
Macro-Level Factors Shaping Residential Location Choices: Examining the Impacts of Density and Land-Use Mix

Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Sources
2.2. Description of Explanatory Variables
2.2.1. Demographics
2.2.2. Travel-Related Attributes
2.2.3. Employment and Economic Indicators
2.2.4. Housing-Related Index
2.2.5. Lifestyle Factors and Transit Accessibility
2.2.6. Interacting Terms
3. Results
3.1. Model Results I (Housing Density at Census Block or Tract Level)
- I.
- Effects of Demographics
- II.
- Effects of Travel-Related Attributes
- III.
- Effects of Employment and Economic Indicators
- IV.
- Effects of Housing-Related Index
- V.
- Model Fit and Threshold Parameters
3.2. Model Results II (Population Density at Census Block or Tract Level)
- I.
- Effects of Demographics
- II.
- Effects of Travel-Related Attributes
- III.
- Effects of Employment and Economic Indicators
- IV.
- Effects of Housing-Related Index
- V.
- Effects of Lifestyle Factors and Transit Accessibility
- VI.
- Model fit and threshold parameters
3.3. Model Results III (Land-Use Diversity Index at 0.25-Mile or 0.5-Mile)
- I.
- Effects of demographics
- II.
- Effects of Travel-Related Attributes
- III.
- Effects of Employment and Economic Indicators
- IV. Effects of Housing-Related Index
- V. Effects of Lifestyle Factors and Transit Accessibility
- VI.
- Model Fit and Threshold Parameters
4. Discussion
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guo, J.Y.; Bhat, C.R. Operationalizing the concept of neighborhood: Application to residential location choice analysis. J. Transp. Geogr. 2007, 15, 31–45. [Google Scholar] [CrossRef] [Green Version]
- Habib, M.A.; Miller, E.J. Modeling Residential and Spatial Search Behaviour: Evidence from the Greater Toronto Area. In Proceedings of the 6th Triennial Symposium on Transportation Analysis, Phuket Island, Thailand, 10–15 June 2007. [Google Scholar]
- Ben-Akiva, M.E.; Lerman, S.R.; Lerman, S.R. Discrete Choice Analysis: Theory and Application to Travel Demand; MIT Press: Cambridge, MA, USA, 1985. [Google Scholar]
- Weisbrod, G.; Lerman, S.R.; Ben-Akiva, M. Tradeoffs in residential location decisions: Transportation versus other factors. Transp. Policy Decis. Mak. 1980, 1, 13–26. [Google Scholar]
- Ben-Akiva, M.; Bowman, J.L. Integration of an activity-based model system and a residential location model. Urban Stud. 1998, 35, 1131–1153. [Google Scholar] [CrossRef]
- Zhan, C. School and neighborhood: Residential location choice of immigrant parents in the Los Angeles Metropolitan area. J. Popul. Econ. 2015, 28, 737–783. [Google Scholar] [CrossRef]
- Duncombe, W.; Robbins, M.; Wolf, D.A. Retire to where? A discrete choice model of residential location. Int. J. Popul. Geogr. 2001, 7, 281–293. [Google Scholar] [CrossRef]
- Caughy, M.O.B.; O’Campo, P.J.; Muntaner, C. When being alone might be better: Neighborhood poverty, social capital, and child mental health. Soc. Sci. Med. 2003, 57, 227–237. [Google Scholar] [CrossRef]
- Coulton, C.J.; Korbin, J.; Chan, T.; Su, M. Mapping residents’ perceptions of neighborhood boundaries: A methodological note. Am. J. Community Psychol. 2001, 29, 371–383. [Google Scholar] [CrossRef] [PubMed]
