
CA-BIT: A Change Detection Method of Land Use in Natural Reserves


Abstract
:1. Introduction
2. Network Model
2.1. CA-BIT Model Overview
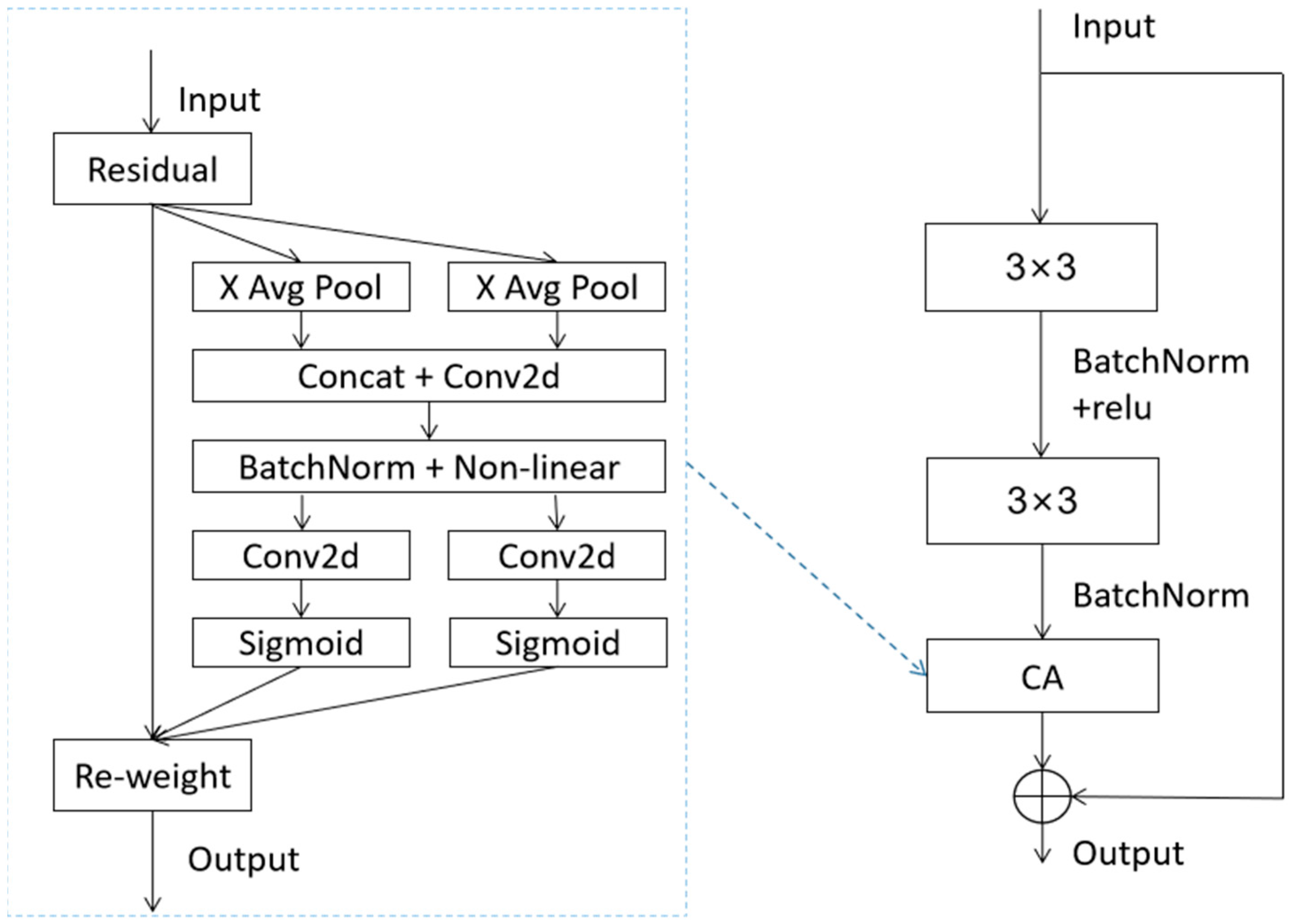
2.2. Residual Attention Network
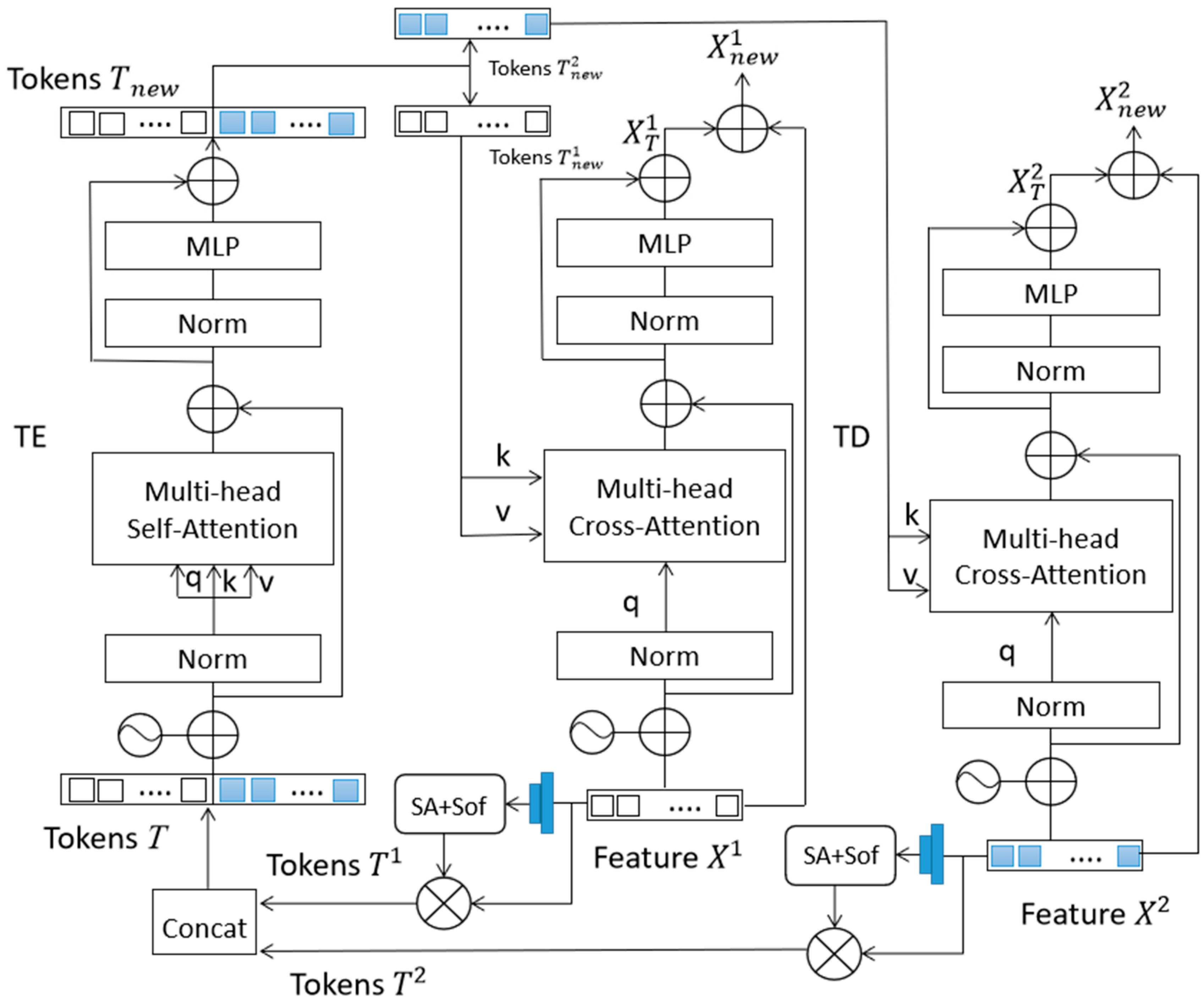
2.3. Bitemporal Image Transformer
2.3.1. Transformer Encoder
2.3.2. Transformer Decoder
