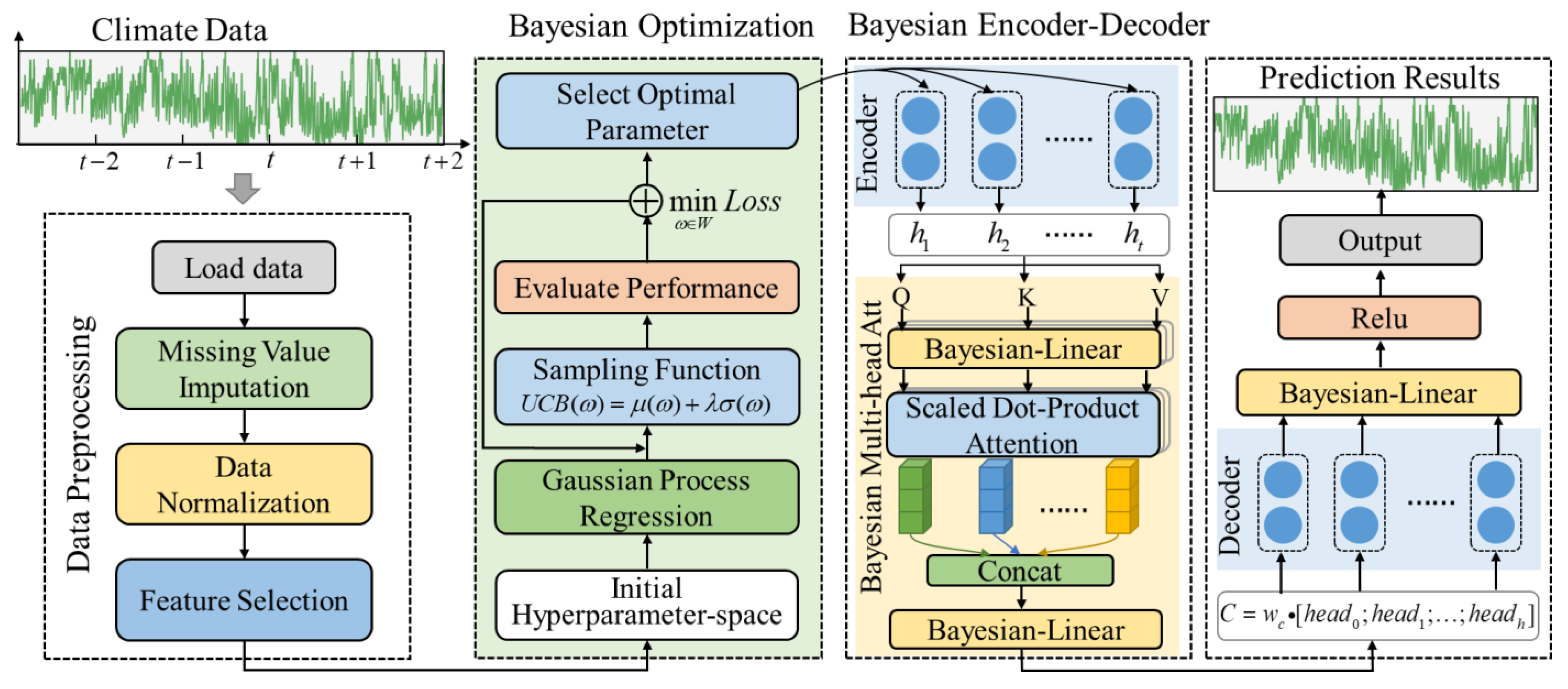
4.1. Datasets and Evaluation Metrics
With economic development and people’s pursuit of a better life, accurate prediction of meteorological data is of practical importance to support agriculture. Temperature variation is closely related to agricultural production and is a major factor affecting the growth and development of crops. Temperature prediction helps in agricultural planning, disaster weather prevention, and the planning of agricultural output, thus improving crop yield and quality and increasing economic growth.
The temperature substantially affects the crop’s distribution and quality, so this experiment uses temperature data collected from meteorological stations in agricultural areas at three locations in China as the study object. The source code is available at
https://github.com/btbuIntelliSense/Temperature-and-humidity-dataset (accessed on 29 November 2022). The three cities are located in the northeast, north, and south of China, Shenyang, Beijing, and Guangzhou, and the latest data showed that these three locations have 10.3 million, 1.77 million, and 0.44 million mu (a Chinese unit of area, where 1 mu = 666.7 m
2) of grain sown in 2022. The different locations show different temperature variations, meaning that the distribution of crops varies from location to location, with wheat being the main grain crop in Shenyang, maize being grown more in Beijing, and indica rice being the main crop in Guangzhou.