- Ardeshiri, A.; Vij, A. Lifestyles, residential location, and transport mode use: A hierarchical latent class choice model. Transp. Res. Part A Policy Pract. 2019, 126, 342–359. [Google Scholar] [CrossRef]
- Craig, A. Commute Mode and Residential Location Choice; University of Windsor, Department of Economics: Windsor, ON, Canada, 2019. [Google Scholar]
- De Vos, J.; Alemi, F. Are young adults car-loving urbanites? Comparing young and older adults’ residential location choice, travel behavior and attitudes. Transp. Res. Part A Policy Pract. 2020, 132, 986–998. [Google Scholar] [CrossRef]
- Gomaa, M.M. Investigating the Socioeconomic Factors Influencing Households’ Residential Location Choice Using Multinomial Logit Analysis. Int. J. Archit. Eng. Urban Res. 2022, 5, 92–115. [Google Scholar] [CrossRef]
- Frenkel, A.; Bendit, E.; Kaplan, S. Residential location choice of knowledge-workers: The role of amenities, workplace and lifestyle. Cities 2013, 35, 33–41. [Google Scholar] [CrossRef]
- Livy, M.R. Assessing the Impact of Environmental Amenities on Residential Location Choice; The Ohio State University: Columbus, OH, USA, 2015. [Google Scholar]
- Lu, J. Household residential location choice in retirement: The role of climate amenities. Reg. Sci. Urban Econ. 2020, 84, 103489. [Google Scholar] [CrossRef]
- Gabriel, S.A.; Rosenthal, S.S. Household location and race: Estimates of a multinomial logit model. Rev. Econ. Stat. 1989, 71, 240–249. [Google Scholar] [CrossRef]
- McFadden, D. Modelling the choice of residential location. In Spatial Interaction Theory and Residential Location; Karlquist, A., Ed.; North Holland: Amsterdam, The Netherlands, 1978; pp. 75–96. [Google Scholar]
- Hunt, L.M.; Boots, B.; Kanaroglou, P.S. Spatial choice modelling: New opportunities to incorporate space into substitution patterns. Prog. Hum. Geogr. 2004, 28, 746–766. [Google Scholar] [CrossRef]
- Pellegrini, P.A.; Fotheringham, A.S. Modelling spatial choice: A review and synthesis in a migration context. Prog. Hum. Geogr. 2002, 26, 487–510. [Google Scholar] [CrossRef]
- Lee, B.H.; Waddell, P. Residential mobility and location choice: A nested logit model with sampling of alternatives. Transportation 2010, 37, 587–601. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Sun, H.; Wu, J.; Lee, D.-H. Household residential location choice equilibrium model based on reference-dependent theory. J. Urban Plan. Dev. 2020, 146, 4019024. [Google Scholar] [CrossRef]
- Gluszak, M.; Marona, B. Discrete choice model of residential location in Krakow. J. Eur. Real Estate Res. 2017, 10, 4–16. [Google Scholar] [CrossRef]
- Vorel, J. Residential location choice modelling: A micro-simulation approach. AUC Geogr. 2014, 49, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Sener, I.N.; Pendyala, R.M.; Bhat, C.R. Accommodating spatial correlation across choice alternatives in discrete choice models: An application to modeling residential location choice behavior. J. Transp. Geogr. 2011, 19, 294–303. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Yang, Y.; Jin, S.; Gu, L.; Zhang, H. Social and cultural factors that influence residential location choice of urban senior citizens in China–The case of Chengdu city. Habitat Int. 2016, 53, 55–65. [Google Scholar] [CrossRef]
