

A Framework for Data-Driven Agent-Based Modelling of Agricultural Land Use

{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- ABMs can simulate the decentralised and heterogeneous decision-making of farmers with a high level of detail and consider uncertainty regarding their behaviour. This allows for the evaluation of policy effects at the individual level.
- ABMs can explicitly model social interactions, which have an important influence on farmers’ behaviour, and therefore allow the study of the diffusion of technologies and practices.
- ABMs can explicitly include a spatial dimension and the biophysical properties of land, linking it with farmers’ decision-making and thus addressing the feedback between the socio-economic and biophysical spheres.
- ABMs provide a natural framework to consider out-of-equilibrium dynamics.
- ABMs can consider the complex and distributed effects of climate change on agriculture, which are likely to gain increasing relevance.
2. Empirically Grounded Land Use ABMs
3. Modelling Agents’ Behaviours in ABMs
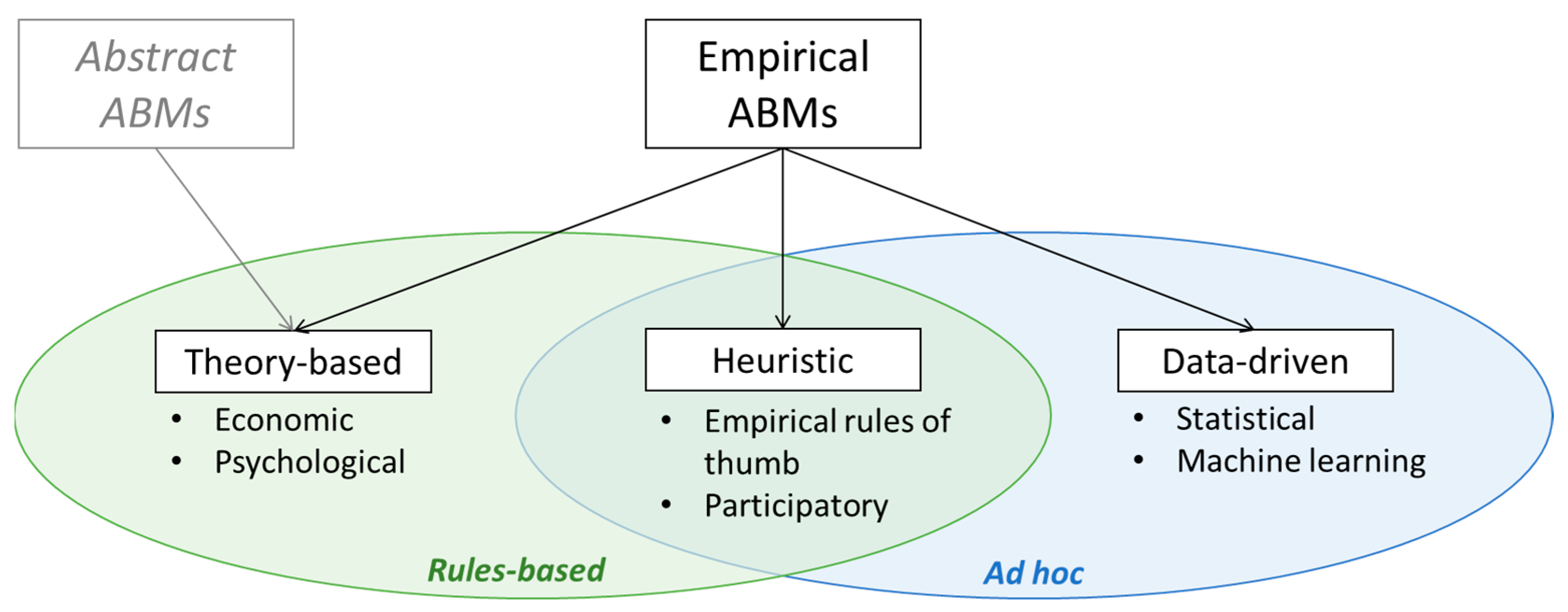
3.1. Theory-Based ABMs
3.2. Heuristic ABMs
3.3. Data-Driven ABMs
4. Machine Learning and ABMs
5. A Framework for Data-Driven LU ABMs
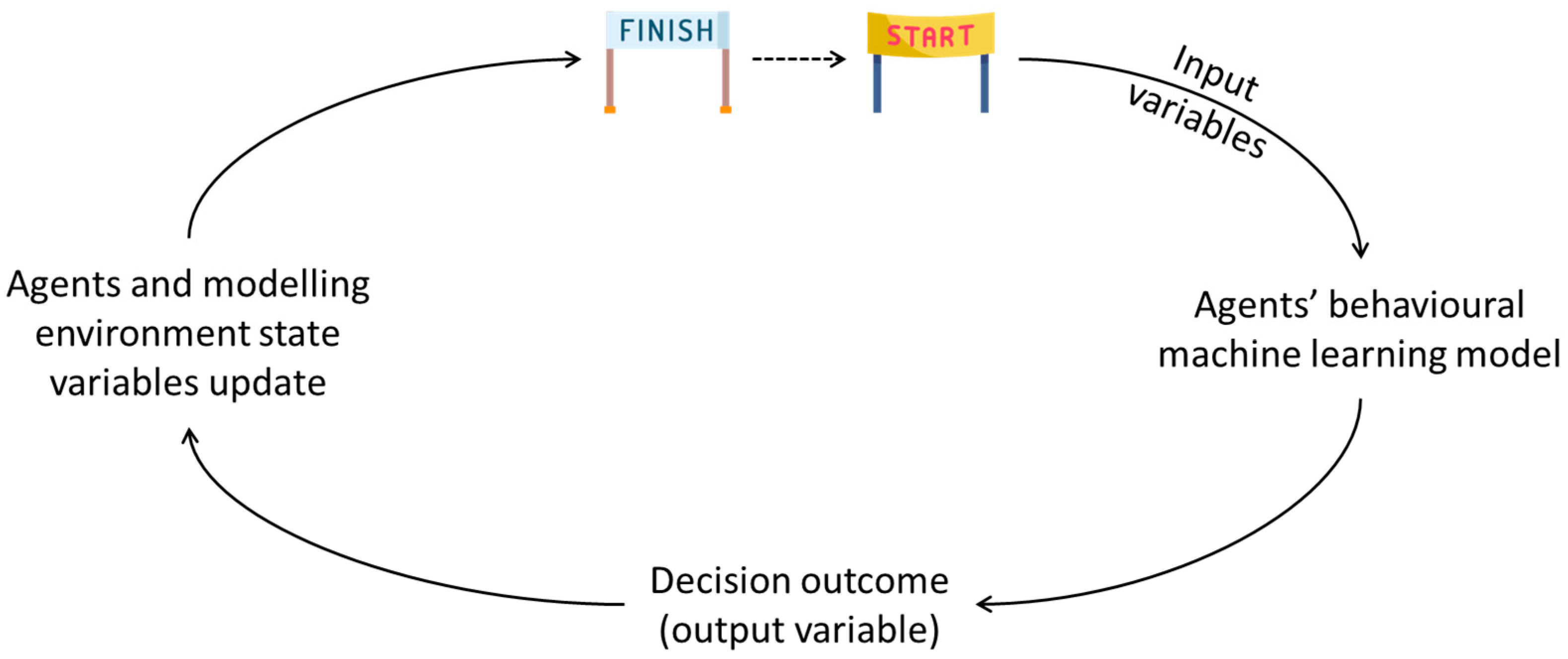
5.1. Model Timestep
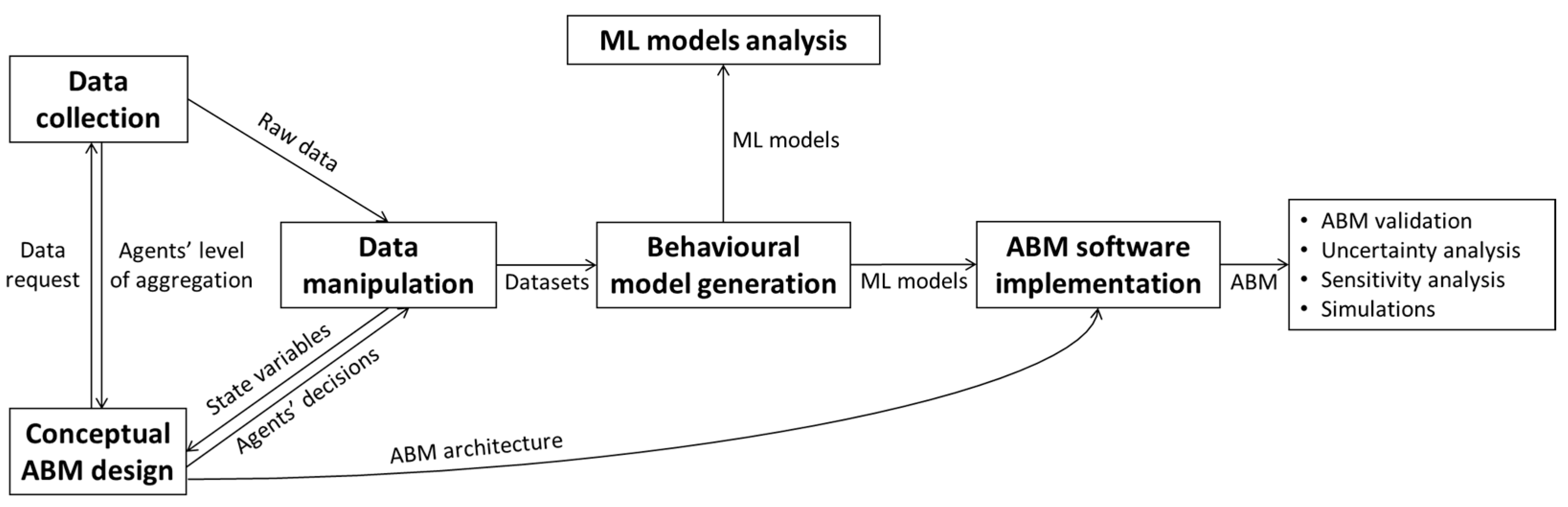
5.2. Model Implementation
5.2.1. Data Collection
5.2.2. Conceptual ABM Design
5.2.3. Data Manipulation
5.2.4. Behavioural Model Generation
5.2.5. ABM Software Implementation
5.2.6. ML Models Analysis
5.2.7. Following Stages
6. Discussion
6.1. Challenges for Data-Driven LU ABMs
6.2. Integration of Rules-Based and Data-Driven Approaches
7. Conclusions
- Use of empirical data since the very beginning of the modelling process and continuous feedback between model design and data collection and manipulation steps.
