
A Refined Apple Binocular Positioning Method with Segmentation-Based Deep Learning for Robotic Picking

Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset Acquisition
2.2. Training Platform
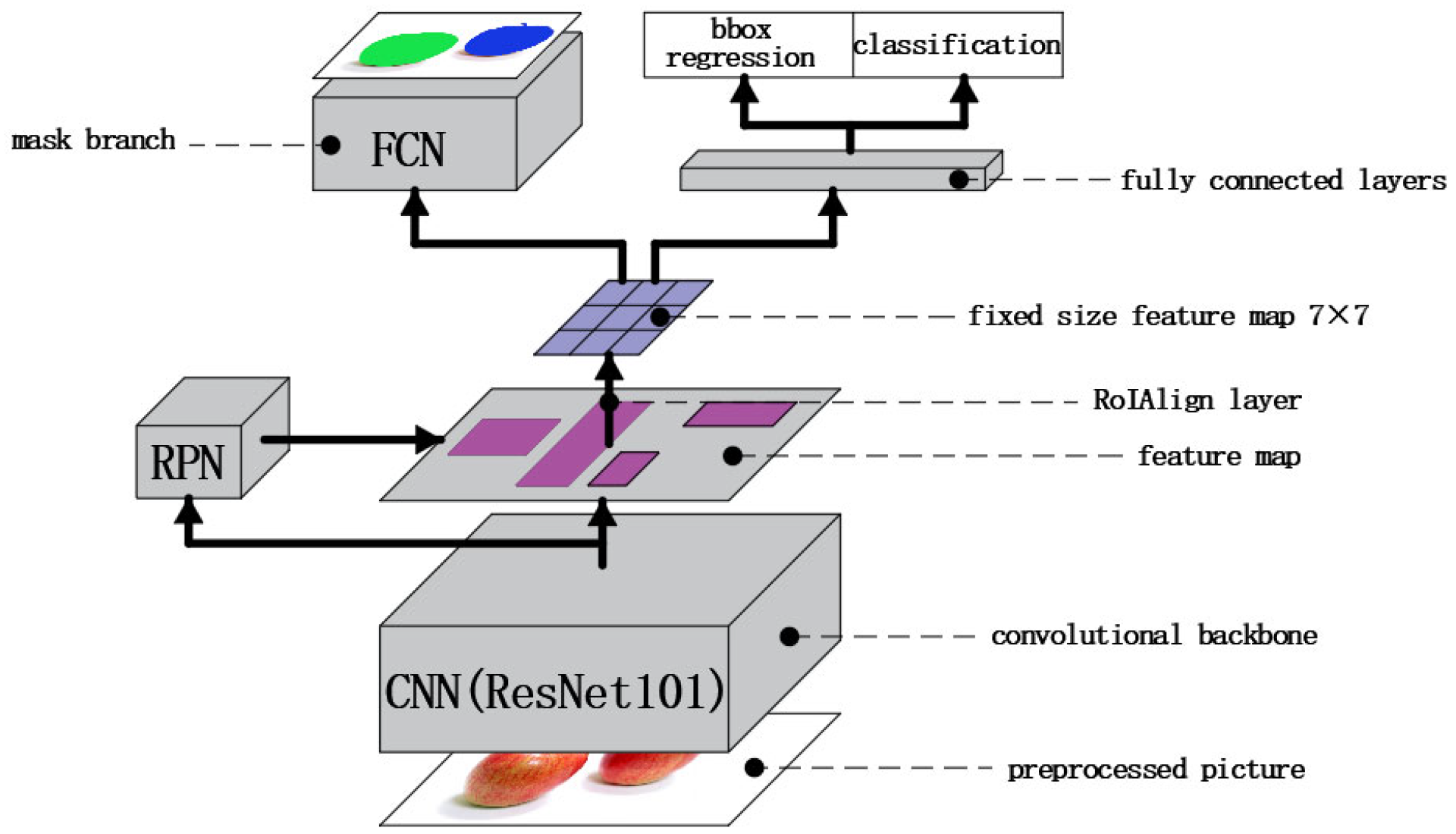
2.3. Deep Learning Model
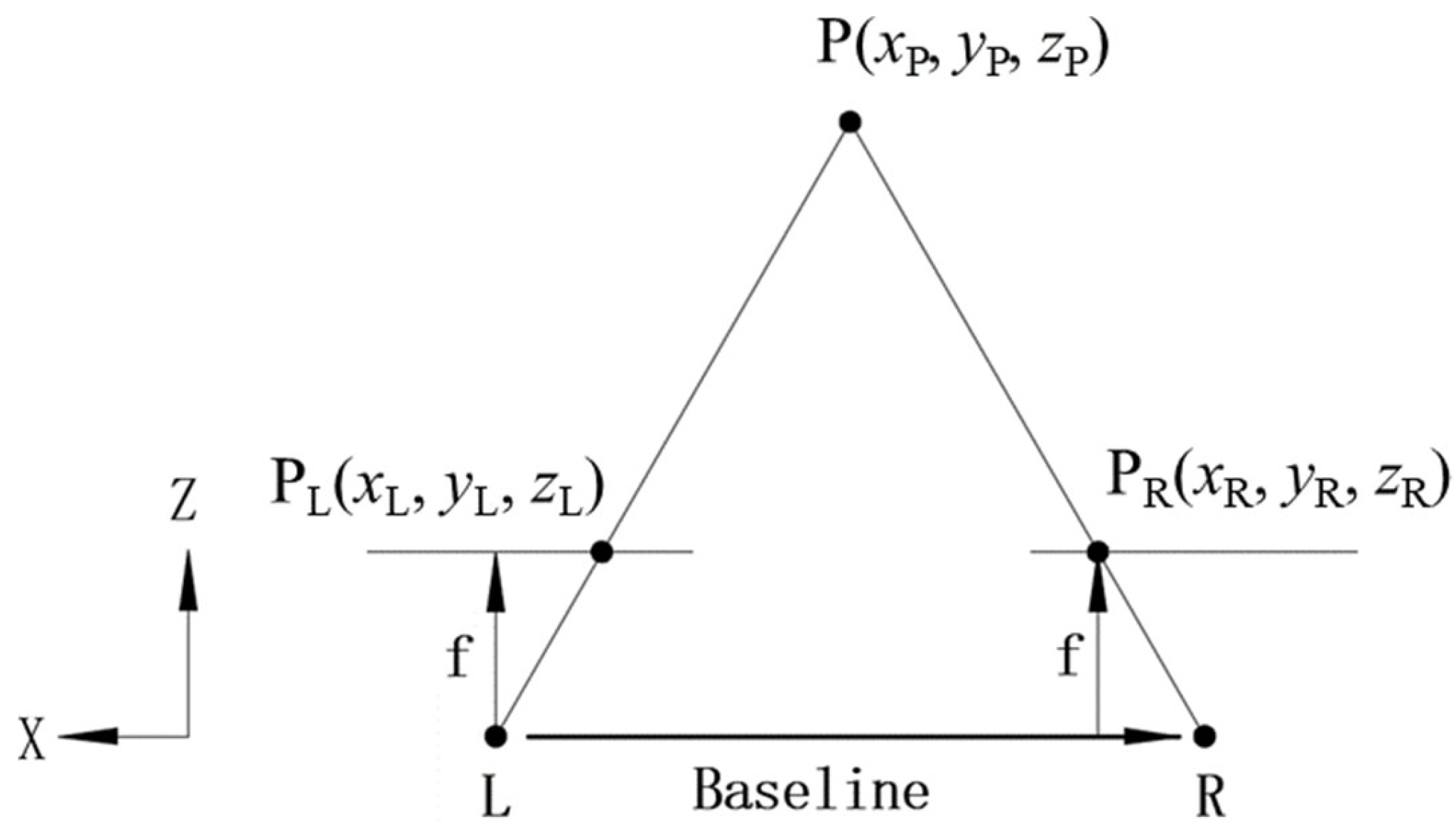
2.4. The Binocular Calibration and Binocular Positioning Principle
