
Malware Detection Using Deep Learning and Correlation-Based Feature Selection
 ,
,  ,
,  , , and
, , and
Abstract
:1. Introduction
Related Work
2. Materials and Methods
2.1. Datasets
2.1.1. First Dataset (Malware Detection)
2.1.2. Second Dataset (Android Malware Dataset for Machine Learning)
2.2. Proposed Methodology
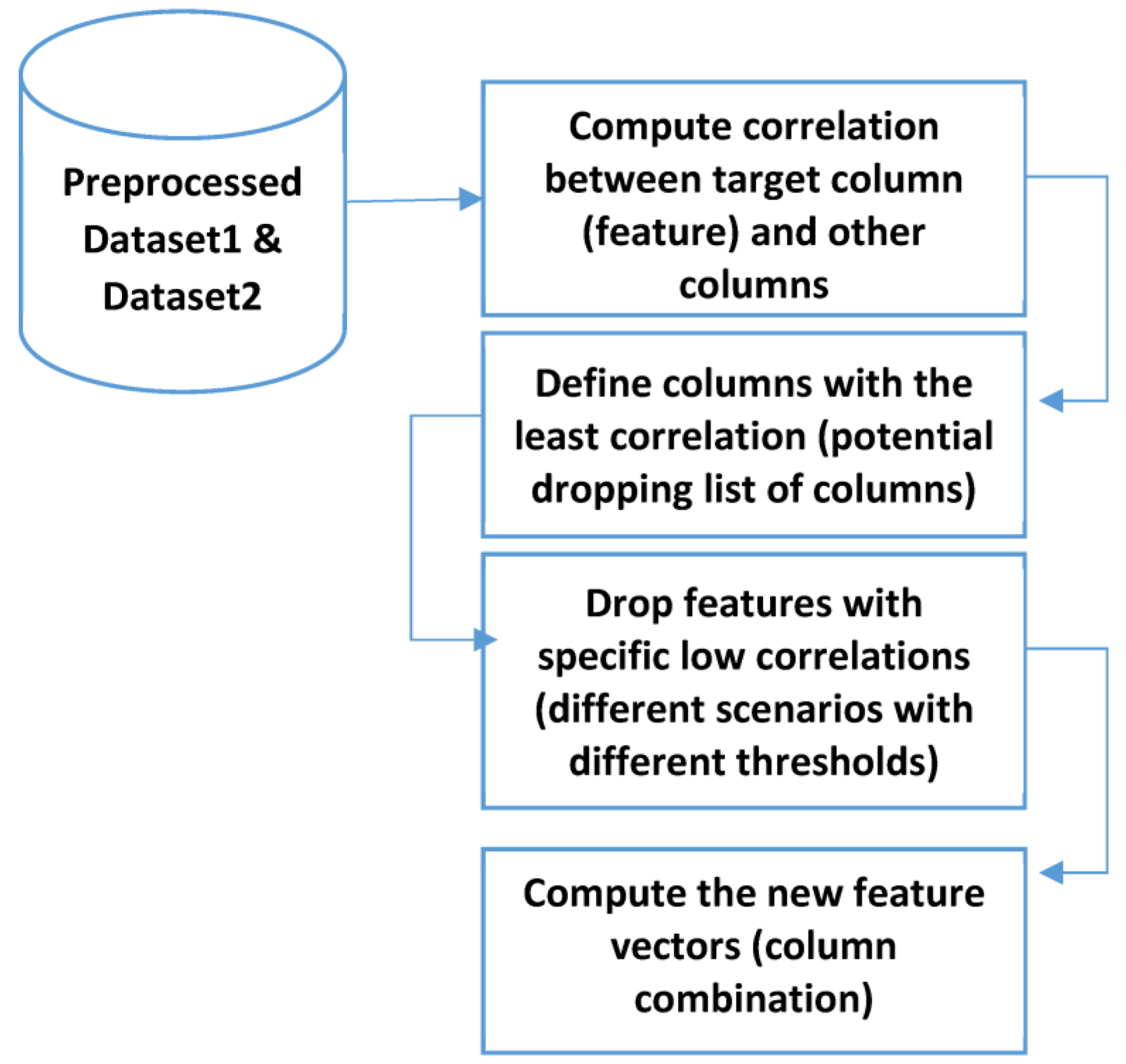
2.2.1. Correlation-Based Feature Selection
2.2.2. Dense Layers Model
2.2.3. LSTM Model
2.2.4. Evaluation Criteria
3. Results and Discussion
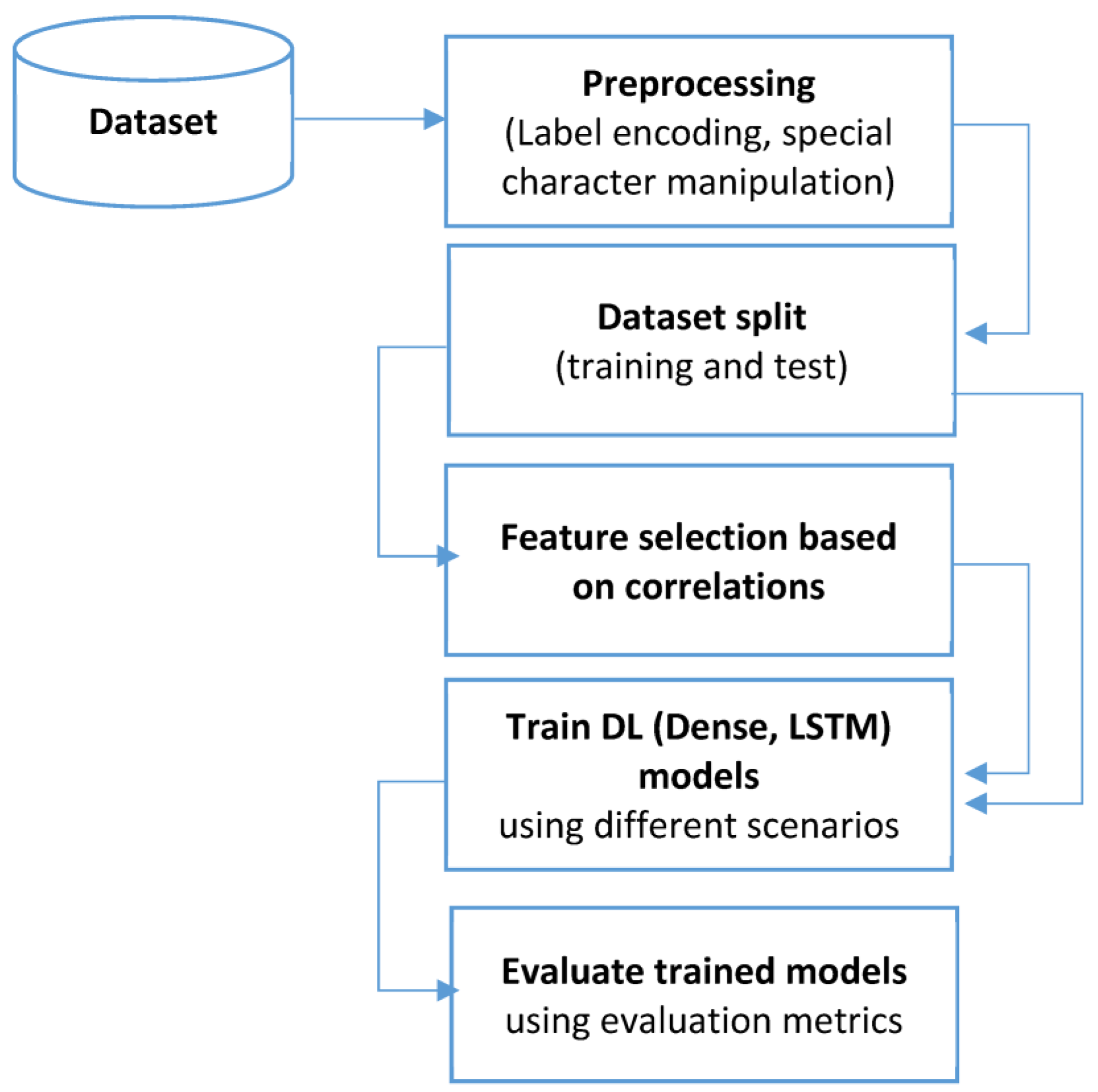
3.1. Dataset Preprocessing
- Handle the special characters by replacing them with “NaN” values.
