
TreeMerge: A Visual Comparative Analysis Method for Food Classification Tree in Pesticide Residue Maximum Limit Standards

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
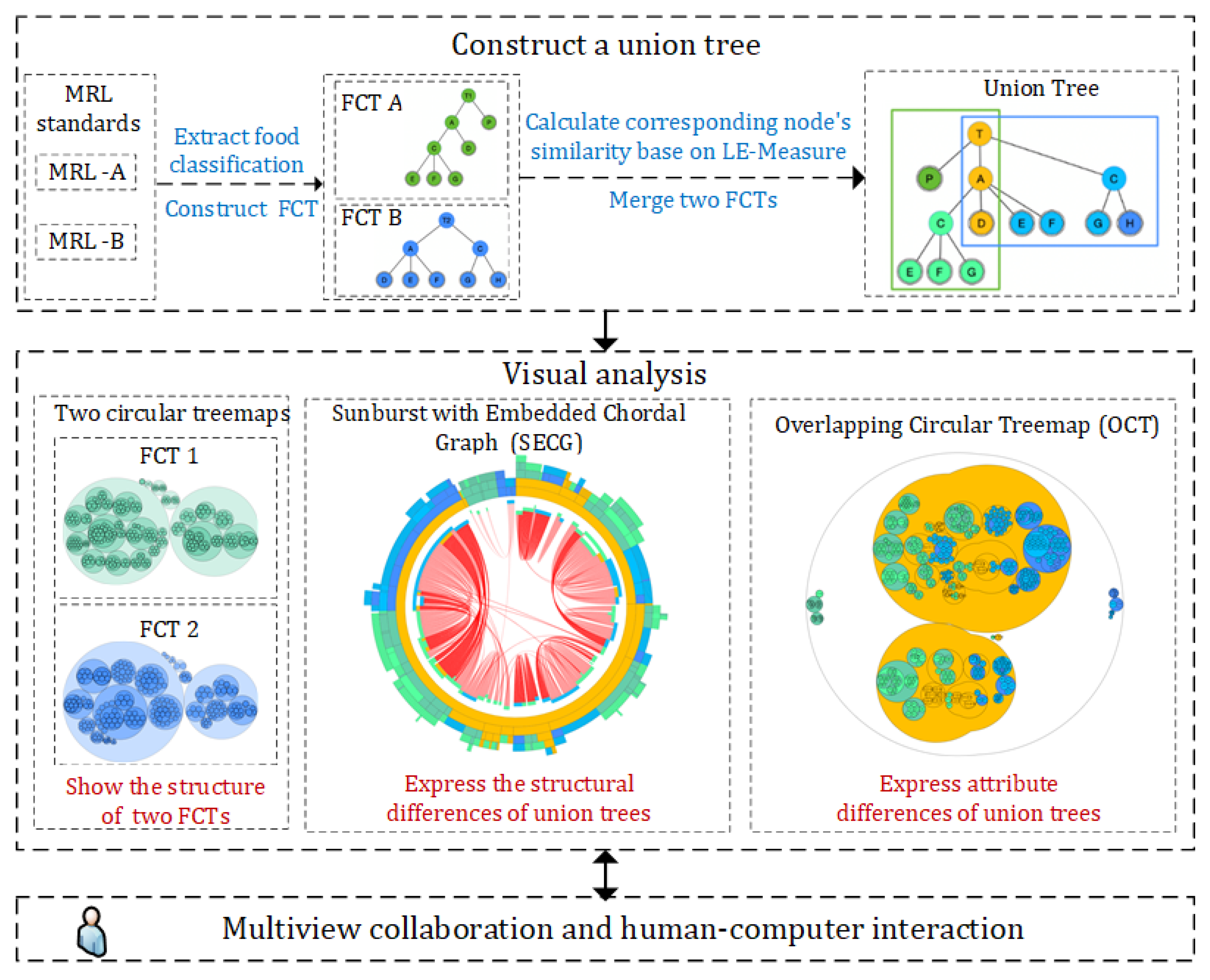
- A union tree construction method is proposed, which merges two FCTs into a single union tree based on the improved node similarity metric LE-Measure in this paper. The union tree provides the basis for a visual associative representation of the structural and attribute differences between the two FCTs to be compared.
- (2)
- Two new visualization solutions called sunburst with an embedded chordal graph (SECG) and the overlapping circular treemap (OCT) are proposed to visualize the similarities and differences between two trees to be compared contained in a union tree. They support the exploration of the structural difference pattern of food classification in the two regions and realize the correlation analysis of food classification and the number of residue limits in food or food classification.
- (3)
- A visual analysis system for comprising food classification trees, FCTvis, is designed and implemented. Case studies were conducted on the pesticide MRL standards in the Chinese Mainland and Chinese Hong Kong to verify the effectiveness of the TreeMerge method.
