
A Stacking Ensemble Learning Model for Monthly Rainfall Prediction in the Taihu Basin, China


Abstract
:1. Introduction
2. Study Area and Data
3. Methodology
3.1. Machine Learning Methods
3.1.1. K-Nearest Neighbors (KNN)
3.1.2. Extreme Gradient Boosting (XGB)
3.1.3. Support Vector Regression (SVR)
3.1.4. Artificial Neural Network (ANN)
3.2. Stacking Ensemble Learning
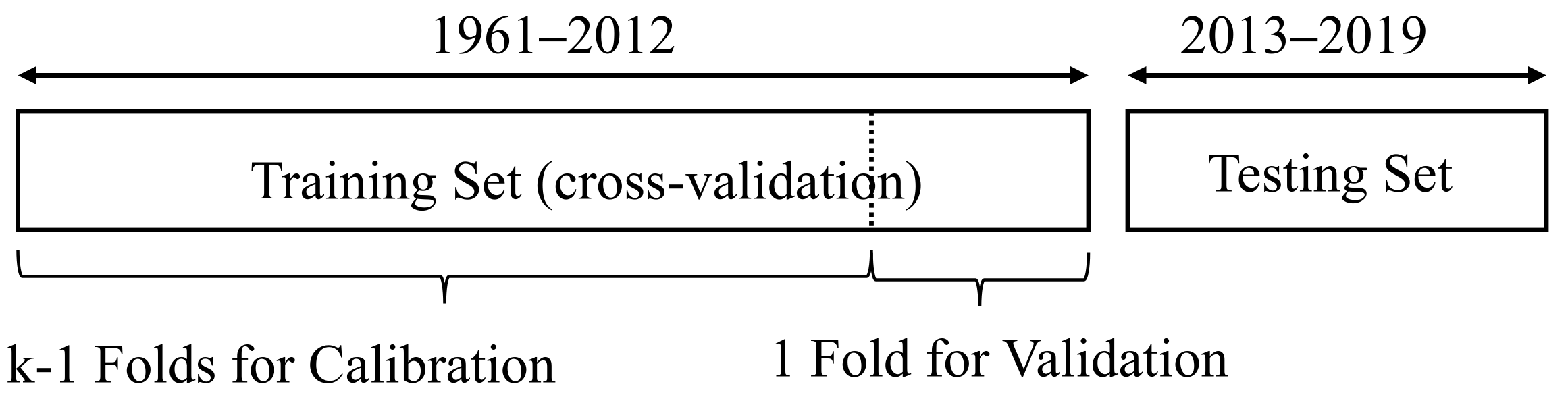
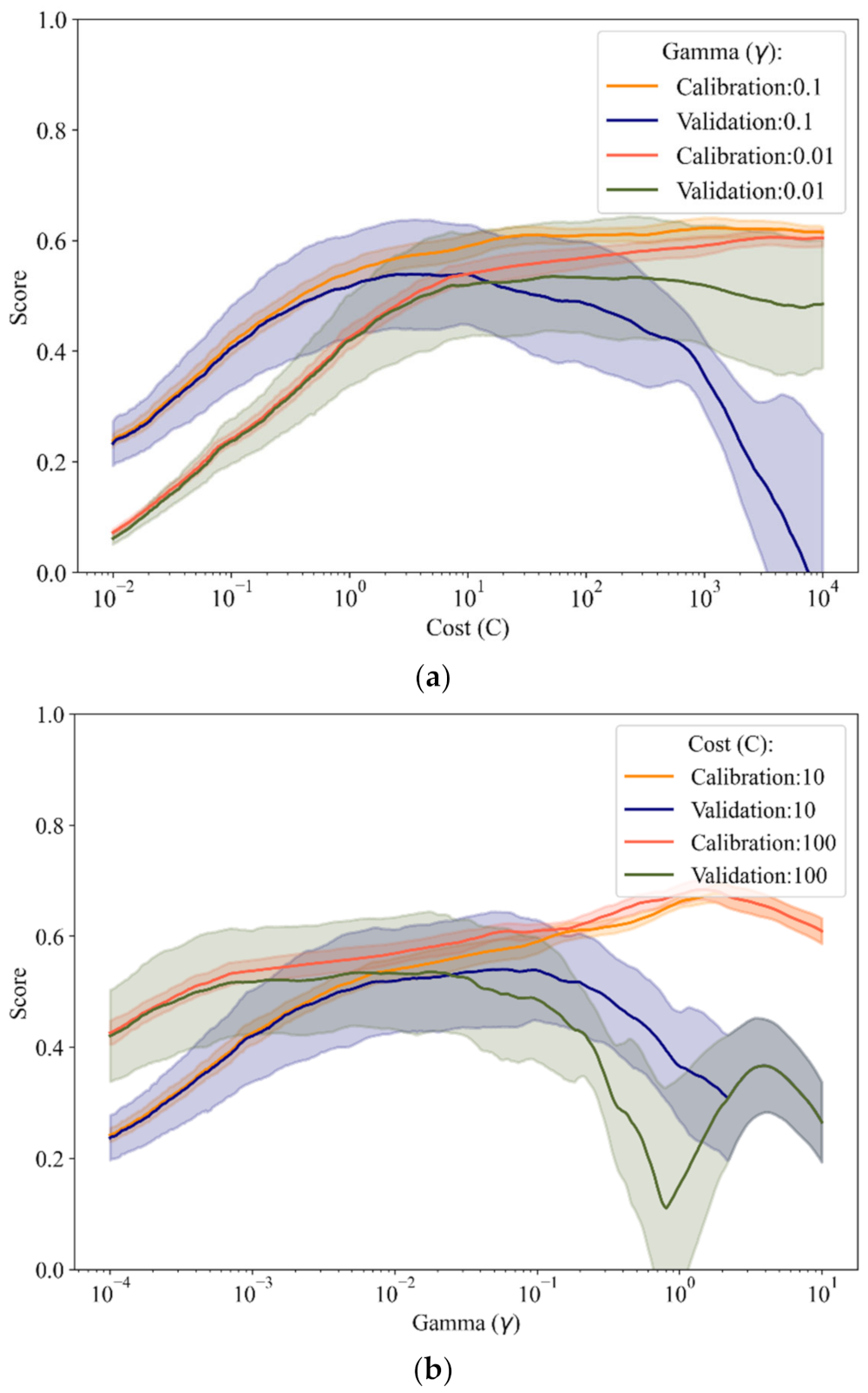
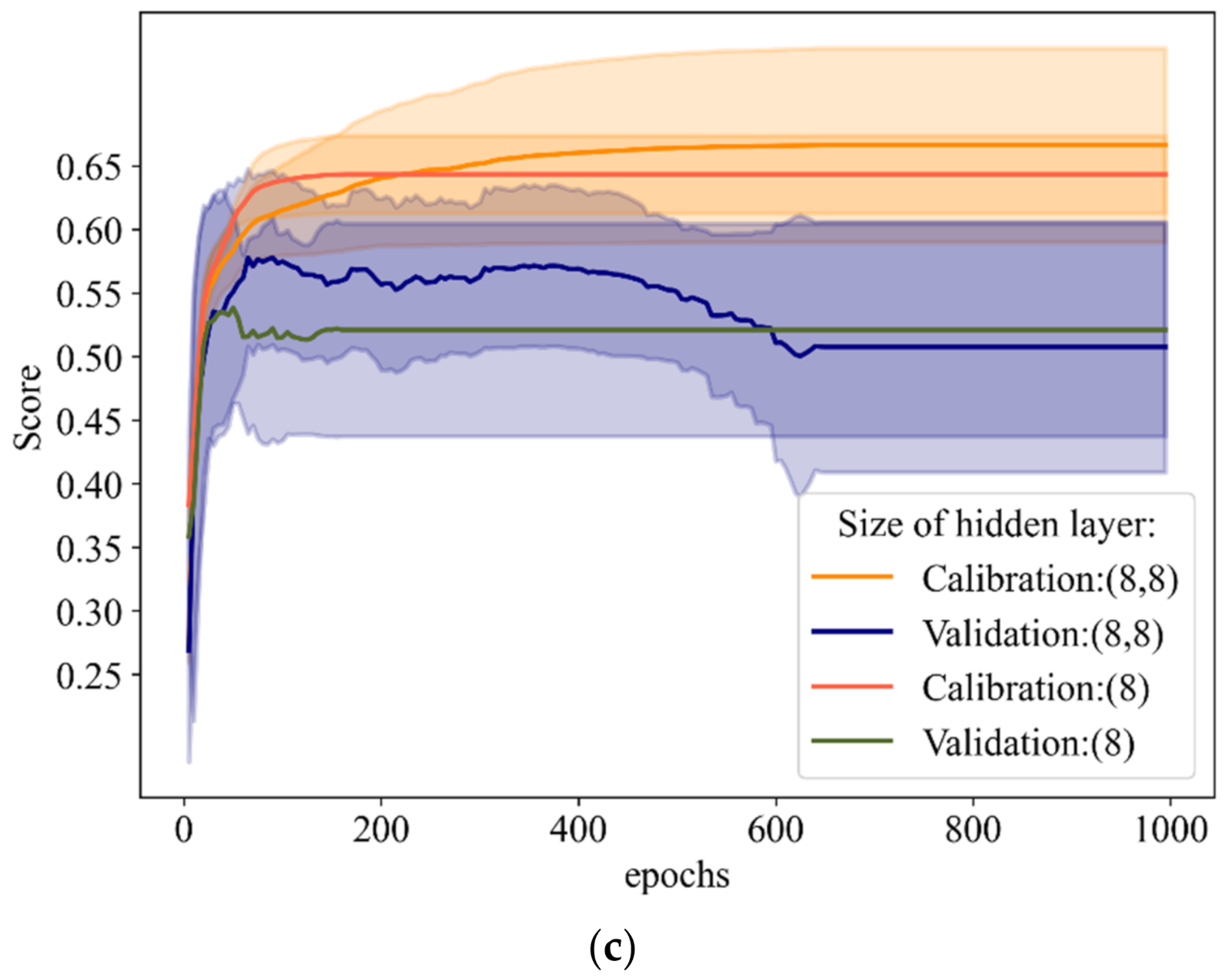
3.3. Hyper-Parameter Optimization
3.4. Performance Evaluation
