1. Introduction
Precision agriculture uses cutting-edge technology to improve crop yield and quality while meeting growing food demand [
1]. Farmers may optimize the efficacy of their seeds, water, fertilizers, and other inputs by employing advanced farming techniques. The goal is to maximize financial benefit while reducing expenditures and the effects on the natural environment by using the correct parameters at the right time and place.
Farmers must monitor soil moisture. This entails obtaining a more precise image of the soil’s needs and available water. An amount of 70% of the world’s water is utilized for agriculture, 20% is utilized for industry, and 10% is utilized for residences, according to UN figures (
http://www.worldometers.info/) (accessed on 10 February 2022) [
2]. To monitor and plan irrigation, you must know the soil’s water content. Sugarcane is a popular crop in India. It is the critical raw material for the nation’s second-largest agricultural sector, behind only the textile industry.
Additionally, it serves as the foundation for producing every significant sweetener in the country. Long-term growth does not need a specific soil type, but it requires much water. The soil must have enough water during the growing season, and cane growth depends on how much cane sheds. In addition to categorizing sugarcane yield, the research aims to anticipate soil moisture.
Hybrid Model for Better Sugarcane Yield Production
Agriculture has since incorporated soft computing to manage crops, anticipate agricultural yields, and monitor environmental conditions [
3]. In India, sugarcane is one of the most important crops [
4].
Sugarcane businesses provide significant benefits to rural areas in terms of the extra cash they generate and the job possibilities they make available. The proposed study will investigate how different soft computing technologies may be used to improve the categorization and forecasting of agricultural data to find better solutions to existing problems.
This section offers a condensed summary of the critical issues and contributions that this study has made.
In order to provide predictions about the amount of moisture present in the soil, a mixed model was used. In order to do this, the most advantageous aspects of the GPM, CNN, and SVM algorithms may be merged.
CNN is used to sort the data on the production of sugarcane.
According to a thorough literature survey, CNN analysis is helpful for crop management and yield research in precision agriculture. They improve over time by uncovering new patterns, not in the training datasets.
Ensemble learning’s power comes from its capacity to train several algorithms and combine their results to obtain more accurate conclusions. The hybrid model, an ensembling technique, produces accurate predictions. To make hybrid solutions for real-world problems, you must combine at least two methods to compensate for each other’s flaws. Because agriculture generates so much data, precision agriculture applications require various data processing technologies.
Academics have created algorithms for agricultural data applications. These algorithms will help farmers and agronomists manage crops and adopt agricultural strategies to guarantee a continual crop supply. This study uses neural networks, GPM, and SVM algorithms to improve agricultural data prediction and categorization.
The primary objective of this research is to enhance the precision of agricultural yield in sugarcane production in agriculture.
Sugarcane production has been the most prominent crop in Andhra Pradesh, India.
Certain soil moisture methods may be deployed for better crop yield.
Developing forecasting models for soil moisture data sets using convolutional neural network ensembles was performed. To do this, the attributes of SVM and Gaussian function were combined. Hybrid model (CNN + SVM + Gaussian) approaches are being used to train the model’s parameters to increase the accuracy of a model that detects sugarcane yields.
2. Related Works
Precision agriculture and smart farming need rapid disease diagnosis [
5]. Farmers may benefit from using plant pictures and existing machine-learning algorithms to detect crop illnesses early. Modern diagnostics may help rural farmers save their harvests. Yet, current technologies cannot accurately identify diseases. Academics and software developers are interested in how to pick a machine-learning model and scale it down to run efficiently on a device at the network’s perimeter. This study yields a model for the Plant-Village and Plant-Doc datasets [
6]. The technique relies on deep learning model performance assessment research. The analysis found that the proposed model is similar to the most sophisticated option on the market. Quantization ensures that the reduction in model size to suit an edge device will not affect system performance.
The N nutrition index helps farmers determine whether their crops have enough nitrogen (N) for safe harvesting. Nitrogen utilization efficiency (NUE) [
7] will rise, reducing environmental damage. However, active canopy sensor data cannot accurately detect the crop’s N condition or topdressing N quantity. Reflectance data from several active crop sensors is unpredictable because many environmental and management elements vary by location. To ensure food security and long-term growth, further study is needed to develop ways for monitoring and prescribing N levels throughout the growing season in various contexts.
The average phosphorus surplus in the Andhra-Pradesh and Telangana regions was 0.8 kg per acre per year. However, this varied by location. When inputs were lowered in regions with big phosphorus surpluses and easy-to-access soil, the region’s yearly phosphorus budget revealed plenty of potential for improvement [
8,
9].
Agriculture is important to India’s economy [
10]. Most farmers know little about soil preservation. Grow the right crops and use the right fertilizers to maximise land production. Modern agriculture depends on technology. More productive and efficient agriculture practices are replacing older ones. A rising number of individuals are concerned about fertilizer consumption. Farmers may use several machine learning algorithms to determine fertilizer quantities. Fertilizer consumption rates vary according to crop-specific fertilizer needs. Machine learning (ML) researchers aim to create computer programs that can explore massive amounts of data for patterns and use those patterns to anticipate fresh data. Machine learning (ML) methods assist in solving prediction and classification issues. Machine learning, utilized in many agricultural contexts, helps farmers overcome their biggest challenges. This experiment tested the support vector machine (SVM), decision tree (DT), and CNN for soil nutritional analysis. The CNN algorithm is 4% more accurate than other algorithms [
11,
12].
New technologies affect farming, textiles, vehicles, engineering, and education. AI has shaped educational practices throughout time. This study [
13] examines how current AI advances may influence new educational methods. The research created a useful random forest algorithm teaching methods learning companion. The proposed random forest technique performed inconsistently during training, but, thereafter, it performed better. The recommended strategy outperformed the support vector machine, a hesitant fuzzy set, and the overall expert score in the 30–35 range of the final weighted evaluation. 7%, 6%, and 17% were the results of this strategy.
Villupuram is a rural Tamil Nadu city. This research will focus on future climate and agriculture harvest advice [
14]. The seasonality of agricultural production is another aspect that must be considered. This work computed 1990 agricultural production using Villupuram district data from 1990–1991 and 2019–2020. Moreover, agricultural production patterns will be examined. IMD forecasts weather and environment. Seasons alter the maximum temperature and lowest rainfall. SVM is the most reliable machine-learning method for seasonal output forecasting. We will also evaluate the SVM machine algorithm’s efficiency and accuracy. A support vector machine (SVM) [
15] showed that the seasonal temperature scale will accurately predict the global average temperature in 20 years. Researchers used agronomic practices to show when and how to grow different crops throughout this research.
Humans are endangering Madagascar’s unique vegetation and fauna. This article presents data and analysis on the most prevalent and vital threats, collections, and programs, as well as protected area extent and breadth, to evaluate Madagascar’s terrestrial and freshwater biodiversity’s conservation status. An amount of 10.4% of Madagascar is preserved as terrestrial parks and reserves. Ninety-seven percent of freshwater fish, amphibians, reptiles, birds, and mammals, and 67% of native plants, live inside its boundaries. Rarer species exist (at least 79.6 percent of endangered plant species and 97.3 percent of endangered animal species reside in at least one protected location). Overexploitation of biological resources and unsustainable farming are the most significant risks to biodiversity, according to Bayesian neural network plant research and International Union for Conservation of Nature (IUCN) Red List evaluations. We concentrate on five action levels to ensure that conservation and ecological restoration goals, methods, and activities address complex underlying and interrelated causes and benefit Madagascar’s biodiversity and people. Due to cassava’s weekly price increases, it is hard to anticipate agricultural expenditures and similar group inputs. Machine learning may be used to calculate cassava costs in the future [
16,
17].
The Office of Agricultural Economics under the Ministry of Agriculture and Cooperatives studied cassava prices from January 2005 to February 2022, which represents strategy development using the data. The support vector machine approach, incorporating potato and garlic prices, had the lowest root mean squared error (RMSE) [
18] of 0.10 compared to the previous methodology that utilized the same information. Comparing the support vector machine to the previous approach revealed this. The recommended technique is 0.61% more successful, despite its 3.45% MAPE. The penultimate phase of price clustering, K-mean analysis, gave a December peak pricing period of 14.08%. The study would help the agricultural firm maximize profits by guiding its planting strategies.
