
FPGA Implementation for Elliptic Curve Cryptography Algorithm and Circuit with High Efficiency and Low Delay for IoT Applications

Abstract
:1. Introduction
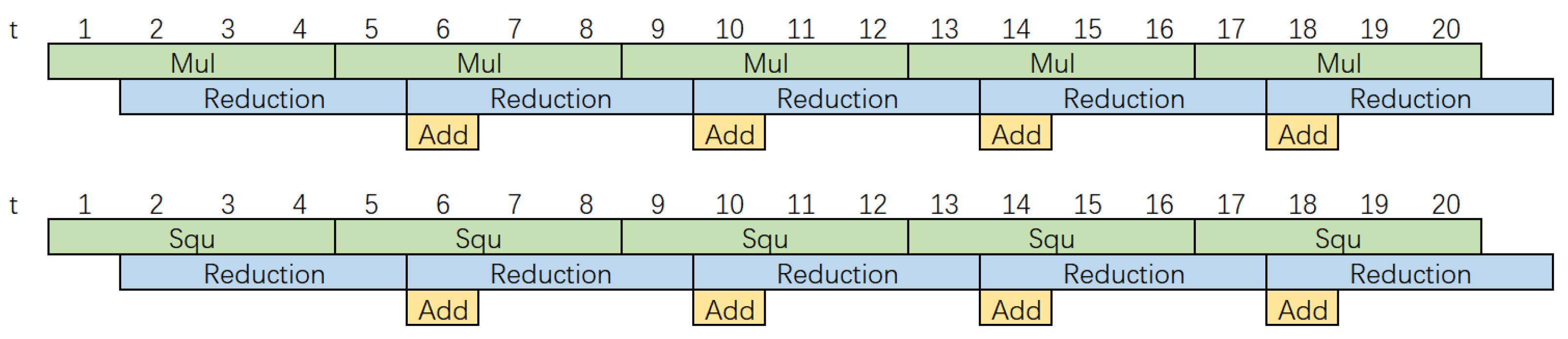
- A modular square unit using a fast partial Montgomery reduction algorithm is proposed to significantly reduce the area. It takes only four clock cycles to complete a modular square operation. Modular multiplication and modular square operations can be computed in parallel to achieve high speed.
- A modified point addition (PA) operation and a modified point doubling (PD) operation are proposed. It takes 21 cycles to compute a PD and 32 cycles to compute a PA. The number of operation clock cycles is reduced to the minimum.
- This paper proposes a high-speed modular inversion algorithm based on the extended Euclidean algorithm, but some modifications were performed using the two modular adders. It takes about 300 clock cycles to perform a modular inverse operation, which is only 83% of the Radix-2 algorithm.
2. Preliminaries
2.1. Elliptic Curve Cryptograph
| Algorithm 1 On-the-fly NAF method for PM |
Input: , Output: 1: ,where is 1 2: 3: For i from down to 1 do 3.1: 3.2: if and , then 3.3: if and , then 4: return Q. |
2.2. Modular Multiplier Algorithm
| Algorithm 2 Montgomery multiplication algorithm |
Input: , b, p with Output: 1: 2: For i from 0 up to do 2.1: 2.2: 2.3: 2.4: 3: if , then return else return u |
3. Implementations
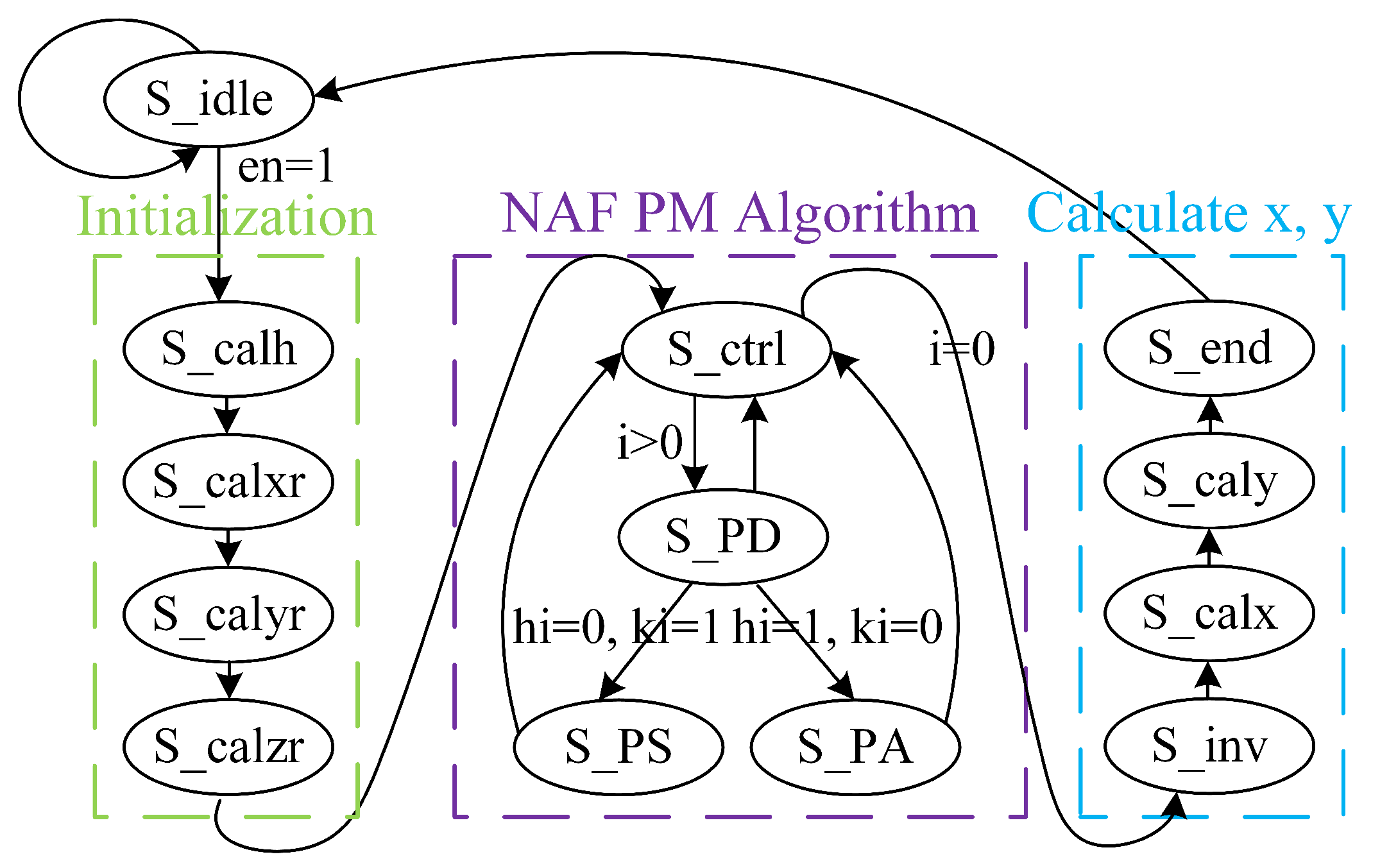
3.1. Proposed PM Architecture
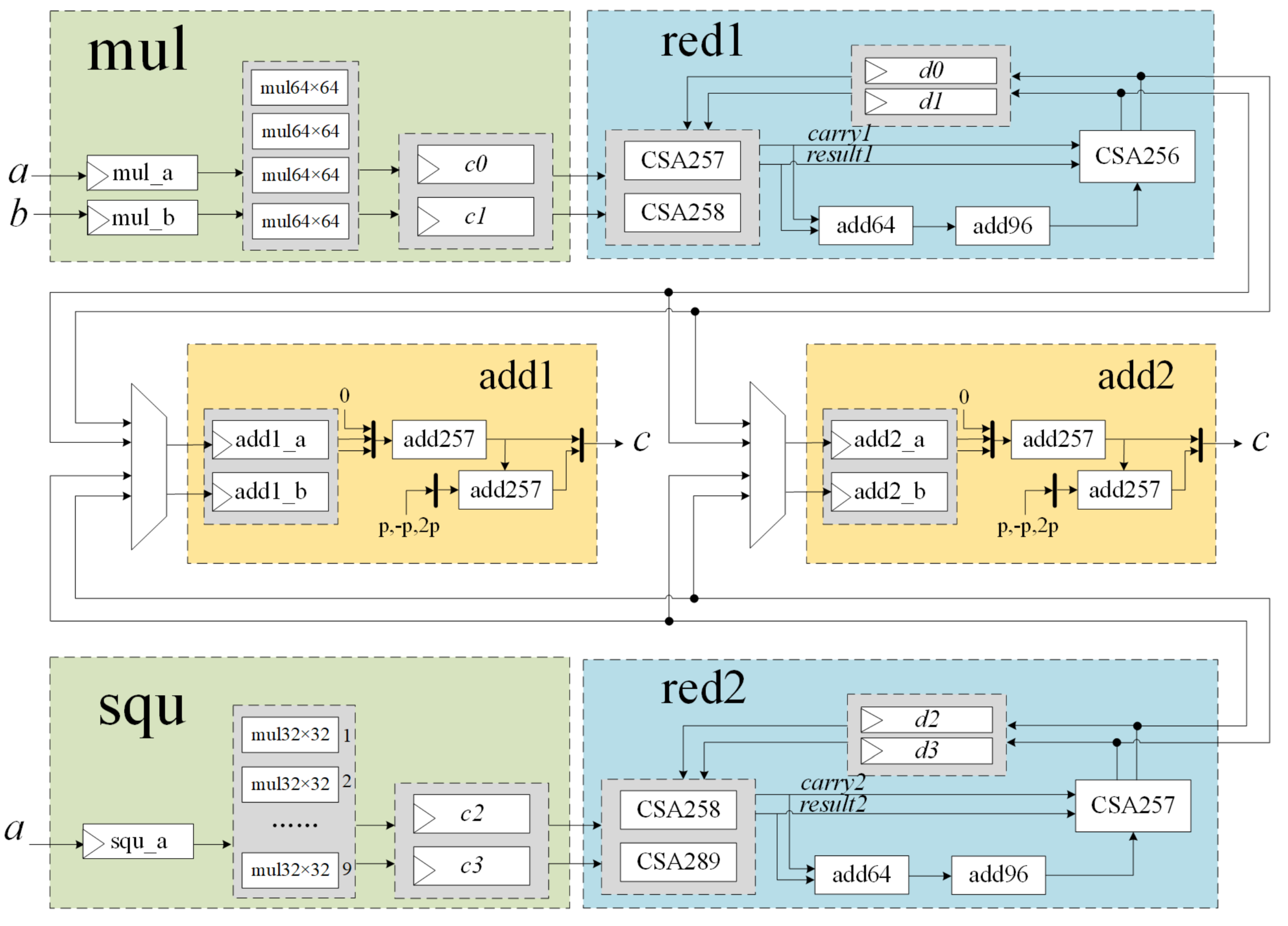
3.2. Modular Multiplication Unit and Modular Square Unit
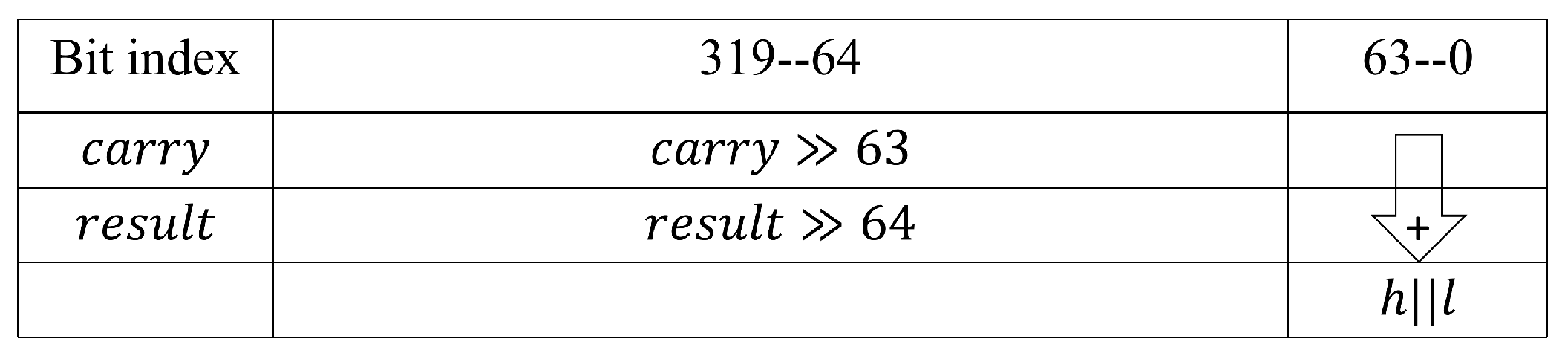
