
Spatiotemporal Analysis of Haze in Beijing Based on the Multi-Convolution Model



Abstract
:1. Introduction
2. Data Processing and Calibration
2.1. Remote Sensing Image Processing
- (1)
- Real-time PM2.5 concentration was released by ground monitoring stations in Beijing in 2013 and 2014. The data in 2014 are converted into haze levels according to the correspondence table of haze concentration and haze level, which formed a training set of multi-convolution combined haze-level prediction models. The data in 2015 is also converted to haze levels to test model accuracy.
- (2)
- MOD02_1km data for the Beijing area in 2013 and 2014. The MOD02_1km data is a remote sensing satellite image containing latitude and longitude information in the Beijing area and is the model input.
- (1)
- Radiation correction. We use ENVI 5.0 to automate the radiation correction of MOD02_1km data.
- (2)
- Geometric correction. We use the MODIS data processing tool, Georeference MODIS in the ENVI software, to geometrically correct the data of the emissivity channel. In the calibration, we select the Beijing coordinate system in World Geodetic System 1984 (WGS-84) standard to geometrically correct the emissivity file and establish Ground Control Points (GCPS) as the standard for other channels to maintain consistent geometric correction results. Then we use GCPS generated by the emissivity to correct the reflectance file. After reading the GCPS, the Triangulation correction method and the Bilinear resampling method are selected so that the correction result of the reflectance can match the emissivity.
