3. Tensor-Based LMS Algorithms
The matrix inversion and the statistics estimation needed when using the Wiener solutions presented before could be unsuitable in real-world scenarios (e.g., when dealing with nonstationary environments and/or requiring real-time processing). Consequently, it may be more practical to use adaptive filters, and among them, the LMS algorithm is one of the simplest and most practical solutions [
7,
28].
First, let us consider the estimated impulse responses of the channels,
, with
. Therefore, we may define the corresponding a priori error signals:
with
, where
with
being the identity matrices of sizes
. It is easy to check that
. Consequently, the LMS updates of the individual filters result in
where
are the step-size parameters. Relations (
20) define the tensor-based LMS (LMS-T) algorithm. The initialization of the algorithm could be
where
and
are two vectors of length
P, whose all elements are equal to zero and one, respectively. We should also note that the classical “all-zeros” initialization used in most of the conventional adaptive filtering algorithms cannot be used in this case, due to the connection between the individual filters. In other words, using
would “freeze” the updates (
20) of the LMS-T algorithm, due to (
19).
Finally, the estimate of the global system is obtained as
The global impulse response may also be identified using the conventional LMS algorithm [
5]:
where
is the global step-size parameter. According to (
18), (
19) and (
23), it can be noticed that
. However, the update (
24) involves an adaptive filter of length
, while the LMS-T algorithm combines the solutions of
N shorter filters of lengths
, with
. Since the global performance of any adaptive algorithm is highly influenced by the length of the filter, the LMS-T algorithm should own improved features as compared to the conventional LMS counterpart. Simulation results provided in
Section 6 support this aspect.
The convergence analysis of the LMS-T algorithm is not a straightforward task. The main challenge is related to the connection between the individual filters. According to (
18)–(
20), the coefficients of the
i-th filter (
) at time index
n depend on the coefficients of the other
individual filters from the previous time index (
). Based on the analogy with bilinear forms [
7,
22], the stability of the LMS-T algorithm is guaranteed for
, assuming that
. This setup is also used by the tensor LMS algorithm proposed by Rupp and Schwarz in [
7]. On the other hand, taking into account the well-known compromise between the convergence rate and misadjustment, this condition could be too restrictive if targeting different adaptation modes (i.e., different step-sizes) for the individual filters. Consequently, a detailed convergence analysis of the LMS-T algorithm is considered for future works.
Nevertheless, the selection of the step-sizes represents an important challenge when setting the parameters of the LMS-T algorithm. It can be noticed that, in (
20), the step-size parameters are constant. A good compromise between convergence speed and misadjustment needs to be considered when choosing their values. Nevertheless, in nonstationary environments, it could be more useful to choose variable step-size (i.e., time-dependent) parameters. Consequently, the updates for the LMS algorithm should be reformulated as
with
. Next, we define the a posteriori error signals:
with
. By replacing (
20) in (
27), then forcing the a posteriori error signals to zero, we obtain
for
. By assuming that
, the expressions of the time-dependent step-sizes result as
We also need to introduce some regularization constants
in the denominators of the above expressions [
29], in order to achieve a robust adaptation. Moreover, in order to obtain a good compromise between convergence rate and steady-state misadjustment, the normalized step-size parameters
are used. Hence, the update equations of the tensor-based normalized LMS (NLMS-T) algorithm are obtained as
with
, while the global impulse response results similar to (
23). Similarly, the individual impulse responses may be initialized using (
21)–(
22). The NLMS-T algorithm is summarized in Algorithm 1.
| Algorithm 1: NLMS-T algorithm. |
Initialization:
Set , based on (21)–(22)
Set
For n = 1,2,…, number of iterations:
Compute , based on (19)
, for any
|
Another way to identify the global impulse response is to use the conventional normalized LMS (NLMS) algorithm [
5], defined by
where
denotes the normalized step-size parameter,
is the regularization constant, and
was defined in (
25). Nevertheless, similar to the previous discussion related to the LMS-T and LMS algorithms, the NLMS-T uses
N adaptive filters of lengths
, while the length of the conventional NLMS filter is
.
4. Tensor-Based RLS Algorithm
The main advantage of the RLS-based algorithms consists of a faster convergence rate, as compared to the LMS family. This gain is more apparent for correlated input signals. On the other hand, the price to pay is a higher computational complexity. In this context, the tensor-based algorithms could be more advantageous. In the following, we exploit this approach in the case of the RLS algorithm.
Let us consider the context of (
13) and (
15), where we apply the least-squares error criterion [
5]. As a result, the conventional RLS algorithm can be derived following the minimization of the cost function:
where
is the forgetting factor of the algorithm. Equivalently, using (
19), the cost function (
32) can be reformulated in
N alternative ways, following the optimization procedure of the individual impulse responses, i.e.,
with
, where the
’s are the individual forgetting factors. These cost functions are further processed following a multilinear optimization strategy [
27]. In other words, we consider that
components are fixed, while the optimization procedure is related to the remaining one. Therefore, following the minimization of (
33) with respect to
, for
, we obtain a set of normal equations:
where
with
. Solving (
34), we obtain
N update relations related to the individual filters, which result in
for
, where
are the Kalman gain vectors. Furthermore, we can use (
18) to compute the error signal.
An important issue is related to the inverse of the matrices
. This can be efficiently addressed based on the matrix inversion lemma, which is also known as the Woodbury matrix identity [
5]. This states that having the matrices
,
,
,
, and
(with consistent sizes), such that
, the inverse of this matrix results in
. Consequently, in (
35), we can associate
,
,
,
, and
, thus resulting the following updates:
with
. The stability of such an update is guaranteed if the matrix
is nonsingular and
. Consequently, the initialization should be
, where
is a positive constant.
Furthermore, the evaluation of the Kalman gain vectors results in
for
. For initialization, we can follow the same rule from (
21)–(
22), while the global impulse response is obtained using (
23). The resulting tensor-based RLS (RLS-T) algorithm is provided in Algorithm 2.
| Algorithm 2: RLS-T algorithm. |
Initialization:
Set , based on (21)–(22)
For n = 1, 2,…, number of iterations:
Compute , based on (19)
, for any
|
The convergence of the RLS-T algorithm can be assessed in terms of its conversion factors [
5], based on the evaluation of the a posteriori errors. Using the update (
37) in (
27) and taking (
15) into account, we obtain
where
are the conversion factors. Next, replacing (
39) into the expressions of the corresponding conversion factors, we obtain
for
. Since
is a positive-definite matrix, we have
. Consequently,
, so that
, for any
. Therefore, the RLS-T algorithm is convergent.
Using the conventional RLS algorithm [
5] for the estimation of the global impulse response could be prohibitive for large values of
L, since the computational complexity order would be
. On the other hand, the computational complexity of the RLS-T algorithm is proportional to
, which could be much more advantageous when
. In addition, since the RLS-T operates with shorter filters, improved performance is expected, as compared to the conventional RLS algorithm. This is also supported by the simulation results provided in
Section 6.
5. Beyond the Identification of Rank-1 Tensors
The tensor-based algorithms developed in
Section 3 and
Section 4 are designed based the model presented in
Section 2, so that they are suitable for the identification of rank-1 tensors. The optimization approach can be formulated in terms of the minimization of the system misalignment, which can be defined as
where
denotes the Frobenius norm and
is defined in (
4). Alternatively, (
42) can also be expressed as
where
is the
norm and
is given in (
10).
As we can notice in (
4),
is a rank-1 tensor [
20], so that its individual components
form the global impulse response
from (
10), which represents a perfectly separable system. This repetitive (but not periodic) structure can result if a certain impulse response is followed by its reflections, e.g., as in wireless transmissions [
7]. In addition, an external noise could also corrupt such impulse responses. However, even in this case, the tensor-based adaptive algorithms can efficiently model the separable part of the system, as will be shown in the last set of experiments reported in
Section 6.
Nevertheless, the next goal is to extend the ideas behind the tensor-based algorithms for the identification of more general forms of impulse responses. This problem can be formulated in terms of identifying a higher rank tensor. It is known that the rank (
R) of a tensor
is defined as the minimum number of rank-1 tensors that generate
as their sum, i.e.,
which represents the canonical polyadic decomposition (CPD) of the tensor [
20]. Consequently, the optimization problem can be reformulated in terms of minimizing
or, alternatively,
where
represents the estimate of
and
.
Furthermore, in many real-world applications, we could exploit low-rank approximation methods in conjunction with tensor-based decompositions. In other words, we can use the approximation:
with
, so that an estimate of the impulse response can be obtained as
In our recent works [
30,
31], we approached these ideas in the two-dimensional case (i.e.,
), by exploiting the singular value decomposition (SVD) of the system matrix (i.e., a second-order tensor). The framework was the echo cancellation problem, where the low-rank approximation fits very well, since the system matrix is never really full rank (due to the reflections and sparseness in the system).
For example, let us consider a single-input/single-output (SISO) system identification problem, where the reference signal is obtained as
where
(of length
) is the unknown impulse response,
contains the most recent
time samples of the zero-mean input signal, and
is the additive noise (similar to (
13)). In addition, we consider that
, with
, so that the impulse response can be decomposed as
where
are
impulse responses, each of them having the length
. Furthermore, the impulse response could be reshaped in a matrix form (of size
), i.e.,
As outlined before, if the rank of this matrix is
, the impulse response
can be decomposed as
where
and
(with
) are impulse responses of lengths
and
, respectively.
Consequently, the impulse response of the adaptive filter could also be decomposed as
where
and
have the lengths
and
, respectively, while the error signal is evaluated as
Following the least-squares error criterion [
5] and taking (
53) and (
54) into account, the cost functions can be defined as
where
and
represent the forgetting factors, and
Based on the minimization of (
55) and (
56) with respect to
and
, respectively, we obtain the RLS algorithm based on the nearest Kronecker product decomposition, namely, RLS-NKP [
31]. This algorithm represents an extension of the RLS algorithm for bilinear forms (RLS-BF) developed in [
23], while the RLS-BF is a particular case of the RLS-T algorithm for
.
Nevertheless, for a higher-order tensor (
), the problem becomes more complicated. In this context, the higher-order SVD (HOSVD) of the tensor can be exploited [
32,
33]. However, handling the rank of a higher-order tensor is a more challenging issue. For example, the rank of a matrix can never be larger than the minimum of its dimensions, while the rank of the tensor
can be greater than
. The development of the tensor-based adaptive algorithms presented in this paper could be a preliminary step toward the generalization of the approach beyond the identification of rank-1 tensors.
6. Simulation Results
Simulations are performed in the context of the MISO system identification problem described in
Section 2 and the SISO scenario presented in
Section 5. In the first case (MISO scenario), the input signals are either white Gaussian noises or highly-correlated AR(1) processes. The latter ones are obtained by passing white Gaussian noises through a first-order system having the transfer function
. The input signals form the tensor
. The additive noise
is white and Gaussian, with the variance equal to
. In the second case (SISO scenario in the framework of echo cancellation), the input signal is either a highly-correlated AR(1) process or a speech sequence, while the measurement noise is generated such that the echo-to-noise ratio (ENR) is 20 dB.
In different real-world applications, we could also encounter data (i.e., input signals and/or external noises) with heavy-tail distributions [
34,
35,
36]. In order to cope with such challenging scenarios, the adaptive algorithms should be further equipped with additional control and robustness mechanisms. For example, the sign-based algorithms [
37,
38,
39] proved to be efficient under impulsive interferences. However, in this paper, we do not investigate tensor-based versions of these algorithms, but only focus on the basic adaptive filtering algorithms of the LMS and RLS families.
Most of our experiments are performed in the context of the MISO system identification problem (
Section 2), using two different orders of the system, i.e.,
and
, while the individual impulse responses
are generated as follows. The first impulse response (
) contains the first 16 coefficients of the first network echo path specified in the ITU-T G168 Recommendation [
40], so that its length is
. The second impulse response (
) is randomly generated using a Gaussian distribution and its length is set to
. The other impulse responses follow an exponential decay based on the rule
, with
and
taking the values 0.9, 0.5, and 0.1, respectively. Their lengths are set to
and
. Consequently, the global impulse responses
that result based on (
10) have the lengths 2048 and 4096, for
and
, respectively. Furthermore, the corresponding tensor
is given by (
4). For example, when
, the individual impulse responses
,
,
, and
, together with the resulting global impulse response
, are depicted in
Figure 1. Another set of experiments is dedicated to a more general case, in which the impulse response of the system is obtained as
, where
is randomly generated using a Gaussian distribution. In this scenario, the tensor-based adaptive filters are able to model only the decomposable part of the system (i.e., the impulse response
), while
acts like an additional noise.
