
Generating Image Captions Using Bahdanau Attention Mechanism and Transfer Learning



Abstract
:1. Introduction
1.1. Motivation
1.2. Related Work
- (a)
- Attribute-based visual representation: The features of an image are represented by a confidence vector, which is a combination of objects, attributes, stuff, interactions, relations, and so forth. In this paper [23], the authors presented a semantic attention model based on text conditions. Using this attention model, on the basis of the previously generated text, the encoder can learn on which parts of the image the model needs to focus.
- (b)
- Grid-based visual feature representation without semantic labels: In this type of attention model, the features are extracted using CNN and fed to the attention model. It focuses on those spatial regions that need attention. K. Xu et al. [24], propose an end to end 14 × 14 VGG-based spatial attention model using hard and soft methods.
- (c)
- Object-based visual representation: In order to infer the latent alignments between image regions and segments of sentences by treating the sentences as weak labels, A. Karpathy et al. [35] presented an alignment model based on Bidirectional RNN (BRNN) and Region-CNN (RCNN). To generate descriptions of the image, they used an end-to-end RNN model.
1.3. Contribution
- In this work, we propose to use two deep learning architectures called VGG16 and InceptionV3 followed by an attribute-based visual representation attention mechanism.
- Based on this comparative analysis, we investigate how attention mechanisms can be used to find non-visual words present in the image and thus improve the overall image captioning performance.
