
Analysis of Social Acceptance for the Use of Digital Identities




Abstract
:1. Introduction
2. Literature Review and Hypotheses
3. Qualitative and Limited Model of the Dependent Variable
3.1. Model Theoretical Description
3.2. Model Specifications
3.2.1. Demographic Differences
- Gender: dummy variable with 1 = male and 0 = not male (female, diverse) ➞ With this, we would like to find out whether a gender-specific urge to use digital identities can be recognised.
- Age: Metric variable with age in years ➞ The question here is whether younger or older German citizens tend to use digital identities in wallet apps.
- Net income: Metric variable with monthly net salary in EUR ➞ Do higher-income citizens tend to use digital identities through wallet apps, who in connection with their salary may have several bank accounts and several customer memberships in the form of online accounts for shopping on the internet, for which they can register and log in more frequently (and more conveniently + quickly) with the providers? (See model 4)
- Academic background: The answers are given as a nominally scaled variable in the form of ascending educational level (no degree, intermediate school leaving certificate, (technical) school leaving certificate, vocational training, bachelor’s/diploma, state examination, master’s, doctorate, habilitation) and coded as a dummy variable in 1 = academic educational level and 0 = no academic educational level. ➞ In this way, we want to investigate the question of whether citizens with an academic educational background have a different understanding of the use of digital identities than citizens without an academic background.
- Employment situation: The answer to this question is given as a nominally scaled variable in the form of the employment relationship (job-seeking, part-time or full-time employed or self-employed/freelance) and is coded as a dummy variable in 1 = is in employment and 0 = is not in employment. ➞ We want to find out whether permanently employed citizens tend to use digital identities.
- Living in one’s own property: This variable is also originally based on a nominal scaling, which provides information about the current living situation of the respondents (own house, condominium, rented house, rented flat (incl. shared flat)). It is coded in a dummy variable and says 1 = living situation in own property and 0 = living situation as tenant. ➞ Can the resulting security in the form of ownership explain the use of digital identities?
- Relationship: Originally nominally scaled variable (in committed relationship, married, single, widowed) and coded into a dummy variable with 1 = in committed relationship and married and 0 = living alone. ➞ The security triggered by this could also explain the likelihood of using digital identities.
- Number of children: This is a metrically scaled variable containing the number of children.
3.2.2. Private Individuals’ Experiences with Blockchain Products
- Ever heard of Blockchain: This variable is based on the question whether the respondent has ever heard of Blockchain and can be answered in its dichotomous form with 1 = Yes and 0 = No. ➞ We are investigating the question of whether citizens who have heard of blockchain are more inclined to adopt digital identities or vice versa. The background to this is that due to the simple design of digital identities in wallet apps, no knowledge of blockchain would need to be present. Many providers, such as Apple and Google, actively advertise easy-to-use and self-explanatory wallet apps that can be used by citizens.
- Blockchain functionality know-how: Here, the question is about how well the respondents assess their knowledge of blockchain functionality. The answers are presented with an ordinal-scaled variable with a Likert scale of 1 to 3 (1 = No, 2 = Partially, 3 = Yes), whereby we decide to code this variable into a dummy variable with 1 = Yes and 0 = No due to imprecision in the citizens’ own self-assessment. ➞ Could citizens who have good knowledge of blockchain functionality also be more inclined to use or not use digital identities managed in wallet apps. Their willingness to use depending on their knowledge is thereby guided by the idea of a decentralised order structure, as this has always functioned as a leitmotif of DLT. Centralised power structures or institutions could misuse identities, which would be conspicuous in a decentralised network structure. Experienced blockchain users are familiar with this advantage, for example, when carrying out transactions using payment tokens such as Bitcoin or Ether. The peer-to-peer (P2P) approach is particularly appreciated here, where central institutions such as banks lose out. With reference to digital identities, identities and their proofs can thus be transmitted directly from the user to a company, eliminating essential intermediate steps or verifying companies. Using the example of financing in a goods shop, the digital credit identity (if already successfully issued) can be shared directly from the customer to the shop. The intermediate step of querying the creditworthiness at Schufa thus becomes obsolete, which leads to a simplification of the customer journey in the example. A negative attitude towards wallet apps could exist if users do not believe in the decentralisation of a network and suspect risks in the blockchain protocol. This could also have a negative impact on the likelihood of using digital identities.
