
Development of Deep Learning Models to Improve the Accuracy of Water Levels Time Series Prediction through Multivariate Hydrological Data


Abstract
:1. Introduction
2. Methods
2.1. Applied DNN Models
2.1.1. Long Short-Term Memory (LSTM)
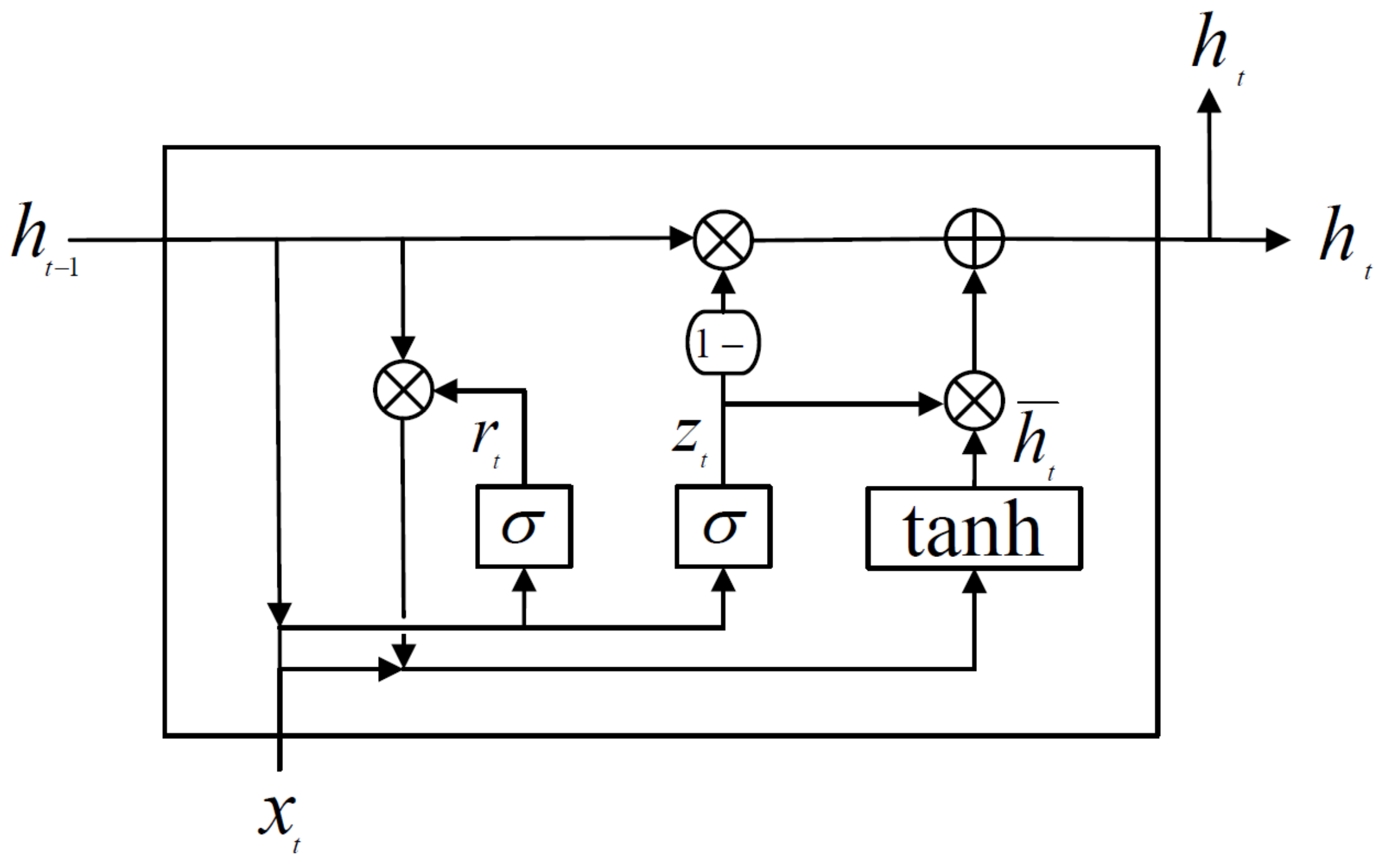
2.1.2. Gated Recurrent Unit (GRU)
2.2. Model Performance Indicators
- (1)
- Mean Absolute Error (MAE)
- (2)
- Mean Squared Error (MSE)
- (3)
- Root Mean Squared Error (RMSE)
- (4)
- Coefficient of determination ()
- (5)
- Nash–Sutcliffe model efficiency coefficient (NSE)
- (6)
- Mean Relative Peak Error (MRPE)
2.3. Application of Models
3. Study Area and Data
3.1. Study Area
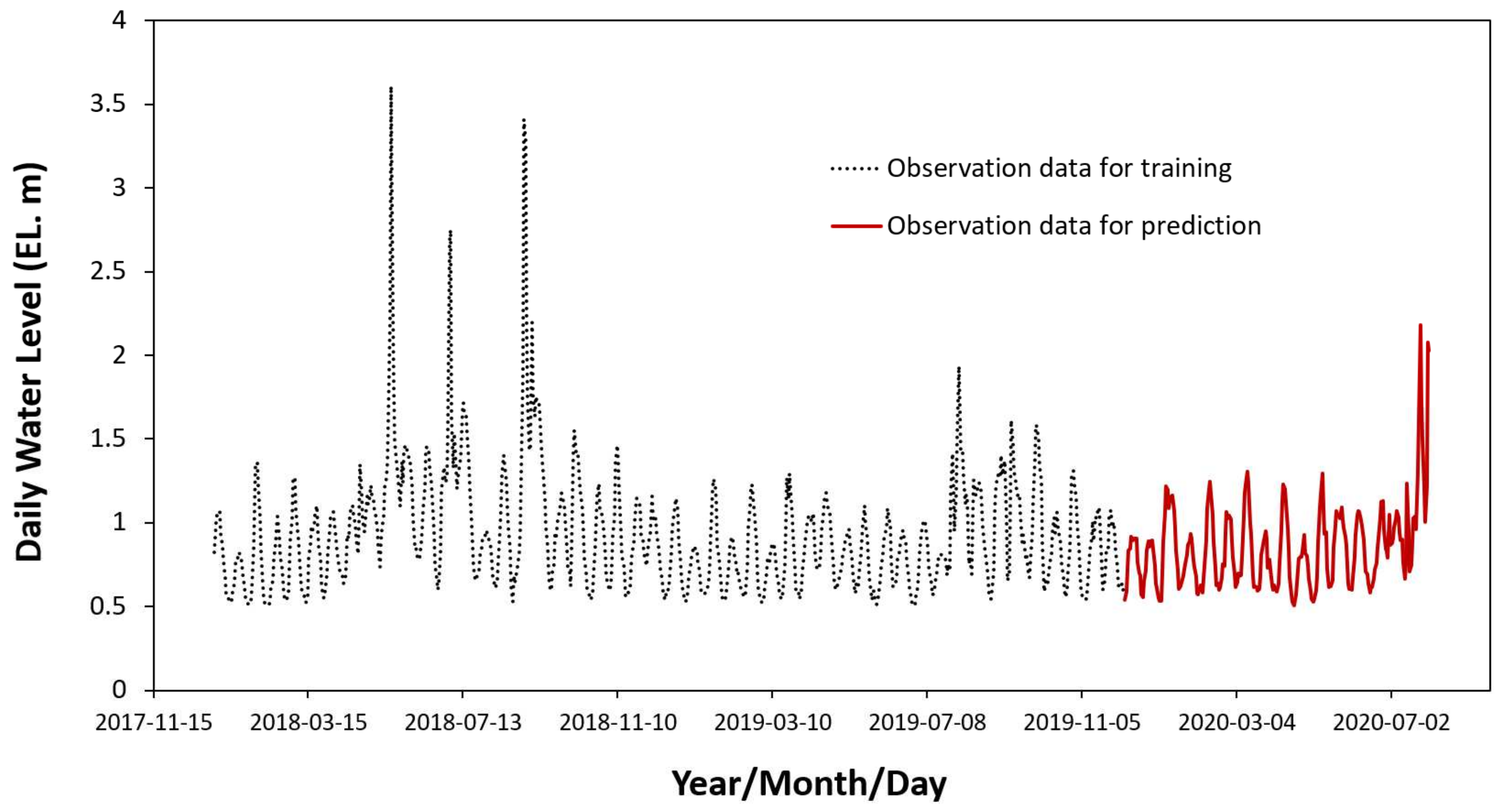
3.2. Hydrologic Data
- (1)
- Daily water level
- (2)
- Hydrological and meteorological data
3.3. Composition of Models
- (1)
- Composition of LSTM and GRU models
- (2)
- Composition of training data in LSTM and GRU models
4. Results
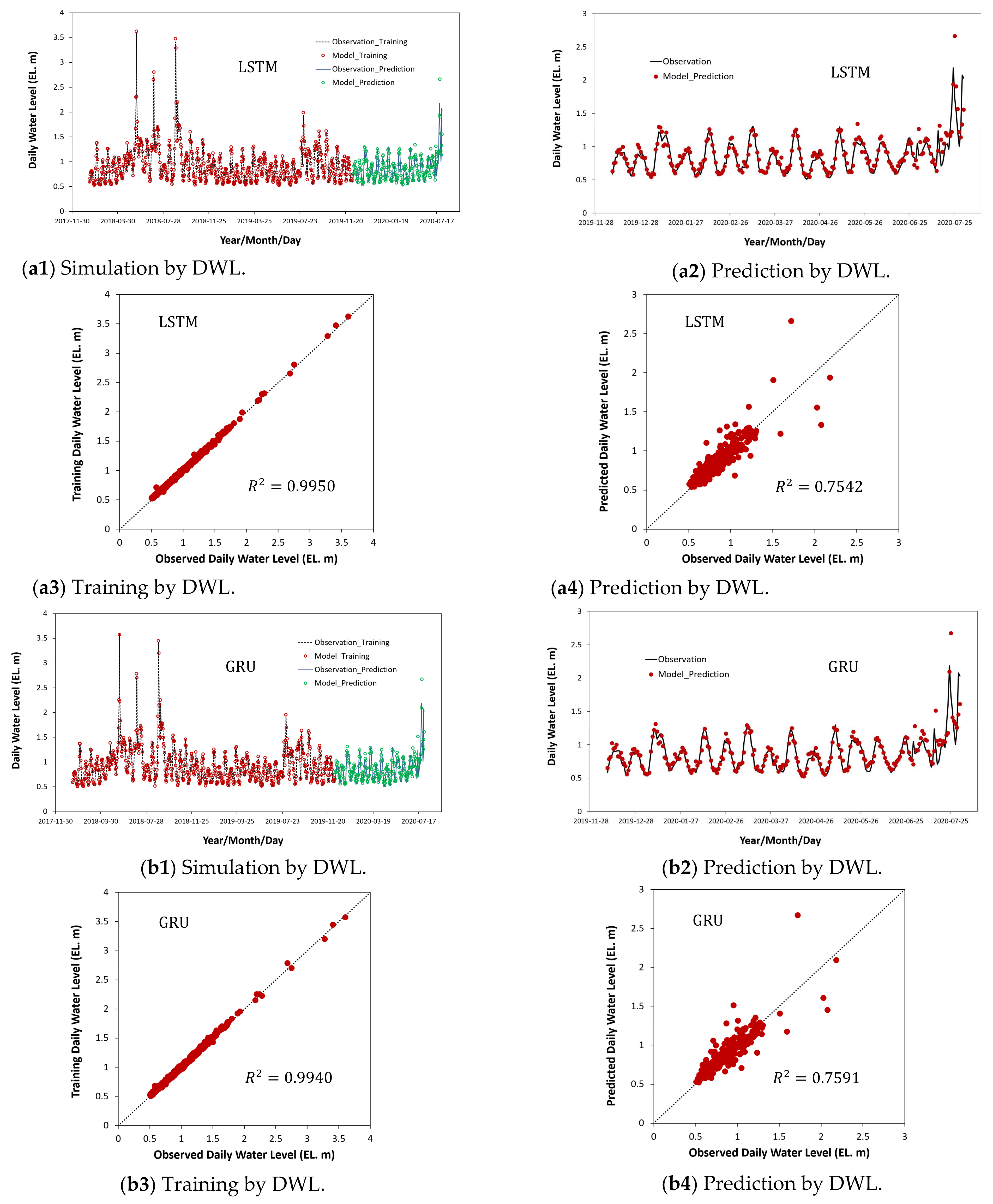
4.1. Results on Training and Prediction Using Water Levels as Univariate Input Data
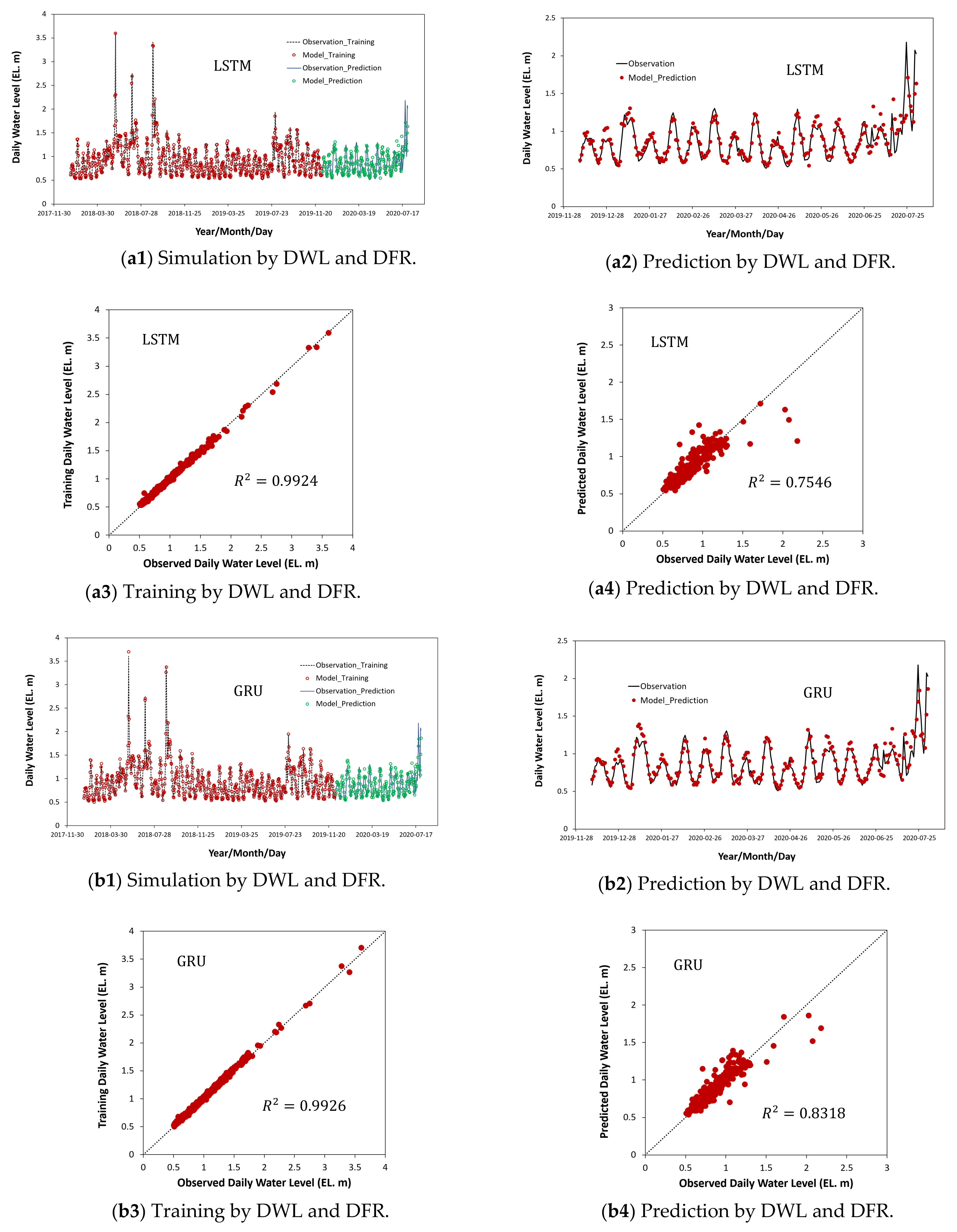
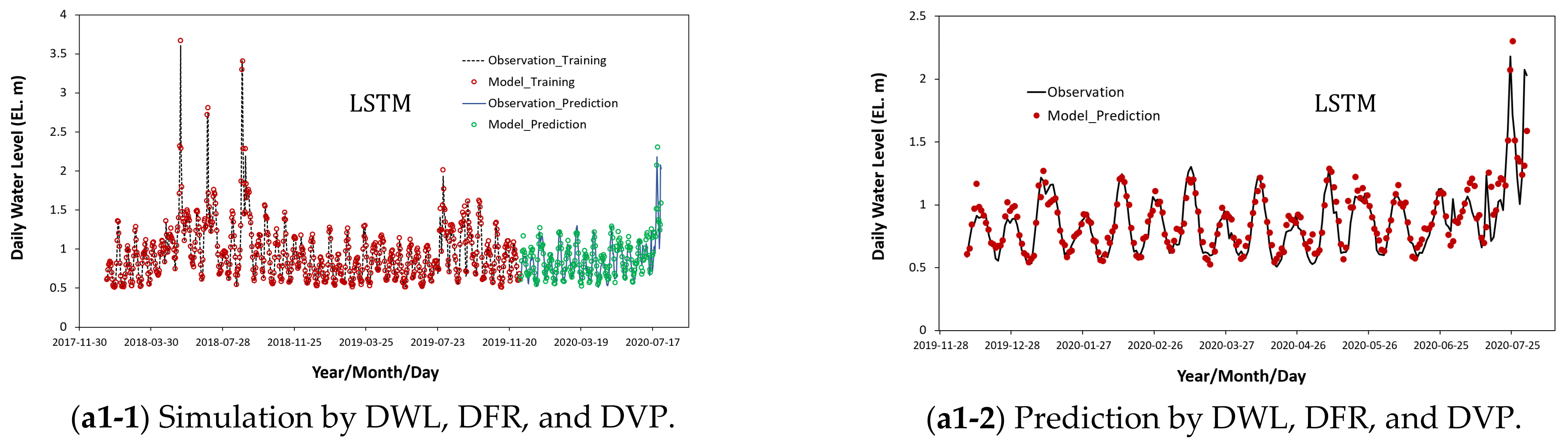
4.2. Results on Training and Prediction Using Water Levels and Flow Rates as Bivariate Input Data
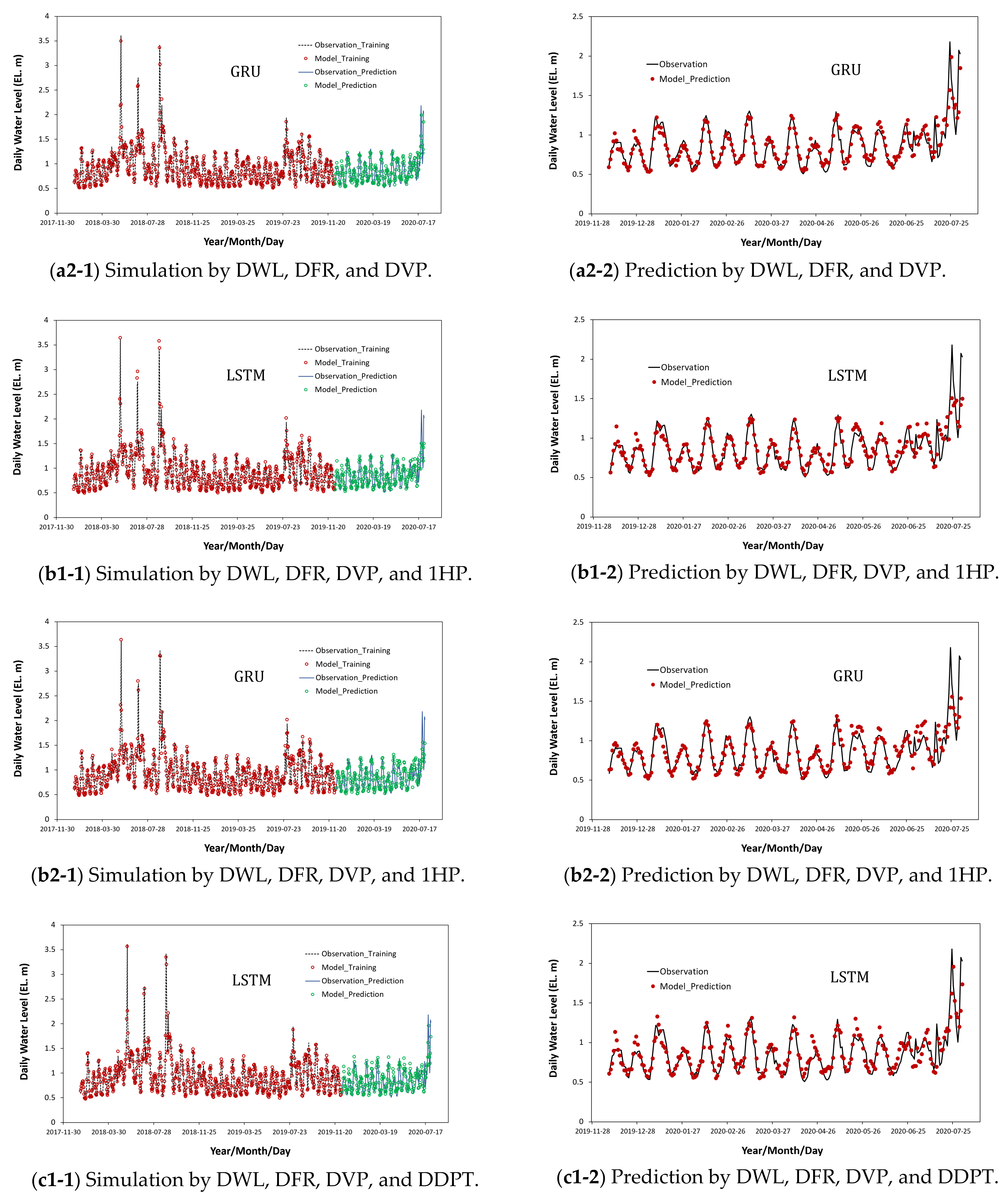
4.3. Results on Training and Prediction Using Water Levels and Flow Rates as Multivariate Input Data
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lee, K.S. Rehabilitation of the Hydrologic Cycle in the Anyangcheon Watershed; Sustainable Water Resources Research Center, Ministry of Education, Science and Technology: Seoul, Korea, 2007. [Google Scholar]
- Lee, K.S.; Chung, E.S. Development of integrated watershed management schemes for an intensively urbanized region in Korea. J. Hydro Environ. Res. 2007, 1, 95–109. [Google Scholar] [CrossRef]