- Źróbek, S.; Trojanek, M.; Źróbek-Sokolnik, A.; Trojanek, R. The influence of environmental factors on property buyers’ choice of residential location in Poland. J. Int. Stud. 2015, 7, 163–173. [Google Scholar]
- Usman, B.; Malik, N.; Alausa, K. Factors determining the choice of residential location in Ilorin, Nigeria. Zaria Geogr. 2015, 22, 109–122. [Google Scholar]
- Xie, X.B.; Bu, X.Q.; Zheng, M.J.; Wen, H.Z. An empirical study on influencing factors of residential location choice in Hangzhou, China. Appl. Mech. Mater. 2013, 357, 1747–1751. [Google Scholar] [CrossRef]
- Aslam, A.B.; Masoumi, H.E.; Naeem, N.; Ahmad, M. Residential location choices and the role of mobility, socioeconomics, and land use in Hafizabad, Pakistan. Urbani Izziv 2019, 30, 115–128. [Google Scholar] [CrossRef]
- Guo, J.; Bhat, C. Residential Location Choice Modeling: Accommodating Sociodemographic, School Quality and Accessibility Effects; University of Texas: Austin, TX, USA, 2001. [Google Scholar]
- Bhat, C.R.; Guo, J. A mixed spatially correlated logit model: Formulation and application to residential choice modeling. Transp. Res. Part B Methodol. 2004, 38, 147–168. [Google Scholar] [CrossRef] [Green Version]
- McKelvey, R.D.; Zavoina, W. A statistical model for the analysis of ordinal level dependent variables. J. Math. Sociol. 1975, 4, 103–120. [Google Scholar] [CrossRef]
- Clark, S.D. Estimating local car ownership models. J. Transp. Geogr. 2007, 15, 184–197. [Google Scholar] [CrossRef] [Green Version]
- Golob, T.F. The dynamics of household travel time expenditures and car ownership decisions. Transp. Res. Part A Gen. 1990, 24, 443–463. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
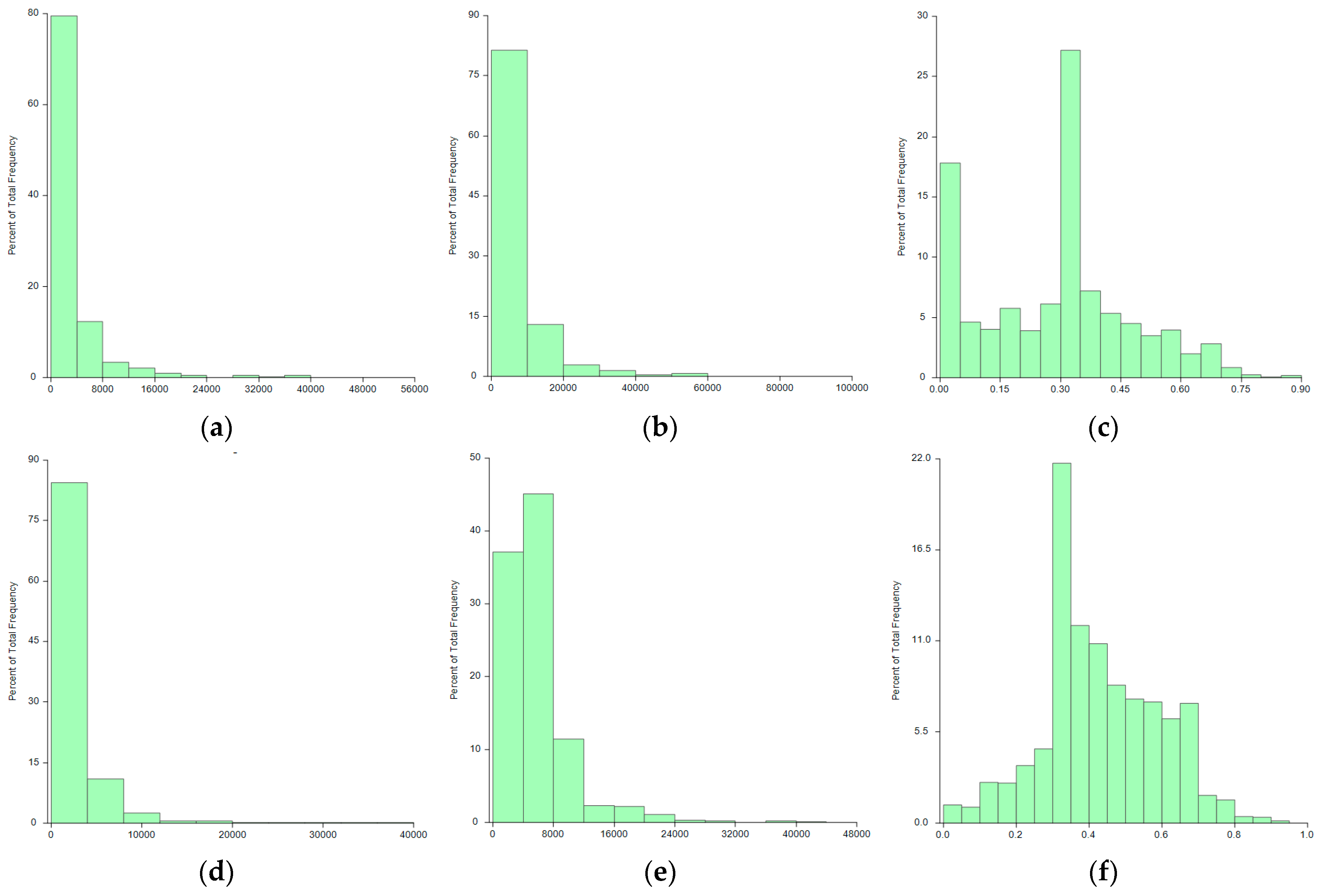
| Choice Sets | Minimum | Mean | Maximum | Standard Deviation | Observations | |
|---|---|---|---|---|---|---|
| Block level (1000/square mile) | Housing density index | 2.60 | 3384.20 | 53,499.14 | 4752.22 | 3026 |
| Population density index | 4.64 | 7268.73 | 99,411.00 | 8119.06 | 3026 | |
| Tract level (1000/square mile) | House density index | 2.41 | 2889.06 | 38,555.15 | 3295.13 | 3026 |
| Population density index | 6.93 | 5673.37 | 41,911.28 | 4297.53 | 3026 | |
| 0.25-mile buffer area | Land-use mix index | 0 | 0.29 | 0.89 | 0.19 | 3026 |
| 0.5-mile buffer area | Land-use mix index | 0 | 0.43 | 0.93 | 0.16 | 3026 |
| Choice Sets | Least Dense | Densest | |||
|---|---|---|---|---|---|
| Block level (1000/square mile) | Housing density index | (min, 1171.88) | (1171.89, 2141.69) | (2141.70, 3473.66) | (3473.67, max) |
| Market share | 756 (24.98%) | 758 (25.05%) | 759 (25.08%) | 753 (24.88%) | |
| Population density index | (min, 2808.57) | (2810.58, 5300.21) | (5300.22, 8599.48) | (8599.49, max) | |
| Market share | 757 (25.02%) | 757 (25.02%) | 756 (24.98%) | 756 (24.98%) | |
| Tract level (1000/square mile) | Housing density index | (min, 1404.80) | (1404.81, 2140.33) | (2140.34, 3197.09) | (3197.10, max) |
| Market share | 759 (25.08%) | 757 (25.02%) | 756 (24.98%) | 754 (24.92%) | |
| Population density index | (min, 3014.76) | (3014.77, 4757.71) | (4757.72, 6924.86) | (6924.87, max) | |
| Market share | 756 (24.98%) | 759 (25.08%) | 756 (24.98%) | 755 (24.95%) | |
| Least diverse land-use | most diverse land-use | ||||