- (3)
- Area extraction and synthesis. According to the administrative area of Beijing: 39.4° N–41.1° N; 115.4° E–117.4° E, we cut the administrative regional geographic graphic files in ENVI software to obtain satellite images of the Beijing area. Next, we use the same method to cut the emissivity file and reflectivity file of the satellite image, then place the file of the emissivity channel on the top, and the reflectivity channel file on the bottom. Finally, we synthesize the image to obtain the full channel satellite image with the same administrative scope and uniform size.
- (4)
- RGB image synthesis. The processed satellite image contains multiple channels, where channels 1–7 monitor the edge of the land and cloud. The wavelength and spatial resolution of each channel are shown in Table 1. We want to convert satellite images into three-channel RGB images by combining multiple suitable channels. The wavelength range of red light is between 622 and 780; green light is between 492 and 577; blue light is between 455 and 470. Comparing the visible light and satellite channel information, we synthesize the satellite’s channel 1, channel 4, and channel 3, and the synthesized results are shown in Figure 1a,b.
- (5)
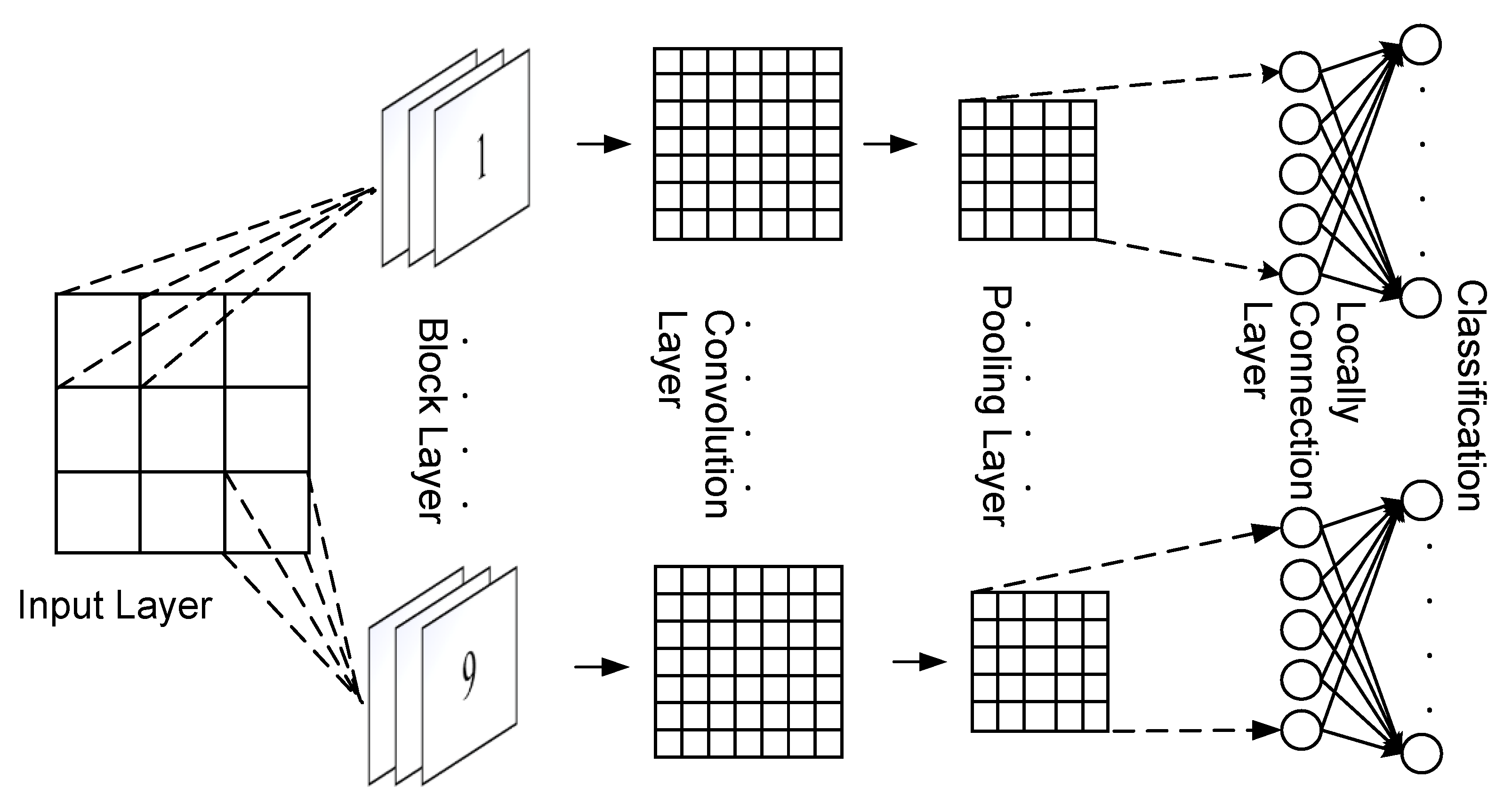
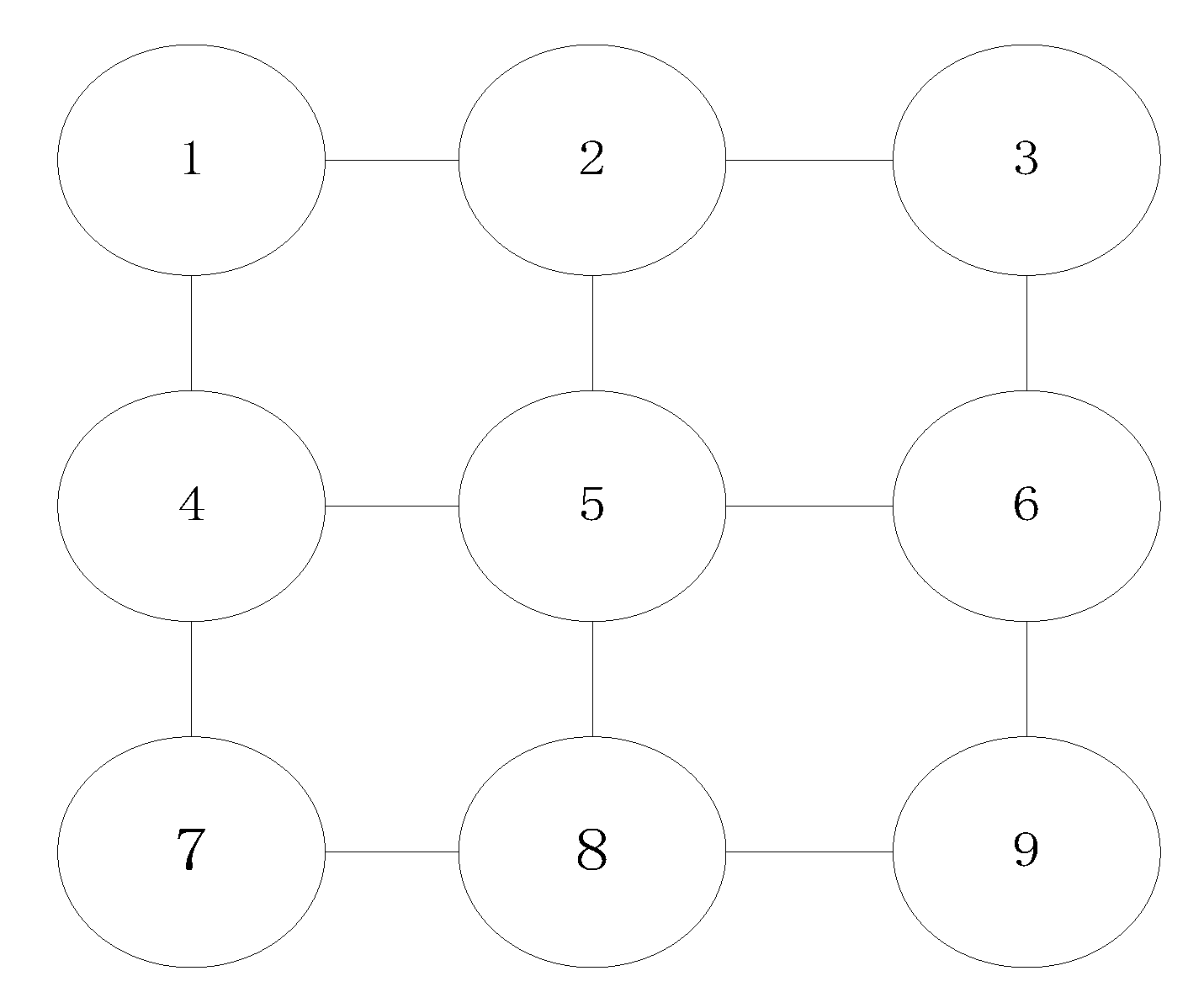
- Image cutting: We cut the satellite image into nine equally sized blocks, as shown in Figure 1c. Every block of the image contains an actual region of Beijing. Thus, different blocks are adjacent from spatial relationships, which helps us study the haze’s spatial evolution.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Channel | Wavelength Interval (nm) | Spatial Resolution (m) |
|---|---|---|
| 1 | 620–670 | 250 |
| 2 | 841–876 | 250 |
| 3 | 459–479 | 500 |
| 4 | 545–565 | 500 |
| 5 | 1230–1250 | 500 |
| 6 | 1628–1652 | 500 |
| 7 | 2105–2155 | 500 |
| Block | Administrative Divisions |
|---|---|
| 1 | Yanqing |
| 2 | Huairou |
| 3 | Miyun |
| 4 | Changping + Haidian (Metropolitan Area) |
| 5 | Shunyi + Chaoyang (Metropolitan Area) |
| 6 | Pinggu |
| 7 | Mentougou + Fangshan |
| 8 | Metropolitan Area + Daxing |
| 9 | Tongzhou |
2.2. Haze Level Transformation
3. Method
3.1. Joint Structure of Multi-Convolution Neural Networks
3.2. Spatial Autocorrelation Analysis of Haze Concentration
3.2.1. Global Moran’s I
3.2.2. Local Moran’s I
4. Results
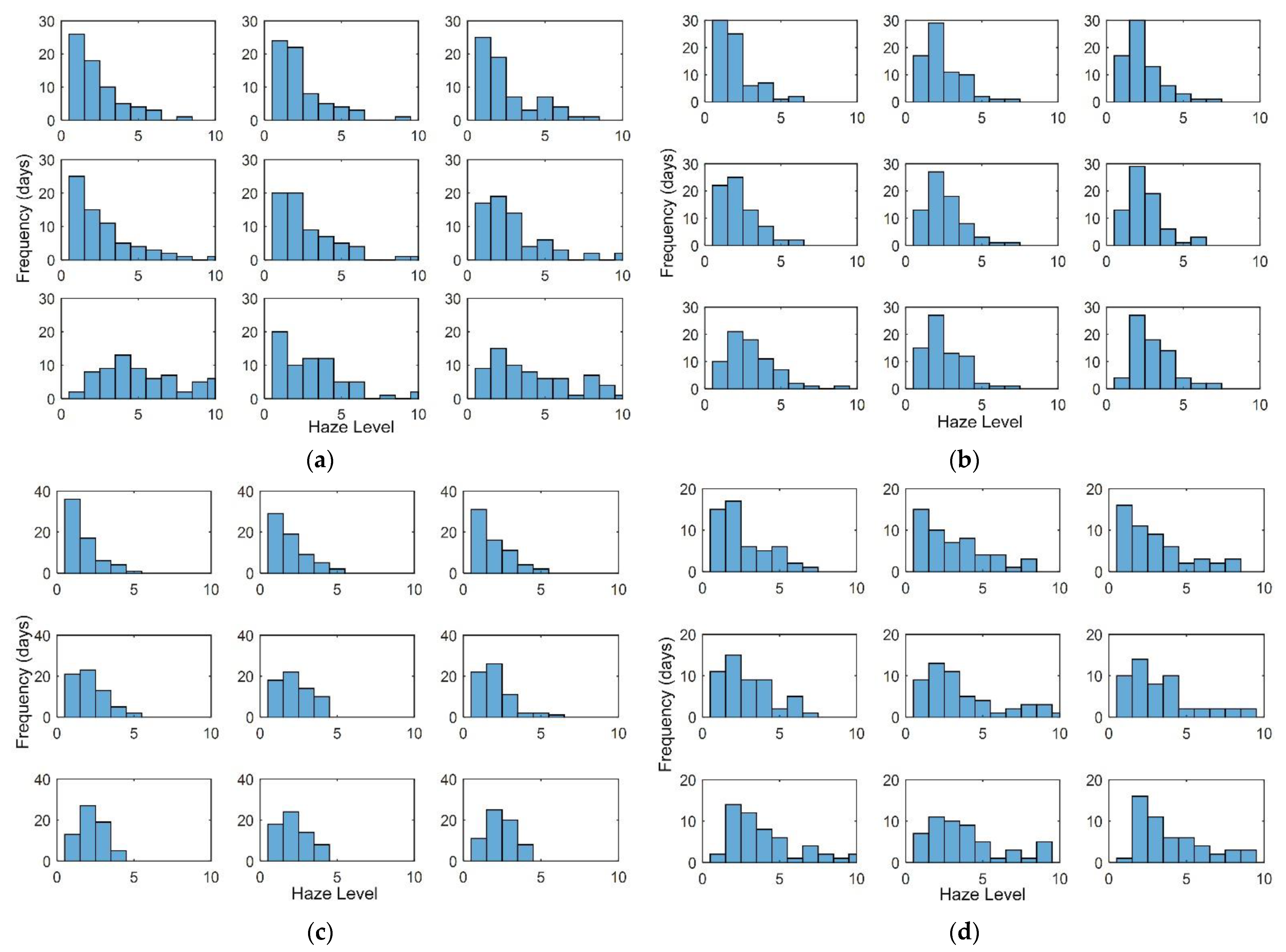
4.1. Analysis of Output Multi-Convolutional Neural Network
- The concentration of haze in winter is generally high, especially in Block 7, Block 8, and Block 9. Block 7 is average in different levels and has the most severe haze pollution.