- Henonin, J.; Russo, B.; Mark, O.; Gourbesville, P. Real-time urban flood forecasting and modelling—A state of the art. J. Hydroinform. 2013, 15, 717–736. [Google Scholar] [CrossRef]
- Park, K.; Jung, Y.; Kim, K.; Park, S.K. Determination of deep learning model and optimum length of training data in the river with large fluctuations in flow rates. Water 2020, 12, 3537. [Google Scholar] [CrossRef]
- Irvine, K.N.; Eberhardt, A.J. Multiplicative, seasonal ARIMA models for Lake Erieand Lake Ontario water levels. JAWRA J. Am. Water Resour. Assoc. 1992, 28, 385–396. [Google Scholar] [CrossRef]
- Tokar, A.S.; Johnson, P.A. Rainfall-runoff modeling using artificial neural networks. J. Hydrol. Eng. ASCE 1999, 4, 232–239. [Google Scholar] [CrossRef]
- Yan, Q.; Ma, C. Application of integrated ARIMA and RBF network for groundwater level forecasting. Environ. Earth Sci. 2016, 75, 396. [Google Scholar] [CrossRef]
- Shirmohammadi, B.; Vafakhah, M.; Moosavi, V.; Moghaddamnia, A. Application of several data-driven techniques for predicting groundwater level. Water Resour. Manag. 2013, 27, 419–432. [Google Scholar] [CrossRef]
- Hasebe, M.; Nagayama, Y. Reservoir operation using the neural network and fuzzy systems for dam control and operation support. Adv. Eng. Softw. 2002, 33, 245–260. [Google Scholar] [CrossRef]
- Chang, F.J.; Chang, Y.T. Adaptive neuro-fuzzy inference system for prediction of water level in reservoir. Adv. Water Resour. 2006, 29, 1–10. [Google Scholar] [CrossRef]
- Tran, Q.-K.; Song, S.-K. Water level forecasting based on deep learning: A use case of Trinity River-Texas-the United States. J. KIISE 2017, 44, 607–612. [Google Scholar] [CrossRef]
