
Identification of HIR, EDS1 and PAD4 Genes Reveals Differences between Coffea Species That May Impact Disease Resistance
 , , and
, , and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Coffee Plants, Rust Isolates, Growth and Inoculation Conditions
2.2. Light Microscope Observation of Fresh Tissues
2.3. RNA Isolation, cDNA Synthesis for Pyrosequencing and Reads Assembly
2.4. Primer Design and Standard Molecular Biology Techniques
2.5. RNA Isolation and cDNA Synthesis for RT-qPCR Analysis
2.6. Identification of HIR, EDS1 and PAD4 Genes in Coffea Arabica, Coffea Canephora and Coffea Eugenioides Genome Databases and Chromosome Localization
2.7. DNA and Protein Sequence Analyses
2.8. Phylogenetic Analysis
2.9. Analysis of the Genomic Structure of PAD4 Gene in Coffea Arabica Genotypes
2.10. Statistical Analyses
3. Results
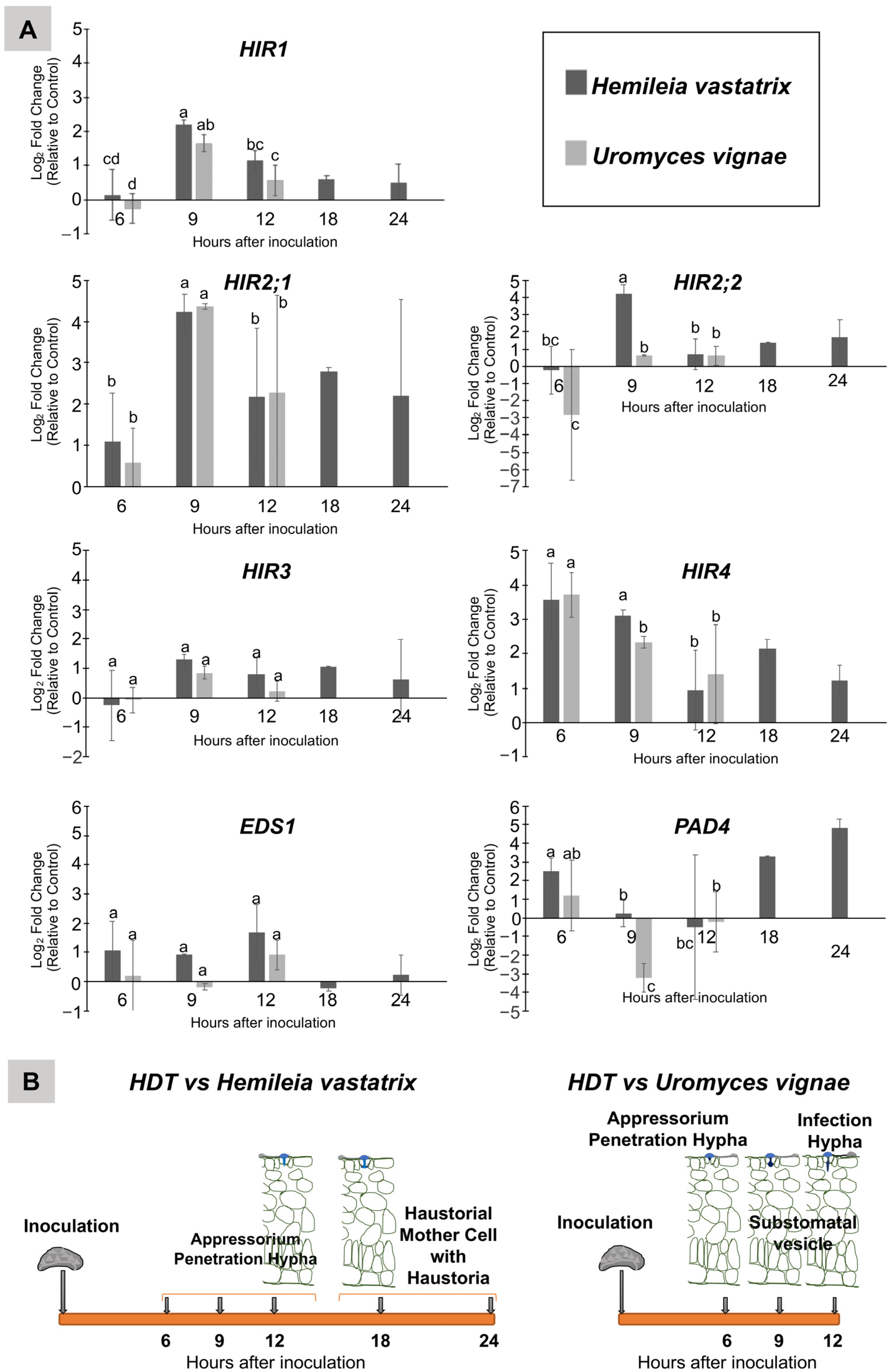
3.1. Transcriptome Analysis of HDT Leaves Inoculated with Hemileia vastatrix and Uromyces vignae
3.2. Relative Expression of HIR, EDS1 and PAD4 Genes in HDT Leaves along the Infection Process
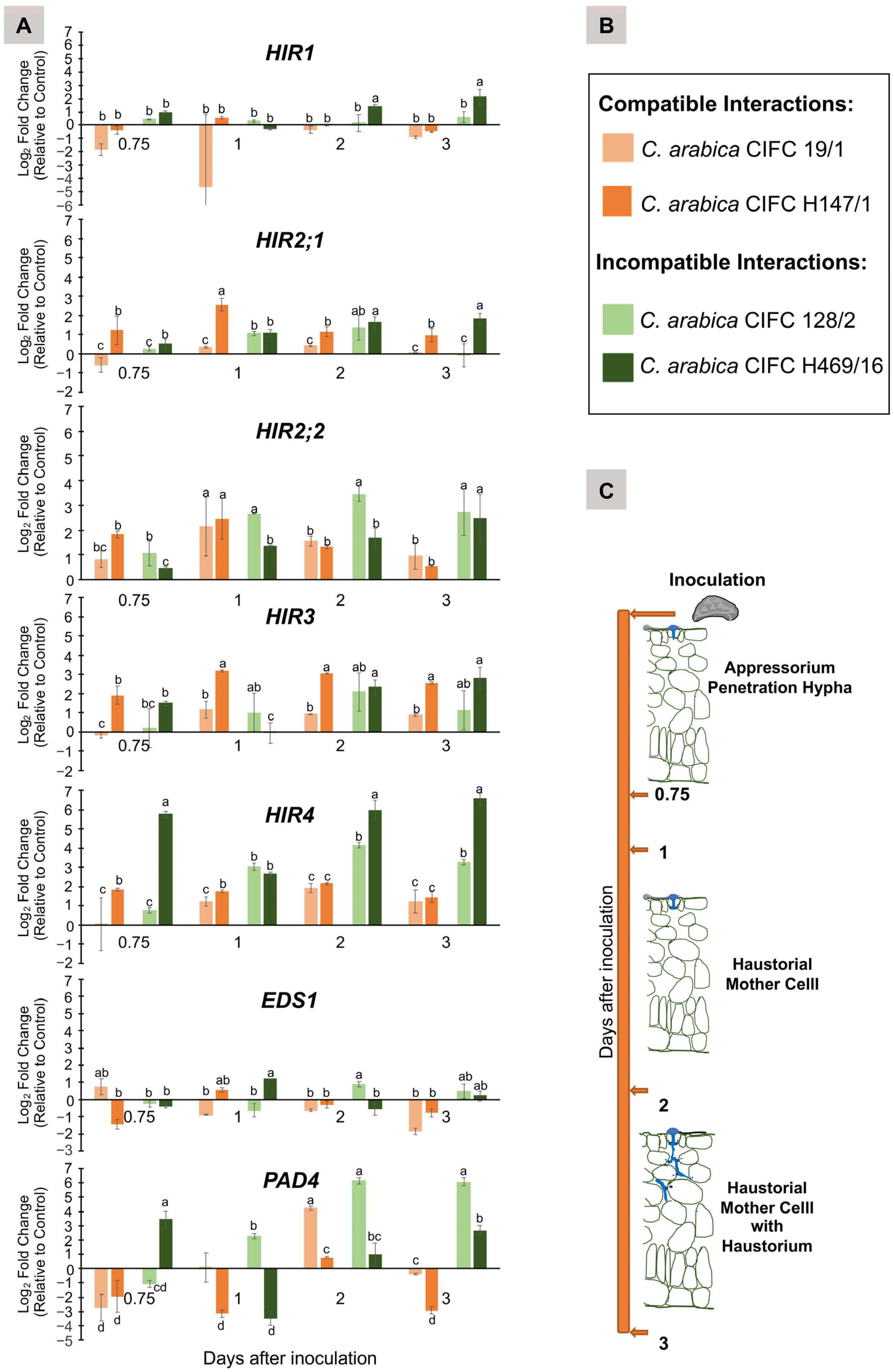
3.3. Transcript Level of HIR, EDS1 and PAD4 Genes in Coffea arabica Genotypes Involved in Compatible and Incompatible Interactions with Hemileia vastatrix Isolate 178a
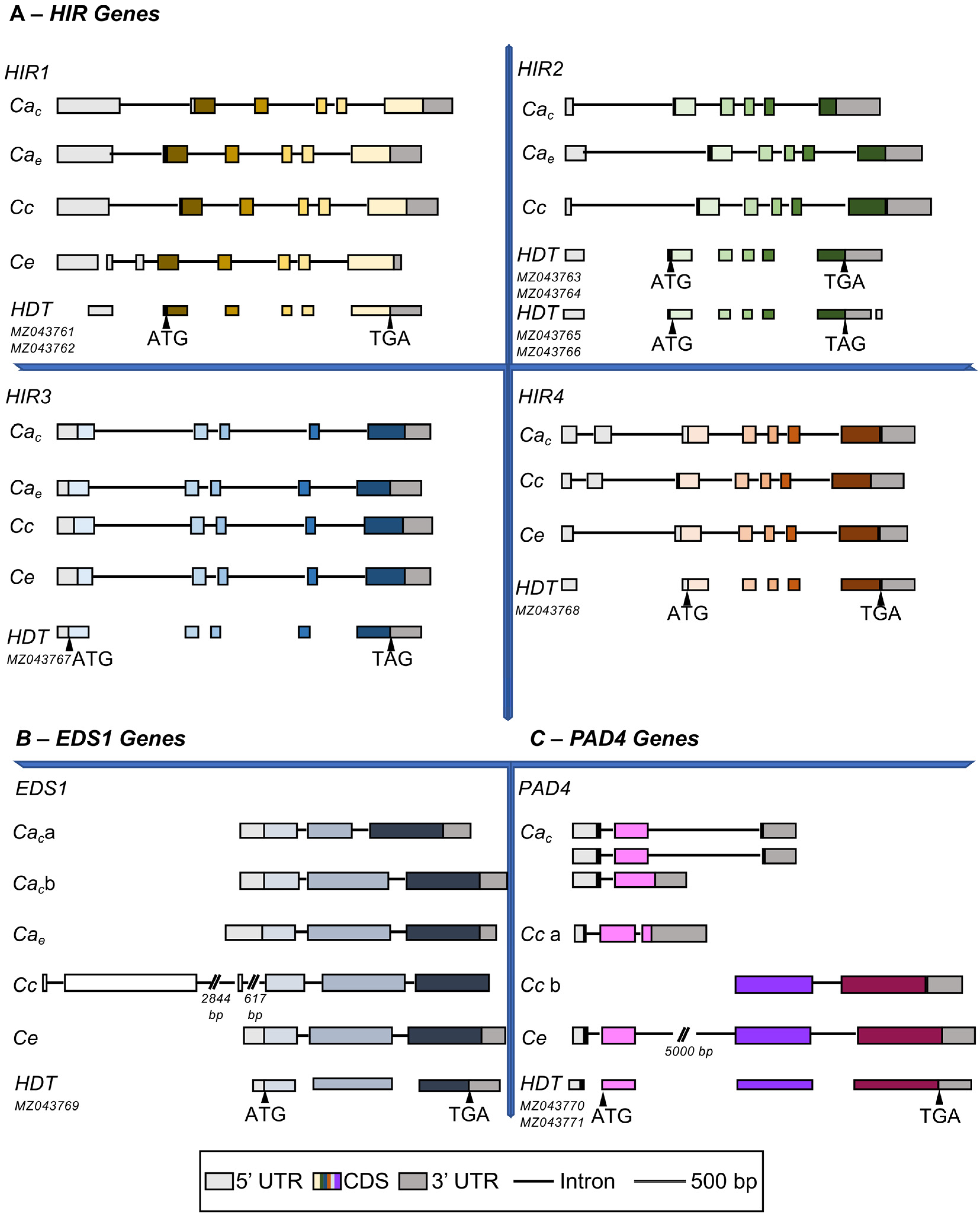
3.4. Identification of HIR, PAD4 and EDS1 Genes in Coffea Genomes and Relationship with HDT Transcripts
3.4.1. HIR Gene Family
3.4.2. EDS1
3.4.3. PAD4
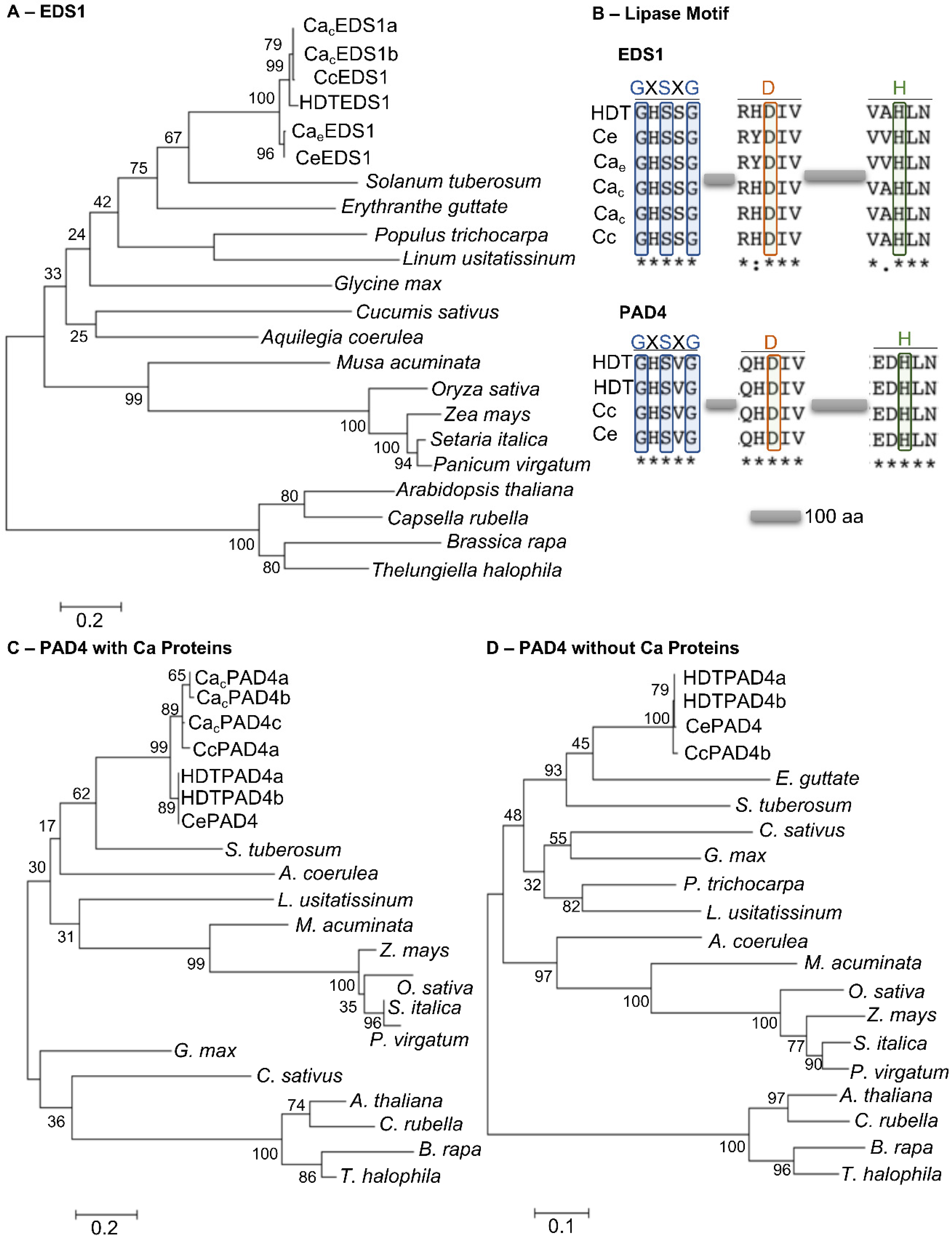
3.5. Phylogenetic Analysis of HIR Genes in Coffea spp. and Arabidopsis
3.6. Phylogenetic Analysis of EDS1 and PAD4 Proteins
3.7. PAD4 Gene Structure in Selected Coffea Genotypes
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Maghuly, F.; Jankowicz-Cieslak, J.; Souleymane, B. Improving coffee species for pathogen resistance. CAB Rev. 2020, 15. [Google Scholar] [CrossRef]
- Silva, M.d.C.; Guerra-Guimarães, L.; Diniz, I.; Loureiro, A.; Azinheira, H.; Pereira, A.P.; Tavares, S.; Batista, D.; Várzea, V. An overview of the mechanisms involved in coffee-Hemileia vastatrix interactions: Plant and Pathogen Perspectives. Agronomy 2022, 12, 326. [Google Scholar] [CrossRef]