- Check for the missing values and “NaN” values and replace them.
- Label the target class (classification column) using 0 for benign and 1 for malware.
- Drop column “hash” in the malware dataset.
3.2. Dataset Split
3.3. Feature Selection
- 1-
- First selected group (Dropping the following columns): ‘vm_truncate_count’, ‘shared_vm’, ‘exec_vm’, ‘nvcsw’, ‘maj_flt’, and ‘utime’, getting in only 27 attributes (since ‘classification’ and ‘Hash’ columns are already removed. The dropped columns are chosen from the columns whose correlation with the target column is low.
- 2-
- Second selected group (Dropping the following columns): ‘vm_truncate_count’, ‘shared_vm’, ‘exec_vm’, ‘nvcsw’, ‘maj_flt’, ‘utime’, ‘static_prio’, ‘map_count’, and ‘end_data’, getting in only 24 attributes. Three new columns with low correlation to the target column are also dropped in addition to the previous dropping list of the first scenario.
- 3-
- Third selected group (Dropping the following columns): ‘vm_truncate_count’, ‘shared_vm’, ‘exec_vm’, ‘nvcsw’, ‘maj_flt’, ‘utime’, ‘static_prio’, ‘map_count’, ‘end_data’, ‘nivcsw’, ‘fs_excl_counter’, and ‘reserved_vm’, getting in only 21 attributes. Again, in this scenario, three columns with low correlation are dropped.
- 4-
- Forth selected group (Dropping the following columns): ‘vm_truncate_count’, ‘shared_vm’, ‘exec_vm’, ‘nvcsw’, ‘maj_flt’, ‘utime’, ‘static_prio’, ‘map_count’, ‘end_data’, ‘nivcsw’, ‘fs_excl_counter’, ‘reserved_vm’, ‘mm_users’, ‘state’, ‘total_vm’, ‘free_area_cache’, ‘stime’, ‘gtime’, and ‘millisecond’ getting in only 14 attributes.
3.4. Training Scenarios
- -
- Train a dense layer-based DL model using the original dataset and different selected groups of dataset features (there are four groups and the original dataset, which means five different scenarios).
- -
- Train the DL model that has been modified (an LSTM layer has been added) using the first set of features that were chosen.
- -
- Train the DL model using three different splitting criteria (two new scenarios).
- -
- Train a dense layer-based DL model with the original dataset and the three groups of selected features (four different scenarios).
- -
- Train the modified DL model (added LSTM layer) using the main dataset.
- -
- Train the DL model using different spitting criteria (two new scenarios).
3.5. Experimental Results
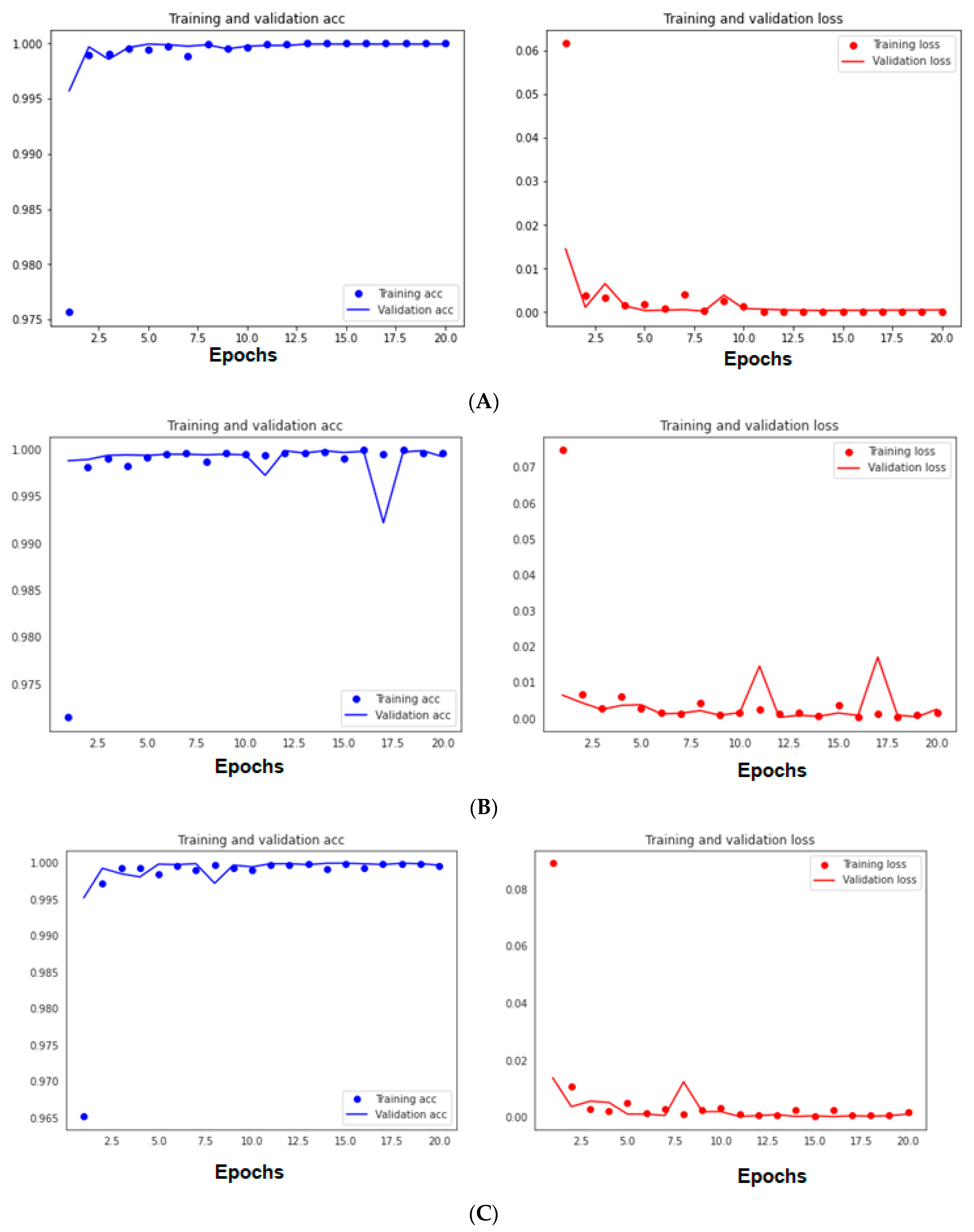
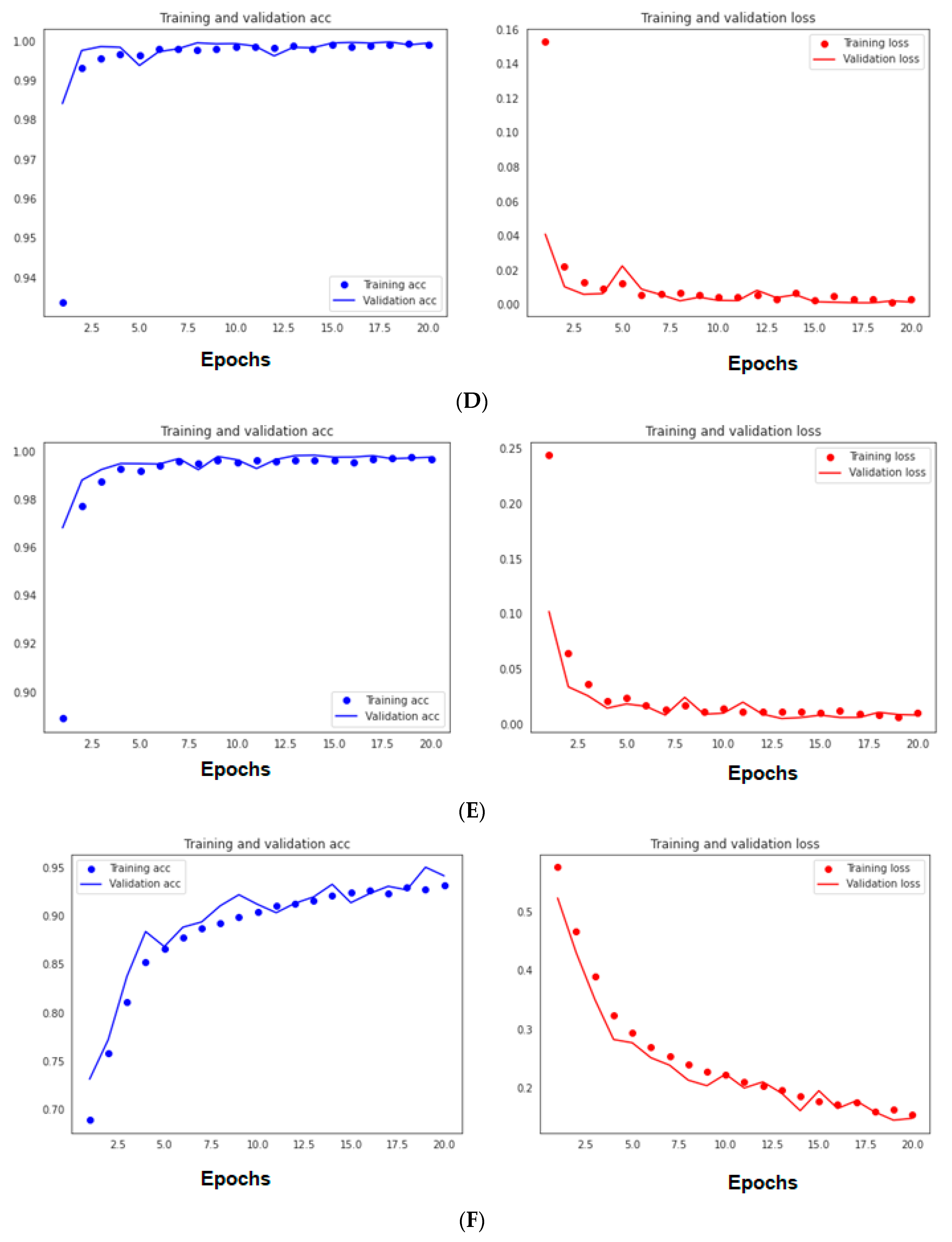
3.5.1. Results of the First Six Training Scenario of the First Malware Dataset
3.5.2. Results of the First Five Training Scenario of the First Malware Dataset
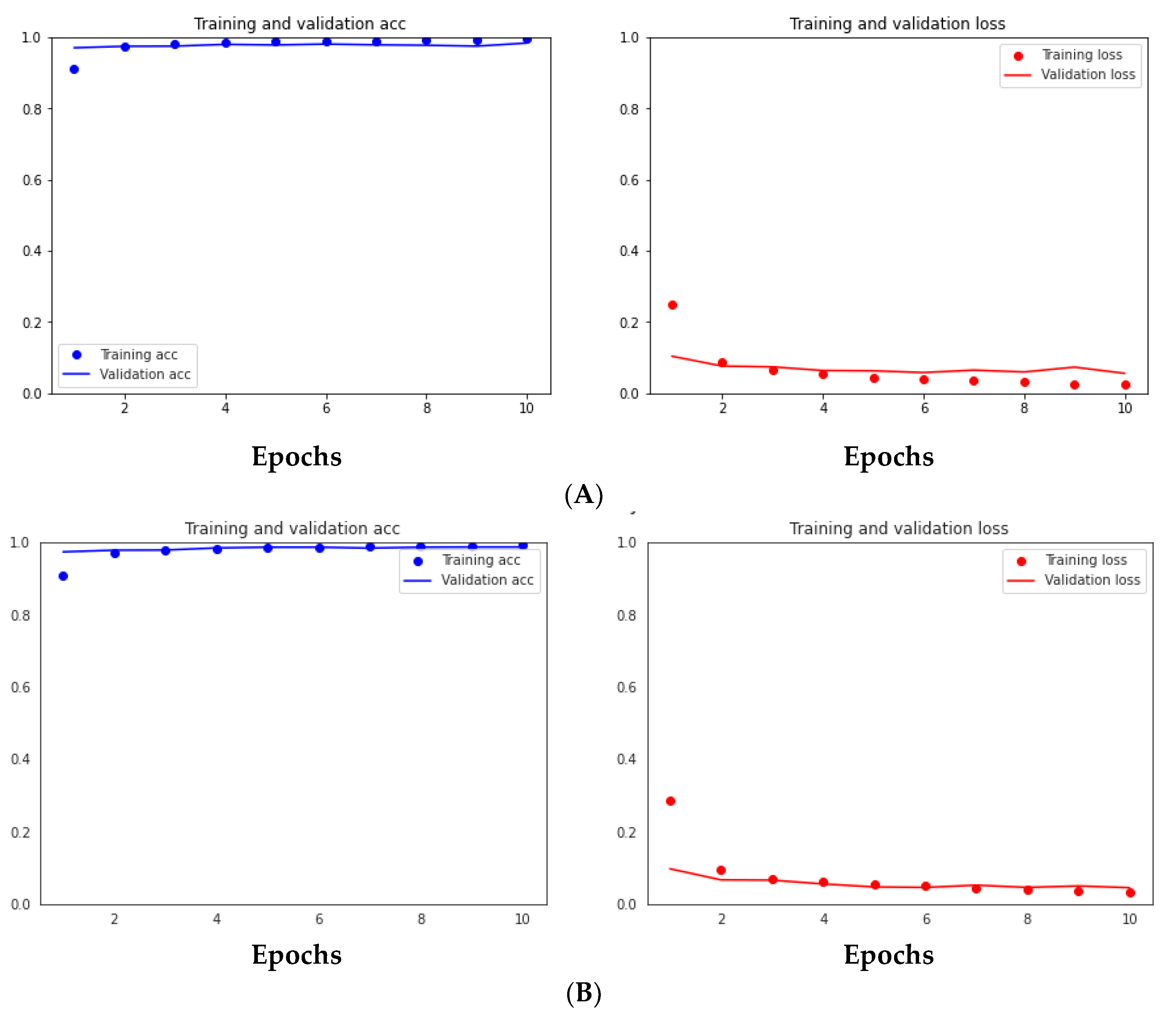
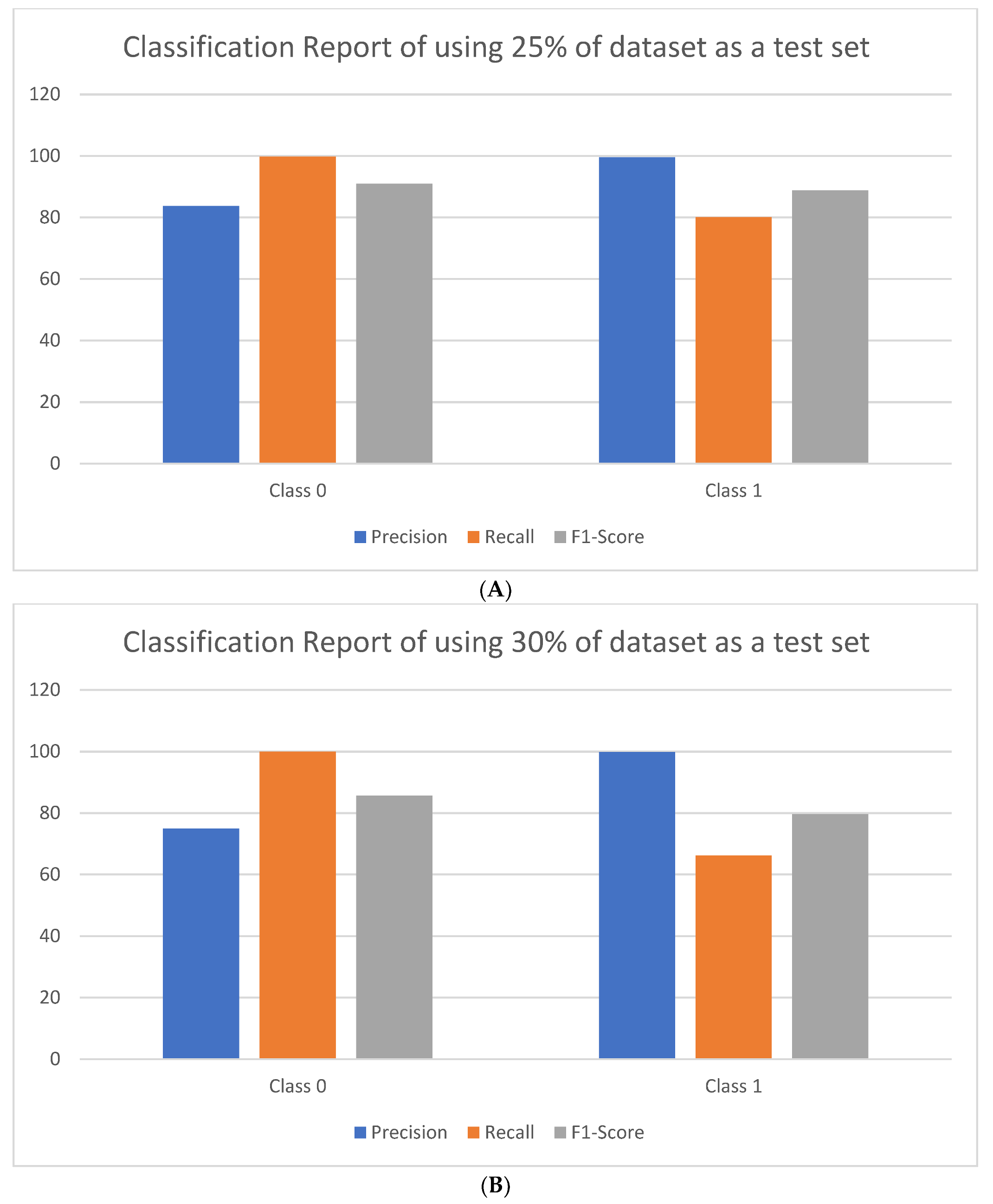
3.5.3. Results of Using Many Split Criteria for Both Malware Datasets

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Methodology | Dataset | Results |
|---|---|---|---|