- Agents’ behavioural models consisting of ML models learned from micro-data at the individual level, without relying on any pre-defined theoretical or heuristic rule.
- No assumption on agents’ interaction and social networks, substituted by proxies for spatial and social influence used to train the agents’ behavioural models.
- Validation performed on independent data at the macro-level and at the micro-level, improving the assessment of policy effects on the individuals.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hardt, L.; O’Neill, D.W. Ecological Macroeconomic Models: Assessing Current Developments. Ecol. Econ. 2017, 134, 198–211. [Google Scholar] [CrossRef]
- Raworth, K. A Safe and Just Space for Humanity: Can We Live within the Doughnut? Oxfam: Nairobi, Kenya, 2012. [Google Scholar]
- Willett, W.; Rockström, J.; Loken, B.; Springmann, M.; Lang, T.; Vermeulen, S.; Garnett, T.; Tilman, D.; DeClerck, F.; Wood, A.; et al. Food in the Anthropocene: The EAT–Lancet Commission on Healthy Diets from Sustainable Food Systems. Lancet 2019, 393, 447–492. [Google Scholar] [CrossRef] [PubMed]
- Vermeulen, S.J.; Campbell, B.M.; Ingram, J.S.I. Climate Change and Food Systems. Annu. Rev. Environ. Resour. 2012, 37, 195–222. [Google Scholar] [CrossRef]
- Tilman, D.; Clark, M.; Williams, D.R.; Kimmel, K.; Polasky, S.; Packer, C. Future Threats to Biodiversity and Pathways to Their Prevention. Nature 2017, 546, 73–81. [Google Scholar] [CrossRef] [PubMed]
- Gaube, V.; Haberl, H. Using Integrated Models to Analyse Socio-Ecological System Dynamics in Long-Term Socio-Ecological Research—Austrian Experiences. In Long Term Socio-Ecological Research; Singh, S.J., Haberl, H., Chertow, M., Mirtl, M., Schmid, M., Eds.; Springer: Dordrecht, The Netherlands, 2013; pp. 53–75. ISBN 978-94-007-1176-1. [Google Scholar]
- Liu, J.; Dietz, T.; Carpenter, S.R.; Alberti, M.; Folke, C.; Moran, E.; Pell, A.N.; Deadman, P.; Kratz, T.; Lubchenco, J.; et al. Complexity of Coupled Human and Natural Systems. Science 2007, 317, 1513–1516. [Google Scholar] [CrossRef]
- Rindfuss, R.R.; Entwisle, B.; Walsh, S.J.; An, L.; Badenoch, N.; Brown, D.G.; Deadman, P.; Evans, T.P.; Fox, J.; Geoghegan, J.; et al. Land Use Change: Complexity and Comparisons. J. Land Use Sci. 2008, 3, 1–10. [Google Scholar] [CrossRef]
- Levin, S.; Xepapadeas, T.; Crépin, A.-S.; Norberg, J.; de Zeeuw, A.; Folke, C.; Hughes, T.; Arrow, K.; Barrett, S.; Daily, G.; et al. Social-Ecological Systems as Complex Adaptive Systems: Modeling and Policy Implications. Environ. Dev. Econ. 2013, 18, 111–132. [Google Scholar] [CrossRef]
- Agent-Based Modelling of Socio-Technical Systems; Dam, K.H.; Nikolic, I.; Lukszo, Z. (Eds.) Springer: Dordrecht, The Netherlands, 2013; ISBN 978-94-007-4932-0. [Google Scholar]
- Holling, C.S. Understanding the Complexity of Economic, Ecological, and Social Systems. Ecosystems 2001, 4, 390–405. [Google Scholar] [CrossRef]
- Ostrom, E. A General Framework for Analyzing Sustainability of Social-Ecological Systems. Science 2009, 325, 419–422. [Google Scholar] [CrossRef]
- Preiser, R.; Biggs, R.; De Vos, A.; Folke, C. Social-Ecological Systems as Complex Adaptive Systems: Organizing Principles for Advancing Research Methods and Approaches. Ecol. Soc. 2018, 23, 46. [Google Scholar] [CrossRef]
- Berger, T.; Troost, C. Agent-Based Modelling of Climate Adaptation and Mitigation Options in Agriculture. J. Agric. Econ. 2014, 65, 323–348. [Google Scholar] [CrossRef]
