
Intelligent System for Estimation of the Spatial Position of Apples Based on YOLOv3 and Real Sense Depth Camera D415

 ,
,  ,
,  , ,
, ,  and
and 
Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
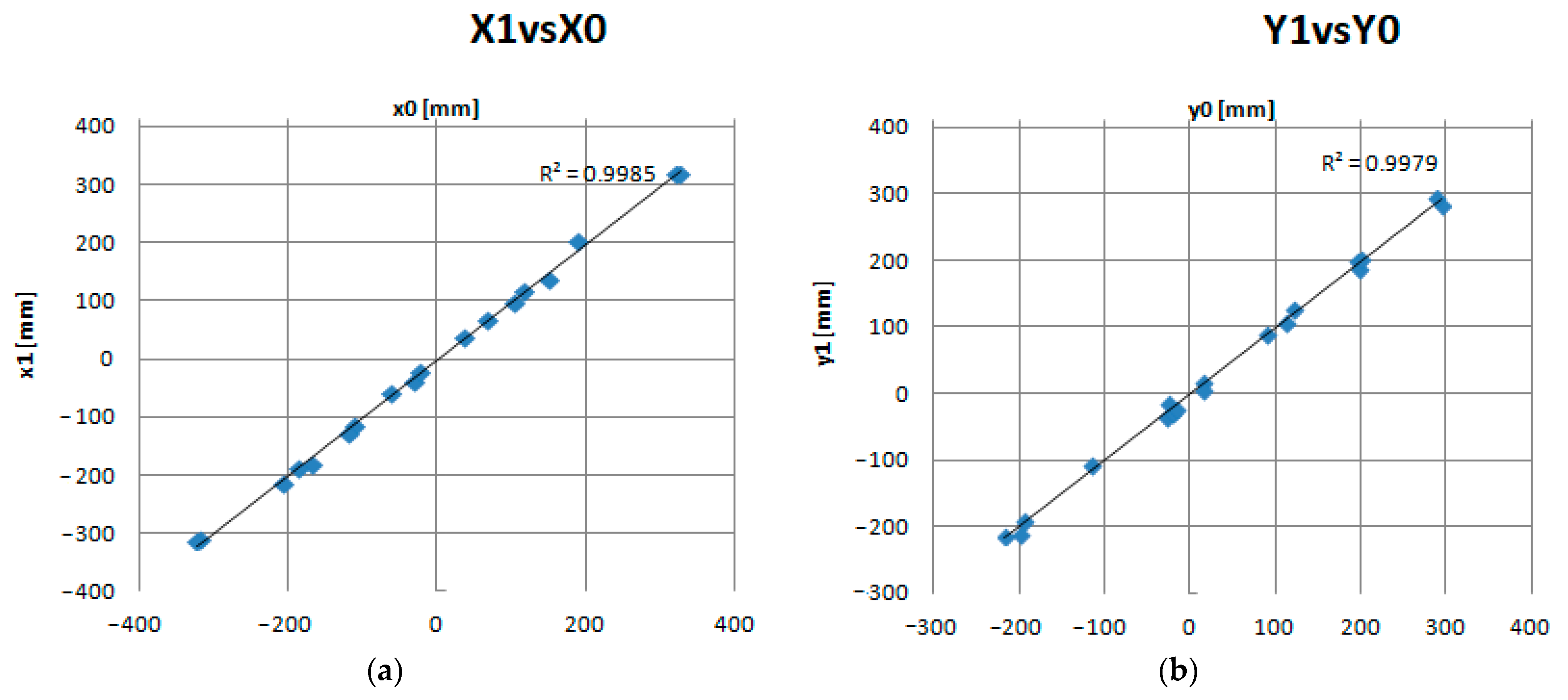
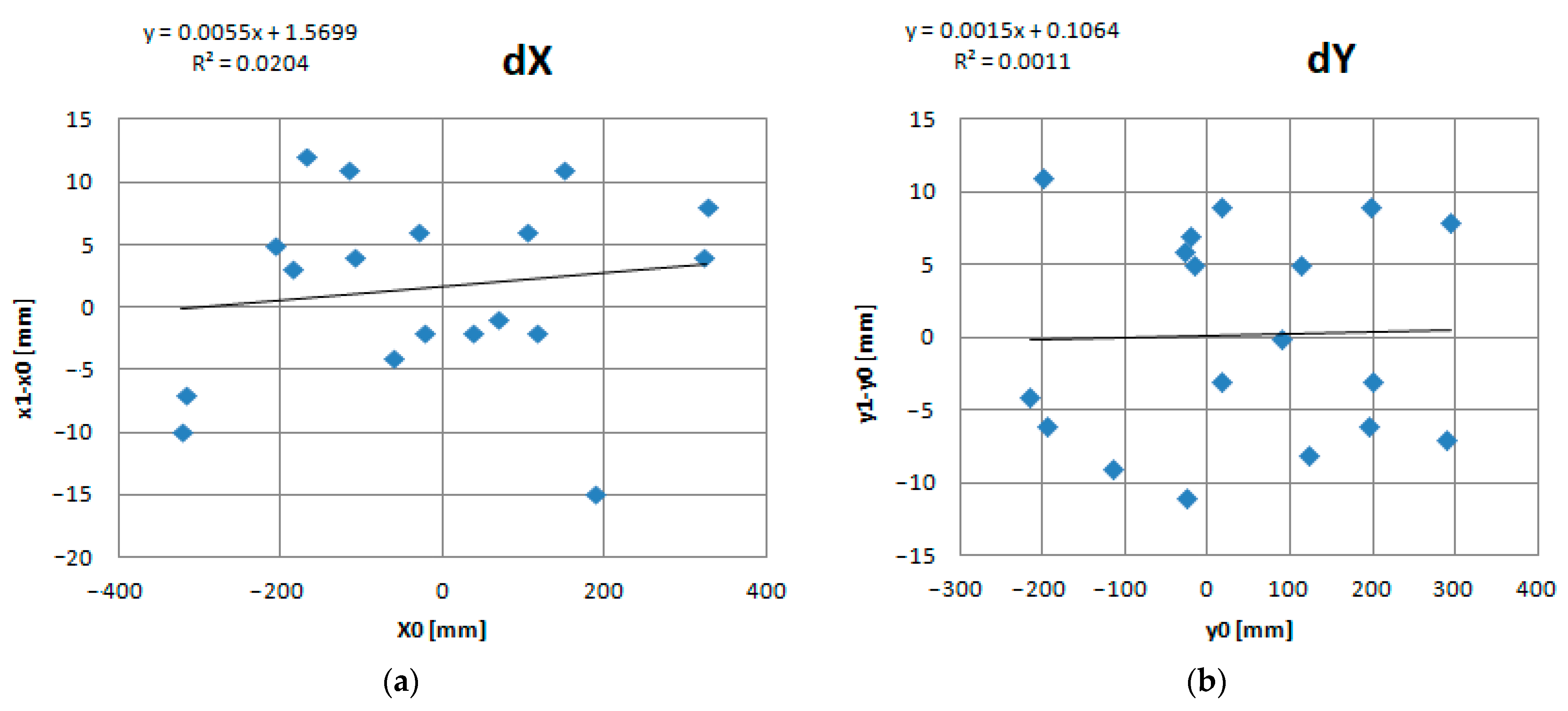
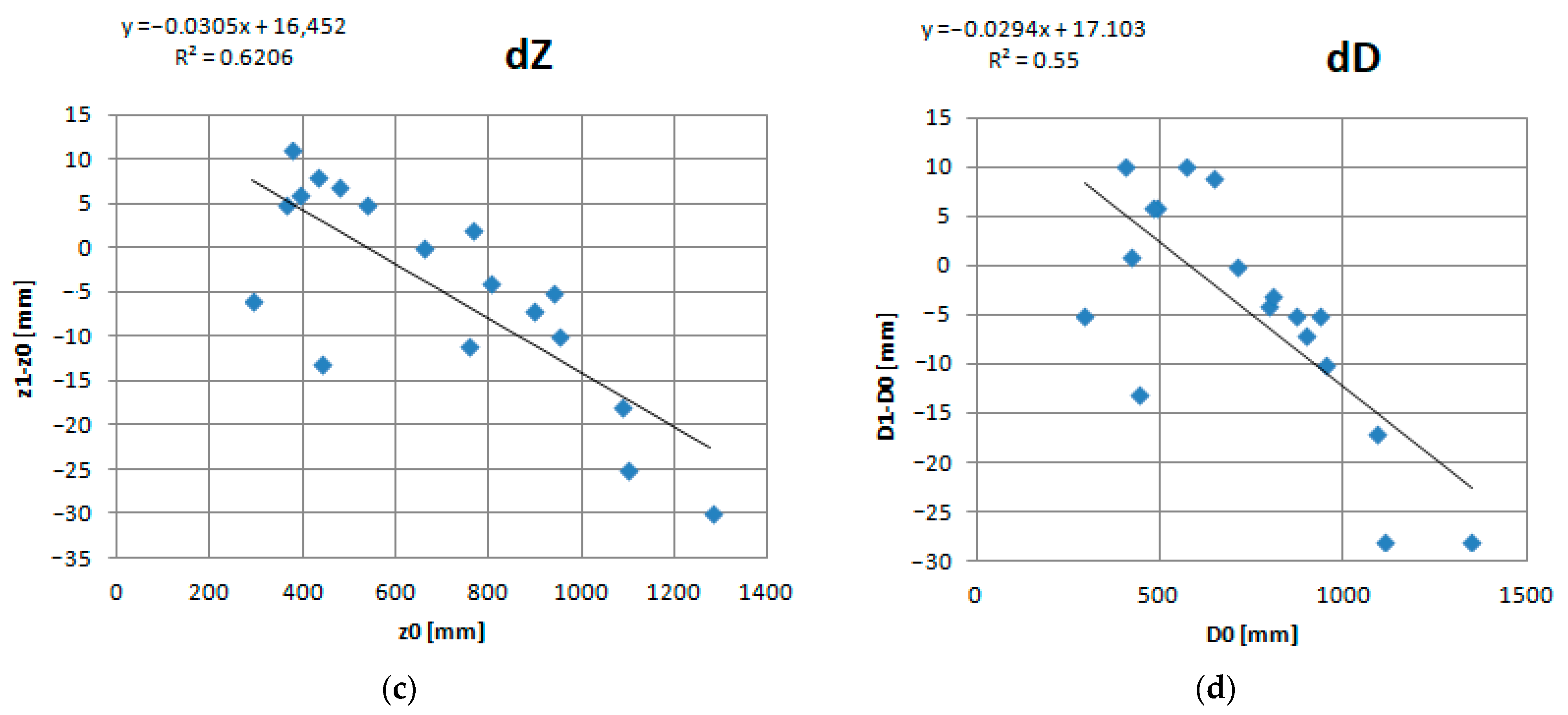
4. Results
- Square Error along the X, Y and Z axes:
- Euclidean distance to the apple using measuring instruments:
- Euclidean distance to the apple using Real Sense:
- Square Error of distance estimation:
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cho, W.; Kim, S.; Na, M.; Na, I. Forecasting of Tomato Yields Using Attention-Based LSTM Network and ARMA Model. Electronics 2021, 10, 1576. [Google Scholar] [CrossRef]
- López-Morales, J.A.; Martínez, J.A.; Skarmeta, A.F. Digital Transformation of Agriculture through the Use of an Interoperable Platform. Sensors 2020, 20, 1153. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rolandi, S.; Brunori, G.; Bacco, M.; Scotti, I. The Digitalization of Agriculture and Rural Areas: Towards a Taxonomy of the Impacts. Sustainability 2021, 13, 5172. [Google Scholar] [CrossRef]
