
StyleGANs and Transfer Learning for Generating Synthetic Images in Industrial Applications


Abstract
:1. Introduction
2. Theoretical Background
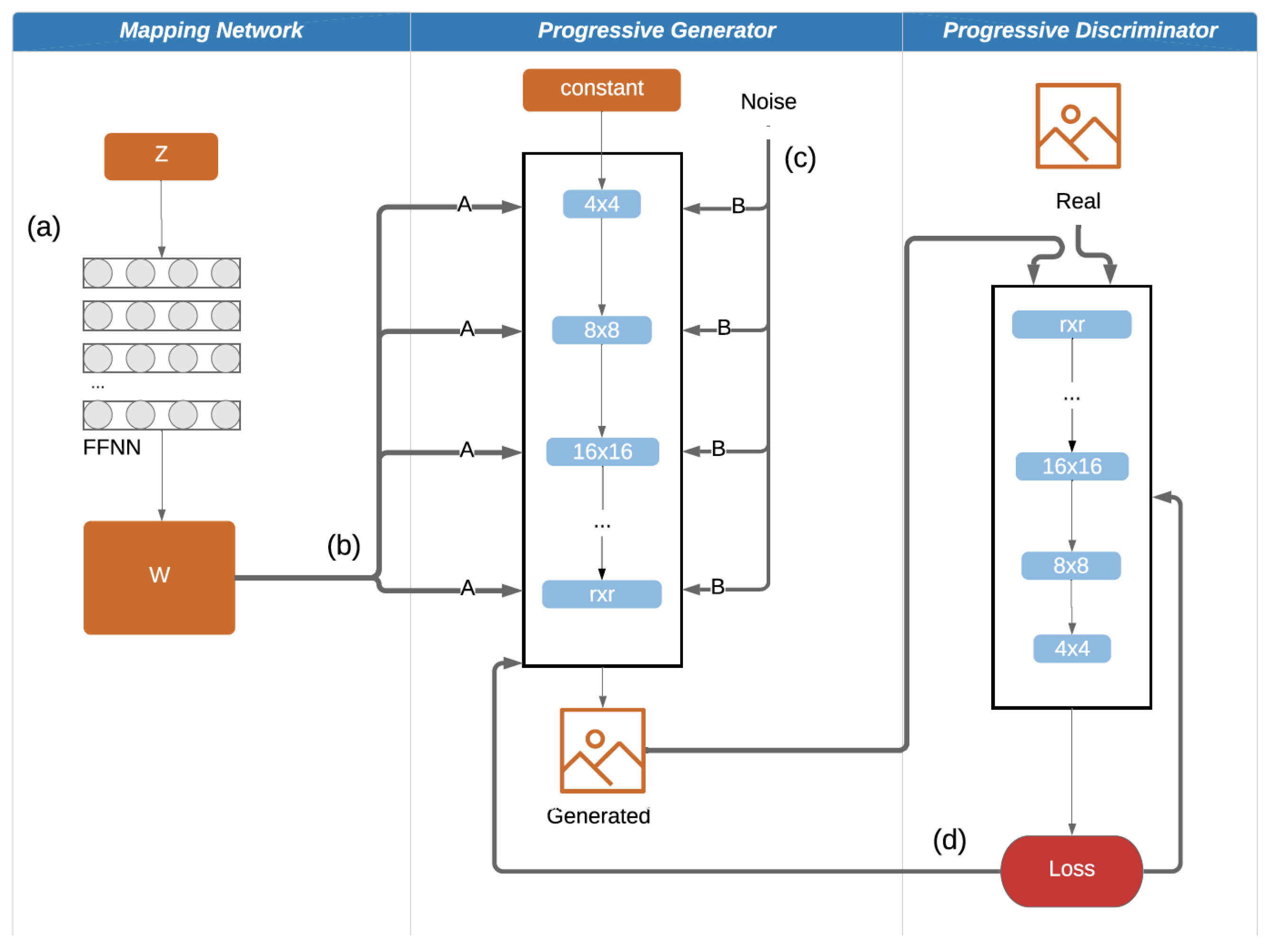
2.1. StyleGAN
2.2. GANs Model Evaluation
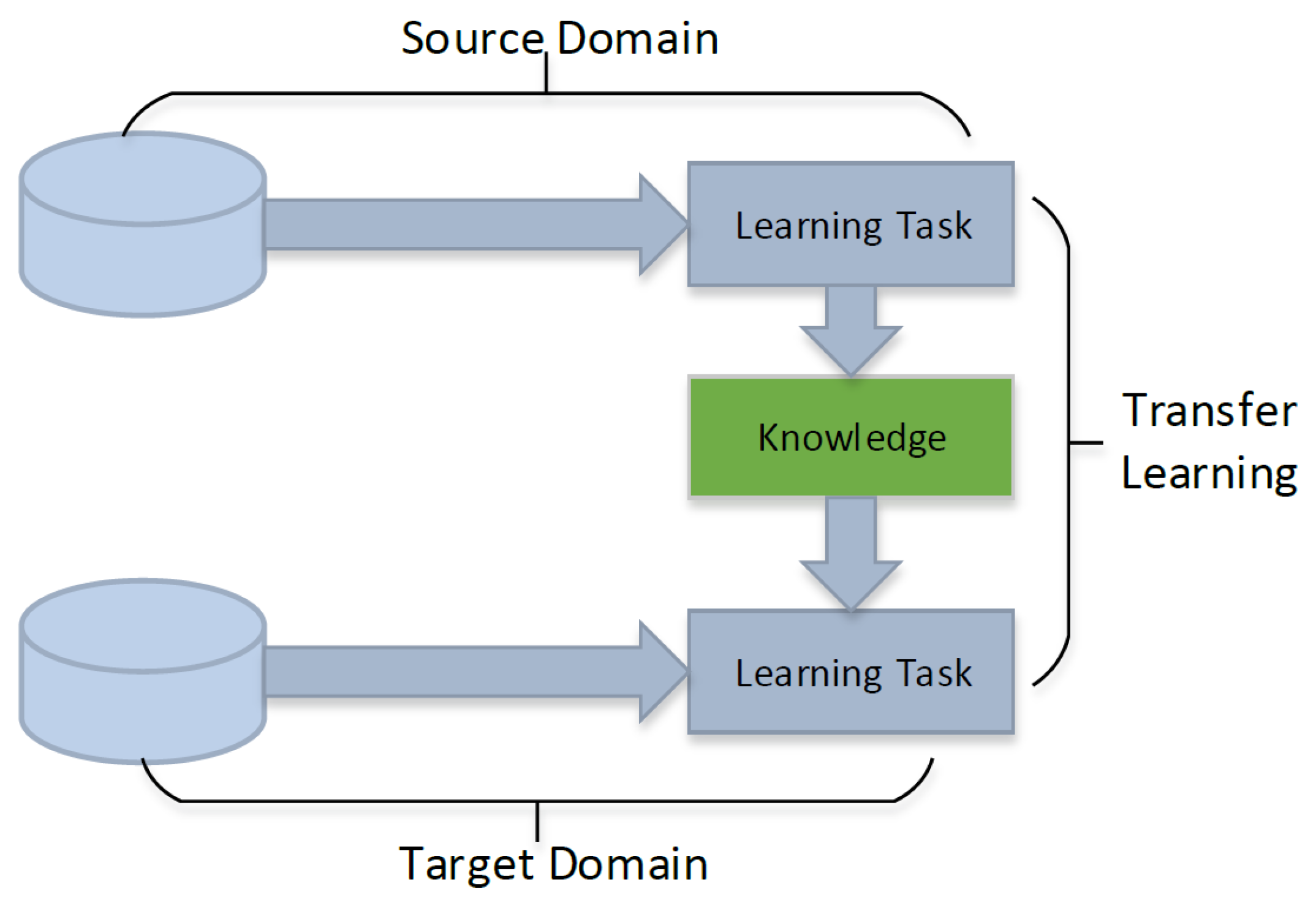
2.3. Transfer Learning
3. Related Works
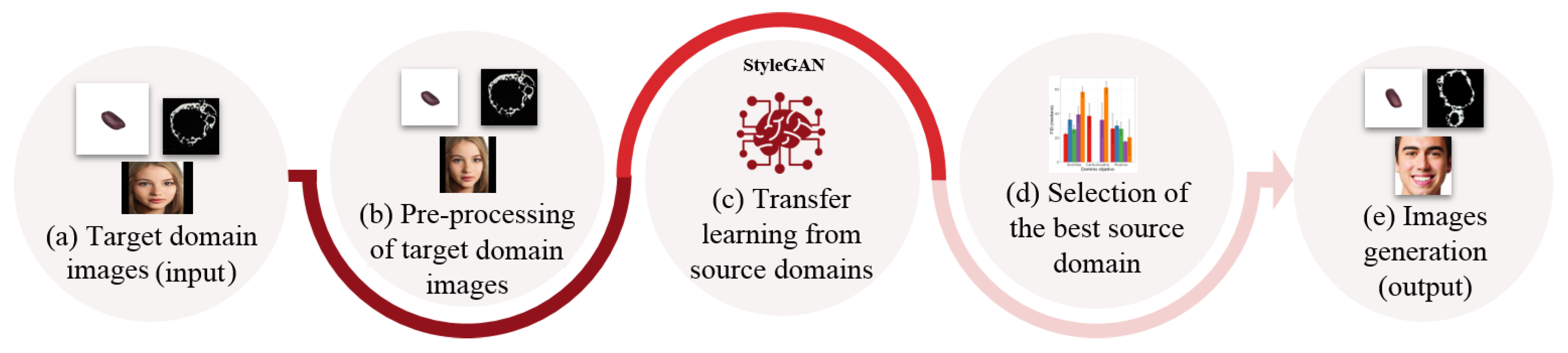
4. Evaluation Synthetic Images Generation Pipeline
4.1. Input Target Domain Images
4.2. Pre-Processing Target Domain Images
4.3. Transfer Learning from Source Domains
4.4. Selection of the Best Source Domain
4.5. Synthetic Images Generation (Output)
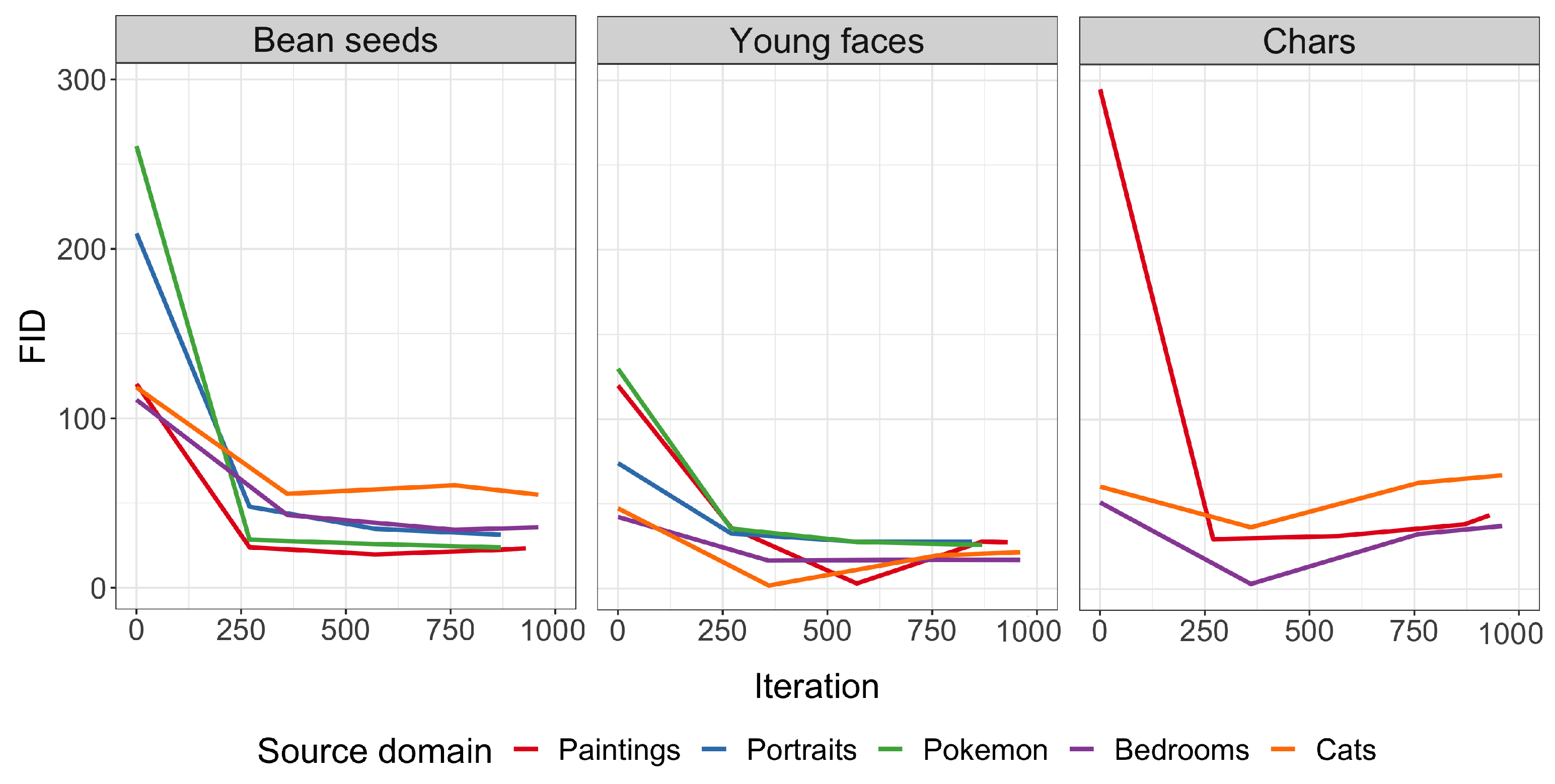
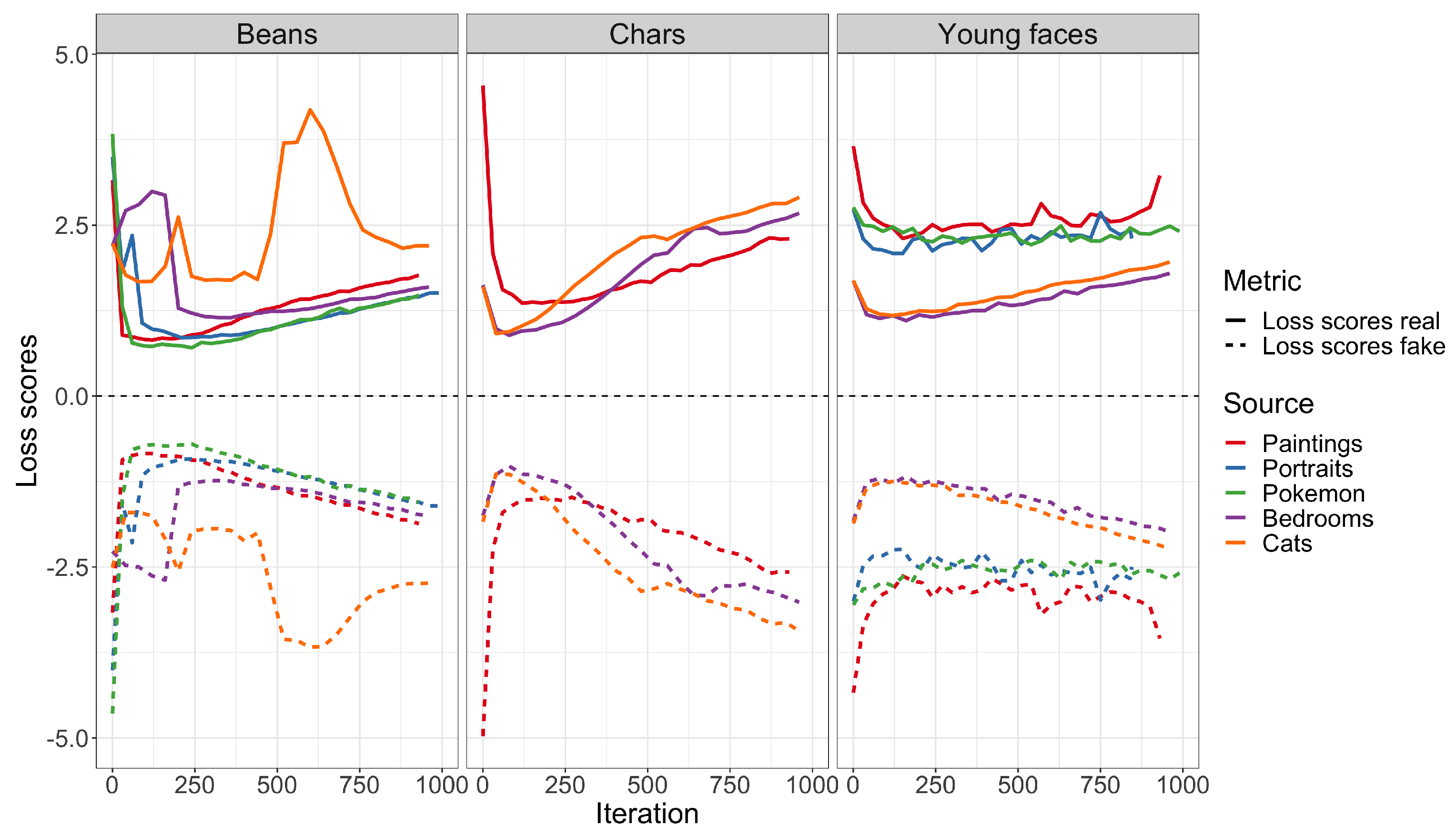
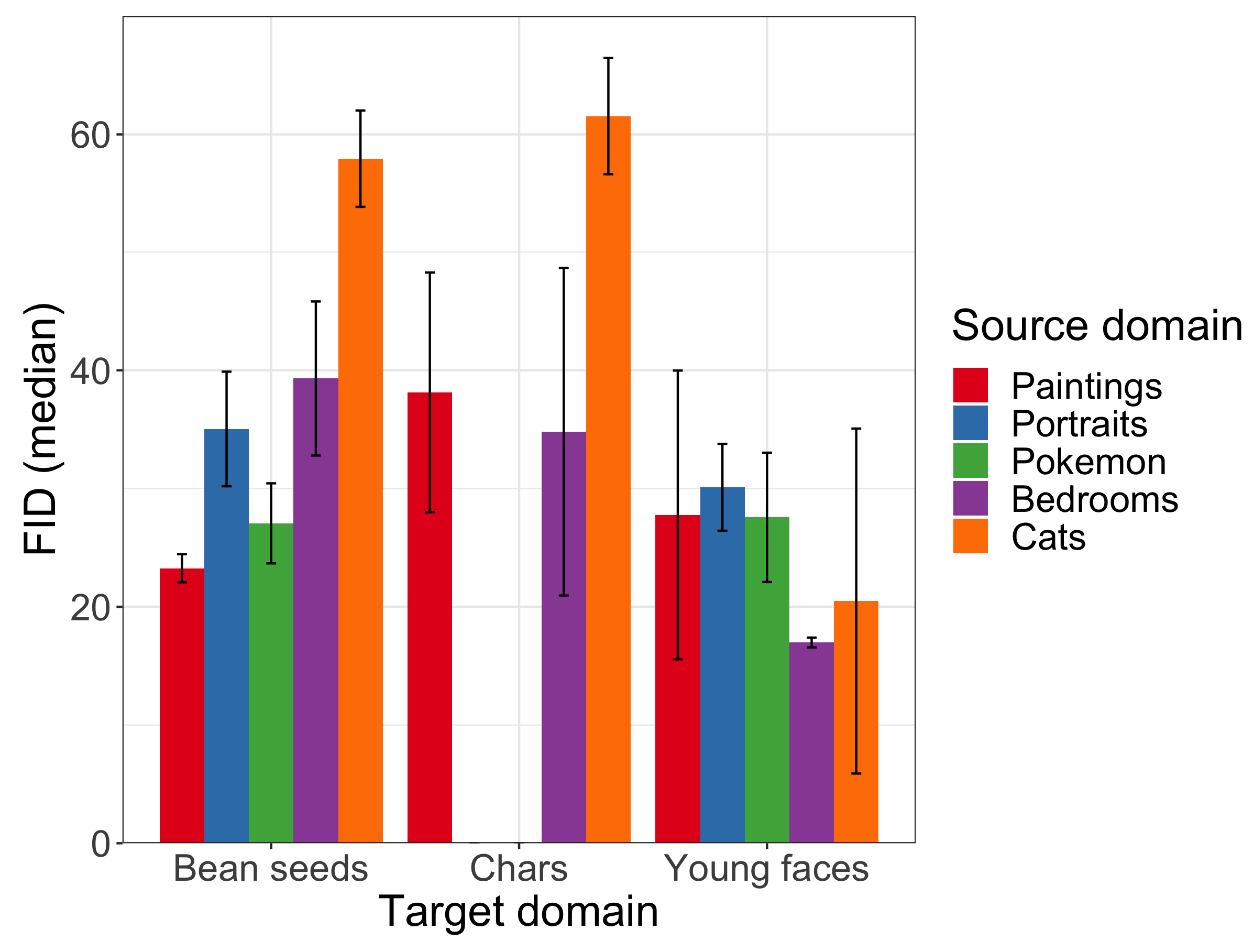
5. Experimental Evaluation
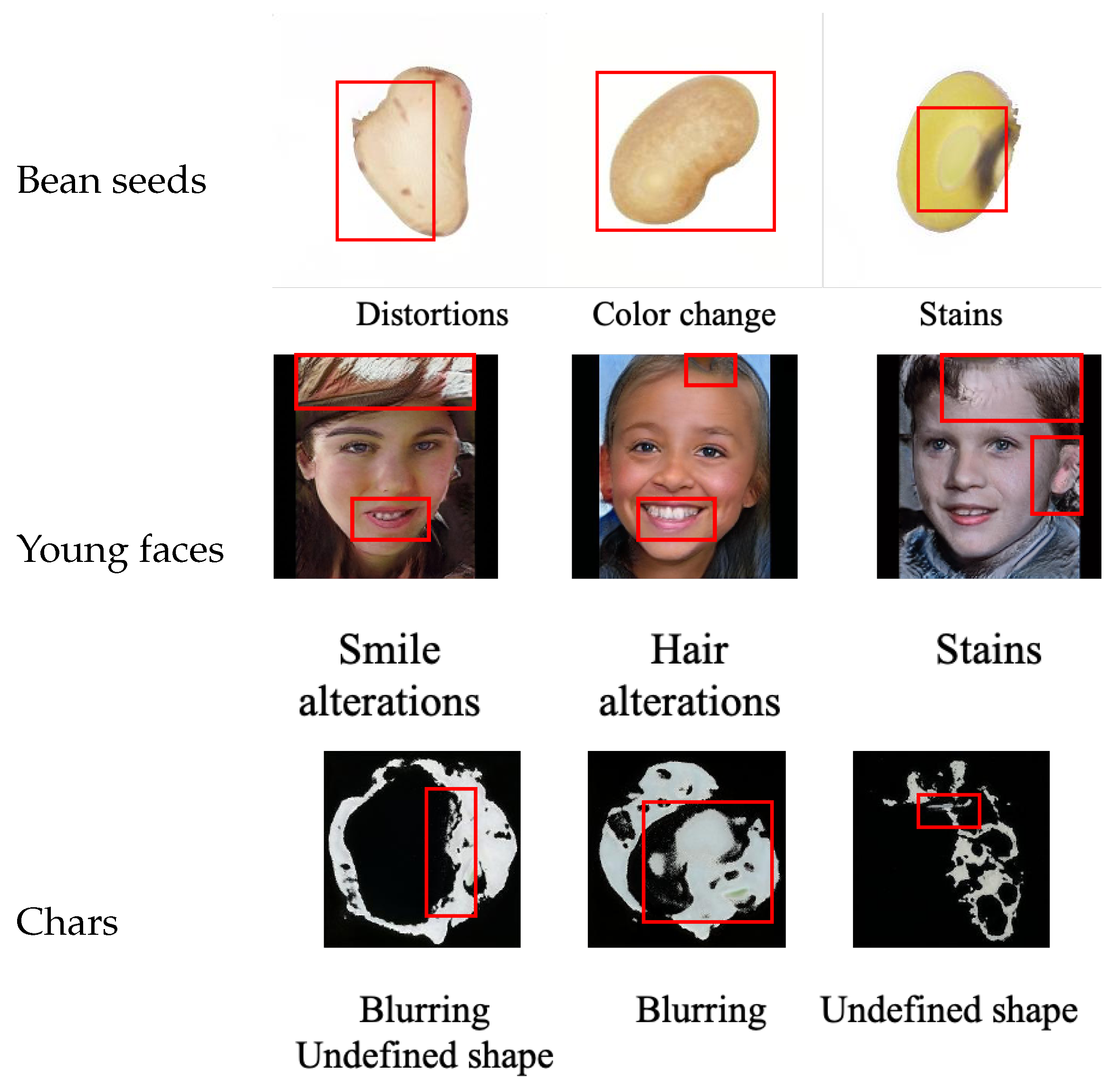
6. Effect of Pre-Trained Models on Synthetic Images Generation
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A Survey of Deep Learning and Its Applications: A New Paradigm to Machine Learning. Arch. Comput. Methods Eng. 2019, 27, 1071–1092. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. arXiv 2018, arXiv:1808.01974. [Google Scholar]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Bowles, C.; Chen, L.; Guerrero, R.; Bentley, P.; Gunn, R.; Hammers, A.; Dickie, D.A.; Hernández, M.V.; Wardlaw, J.; Rueckert, D. GAN augmentation: Augmenting training data using generative adversarial networks. arXiv 2018, arXiv:1810.10863. [Google Scholar]
- Tanaka, F.H.K.d.S.; Aranha, C. Data Augmentation Using GANs. arXiv 2019, arXiv:1904.09135. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Antoniou, A.; Storkey, A.; Edwards, H. Data augmentation generative adversarial networks. arXiv 2017, arXiv:1711.04340. [Google Scholar]