It is essential when formulating food policy and ensuring there is enough food for everyone, to accurately predict what the winter wheat yields will be in each region ahead of time. This is especially important when considering the growing population and the changing environment. Artificial intelligence (AI) and large amounts of data in agriculture are the foundations of intelligent agriculture, which aims to help the agricultural industry find effective and cheap solutions to the challenges it faces [
19]. Profound learning-based crop production predictions have emerged in recent years as an essential tool for controlling agricultural operations’ output. In this study, we offer a Bayesian optimization-based strategy for predicting winter wheat production by fusing data from several sources using a long-term and short-term memory model. Our method can provide more accurate results than previous methods (BO-LSTM) [
20]. Using multi-source data as input variables, analysis of BO-LSTM, support vector machine (SVM), and most minor absolute shrinkage and selection operator (Lasso) give the capability to make predictions. The results showed that Bayesian optimization might be used to adjust deep learning hyperparameters successfully.
The recent advancements in information and communication technology have impacted many aspects of the global economy. The rise of artificial intelligence (AI) and data science, in addition to the ubiquitous availability of digital technology, are likely to be credited as the primary drivers behind the arrival of digital agriculture. Farmers now have access to new farming practices that may increase productivity without affecting the ecological health of the land they work on as a residue of total agricultural improvement. The most recent developments in digital technology and data science have made it possible for agronomists, farmers, and other experts to acquire and analyze large amounts of agricultural data. This allows them to gain insight into farming operations and make better decisions. [
21] examines how data mining methods may be used in contemporary agricultural technologies. [
22] offers a high-level overview of agricultural yield management, focusing on crop production and monitoring as the two most important aspects to discuss. When the data mining approaches for monitoring agricultural production have been sorted into their basic categories, several studies that focus on analytics are discussed and evaluated. After that, a comprehensive analysis and discussion of big data’s influence on agriculture follows.
The algorithm for predicting time series in decision support systems has seen substantial advancements in recent years. Automating and improving prediction models by using machine learning (ML) methods to analyze time series may be possible. This would come about when managing enormous amounts of data becomes more accessible. The most important thing this research brings is a hybrid model that performs better than previous forecasting models. To do this, its innovative take on the traditional Kalman filter is performed by incorporating machine learning techniques, such as support vector regression (SVR) [
23] and nonlinear autoregressive (NAR) [
24] neural networks into the mix. The proposed hybrid model addresses the problem of high error fluctuation in time series data convergence by combining an updated Kalman filter strategy with a machine learning technique as a correction factor to estimate model error. The ML technique serves as a correction factor to estimate model error. The findings indicate that, compared to traditional and alternative Kalman filter models [
25], our hybrid models have a goodness of fit of more than 0.95 and much lower root mean square and absolute mean errors. The method’s applicability to various settings was shown further in two different ways.
Gap Analysis
The thorough literature review [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25] indicates the need to improve crop yield production. The authors offer a heavyweight model that calls for extended training and generates results that vary, depending on the computer. No matter how complicated the machine learning model is, domain experts cannot understand how it works. They have a hard time maintaining their consistency. Recent research has shown that all models, particularly machine learning models, can be accurate. However, it is pointless to utilize them if the pitching expert disagrees with the model. To clarify the decision-making process, to increase farmers’ trust, and to normalize attitudes towards the concept, all of which would increase the likelihood of its eventual adoption, the goal is to use the lightweight process model and methods, such as integrating the SVM, as well as the radial basis function, with the ensemble learning techniques. This will be accomplished by using the proposed classifier.
The soil’s moisture content is determined by its current water content. This factor affects air temperature, precipitation, and other weather aspects. Agriculture, precision farming, and drought monitoring benefit from their usage. When deciding when and how much to irrigate, growers must monitor soil moisture [
26]. This increases output, improves product quality, and reduces disease and irrigation costs. Most Indians make their living via agriculture. Population growth will continue as a significator for water conservation for human consumption, with the rest used for agricultural irrigation. You must understand the crop’s water needs to meet this growing need. In locations with little water, monitoring soil moisture for effective irrigation management is increasingly important. Soil moisture explains how water and energy are moved from the ground surface to the atmosphere.
Real-time soil moisture data is needed to predict the weather, monitor floods, identify droughts early, and calculate crop growth. Forecasting is constructing a model to predict the future based on current knowledge. The capacity to accurately anticipate soil moisture affects crop growth, cultivation, and soil temperature. The challenge is creating a system that can continuously evaluate soil moisture levels. Researchers studied several statistical techniques, algorithms, and tools to construct ensemble models for weather forecasting and assessing soil moisture. The created ensembles’ performance is estimated using a statistical method. A neural network-based annealing method was used to anticipate soil moisture. The suggested technique outperforms BPN and GPM networks [
27]. A network-based model that can predict tomorrow’s ground temperature. The model received ground and air temperatures. A good prediction helps navigate the unpredictable future. Random forest, bagging, boosting, voting, stacking, and boosting are popular data-gathering methods.
To precisely measure moisture in the soil, we must also have excellent and reliable sensors, such as quartz sensors that work on the principle of open capacitive sensitive elements pushed to different depths into the ground, such as those described in ref: [
28,
29].
3. Materials and Methods
3.1. The Proposed Ensemble Model for Soil Moisture (Hybrid Model)
Introduction to the Model Deployment
A network of wireless soil moisture sensors is placed to assess how wet the top layer of soil is. The base station stored the sensor’s time series data. The soil moisture data from the base station are analyzed to fix the problem.
The study presented aims to enhance soil moisture forecasting. The suggested ensemble model comprises GPM, CNN, and SVM individual learners. The ZeroR classifier provides predictions and is a meta-learner. The ZeroR classifier is the easiest to use and can predict the most frequent category. It helps to compare classifiers to a standard.
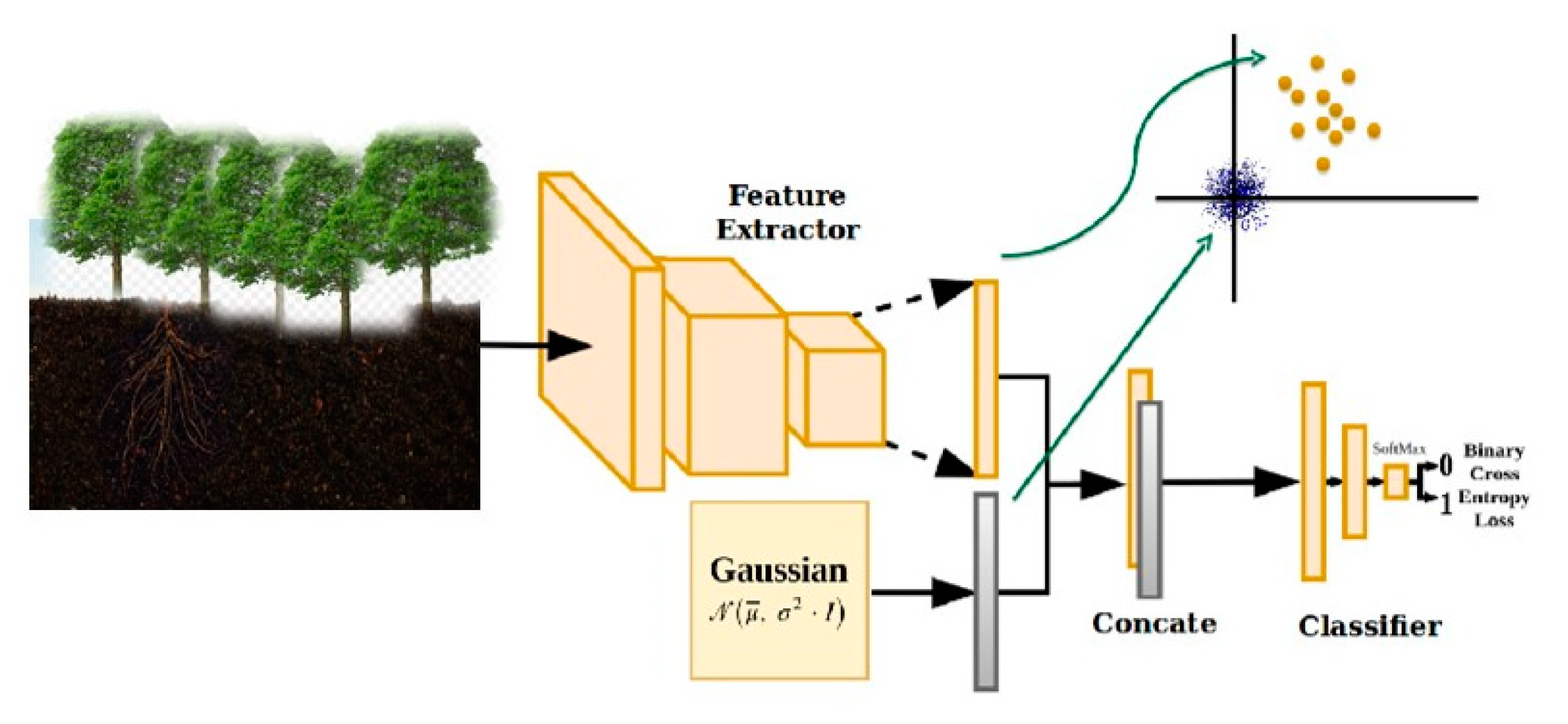
3.2. Gaussian Probabilistic Method for CNN-SVM
The Gaussian probabilistic functions were used with the CNN. The network’s output is a linear blend of the inputs’ GPM functions [
30] and neuronal characteristics. Because it uses supervised learning, it can represent nonlinear data and help find the proper application. Input, concealed, and output are GPM network layers (
Figure 1). GPM allows faster learning, better approximation, and more accessible network design than other CNNs. We will utilize least-squares mean-squared to determine optimum weights.
