
Compressed-Encoding Particle Swarm Optimization with Fuzzy Learning for Large-Scale Feature Selection


Abstract
:1. Introduction
- (1)
- Proposing a compressed-encoding representation for particles. The compressed-encoding method adopts the N-base encoding instead of the traditional binary encoding for representation. It divides all features into small neighborhoods. The feature selection process then can be performed comprehensively on each neighborhood instead of on every single feature, which provides more information for the search process.
- (2)
- Developing an update mechanism of velocity and position for particles based on the Hamming distance and a fuzzy learning strategy. The update mechanism has a good explanation in the discrete space, overcoming the difficulty that traditional PSO update mechanisms often work in real-value space but is hard to be explained in discrete space.
- (3)
- Proposing a local search mechanism based on the compressed-encoding representation for large-scale features. The local search mechanism can skip some dimensions dynamically when updating particles, which decreases the search space and reduces the difficulty of searching for a better solution, so as to reduce running time.
2. Related Work
2.1. Discrete Binary PSO
2.2. Two Main Design Schemes for Applying PSO to Feature Selection
2.3. PSO for Large-Scale Feature Selection
3. Proposed CEPSO-FL Method
3.1. Compressed-Encoding Representation of Particle Position
3.2. Definitions Based on Compressed-Encoding Representation
3.2.1. Difference between the Positions of Two Particles
3.2.2. Velocity of the Particle
3.2.3. Addition Operation between the Position and the Velocity
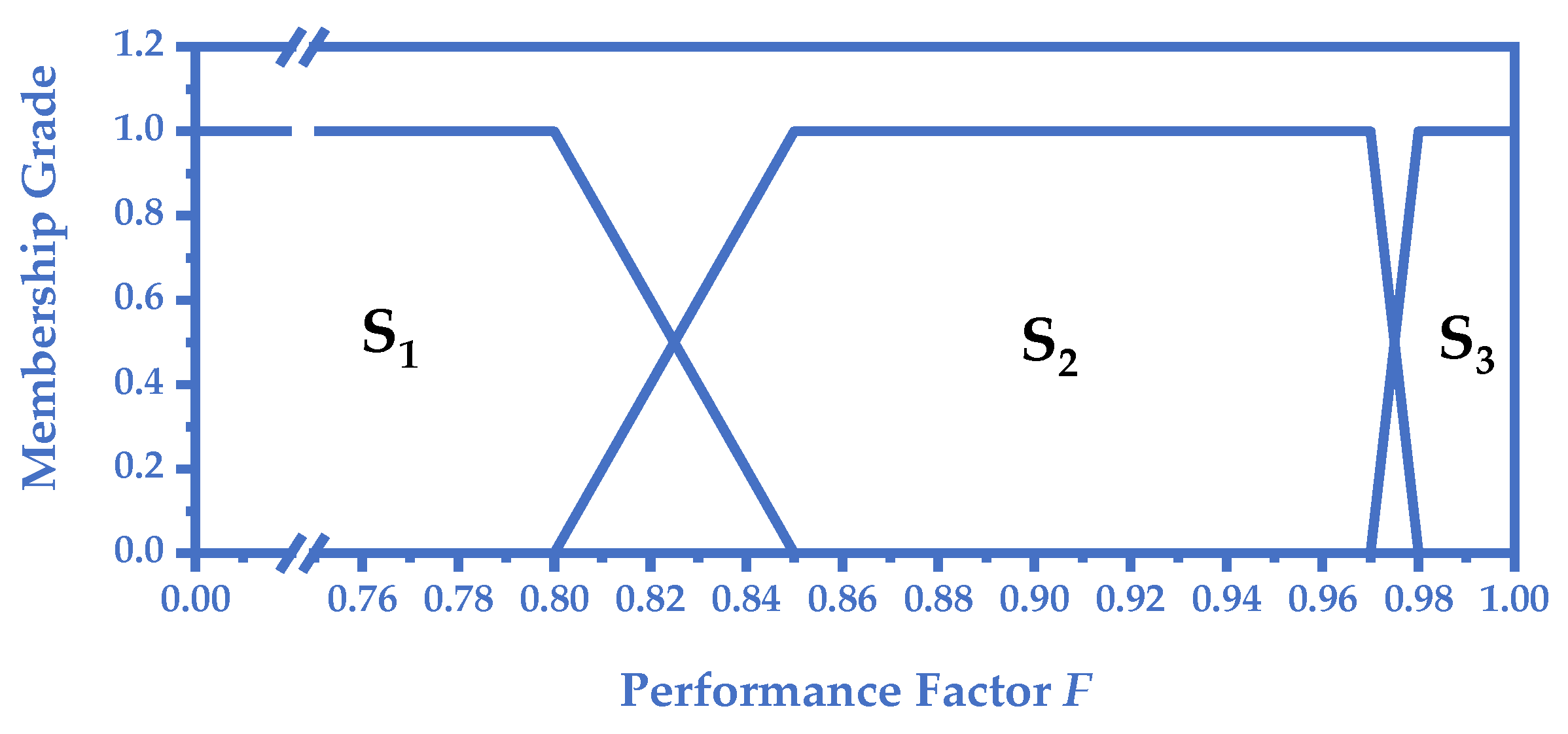
3.3. Update Mechanism with Fuzzy Learning
3.4. Local Search Strategy
| Algorithm 1: Local Search Strategy |
| Input: The position xi of particle pi, the encoding length D′ after compression, the index of the particle i. Output: The updated by the local search strategy.
|
3.5. Overall Framework