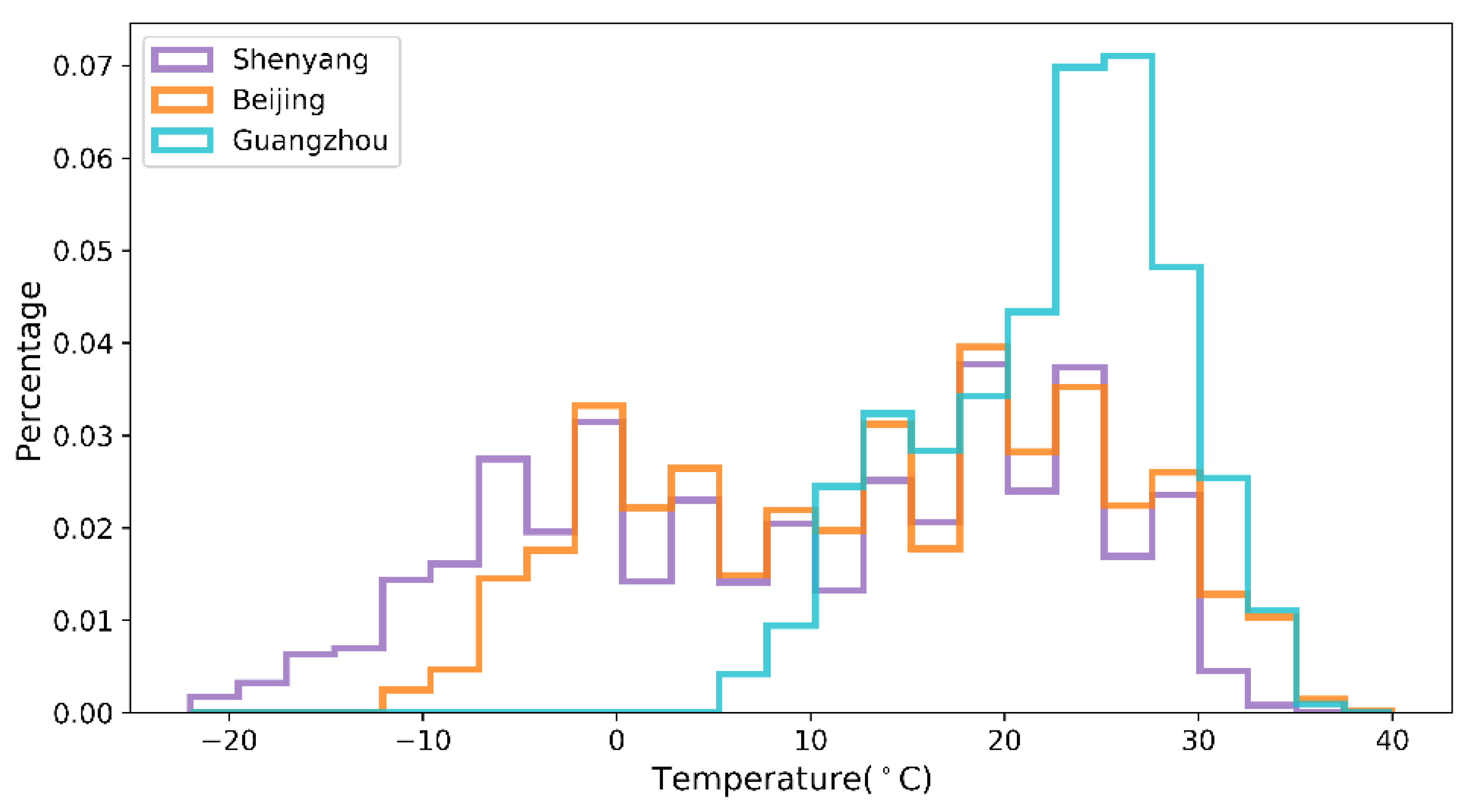
The temperature dataset records the temperature values for the three cities from 1 January 2015, at 00:00 h, to 31 December 2015, at 24:00 h, with a sampling frequency of 1 h for the sensors and a total of 24 datasets per day. The length of each dataset is 8760. The datasets are relatively complete, with only 1.3% of missing values (113 sets); the data are missing randomly, without continuous missing values. The missing values are filled and replaced using the average of two adjacent measurements. The temperature data of the three cities are shown in
Figure 4. Shenyang and Beijing have four distinct seasons, while Guangzhou has more sunny and hotter weather. The lowest temperature in Shenyang in winter can reach −20 °C, while the lowest temperature in Guangzhou is only 5 °C. Moreover, the temperature fluctuation in Guangzhou is slight throughout the year, with a difference of 30 °C between the minimum and maximum temperatures, while the maximum temperature difference in Shenyang can reach 53 °C.
In December, most Chinese cities adopt greenhouse farming; 67% of these are plastic greenhouses. These plastic greenhouses do not have intelligent heating and ventilation equipment and rely entirely on physical methods, such as the laying out of insulation quilts, to control temperature. Temperature control in plastic greenhouses is heavily dependent on outdoor temperatures. Therefore, accurate prediction of the outdoor temperature is essential for greenhouse crop cultivation, and accurate temperature prediction can provide a basis for agricultural production planning to provide a suitable growing environment for crops in greenhouses. Therefore, we selected 8040 datasets from the first 11 months for model training and 720 datasets from December for testing.
The experiments in this paper use the root mean squared error (RMSE), mean absolute error (MAE), Pearson’s correlation coefficient (R), the symmetric mean absolute percentage error (SMAPE), the mean error (ME), and the standard deviation of errors (SDE) as evaluation model indicators. RMSE and MAE are standard error measures between the actual value and the forecast, while SMAPE is the deviation ratio, with smaller values indicating a closer match. The ME value is equal to or close to 0 for unbiased predictions. SDE measures the extent to which the error value deviates from the mean. R is used to measure the correlation between the predicted and actual values. The R value is close to 1, showing that the higher the correlation between the prediction and the ground truth, the better the model will fit. The formulas for these four metrics are shown below:
where
is the ground truth value,
is the prediction,
represents the number of samples,
is the average of the ground truth value, and
is the average of the prediction.