| Algorithm 3 Proposed Montgomery multiplication algorithm |
Input: , b, p with Output: 1: ← 2: ← ) ← 3: For i from 2 up to do ← ← 4: ← 5: c ← |
| Algorithm 4 Proposed Montgomery square algorithm |
Input: a, p with Output: 1: ← 2: ← ) ← 3: For i from 2 up to do ← ← 4: ← 5: c ← |
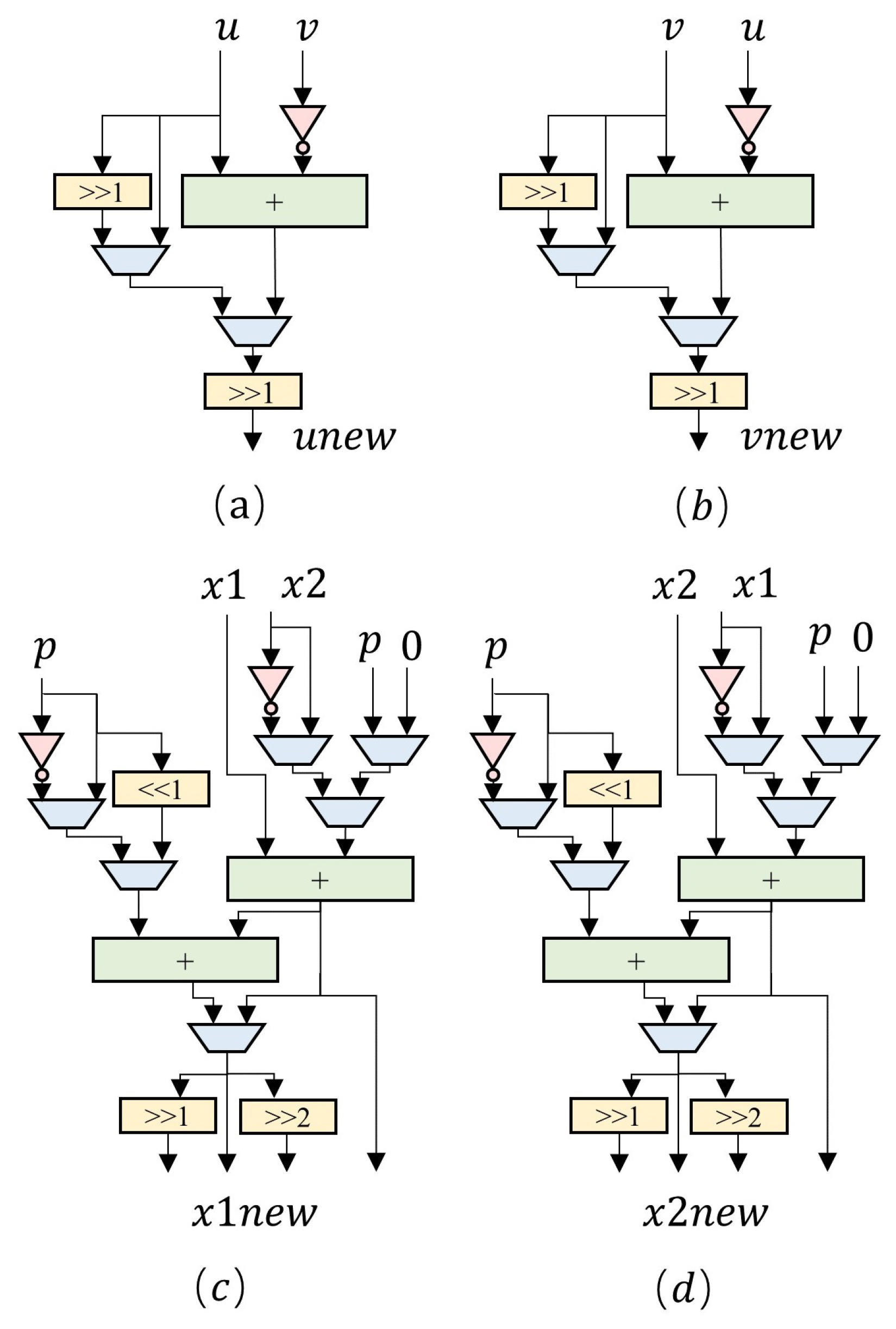
3.3. Modular Inversion Unit
| Algorithm 5 Proposed modular inversion algorithm |
Input: a, p with Output: 1: 2: while 2.1: if 2.2: else if 2.3: else if 2.4: else if 2.5: else if 2.6: else 3: if , return else return |
3.4. Calculation of PA and PD
4. Results and Comparisons
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviations | Full Names |
|---|---|
| ECC | Elliptic curve cryptography |
| FPGA | Field-Programmable Gate Array |
| ASIC | Application-Specific Integrated Circuit |
| IoT | Internet of Things |
| PM | Point multiplication |
| PA | Point addition |
| PD | Point doubling |
| PS | Point subtraction |
| NAF | Non-adjacent form |
References
- Koblitz, N. Elliptic curve cryptosystems. Math. Comput. 1987, 48, 203–209. [Google Scholar] [CrossRef]
- Miller, V.S. Use of Elliptic Curves in Cryptography; Springer: Berlin/Heidelberg, Germany, 1986. [Google Scholar]
- American National Standards Institute (ANSI). Public Key Cryptography for the Financial Services Industry: The Elliptic Curve Digital Signature Algorithm (ECDSA); ANSI X9.62; ANSI: Washington, DC, USA, 2005. [Google Scholar]
- Institute of Electrical and Electronics Engineers (IEEE). Standard Specifications for Public-Key Cryptography; IEEE P1363-2000; IEEE: Piscataway, NJ, USA, 2000. [Google Scholar]
