
A Machine Learning Approach to Predict Watershed Health Indices for Sediments and Nutrients at Ungauged Basins

Abstract
:1. Introduction
- To evaluate machine learning (ML) models to predict watershed health at ungauged basins with respect to suspended sediment concentration (SSC) and nutrients (nitrogen and phosphorus). ML models, namely random forest, AdaBoost, gradient boosting regressor, and Bayesian ridge regression, were chosen in this study because these models do not make any assumptions about input data distributions, they work well with high dimensional datasets, and they avoid overfitting by using random combinations of predictor variables to develop uncorrelated set of models.
- To identify predictors such as watershed attributes (e.g., drainage area, stream order, drainage density, watershed slope, etc.), long-term climate data (monthly, seasonal and annual precipitation, and/or temperature data), soil data, land use/land cover data, and fertilizer sales data to train machine learning models for predicting watershed health over any area of interest within three Midwest river basins.
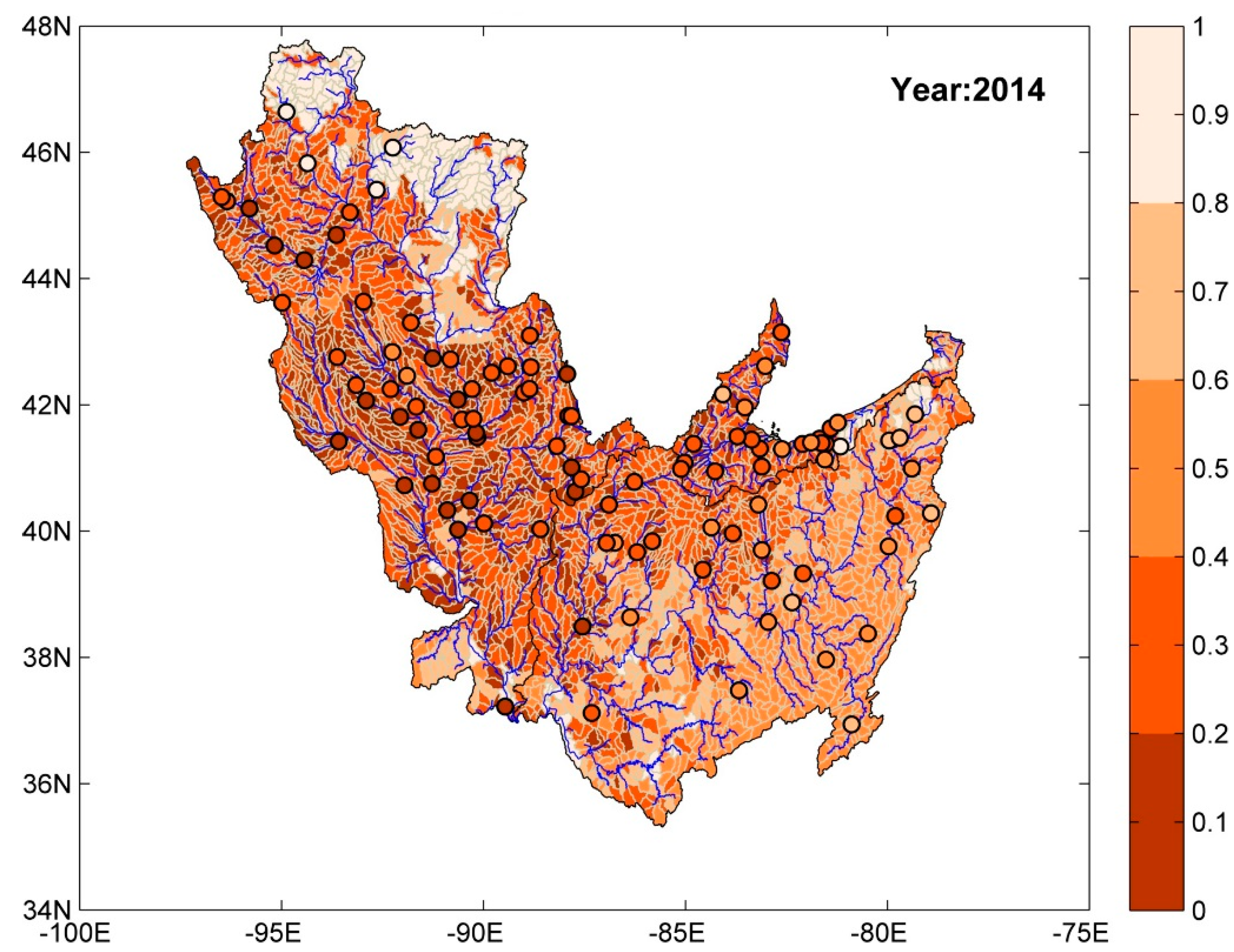
- To develop spatial maps of watershed health at HUC-10 resolution to aid decision makers in identifying critical source areas in the Midwest river basins.
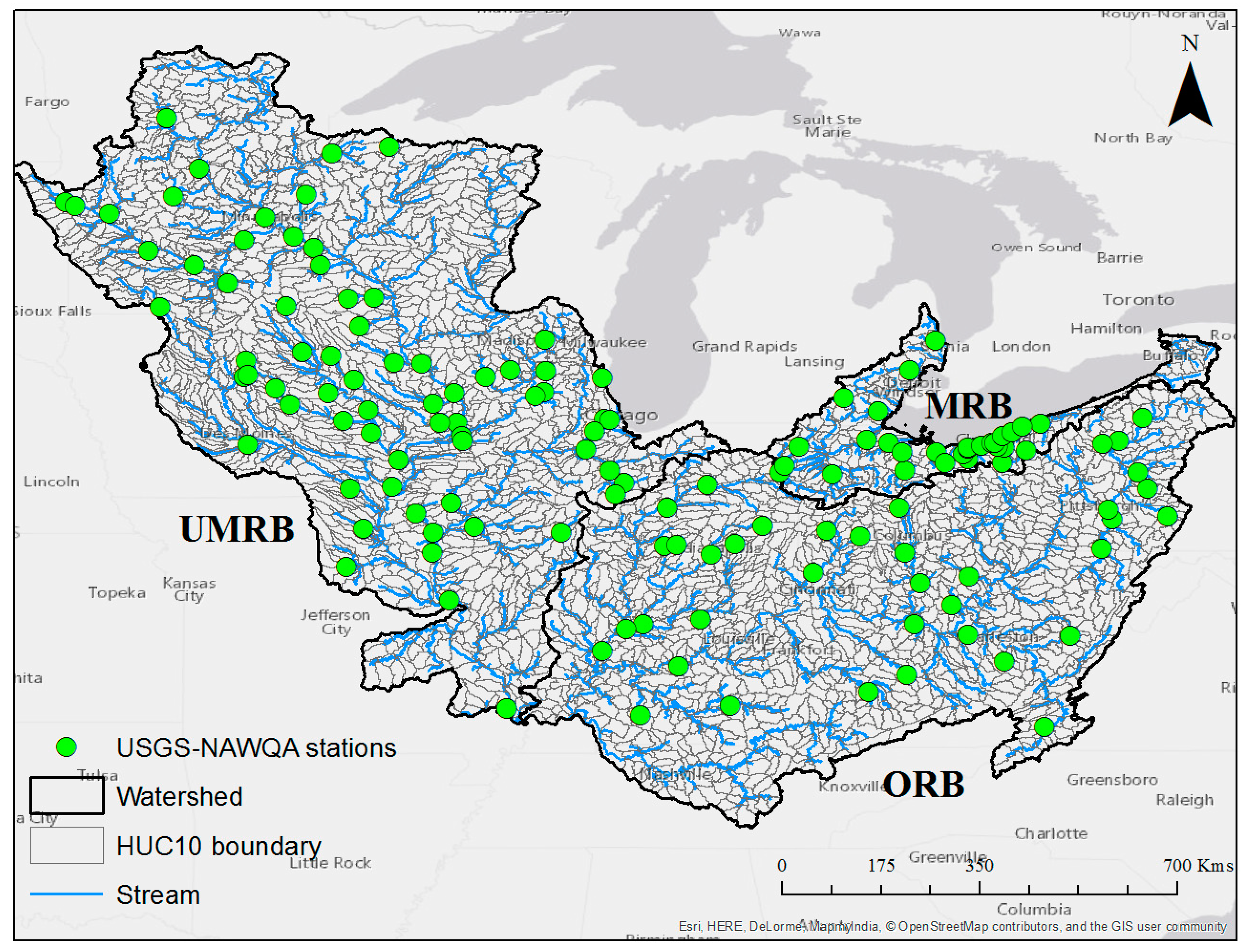
2. Study Area and Datasets
3. Methodology
3.1. Risk and Watershed Health Measures
3.2. Machine Learning Models
3.2.1. Decision Trees
3.2.2. Random Forest
- First random samples () are drawn with replacement (also known as bootstrapping or bagging). Here, the assumption is that the samples are independent and identically distributed.