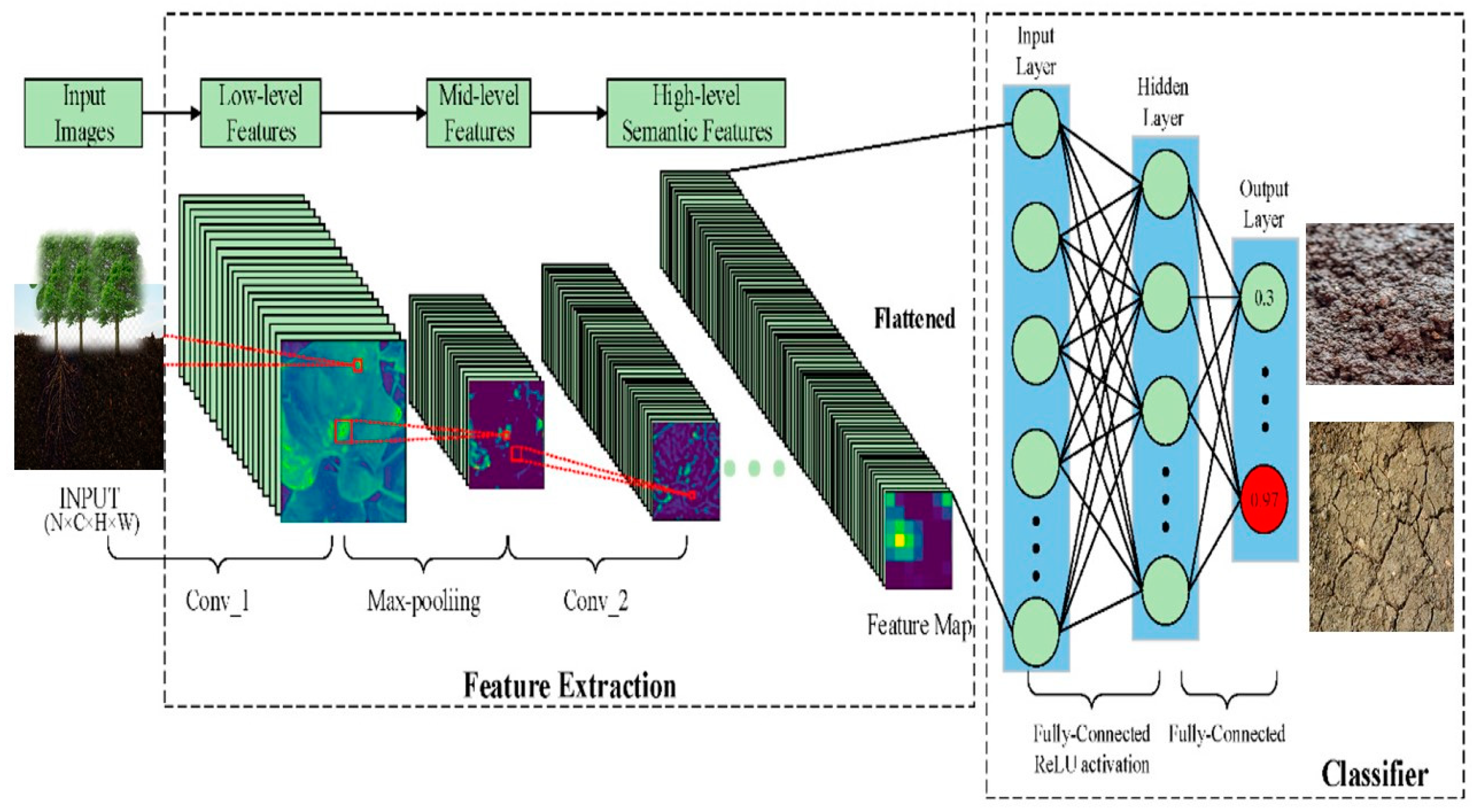
3.3. Convolutional Neural Networks (CNN)
A feed-forward neural network is similar to a CNN. Data are processed to provide valuable results. CNN uses backpropagation, as well as semi-structured data [
31], to train networks. Except for the input nodes, every node in the web is a processing element or a neuron. During “training,” the output and hidden layer weights are changed. Two successive layers cannot be fully connected. Unnecessary consequences may be removed after or during learning.
Figure 2 shows a CNN network with hidden layers. Multilayer perceptrons offer two advantages over other varieties.
Discriminant analysis approaches multilayer perceptrons to make no assumptions about how data are arranged or how covariance matrices of categorizable data sets are presented. Second, multilayer perceptrons allow for the creation of disconnected and nonsequential regions.
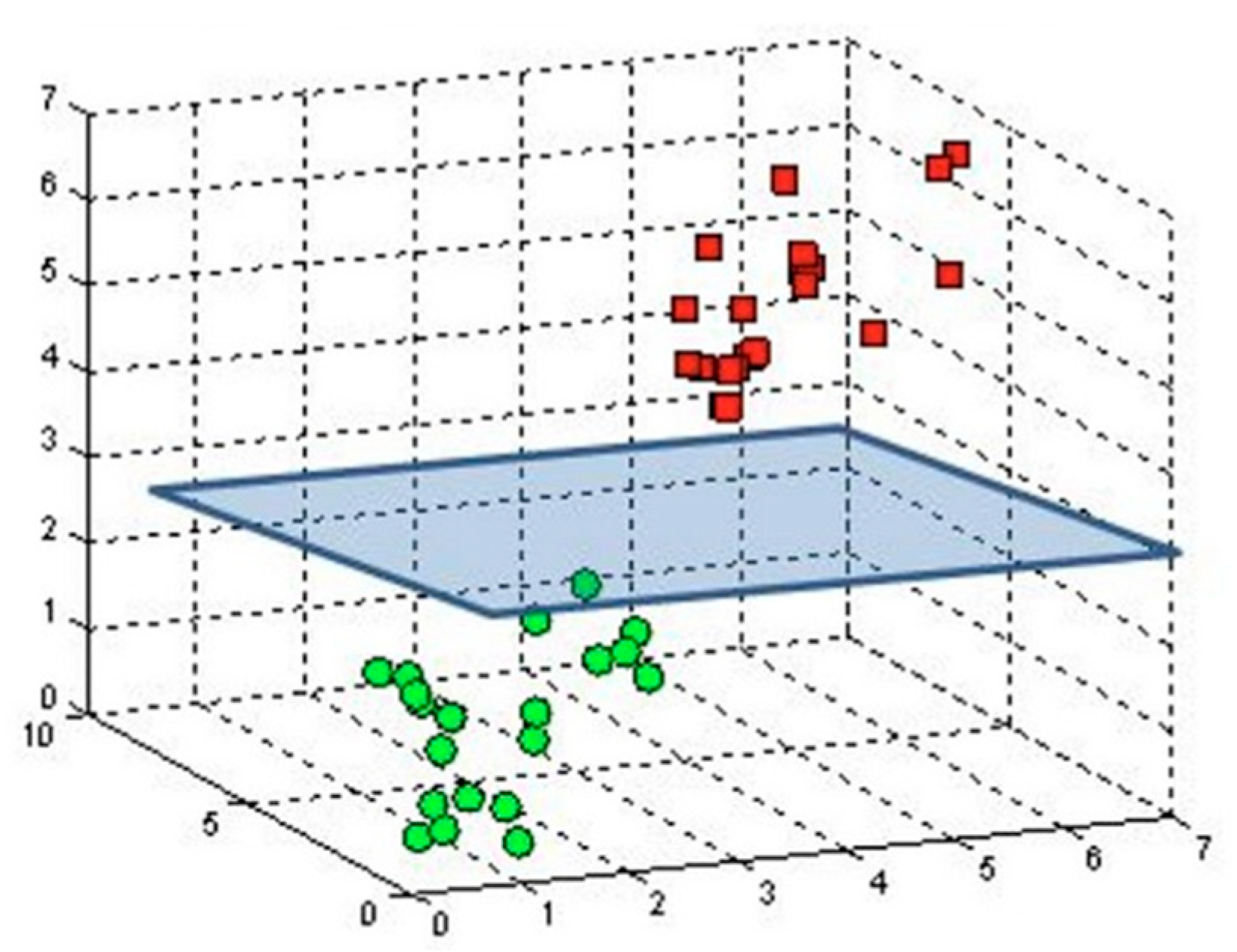
3.4. Support Vector Machines
SVMs are a “supervised machine learning” approach used for classification. This is machine learning. It develops an objective function using Vapnik-Chervonenkis (VC) [
32] theory and structural risk reduction, and then it finds a partition hyperplane that meets class requirements. A SVM training approach organizes incoming data into one of two classes using a series of training datasets. Using two classifications, this model contains incoming data. SVM operates binary division to establish the border between two classes, such as Positive-class 1 and Negative-class 2.