- This paper provides an extensive analysis to compare the architecture difference between two pre-trained deep learning models viz VGG16 and InceptionV3 for image captioning.
- We evaluate the two deep learning architectures on a famous challenging dataset Flicker8k dataset.
2. Proposed Methodology
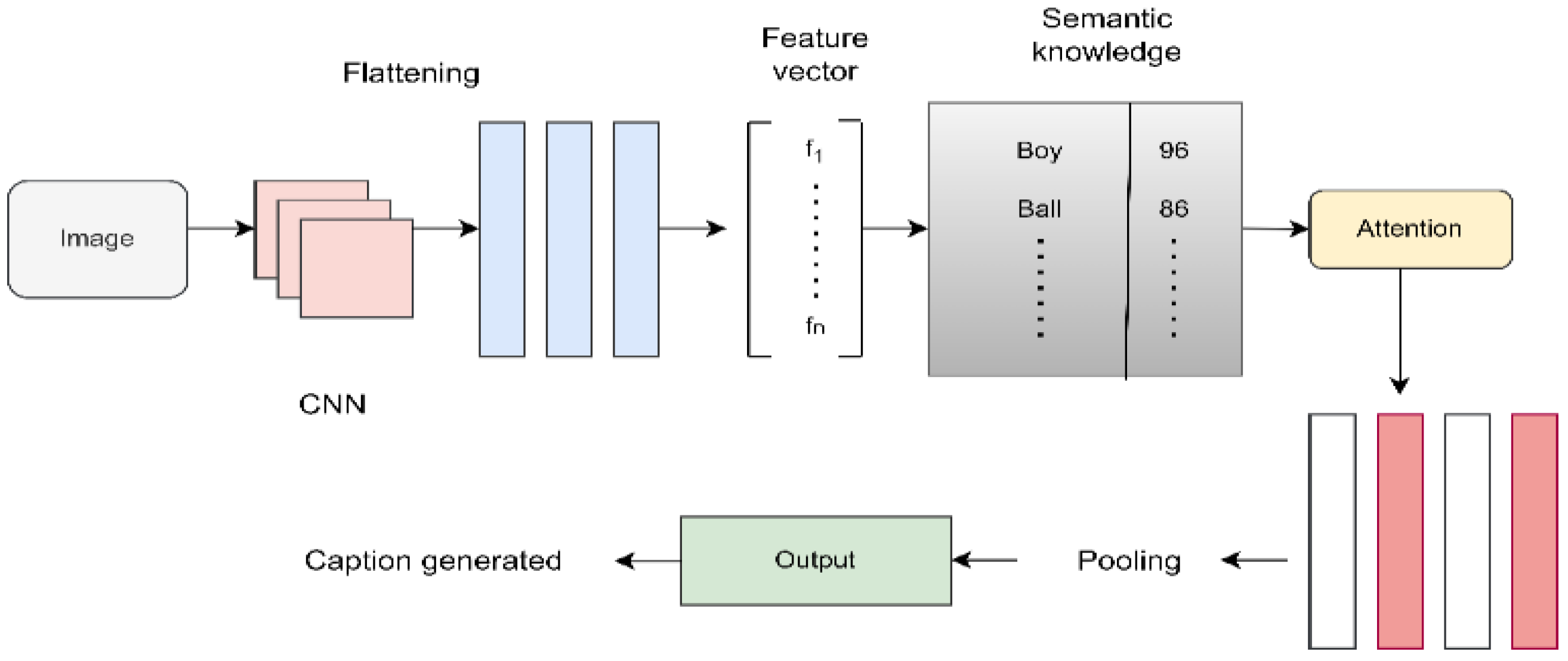
2.1. Deep Feature Extractor
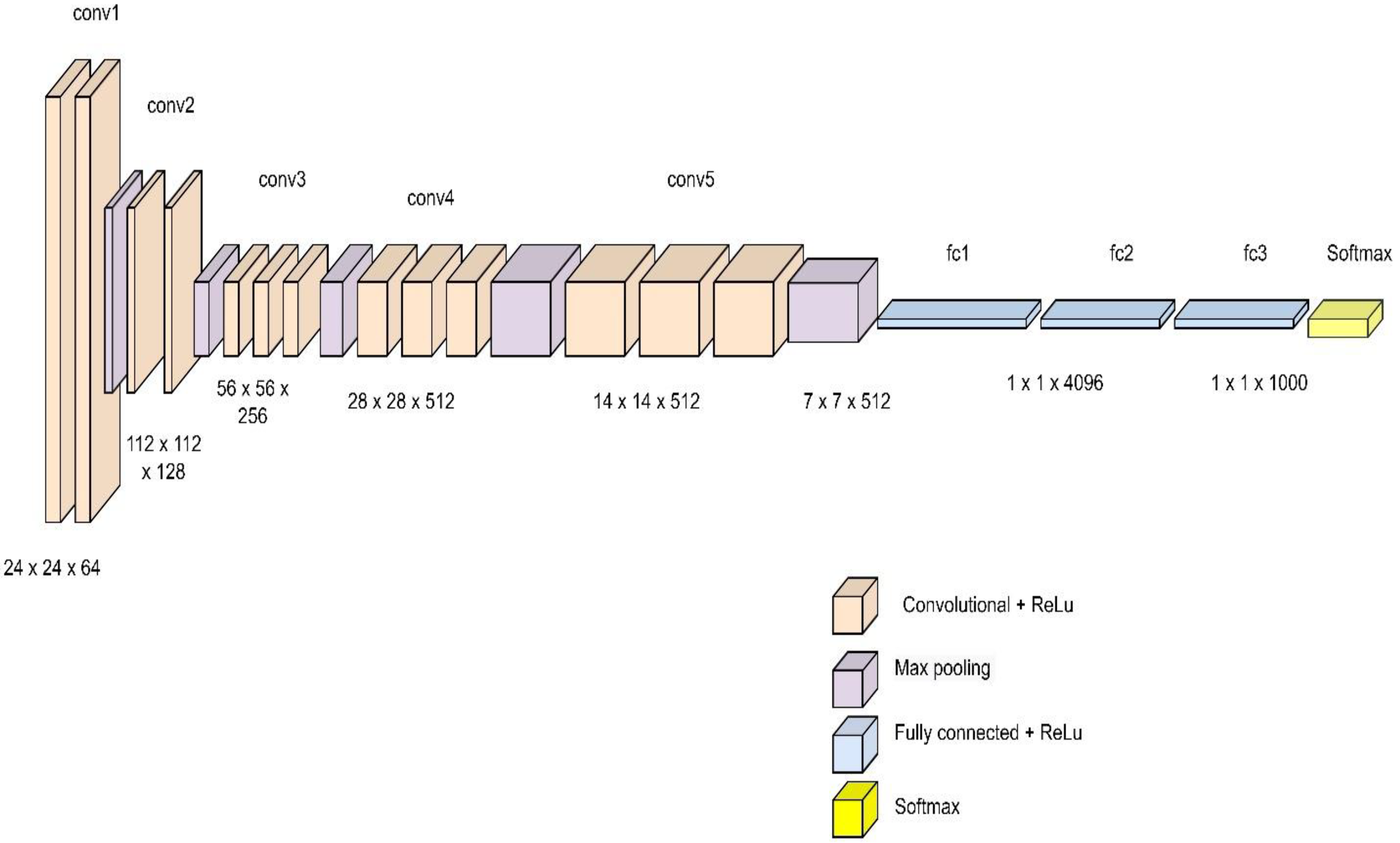
2.1.1. Basic VGG16 Architecture for Image Captioning
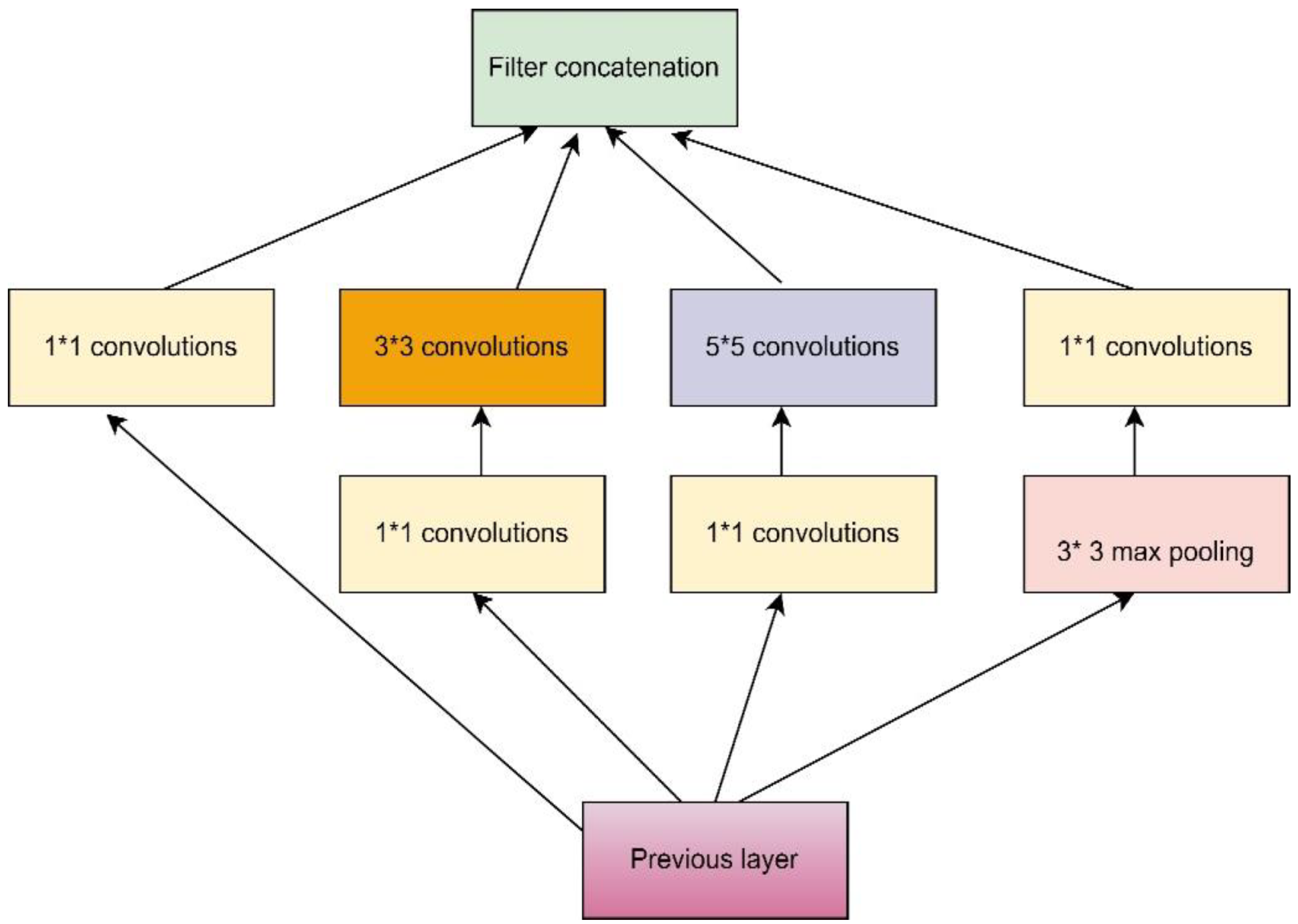
2.1.2. Basic Inception Architecture for Image Captioning
2.1.3. Transfer Learning
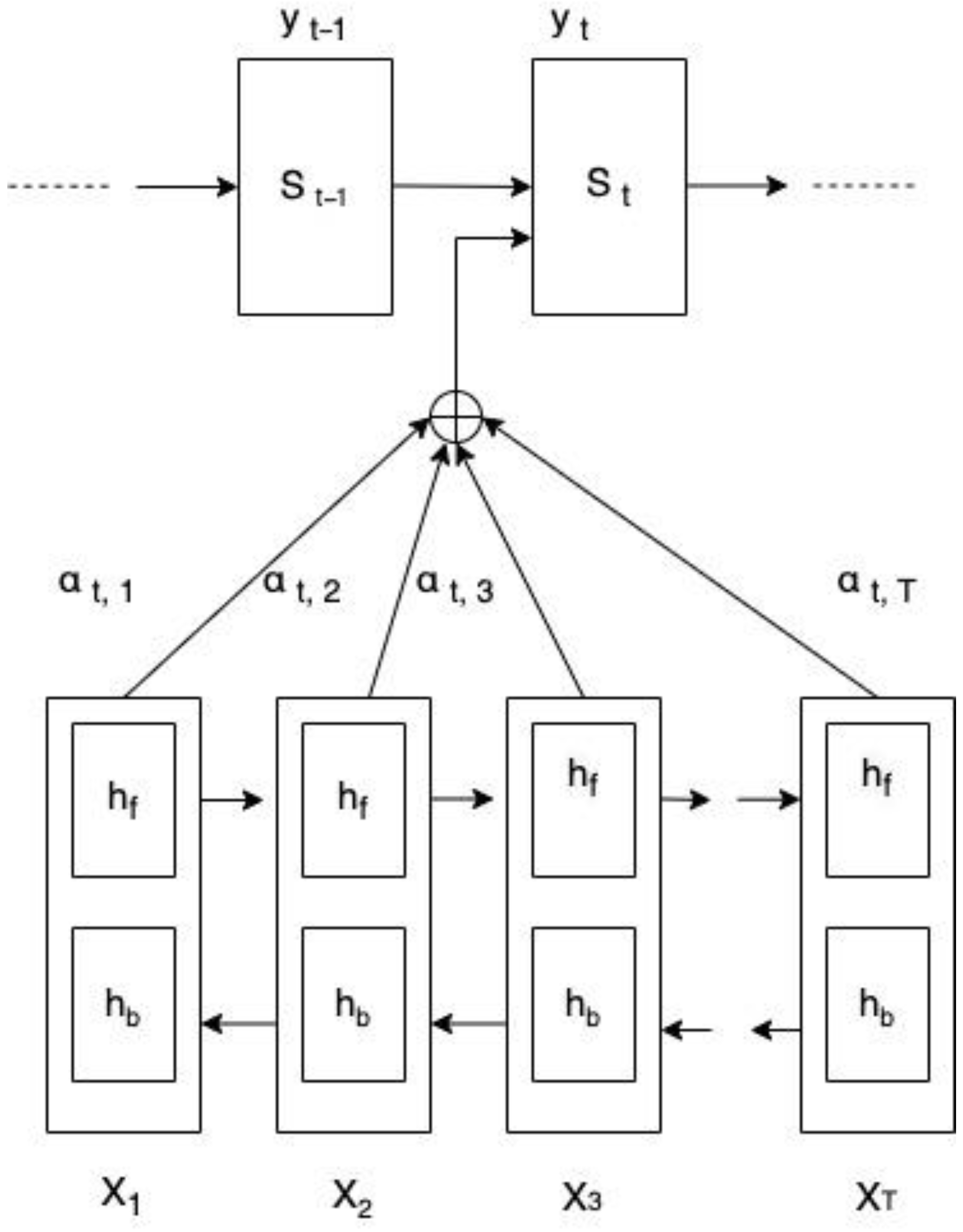
2.1.4. Attention Mechanism
- The hidden decoder state present at the previous time step t − 1 is S t–1.
