1. Introduction
The hydrological process by which the liquid water from water bodies and landmass is converted to vapor and transferred to the atmosphere is known as evaporation, which is a significant constituent member of the hydrological cycle. The driving factor for this process is the pressure gradient between the atmosphere–earth system [
1,
2]. Water scarcity has become a serious concern and evaporation losses have increased significantly during the last few decades; therefore, precise estimation of evaporation is crucial, particularly in regions of limited water resources [
3,
4,
5]. Evaporation losses alone account for 61% of the global precipitation. Daily pan evaporation (EP
d) has been extensively used in irrigation scheduling, water balance studies, sustainable water resources management, and hydrological modelling, etc. [
2,
6,
7,
8].
In most cases, evaporation is quantified using the direct approach (i.e., pan evaporimeter) [
9]. Pan-evaporimeter-based evaporation losses measurement is an ancient and widely used technique [
1,
10,
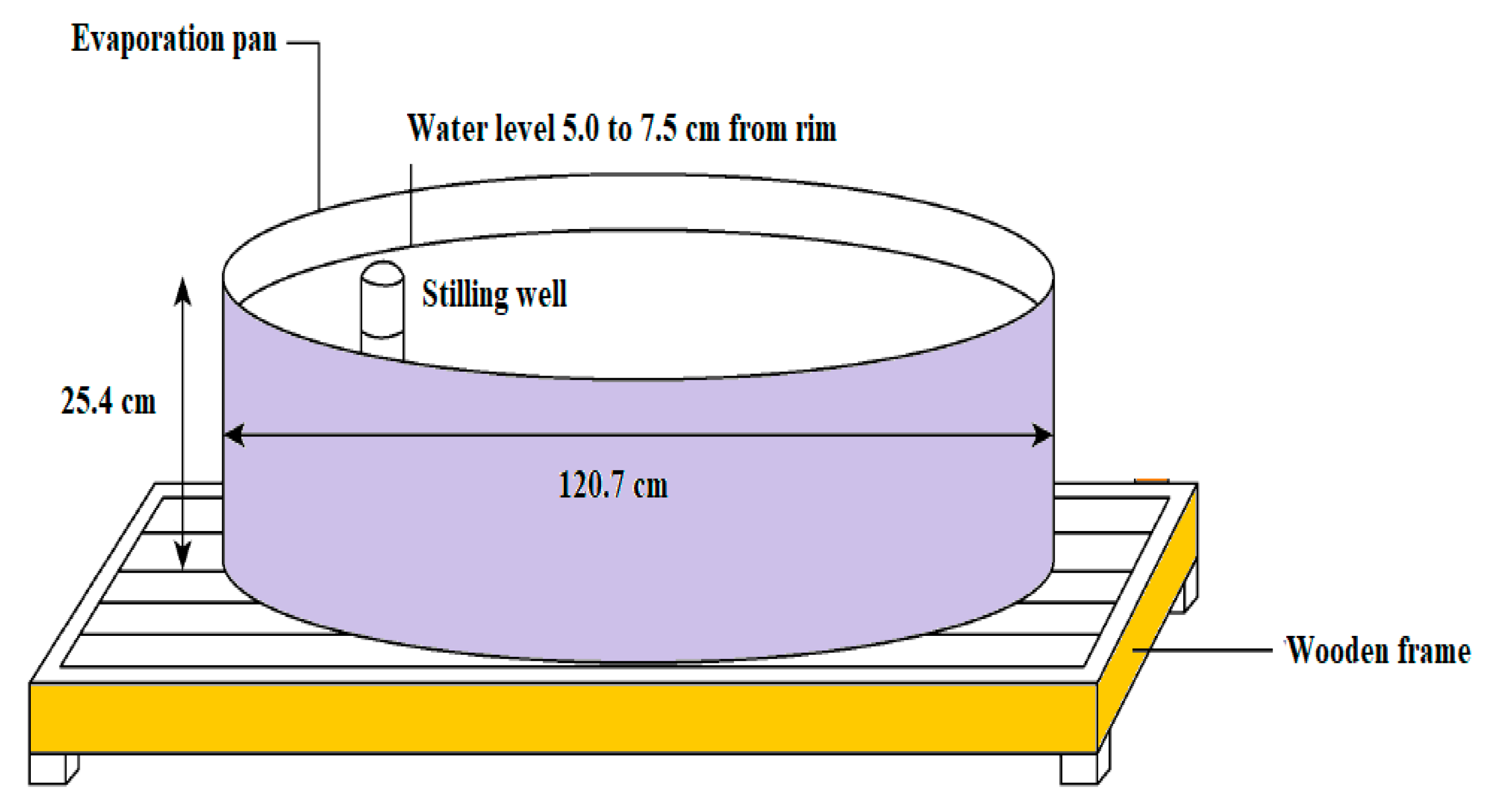
11]. The class A type pan, developed in the United States by the National Weather Service (NWS), has standardized dimensions having a diameter of 120.7 cm, depth of 25.4 cm, and placed at 15 cm above the ground surface [
1,
12]. Although pan evaporation gives realistic measurements, it has limitations in high initial and maintenance costs [
10,
11]. In the absence of direct measurement, complexities arising from near-surface climatic conditions pose difficulties in developing universal and explicit expressions to compute evaporation [
2,
13,
14]. Most of the meteorological variables, such as temperature (maximum and minimum), wind speed (WS), relative humidity (RH), vapor pressure and others have a substantial role in influencing the processes leading to evaporation [
1,
15]. Therefore, these variables in their individual capacities or in combinations contributed to various models and approaches to estimate evaporation in areas where direct measurements were not done.