4.2. Comparative Experiments
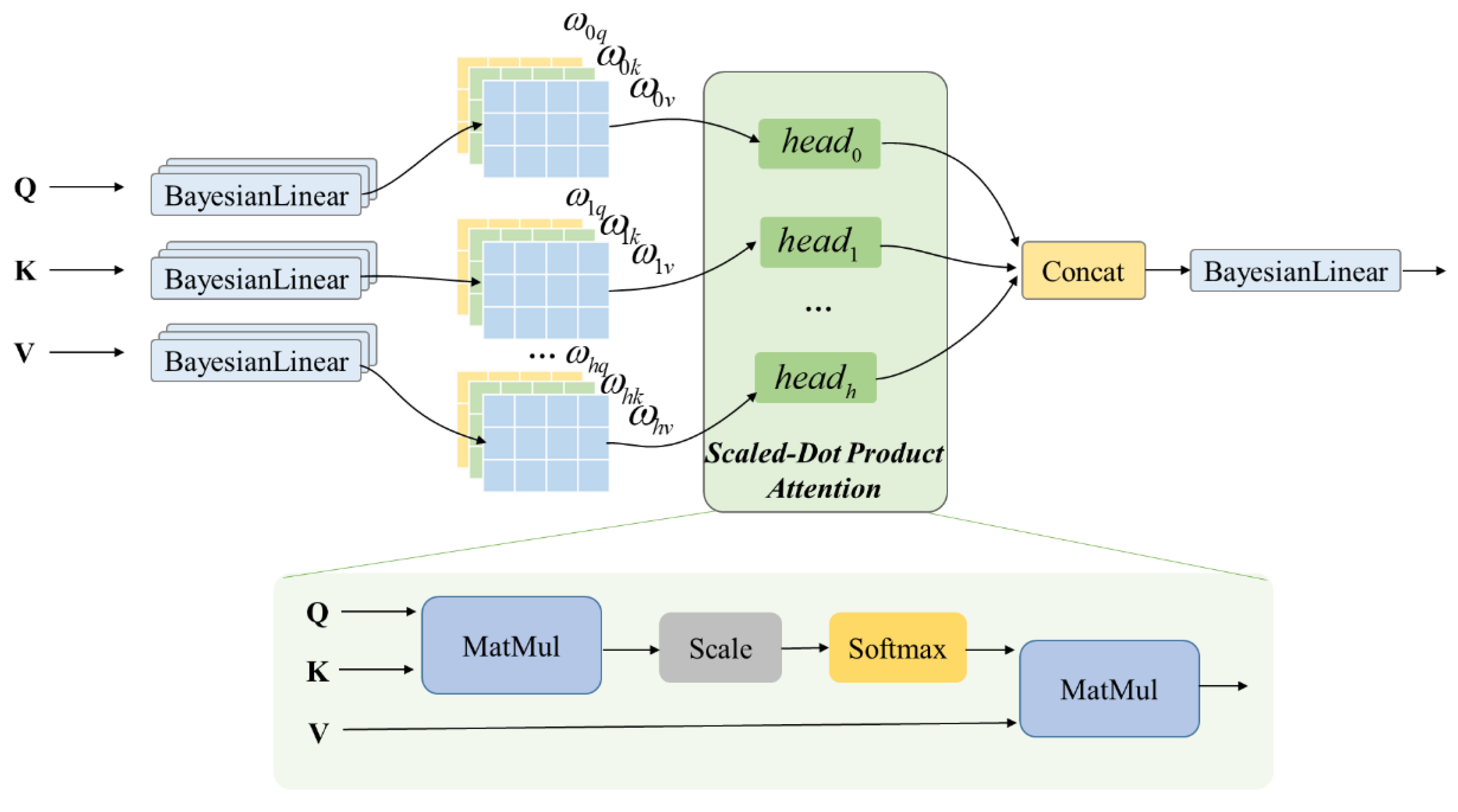
To verify the effectiveness of our proposed model, we selected nine deep-learning models for comparative experiments. The baseline models we used were the Linear, RNN, GRU, LSTM, Bi-LSTM, ESN, Encoder-Decoder, attention, and informer models.
Three cases were considered:
Case 1: 24 h of the past day was used to predict 24 h in the next day.
Case 2: 48 h of the past two days were used to predict 24 h in the next day.
Case 3: 48 h of the past two days were used to predict 48 h in the next two days.
The training parameters of the model were set as follows: the epoch was 200, the learning rate was 0.0001, and the optimizer was Adam. Other parameters are shown in
Table 1.
The BMAE-Net has many hyperparameters, among which the number of hidden layer units and batch size are the most sensitive hyperparameters and significantly impact the model performance. Other adjustable hyperparameters include epoch, dropout, the number of encoder/decoder layers, heads of multi-head attention, and optimizer. The detailed hyperparameter settings are shown in
Table 2.
All models were written in a Python 3.8 environment, based on the PyTorch deep learning framework. All experiments were performed on a server with the following parameters: Ubuntu 20.04 64-bit operating system; Intel Core i7-6800K 3.4 GHz CPU; NVIDIA GTX 1080Ti 11G. The evaluation of model prediction performance is conducted using the evaluation metrics mentioned in
Section 4.1.
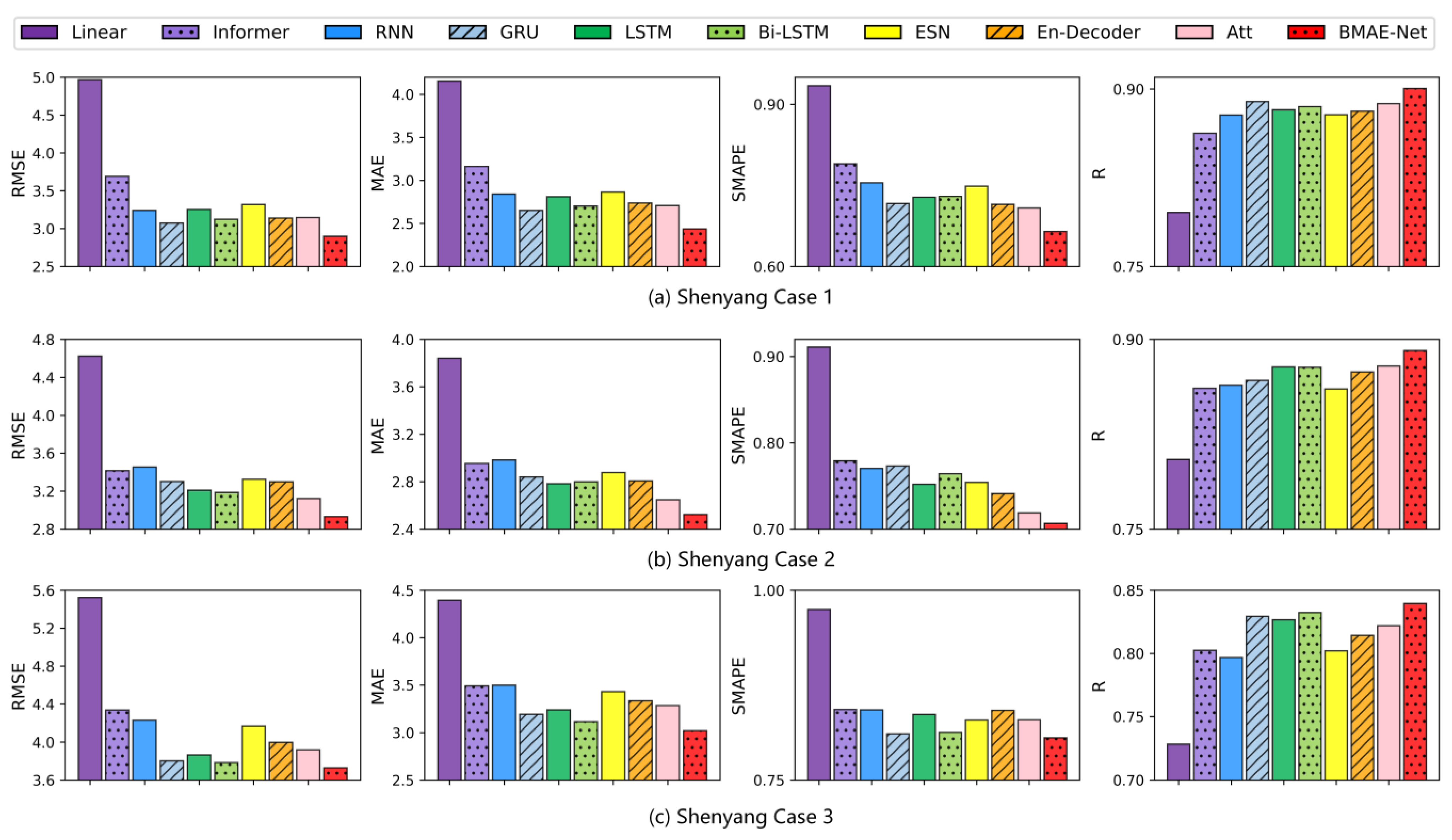
