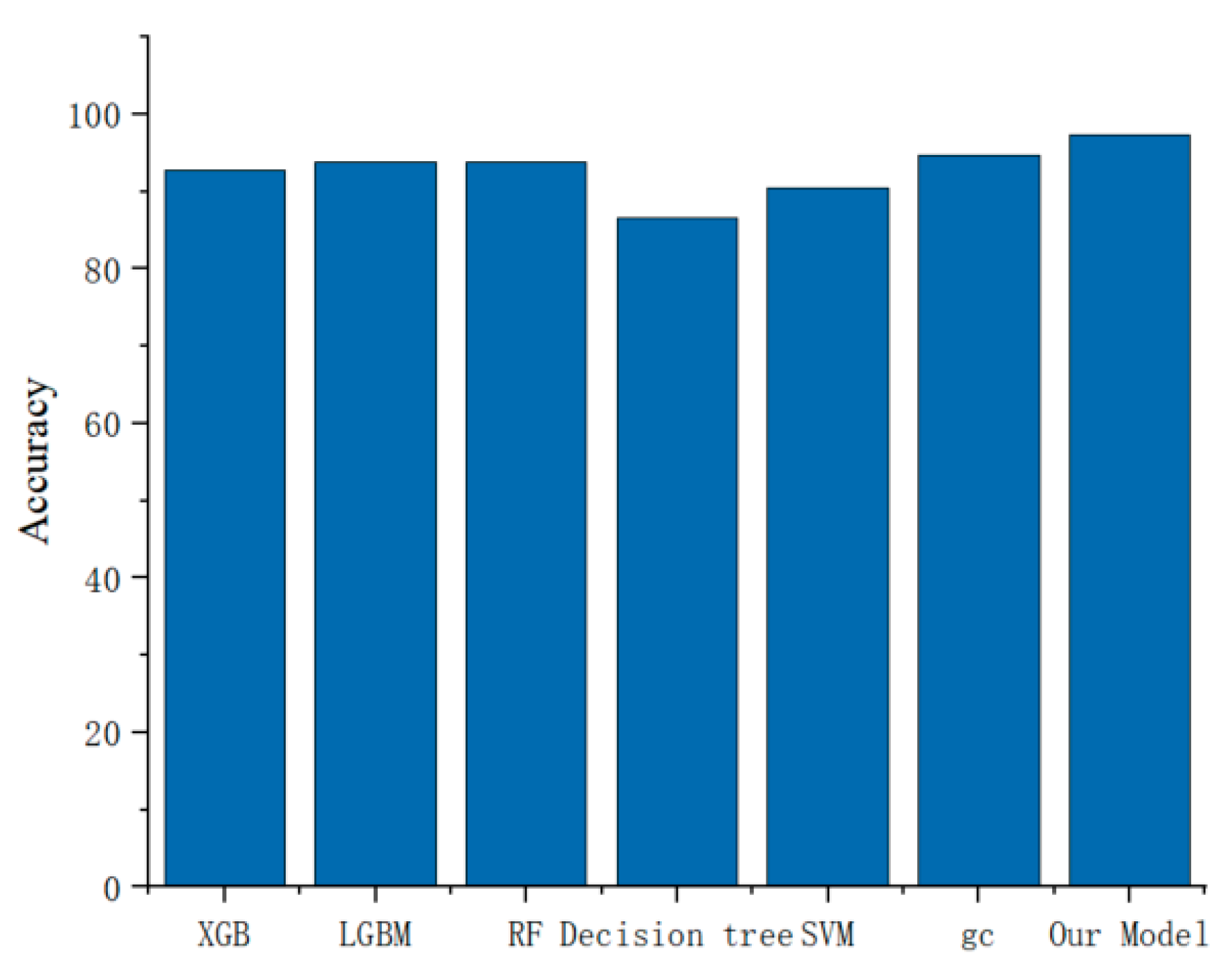
37]. As the location of malicious code is not fixed, CNN is more suitable for the malicious code detection in binary PE files. In addition, with the increasing length of sequence fragments, the computation amount of the LSTM model will be very large and the procedure is time-consuming. Although the training duration of the ordinary CNN model is shorter than that of the LSTM, the training effect of CNN is similar to that of LSTM in terms of accuracy. Our model architecture is designed to maximize learning from preprocessed samples, as shown in
Figure 7. We adopted a network model with a 12-layer structure based on CNN, in which we primarily used multiple convolutional layers for the model’s architecture. To prevent overfitting of the model during training, we added multiple dropout layers. The general dropout layer hides a quarter of the neuron nodes. In the study that proposed the famous VGG structure, Simonyan and Zisserman [
21] observed that for a given receiving field, the performance of the stacked small convolutional kernel is better than that of the large convolutional kernel because multiple nonlinear layers can increase the network depth. Hence, the convolution kernels used in this study are small. For the optimizer in deep learning, the accuracy rate of Adam was found to be better than that of the SGD. Therefore, Adam was adopted, and a cross-entropy loss function was adopted for the loss function of deep learning back propagation. The pre-processed dataset in
Section 4.2 is one-dimensional data, so the one-dimensional convolutional neural network (CNN1D) is adopted in our model. The difference between CNN1D and CNN is that CNN is mainly used for the detection of two-dimensional images, while CNN1D is used for the detection of one-dimensional data. We use CNN1D to input one-dimensional data into the model with a multi-channel mode, and then we do continuous translation calculation by the convolution kernel. The tag values are compared by using the softmax function. Finally, the cross entropy loss function is used for back propagation to optimize the model; thus, achieving the accurate detection of malicious code detection can be achieved with high accuracy. The processing procedure of LSTM model is similar to the above method. The preprocessed one-dimensional data are also input to the LSTM model for training and malicious code detection can be realized.
