
Evaluation of Hyperspectral Monitoring Model for Aboveground Dry Biomass of Winter Wheat by Using Multiple Factors
 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Design
2.2. Data Acquisition
2.3. Data Analysis Method
3. Results
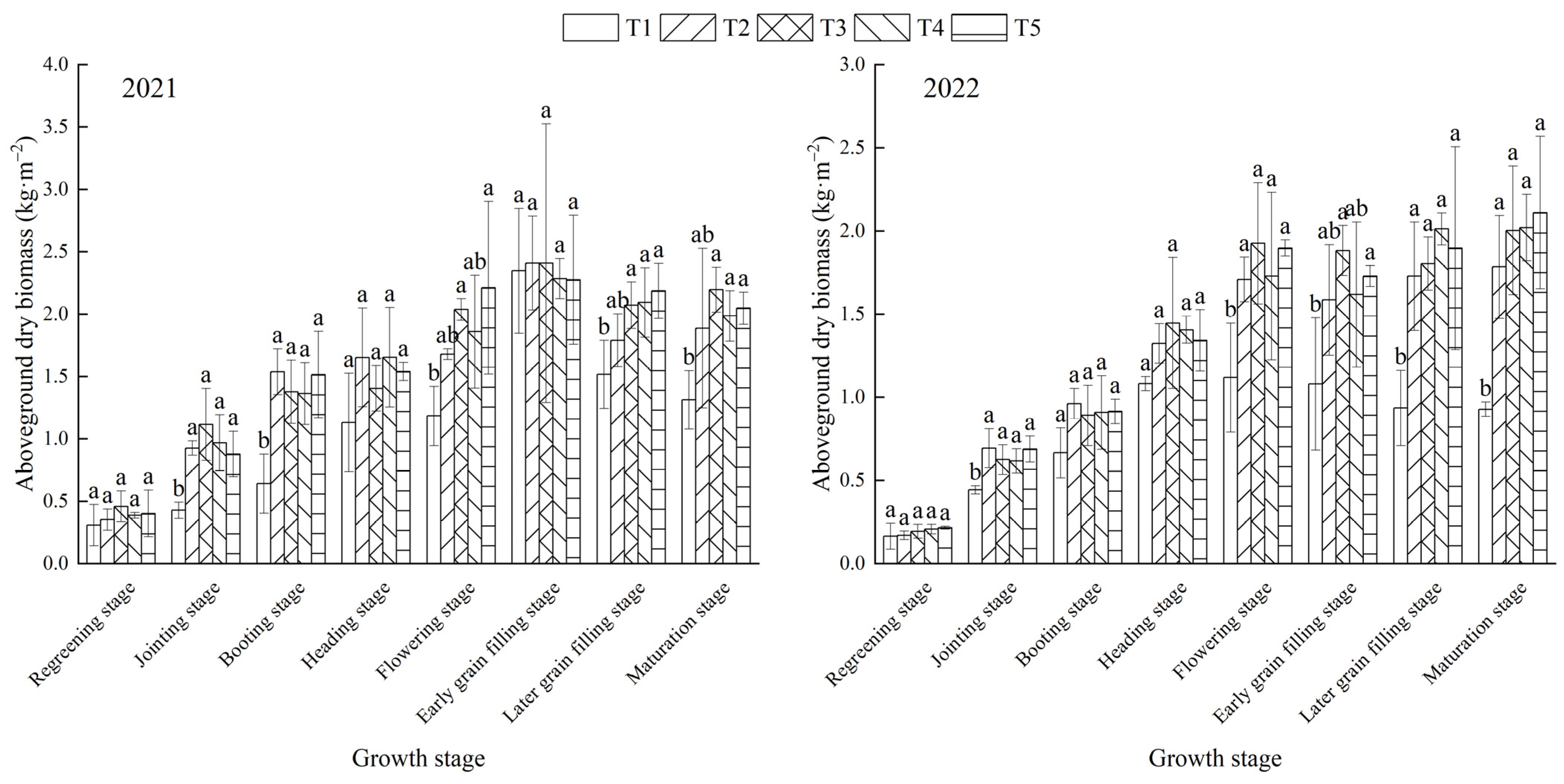
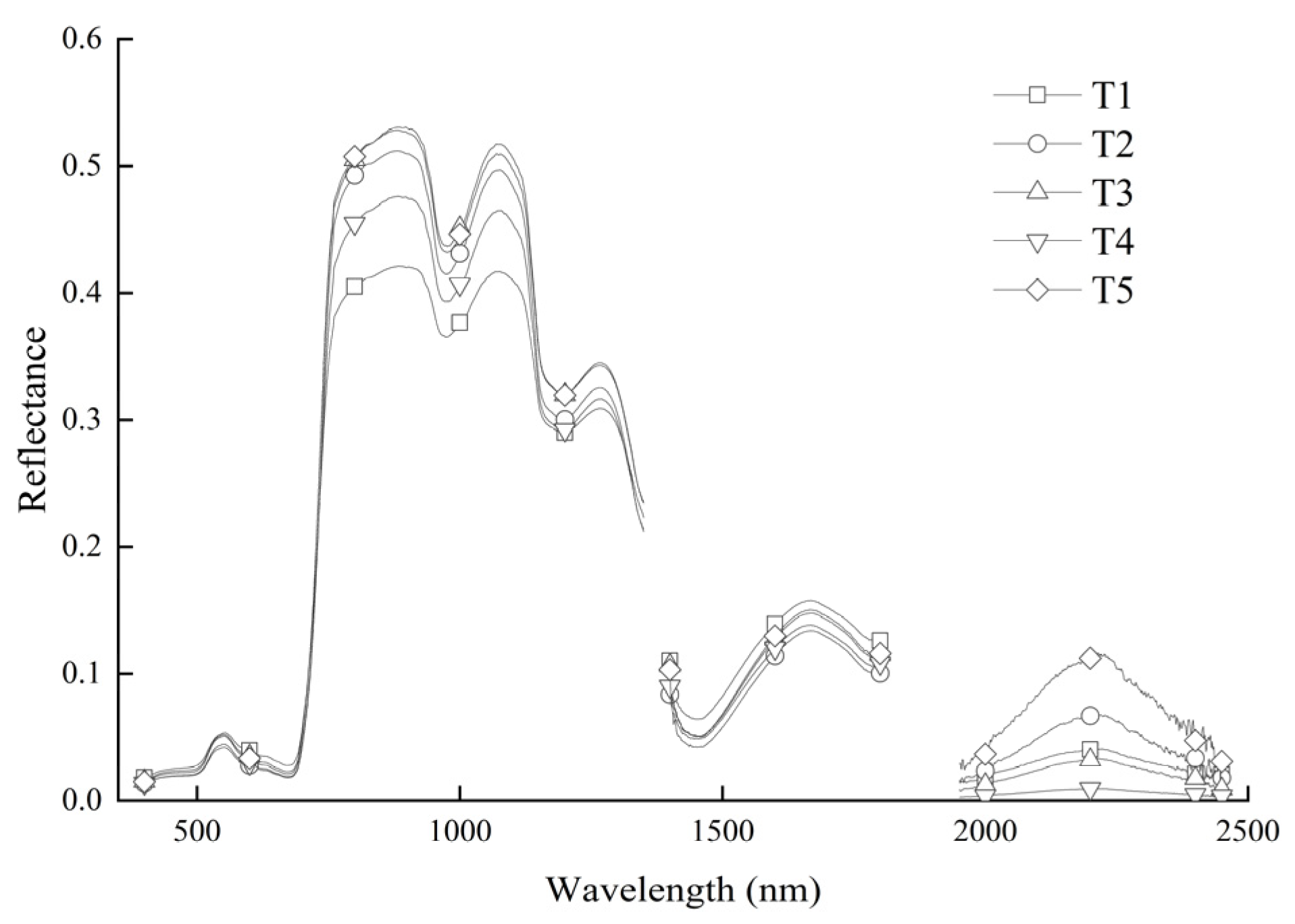
3.1. Variation in AGDB and Spectral Reflectance under Different Treatments
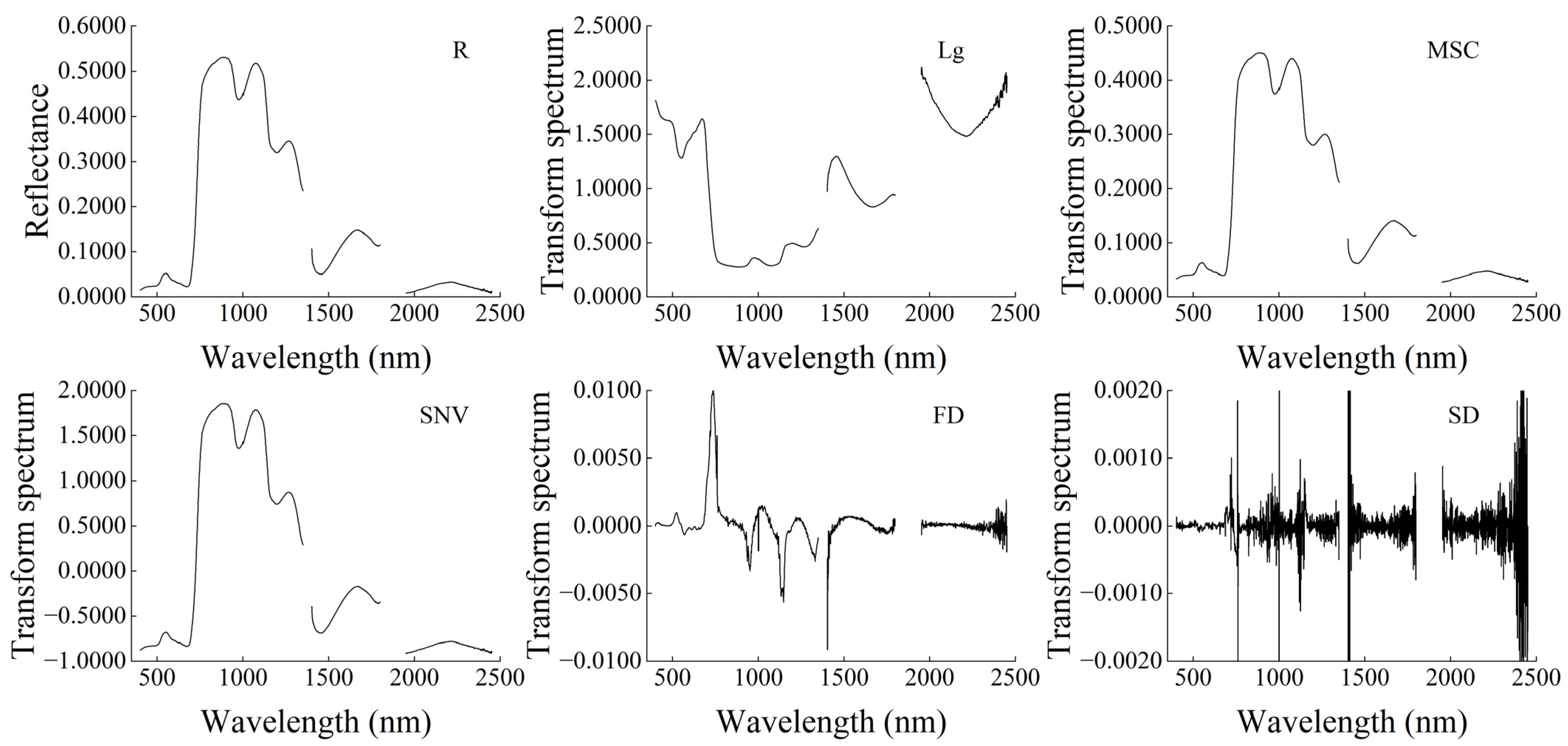
3.2. Effect of Preprocessing Algorithm on Spectral Reflectance
3.3. Descriptive Statistics
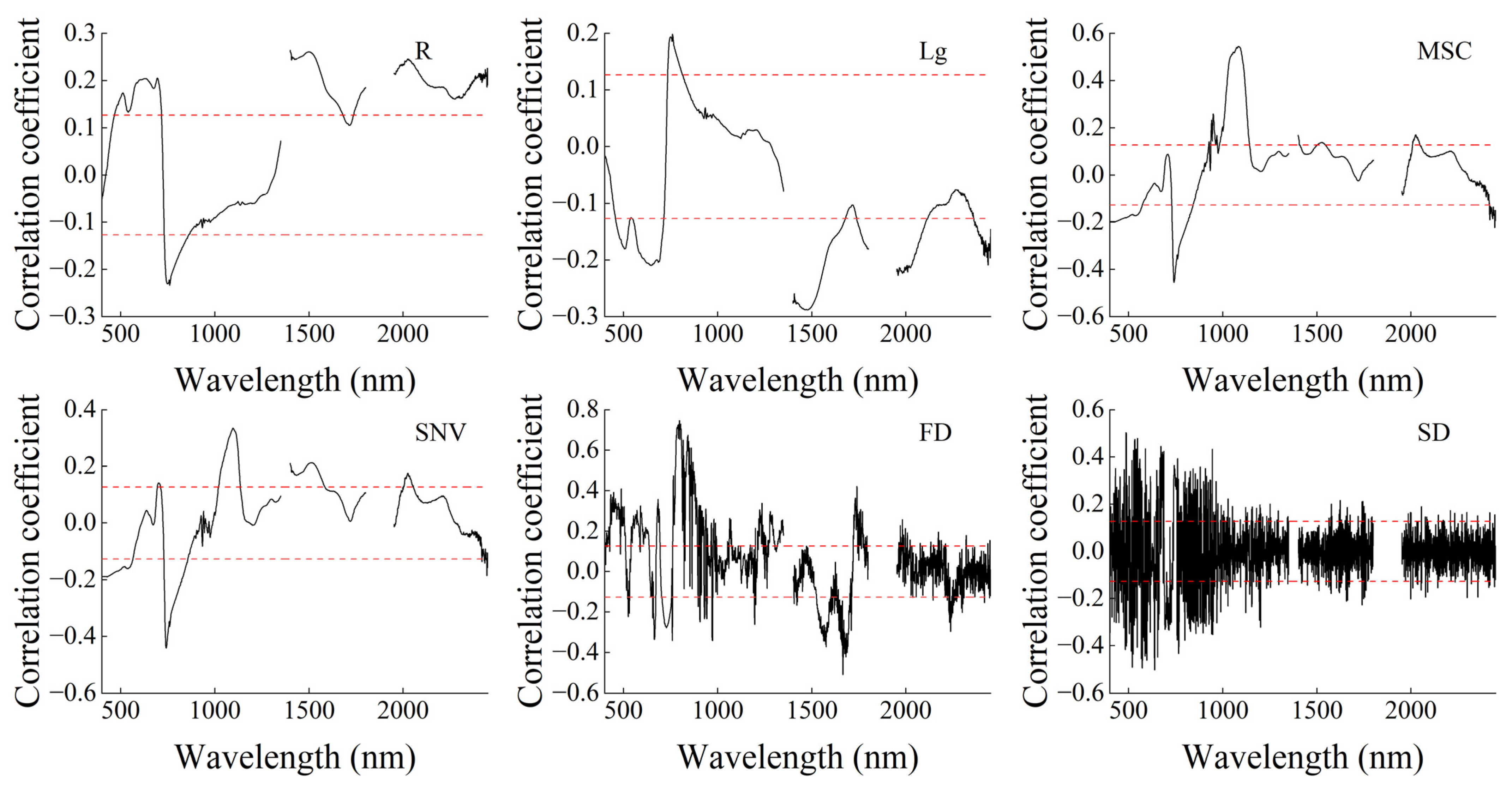
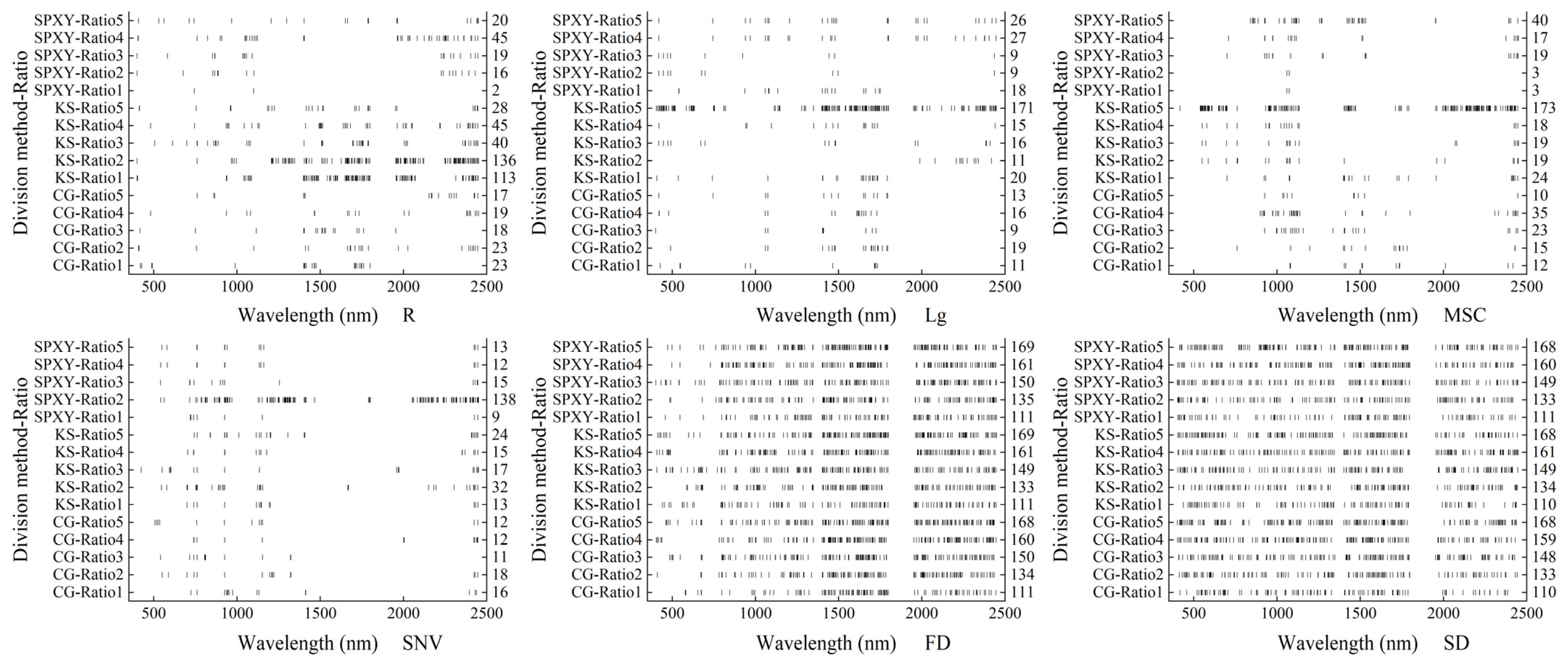
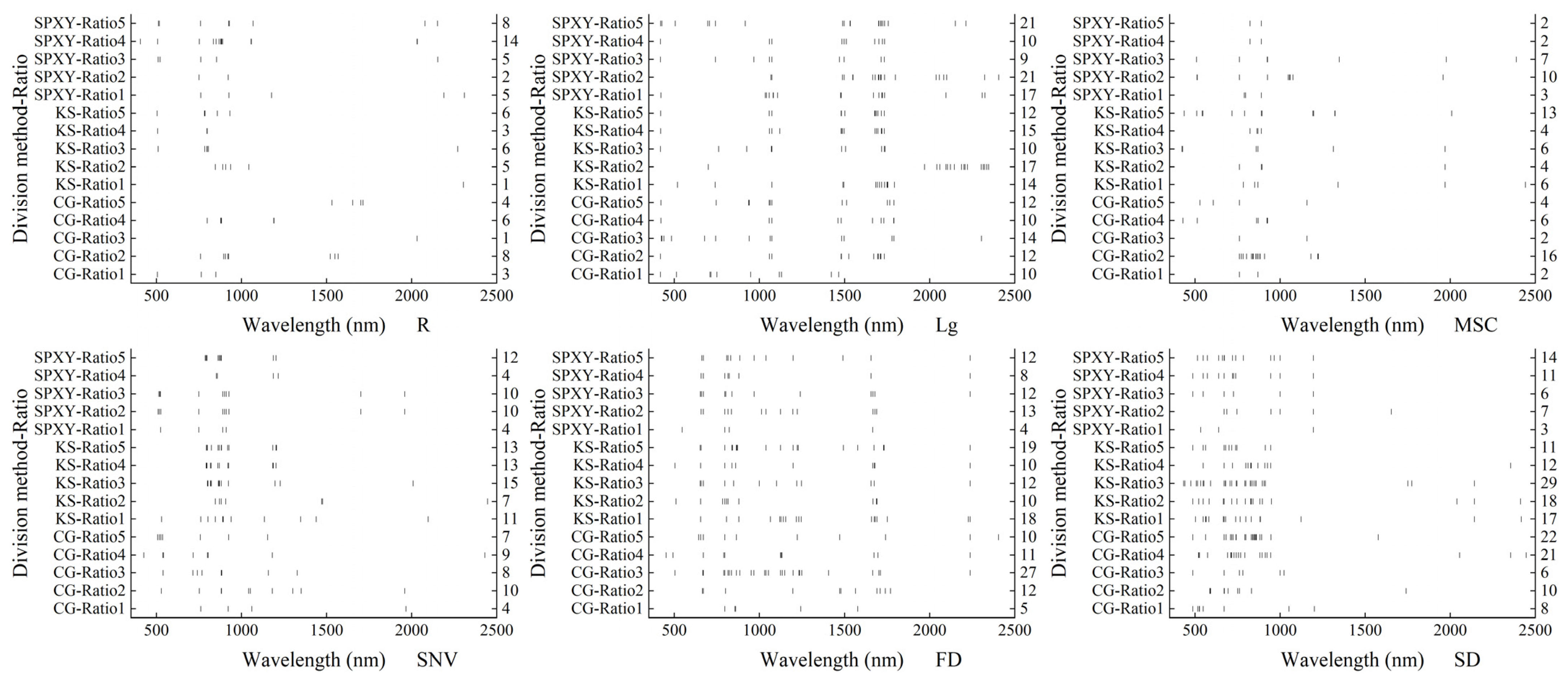
3.4. Screening Band Effect by Dimension Reduction Algorithm
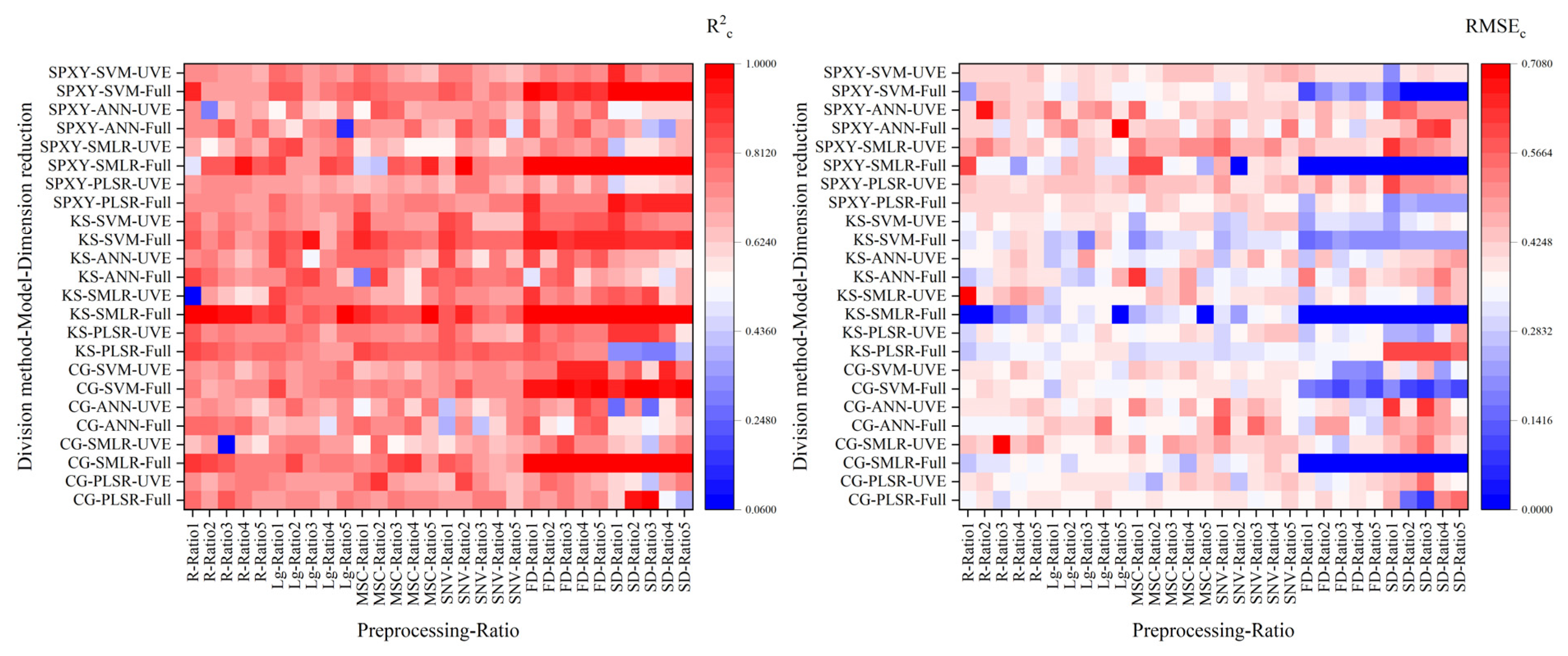
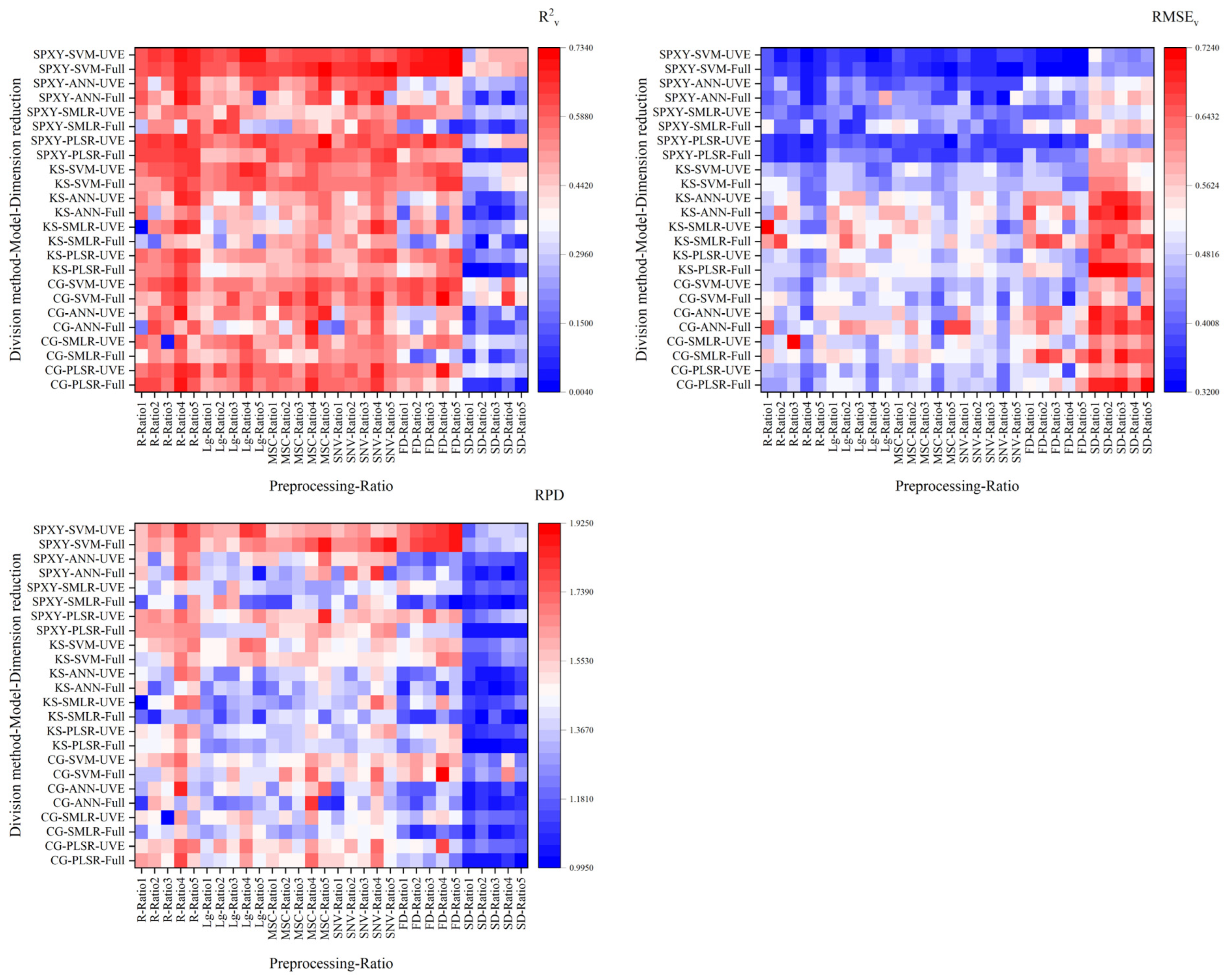
3.5. Modeling Results of Different Modeling Algorithms
3.6. Effect of Different Factors on Model Accuracy
4. Discussion
5. Conclusions
- (1)
- Irrigation can improve the AGDB and canopy spectral reflectance of winter wheat.
- (2)
- The preprocessing algorithm can change the original spectral curve to varying degrees and improve the correlation between the original spectrum and the AGDB of winter wheat. At the same time, 1400 nm, 1479 nm, 1083 nm, 741 nm, 797 nm, and 486 nm with high correlation with AGDB were selected.
- (3)
- The calibration set and the validation set were divided based on different sample division methods, and sample division ratios had different data distribution characteristics.
- (4)
- The UVE method can obviously eliminate some bands in the full-spectrum band and reduce the model complexity.
- (5)
- In modeling algorithm, SVM had a better effect.
- (6)
- According to the universality of the data, by using the original spectrum, combining the SPXY method to divide the samples according to the ratio of 5:2, using UVE to screen the bands, and using SVM to construct the model, we can obtain a stable and high accuracy model when using other data to construct the hyperspectral monitoring model for the AGDB of winter wheat.
- (7)
- According to its particularity, the FD-CG-Ratio4-Full-SVM model had the highest accuracy in this study, with R2c, RMSEc, R2v, RMSEv, and RPD values of 0.9487, 0.1663 kg·m−2, 0.7335, 0.3600 kg·m−2, and 1.9226, respectively, which can realize hyperspectral monitoring for the AGDB of winter wheat.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, C.; Liu, J.; Shang, J.; Cai, H. Capability of crop water content for revealing variability of winter wheat grain yield and soil moisture under limited irrigation. Sci. Total Environ. 2018, 631–632, 677–687. [Google Scholar] [CrossRef]