- United Nations. Global Issues. Available online: https://www.un.org/en/global-issues/population (accessed on 1 December 2021).
- Bahn, R.A.; Yehya, A.A.K.; Zurayk, R. Digitalization for Sustainable Agri-Food Systems: Potential, Status, and Risks for the MENA Region. Sustainability 2021, 13, 3223. [Google Scholar] [CrossRef]
- Krakhmalev, O.; Krakhmalev, N.; Gataullin, S.; Makarenko, I.; Nikitin, P.; Serdechnyy, D.; Liang, K.; Korchagin, S. Mathematics Model for 6-DOF Joints Manipulation Robots. Mathematics 2021, 9, 2828. [Google Scholar] [CrossRef]
- Krakhmalev, O.; Korchagin, S.; Pleshakova, E.; Nikitin, P.; Tsibizova, O.; Sycheva, I.; Liang, K.; Serdechnyy, D.; Gataullin, S.; Krakhmalev, N. Parallel Computational Algorithm for Object-Oriented Modeling of Manipulation Robots. Mathematics 2021, 9, 2886. [Google Scholar] [CrossRef]
- Korchagin, S.A.; Gataullin, S.T.; Osipov, A.V.; Smirnov, M.V.; Suvorov, S.V.; Serdechnyi, D.V.; Bublikov, K.V. Development of an Optimal Algorithm for Detecting Damaged and Diseased Potato Tubers Moving along a Conveyor Belt Using Computer Vision Systems. Agronomy 2021, 11, 1980. [Google Scholar] [CrossRef]
- Osipov, A.; Filimonov, A.; Suvorov, S. Applying Machine Learning Techniques to Identify Damaged Potatoes. In Artificial Intelligence and Soft Computing, Proceedings of the 20th International Conference on Artificial Intelligence and Soft Computing, Online, 21–23 June 2021; Rutkowski, L., Scherer, R., Korytkowski, M., Pedrycz, W., Tadeusiewicz, R., Zurada, J.M., Eds.; Springer: Cham, Switzerland, 2021; pp. 193–201. [Google Scholar] [CrossRef]
- Andriyanov, N.A.; Dementiev, V.E.; Tashlinskii, A.G. Detection of objects in the images: From likelihood relationships towards scalable and efficient neural networks. Comput. Opt. 2022, 46, 139–159. [Google Scholar] [CrossRef]
- Titov, V.S.; Spevakov, A.G.; Primenko, D.V. Multispectral optoelectronic device for controlling an autonomous mobile platform. Comput. Opt. 2021, 45, 399–404. [Google Scholar] [CrossRef]
- Intel RealSense Depth Camera D415. Available online: https://www.intelrealsense.com/depth-camera-d415 (accessed on 1 December 2021).