- Used blockchain products: Whether respondents have already used products with blockchain technology (e.g., crypto, staking, NFT investment) answers this variable, which is based on dichotomous coding with 1 = Yes and 0 = No. The aim here is to discuss the extent to which the likelihood of using digital identities depends on previous experience with blockchain products or services.
- Convenience rating: This variable is based on the question of how the product’s usefulness is rated in terms of convenience, where 1 = no usefulness, 2 = less usefulness, 3 = moderate usefulness, 4 = high usefulness and 5 = very high usefulness (also for the following categories).
- Assessment of time saving: Assessment of time saving.
- Assessment of clarity: Assessment of clarity.
- Assessment of self-determination: Assessment of self-determination.
3.2.3. Affinity of Citizens to (Digital) Financial and ID Products
- Bank cards: Do citizens with higher numbers of bank cards tend to use digital identities? This includes, for example, debit and credit cards, which are typically used for digital and analogue payment transactions.
- Customer cards: How many loyalty cards do the respondents have with which online shopping is also possible? There are a variety of options here, ranging from classic loyalty cards for discounts to points cards from certain providers (e.g., Payback).
- Online accounts: How many online accounts do ISP respondents have and, if more, do they tend to manage digital identities in wallet apps for convenience, which store respondents’ data directly and thus help save time or reduce login procedures? This includes, for example, social media accounts, mail accounts and all other user accounts used in digital customer journeys.
- Identification documents: Identity documents are documents or proofs issued by an official authority. These include classic identity cards, birth certificates or driving licences. In Germany, for example, the German Federal Press issues a citizen’s official identity card.
- Testimonial documents: This includes documents such as the employer’s reference or other documents that contain an evaluative character about a person. These are not certified separately. Typically, assessments may be in the form of grades that can be used as evidence by the user.
- Certificate documents: Certificate documents are proofs such as the university degree certificate or proof of a specific further education or training course. These documents are characterised by the fact that they are certified by a specific organisation or entity.
3.2.4. Privacy Concerns
- Importance of data security: This is an ordinal scaled variable based on the question of the importance of data protection, with Likert scale (1 = not thought about it yet, 2 = unimportant, 3 = moderately important, 4 = important and 5 = very important). ➞ We are thus pursuing the question in the literature as to whether German citizens are also oriented towards higher data protection when using digital identities.
- Trust in companies and governments: This ordinal scaled variable provides information on the question of how high the trust towards private companies and governments is with regard to the protection of the respondents’ personal data? Answers could be selected from the Likert scale with 1 = no trust, 2 = low trust, 3 = medium trust, 4 = high trust and 5 = very high trust. ➞ The main concern here is that data is not misused or kept secure. Could citizens whose trust in private companies and governments is very high also be more inclined to use digital identities?
- Assessment of data security at usage blockchain: This is originally an ordinal scaled variable that asks about the assessment of data protection in the event that blockchain technology is used. Answers could be 1 = Yes, 2 = Partially and 3 = No. We decided to code this variable dichotomously with 1 = “Yes” and “Partially” and 0 = “No”, as the respondents’ assessment could contain knowledge gaps and the discriminatory power between “Yes” and “Partially” is only partially given.
- Knowledge store data by companies: This is an ordinal scaled variable for the question, “How do you rate your own level of knowledge regarding what personal data of yours is stored by companies?”, where on a Likert scale of 1-5, with: 1 = not knowledgeable, 2 = less knowledgeable, 3 = medium knowledgeable, 4 = high knowledgeable and 5 = very knowledgeable. We thus address the question of whether citizens with very high knowledge of corporate data storage also tend to use digital identities.
4. Survey and Data
4.1. Survey and Data Sample
4.2. Pre-Check of the Data
5. Results and Implications
5.1. Demographic Differences
5.2. Private Individuals’ Experiences with Blockchain Products
5.3. Affinity of Citizens to (Digital) Financial and ID Products
5.4. Privacy Concerns
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Roussos, G.; Peterson, D.; Patel, U. Mobile identity management: An enacted view. Int. J. Electron. Commer. 2013, 8, 81–100. [Google Scholar] [CrossRef] [Green Version]
- Bundesdruckerei. Digitale Identitäten—Schlüsselthema unserer Gesellschaft. Available online: https://www.bundesdruckerei.de/de/innovation-hub/digitale-identitaeten-schluesselthema-unserer-gesellschaft (accessed on 15 May 2022).