The results of temperature experiments in the Shenyang area are shown in
Table 3. As seen from
Table 3 and
Figure 5, the RMSE, MAE, and SMAPE indicators of the model proposed in this paper are lower than those of the other baseline models, which indicates that the model has the smallest difference between the prediction and the ground truth. The R indicators are greater than the other models, meaning that the BMAE-Net model has the highest goodness of fit. In Case 1, the RMSE, MAE, and SMAPE of the BMAE-Net model were 5.7%, 8.1%, and 7.2% lower than the GRU model, which was the best-performing model on this dataset, and the R indicator was 1.2% higher. In Case 2, compared to the attention model, which was the best-performing model on this dataset, the BMAE-Net model’s RMSE, MAE, and SMAPE were 6.1%, 4.7%, and 1.7% lower than the attention model, and the R metric improved by 1.4%. In Case 3, compared to the best-performing Bi-LSTM model on this dataset, the BMAE-Net model’s RMSE, MAE, and SMAPE were 1.5%, 2.9%, and 0.9%, and the R metric improved by 0.9%.
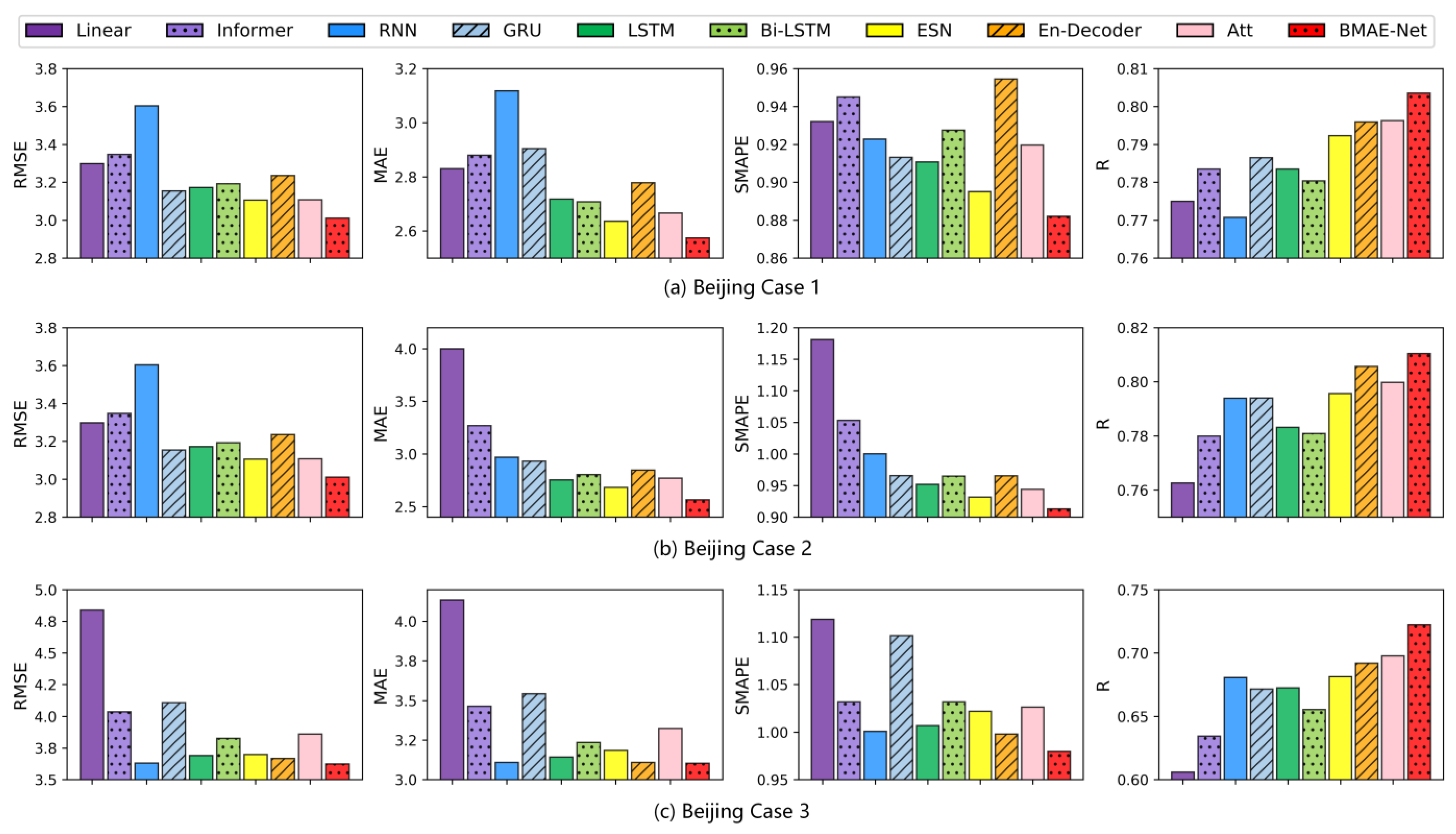
The results of the temperature experiments in the Beijing area are shown in
Table 4. As can be seen from
Table 4 and
Figure 6, the RMSE, MAE, and SMAPE indicators of the model proposed are lower than the other baseline models, which indicates that the model exhibits the smallest difference between the prediction and the ground truth. The R indicators are greater than in the other models, indicating that the model has the highest goodness of fit.