| Algorithm 2: CEPSO-FL |
| Input: The maximum number of fitness evaluations , the size of the swarm , the number of the features , the base for encoding compression . Output: The global optimal position .
|
4. Experiments and Analysis
4.1. Datasets
4.2. Algorithms for Comparison and Parameter Settings
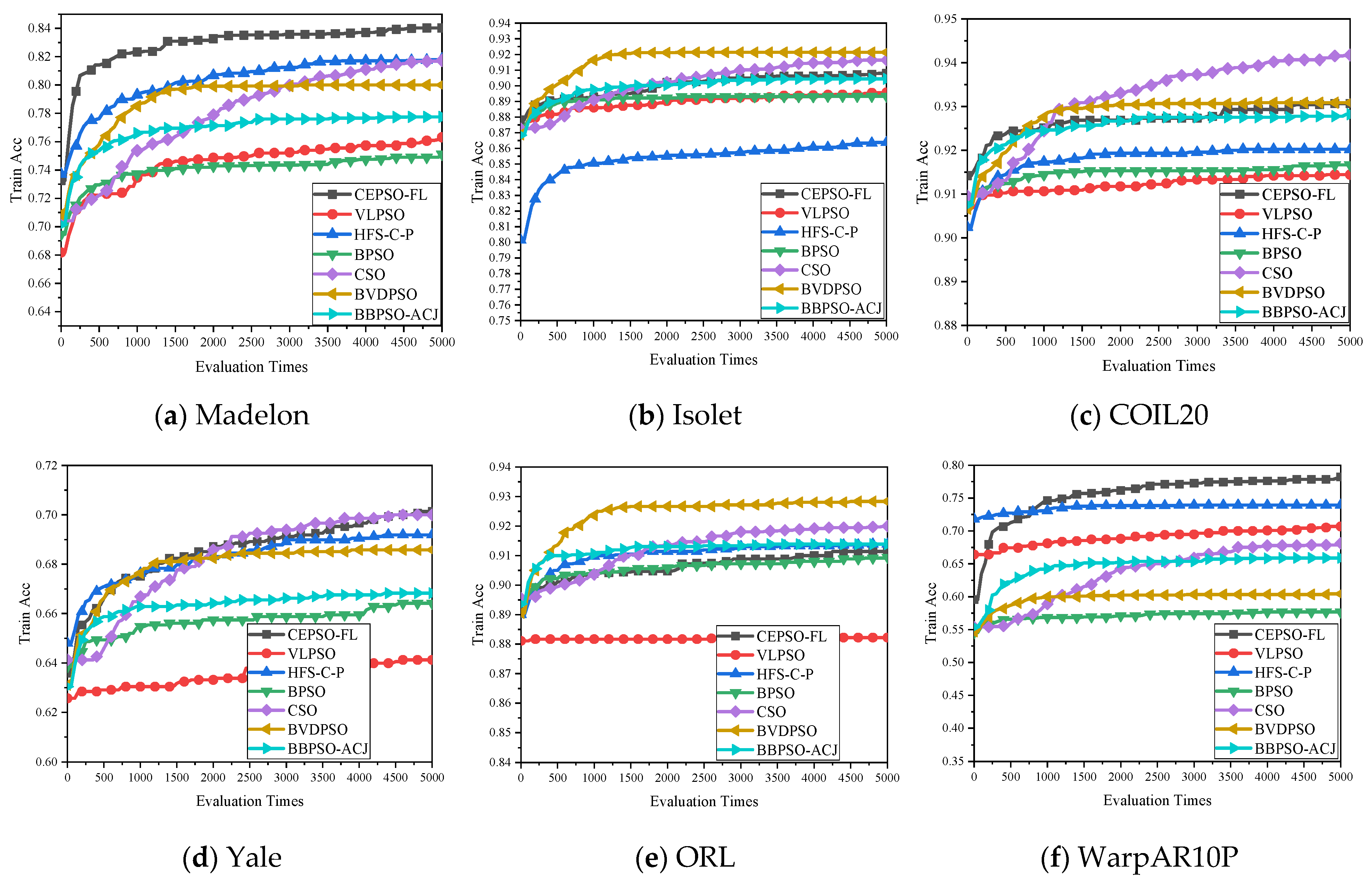
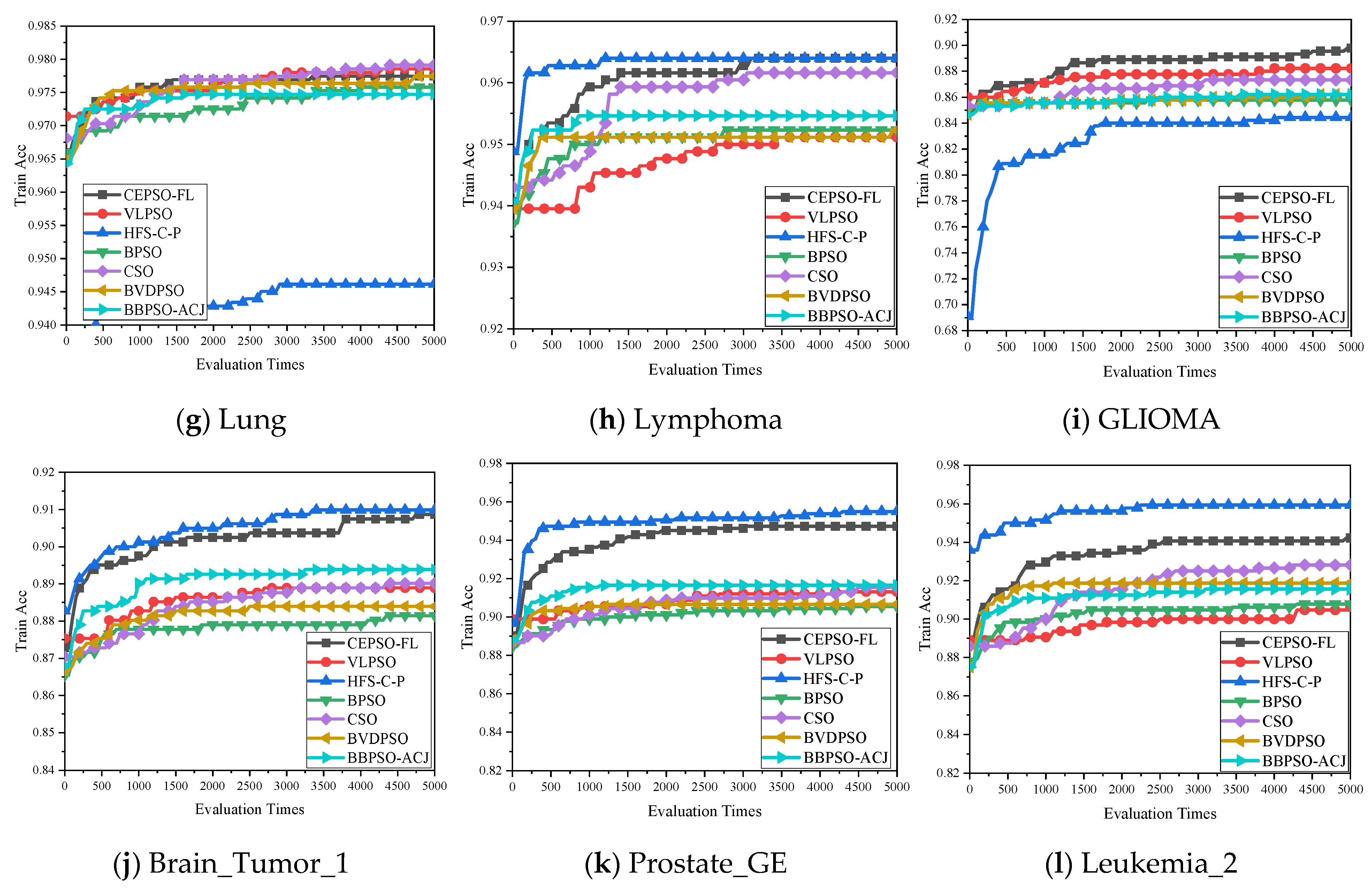
4.3. Experimental Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dash, M. Feature Selection via set cover. In Proceedings of the Proceedings 1997 IEEE Knowledge and Data Engineering Exchange Workshop, Newport Beach, CA, USA, 4 November 1997; pp. 165–171. [Google Scholar]
- Ladha, L.; Deepa, T. Feature selection methods and algorithms. Int. J. Comput. Sci. Eng. 2011, 3, 1787–1797. [Google Scholar]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar]
- Xue, B.; Zhang, M.; Browne, W.N.; Yao, X. A Survey on Evolutionary Computation Approaches to Feature Selection. IEEE Trans. Evol. Comput. 2016, 20, 606–626. [Google Scholar] [CrossRef] [Green Version]
- Oreski, S.; Oreski, G. Genetic algorithm-based heuristic for feature selection in credit risk assessment. Expert Syst. Appl. 2014, 41, 2052–2064. [Google Scholar] [CrossRef]
- Mistry, K.; Zhang, L.; Neoh, S.C.; Lim, C.P.; Fielding, B. A micro-GA embedded PSO feature selection approach to intelligent facial emotion recognition. IEEE Trans. Cybern. 2017, 47, 1496–1509. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Gong, D.; Gao, X.; Tian, T.; Sun, X. Binary differential evolution with self-learning for multi-objective feature selection. Inf. Sci. 2020, 507, 67–85. [Google Scholar] [CrossRef]
- Xu, H.; Xue, B.; Zhang, M. A duplication analysis-based evolutionary algorithm for biobjective feature selection. IEEE Trans. Evol. Comput. 2021, 25, 205–218. [Google Scholar] [CrossRef]
- Liu, X.F.; Zhan, Z.H.; Gao, Y.; Zhang, J.; Kwong, S.; Zhang, J. Coevolutionary particle swarm optimization with bottleneck objective learning strategy for many-objective optimization. IEEE Trans. Evol. Comput. 2019, 23, 587–602. [Google Scholar] [CrossRef]