- Kang, S.; Zhang, L.; Liang, Y.; Hu, X.; Cai, H.; Gu, B. Effects of limited irrigation on yield and water use efficiency of winter wheat in the Loess Plateau of China. Agric. Water Manag. 2002, 55, 203–216. [Google Scholar] [CrossRef]
- Yang, C.B.; Feng, M.C.; Sun, H.; Wang, C.; Yang, W.D.; Xie, Y.K.; Jing, B.H. Hyperspectral monitoring of aboveground dry biomass of winter wheat under different irrigation treatments. Chin. J. Ecol. 2019, 38, 1767–1773. [Google Scholar] [CrossRef]
- Zhong, W.W.; Liu, J.Q.; Zhou, X.B.; Chen, Y.H.; Bi, J.J. Row spacing and irrigation effect on radiation use efficiency of winter wheat. J. Anim. Plant Sci. 2015, 25, 448–455. [Google Scholar]
- Morgun, V.; Priadkina, G.; Stasik, O.; Zborivskaia, O. Biomass as a factor contributing to winter wheat yield increase. Fakt. Eksperimental Noi Evol. Org. 2019, 24, 265–270. [Google Scholar] [CrossRef] [Green Version]
- Ljubicic, N.; Kostić, M.; Marko, O.; Panić, M.; Brdar, S.; Lugonja, P.; Knežević, M.; Minić, V.; Ivosevic, B.; Jevtic, R.; et al. Estimation of aboveground biomass and grain yield of winter wheat using NDVI measurements. In Proceedings of the IX International Agricultural Symposium “Agrosym 2018”, Jahorina, Bosnia and Herzegovina, 4–7 October 2018. [Google Scholar]
- Fu, Y.; Yang, G.; Wang, J.; Song, X.; Feng, H. Winter wheat biomass estimation based on spectral indices, band depth analysis and partial least squares regression using hyperspectral measurements. Comput. Electron. Agric. 2014, 100, 51–59. [Google Scholar] [CrossRef]
- Fan, Y.; Ma, Y.; Zaman, A.M.; Zhang, M.; Li, Q. Delayed irrigation at the jointing stage increased the post-flowering dry matter accumulation and water productivity of winter wheat under wide-precision planting pattern. J. Sci. Food Agric. 2022, 103, 1925–1934. [Google Scholar] [CrossRef] [PubMed]
- Jia, M.; Li, W.; Wang, K.; Zhou, C.; Cheng, T.; Tian, Y.; Zhu, Y.; Cao, W.; Yao, X. A newly developed method to extract the optimal hyperspectral feature for monitoring leaf biomass in wheat. Comput. Electron. Agric. 2019, 165, 104942. [Google Scholar] [CrossRef]
- Kanemoto, M.; Tanaka, S.; Kawamura, K.; Matsufuru, H.; Yoshida, K.; Akiyama, T. Wavelength selection for estimating biomass, LAI, and leaf nitrogen concentration in winter wheat of Gifu prefecture using in situ hyperspectral data. J. Jpn. Agric. Syst. Soc. 2008, 24, 43–56. [Google Scholar] [CrossRef]