2. Related Work
2.1. Tree Comparison Visualization
2.2. Circle Packing
3. Dataset and Analysis Task
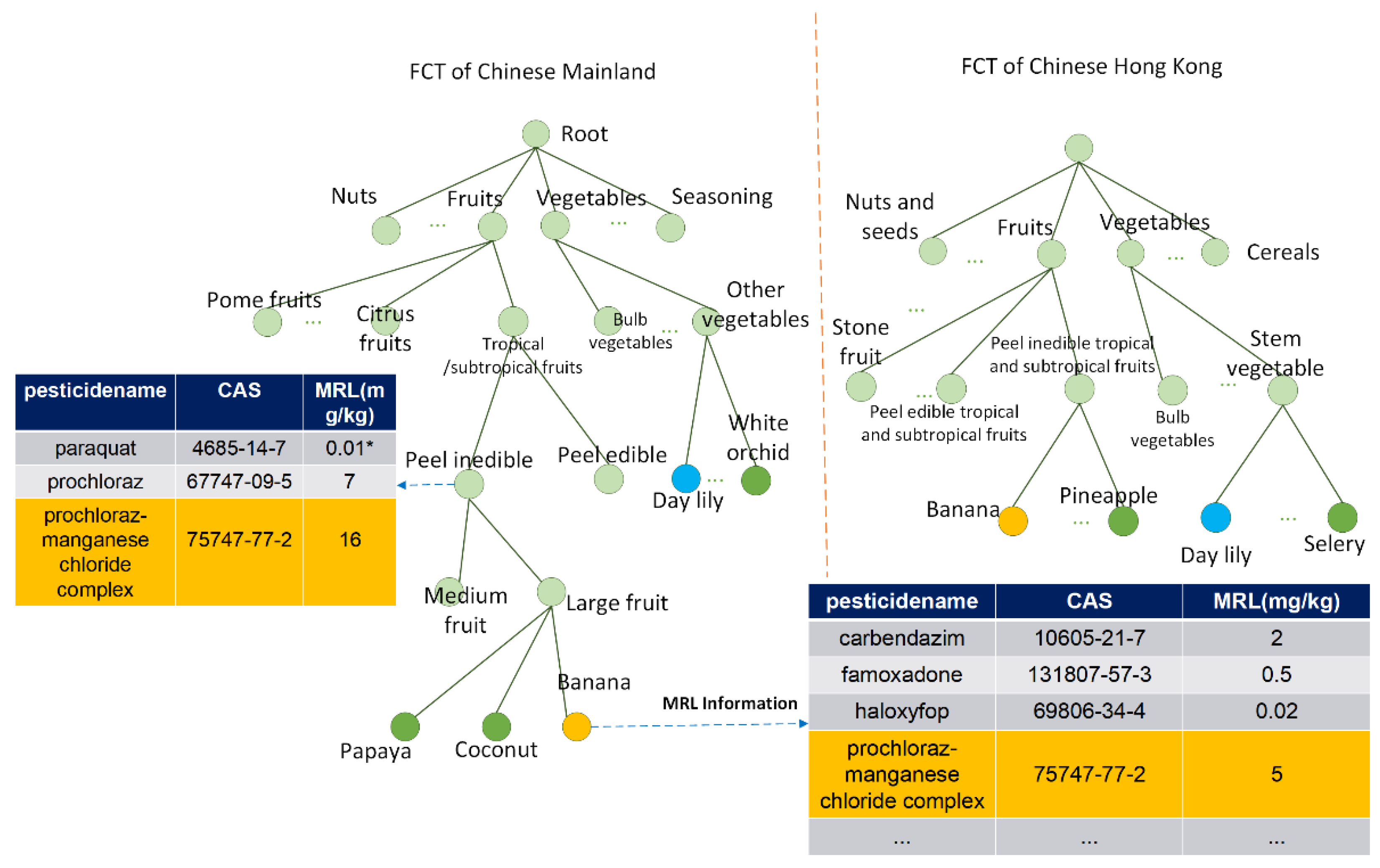
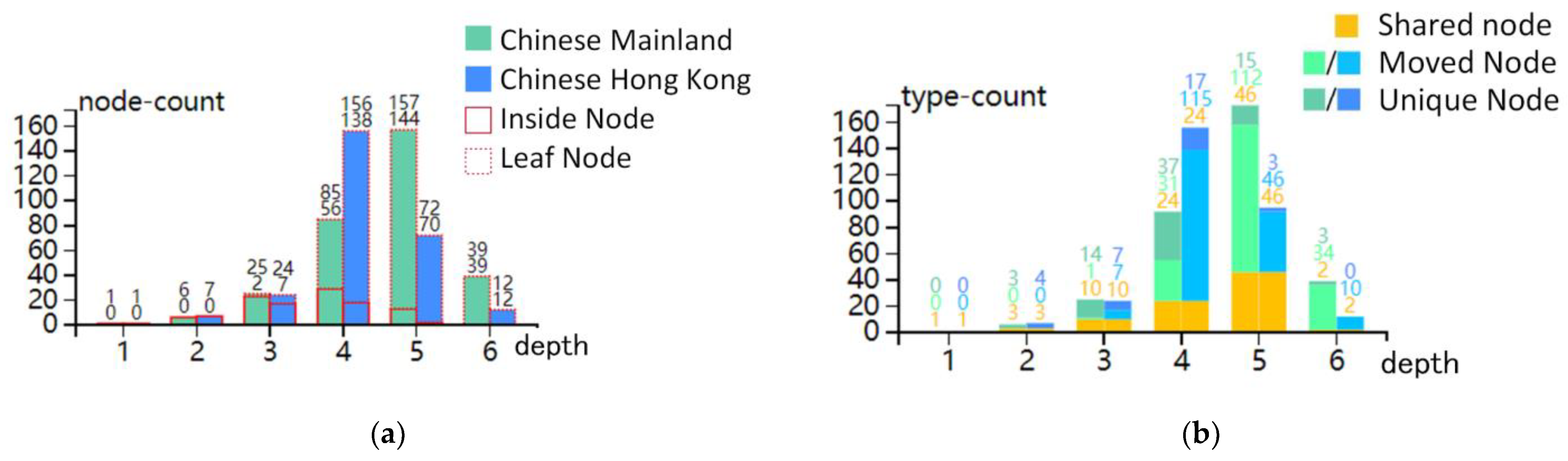
3.1. Dataset and FCT
3.2. Analysis Tasks
3.3. Pipeline of TreeMerge
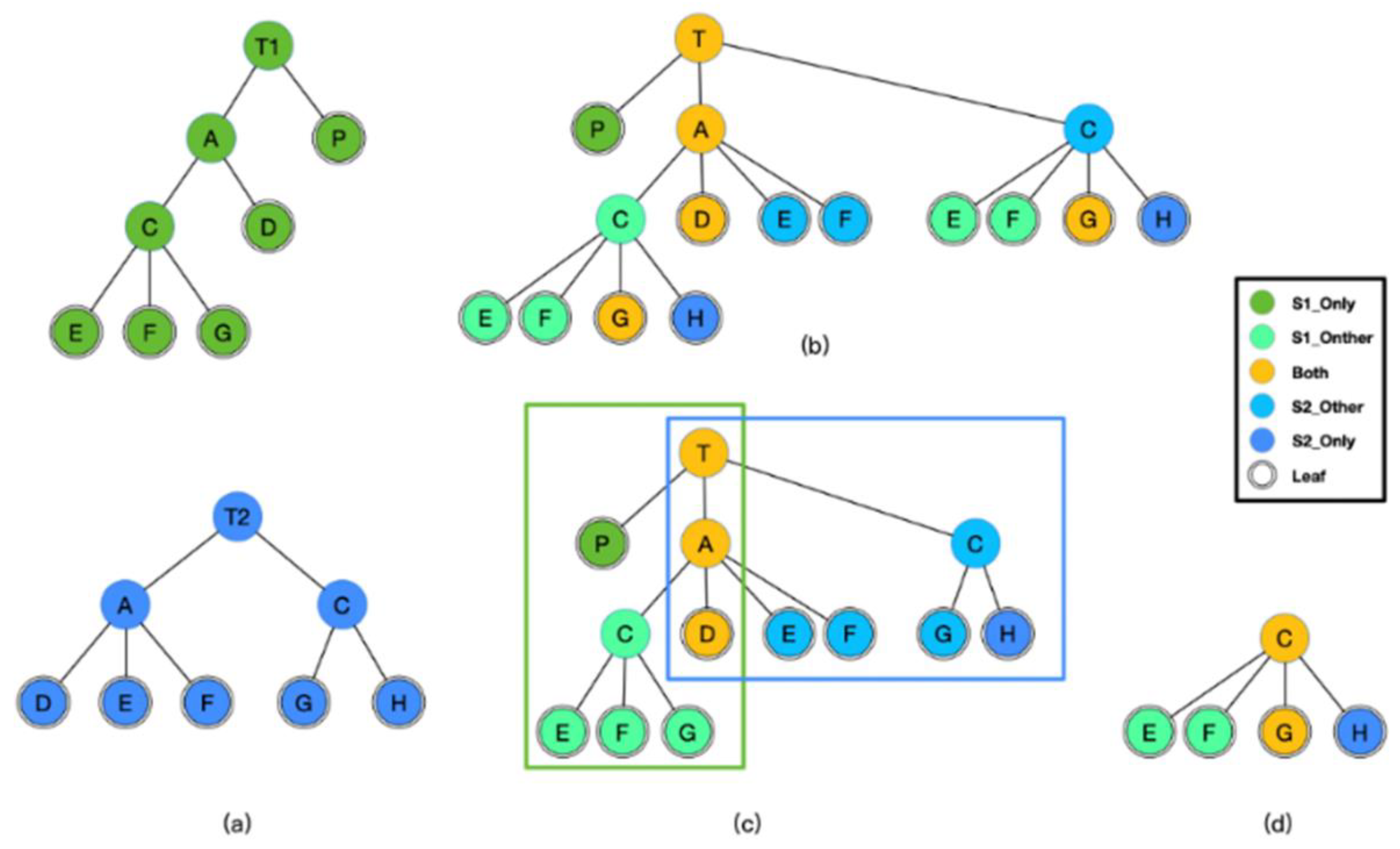
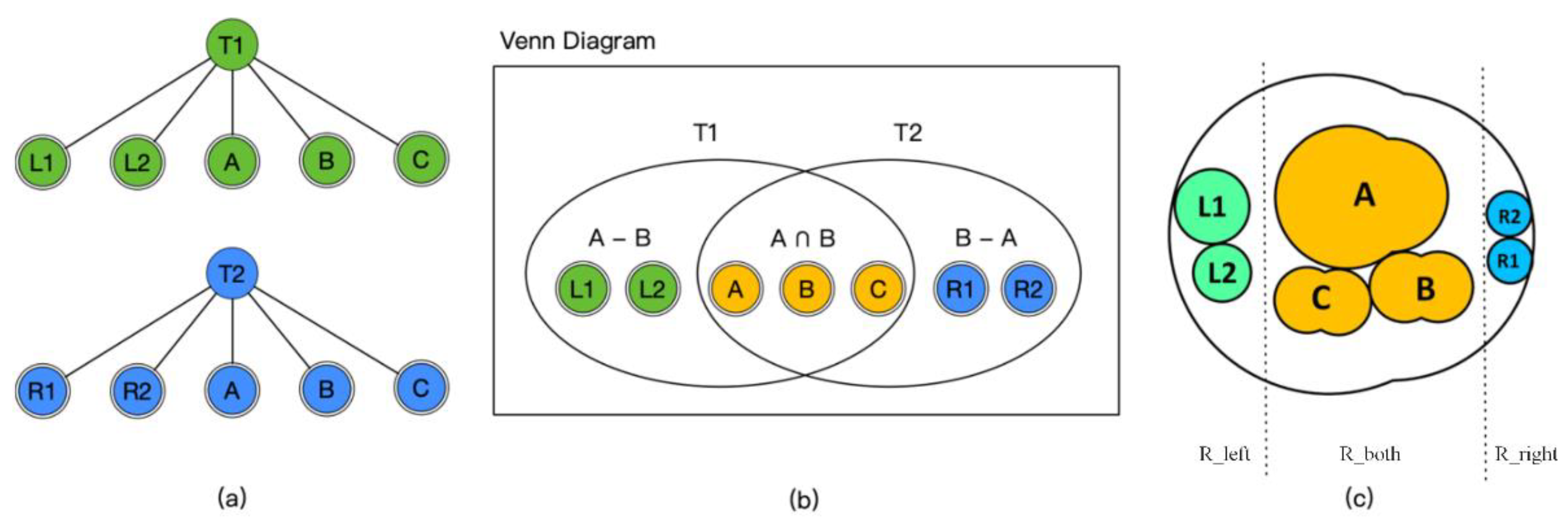
4. Union Tree
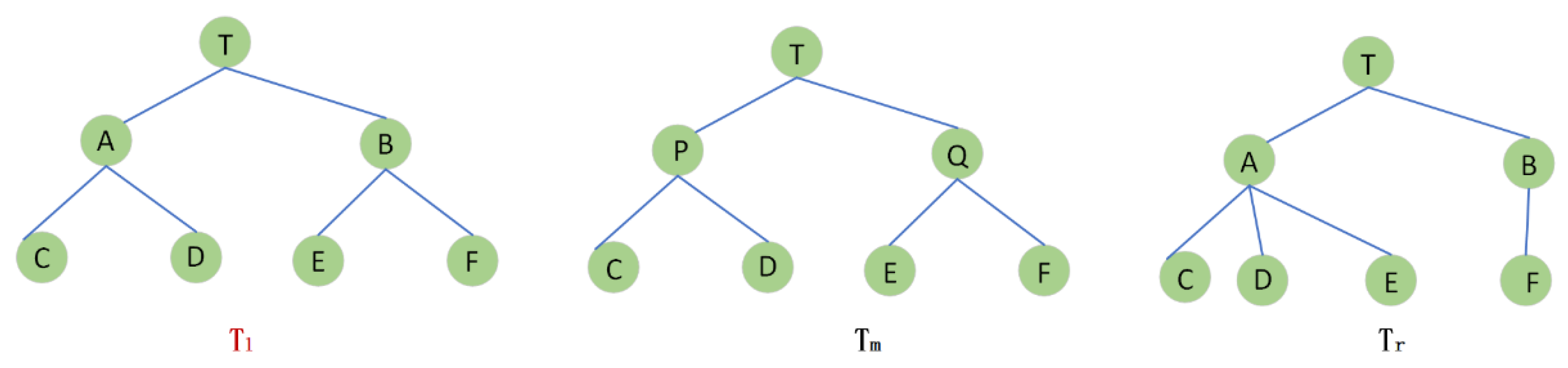
4.1. Definitions of Labeled Tree