- There is a high similarity among Block 3, Block 4 and Block 5, and they have the lowest average of haze levels.
- There is a haze with super-high concentration levels in the middle and southern regions, and these areas have more daily pollution such as that from vehicle emission and urban construction due to high population density.
- 1.
- Overall haze levels in spring are low. Block 1 has the lowest haze level, mainly concentrated between level 1and level 2. The concentration in the blocks adjacent to Block 1 is low, and the trend of increasing concentration follows the increasing speed of distance.
- 2.
- The most extensive average haze level among the nine blocks occurs in Block 7, whose haze levels are concentrated at levels 3 and 4. Block 7 also has severe haze and has low similarity to the surrounding area.
- 3.
- Block 1 and Block 4 have high similarities. Likewise, block 2 is similar to Block 3, and there is a high similarity between Block 5 and Block 8 and Block 9.
- 1.
- Summer is the season with the weakest pollution in a year. In haze distribution, the pollution in the central region is more severe than in the upper region and weaker than in the lower region. The lower region has the most polluted air and the pollution decreases towards the upper region.
- 2.
- All the haze levels in summer are under level 5. The Block with the lowest average concentration is still Block 1. Block 7 and Block 9 have the highest average concentration.
- 3.
- Blocks 4, 7, 8, and 9 exhibit a high correlation, and Blocks 1, 2, and 3 show a high similarity.
- 1.
- The concentration of haze in autumn is generally high with decreasing low levels and increasing severe haze pollution.
- 2.
- Blocks 1, 2, and 4 have mainly low levels, while other blocks have higher haze levels, such as level 8 or level 9.
- 3.
- Block 1 and Block 4 have high similarity, Block 2 and Block 3 have high similarity, Block 5 is similar to Block 6, and the three blocks in the south have high similarity.
4.2. Results of Spatial Autocorrelation Experiment
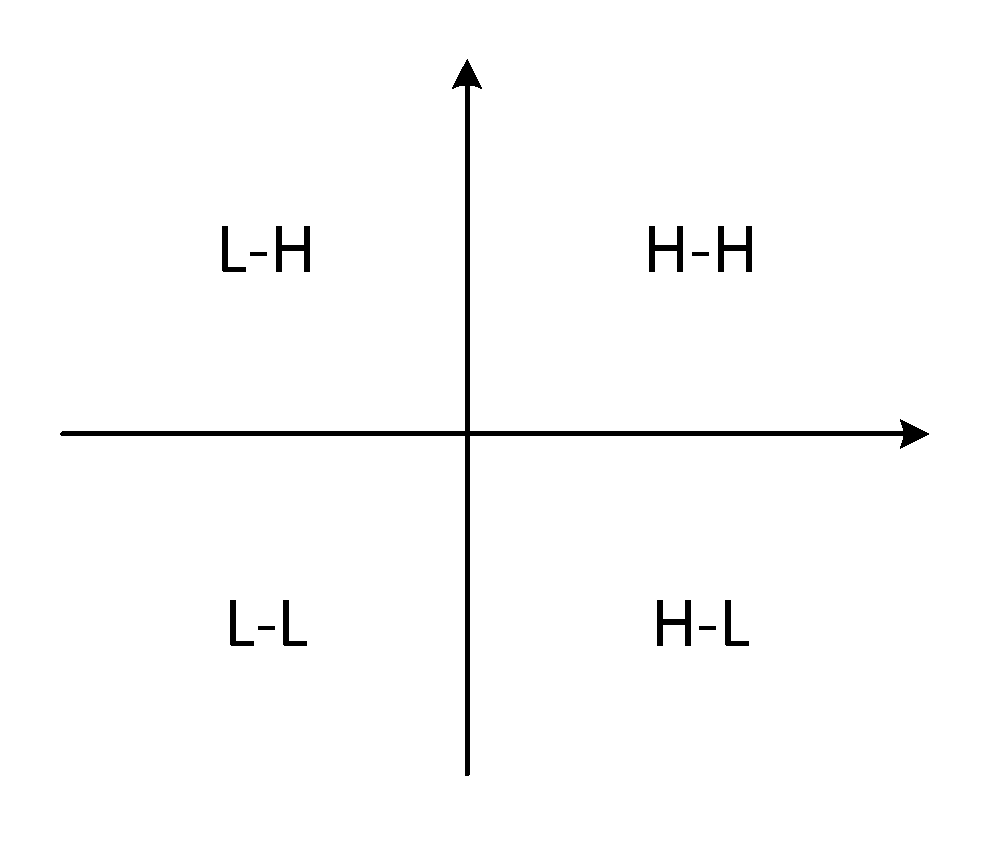
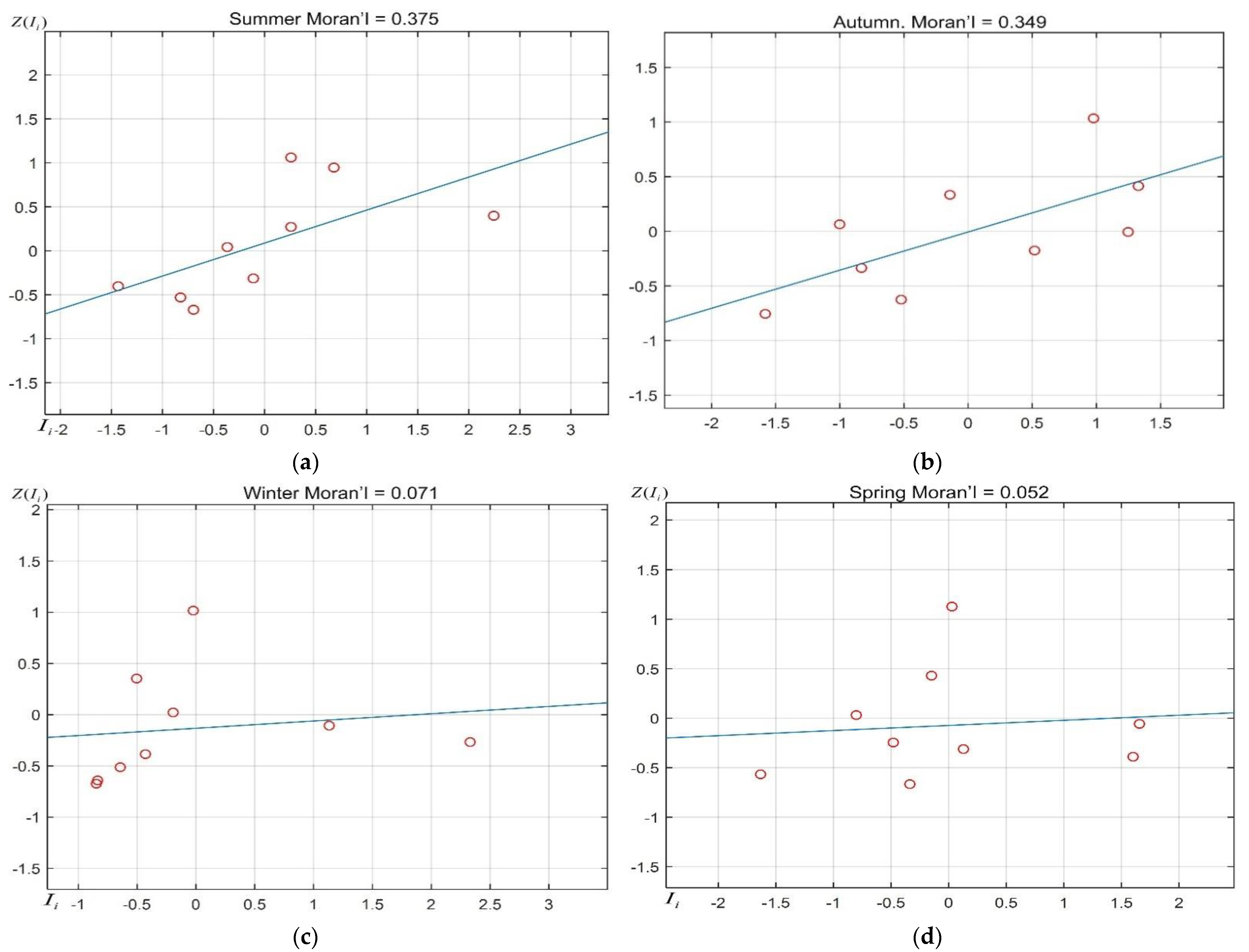
4.2.1. Moran Scatter Plot Results and Analysis
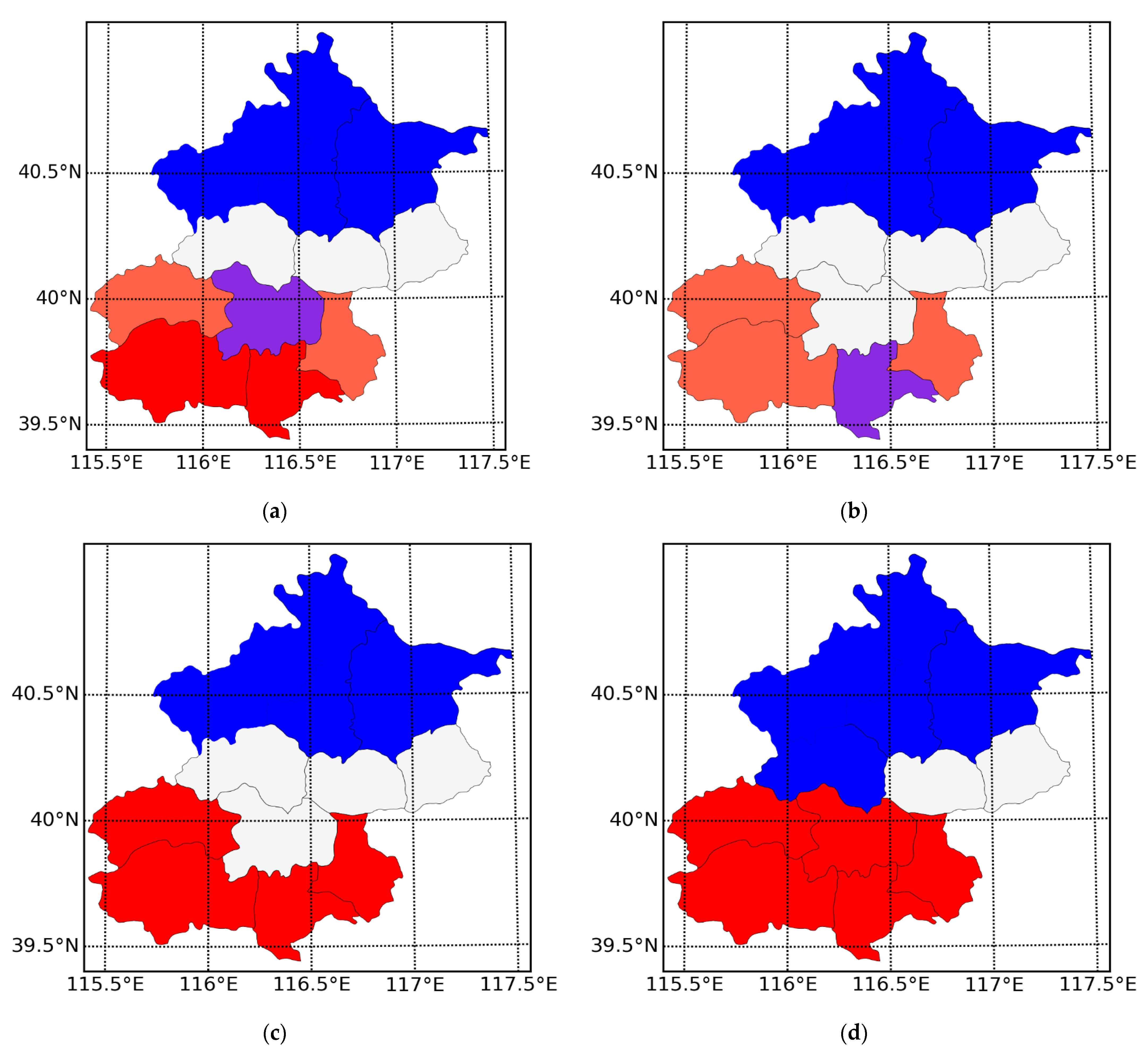
4.2.2. Results and Analysis of LISA Cluster Map
- (1)
- The Yanqing, Huairou, and Miyun in the north of Beijing are stable low-concentration areas. As a result, the overall pollution level is low, and the seasonal impact is small. Changping is also relatively stable and only becomes a non-aggregation zone in summer.
- (2)