- Cressy, D. Coffee rust regains foothold. researchers marshal technology in bid to thwart fungal outbreak in Central America. Nature 2013, 493, 587. [Google Scholar]
- Sieff, K. The migration problem is a coffee problem. Washington Post, 2019. [Google Scholar]
- Bettencourt, A.J.; Rodrigues, C.J. Principles and practice of coffee breeding for resistance to rust and other diseases. Coffee Agron. 1988, 4, 199–234. [Google Scholar]
- Silva, R.A.; Zambolim, L.; Castro, I.S.L.; Rodrigues, H.S.; Cruz, C.D.; Caixeta, E.T. The Híbrido de Timor germplasm: Identification of molecular diversity and resistance sources to coffee berry disease and leaf rust. Euphytica 2018, 214, 153. [Google Scholar] [CrossRef]
- Diniz, I.; Talhinhas, P.; Azinheira, H.G.; Várzea, V.; Medeira, C.; Maia, I.; Petitot, A.S.; Nicole, M.; Fernandez, D.; Silva, M.C. Cellular and molecular analyses of coffee resistance to Hemileia vastatrix and nonhost resistance to Uromyces vignae in the resistance-donor genotype HDT832/2. Eur. J. Plant Pathol. 2012, 133, 141–157. [Google Scholar] [CrossRef]
- Talhinhas, P.; Batista, D.; Diniz, I.; Vieira, A.; Silva, D.N.; Loureiro, A.; Tavares, S.; Pereira, A.P.; Azinheira, H.G.; Guerra-Guimarães, L.; et al. The coffee leaf rust pathogen Hemileia vastatrix: One and a half centuries around the tropics. Mol. Plant Pathol. 2017, 18, 1039–1051. [Google Scholar] [CrossRef]
- Yu, X.; Feng, B.; He, P.; Shan, L. From chaos to harmony: Responses and signaling upon microbial pattern recognition. Annu. Rev. Phytopathol. 2017, 55, 109–137. [Google Scholar] [CrossRef]
- Monteiro, F.; Nishimura, M.T. Structural, functional, and genomic diversity of plant NLR proteins: An evolved resource for rational engineering of plant immunity. Annu. Rev. Phytopathol. 2018, 56, 243–267. [Google Scholar] [CrossRef]
- Panstruga, R.; Moscou, M.J. What is the molecular basis of nonhost resistance? Mol. Plant Microbe Interact. 2020, 33, 1253–1264. [Google Scholar] [CrossRef] [PubMed]
- Qi, Y.; Tsuda, K.; Nguyen, L.V.; Wang, X.; Lin, J.; Murphy, A.S.; Glazebrook, J.; Thordal-Christensen, H.; Katagiri, F. Physical association of Arabidopsis hypersensitive induced reaction proteins (HIRs) with the immune receptor RPS2. J. Biol. Chem. 2011, 286, 1297–1307. [Google Scholar] [CrossRef] [PubMed]