- National Institute of Standards and Technology (NIST). Recommendation for Pair-Wise Key Establishment Schemes Using Discrete Logarithm Cryptography; NIST Special Publication 800-56A; NIST: Gaithersburg, MD, USA, 2006. [Google Scholar]
- State Cryptography Administration of China (SCA). Public Key Cryptographic Algorithm SM2 Based on Elliptic Curves; GM/T 0003.1-2012; State Cryptography Administration of China: Beijing, China, 2012. [Google Scholar]
- Urien, P.; Piramuthu, S. Elliptic curve-based RFID/NFC authentication with temperature sensor input for relay attacks. Decis. Support Syst. 2014, 59, 28–36. [Google Scholar] [CrossRef]
- Liu, D.; Liu, Z.; Yong, Z.; Zou, X.; Cheng, J. Design and Implementation of An ECC-Based Digital Baseband Controller for RFID Tag Chip. IEEE Trans. Ind. Electron. 2015, 62, 4365–4373. [Google Scholar] [CrossRef]
- Banerjee, U.; Wright, A.; Juvekar, C.; Waller, M.; Arvind; Chandrakasan, A.P. An Energy-Efficient Reconfigurable DTLS Cryptographic Engine for Securing Internet-of-Things Applications. IEEE J. Solid-State Circuits 2019, 54, 2339–2352. [Google Scholar] [CrossRef]
- Abdaoui, A.; Erbad, A.; Al-Ali, A.K.; Mohamed, A.; Guizani, M. Fuzzy Elliptic Curve Cryptography for Authentication in Internet of Things. IEEE Internet Things J. 2022, 9, 9987–9998. [Google Scholar] [CrossRef]
- Yeh, L.Y.; Chen, P.J.; Pai, C.C.; Liu, T.T. An Energy-Efficient Dual-Field Elliptic Curve Cryptography Processor for Internet of Things Applications. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 1614–1618. [Google Scholar] [CrossRef]