- Kumar, D.N.; Raju, K.S.; Sathish, T. River flow forecasting using recurrent neural networks. Water Resour. Manag. 2004, 18, 143–161. [Google Scholar] [CrossRef]
- Firat, M. Comparison of artificial intelligence techniques for river flow forecasting. Hydrol. Earth Syst. Sci. 2008, 12, 123–139. [Google Scholar] [CrossRef] [Green Version]
- Sattari, M.T.; Yurekli, K.; Pal, M. Performance evaluation of artificial neural network approaches in forecasting reservoir inflow. Appl. Math. Model. 2012, 36, 2649–2657. [Google Scholar] [CrossRef]
- Chen, P.-A.; Chang, L.-C.; Chang, L.-C. Reinforced recurrent neural networks for multi-step-ahead flood forecasts. J. Hydrol. 2013, 497, 71–79. [Google Scholar] [CrossRef]
- Zhang, D.; Peng, Q.; Lin, J.; Wang, D.; Liu, X.; Zhuang, J. Simulating reservoir operation using a recurrent neural network algorithm. Water 2019, 11, 865. [Google Scholar] [CrossRef] [Green Version]
- Mok, J.-Y.; Choi, J.-H.; Moon, Y.-I. Prediction of multipurpose dam inflow using deep learning. J. Korea Water Resour. Assoc. 2020, 53, 97–105. [Google Scholar]
- Zhang, D.; Lin, J.; Peng, Q.; Wang, D.; Yang, T.; Sorooshian, S.; Liu, X.; Zhuang, J. Modeling and simulating of reservoir operation using the artificial neural network, support vector regression, deep learning algorithm. J. Hydrol. 2018, 565, 720–736. [Google Scholar] [CrossRef] [Green Version]
- Apaydin, H.; Feizi, H.; Sattari, M.T.; Colak, M.S.; Shamshirband, S.; Chau, K.-W. Comparative analysis of recurrent neural network architectures for reservoir inflow forecasting. Water 2020, 12, 1500. [Google Scholar] [CrossRef]
- Adamowski, J.; Chan, H.F. A wavelet neural network conjunction model for groundwater level forecasting. J. Hydrol. 2011, 407, 28–40. [Google Scholar] [CrossRef]