| 0.25-mile buffer area | Land-use mix index | (min, 0.13) | (0.14, 0.33) | (0.34, 0.39) | (0.40, max) |
| Market share | 756 (24.98%) | 1142 (37.74%) | 374 (12.36%) | 754 (24.92%) | |
| 0.5-mile buffer area | Land-use mix index | (min, 0.33) | (0.34, 0.41) | (0.42, 0.55) | (0.56, max) |
| Market share | 898 (29.68%) | 618 (20.42%) | 756 (24.98%) | 754 (24.92%) | |
| Name | Description | Data Type | |
|---|---|---|---|
| Demographics | hsize | Household size | Counts |
| Race (selected) | |||
| White | The race of household respondent is White | Dummy | |
| Black | The race of household respondent is African American, Black | ||
| Asian | The race of household respondent is Asian | ||
| Indian | The race of household respondent is American Indian, Alaskan Native | ||
| Rother | The race of household respondent is any other race type | ||
| Structure of household (selected) | |||
| sadult | one adult, no children | Dummy | |
| sretire | one adult, retired, no children | ||
| sparyc | one adult, youngest child 0–5 | ||
| madunc | 2+ adult, no children | ||
| mretire | 2+ adult, retired, no children | ||
| madyc | 2+ adult, youngest child 0–5 | ||
| Travel attributes | hhveh | The number of vehicles in households | Counts |
| cnht | Category of number of household trips on travel days | ||
| clwork | Proximity to work | Dummy | |
| Employment and economic indicators | nworker | Number of workers | Counts |
| Household income | |||
| hinc | High-income (total annual income is equal or greater than USD 60,000) | Dummy | |
| minc | Medium-income (total annual income is between USD 30,000 and USD 59,999) | ||
| linc | Low-income (total annual income is less than USD 30,000) | ||
| nadult | Number of adults at least 18 years old | Counts | |
| Housing index | htenure | Housing units owned | Dummy |
| The type of housing units | |||
| dsingle | The type of housing unit is detached single house | Dummy | |
| Duplex | The type of housing unit is duplex | ||
| Townh | The type of housing unit is rowhouse or townhouse | ||
| Apt | The type of housing unit is apartment or condominium | ||
| Mobhm | The type of housing unit is mobile home or trailer | ||
| Hothert | The type of housing unit is any other type | ||
| Lifestyle factors | cschool | Close to school | |
| cretail | Close to retail services | ||
| cfriend | Close to friends | ||
| Transit | ctrans | Close to transit | |
| Variables | Parameter | T Stat |
|---|---|---|
| Demographics with interactions | ||
| Household size interacted with the type of housing unit of rowhouse or townhouse | 0.22 | 8.43 |
| Household size interacted with housing units owned | 0.07 | 2.26 |
| Structures of households (base is any other household type) | ||
| One adult, retired, no children | 0.45 | 4.02 |
| Two or more adults, no children | 0.36 | 3.87 |
| One adult, no children | 0.35 | 3.10 |
| Two or more adults, retired, no children | 0.27 | 3.06 |
| Two or more adults, youngest child 0–5 | 0.20 | 1.84 |
| Two or more adults, youngest child 6–15 | 0.17 | 1.71 |
| Travel-related attributes | ||
| The number of vehicles in a household | −0.07 | −2.45 |
| Employment and economic indicators with interactions | ||
| High-income households (base is medium- and low-income households) | −0.29 | −5.54 |