3.5. Categorization of Dry, Intermediate and Wet Months in Terms of Standardized Precipitation Index (SPI)
4. Results and Discussion
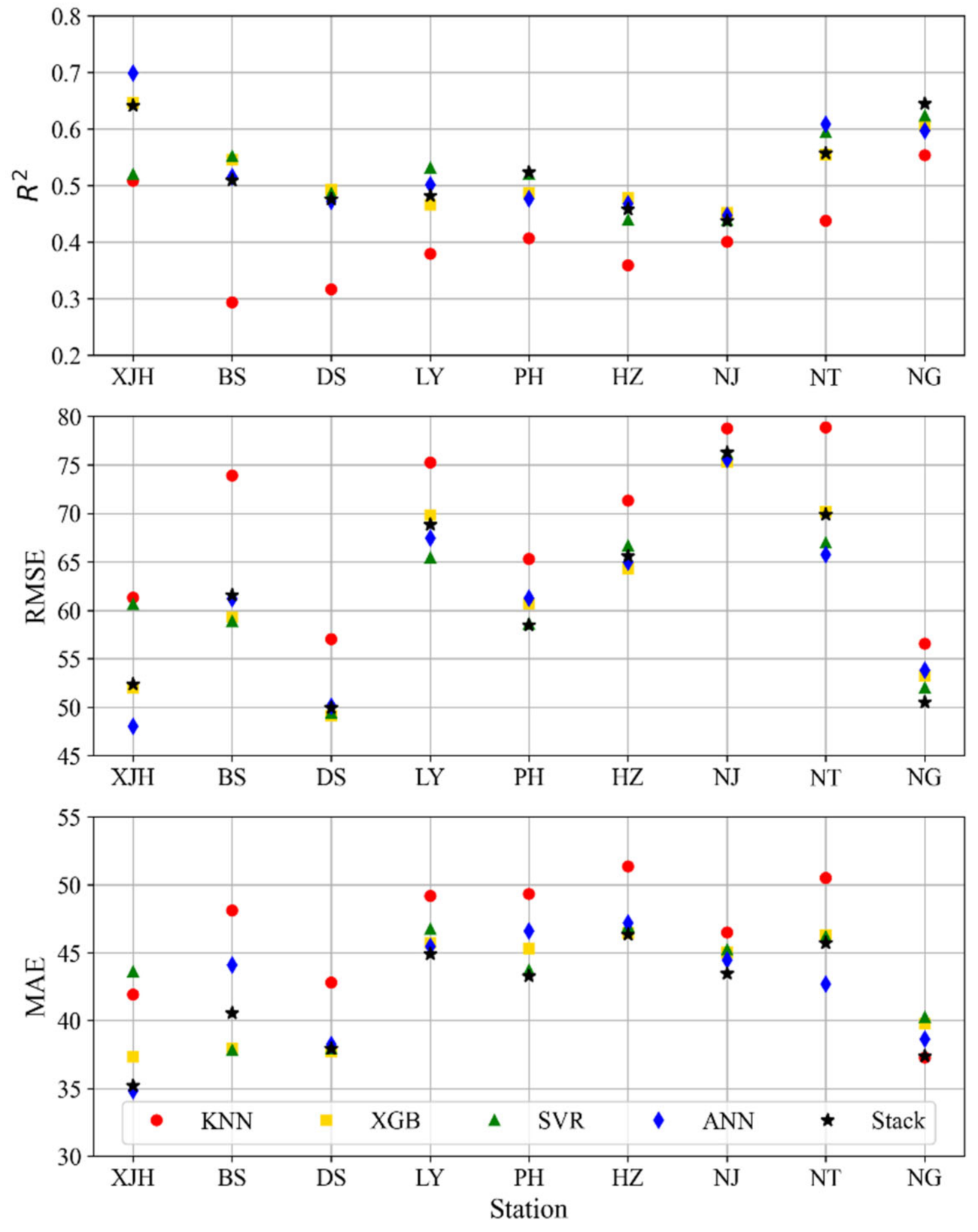
4.1. Intercomparison of Model Performances
4.2. Prediction Skills at Different Time Scales
4.3. Discussions
5. Conclusions
- (1)
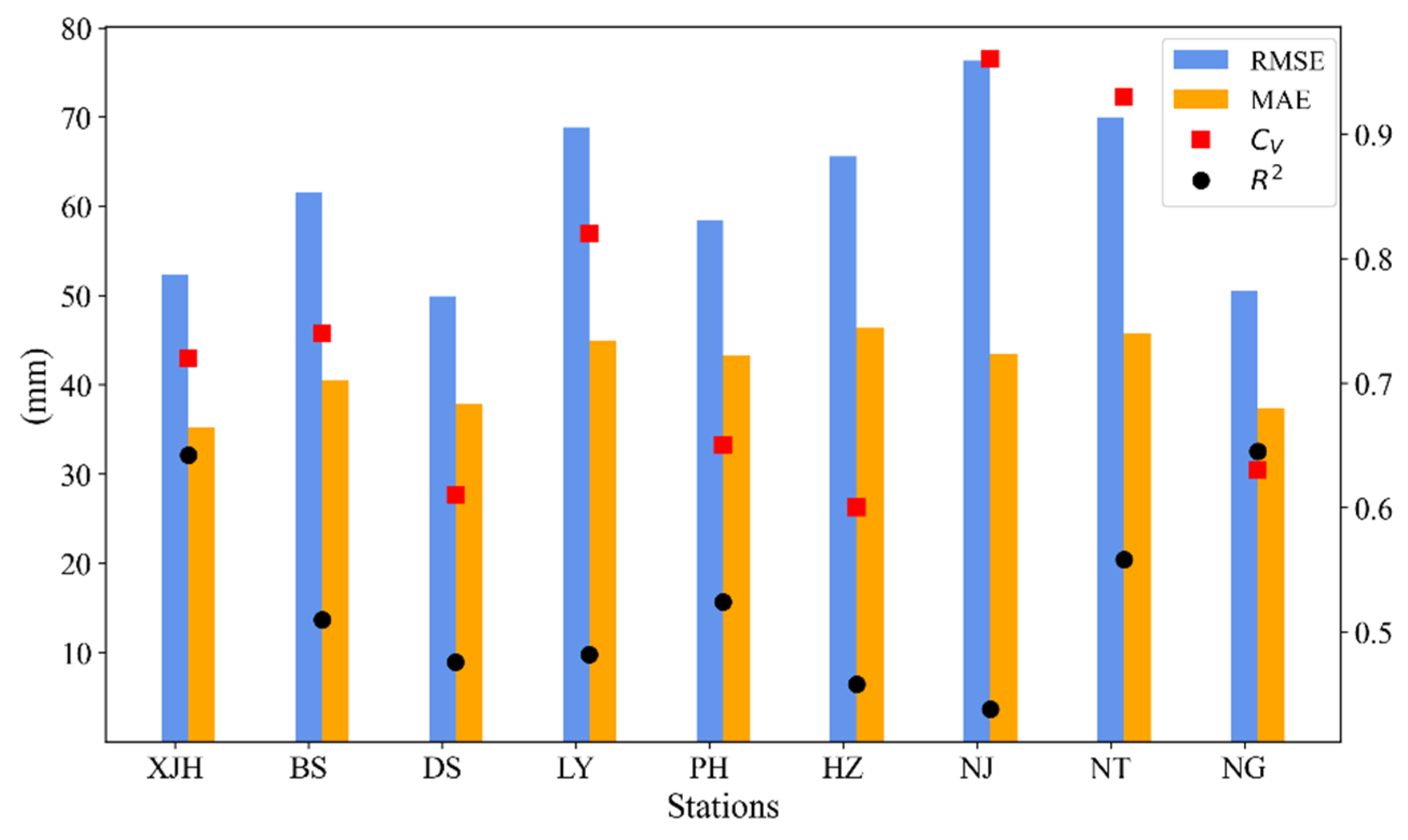
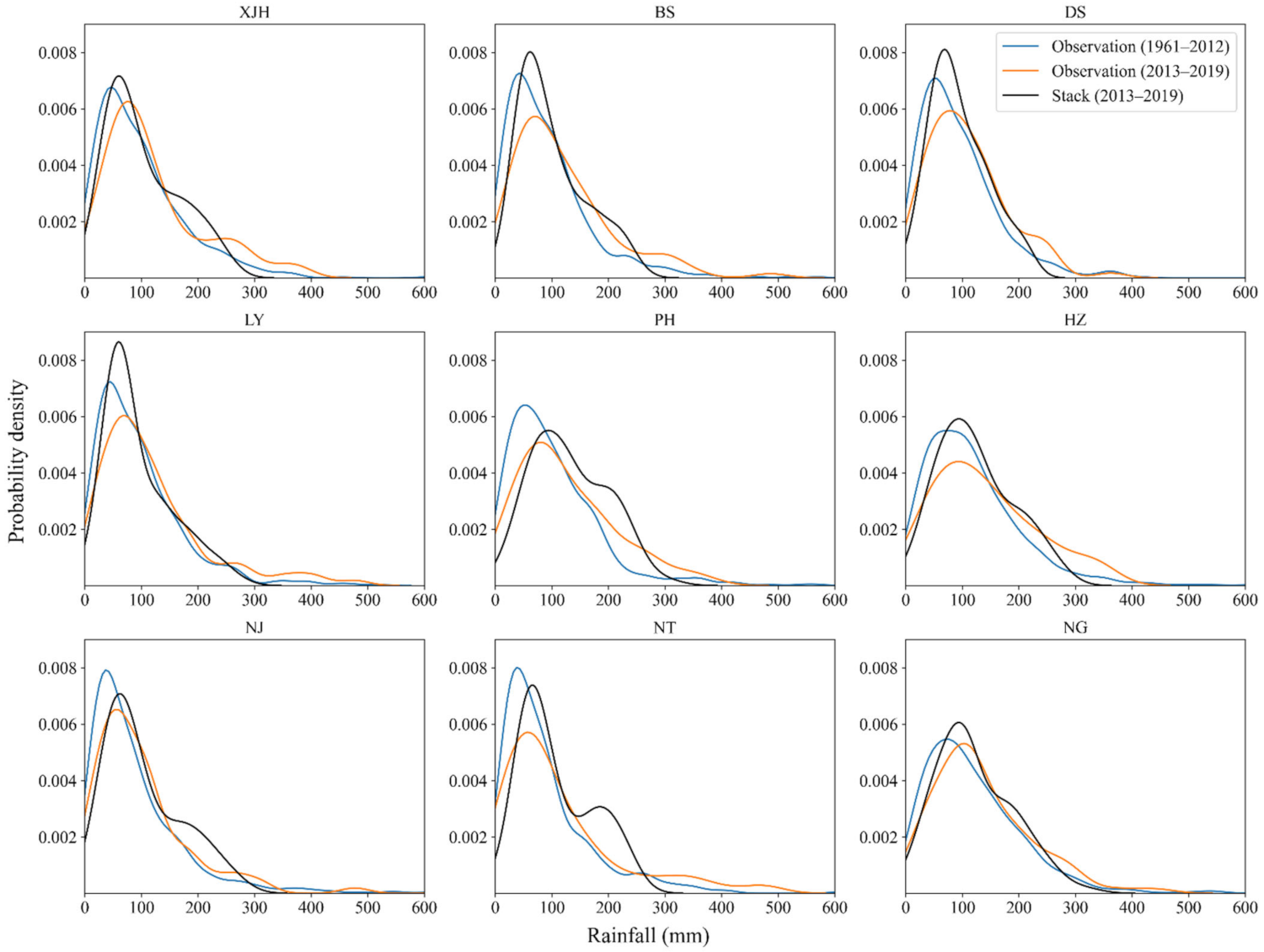
- Through combining models of diverse structures, the stacking model showed the potential to over-perform all the base models. In terms of different evaluation metrics, the results varied