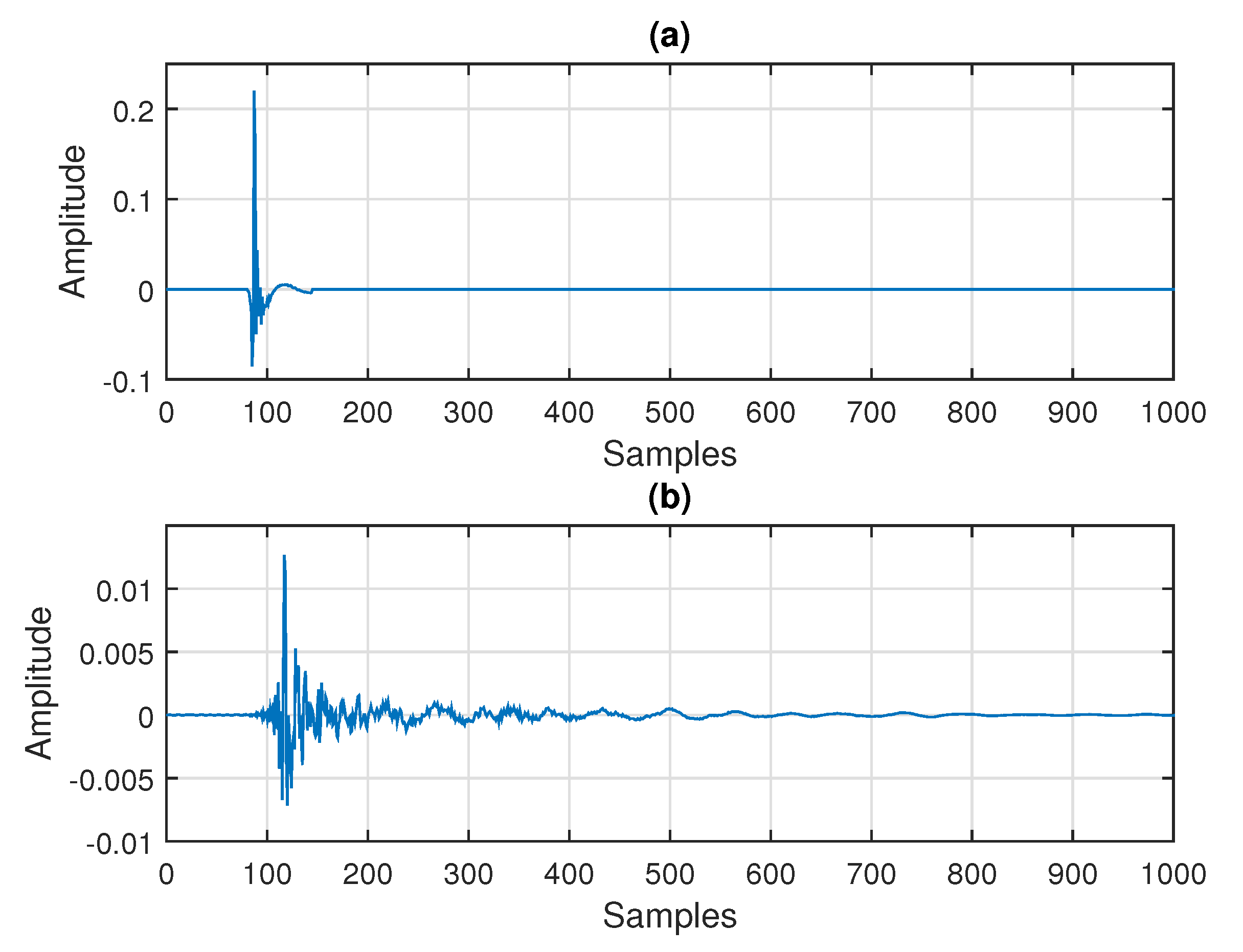
In the last set of experiments, two echo paths are considered in the context of an SISO system identification problem (i.e., echo cancellation scenario), following the discussion from
Section 5. The length of both impulse responses is
. The first echo path (shown in
Figure 2a) is a network impulse response from the ITU-T G168 Recommendation [
40], i.e., the first cluster padded with zeros up to the length
. The second echo path (depicted in
Figure 2b) is a measured acoustic impulse response, which is available on-line at
www.comm.pub.ro/plant (accessed on 5 March 2021).
In most of the experimental scenarios (i.e., MISO system identification), the proposed tensor-based algorithms, namely, LMS-T, NLMS-T, and RLS-T, are mainly compared to their conventional counterparts, i.e., LMS, NLMS, and RLS, respectively. In addition, in some of the experiments, the tensor LMS algorithm [
7] is included in comparisons. In the last set of experiments (i.e., SISO system identification), the RLS-NKP [
31] is compared to the conventional RLS algorithm.
In most of the experiments (i.e., MISO scenario), the performance measure is the normalized misalignment (in dB) for the identification of the global impulse response, which is evaluated as
. In the second to last sets of experiments, this performance measure is evaluated as
. In order to test the tracking capabilities of the algorithms, we also introduce an abrupt change of the system (in the middle of each simulation), by changing the sign of the coefficients of
. Finally, in the last set of experiments (i.e., SISO scenario), the normalized misalignment is evaluated as
, according to the notation from
Section 5. Here, we also introduce an abrupt change of the impulse response in the middle of each simulation, by changing the sign of the coefficients of
.
In the first set of experiments, we evaluate the performance of the LMS-T and LMS algorithms. The main challenge related to these algorithms is the selection of their step-size parameters. For example, in the case of the conventional LMS algorithm, the theoretical upper bound for its step-size is given by
, where
is the variance of the input signal [
5]. However, for stability reasons, this value should be lower in practice. In our experiments, we set the step-sizes of the LMS-T and LMS algorithms in order to reach similar misalignment levels, so that we can fairly compare their performance in terms of the convergence rate and tracking. Furthermore, the largest step-size of the conventional LMS algorithm is set close to its stability limit, in order to provide the fastest convergence mode of the algorithm. Clearly, since the LMS-T algorithm combines the solutions of much shorter filters (of lengths
), the corresponding values of its step-sizes are larger as compared to the step-size of the conventional LMS counterpart (with the length
).
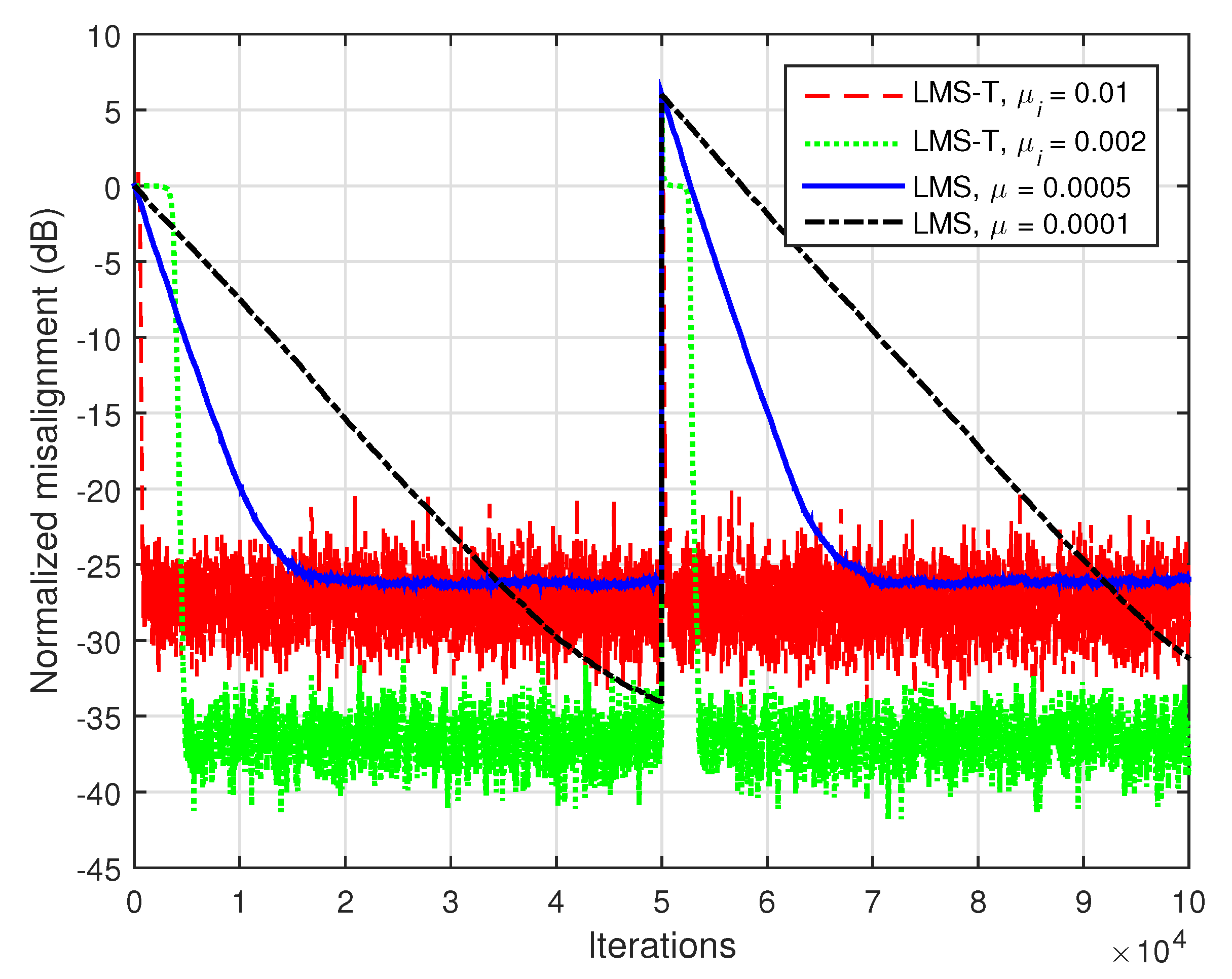
In
Figure 3, we consider
and we use white Gaussian noises as input signals. In this case, the length of the global impulse response is
. As expected, a lower value of the step-size improves the misalignment but pays with a slower convergence rate and tracking. This is valid for both LMS-T and LMS algorithms. However, the LMS-T algorithm converges and tracks significantly faster than its conventional counterpart.