- Partal, T.; Cigizoglu, H.K. Estimation and forecasting of daily suspended sediment data using wavelet-neural networks. J. Hydrol. 2008, 358, 317–331. [Google Scholar] [CrossRef]
- Rajaee, T.; Nourani, V.; Mohammad, Z.K.; Kisi, O. River suspended sediment load prediction: Application of ANN and wavelet conjunction model. J. Hydrol. Eng. 2011, 16, 613–627. [Google Scholar] [CrossRef]
- Adnan, R.; Ruslan, F.A.; Samad, A.M.; Zain, Z.M. Flood Water Level Modelling and Prediction Using Artificial Neural Network: Case Study of Sungai Batu Pahat in Johor. In Proceedings of the 2012 IEEE Control and System Graduate Research Colloquium, Shah Alam, Malaysia, 16–17 July 2012; pp. 22–25. [Google Scholar]
- Rezaeianzadeh, M.; Kalin, L.; Hantush, M. An integrated approach for modeling wetland water level: Application to a headwater wetland in coastal Alabama, USA. Water 2018, 10, 879. [Google Scholar] [CrossRef] [Green Version]
- Choi, C.; Kim, J.; Han, H.; Han, D.; Kim, H.S. Development of water level prediction models using machine learning in wetlands: A case study of Upo wetland in South Korea. Water 2020, 12, 93. [Google Scholar] [CrossRef] [Green Version]
- Kisi, O.; Shiri, J.; Nikoofar, B. Forecasting daily lake levels using artificial intelligence approaches. Comput. Geosci. 2012, 41, 169–180. [Google Scholar] [CrossRef]
- Hipni, A.; El-Shafie, A.; Najah, A.; Karim, O.A.; Hussain, A.; Mukhlisin, M. Daily forecasting of dam water levels: Comparing a support vector machine (SVM) model with adaptive neuro fuzzy inference system (ANFIS). Water Resour. Manag. 2013, 27, 3803–3823. [Google Scholar] [CrossRef]