In Case 1, the BMAE-Net model had 3.1%, 2.4%, and 1.5% lower RMSE, MAE, and SMAPE values and a 1.4% higher R-indicator compared to the ESN model that performed best on this dataset. In Case 2, the BMAE-Net model had lower RMSE, MAE, and SMAPE values, which decreased by 4.1%, 4.4%, and 2% compared to the ESN model, and the R metric improved by 1.9%. In Case 3, the RMSE, MAE, and SMAPE of the BMAE-Net model decreased by 1%, 0.2%, and 1.8% compared to the encoder-decoder model, which was the best-performing model on this dataset, and the R indicators improved by 4.4%.
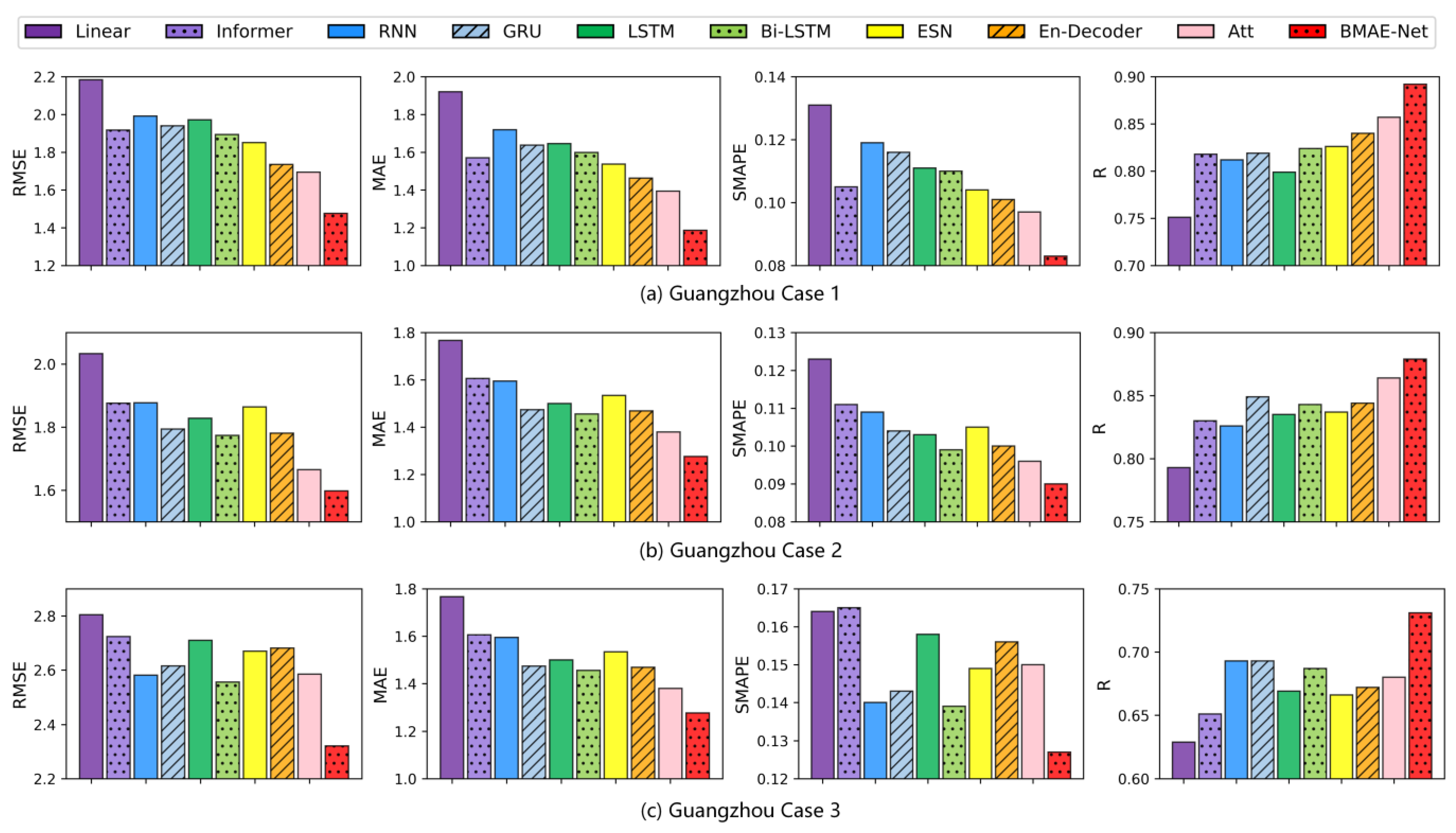
The results of the temperature experiments in the Guangzhou area are shown in
Table 5. As seen from
Table 5 and
Figure 7, the RMSE, MAE, and SMAPE metrics of the model proposed in this paper are lower than those of the other baseline models, which indicates that the model has a minor difference between the prediction and the ground truth. The R metrics are greater than those of the other models, meaning that the model has the best fit. In Case 1, the BMAE-Net model had 13%, 15%, and 14.4% lower RMSE, MAE, and SMAPE values and a 4.1% higher R-indicator than the attention model, compared to the best-performing attention model on this dataset. In Case 2, compared to the best-performing attention model on this dataset, the BMAE-Net model had 4%, 7.5%, and 6.3% lower RMSE, MAE, and SMAPE values and 1.7% better R metrics than the attention model. In Case 3, compared to the best-performing Bi-LSTM model on this dataset, the BMAE-Net model had 9%, 9%, and 8.6% lower RMSE, MAE, and SMAPE values than the Bi-LSTM model, and the R metric improved by 6.4%.