Figure 3 shows two classes, with the hyperplane in between. This minimizes the distance between the plane and each data point. The nearest data points are used to create the support vectors.
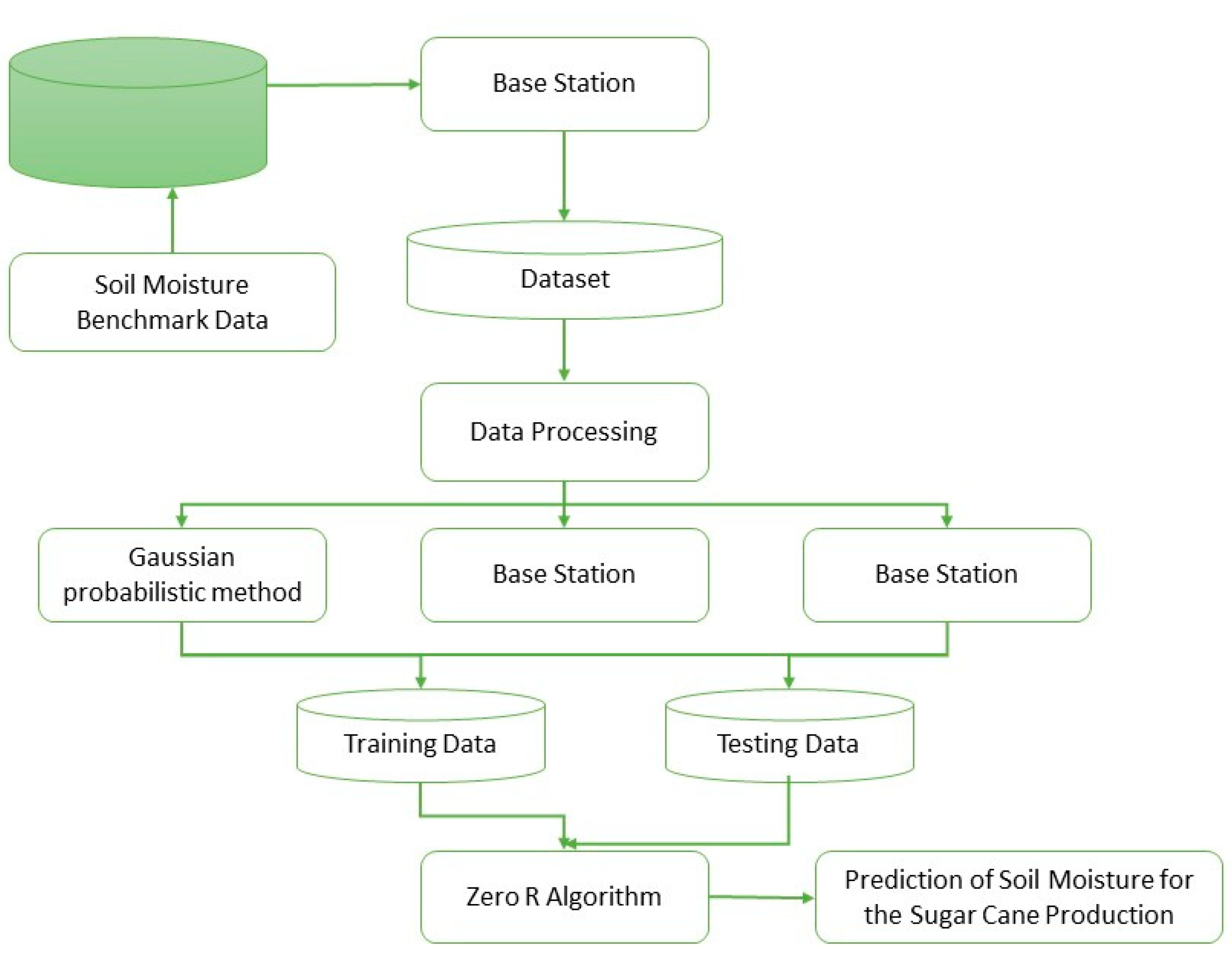
3.5. Two-Hierarchical Hybrid Ensemble Model
Figure 4 illustrates how the two-level soil moisture forecasting ensemble model presented is constructed from individual blocks and how it operates. And the working of the proposed algorithm is elaborated below.
The algorithm of the proposed approach is given below.
Input: Original data set Do and the Preprocessed Dataset Dp.
Set of heterogeneous first level learning classifiers Lf = {GPM, CNN, SVM}
Second-level learning algorithm Ls = {ZeroR}
Start
Prepare the dataset for ensemble training and testing.
Training dataset—Dataset used for ensemble training (TR). This
dataset contains soil moisture data.
Testing dataset—Dataset used for ensemble testing (TE). This
dataset contains soil moisture data.
for i = 1 to n
//where n represents the number of heterogeneous classifiers
hti = Lfi (TR)
Train an individual first-level learner by applying the corresponding
learning algorithm and the training data set
end
The output of base classifiers
Test the output from step 4 by using the second-level learning
algorithm Ls.