- Wang, Z.J.; Zhan, Z.H.; Kwong, S.; Jin, H.; Zhang, J. Adaptive granularity learning distributed particle swarm optimization for large-scale optimization. IEEE Trans. Cybern. 2021, 51, 1175–1188. [Google Scholar] [CrossRef]
- Jian, J.R.; Chen, Z.G.; Zhan, Z.H.; Zhang, J. Region encoding helps evolutionary computation evolve faster: A new solution encoding scheme in particle swarm for large-scale optimization. IEEE Trans. Evol. Comput. 2021, 25, 779–793. [Google Scholar] [CrossRef]
- Li, J.Y.; Zhan, Z.H.; Liu, R.D.; Wang, C.; Kwong, S.; Zhang, J. Generation-level parallelism for evolutionary computation: A pipeline-based parallel particle swarm optimization. IEEE Trans. Cybern. 2021, 51, 4848–4859. [Google Scholar] [CrossRef] [PubMed]
- Tran, B.; Xue, B.; Zhang, M. Improved PSO for feature selection on high-dimensional datasets. In Lecture Notes in Computer Science, Proceedings of the Simulated Evolution and Learning, Dunedin, New Zealand, 2014; Dick, G., Browne, W.N., Whigham, P., Zhang, M., Bui, L.T., Ishibuchi, H., Jin, Y., Li, X., Shi, Y., Singh, P., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 503–515. [Google Scholar]
- Zhang, Y.; Gong, D.; Sun, X.; Geng, N. Adaptive bare-bones particle swarm optimization algorithm and its convergence analysis. Soft Comput. 2014, 18, 1337–1352. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Khader, A.T.; Hanandeh, E.S. A new feature selection method to improve the document clustering using particle swarm optimization algorithm. J. Comput. Sci. 2018, 25, 456–466. [Google Scholar] [CrossRef]
- Wang, Y.Y.; Zhang, H.; Qiu, C.H.; Xia, S.R. A novel feature selection method based on extreme learning machine and fractional-order darwinian PSO. Comput. Intell. Neurosci. 2018, 2018, e5078268. [Google Scholar] [CrossRef]