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; Volume 1, pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In NIPS’12, Proceedings of 25th Conference on Neural Information Processing Systems (NeurIPS), Lake Tahoe, NV, USA, 3–6 December 2012; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates Inc.: Red Hook, NY, USA, 2012; Volume 1, pp. 1106–1114. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. Available online: https://arxiv.org/abs/1804.02767 (accessed on 15 December 2021).
- GitHub. DarkNet-53. Available online: https://github.com/pjreddie/darknet (accessed on 1 December 2021).
- Andriyanov, N.; Dementiev, V.; Kondratiev, D. Tracking of Objects in Video Sequences. Smart Innov. Syst. Technol. 2021, 238, 253–262. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Using YOLOv3 Algorithm with Pre- and Post-Processing for Apple Detection in Fruit-Harvesting Robot. Agronomy 2020, 10, 1016. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Huang, Z.; Zhang, P.; Liu, R.; Li, D. Immature Apple Detection Method Based on Improved Yolov3. ASP Trans. Internet Things 2021, 1, 9–13. [Google Scholar] [CrossRef]
- Andriyanov, N.A.; Andriyanov, D.A. The using of data augmentation in machine learning in image processing tasks in the face of data scarcity. J. Phys. Conf. Ser. 2020, 1661, 012018. [Google Scholar] [CrossRef]