| Low-income households interacted with the housing unit of detached single house | −0.30 | −3.63 |
| Low-income households interacted with housing units owned | 0.26 | 3.46 |
| Housing-related index | ||
| Housing units owned | −0.19 | −1.96 |
| Number of cases | 3026 | |
| Log likelihood at convergence | −4054.67 | |
| Log likelihood for constant-only model | −4194.91 | |
| Mu(1) | 0.70 | |
| Mu(2) | 1.43 | |
| Variables | Parameter | T Stat |
|---|---|---|
| Demographics with interactions | ||
| Household size interacted with the type of housing unit of apartment or condominium | 0.17 | 2.29 |
| Household size interacted with the type of housing unit of duplex | 0.13 | 4.70 |
| Structures of households (base is any other household type) | ||
| One adult, retired, no children | 0.11 | 1.64 |
| Race (base is any other ethnic type) | ||
| American Indian, Alaskan Native | −0.64 | −1.97 |
| Asian | −0.42 | −2.43 |
| Hispanic/Mexican | −0.23 | −1.63 |
| White | −0.19 | −3.28 |
| Travel-related attributes | ||
| The number of vehicles in a household | −0.06 | −2.05 |
| Category of number of household trips on travel days | −0.01 | −2.07 |
| Employment and economic indicators | ||
| Household income (base is the low-income households) | ||
| High-income households | −0.36 | −6.53 |
| Medium-income households | −0.10 | −1.85 |
| Number of adults at least 18 years old | 0.06 | 1.63 |
| Housing-related index | ||
| The type of housing units (base is any other housing unit type) | ||
| The type of housing unit is rowhouse or townhouse | 0.80 | 15.36 |
| Number of cases | 3026 | |
| Log likelihood at convergence | −3933.88 | |
| Log likelihood for constant-only model | −4194.91 | |
| Mu(1) | 0.74 | |
| Mu(2) | 1.49 | |
| Variables | Parameter | T Stat |
|---|---|---|
| Demographics | ||
| Structures of households (base is any other household type) | ||
| Two or more adults, youngest child 0–5 | 0.30 | 3.75 |
| Two or more adults, youngest child 6–15 | 0.24 | 3.33 |
| Two or more adults, retired, no children | 0.21 | 3.94 |
| Race (the base is any other ethnic type) | ||
| White | −0.19 | −3.59 |
| Travel-related attributes | ||
| The number of vehicles in a household | −0.06 | −2.31 |
| Category of number of household trips on travel days | −0.01 | −2.31 |
| Proximity to work | 0.16 | 1.69 |
| Employment and economic indicators | ||
| Household income (the base is low-income households) | ||
| High-income households | −0.41 | −7.52 |
| Medium-income households | −0.15 | −2.76 |
| Number of adults at least 18 years old | 0.14 | 4.23 |
| Housing-related index | ||
| The type of housing units (the base in any other type) | ||
| The type of housing unit is detached single house | −0.26 | −5.70 |
| Lifestyle factors and transit accessibility | ||
| Proximity to friends | −0.19 | −1.77 |
| Number of cases | 3026 | |
| Log likelihood at convergence | −4089.05 | |
| Log likelihood for constant-only model | −4194.93 | |
| Mu(1) | 0.70 | |
| Mu(2) | 1.430 | |
| Variables | Parameter | T Stat |
|---|---|---|
| Demographics with interactions | ||
| Household size interacted with the type of housing unit of rowhouse or townhouse | 0.12 | 4.98 |
| Household size interacted with the type of housing unit of duplex | 0.06 | 2.28 |
| Structures of households (base is any other household type) | ||
