1. Introduction
Measuring the distances of a driver’s vehicle to its surroundings is essential in advanced driver assistance systems (ADAS) for road safety. Existing distance measurement methods can be classified into three groups: active sensor-based, passive vision-based, and fusion-based methods. Active sensor-based approaches use sensors such as radar and light detection and ranging (LiDAR) for distance measurement. Radars are able to detect objects up to 150 m away [
1], but they are limited by low resolutions [
2]. LiDAR provides higher resolutions [
3] but is costly [
4,
5,
6,
7]. The main advantages of active sensors are that they are efficient in distance measurement [
2] and applicable in different visibility conditions [
5].
Passive vision-based approaches use vision sensors such as cameras for distance estimation. Existing vision-based methods can be classified into two groups: stereo camera-based methods and monocular camera-based methods. Stereo camera-based methods consider multiple-view geometry and provide depth for each pixel by matching stereo image pairs [
2,
5]. However, stereo camera-based methods are limited by the complexity of stereo calibration, errors in matching stereo image pairs, and efficiency in actual road scenarios [
2,
5,
6,
8]. Monocular camera-based methods use a single camera for distance estimation and therefore are inexpensive [
5,
6], and they have become a trend in distance estimation.
The monocular camera-based approaches can be further classified into geometric approaches and deep learning-based approaches. Geometric approaches use geometric properties in a two-dimensional (2D) image and camera parameters for distance estimation. Kim and Cho [