| Taha and Barukab [41] | SVM, logistic regression (LR), gradient boosting (GB), decision tree (DT), and AdaBoost, Ensemble Learning | Second Dataset | Acc= DT: 93.75% LR: 92.86% GB: 93.53% AdaBoost: 90.96% Ensemble Learning: 94.15% |
| Masum and Shahriar [42] | DT, SVM, LR | Second Dataset | Acc= DT: 97.83% SVM: 97.29% LR: 97.77% |
| Gumaa [37] | DT, RF, K-NN, LOG | Second Dataset | Acc= RF: 97% LR: 95% DT: 96.5% LOG: 95.5% |
| Current study | Dense Model, LSTM model | First Dataset | Acc = 99.99%, F1-score = 100% (no feature selection) Acc = 99.75%, F1-score = 99.8% (63.63% selected features) |
| Current study | Dense Model, LSTM model | Second Dataset | Acc = 98.38%, F1-score = 98.9% (no feature selection) Acc = 94.59%, F1-score = 94.9% (18.22% selected features) |
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rathore, H.; Agarwal, S.; Sahay, S.; Sewak, M. Malware detection using machine learning and deep learning. In Proceedings of the International Conference on Big Data Analytics, Seattle, WA, USA, 10–13 December 2018; pp. 402–411. [Google Scholar]
- Nasif, A.; Othman, Z.; Sani, N.S. The deep learning solutions on lossless compression methods for alleviating data load on IoT nodes in smart cities. Sensors 2021, 21, 4223. [Google Scholar] [CrossRef] [PubMed]
- Vinayakumar, R.; Alazab, M.; Soman, K.; Poornachandran, P.; Venkatraman, S. Robust intelligent malware detection using deep learning. IEEE Access 2019, 7, 46717–46738. [Google Scholar] [CrossRef]
- Singh, A.; Kumar, R. A two-phase load balancing algorithm for cloud environment. Int. J. Softw. Sci. Comput. Intell. 2021, 13, 38–55. [Google Scholar] [CrossRef]
- Mat, S.R.T.; Razak, M.A.; Kahar, M.; Arif, J.; Firdaus, A. A Bayesian probability model for Android malware detection. ICT Express 2022, 8, 424–431. [Google Scholar] [CrossRef]
- Yen, S.; Moh, M.; Moh, T.-S. Detecting compromised social network accounts using deep learning for behavior and text analyses. Int. J. Cloud Appl. Comput. 2021, 11, 97–109. [Google Scholar] [CrossRef]
- Shabudin, S.; Sani, N.; Ariffin, K.; Aliff, M. Feature selection for phishing website classification. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 587–595. [Google Scholar] [CrossRef]
- Liu, C.-H.; Zhang, Z.-J.; Wang, S.-D. An android malware detection approach using Bayesian inference. In Proceedings of the 2016 IEEE International Conference on Computer and Information Technology (CIT), Nadi, Fiji, 8–10 December 2016; pp. 476–483. [Google Scholar]
- GDATA Mobile Malware Report—No let-up with Android malware. 2019. Available online: https://www.gdatasoftware.com/news/2019/07/35228-mobile-malware-report-no-let-up-with-android-malware (accessed on 22 November 2022).
- Qiu, J.; Zhang, J.; Luo, W.; Pan, L.; Nepal, S.; Xiang, Y. A survey of android malware detection with deep neural models. ACM Comput. Surv. 2020, 53, 1–36. [Google Scholar] [CrossRef]
- Sihwail, R.; Omar, K.; Ariffin, K.A.Z. An effective memory analysis for malware detection and classification. Comput. Mater. Contin. 2021, 67, 2301–2320. [Google Scholar] [CrossRef]