- A unique context vector ct at time step t is generated at each decoder step to generate a target word yt.
- An annotation h i that captures the crucial information on words focusing around the i-th word out of the total words.
- At the current time step t, the weight value assigned to each annotation h i is αt,i.
- An assigned model a (.) generates an attention score et,i. that shows how well S t−1 and h i matches.
| Algorithm 1. Pseudo code of Bahdanau architecture with attention mechanism. |
| 1. Using input sentence, the encoder generates a set of annotations, h i |
| 2. h i along with S t−1 (previous hidden decoder state) is fed to a (.); to calculate attention score, i.e., e t, i: e t, i = a (S t−1, h i) |
| 3. Apply Softmax function as: α t, i.= Softmax (e t, i) |
| 4. Generate context vector: Ct = h i |
| 5. To compute the final output yt, Ct and S t−1 are fed to the decoder. |
| 6. Repeat steps 2–6 till the end of the sentence. |
3. Experimental Setup
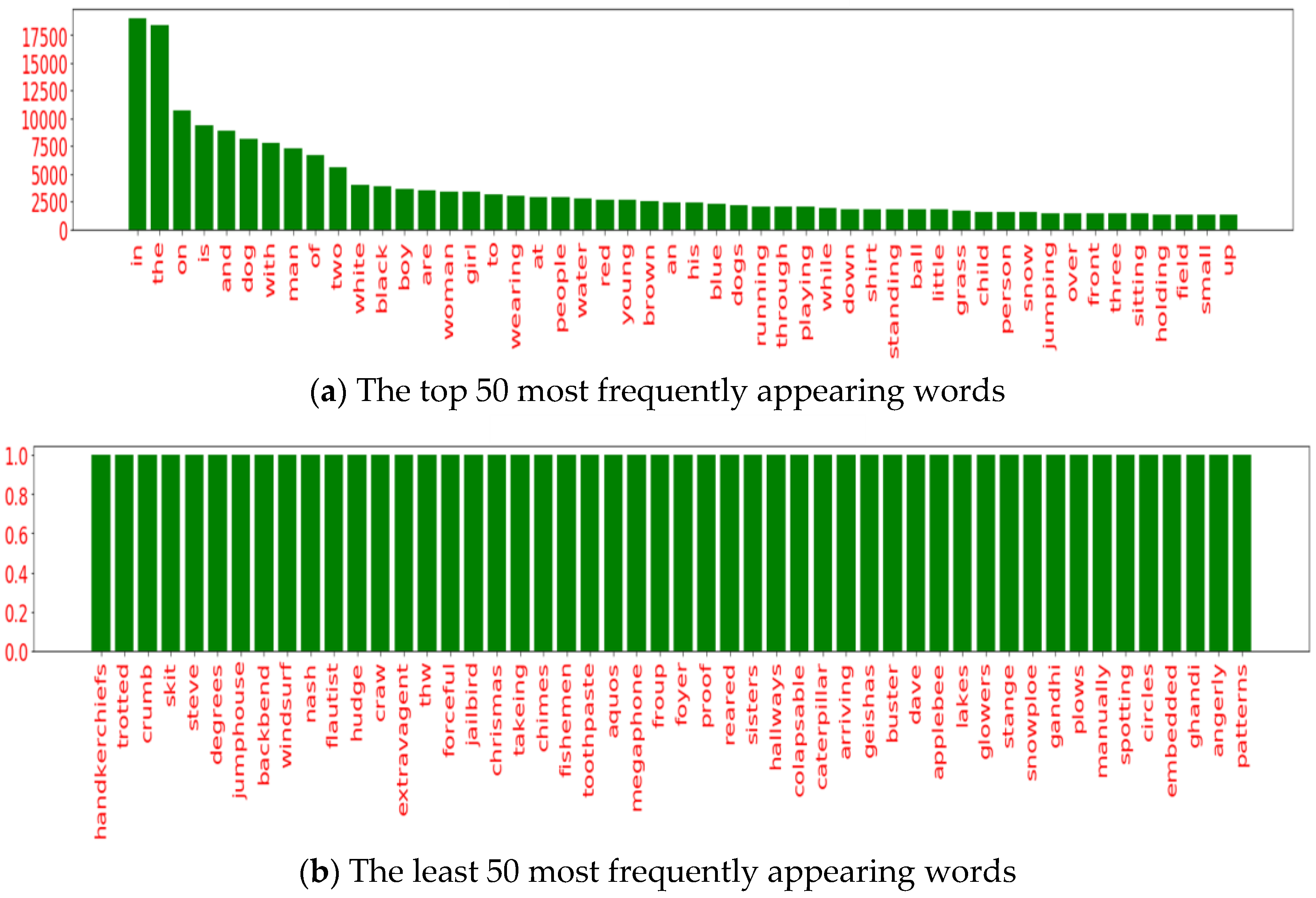
3.1. Dataset
3.2. Performance Metrics
- BLEU (Bilingual evaluation understudy): a well-known machine translation statistic is used to measure the similarity of one sentence with reference to multiple sentences. It was proposed by Papineni et al. in [45]. It returns a value where a higher value represents more similarity. This method works by counting the number of n-grams in one sentence with the n-grams in the reference sentence. A unigram or 1-gram represents a token, whereas a bi-gram indicates each pair of a word. For calculating the BLEU score of multiple sentences, Corpus BLEU is employed, in which a reference list is indicated using a list of documents, and a candidate document is a list where the document is a list of tokens.