among the models. In terms of R2 and RMSE, the stacking model performed best at two stations (Pinghu and Ningguo). In terms of MAE, the stacking model performed best at four stations (Liyang, Pinghu, Hangzhou and Nanjing). At the other rainfall stations, the stacking approach also showed satisfactory performance, close to the best one of the individual base models, and especially showed favorable results in term of MAE. Thus, the proposed stacking model can produce reasonable predictions for the entire rainfall series.
- (2)
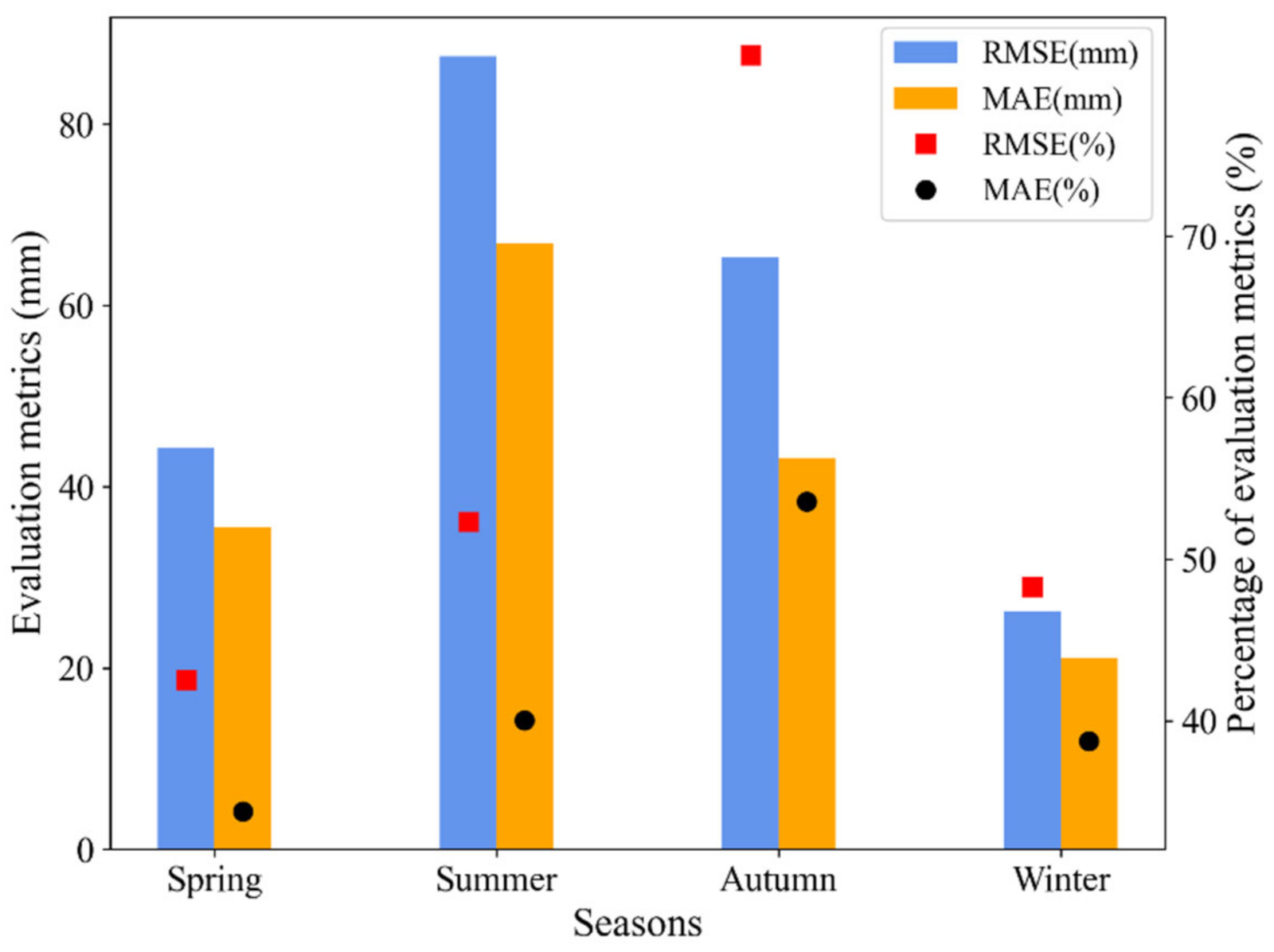
- At the annual aggregation scale, the stacking model and ML models (SVR and XGB) performed satisfactorily, showing good ability in applying long-term rainfall prediction for regional water resources management. Over four seasons, the stacking model generally showed better performance in spring and winter than in summer and autumn. In terms of dry/intermediate/wet months, the models showed a greater minor error range in dry and intermediate months than wet months, with underestimation of the wet months and slight overestimation of the dry months.