- Mat, S.R.T.; Razak, M.A.; Kahar, M.; Arif, J.; Mohamad, S.; Firdaus, A. Towards a systematic description of the field using bibliometric analysis: Malware evolution. Scientometrics 2021, 126, 2013–2055. [Google Scholar] [CrossRef]
- Bassel, A.; Abdulkareem, A.; Alyasseri, Z.; Sani, N.; Mohammed, H.J. Automatic Malignant and Benign Skin Cancer Classification Using a Hybrid Deep Learning Approach. Diagnostics 2022, 12, 2472. [Google Scholar] [CrossRef]
- Jerlin, M.A.; Marimuthu, K. A new malware detection system using machine learning techniques for API call sequences. J. Appl. Secur. Res. 2018, 13, 45–62. [Google Scholar] [CrossRef]
- Abdallah, A.; Ishak, M.K.; Sani, N.S.; Khan, I.; Albogamy, F.R.; Amano, H.; Mostafa, S.M. An Optimal Framework for SDN Based on Deep Neural Network. Comput. Mater. Contin. 2022, 73, 1125–1140. [Google Scholar] [CrossRef]
- Han, H.; Lim, S.; Suh, K.; Park, S.; Cho, S.; Park, M. Enhanced android malware detection: An svm-based machine learning approach. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Republic of Korea, 19–22 February 2020; pp. 75–81. [Google Scholar]
- Singh, P.; Borgohain, S.; Kumar, J. Performance Enhancement of SVM-based ML Malware Detection Model Using Data Preprocessing. In Proceedings of the 2022 2nd International Conference on Emerging Frontiers in Electrical and Electronic Technologies (ICEFEET), Patna, India, 24–25 June 2022; pp. 1–4. [Google Scholar]
- Droos, A.; Al-Mahadeen, A.; Al-Harasis, T.; Al-Attar, R.; Ababneh, M. Android Malware Detection Using Machine Learning. In Proceedings of the 2022 13th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 21–23 June 2022; pp. 36–41. [Google Scholar]
- Baldini, G.; Geneiatakis, D. A performance evaluation on distance measures in KNN for mobile malware detection. In Proceedings of the 2019 6th international conference on control, decision and information technologies (CoDIT), Paris, France, 23–26 April 2019; pp. 193–198. [Google Scholar]
- Assegie, T.A. An optimized KNN model for signature-based malware detection. Tsehay Admassu Assegie. Int. J. Comput. Eng. Res. Trends (IJCERT) 2021, 8, 2349–7084. [Google Scholar]
- Castillo-Zúñiga, I.; Luna-Rosas, F.; Rodríguez-Martínez, L.; Muñoz-Arteaga, J.; López-Veyna, J.; Rodríguez-Díaz, M.A. Internet data analysis methodology for cyberterrorism vocabulary detection, combining techniques of big data analytics, NLP and semantic web. Int. J. Semant. Web Inf. Syst. 2020, 16, 69–86. [Google Scholar] [CrossRef]
- Yilmaz, A.B.; Taspinar, Y.; Koklu, M. Classification of Malicious Android Applications Using Naive Bayes and Support Vector Machine Algorithms. Int. J. Intell. Syst. Appl. Eng. 2022, 10, 269–274. [Google Scholar]
- Yildiz, O.; Doğru, I.A. Permission-based android malware detection system using feature selection with genetic algorithm. Int. J. Softw. Eng. Knowl. Eng. 2019, 29, 245–262. [Google Scholar] [CrossRef]