- Zhang, M.; Wu, B.; Meng, J. Quantifying winter wheat residue biomass with a spectral angle index derived from China Environmental Satellite data. Int. J. Appl. Earth Obs. 2014, 32, 105–113. [Google Scholar] [CrossRef]
- Bao, Y.; Gao, W.; Gao, Z. Estimation of winter wheat biomass based on remote sensing data at various spatial and spectral resolutions. Front. Earth Sci. China 2009, 3, 118–128. [Google Scholar] [CrossRef] [Green Version]
- Ji, W.; Li, X.; Li, X.; Zhou, Y.; Shi, Z. Using different data mining algorithms to predict soil organic matter based on visible-near infrared spectroscopy. Spectrosc. Spec. Anal. 2012, 32, 2393–2398. [Google Scholar]
- Li, C.; Zhao, J.; Li, Y.; Meng, Y.; Zhang, Z. Modeling and prediction of soil organic matter content based on visible-near-Infrared spectroscopy. Forests 2021, 12, 1809. [Google Scholar] [CrossRef]
- Shi, B.; Yuan, Y.; Zhuang, T.; Xu, X.; Schmidhalter, U.; Ata-UI-Karim, S.T.; Zhao, B.; Liu, X.; Tian, Y.; Zhu, Y.; et al. Improving water status prediction of winter wheat using multi-source data with machine learning. Eur. J. Agron. 2022, 139, 126548. [Google Scholar] [CrossRef]
- Lee, M.; Chen, X.Y.; Lee, H.C. Spectral perprocessing for hyperspetral remote sensing of heavy metals in water. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 1869–1873. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Zhang, W.; Xiong, S.; Song, Z.; Tian, W.; Shi, L.; Ma, X. Comparison of new hyperspectral index and machine learning models for prediction of winter wheat leaf water content. Plant Methods 2021, 17, 34. [Google Scholar] [CrossRef]
- Xu, X.; Chen, S.; Xu, Z.; Yu, Y.; Zhang, S.; Dai, R. Exploring appropriate preprocessing techniques for hyperspectral soil organic matter content estimation in black soil area. Remote Sens. 2020, 12, 3765. [Google Scholar] [CrossRef]
- Li, H.; Jia, S.; Le, Z. Quantitative analysis of soil total nitrogen using hyperspectral imaging technology with extreme learning machine. Sensors 2019, 19, 4355. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.; Feng, M.; Song, L.; Wang, C.; Yang, W.; Xie, Y.; Jing, B.; Xiao, L.; Zhang, M.; Song, X.; et al. Study on hyperspectral estimation model of soil organic carbon content in the wheat field under different water treatments. Sci. Rep. 2021, 11, 18582. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, J.; Xia, A.; Zhang, K.; Dong, X.; Wu, K.; Wu, G. Continuous wavelet analysis of leaf reflectance improves classification accuracy of mangrove species. Remote Sens. 2019, 11, 254. [Google Scholar] [CrossRef] [Green Version]