| One adult, youngest child 16–21 | 0.37 | 1.56 |
| Two or more adults, youngest child 6–15 | 0.18 | 2.61 |
| Race (base is any other ethnic type) | ||
| Asian | −0.56 | −3.24 |
| White | −0.46 | −8.28 |
| Travel-related attributes | ||
| Category of number of household trips on travel days | −0.01 | −2.32 |
| Employment and economic indicators with interactions | ||
| High-income households (base is medium- and low-income households) | −0.31 | −6.30 |
| Number of adults at least 18 years old | 0.09 | 3.25 |
| Low-income households interacted with housing units owned | 0.27 | 4.67 |
| Housing-related index | ||
| Housing units owned | −0.44 | −5.95 |
| Number of cases | 3026 | |
| Log likelihood at convergence | −4002.19 | |
| Log likelihood for constant-only model | −4194.92 | |
| Mu(1) | 0.72 | |
| Mu(2) | 1.46 | |
| Variables | Parameter | T Stat |
|---|---|---|
| Demographics with interactions | ||
| Household size interacted with the housing unit owned | 0.16 | 4.99 |
| Household size interacted with the type of housing unit is detached single house | −0.15 | −7.87 |
| White (the base is any other ethnic type) | −0.16 | −2.96 |
| Employment and economic indicators | ||
| High-income households (base is medium and low-income households) | −0.14 | −3.33 |
| Number of adults at least 18 years old | −0.09 | −2.30 |
| Housing-related index | ||
| Housing units owned | −0.64 | −7.20 |
| Lifestyle and transit accessibility | ||
| Proximity to friends | −0.19 | −1.81 |
| Number of cases | 3026 | |
| Log likelihood at convergence | −3901.85 | |
| Log likelihood for constant-only model | −3991.07 | |
| Mu(1) | 1.03 | |
| Mu(2) | 1.40 | |
| Variables | Parameter | T Stat |
|---|---|---|
| Demographics with interactions | ||
| Household size interacted with the type of housing unit owned | 0.11 | 4.07 |
| Household size interacted with housing unit of detached single house | −0.09 | −3.97 |
| Race (the base is any other ethnic type) | ||
| Asian | −0.36 | −2.09 |
| White | −0.17 | −6.59 |
| Structures of households (base is any other household type) | ||
| One adult, youngest child 0–5 | −0.70 | −1.82 |
| Employment and economic indicators | ||
| Household income (the base is low-income households) | ||
| High-income households | −0.34 | −6.59 |
| Medium-income households | −0.13 | −2.45 |
| Housing-related index | ||
| Housing units owned | −0.53 | −6.58 |
| The type of housing unit is duplex (the base is any other type of housing units) | −0.19 | −2.54 |
| Number of cases | 3026 | |
| Log likelihood at convergence | −4091.20 | |
| Log likelihood for constant-only model | −4168.91 | |
| Mu(1) | 0.56 | |
| Mu(2) | 1.25 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gomaa, M.M. Macro-Level Factors Shaping Residential Location Choices: Examining the Impacts of Density and Land-Use Mix. Land 2023, 12, 748. https://doi.org/10.3390/land12040748
Gomaa MM. Macro-Level Factors Shaping Residential Location Choices: Examining the Impacts of Density and Land-Use Mix. Land. 2023; 12(4):748. https://doi.org/10.3390/land12040748
Chicago/Turabian StyleGomaa, Mohammed M. 2023. "Macro-Level Factors Shaping Residential Location Choices: Examining the Impacts of Density and Land-Use Mix" Land 12, no. 4: 748. https://doi.org/10.3390/land12040748