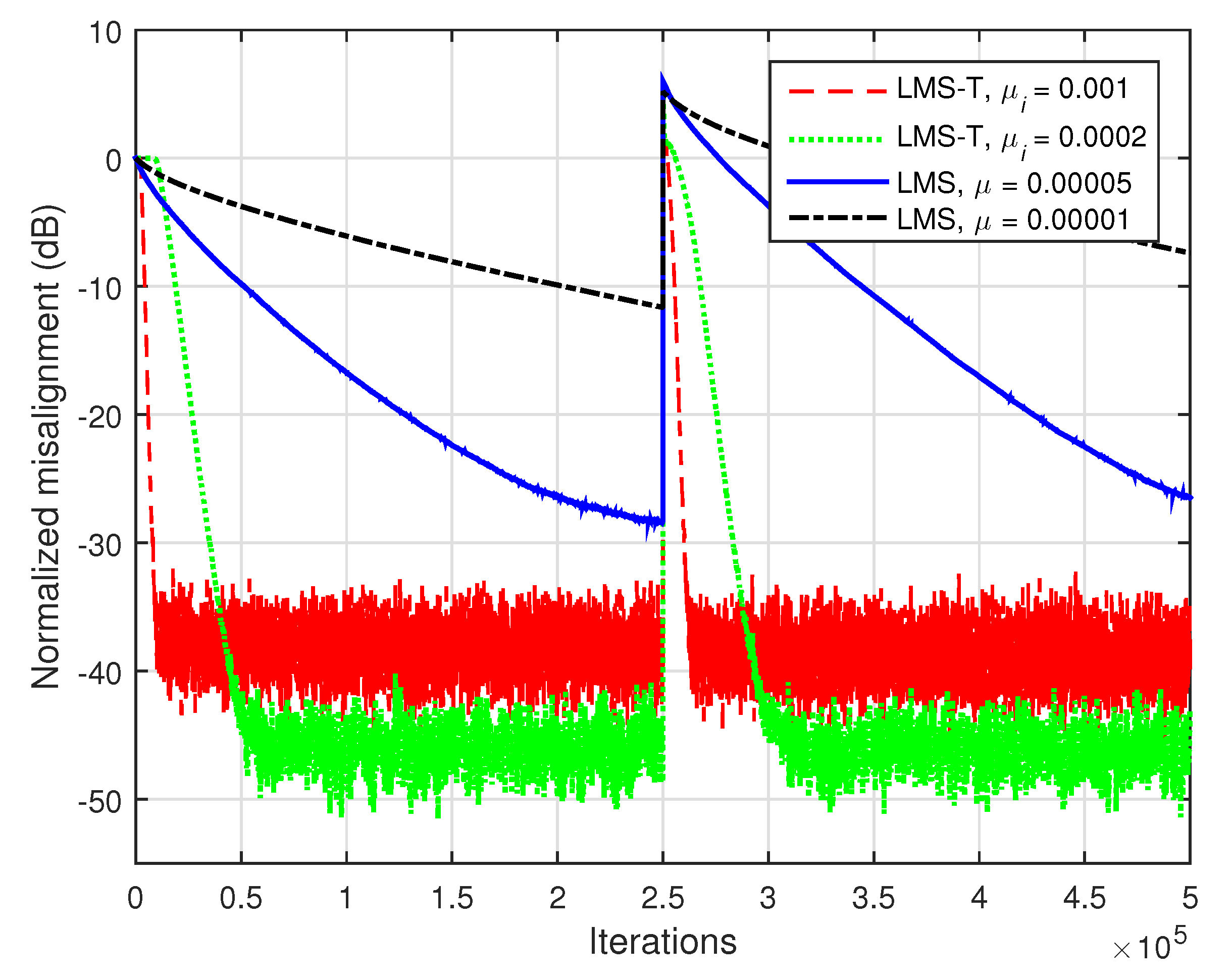
The gain is much more apparent in case of highly-correlated inputs. Such a scenario is considered in
Figure 4, where
and the input signals are AR(1) processes. As we can notice, the proposed LMS-T outperforms the conventional LMS algorithm in terms of both convergence rate/tracking and misalignment.
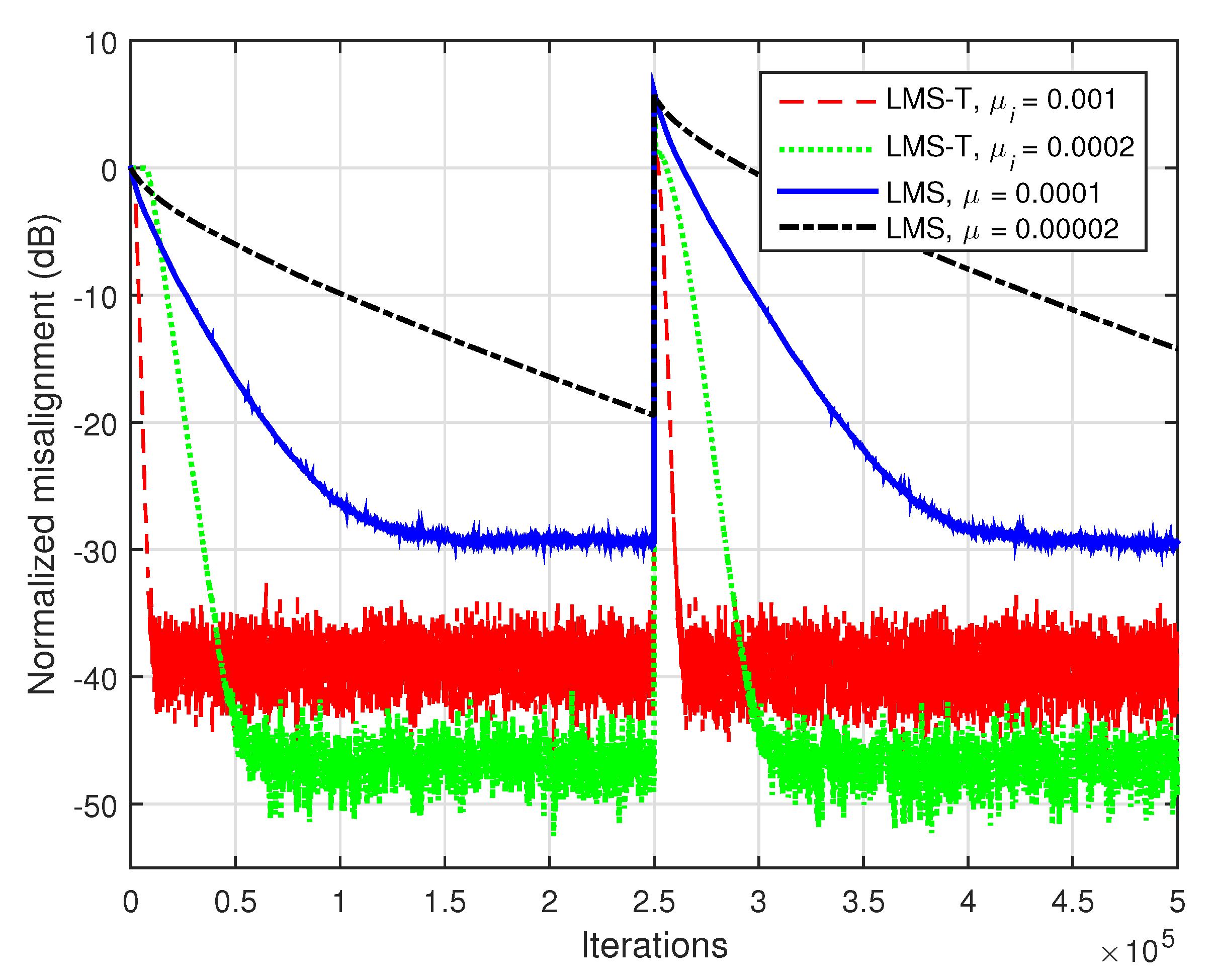
The performance gain of the LMS-T algorithm increases for higher orders, in comparison with the conventional LMS algorithm. This is supported in
Figure 5, where the input signals are AR(1) processes and
, so that the length of the global impulse response is
. The identification of such a long impulse response (especially using correlated inputs) is challenging for any conventional adaptive algorithm, highly influencing the convergence rate, tracking, and accuracy of the solution. It can be noticed that the LMS-T algorithm outperforms by far its conventional counterpart, in terms of all these performance criteria.
The second set of experiments is dedicated to the normalized versions, i.e., the NLMS-T and NLMS algorithms. The main advantage of these algorithms is related to the selection of the normalized step-sizes and, consequently, to their ability to operate in nonstationary conditions (related to the input and/or the environment). For example, the fastest convergence mode of the conventional NLMS algorithm is obtained when the normalized step-size is set to 1 [
5]. Based on the theoretical findings related to the bilinear algorithms [
22], setting the normalized step-sizes of the NLMS-T algorithm such that their sum is equal to 1 could lead to the same value of the misalignment as the conventional NLMS algorithm with the fastest convergence mode.
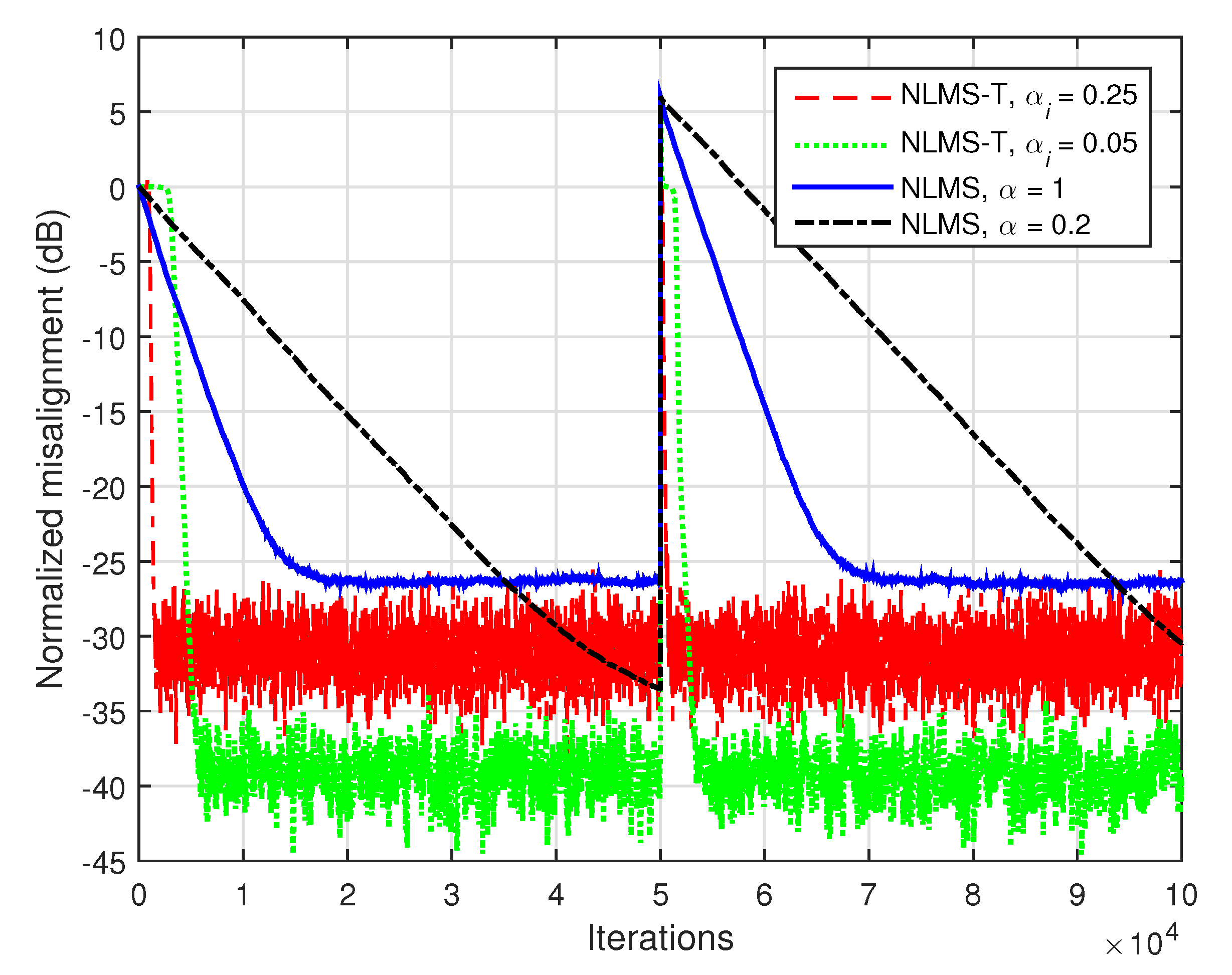
In
Figure 6, the input signals are white Gaussian noises and
. Hence, the impulse responses are those indicated in
Figure 1, with the global impulse response of length
. The conclusions of this experiment are similar to those obtained in the case of the LMS algorithms (related to
Figure 3). Most important, the NLMS-T algorithm significantly outperforms the conventional NLMS algorithm is terms of the convergence rate and tracking, especially for lower values of the normalized step-sizes.