- Young, C.C.; Liu, W.C.; Hsieh, W.L. Predicting the water level fluctuation in an Alpine Lake using physically based, artificial neural network, and time series forecasting models. Math. Probl. Eng. 2015, 2015, 708204. [Google Scholar] [CrossRef] [Green Version]
- Guo, F.; Yang, J.; Li, H.; Li, G.; Zhang, Z. A ConvLSTM conjunction model for groundwater level forecasting in a karst aquifer considering connectivity Characteristics. Water. 2021, 13, 2759. [Google Scholar] [CrossRef]
- Di Nunno, F.; Granata, F.; Gargano, R.; de Marinis, G. Forecasting of extreme storm tide events using NARX neural network-based models. Atmosphere 2021, 12, 512. [Google Scholar] [CrossRef]
- Di Nunno, F.; de Marinis, G.; Gargano, R.; Granata, F. Tide prediction in the Venice Lagoon using Nonlinear Autoregressive Exogenous (NARX) neural network. Water 2021, 13, 1173. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, H.; Feng, W.; Huang, H. Short term real-time rolling forecast of urban river water levels based on LSTM: A case study in Fuzhou City, China. Int. J. Environ. Res. Public Health 2021, 18, 9287. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 7 October 2014; pp. 103–111. [Google Scholar]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Soil Water Div. ASABE 2007, 50, 885–900. [Google Scholar]
- Segura-Beltrán, F.; Sanchis-Ibor, C.; Morales-Hernández, M.; González-Sanchis, M.; Bussi, G.; Ortiz, E. Using post-flood surveys and geomorphologic mapping to evaluate hydrological and hydraulic models: The flash flood of the Girona River (Spain) in 2007. J. Hydrol. 2016, 541, 310–329. [Google Scholar] [CrossRef] [Green Version]
- Kastridis, A.; Kirkenidis, C.; Sapountzis, M. An integrated approach of flash flood analysis in ungauged Mediterranean watersheds using post-flood surveys and unmanned aerial vehicles. Hydrol. Process. 2020, 34, 4920–4939. [Google Scholar] [CrossRef]