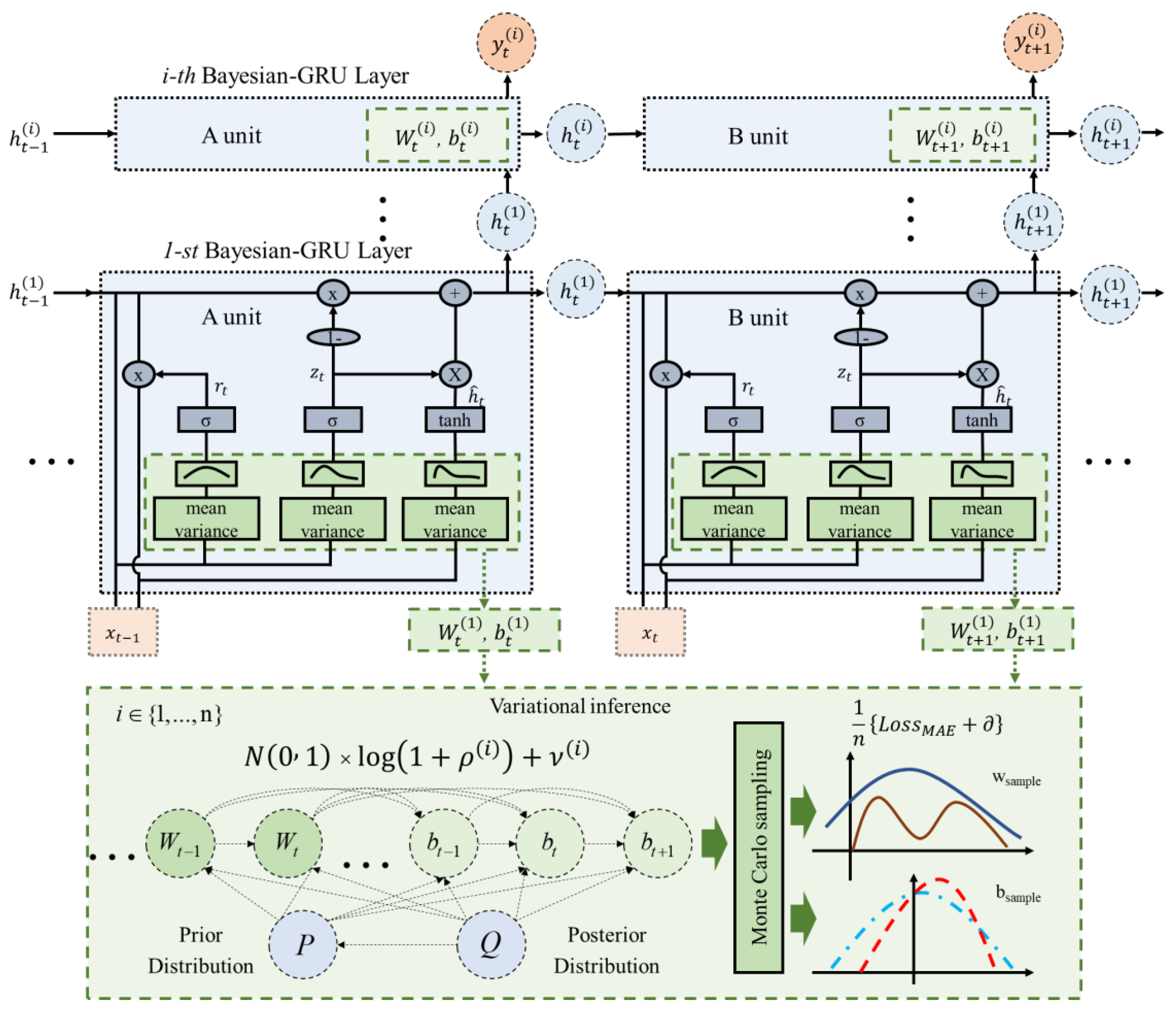
4.3. Ablation Experiments
In order to validate the Bayesian encoder-decoder model based on the attention mechanism proposed in this paper, the modeling predictions were validated using the temperature data from three cities. The same arrangement used in the comparison experiments in
Section 4.2 was employed to set up MHAtt, BLinear, BLSTM, BGRU, and BMED-Net, to compare the prediction results for the three cases.