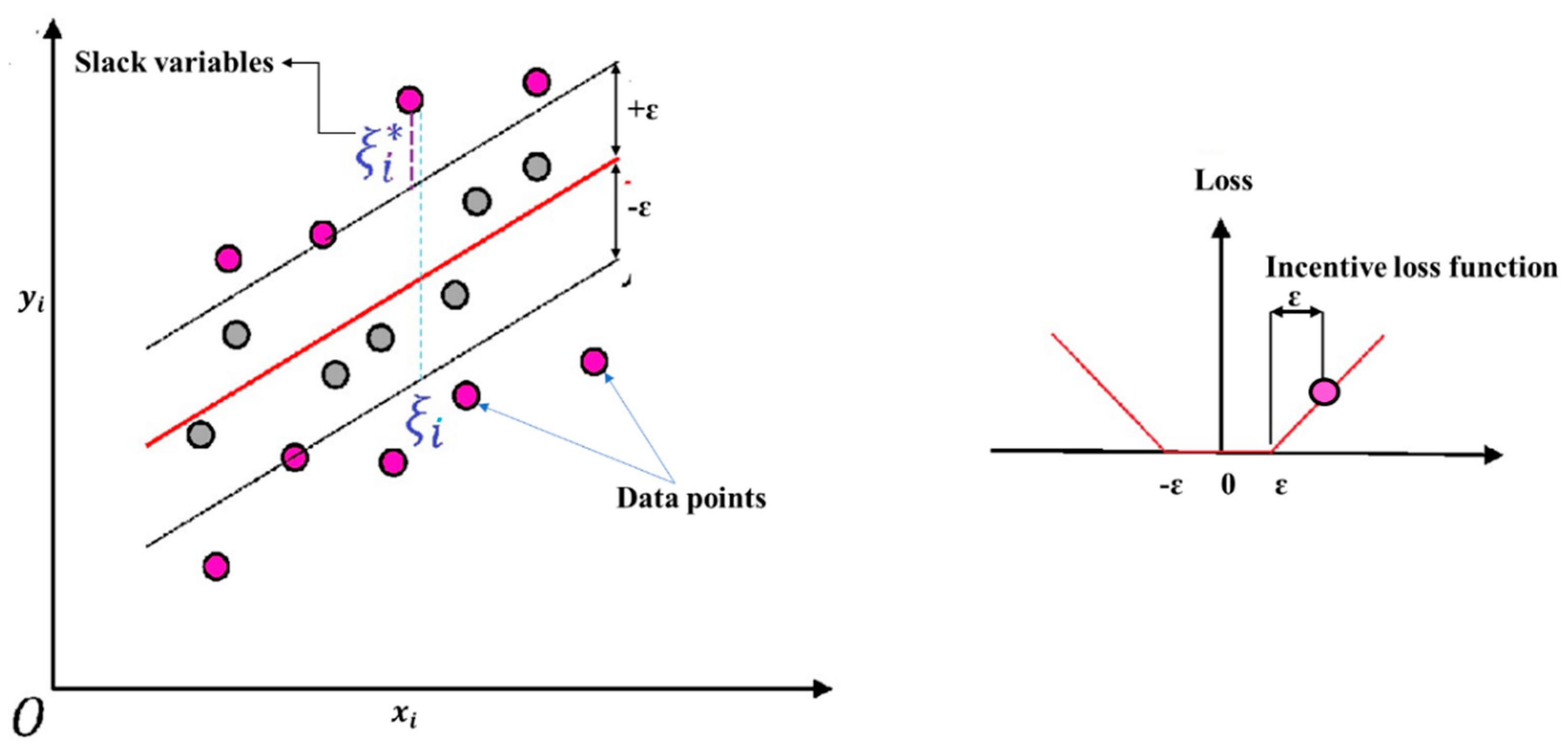
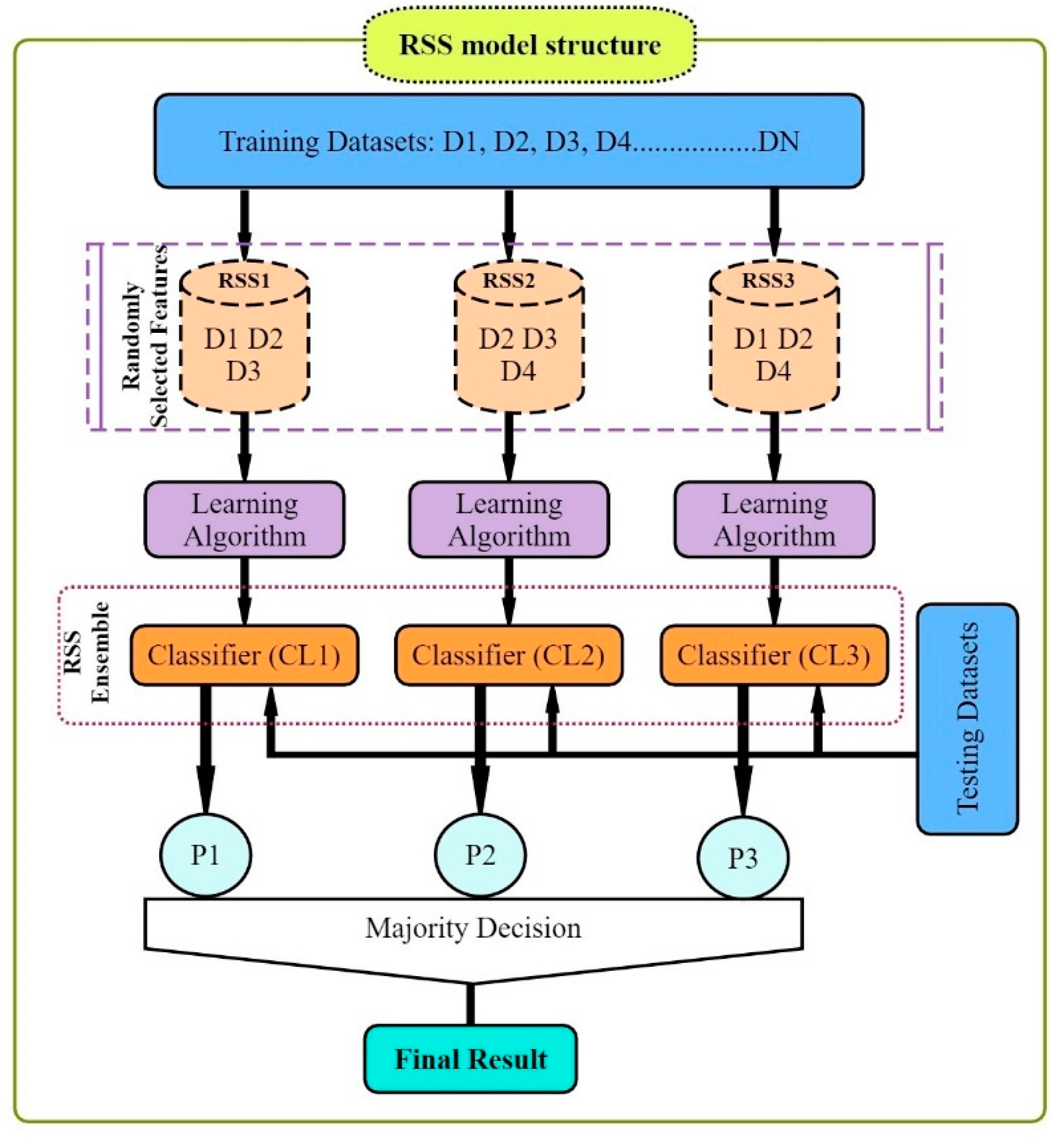
In the advent of soft computing tools, developments in data-driven models using meta-heuristic algorithms have been incorporated to model various hydrological processes. The most common meta-heuristic algorithms are support vector machine (SVM) [
2,
8,
10], random tree (RT), artificial neural networks (ANNs), M5 pruning tree (M5P) [
2,
16,
17], reduced error pruning tree (REPTree), multivariate adaptive regression splines (MARS) [
2,
13,
16], extreme learning machine (ELM), gene expression programming (GEP), and random subspace (RSS). Furthermore, their hybrids with a variety of algorithms have been efficiently used to estimate pan evaporation [
14,
18,
19].