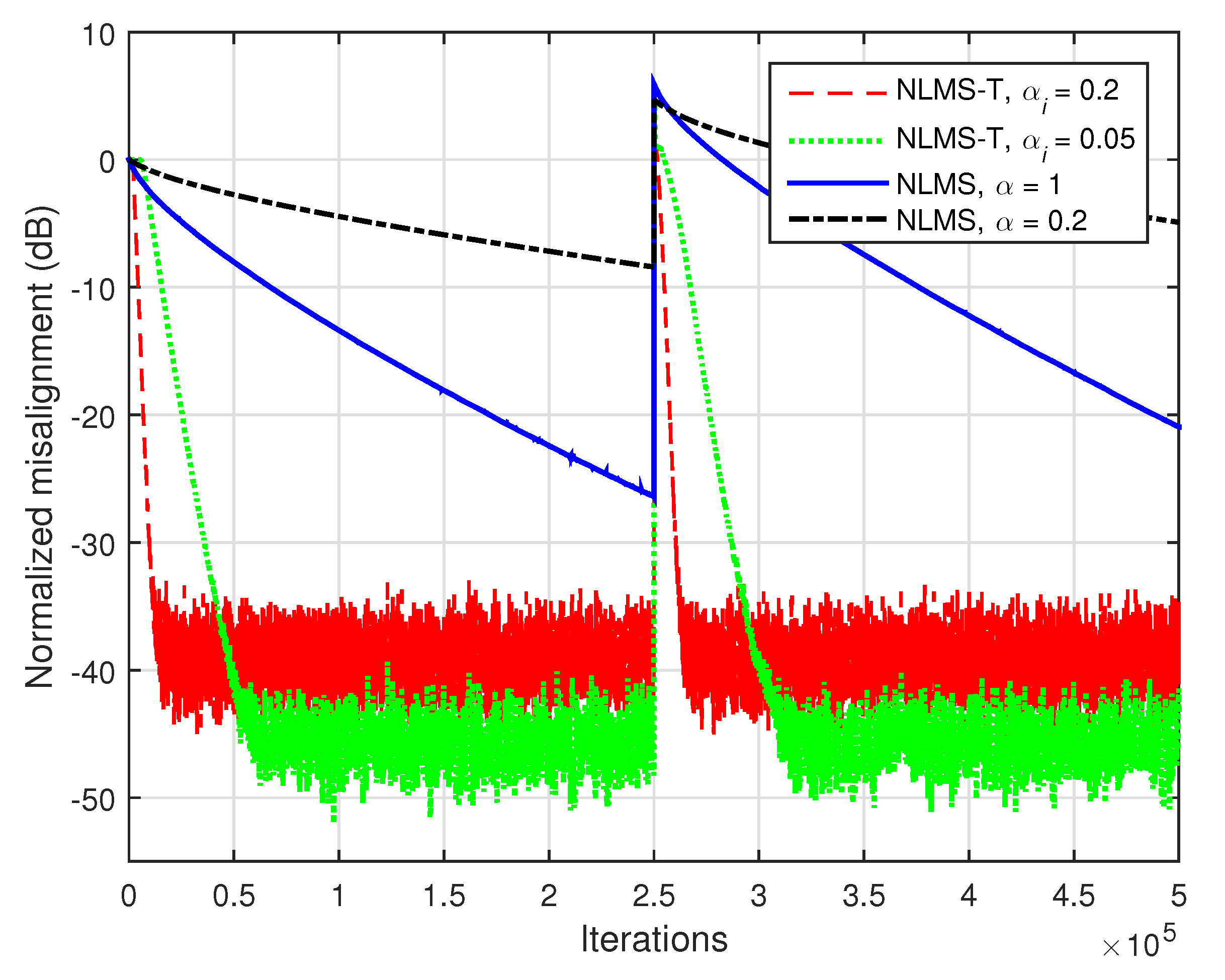
In addition, when the input signals are correlated, the gain of the proposed NLMS-T algorithm is even more apparent. This can be noticed in
Figure 7, where the input signals are AR(1) processes. As we can see from this figure, the fastest convergence mode of the conventional NLMS algorithm is outperformed by far even by the NLMS-T algorithm using the lower normalized step-sizes.
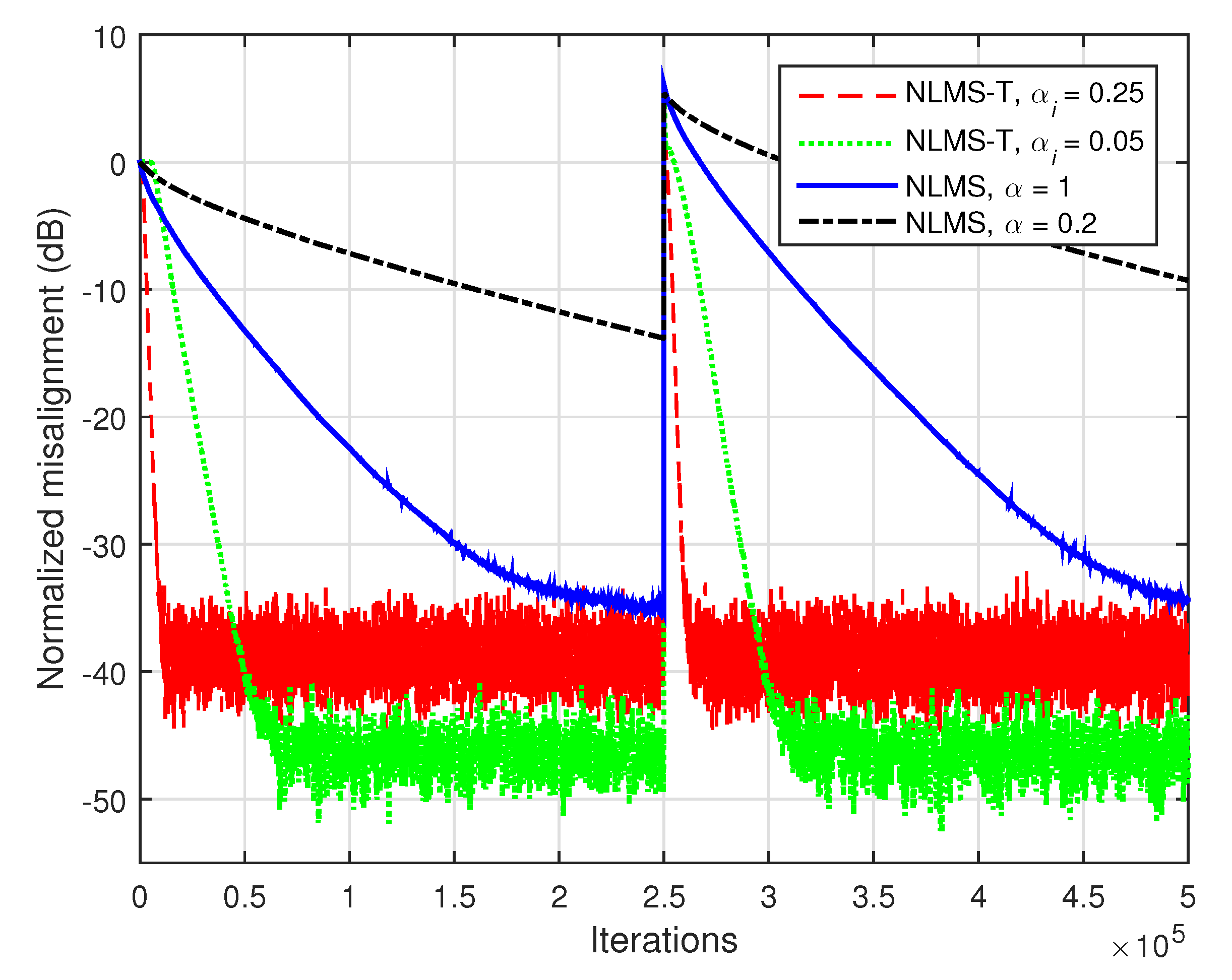
Increasing the system order also outlines the performance gain of the NLMS-T algorithm. This aspect is supported in
Figure 8, where
and the global impulse response has the length
. As we can notice, the fastest convergence mode of the conventional NLMS algorithm does not reach the steady-state before the system changes, while the NLMS-T algorithm converges (and tracks) much faster, despite the values of its normalized step-sizes.
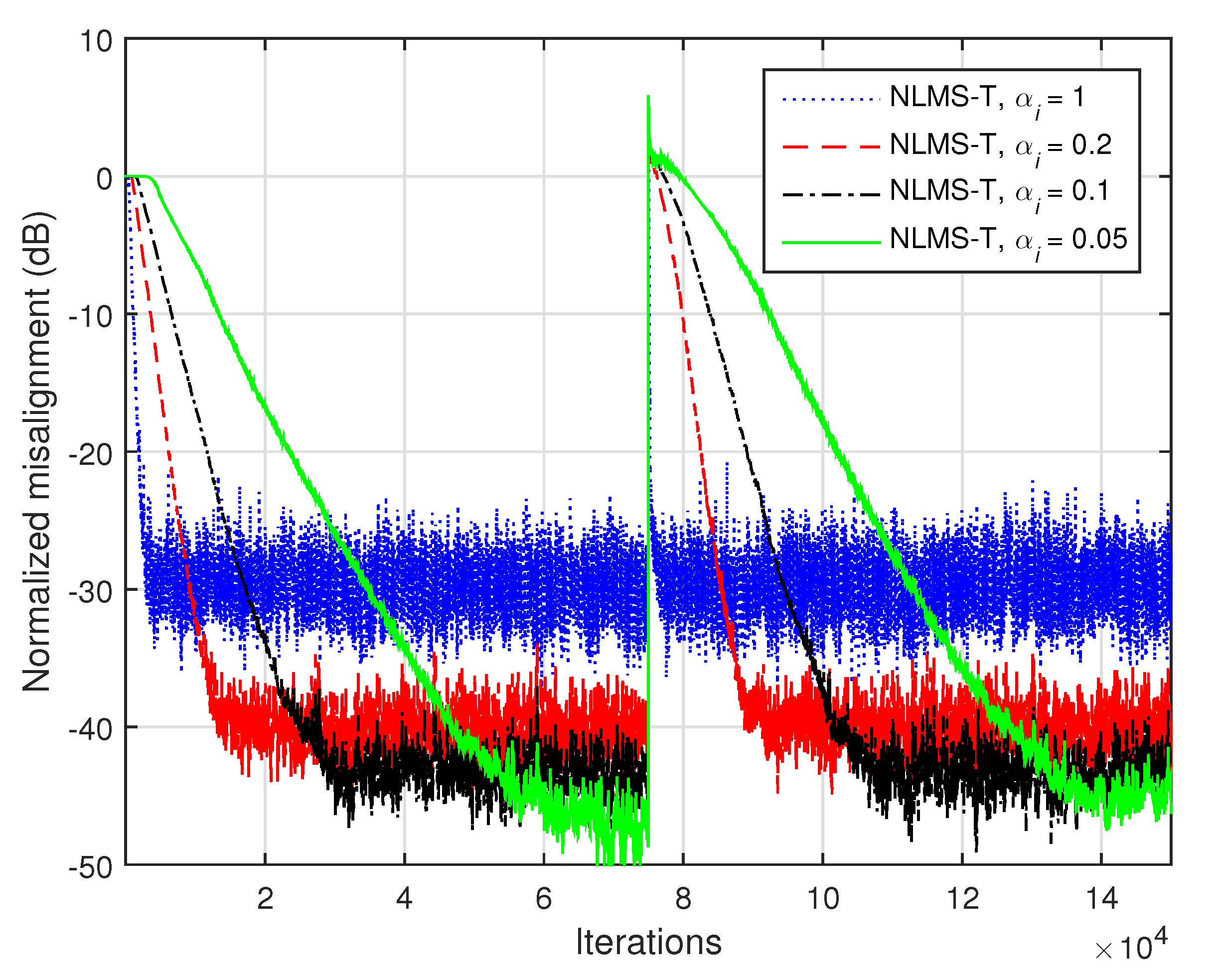
The influence of the normalized step-sizes on the performance of the NLMS-T algorithm is analyzed in
Figure 9, where the input signals are AR(1) processes and
. As expected, higher values of the normalized step-sizes improve the convergence rate and tracking but increase the misalignment.
In the previous experiment, we used equal values of
(
) for the individual filters. However, since these filters have different lengths, an alternative strategy would be to set different values of the normalized step-sizes for each individual filter. Such a scenario is considered in
Figure 10, where we set
for the first filter (of length
), while varying the other normalized step-sizes
. The other conditions are the same as in the previous experiment, i.e.,
and AR(1) inputs. We can notice the same compromise in terms of the main performance criteria (convergence rate/tracking versus misalignment). Consequently, several strategies to set these parameters can be adopted in different contexts, taking into account that the convergence features are mainly influenced by the longest individual filter [
22].
The third set of experiments is dedicated to the RLS-based algorithms. The performance of these algorithms is mainly influenced by the forgetting factors [
41]. In the case of the conventional RLS algorithm [
5], the value of this parameter is usually set as
, where
. A higher value of the forgetting factor (i.e., closer to 1) improves the misalignment, but significantly slows down the tracking reaction. A natural choice is to set the forgetting factors of the RLS-T algorithm using a similar strategy, such that
. Nevertheless, depending on the character and requirements of a particular application, different other strategies can be considered. For example, one can set all the forgetting factors equal to that associated to the longest filter. However, analyzing the impact of different strategies for the selection of the forgetting factors is beyond the scope of this paper.