4.2. LE-Measure
4.3. Construction of the Union Tree
5. Visualization Design
5.1. Sunburst with Embedded Chordal Graph Design
5.2. Overlapping Circular Treemap Design
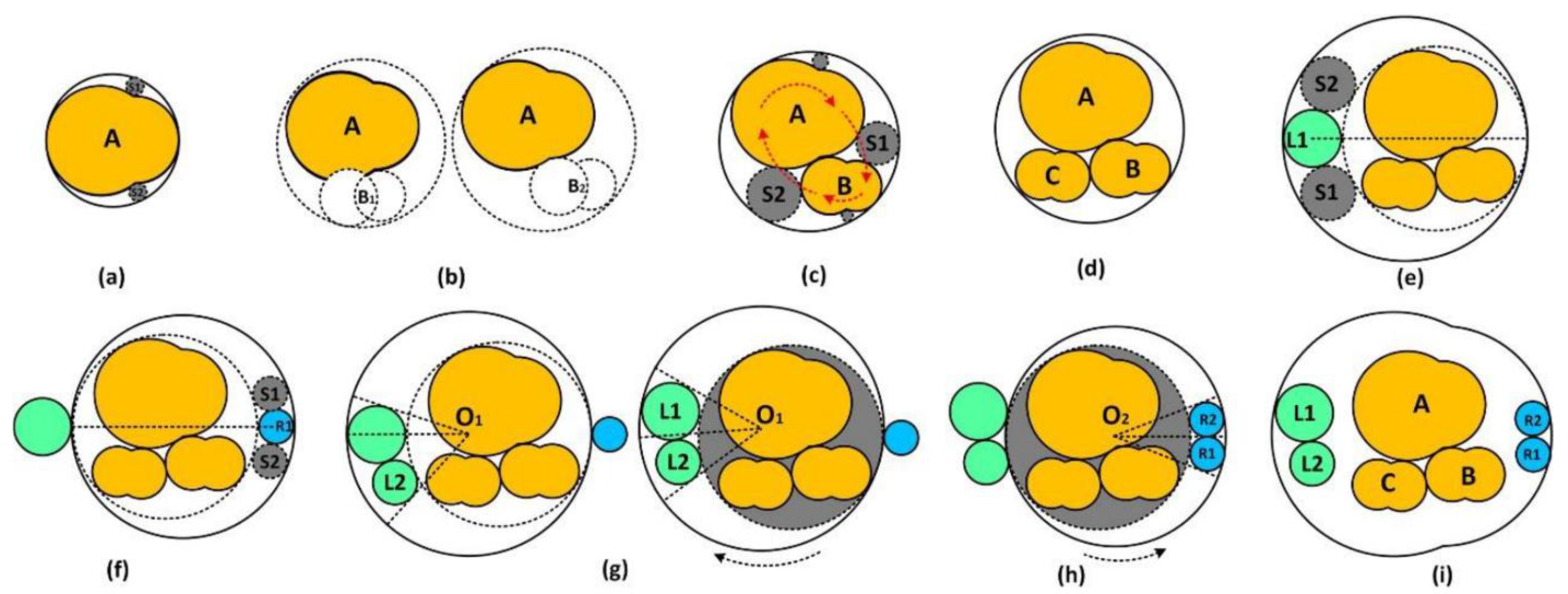
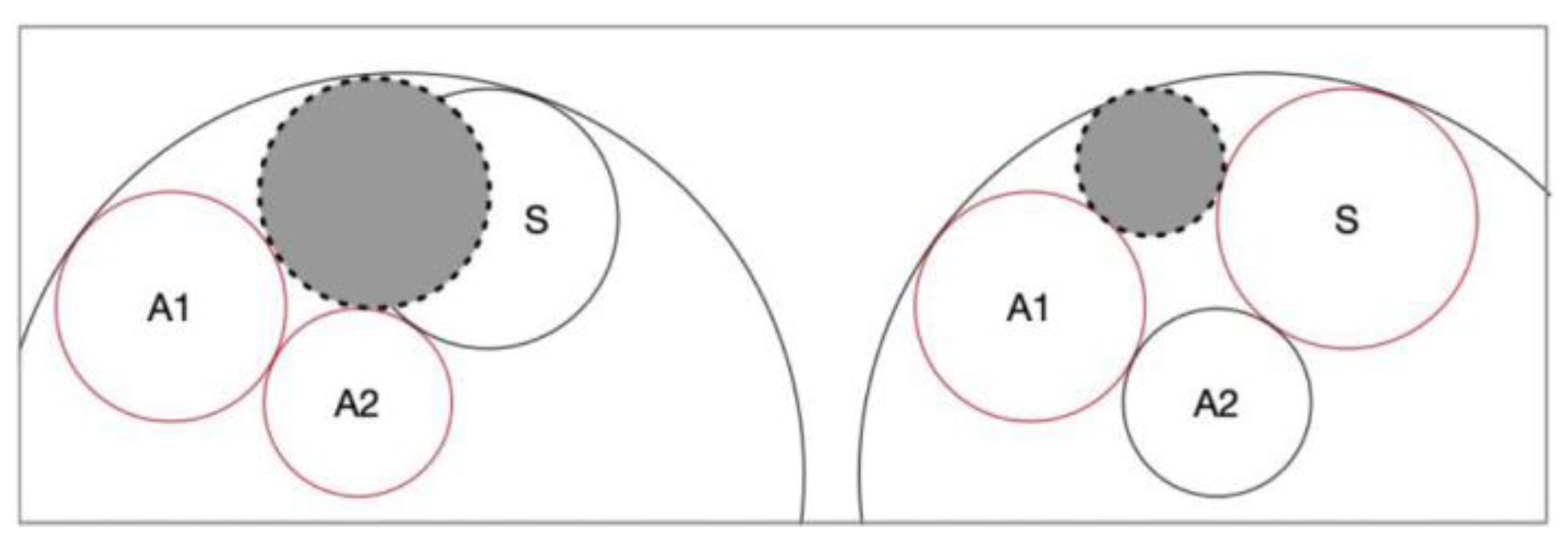
5.2.1. Node Shape Mapping
5.2.2. Child Set Layout
5.2.3. Construction of the Entire OCT
5.3. SECG-OCT Interactive
6. FCTvis System
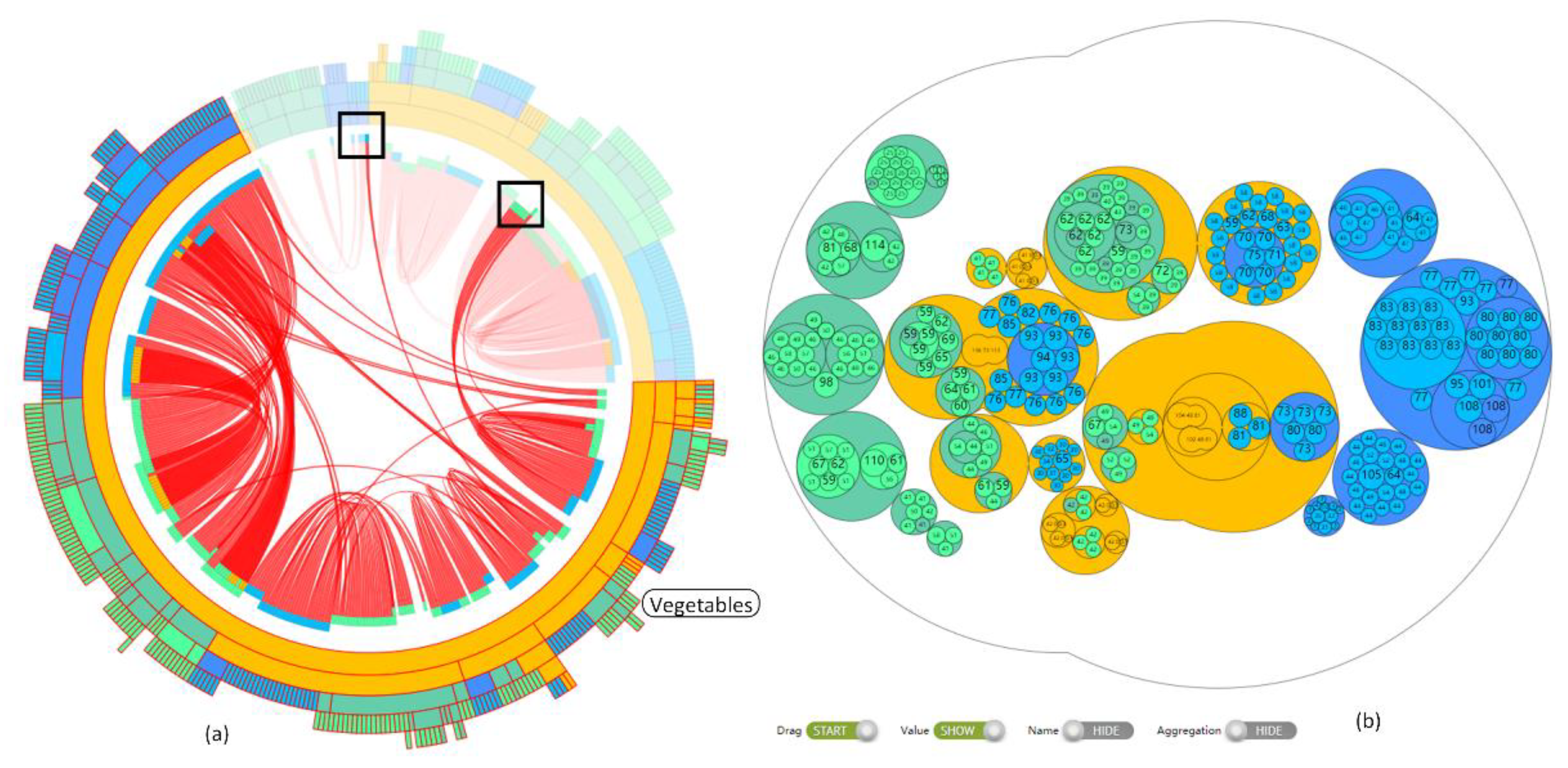
6.1. FCTvis Interface
- (a)
- The two circular treemaps are visual mappings of the two FCTs to be compared, and the histograms show the statistical information of the nodes on the different levels. In the circular treemap, when the mouse hovers over a node in a tree, the node and its descendant structure are highlighted. If the node is related to a node in another tree, then the corresponding structure in the other tree is also highlighted. This interaction is a juxtaposition of comparisons and is used to prompt the user. When the mouse clicks on an internal node, the SECG view displays information about that node only, facilitating further observation of the local structure. The circular treemap can also be associated to show the structural information of the selected nodes of the SECG view and the OCT view.
