1. Introduction
The weather forecast refers to the comprehensive use of modern science and technology for a region in the future for a period of time to forecast the temperature, humidity, wind, etc. In today’s society, the weather forecast has a significant influence on people’s production and living, and daily travel, agricultural production, natural disaster prevention and other fields are an integral part of the normal operation of modern society. In recent years, Shenzhen has been affected by typhoon [
1] and flood disasters, and accurate prediction of weather conditions can prevent flood disasters [
2]. The results of forecast weather conditions are used to assist weather warning systems and provide reasonable information for emergency response and contingency planning [
3]. Therefore, the Shenzhen daily weather forecast is of great significance in preventing natural disasters. Air pollutants can threaten human health by causing respiratory and cardiovascular diseases and even death [
4], while previous studies have shown that meteorology [
5] is an important determinant of atmospheric pollutant concentration. Among meteorological parameters, land surface temperature has a strong and lasting positive correlation with the concentration of air pollutants [
6]. One study showed [
7] that the concentration of atmospheric particulate matter is related to the daily wind speed, daily temperature and daily humidity. Therefore, accurate prediction of the maximum temperature, minimum humidity, wind speed and other meteorological indicators of the daily weather conditions of Shenzhen is of great significance to people’s healthy living in the city and to prevent the high concentration of air pollutants.
With the increasing scale of meteorological data, represented by big data, automatic and intelligent technology began to play an important role in the weather forecast [
8]. Therefore, people’s demand for improving the accuracy of future weather forecasts is increasing day by day. To improve the accuracy of forecasting weather conditions, one should make full use of various meteorological history data, since research on weather conditions previously found that most have seasonal trends and the weather forecast error of traditional time-series models, such as the ARIMA model, is bigger [
9]. With the rapid development of machine learning and deep learning technology, processing and prediction of massive data using independent methods such as artificial neural networks and the support vector machine has relatively good effects, but it is easy to fall into a local optimum. At present, it is found that the characteristic fluctuations in various data of weather conditions are obvious, and the forecasting of weather conditions has been widely used in academia. Support vector machine (SVM) was used to forecast the short-term wind speed of single wind speed data. The experiment proved that the prediction accuracy of the SVM is higher than that of other traditional combined models [
10]. The LSTM model was used to forecast the temperature in Nanjing, and the results show that the LSTM model is more accurate than other models [
11]. EMD was used to deal with nonlinear sequence problems and proved to have better performance in data processing than traditional methods [
12,
13,
14,
15]. Wind speed was decomposed into several components through the EMD sequence decomposition algorithm [
16,
17], a certain prediction model was used to predict each component, and the output of each model was aggregated to obtain the final prediction result. It was proved that the prediction model results after EMD decomposition are more accurate. EMD was used to input the decomposed components of short-term wind speed into an LSTM neural network for prediction [
18], which fully demonstrated the excellent performance of the EMD-LSTM prediction model. The EMD-LSTM model was used to forecast ammonia concentration, and a comparison experiment was conducted between a single-cycle neural network and the LSTM model. The results show that the EMD-LSTM model has higher forecasting accuracy [
19]. However, most of the above combination forecasting methods only consider the mapping relationship between single weather indicators, taking into account neither the long-term correlation of weather indicators nor the related factors of other weather indicators. Therefore, on the basis of previous studies, we added the interrelationship between weather conditions and long-term annual factors and achieved accurate prediction of multivariable weather conditions through experiments.
