Using Machine Learning Algorithms to Estimate Soil Organic Carbon Variability with Environmental Variables and Soil Nutrient Indicators in an Alluvial Soil

 , and
, and
Abstract
:1. Introduction
2. Materials and Methods
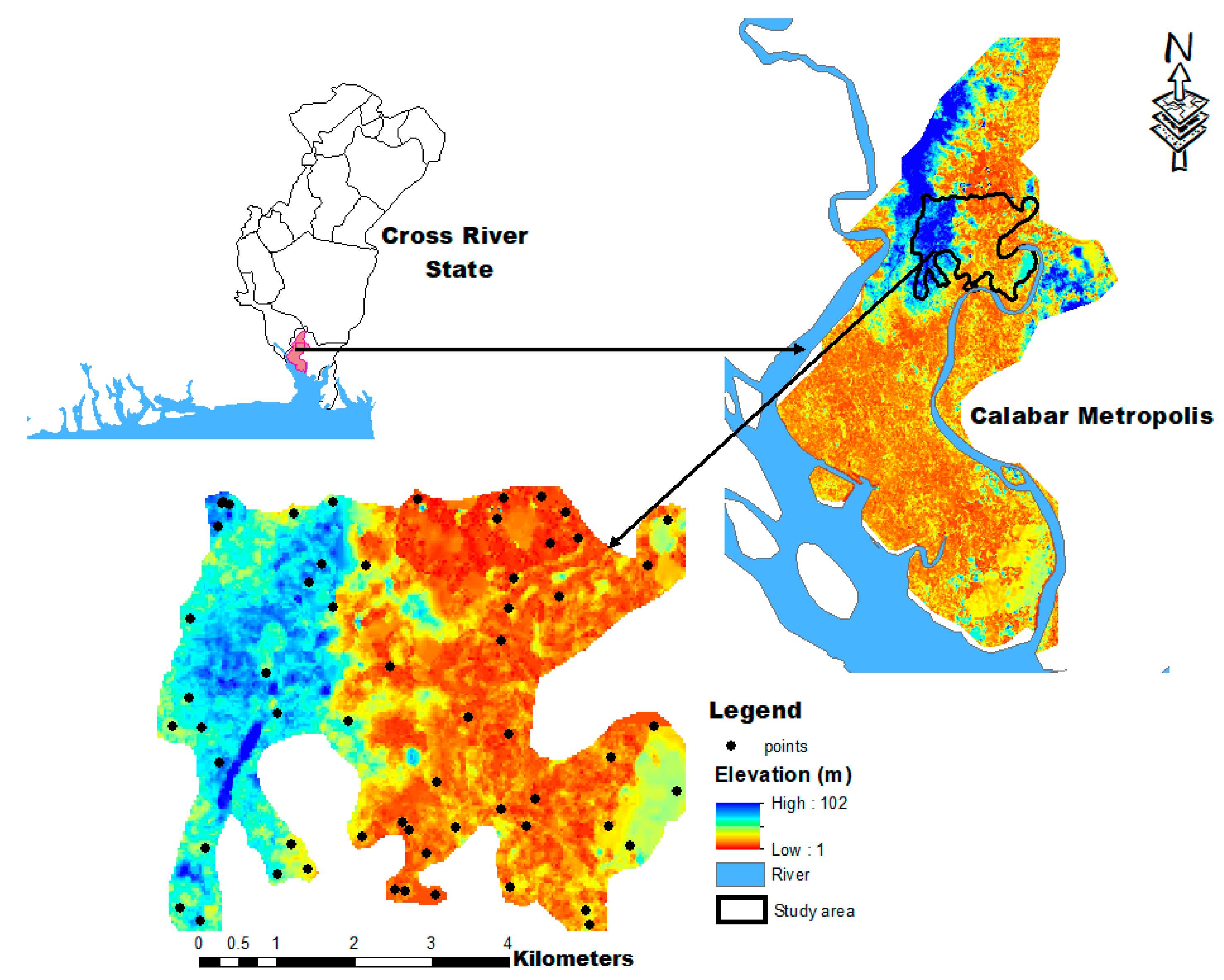
2.1. Description of the Study Area
2.2. Soil Sampling Regime and Laboratory Analysis
2.3. Environmental Covariates
2.4. Machine Learning Techniques
2.4.1. Random forest
2.4.2. Cubist Regression
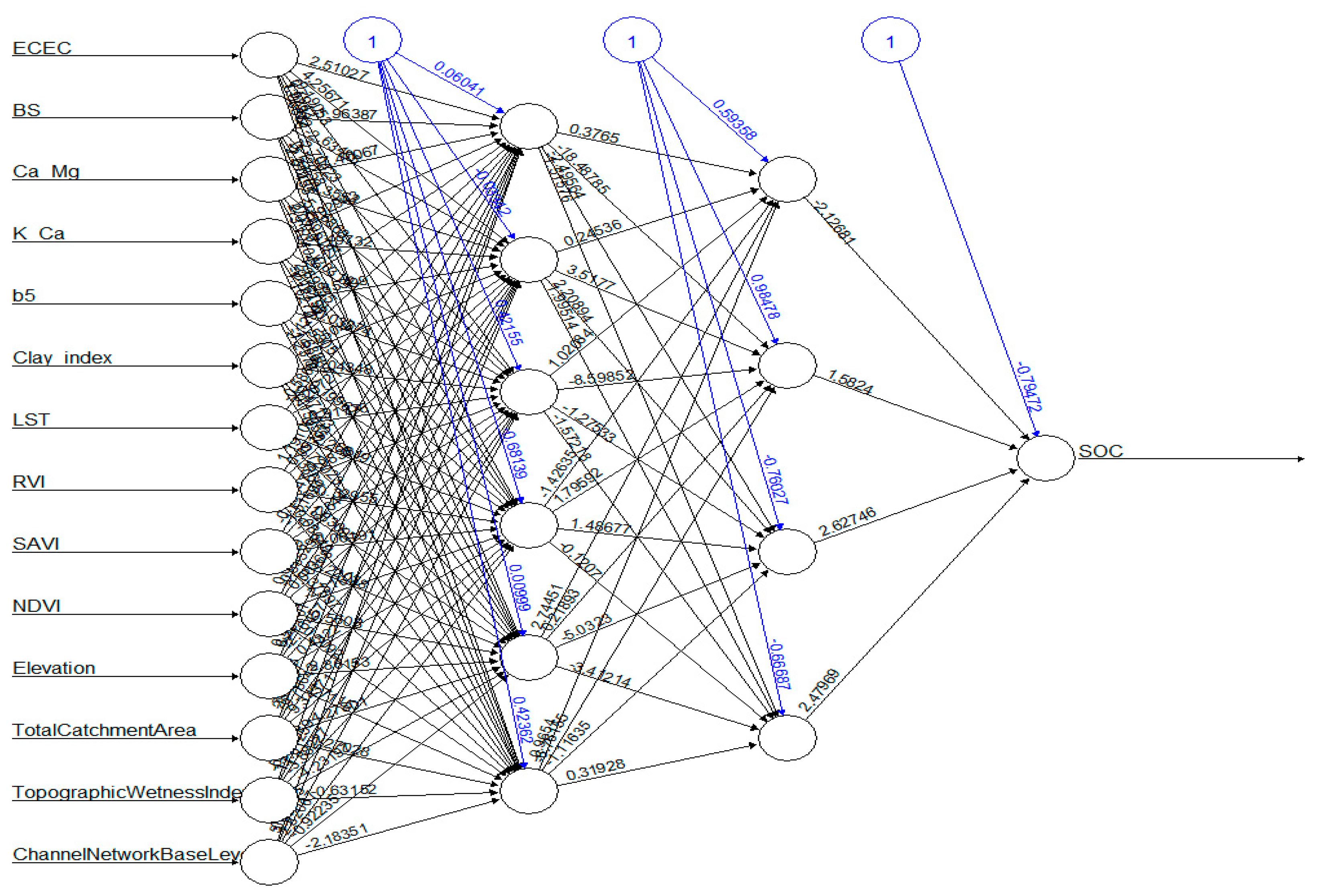
2.4.3. Artificial Neural Network
2.4.4. Multiple Linear Regression
2.4.5. Support Vector Machine (SVM)
2.5. Data Scaling and Partitioning
2.6. Model Validation and Accuracy Assessment
3. Results and Discussion
3.1. Descriptive Statistics
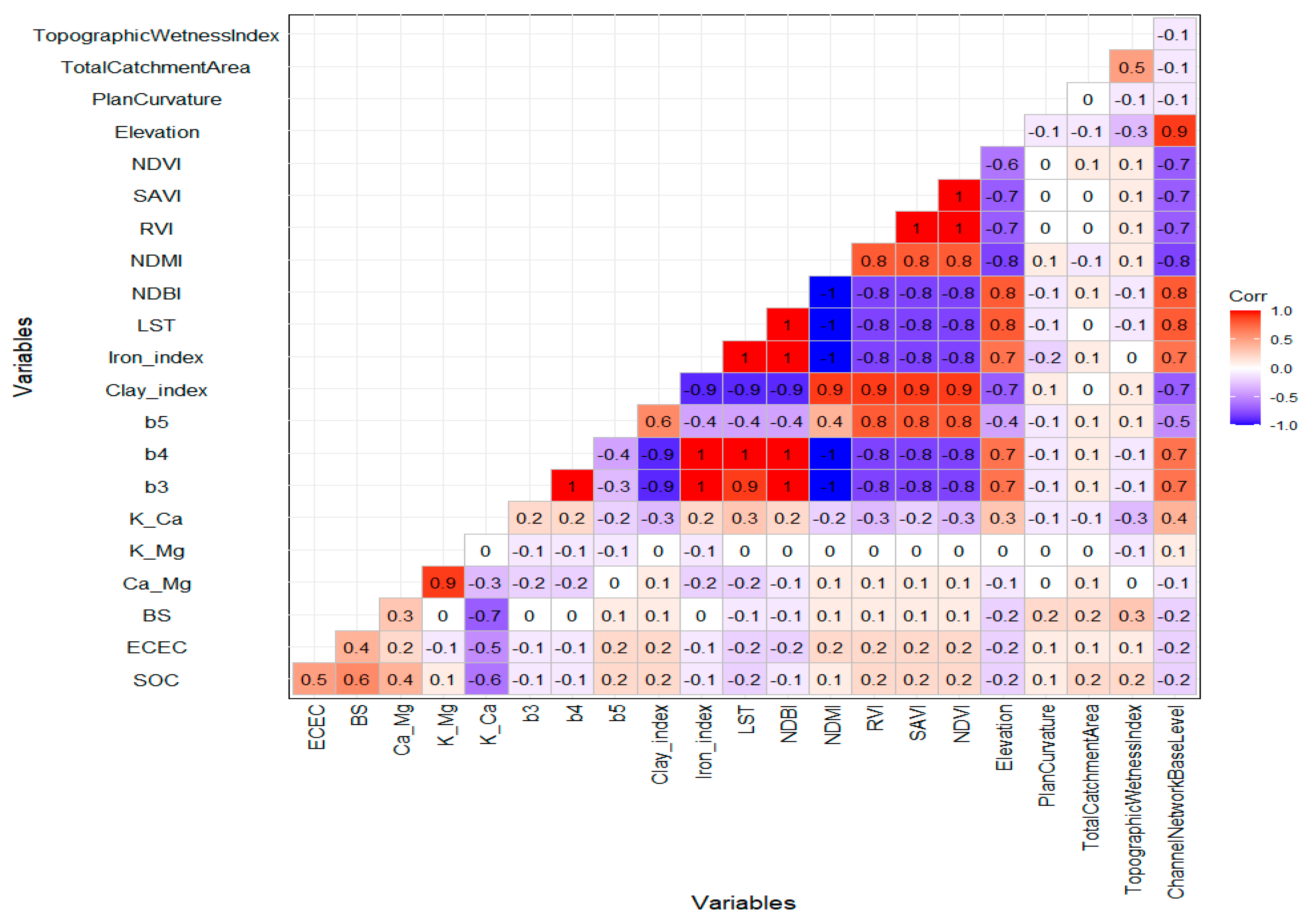
3.2. Correlation between SOC and Environmental Variables and Soil Indicators
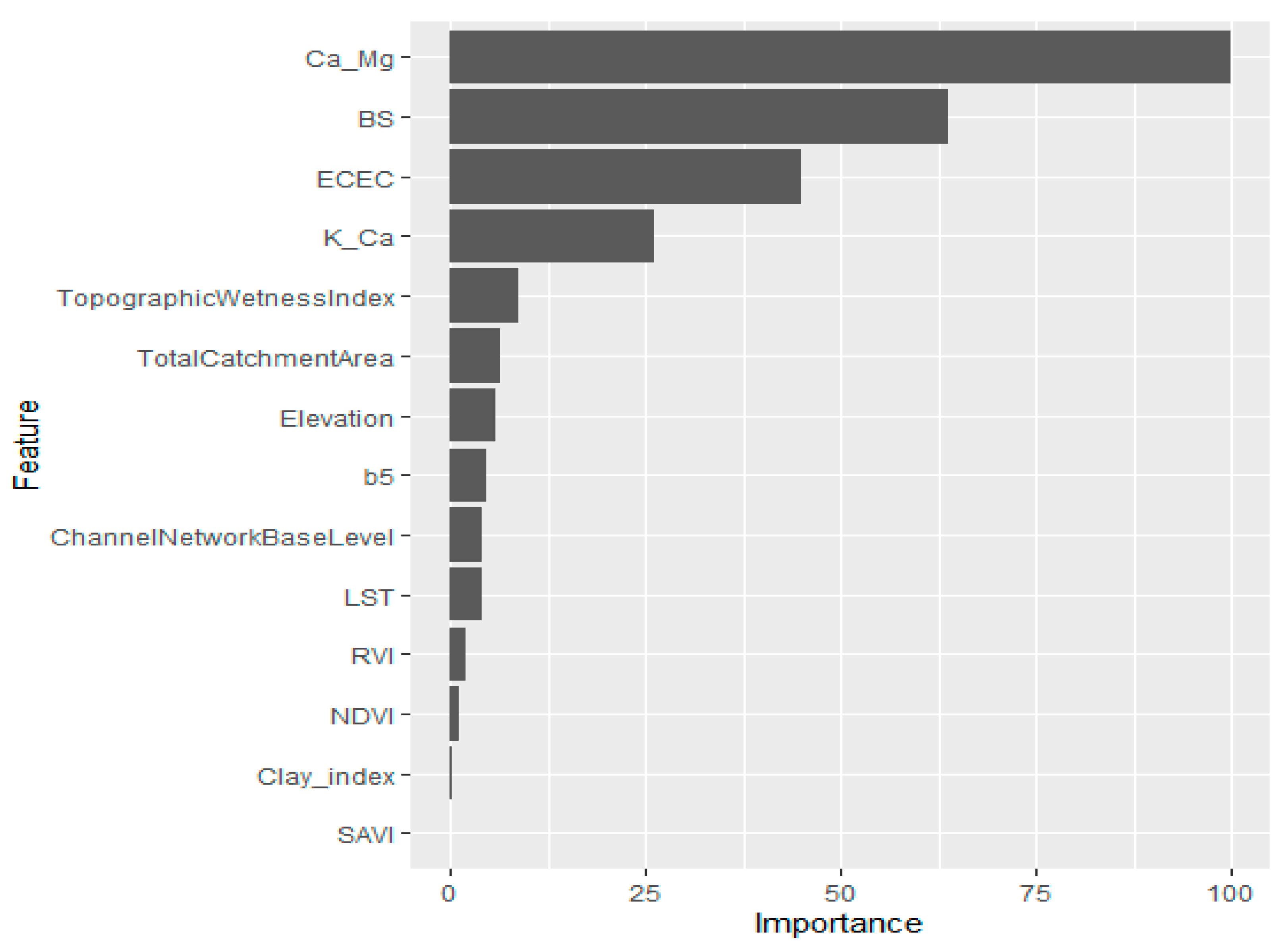
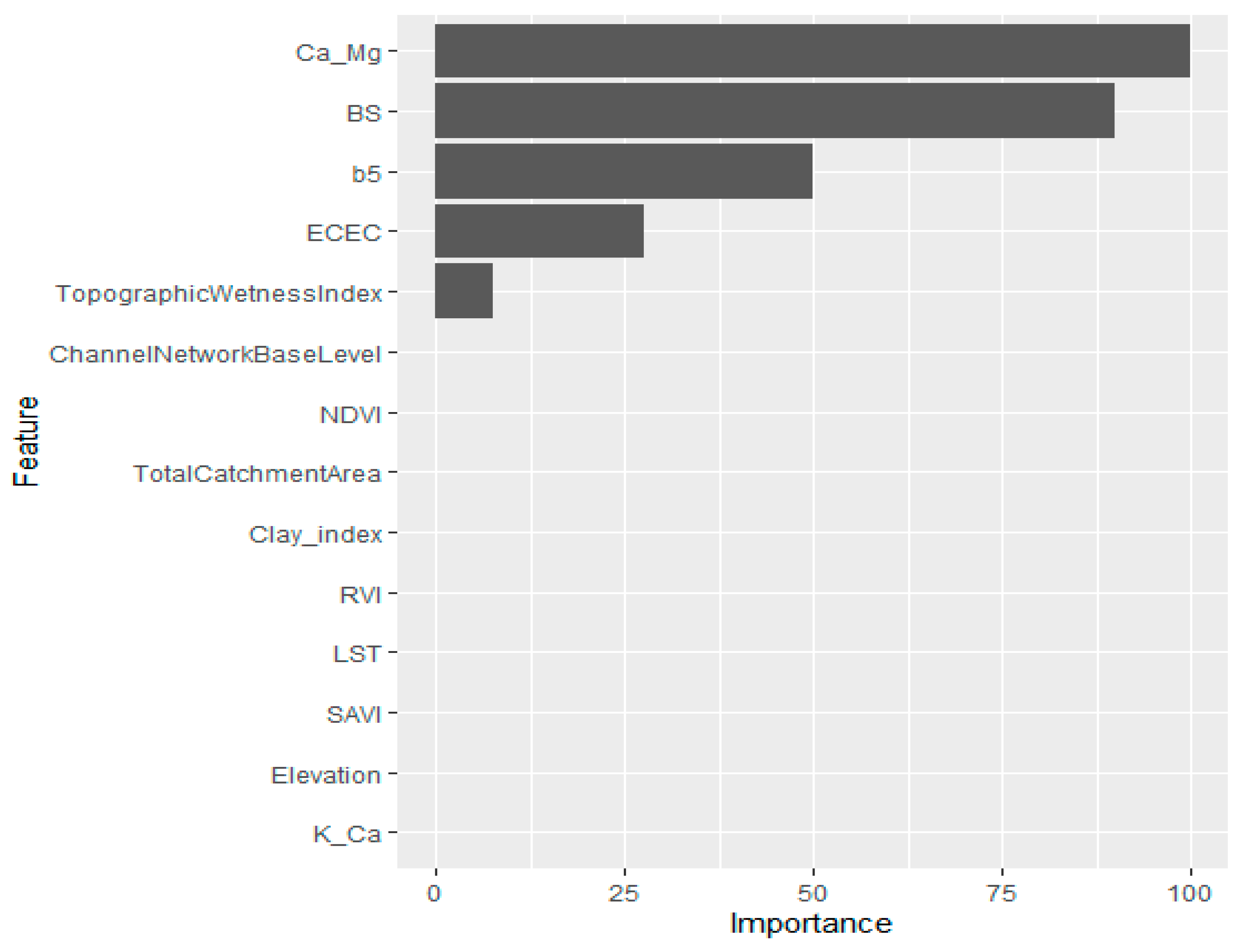
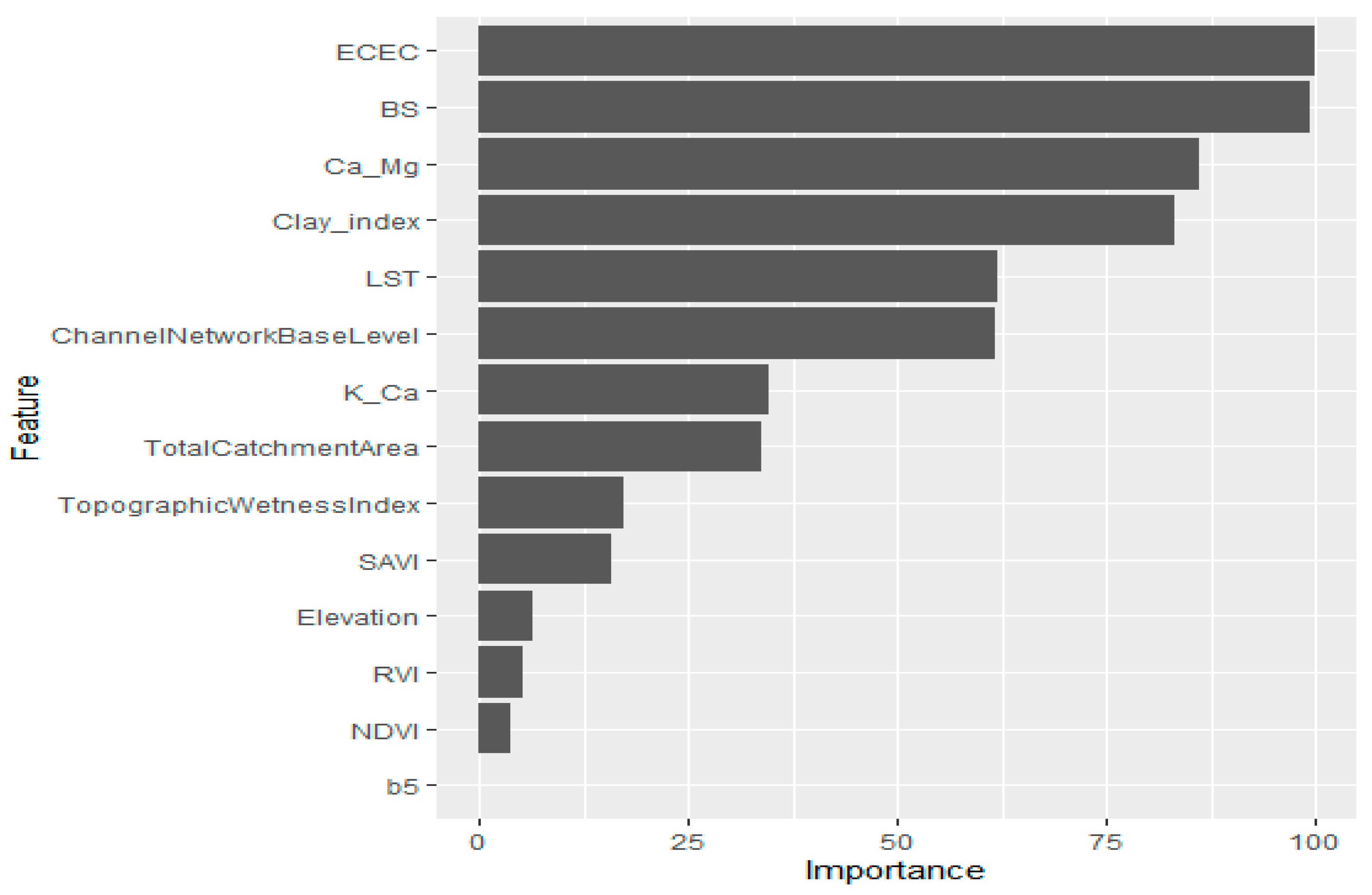
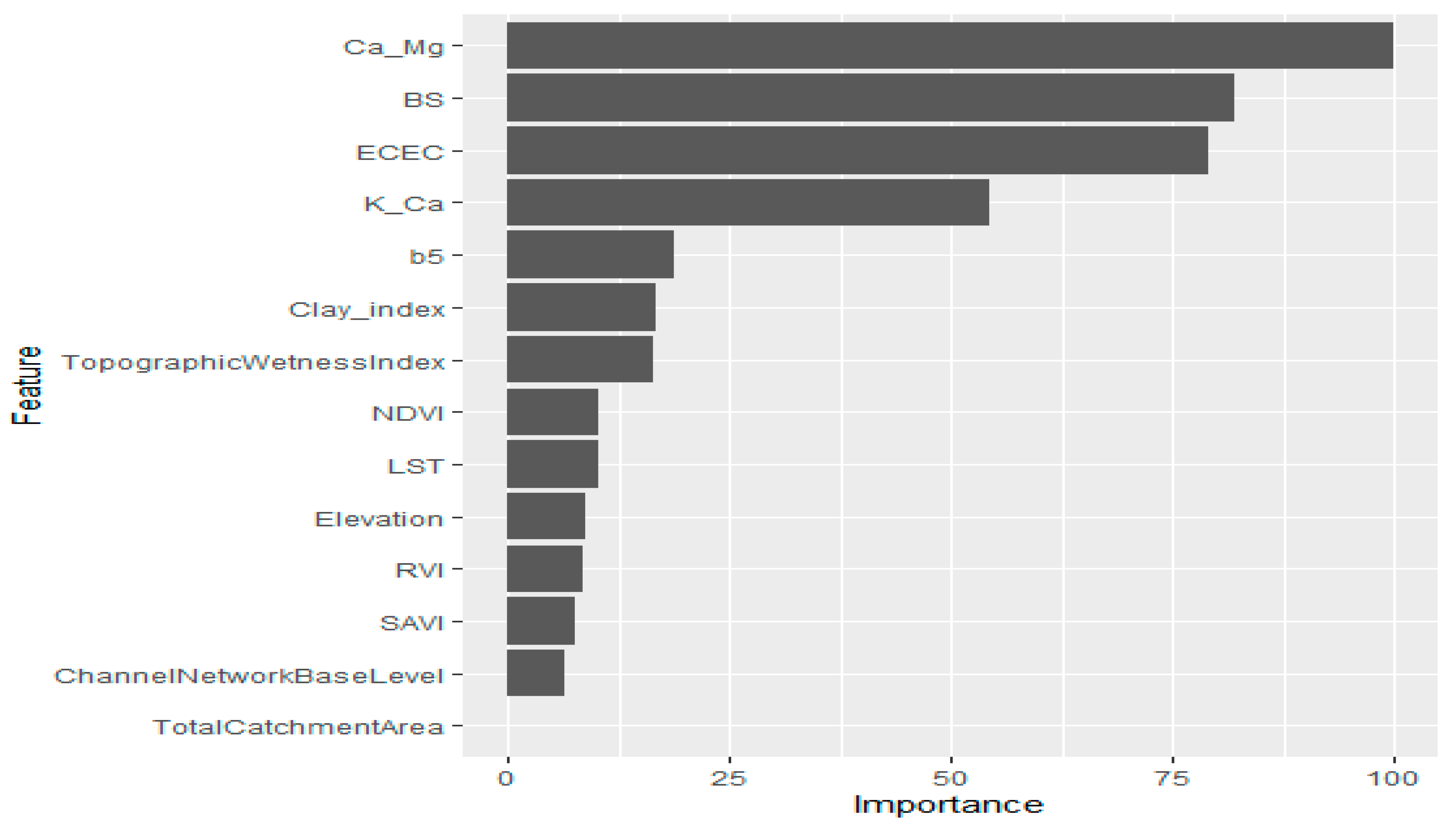
3.3. Modeling Approach and Variables of Importance in the Individual Models
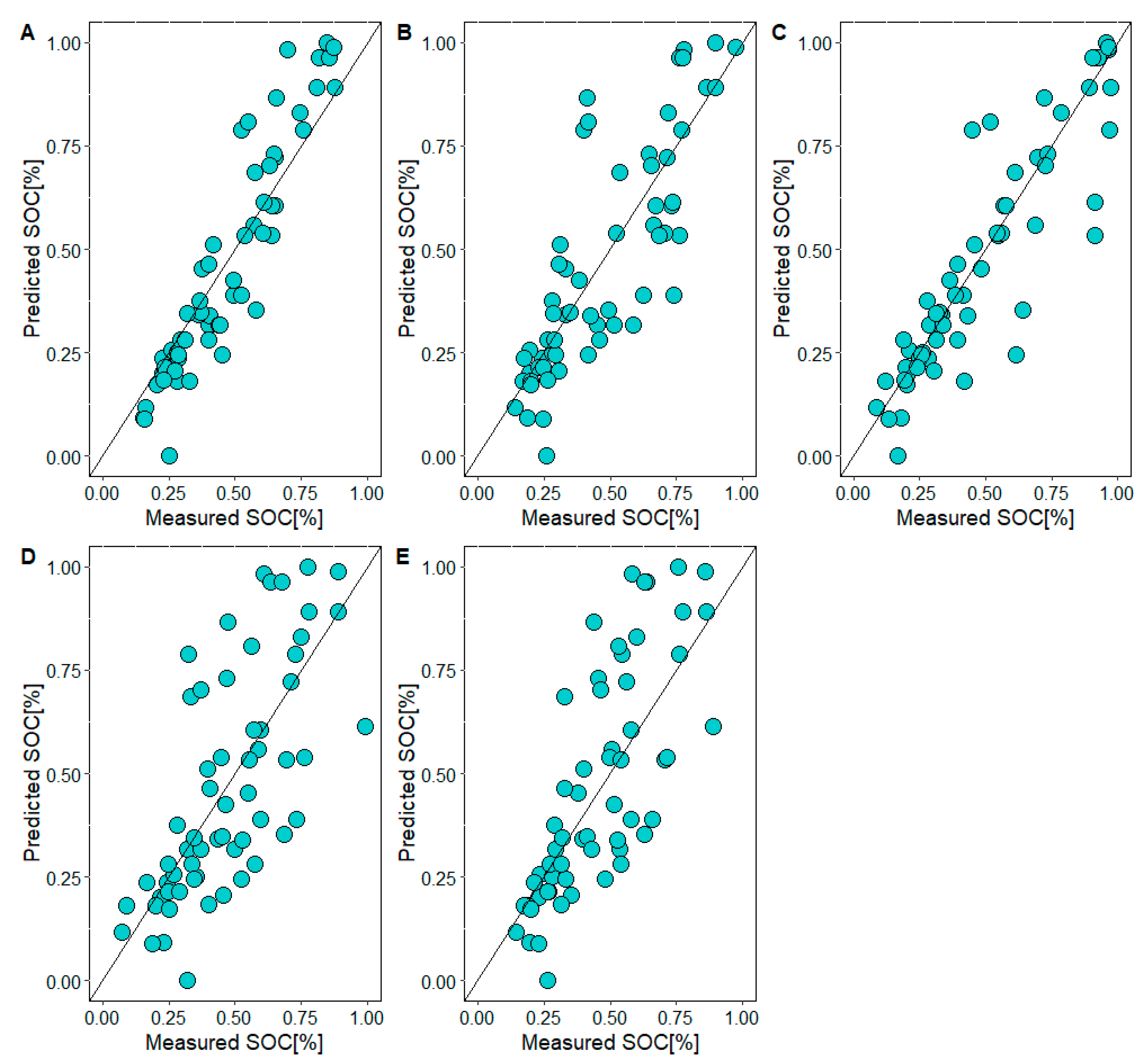
3.4. SOC Estimation Using Different MLAs
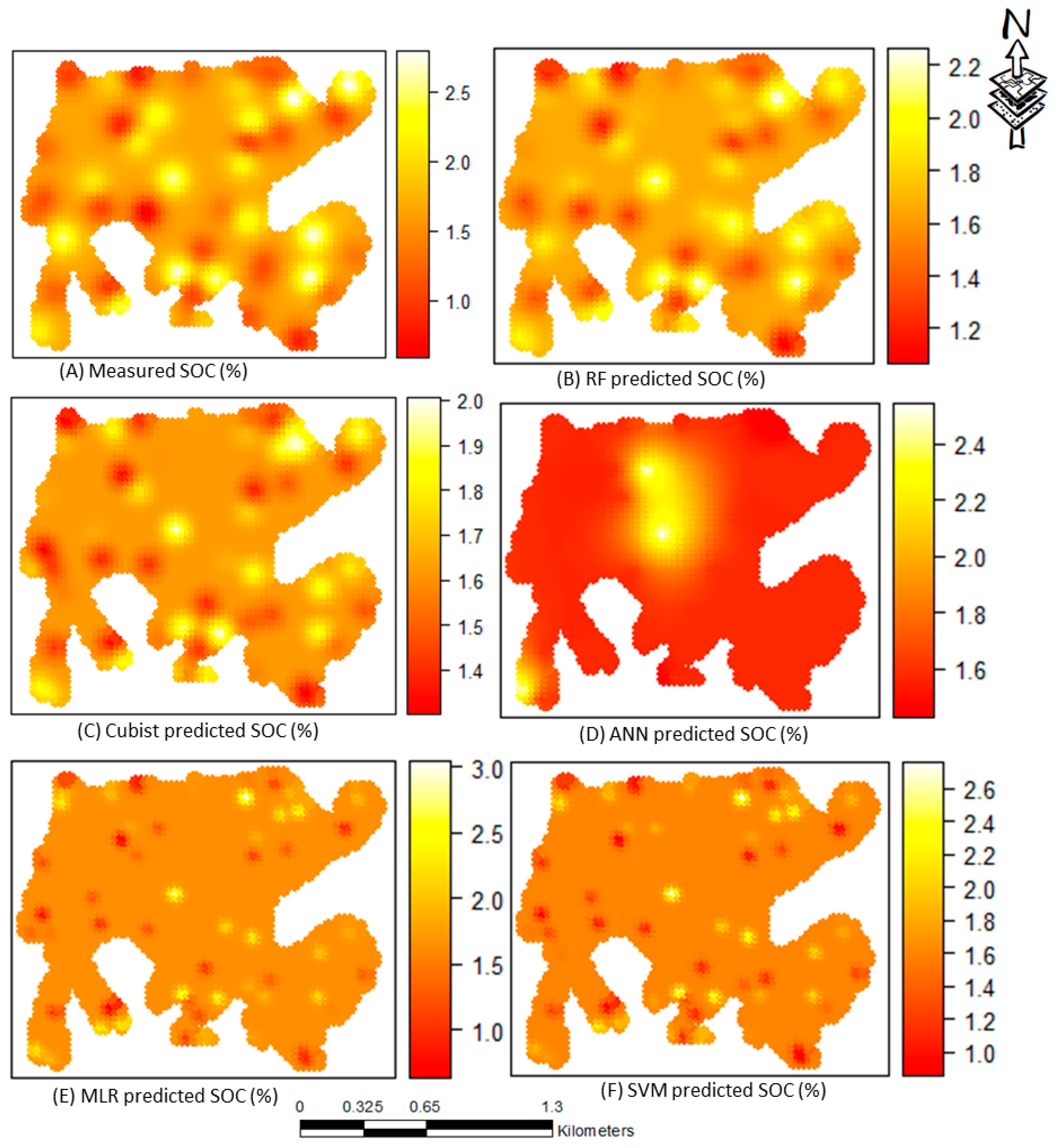
3.5. Digital Soil Mapping of SOC