Output the predicted soil moisture value
Stop
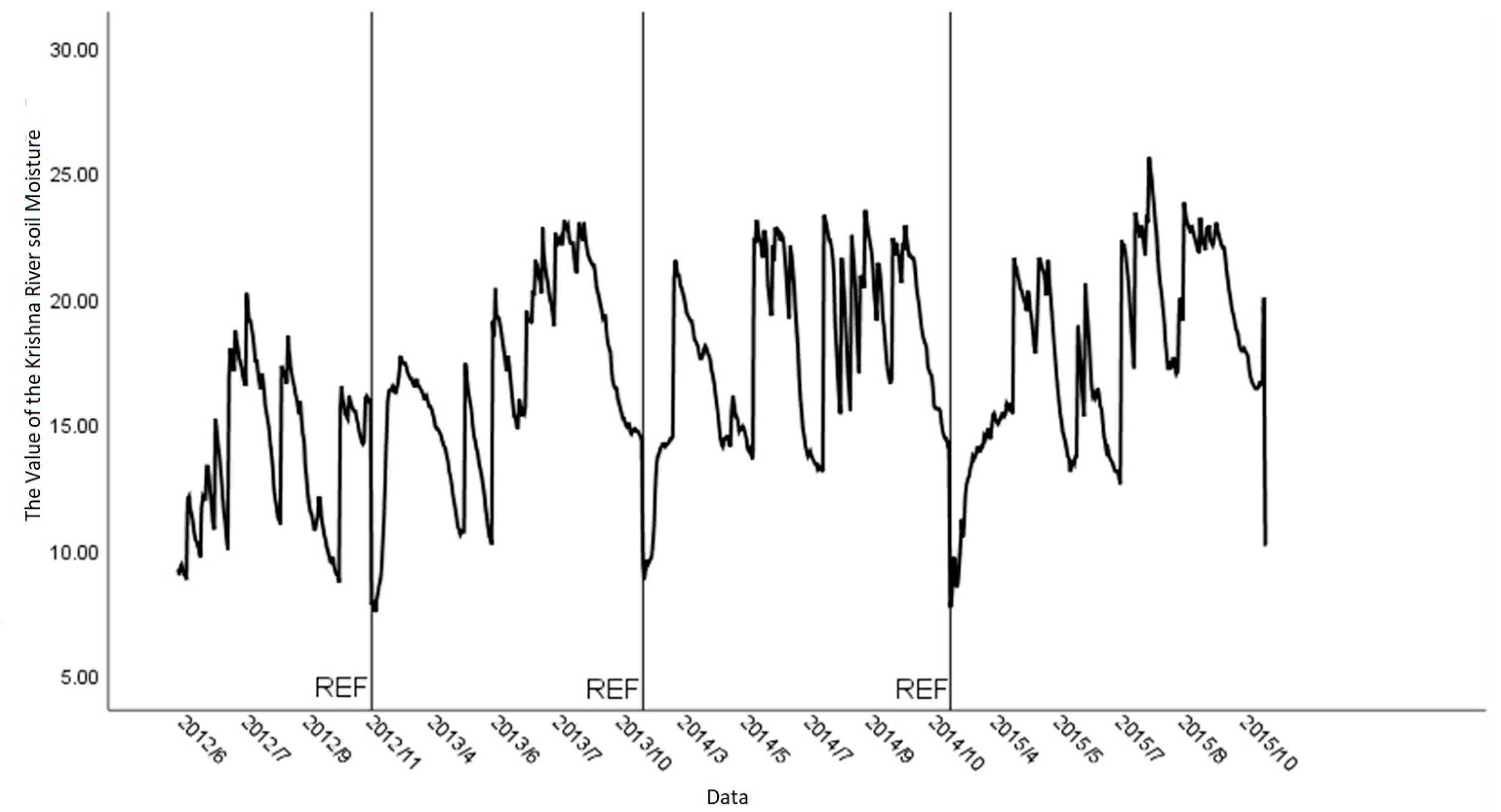
3.6. Godavari Plateau Delta Region Dataset
The research used soil moisture measurements from the Godavari River Plateau (
https://apwrims.ap.gov.in) (accessed on 10 November 2022) and Krishna River Plateau (
https://krmb.gov.in/krmb/home) [
33], which involved online databases for both. The Krishna River plateau Soil Moisture Monitoring Network provides long-term soil moisture time data from 18 stations. The average of twice-monthly measurements is used.
Figure 5 shows monthly data from 2016 to 2021 from a 10–30 cm layer at Station 1. Godavari river plateau Creek drains 600 km
2. Fourteen stations detect soil moisture in the Godavari River plateau Creek’s basin. At 30-min intervals, soil moisture is monitored and averaged.
Figure 6 shows the average daily soil moisture in the top 30 cm of station K4’s profile from 3 January 2022, to 31 August 2022.
3.7. Performance Evaluation Metrics of the Proposed Model
To determine how well the proposed model functions, statistical metrics, such as mean absolute error (MAE), root mean square error (RMSE), and mean absolute % error (MAPE), which are shown in Equations (1)–(3), are utilized.
The main objective of the function was to decrease the cost function between the actual and predicted values.
4. Results and Discussions
The Keras toolkit was used in the simulation-based testing that was carried out. This open-source program can predict time series and provides a machine-learning library that may be used for data mining jobs. As a consequence of this, this instrument is utilized to evaluate how well the proposed plan works. It is essential to partition the initial dataset into training and test sets before attempting any model evaluation. In this scenario, 70% of the dataset is put toward the training process, while the remaining 30% is used for testing.
Concerning the soil moisture datasets from the Krishna River plateau and the Godavari River plateau, tests were run with GPM, CNN, SVM, single-level GPM ensemble, single-level CNN ensemble, single-level SVM ensemble, and the proposed two-level soil moisture prediction model. Additionally, GPM, CNN, and SVM ensembles were tested individually.
The bagging approach generates single-level ensembles from GPM, CNN, and SVM classifiers. Examples of these ensembles are the GPM ensemble, the CNN ensemble, and the SVM ensemble.
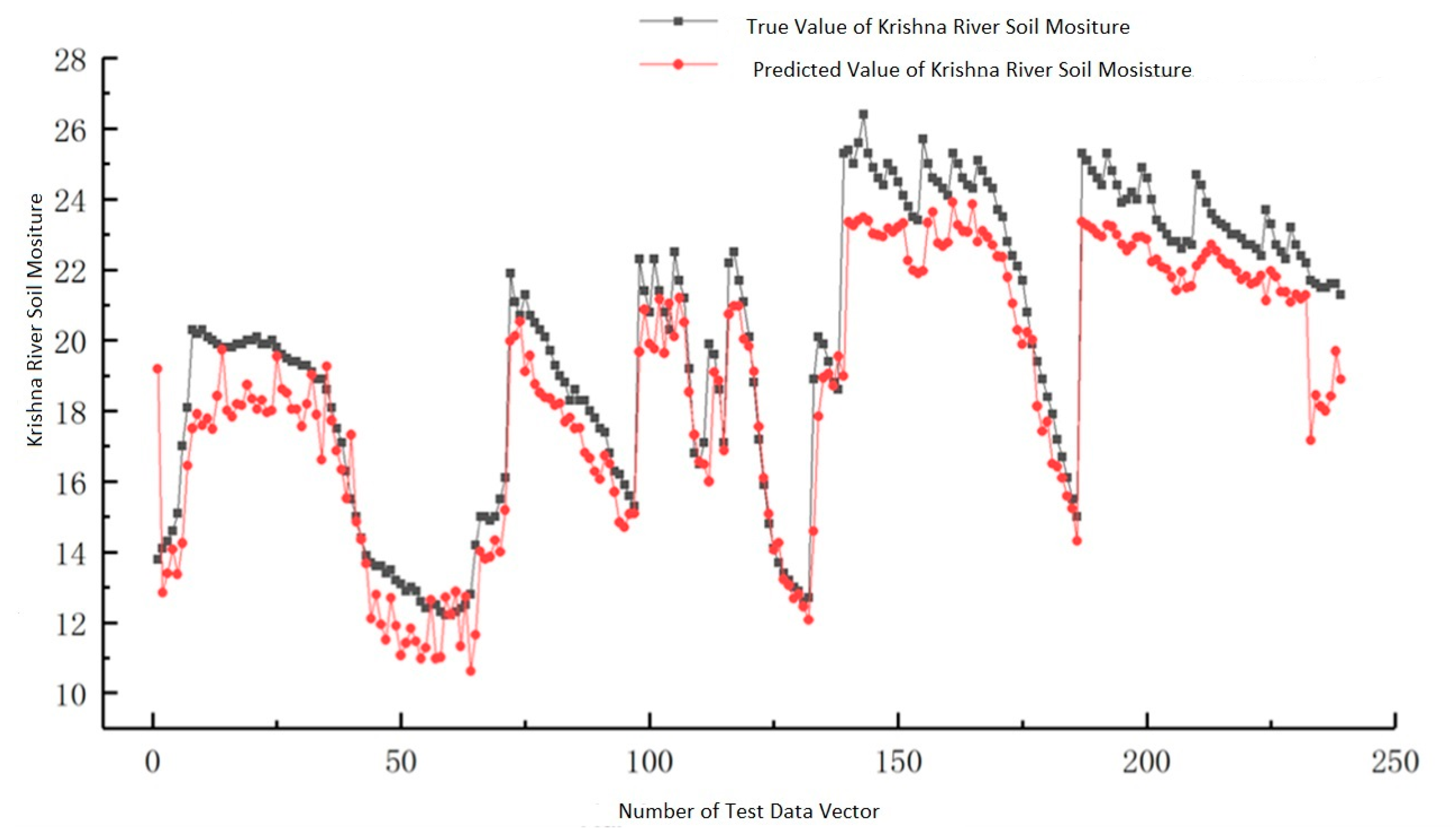
Figure 7 and
Figure 8 show the intended training and testing data projections for the Krishna River plateau data set when it was in the training phase and while it was in the testing phase, respectively.