- Garcia Torres, D. Generation of Synthetic Data with Generative Adversarial Networks. Ph.D. Thesis, School of Electrical Engineering and Computer Science, KTH Royal Institute of Technology, Karlskrona, Sweden, 2018. [Google Scholar]
- Zeid Baker, M. Generation of Synthetic Images with Generative Adversarial Networks. Master’s Thesis, Department of Computer Science and Engineering, Blekinge Institute of Technology, Karlskrona, Sweden, 2018. [Google Scholar]
- Ma, Y.; Liu, K.; Guan, Z.; Xu, X.; Qian, X.; Bao, H. Background Augmentation Generative Adversarial Networks (BAGANs): Effective Data Generation Based on GAN-Augmented 3D Synthesizing. Symmetry 2018, 10, 734. [Google Scholar] [CrossRef] [Green Version]
- Loey, M.; Smarandache, F.; Khalifa, N.E.M. Within the Lack of Chest COVID-19 X-ray Dataset: A Novel Detection Model Based on GAN and Deep Transfer Learning. Symmetry 2020, 12, 651. [Google Scholar] [CrossRef] [Green Version]
- Zulkifley, M.A.; Abdani, S.R.; Zulkifley, N.H. COVID-19 Screening Using a Lightweight Convolutional Neural Network with Generative Adversarial Network Data Augmentation. Symmetry 2020, 12, 1530. [Google Scholar] [CrossRef]
- Sandfort, V.; Yan, K.; Pickhardt, P.J.; Summers, R.M. Data augmentation using generative adversarial networks (CycleGAN) to improve generalizability in CT segmentation tasks. Sci. Rep. 2019, 9, 16884. [Google Scholar] [CrossRef]
- Frid-Adar, M.; Diamant, I.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. GAN-based Synthetic Medical Image Augmentation for increased CNN Performance in Liver Lesion Classification. Neurocomputing 2018, 321, 321–331. [Google Scholar] [CrossRef] [Green Version]