- Federal Ministry of Economic Affairs and Climate Action. In Focus—Secure Digital Identities. Available online: https://www.bmwk.de/Redaktion/DE/Schlaglichter-der-Wirtschaftspolitik/2021/11/05-im-fokus-digitale-identit%C3%A4ten.html (accessed on 20 May 2022).
- Venkatesh, V.; Morris, M.G.; Davis, G.B.; Davis, F.D. User acceptance of information technology: Toward a unified view. MIS Q. 2003, 27, 425–478. [Google Scholar] [CrossRef] [Green Version]
- Alkhalifah, A.; Al Amro, S. Understanding the Effect of Privacy Concerns on User Adoption of Identity Management Systems. J. Comput. 2015, 12, 174–182. [Google Scholar] [CrossRef]
- Satchell, C.; Shanks, D.; Howard, S.; Murphy, J. Identity crisis: User perspectives on multiplicity and control in federated identity management. Behav. Inf. Technol. 2009, 30, 51–62. [Google Scholar] [CrossRef] [Green Version]
- Beduschi, A. Digital identity: Contemporary challenges for data protection, privacy and non-discrimination rights. Big Data Soc. 2019, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Khatchatourov, A.; Laurent, M.; Levallois-Barth, C. Privacy in Digital Identity Systems: Models, Assessment, and User Adoption. In IFIP International Federation for Information Processing 2015; Springer: Cham, Switzerland, 2015; pp. 273–290. [Google Scholar] [CrossRef] [Green Version]
- Brugger, J.; Fraefel, M.; Riedl, R. Raising Acceptance of Cross-Border eID Federation by Value Alignment. Electron. J. E-Gov. 2014, 12, 179–189. [Google Scholar]
- Wolfond, G. A Blockchain Ecosystem for Digital Identity: Improving Service Delivery in Canada’s Public and Private Sectors. Technol. Innov. Manag. Rev. 2017, 7, 35–40. [Google Scholar] [CrossRef] [Green Version]
- Zhao, D.; Hu, W. Determinants of public trust in government: Empirical evidence from urban China. Int. Rev. Adm. Sci. 2017, 83, 358–377. [Google Scholar] [CrossRef]
- Takemiya, M.; Vanieiev, B. Sora Identity: Secure, Digital Identity on the Blockchain. In Proceedings of the 42nd IEEE International Conference on Computer Software & Applications, Tokyo, Japan, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Bakogiannis, T.; Mytilinis, I.; Doka, K.; Goumas, G. Leveraging Blockchain Technology to Break the Cloud Computing Market Monopoly. Computers 2020, 9, 9. [Google Scholar] [CrossRef] [Green Version]
- Lykidis, I.; Drostos, G.; Rantos, K. The Use of Blockchain Technology in e-Government Services. Computers 2021, 10, 168. [Google Scholar] [CrossRef]