- Karrer, E.E.; Beachy, R.N.; Holt, C.A. Cloning of tobacco genes that elicit the hypersensitive response. Plant Mol. Biol. 1998, 36, 681–690. [Google Scholar] [CrossRef] [PubMed]
- Duan, Y.; Guo, J.; Shi, X.; Guan, X.; Liu, F.; Bai, P.; Huang, L.; Kang, Z. Wheat hypersensitive-induced reaction genes TaHIR1 and TaHIR3 are involved in response to stripe rust fungus infection and abiotic stresses. Plant Cell Rep. 2013, 32, 273–283. [Google Scholar] [CrossRef]
- Yu, X.-M.; Zhao, W.-Q.; Yang, W.-X.; Liu, F.; Chen, J.-P.; Goyer, C.; Liu, D.-Q. Characterization of a Hypersensitive Response-Induced gene TaHIR3 from wheat leaves infected with leaf rust. Plant Mol. Biol. Rep. 2012, 31, 314–322. [Google Scholar] [CrossRef]
- Rostoks, N.; Schmierer, D.; Kudrna, D.; Kleinhofs, A. Barley putative hypersensitive induced reaction genes: Genetic mapping, sequence analyses and differential expression in disease lesion mimic mutants. Theor. Appl. Genet. 2003, 107, 1094–1101. [Google Scholar] [CrossRef]
- Li, S.; Zhao, J.; Zhai, Y.; Yuan, Q.; Zhang, H.; Wu, X.; Lu, Y.; Peng, J.; Sun, Z.; Lin, L.; et al. The Hypersensitive Induced Reaction 3 (HIR3) Gene Contributes to Plant Basal Resistance via an EDS1 and Salicylic Acid-Dependent Pathway. Plant J. 2019, 98, 783–797. [Google Scholar] [CrossRef]
- Dongus, J.A.; Parker, J.E. EDS1 signalling: At the nexus of intracellular and surface receptor immunity. Curr. Opin. Plant Biol. 2021, 62, 102039. [Google Scholar] [CrossRef]
- Rietz, S.; Stamm, A.; Malonek, S.; Wagner, S.; Becker, D.; Medina-Escobar, N.; Vlot, A.C.; Feys, B.J.; Niefind, K.; Parker, J.E. Different roles of enhanced disease susceptibility 1 (EDS1) bound to and dissociated from phytoalexin deficient 4 (PAD4) in Arabidopsis immunity. New Phytol. 2011, 191, 107–119. [Google Scholar] [CrossRef]
- Wagner, S.; Stuttmann, J.; Rietz, S.; Guerois, R.; Brunstein, E.; Bautor, J.; Niefind, K.; Parker, J.E. Structural basis for signaling by exclusive EDS1 heteromeric complexes with SAG101 or PAD4 in plant innate immunity. Cell Host Microbe 2013, 14, 619–630. [Google Scholar] [CrossRef]
- Denoeud, F.; Carretero-Paulet, L.; Dereeper, A.; Droc, G.; Guyot, R.; Pietrella, M.; Zheng, C.; Alberti, A.; Anthony, F.; Aprea, G. The coffee genome provides insight into the convergent evolution of caffeine biosynthesis. Science 2014, 345, 1181–1184. [Google Scholar] [CrossRef] [PubMed]