- (b)
- The SECG view is used to provide a visual overview of the structural differences. By default, it displays structural information about the root node descendants of the union tree constructed with all food products and the related relationships between the descendant nodes. Mouse hovering will highlight the curve between this node and the related nodes internally, and the node label will be displayed externally. The SECG view displays the descendant structure information of the selected node when the left mouse button is clicked on the internal node in Figure 11a or on the dark green, dark blue, or yellow area in the external sunburst in the SECG view. The type of node pairs connected by internal curves can be changed via the toggle button. By default, curves that connect two identically labeled leaf nodes are displayed. Clicking the toggle button above will display curves that connect explicitly related internal node pairs. Clicking the toggle button below allows SECG to display curves that connect implicitly related node pairs.
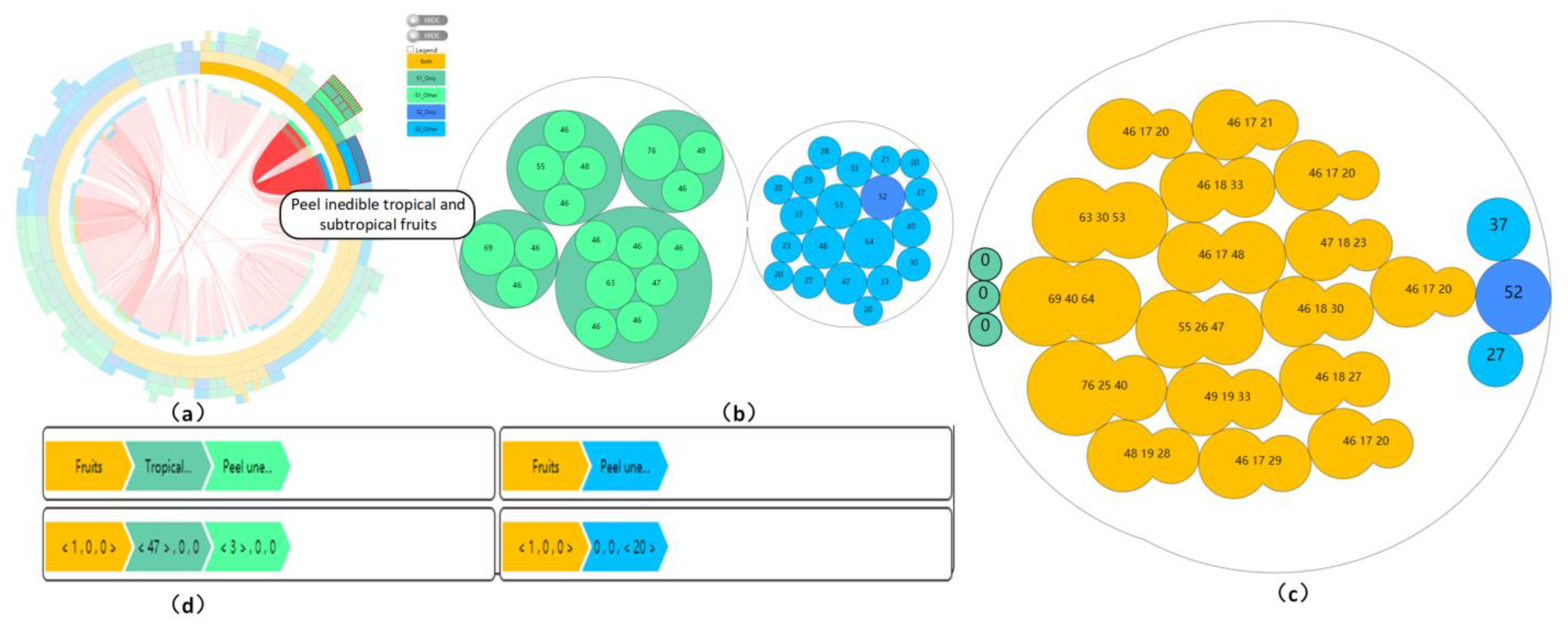
- (c)
- This is used to show the path of the selected node in Figure 11b and the changes in the node value attributes in that path, i.e., it is used to show the complete genetic process of the MRL of the selected node. Each node has three values: The value of the leaf node corresponds to its attribute value in different FCT trees according to the color of the node; the value in the middle region of the attribute value of the internal node, i.e., the food classification node, represents the number of the same MRL value inherited by the present selected node under the two classifications; and the values on both sides correspond to the number of MRL value related to this classification node inherited by the selected node in the two FCTs, respectively.
- (d)
- The OCT view is used for the visual mapping of structural difference patterns and node attribute values. The OCT view by default displays the union tree built with all food products. Left clicking on a node in the middle area of the overlapping circle or a blank area is used to drill down and scroll up the data, i.e., switch the nodes displayed in the OCT view. Using the given button, we can lock the current view position, display node attribute values, display node labels, and switch the aggregation mode. Clicking the right mouse button can be linked with the circular treemap and the SECG view in Figure 11a to compensate for topological information that cannot be displayed by OCT.