- Shin, H.C.; Tenenholtz, N.A.; Rogers, J.K.; Schwarz, C.G.; Senjem, M.L.; Gunter, J.L.; Andriole, K.; Michalski, M. Medical Image Synthesis for Data Augmentation and Anonymization using Generative Adversarial Networks. arXiv 2018, arXiv:1807.10225. [Google Scholar]
- Fetty, L.; Bylund, M.; Kuess, P.; Heilemann, G.; Nyholm, T.; Georg, D.; Löfstedt, T. Latent Space Manipulation for High-Resolution Medical Image Synthesis via the StyleGAN. Z. Med. Phys. 2020, 30, 305–314. [Google Scholar] [CrossRef]
- Coulibaly, S.; Kamsu-Foguem, B.; Kamissoko, D.; Traore, D. Deep neural networks with transfer learning in millet crop images. Comput. Ind. 2019, 108, 115–120. [Google Scholar] [CrossRef] [Green Version]
- Abu Mallouh, A.; Qawaqneh, Z.; Barkana, B.D. Utilizing CNNs and transfer learning of pre-trained models for age range classification from unconstrained face images. Image Vis. Comput. 2019, 88, 41–51. [Google Scholar] [CrossRef]
- Liu, X.; Wang, C.; Bai, J.; Liao, G. Fine-tuning Pre-trained Convolutional Neural Networks for Gastric Precancerous Disease Classification on Magnification Narrow-band Imaging Images. Neurocomputing 2020, 392, 253–267. [Google Scholar] [CrossRef]
- Ferguson, M.; Ak, R.; Lee, Y.T.T.; Law, K.H. Detection and Segmentation of Manufacturing Defects with Convolutional Neural Networks and Transfer Learning. Smart Sustain. Manuf. Syst. 2018, 2, 137–164. [Google Scholar] [CrossRef]