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Amalu, U.C.; Isong, I.A. Status and spatial variability of soil properties in relation to fertilizer placement for intercrops in an oil palm plantation in Calabar, Nigeria. Niger. J. Crop Sci. 2018, 5, 58–72. [Google Scholar]
- Akpan, J.F.; Aki, E.E.; Isong, I.A. Comparative assessment of wetland and coastal plain soils in Calabar, Cross River State. Glob. J. Agric. Sci. 2017, 16, 17–30. [Google Scholar] [CrossRef] [Green Version]
- Jenny, H. Factors of Soil Formation: A System of Quantitative Pedology, 1st ed.; McGraw-Hill Inc.: New York, NY, USA, 1941. [Google Scholar]
- Chikezie, I.A.; Eswaran, H.; Asawalam, D.O.; Ano, A.O. Characterization of two benchmark soils of contrasting parent materials in Abia State, Southeastern Nigeria. Glob. J. Pure Appl. Sci. 2010, 16, 23–29. [Google Scholar] [CrossRef]
- Amalu, U.C.; Isong, I.A. Land capability and soil suitability of some acid sand soil supporting oil palm (Elaeis guinensis Jacq) trees in Calabar, Nigeria. Niger. J. Soil Sci. 2015, 25, 92–109. [Google Scholar]
- Taghizadeh-Mehrjardi, R.; Nabiollahi, K.; Kerry, R. Digital mapping of soil organic carbon at multiple depths using different data mining techniques in Baneh region, Iran. Geoderma 2016, 266, 98–110. [Google Scholar] [CrossRef]