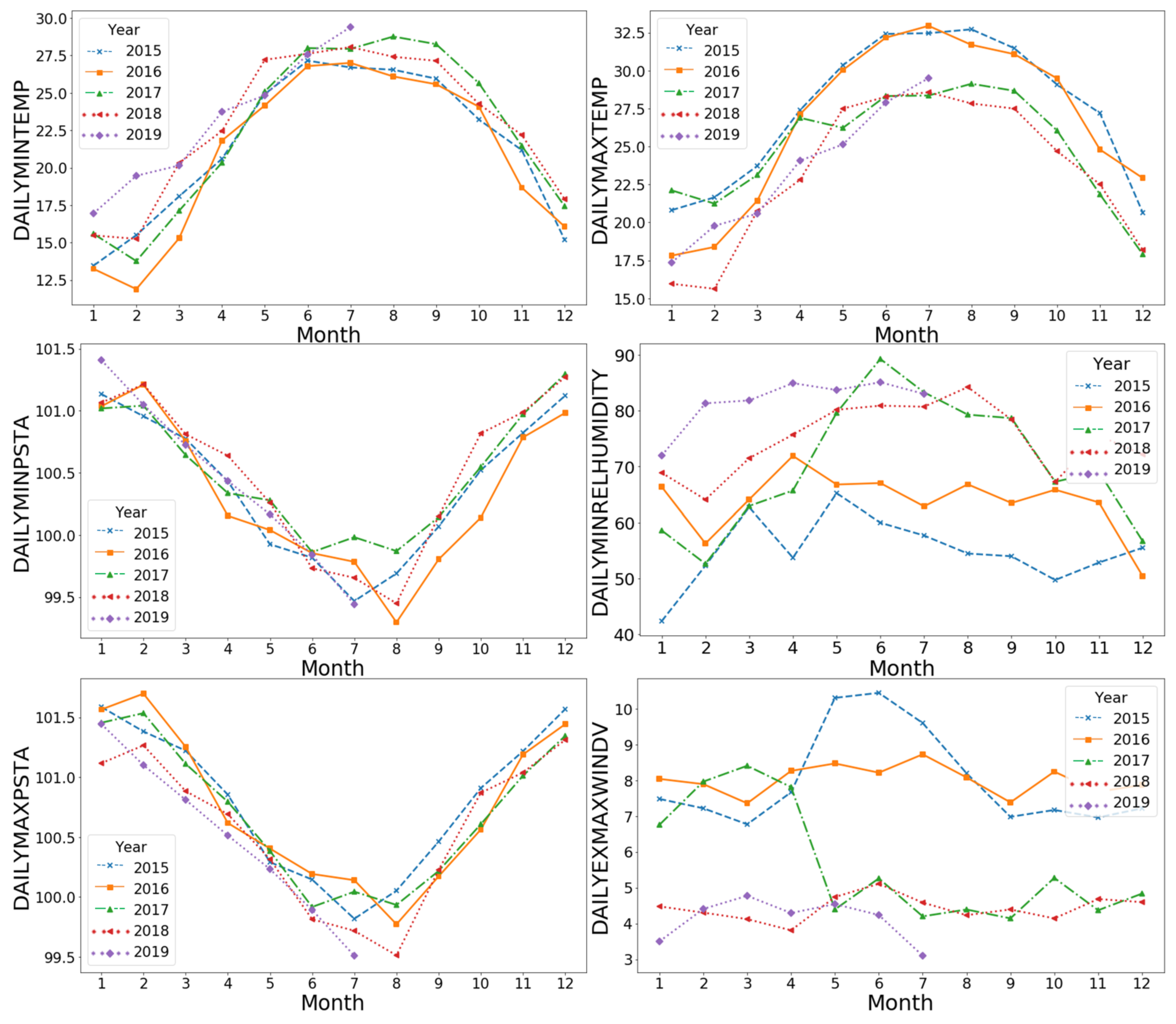
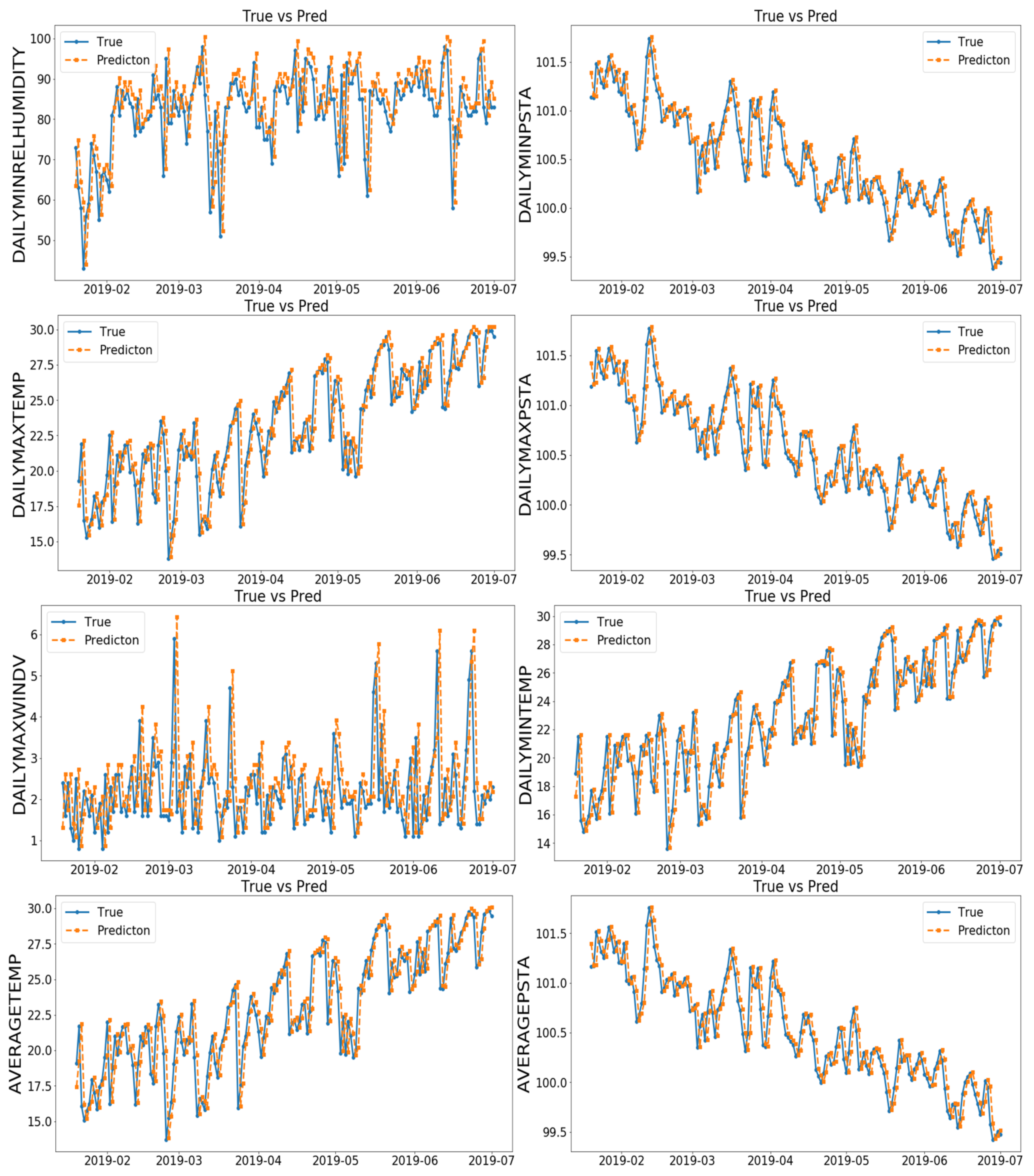
The meteorological conditions of Shenzhen are changeable, often with “sudden warm and cold” weather and a lack of relevant weather research. In this paper, the EMD-LSTM model was used to forecast the daily weather conditions of Shenzhen city by analyzing the historical weather data and related experiments. In order to reduce the use of a single machine learning method to predict the characteristics of a data error, this paper used empirical mode decomposition (EMD) on the various characteristics of weather data noise reduction decomposition, with stability and with different frequencies of multiple components and a residual error sequence, and picked out the greater influence on the characteristics of the original sequence to merge the data. Combined with the long- and short-term memory neural network (LSTM) in deep learning, multivariable forecasting was realized, so as to provide more accurate prediction of the minimum humidity, minimum air pressure, maximum temperature, maximum air pressure, maximum wind speed, minimum temperature, average temperature, average pressure and minimum temperature of daily weather conditions in Shenzhen.