- Arora, A.; Peddoju, S.; Chouhan, V.; Chaudhary, A. Hybrid Android malware detection by combining supervised and unsupervised learning. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking, New Delhi, India, 29 October–2 November 2018; pp. 798–800. [Google Scholar]
- Jeon, S.; Moon, J. Malware-detection method with a convolutional recurrent neural network using opcode sequences. Inf. Sci. 2020, 535, 1–15. [Google Scholar] [CrossRef]
- Yazdinejad, A.; HaddadPajouh, H.; Dehghantanha, A.; Parizi, R.; Srivastava, G.; Chen, M.-Y. Cryptocurrency malware hunting: A deep recurrent neural network approach. Appl. Soft Comput. 2020, 96, 106630. [Google Scholar] [CrossRef]
- Darabian, H.; Homayounoot, S.; Dehghantanha, A.; Hashemi, S.; Karimipour, H.; Parizi, R.M.; Choo, K.K.R. Detecting cryptomining malware: A deep learning approach for static and dynamic analysis. J. Grid Comput. 2020, 18, 293–303. [Google Scholar] [CrossRef]
- Hwang, C.; Hwang, J.; Kwak, J.; Lee, T. Platform-independent malware analysis applicable to windows and linux environments. Electronics 2020, 9, 793. [Google Scholar] [CrossRef]
- Ban, Y.; Lee, S.; Song, D.; Cho, H.; Yi, J.H. FAM: Featuring Android Malware for Deep Learning-Based Familial Analysis. IEEE Access 2022, 10, 20008–20018. [Google Scholar] [CrossRef]
- Smmarwar, S.K.; Gupta, G.; Kumar, S. A Hybrid Feature Selection Approach-Based Android Malware Detection Framework Using Machine Learning Techniques. In Cyber Security, Privacy and Networking; Springer: Berlin, Germany, 2022; pp. 347–356. [Google Scholar]
- Toan, N.N.; Thang, D.Q. Static Feature Selection for IoT Malware Detection. J. Sci. Technol. Inf. Secur. 2022, 1, 74–84. [Google Scholar] [CrossRef]
- N SARAVANA. Malware Detection|Kaggle. 2018. Available online: https://www.kaggle.com/datasets/nsaravana/malware-detection?select=Malware+dataset.csv (accessed on 22 November 2022).
- SHASHWAT TIWARI. Android Malware Dataset for Machine Learning|Kaggle. 2018. Available online: https://www.kaggle.com/datasets/shashwatwork/android-malware-dataset-for-machine-learning (accessed on 22 November 2022).
- Yerima, S.Y.; Sezer, S. Droidfusion: A novel multilevel classifier fusion approach for android malware detection. IEEE Trans. Cybern. 2018, 49, 453–466. [Google Scholar] [CrossRef] [PubMed]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In Proceedings of the European conference on information retrieval, Santiago de Compostela, Spain, 21–23 March 2005; pp. 345–359. [Google Scholar]
- Van Hulse, J.; Khoshgoftaar, T.; Napolitano, A.; Wald, R. Threshold-based feature selection techniques for high-dimensional bioinformatics data. Netw. Model. Anal. Heal. informatics Bioinforma. 2012, 1, 47–61. [Google Scholar] [CrossRef] [Green Version]
- Gumaa, M.A. Graph approach for android malware detection using machine learning techniques. Humanit. Nat. Sci. J. 2021, 2, 189–203. [Google Scholar] [CrossRef]