- Using these samples, we train a decision tree such that, at each node, the best split is decided using a randomly selected subset of attributes. An unpruned decision tree may be grown such that no further splits are possible at the end nodes. However, in this approach we treated both the depth of the tree and the number of attributes () used at each node as variables.
- The above two steps are repeated until decision trees are grown.
3.2.3. AdaBoost
3.2.4. Gradient Boosting
3.2.5. Bayesian Ridge Regression
4. Results and Discussion
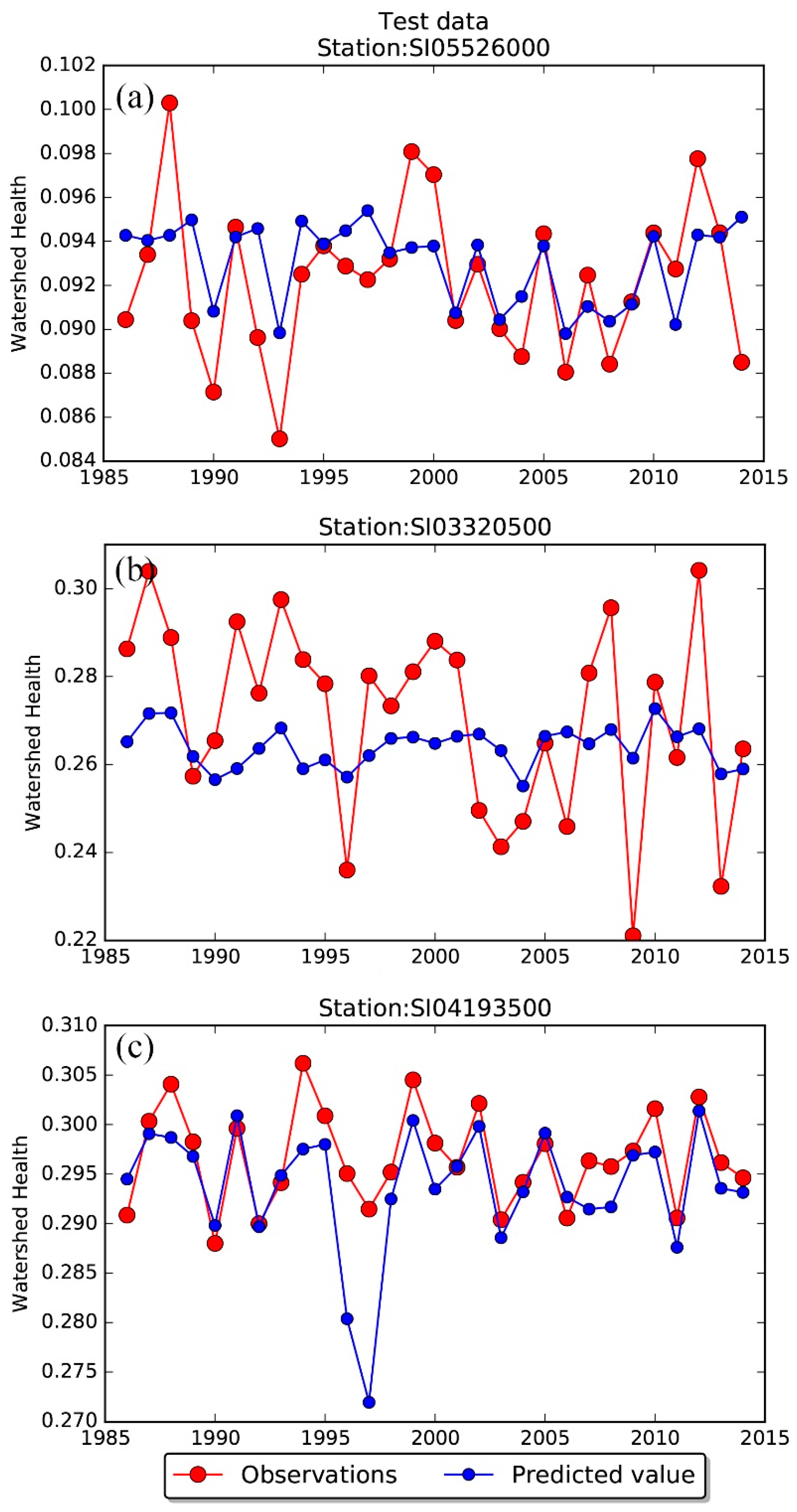
4.1. Prediction of Watershed Health
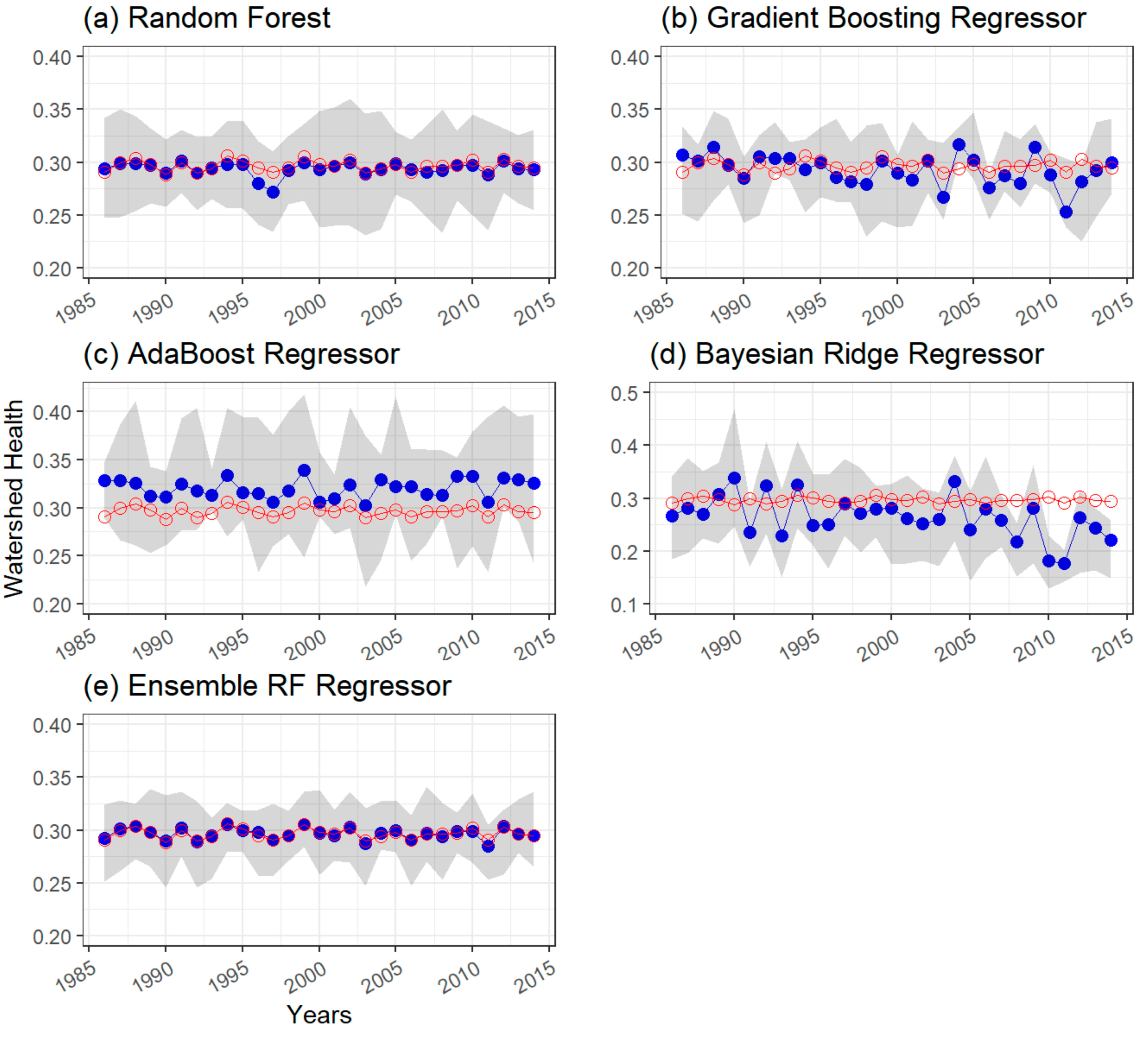
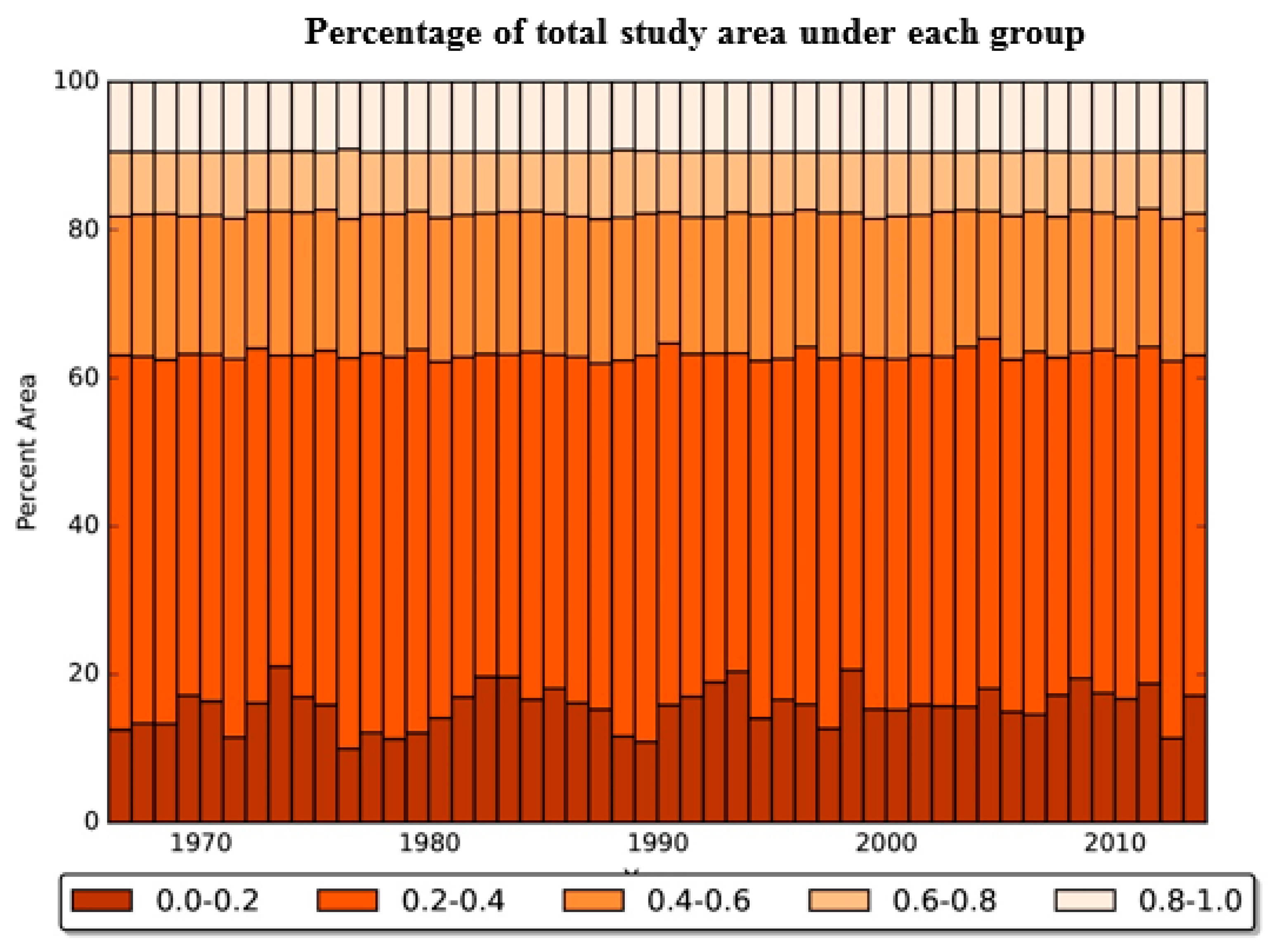
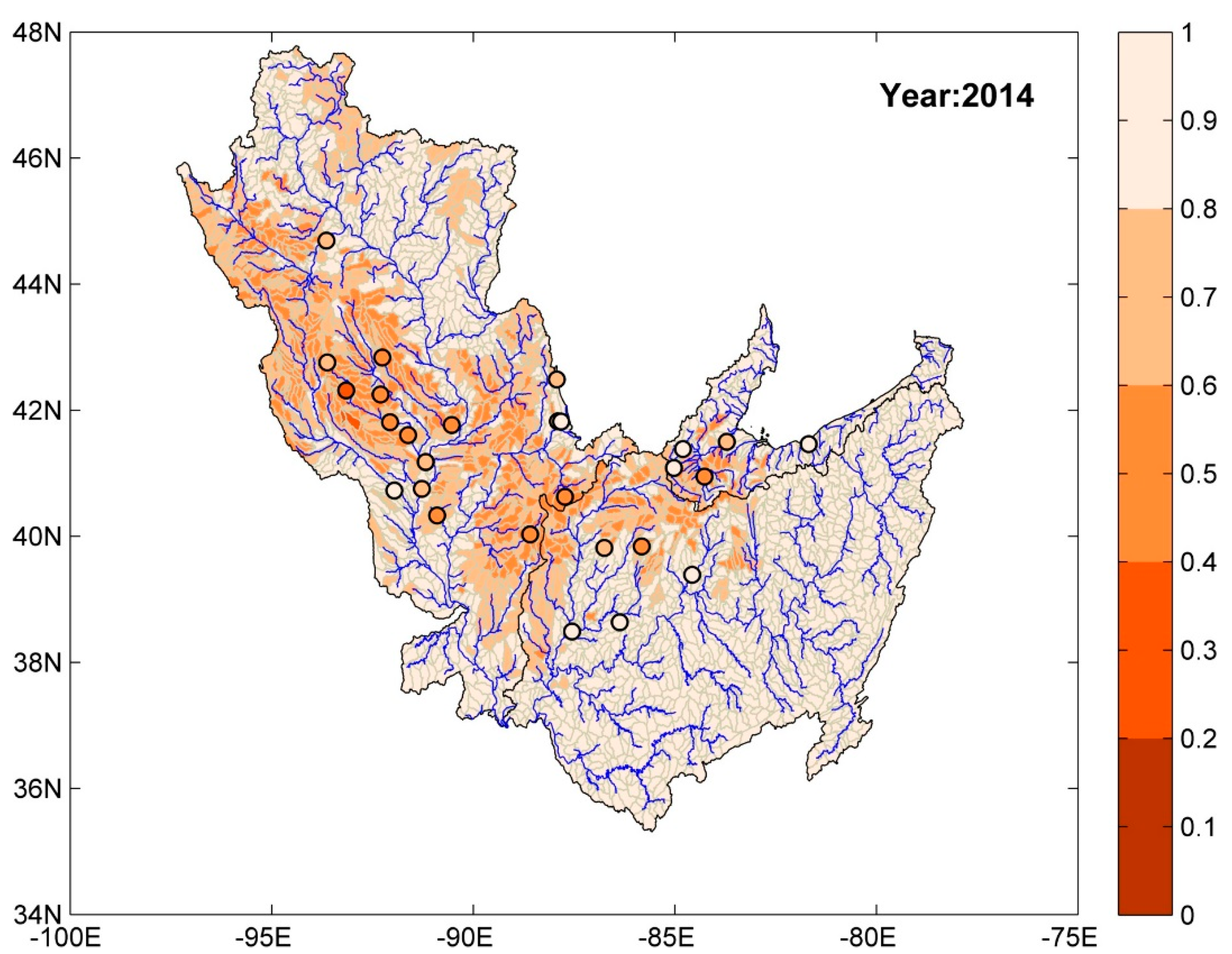
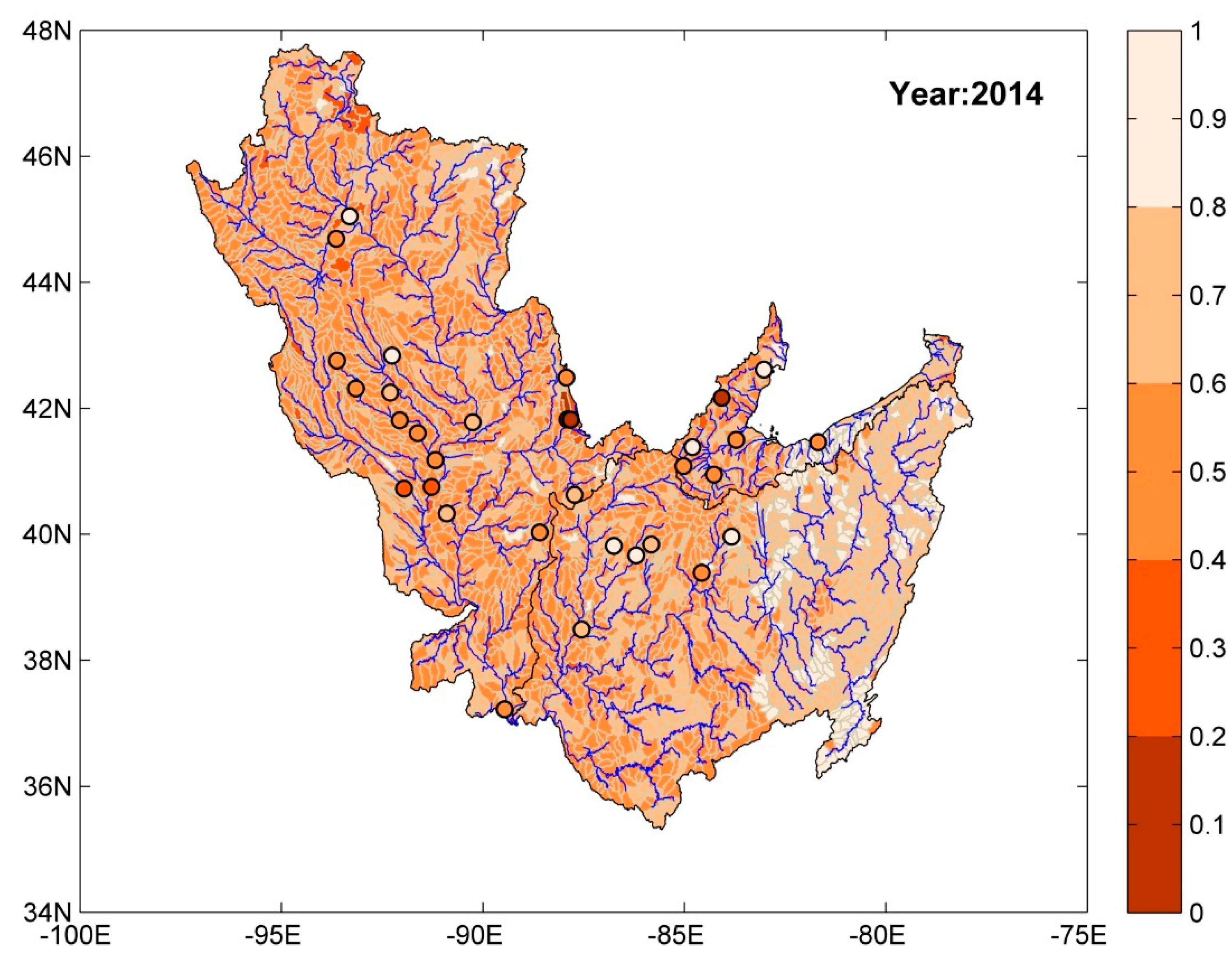
4.1.1. Watershed Health for Suspended Sediment Concentration
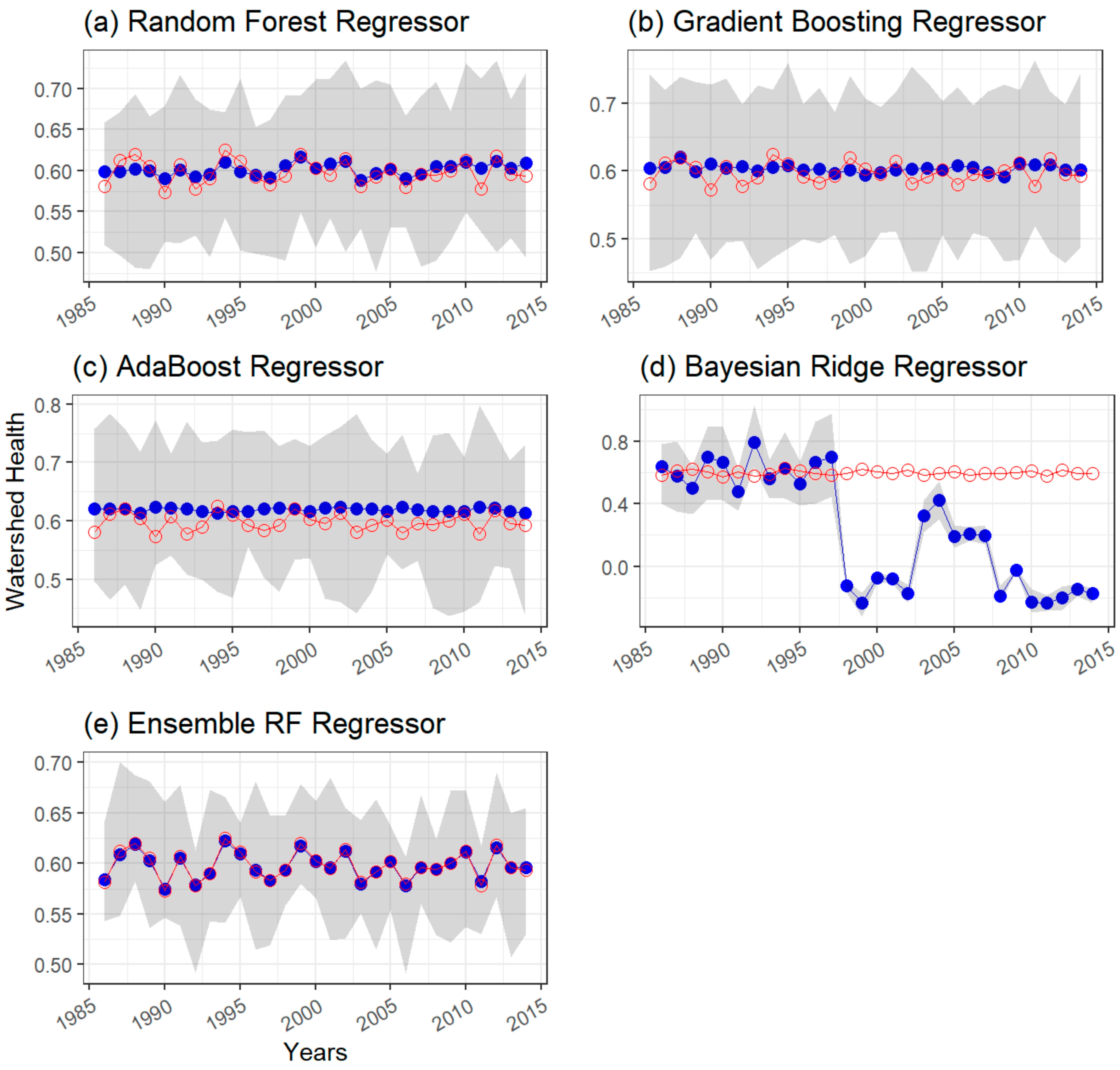