- Loureiro, A.; Azinheira, H.G.; Silva, M.C.; Talhinhas, P. A method for obtaining RNA from Hemileia vastatrix appressoria produced in planta, suitable for transcriptomic analyses. Fungal Biol. 2015, 119, 1093–1099. [Google Scholar] [CrossRef] [PubMed]
- Silva, M.C.; Nicole, M.; Rijo, L.; Geiger, J.P.; Rodrigues, C.J., Jr. Cytochemical aspects of the plant-rust fungus interface during the compatible interaction Coffea arabica (cv. Caturra)-Hemileia vastatrix (race III). Int. J. Plant Sci. 1999, 160, 79–91. [Google Scholar] [CrossRef]
- Silva, M.C.; Nicole, M.; Guerra-Guimarães, L.; Rodrigues, C.J. Hypersensitive cell death and post-haustorial defence responses arrest the orange rust (Hemileia vastatrix) growth in resistant coffee leaves. Physiol. Mol. Plant Pathol. 2002, 60, 169–183. [Google Scholar] [CrossRef]
- Vega-Arreguín, J.C.; Ibarra-Laclette, E.; Jiménez-Moraila, B.; Martínez, O.; Vielle-Calzada, J.P.; Herrera-Estrella, L.; Herrera-Estrella, A. Deep Sampling of the Palomero Maize Transcriptome by a High Throughput Strategy of Pyrosequencing. BMC Genom. 2009, 10, 299. [Google Scholar] [CrossRef]
- Sambrook, J.; Russell, D.W. Molecular Cloning: A Laboratory Manual; Cold Spring Harbor Laboratory: Cold Spring Harbor, NY, USA, 2001. [Google Scholar]
- Xie, F.; Xiao, P.; Chen, D.; Xu, L.; Zhang, B. miRDeepFinder: A miRNA analysis tool for deep sequencing of plant small RNAs. Plant Mol. Biol. 2012, 80, 75–84. [Google Scholar] [CrossRef]
- Ramakers, C.M.; Ruijter, J.; Lekanne Deprez, R.H.; Moorman, A.F.M. Assumption-free analysis of quantitative real-time polymerase chain reaction (PCR) data. Neurosci. Lett. 2003, 339, 62–66. [Google Scholar] [CrossRef]
- Pfaffl, M.W. A new mathematical model for relative quantification in real-time RT-PCR. Nucleic Acids Res. 2001, 29, e45. [Google Scholar] [CrossRef]
- Notredame, C.; Higgins, D.G.; Heringa, J. T-coffee: A novel method for fast and accurate multiple sequence alignment. J. Mol. Biol. 2000, 302, 205–217. [Google Scholar] [CrossRef]