- Abdalla, A.; Cen, H.; Wan, L.; Rashid, R.; Weng, H.; Zhou, W.; He, Y. Fine-tuning convolutional neural network with transfer learning for semantic segmentation of ground-level oilseed rape images in a field with high weed pressure. Comput. Electron. Agric. 2019, 167, 105091. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, C.; Herranz, L.; van de Weijer, J.; Gonzalez-Garcia, A.; Raducanu, B. Transferring GANs: Generating images from limited data. arXiv 2018, arXiv:1805.01677. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. arXiv 2018, arXiv:1710.10196. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization. arXiv 2017, arXiv:1703.06868. [Google Scholar]
- Oeldorf, C. Conditional Implementation for NVIDIA’s StyleGAN Architecture. 2019. Available online: https://github.com/cedricoeldorf/ConditionalStyleGAN (accessed on 13 November 2019).
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2017; pp. 6626–6637. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Arsenovic, M.; Karanovic, M.; Sladojevic, S.; Anderla, A.; Stefanovic, D. Solving Current Limitations of Deep Learning Based Approaches for Plant Disease Detection. Symmetry 2019, 11, 939. [Google Scholar] [CrossRef] [Green Version]
- Arun Pandian, J.; Geetharamani, G.; Annette, B. Data Augmentation on Plant Leaf Disease Image Dataset Using Image Manipulation and Deep Learning Techniques. In Proceedings of the 2019 IEEE 9th International Conference on Advanced Computing (IACC), Tiruchirappalli, India, 13–14 December 2019; pp. 199–204. [Google Scholar] [CrossRef]
- Noguchi, A.; Harada, T. Image generation from small datasets via batch statistics adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 2750–2758. [Google Scholar]