Random Forest Regression Model
Other Regression Models
Ensemble of Model Outputs
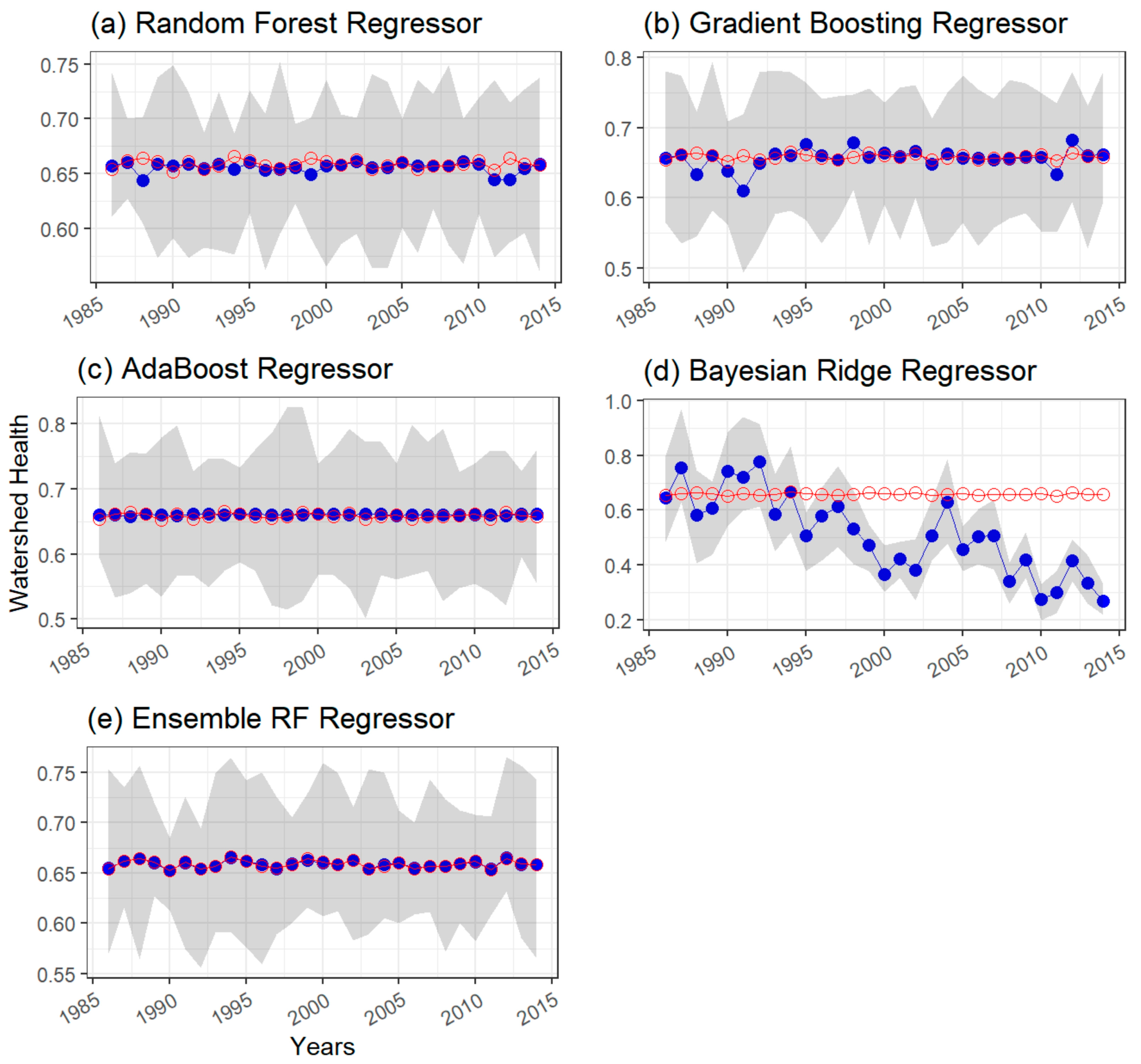
4.1.2. Watershed Health for Nutrients
Watershed Health for Nitrite + Nitrate
Watershed Health for Orthophosphate
5. Summary and Conclusions
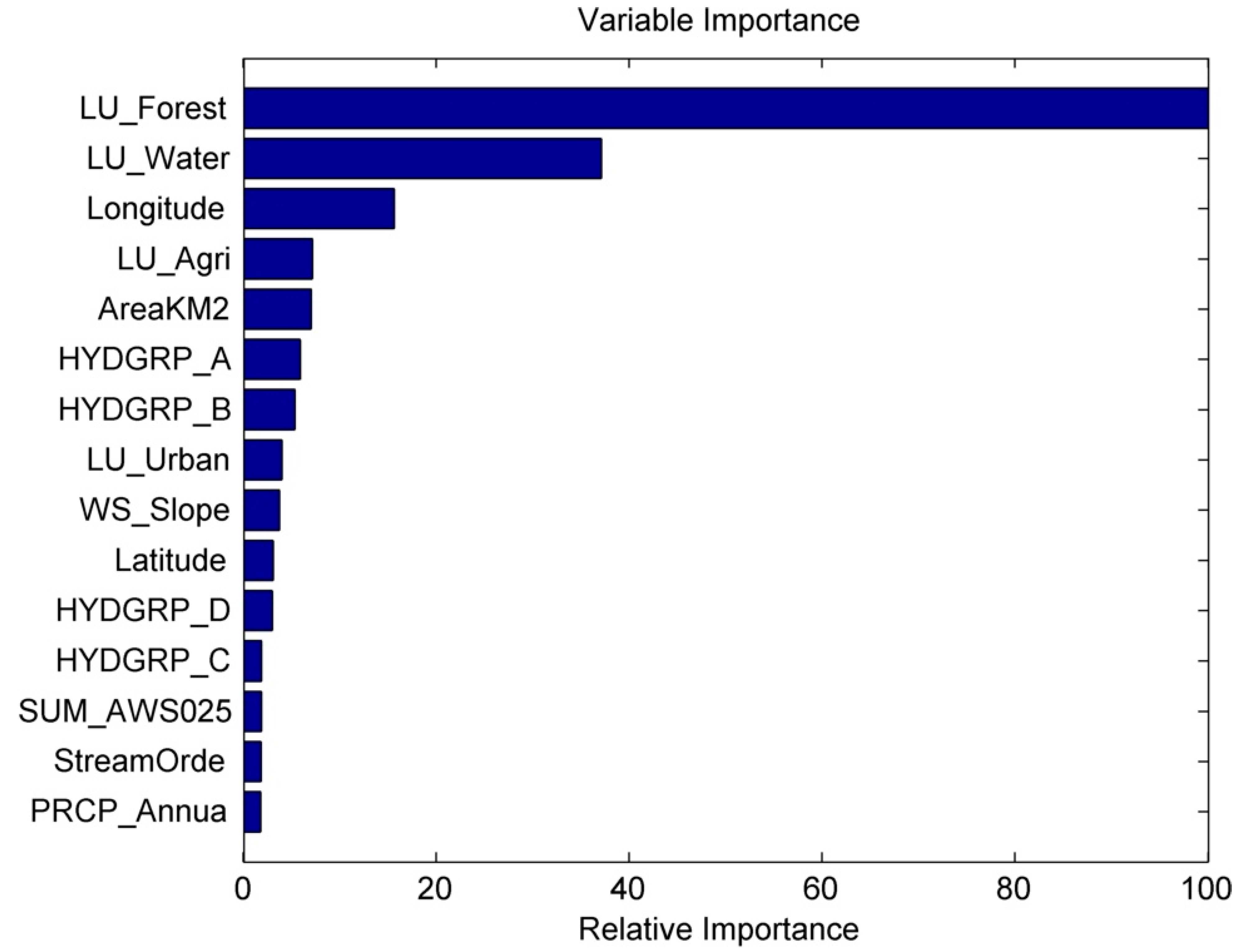
- For suspended sediment concentration and nitrogen, high watershed health values were often associated with lower order streams and regions with dominant forest land use. Regions with dominant agricultural land use had poor watershed health. Among the predictor variables, land use, geographic position, drainage area, available water storage in soil, hydrologic soil group, fertilizer sales (for nitrogen and orthophosphate), and annual precipitation were found to be significant for the three WQ constituents considered in this study.
- As a smaller number of stations with phosphorus data were available over the region, the resulting ML models were not robust compared with models developed for SSC and nitrogen. Counter to expectation, even forested watersheds in the UMRB indicated poor WH values with this constituent. More orthophosphate data would be needed at multiple watersheds to not only obtain robust results but to also address the question of attribution to poor (or good) watershed health.