- Li, F.; Mistele, B.; Hu, Y.; Chen, X.; Schmidhalter, U. Optimising three-band spectral indices to assess aerial N concentration, N uptake and aboveground biomass of winter wheat remotely in China and Germany. ISPRS J. Photogramm. 2014, 92, 112–123. [Google Scholar] [CrossRef]
- Fu, Y.Y.; Yang, G.J.; Feng, H.K.; Song, X.Y.; Xu, X.G.; Wang, J.H. Comparative analysis of three regression methods for the winter wheat biomass estimation using hyperspectral measurements. In Proceedings of the 2nd International Conference on Computer Science and Electronics Engineering, Hangzhou, China, 22–23 March 2013; Volume 2013, pp. 1733–1736. [Google Scholar] [CrossRef] [Green Version]
- Rinnan, A.; Berg, F.V.D.; Engelsen, S.B. Review of the most common pre-processing techniques for near-infrared spectra. TrAC-Trend. Anal. Chem. 2009, 28, 1201–1222. [Google Scholar] [CrossRef]
- Buddenbaum, H.; Steffens, M. The effects of spectral pretreatments on chemometric analyses of soil profiles using laboratory imaging spectroscopy. Appl. Environ. Soil Sci. 2012, 2012, 274903. [Google Scholar] [CrossRef] [Green Version]
- Cees, D.; Boeriu, C.G.; Stolle-Smits, T.; Tijskens, P. The firmness of stored tomatoes (cv. Tradiro). 2. Kinetic and Near Infrared models to describe pectin degrading enzymes and firmness loss. J. Food Eng. 2006, 77, 585–593. [Google Scholar] [CrossRef]
- Pereira, A.; Pontes, M.; Fernandes Gambarra Neto, F.; Santos, S.; Galvão, R. NIR spectrometric determination of quality parameters in vegetable oils using PLS and variable selection. Food Res. Int. 2008, 41, 341–348. [Google Scholar] [CrossRef]
- Zhang, S.; Shen, Q.; Nie, C.; Huang, Y.; Wang, J.; Hu, Q.; Ding, X.; Zhou, Y.; Chen, Y. Hyperspectral inversion of heavy metal content in reclaimed soil from a mining wasteland based on different spectral transformation and modeling methods. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 211, 393–400. [Google Scholar] [CrossRef] [PubMed]
- Yin, X.; Zhu, H.; Zhang, Q.; Liu, J.; Zhao, Q.; Wang, C.; Ning, C. The disease severity estimation of bacterial spot disease of processing tomato based on hyperspectral remote sensing. In Proceedings of the 2015 23rd International Conference on Geoinformatics, Wuhan, China, 19–21 June 2015. [Google Scholar]