- Fangshan in winter is the ‘H-H’ agglomeration area, which became the ‘H-L’ agglomeration area in the spring, indicating the concentration of haze in the vicinity of Fangshan has decreased in the spring.
- (3)
- Mentougou and Tongzhou have high haze concentrations in summer and autumn, affecting the haze level of the surrounding areas, forming a high concentration area in southern Beijing and the Fangshan and Daxing.
- (4)
- The areas belonging to ‘H-L’ and ‘L-H’ are easily affected by the haze around them and become high or low accumulation areas in summer and autumn, improving spatial autocorrelation.
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, M.; Song, Y.; Cai, X. A health-based assessment of particulate air pollution in urban areas of Beijing in 2000–2004. Sci. Total Environ. 2007, 376, 100–108. [Google Scholar] [CrossRef]
- Boldo, E.; Medina, S.; Le Tertre, A.; Hurley, F.; Mücke, H.-G.; Ballester, F.; Aguilera, I. Apheis: Health impact assessment of long-term exposure to PM 2.5 in 23 European cities. Eur. J. Epidemiol. 2006, 21, 449–458. [Google Scholar] [CrossRef]
- Zhang, R.; Jing, J.; Tao, J.; Hsu, S.-C.; Wang, G.; Cao, J.; Lee, C.S.L.; Zhu, L.; Chen, Z.; Zhao, Y. Chemical characterization and source apportionment of PM 2.5 in Beijing: Seasonal perspective. Atmos. Chem. Phys. 2013, 13, 7053–7074. [Google Scholar] [CrossRef] [Green Version]
- Prospero, J.M.; Olmez, I.; Ames, M. Al and Fe in PM 2.5 and PM 10 suspended particles in south-central Florida: The impact of the long range transport of African mineral dust. Water Air Soil Pollut. 2001, 125, 291–317. [Google Scholar] [CrossRef]
- Chen, X.; Yin, L.; Fan, Y.; Song, L.; Ji, T.; Liu, Y.; Tian, J.; Zheng, W. Temporal evolution characteristics of PM2.5 concentration based on continuous wavelet transform. Sci. Total Environ. 2020, 699, 134244. [Google Scholar] [CrossRef]
- Dankwa, S.; Zheng, W.; Gao, B.; Li, X. Terrestrial Water Storage (TWS) Patterns Monitoring in the Amazon Basin Using Grace Observed: Its Trends and Characteristics. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 768–771. [Google Scholar]
- Ding, Y.; Tian, X.; Yin, L.; Chen, X.; Liu, S.; Yang, B.; Zheng, W. Multi-scale Relation Network for Few-Shot Learning Based on Meta-learning. In Proceedings of the International Conference on Computer Vision System (2019), Thessaloniki, Greece, 23–25 September 2019; pp. 343–352. [Google Scholar]
- Zhou, Y.; Zheng, W.; Shen, Z. A New Algorithm for Distributed Control Problem with Shortest-Distance Constraints. Math. Probl. Eng. 2016, 2016, 1604824. [Google Scholar] [CrossRef]