- Bhattacharya, A.; Goswami, R.T.; Mukherjee, K. A feature selection technique based on rough set and improvised PSO algorithm (PSORS-FS) for permission based detection of android malwares. Int. J. Mach. Learn. Cyber. 2019, 10, 1893–1907. [Google Scholar] [CrossRef]
- Huda, R.K.; Banka, H. Efficient feature selection and classification algorithm based on PSO and rough sets. Neural Comput. Applic. 2019, 31, 4287–4303. [Google Scholar] [CrossRef]
- Huda, R.K.; Banka, H. New efficient initialization and updating mechanisms in PSO for feature selection and classification. Neural Comput. Applic. 2020, 32, 3283–3294. [Google Scholar] [CrossRef]
- Zhou, Y.; Lin, J.; Guo, H. Feature subset selection via an improved discretization-based particle swarm optimization. Appl. Soft Comput. 2021, 98, 106794. [Google Scholar] [CrossRef]
- Nguyen, B.H.; Xue, B.; Zhang, M. A survey on swarm intelligence approaches to feature selection in data mining. Swarm Evol. Comput. 2020, 54, 100663. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Kennedy, J.; Eberhart, R.C. A discrete binary version of the particle swarm algorithm. In Proceedings of the Computational Cybernetics and Simulation 1997 IEEE International Conference on Systems, Man, and Cybernetics, Orlando, EL, USA, 12–15 October 1997; Volume 5, pp. 4104–4108. [Google Scholar]
- Shen, M.; Zhan, Z.H.; Chen, W.; Gong, Y.; Zhang, J.; Li, Y. Bi-Velocity discrete particle swarm optimization and its application to multicast routing problem in communication networks. IEEE Trans. Ind. Electron. 2014, 61, 7141–7151. [Google Scholar] [CrossRef]
- Qiu, C. Bare bones particle swarm optimization with adaptive chaotic jump for feature selection in classification. Int. J. Comput. Intell. Syst. 2018, 11, 1. [Google Scholar] [CrossRef] [Green Version]
- Gu, S.; Cheng, R.; Jin, Y. Feature selection for high-dimensional classification using a competitive swarm optimizer. Soft Comput. 2018, 22, 811–822. [Google Scholar] [CrossRef] [Green Version]
- Tran, B.; Xue, B.; Zhang, M. Variable-length particle swarm optimization for feature selection on high-dimensional classification. IEEE Trans. Evol. Comput. 2019, 23, 473–487. [Google Scholar] [CrossRef]