- Yuan, Y.; Wang, W.; Chu, X.; Xi, M.J. Selection of characteristic wavelengths using SPA and qualitative discrimination of mildew degree of corn kernels based on SVM. Spectrosc. Spect. Anal. 2016, 36, 226–230. [Google Scholar] [CrossRef]
- Galvão, R.; Emidio, G.; Pontes, M.; Silva, E.; Bezerra, S. A method for calibration and validation subset partitioning. Talanta 2005, 67, 736–740. [Google Scholar] [CrossRef]
- Yang, Z.; Xiao, H.; Feng, D.J.; Zhang, F.; Jiang, M.; Sui, Q.; Jia, L. Fast determination of oxides content in cement raw meal using NIR spectroscopy with SPXY algorithm. Anal. Methods 2019, 11, 3936–3942. [Google Scholar] [CrossRef]
- Chen, Y.; Qi, T.; Huang, Y.; Wan, Y.; Zhao, R.; Qi, L.; Zhang, C.; Fei, T. Optimization method of calibration dataset for VIS-NIR spectral inversion model of soil organic matter content. Trans. Chin. Soc. Agric. Eng. 2017, 33, 107–114. [Google Scholar] [CrossRef]
- Yang, C.; Feng, M.; Song, L.; Jing, B.; Xie, Y.; Wang, C.; Yang, W.; Xiao, L.; Zhang, M.; Song, X. Study on hyperspectral monitoring model of soil total nitrogen content based on fractional-order derivative. Comput. Electron. Agric. 2022, 201, 107307. [Google Scholar] [CrossRef]
- Ma, F.; Du, C.W.; Zhou, J.M.; Shen, Y.Z. Investigation of soil properties using different techniques of mid-infrared spectroscopy. Eur. J. Soil Sci. 2019, 70, 96–106. [Google Scholar] [CrossRef] [Green Version]
- Zhou, L.; Wen, H.; Li, C. Research of dam deformation analysis model based on grey system, stepwise regression and the combined. Urban Geotech. Investig. Surv. 2012, 4, 135–138. [Google Scholar]
- Mokhtari, M.H.; Busu, I.; Mokhtari, H.; Zahedi, G.; Sheikhattar, L.; Movahed, M.A. Neural network and multiple linear regression for estimating surface albedo from ASTER visible and near-infrared apectral bands. Earth Interact. 2013, 17, 1–20. [Google Scholar] [CrossRef]
- Hassan-Esfahani, L.; Torres-Rua, A.; Jensen, A.; McKee, M. Assessment of surface soil moisture using high-resolution multi-spectral imagery and artificial neural networks. Remote Sens. 2015, 7, 2627–2646. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.; Feng, M.; Song, L.; Jing, B.; Xie, Y.; Wang, C.; Qin, M.; Yang, W.; Xiao, L.; Sun, J.; et al. Hyperspectral monitoring of soil urease activity under different water regulation. Plant Soil 2022, 477, 779–792. [Google Scholar] [CrossRef]