- Narbondo, S.; Gorgoglione, A.; Crisci, M.; Chreties, C. Enhancing physical similarity approach to predict runoff in ungauged watersheds in sub-tropical regions. Water 2020, 12, 528. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Luo, Y.; Potter, C.; Moran, P.J.; Grieneisen, M.L.; Zhang, M. Modeling pesticide diuron loading from the San Joaquin watershed into the Sacramento-San Joaquin Delta using SWAT. Water Res. 2017, 121, 374–385. [Google Scholar] [CrossRef]
- Chiew, F.; Stewardson, M.J.; McMahon, T. Comparison of six rainfall-runoff modelling approaches. J. Hydrol. 1993, 147, 1–36. [Google Scholar] [CrossRef]
- Al-Smadi, M. Incorporating Spatial and Temporal Variation of Watershed Response in a GIS-based Hydrological Model. Master’s Thesis, Virginia Institute of Technology, Blacksburg, VA, USA, 1998. [Google Scholar]
- Seoul Metropolitan Government. Study on River Management by Universities; Seoul Metropolitan Government: Seoul, Korea, 2013.
- Seoul Metropolitan Government. Statistical Yearbook of Seoul; Seoul Metropolitan Government: Seoul, Korea, 2004.
- Ministry of Construction and Transportation. Master Plan for River Modification of the Han River Basin; Ministry of Construction and Transportation: Seoul, Korea, 2002.
- Water Resources Management Information System. Hydrological Data. Available online: http://www.wamis.go.kr (accessed on 1 August 2021).
- Korea Meteorological Administration, National Climate Data Center. Meteorological Data. Available online: https://data.kma.go.kr (accessed on 1 August 2021).
- Google Earth. Available online: http://www.google.com/maps (accessed on 1 October 2021).