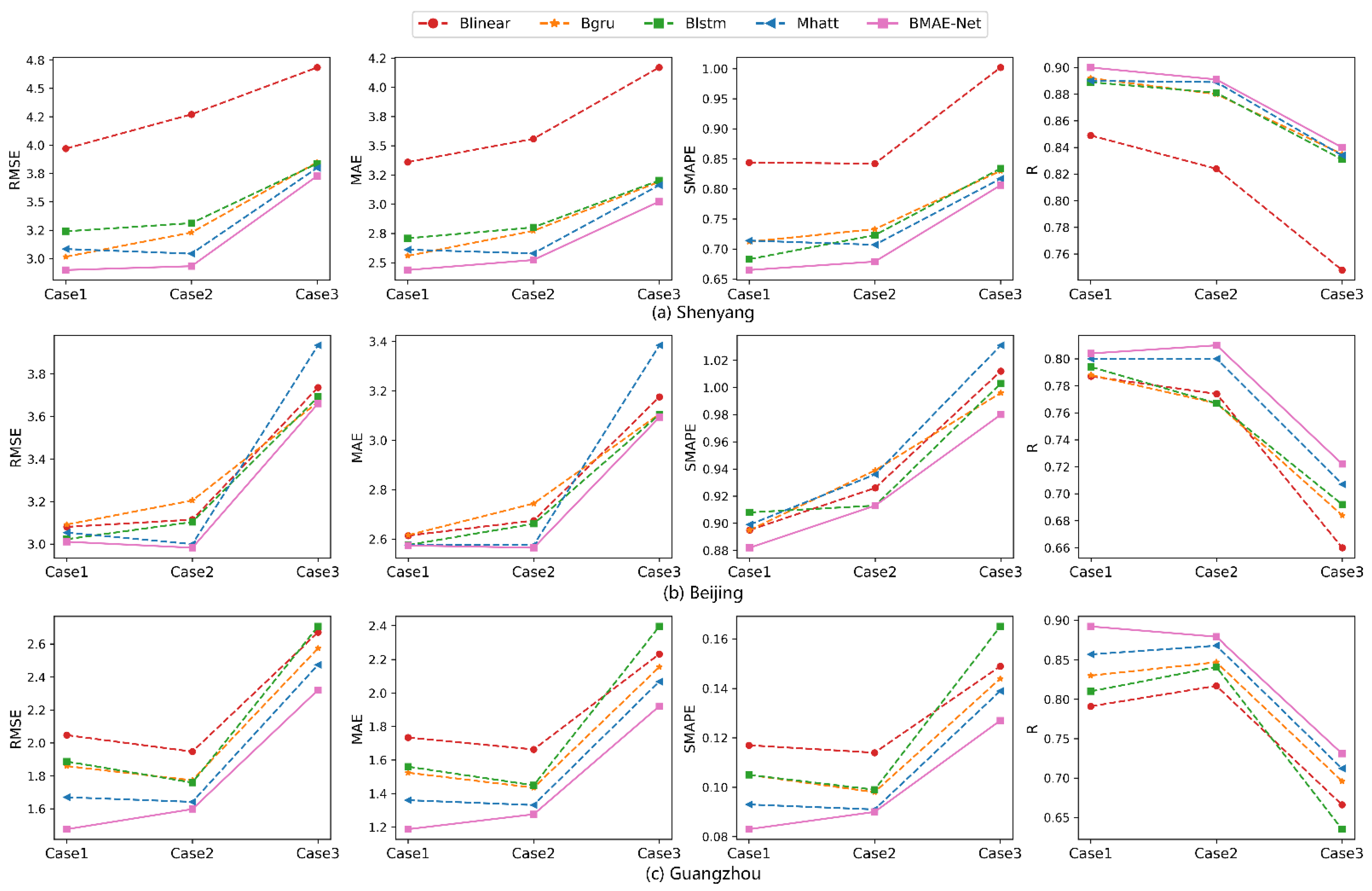
As seen from
Table 6 and
Figure 8, in the temperature prediction experiments in each location, compared with the MHAtt model, the BMAE-Net model that incorporated variational inference improved in all evaluation indexes, and the model prediction was better. Meanwhile, the model results for BLinear, BGRU, and BLSTM were also better than those for Linear, GRU, and LSTM, which indicates that with the inclusion of variational inference, the fitting ability of the model was improved, and better prediction could be achieved.
In order to see the magnitude of each metric more clearly, a line graph of the evaluation metrics of each compared model was plotted. As seen from
Figure 8, for nonlinear time series data with sensor measurement errors and severe interference from the external environment, the proposed multi-head attention encoder-decoder neural network, optimized via a Bayesian inference strategy, has the advantages of higher accuracy and better generalization than other prediction models.
We selected four comparison models to calculate the ME and SDE values. The closer the value for ME is to 0, the smaller the model error is, while a value for ME of less than 0 indicates that the overall predicted value is smaller than the ground truth value, and a value greater than 0 is the opposite. The smaller the SDE, the smaller the error deviation from the mean, and vice versa.
Table 7 shows that the proposed model has lower ME and SDE values than other baselines in Case 1, proving that BMAE-Net has better prediction performance.