- Reidsma, P.; Janssen, S.; Jansen, J.; van Ittersum, M.K. On the Development and Use of Farm Models for Policy Impact Assessment in the European Union—A Review. Agric. Syst. 2018, 159, 111–125. [Google Scholar] [CrossRef]
- Groeneveld, J.; Müller, B.; Buchmann, C.; Dressler, G.; Guo, C.; Hase, N.; Hoffmann, F.; John, F.; Klassert, C.; Lauf, T.; et al. Theoretical Foundations of Human Decision-Making in Agent-Based Land Use Models—A Review. Environ. Model. Softw. 2017, 87, 39–48. [Google Scholar] [CrossRef]
- O’Sullivan, D.; Evans, T.; Manson, S.; Metcalf, S.; Ligmann-Zielinska, A.; Bone, C. Strategic Directions for Agent-Based Modeling: Avoiding the YAAWN Syndrome. J. Land Use Sci. 2016, 11, 177–187. [Google Scholar] [CrossRef]
- Kremmydas, D.; Athanasiadis, I.N.; Rozakis, S. A Review of Agent Based Modeling for Agricultural Policy Evaluation. Agric. Syst. 2018, 164, 95–106. [Google Scholar] [CrossRef]
- Macal, C.M. Everything You Need to Know about Agent Based Modelling and Simulation. J. Simul. 2016, 10, 144–156. [Google Scholar] [CrossRef]
- Epstein, J.M. Agent-Based Computational Models and Generative Social Science. Complexity 2006, 4, 41–60. [Google Scholar] [CrossRef]
- Parker, D.C.; Manson, S.M.; Janssen, M.A.; Hoffmann, M.J.; Deadman, P. Multi-Agent Systems for the Simulation of Land-Use and Land-Cover Change: A Review. Ann. Assoc. Am. Geogr. 2003, 93, 314–337. [Google Scholar] [CrossRef]
- Robinson, D.T.; Brown, D.G.; Parker, D.C.; Schreinemachers, P.; Janssen, M.A.; Huigen, M.; Wittmer, H.; Gotts, N.; Promburom, P.; Irwin, E.; et al. Comparison of Empirical Methods for Building Agent-Based Models in Land Use Science. J. Land Use Sci. 2007, 2, 31–55. [Google Scholar] [CrossRef]
- Dullinger, I.; Gattringer, A.; Wessely, J.; Moser, D.; Plutzar, C.; Willner, W.; Egger, C.; Gaube, V.; Haberl, H.; Mayer, A.; et al. A Socio-ecological Model for Predicting Impacts of Land-use and Climate Change on Regional Plant Diversity in the Austrian Alps. Glob. Chang. Biol. 2020, 26, 2336–2352. [Google Scholar] [CrossRef]
- Filatova, T.; Verburg, P.H.; Parker, D.C.; Stannard, C.A. Spatial Agent-Based Models for Socio-Ecological Systems: Challenges and Prospects. Environ. Model. Softw. 2013, 45, 1–7. [Google Scholar] [CrossRef]
- Happe, K.; Kellermann, K.; Balmann, A. Agent-Based Analysis of Agricultural Policies: An Illustration of the Agricultural Policy Simulator AgriPoliS, Its Adaptation and Behavior. Ecol. Soc. 2006, 11, 49. [Google Scholar] [CrossRef]
- Matthews, R.B.; Gilbert, N.G.; Roach, A.; Polhill, J.G.; Gotts, N.M. Agent-Based Land-Use Models: A Review of Applications. Landsc. Ecol. 2007, 22, 1447–1459. [Google Scholar] [CrossRef]
- Schreinemachers, P.; Berger, T. An Agent-Based Simulation Model of Human–Environment Interactions in Agricultural Systems. Environ. Model. Softw. 2011, 26, 845–859. [Google Scholar] [CrossRef]
- Grimm, V.; Berger, U.; DeAngelis, D.L.; Polhill, J.G.; Giske, J.; Railsback, S.F. The ODD Protocol: A Review and First Update. Ecol. Model. 2010, 221, 2760–2768. [Google Scholar] [CrossRef]
- Grimm, V.; Railsback, S.F.; Vincenot, C.E.; Berger, U.; Gallagher, C.; DeAngelis, D.L.; Edmonds, B.; Ge, J.; Giske, J.; Groeneveld, J.; et al. The ODD Protocol for Describing Agent-Based and Other Simulation Models: A Second Update to Improve Clarity, Replication, and Structural Realism. JASSS 2020, 23, 7. [Google Scholar] [CrossRef]
- Laatabi, A.; Marilleau, N.; Nguyen-Huu, T.; Hbid, H.; Ait Babram, M. ODD+2D: An ODD Based Protocol for Mapping Data to Empirical ABMs. JASSS 2018, 21, 9. [Google Scholar] [CrossRef]