- Pandolfi, M.; Gonzalez-Castanedo, Y.; Alastuey, A.; Jesus, D.; Mantilla, E.; De La Campa, A.S.; Querol, X.; Pey, J.; Amato, F.; Moreno, T. Source apportionment of PM 10 and PM 2.5 at multiple sites in the strait of Gibraltar by PMF: Impact of shipping emissions. Environ. Sci. Pollut. Res. 2011, 18, 260–269. [Google Scholar] [CrossRef]
- Li, X.; Zheng, W.; Yin, L.; Yin, Z.; Song, L.; Tian, X. Influence of social-economic activities on air pollutants in Beijing, China. Open Geosci. 2017, 9, 314–321. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Gao, Y.; Zheng, W.; Li, X. Performance of two neural network models in bathymetry. Remote Sens. Lett. 2015, 6, 321–330. [Google Scholar] [CrossRef]
- Ni, X.; Yin, L.; Chen, X.; Liu, S.; Yang, B.; Zheng, W. Semantic representation for visual reasoning. MATEC Web Conf. 2019, 277, 02006. [Google Scholar] [CrossRef]
- Tang, Y.; Liu, S.; Deng, Y.; Zhang, Y.; Yin, L.; Zheng, W. Construction of force haptic reappearance system based on Geomagic Touch haptic device. Comput. Methods Programs Biomed. 2020, 190, 105344. [Google Scholar] [CrossRef] [PubMed]
- Zheng, W.; Li, X.; Xie, J.; Yin, L.; Wang, Y. Impact of human activities on haze in Beijing based on grey relational analysis. Rend. Lincei 2015, 26, 187–192. [Google Scholar] [CrossRef]
- Zheng, W.; Li, X.; Yin, L.; Wang, Y. The retrieved urban LST in Beijing based on TM, HJ-1B and MODIS. Arab. J. Sci. Eng. 2016, 41, 2325–2332. [Google Scholar] [CrossRef]
- Yin, L.; Li, X.; Zheng, W.; Yin, Z.; Song, L.; Ge, L.; Zeng, Q. Fractal dimension analysis for seismicity spatial and temporal distribution in the circum-Pacific seismic belt. J. Earth Syst. Sci. 2019, 128, 22. [Google Scholar] [CrossRef] [Green Version]
- Schwartz, J.; Laden, F.; Zanobetti, A. The concentration-response relation between PM (2.5) and daily deaths. Environ. Health Perspect. 2002, 110, 1025–1029. [Google Scholar] [CrossRef] [Green Version]
- Franklin, M.; Zeka, A.; Schwartz, J. Association between PM 2.5 and all-cause and specific-cause mortality in 27 US communities. J. Expo. Sci. Environ. Epidemiol. 2007, 17, 279–287. [Google Scholar] [CrossRef] [Green Version]
- Tucker, W.G. An overview of PM2. 5 sources and control strategies. Fuel Process. Technol. 2000, 65, 379–392. [Google Scholar] [CrossRef]
- Liu, S.; Wang, L.; Liu, H.; Su, H.; Li, X.; Zheng, W. Deriving bathymetry from optical images with a localized neural network algorithm. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5334–5342. [Google Scholar] [CrossRef]