- Alam, T. Blockchain-Based Internet of Things: Review, Current Trends, Applications, and Future Challenges. Computers 2023, 12, 6. [Google Scholar] [CrossRef]
- Palaiokrassas, G.; Skoufis, P.; Voutyras, O.; Kawasaki, T.; Gallissot, M.; Azzabi, R.; Tsuge, A.; Litke, A.; Okoshi, T.; Nakazawa, J.; et al. Combining Blockchains, Smart Contracts, and Complex Sensors Management Platform for Hyper-Connected SmartCities: An IoT Data Marketplace Use Case. Computers 2021, 10, 133. [Google Scholar] [CrossRef]
- Huckle, S.; Bhattacharya, R.; White, M.; Beloff, N. Internet of Things, Blockchain and Shared Economy Applications. Procedia Comput. Sci. 2016, 98, 461–466. [Google Scholar] [CrossRef] [Green Version]
- Fernández-Caramés, T.M.; Fraga-Lamas, P. A Review on the Use of Blockchain for the Internet of Things. IEEE 2018, 6, 32979–33001. [Google Scholar] [CrossRef]
- Li, X.; Jiang, P.; Chen, T.; Luo, X.; Wen, Q. A Survey on the Security of Blockchain Systems. Future Gener. Comput. Syst. 2020, 107, 841–853. [Google Scholar] [CrossRef] [Green Version]
- Rathore, H.; Mohamed, A.; Guizani, M. A Survey of Blockchain Enabled Cyber-Physical Systems. Sensors 2020, 20, 282. [Google Scholar] [CrossRef] [Green Version]
- Taherdoost, H. A Critical Review of Blockchain Acceptance Models—Blockchain Technology Adoption Frameworks and Applications. Computers 2022, 11, 24. [Google Scholar] [CrossRef]
- Mir, U.; Kar, A.K.; Gupta, M. Digital Identity Evaluation Framework for Social Welfare. In Re-Imagining Diffusion and Adoption of Information Technology and Systems: A Continuing Conversation; Springer: Cham, Switzerland, 2020; pp. 401–414. [Google Scholar] [CrossRef]
- Kalvet, T.; Tiits, M.; Laas-Mikko, K. Public Acceptance of Advanced Identity Documents. In Proceedings of the 11th International Conference on Theory and Practice of Electronic Governance, Galway, Ireland, 4–6 April 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Westerlund, M.; Isabelle, D.A.; Leminen, S. The Acceptance of Digital Surveillance in an Age of Big Data. Technol. Innov. Manag. Rev. 2021, 11, 32–44. [Google Scholar] [CrossRef]
- Tiits, M.; Kalvet, T.; Laas-Mikko, K. Social Acceptance of ePassports. Lect. Notes Inform. 2014, 230, 15–26. [Google Scholar]
- Tiits, M.; Ubakivi-Hadachi, P. Common Patterns on Identity Document Usage in EU. EKSISTENZ Working Paper, 2015, 9.1. Available online: https://www.ibs.ee/en/publications/tackling-identity-theft-with-a-harmonized-framework-allowing-a-sustainable-and-robust-identity-for-european-citizens/ (accessed on 15 May 2022).