- Xuan, G.; Gao, C.; Shao, Y.; Zhang, M.; Wang, Y.; Zhong, J.; Li, Q.; Peng, H. Apple Detection in Natural Environment Using Deep Learning Algorithms. IEEE Access 2020, 8, 216772–216780. [Google Scholar] [CrossRef]
- Itakura, K.; Narita, Y.; Noaki, S.; Hosoi, F. Automatic pear and apple detection by videos using deep learning and a Kalman filter. OSA Contin. 2021, 4, 1688–1695. [Google Scholar] [CrossRef]
- Gómez-Espinosa, A.; Rodríguez-Suárez, J.B.; Cuan-Urquizo, E.; Cabello, J.A.E.; Swenson, R.L. Colored 3D Path Extraction Based on Depth-RGB Sensor for Welding Robot Trajectory Generation. Automation 2021, 2, 252–265. [Google Scholar] [CrossRef]
- Servi, M.; Mussi, E.; Profili, A.; Furferi, R.; Volpe, Y.; Governi, L.; Buonamici, F. Metrological Characterization and Comparison of D415, D455, L515 RealSense Devices in the Close Range. Sensors 2021, 21, 7770. [Google Scholar] [CrossRef] [PubMed]
- Maru, M.B.; Lee, D.; Tola, K.D.; Park, S. Comparison of Depth Camera and Terrestrial Laser Scanner in Monitoring Structural Deflections. Sensors 2021, 21, 201. [Google Scholar] [CrossRef] [PubMed]
- Laganiere, R.; Gilbert, S.; Roth, G. Robust object pose estimation from feature-based stereo. IEEE Trans. Instrum. Meas. 2006, 55, 1270–1280. [Google Scholar] [CrossRef]