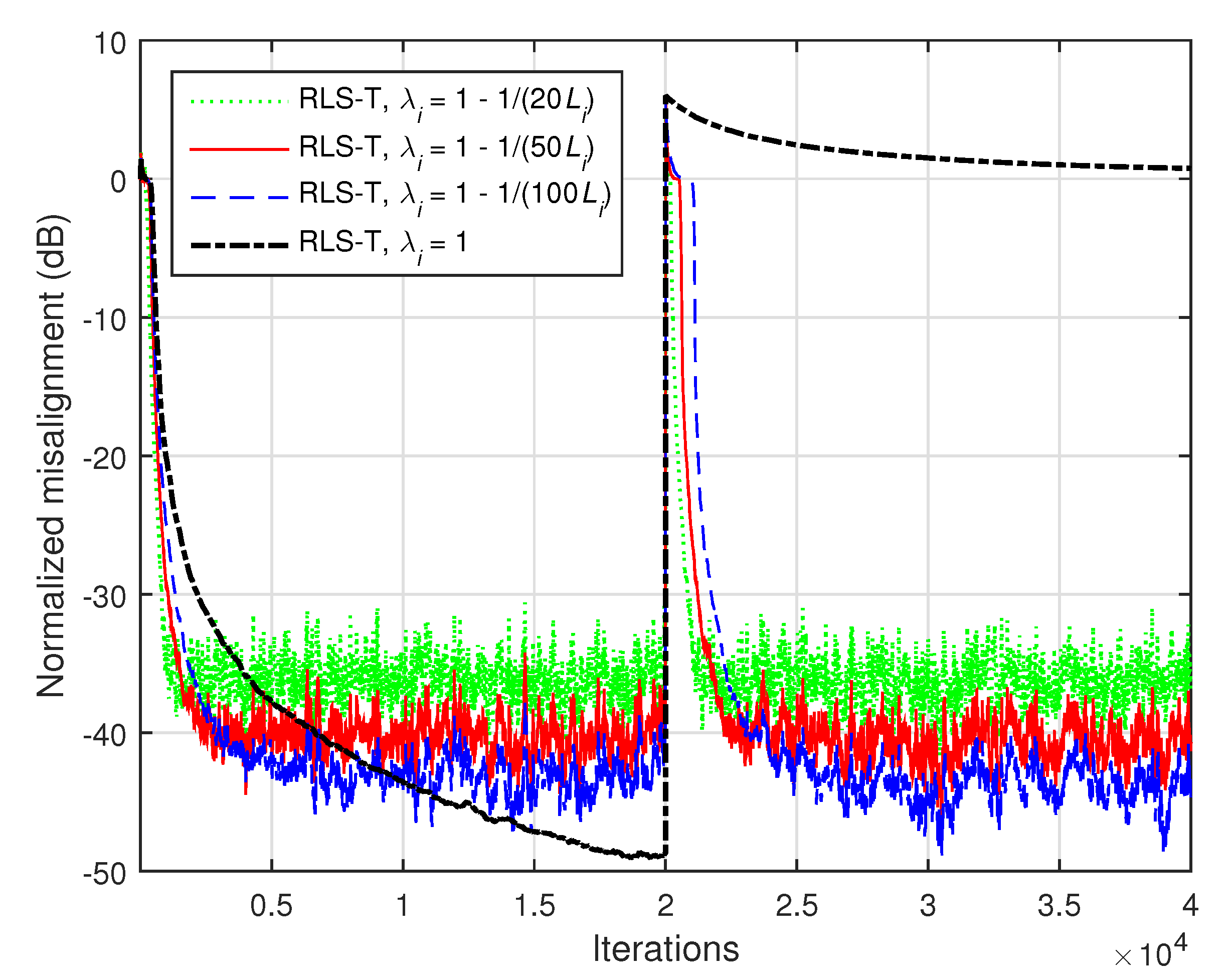
The influence of the forgetting factors on the performance of the proposed RLS-T algorithm is investigated in
Figure 11. In this simulation, the input signals are white Gaussian noises and the system order is
(i.e., the impulse responses from
Figure 1). The forgetting factors are set based on the previous rule, i.e.,
, using different values of
K. As expected, increasing the values of the forgetting factors reduces the tracking capability of the algorithm but improves its accuracy by achieving a lower steady-state misalignment. Clearly, the lowest misalignment is obtained for
(i.e.,
), while this produces the slowest tracking reaction.
The computational complexity of the conventional RLS algorithm (which is proportional to
) makes it prohibitive for the identification of long length impulse responses, especially in real-time applications and taking into account the implementation costs. On the other hand, due to the decomposition feature and the operation with shorter impulse responses, the proposed RLS-T algorithm could be more suitable in such scenarios. In addition, due to the fact that the filter’s length has an influence on the main performance criteria (e.g., convergence rate/tracking and accuracy), the RLS-T algorithm outperforms its conventional counterpart. This is supported in
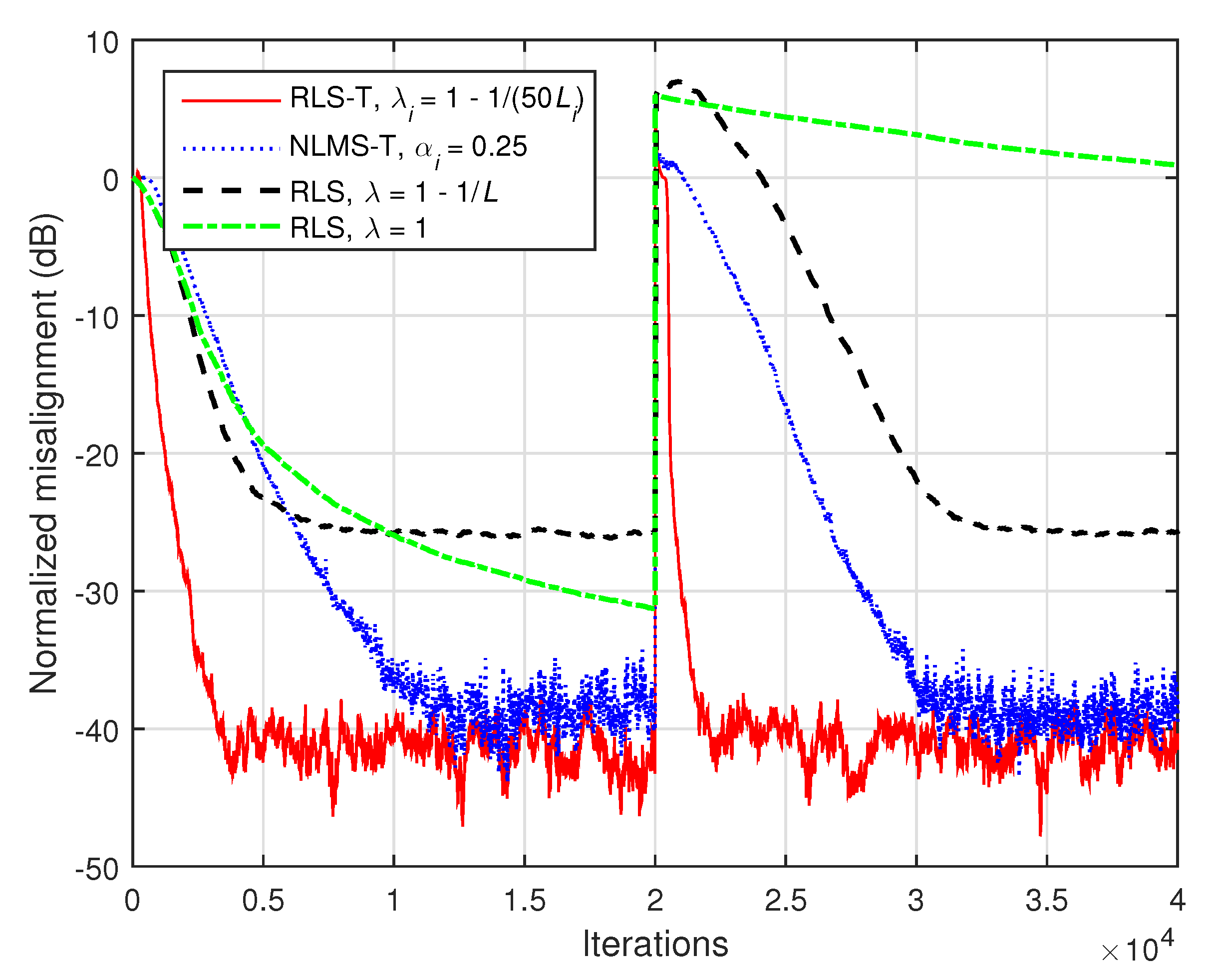
Figure 12, where the conventional RLS algorithm is used as benchmark. Furthermore, the NLMS-T algorithm is introduced in comparisons. In this simulation, the input signals are AR(1) processes and
, while the length of the global impulse response is
. As we can notice, the initial convergence rate of the conventional RLS algorithm using a lower value of the forgetting factor (
) is similar to that obtained by the NLMS-T algorithm. On the other hand, the tracking reaction of the RLS algorithm is slower as compared to the NLMS-T algorithm, while its steady-state misalignment is higher. A lower misalignment level could be achieved by the RLS algorithm with the maximum forgetting factor (i.e.,
), but paying with the slowest tracking capability. It can be noticed that the proposed RLS-T algorithm clearly outperforms all the other algorithms involved in comparisons.
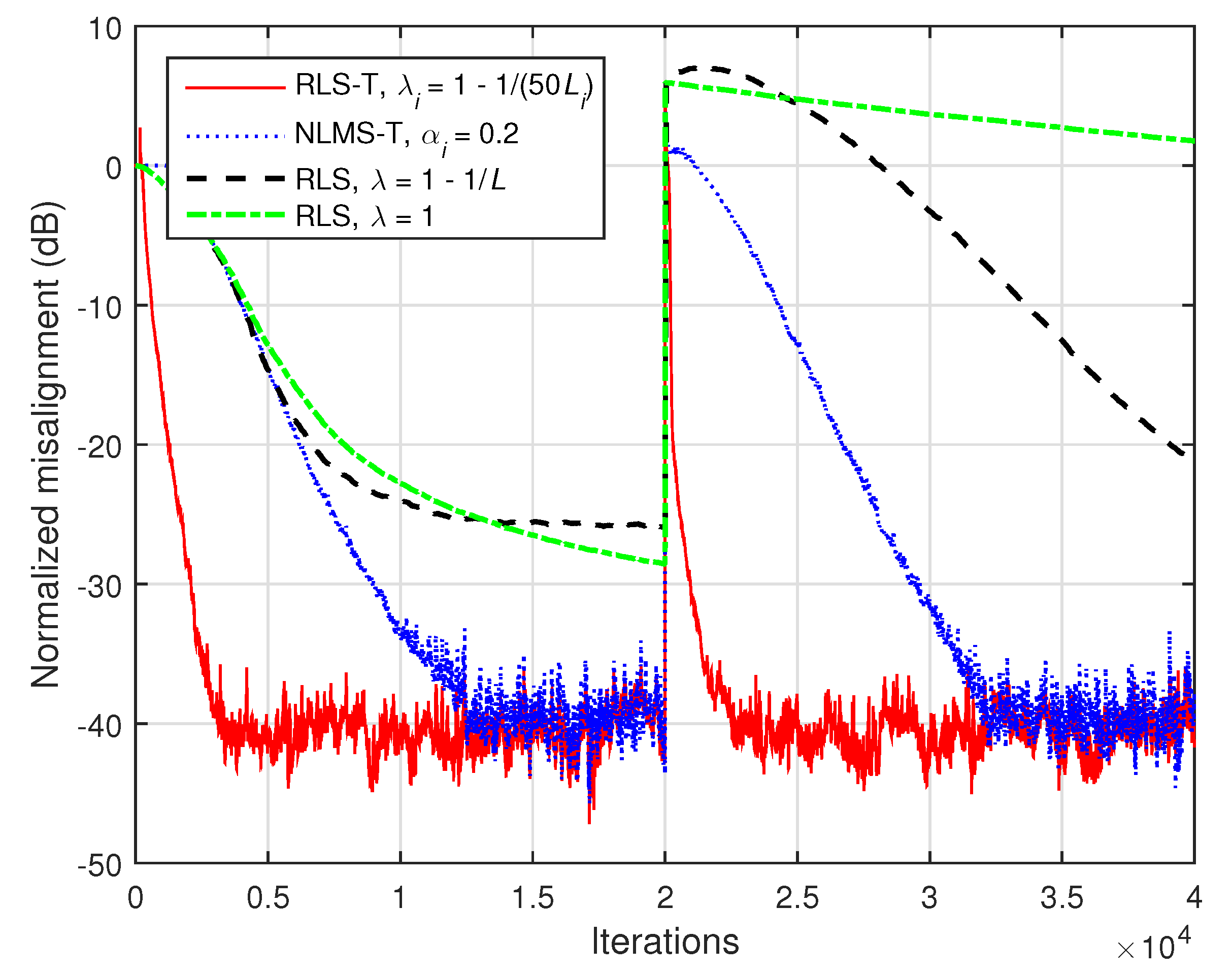
Next, the previous algorithms are compared in a more challenging scenario, using
and
, while the input signals are AR(1) processes. Such a filter length is excessively high for the conventional RLS algorithm. The results provided in
Figure 13 show that the NLMS-T algorithm outperforms the conventional RLS algorithm in this scenario. As expected, the RLS-T algorithm achieves a faster convergence rate and tracking reaction as compared to the NLMS-T algorithm.