- Ma, Z.; Zheng, W.; Chen, X.; Yin, L. Joint embedding VQA model based on dynamic word vector. PeerJ Comput. Sci. 2021, 7, e353. [Google Scholar] [CrossRef] [PubMed]
- Zheng, W.; Li, X.; Yin, L.; Wang, Y. Spatiotemporal heterogeneity of urban air pollution in China based on spatial analysis. Rend. Lincei 2016, 27, 351–356. [Google Scholar] [CrossRef]
- Zheng, W.; Liu, X.; Yin, L. Research on image classification method based on improved multi-scale relational network. PeerJ Comput. Sci. 2021, 7, e613. [Google Scholar] [CrossRef]
- Zheng, W.; Yin, L.; Chen, X.; Ma, Z.; Liu, S.; Yang, B. Knowledge base graph embedding module design for Visual question answering model. Pattern Recognit. 2021, 120, 108153. [Google Scholar] [CrossRef]
- Zheng, W.; Liu, X.; Ni, X.; Yin, L.; Yang, B. Improving Visual Reasoning Through Semantic Representation. IEEE Access 2021, 9, 91476–91486. [Google Scholar] [CrossRef]
- Zheng, W.; Liu, X.; Yin, L. Sentence Representation Method Based on Multi-Layer Semantic Network. Appl. Sci. 2021, 11, 1316. [Google Scholar] [CrossRef]
- Zhao, C.-X.; Wang, Y.-Q.; Wang, Y.-J.; Zhang, H.-L.; Zhao, B.-Q. Temporal and spatial distribution of PM2. 5 and PM10 pollution status and the correlation of particulate matters and meteorological factors during winter and spring in Beijing. Huan Jing Ke Xue Huanjing Kexue 2014, 35, 418–427. [Google Scholar] [PubMed]
- Ando, M.; Katagiri, K.; Tamura, K.; Yamamoto, S.; Matsumoto, M.; Li, Y.; Cao, S.; Ji, R.; Liang, C. Indoor and outdoor air pollution in Tokyo and Beijing supercities. Atmos. Environ. 1996, 30, 695–702. [Google Scholar] [CrossRef]
- Gehrig, R.; Buchmann, B. Characterising seasonal variations and spatial distribution of ambient PM10 and PM2. 5 concentrations based on long-term Swiss monitoring data. Atmos. Environ. 2003, 37, 2571–2580. [Google Scholar] [CrossRef]
- Zhang, Y.-L.; Cao, F. Fine particulate matter (PM 2.5) in China at a city level. Sci. Rep. 2015, 5, 14884. [Google Scholar] [CrossRef] [Green Version]
- Zhao, X.; Zhang, X.; Xu, X.; Xu, J.; Meng, W.; Pu, W. Seasonal and diurnal variations of ambient PM2.5 concentration in urban and rural environments in Beijing. Atmos. Environ. 2009, 43, 2893–2900. [Google Scholar] [CrossRef]
- Fuller, G.W.; Carslaw, D.C.; Lodge, H.W. An empirical approach for the prediction of daily mean PM10 concentrations. Atmos. Environ. 2002, 36, 1431–1441. [Google Scholar] [CrossRef]
- Dong, M.; Yang, D.; Kuang, Y.; He, D.; Erdal, S.; Kenski, D. PM2.5 concentration prediction using hidden semi-Markov model-based times series data mining. Expert Syst. Appl. 2009, 36, 9046–9055. [Google Scholar] [CrossRef]