- Song, X.F.; Zhang, Y.; Guo, Y.N.; Sun, X.Y.; Wang, Y.L. Variable-size cooperative coevolutionary particle swarm optimization for feature selection on high-dimensional data. IEEE Trans. Evol. Comput. 2020, 24, 882–895. [Google Scholar] [CrossRef]
- Chen, K.; Xue, B.; Zhang, M.; Zhou, F. An evolutionary multitasking-based feature selection method for high-dimensional classification. IEEE Trans. Cybern. 2020, in press. [Google Scholar] [CrossRef]
- Song, X.F.; Zhang, Y.; Gong, D.W.; Gao, X.Z. A fast hybrid feature selection based on correlation-guided clustering and particle swarm optimization for high-dimensional data. IEEE Trans. Cybern. 2021, in press. [Google Scholar] [CrossRef] [PubMed]
- Bommert, A.; Sun, X.; Bischl, B.; Rahnenführer, J.; Lang, M. Benchmark for filter methods for feature selection in high-dimensional classification data. Comput. Stat. Data Anal. 2020, 143, 106839. [Google Scholar] [CrossRef]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature selection: A data perspective. ACM Comput. Surv. 2017, 50, 94:1–94:45. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.H.; Zhan, Z.H.; Zhang, J. SAFE: Scale-adaptive fitness evaluation method for expensive optimization problems. IEEE Trans. Evol. Comput. 2021, 25, 478–491. [Google Scholar] [CrossRef]
- Li, J.Y.; Zhan, Z.H.; Zhang, J. Evolutionary computation for expensive optimization: A survey. Mach. Intell. Res. 2022, 19, 3–23. [Google Scholar] [CrossRef]
- Zhan, Z.H.; Shi, L.; Tan, K.C.; Zhang, J. A survey on evolutionary computation for complex continuous optimization. Artif. Intell. Rev. 2022, 55, 59–110. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Dataset | Samples | Features | Categories |
|---|---|---|---|---|
| 1 | Madelon | 500 | 500 | 2 |
| 2 | Isolet | 500 | 617 | 26 |
| 3 | COIL20 | 500 | 1024 | 20 |
| 4 | Yale | 165 | 1024 | 15 |
| 5 | ORL | 400 | 1024 | 40 |
| 6 | WarpAR10P | 130 | 2400 | 10 |
| 7 | Lung | 203 | 3312 | 5 |