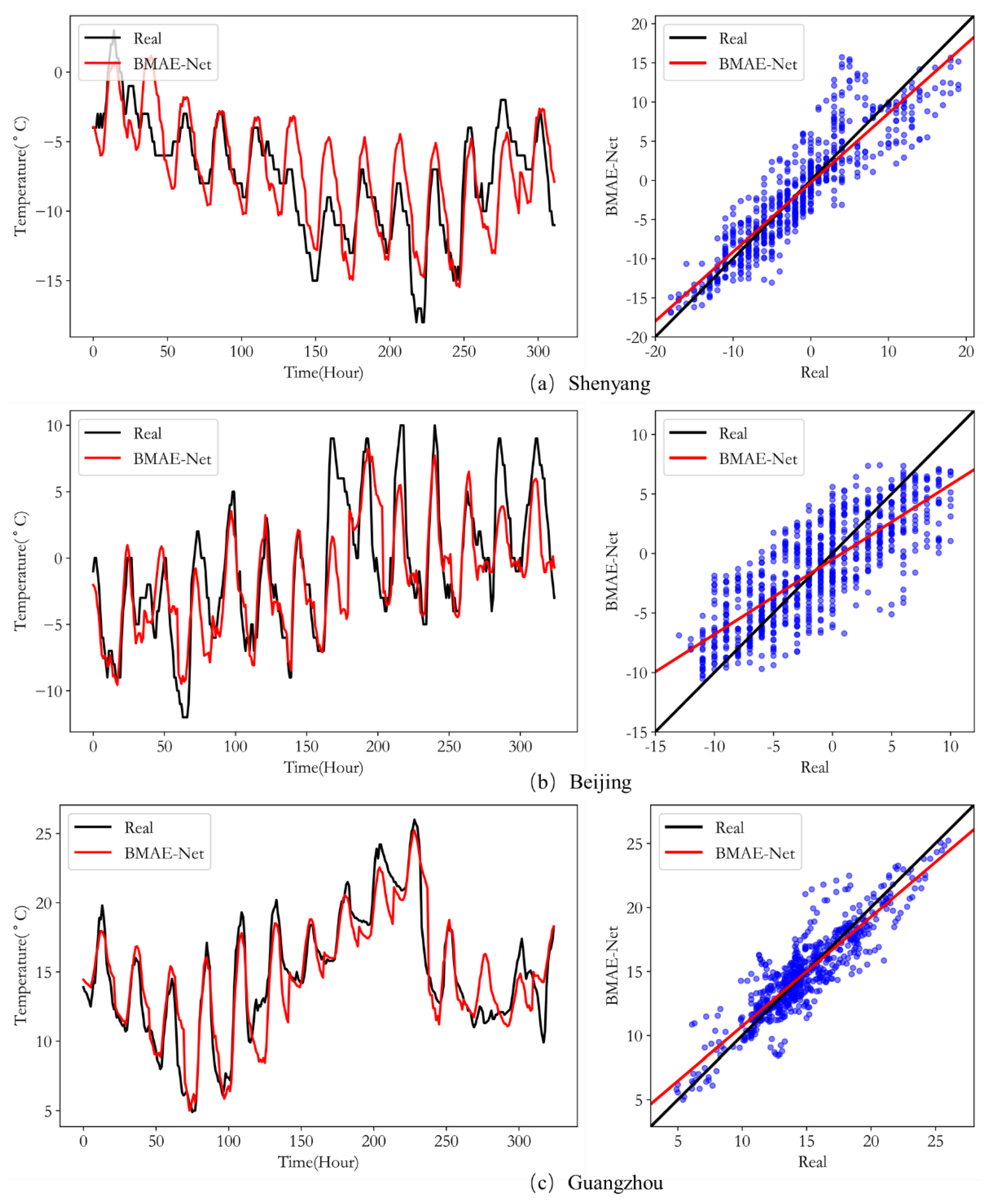
Figure 9 plots the curves of the predicted and ground truth values (left) and the scatter plot (right) for our model in the test for Case 1. The
x-axis of the fit plot is time, while the
y-axis is temperature. The more the curves of the ground truth and predicted values repeat, the closer the predicted values are to the ground truth values. As shown in each subplot on the left of
Figure 9, the model can predict the temperature trend in Case 1; the model works best on the Guangzhou dataset, followed by Shenyang. This is because Guangzhou has a relatively concentrated temperature distribution throughout the year, while Shenyang and Beijing have cold winters in December and undergo large temperature changes in the morning and evening, so the temperature dataset is more of a challenge to fit. The scatter plot is drawn using the linear regression model of the predicted and ground truth values; the
x-axis is the ground truth value, the
y-axis is the predicted value, the black line is the linear regression of the ground truth value, and the red line is the prediction model. The closer the two lines are, the closer the predicted value is to the ground truth value; the closer the blue points in the plot are to the black line, the higher the correlation between the predicted and ground truth values. As shown by the subplots in
Figure 9, the predicted and ground truth values are strongly correlated, which is especially evident in the Guangzhou data, where the predicted values are concentrated around the regression line, indicating that our model performs well on the temperature prediction task. In summary, the experimental results demonstrate that the model has excellent multi-step prediction performance under different datasets.
4.4. Discussion
In the comparison experiments, we performed three cases of effect validation on the temperature datasets of three locations separately. The experimental results are shown in the first two subsections; in most cases, the BMAE-Net error designed in this paper is smaller than the remaining nine comparison models, and the fit is better than the comparison models. For example, the R evaluation metrics for temperature prediction in the three locations are 0.9, 0.804, and 0.892, respectively, while the RMSE is reduced to 2.899, 3.011, and 1.476 in the Case 1 temperature data. Among the prediction performances of the three locations, the best results were obtained for the Guangzhou site, which we speculate is because the temperature data distribution in Guangzhou is more concentrated, while the temperature data distribution in Shenyang and Beijing is more dispersed (as shown in
Figure 4), which indicates that the quality of the dataset also has an impact on the model performance.
In the ablation experiments, we incorporated Bayesian mechanisms for the Linear, GRU, LSTM, and multi-headed attention models, respectively, so that the internal parameters conformed to a normal distribution and the weights and biases were continuously corrected to achieve optimal results when backpropagating. Ablation experiments further confirmed that including variational inference improved the R-evaluation metrics of the model, while reducing each error evaluation metric. From the experimental results, it can be concluded that BLinear, BLSTM, BGRU, and BMAE-Net all outperformed the model without incorporating Bayesian principles, proving that the introduction of the Bayesian principle contributes to the model’s performance and can improve its predictive power.
The BMAE-Net model in this paper is based on Bayesian principles for parameter optimization to establish the optimal parameters. The model is continuously trained to establish the optimal parameters within our preset parameter range. The process of finding the optimal parameters was long, and we noted the time needed for the Bayesian optimization process during the experiments. When the Case 1 experiment was conducted, the average training time for the three locations was 17 h 23 min. At the same time, the other comparison models were trained according to our preset parameters, and the usual training time was about 8 min 35 s. It can be seen that the time cost of Bayesian optimization was higher, and the parameters generated during the training process became elevated. However, compared with parameter optimization methods, such as grid and random searches, the time needed has been reduced significantly.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}