- Bian, Z.; Guo, X.; Wang, S.; Zhuang, Q.; Jin, X.; Wang, Q.; Jia, S. Applying statistical methods to map soil organic carbon of agricultural lands in northeastern coastal areas of China. Arch. Agron. Soil Sci. 2020, 66, 532–544. [Google Scholar] [CrossRef]
- Chen, L.; Ren, C.; Li, L.; Wang, Y.; Zhang, B.; Wang, Z.; Li, L. A Comparative Assessment of Geostatistical, Machine Learning, and Hybrid Approaches for Mapping Topsoil Organic Carbon Content. ISPRS Int. J. Geo-Information 2019, 8, 174. [Google Scholar] [CrossRef] [Green Version]
- Kingsley, J.; Lawani, S.O.; Esther, A.O.; Ndiye, K.M.; Sunday, O.J.; Penížek, V. Predictive Mapping of Soil Properties for Precision Agriculture Using Geographic Information System (GIS) Based Geostatistics Models. Mod. Appl. Sci. 2019, 13, 60. [Google Scholar] [CrossRef] [Green Version]
- Mosleh, Z.; Salehi, M.; Jafari, A.; Esfandiarpour, I.; Mehnatkesh, A. The effectiveness of digital soil mapping to predict soil properties over low-relief areas. Environ. Monit. Assess. 2016, 188, 195. [Google Scholar] [CrossRef]
- Zeraatpisheh, M.; Jafari, A.; Bodaghabadi, M.B.; Ayoubi, S.; Taghizadeh-Mehrjardi, R.; Toomanian, N.; Kerry, R.; Xu, M. Conventional and digital soil mapping in Iran: Past, present, and future. Catena 2020, 188, 104424. [Google Scholar] [CrossRef]