We should also outline that in the last two simulations (
Figure 12 and
Figure 13), the main parameters of the RLS-T and NLMS-T algorithms (i.e.,
and
, respectively) are set to achieve the same steady-state misalignment level. However, as previously shown in
Figure 11, using higher values for the forgetting factors of the RLS-T algorithm would further improve the misalignment level, paying with a slightly reduced convergence rate and tracking.
In the next set of experiments, we consider a more general scenario where the impulse response of the system is not perfectly separable. Hence, it is generated as
, where
is obtained as described in the beginning of this section (e.g., see
Figure 1), while
is randomly generated (with Gaussian distribution) and its variance is set to
, where
. Clearly, a higher value of
makes the separation more challenging. In this set of experiments, we consider AR(1) processes as inputs. In addition, we include in comparisons a counterpart of the NLMS-T algorithm, i.e., the tensor LMS developed in [
7]. The step-sizes of this algorithm are evaluated as
, while the NLMS-T algorithm is updated based on (
30). In the following experiments, we used the same values of
and
for both algorithms. As a benchmark, we also evaluate the performance of the conventional RLS algorithm using
.
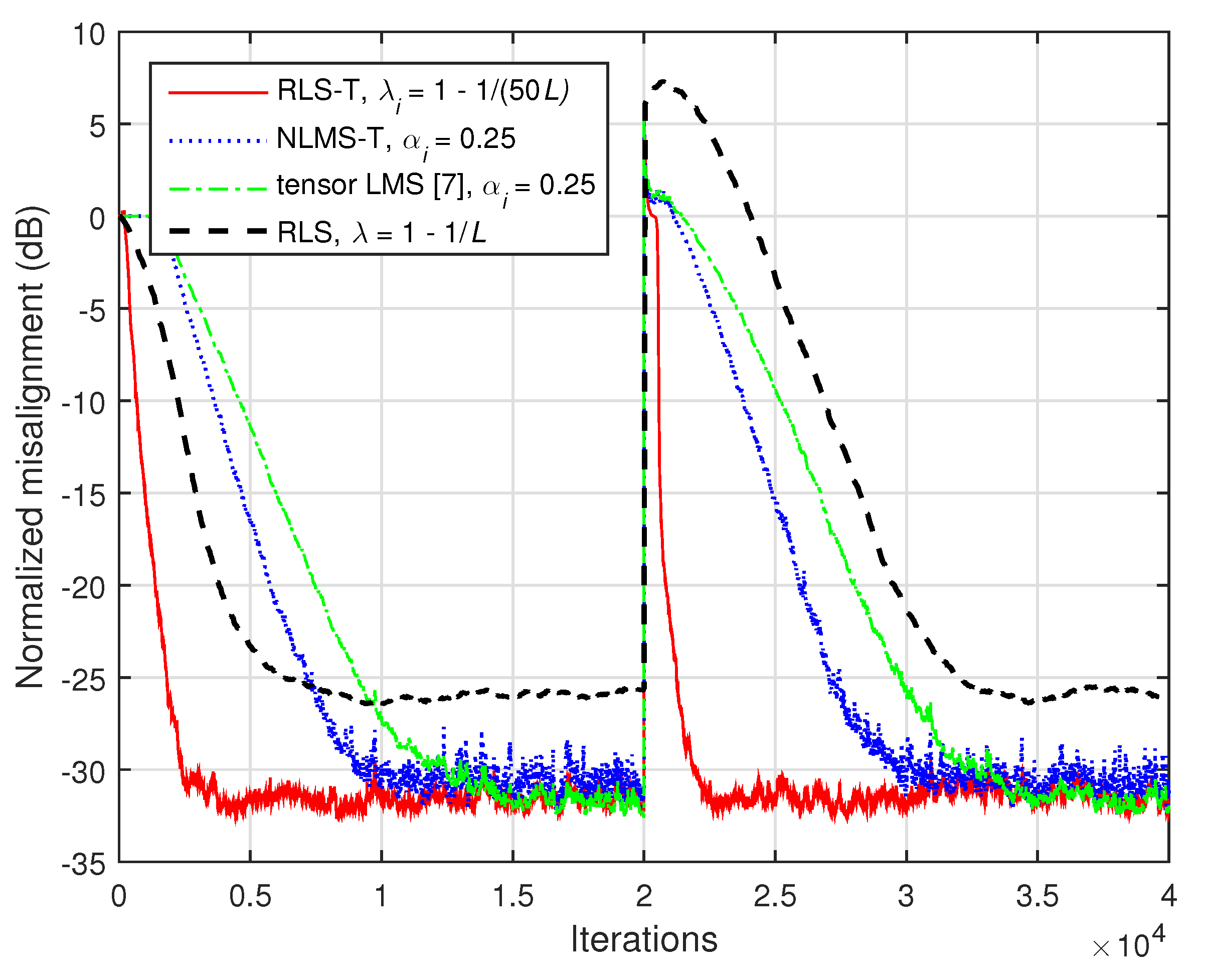
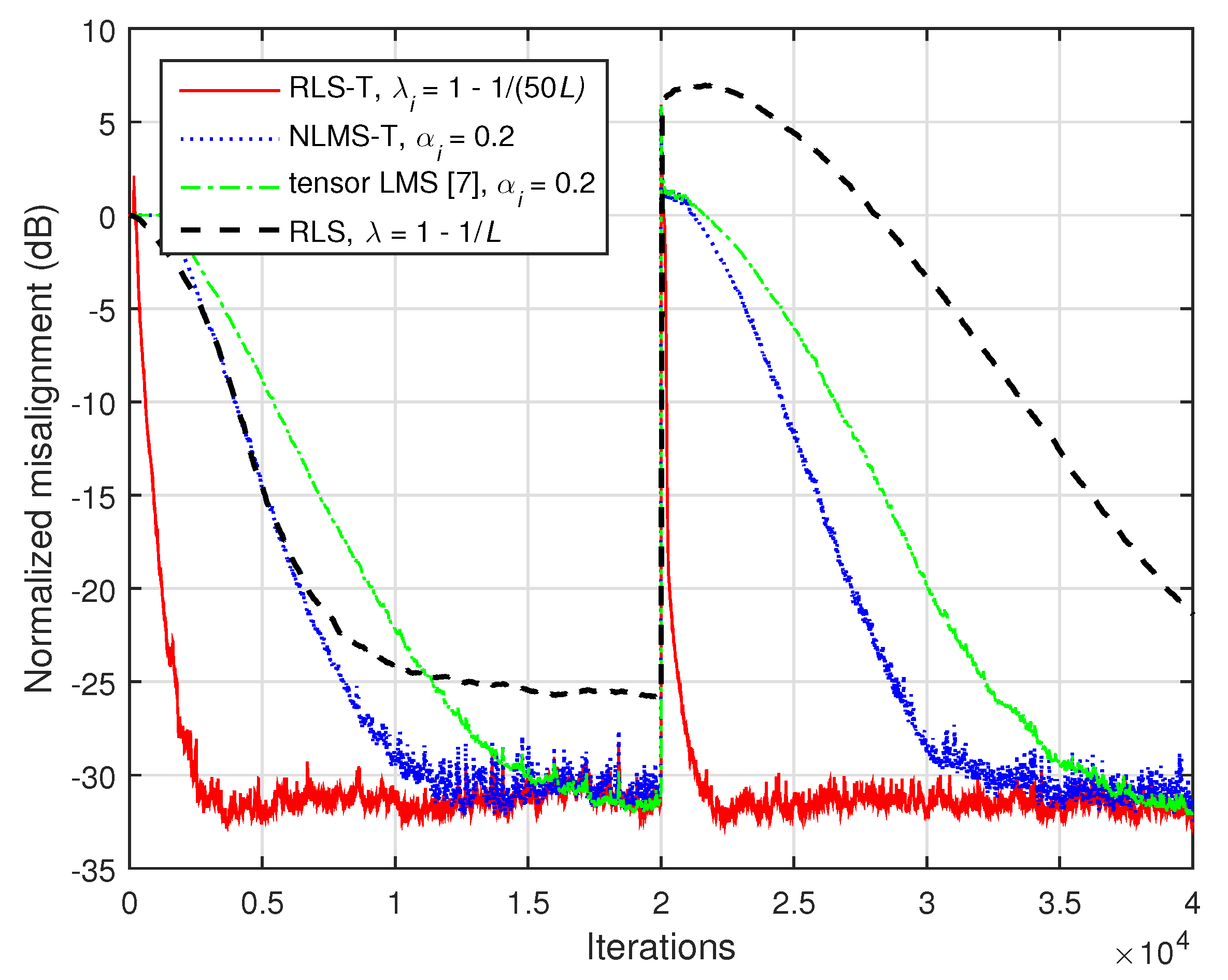
First, in
Figure 14, we consider
and
. As we can notice, the misalignment of the tensor-based algorithms increases in this case (e.g., as compared to the results reported in
Figure 12), since the nonseparable part of the system cannot be modeled. However, the RLS-T algorithm still achieves a faster convergence rate as compared to the conventional RLS algorithm. The convergence rate of the tensor LMS algorithm [
7] is slightly slower as compared to the NLMS-T algorithm, while reaching a similar misalignment level. We can also notice that both algorithms outperform the conventional RLS algorithm in terms of tracking.
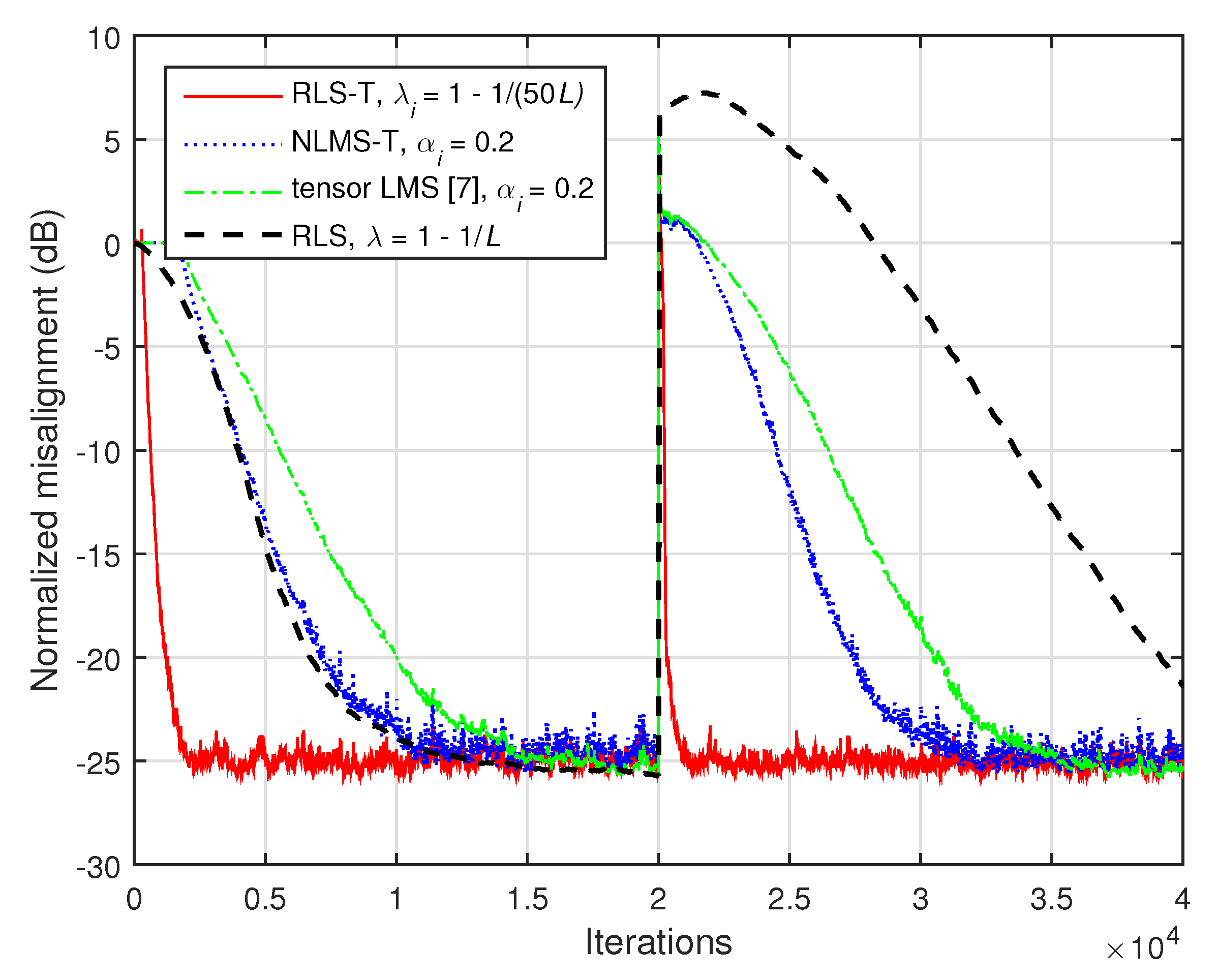
The gain is even more apparent for a higher order of the system, as supported in
Figure 15, where
and
. Here, we can also notice that the performance of the NLMS-T algorithm is improved as compared to the tensor LMS algorithm [
7], in terms of both convergence rate and tracking. As expected, the RLS-T algorithm outperforms by far all the other algorithms.