- Tiits, M.; Ubakivi-Hadachi, P. Societal Risks Deriving from Identity Theft; EKSISTENZ Working Paper 9.2; Institute of Baltic Studies: Tartu, Estonia, 2016. [Google Scholar]
- Zhang, B.; Peterson, H.M., Jr.; Sun, W. Perception of Digital Surveillance: A Comparative Study of High School Students in the U.S. and China. Issues Inf. Syst. 2017, 18, 98–108. [Google Scholar] [CrossRef]
- Clarke, R. Risks inherent in the digital surveillance economy: A research agenda. J. Inf. Technol. 2019, 34, 59–80. [Google Scholar] [CrossRef]
- Cohen, J. A power primer. Psychol. Bull. 1992, 112, 155–159. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, F.Y.; Bloch, D.A.; Larsen, M.D. A simple method of sample size calculation for linear and logistic regression. Stat. Med. 1998, 17, 1623–1634. [Google Scholar] [CrossRef]



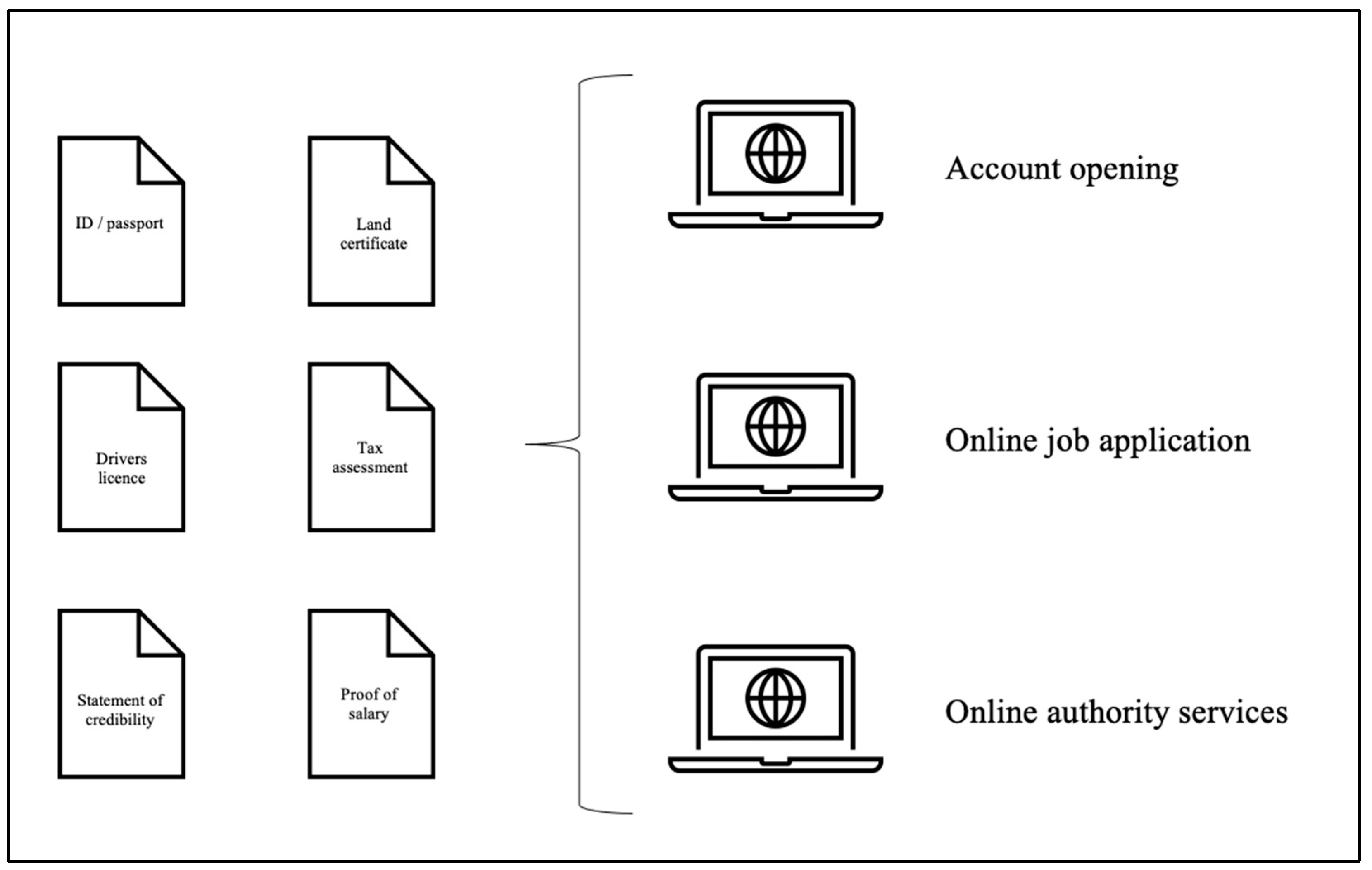{kind=link}
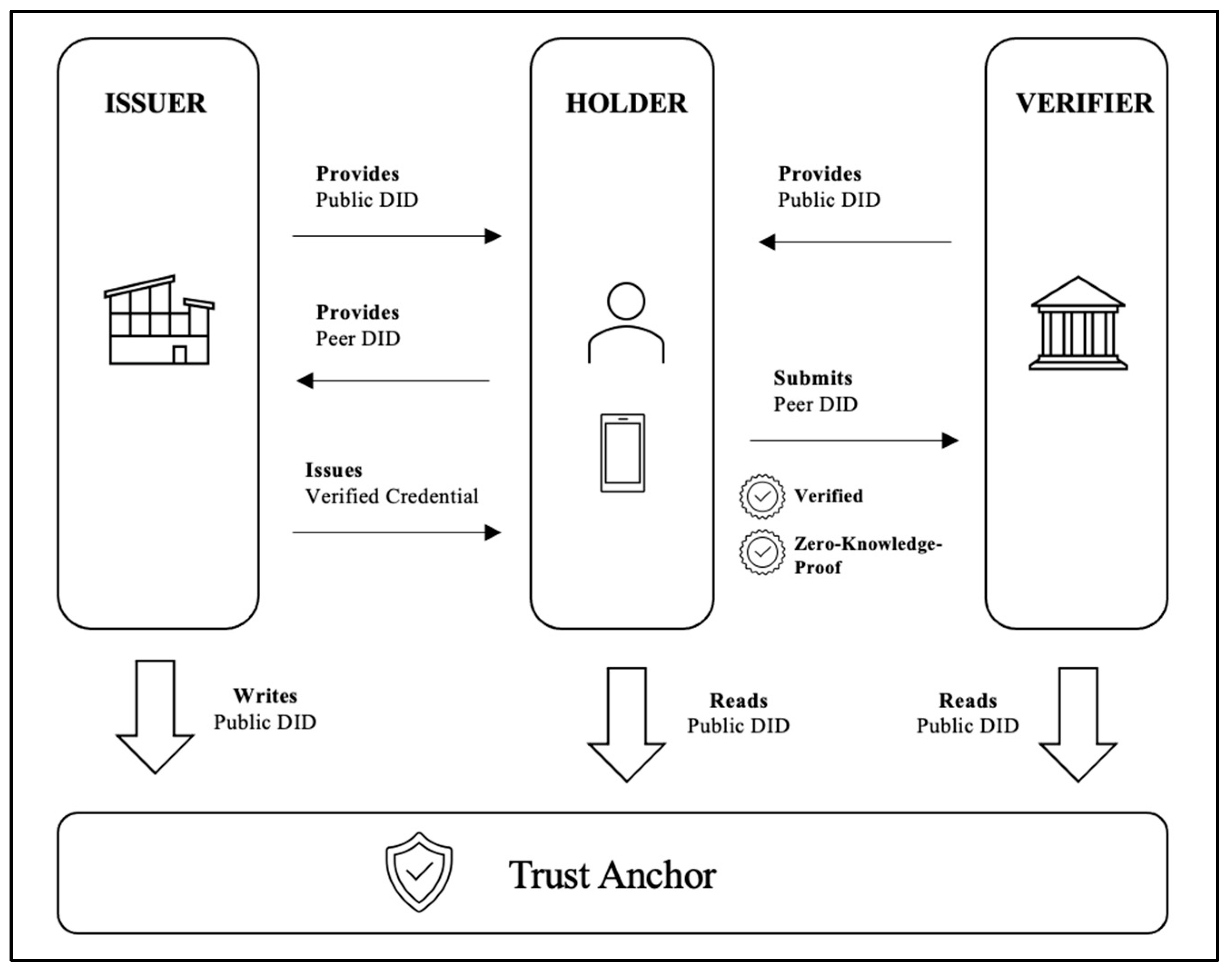{kind=link}
| Metric Variables | ||||||||
| Variable | Class | Amount | Variable | Class | Amount | Variable | Class | Amount |
| Age (in years) | 18–25 | 120 | Net income (in Euro) | 400–1323 | 47 | No. of children | 0 | 278 |
| 26–33 | 148 | 1324–2247 | 85 | |||||
| 34–41 | 26 | 2248–3171 | 131 | 1 | 24 | |||
| 42–49 | 15 | 3172–4095 | 39 | |||||
| 50–57 | 11 | 4096–5019 | 15 | 2 | 17 | |||
| 58–65 | 1 | 5020–5943 | 5 | |||||
| 66–73 | 2 | 5944–6867 | 1 | 3 | 5 | |||
| 74–76 | 1 | 6868–7788 | 1 | |||||
| No. bank cards | 0–3 | 223 | No. ID docs | 0–2 | 63 | No. customer cards | 0–3 | 132 |
| 4–6 | 85 | 3–4 | 178 | 4–6 | 101 | |||
| 7–9 | 14 | 5–6 | 74 | 7–9 | 34 | |||
| 10–12 | 2 | 7–8 | 8 | 10-12 | 38 | |||
| 13–15 | 0 | 9–10 | 1 | 13–15 | 19 | |||
| No. testimony docs | 0–8 | 205 | No. certificate Proofs | 0–6 | 242 | No. online accounts | 0–14 | 143 |
| 9–16 | 61 | 7–12 | 44 | 15–28 | 117 | |||
| 17–24 | 31 | 13–18 | 13 | 29–42 | 34 | |||
| 25–32 | 25 | 19–24 | 9 | 43–56 | 22 | |||
| 33–40 | 2 | 25–30 | 16 | 57–70 | 8 | |||
| Likerts | ||||||||
| Variable | Class | Amount | Variable | Class | Amount | Variable | Class | Amount |
| Assessment of convenience | 1 | 4 | Assessment of timesaving | 1 | 5 | Assessment of clarity | 1 | 5 |
| 2 | 11 | 2 | 17 | 2 | 15 | |||
| 3 | 29 | 3 | 60 | 3 | 30 | |||
| 4 | 100 | 4 | 110 | 4 | 112 | |||
| 5 | 180 | 5 | 132 | 5 | 162 | |||