| 8 | Lymphoma | 96 | 4026 | 9 |
| 9 | GLIOMA | 50 | 4434 | 4 |
| 10 | Brain_Tumor_1 | 90 | 5920 | 5 |
| 11 | Prostate_GE | 102 | 5966 | 2 |
| 12 | Leukemia_2 | 72 | 7129 | 4 |
| Algorithm | Parameter Settings |
|---|---|
| BPSO [24] | P = 20, the range of velocity: [−6, 6], c1 = c2 = 2.01, w = 1. |
| BVDPSO [25] | P = 20, the range of w: [0.4, 0.9], c1 = c2 = 2, selected threshold α = 0.5. |
| BBPSO-ACJ [26] | P = 20, chaotic factor z0 = 0.13, selected threshold λ = 0.5. |
| CSO [27] | P = 100, control factor ϕ = 0.1, selected threshold λ = 0.5. |
| VLPSO [28] | P = min{features/20,300}, c = 1.49445, the range of w: [0.4, 0.9], selected threshold λ = 0.6, max iterations to renew exemplar: 7, number of divisions: 12, max iterations for length changing: 9. |
| HFS-C-P [31] | P = 20. |
| CEPSO-FL | P = 20, archive size: 100, c1 = c2 = 1, the range of w: [0.4, 0.7], N = 8. |
| Data | BPSO | BVDPSO | CSO | BBPSO-ACJ | VLPSO | HFS-C-P | CEPSO-FL |
|---|---|---|---|---|---|---|---|
| Madelon | 0.690(+) | 0.694(+) | 0.720(+) | 0.706(+) | 0.720(+) | 0.748(=) | 0.780 |
| Isolet | 0.878(−) | 0.882(−) | 0.874(−) | 0.890(−) | 0.878(−) | 0.828(=) | 0.834 |
| COIL20 | 0.906(=) | 0.914(=) | 0.910(=) | 0.922(−) | 0.890(=) | 0.898(=) | 0.892 |
| Yale | 0.535(=) | 0.541(=) | 0.535(=) | 0.541(=) | 0.518(=) | 0.547(=) | 0.582 |
| ORL | 0.903(=) | 0.883(=) | 0.900(=) | 0.898(=) | 0.873(=) | 0.903(=) | 0.878 |
| WarpAR10P | 0.531(+) | 0.538(+) | 0.600(=) | 0.600(=) | 0.569(=) | 0.654(=) | 0.669 |
| Lung | 0.914(=) | 0.919(=) | 0.910(=) | 0.919(=) | 0.895(=) | 0.867(+) | 0.910 |
| Lymphoma | 0.810(=) | 0.810(=) | 0.800(=) | 0.830(=) | 0.820(=) | 0.810(=) | 0.790 |
| GLIOMA | 0.760(=) | 0.800(=) | 0.740(=) | 0.800(=) | 0.740(=) | 0.700(=) | 0.740 |
| Brain_Tumor_1 | 0.856(=) | 0.822(=) | 0.844(=) | 0.844(=) | 0.856(=) | 0.867(=) | 0.822 |
| Prostate_GE | 0.773(=) | 0.782(=) | 0.755(+) | 0.736(+) | 0.764(=) | 0.818(=) | 0.809 |
| Leukemia_2 | 0.750(=) | 0.750(=) | 0.750(=) | 0.738(=) | 0.738(=) | 0.763(=) | 0.775 |