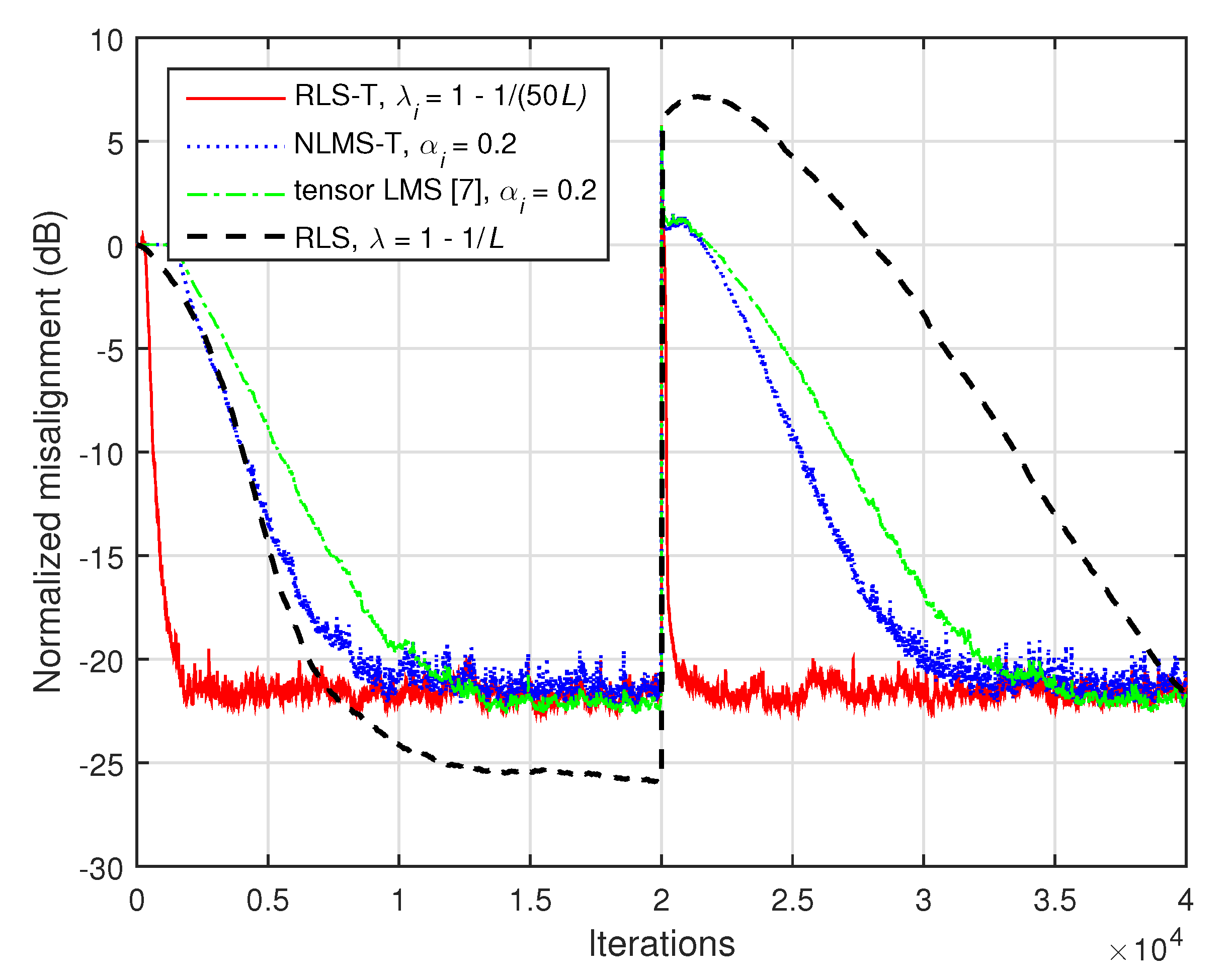
Further, in
Figure 16 and
Figure 17, the previous experiment is repeated, but using
and
, respectively. Since the influence of the nonseparable part of the system is higher in these cases, the tensor-based algorithms reach a higher misalignment level. On the other hand, they still outperform the conventional RLS algorithm, especially in terms of the tracking capability.
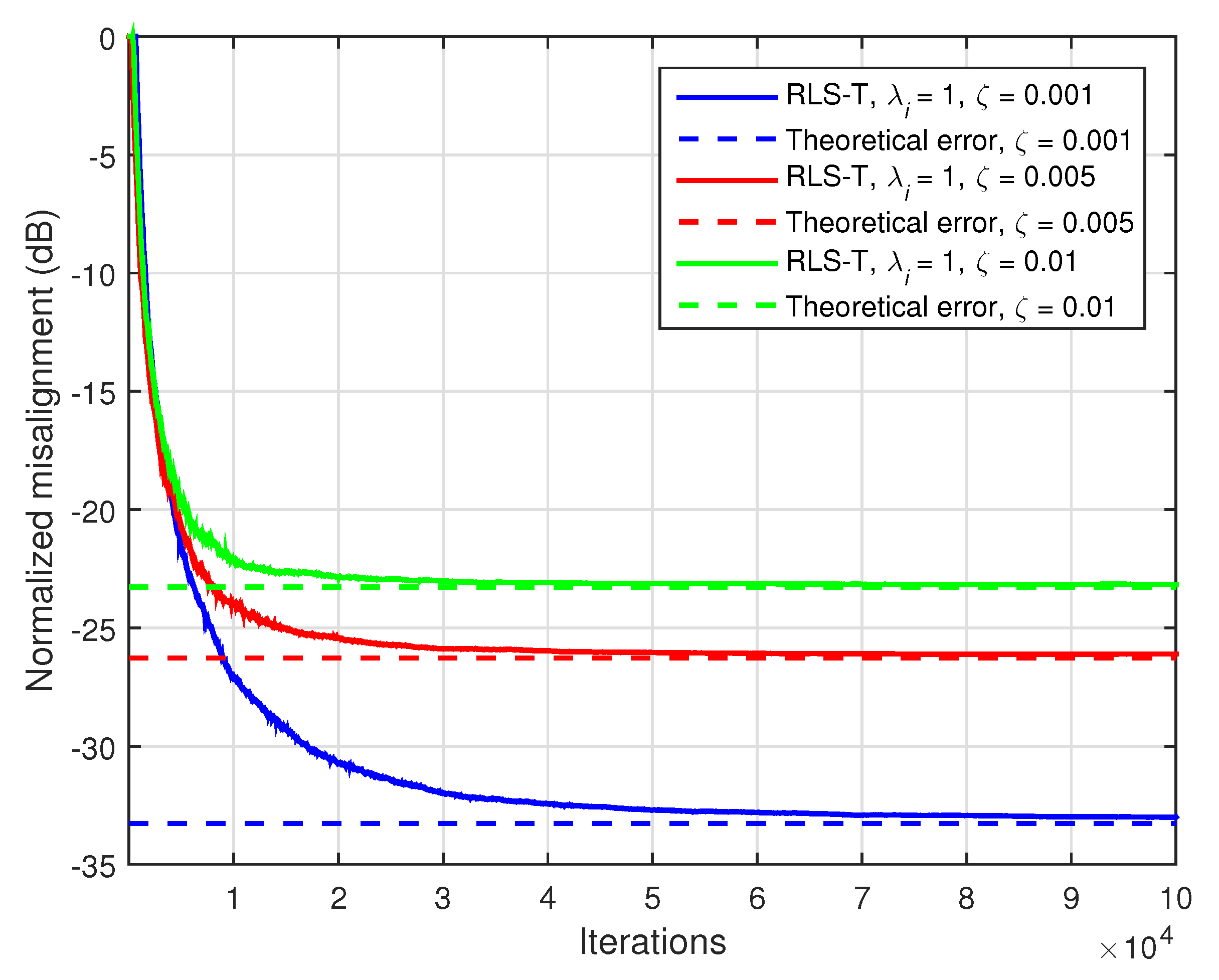
The nonseparable part of the system acts like an additional noise (which cannot be modeled based on the rank-1 decomposition), thus influencing the accuracy of the solution provided by the tensor-based algorithms. In this case, the theoretical error (in terms of the normalized misalignment) results in
. In order to outline this behavior, we evaluate the performance of the RLS-T algorithm using
, for different values of
. It is known that the RLS-based algorithms using the maximum value of the forgetting factor reach the lowest misalignment level, i.e., the highest accuracy of the solution [
5,
41]. In
Figure 18, the input signals are AR(1) processes,
, and
, while the theoretical errors are marked with dashed lines and appropriate colors. As expected, the error increases with the value of
, while the misalignment of the RLS-T algorithm matches very well the theoretical threshold in each case. The overall behavior is similar to the under-modeling scenario [
42], where the length of the adaptive filter is shorter as compared to the length of the unknown impulse response. Therefore, the “tail” of the impulse response that cannot be modeled acts like an additional noise, also increasing the misalignment level.
The last set of experiments is dedicated to the SISO system identification problem described in
Section 5, which aims to go beyond the rank-1 decomposition approach. This represents the main motivation for future developments of the tensor-based adaptive filtering algorithms. In this framework, the RLS-NKP [
31] is basically an extension of the RLS-T algorithm for
, which is suitable for the identification of more general forms of impulse responses. In these experiments, we consider an echo cancellation scenario, using the echo paths from
Figure 2 (of length
). The RLS-NKP algorithm uses
and
, while its forgetting factors are set to
and
, with
. Similarly, for a fair comparison, the forgetting factor of the conventional RLS algorithm is set to
. Nevertheless, the computational complexity of the conventional benchmark is proportional to
, while the RLS-NKP algorithm requires a computational amount of
, which is much more advantageous for
.