9] used the relative position information between the camera and front vehicle, camera setting parameters, and the width of the front vehicle to estimate the inter-vehicle distance. Liu et al. [
10] applied inverse perspective mapping transformation to convert an image to a bird’s eye view and restore the road plane information to estimate the inter-vehicle distance. Such methods are limited by their heavy dependence on image brightness and the accuracy in measuring the camera parameters and the target size.
Recently, deep learning-based approaches have become popular in distance estimation from a monocular camera. Such methods commonly train various neural networks for distance estimation [
6,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20]. Guizilini et al. [
13] proposed using three-dimensional (3D) packing and unpacking blocks in their self-supervised network to preserve spatial information for depth estimation. Zhang et al. [
15] proposed a network with regions with convolutional neural network (R-CNN)-based structures for distance estimation and explored several regression methods to improve distance estimation results. Fu et al. [
17] proposed a deep ordinal regression network and adopted a multi-scale network structure for depth estimation. Xu et al. [
18] proposed fusing the side outputs of multi-scale CNNs with continuous conditional random fields (CRFs) for depth estimation through supervised learning. Liang et al. [
6] proposed a self-supervised, scale-aware network to estimate distance. However, their method requires calibrating the camera and integrating the calibrated parameters into their network.
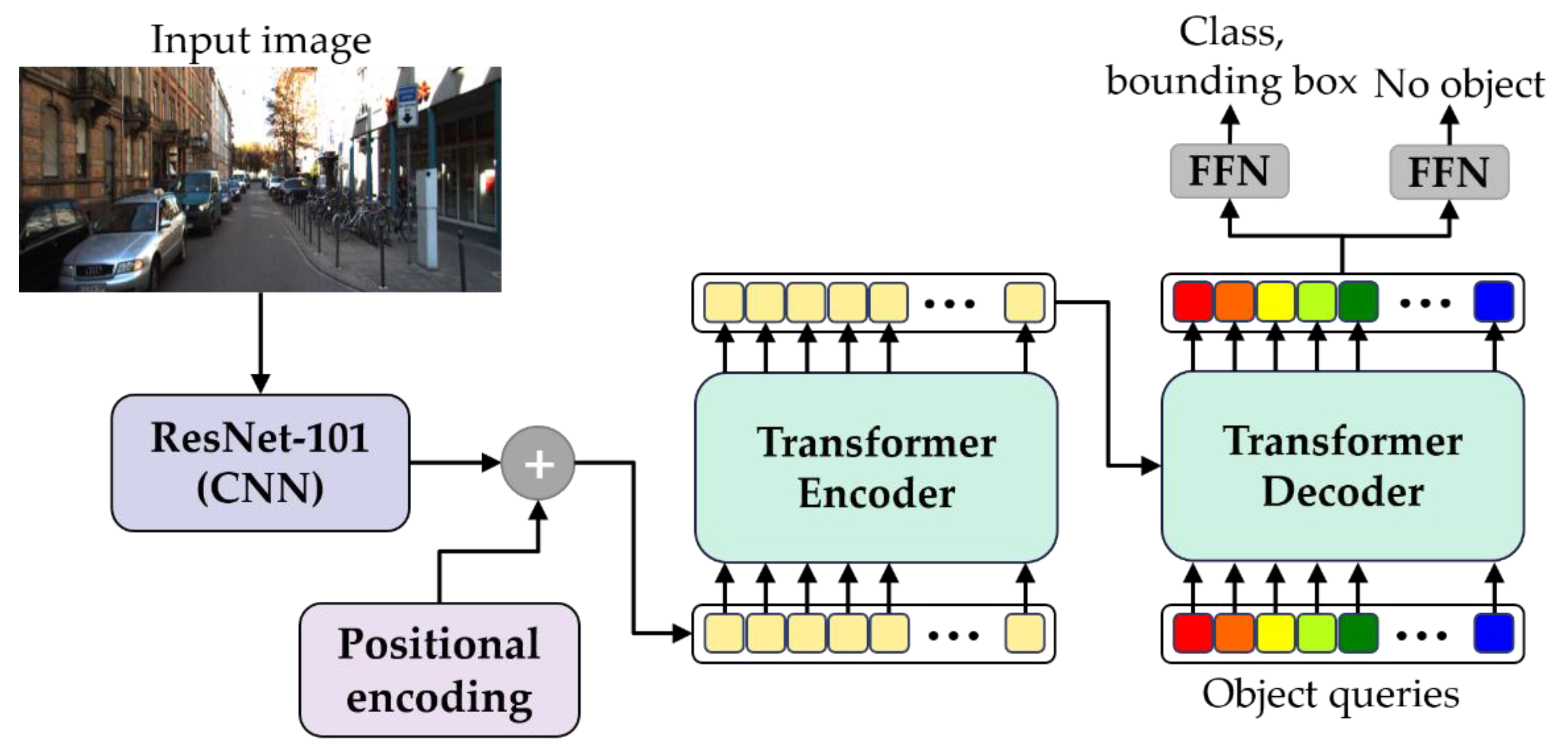
Before distance estimation, object detection needs to be performed to identify different objects that are mostly symmetrical from an image. Object detection methods can be classified into conventional [