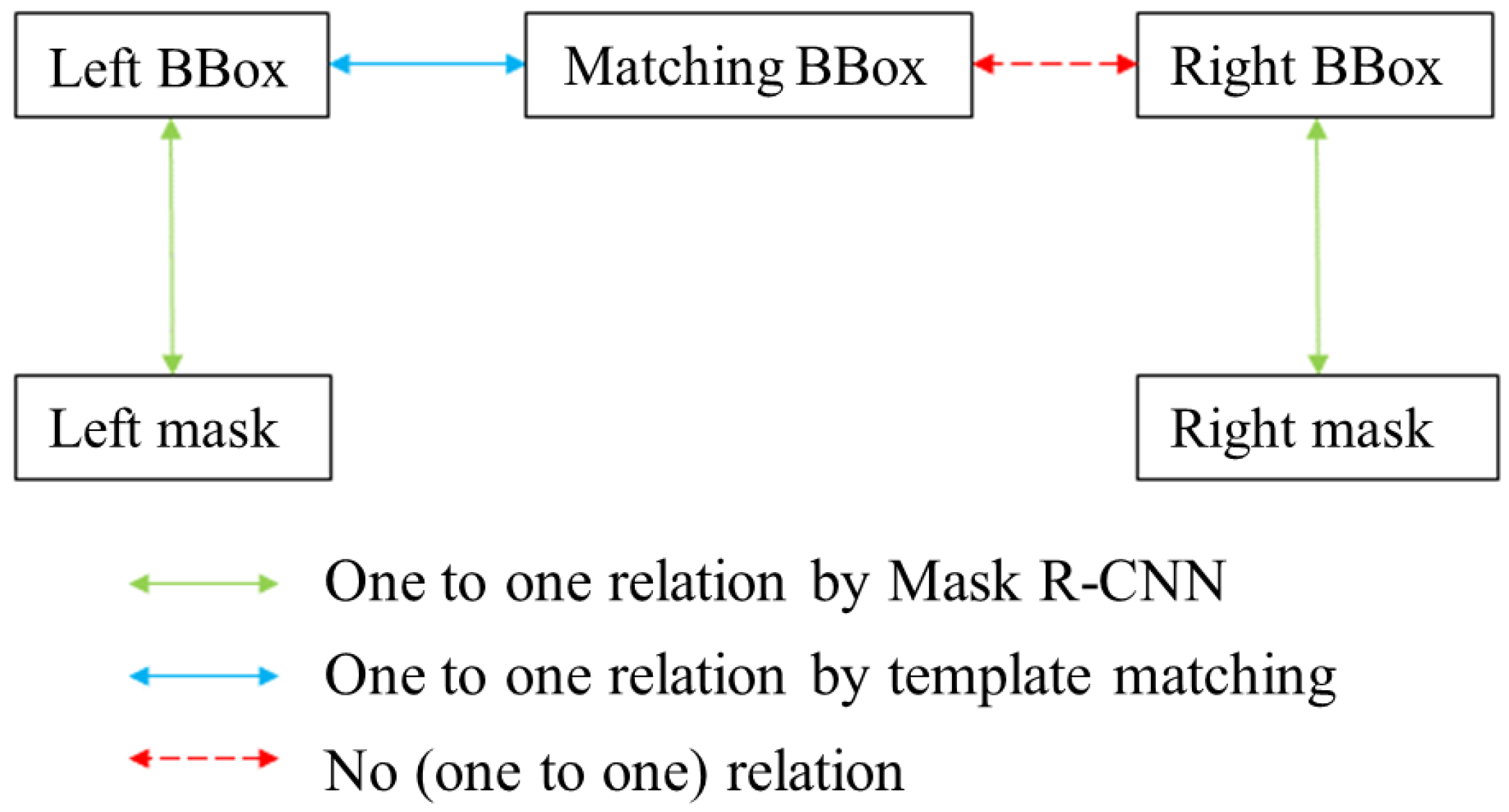
2.5. Apple Stereo Matching
- (1)
- Apples in the left BBox but not the matching BBox. Such apples are detected in the left image but cannot be matched in the right image. This kind of apple exists in the left image but does not exist in the right image because of leaf occlusion, apple occlusion, branch/wire occlusion, or an out-of-camera view.
- (2)
- Apples in the right Bbox but not the matching BBox. Such apples are detected in the right image but cannot be matched in the right image. This kind of apple exists in the right image but does not exist in the left image because of leaf occlusion, apple occlusion, branch/wire occlusion, or an out-of-camera view.