- Andriyanov, N.A. Analysis of the Acceleration of Neural Networks Inference on Intel Processors Based on OpenVINO Toolkit. In Proceedings of the 2020 Systems of Signal Synchronization, Generating and Processing in Telecommunications, Svetlogorsk, Russia, 1–3 July 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Shirokanev, A.; Ilyasova, N.; Andriyanov, N.; Zamytskiy, E.; Zolotarev, A.; Kirsh, D. Modeling of Fundus Laser Exposure for Estimating Safe Laser Coagulation Parameters in the Treatment of Diabetic Retinopathy. Mathematics 2021, 9, 967. [Google Scholar] [CrossRef]











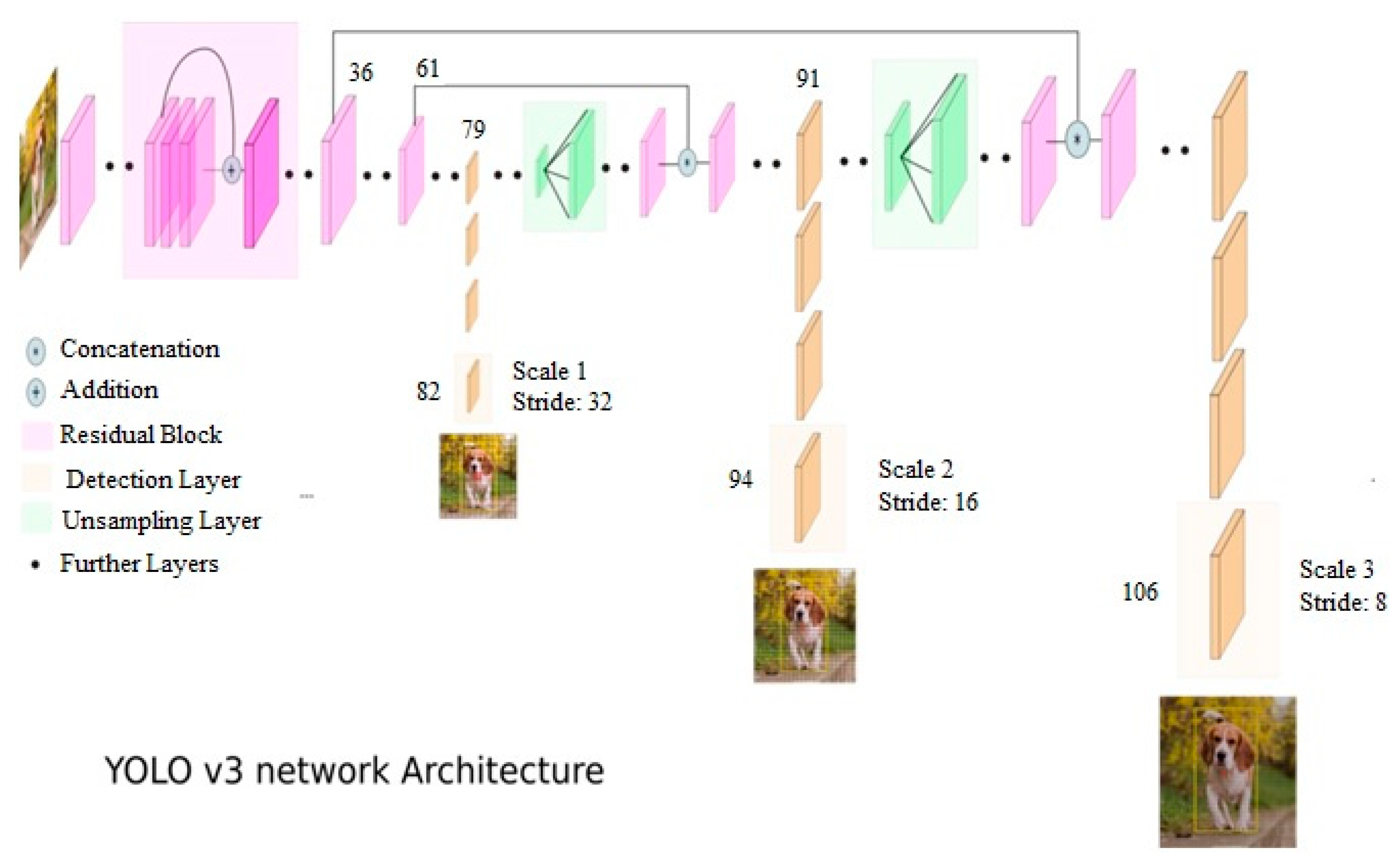{kind=link}
{kind=link}
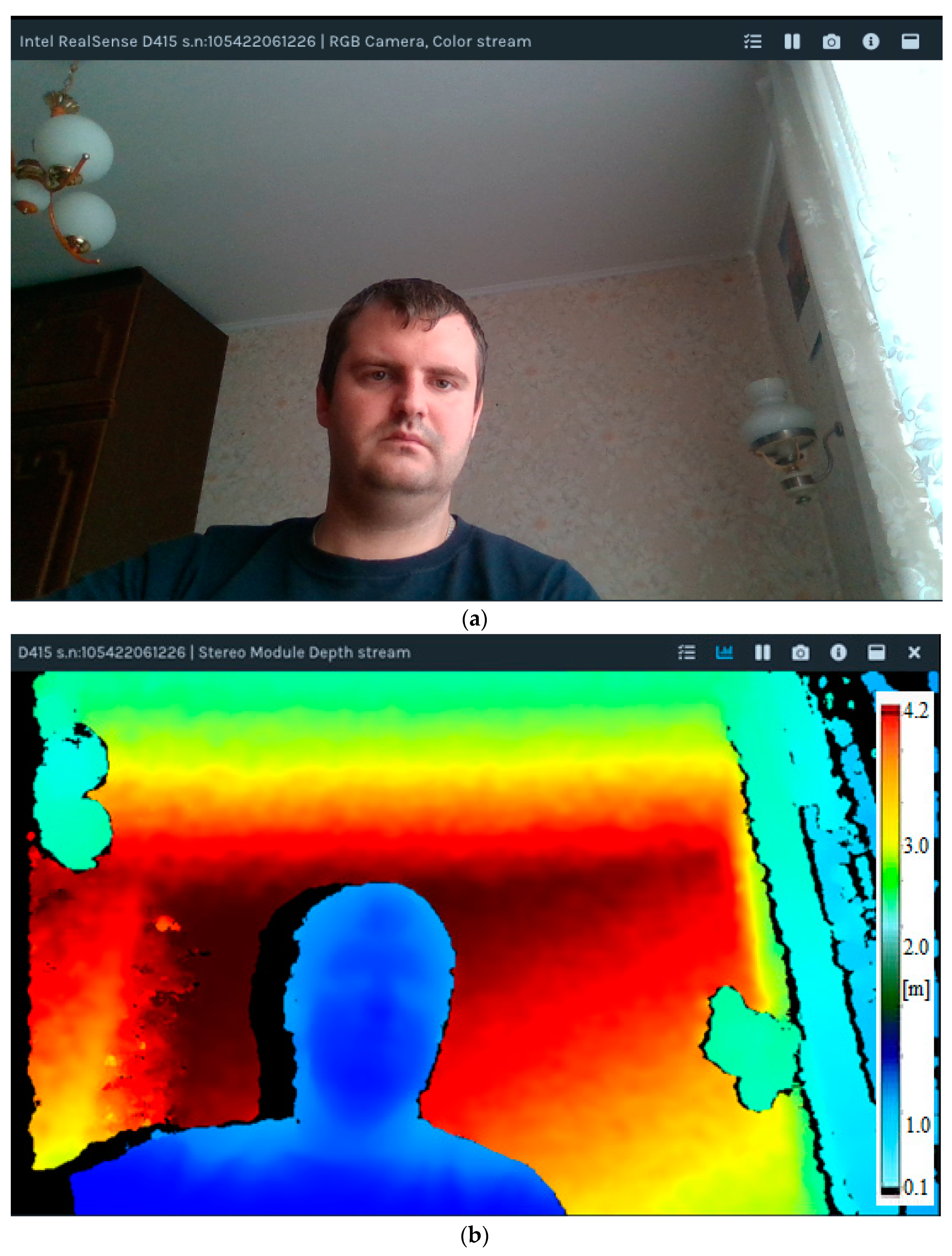{kind=link}
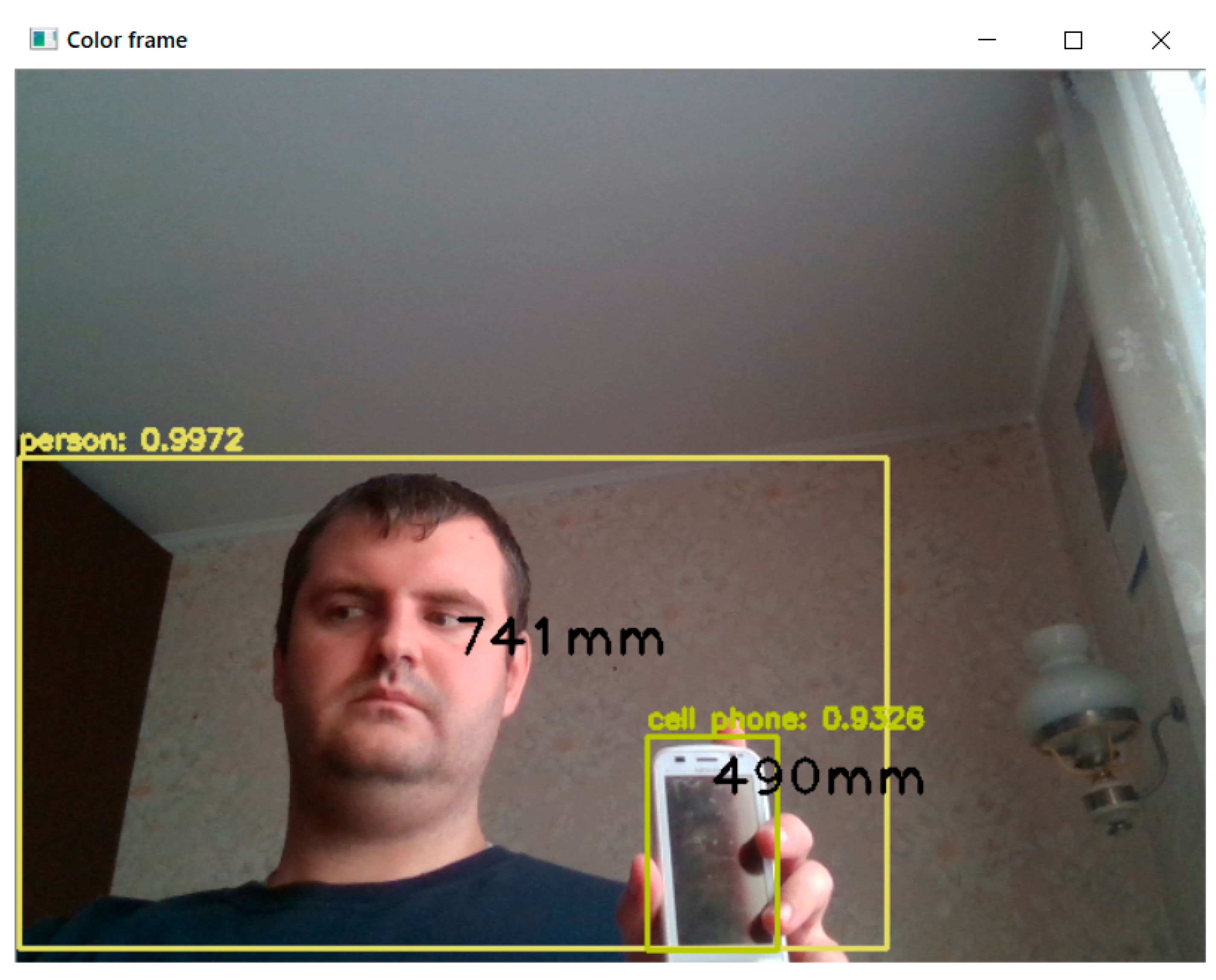{kind=link}
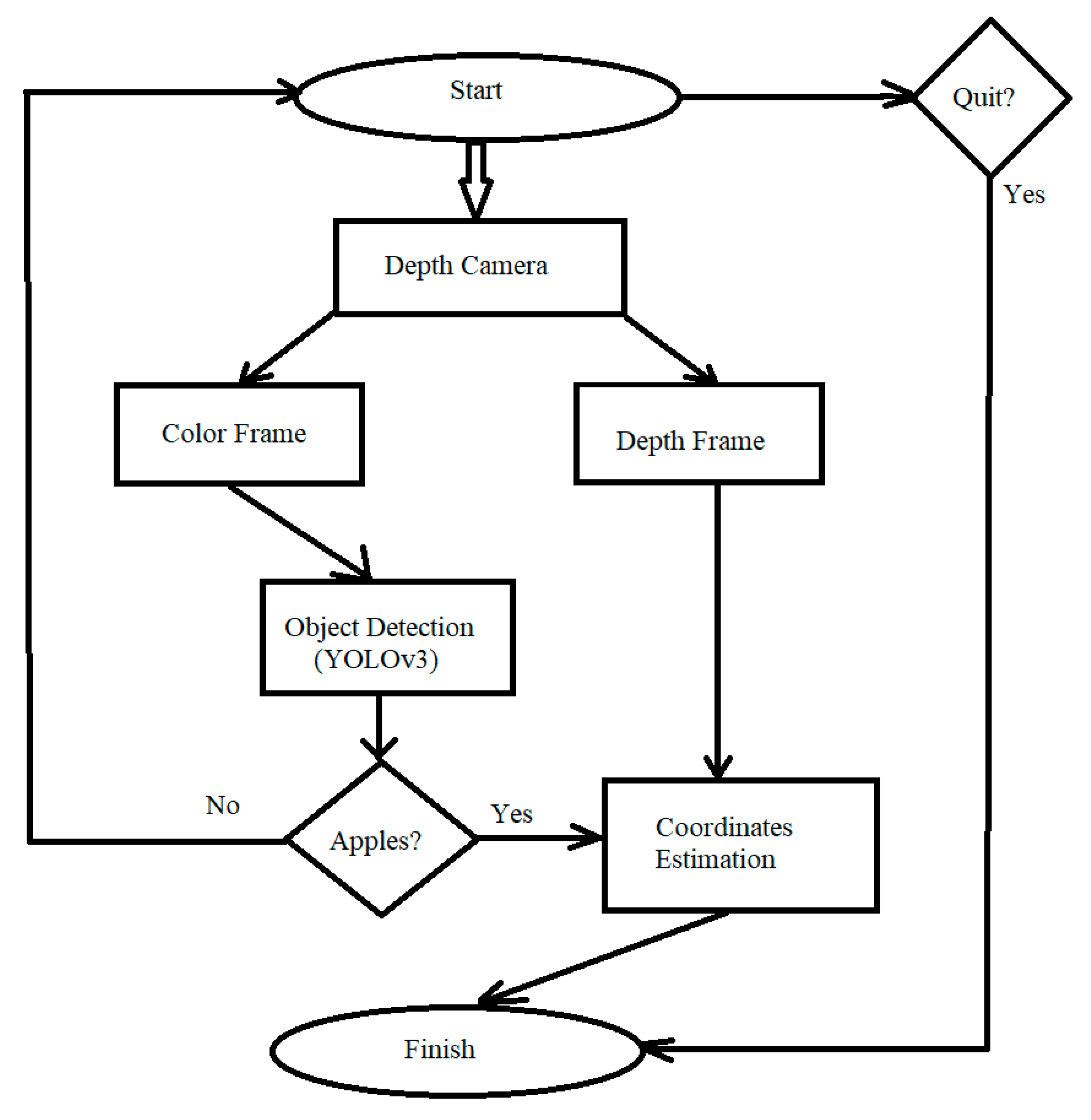{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Probability Threshold, C | 0.25 | 0.5 | 0.75 |
|---|---|---|---|
| Precision | 1.0 | 1.0 | 1.0 |
| Recall | 0.90 | 0.84 | 0.69 |
| Apple 1 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Position | X1 mm | X0 mm | SEx mm2 | Y1 mm | Y0 mm | SEy mm2 | Z1 mm | Z0 mm | SEz mm2 | D1 mm | D0 mm | SEd mm2 |
| 1 | −114 | −110 | 16 | −33 | −27 | 36 | 958 | 948 | 100 | 965 | 955 | 100 |