21,
22,
23] and deep learning-based methods [
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35]. Conventional object detection methods usually manually extract features from the selected region of interest and then classify the extracted features. However, the conventional methods are computationally costly and insufficient in accuracy [
6]. Deep learning-based methods train various CNN-based or transformer-based models in a supervised learning or self-supervised learning manner for object detection. The results of deep learning-based methods are promising.
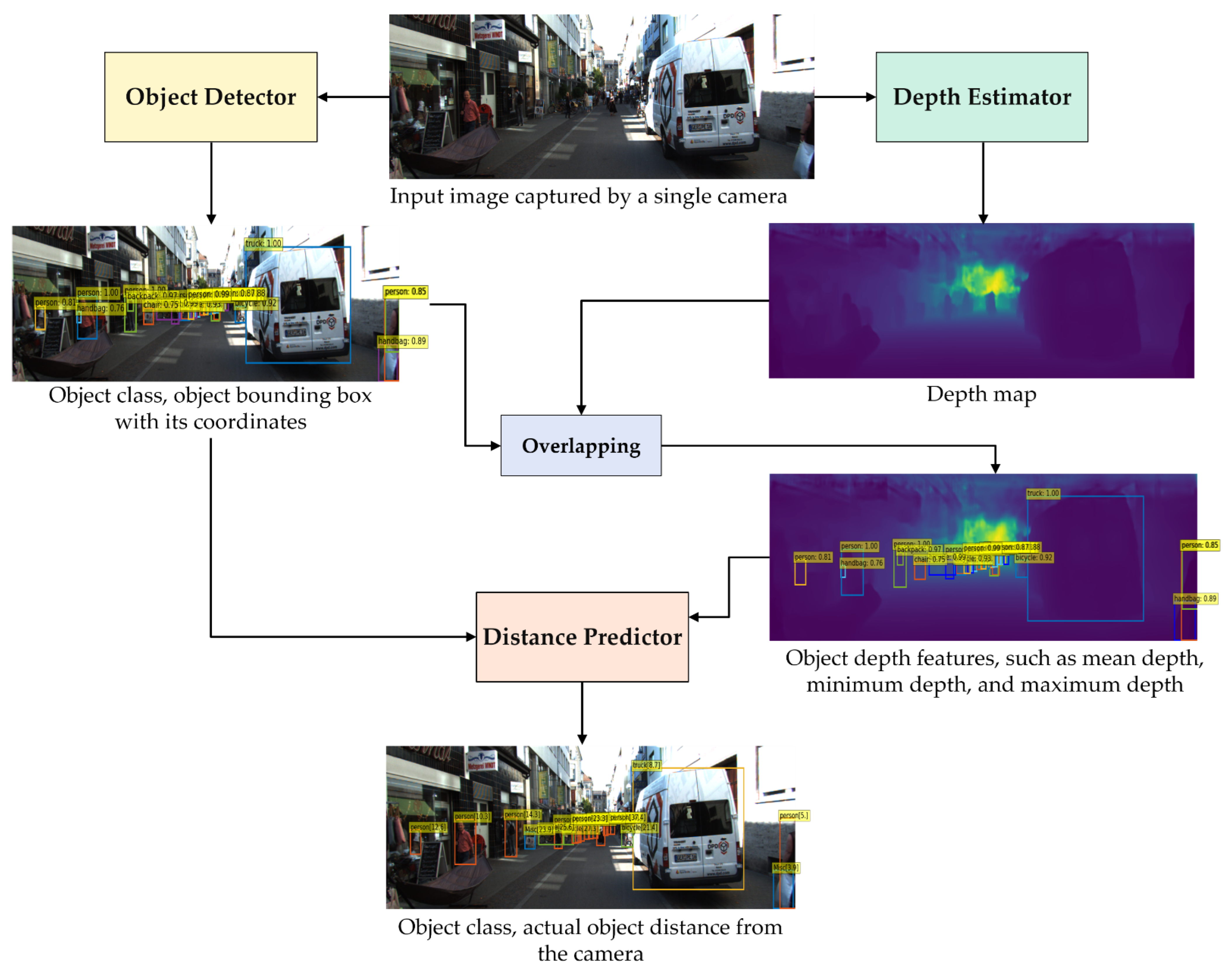
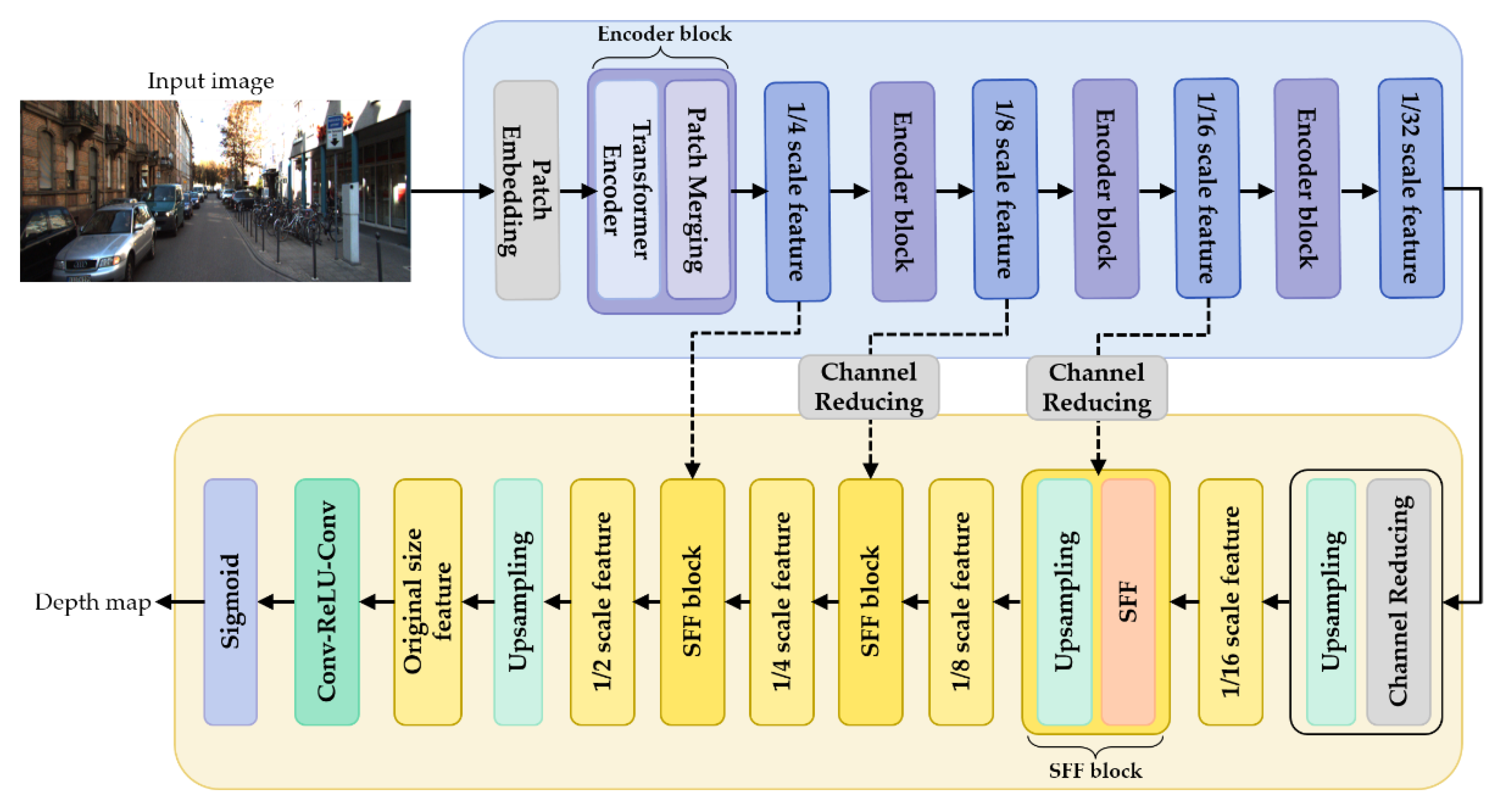
This study was intended to propose and evaluate a framework for better accuracy and efficiency in vehicle distance estimation. The proposed framework consists of an object detector and a depth estimator based on a transformer. After depth estimation, different models were applied to predict vehicle distance from depth information to find the best-performing model.
4. Results and Discussion
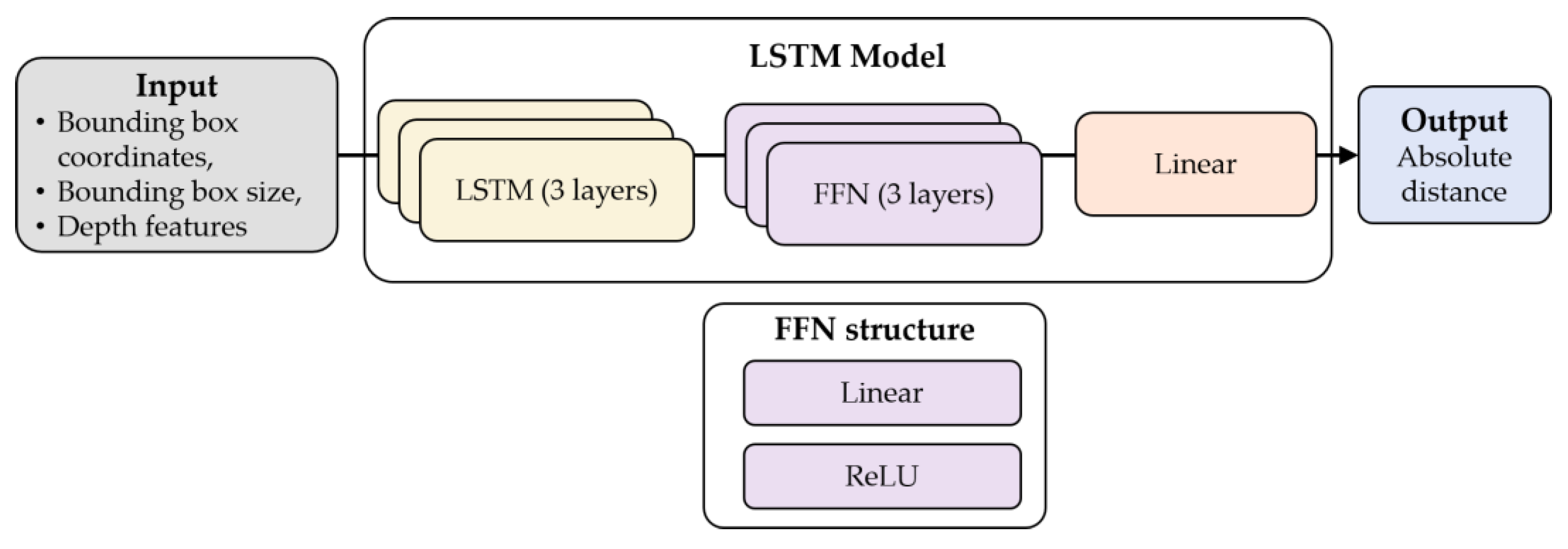
Table 3 shows the evaluation results of the three distance prediction models. Among the three models, LSTM outperformed the other models in terms of the MAE. For different object classes, this study found that the XGBoost model showed the best performance in distance prediction for the car and bicycle classes. For the remaining classes, the LSTM model showed the best performance. Therefore, in the proposed distance prediction framework, if a car or a bicycle was detected, the XGBoost model was used for distance prediction. Otherwise, the LSTM model was used.