- Akpan-Idiok, A.U.; Ukwang, E.E. Characterization and classification of coastal plain soils in Calabar, Nigeria. J. Agric. Biotechnol. Econ. 2012, 5, 19–33. [Google Scholar]
- Baldock, J.A.; Wheeler, I.; McKenzie, N.; McBrateny, A. Soils and climate change: Potential impacts on carbon stocks and greenhouse gas emissions, and future research for Australianagriculture. Crop Pasture Sci. 2012, 63, 269–283. [Google Scholar] [CrossRef] [Green Version]
- Minasny, B.; Setiawan, B.I.; Arif, C.; Saptomo, S.K.; Chadirin, Y. Digital mapping for cost effective and accurate prediction of the depth and carbon stocks in Indonesian peatlands. Geoderma 2016, 272, 20–31. [Google Scholar]
- Emadi, M.; Taghizadeh-Mehrjardi, R.; Cherati, A.; Danesh, M.; Mosavi, A.; Scholten, T. Predicting and Mapping of Soil Organic Carbon Using Machine Learning Algorithms in Northern Iran. Remote Sens. 2020, 12, 2234. [Google Scholar] [CrossRef]
- Wang, B.; Waters, C.; Orgill, S.; Cowie, A.; Clark, A.; Li, L.D.; Simpson, M.; McGowen, I.; Sides, T. Estimating soil organic carbon stocks using different modelling techniques in the semi-arid rangelands of eastern Australia. Ecol. Indic. 2018, 88, 425–438. [Google Scholar] [CrossRef]