- Müller, B.; Bohn, F.; Dreßler, G.; Groeneveld, J.; Klassert, C.; Martin, R.; Schlüter, M.; Schulze, J.; Weise, H.; Schwarz, N. Describing Human Decisions in Agent-Based Models—ODD + D, an Extension of the ODD Protocol. Environ. Model. Softw. 2013, 48, 37–48. [Google Scholar] [CrossRef]
- Bruch, E.; Atwell, J. Agent-Based Models in Empirical Social Research. Sociol. Methods Res. 2015, 44, 186–221. [Google Scholar] [CrossRef]
- Edmonds, B.; Grimm, V.; Meyer, R.; Montañola, C.; Ormerod, P.; Root, H.; Squazzoni, F. Different Modelling Purposes. JASSS 2019, 22, 6. [Google Scholar] [CrossRef]
- Zhang, H.; Vorobeychik, Y. Empirically Grounded Agent-Based Models of Innovation Diffusion: A Critical Review. Artif. Intell. Rev. 2019, 52, 707–741. [Google Scholar] [CrossRef]
- Lempert, R. Agent-Based Modeling as Organizational and Public Policy Simulators. Proc. Natl. Acad. Sci. USA 2002, 99, 7195. [Google Scholar] [CrossRef] [PubMed]
- Data For Policy Policy-Making in the Big Data Era: Opportunities and Challenges. In Proceedings the Book of Data for Policy 2015 Conference, Cambridge, UK, 15–17 June 2015; University of Cambridge: Cambridge, UK, 2015.
- Androutsopoulou, A.; Charalabidis, Y. A Framework for Evidence Based Policy Making Combining Big Data, Dynamic Modelling and Machine Intelligence. In Proceedings of the 11th International Conference on Theory and Practice of Electronic Governance, Galway, Ireland, 4–6 April 2018. [Google Scholar]
- Lee, J.W. Big Data Strategies for Government, Society and Policy-Making. J. Asian Financ. Econ. Bus. 2020, 7, 475–487. [Google Scholar] [CrossRef]
- Zhang, H.; Vorobeychik, Y.; Letchford, J.; Lakkaraju, K. Data-Driven Agent-Based Modeling, with Application to Rooftop Solar Adoption. Auton. Agent Multi-Agent Syst. 2016, 30, 1023–1049. [Google Scholar] [CrossRef]
- Kavak, H.; Padilla, J.J.; Lynch, C.J.; Diallo, S.Y. Big Data, Agents and Machine Learning: Towards a Data-Driven Agent-Based Modeling Approach. In Proceedings of the Annual Simulation Symposium (ANSS 2018), Baltimore, MD, USA, 15–18 April 2018; Society for Modeling and Simulation International (SCS): Baltimore, MD, USA, 2018. [Google Scholar]
- Zhao, L.; Peng, Z.-R. LandSys II: Agent-Based Land Use–Forecast Model with Artificial Neural Networks and Multiagent Model. J. Urban Plann. Dev. 2015, 141, 04014045. [Google Scholar] [CrossRef]
- Heppenstall, A.; Crooks, A.; Malleson, N.; Manley, E.; Ge, J.; Batty, M. Future Developments in Geographical Agent-Based Models: Challenges and Opportunities. Geogr. Anal. 2021, 53, 76–91. [Google Scholar] [CrossRef]
- Buchmann, C.M.; Grossmann, K.; Schwarz, N. How Agent Heterogeneity, Model Structure and Input Data Determine the Performance of an Empirical ABM—A Real-World Case Study on Residential Mobility. Environ. Model. Softw. 2016, 75, 77–93. [Google Scholar] [CrossRef]
- Janssen, M.A.; Ostrom, E. Empirically Based, Agent-Based Models. Ecol. Soc. 2006, 11, 37. [Google Scholar] [CrossRef]
- Hassan, S.; Antunes, L.; Pavon, J.; Gilbert, N. Stepping on Earth: A Roadmap for Data-Driven Agent-Based Modelling. In Proceedings of the 5th Conference of the European Social Simulation Association (ESSA08), Brescia, Italy, 1–5 September 2008; p. 12. [Google Scholar]
- Edmonds, B.; Moss, S. From KISS to KIDS—An ‘Anti-Simplistic’ Modelling Approach. In Multi-Agent and Multi-Agent-Based Simulation; Davidsson, P., Logan, B., Takadama, K., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3415, pp. 130–144. ISBN 978-3-540-25262-7. [Google Scholar]