Table 4 shows the evaluation results of the three models at different distance intervals. As the object distance increased, this study found that the error in distance prediction increased for all the three models.
Table 5 shows the evaluation results when using different levels for the trimmed mean object depth, namely 10%, 20%, and 30%. Among the three different levels, using a 20% trimmed mean depth achieved the best performance in distance prediction for the three distance prediction models, except for the RF model. Since our framework will use the XGBoost and LSTM models only, using the 20% trimmed mean depth is recommended.
Table 6 shows the evaluation results of the three distance prediction models trained using the ground truth bounding boxes from the KITTI dataset and those trained using the identified bounding boxes with the object detector in the proposed framework. This study found that the latter showed better performance. This is the reason why our models were trained using the identified bounding boxes.
Table 7 shows the performance comparison results for the KITTI dataset between the proposed framework and various other methods, including one stereo camera-based study that used stereo image pairs to train their network. The proposed framework outperformed the other studies in terms of the five measurements.
Table 8 shows the on-road evaluation results of the proposed distance prediction framework. Compared with other studies [
7,
42], the proposed framework showed the best performance at different distance levels. The time required for distance prediction by the proposed framework was approximately 0.3 sec per frame. Kim [
7] reported that the processing time was 0.76 sec per frame.
A potential limitation of the proposed distance prediction framework is that the accuracy of the distance predictor depends on the accuracy of the object detector and that of the depth estimator. For the distance predictor, this study suggests that if the detected object is a car or a bicycle, then the XGBoost model is used for distance prediction; otherwise, the LSTM model is used. It is possible that a non-car or non-bicycle object could be falsely detected as a car or a bicycle. In that case, the accuracy of distance prediction could be slightly affected.
To use our proposed framework in a vehicle, any webcam can be used, since the proposed framework does not require a high-end webcam. The webcam needs to be mounted so it is approximately level with the ground plane. The webcam can be mounted at the head of the vehicle. In this case, no calibration is needed. The webcam can be mounted on the platform above the center console of a vehicle or attached to the top of the windshield of the vehicle as well. In this case, simple calibration is needed. The horizontal distance between the head of the vehicle and the camera needs to be measured. The measurement can be performed within one minute using a tape measure or any other distance measurement tools. Then, the measured distance can be input into the proposed framework to subtract the measured distance from the predicted distance, and thus the proposed framework can provide the distance between the front vehicle and the head of the driver’s vehicle. A smartphone can be used instead of a webcam for video recording. In this case, the one-site video stream can be sent to a cloud server with the proposed framework installed for distance prediction, and then the predicted distance can be sent back to the smartphone for driving assistance.