- Chen, D.; Chang, N.; Xiao, J.; Zhou, Q.; Wu, W. Mapping dynamics of soil organic matter in croplands with MODIS data and machine learning algorithms. Sci. Total Environ. 2019, 669, 844–855. [Google Scholar] [CrossRef]
- Liu, S.; An, N.; Yang, J.; Dong, S.; Wang, C.; Yin, Y. Prediction of soil organic matter variability associated with different landuse types in mountainous landscape in southwestern Yunnan province, China. Catena 2015, 133, 137–144. [Google Scholar] [CrossRef]
- Forkuor, G.; Hounkpatin, O.K.; Welp, G.; Thiel, M. High resolution mapping of soil properties using remote sensing variables in southwestern Burkina Faso: A comparison of machine learning and multiple linear regression models. PLoS ONE 2017, 12, e0170478. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, Y.; Atkinson, P.M.; Yao, H. Predicting soil organic carbon content in Spain by combining Landsat TM and ALOS PALSAR images. Int. J. Appl. Earth Obs. Geoinf. 2020, 92, 102182. [Google Scholar] [CrossRef]
- Gehl, R.J.; Rice, C.W. Emerging technologies for in situ measurement of soil carbon. Clim. Chang. 2007, 80, 43–54. [Google Scholar] [CrossRef]
- Al-Abbas, A.H.; Swain, P.H.; Baumgardner, M.F. Relating organic matter and clay content to the multi-spectral radiance of soils. Soil Sci. 1972, 114, 477–485. [Google Scholar] [CrossRef]