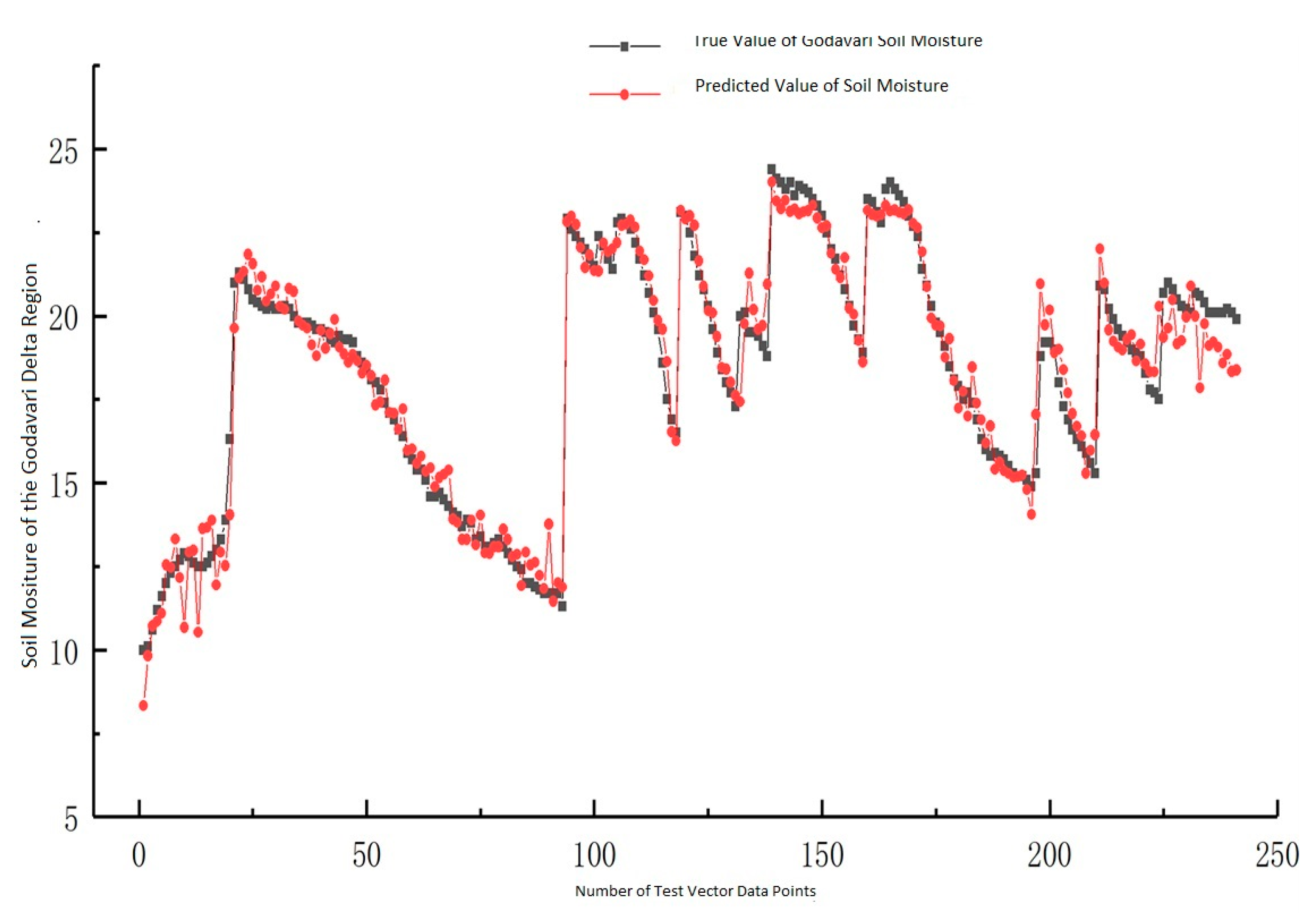
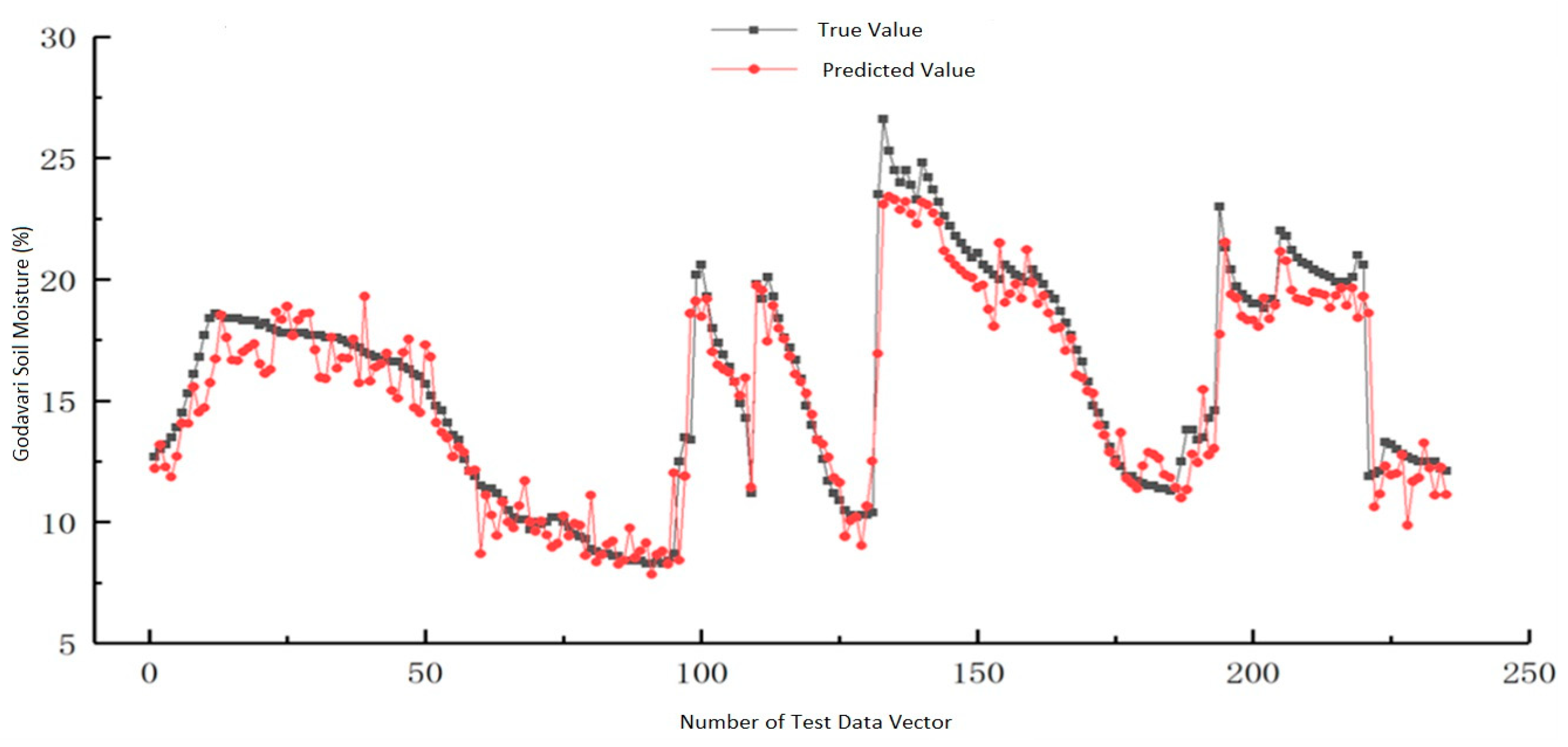
Figure 9 and
Figure 10 illustrate how a prediction was derived from the training and test data in the Godavari River plateau dataset.
The one-step forward estimates of the future are shown in
Figure 11 and
Figure 12 for two different datasets.