| +/=/− | 2/9/1 | 2/9/1 | 2/9/1 | 2/8/2 | 1/10/1 | 1/11/0 | NA |
| Data | BPSO | BVDPSO | CSO | BBPSO-ACJ | VLPSO | HFS-C-P | CEPSO-FL |
|---|---|---|---|---|---|---|---|
| Madelon | 309.5(+) | 321.8(+) | 157.9(+) | 197.8(+) | 87.8(+) | 83.8(+) | 8.3 |
| Isolet | 377.2(+) | 385.8(+) | 356.7(+) | 273.0(+) | 187.5(+) | 238.2(+) | 78.3 |
| COIL20 | 620.3(+) | 595.5(+) | 260.8(+) | 288.1(+) | 287.8(+) | 394.4(+) | 78.7 |
| Yale | 626.5(+) | 602.9(+) | 412.5(+) | 376.7(+) | 330.4(+) | 625.4(+) | 90.2 |
| ORL | 629.4(+) | 649.9(+) | 713.2(+) | 505.5(+) | 390.0(+) | 874.2(+) | 100.6 |
| WarpAR10P | 1485.2(+) | 1431.4(+) | 442.1(+) | 126.1(+) | 478.8(+) | 565.9(+) | 19.5 |
| Lung | 2048.7(+) | 1829.0(+) | 1401.4(+) | 1086.1(+) | 743.1(=) | 19.1(−) | 373.8 |
| Lymphoma | 2356.7(+) | 2219.4(+) | 1402.8(+) | 1382.1(+) | 1135.5(+) | 508.9(+) | 187.5 |
| GLIOMA | 2611.1(+) | 2402.5(+) | 1566.6(+) | 1932.5(+) | 389.1(+) | 9.5(−) | 86.1 |
| Brain_Tumor_1 | 3547.0(+) | 3403.1(+) | 3009.3(+) | 1348.6(+) | 1375.8(+) | 1452.8(+) | 191.2 |
| Prostate_GE | 3667.2(+) | 3392.2(+) | 2186.7(+) | 1043.9(+) | 1474.4(+) | 12.1(−) | 63.0 |
| Leukemia_2 | 4399.9(+) | 4234.6(+) | 3219.4(+) | 2523.4(+) | 2150.6(+) | 607.0(+) | 221.7 |
| +/=/− | 12/0/0 | 12/0/0 | 12/0/0 | 12/0/0 | 11/1/0 | 9/0/3 | NA |
| Data | BPSO | BVDPSO | CSO | BBPSO-ACJ | VLPSO | HFS-C-P | CEPSO-FL |
| Madelon | 64.4 | 64.5 | 62.9 | 50.9 | 26.6 | 53.5 | 52.2 |
| Isolet | 78.7 | 79.9 | 145.9 | 65.6 | 40.1 | 148.1 | 72.7 |
| COIL20 | 136.8 | 127.9 | 143.0 | 112.1 | 51.9 | 178.2 | 112.6 |
| Yale | 15.2 | 14.7 | 16.2 | 12.1 | 7.2 | 23.6 | 13.2 |
| ORL | 83.8 | 87.3 | 102.5 | 73.4 | 47.8 | 195.8 | 80.0 |
| WarpAR10P | 39.0 | 57.7 | 29.8 | 27.6 | 10.4 | 23.3 | 15.8 |
| Lung | 210.3 | 183.2 | 160.6 | 104.9 | 51.2 | 50.1 | 61.7 |
| Lymphoma | 65.0 | 62.6 | 50.4 | 36.8 | 13.9 | 33.3 | 16.2 |
| GLIOMA | 20.1 | 20.5 | 15.4 | 11.2 | 6.1 | 4.0 | 4.2 |
| Brain_Tumor_1 | 84.6 | 96.4 | 66.8 | 51.9 | 28.6 | 66.8 | 19.4 |