- Marchler-Bauer, A.; Bo, Y.; Han, L.; He, J.; Lanczycki, C.J.; Lu, S.; Chitsaz, F.; Derbyshire, M.K.; Geer, R.C.; Gonzales, N.R.; et al. CDD/SPARCLE: Functional classification of proteins via subfamily domain architectures. Nucleic Acids Res. 2017, 45, D200–D203. [Google Scholar] [CrossRef]
- Käll, L.; Krogh, A.; Sonnhammer, E.L.L. Advantages of combined transmembrane topology and signal peptide prediction-the Phobius web server. Nucleic Acids Res. 2007, 35, W429–W432. [Google Scholar] [CrossRef] [PubMed]
- Bailey, T.L.; Boden, M.; Buske, F.A.; Frith, M.; Grant, C.E.; Clementi, L.; Ren, J.; Li, W.W.; Noble, W.S. MEME Suite: Tools for motif discovery and searching. Nucleic Acids Res. 2009, 37, W202–W208. [Google Scholar] [CrossRef] [PubMed]
- Jones, D.T.; Taylor, W.R.; Thornton, J.M. The rapid generation of mutation data matrices from protein sequences. Comput. Appl. Biosci. 1992, 8, 275–282. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.; Stecher, G.; Tamura, K. MEGA7: Molecular evolutionary genetics analysis version 7.0 for bigger datasets. Mol. Biol. Evol. 2016, 33, 1870–1874. [Google Scholar] [CrossRef]
- Martin, M. Cutadapt removes adapter sequences from high-throughput sequencing reads. EMBnet J. 2011, 17, 10–12. [Google Scholar] [CrossRef]
- Li, H.; Durbin, R. Fast and Accurate Short Read Alignment with Burrows-Wheeler Transform. Bioinformatics 2009, 25, 1754–1760. [Google Scholar] [CrossRef]
- Rivera-Milla, E.; Stuermer, C.A.; Malaga-Trillo, E. Ancient origin of reggie (flotillin), reggie-like, and other lipid-raft proteins: Convergent evolution of the SPFH domain. Cell. Mol. Life Sci. 2006, 63, 343–357. [Google Scholar] [CrossRef]
- Blanchoin, L.; Staiger, C.J. Plant formins: Diverse isoforms and unique molecular mechanism. Biochim. Biophys. Acta 2010, 1803, 201–206. [Google Scholar] [CrossRef]
- Scalabrin, S.; Toniutti, L.; Gaspero, G.; Scaglione, D.; Magris, G.; Vidotto, M.; Pinosio, S.; Cattonaro, F.; Magni, F.; Jurman, I.; et al. A single polyploidization event at the origin of the tetraploid genome of Coffea arabica is responsible for the extremely low genetic variation in wild and cultivated germplasm. Sci. Rep. 2020, 10, 4642. [Google Scholar] [CrossRef]
- Choi, H.W.; Kim, Y.J.; Hwang, B.K. The hypersensitive induced reaction and leucine-rich repeat proteins regulate plant cell death associated with disease and plant immunity. Mol. Plant-Microbe Interact. 2011, 24, 68–78. [Google Scholar] [CrossRef]