6.2. Case Study
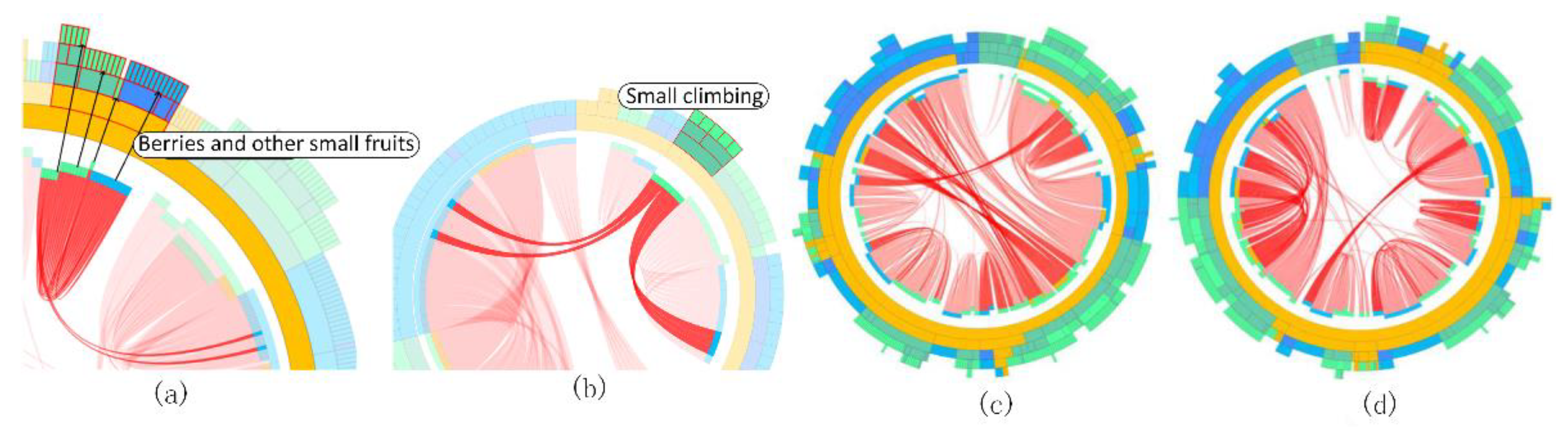
6.2.1. Topology Discovery by the SECG Overview
6.2.2. Attribute Detail Analysis
6.2.3. Case Exploration Process
7. Discussion
8. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bakirci, G.T.; Acay, D.B.Y.; Bakirci, F.; Otles, S. Pesticide residues in fruits and vegetables from the Aegean region, Turkey. Food Chem. 2014, 160, 379–392. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Dou, H.F.; Chang, Q.Y.; Fan, C.L. PRIAS: An Intelligent Analysis System for Pesticide Residue Detection Data. Food Saf. Superv. 2022, 11, 780. [Google Scholar]
- National Health and Family Planning Commission of PRC; The Ministry of Agriculture of the People’s Republic of China. National Food Safety Standard-Maximum Residue Limits for Pesticides in Food; Standards Press: Beijing, China, 2016.
- Food and Environmental Hygiene Department. Pesticide Residues in Food Regulation; Food and Environmental Hygiene Department: Hong Kong, China, 2014.
- Chen, Y.H.; Li, J. A tree similarity computation method based on structure feature. Comput. Eng. 2018, 44, 197–201. [Google Scholar]
- Ward, M.; Grinstein, G.; Keim, D. Interactive Data Visualization: Foundations, Techniques, and Applications, 2nd ed.; A K Peters Ltd.: Natick, MA, USA, 2014. [Google Scholar]
- Munzner, T. Visualization Analysis and Design; A K Peters/CRC Press: New York, NY, USA, 2014. [Google Scholar]
- Chen, Y.; Du, X.M.; Yuan, X.R. Ordered Small Multiple Treemaps for Visualizing Time-Varying Hierarchical Pesticide Residue Data. Vis. Comput. 2017, 33, 1073–1084. [Google Scholar] [CrossRef]
- Li, G.Z.; Zhang, Y.; Dong, Y.; Liang, J.; Zhang, J.S.; Wang, J.S.; McGuffin, M.J.; Yuan, X.R. BarcodeTree: Scalable Comparison of Multiple Hierarchies. IEEE Trans. Vis. Comput. Graph. 2020, 26, 1022–1032. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, Q.H.; Guan, Z.L.; Zhao, Y.; Chen, W. GEMvis: A visual analysis method for the comparison and refinement of graph embedding models. Vis. Comput. 2022, 38, 3449–3462. [Google Scholar] [CrossRef]
- Chen, Y.; LV, C.; Li, Y.; Chen, W.; Ma, K.-L. Ordered matrix representation supporting the visual analysis of associated data. Sci. China Inf. Sci. 2020, 63, 184101. [Google Scholar] [CrossRef]
- Chen, Y.; Guan, Z.L.; Zhang, R.; Du, X.M.; Wang, Y.H. A Survey on Visualization Approaches for Exploring Association Relationships in Graph Data. J. Vis. 2019, 22, 625–639. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, X.Y.; Feng, Y.C.; Liang, J.; Chen, H.Q. Sunburst with Ordered Nodes based on Hierarchical Clustering: A Visual Analyzing Method for Associated Hierarchical Pesticide Residue Data. J. Vis. 2015, 18, 237–254. [Google Scholar] [CrossRef]
- Chevalier, F.; Auber, D.; Telea, A. Structural analysis and visualization of C++ code evolution using syntax trees. In Proceedings of the ACM International Conference Proceeding Series, Dubrovnik, Croatia, 3–4 September 2007; pp. 90–97. [Google Scholar]
- Holten, D.; Van Wijk, J.J. Visual comparison of hierarchically organized data. Comput. Graph. Forum. 2018, 27, 759–766. [Google Scholar] [CrossRef]
- Bremm, S.; Von Landesberger, T.; Hess, M.; Schreck, T.; Weil, P.; Hamacherk, K. Interactive visual comparison of multiple trees. In Proceedings of the IEEE Conference on Visual Analytics Science and Technology, Providence, RI, USA, 23–28 October 2011; Miksch, S., Ed.; IEEE Computer Society Press: Providence, RI, USA, 2011; pp. 31–40. [Google Scholar]
- Liu, Z.; Zhan, S.H.; Munzner, T. Aggregated Dendrograms for Visual Comparison Between Many Phylogenetic Trees. IEEE Trans. Vis. Comput. Graph. 2019, 2019, 2732–2747. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y.; Dong, Y.; Sun, Y.H.; Liang, J. A Multi-comparable visual analytic approach for complex hierarchical data. J. Vis. Lang. Comput. 2019, 47, 19–30. [Google Scholar] [CrossRef]
- Beck, F.; Wiszniewsky, F.; Burch, M.; Diehl, S.; Weiskopf, D. Asymmetric visual hierarchy comparison with nested icicle plots. In Proceedings of the Fourth International Workshop on Euler Diagrams and the First International Workshop on Graph Visualization in Practice Co-Located with Diagrams, Melbourne, Australia, 28 July–1 August 2014; pp. 53–62. [Google Scholar]
- Dinkla, K.; Westenberg, M.A.; Timmerman, H.; van Hijum, S.A.; van Wijk, J.J. Comparison of multiple weighted hierarchies: Visual analytics for microbe community profiling. Comput. Graph. Forum 2011, 30, 1141–1150. [Google Scholar] [CrossRef]