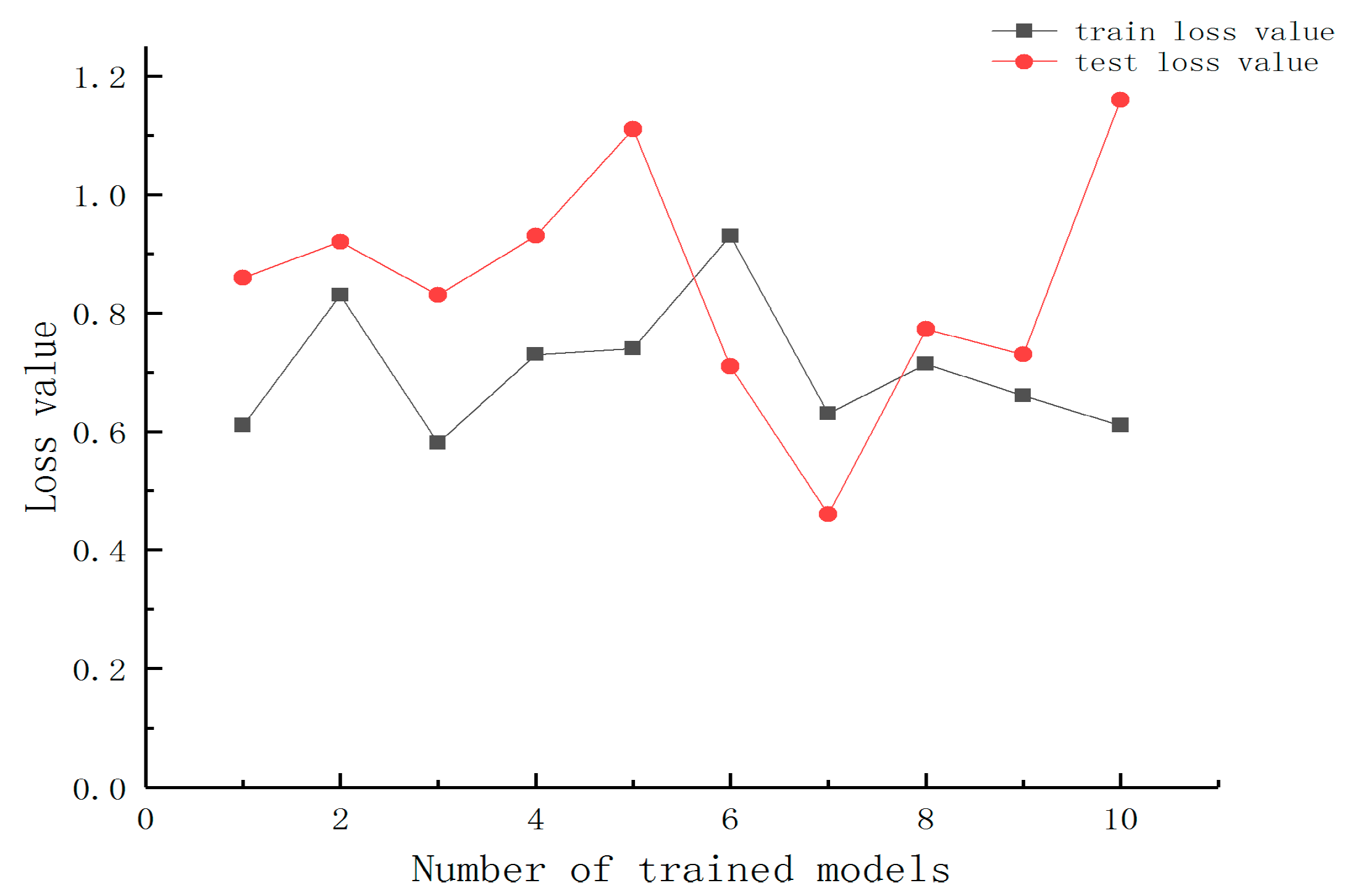
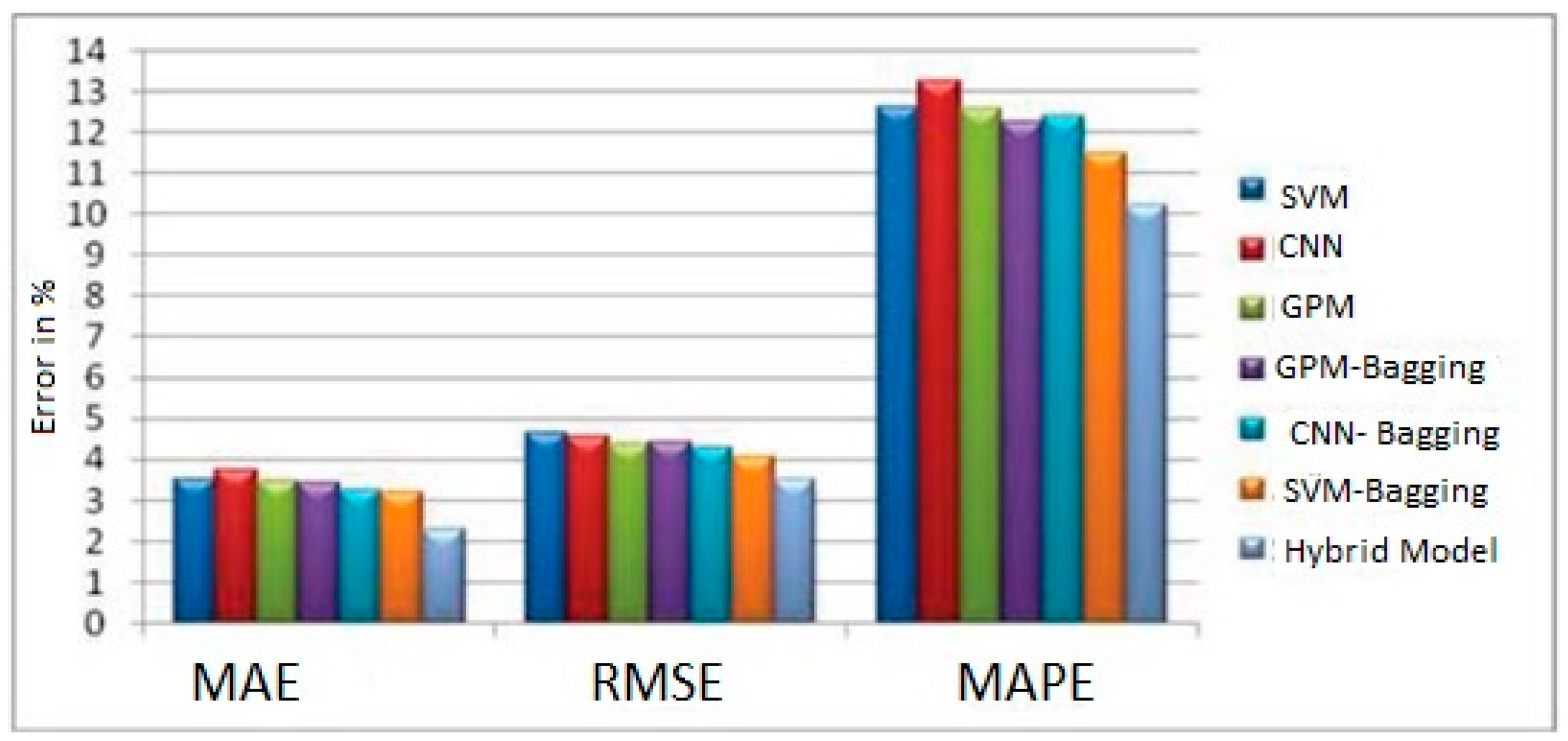
Each machine learning method was applied to the same datasets to determine how accurately the suggested ensemble model could categorize items. Examples of individual classifiers are GPM, CNN, and SVM, in addition to the ensembles that go along with each of these. Using prediction accuracy, mean absolute error (MAE), root mean squared error (RMSE), and mean absolute % age error, the performance of the proposed model was compared to that of current machine learning approaches.