- McMorrow, J.M.; Cutler, M.E.J.; Evans, M.G.; Al-Roichdi, A. Hyperspectral indices for characterizing upland peat composition. Int. J. Remote Sens. 2004, 25, 313–325. [Google Scholar] [CrossRef]
- Viscarra Rossel, R.A.; Behrens, T. Using data mining to model and interpret soil diffuse reflectance spectra. Geoderma 2010, 158, 46–54. [Google Scholar] [CrossRef]
- Fathololoumi, S.; Vaezi, A.R.; Alavipanah, S.K.; Ghorbani, A.; Saurette, D.; Biswas, A. Improved digital soil mapping with multitemporal remotely sensed satellite data fusion: A case study in Iran. Sci. Total. Environ. 2020, 721, 137703. [Google Scholar] [CrossRef]
- Amalu, U.C.; Isong, I.A. Long-term impact of climate variables on agricultural lands in Calabar, Nigeria, I. Trend analysis of rainfall, temperature and relative humidity. Niger. J. Crop Sci. 2017, 4, 79–94. [Google Scholar]
- Afu, S.M.; Isong, I.A.; Awaogu, C.E. Agricultural potentials of floodplain soils with contrasting parent material in Cross River State, Nigeria. Glob. J. Pure Appl. Sci. 2019, 25, 13–22. [Google Scholar] [CrossRef]
- USDA NRCS. Soil Survey Staff. Keys to Soil Taxonomy, 12th ed.; United States Department of Agriculture, Natural Resources Conservation Service: Washington, DC, USA, 2014.