- ROUGE (Recall Oriented Understudy for Gisting Evaluation): It counts the number of “n-grams” that match between the caption generated by our model and a reference. For example, ROUGE-N means using n-grams, etc.
- METEOR (Metric for Evaluation for Translation with Explicit Ordering): Unlike BLEU, this metric calculates F-score based on mapping unigrams.
3.3. Experimental Setting
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, P.; Yang, A.; Men, R.; Lin, J.; Bai, S.; Li, Z.; Ma, J.; Zhou, C.; Zhou, J.; Yang, H. OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework. arXiv 2022, arXiv:2202.03052. Available online: https://arxiv.org/abs/2202.03052 (accessed on 14 July 2022).
- Hsu, T.Y.; Giles, C.L.; Huang, T.H. SCICAP: Generating Captions for Scientific Figures. In Findings of the Association for Computational Linguistics, Findings of ACL: EMNLP 2021; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 3258–3264. [Google Scholar] [CrossRef]
- Hossain, M.Z.; Sohel, F.; Shiratuddin, M.F.; Laga, H.; Bennamoun, M. Text to Image Synthesis for Improved Image Captioning. IEEE Access 2021, 9, 64918–64928. [Google Scholar] [CrossRef]
- Sehgal, S.; Sharma, J.; Chaudhary, N. Generating Image Captions Based on Deep Learning and Natural Language Processing. In Proceedings of the ICRITO 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) IEEE, Noida, India, 4–5 June 2020; pp. 165–169. [Google Scholar] [CrossRef]
- Jain, H.; Zepeda, J.; Perez, P.; Gribonval, R. Learning a Complete Image Indexing Pipeline. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4933–4941. [Google Scholar] [CrossRef] [Green Version]
- Pang, S.; Orgun, M.A.; Yu, Z. A Novel Biomedical Image Indexing and Retrieval System via Deep Preference Learning. Comput. Methods Prog. Biomed. 2018, 158, 53–69. [Google Scholar] [CrossRef] [PubMed]
- Makav, B.; Kilic, V. A New Image Captioning Approach for Visually Impaired People. In Proceedings of the 11th International Conference on Electrical and Electronics Engineering (ELECO 2019), Bursa, Turkey, 28–30 November 2019; pp. 945–949. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, Q.; Wang, Y.; Chen, F. High-Quality Image Captioning with Fine-Grained and Semantic-Guided Visual Attention. IEEE Trans. Multimed. 2019, 21, 1681–1693. [Google Scholar] [CrossRef]
- Alam, S.; Raja, P.; Gulzar, Y. Investigation of Machine Learning Methods for Early Prediction of Neurodevelopmental Disorders in Children. Wirel. Commun. Mob. Comput. 2022, 2022, 5766386. [Google Scholar] [CrossRef]
- Sahlan, F.; Hamidi, F.; Misrat, M.Z.; Adli, M.H.; Wani, S.; Gulzar, Y. Prediction of Mental Health Among University Students. Int. J. Perceptive Cogn. Comput. 2021, 7, 85–91. [Google Scholar]
- Khan, S.A.; Gulzar, Y.; Turaev, S.; Peng, Y.S. A Modified HSIFT Descriptor for Medical Image Classification of Anatomy Objects. Symmetry 2021, 13, 1987. [Google Scholar] [CrossRef]
- Gulzar, Y.; Khan, S.A. Skin Lesion Segmentation Based on Vision Transformers and Convolutional Neural Networks—A Comparative Study. Appl. Sci. 2022, 12, 5990. [Google Scholar] [CrossRef]