- Sparse water quality data can be used to predict watershed health and identify impairment source areas in ungauged watersheds.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, R.; Kalin, L.; Kuang, W.; Tian, H. Individual and combined effects of land use/cover and climate change on Wolf Bay watershed streamflow in southern Alabama. Hydrol. Process. 2014, 28, 5530–5546. [Google Scholar] [CrossRef]
- Anderson, D.M.; Glibert, P.M.; Burkholder, J.M. Harmful Algal Blooms and Eutrophication: Nutrient Sources, Composition, and Consequences. Estuaries 2002, 25, 704–726. [Google Scholar] [CrossRef]
- Michalak, A.M.; Anderson, E.J.; Beletsky, D.; Boland, S.; Bosch, N.S.; Bridgeman, T.B.; Chaffin, J.D.; Cho, K.; Confesor, R.; Daloğlu, I.; et al. Record-setting algal bloom in Lake Erie caused by agricultural and meteorological trends consistent with expected future conditions. Proc. Natl. Acad. Sci. USA 2013, 110, 6448–6452. [Google Scholar] [CrossRef] [PubMed]
- Taebi, A.; Droste, R.L. Pollution loads in urban runoff and sanitary wastewater. Sci. Total Environ. 2004, 327, 175–184. [Google Scholar] [CrossRef]
- Abolfathi, S.; Pearson, J.M. Solute dispersion in the nearshore due to oblique waves. In Proceedings of the 14th International Conference on Coastal Engineering, Seoul, Republic of Korea, 15–20 June 2014; pp. 1028–2156. [Google Scholar]
- Noori, R.; Farahani, F.; Jun, C.; Aradpour, S.; Bateni, S.M.; Ghazban, F.; Hosseinzadeh, M.; Maghrebi, M.; Naseh, M.R.V.; Abolfathi, S. A non-threshold model to estimate carcinogenic risk of nitrate-nitrite in drinking water. J. Clean. Prod. 2022, 363, 132432. [Google Scholar] [CrossRef]
- Worm, B.; Barbier, E.B.; Beaumont, N.; Duffy, J.E.; Folke, C.; Halpern, B.S.; Jackson, J.B.C.; Lotze, H.K.; Micheli, F.; Palumbi, S.R.; et al. Impacts of Biodiversity Loss on Ocean Ecosystem Services. Science 2006, 314, 787–790. [Google Scholar] [CrossRef]
- Hoque, Y.M.; Tripathi, S.; Hantush, M.M.; Govindaraju, R.S. Watershed reliability, resilience and vulnerability analysis under uncertainty using water quality data. J. Environ. Manag. 2012, 109, 101–112. [Google Scholar] [CrossRef]
- Runkel, R.L.; Crawford, C.G.; Cohn, T.A. Load Estimator (LOADEST): A FORTRAN Program for Estimating Constituent Loads in Streams and Rivers; US Department of the Interior, US Geological Survey: Washington, DC, USA, 2004. [Google Scholar]
- Arnold, J.; Williams, J.; Srinivasan, R.; King, K.; Griggs, R. SWAT: Soil and Water Assessment Tool; US Department of Agriculture, Agricultural Research Service, Grassland, Soil and Water Research Laboratory: Temple, TX, USA, 1994; p. 494. [Google Scholar]
- Bicknell, B.R.; Imhoff, J.C.; Kittle, J.L., Jr.; Jobes, T.H.; Donigian, A.S., Jr.; Johanson, R. Hydrological Simulation Program-Fortran: HSPF Version 12 User’s Manual; AQUA TERRA Consultants: Mountain View, CA, USA, 2001. [Google Scholar]
- Ko, B.C.; Kim, H.H.; Nam, J.Y. Classification of potential water bodies using Landsat 8 OLI and a combination of two boosted random forest classifiers. Sensors 2015, 15, 13763–13777. [Google Scholar] [CrossRef]
- Herrera, M.; Torgo, L.; Izquierdo, J.; Pérez-García, R. Predictive models for forecasting hourly urban water demand. J. Hydrol. 2010, 387, 141–150. [Google Scholar] [CrossRef]
- Bhattacharya, B.; Price, R.K.; Solomatine, D.P. Machine Learning Approach to Modeling Sediment Transport. J. Hydraul. Eng. 2007, 133, 440–450. [Google Scholar] [CrossRef]
- Noori, R.; Ghiasi, B.; Salehi, S.; Esmaeili Bidhendi, M.; Raeisi, A.; Partani, S.; Meysami, R.; Mahdian, M.; Hosseinzadeh, M.; Abolfathi, S. An Efficient Data Driven-Based Model for Prediction of the Total Sediment Load in Rivers. Hydrology 2022, 9, 36. [Google Scholar] [CrossRef]
- Sharafati, A.; Haji Seyed Asadollah, S.B.; Motta, D.; Yaseen, Z.M. Application of newly developed ensemble machine learning models for daily suspended sediment load prediction and related uncertainty analysis. Hydrol. Sci. J. 2020, 65, 2022–2042. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards, T.C.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random Forests for Classification in Ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef]
- Džeroski, S. Applications of symbolic machine learning to ecological modelling. Ecol. Model. 2001, 146, 263–273. [Google Scholar] [CrossRef]
- Malekmohammadi, B.; Uvo, C.B.; Moghadam, N.T.; Noori, R.; Abolfathi, S. Environmental Risk Assessment of Wetland Ecosystems Using Bayesian Belief Networks. Hydrology 2023, 10, 16. [Google Scholar] [CrossRef]
- Tuia, D.; Kellenberger, B.; Beery, S.; Costelloe, B.R.; Zuffi, S.; Risse, B.; Mathis, A.; Mathis, M.W.; van Langevelde, F.; Burghardt, T.; et al. Perspectives in machine learning for wildlife conservation. Nat. Commun. 2022, 13, 792. [Google Scholar] [CrossRef] [PubMed]
- Vincenzi, S.; Zucchetta, M.; Franzoi, P.; Pellizzato, M.; Pranovi, F.; De Leo, G.A.; Torricelli, P. Application of a Random Forest algorithm to predict spatial distribution of the potential yield of Ruditapes philippinarum in the Venice lagoon, Italy. Ecol. Model. 2011, 222, 1471–1478. [Google Scholar] [CrossRef]
- Lee, J.Y.; Choi, C.; Kang, D.; Kim, B.S.; Kim, T.W. Estimating design floods at ungauged watersheds in South Korea using machine learning models. Water 2020, 12, 3022. [Google Scholar] [CrossRef]
- Choubin, B.; Moradi, E.; Golshan, M.; Adamowski, J.; Sajedi-Hosseini, F.; Mosavi, A. An ensemble prediction of flood susceptibility using multivariate discriminant analysis, classification and regression trees, and support vector machines. Sci. Total Environ. 2019, 651, 2087–2096. [Google Scholar] [CrossRef]
- Li, X.; Yan, D.; Wang, K.; Weng, B.; Qin, T.; Liu, S. Flood risk assessment of global watersheds based on multiple machine learning models. Water 2019, 11, 1654. [Google Scholar] [CrossRef] [Green Version]
- Donnelly, J.; Abolfathi, S.; Pearson, J.; Chatrabgoun, O.; Daneshkhah, A. Gaussian process emulation of spatio-temporal outputs of a 2D inland flood model. Water Res. 2022, 225, 119100. [Google Scholar] [CrossRef] [PubMed]
- Mosavi, A.; Ozturk, P.; Chau, K.W. Flood prediction using machine learning models: Literature review. Water 2018, 10, 1536. [Google Scholar] [CrossRef]
- Deng, T.; Chau, K.W.; Duan, H.F. Machine learning based marine water quality prediction for coastal hydro-environment management. J. Environ. Manag. 2021, 284, 112051. [Google Scholar] [CrossRef] [PubMed]
- McAllister, E.; Payo, A.; Novellino, A.; Dolphin, T.; Medina-Lopez, E. Multispectral satellite imagery and machine learning for the extraction of shoreline indicators. Coast. Eng. 2022, 174, 104102. [Google Scholar] [CrossRef]
- Yeganeh-Bakhtiary, A.; EyvazOghli, H.; Shabakhty, N.; Kamranzad, B.; Abolfathi, S. Machine Learning as a Downscaling Approach for Prediction of Wind Characteristics under Future Climate Change Scenarios. Complexity 2022, 2022, 8451812. [Google Scholar]