4.4. Neural Network Algorithm
This section introduces the algorithm in the neural network model designed for this study.
The output characteristics of the first, second, and third convolution layers in the PyTorch environment can be expressed as:
where
N is the batch size,
C is the channel size,
L is the sequence length, and bias is the offset value of the neural network. Batch refers to the number of samples processed in batches, as the samples are divided into several groups. The number of samples in each group is the size of the batch,
i is the index of the sample groups,
j is the index of the number of samples, and
k is the index of the input channel.
The length of the output sequence comprising the first, second, and third convolution layers is calculated using the following equation:
where
Lout is the output sequence length,
Lin is the length of the input sequence, padding is the filling length, dilation is the size of the cavity convolution, which is set to 1,
kernel_size is the size of the convolution kernel, and stride is the size of the step.
The input parameters of the flatten layer are computed using the output parameters of the pooling layer. The sequence is flattened using a flattened layer, then transformed into two neuron nodes by a fully connected layer, and finally classified by a softmax function.
The softmax layer, which is the last layer of the hidden layer, namely the classifier, is expressed as:
The exp (x) denotes the exponential function of ex (e is the Napier’s constant = 2.7182...), n represents the total number of neurons in the output layer, and yk represents the output of the k neurons in the output layer, where the numerator is the exponential function of input signal ak of the k neuron, and the denominator is the sum of the exponential functions of all input signals.
The loss function of the neural network model adopts the min-batch cross-entropy loss function:
where
M represents the number of training set samples,
tmk represents the value of the
k element of the m prediction sample,
ymk is the neural network’s output to the m prediction sample, and
tmk is the supervised data. By extending the loss function of a single piece of data to
M pieces of data and dividing by
M at the end, the average loss function of a single prediction fragment can be obtained. A unified indicator independent of the training data can be obtained through such averaging.
Through Equations (1) and (2), we can calculate each convolutional layer’s input and output sizes. In our model, the input parameters of the fully connected layer need to be manually calculated when training sample segments of different sizes. Calculating each layer’s length is complicated through the above formula. By observing and calculating the neural network model we constructed, we obtained the formula for calculating the input length of the fully connected layer in our model:
Falttenin represents the input length of the fully connected layer,
samplelen represents the input sample length,
maxpoolsize means the size of the pooling layer, and
conv_channel represents the output channel size of the last convolutional layer. Taking the fragment length of 2048 as an example, only the convolution layer and the pooling layer affect the data size, and the other neural network layers before the fully connected layer do not affect the data size. Our model has three convolution layers and three pooling layers, and the convolution kernel sizes of the three convolution layers are 3, 4, and 5, respectively. The maximum pooling is used for the pooling layer, and the three pooling layers are all set to 4. In our model, the padding of the convolution layer is set to 0, so the data length will be reduced by 1 after each convolution. It shrinks by a factor of four with each pooling. The order of convolution pooling in our model is convolution, pooling, convolution, convolution, pooling, and pooling; after the convolution pooling of our model, the length of the data with a sample fragment length of 2048 is firstly reduced by 1, and then the length is reduced by four times. By subtracting the output of the previous layer by 1 twice, and twice reducing it by four times, the sample length becomes 31. Finally, multiplying 31 by the number of output channels of the last convolutional layer is the input parameter of the fully connected layer.
Figure 7 shows the detailed calculation process of the input length of the flattening layer in the neural network section.
The detailed parameter settings of the neural network model are introduced in the
Section 5.3.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}