- Marabel, M.; Alvarez-Taboada, F. Spectroscopic determination of aboveground biomass in grasslands using spectral transformations, support vector machine and partial least squares regression. Sensors 2013, 13, 10027–10051. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xue, Q.; Zhu, Z.; Musick, J.T.; Stewart, B.A.; Dusek, D.A. Physiological mechanisms contributing to the increased water-use efficiency in winter wheat under deficit irrigation. J. Plant Physiol. 2006, 163, 154–164. [Google Scholar] [CrossRef] [PubMed]
- Stallmann, J.; Schweiger, R.; Pons, C.A.A.; Müller, C. Wheat growth, applied water use efficiency and flag leaf metabolome under continuous and pulsed deficit irrigation. Sci. Rep. 2020, 10, 10112. [Google Scholar] [CrossRef]
- Stallmann, J.; Schweiger, R.; Müller, C. Effects of continuous versus pulsed drought stress on physiology and growth of wheat. Plant Biol. 2018, 20, 1005–1013. [Google Scholar] [CrossRef]
- Gupta, N.K.; Gupta, S.; Kumar, A. Effect of water stress on physiological attributes and their relationship with growth and yield of wheat cultivars at different stages. J. Agron. Crop Sci. 2001, 186, 55–62. [Google Scholar] [CrossRef]
- Patil, R.H.; Laegdsmand, M.; Olesen, J.E.; Porter, J.R. Growth and yield response of winter wheat to soil warming and rainfall patterns. J. Agric. Sci. 2010, 148, 553–566. [Google Scholar] [CrossRef] [Green Version]
- Yue, S.; Zhang, Z.; Ren, T.; Wang, C.; Yu, H. Morphology-based fusion method of hyperspectral image. Int. Soc. Opt. Photonics 2014, 9298, 63–72. [Google Scholar] [CrossRef]
- Boggavarapu, L.P.K.; Manoharan, P. A new framework for hyperspectral image classification using Gabor embedded patch based convolution neural network. Infrared Phys. Technol. 2020, 110, 103455. [Google Scholar] [CrossRef]
- Wang, W.; Peng, Y.K.; Zhang, X.L. Study on modeling method of total viable count of fresh pork meat based on hyperspectral imaging system. Spectrosc. Spect. Anal. 2010, 30, 411–415. [Google Scholar]
- Wang, F.; Li, M.Y. Extracting and monitoring of hyperspectral sensitive bands of winter wheat biomass. J. Shanxi Agric. Sci. 2018, 46, 718–721, 784. [Google Scholar]
- Wu, J.; Wang, Y.; Zhang, X.; Zhang, Q. Study on algorithms of selection of representative samples for calibration in near infrared spectroscopy analysis. J. Agric. Mach. 2006, 37, 80–82, 101. [Google Scholar]
- Guo, B.B.; Feng, Y.L.; Ma, C.; Zhang, J.; Song, X.; Wang, M.Y.; Sheng, D.H.; Feng, W.; Jiao, N.Y. Suitability of different multivariate analysis methods for monitoring leaf N accumulation in winter wheat using in situ hyperspectral data. Comput. Electron. Agric. 2022, 198, 107115. [Google Scholar] [CrossRef]