| 2 | −56 | −60 | 16 | −14 | −25 | 121 | 296 | 290 | 36 | 302 | 297 | 25 |
| 3 | 38 | 36 | 4 | 19 | 16 | 9 | 802 | 798 | 16 | 803 | 799 | 16 |
| 4 | 118 | 116 | 4 | 90 | 90 | 0 | 465 | 472 | 49 | 488 | 494 | 36 |
| 5 | −128 | −117 | 121 | −106 | −115 | 81 | 361 | 372 | 121 | 397 | 407 | 100 |
| 6 | 204 | 189 | 225 | 202 | 196 | 36 | 760 | 762 | 4 | 812 | 809 | 9 |
| Apple 2 | ||||||||||||
| Position | X1 mm | X0 mm | SEx mm2 | Y1 mm | Y0 mm | SEy mm2 | Z1 mm | Z0 mm | SEz mm2 | D1 mm | D0 mm | SEd mm2 |
| 1 | −37 | −31 | 36 | −27 | −20 | 49 | 941 | 936 | 25 | 942 | 937 | 25 |
| 2 | 69 | 68 | 1 | −22 | −17 | 25 | 449 | 436 | 169 | 455 | 442 | 169 |
| 3 | −180 | −168 | 144 | 130 | 122 | 64 | 1121 | 1096 | 625 | 1143 | 1115 | 784 |
| 4 | 318 | 322 | 16 | 286 | 294 | 64 | 765 | 754 | 121 | 876 | 871 | 25 |
| 5 | −310 | −317 | 49 | −189 | −195 | 36 | 526 | 531 | 25 | 639 | 648 | 81 |
| 6 | 98 | 104 | 36 | −211 | −200 | 121 | 355 | 360 | 25 | 424 | 425 | 1 |
| Apple 3 | ||||||||||||
| Position | X1 mm | X0 mm | SEx mm2 | Y1 mm | Y0 mm | SEy mm2 | Z1 mm | Z0 mm | SEz mm2 | D1 mm | D0 mm | SEd mm2 |
| 1 | 139 | 150 | 121 | 7 | 16 | 81 | 1101 | 1083 | 324 | 1110 | 1093 | 289 |
| 2 | −20 | −22 | 4 | 107 | 112 | 25 | 897 | 890 | 49 | 904 | 897 | 49 |
| 3 | −212 | −207 | 25 | 189 | 198 | 81 | 382 | 388 | 36 | 476 | 482 | 36 |