- (3)
- In terms of extreme rainfall, ANN outperformed the stacking model. The ML models generally undervalue extreme rainfall. ANN, relatively, generated the closest prediction, showing the potential to capture the extreme wet condition. Further work is needed to explore ML methods to enhance the ability of predicting extreme rainfall, especially in regions vulnerable to flooding.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ali, M.; Deo, R.C.; Downs, N.J.; Maraseni, T. Multi-stage hybridized online sequential extreme learning machine integrated with Markov Chain Monte Carlo copula-Bat algorithm for rainfall forecasting. Atmos. Res. 2018, 213, 450–464. [Google Scholar] [CrossRef]
- Bagirov, A.; Mahmood, A.; Barton, A. Prediction of monthly rainfall in Victoria, Australia: Clusterwise linear regression approach. Atmos. Res. 2017, 188, 20–29. [Google Scholar] [CrossRef]
- Zeynoddin, M.; Bonakdari, H.; Azari, A.; Ebtehaj, I.; Gharabaghi, B.; Madvar, H.R. Novel hybrid linear stochastic with non-linear extreme learning machine methods for forecasting monthly rainfall a tropical climate. J. Environ. Manag. 2018, 222, 190–206. [Google Scholar] [CrossRef] [PubMed]
- Climate Change 2014: Synthesis Report. Contribution of Working Groups I, II and III to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change. Geneva. 2014. Available online: https://www.ipcc.ch/report/ar5/syr (accessed on 20 December 2021).
- Das, P.; Chanda, K. Bayesian Network based modeling of regional rainfall from multiple local meteorological drivers. J. Hydrol. 2020, 591, 125563. [Google Scholar] [CrossRef]
- Abbot, J.; Marohasy, J. Input selection and optimisation for monthly rainfall forecasting in Queensland, Australia, using artificial neural networks. Atmos. Res. 2014, 138, 166–178. [Google Scholar] [CrossRef]
- Shahrban, M.; Walker, J.; Wang, Q.; Seed, A.; Steinle, P. An evaluation of numerical weather prediction based rainfall forecasts. Hydrol. Sci. J. 2016, 61, 2704–2717. [Google Scholar] [CrossRef] [Green Version]
- Ali, M.; Deo, R.C.; Downs, N.J.; Maraseni, T. Chapter 3—Monthly Rainfall Forecasting with Markov Chain Monte Carlo Simulations Integrated with Statistical Bivariate Copulas. In Handbook of Probabilistic Models; Samui, P., Tien Bui, D., Chakraborty, S., Deo, R.C., Eds.; Butterworth-Heinemann: Boston, MA, USA, 2020; pp. 89–105. ISBN 978-0-12-816514-0. [Google Scholar]
- Giebel, G.; Kariniotakis, G. Wind power forecasting—A review of the state of the art. In Renewable Energy Forecasting: From Models to Applications; Woodhead Publishing: Cambridge, UK, 2017; ISBN 978-0081005040. [Google Scholar]
- Yu, W.; Nakakita, E.; Jung, K. Flood Forecast and Early Warning with High-Resolution Ensemble Rainfall from Numerical Weather Prediction Model. Procedia Eng. 2016, 154, 498–503. [Google Scholar] [CrossRef] [Green Version]
- Carlson, R.F.; MacCormick, A.J.A.; Watts, D.G. Application of Linear Random Models to Four Annual Streamflow Series. Water Resour. Res. 1970, 6, 1070–1078. [Google Scholar] [CrossRef]
- Burlando, P.; Rosso, R.; Cadavid, L.G.; Salas, J.D. Forecasting of short-term rainfall using ARMA models. J. Hydrol. 1993, 144, 193–211. [Google Scholar] [CrossRef]
- Valipour, M.; Banihabib, M.E.; Behbahani, S.M.R. Comparison of the ARMA, ARIMA, and the autoregressive artificial neural network models in forecasting the monthly inflow of Dez dam reservoir. J. Hydrol. 2012, 476, 433–441. [Google Scholar] [CrossRef]
- Rahman, M.A.; Yunsheng, L.; Sultana, N. Analysis and prediction of rainfall trends over Bangladesh using Mann–Kendall, Spearman’s rho tests and ARIMA model. Arch. Meteorol. Geophys. Bioclimatol. Ser. B 2016, 129, 409–424. [Google Scholar] [CrossRef]
- Lana, X.; Rodríguez-Solà, R.; Martínez, M.D.; Casas-Castillo, M.C.; Serra, C.; Kirchner, R. Autoregressive process of monthly rainfall amounts in Catalonia (NE Spain) and improvements on predictability of length and intensity of drought episodes. Int. J. Clim. 2020, 41. [Google Scholar] [CrossRef]
- Basha, C.Z.; Bhavana, N.; Bhavya, P. Rainfall Prediction Using Machine Learning Amp; Deep Learning Techniques. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020; pp. 92–97. [Google Scholar]
- Ortiz-García, E.; Salcedo-Sanz, S.; Casanova-Mateo, C. Accurate precipitation prediction with support vector classifiers: A study including novel predictive variables and observational data. Atmos. Res. 2014, 139, 128–136. [Google Scholar] [CrossRef]
- Grace, R.K.; Suganya, B. Machine Learning Based Rainfall Prediction. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 227–229. [Google Scholar]
- Diez-Sierra, J.; del Jesus, M. Long-term rainfall prediction using atmospheric synoptic patterns in semi-arid climates with statistical and machine learning methods. J. Hydrol. 2020, 586, 124789. [Google Scholar] [CrossRef]