- Yang, D.; Dai, Z.; Li, W.; Chen, T. An Efficient ASIC Implementation of Public Key Cryptography Algorithm SM2 Based on Module Arithmetic Logic Unit. In Proceedings of the 2019 IEEE 13th International Conference on ASIC (ASICON), Chongqing, China, 29 October–1 November 2019; pp. 1–4. [Google Scholar]
- Zhao, Z.; Bai, G. Ultra High-Speed SM2 ASIC Implementation. In Proceedings of the 2014 IEEE 13th International Conference on Trust, Security and Privacy in Computing and Communications, Beijing, China, 24–26 September 2014; pp. 182–188. [Google Scholar]
- Hu, X.; Cai, S.; Zhan, R.; Xiong, X. High Performance SM2 Elliptic Curve Cryptographic Processor over GF(p). In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 8904–8908. [Google Scholar]
- Ding, J.; Li, S.; Gu, Z. High-Speed ECC Processor Over NIST Prime Fields Applied With Toom–Cook Multiplication. IEEE Trans. Circuits Syst. I Regul. Pap. 2019, 66, 1003–1016. [Google Scholar] [CrossRef]
- Choi, P.; Lee, M.K.; Kim, J.H.; Kim, D.K. Low-Complexity Elliptic Curve Cryptography Processor Based on Configurable Partial Modular Reduction Over NIST Prime Fields. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1703–1707. [Google Scholar] [CrossRef]
- Choi, P.; Lee, M.K.; Kim, D.K. ECC Coprocessor Over a NIST Prime Field Using Fast Partial Montgomery Reduction. IEEE Trans. Circuits Syst. I: Regul. Pap. 2021, 68, 1206–1216. [Google Scholar] [CrossRef]
- Li, B.; Lei, B.; Zhang, Y.; Lei, S. A Novel and High-Performance Modular Square Scheme for Elliptic Curve Cryptography Over GF(p). IEEE Trans. Circuits Syst. II: Express Briefs 2019, 66, 647–651. [Google Scholar] [CrossRef]