- Lee, J.S. Water Resources Engineering; Goomibook: Seoul, Korea, 2008. [Google Scholar]
- Anaconda. Python. Available online: https://www.anaconda.com (accessed on 1 August 2021).
- TensorFlow. TensorFlow. Available online: https://www.tensorflow.org (accessed on 1 August 2021).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Performance Rating | ||
|---|---|---|
| Very good | ||
| Good | ||
| Satisfactory | ||
| Unsatisfactory |
| Length of River (km) | Basin Area | Mean Rainfall (mm/Year) | Mean Water Level | Mean Streamflow |
|---|---|---|---|---|
| 494.44 | 25,953.60 | 1313.42 | 0.91 | 355.97 |
| Minimum Water Level | Maximum Water Level | Average Water Level | Standard Deviation of Water Level | Coefficient of Flow Fluctuation (CFF) |
|---|---|---|---|---|
| 0.504 | 3.606 | 0.915 | 0.336 | 70.32 |
| Variable | Training Data | Prediction Data | Train/Predict | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ave | Max | Min | SD | Ave | Max | Min | SD | Ave | Max | Min | SD | |
| Daily Water Level (EL.m) | 1.02 | 3.61 | 0.51 | 0.43 | 0.86 | 2.18 | 0.50 | 0.25 | 0.84 | 0.60 | 0.98 | 0.58 |
| Daily Flow Rate (m3/s) | 451.66 | 5752.81 | 64.65 | 640.31 | 275.33 | 2923.08 | 59.25 | 240.95 | 0.61 | 0.51 | 0.92 | 0.38 |
| Daily Vapor Pressure (hPa) | 11.78 | 31.60 | 0.70 | 8.24 | 10.58 | 31.80 | 0.80 | 7.84 | 0.90 | 1.01 | 1.14 | 0.95 |
| Daily Dew-Point Temperature (°C) | 5.21 | 25.00 | −27.60 | 12.45 | 3.59 | 25.00 | −25.80 | 11.98 | 0.69 | 1.00 | 0.94 | 0.96 |
| 1-Hour-Max Precipitation (mm) | 1.35 | 43.50 | 0.00 | 4.65 | 0.84 | 29.40 | 0.00 | 3.19 | 0.62 | 0.68 | 0.00 | 0.69 |
| Precipitation Duration (hour) | 2.48 | 24.00 | 0.00 | 4.85 | 2.34 | 24.00 | 0.00 | 4.70 | 0.94 | 1.00 | 0.00 | 0.97 |
| Daily Precipitation (mm) | 3.76 | 96.50 | 0.00 | 12.42 | 2.60 | 103.10 | 0.00 | 9.14 | 0.69 | 1.07 | 0.00 | 0.74 |
| Daily Temperature (°C) | 14.05 | 33.70 | −14.80 | 11.09 | 12.69 | 31.60 | −10.50 | 10.16 | 0.90 | 0.94 | 0.72 | 0.92 |
| 10-Minute-Max Precipitation (mm) | 0.59 | 25.50 | 0.00 | 2.11 | 0.34 | 11.90 | 0.00 | 1.24 | 0.58 | 0.47 | 0.00 | 0.59 |
| Variable | Daily Water Level (EL.m) | Daily Flow Rate (m3/s) | Daily Vapor Pressure (hPa) | Daily Dew-Point Temperature (°C) | 1-Hour-Max Precipitation (mm) |
|---|---|---|---|---|---|
| Daily Water Level (EL.m) | 1.0000 | 0.7731 | 0.3622 | 0.3444 | 0.3305 |
| Daily Flow Rate (m3/s) | 0.7731 | 1.0000 | 0.3397 | 0.3112 | 0.3563 |
| Daily Vapor Pressure (hPa) | 0.3622 | 0.3397 | 1.0000 | 0.9465 | 0.3746 |
| Daily Dew-Point Temperature (°C) | 0.3444 | 0.3112 | 0.9465 | 1.0000 | 0.3140 |
| 1-Hour-Max Precipitation (mm) | 0.3305 | 0.3563 | 0.3746 | 0.3140 | 1.0000 |
| Precipitation Duration (hour) | 0.2271 | 0.2641 | 0.2934 | 0.2800 | 0.5210 |
| Daily Precipitation (mm) | 0.2993 | 0.3203 | 0.3118 | 0.2741 | 0.8263 |
| Daily Temperature (°C) | 0.3038 | 0.2656 | 0.8964 | 0.9509 | 0.2198 |
| 10-Minute-Max Precipitation (mm) | 0.3226 | 0.3470 | 0.3836 | 0.3160 | 0.9522 |
| Model | Activation Function | Input Layer | Hidden Layer 1 | Dropout | Hidden Layer 2 | Dense Layer 1 | Dense Layer 2 |
|---|---|---|---|---|---|---|---|
| LSTM | ReLU | LSTM | LSTM 50 units | 0.25 | LSTM 50 units | 25 units | 1 unit |
| GRU | ReLU | GRU | GRU 50 units | 0.25 | GRU 50 units | 25 units | 1 unit |
| Number of Input Variables | Training Data | Prediction Data |
|---|---|---|
| 1 | Daily Water Level (DWL) | Daily Water Level (DWL) |
| 2 | Daily Water Level (DWL), Daily Flow Rate (DFR) | |
| 3 | Daily Water Level (DWL), Daily Flow Rate (DFR), Daily Vapor Pressure (DVP) | |
| 4 | Daily Water Level (DWL), Daily Flow Rate (DFR), Daily Vapor Pressure (DVP), 1-Hour-Max Precipitation (1HP) | |