- Hong, Y.; Liu, Y.; Chen, Y.; Liu, Y.; Yu, L.; Liu, Y.; Cheng, H. Application of fractional-order derivative in the quantitative estimation of soil organic matter content through visible and near-infrared spectroscopy. Geoderma 2019, 337, 758–769. [Google Scholar] [CrossRef]
- Zhu, S.; Zhang, J. Influence factors analysis on accuracies of winter wheat distribution from low and medium resolution composited remote sensing images. Remote Sens. Technol. Appl. 2022, 37, 608–619. [Google Scholar] [CrossRef]
- Yan, C. Research on Variable Selection in Multiple Regression Model; Heilongjiang University: Harbin, China, 2011. [Google Scholar]
- Elberth, H.P.; Helber, E.B.; Pedro, J.A. Evaluation of SPAD index for estimating nitrogen and magnesium contents in three blueberry varieties (Vaccinium corymbosum L.) on the Andean tropics. Horticulturae 2023, 9, 269. [Google Scholar] [CrossRef]
- Yang, L.C.; Deng, S.; Zhang, Z. New spectral model for estimating leaf area index based on gene expression programming. Comput. Electr. Eng. 2020, 83, 106604. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Division Method | Data Sets | Num | Max (kg·m−2) | Min (kg·m−2) | Avg (kg·m−2) | SD (kg·m−2) | Kurtosis | Skewness |
|---|---|---|---|---|---|---|---|---|
| Total | 240 | 3.7185 | 0.0785 | 1.3392 | 0.7196 | −0.3388 | 0.2536 | |
| CG | Cal-Ratio1 | 120 | 3.7185 | 0.0785 | 1.3342 | 0.7228 | −0.2125 | 0.2767 |
| Val-Ratio1 | 120 | 3.5210 | 0.0865 | 1.3442 | 0.7193 | −0.4290 | 0.2336 | |
| Cal-Ratio2 | 144 | 3.7185 | 0.0785 | 1.3390 | 0.7199 | −0.3090 | 0.2566 | |
| Val-Ratio2 | 96 | 3.5210 | 0.0865 | 1.3395 | 0.7229 | −0.3373 | 0.2531 | |
| Cal-Ratio3 | 160 | 3.7185 | 0.0785 | 1.3385 | 0.7182 | −0.3585 | 0.2398 | |
| Val-Ratio3 | 80 | 3.5210 | 0.0865 | 1.3405 | 0.7268 | −0.2443 | 0.2855 | |
| Cal-Ratio4 | 172 | 3.7185 | 0.0785 | 1.3473 | 0.7319 | −0.1795 | 0.3167 | |
| Val-Ratio4 | 68 | 2.7240 | 0.1210 | 1.3188 | 0.6922 | −0.8785 | 0.0536 | |
| Cal-Ratio5 | 180 | 3.7185 | 0.0785 | 1.3355 | 0.7164 | −0.4086 | 0.2225 | |
| Val-Ratio5 | 60 | 3.5210 | 0.1210 | 1.3501 | 0.7349 | −0.0706 | 0.3477 | |
| KS | Cal-Ratio1 | 120 | 2.8690 | 0.0785 | 1.2936 | 0.7276 | −0.9945 | −0.0191 |
| Val-Ratio1 | 120 | 3.7185 | 0.1470 | 1.3848 | 0.7116 | 0.2538 | 0.5605 | |
| Cal-Ratio2 | 144 | 2.8690 | 0.0785 | 1.3135 | 0.7234 | −0.8989 | 0.0515 | |