- Lee, H.; Liu, Y.; Coull, B.; Schwartz, J.; Koutrakis, P. A novel calibration approach of MODIS AOD data to predict PM2.5 concentrations. Atmos. Chem. Phys. 2011, 11, 7991–8002. [Google Scholar] [CrossRef] [Green Version]
- Ordieres, J.; Vergara, E.; Capuz, R.; Salazar, R. Neural network prediction model for fine particulate matter (PM2.5) on the US–Mexico border in El Paso (Texas) and Ciudad Juárez (Chihuahua). Environ. Model. Softw. 2005, 20, 547–559. [Google Scholar] [CrossRef]
- Reid, C.E.; Jerrett, M.; Petersen, M.L.; Pfister, G.G.; Morefield, P.E.; Tager, I.B.; Raffuse, S.M.; Balmes, J.R. Spatiotemporal prediction of fine particulate matter during the 2008 Northern California wildfires using machine learning. Environ. Sci. Technol. 2015, 49, 3887–3896. [Google Scholar] [CrossRef] [PubMed]
- He, L.; Li, H.; Liu, F.; Liu, N.; Sun, Z.; He, Z. Multi-patch convolution neural network for iris liveness detection. In Proceedings of the 2016 IEEE 8th International Conference on Biometrics Theory, Applications and Systems (BTAS), Niagara Falls, NY, USA, 6–9 September 2016; pp. 1–7. [Google Scholar]






| Positive | low-high | high-high |
| negative | low-low | high-low |
| Season | Winter | Spring | Summer | Autumn |
|---|---|---|---|---|
| global Moran’s I | 0.071 | 0.052 | 0.375 | 0.349 |
| Seasons | H-H | H-L | L-L | L-H |
|---|---|---|---|---|
| Winter | Fangshan, Daxing | Mentougou, Tongzhou | Yanqing, Huairou, Miyun, Changping | Metropolitan Area |
| Spring | - | Mentougou, Fangshan, Tongzhou | Yanqing, Huairou, Miyun, Changping | Daxing |
| Summer | Mentougou, Fangshan, Daxing, Tongzhou | - | Yanqing, Huairou, Miyun | - |
| Autumn | Mentougou, Fangshan, Daxing, Tongzhou, Metropolitan Area | - | Yanqing, Huairou, Miyun, Changping | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, L.; Wang, L.; Huang, W.; Liu, S.; Yang, B.; Zheng, W. Spatiotemporal Analysis of Haze in Beijing Based on the Multi-Convolution Model. Atmosphere 2021, 12, 1408. https://doi.org/10.3390/atmos12111408
Yin L, Wang L, Huang W, Liu S, Yang B, Zheng W. Spatiotemporal Analysis of Haze in Beijing Based on the Multi-Convolution Model. Atmosphere. 2021; 12(11):1408. https://doi.org/10.3390/atmos12111408
Chicago/Turabian StyleYin, Lirong, Lei Wang, Weizheng Huang, Shan Liu, Bo Yang, and Wenfeng Zheng. 2021. "Spatiotemporal Analysis of Haze in Beijing Based on the Multi-Convolution Model" Atmosphere 12, no. 11: 1408. https://doi.org/10.3390/atmos12111408