- Tian, D.; He, X.; Srivastava, P.; Kalin, L. A hybrid framework for forecasting monthly reservoir inflow based on machine learning techniques with dynamic climate forecasts, satellite-based data, and climate phenomenon information. Stoch. Hydrol. Hydraul. 2021, 1–23. [Google Scholar] [CrossRef]
- Yu, P.-S.; Yang, T.-C.; Chen, S.-Y.; Kuo, C.-M.; Tseng, H.-W. Comparison of random forests and support vector machine for real-time radar-derived rainfall forecasting. J. Hydrol. 2017, 552, 92–104. [Google Scholar] [CrossRef]
- Cramer, S.; Kampouridis, M.; Freitas, A.; Alexandridis, A.K. An extensive evaluation of seven machine learning methods for rainfall prediction in weather derivatives. Expert Syst. Appl. 2017, 85, 169–181. [Google Scholar] [CrossRef] [Green Version]
- Pour, S.H.; Wahab, A.K.A.; Shahid, S. Physical-empirical models for prediction of seasonal rainfall extremes of Peninsular Malaysia. Atmos. Res. 2019, 233, 104720. [Google Scholar] [CrossRef]
- Sachindra, D.; Ahmed, K.; Rashid, M.; Shahid, S.; Perera, B. Statistical downscaling of precipitation using machine learning techniques. Atmos. Res. 2018, 212, 240–258. [Google Scholar] [CrossRef]
- Zhou, Z.; Ren, J.; He, X.; Liu, S. A comparative study of extensive machine learning models for predicting long-term monthly rainfall with an ensemble of climatic and meteorological predictors. Hydrol. Process. 2021, 35, e14424. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Rice, J.S.; Emanuel, R.E. How are streamflow responses to the El Nino Southern Oscillation affected by watershed characteristics? Water Resour. Res. 2017, 53, 4393–4406. [Google Scholar] [CrossRef]
- Zhai, B.; Chen, J. Development of a stacked ensemble model for forecasting and analyzing daily average PM2.5 concentrations in Beijing, China. Sci. Total Environ. 2018, 635, 644–658. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.; Trevor, B. A stacking ensemble learning framework for annual river ice breakup dates. J. Hydrol. 2018, 561, 636–650. [Google Scholar] [CrossRef]
- Breiman, L. Stacked Regressions. Mach. Learn. 1996, 24, 49–64. [Google Scholar] [CrossRef] [Green Version]
- Zounemat-Kermani, M.; Batelaan, O.; Fadaee, M.; Hinkelmann, R. Ensemble machine learning paradigms in hydrology: A review. J. Hydrol. 2021, 598, 126266. [Google Scholar] [CrossRef]
- Li, Y.; Liang, Z.; Hu, Y.; Li, B.; Xu, B.; Wang, D. A multi-model integration method for monthly streamflow prediction: Modified stacking ensemble strategy. J. Hydroinform. 2019, 22, 310–326. [Google Scholar] [CrossRef]
- Wang, L.; Zhu, Z.; Sassoubre, L.; Yu, G.; Liao, C.; Hu, Q.; Wang, Y. Improving the robustness of beach water quality modeling using an ensemble machine learning approach. Sci. Total Environ. 2020, 765, 142760. [Google Scholar] [CrossRef]
- Peng, D.; Qiu, L.; Fang, J.; Zhang, Z. Quantification of Climate Changes and Human Activities That Impact Runoff in the Taihu Lake Basin, China. Math. Probl. Eng. 2016, 2016, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Wu, Z.-Y.; Lin, H.-J.; Ji, H.-P.; Liu, M. Hydrological response to climate change and human activities: A case study of Taihu Basin, China. Water Sci. Eng. 2020, 13, 83–94. [Google Scholar] [CrossRef]
- Liang, W.; Yongli, C.; Hongquan, C.; Daler, D.; Jingmin, Z.; Juan, Y. Flood disaster in Taihu Basin, China: Causal chain and policy option analyses. Environ. Earth Sci. 2010, 63, 1119–1124. [Google Scholar] [CrossRef]
- Ge, Q.; Bian, J.; Zheng, J.; Liao, Y.; Hao, Z.; Yin, Y. The climate regionalization in China for 1981-2010. Chin. Sci. Bull. 2013, 58, 3088–3099. [Google Scholar] [CrossRef] [Green Version]
- Tao, L.; He, X.; Qin, J. Multiscale teleconnection analysis of monthly total and extreme precipitations in the Yangtze River Basin using ensemble empirical mode decomposition. Int. J. Clim. 2020, 41, 348–373. [Google Scholar] [CrossRef]
- Liu, Y.; Li, W.; Ai, W.; Li, Q. Reconstruction and Application of the Monthly Western Pacific Subtropical High Indices. J. Appl. Meteorol. Sci. 2012, 23, 414–423. [Google Scholar]
- Nan, S.; Li, J. The relationship between the summer precipitation in the Yangtze River valley and the boreal spring Southern Hemisphere annular mode. Geophys. Res. Lett. 2003, 30. [Google Scholar] [CrossRef]
- Tang, Y.; Huang, A.; Wu, P.; Huang, D.; Xue, D.; Wu, Y. Drivers of Summer Extreme Precipitation Events Over East China. Geophys. Res. Lett. 2021, 48. [Google Scholar] [CrossRef]
- Fan, K.; Wang, H.; Choi, Y.-J. A physically-based statistical forecast model for the middle-lower reaches of the Yangtze River Valley summer rainfall. Chin. Sci. Bull. 2008, 53, 602–609. [Google Scholar] [CrossRef]