- (3)
- Apples in the matching Bbox but not the right BBox. Such apples are matched in the right image but there is no corresponding right BBox in the right image. This kind of apple exists in both the left and right images but is not detected in the right image.
2.6. Apple Positioning
| Algorithm 1: Binocular positioning with the Mask R-CNN | |
| INPUT: leftimg, rightimg | |
| OUTPUT: coordinates | |
| START: | |
| 1: | leftapples, rightapples = segmentByMaskRCNN(leftimg, rightimg) |
| 2: | FOR each leftapple in leftapples DO |
| 3: | matching_box searches the most similar region in the right image that has the same height and smaller abscissa as leftapple by using matchTemplate(); |
| 4: | rightapple searches apple in the rightapples with maximal IoU between it and the matching_box; |
| 5: | disparitys are consist of four pairs of feature points on the apple mask, four feature points are defined as the points with xmax, xmin, ymax, ymin on the apple mask from two view; |
| 6: | FOR each disp in disparitys DO |
| 7: | coordinates.append(calculateCoordinate(focal, baseline, disp)) |
| 8: | return coordinates |
| 9: | END |
2.7. Evaluation Criteria of the Mask R-CNN
2.8. Evaluation Criteria of Apple Binocular Positioning
3. Result and Discussion
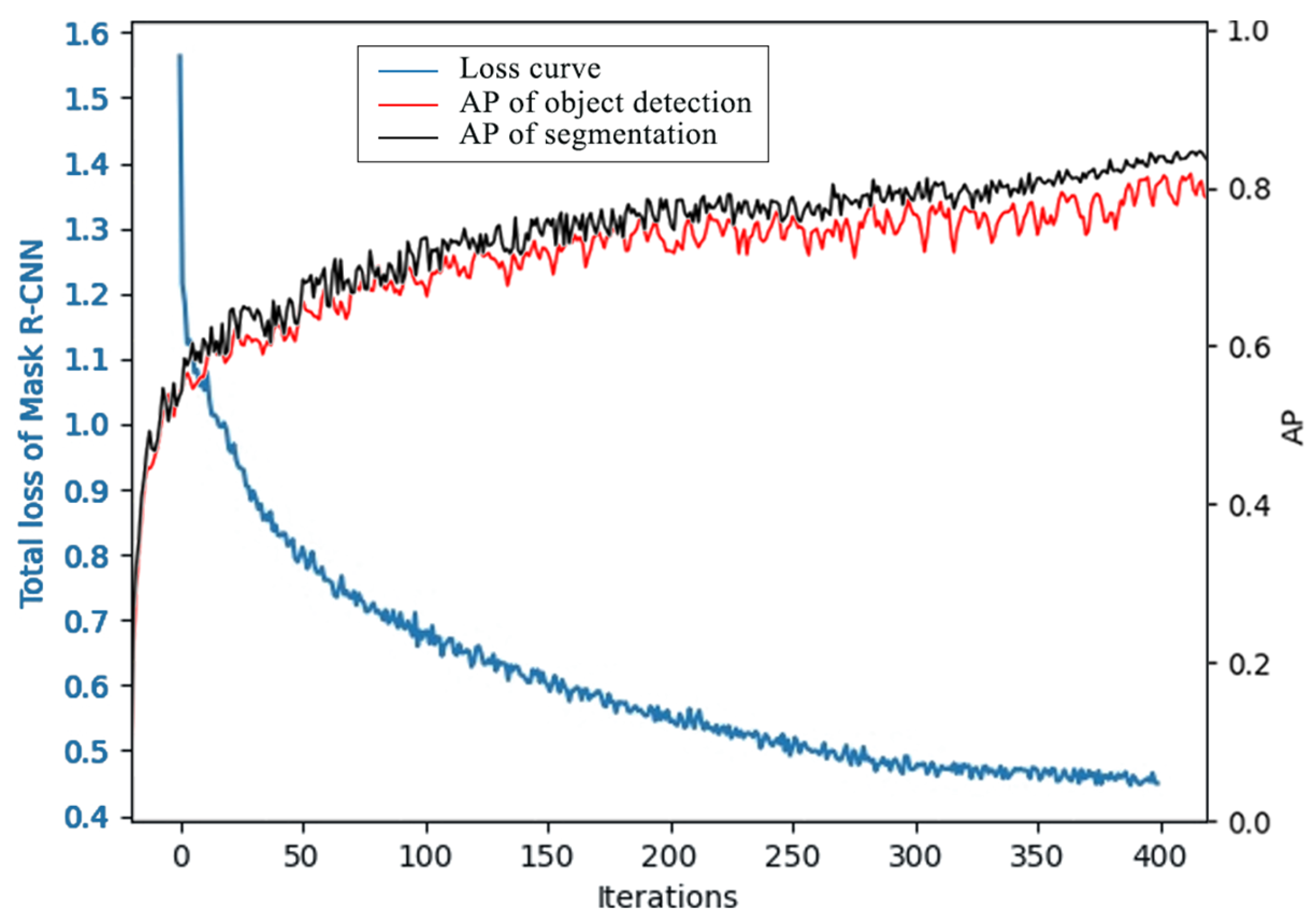
3.1. Training Assessment and Performance of the Mask R-CNN
3.2. Performance Evaluation of Binocular Positioning
3.3. Results from Other Studies
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- UN Food & Agriculture Organization. Production of Apple (Fruit) by Countries. 2021. Available online: http://www.fao.org/faostat/en/#data/QCL (accessed on 10 April 2021).
- Silwal, A.; Karkee, M.; Zhang, Q. A hierarchical approach to apple identification for robotic harvesting. Trans. ASABE 2016, 59, 1079–1086. [Google Scholar] [CrossRef]
- Zhao, D.; Lv, J.; Ji, W.; Zhang, Y.; Chen, Y. Design and control of an apple harvesting robot. Biosyst. Eng. 2011, 110, 112–122. [Google Scholar] [CrossRef]
- Zhang, K.; Lammers, K.; Chu, P.; Li, Z.; Lu, R. System design and control of an apple harvesting robot. Mechatronics 2021, 79, 102644. [Google Scholar] [CrossRef]
- Gené-Mola, J.; Gregorio, E.; Guevara, J.; Auat, F.; Sanz-Cortiella, R.; Escolà, A.; Llorens, J.; Morros, J.-R.; Ruiz-Hidalgo, J.; Vilaplana, V.; et al. Fruit detection in an apple orchard using a mobile terrestrial laser scanner. Biosyst. Eng. 2019, 187, 171–184. [Google Scholar] [CrossRef]
- Karkee, M.; Adhikari, B.; Amatya, S.; Zhang, Q. Identification of pruning branches in tall spindle apple trees for automated pruning. Comput. Electron. Agric. 2014, 103, 127–135. [Google Scholar] [CrossRef]