- Marvuglia, A.; Navarrete Gutiérrez, T.; Baustert, P.; Benetto, E. Luxembourg Institute of Science and Technology (LIST), 5, avenue des Hauts-Fourneaux, L-4362 Esch-sur-Alzette, Luxembourg Implementation of Agent-Based Models to Support Life Cycle Assessment: A Review Focusing on Agriculture and Land Use. AIMS Agric. Food 2018, 3, 535–560. [Google Scholar] [CrossRef]
- Acosta, A.L.; Rounsevell, D.A.M.; Bakker, M.; Van Doorn, A.; Gómez-Delgado, M.; Delgado, M. An Agent-Based Assessment of Land Use and Ecosystem Changes in Traditional Agricultural Landscape of Portugal. Intell. Inf. Manag. 2014, 6, 55–80. [Google Scholar] [CrossRef]
- Chen, X.; Viña, A.; Shortridge, A.; An, L.; Liu, J. Assessing the Effectiveness of Payments for Ecosystem Services: An Agent-Based Modeling Approach. Ecol. Soc. 2014, 19, art7. [Google Scholar] [CrossRef]
- Sun, Z.; Müller, D. A Framework for Modeling Payments for Ecosystem Services with Agent-Based Models, Bayesian Belief Networks and Opinion Dynamics Models. Environ. Model. Softw. 2013, 45, 15–28. [Google Scholar] [CrossRef]
- Smajgl, A.; Brown, D.G.; Valbuena, D.; Huigen, M.G.A. Empirical Characterisation of Agent Behaviours in Socio-Ecological Systems. Environ. Model. Softw. 2011, 26, 837–844. [Google Scholar] [CrossRef]
- Dahlke, J.; Bogner, K.; Müller, M.; Berger, T.; Pyka, A. Bernd Ebersberger Is the Juice Worth the Squeeze? Machine Learning in and for Agent-Based Modelling. arXiv 2020. [Google Scholar] [CrossRef]
- Bartkowski, B.; Bartke, S. Leverage Points for Governing Agricultural Soils: A Review of Empirical Studies of European Farmers’ Decision-Making. Sustainability 2018, 10, 3179. [Google Scholar] [CrossRef]
- Huber, R.; Bakker, M.; Balmann, A.; Berger, T.; Bithell, M.; Brown, C.; Grêt-Regamey, A.; Xiong, H.; Le, Q.B.; Mack, G.; et al. Representation of Decision-Making in European Agricultural Agent-Based Models. Agric. Syst. 2018, 167, 143–160. [Google Scholar] [CrossRef]
- An, L. Modeling Human Decisions in Coupled Human and Natural Systems: Review of Agent-Based Models. Ecol. Model. 2012, 229, 25–36. [Google Scholar] [CrossRef]
- Bakker, M.M.; van Doorn, A.M. Farmer-Specific Relationships between Land Use Change and Landscape Factors: Introducing Agents in Empirical Land Use Modelling. Land Use Policy 2009, 26, 809–817. [Google Scholar] [CrossRef]
- Farmer, J.D.; Hepburn, C.; Mealy, P.; Teytelboym, A. A Third Wave in the Economics of Climate Change. Environ. Resour. Econ. 2015, 62, 329–357. [Google Scholar] [CrossRef]
- Ajzen, I. The Theory of Planned Behavior. Organ. Behav. Hum. Decis. Process. 1991, 50, 179–211. [Google Scholar] [CrossRef]
- Jager, W.; Janssen, M.A.; De Vries, H.J.M.; De Greef, J.; Vlek, C.A.J. Behaviour in Commons Dilemmas: Homo Economicus and Homo Psychologicus in an Ecological-Economic Model. Ecol. Econ. 2000, 35, 357–379. [Google Scholar] [CrossRef]
- Runck, B.C.; Manson, S.; Shook, E.; Gini, M.; Jordan, N. Using Word Embeddings to Generate Data-Driven Human Agent Decision-Making from Natural Language. Geoinformatica 2019, 23, 221–242. [Google Scholar] [CrossRef]
- Schenk, T.A. Using Stakeholders’ Narratives to Build an Agent-Based Simulation of a Political Process. Simulation 2014, 90, 85–102. [Google Scholar] [CrossRef]
- Gaube, V.; Kaiser, C.; Wildenberg, M.; Adensam, H.; Fleissner, P.; Kobler, J.; Lutz, J.; Schaumberger, A.; Schaumberger, J.; Smetschka, B.; et al. Combining Agent-Based and Stock-Flow Modelling Approaches in a Participative Analysis of the Integrated Land System in Reichraming, Austria. Landsc. Ecol 2009, 24, 1149–1165. [Google Scholar] [CrossRef]