Deo et al. [
20] developed and evaluated the relevance vector machine (RVM), ELM, and MARS algorithms in Amberley weather station, Australia. The results showed a small difference in the prediction among selected algorithms. However, RVM showed to be more accurate in terms of predicting monthly evaporation than other methods. Tezel and Buyukyildiz [
18] estimated monthly pan evaporation using ɛ-SVM and ANNs algorithms during the period 1972 to 2005 for Beysehir meteorological station, located in the southwestern part of Turkey. The study concluded that both algorithms had similar performance and showed superiority over the Romanenko and Meyer methods. A similar attempt was made by Al-Mukhtar [
12] and compared the effectiveness of distinct machine learning algorithms in modelling monthly pan evaporation for different agro-climatic regions (i.e., Baghdad, Basrah, and Mosul) in Iraq. They concluded that the weighted k-nearest neighbor model gave the best prediction with statistical criteria R
2, RMSE, MAE, NSE, and percent bias (PBIAS) values of 0.98, 26.39, 18.62, 0.97, and 3.8, respectively. Pammar and Deka [
21] investigated hybrid modeling using discrete wavelet transform (DWT) and support vector regression (SVR) for pan evaporation estimation at two different climatic conditions, namely, Bajpe and Bangalore, Karnataka, India. The study concluded that DWT–SVR-estimated pan evaporation values were more accurate for the humid station, i.e., Bajpe, than the semi-arid station, i.e., Bangalore. Other wavelet analysis techniques, such as the least-squares wavelet analysis were successfully applied to analyze and forecast climate and hydrologic data [
22]. Several studies [
1,
2,
5,
8,
10,
21] applied various meta-heuristic algorithms for estimation of pan evaporation in specific agro-climatic regions and endorsed the applicability of meta-heuristic algorithms.
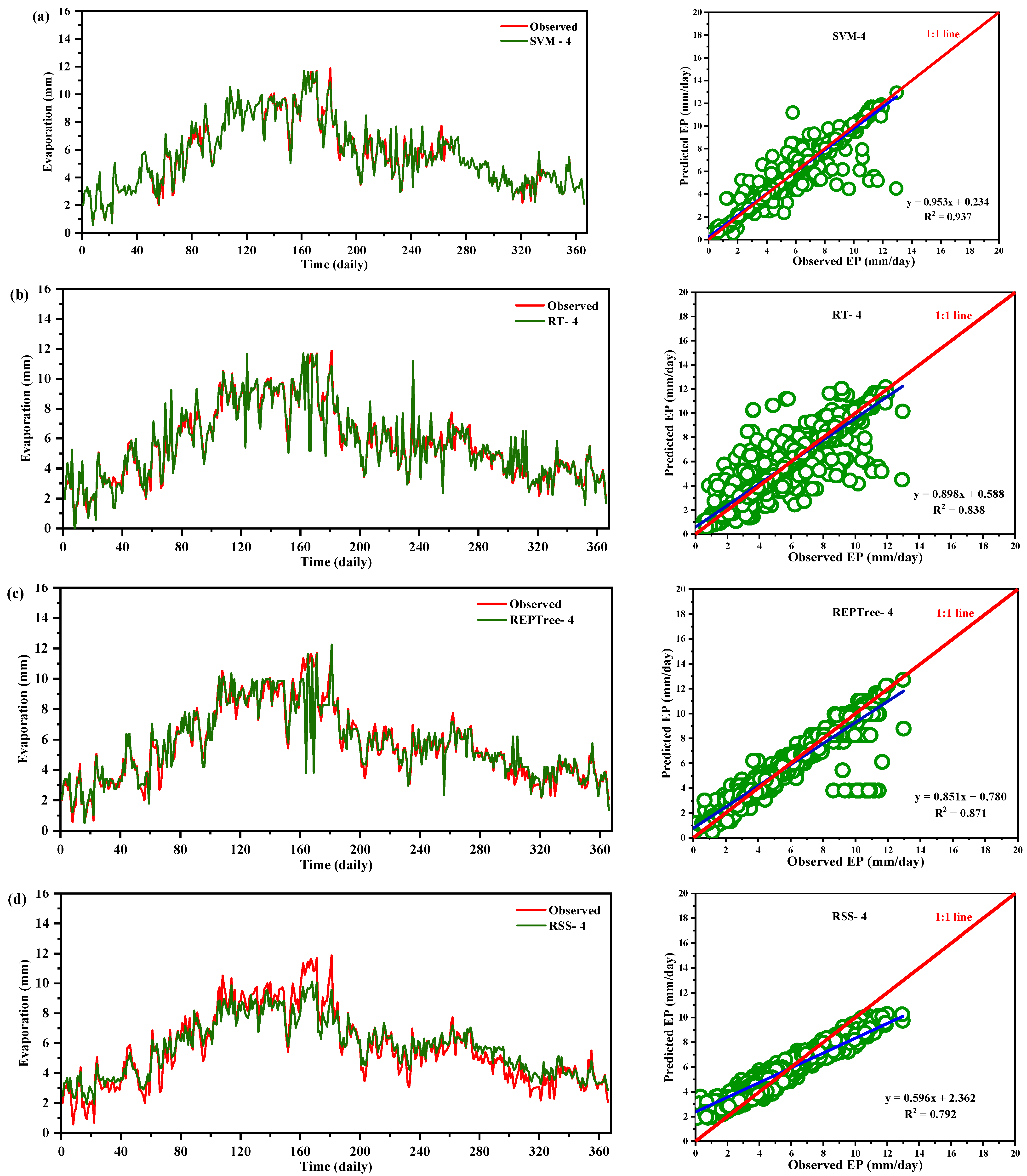
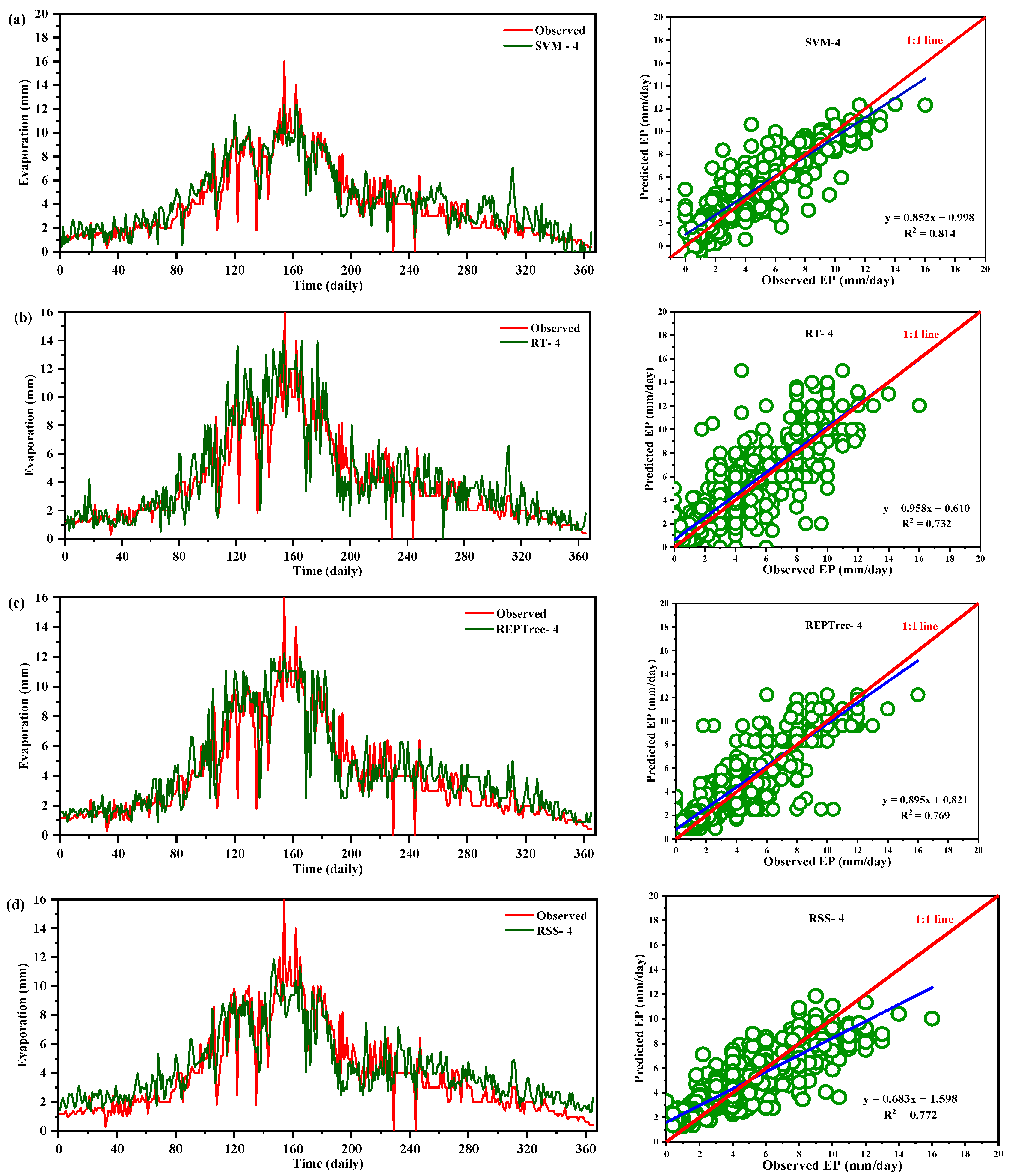