- Howard, I.P.; Rogers, B.J. Binocular Vision and Stereopsis. Trends Neurosci. 1996, 19, 407–408. [Google Scholar] [CrossRef]
- Tang, Y.; Chen, M.; Wang, C.; Luo, L.; Li, J.; Lian, G.; Zou, X. Recognition and Localization Methods for Vision-Based Fruit Picking Robots: A Review. Front. Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef]
- Wang, F.; Chen, X.; Tan, C.; Li, J.; Zhang, Y. Hexagon-Shaped Screw Recognition and Positioning System Based on Binocular Vision. In Proceedings of the Chinese Control Conference, Wuhan, China, 25–27 July 2018; pp. 5481–5486. [Google Scholar] [CrossRef]
- Williams, H.; Ting, C.; Nejati, M.; Jones, M.H.; Penhall, N.; Lim, J.Y.; Seabright, M.; Bell, J.; Ahn, H.S.; Scarfe, A.; et al. Improvements to and large-scale evaluation of a robotic kiwifruit harvester. J. Field Robot. 2020, 37, 187–201. [Google Scholar] [CrossRef]
- Wang, C.; Zou, X.; Tang, Y.; Luo, L.; Feng, W. Localisation of litchi in an unstructured environment using binocular stereo vision. Biosyst. Eng. 2016, 145, 39–51. [Google Scholar] [CrossRef]
- Luo, L.; Tang, Y.; Zou, X.; Ye, M.; Feng, W.; Li, G. Vision-based extraction of spatial information in grape clusters for harvesting robots. Biosyst. Eng. 2016, 151, 90–104. [Google Scholar] [CrossRef]
- Si, Y.; Liu, G.; Feng, J. Location of apples in trees using stereoscopic vision. Comput. Electron. Agric. 2015, 112, 68–74. [Google Scholar] [CrossRef]
- Zhao, G.; Yang, R.; Jing, X.; Zhang, H.; Wu, Z.; Sun, X.; Jiang, H.; Li, R.; Wei, X.; Fountas, S.; et al. Phenotyping of individual apple tree in modern orchard with novel smartphone-based heterogeneous binocular vision and YOLOv5s. Comput. Electron. Agric. 2023, 209, 107814. [Google Scholar] [CrossRef]
- Fu, L.; Tola, E.; Al-Mallahi, A.; Li, R.; Cui, Y. A novel image processing algorithm to separate linearly clustered kiwifruits. Biosyst. Eng. 2019, 183, 184–195. [Google Scholar] [CrossRef]
- Mizushima, A.; Lu, R. An image segmentation method for apple sorting and grading using support vector machine and Otsu’s method. Comput. Electron. Agric. 2013, 94, 29–37. [Google Scholar] [CrossRef]
- Chapelle, O.; Haffner, P.; Vapnik, V.N. Support Vector Machines for Histogram-Based Image Classificatio. IEEE Trans. Neural Netw. 1999, 10, 1055–1064. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning-Method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234. [Google Scholar] [CrossRef]