- Zhao, X.; Li, B.; Zhang, L.; Wang, Y.; Zhang, Y.; Chen, R. FPGA implementation of high-efficiency ECC point multiplication circuit. Electronics 2021, 10, 1252. [Google Scholar] [CrossRef]
- Nawari, M.; Ahmed, H.; Hamid, A.; Elkhidir, M. Fpga based implementation of elliptic curve cryptography. In Proceedings of the 2015 World Symposium on Computer Networks and Information Security (WSCNIS), Nabeul, Tunisia, 11–13 June 2015; pp. 1–8. [Google Scholar]
- Hankerson, D.; Menezes, A.J.; Vanstone, S. Guide to Elliptic Curve Cryptography; Springer Science & Business Media: New York, NY, USA, 2006. [Google Scholar]
- Hossain, M.S.; Kong, Y. High-Performance FPGA Implementation of Modular Inversion over F256 for Elliptic Curve Cryptography. In Proceedings of the 2015 IEEE International Conference on Data Science and Data Intensive Systems, Sydney, NSW, Australia, 11–13 December 2015; pp. 169–174. [Google Scholar]
- Mrabet, A.; El-Mrabet, N.; Bouallegue, B.; Mesnager, S.; Machhout, M. An efficient and scalable modular inversion/division for public key cryptosystems. In Proceedings of the 2017 International Conference on Engineering & MIS (ICEMIS), Monastir, Tunisia, 8–10 May 2017; pp. 1–6. [Google Scholar]
- Choi, P.; Lee, M.K.; Kong, J.T.; Kim, D.K. Efficient design and performance analysis of a hardware right-shift binary modular inversion algorithm in GF (p). JSTS: J. Semicond. Technol. Sci. 2017, 17, 425–437. [Google Scholar]
- Li, W.; Liu, J.; Bai, G. High-speed implementation of SM2 based on fast modulus inverse algorithm. In Proceedings of the 2018 China Semiconductor Technology International Conference (CSTIC), Shanghai, China, 11–12 March 2018; pp. 1–3. [Google Scholar]