- Mei, Y.; Ma, Z.; Wang, Y.; Zhou, X. Geminivirus C4 antagonizes the HIR1-mediated hypersensitive response by inhibiting the HIR1 self-interaction and promoting degradation of the protein. New Phytol. 2020, 225, 1311–1326. [Google Scholar] [CrossRef] [PubMed]
- Bhandari, D.D.; Lapin, D.; Kracher, B.; von Born, P.; Bautor, J.; Niefind, K.; Parker, J.E. An EDS1 heterodimer signalling surface enforces timely reprogramming of immunity genes in Arabidopsis. Nat. Commun. 2019, 10, 772. [Google Scholar] [CrossRef]
- Cui, H.; Gobbato, E.; Kracher, B.; Qiu, J.; Bautor, J.; Parker, J.E. A core function of EDS1 with PAD4 is to protect the salicylic acid defense sector in Arabidopsis immunity. New Phytol. 2017, 213, 1802–1817. [Google Scholar] [CrossRef]
- Gao, F.; Shu, X.; Ali, M.B.; Howard, S.; Li, N.; Winterhagen, P.; Qiu, W.; Gassmann, W. A functional EDS1 ortholog is differentially regulated in powdery mildew resistant and susceptible grapevines and complements an Arabidopsis eds1 mutant. Planta 2010, 231, 1037–1047. [Google Scholar] [CrossRef] [PubMed]
- Gao, F.; Dai, R.; Pike, S.M.; Qiu, W.; Gassmann, W. Functions of EDS1-like and PAD4 genes in grapevine defenses against powdery mildew. Plant Mol. Biol. 2014, 86, 381–393. [Google Scholar] [CrossRef] [PubMed]
- Garcia, A.V.; Blanvillain-Baufume, S.; Huibers, R.P.; Wiermer, M.; Li, G.; Gobbato, E.; Rietz, S.; Parker, J.E. Balanced nuclear and cytoplasmic activities of EDS1 are required for a complete plant innate immune response. PLoS Pathog. 2010, 6, e1000970. [Google Scholar] [CrossRef]
- Liu, H.; Li, Y.; Hu, Y.; Yang, Y.; Zhang, W.; He, M.; Li, X.; Zhang, C.; Kong, F.; Liu, X.; et al. EDS1-interacting J protein 1 is an essential negative regulator of plant innate immunity in Arabidopsis. Plant Cell 2021, 33, 153–171. [Google Scholar] [CrossRef]
- Yi, K.; Guo, C.; Chen, D.; Zhao, B.; Yang, B.; Ren, H. Cloning and functional characterization of a formin-like protein (AtFH8) from Arabidopsis. Plant Physiol. 2005, 138, 1071–1082. [Google Scholar] [CrossRef]