| Prostate_GE | 113.4 | 113.5 | 88.5 | 64.9 | 37.8 | 21.7 | 24.1 |
| Leukemia_2 | 70.9 | 68.1 | 44.7 | 38.8 | 28.5 | 28.9 | 16.1 |
| Data | Test Acc | Feature Num | Time (min) | ||||||
| N = 2 | N = 8 | N = 32 | N = 2 | N = 8 | N = 32 | N = 2 | N = 8 | N = 32 | |
| Madelon | 0.788 | 0.780 | 0.802 | 7.7 | 8.3 | 19.6 | 49.8 | 52.2 | 70.6 |
| Isolet | 0.838 | 0.834 | 0.844 | 90.6 | 78.3 | 67.4 | 70.9 | 72.7 | 75.4 |
| COIL20 | 0.874 | 0.892 | 0.902 | 45.0 | 78.7 | 75.2 | 111.5 | 112.6 | 114.3 |
| Yale | 0.547 | 0.582 | 0.535 | 99.4 | 90.2 | 127.0 | 14.0 | 13.2 | 13.4 |
| ORL | 0.868 | 0.878 | 0.838 | 115.6 | 100.6 | 100.4 | 81.6 | 80.0 | 76.5 |
| WarpAR10P | 0.592 | 0.669 | 0.692 | 22.9 | 19.5 | 43.7 | 15.7 | 15.8 | 16.3 |
| Lung | 0.895 | 0.910 | 0.895 | 359.7 | 373.8 | 286.7 | 57.8 | 61.7 | 69.3 |
| Lymphoma | 0.790 | 0.790 | 0.840 | 266.4 | 187.5 | 349.6 | 16.1 | 16.2 | 16.3 |
| GLIOMA | 0.680 | 0.740 | 0.700 | 136.2 | 86.1 | 74.8 | 4.6 | 4.2 | 4.6 |
| Brain_Tumor_1 | 0.778 | 0.822 | 0.822 | 204.4 | 191.2 | 145.6 | 19.7 | 19.4 | 20.5 |
| Prostate_GE | 0.782 | 0.809 | 0.800 | 17.7 | 63.0 | 99.7 | 23.9 | 24.1 | 26.0 |
| Leukemia_2 | 0.713 | 0.775 | 0.775 | 219.9 | 221.7 | 305.3 | 15.9 | 16.1 | 15.7 |
| Rank Sum | 31 | 19 | 20 | 24 | 23 | 25 | 20 | 22 | 30 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.-Q.; Chen, C.-H.; Li, J.-Y.; Liu, D.; Li, T.; Zhan, Z.-H. Compressed-Encoding Particle Swarm Optimization with Fuzzy Learning for Large-Scale Feature Selection. Symmetry 2022, 14, 1142. https://doi.org/10.3390/sym14061142
Yang J-Q, Chen C-H, Li J-Y, Liu D, Li T, Zhan Z-H. Compressed-Encoding Particle Swarm Optimization with Fuzzy Learning for Large-Scale Feature Selection. Symmetry. 2022; 14(6):1142. https://doi.org/10.3390/sym14061142
Chicago/Turabian StyleYang, Jia-Quan, Chun-Hua Chen, Jian-Yu Li, Dong Liu, Tao Li, and Zhi-Hui Zhan. 2022. "Compressed-Encoding Particle Swarm Optimization with Fuzzy Learning for Large-Scale Feature Selection" Symmetry 14, no. 6: 1142. https://doi.org/10.3390/sym14061142