- Gheisari, M.; Wang, G.; Bhuiyan, M.Z.A. A Survey on Deep Learning in Big Data. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing, (EUC), Guangzhou, China, 21–24 July 2017; Volume 2, pp. 173–180. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv, 2017; arXiv:1704.06857. [Google Scholar]
- Suo, R.; Fu, L.; He, L.; Li, G.; Majeed, Y.; Liu, X.; Zhao, G.; Yang, R.; Li, R. A novel labeling strategy to improve apple seedling segmentation using BlendMask for online grading. Comput. Electron. Agric. 2022, 201, 107333. [Google Scholar] [CrossRef]
- Gao, F.; Fu, L.; Zhang, X.; Majeed, Y.; Li, R.; Karkee, M.; Zhang, Q. Multi-class fruit-on-plant detection for apple in SNAP system using Faster RCNN. Comput. Electron. Agric. 2020, 176, 105634. [Google Scholar] [CrossRef]
- Sun, X.; Fang, W.; Gao, C.; Fu, L.; Majeed, Y.; Liu, X.; Gao, F.; Yang, R.; Li, R. Remote estimation of grafted apple tree trunk diameter in modern orchard with RGB and point cloud based on SOLOv2. Comput. Electron. Agric. 2022, 199, 107209. [Google Scholar] [CrossRef]
- Sun, K.; Wang, X.; Liu, S.; Liu, C.H. Apple, peach, and pear flower detection using semantic segmentation network and shape constraint level set. Comput. Electron. Agric. 2021, 185, 106150. [Google Scholar] [CrossRef]
- Chen, Z.; Ting, D.; Newbury, R.; Chen, C. Semantic segmentation for partially occluded apple trees based on deep learning. Comput. Electron. Agric. 2021, 181, 105952. [Google Scholar] [CrossRef]
- Dias, P.A.; Tabb, A.; Medeiros, H. Multispecies Fruit Flower Detection Using a Refined Semantic Segmentation Network. IEEE Robot. Autom. Lett. 2018, 3, 3003–3010. [Google Scholar] [CrossRef]
- Kang, H.; Chen, C. Fruit detection, segmentation and 3D visualisation of environments in apple orchards. Comput. Electron. Agric. 2020, 171, 105302. [Google Scholar] [CrossRef]
- Gené-Mola, J.; Sanz-Cortiella, R.; Rosell-Polo, J.R.; Morros, J.R.; Ruiz-Hidalgo, J.; Vilaplana, V.; Gregorio, E. Fruit detection and 3D location using instance segmentation neural networks and structure-from-motion photogrammetry. Comput. Electron. Agric. 2020, 169, 105165. [Google Scholar] [CrossRef]
- Wang, J.; Wang, L.; Han, Y.; Zhang, Y.; Zhou, R. On combining deepsnake and global saliency for detection of orchard apples. Appl. Sci. 2021, 11, 6269. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar] [CrossRef]
- Zhang, Z.; Member, S. A Flexible New Technique for Camera Calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L.V. SURF: Speeded Up Robust Features. Comput. Vis.-ECCV 2006, 3951, 404–417. [Google Scholar]
- Wang, X.; Kang, H.W.; Zhou, H.Y.; Au, W.; Chen, C. Geometry-aware fruit grasping estimation for robotic harvesting in apple orchards. Comput. Electron. Agric. 2022, 193, 106716. [Google Scholar] [CrossRef]