- Jäger, G. Using Neural Networks for a Universal Framework for Agent-Based Models. Math. Comput. Model. Dyn. Syst. 2021, 27, 162–178. [Google Scholar] [CrossRef]
- Edmonds, B.; Aodha, L. ní Using Agent-Based Simulation to Inform Policy—What Could Possibly Go Wrong? In Simulating Social Complexity—A Handbook; Springer: Berlin/Heidelberg, Germany, 2017; pp. 801–822. [Google Scholar]
- Lee, J.-S.; Filatova, T.; Ligmann-Zielinska, A.; Hassani-Mahmooei, B.; Stonedahl, F.; Lorscheid, I.; Voinov, A.; Polhill, G.; Sun, Z.; Parker, D.C. The Complexities of Agent-Based Modeling Output Analysis. JASSS 2015, 18, 4. [Google Scholar] [CrossRef]
- Bzdok, D.; Altman, N.; Krzywinski, M. Statistics versus Machine Learning. Nat. Methods 2018, 15, 233–234. [Google Scholar] [CrossRef]
- Domingos, P. A Few Useful Things to Know about Machine Learning. Commun. ACM 2012, 55, 78–87. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine Learning: Trends, Perspectives, and Prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Rolnick, D.; Donti, P.L.; Kaack, L.H.; Kochanski, K.; Lacoste, A.; Sankaran, K.; Ross, A.S.; Milojevic-Dupont, N.; Jaques, N.; Waldman-Brown, A.; et al. Tackling Climate Change with Machine Learning. arXiv 2019. [Google Scholar] [CrossRef]
- von Rueden, L.; Mayer, S.; Sifa, R.; Bauckhage, C.; Garcke, J. Combining Machine Learning and Simulation to a Hybrid Modelling Approach: Current and Future Directions. In Advances in Intelligent Data Analysis XVIII; Berthold, M.R., Feelders, A., Krempl, G., Eds.; Springer International Publishing: Cham, Swizerlands, 2020; pp. 548–560. [Google Scholar]
- An, L.; Grimm, V.; Sullivan, A.; Turner, B.L., II; Malleson, N.; Heppenstall, A.; Vincenot, C.; Robinson, D.; Ye, X.; Liu, J.; et al. Challenges, Tasks, and Opportunities in Modeling Agent-Based Complex Systems. Ecol. Model. 2021, 457, 109685. [Google Scholar] [CrossRef]
- Li, F.; Li, Z.; Chen, H.; Chen, Z.; Li, M. An Agent-Based Learning-Embedded Model (ABM-Learning) for Urban Land Use Planning: A Case Study of Residential Land Growth Simulation in Shenzhen, China. Land Use Policy 2020, 95, 104620. [Google Scholar] [CrossRef]
- Pereda, M.; Santos, J.I.; Galán, J.M. A Brief Introduction to the Use of Machine Learning Techniques in the Analysis of Agent-Based Models. In Advances in Management Engineering; Hernández, C., Ed.; Lecture Notes in Management and Industrial Engineering; Springer International Publishing: Cham, Swizerlands, 2017; pp. 179–186. ISBN 978-3-319-55888-2. [Google Scholar]
- van Strien, M.J.; Huber, S.H.; Anderies, J.M.; Grêt-Regamey, A. Resilience in Social-Ecological Systems: Identifying Stable and Unstable Equilibria with Agent-Based Models. Ecol. Soc. 2019, 24, art8. [Google Scholar] [CrossRef]
- Lamperti, F.; Roventini, A.; Sani, A. Agent-Based Model Calibration Using Machine Learning Surrogates. J. Econ. Dyn. Control. 2018, 90, 366–389. [Google Scholar] [CrossRef]
- Zhao, X.; Ma, X.; Tang, W.; Liu, D. An Adaptive Agent-Based Optimization Model for Spatial Planning: A Case Study of Anyue County, China. Sustain. Cities Soc. 2019, 51, 101733. [Google Scholar] [CrossRef]
- Hashemi Aslani, Z.; Omidvar, B.; Karbassi, A. Integrated Model for Land-Use Transformation Analysis Based on Multi-Layer Perception Neural Network and Agent-Based Model. Environ. Sci. Pollut. Res. 2022. [Google Scholar] [CrossRef]
- Ravaioli, G.; Domingos, T.; Teixeira, R.F. Data-driven agent-based modelling of incentives for carbon sequestration: The case of sown biodiverse pastures in Portugal. J. Environ. Manag. 2023, 338, 117834. [Google Scholar]