| 4 | 318 | 326 | 64 | 295 | 288 | 49 | 1308 | 1278 | 900 | 1378 | 1350 | 784 |
| 5 | −188 | −185 | 9 | −212 | −216 | 16 | 655 | 655 | 0 | 714 | 714 | 0 |
| 6 | −312 | −322 | 100 | 204 | 201 | 9 | 420 | 428 | 64 | 562 | 572 | 100 |
| MSE(mm2) | 55.06 | 50.17 | 149.39 | 146.06 | ||||||||
| RMSE(mm) | 7.42 | 7.08 | 12.22 | 12.09 | ||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Andriyanov, N.; Khasanshin, I.; Utkin, D.; Gataullin, T.; Ignar, S.; Shumaev, V.; Soloviev, V. Intelligent System for Estimation of the Spatial Position of Apples Based on YOLOv3 and Real Sense Depth Camera D415. Symmetry 2022, 14, 148. https://doi.org/10.3390/sym14010148
Andriyanov N, Khasanshin I, Utkin D, Gataullin T, Ignar S, Shumaev V, Soloviev V. Intelligent System for Estimation of the Spatial Position of Apples Based on YOLOv3 and Real Sense Depth Camera D415. Symmetry. 2022; 14(1):148. https://doi.org/10.3390/sym14010148
Chicago/Turabian StyleAndriyanov, Nikita, Ilshat Khasanshin, Daniil Utkin, Timur Gataullin, Stefan Ignar, Vyacheslav Shumaev, and Vladimir Soloviev. 2022. "Intelligent System for Estimation of the Spatial Position of Apples Based on YOLOv3 and Real Sense Depth Camera D415" Symmetry 14, no. 1: 148. https://doi.org/10.3390/sym14010148