| Val-Ratio2 | 96 | 3.7185 | 0.1470 | 1.3776 | 0.7158 | 0.4846 | 0.5797 | |
| Cal-Ratio3 | 160 | 2.8690 | 0.0785 | 1.3202 | 0.7180 | −0.8951 | 0.0396 | |
| Val-Ratio3 | 80 | 3.7185 | 0.1970 | 1.3772 | 0.7258 | 0.6863 | 0.6796 | |
| Cal-Ratio4 | 172 | 3.5210 | 0.0785 | 1.3612 | 0.7315 | −0.6462 | 0.0746 | |
| Val-Ratio4 | 68 | 3.7185 | 0.1970 | 1.2836 | 0.6907 | 0.9729 | 0.7826 | |
| Cal-Ratio5 | 180 | 3.5210 | 0.0785 | 1.3581 | 0.7348 | −0.6776 | 0.0915 | |
| Val-Ratio5 | 60 | 3.7185 | 0.1995 | 1.2823 | 0.6746 | 1.4735 | 0.8602 | |
| SPXY | Cal-Ratio1 | 120 | 3.7185 | 0.0785 | 1.4037 | 0.8062 | −0.4957 | 0.2753 |
| Val-Ratio1 | 120 | 2.6310 | 0.0865 | 1.2747 | 0.6177 | −0.7892 | −0.0241 | |
| Cal-Ratio2 | 144 | 3.7185 | 0.0785 | 1.4045 | 0.7924 | −0.5280 | 0.2215 | |
| Val-Ratio2 | 96 | 2.4780 | 0.0865 | 1.2412 | 0.5842 | −0.8944 | −0.0622 | |
| Cal-Ratio3 | 160 | 3.7185 | 0.0785 | 1.3955 | 0.7693 | −0.4498 | 0.2321 | |
| Val-Ratio3 | 80 | 2.4780 | 0.0865 | 1.2265 | 0.5967 | −0.8646 | −0.0312 | |
| Cal-Ratio4 | 172 | 3.7185 | 0.0785 | 1.3786 | 0.7626 | −0.4159 | 0.2226 | |
| Val-Ratio4 | 68 | 2.4780 | 0.1500 | 1.2396 | 0.5905 | −0.8782 | 0.0748 | |
| Cal-Ratio5 | 180 | 3.7185 | 0.0785 | 1.3834 | 0.7503 | −0.3605 | 0.2138 | |
| Val-Ratio5 | 60 | 2.4780 | 0.1500 | 1.2065 | 0.6047 | −0.9547 | 0.1391 |
| Preprocessing | Division Method | Ratio | Dimension Reduction | Model | |
|---|---|---|---|---|---|
| Correlation coefficient | 0.3923 ** | −0.4629 ** | −0.1804 ** | −0.1345 ** | −0.1316 ** |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, C.; Xu, J.; Feng, M.; Bai, J.; Sun, H.; Song, L.; Wang, C.; Yang, W.; Xiao, L.; Zhang, M.; et al. Evaluation of Hyperspectral Monitoring Model for Aboveground Dry Biomass of Winter Wheat by Using Multiple Factors. Agronomy 2023, 13, 983. https://doi.org/10.3390/agronomy13040983
Yang C, Xu J, Feng M, Bai J, Sun H, Song L, Wang C, Yang W, Xiao L, Zhang M, et al. Evaluation of Hyperspectral Monitoring Model for Aboveground Dry Biomass of Winter Wheat by Using Multiple Factors. Agronomy. 2023; 13(4):983. https://doi.org/10.3390/agronomy13040983
Chicago/Turabian StyleYang, Chenbo, Jing Xu, Meichen Feng, Juan Bai, Hui Sun, Lifang Song, Chao Wang, Wude Yang, Lujie Xiao, Meijun Zhang, and et al. 2023. "Evaluation of Hyperspectral Monitoring Model for Aboveground Dry Biomass of Winter Wheat by Using Multiple Factors" Agronomy 13, no. 4: 983. https://doi.org/10.3390/agronomy13040983