| 4 | Daily Water Level (DWL), Daily Flow Rate (DFR), Daily Vapor Pressure (DVP), Daily Dew-Point Temperature (DDPT) | |
| 5 | Daily Water Level (DWL), Daily Flow Rate (DFR), Daily Vapor Pressure (DVP), Daily Dew-Point Temperature (DDPT), 1-Hour-Max Precipitation (1HP) |
| Model | Computational State | MAE | MSE | RMSE | NSE | MRPE | |
|---|---|---|---|---|---|---|---|
| LSTM | Training | 0.0136 | 0.0003 | 0.0179 | 0.9950 | 0.9975 | 0.0126 |
| Prediction | 0.0824 | 0.0181 | 0.1344 | 0.7542 | 0.7345 | 0.0919 | |
| GRU | Training | 0.0158 | 0.0004 | 0.0207 | 0.9940 | 0.9966 | 0.0158 |
| Prediction | 0.0796 | 0.0171 | 0.1306 | 0.7591 | 0.7362 | 0.0719 |
| Model | Computational State | MAE | MSE | RMSE | NSE | MRPE | |
|---|---|---|---|---|---|---|---|
| LSTM | Training | 0.0181 | 0.0006 | 0.0245 | 0.9924 | 0.9951 | 0.0177 |
| Prediction | 0.0787 | 0.0163 | 0.1278 | 0.7546 | 0.6694 | 0.0887 | |
| GRU | Training | 0.0200 | 0.0007 | 0.0268 | 0.9926 | 0.9945 | 0.0221 |
| Prediction | 0.0719 | 0.0117 | 0.1081 | 0.8318 | 0.7965 | 0.0895 |
| Model | Variables | Computational State | MAE | MSE | RMSE | NSE | MRPE | |
|---|---|---|---|---|---|---|---|---|
| LSTM | DWL, DFR | Training | 0.0181 | 0.0006 | 0.0245 | 0.9924 | 0.9951 | 0.0177 |
| Prediction | 0.0787 | 0.0163 | 0.1278 | 0.7546 | 0.6694 | 0.0887 | ||
| GRU | DWL, DFR | Training | 0.0200 | 0.0007 | 0.0268 | 0.9926 | 0.9945 | 0.0221 |
| Prediction | 0.0719 | 0.0117 | 0.1081 | 0.8318 | 0.7965 | 0.0895 | ||
| LSTM | DWL, DFR, DVP | Training | 0.0254 | 0.0012 | 0.0342 | 0.9917 | 0.9914 | 0.0239 |
| Prediction | 0.0812 | 0.0153 | 0.1235 | 0.7846 | 0.7447 | 0.0966 | ||
| GRU | DWL, DFR, DVP | Training | 0.0261 | 0.0012 | 0.0351 | 0.9887 | 0.9898 | 0.0287 |
| Prediction | 0.0710 | 0.0129 | 0.1137 | 0.8033 | 0.7558 | 0.1019 | ||
| LSTM | DWL, DFR, DVP, 1HP | Training | 0.0233 | 0.0011 | 0.0332 | 0.9902 | 0.9919 | 0.0256 |
| Prediction | 0.0802 | 0.0157 | 0.1254 | 0.7625 | 0.6547 | 0.0953 | ||
| GRU | DWL, DFR, DVP, 1HP | Training | 0.0294 | 0.0016 | 0.0396 | 0.9853 | 0.9883 | 0.0324 |
| Prediction | 0.0815 | 0.0166 | 0.1287 | 0.7480 | 0.6688 | 0.0999 | ||
| LSTM | DWL, DFR, DVP, DDPT | Training | 0.0267 | 0.0008 | 0.0283 | 0.9895 | 0.9936 | 0.0228 |
| Prediction | 0.0766 | 0.0154 | 0.1240 | 0.7686 | 0.7131 | 0.1104 | ||
| GRU | DWL, DFR, DVP, DDPT | Training | 0.0267 | 0.0013 | 0.0359 | 0.9875 | 0.9892 | 0.0232 |
| Prediction | 0.0766 | 0.0123 | 0.1110 | 0.8135 | 0.7580 | 0.0882 | ||
| LSTM | DWL, DFR, DVP, DDPT, 1HP | Training | 0.0234 | 0.0009 | 0.0303 | 0.9897 | 0.9928 | 0.0217 |
| Prediction | 0.0882 | 0.0169 | 0.1301 | 0.7437 | 0.6489 | 0.1271 | ||
| GRU | DWL, DFR, DVP, DDPT, 1HP | Training | 0.0331 | 0.0019 | 0.0435 | 0.9846 | 0.9857 | 0.0305 |
| Prediction | 0.0826 | 0.0129 | 0.1135 | 0.8120 | 0.7524 | 0.0807 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, K.; Jung, Y.; Seong, Y.; Lee, S. Development of Deep Learning Models to Improve the Accuracy of Water Levels Time Series Prediction through Multivariate Hydrological Data. Water 2022, 14, 469. https://doi.org/10.3390/w14030469
Park K, Jung Y, Seong Y, Lee S. Development of Deep Learning Models to Improve the Accuracy of Water Levels Time Series Prediction through Multivariate Hydrological Data. Water. 2022; 14(3):469. https://doi.org/10.3390/w14030469
Chicago/Turabian StylePark, Kidoo, Younghun Jung, Yeongjeong Seong, and Sanghyup Lee. 2022. "Development of Deep Learning Models to Improve the Accuracy of Water Levels Time Series Prediction through Multivariate Hydrological Data" Water 14, no. 3: 469. https://doi.org/10.3390/w14030469