- Kaufmann, J.; Schering, A. Analysis of Variance ANOVA. In Wiley StatsRef: Statistics Reference Online; Bala-krishnan, N., Colton, T., Everitt, B., Piegorsch, W., Ruggeri, F., Teugels, J.L., Eds.; Wiley: Hoboken, NJ, USA, 2014; ISBN 978-1-118-44511-2. [Google Scholar]
- Pearson, K.X. On the Criterion That a given System of Deviations from the Probable in the Case of a Correlated System of Variables Is Such That It Can Be Reasonably Supposed to Have Arisen from Random Sampling. Philos. Mag. Ser. 1900, 5, 157–175. [Google Scholar] [CrossRef]
- Daoud, J. Multicollinearity and Regression Analysis. In Journal of Physics: Conference Series; International Islamic University Malaysia: Kuala Lumpur, Malaysia, 2017; Volume 949, p. 012009. [Google Scholar]
- Cragg, J.G. Some Statistical Models for Limited Dependent Variables with Application to the Demand for Durable Goods. Econometrica 1971, 39, 829. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning. Independently published. 2019; ISBN 979-8411463330. [Google Scholar]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Definitions, Methods, and Applications in Interpretable Machine Learning. Proc. Natl. Acad. Sci. USA 2019, 116, 22071–22080. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Statist. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Fisher, A.; Rudin, C.; Dominici, F. All Models Are Wrong, but Many Are Useful: Learning a Variable’s Importance by Studying an Entire Class of Prediction Models Simultaneously. J. Mach. Learn. Res. 2019, 20, 177. [Google Scholar] [PubMed]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- ten Broeke, G.; van Voorn, G.; Ligtenberg, A. Which Sensitivity Analysis Method Should I Use for My Agent-Based Model? JASSS 2016, 19, 5. [Google Scholar] [CrossRef]
- Viana, C.M.; Santos, M.; Freire, D.; Abrantes, P.; Rocha, J. Evaluation of the Factors Explaining the Use of Agricultural Land: A Machine Learning and Model-Agnostic Approach. Ecol. Indic. 2021, 131, 108200. [Google Scholar] [CrossRef]
- Koomen, E.; Diogo, V.; Dekkers, J.; Rietveld, P. A Utility-Based Suitability Framework for Integrated Local-Scale Land-Use Modelling. Comput. Environ. Urban Syst. 2015, 50, 1–14. [Google Scholar] [CrossRef]
- Sun, Z.; Lorscheid, I.; Millington, J.D.; Lauf, S.; Magliocca, N.R.; Groeneveld, J.; Balbi, S.; Nolzen, H.; Müller, B.; Schulze, J.; et al. Simple or Complicated Agent-Based Models? A Complicated Issue. Environ. Model. Softw. 2016, 86, 56–67. [Google Scholar] [CrossRef]
- Harb, M.; Garschagen, M.; Cotti, D.; Krätzschmar, E.; Baccouche, H.; Ben Khaled, K.; Bellert, F.; Chebil, B.; Ben Fredj, A.; Ayed, S.; et al. Integrating Data-Driven and Participatory Modeling to Simulate Future Urban Growth Scenarios: Findings from Monastir, Tunisia. Urban Sci. 2020, 4, 10. [Google Scholar] [CrossRef]
- Filatova, T. Empirical Agent-Based Land Market: Integrating Adaptive Economic Behavior in Urban Land-Use Models. Comput. Environ. Urban Syst. 2015, 54, 397–413. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ravaioli, G.; Domingos, T.; Teixeira, R.F.M. A Framework for Data-Driven Agent-Based Modelling of Agricultural Land Use. Land 2023, 12, 756. https://doi.org/10.3390/land12040756
Ravaioli G, Domingos T, Teixeira RFM. A Framework for Data-Driven Agent-Based Modelling of Agricultural Land Use. Land. 2023; 12(4):756. https://doi.org/10.3390/land12040756
Chicago/Turabian StyleRavaioli, Giacomo, Tiago Domingos, and Ricardo F. M. Teixeira. 2023. "A Framework for Data-Driven Agent-Based Modelling of Agricultural Land Use" Land 12, no. 4: 756. https://doi.org/10.3390/land12040756