- Albarrak, K.; Gulzar, Y.; Hamid, Y.; Mehmood, A.; Soomro, A.B. A Deep Learning-Based Model for Date Fruit Classification. Sustainability 2022, 14, 6339. [Google Scholar] [CrossRef]
- Gulzar, Y.; Hamid, Y.; Soomro, A.B.; Alwan, A.A.; Journaux, L. A Convolution Neural Network-Based Seed Classification System. Symmetry 2020, 12, 2018. [Google Scholar] [CrossRef]
- Hamid, Y.; Wani, S.; Soomro, A.B.; Alwan, A.A.; Gulzar, Y. Smart Seed Classification System Based on MobileNetV2 Architecture. In Proceedings of the 2nd International Conference on Computing and Information Technology, ICCIT 2022, Tabuk, Saudi Arabia, 25–27 January 2022; pp. 217–222. [Google Scholar] [CrossRef]
- Hamid, Y.; Elyassami, S.; Gulzar, Y.; Balasaraswathi, V.R.; Habuza, T.; Wani, S. An Improvised CNN Model for Fake Image Detection. Int. J. Inf. Technol. 2022, 1–11. [Google Scholar] [CrossRef]
- Faris, M.; Hanafi, F.M.; Sukri Faiz, M.; Nasir, M.; Wani, S.; Abdulkhaleq, R.; Abdulghafor, A.; Gulzar, Y.; Hamid, Y. A Real Time Deep Learning Based Driver Monitoring System. Int. J. Perceptive Cogn. Comput. 2021, 7, 79–84. [Google Scholar]
- Sharma, H.; Jalal, A.S. Incorporating External Knowledge for Image Captioning Using CNN and LSTM. Mod. Phys. Lett. B 2020, 34, 2050315. [Google Scholar] [CrossRef]
- Wang, C.; Yang, H.; Bartz, C.; Meinel, C. Image Captioning with Deep Bidirectional LSTMs. In Proceedings of the 2016 ACM Multimedia Conference, Amsterdam, The Netherlands, 15–19 October 2016; pp. 988–997. [Google Scholar] [CrossRef] [Green Version]
- Aneja, J.; Deshpande, A.; Schwing, A.G. Convolutional Image Captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5561–5570. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Zhang, H.; Cai, J. Learning to Collocate Neural Modules for Image Captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2019; pp. 4249–4259. [Google Scholar] [CrossRef] [Green Version]
- Khan, R.; Islam, M.S.; Kanwal, K.; Iqbal, M.; Hossain, M.I.; Ye, Z. A Deep Neural Framework for Image Caption Generation Using GRU-Based Attention Mechanism. arXiv 2022, arXiv:2203.01594. [Google Scholar]
- Zhou, L.; Xu, C.; Koch, P.; Corso, J.J. Watch What You Just Said: Image Captioning with Text-Conditional Attention. In Proceedings of the Thematic Workshops 2017—Proceedings of the Thematic Workshops of ACM Multimedia 2017, Co-Located with MM 2017, Mountain View, CA, USA, 23–27 October 2017; pp. 305–313. [Google Scholar] [CrossRef]
- Xu, K.; Ba, J.L.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.S.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; Volume 3, pp. 2048–2057. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing When to Look: Adaptive Attention via a Visual Sentinel for Image Captioning. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 3242–3250. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar] [CrossRef] [Green Version]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Exploring Visual Relationship for Image Captioning. In Computer Vision—ECCV 2018, 15th European Conference, Munich, Germany, 8–14 September 2018; Part XIV; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2018; Volume 11218, pp. 711–727. [Google Scholar] [CrossRef] [Green Version]