- Guo, Y.; Li, J.; Li, Y. Seasonal Forecasting of North China Summer Rainfall Using a Statistical Downscaling Model. J. Appl. Meteorol. Clim. 2014, 53, 1739–1749. [Google Scholar] [CrossRef]
- Wang, C.; Jia, Z.; Yin, Z.; Liu, F.; Lu, G.; Zheng, J. Improving the Accuracy of Subseasonal Forecasting of China Precipitation with a Machine Learning Approach. Front. Earth Sci. 2021, 9. [Google Scholar] [CrossRef]
- Babel, M.S.; Sirisena, T.A.J.G.; Singhrattna, N. Incorporating large-scale atmospheric variables in long-term seasonal rainfall forecasting using artificial neural networks: An application to the Ping Basin in Thailand. Water Policy 2016, 48, 867–882. [Google Scholar] [CrossRef] [Green Version]
- Kalnay, E.; Kanamitsu, M.; Kistler, R.; Collins, W.; Deaven, D.; Gandin, L.; Iredell, M.; Saha, S.; White, G.; Woollen, J.; et al. The NCEP/NCAR 40-Year Reanalysis Project. Bull. Am. Meteorol. Soc. 1996, 77, 437–472. [Google Scholar] [CrossRef] [Green Version]
- Hofmann, T.; Schölkopf, B.; Smola, A.J. Kernel methods in machine learning. Ann. Stat. 2008, 36, 1171–1220. [Google Scholar] [CrossRef] [Green Version]
- Marsland, S. Machine Learning: An Algorithmic Perspective, 2nd ed.; Chapman and Hall/CRC: New York, NY, USA, 2014; ISBN 978-0-429-10250-9. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Ahmadi, A.; Moridi, A.; Lafdani, E.K.; Kianpisheh, G. Assessment of climate change impacts on rainfall using large scale climate variables and downscaling models—A case study. J. Earth Syst. Sci. 2014, 123, 1603–1618. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13 August 2016; pp. 785–794. [Google Scholar]
- Ma, M.; Zhao, G.; He, B.; Li, Q.; Dong, H.; Wang, S.; Wang, Z. XGBoost-based method for flash flood risk assessment. J. Hydrol. 2021, 598, 126382. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Raghavendra, N.S.; Deka, P.C. Support vector machine applications in the field of hydrology: A review. Appl. Soft Comput. 2014, 19, 372–386. [Google Scholar] [CrossRef]
- Ferreira, L.B.; da Cunha, F.F.; de Oliveira, R.A.; Filho, E.I.F. Estimation of reference evapotranspiration in Brazil with limited meteorological data using ANN and SVM—A new approach. J. Hydrol. 2019, 572, 556–570. [Google Scholar] [CrossRef]
- Agatonovic-Kustrin, S.; Beresford, R. Basic concepts of artificial neural network (ANN) modeling and its application in pharmaceutical research. J. Pharm. Biomed. Anal. 2000, 22, 717–727. [Google Scholar] [CrossRef]
- Ahmed, K.; Shahid, S.; Bin Haroon, S.; Xiao-Jun, W. Multilayer perceptron neural network for downscaling rainfall in arid region: A case study of Baluchistan, Pakistan. J. Earth Syst. Sci. 2015, 124, 1325–1341. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Frank, M.; Wolfe, P. An algorithm for quadratic programming. Nav. Res. Logist. Q. 1956, 3, 95–110. [Google Scholar] [CrossRef]
- Markatou, M.; Tian, H.; Biswas, S.; Hripcsak, G.M. Analysis of Variance of Cross-Validation Estimators of the Generalization Error. J. Mach. Learn. Res. 2005, 6, 1127–1168. [Google Scholar] [CrossRef]
- Lever, J.; Krzywinski, M.; Altman, N. Model selection and overfitting. Nat. Methods 2016, 13, 703–704. [Google Scholar] [CrossRef]
- Fox, D.G. Judging Air Quality Model Performance: A Summary of the AMS Workshop on Dispersion Model Performance, Woods Hole, Mass., 8–11 September 1980. Bull. Am. Meteorol. Soc. 1981, 62, 599–609. [Google Scholar] [CrossRef] [Green Version]
- McKee, T.B.; Doesken, N.J.; Kleist, J. The Relationship of Drought Frequency and Duration to Time Scales. In Proceedings of the 8th Conference on Applied Climatology, Anaheim, CA, USA, 17–22 January 1993; p. 6. [Google Scholar]
- Angelidis, P.B.; Maris, F.; Kotsovinos, N.; Hrissanthou, V. Computation of Drought Index SPI with Alternative Distribution Functions. Water Resour. Manag. 2012, 26, 2453–2473. [Google Scholar] [CrossRef]
- Willmott, C.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Yang, J.; Wang, B.; Bao, Q. Biweekly and 21–30-Day Variations of the Subtropical Summer Monsoon Rainfall over the Lower Reach of the Yangtze River Basin. J. Clim. 2010, 23, 1146–1159. [Google Scholar] [CrossRef]
- Solomatine, D.P.; Ostfeld, A. Data-driven modelling: Some past experiences and new approaches. J. Hydroinform. 2008, 10, 3–22. [Google Scholar] [CrossRef] [Green Version]
- Patel, D.; Canaday, D.; Girvan, M.; Pomerance, A.; Ott, E. Using machine learning to predict statistical properties of non-stationary dynamical processes: System climate, regime transitions, and the effect of stochasticity. Chaos Interdiscip. J. Nonlinear Sci. 2021, 31, 033149. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Station | Abbr. | Longitude (°E) | Latitude (°N) | Altitude (m) | Monthly Precipitation | ||
|---|---|---|---|---|---|---|---|---|
| Mean (mm) | Maximum (mm) | Coefficient of Variation (Cv) | ||||||