| Assessment of self-determination | 1 | 19 | Importance of data security | 1 | 3 | Trust in governments and companies | 1 | 25 |
| 2 | 47 | 2 | 13 | 2 | 103 | |||
| 3 | 99 | 3 | 64 | 3 | 133 | |||
| 4 | 89 | 4 | 144 | 4 | 49 | |||
| 5 | 70 | 5 | 100 | 5 | 14 | |||
| Dummies (1 = “Yes”; 0 = “No”) | ||||||||
| Variable | Class | Amount | Variable | Class | Amount | Variable | Class | Amount |
| Gender (male) | 1 | 161 | Relationship | 1 | 227 | Academic background | 1 | 235 |
| 0 | 163 | 0 | 97 | 0 | 89 | |||
| Employment situation | 1 | 301 | Living in own real estate | 1 | 74 | Ever heard of Blockchain | 1 | 299 |
| 0 | 23 | 0 | 250 | 0 | 25 | |||
| Know-How Blockchain | 1 | 225 | Used Blockchain products | 1 | 75 | Assessment of data security | 1 | 224 |
| 0 | 99 | 0 | 249 | 0 | 100 | |||
| Knowledge data storage comp. | 1 | 119 | ||||||
| 0 | 205 | |||||||
| Model | Variable | Coefficient | Interpretation |
|---|---|---|---|
| Demographics differences | Age | −0.2262 *** | − |
| No. of children | 1.3719 ** | + | |
| Net income (in EUR) | −0.0012 *** | − | |
| Academic background | 4.6595 *** | + | |
| Citizens‘ experiences | Ever heard Blockchain | 2.5211 *** | + |
| Knowhow Blockchain | 2.7885 *** | + | |
| Assessment of Blockchain | Assessment of convenience | 0.8475 *** | + |
| Assessment of clarity | 0.4094 * | + | |
| Affinity with (digital) financial products | No. of bank cards | 0.2773 ** | + |
| No. of customer cards | 0.1008 * | + | |
| No. of online accounts | 0.1061 *** | + | |
| No. of testimony documents | 0.0868 *** | + | |
| No. of certification proofs | −0.0963 *** | − | |
| Data protection concerns | Importance of data security | −0.5192 *** | − |
| Trust in governments & companies | 0.3673 ** | + | |
| Assessment of data security | 0.5640 * | + |
| Variable | Min | Max | Range | Mean | Median | STD | Skewness |
|---|---|---|---|---|---|---|---|
| Age (in years) | 18 | 76 | 58 | 29.29 | 27 | 8.72 | 2.33 |
| No. children | 0 | 3 | 3 | 0.23 | 0 | 0.61 | 2.87 |
| Net income (in Euro) | 400 | 7780 | 7380 | 2480.81 | 2400 | 1033.97 | 1.01 |
| No. bank cards | 1 | 12 | 11 | 3.18 | 3 | 1.67 | 1.69 |
| No. ID docs | 1 | 10 | 9 | 3.72 | 4 | 1.36 | 0.56 |
| No. loyalty cards | 0 | 15 | 15 | 5.13 | 4 | 3.79 | 0.94 |
| No. testimony docs | 0 | 36 | 36 | 9.38 | 6 | 7.96 | 1.40 |
| No. certificate proofs | 0 | 30 | 30 | 6.00 | 4 | 6.82 | 2.21 |
| No. online accounts | 2 | 70 | 68 | 19.24 | 15 | 14.24 | 1.39 |