- Akpan-Idiok, A.U.; Ogbaji, P.O. Characterization and Classification of Onwu River Floodplain Soils in Cross River State, Nigeria. Int. J. Agric. Res. 2013, 8, 107–122. [Google Scholar] [CrossRef]
- Udo, E.J.; Ibia, T.O.; Ogunwale, J.A.; Ano, A.O.; Esu, I.E. Manual of Soil, Plant and Water Analyses; Sibon Books Limited: Lagos, Nigeria, 2009. [Google Scholar]
- Roy, D.P.; Wulder, M.A.; Loveland, T.R.C.E.W.; Allen, R.G.; Anderson, M.C.; Helder, D.; Irons, J.R.; Johnson, D.M.; Kennedy, R.; Scambos, T.A.; et al. Landsat-8: Science and product vision for terrestrial global change research. Remote Sens. Environ. 2014, 145, 154–172. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Heung, B.; Bulmer, C.E.; Schmidt, M.G. Predictive soil parent material mapping at a regional scale: A Random Forest approach. Geoderma 2014, 214, 141–154. [Google Scholar] [CrossRef]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forests for land cover classification. Pattern Recogn. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Díaz-Uriarte, R.; De Andres, S.A. Gene selection and classification of microarray data using random forest. BMC Bioinform. 2006, 7, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.; Li, E.; Wei, H.; Li, C.; Qiao, Q.; Armaghani, D.J. Random Forests and Cubist Algorithms for Predicting Shear Strengths of Rockfill Materials. Appl. Sci. 2019, 9, 1621. [Google Scholar] [CrossRef] [Green Version]
- Rodríguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity Analysis of k-Fold Cross Validation in Prediction Error Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 569–575. [Google Scholar] [CrossRef]
- Quinlan, J.R. Learning with continuous classes. In Proceedings of the 5th Australian Joint Conference on Artificial Intelligence, Tasmania, Australia, 16–18 November 1992; pp. 343–348. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin, Germany, 2013; Volume 26. [Google Scholar]
- Wang, Y.W.I. Inducing Model Trees for Continuous Classes. In Proceedings of the 9th European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 1997; pp. 128–137. [Google Scholar]
- Behrens, T.; Forster, H.; Scholten, T.; Steinrücken, U.; Spies, E.D.; Goldschmitt, M. Digital soil mapping using artificialneural networks. J. Plant Nutr. Soil Sci. 2005, 168, 21–33. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Cherkassky, V.; Mulier, F. Learning from Data: Concept, Theory and Methods; John Wiley and Sons: New York, NY, USA, 1998. [Google Scholar]
- Siewert, M.B. High-resolution digital mapping of soil organic carbon in permafrost terrain using machine learning: A case study in a sub-Arctic peatland environment. Biogeosciences 2018, 15, 1663–1682. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Sui, B.; Shen, H.; Ouyang, L. Mapping stocks of soil total nitrogen using remote sensing data: A comparison of random forest models with different predictors. Comput. Electron. Agric. 2019, 160, 23–30. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019; Available online: https://www.r-project.org/ (accessed on 13 May 2020).
- Li, L.; Lu, J.; Wang, S.; Ma, Y.; Wei, Q.; Li, X.; Cong, R.; Ren, T. Methods for estimating leaf nitrogen concentration of winter oilseed rape (Brassica napus L.) using in situ leaf spectroscopy. Ind. Crop. Prod. 2016, 91, 194–204. [Google Scholar] [CrossRef]
- Wilding, L.P.; Drees, L.R. Spatial variability and pedology. In Pedogenesis and Soil Taxonomy: Concepts and Interactions; Wilding, L.P., Smeck, N.E., Hall, G.F., Eds.; Elsevier: New York, NY, USA, 1983; pp. 83–116. [Google Scholar]
- Denton, O.; Modupe, A.; Ojo, V.O.A.; Adeoyolanu, A.O.; Are, O.D.; Adelana, K.S.; Oyedele, A.O.; Adetayo, A.O.; Oke, A.O. Assessment of spatial variability and mapping of soil properties for sustainable agricultural production using geographic information system techniques. Cogent Food Agric. 2017, 3, 1–12. [Google Scholar] [CrossRef]
- Reza, S.K.; Nayak, D.C.; Chattopadhyay, T.; Mukhopadhyay, S.; Singh, S.K.; Srinivasan, R. Spatial distribution of soil physical properties of alluvial soils: A geostatistical approach. Arch. Agron. Soil Sci. 2016, 62, 972–981. [Google Scholar] [CrossRef]
- Landon, J.R. Booker Tropical Soil Manual: A Handbook for Soil Survey and Agricultural Land Evaluation in the Tropics and Subtropics; Longman: New York, NY, USA, 1991. [Google Scholar]
- Bednářa, M.; Šarapatkaa, B. Relationships between physical–geographical factors and soil degradation on agricultural land. Environ. Res. 2018, 164, 660–668. [Google Scholar] [CrossRef]
- Gelaw, A.M.; Singh, B.R.; Lal, R. Organic carbon and nitrogen associated with soil aggregates and particle sizes under different land uses in Tigray, Northern Ethiopia. Land Degrad. Dev. 2013, 26, 690–700. [Google Scholar] [CrossRef]
- Anikwe, M.A.N. Carbon storage in soils of southeastern Nigeria under different management practices. Carbon Balance Manag. 2010, 5, 5. [Google Scholar] [CrossRef] [Green Version]
- Six, J.; Feller, C.; Denef, K.; Ogle, S.M.; Sa, J.C.M.; Albrecht, A. Soil organic matter, biota and aggregation in temperate and tropical soils- Effect of no-tillage. Agronomie 2002, 22, 755–775. [Google Scholar] [CrossRef] [Green Version]
- Lal, R. Soil Carbon sequestration impacts on global climate change and food security. Science 2004, 30, 1623–1627. [Google Scholar] [CrossRef] [Green Version]