- Fregier, Y.; Gouray, J.B. Mind2Mind: Transfer learning for GANs. In Proceedings of the International Conference on Geometric Science of Information, Paris, France, 21–23 July 2021; Springer: Berlin, Germany, 2021; pp. 851–859. [Google Scholar]
- Luo, L.; Hsu, W.; Wang, S. Data Augmentation Using Generative Adversarial Networks for Electrical Insulator Anomaly Detection. In Proceedings of the 2020 2nd International Conference on Management Science and Industrial Engineering, Osaka, Japan, 7–9 April 2020; Association for Computing Machinery: Osaka, Japan, 2020; pp. 231–236. [Google Scholar] [CrossRef]
- Hirte, A.U.; Platscher, M.; Joyce, T.; Heit, J.J.; Tranvinh, E.; Federau, C. Diffusion-Weighted Magnetic Resonance Brain Images Generation with Generative Adversarial Networks and Variational Autoencoders: A Comparison Study. arXiv 2020, arXiv:2006.13944. [Google Scholar]
- Xia, Y.; Ravikumar, N.; Greenwood, J.P.; Neubauer, S.; Petersen, S.E.; Frangi, A.F. Super-Resolution of Cardiac MR Cine Imaging using Conditional GANs and Unsupervised Transfer Learning. Med. Image Anal. 2021, 71, 102037. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Gonzalez-Garcia, A.; Berga, D.; Herranz, L.; Khan, F.S.; Weijer, J.V.D. Minegan: Effective knowledge transfer from gans to target domains with few images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9332–9341. [Google Scholar]
- Mo, S.; Cho, M.; Shin, J. Freeze the discriminator: A simple baseline for fine-tuning gans. arXiv 2020, arXiv:2002.10964. [Google Scholar]
- Zhao, M.; Cong, Y.; Carin, L. On leveraging pretrained GANs for generation with limited data. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 11340–11351. [Google Scholar]