- Ahmed, U.; Mumtaz, R.; Anwar, H.; Shah, A.A.; Irfan, R.; García-Nieto, J. Efficient water quality prediction using supervised machine learning. Water 2019, 11, 2210. [Google Scholar] [CrossRef]
- Azrour, M.; Mabrouki, J.; Fattah, G.; Guezzaz, A.; Aziz, F. Machine learning algorithms for efficient water quality prediction. Model. Earth Syst. Environ. 2022, 8, 2793–2801. [Google Scholar] [CrossRef]
- Ghiasi, B.; Noori, R.; Sheikhian, H.; Zeynolabedin, A.; Sun, Y.; Jun, C.; Hamouda, M.; Bateni, S.M.; Abolfathi, S. Uncertainty quantification of granular computing-neural network model for prediction of pollutant longitudinal dispersion coefficient in aquatic streams. Sci. Rep. 2022, 12, 1–15. [Google Scholar] [CrossRef]
- Hollister, J.W.; Milstead, W.B.; Kreakie, B.J. Modeling lake trophic state: A random forest approach. Ecosphere 2016, 7, e01321. [Google Scholar] [CrossRef]
- Khullar, S.; Singh, N. Water quality assessment of a river using deep learning Bi-LSTM methodology: Forecasting and validation. Environ. Sci. Pollut. Res. 2022, 29, 12875–12889. [Google Scholar] [CrossRef]
- Kim, Y.H.; Im, J.; Ha, H.K.; Choi, J.-K.; Ha, S. Machine learning approaches to coastal water quality monitoring using GOCI satellite data. GISci. Remote Sens. 2014, 51, 158–174. [Google Scholar] [CrossRef]
- Lee, Y.J.; Park, C.; Lee, M.L. Identification of a Contaminant Source Location in a River System Using Random Forest Models. Water 2018, 10, 391. [Google Scholar] [CrossRef]
- Mohammadpour, R.; Shaharuddin, S.; Chang, C.K.; Zakaria, N.A.; Ghani, A.A.; Chan, N.W. Prediction of water quality index in constructed wetlands using support vector machine. Environ. Sci. Pollut. Res. 2015, 22, 6208–6219. [Google Scholar] [CrossRef]
- Nasir, N.; Kansal, A.; Alshaltone, O.; Barneih, F.; Sameer, M.; Shanableh, A.; Al-Shamma’a, A. Water quality classification using machine learning algorithms. J. Water Process Eng. 2022, 48, 102920. [Google Scholar] [CrossRef]
- Qianqian, G.; Ying, Z. A kind of classification method for evaluating water qualities. In Proceedings of the 27th Chinese Control and Decision Conference (2015 CCDC), Qingdao, China, 23–25 May 2015; pp. 4142–4146. [Google Scholar] [CrossRef]
- Singh, B.; Sihag, P.; Singh, K. Modelling of impact of water quality on infiltration rate of soil by random forest regression. Model. Earth Syst. Environ. 2017, 3, 999–1004. [Google Scholar] [CrossRef]
- Singh, K.P.; Basant, N.; Gupta, S. Support vector machines in water quality management. Anal. Chim. Acta 2011, 703, 152–162. [Google Scholar] [CrossRef]
- Tan, G.; Yan, J.; Gao, C.; Yang, S. Prediction of water quality time series data based on least squares support vector machine. Procedia Eng. 2012, 31, 1194–1199. [Google Scholar] [CrossRef]
- Walley, W.J.; Džeroski, S. Biological Monitoring: A Comparison between Bayesian, Neural and Machine Learning Methods of Water Quality Classification. In Environmental Software Systems, IFIP—The International Federation for Information Processing; Springer: Boston, MA, USA, 1996; pp. 229–240. [Google Scholar]
- Walsh, E.S.; Kreakie, B.J.; Cantwell, M.G.; Nacci, D. A Random Forest approach to predict the spatial distribution of sediment pollution in an estuarine system. PLoS ONE 2017, 12, e0179473. [Google Scholar] [CrossRef]
- Kjeldsen, T.R.; Rosbjerg, D. Choice of reliability, resilience and vulnerability estimators for risk assessments of water resources systems. Hydrol. Sci. J. 2004, 49, 767. [Google Scholar] [CrossRef]
- Hoque, Y.M.; Hantush, M.M.; Govindaraju, R.S. On the scaling behavior of reliability–resilience–vulnerability indices in agricultural watersheds. Ecol. Indic. 2014, 40, 136–146. [Google Scholar] [CrossRef]
- Hoque, Y.M.; Raj, C.; Hantush, M.M.; Chaubey, I.; Govindaraju, R.S. How Do Land-Use and Climate Change Affect Watershed Health? A Scenario-Based Analysis. Water Qual. Expo. Health 2013, 6, 19–33. [Google Scholar] [CrossRef]
- Mallya, G.; Hantush, M.; Govindaraju, R.S. Composite measures of watershed health from a water quality perspective. J. Environ. Manag. 2018, 214, 104–124. [Google Scholar] [CrossRef] [PubMed]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009; Volume 2, pp. 1–758. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Tipping, M.E. Sparse Bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- US EPA. Quality Criteria for Water 1986 [The Gold Book]|US EPA [WWW Document]. 1986. Available online: http://yosemite.epa.gov/water/owrccatalog.nsf/9da204a4b4406ef885256ae0007a79c7/18888fcb7d1b9dc285256b0600724b5f!OpenDocument (accessed on 16 June 2015).
- Demšar, J. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Diebel, M.W.; Maxted, J.T.; Robertson, D.M.; Han, S.; Vander Zanden, M.J. Landscape planning for agricultural nonpoint source pollution reduction III: Assessing phosphorus and sediment reduction potential. Environ. Manag. 2009, 43, 69–83. [Google Scholar] [CrossRef]
- Hansen, L.K.; Salamon, P. Neural network ensembles. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 993–1001. [Google Scholar] [CrossRef]
- Schapire, R.E. The strength of weak learnability. Mach Learn. 1990, 5, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.-H. Ensemble methods: Foundations and Algorithms; Chapman and Hall/CRC: Boca Raton, FL, USA, 2012. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SSC | Nitrite + Nitrate | Orthophosphate | |
|---|---|---|---|
| Number of stations | 151 | 70 | 49 |
| US EPA standard (mg/L) | 30 | 10 | 0.1 |
| training (testing) | |||
| Random forest | 0.98 (0.95) | 0.98 (0.81) | 0.99 (0.26) |
| Gradient boosting | 0.99 (0.94) | 0.99 (0.84) | 0.98 (0.57) |
| AdaBoost | 0.87 (0.84) | 0.99 (0.88) | 0.94 (0.32) |
| Bayesian ridge | 0.75 (0.68) | 0.75 (−1.31) | 0.83 (−22) |
| Ensemble | 0.98 (0.98) | 0.97 (0.98) | 0.98 (0.99) |
| Top 5 predictors | Forest land-use percentage | Agricultural land-use percentage | Water land-use percentage |
| Water land-use percentage | Available water storage in top 25 cm of soil | Average fertilizer sales | |
| Longitude | Drainage area | Longitude | |
| Agricultural land-use percentage | Forest land-use percentage | Forest land-use percentage | |
| Drainage area | Longitude | Percentage area with hydrologic soil group B |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mallya, G.; Hantush, M.M.; Govindaraju, R.S. A Machine Learning Approach to Predict Watershed Health Indices for Sediments and Nutrients at Ungauged Basins. Water 2023, 15, 586. https://doi.org/10.3390/w15030586
Mallya G, Hantush MM, Govindaraju RS. A Machine Learning Approach to Predict Watershed Health Indices for Sediments and Nutrients at Ungauged Basins. Water. 2023; 15(3):586. https://doi.org/10.3390/w15030586
Chicago/Turabian StyleMallya, Ganeshchandra, Mohamed M. Hantush, and Rao S. Govindaraju. 2023. "A Machine Learning Approach to Predict Watershed Health Indices for Sediments and Nutrients at Ungauged Basins" Water 15, no. 3: 586. https://doi.org/10.3390/w15030586