- Purwanto, B.H.; Alam, S. Impact of intensive agricultural management on carbon and nitrogen dynamics in the humid tropics. Soil Sci. Plant Nutr. 2020, 66, 50–59. [Google Scholar] [CrossRef]
- Florinsky, I.V.; McMahon, S.; Burton, D.L. Topographic control of soil microbial activity: A case study of denitrifiers. Geoderma 2004, 119, 33–53. [Google Scholar] [CrossRef]
- Akpan-Idiok, A.U.; Ogbaji, P.O.; Antigha, N.R.B. Infiltration, degradation rate and vulnerability potential of Onwu River floodplain soils in Cross River State, Nigeria. J. Agric. Biotechnol. Ecol. 2012, 5, 62–74. [Google Scholar]
- Solly, E.F.; Weber, V.; Zimmermann, S.; Walthert, L.; Hagedorn, F.; Schmidt, M.W.I. A Critical Evaluation of the Relationship between the Effective Cation Exchange Capacity and Soil Organic Carbon Content in Swiss Forest Soils. Front. For. Glob. Chang. 2020, 3, 98. [Google Scholar] [CrossRef]
- Song, Y.Q.; Yang, L.A.; Li, B.; Hu, Y.M.; Wang, A.L.; Zhou, W.; Cui, X.S.; Liu, Y.L.; Song, Y.Q.; Yang, L.A.; et al. Spatial prediction of soil organic matter using a hybrid geostatistical model of an extreme learning machine and ordinary kriging. Sustainability 2017, 9, 754. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; McCarty, G.W.; Du, L.; Lee, S. Use of Topographic Models for Mapping Soil Properties and Processes. Soil Syst. 2020, 4, 32. [Google Scholar] [CrossRef]
- Nath, D.A. Soil Landscape Modeling in the Northwest Iowa Plains Region of O’Brien County, Iowa. Master’s Thesis, Iowa State University, Ames, IA, USA, 2006. [Google Scholar]
- Padarian, J.; Minasny, B.; McBratney, A.B. Using deep learning for digital soil mapping. Soil 2019, 5, 79–89. [Google Scholar] [CrossRef] [Green Version]
- Bou Kheir, R.; Greve, M.H.; Bøcher, P.K.; Greve, M.B.; Larsen, R.; McCloy, K. Predictive mapping of soil organic carbon in wet cultivated lands using classification-tree based models: The case study of Denmark. J. Environ. Manag. 2010, 91, 1150–1160. [Google Scholar] [CrossRef]
- Wiesmeier, M.; Barthold, F.; Blank, B.; Kögel-Knabner, I. Digital mapping of soil organic matter stocks using Random Forest modeling in a semi-arid steppe ecosystem. Plant. Soil 2011, 340, 7–24. [Google Scholar] [CrossRef]
- Adhikari, K.; Hartemink, A.E.; Minasny, B.; Kheir, R.B.; Greve, M.B.; Greve, M.H. Digital mapping of soil organic carbon contents and stocks in Denmark. PLoS ONE 2014, 9, e105519. [Google Scholar] [CrossRef]
- Andersson, S.; Nilsson, I.; Valeur, I. Influence of dolomiticlime on DOC and DON leaching in a forest soil. Biogeo-Chemistry 1999, 47, 295–315. [Google Scholar] [CrossRef]
- Chan, K.Y.; Heenan, D.P. Lime-induced loss of soil organiccarbon and effect on aggregate stability. Soil Sci. Soc. Am. J. 1999, 63, 1841–1844. [Google Scholar] [CrossRef]
- Thirukkumaran, C.M.; Morrison, I.K. Impact of simulated acid rain on microbial respiration, biomass, and metabolic quotient in a mature sugar maple (Acer saccharum) forest floor. Can. J. For. Res. 1996, 26, 1446–1453. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environmental Covariates | Variable | Description |
|---|---|---|
| Landsat 8 OLI | b3 | Green, 0.525–0.600 μm |
| b4 | Red, 0.630–0.680 μm | |
| b5 | NIR, 0.845–0.885 μm | |
| Clay index (CI) | ||
| Iron index | ||
| Normalized Difference build-up Index (NDBI) | ||
| Ratio Vegetation Index (RVI) | ||
| Soil Adjusted Vegetation Index (SAVI) | ||
| Normalized Difference Vegetation Index (NDVI) | ||
| Normalized Difference Moisture Index (NDMI) | ||
| Land surface temperature (LST) | ||
| ASTER GDEM | Elev | Elevation |
| PCurv | Plan curvature | |
| TCA | Total catchment area | |
| CNBL | Channel Network base level | |
| TWI | Topographic wetness index |
| n | Mean | Median | SD | Min | Max | 1st Quartile | 3rd Quartile | CV | |
|---|---|---|---|---|---|---|---|---|---|
| ⟶ % ⟵ | |||||||||
| SOC | 60 | 1.62 | 1.38 | 0.76 | 0.32 | 3.10 | 1.0 | 2.24 | 47 |
| Model | Calibration (n = 48) | Validation (n = 12) | ||||
|---|---|---|---|---|---|---|
| MAE | RMSE | R2 | MAE | RMSE | R2 | |
| RF | 0.15 | 0.17 | 0.64 | 0.17 | 0.20 | 0.68 |
| Cubist | 0.18 | 0.22 | 0.54 | 0.49 | 0.57 | 0.51 |
| ANN | 0.04 | 0.06 | 0.94 | 0.22 | 0.26 | 0.36 |
| MLR | 0.60 | 0.77 | 0.42 | 0.23 | 0.28 | 0.17 |
| SVM | 0.17 | 0.21 | 0.52 | 0.19 | 0.22 | 0.36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
JOHN, K.; Abraham Isong, I.; Michael Kebonye, N.; Okon Ayito, E.; Chapman Agyeman, P.; Marcus Afu, S. Using Machine Learning Algorithms to Estimate Soil Organic Carbon Variability with Environmental Variables and Soil Nutrient Indicators in an Alluvial Soil. Land 2020, 9, 487. https://doi.org/10.3390/land9120487
JOHN K, Abraham Isong I, Michael Kebonye N, Okon Ayito E, Chapman Agyeman P, Marcus Afu S. Using Machine Learning Algorithms to Estimate Soil Organic Carbon Variability with Environmental Variables and Soil Nutrient Indicators in an Alluvial Soil. Land. 2020; 9(12):487. https://doi.org/10.3390/land9120487
Chicago/Turabian StyleJOHN, Kingsley, Isong Abraham Isong, Ndiye Michael Kebonye, Esther Okon Ayito, Prince Chapman Agyeman, and Sunday Marcus Afu. 2020. "Using Machine Learning Algorithms to Estimate Soil Organic Carbon Variability with Environmental Variables and Soil Nutrient Indicators in an Alluvial Soil" Land 9, no. 12: 487. https://doi.org/10.3390/land9120487