- Wang, Y.; Gonzalez-Garcia, A.; Wu, C.; Herranz, L.; Khan, F.S.; Jui, S.; van de Weijer, J. MineGAN++: Mining Generative Models for Efficient Knowledge Transfer to Limited Data Domains. arXiv 2021, arXiv:2104.13742. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; International Convention Centre: Sydney, Australia, 2017; Volume 70, pp. 214–223. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and Improving the Image Quality of StyleGAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Diaz, H. Bean seeds images calibration dataset. Alliance of Bioversity International and CIAT. Unpublished raw data. 2019. [Google Scholar]
- Beebe, S. Breeding in the Tropics. In Plant Breeding Reviews; John Wiley & Sons, Ltd.: New York, NY, USA, 2012; Chapter 5; pp. 357–426. [Google Scholar]
- Rothe, R.; Timofte, R.; Gool, L.V. DEX: Deep EXpectation of apparent age from a single image. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Santiago, Chile, 7–13 December 2015; pp. 10–15. [Google Scholar]
- Agustsson, E.; Timofte, R.; Escalera, S.; Baró, X.; Guyon, I.; Rothe, R. Apparent and real age estimation in still images with deep residual regressors on APPA-REAL database. In Proceedings of the FG 2017—12th IEEE International Conference on Automatic Face and Gesture Recognition, Washington, DC, USA, 30 May–3 June 2017; pp. 1–12. [Google Scholar]
- Moschoglou, S.; Papaioannou, A.; Sagonas, C.; Deng, J.; Kotsia, I.; Zafeiriou, S. AgeDB: The First Manually Collected, In-the-Wild Age Database. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1997–2005. [Google Scholar]