- Chen, F.C.; Jahanshahi, M.R. NB-CNN: Deep Learning-Based Crack Detection Using Convolutional Neural Network and Naïve Bayes Data Fusion. IEEE Trans. Ind. Electron. 2018, 65, 4392–4400. [Google Scholar] [CrossRef]
- Gupta, R.; Bhardwaj, K.K.; Sharma, D.K. Transfer Learning. In Machine Learning and Big Data: Concepts, Algorithms, Tools and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2020; pp. 337–360. [Google Scholar] [CrossRef]
- Huang, L.; Wang, W.; Chen, J.; Wei, X.Y. Attention on Attention for Image Captioning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4633–4642. [Google Scholar] [CrossRef] [Green Version]
- Hodosh, M.; Young, P.; Hockenmaier, J. Framing Image Description as a Ranking Task: Data, Models and Evaluation Metrics. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2015), Buenos Aires, Argentina, 25–31 July 2015; pp. 4188–4192. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and Tell: A Neural Image Caption Generator. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Karpathy, A.; Li, F.-F. Deep Visual-Semantic Alignments for Generating Image Descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 664–676. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Tang, S.; Zhang, Y.; Deng, L.; Tian, Q. GLA: Global-Local Attention for Image Description. IEEE Trans. Multimed. 2018, 20, 726–737. [Google Scholar] [CrossRef]
- Ding, G.; Chen, M.; Zhao, S.; Chen, H.; Han, J.; Liu, Q. Neural Image Caption Generation with Weighted Training and Reference. Cogn. Comput. 2019, 11, 763–777. [Google Scholar] [CrossRef] [Green Version]
- Yan, S.; Xie, Y.; Wu, F.; Smith, J.S.; Lu, W.; Zhang, B. Image Captioning via Hierarchical Attention Mechanism and Policy Gradient Optimization. Signal Process. 2020, 167, 107329. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Seo, J.; Han, S.; Lee, S.; Kim, H. Computer Vision Techniques for Construction Safety and Health Monitoring. Adv. Eng. Inform. 2015, 29, 239–251. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014—Conference Track Proceedings, Banff, AB, Canada, 14–16 April 2014; pp. 1–10. [Google Scholar]
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015 Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Maru, H.; Chandana, T.S.S.; Naik, D. Comparison of Image Encoder Architectures for Image Captioning. In Proceedings of the 5th International Conference on Computing Methodologies and Communication, ICCMC 2021, Erode, India, 8–10 April 2021; pp. 740–744. [Google Scholar] [CrossRef]










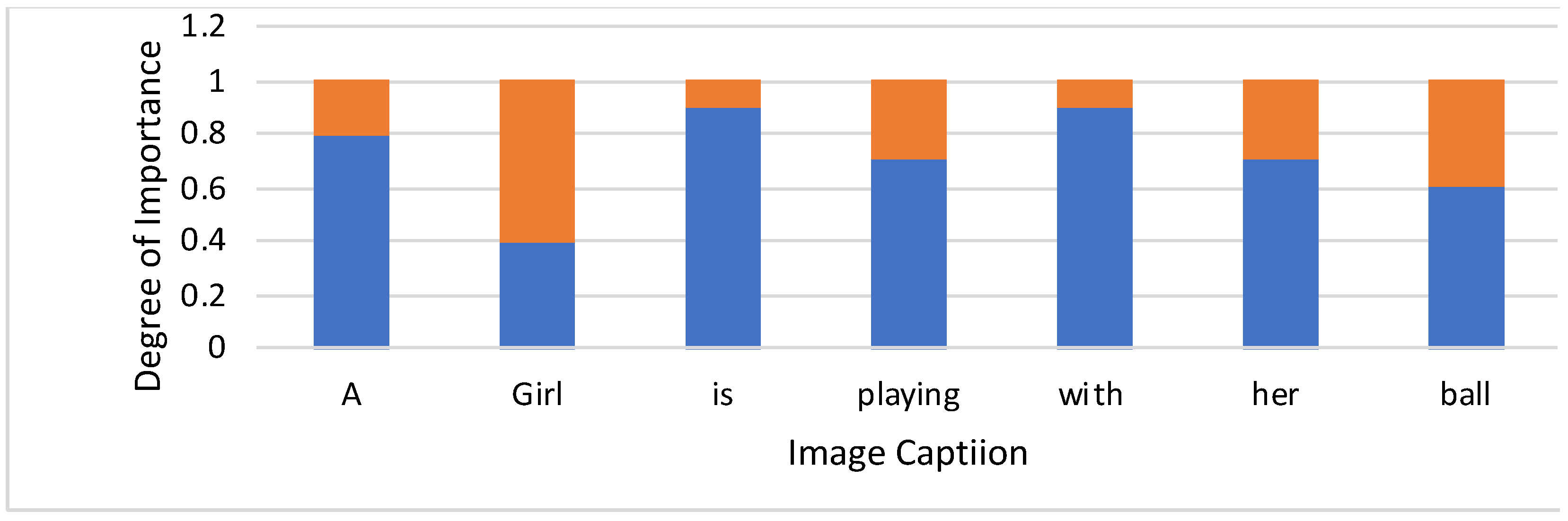{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No | Dataset | Year | Model | Attention Mechanism | Remarks |
|---|---|---|---|---|---|
| 1. | ILSVRC-2012 | 2015 | ConvNet [27] | × | No focus on non-visual objects |
| 2. | ImageNet | 2015 | ResNet 101 [26] | × | No focus on attention mechanism |
| 3. | Pascal VOC 2008, Flickr8k, Flickr30k, MSCOCO, SBU | 2015 | CNN-LSTM [33] | × | No focus on attention mechanism |