2.4. Prediction Part
2.5. Loss Function
3. Data and Experiments
3.1. Study Area and Data Sources
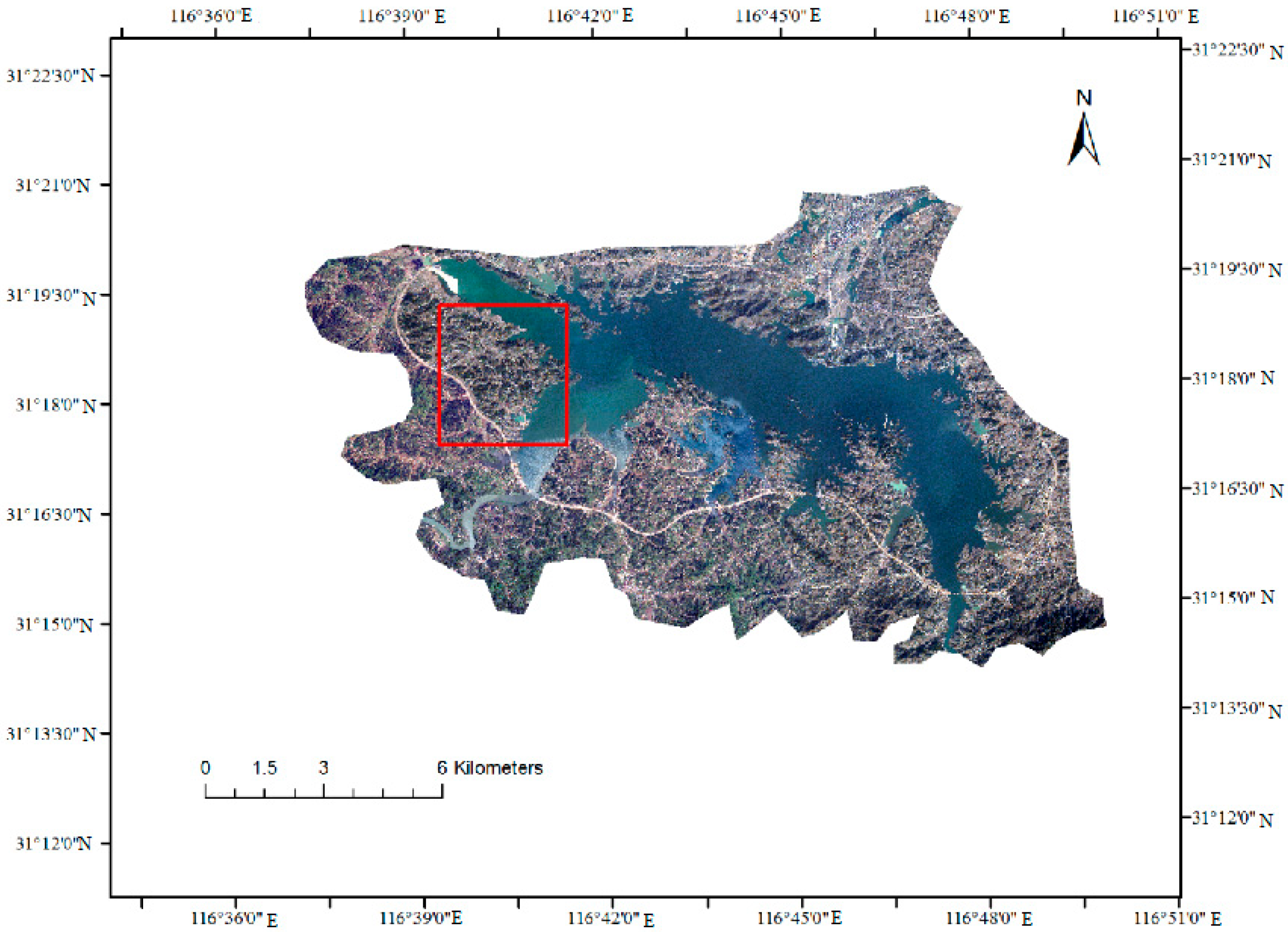
3.1.1. Overview of the Study Area
3.1.2. Experimental Data
3.2. Experimental Environment Configuration and Evaluation Indicators
3.2.1. Experimental Environment Configuration
3.2.2. Evaluating Indicator
4. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Authorless, Guiding Opinions on the Establishment of a Nature Reserve System with National Parks as the Mainstay, issued by the State Office of the Central Government, Green China. 2019; pp. 26–32. Available online: http://www.gov.cn/zhengce/2019-06/26/content_5403497.htm (accessed on 10 January 2023).