- Deeks, M.J.; Cvrčková, F.; Machesky, L.M.; Mikitová, V.; Ketelaar, T.; Žárský, V.; Davies, B.; Hussey, P.J. Arabidopsis group Ie formins localize to specific cell membrane domains, interact with actin-binding proteins and cause defects in cell expansion upon aberrant expression. New Phytol. 2005, 168, 529–540. [Google Scholar] [CrossRef]
- Porter, K.; Day, B. From filaments to function: The role of the plant actin cytoskeleton in pathogen perception, signaling and immunity. J. Integr. Plant Biol. 2016, 58, 299–311. [Google Scholar] [CrossRef]
- Lapin, D.; Bhandari, D.D.; Parker, J.E. Origins and immunity networking functions of EDS1 family proteins. Annu. Rev. Phytopathol. 2020, 58, 253–276. [Google Scholar] [CrossRef] [PubMed]
- Bernacki, M.J.; Czarnocka, W.; Szechynska-Hebda, M.; Mittler, R.; Karpinski, S. Biotechnological potential of LSD1, EDS1, and PAD4 in the improvement of crops and industrial plants. Plants 2019, 8, 290. [Google Scholar] [CrossRef] [PubMed]
- Szechyńska-Hebda, M.; Czarnocka, W.; Hebda, M.; Bernacki, M.J.; Karpiński, S. PAD4, LSD1 and EDS1 regulate drought tolerance, plant biomass production, and cell wall properties. Plant Cell Rep. 2016, 35, 527–539. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Contigs | Reads | Relative Abundance 1 | Gene ID 2 | Gene Name 3 | ||||
|---|---|---|---|---|---|---|---|---|
| H | U | C | H (×1000) | U (×1000) | C (×1000) | |||
| 1977 | 77 | 192 | 130 | 48 | 119 | 80 | MZ043763 | HIR2;1 |
| 1978 | 74 | 187 | 125 | 49 | 125 | 83 | MZ043764 | HIR2;1 |
| 1979 | 76 | 190 | 122 | 51 | 127 | 81 | MZ043765 | HIR2;2 |
| 1980 | 51 | 32 | 19 | 42 | 26 | 16 | MZ043766 | HIR2;2 |
| 3670 | 3 | 3 | 0 | 6 | 6 | 0 | MZ043769 | EDS1 |
| 3754 | 43 | 48 | 10 | 19 | 21 | 4 | MZ043770 | PAD4 |
| 3755 | 43 | 48 | 9 | 19 | 21 | 4 | MZ043771 | PAD4 |
| 4974 | 53 | 29 | 19 | 43 | 24 | 16 | MZ043761 | HIR1 |
| 4975 | 50 | 31 | 18 | 38 | 24 | 14 | MZ043762 | HIR1 |
| 9472 | 52 | 28 | 18 | 40 | 22 | 14 | MZ043767 | HIR3 |
| 9636 | 30 | 50 | 15 | 21 | 35 | 11 | MZ043768 | HIR4 |
| Gene Name * | Gene ID 1 | Coffea arabica | Coffea canephora | Coffea eugenioides | |||
| E | Gene ID 2 Gene Name * | E | Gene ID 3 Gene Name * | E | Gene ID 4 Gene Name * | ||
| HDTHIR1 | MZ043761 MZ043762 | 0 0 | c-LOC113716961CaeHIR1 e-LOC113717595 CacHIR1 | 0 | Cc11_g13450 CcHIR1 | 0 | LOC113754397 CeHIR1 |