- Guerra, G.J.A.; Pack, M.; Plaisant, C.; Shneiderman, B. Visualizing change over time using dynamic hierarchies: Treeversi-ty2 and the stemview. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2566–2575. [Google Scholar] [CrossRef] [PubMed]
- Guerra-G’omez, J.A.; Buck-Coleman, A.; Plaisant, C.; Shneiderman, B. TreeVersity: Interactive visualizations for comparing two trees with struc-ture and node value changes. In Proceedings of the Conference Design Research Society, Bangkok, Thailand, 1–4 July 2012; Volume 2, pp. 640–653. [Google Scholar]
- Lee, B.; Robertson, G.G.; Czerwinski, M.; Parr, C.S. CandidTree: Visualizing structural uncertainty in similar hierarchies. Inf. Visu-Alization 2007, 6, 233–246. [Google Scholar] [CrossRef]
- Tu, Y.; Shen, H.W. Visualizing changes of hierarchical data using treemaps. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1286–1293. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leschke, T.R.; Nicholas, C. Change-link 2.0: A digital forensic tool for visualizing changes to shadow volume data. In Proceedings of the Tenth Workshop on Visualization for Cyber Security, Atlanta, GA, USA, 14 October 2013; pp. 17–24. [Google Scholar]
- Fu, S.; Dong, H.; Cui, W.; Zhao, J.; Qu, H. How do ancestral traits shape family trees over generations? IEEE TVCG 2018, 24, 205–214. [Google Scholar] [CrossRef]
- Sankaran, K.; Holmes, S. Interactive Visualization of Hierarchically Structured Data. J. Comput. Graph. Stat. 2018, 27, 553–563. [Google Scholar] [CrossRef]
- Card, S.K.; Suh, B.; Pendleton, B.; Heer, J.; Bodnar, J.W. TimeTree: Exploring Time Changing Hierarchies. In Proceedings of the IEEE Symposium on Visual Analytics Science & Technology, Baltimore, MD, USA, 31 October–2 November 2006. [Google Scholar]
- Johnson, B.; Shneiderman, B. Tree-maps: A space-filling approach to the visualization of hierarchical information structures. In Proceedings of the IEEE Conference on Visualization, San Diego, CA, USA, 21–25 October 1991; pp. 284–291. [Google Scholar]
- Zheng, B.Y.; Sadlo, F.L. On the visualization of hierarchical multivariate data. In Proceedings of the IEEE Pacific Visualization Symposium, Tianjin, China, 19–21 April 2021; pp. 136–145. [Google Scholar]
- Gou, L.; Zhang, X.L. TreeNetViz: Revealing patterns of networks over tree structures. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2449–2458. [Google Scholar]
- Görtler, J.; Schulz, C.; Weiskopf, D.; Deussen, O. Bubble Treemaps for Uncertainty Visualization. IEEE Trans. Vis. Comput. Graph. 2017, 24, 719–728. [Google Scholar] [CrossRef]
- Zhao, H.S.; Lu, L. Variational circular treemaps for interactive visualization of hierarchical data. In Proceedings of the IEEE Pacific Visualization Symposium, Hangzhou, China, 14–17 April 2015; pp. 81–85. [Google Scholar]
- Wang, W.X.; Wang, H.; Dai, G.Z.; Wang, H.G. Visualization of large hierarchical data by circle packing. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Montréal, QU, Canada, 22–27 April 2006; ACM Press: New York, NY, USA, 2006; pp. 517–520. [Google Scholar]
- Huang, W.Q.; Ye, T. Global optimization method for finding dense packings of equal circles in a circle. Eur. J. Oper. Res. 2011, 210, 474–481. [Google Scholar] [CrossRef]
- Birgin, E.G.; Sobral, F.N.C. Minimizing the object dimensions in circle and sphere packing problems. Comput. Oper. Res. 2008, 35, 2357–2375. [Google Scholar] [CrossRef]
- Huang, W.Q.; Li, Y.; Li, C.M.; Xu, R.C. New heuristics for packing unequal circles into a circular container. Comput. Oper. Res. 2006, 33, 2125–2142. [Google Scholar] [CrossRef]
- Day, W.H.E. Optimal algorithms for comparing trees with labeled leaves. J. Classif. 1985, 2, 7–28. [Google Scholar] [CrossRef]
- Arslan, O.; Guralnik, D.P.; Koditschek, D. Discriminative measures for comparison of phylogenetic trees. Discret. Appl. Math. 2017, 217, 405–426. [Google Scholar] [CrossRef]













Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Z.; Chen, Y.; Li, H.; Li, Y.; Guo, Y. TreeMerge: A Visual Comparative Analysis Method for Food Classification Tree in Pesticide Residue Maximum Limit Standards. Agronomy 2022, 12, 3148. https://doi.org/10.3390/agronomy12123148
Luo Z, Chen Y, Li H, Li Y, Guo Y. TreeMerge: A Visual Comparative Analysis Method for Food Classification Tree in Pesticide Residue Maximum Limit Standards. Agronomy. 2022; 12(12):3148. https://doi.org/10.3390/agronomy12123148
Chicago/Turabian StyleLuo, Zhiying, Yi Chen, Hanqiang Li, Yue Li, and Yandi Guo. 2022. "TreeMerge: A Visual Comparative Analysis Method for Food Classification Tree in Pesticide Residue Maximum Limit Standards" Agronomy 12, no. 12: 3148. https://doi.org/10.3390/agronomy12123148