| Model | Variables | VIF | Result |
|---|---|---|---|
| I. Demographic differences (Personal and family information, with the first six variables representing personal information and the other two variables representing family information). | Gender, age, net income, academic background, Employment situation, living in own property, Kinship, number of children | >1.06 < 2.75 | Suitable |
| II. Experience of private citizens with blockchain products | Ever heard of blockchain, know-how of blockchain functionality, blockchain products used | >1.07 < 1.19 | Suitable |
| Convenience rating, Time saving rating, Clarity rating, Self-determination rating | >1.29 < 2.34 | Suitable | |
| III. Affinity of private citizens with (digital) financial and identification products | Bank cards, loyalty cards, online accounts, identity documents, certificate documents, testimonial documents | >1.04 < 1.13 | Suitable |
| IV. Privacy concerns | Importance of data security, trust in companies and governments, assessment of data security when using blockchain, knowledge storage of data by companies | >1.00 < 1.03 | Suitable |
| Variable | Coefficient | Standard Error | z Value | p Value | Significance |
|---|---|---|---|---|---|
| Constant | 7.03735 | 2.04582 | 3.440 | 0.0006 | *** |
| Gender (male) | 0.603305 | 0.520271 | 1.160 | 0.2462 | |
| Age | −0.226232 | 0.0552025 | −4.098 | 4.16 × 10−5 | *** |
| Relationship | 0.422062 | 0.525967 | 0.8024 | 0.4223 | |
| No. of children | 1.37194 | 0.641644 | 2.138 | 0.0325 | ** |
| Net income (in Euro) | −0.001178 | 0.0003176 | −3.714 | 0.0002 | *** |
| Academic background | 4.65954 | 0.704730 | 6.612 | 3.80 × 1011 | *** |
| Employment situation | 1.27480 | 1.33802 | 0.9528 | 0.3407 | |
| Living own real estate | 0.735253 | 0.634665 | 1.158 | 0.2467 | |
| Adjusted R2 | 0.538162 | ||||
| AIC | 131.8254 | ||||
| Likelihood ratio test–Chi2 (8) | 171.611 (0.00) *** | ||||
| Variable | Coefficient | Standard Error | z Value | p Value | Significance |
|---|---|---|---|---|---|
| Constant | −1.89618 | 0.573752 | −3.305 | 0.0010 | *** |
| Ever heard Blockchain | 2.52106 | 0.608381 | 4.144 | 3.41 × 10−5 | *** |
| Knowhow Blockchain | 2.78849 | 0.456566 | 6.108 | 1.01 × 10−9 | *** |
| Used Blockchain | 0.602337 | 0.669625 | 0.8995 | 0.3684 | |
| Adjusted R2 | 0.361809 | ||||
| AIC | 182.1627 | ||||
| Likelihood ratio test–Chi2 (3) | 111.273 (0.00) *** | ||||
| Variable | Coefficient | Standard Error | z Value | p Value | Significance |