ADAS plays a more and more important role in preventing deaths and injuries by decreasing the number of car accidents. Typical ADAS features include adaptive cruise control, forward collision warnings, automatic emergency braking (AEB), pedestrian AEB, rear AEB, lane keeping assistance, blind spot warnings, parking sensor ADAS, and rearview camera ADAS. Based on each ADAS feature, its sensors are mounted at different locations of a vehicle, including the top of the front windshield, the lower front bumper, and the front, rear, and sides of a vehicle. In the U.S., 92.7% of new vehicles had at least one ADAS feature in 2018 [
43]. Distance prediction between a driver’s vehicle and its surroundings is an essential task for ADAS. The proposed framework can be used for accomplishing the distance prediction task.
5. Conclusions
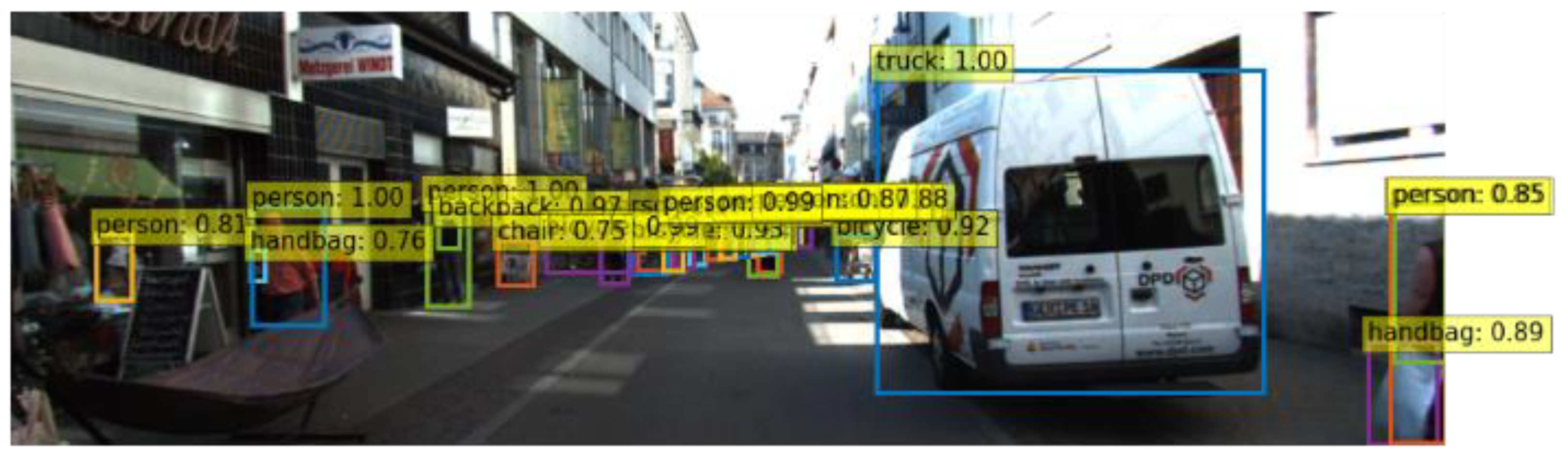
The proposed framework estimates the distances between one’s vehicle and the objects in front of the vehicle from an image captured by a webcam mounted in the vehicle. The object detector in the proposed framework detects the classes and bounding boxes of the objects. The depth estimator in the proposed framework estimates the depth map of the captured image. The depth map is overlaid with the bounding boxes to extract the depth features for each object. If the object is a car or a bicycle, then the XGBoost model is used for predicting the distance between the camera and the object, based on the bounding box and depth features of the object. Otherwise, the LSTM model is used.
In the on-road experiment, the accuracy of the proposed framework for distance estimation was 93.19–99.50% at different distance levels. The processing time was 0.3 sec per frame. The proposed framework outperformed the existing studies in terms of accuracy and efficiency. A limitation of this work is that the experiment was conducted on a wide road without many cars in order to mark the ground truth distances. For future work, the proposed framework needs to be comprehensively evaluated in various road conditions.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}