- Smmarwar, S.K.; Gupta, G.; Kumar, S.; Kumar, P. An optimized and efficient android malware detection framework for future sustainable computing. Sustain. Energy Technol. Assess. 2022, 54, 102852. [Google Scholar] [CrossRef]
- Xiao, X.; Zhang, S.; Mercaldo, F.; Hu, G.; Sangaiah, A.K. Android malware detection based on system call sequences and LSTM. Multimed. Tools Appl. 2019, 78, 3979–3999. [Google Scholar] [CrossRef]
- Vinod, P.; Zemmari, A.; Conti, M. A machine learning based approach to detect malicious android apps using discriminant system calls. Futur. Gener. Comput. Syst. 2019, 94, 333–350. [Google Scholar]
- Taha, A.; Barukab, O. Android Malware Classification Using Optimized Ensemble Learning Based on Genetic Algorithms. Sustainability 2022, 14, 14406. [Google Scholar] [CrossRef]
- Masum, M.; Shahriar, H. Droid-NNet: Deep learning neural network for android malware detection. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 5789–5793. [Google Scholar]








| No. | Attribute/Type | Description | Type |
|---|---|---|---|
| 1. | Hash | APK/ SHA256 file name | Text |
| 2. | Millisecond/ number | Time | number |
| 3. | Classification | Malware or benign | Text |
| 4. | State | State of the tasks (non-runnable, runnable or stopped) | number |
| 5. | usage_counter | task structure usage counter | number |
| 6. | prio | Holds the dynamic priority of a task | Number |
| 7. | Static_prio | Static priority of a task | Number |
| 8. | normal_prio | Normal Priority (without taking into account the RT-inheritance) | Number |
| 9. | Policy | Task planning policy | Number |
| 10. | vm_pgoff | Offset of the area in the file (in pages) | Number |
| 11. | vm_truncate_count | used to mark a vma as now dealt with | Number |
| 12. | task_size | Current task size | Number |
| 13. | cached_hole_size | Free address space hole size | Number |
| 14. | free_area_cache | First address of space hole | Number |
| 15. | mm_users | Space users | Number |
| 16. | map_count | Count of memory areas | Number |
| 17. | hiwater_rss | Peak of resident set size | Number |
| 18. | total_vm | Total number of pages | Number |
| 19. | shared_vm | shared pages count | Number |
| 20. | exec_vm | Executable pages count | Number |
| 21. | reserved_vm | Reserved pages count | Number |
| 22. | nr_ptes | Page table entries count | Number |
| 23. | end_data | End address of code component | Number |
| 24. | last_interval | Last interval time before thrashing | Number |
| 25. | Nvcsw | Volunteer context switches count | Number |
| 26. | Nivcsw | in-volunteer context switches count | Number |
| 27. | min_flt | Minor faults (page faults) | Number |
| 28. | maj_flt | Major faults (page faults) | Number |
| 29. | fs_excl_counter | Count of file system exclusive resources | Number |
| 30. | Lock | Read-write synchronization lock which is used for file system access | Number |
| 31. | Utime | User time | Number |
| 32. | Stime | System time | Number |