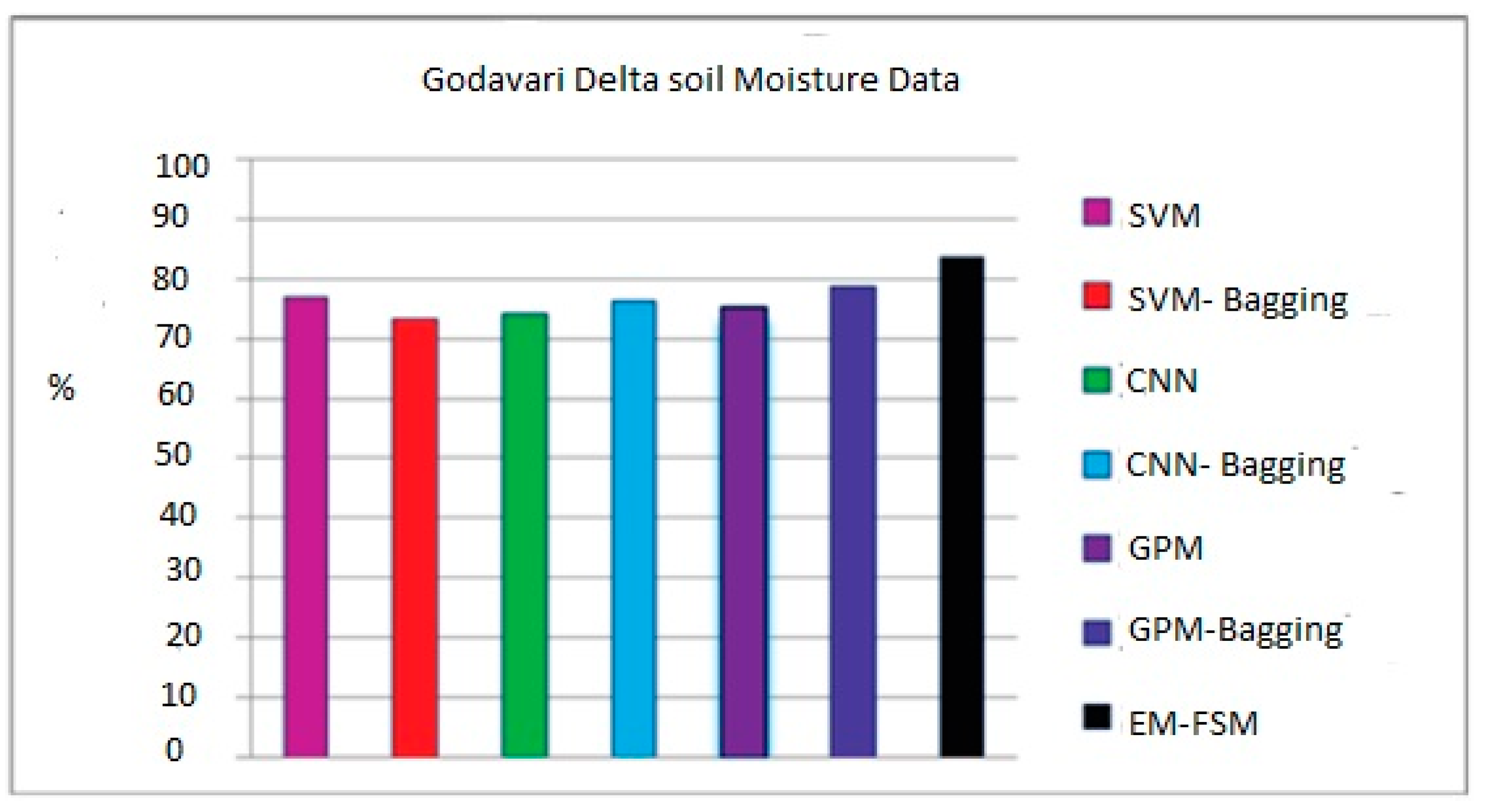
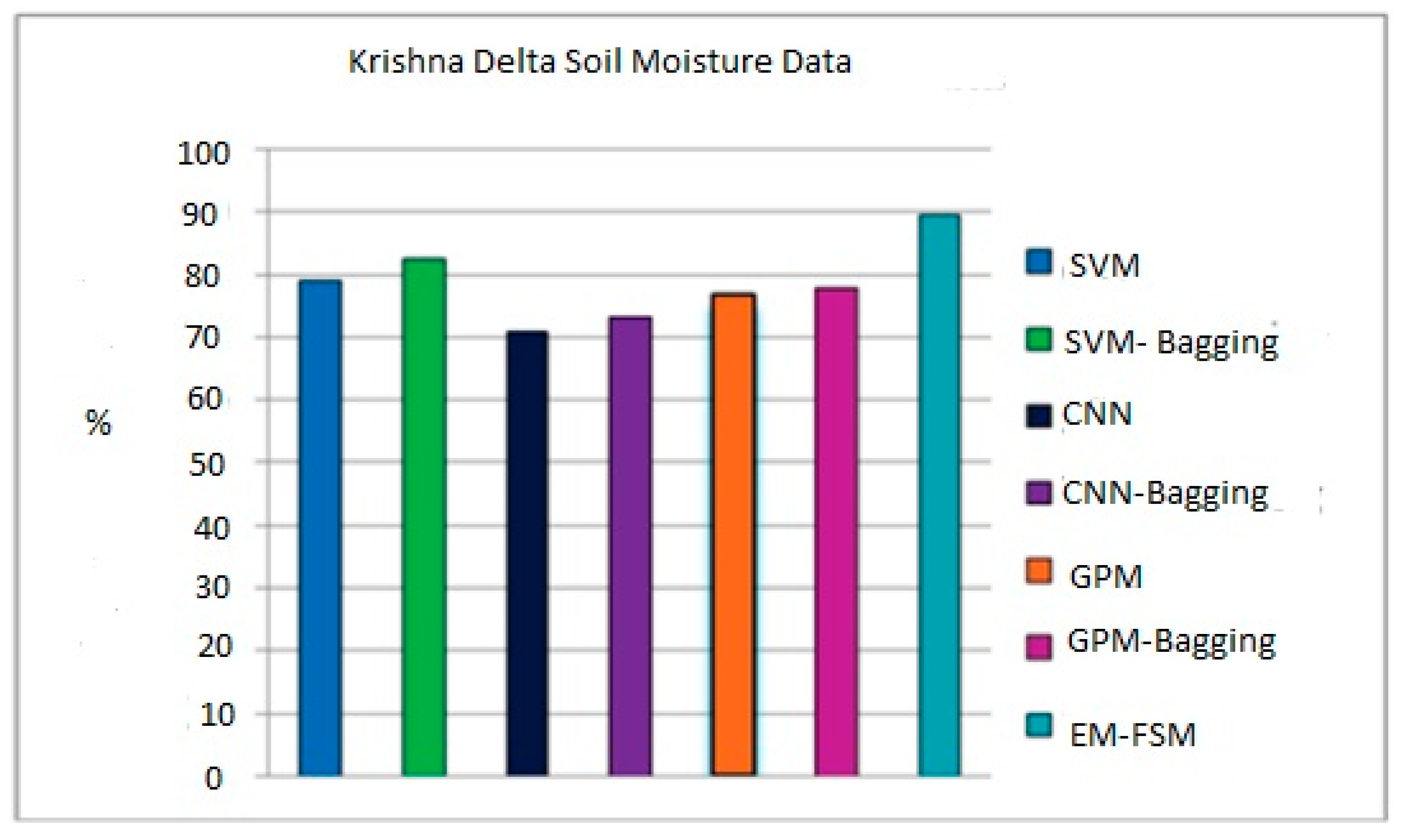
Table 1 compares the effectiveness of several classifiers about the version of the one selected for use with the soil moisture data from the Krishna River plateau and Godavari River plateau. This is seen in
Figure 13 and
Figure 14.
The ability of the two sets of data presented in
Table 2 to accurately anticipate measurements is seen in
Figure 15 and
Figure 16. The number of various classifiers in the testing set that could predict the one displayed accurately is one way to determine how accurate a measurement’s prediction is.
Compared to other individual classifiers, the SVM classifier has an accuracy ranging between 76.85% and 79%. The accuracy of the SVM-bagging ensemble is 78.81% and 82.56% higher than that of other bagging ensembles. Still, the accuracy of the proposed two-level ensemble model is 83.52% and 89.56% higher than that of all other ensemble models. The previously used solo classifiers and the single-level ensemble classifiers constructed using GPM, CNN, and SVM outperform the newly presented ensemble model. According to this research’s findings, ensemble neural networks to forecast soil moisture data may result in more accurate forecasts. Using this model will assist farmers and others responsible for making policies in creating future irrigation plans. In this particular piece of research, a method for the long-term collection of data on soil moisture is investigated. The GPM, CNN, and SVM classifiers each provide their own set of helpful rules to the ensemble model that is being proposed. The experiment’s findings demonstrate that, when several models are effectively connected, they are superior to individual learners in predicting soil moisture. Farmers can profit from this strategy, since it provides them with reliable information.
Alterations to the methods used to cultivate crops, as well as new knowledge on the moisture content of the ground in the years to come. The findings of the studies indicate that the suggested ensemble model accomplishes its objective of increasing prediction accuracy. The most fantastic accuracy of prediction was found to be 83.53% for both of the datasets utilized and 89.53%, respectively. In addition to these applications, soil moisture estimates may be used to plan irrigation, calculate agricultural productivity, provide early warning of drought conditions, and forecast runoff.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}