- Xie, Y.; Liu, Y.; Zheng, X.; Zhu, W.; Li, J.; Li, J.; Cai, S.; Xiong, X. A Dual-Core High-Performance Processor for Elliptic Curve Cryptography in GF(p) Over Generic Weierstrass Curves. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 4523–4527. [Google Scholar] [CrossRef]
- Yang, G.; Kong, F.; Xu, Q. Optimized FPGA Implementation of Elliptic Curve Cryptosystem over Prime Fields. In Proceedings of the 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 29 December 2020–1 January 2021; pp. 243–249. [Google Scholar]













| Coordinate | PA | PD |
|---|---|---|
| Affine coordinate | 1I + 2M + 1S | 1I + 2M + 2S |
| Projective coordinate | 12M + 2S | 7M + 3S |
| Jacobin coordinate | 12M + 4S | 4M + 4S |
| Chudnovsky coordinate | 11M + 3S | 5M + 4S |
| Mixed Jacobin-affine coordinate | 8M + 3S |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Lin, Y.; Hu, J.; Zhang, C.; Zhong, Q. FPGA Implementation for Elliptic Curve Cryptography Algorithm and Circuit with High Efficiency and Low Delay for IoT Applications. Micromachines 2023, 14, 1037. https://doi.org/10.3390/mi14051037
Wang D, Lin Y, Hu J, Zhang C, Zhong Q. FPGA Implementation for Elliptic Curve Cryptography Algorithm and Circuit with High Efficiency and Low Delay for IoT Applications. Micromachines. 2023; 14(5):1037. https://doi.org/10.3390/mi14051037
Chicago/Turabian StyleWang, Deming, Yuhang Lin, Jianguo Hu, Chong Zhang, and Qinghua Zhong. 2023. "FPGA Implementation for Elliptic Curve Cryptography Algorithm and Circuit with High Efficiency and Low Delay for IoT Applications" Micromachines 14, no. 5: 1037. https://doi.org/10.3390/mi14051037