In the present state of soft computing wisdom, there are obscured or insufficient references to studies using meta-heuristics/artificial intelligence tools in the evaporation modeling in the Indian context especially covering the northern part. Thus, this study aims to evaluate and compare the predictability of four meta-heuristic algorithms, i.e., SVM, RT, REPTree, and RSS as predictive tools to estimate pan evaporation in two diverse agro-climate conditions in India. The predictive efficacies of the algorithms were compared in quantitative and qualitative terms to find the best candidate algorithm suitable for evaporation modeling for this region.
4. Discussion
The results obtained from the present study were also validated with other recent work [
2,
8,
19,
46] conducted across different continents of the world. Al-Mukhtar [
12] evaluated two different machine learning techniques (i.e., SVM and backpropagation network) in the estimation of daily evaporation values. Results revealed that applied SVM machine learning algorithms offer great ability to predict the daily pan evaporation values and can be used as a promising alternative for pan evaporation estimation. The accuracy of five machine learning methods (i.e., MARS, multi-model artificial neural network (MM-ANN), SVM, multi-gene genetic programming (MGGP), and M5Tree) to predict the monthly pan evaporation in India was evaluated by Malik et al. [
2] which also revealed a similar outcome with SVM being more prolific. In this study, they observed that the MM-ANN and MGGP algorithms had superior prediction performance when compared with the MARS and SVM algorithms, as well as the M5Tree method, as shown by their high levels of RMSE. Tezel and Buyukyildiz [
18] evaluated the ANN, radial basis function network (RBFN), and SVM machine learning algorithm approaches for monthly pan evaporation at the Beysehir meteorological observatory, which is situated in Turkey’s southwestern region. Based on the performance indicators selected in the study, both the algorithms ANN and ɛ-SVM produced similar results. Chen et al. [
19] investigated the performance of SVM for the prediction of monthly pan evaporation at six different stations located in the Yangtze River basin of China. The study concluded that the SVM techniques showed superiority over the traditional methods for estimating pan evaporation. The present study also confirmed that the SVM machine learning algorithm has higher accuracy than other applied algorithms in the prediction of daily pan evaporation (EP
d) in diverse agro-climatic settings.