- Yang, Z.; Guo, S.; Lin, S.; Xu, Q. Analysis of the quantity type and spatial overlap of natural reserves in Guangdong Province. For. Environ. Sci. 2021, 37, 54–60. [Google Scholar] [CrossRef]
- Singh, A. Review Article Digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Zhang, L.; Zhu, T. Building Change Detection from Multitemporal High-Resolution Remotely Sensed Images Based on a Morphological Building Index. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 7, 105–115. [Google Scholar] [CrossRef]
- Chen, C.-F.; Son, N.-T.; Chang, N.-B.; Chen, C.-R.; Chang, L.-Y.; Valdez, M.; Centeno, G.; Thompson, C.A.; Aceituno, J.L. Multi-Decadal Mangrove Forest Change Detection and Prediction in Honduras, Central America, with Landsat Imagery and a Markov Chain Model. Remote Sens. 2013, 5, 6408–6426. [Google Scholar] [CrossRef] [Green Version]
- Fang, J.; Zhigang, Y.; Shengcai, G.; Qihu, X.; Yingqin, L.; Yali, S. Remote sensing monitoring of human activities in Guangdong Province in national natural reserves based on high-resolution images. Guangdong For. Sci. Technol. 2022, 2, 038. [Google Scholar]
- Zhai, P.; Li, S.; Hu, Y. Object-oriented land cover change detection of collaborative optical and radar remote sensing data. J. Agric. Engineer. 2021, 37, 216–224. [Google Scholar]
- Brunner, D.; Lemoine, G.; Bruzzone, L. Earthquake Damage Assessment of Buildings Using VHR Optical and SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2403–2420. [Google Scholar] [CrossRef] [Green Version]
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change Detection Based on Artificial Intelligence: State-of-the-Art and Challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar] [CrossRef] [Green Version]
- El Amin, A.M.; Liu, Q.; Wang, Y. Zoom out CNNs features for optical remote sensing change detection. In Proceedings of the 2017 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017; pp. 812–817. [Google Scholar] [CrossRef]
- Lei, T.; Zhang, Y.; Lv, Z.; Li, S.; Liu, S.; Nandi, A.K. Landslide Inventory Mapping From Bitemporal Images Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 982–986. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual Attentive Fully Convolutional Siamese Networks for Change Detection in High-Resolution Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1194–1206. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Liu, Y.; Pang, C.; Zhan, Z.; Zhang, X.; Yang, X. Building Change Detection for Remote Sensing Images Using a Dual-Task Constrained Deep Siamese Convolutional Network Model. IEEE Geosci. Remote Sens. Lett. 2020, 18, 811–815. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Park, J.; Woo, S.; Lee, J.-Y.; Kweon, I.S. BAM: Bottleneck Attention Module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef] [Green Version]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. arXiv 2021, arXiv:2103.02907. [Google Scholar]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection with Transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Patel, V.M. A Transformer-Based Siamese Network for Change Detection. arXiv 2022, arXiv:2201.01293. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2016. [CrossRef]
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Natural Reserve CD | LEVIR_CD | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 | IoU | OA | Precision | Recall | F1 | IoU | OA | |
| FC-Siam-Conc | 37.25 | 64.76 | 47.3 | 30.98 | 96.02 | 91.99 | 76.77 | 83.69 | 71.96 | 98.49 |
| FC-Siam-Di | 39.18 | 50.8 | 44.24 | 28.41 | 96.47 | 89.53 | 83.31 | 86.31 | 75.92 | 98.67 |
| ResNet34-CA | 43.55 | 44.68 | 44.11 | 28.29 | 96.87 | 86.13 | 80.63 | 83.29 | 71.36 | 98.35 |
| BIT | 69.37 | 41.55 | 51.97 | 35.11 | 97.20 | 89.24 | 89.37 | 89.31 | 80.68 | 98.92 |
| DTCDSCN | 52.30 | 73.3 | 61.04 | 43.93 | 97.42 | 88.53 | 86.83 | 87.67 | 78.05 | 98.77 |
| ChangeFormer | 68.55 | 53.89 | 60.34 | 43.21 | 98.04 | 92.05 | 88.80 | 90.40 | 82.48 | 99.04 |
| CA-BIT | 74.61 | 60.32 | 66.71 | 50.05 | 98.34 | 92.30 | 88.72 | 90.48 | 82.61 | 99.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, B.; Cheng, Z.; Wang, C.; Zhao, J.; An, N. CA-BIT: A Change Detection Method of Land Use in Natural Reserves. Agronomy 2023, 13, 635. https://doi.org/10.3390/agronomy13030635
Jia B, Cheng Z, Wang C, Zhao J, An N. CA-BIT: A Change Detection Method of Land Use in Natural Reserves. Agronomy. 2023; 13(3):635. https://doi.org/10.3390/agronomy13030635
Chicago/Turabian StyleJia, Bin, Zhiyou Cheng, Chuanjian Wang, Jinling Zhao, and Ning An. 2023. "CA-BIT: A Change Detection Method of Land Use in Natural Reserves" Agronomy 13, no. 3: 635. https://doi.org/10.3390/agronomy13030635