| 1 | Xujiahui | XJH | 121.43 | 31.20 | 4.6 | 101.3 | 725.5 | 0.809 |
| 2 | Baoshan | BS | 121.45 | 31.40 | 5.5 | 94.5 | 570.9 | 0.834 |
| 3 | Dongshan | DS | 120.43 | 31.07 | 17.5 | 95.8 | 696.6 | 0.764 |
| 4 | Liyang | LY | 119.48 | 31.43 | 7.7 | 97.3 | 521.3 | 0.820 |
| 5 | Pinghu | PH | 121.08 | 30.62 | 5.4 | 103.4 | 569.3 | 0.788 |
| 6 | Hangzhou | HZ | 120.17 | 30.23 | 41.7 | 119.2 | 611.0 | 0.712 |
| 7 | Nanjing | NJ | 118.90 | 31.93 | 35.2 | 90.5 | 661.5 | 0.952 |
| 8 | Nantong | NT | 120.98 | 32.08 | 4.8 | 91.6 | 604.4 | 0.909 |
| 9 | Ningguo | NG | 118.98 | 30.62 | 87.3 | 120.8 | 783.2 | 0.730 |
| No. | Multiscale Predictors | Data Source | |
|---|---|---|---|
| 1 | Large-scale climate indices | Nino 3.4 index (Nino 3.4) | Hadley Centre Global Sea Ice and Sea Surface Temperature (Had-ISST). (https://psl.noaa.gov/gcos_wgsp/Timeseries/Data/nino34.long.data (accessed on 17 March 2021)) |
| 2 | Southern Oscillation Index (SOI) | Climatic Research Unit, University of East Anglia. (https://crudata.uea.ac.uk/cru/data/soi/ (accessed on 8 March 2021)) | |
| 3 | Southern Hemisphere annular mode index (SAMI) | (http://ljp.gcess.cn/dct/page/65609 (accessed on 15 June 2021)) | |
| 4 | Western Pacific subtropic high intensity (WPSH) | National Climate Center (https://cmdp.ncc-cma.net/Monitoring/ (accessed on 3 June 2021)) | |
| 5 | Large-scale atmospheric variables | sea level pressure (15° S to 25° S, 55° E to 70° E) (SLP) | Reanalysis data of NCEP/NOAA [46] (http://www.esrl.noaa.gov/psd/cgi-bin/data/timeseries/timeseries1.pl (accessed on 17 June 2021)) |
| 6 | meridional wind (20° N to 47.5° N, 105° E to 125° E) (V-wind(1)) | ||
| 7 | meridional wind (32.5° N, 120° E) (V-wind(2)) | ||
| 8 | Local meteorological variables | Monthly mean air temperature (°C) (Tmean) | China Meteorological Data Service Centre, China Meteorological Administration (CMA) (http://data.cma.cn/data/cdcdetail/dataCode/SURF_CLI_CHN_MUL_DAY_V3.0.html (accessed on 27 February 2021)) |
| 9 | Monthly maximum air temperature (°C) (Tmax) | ||
| 10 | Monthly minimum air temperature (°C) (Tmin) | ||
| 11 | Monthly mean air pressure (Pmean) | ||
| 12 | Monthly mean vapor pressure (emean) | ||
| 13 | Relative humidity (dmean) | ||
| 14 | Sunshine duration (Dsun) | ||
| Machine Learning Model | Hyper-Parameters |
|---|---|
| K-nearest neighbors (KNN) | Number of neighbors |
| Weights | |
| Extreme gradient boosting (XGB) | Number of estimators |
| Learning rate | |
| Max depth | |
| Support vector regression (SVR) | Cost C |
| Parameter of Gaussian Kernel—Gamma(γ) | |
| Artificial neural network (ANN) | Size of hidden layer |
| Activation function | |
| Learning rate | |
| Batch size |
| Evaluation Metrics | KNN | XGB | SVR | ANN | Stack | |
|---|---|---|---|---|---|---|
| All months | R2 | 0.407 | 0.526 | 0.523 | 0.532 | 0.526 |
| RMSE (mm) | 68.72 | 61.57 | 61.65 | 60.92 | 61.51 | |
| MAE (mm) | 46.34 | 42.41 | 43.16 | 42.47 | 41.65 | |
| Annual aggregation scale | RMSE (%) | 26.12 | 22.33 | 22.12 | 24.63 | 23.34 |
| MAE (%) | 21.39 | 18.31 | 18.61 | 21.02 | 19.40 | |
| Spring | RMSE (mm) | 43.82 | 45.74 | 45.79 | 47.16 | 44.22 |
| MAE (mm) | 33.86 | 37.18 | 36.88 | 37.89 | 35.58 | |
| Summer | RMSE (mm) | 95.50 | 87.56 | 87.06 | 85.19 | 87.44 |
| MAE (mm) | 73.85 | 66.46 | 66.21 | 66.72 | 66.82 | |
| Autumn | RMSE (mm) | 77.17 | 64.35 | 64.02 | 62.89 | 65.27 |
| MAE (mm) | 50.55 | 44.21 | 44.03 | 42.61 | 43.15 | |
| Winter | RMSE (mm) | 34.45 | 27.46 | 29.52 | 28.06 | 26.22 |
| MAE (mm) | 27.09 | 21.77 | 25.54 | 22.67 | 21.05 | |
| Dry months | RMSE (mm) | 61.05 | 47.56 | 49.45 | 43.03 | 46.78 |
| MAE (mm) | 49.90 | 37.47 | 40.39 | 32.33 | 35.87 | |
| Intermediate months | RMSE (mm) | 36.98 | 40.53 | 42.27 | 43.94 | 38.77 |
| MAE (mm) | 28.08 | 32.26 | 33.06 | 33.98 | 30.21 | |
| Wet months | RMSE (mm) | 121.23 | 101.22 | 99.03 | 96.82 | 103.43 |
| MAE (mm) | 97.86 | 73.15 | 72.94 | 71.33 | 76.69 | |
| Months of extreme rainfall | RMSE (mm) | 197.70 | 172.36 | 164.65 | 157.80 | 173.26 |
| MAE (mm) | 188.36 | 162.22 | 153.26 | 143.32 | 163.38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, J.; Liu, S.; Zhou, Z.; Chalov, S.R.; Zhuang, Q. A Stacking Ensemble Learning Model for Monthly Rainfall Prediction in the Taihu Basin, China. Water 2022, 14, 492. https://doi.org/10.3390/w14030492
Gu J, Liu S, Zhou Z, Chalov SR, Zhuang Q. A Stacking Ensemble Learning Model for Monthly Rainfall Prediction in the Taihu Basin, China. Water. 2022; 14(3):492. https://doi.org/10.3390/w14030492
Chicago/Turabian StyleGu, Jiayue, Shuguang Liu, Zhengzheng Zhou, Sergey R. Chalov, and Qi Zhuang. 2022. "A Stacking Ensemble Learning Model for Monthly Rainfall Prediction in the Taihu Basin, China" Water 14, no. 3: 492. https://doi.org/10.3390/w14030492