| HDTHIR2;1 | MZ043763 MZ043764 | 0 | e-LOC113742674 CaeHIR2 | 0 | Cc04_g15530 CcHIR2 | 0 | LOC113767564 CeHIR2 |
| HDTHIR2;2 | MZ043765 MZ043766 | 0 | c-LOC113740361 CacHIR2 | ||||
| HDTHIR3 | MZ043767 | 0 0 | c-LOC113725125 CaeHIR3 e-LOC113730151 CacHIR3 | 0 | Cc02_g03940 CcHIR3 | 0 | LOC113762209 CeHIR3 |
| HDTHIR4 | MZ043768 | 0 0 | c-LOC113700021 CacHIR4 NW_020850478.1-LOC113723124 - | 0 | Cc07_g03000 CcHIR4 | 0 | LOC113753487 CeHIR4 |
| HDTEDS1 | MZ043769 | 0 0 0 | c-LOC113740411 CacEDS1a c-LOC113738521 CacEDS1b e-LOC113742236 CaeEDS1 | 0 | Cc04_g126220 CcEDS1 | 0 | LOC113767316 CeEDS1 |
| HDTPAD4 | MZ043770 MZ043771 | 3 × 10−160 | c-LOC113698404 CacPAD4 | 0 0 | Cc02_g3389 CcPAD4a Cc02_g3390 CcPAD4b | 0 | LOC113777610 CePAD4 |
| C. arabica Genotype | Paired-Read Ends Mapped on the Same Contig (%) | Mapping Quality (q) | Distance between Paired Ends (bp) | |||
|---|---|---|---|---|---|---|
| C. canephora | C. eugenioides | C. canephora | C. eugenioides | C. canephora | C. eugenioides | |
| 19/1 | 61.34 | 45.47 | 57.56 (40–60) | 53.37 (28–60) | 549 (59–2051) | 10,706 (117–10,798) |
| 128/8 | 60.38 | 24.61 | 57.62 (40–60) | 52.86 (27–60) | 514 (59–1068) | 7453 (89–10,809) |
| H147/1 | 62 | 27.31 | 57.69 (40–60) | 53.54 (27–60) | 510 (59–1062) | 8646 (112–10,797) |
| H469 | 59.42 | 53.88 | 57.63 (40–60) | 53.89 (27–60) | 549 (59–1064) | 10,706 (114–10,798) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tavares, S.; Azinheira, H.; Valverde, J.; Muñoz-Pajares, A.J.; Talhinhas, P.; Silva, M.d.C. Identification of HIR, EDS1 and PAD4 Genes Reveals Differences between Coffea Species That May Impact Disease Resistance. Agronomy 2023, 13, 992. https://doi.org/10.3390/agronomy13040992
Tavares S, Azinheira H, Valverde J, Muñoz-Pajares AJ, Talhinhas P, Silva MdC. Identification of HIR, EDS1 and PAD4 Genes Reveals Differences between Coffea Species That May Impact Disease Resistance. Agronomy. 2023; 13(4):992. https://doi.org/10.3390/agronomy13040992
Chicago/Turabian StyleTavares, Sílvia, Helena Azinheira, Javier Valverde, A. Jesus Muñoz-Pajares, Pedro Talhinhas, and Maria do Céu Silva. 2023. "Identification of HIR, EDS1 and PAD4 Genes Reveals Differences between Coffea Species That May Impact Disease Resistance" Agronomy 13, no. 4: 992. https://doi.org/10.3390/agronomy13040992