5. Conclusions
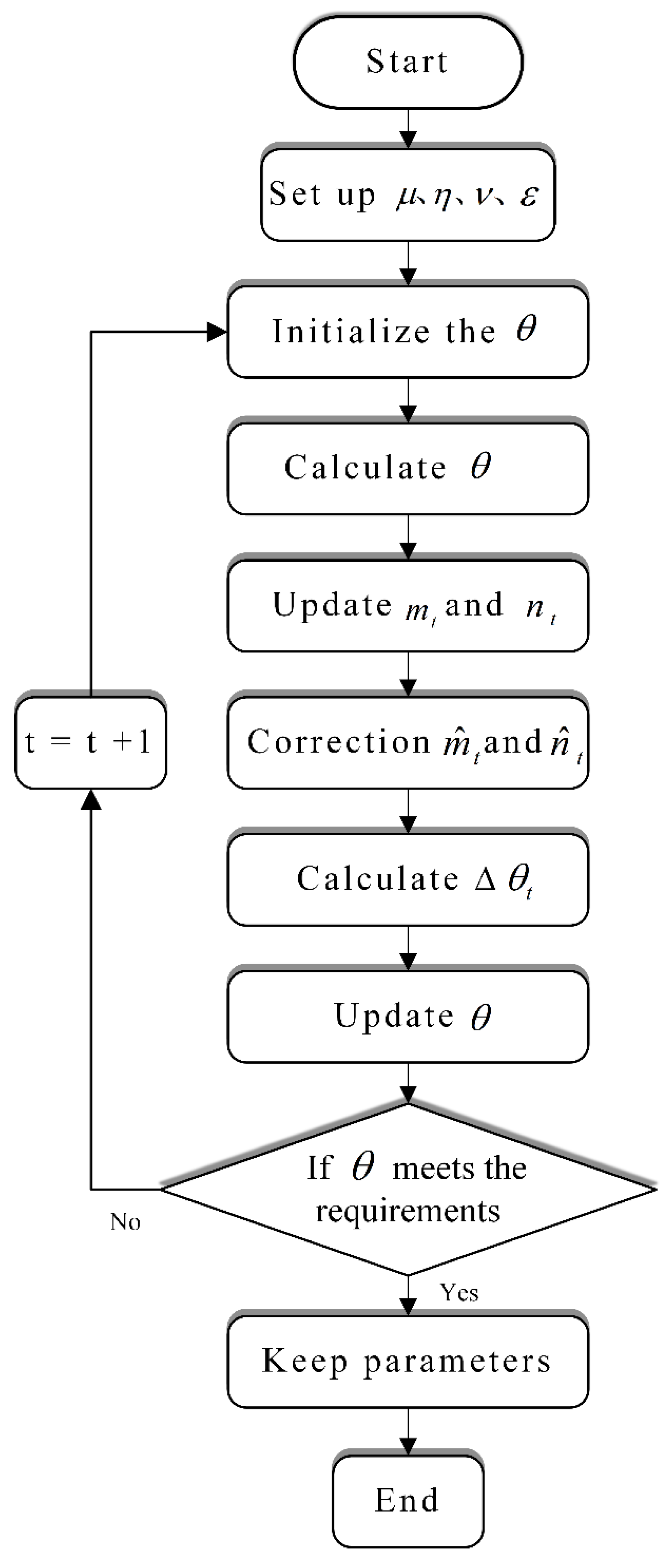
In order to improve the accuracy of weather forecasts, this paper proposes a fusion model based on a deep learning neural network of long and short memory. The minimum humidity, minimum air pressure, maximum temperature, maximum air pressure, maximum wind speed, minimum temperature, average temperature and average pressure were predicted under daily weather conditions in Shenzhen, China. The method of filtering the correlation coefficients of the components of each variable decomposed by EMD and then recombining the data into an LSTM network makes full use of the advantages of EMD in the decomposition of non-stationary data with seasonal trends and reduces the influence of data noise and seasonal fluctuations. Combined with the LSTM model, it has the advantage of “memory ability and forgetting ability” in time-series data processing, the grid search is used to find the optimal combination of hyperparameters, and the gradient descent optimization algorithm is used to find the optimal weight and bias of the model, so as to improve the prediction accuracy of Shenzhen’s weather characteristics. Four kinds of traditional machine learning models and four Kernel regression model experiments fully prove that the EMD-LSTM combined model designed in this paper is a more efficient and accurate model, which is suitable for weather prediction and can provide new ideas for weather prediction.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}