| 4. | Pascal VOC 2012, Pascal Context, Pascal Pearson part, cityscape | 2017 | ResNet 101 [34] | × | Proposed model failed to capture boundaries |
| 5. | COCO, Flickr30K, Flickr8k | 2016 | Bi-LSTM [19] | × | No focus on attention mechanism |
| 6. | COCO, Flickr30K, Flickr8k | 2017 | CNN [35] | √ | Proposed model requires more investigation to avoid overfitting |
| 7. | COCO dataset Flickr30K, Flickr8k | 2018 | CNN- RNN [36] | √ | Framework is not end to end |
| 8. | MSCOCO, COCO stuff | 2018 | FCN-LSTM [8] | √ | Did not evaluate different pre-trained models |
| 9. | MSCOCO, Visual Genome dataset, VQA v2.0 dataset | 2018 | Faster R-CNN + ResNet 101-LSTM [21] | √ | Proposed model is computationally costly |
| 10. | COCO dataset | 2018 | Graph CNN- LSTM [28] | √ | Evaluated their model only on one dataset |
| 11. | MS-COCO, Flickr30K | 2019 | Reference LSTM [37] | × | Did not incorporate attention mechanism |
| 12. | MS-COCO | 2019 | RCNN-LSTM [31] | √ | Attention on attention may lead to loss of significant information |
| 13. | MS-COCO | 2019 | CNN-LSTM [38] | √ | Training GAN is computationally very costly |
| 14. | Flickr30K, Flickr8k | 2020 | CNN-LSTM [18] | √ | Did not evaluate different pre- trained models |
| 15. | MS-COCO | 2022 | CNN-GRU [22] | √ | Evaluated the model only on one dataset |
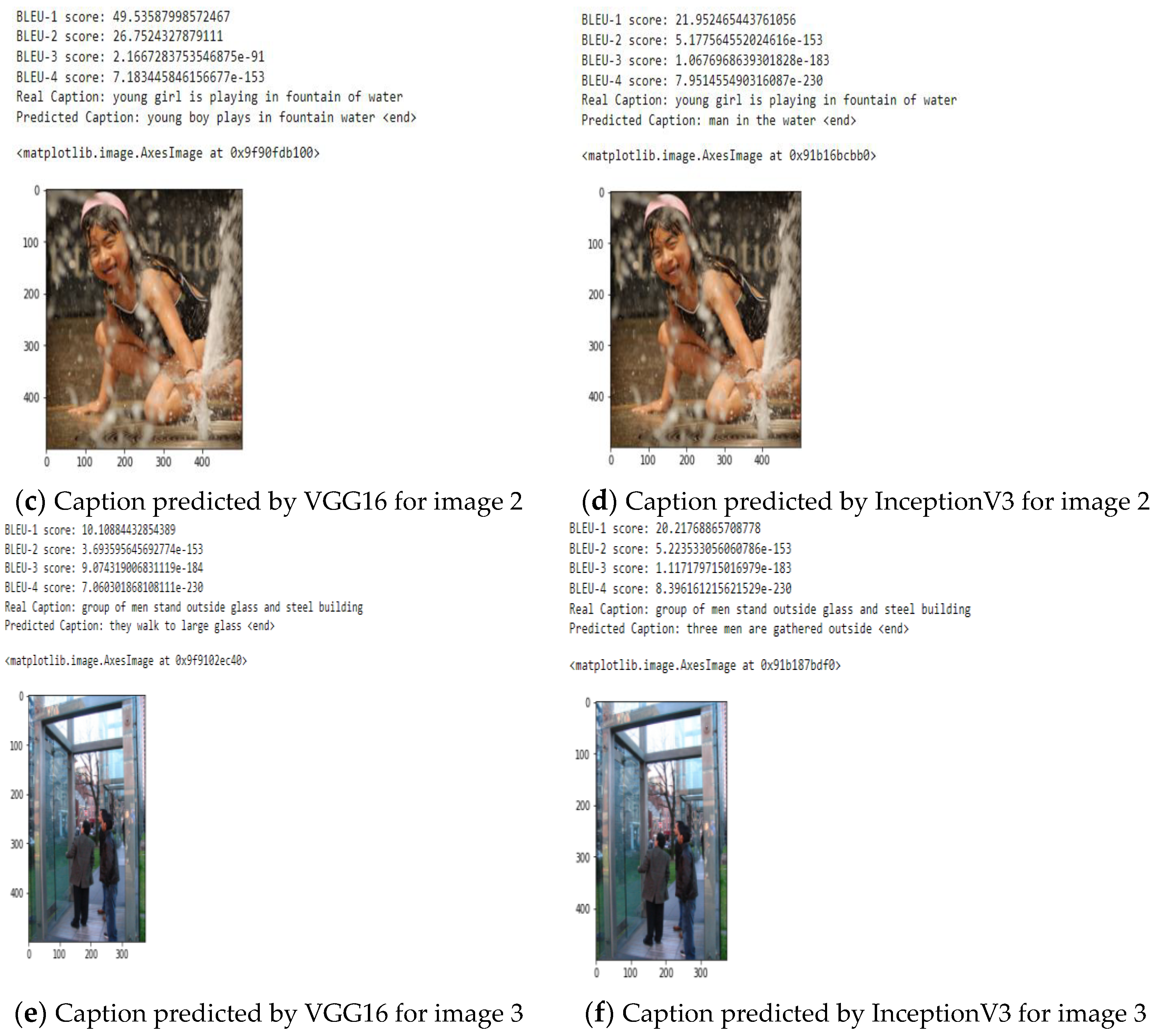
| Model | Score | Image 1 | Image 2 | Image 3 |
|---|---|---|---|---|
| VGG16 | BLEU-1 | 62.5 | 49.5 | 10.1 |
| BLEU-2 | 42.2 | 26.7 | 3.69 | |
| BLEU-3 | 3 | 2.1 | 9.07 | |
| BLEU-4 | 9.6 | 7.1 | 7.06 | |
| ROUGE | 0.56 | 0.60 | 0.59 | |
| METEOR | 0.26 | 0.31 | 0.33 |
| Model | Score | Image 1 | Image 2 | Image 3 |
|---|---|---|---|---|
| InceptionV3 | BLEU-1 | 28.57 | 21.9 | 20.21 |
| BLEU-2 | 7.97 | 5.17 | 5.22 | |
| BLEU-3 | 1.75 | 1.06 | 1.11 | |
| BLEU-4 | 1.33 | 7.95 | 8.39 | |
| ROUGE | 0.59 | 0.54 | 0.55 | |
| METEOR | 0.27 | 0.29 | 0.23 |
| S. No. | Model | Score | Image 1 |
|---|---|---|---|
| 1. | ResNet [23] | BLEU-1 | 29.5 |
| 2. | BLEU-2 | 30.5 | |
| 3. | BLEU-3 | 29 | |
| 4. | BLEU-4 | 30 | |
| 5. | ROUGE | - | |
| 6. | METEOR | 0.24 | |
| 7. | ResNet with ReLU [23] | BLEU-1 | 29 |
| METEOR | 25 | ||
| ROUGE | - | ||
| 8. | ResNet with tanh [23] | BLEU-1 | 25 |
| METEOR | 25 | ||
| ROUGE | - | ||
| 9. | ResNet with Softmax [23] | BLEU-1 | 29 |
| METEOR | 24 | ||
| ROUGE | - | ||
| 10. | ResNet with Sigmoid [23] | BLEU-1 | 30 |
| METEOR | 24 | ||
| ROUGE | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ayoub, S.; Gulzar, Y.; Reegu, F.A.; Turaev, S. Generating Image Captions Using Bahdanau Attention Mechanism and Transfer Learning. Symmetry 2022, 14, 2681. https://doi.org/10.3390/sym14122681
Ayoub S, Gulzar Y, Reegu FA, Turaev S. Generating Image Captions Using Bahdanau Attention Mechanism and Transfer Learning. Symmetry. 2022; 14(12):2681. https://doi.org/10.3390/sym14122681
Chicago/Turabian StyleAyoub, Shahnawaz, Yonis Gulzar, Faheem Ahmad Reegu, and Sherzod Turaev. 2022. "Generating Image Captions Using Bahdanau Attention Mechanism and Transfer Learning" Symmetry 14, no. 12: 2681. https://doi.org/10.3390/sym14122681