- Li, T.; Fang, W.; Zhao, G.; Gao, F.; Wu, Z.; Li, R.; Fu, L.; Dhupia, J. An improved binocular localization method for apple based on fruit detection using deep learning. Inf. Process. Agric. 2021, 10, 276–281. [Google Scholar] [CrossRef]
- Xiong, J.; He, Z.; Lin, R.; Liu, Z.; Bu, R.; Yang, Z.; Peng, H.; Zou, X. Visual positioning technology of picking robots for dynamic litchi clusters with disturbance. Comput. Electron. Agric. 2018, 151, 226–237. [Google Scholar] [CrossRef]
- Hu, T.; Wang, W.; Gu, J.; Xia, Z.; Zhang, J.; Wang, B. Research on Apple Object Detection and Localization Method Based on Improved YOLOX and RGB-D Images. 2023. Available online: https://ssrn.com/abstract=4348694 (accessed on 5 January 2020).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project | Parameter |
|---|---|
| Baseline | 11.99 cm |
| Focal length | 3.8 mm/6.4 mm |
| Maximum resolution | 1280 × 960 pixels |
| Model | Backbone | Time/ms | Time(TX2)/ms | F1 | IoUmask |
|---|---|---|---|---|---|
| YOLO-V4-416 | CSPD53-PANet | 78 | 592 | 0.864 | N/A |
| YOLO-V4-480 | CSPD53-PANet | 106 | 827 | 0.886 | N/A |
| Mask R-CNN-640 | R50-FPN | 122 | 920 | 0.857 | 0.887 |
| Mask R-CNN-640 | R101-FPN | 157 | 1285 | 0.877 | 0.895 |
| A3N-416 | MN-PANet | 24 | 174 | 0.873 | 0.851 |
| A3N-416 * | R50-PANet | 35 | 282 | 0.890 | 0.873 |
| A3N-480 | R101-PANet | 75 | 598 | 0.923 | 0.891 |
| A3N-640 | R101-PANet | 97 | 782 | 0.923 | 0.893 |
| Reference | Hardware | Model/Method | Criteria |
|---|---|---|---|
| Li et al. [37] | Binocular camera | Faster R-CNN | Precision: 99.64% |
| Xiong et al. [38] | Binocular camera | Fuzzy clustering | Depth error: 1.96 cm |
| Si et al. [13] | Binocular camera | Traditional image processing | Depth error: 0.013–5% |
| Hu et al. [39] | RGB-D camera | YOLOX | Depth error: less than 5 mm |
| Our method | Binocular camera | Mask R-CNN | PA: 99.49% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Tang, C.; Sun, X.; Fu, L. A Refined Apple Binocular Positioning Method with Segmentation-Based Deep Learning for Robotic Picking. Agronomy 2023, 13, 1469. https://doi.org/10.3390/agronomy13061469
Zhang H, Tang C, Sun X, Fu L. A Refined Apple Binocular Positioning Method with Segmentation-Based Deep Learning for Robotic Picking. Agronomy. 2023; 13(6):1469. https://doi.org/10.3390/agronomy13061469
Chicago/Turabian StyleZhang, Huijun, Chunhong Tang, Xiaoming Sun, and Longsheng Fu. 2023. "A Refined Apple Binocular Positioning Method with Segmentation-Based Deep Learning for Robotic Picking" Agronomy 13, no. 6: 1469. https://doi.org/10.3390/agronomy13061469