| 33. | Gtime | Guest time | Number |
| 34. | Cgtime | Cumulative group time | Number |
| 35. | signal_nvcsw | Cumulative resource counter | Number |
| Attribute/Type | Correlation with Target Column |
|---|---|
| Prio | 0.100359 |
| last_interval | 0.006952 |
| min_flt | 0.003069595 |
| Millisecond | −2.479903 × 10−17 |
| Gtime | −1.441608 × 10−2 |
| Stime | −4.203713 × 10−2 |
| free_area_cache | −5.123678 × 10−2 |
| total_vm | −5.929110 × 10−2 |
| State | −6.470178 × 10−2 |
| mm_users | −9.364091 × 10−2 |
| reserved_vm | −1.186078 × 10−1 |
| fs_excl_counter | −1.378830 × 10−1 |
| Nivcsw | −1.437912 × 10−1 |
| exec_vm | −2.551234 × 10−1 |
| map_count | −2.712274 × 10−1 |
| static_prio | −3.179406 × 10−1 |
| end_data | −3.249535 × 10−1 |
| maj_flt | −3.249535 × 10−1 |
| shared_vm | −3.249535 × 10−1 |
| vm_truncate_count | −3.548607 × 10−1 |
| Utime | −3.699309 × 10−1 |
| Nvcsw | −3.868893 × 10−1 |
| Attribute (Column) | Correlation Threshold = 0.1 | Exist with Threshold = 0.2? |
|---|---|---|
| send_sms | 0.546075 | Yes |
| android.telephony.smsmanager | 0.435190 | Yes |
| read_phone_state | 0.409344 | Yes |
| receive_sms | 0.388328 | Yes |
| read_sms | 0.370336 | Yes |
| android.intent.action.boot_completed | 0.314303 | Yes |
| telephonymanager.getline1number | 0.305944 | Yes |
| write_sms | 0.267501 | Yes |
| write_history_bookmarks | 0.242250 | Yes |
| telephonymanager.getsubscriberid | 0.241551 | Yes |
| android.telephony.gsm.smsmanager | 0.241038 | Yes |
| install_packages | 0.235660 | Yes |
| read_history_bookmarks | 0.231044 | Yes |
| Internet | 0.204219 | Yes |
| access_location_extra_commands | 0.197165 | No |
| write_apn_settings | 0.193827 | No |
| Abortbroadcast | 0.191727 | No |
| Createsubprocess | 0.185971 | No |
| telephonymanager.getdeviceid | 0.179910 | No |
| receive_boot_completed | 0.159870 | No |
| restart_packages | 0.157646 | No |
| Chmod | 0.146465 | No |
| telephonymanager.getsimserialnumber | 0.135075 | No |
| Packageinstaller | 0.113861 | No |
| Remount | 0.112943 | No |
| Senddatamessage | 0.110062 | No |
| Chownz | 0.107540 | No |
| Scenario | V.acc% | T.acc% | Precision % | Recall % | F1-Score% | T.Time (S/Ep) |
|---|---|---|---|---|---|---|
| First original dataset (33 features) | 99.99 | 100 | 100 | 100 | 100 | 2.15 |
| Using 27 out of 33 features | 99.92 | 99.54 | 100 | 100 | 100 | 2.05 |
| Using 27 out of 33 features (Adding LSTM layer) | 99.97 | 99.98 | 100 | 100 | 100 | 3 |
| Using 24 out of 33 features | 99.95 | 99.91 | 99.9 | 99.9 | 99.9 | 2 |
| Using 21 out of 33 features | 99.75 | 99.79 | 99.8 | 99.8 | 99.8 | 2 |
| Using 14 out of 33 features | 94.15 | 93.79 | 93.9 | 93.8 | 93.8 | 2.15 |
| Scenario | V.acc% | T.acc% | Precision % | Recall % | F1-Score% | T.Time (S/Ep) |
|---|---|---|---|---|---|---|
| First original dataset (214 features) | 98.38 | 98.93 | 98.9 | 98.8 | 98.9 | 2.1 |
| Adding LSTM layer | 98.67 | 98.3 | 98.1 | 98.3 | 98.2 | 7.8 |