5. Conclusions
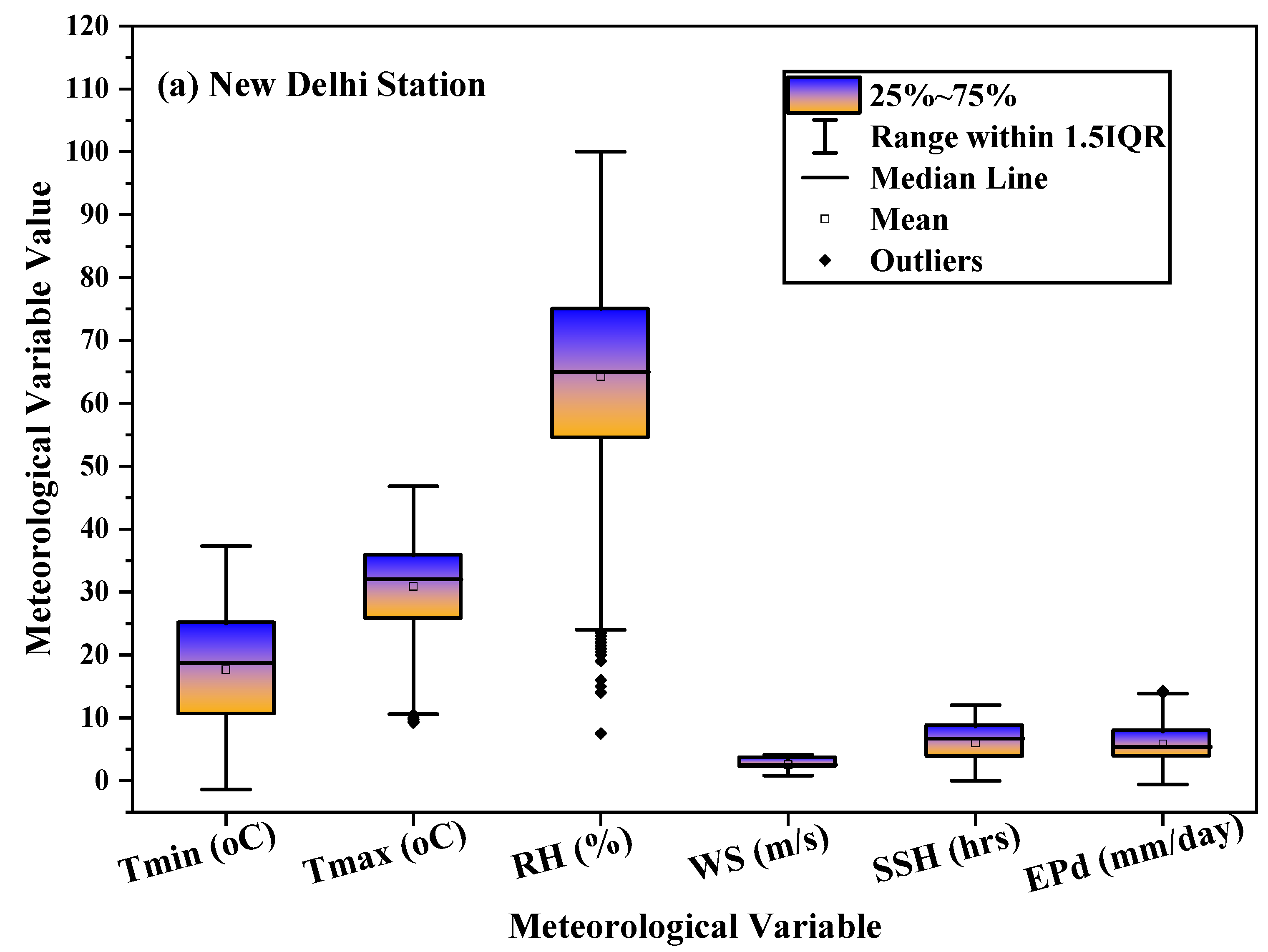
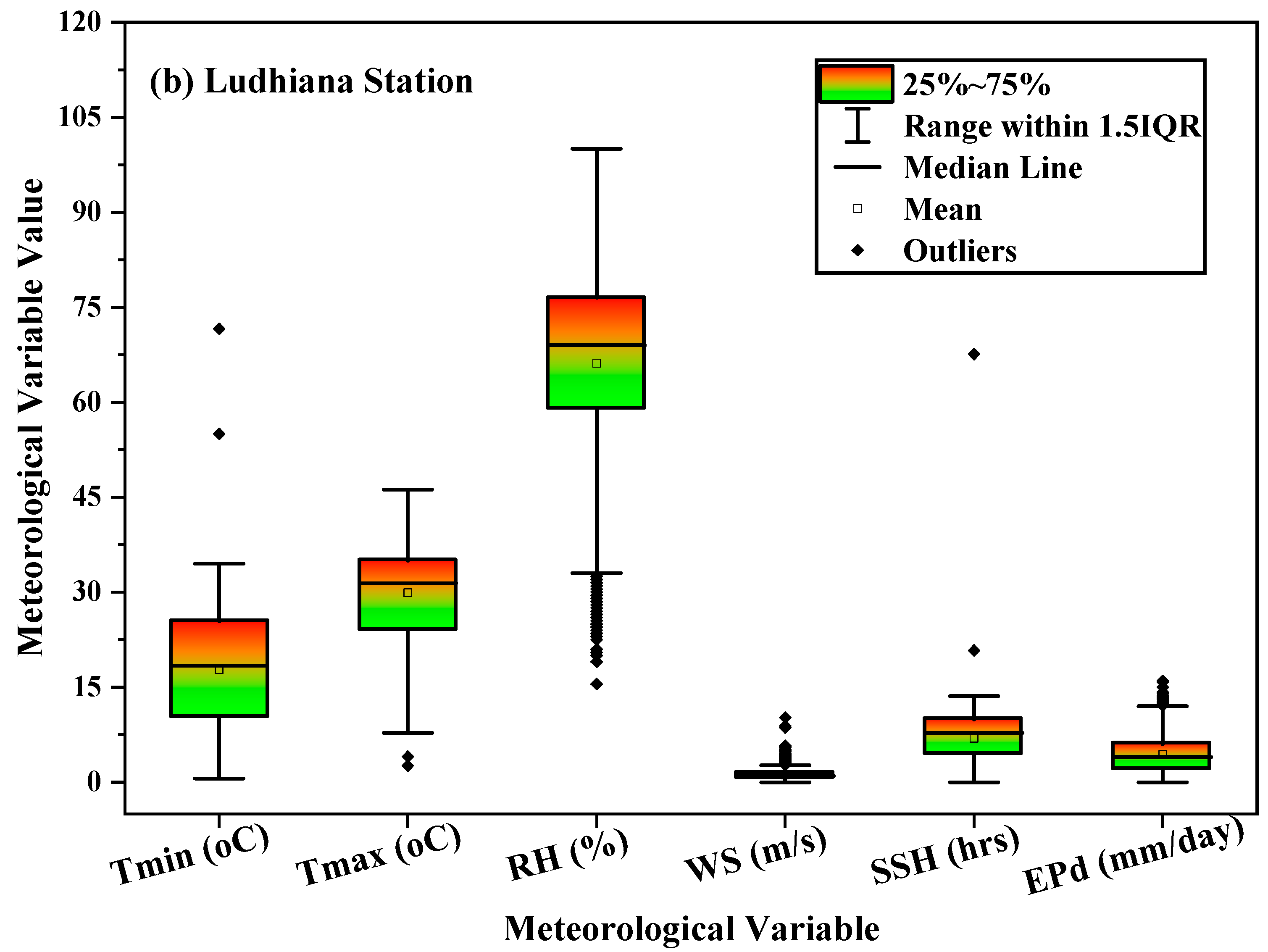
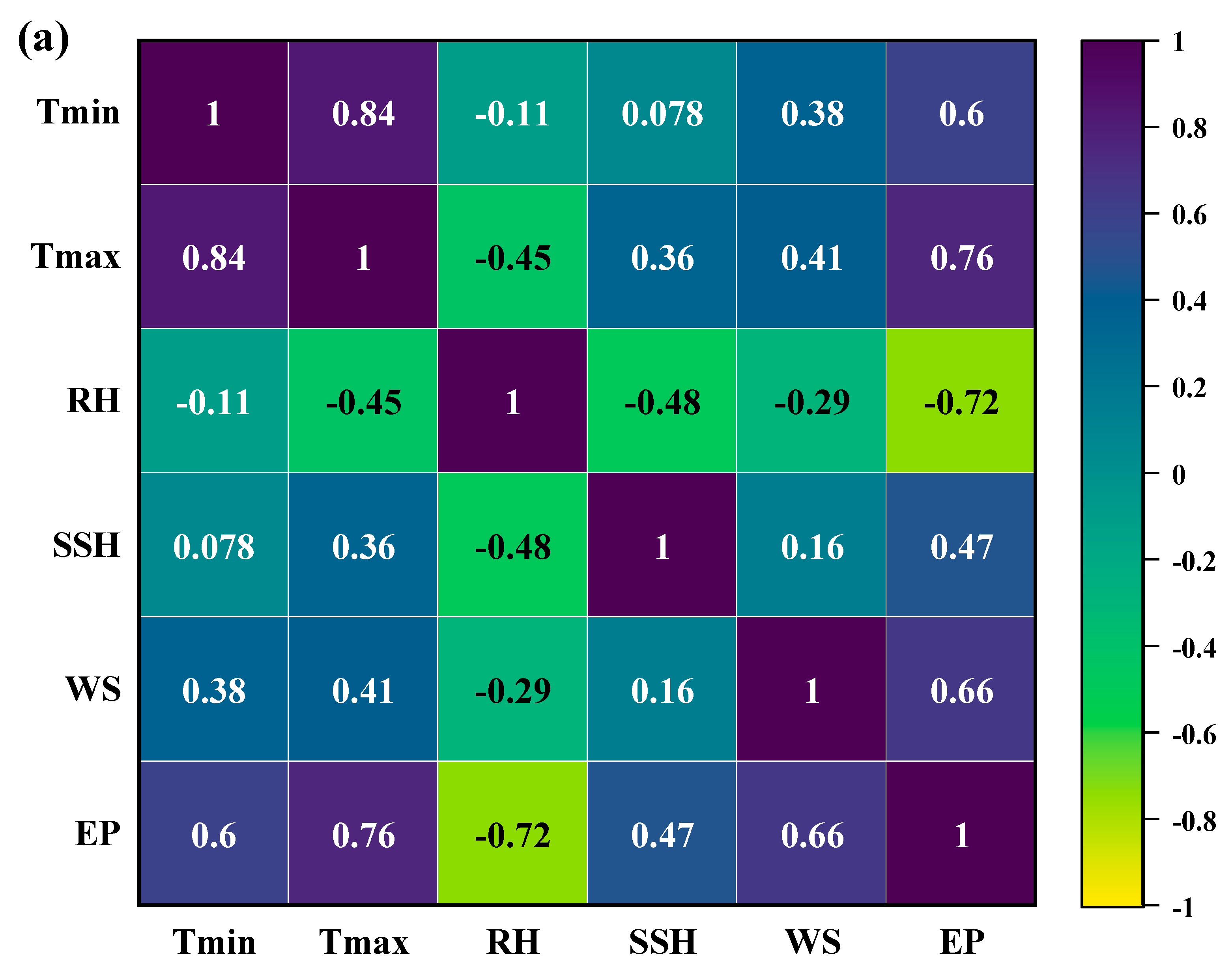
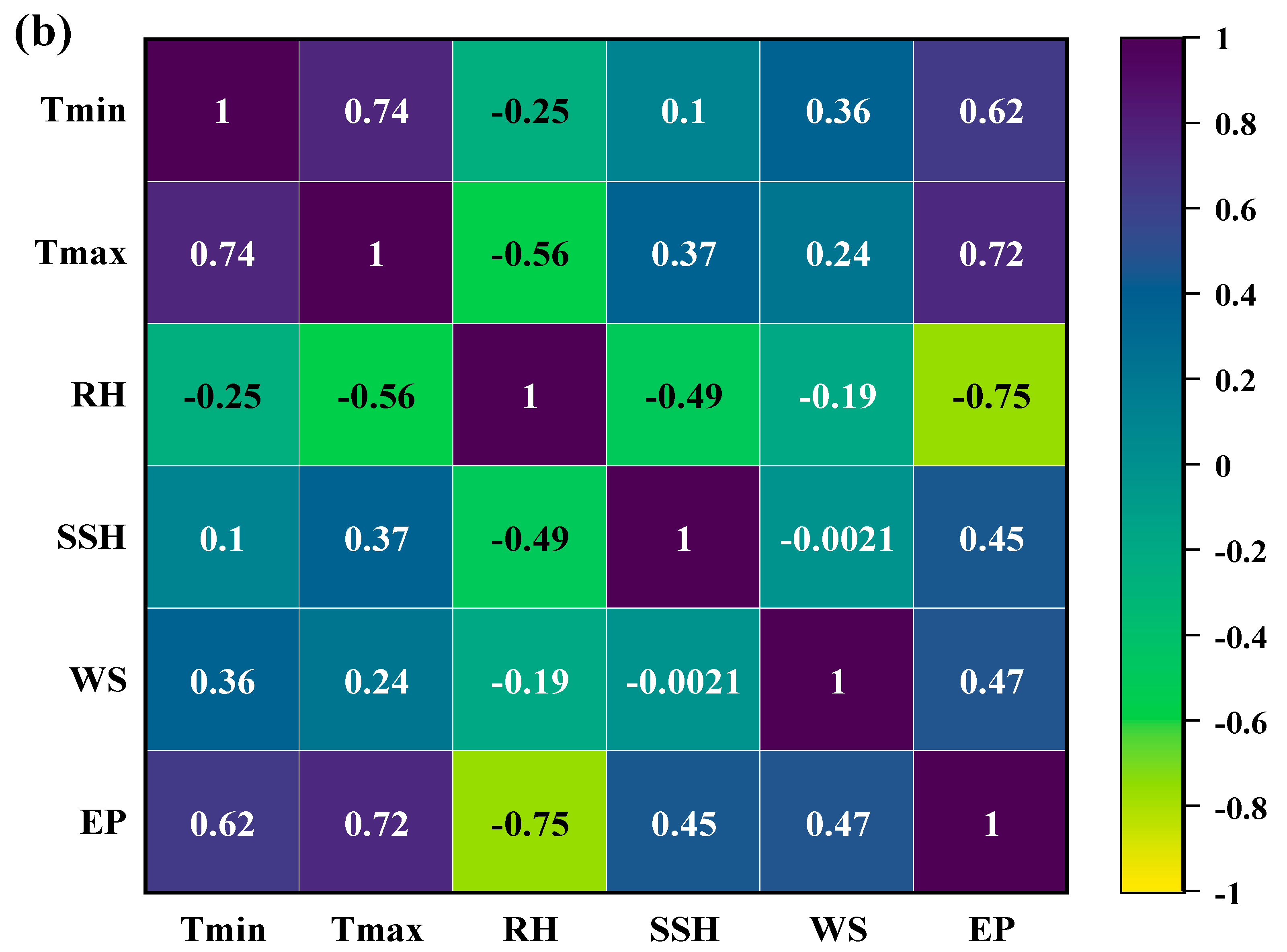
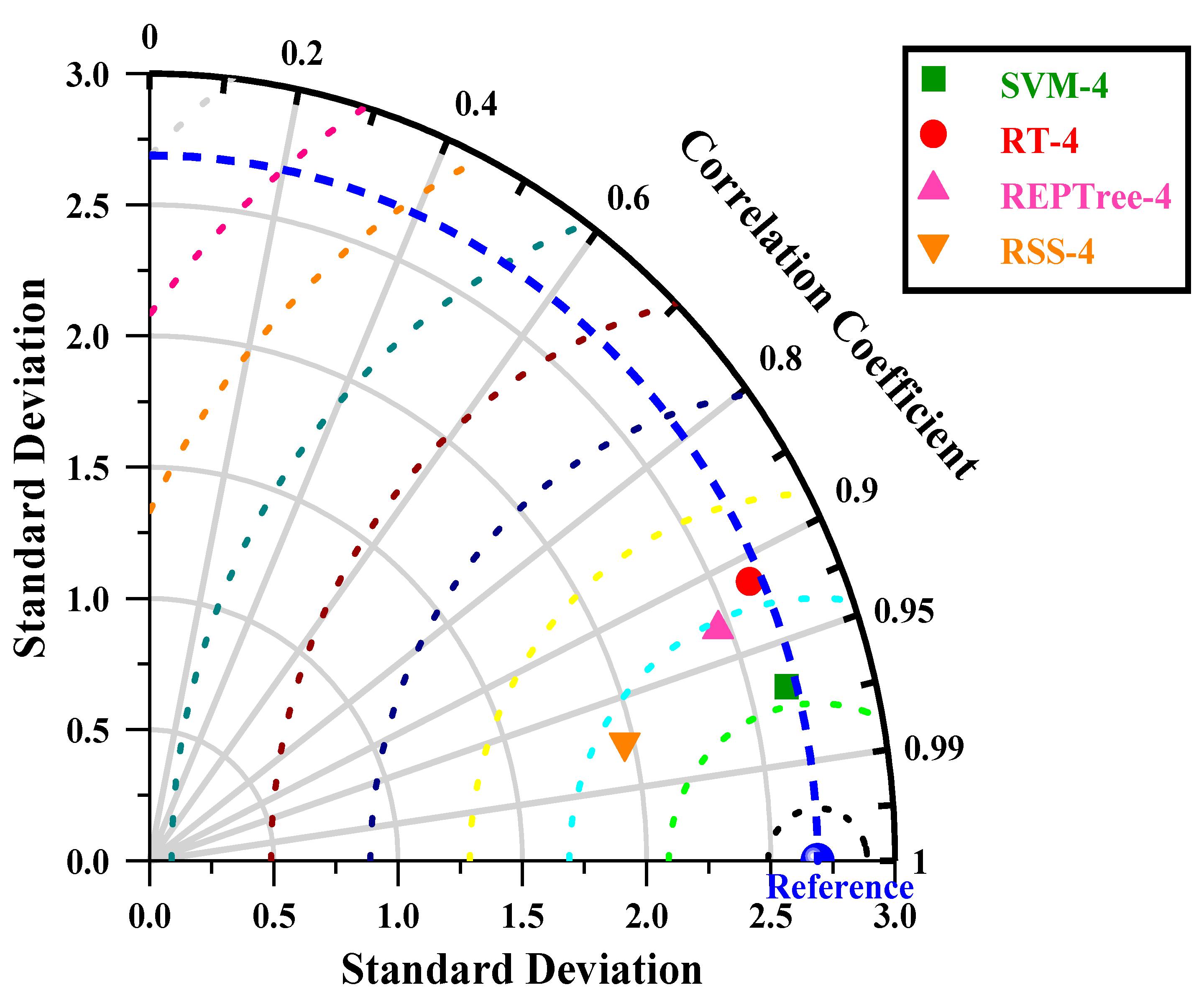
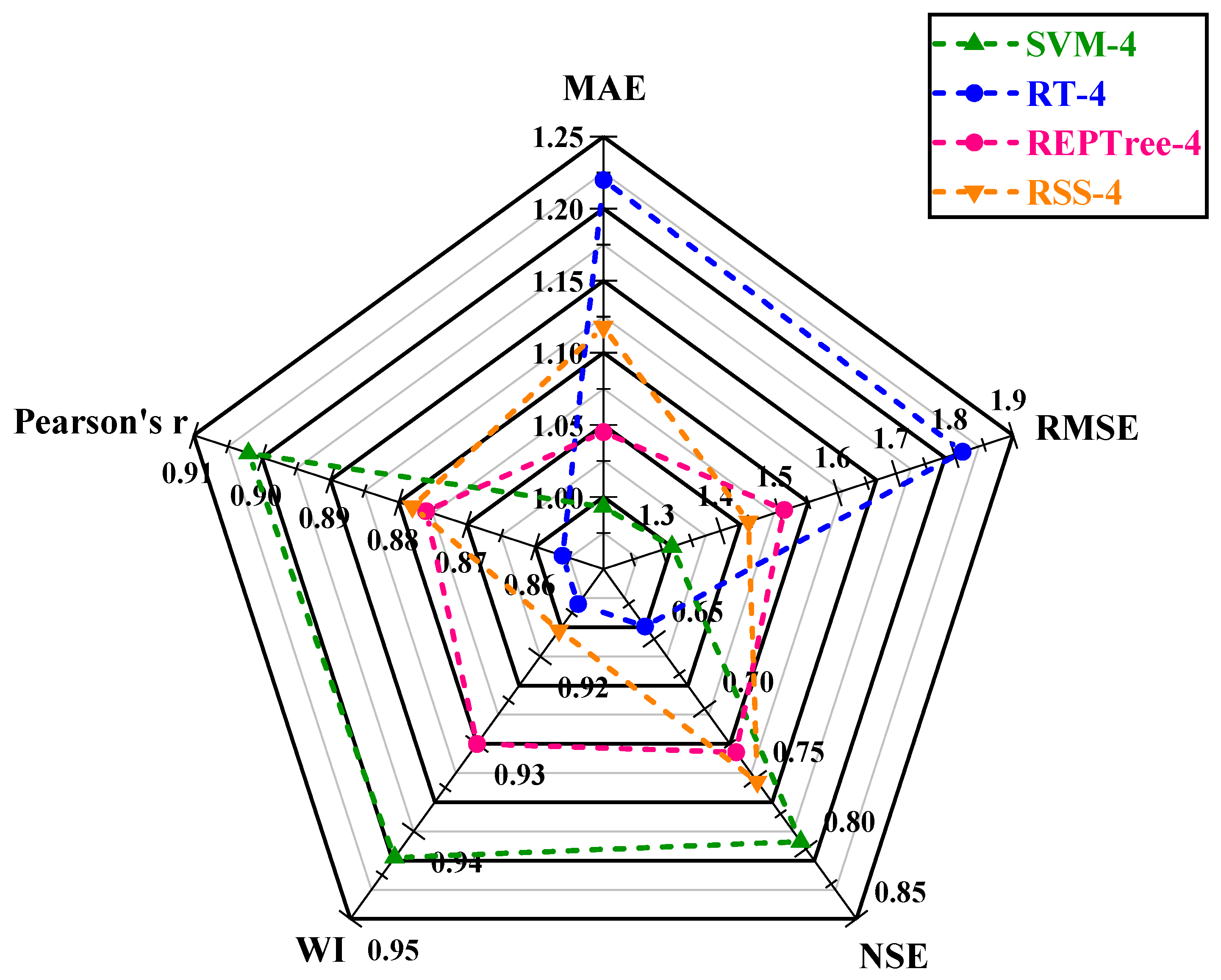
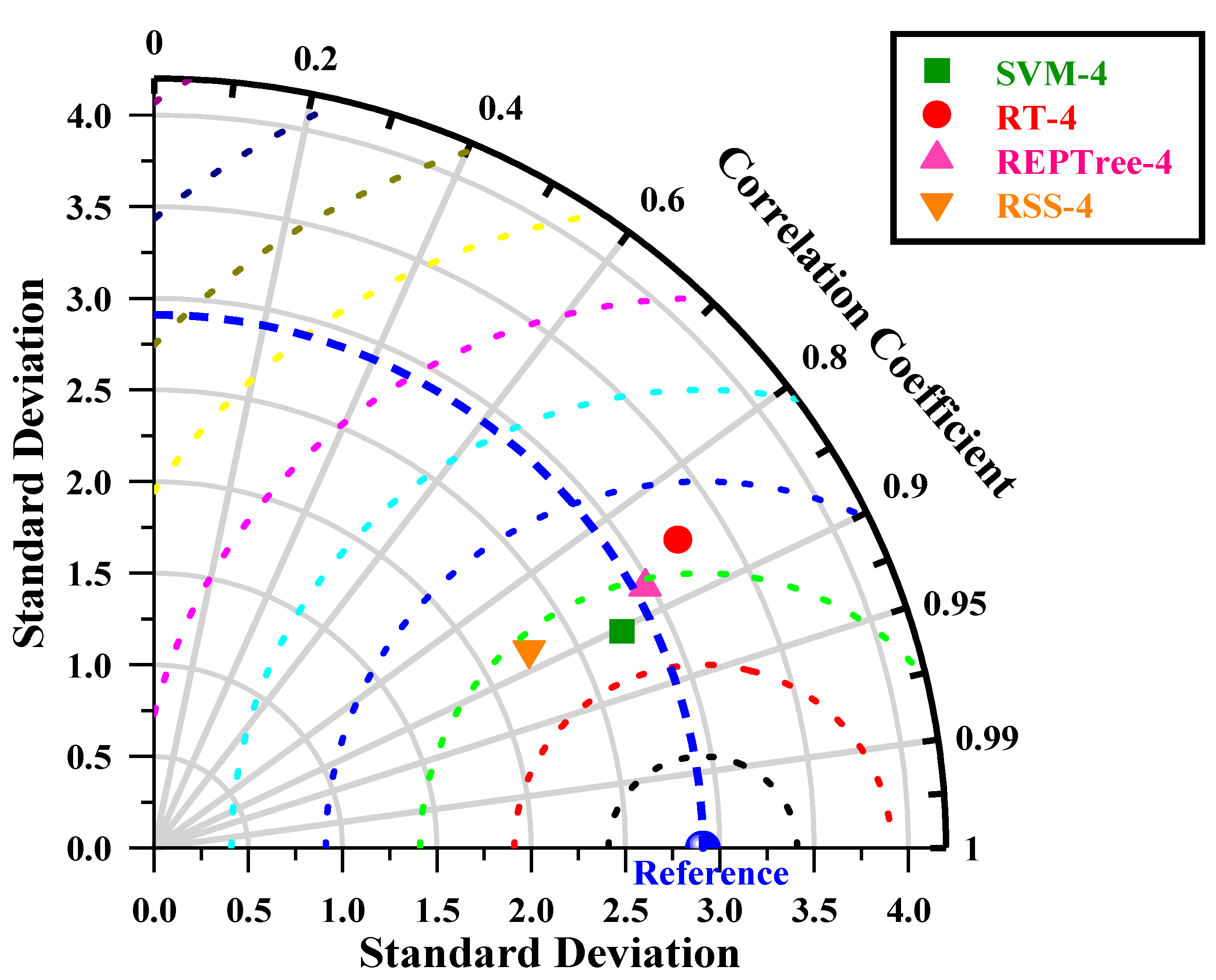
This study evaluated the potential of meta-heuristic approaches in forecasting daily pan evaporation (EPd) at two different meteorological stations. Four models were developed: support vector machine (SVM), random tree (RT), reduced error pruning tree (REPTree), and random subspace (RSS). Furthermore, the assortment and influence of input combinations on the performance of the meta-heuristic algorithms in EPd prediction were carried out through regression and sensitivity analysis. The results of regression analysis on all input parameters showed that Tmin, RH, SSH, and WS, by having absolute standard coefficients (0.404/0.393, −0.516/−0.533, 0.132/0.147, and 0.336/0.223), were identified as the most influential input parameters at the New Delhi and Ludhiana stations, respectively. The performance of applied models was assessed using well-known performance indicators (i.e., MAE. RMSE, NSE, WI, and r) and interpreting the visual graphics. The SVM algorithm outperformed the other applied algorithms during the testing period and is consistent over the two locations tested representing two diverse climatic zones of India and mostly covering the northern region. Thus, SVM algorithms may be adopted for the estimation of daily pan evaporation in the selected two different climatic conditions. Overall, the developed methodology allows prediction with a model trained on the available meteorological data as input, which could be an interesting tool for irrigation engineers, hydrologists, and environmentalists for irrigation scheduling and sustainable management of available water resources.


 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}