- Ye, L.; Li, B.; Mohammed, N.; Wang, Y.; Liang, J. Privacy-Preserving Age Estimation for Content Rating. In Proceedings of the 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), Vancouver, BC, Canada, 29–31 August 2018; pp. 1–6. [Google Scholar]
- Anda, F.; Lillis, D.; Kanta, A.; Becker, B.A.; Bou-Harb, E.; Le-Khac, N.A.; Scanlon, M. Improving Borderline Adulthood Facial Age Estimation through Ensemble Learning. In Proceedings of the 14th International Conference on Availability, Reliability and Security, Canterbury, UK, 26–29 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Chaves, D.; Fidalgo, E.; Alegre, E.; Jáñez-Martino, F.; Biswas, R. Improving Age Estimation in Minors and Young Adults with Occluded Faces to Fight Against Child Sexual Exploitation. In Proceedings of the 15th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications—Volume 5: VISAPP, Valletta, Malta, 27–19 February 2020; INSTICC. SciTePress: Setúbal, Portugal, 2020; pp. 721–729. [Google Scholar] [CrossRef]
- Chaves, D.; Fernández-Robles, L.; Bernal, J.; Alegre, E.; Trujillo, M. Automatic characterisation of chars from the combustion of pulverised coals using machine vision. Powder Technol. 2018, 338, 110–118. [Google Scholar] [CrossRef]
- StyleGAN Trained on Paintings (512 × 512). Available online: https://colab.research.google.com/drive/1cFKK0CBnev2BF8z9BOHxePk7E-f7TtUi (accessed on 9 March 2020).
- StyleGAN-Art. Available online: https://github.com/ak9250/stylegan-art (accessed on 15 March 2020).
- StyleGAN-Pokemon. Available online: https://www.kaggle.com/ahsenk/stylegan-pokemon (accessed on 15 March 2020).
- StyleGAN—Official TensorFlow Implementation. Available online: https://github.com/NVlabs/stylegan (accessed on 19 December 2020).