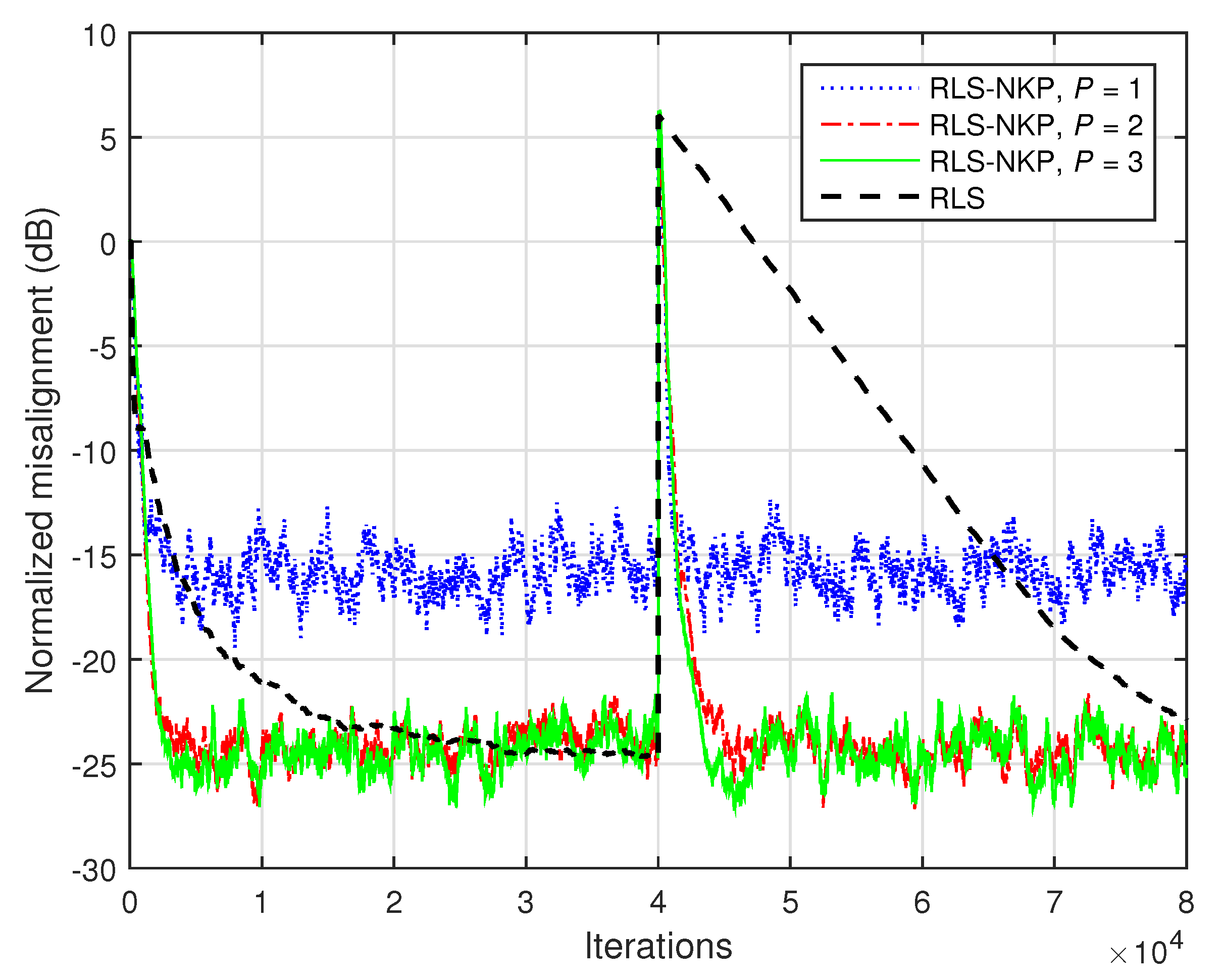
In
Figure 19, the identification of the network impulse response from
Figure 2a is evaluated. The input signal is a highly correlated AR(1) process and
dB. The RLS-NKP algorithm uses different values of
. As shown in
Section 5, this algorithm combines the estimates of two shorter filters of length
and
, while the conventional RLS algorithm involves a single (long) adaptive filter of length
. Consequently, the tracking reaction of the RLS algorithm is much slower as compared to the RLS-NKP, as we can notice in
Figure 19. Furthermore, it should be noticed that a very small value of
P (e.g.,
) leads to an accuracy of the solution (i.e., misalignment level) similar to the conventional RLS algorithm. On the other hand, the computational complexity of the RLS-NKP algorithm is much lower in this case.
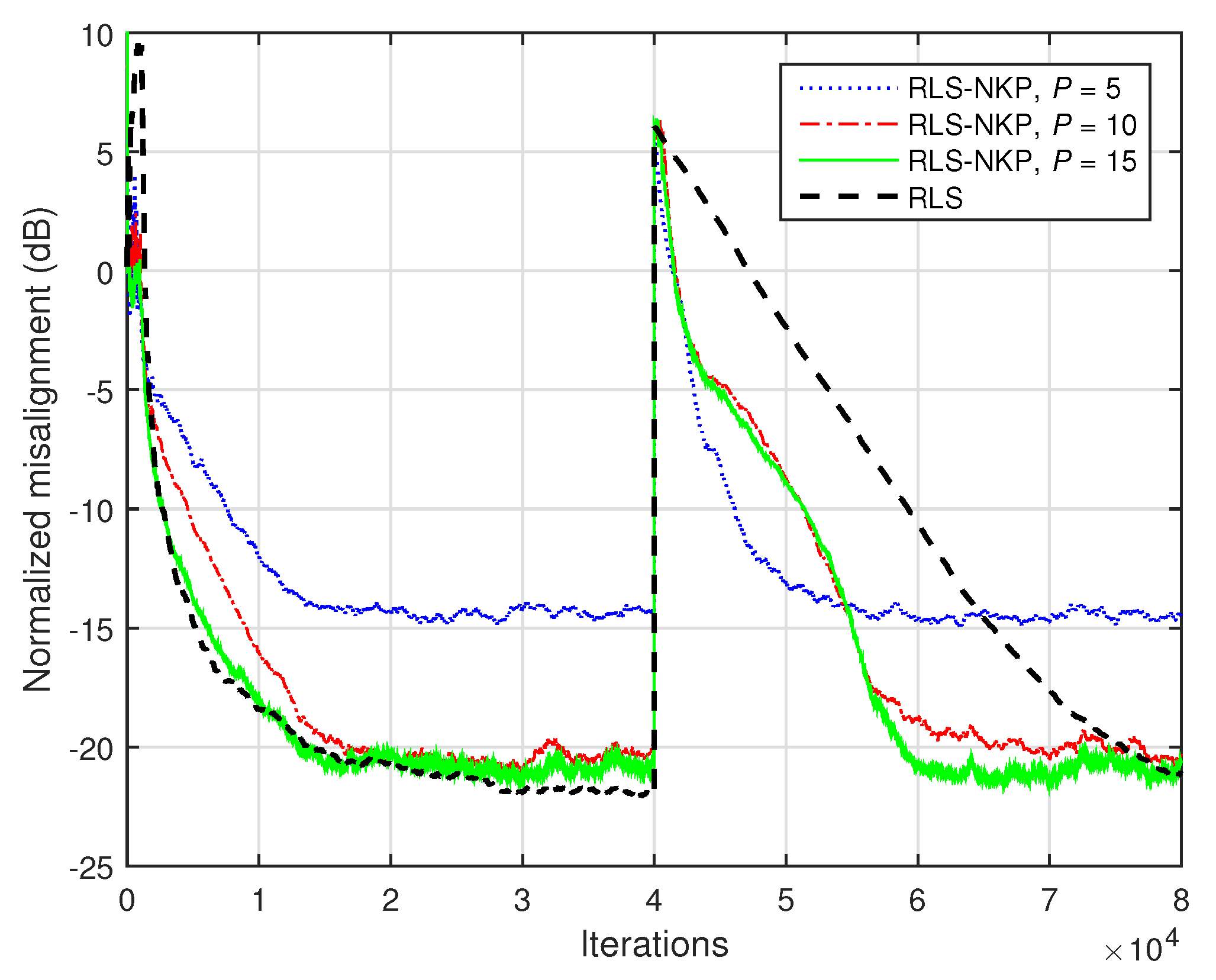
The previous experiment is repeated in
Figure 20 but uses the acoustic impulse response from
Figure 2b. As expected, the low-rank approximation is more challenging in this case, since the matrix
is closer to full-rank. Consequently, the value of
P should be increased. However, a moderate value of
P (as compared to
) is sufficient for the RLS-NKP algorithm, in order to reach a misalignment level close to the conventional RLS algorithm, while outperforming its counterpart in terms of the tracking capabilities.
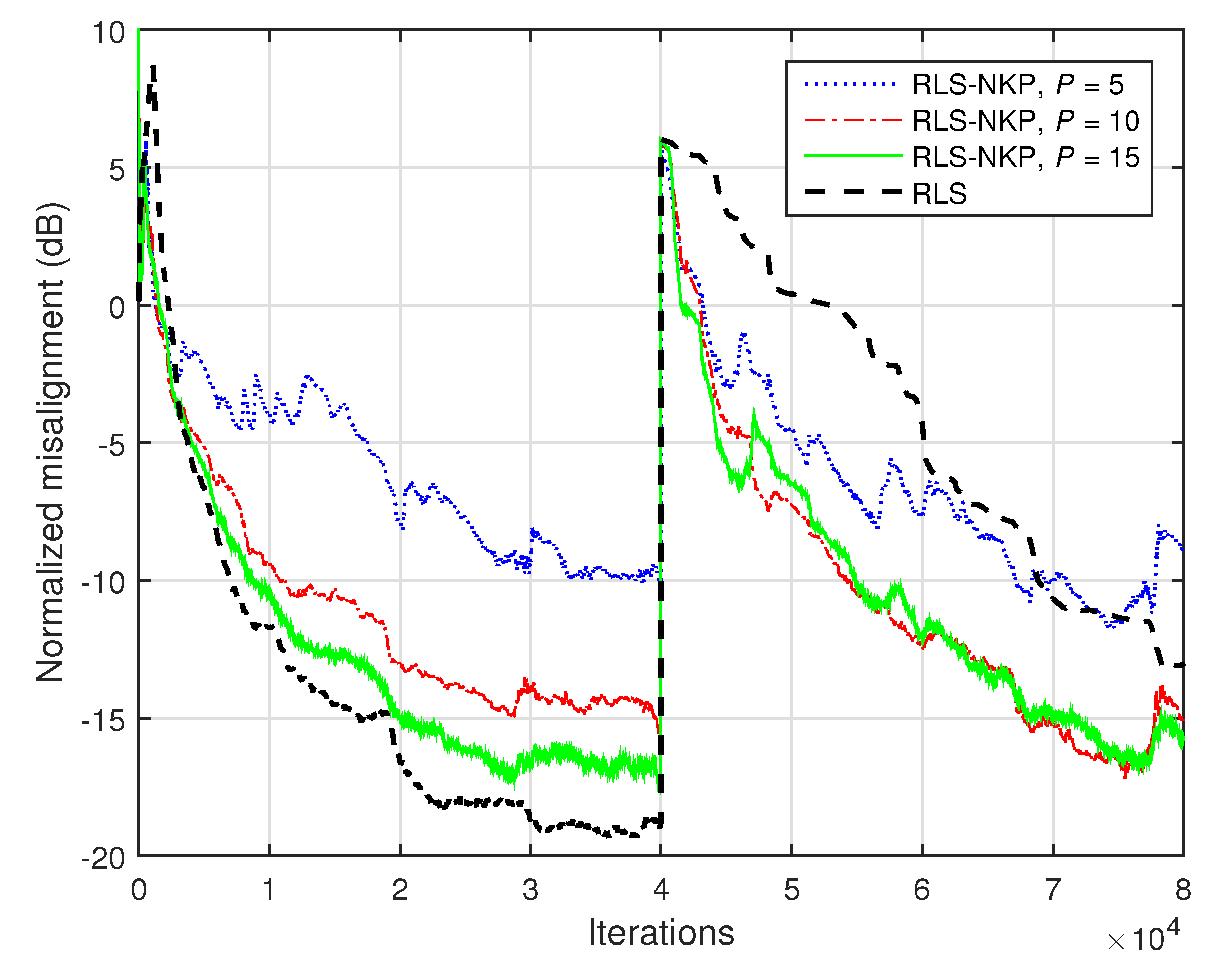
Finally, in
Figure 21, the identification of the acoustic impulse response from
Figure 2b is evaluated when using a speech signal as input. The nonstationary character of the speech signal represents a challenge for any adaptive algorithm. Nevertheless, the tracking capability of the RLS-NKP is still better as compared to the conventional RLS algorithm.
As explained in
Section 5, the RLS-NKP exploits a low-rank approximation approach and represents an extension of the RLS-T algorithm for
. Thus, it is efficient for the identification of more general forms of impulse responses, in the context of SISO scenarios. On the other hand, the RLS-T algorithm is developed based on the decomposition of rank-1 tensors, in the framework of a MISO system identification problem. Therefore, it is suitable when dealing with linearly separable systems, e.g., [
8,
10,
14], even affected by a nonseparable part. Concluding, an extension of the RLS-T algorithm for higher-rank (
) and higher-order tensors (
) could inherit the advantages of the decomposition-based approach and the applicability features of the low-rank approximation method.



 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




