|---|---|---|---|---|---|
| Constant | −2.88182 | 0.789570 | −3.650 | 0.0003 | *** |
| Assessm. convenience | 0.847465 | 0.253149 | 3.348 | 0.0008 | *** |
| Assessm. timesaving | −0.373879 | 0.258620 | −1.446 | 0.1483 | |
| Assessm. clarity | 0.409453 | 0.239233 | 1.712 | 0.0870 | * |
| Assessm. self-determ. | 0.260675 | 0.166234 | 1.568 | 0.1169 | |
| Adjusted R2 | 0.120295 | ||||
| AIC | 251.0995 | ||||
| Likelihood ratio test–Chi2 (4) | 44.3366 (0.00) *** | ||||
| Variable | Coefficient | Standard Error | z Value | p Value | Significance |
|---|---|---|---|---|---|
| Constant | −1.70210 | 0.674935 | −2.522 | 0.0117 | ** |
| No. of bank cards | 0.277275 | 0.139938 | 1.981 | 0.0475 | ** |
| No. of customer cards | 0.100782 | 0.0561506 | 1.795 | 0.0727 | * |
| No. of online accounts | 0.106090 | 0.0251347 | 4.221 | 2.43 × 10−5 | *** |
| No. of ID documents | 0.154521 | 0.134609 | 1.148 | 0.2510 | |
| No. of testimony docs. | 0.0867526 | 0.0315866 | 2.746 | 0.0060 | *** |
| No. of certific. proofs | −0.0962794 | 0.0267416 | −3.600 | 0.0003 | *** |
| Adjusted R2 | 0.182076 | ||||
| AIC | 233.4651 | ||||
| Likelihood ratio test–Chi2 (6) | 65.971 (0.00) *** | ||||
| Variable | Coefficient | Standard Error | z Value | p Value | Significance |
|---|---|---|---|---|---|
| Constant | 2.32136 | 0.932781 | 2.489 | 0.0128 | ** |
| Import. of data security | −0.519211 | 0.201051 | −2.582 | 0.0098 | *** |
| Trust in governments and companies | 0.364732 | 0.171866 | 2.122 | 0.0338 | ** |
| Assessm. data security | 0.564012 | 0.323680 | 1.742 | 0.0814 | * |
| Knowledge data storage companies | 0.375033 | 0.335349 | 1.118 | 0.2634 | |
| Adjusted R2 | 0.017833 | ||||
| AIC | 280.3459 | ||||
| Likelihood ratio test–Chi2 (4) | 15.0902 (0.0045) *** | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Friedhoff, T.; Au, C.-D.; Ladnar, N.; Stein, D.; Zureck, A. Analysis of Social Acceptance for the Use of Digital Identities. Computers 2023, 12, 51. https://doi.org/10.3390/computers12030051
Friedhoff T, Au C-D, Ladnar N, Stein D, Zureck A. Analysis of Social Acceptance for the Use of Digital Identities. Computers. 2023; 12(3):51. https://doi.org/10.3390/computers12030051
Chicago/Turabian StyleFriedhoff, Tim, Cam-Duc Au, Nadine Ladnar, Dirk Stein, and Alexander Zureck. 2023. "Analysis of Social Acceptance for the Use of Digital Identities" Computers 12, no. 3: 51. https://doi.org/10.3390/computers12030051