| Using 39 out of 214 features (Th = 0.05) | 94.59 | 95.34 | 95.9 | 94.1 | 94.9 | 1.1 |
| Using 27 out of 214 features (Th = 0.1) | 93.56 | 93.28 | 93.6 | 92.1 | 92.8 | 1.1 |
| Using 14 out of 214 features (Th = 0.2) | 88.94 | 88.95 | 88 | 88.1 | 88.1 | 1.1 |
| Scenario | V.acc% | T.acc% | Precision % | Recall % | F1-Score% | T.Time (S/Ep) |
|---|---|---|---|---|---|---|
| 21 features with 20% for test set | 99.75 | 99.79 | 99.8 | 99.8 | 99.8 | 2.1 |
| 21 features with 25% for test set | 99.65 | 99.62 | 91.6 | 89.9 | 89.9 | 2.3 |
| 21 features with 30% for test set | 99.67 | 99.62 | 87.5 | 83.1 | 82.7 | 2.1 |
| Scenario | V.acc% | T.acc% | Precision % | Recall % | F1-Score% | T.Time (S/Ep) |
|---|---|---|---|---|---|---|
| 39 features with 20% for test set | 94.59 | 95.34 | 95.9 | 94.1 | 94.9 | 1.1 |
| 39 features with 25% for test set | 95.03 | 94.86 | 94.9 | 94 | 94.4 | 1.1 |
| 39 features with 30% for test set | 94.49 | 94.43 | 94.3 | 93.7 | 94 | 1.1 |
| Study | Methodology | Dataset | Results |
|---|---|---|---|
| Xiao et al. [39] | LSTM | 3536 benign 3567 malware | Acc = 93% |
| Vinayakumar et al. [3] | KNN, SVM, RF, LR, NB, DNN | 70,140 benign and 69,869 malware recodes | Acc = 98.9% |
| Vinod et al. [40] | RF | 100 benign 100 malware records | Acc = 91.7% |
| Jeon and Moon [25] | CNN encoder and RNN | 1000 benign and 1000 malware files | Acc = 96%, Recall = 95% |
| Yazdinejad et al. [26] | LSTM | 200 benign and 500 malware records | Acc = 98% |
| Darabian et al. [27] | CNN-LSTM | 1500 executable samples | Acc = 99% |
| Hwang et al. [28] | DNN | 10,000 malware records and 10,000 benign files | Acc = 94% |
| Ban et al. [29] | CNN | 28,179 records | Acc = 98%, F1-score = 82% |
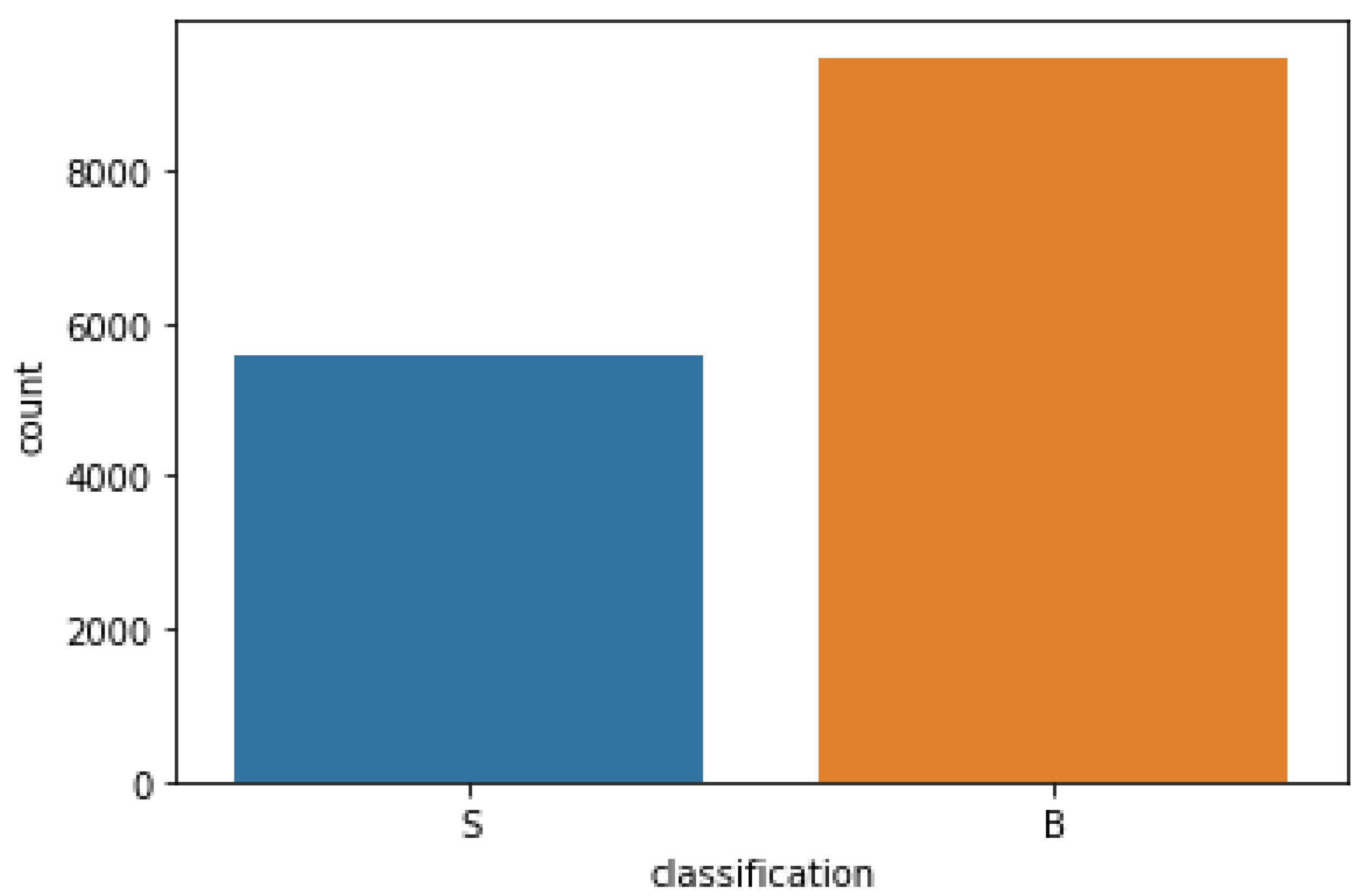
| Current study | Dense Model, LSTM model | 50,000 malware and 50,000 benign records (35 attributes) | Acc = 99.99%, F1-score = 100% (no feature selection) Acc = 99.75%, F1-score = 99.8% (63.63 selected features) |
| 9476 benign and 5560 malware records (215 attributes) | Acc = 98.38%, F1-score = 98.9% (no feature selection) Acc = 94.59%, F1-score = 94.9% (18.22% selected features) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alomari, E.S.; Nuiaa, R.R.; Alyasseri, Z.A.A.; Mohammed, H.J.; Sani, N.S.; Esa, M.I.; Musawi, B.A. Malware Detection Using Deep Learning and Correlation-Based Feature Selection. Symmetry 2023, 15, 123. https://doi.org/10.3390/sym15010123
Alomari ES, Nuiaa RR, Alyasseri ZAA, Mohammed HJ, Sani NS, Esa MI, Musawi BA. Malware Detection Using Deep Learning and Correlation-Based Feature Selection. Symmetry. 2023; 15(1):123. https://doi.org/10.3390/sym15010123
Chicago/Turabian StyleAlomari, Esraa Saleh, Riyadh Rahef Nuiaa, Zaid Abdi Alkareem Alyasseri, Husam Jasim Mohammed, Nor Samsiah Sani, Mohd Isrul Esa, and Bashaer Abbuod Musawi. 2023. "Malware Detection Using Deep Learning and Correlation-Based Feature Selection" Symmetry 15, no. 1: 123. https://doi.org/10.3390/sym15010123