- Gwern. Making Anime Faces With StyleGAN. 2019. Available online: https://www.gwern.net/Faces (accessed on 9 March 2020).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application Description | Model Description | ||||||
|---|---|---|---|---|---|---|---|
| Year | Context | Images Number | Images Quality | Generative Model | Transfer Learning | Training Time | Evaluation Metric |
| 2017 [8] | Data augmentation in alphabets, handwritten characters, and faces | Alphabets: 1200, Characters: 3400, Faces: 1802 | Low-resolution | Conditional GAN | Yes | Not available | Not available |
| 2018 [4] | Data augmentation using computed tomography images | Different variations | Low-resolution | Progressive Growing GAN | No | ∼36 GPU hours | Not available |
| 2018 [15] | Data augmentation using GANs for liver injuries classification | Computed tomography images: 182 | Low-resolution | Deep Convolutional GAN (DCGAN) | No | Not available | Not available |
| 2018 [16] | Medical image data augmentation using GANs | Alzheimer’s Disease Neuroimaging Initiative: 3416 | Low-resolution | Pix2Pix GAN | No | Not available | Not available |
| 2018 [23] | Transfer learning in GANs for data augmentation | Varies from 1000 to 100,000 | Low-resolution | Wasserstein GAN with Gradient Penality (WGAN-GP) | Yes | Not available | FID minimum: 7.16, FID maximum: 122.46 |
| 2020 [12] | Transfer learning in GANs for COVID-19 detection on chest X-ray images | Normal cases: 79, COVID-19: 69, Pneumonia bacterial: 79, Pneumonia virus: 79 | Low-resolution | Shallow GAN | Yes | Not available | Not available |
| 2020 [13] | COVID-19 Screening on chest X-ray images | Normal cases: 1341, Pneumonia: 1345 | Low-resolution | Deep Convolutional GAN (DCGAN) | No | GPU Titan RTX; 100 epochs | Not available |
| 2019 [31] | Plant diseases detection | Plant leafs: 79,265 | High-resolution | StyleGAN | No | Not available | Not available |
| 2019 [32] | Data augmentation on plant leaf diseases | Plant leaf disease: 54,305 | High-resolution | DCGAN & WGAN | No | 1000 epochs | Not available |
| 2019 [14] | Data augmentation using GANs to improve CT segmentation | Pancreas CT: 10,681 | High-resolution | CycleGAN | No | 3 M iterations | Qualitative evaluation |
| 2019 [33] | Image generation from small datasets via batch statistics adaptation | Face, Anime, and Flowers: 251–10,000 | High-resolution | SNGAN, BigGAN | Yes | 3000, 6000–10,000 iterations | FID: 84–130 |
| 2019 [34] | Mind2Mind: transfer learning for GANs | MNIST, KMNIST, and CelebHQ: 30,000–60,000 | High-resolution | MindGAN | Yes | Not available | FID: 19.21 |
| 2020 [35] | Data augmentation using GANs for electrical insulator anomaly detection | Individual insulators: 3861 | High-resolution | BGAN, AC-GAN, PGAN, StyleGAN, BPGAN | No | Not available | Not available |
| 2020 [17] | Data augmentation using StyleGAN for pelvic malignancies images | 17,542 | High-resolution | StyleGAN | No | One GPU month | FID: 12.3 |
| 2020 [36] | Data augmentation for Magnetic Resonance Brain Images | 50,000 | High-resolution | StyleGAN and Variational autoencoders | No | Not available | Not available |
| 2020 [38] | MineGAN: effective knowledge transfer from GANs to target domains with few images | MNIST, CelebA, and LSUN: 1000 | High-resolution | Progressive GAN, SNGAN, and BigGAN | Yes | 200 iterations | FID: 40–160 |
| 2020 [39] | Freeze the discriminator: a simple baseline for fine-tuning GANs | Animal face, Flowers: 1000 | High-resolution | StyleGAN, SNGAN | Yes | 50,000 iterations | FID: 24–80 |
| 2020 [40] | On leveraging pretrained GANs for generation with limited data | CelebA, Flowers, Cars, and Cathedral: 1000 | High-resolution | GP-GAN | Yes | 60,000 iterations | FID: 10–80 |
| 2021 [37] | Data augmentation for Cardiac Magnetic Resonance | 6000 | High-resolution | Conditional GAN-based method | Yes | Not available | Not available |
| 2021 [41] | MineGAN++: mining generative models for efficient knowledge transfer to limited data domains | MNIST, FFHQ, Anime, Bedroom, and Tower: 1000 | High-resolution | BigGAN, Progressive GAN, and StyleGAN | Yes | 200 iterations | FID: 40–100 |
| Target Domain | # of Images | # of Classes | Content Variability |
|---|---|---|---|
| Bean seeds [44] | 1500 | 16 | Low |
| Young faces [46,47,48] | 3000 | 14 | Medium |
| Chars [52] | 2928 | 3 | High |
| Source Domain | Image Resolution | Number of Iterations |
|---|---|---|
| Paintings [53] | 8040 | |
| Portraits [54] | 11,125 | |
| Pokemon [55] | 7961 | |
| Bedrooms [56] | 7000 | |
| Cats [56] | 7000 |
| Source Target | Bean Seeds | Young Faces | Chars |
|---|---|---|---|
| Paintings | 23.26 | 27.77 | 38.13 |
| Portraits | 35.04 | 30.11 | — |
| Pokémon | 27.06 | 27.56 | — |
| Bedrooms | 39.31 | 16.98 | 34.81 |
| Cats | 57.92 | 20.48 | 61.52 |
| Source Target | Bean Seeds | Young Faces | Chars |
|---|---|---|---|
| Original image |  |  |  |
| Paintings |  |  |  |
| Portraits |  |  | — |
| Pokémon |  |  | — |
| Bedrooms |  |  |  |
| Cats |  |  |  |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Achicanoy, H.; Chaves, D.; Trujillo, M. StyleGANs and Transfer Learning for Generating Synthetic Images in Industrial Applications. Symmetry 2021, 13, 1497. https://doi.org/10.3390/sym13081497
Achicanoy H, Chaves D, Trujillo M. StyleGANs and Transfer Learning for Generating Synthetic Images in Industrial Applications. Symmetry. 2021; 13(8):1497. https://doi.org/10.3390/sym13081497
Chicago/Turabian StyleAchicanoy, Harold, Deisy Chaves, and Maria Trujillo. 2021. "StyleGANs and Transfer Learning for Generating Synthetic Images in Industrial Applications" Symmetry 13, no. 8: 1497. https://doi.org/10.3390/sym13081497